
Molecular Design-Based Breeding: A Kinship Index-Based Selection Method for Complex Traits in Small Livestock Populations
 and
and
Abstract
1. Introduction
2. Materials and Methods
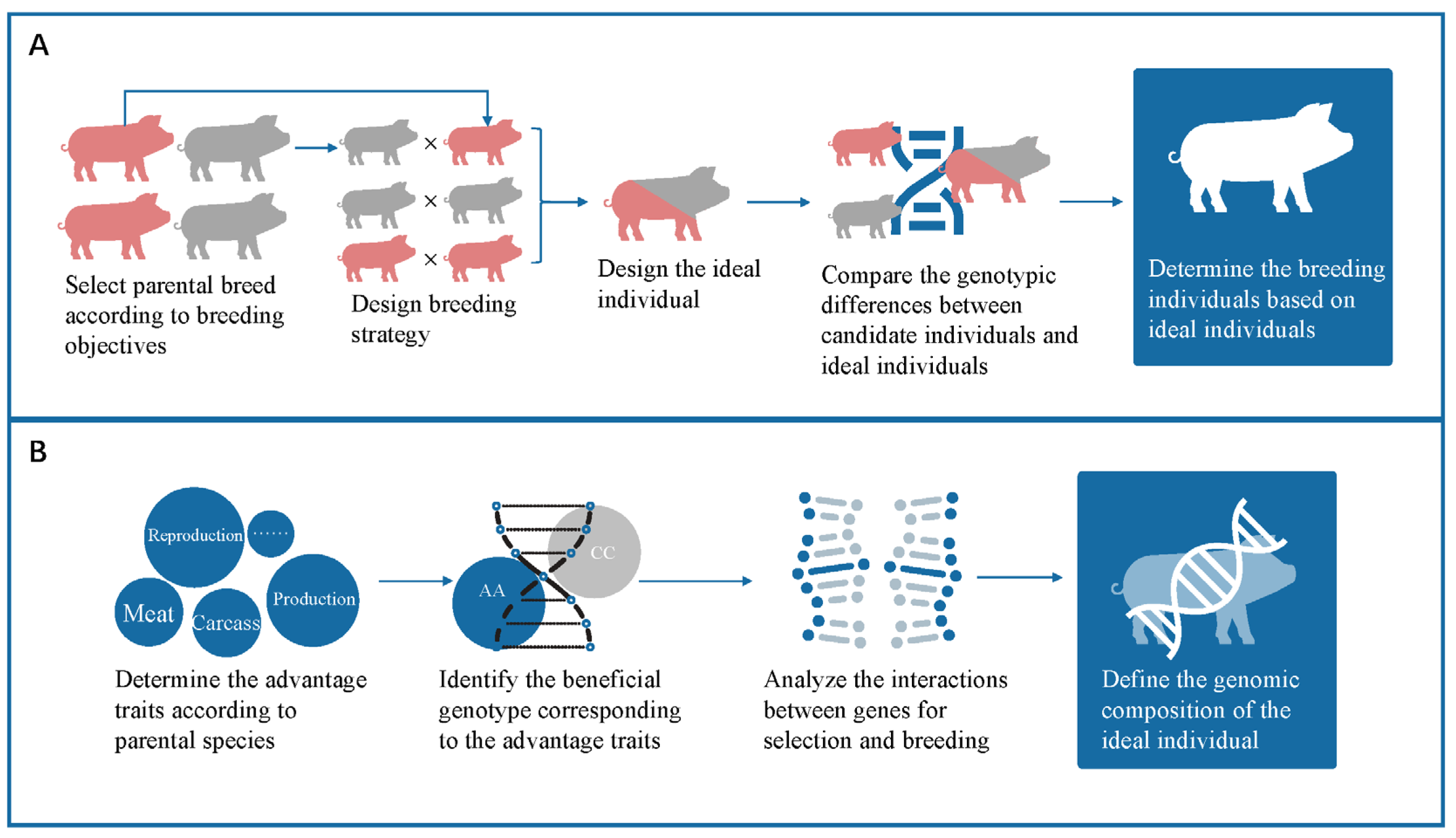
2.1. Methods
2.2. Simulation
2.2.1. Historical Population
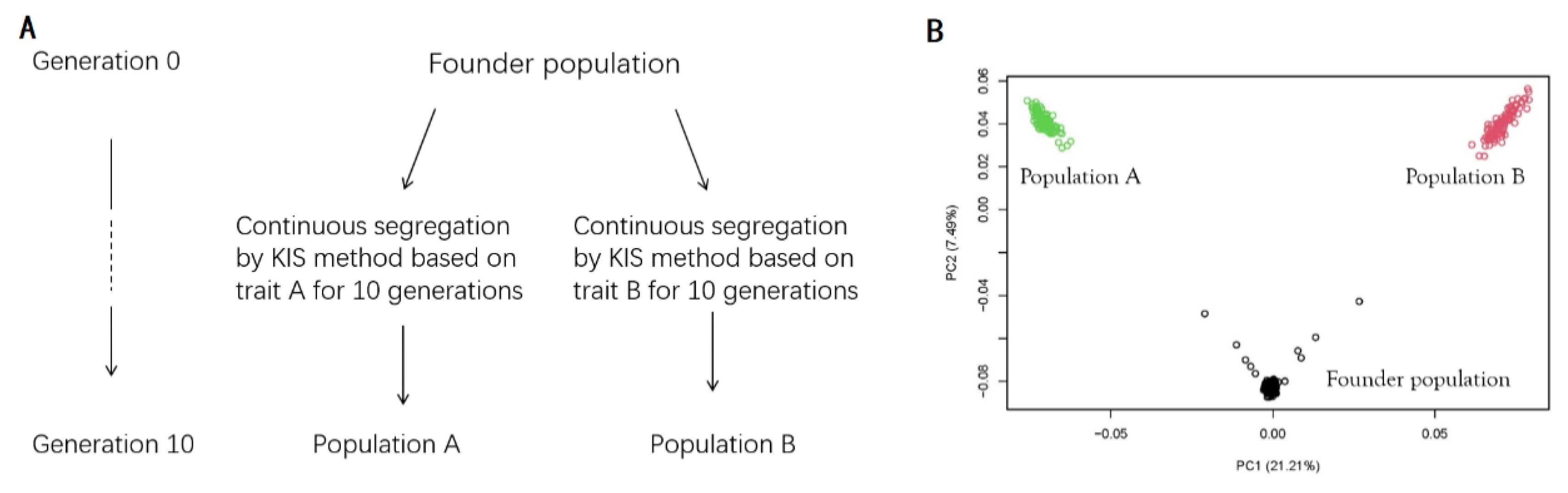
2.2.2. Breeding Program
2.2.3. Evaluation Criteria
2.3. Feasibility Test
2.4. Robustness Test
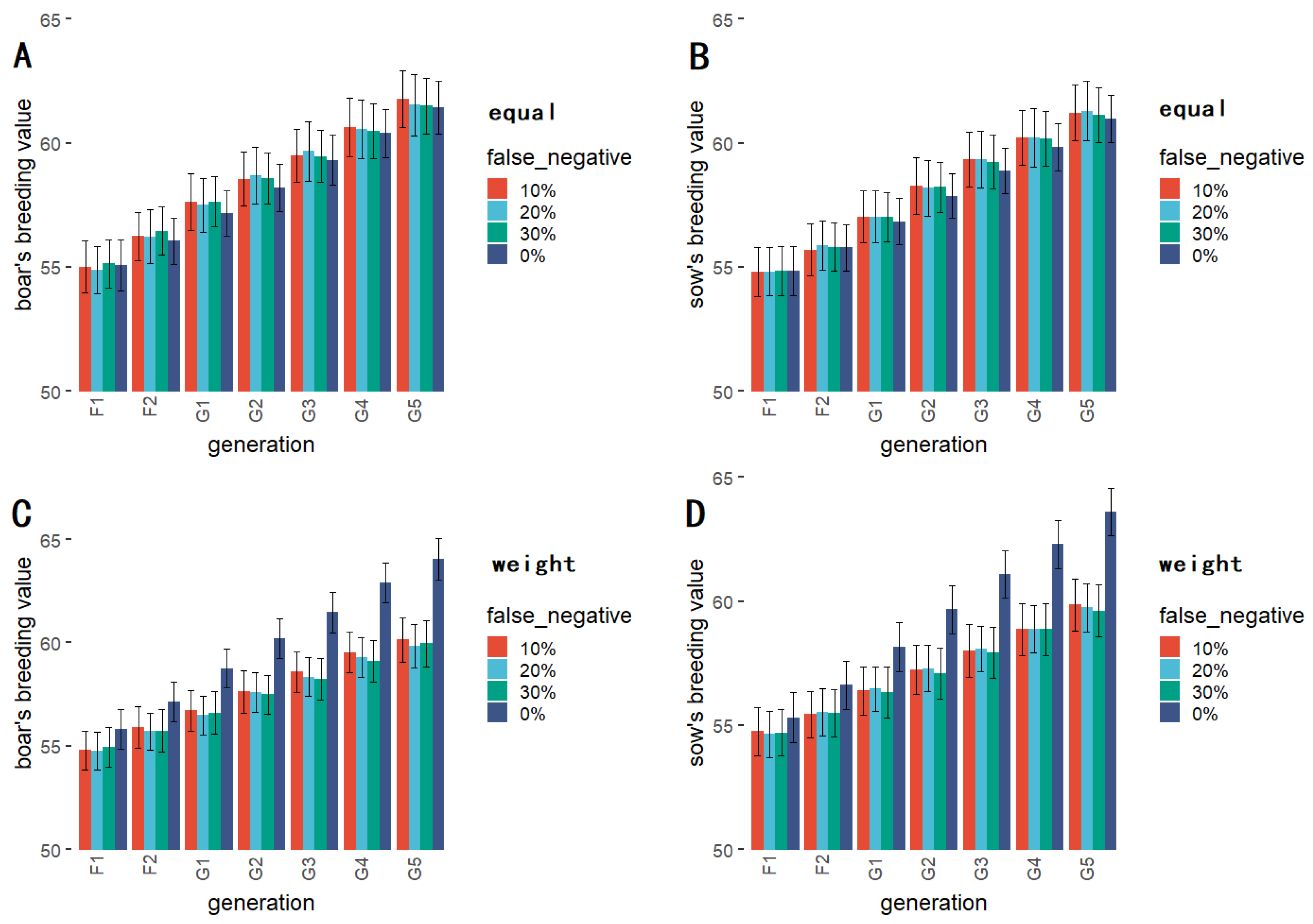
2.4.1. QTL with Different False Negative Rates
2.4.2. QTLs with Different Pseudo-Positive Rates
2.4.3. QTLs with Different Quantitative Gradients
2.4.4. Scale of Foundation Population
2.4.5. Selection Proportion
2.4.6. Simulation of Dominance and Epistatic Effects
3. Result
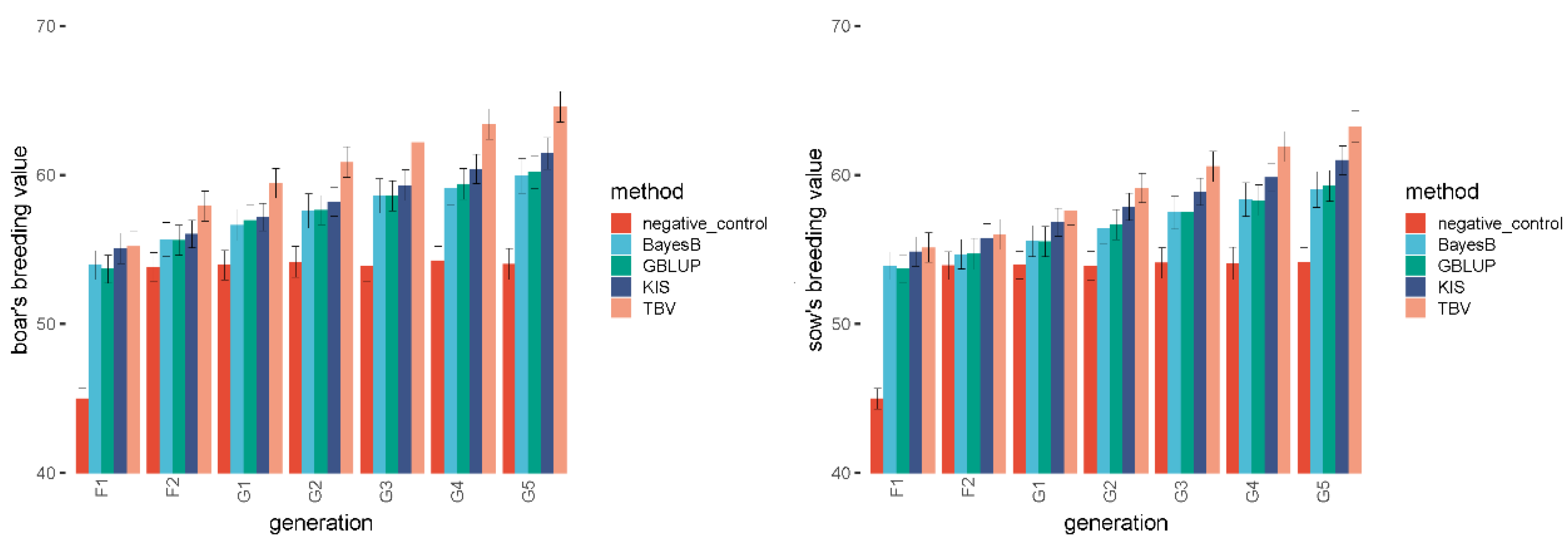
3.1. Negative Control Simulation
3.2. Feasibility Test
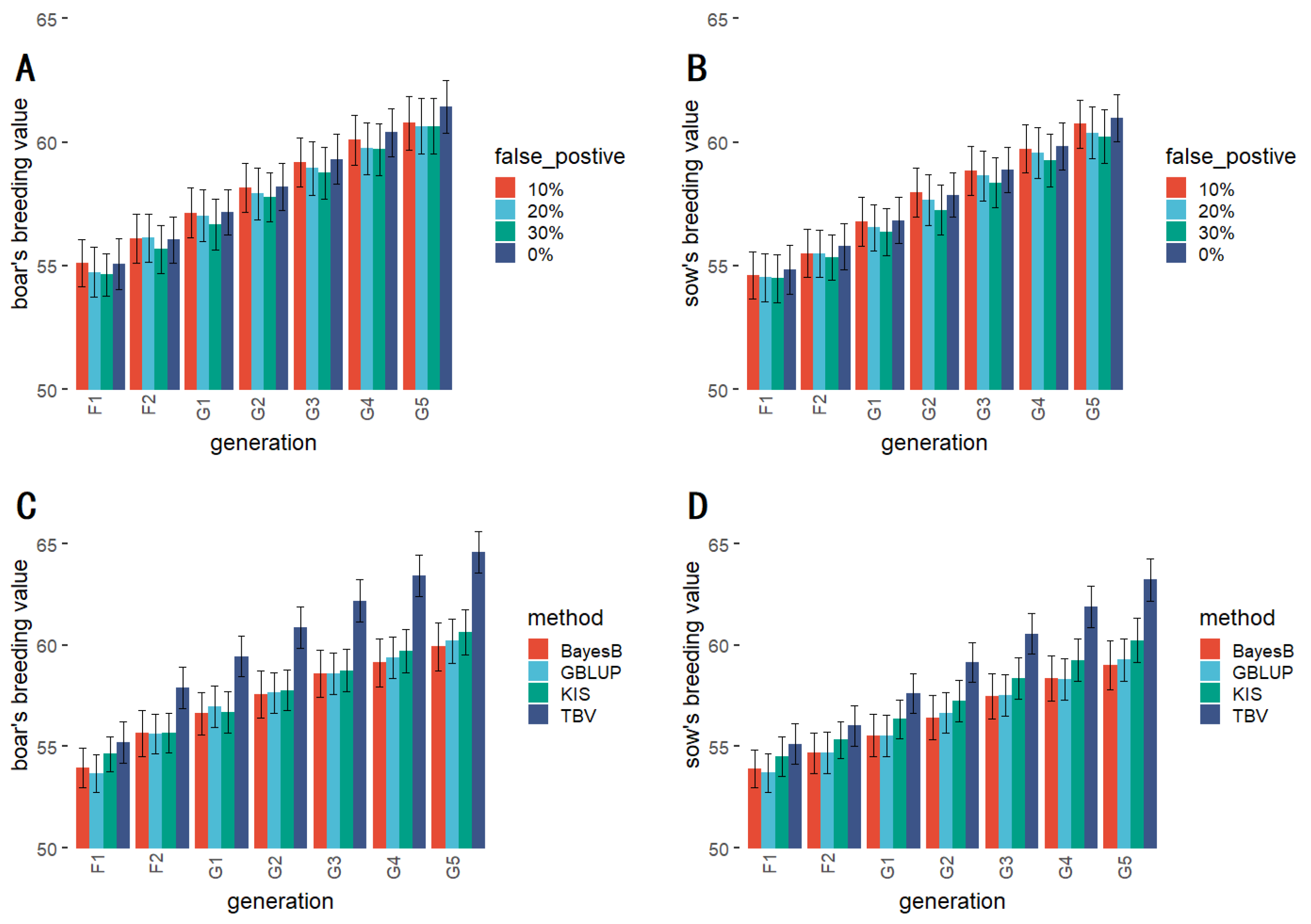
3.3. QTLs with Different False Negative Rates
3.4. QTLs with Different Pseudo-Positive Rates
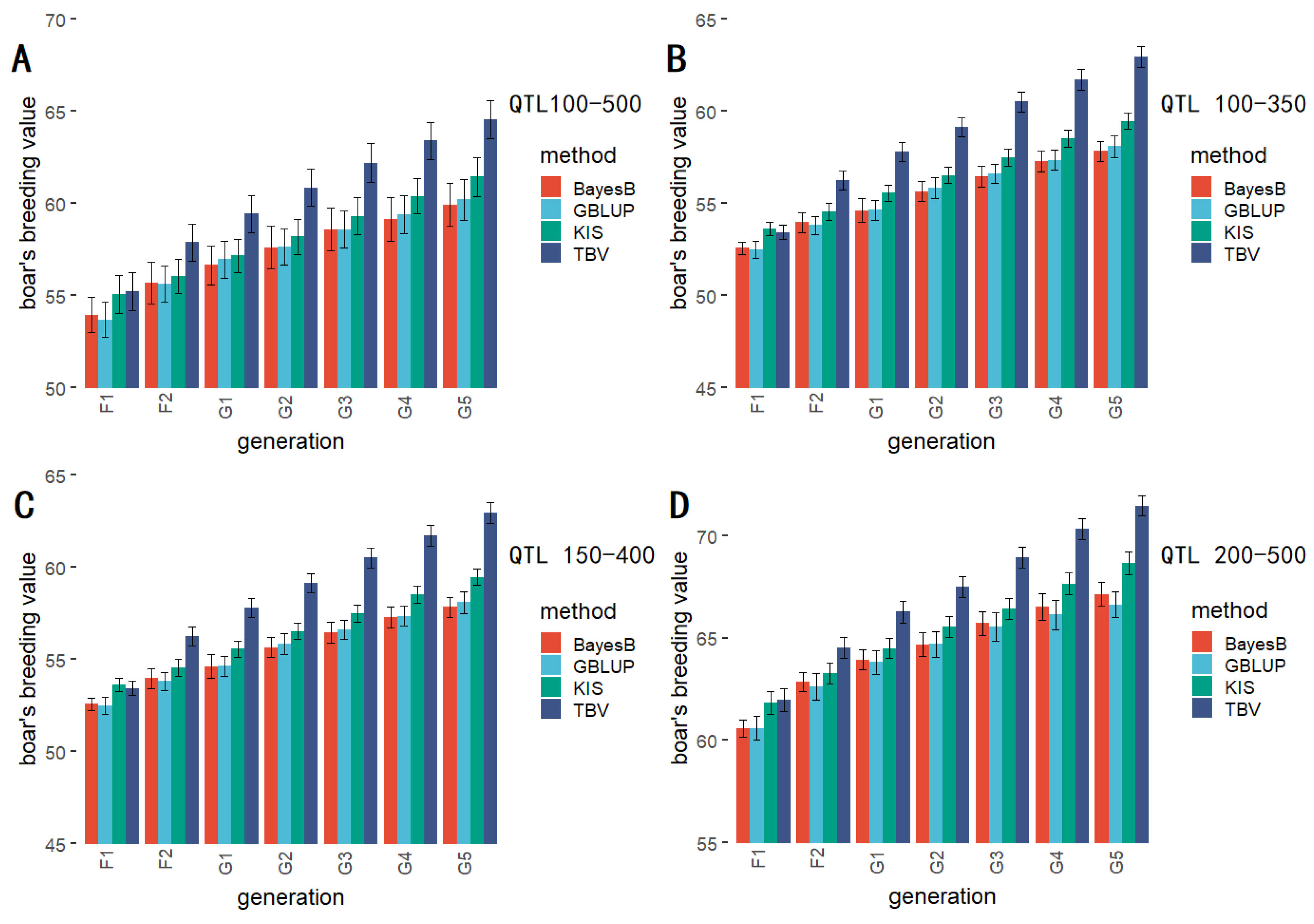
3.5. QTLs with Different Quantitative Gradients
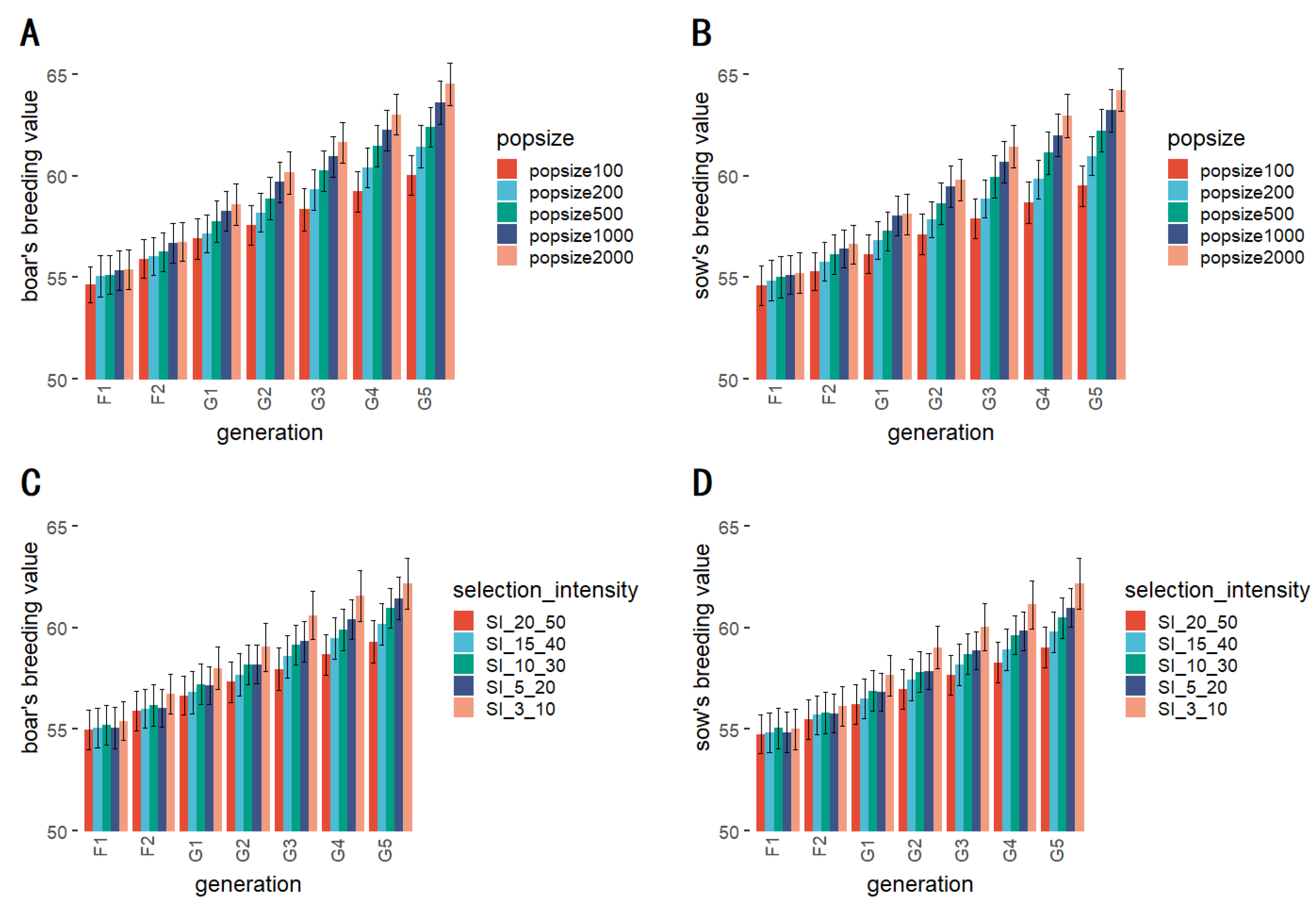
3.6. Scale of Foundation Population
3.7. Selection Proportion
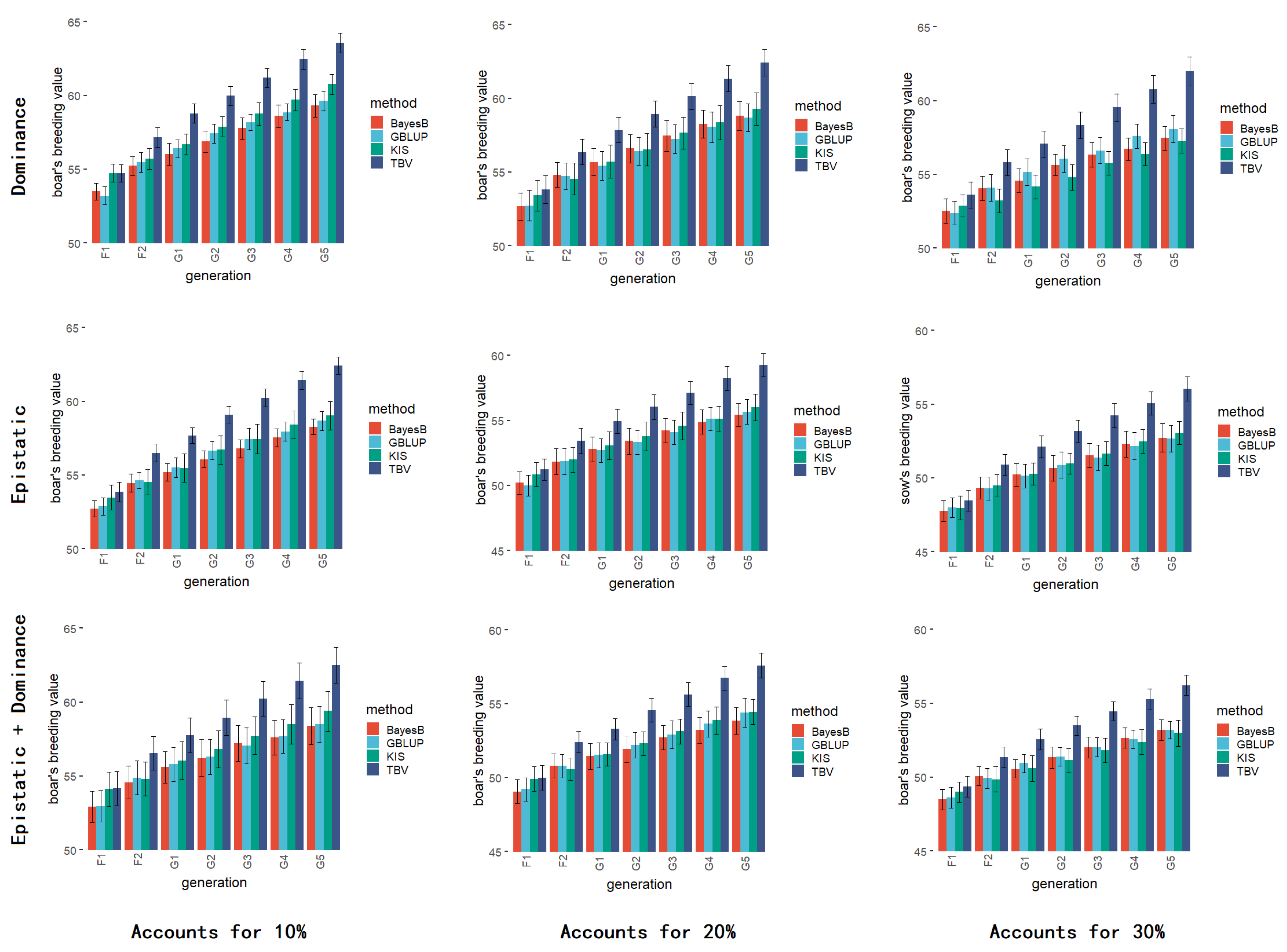
3.8. Simulation Results of Dominance and Epistatic Effects
4. Discussion
5. Limitations and the Future of Applying the KIS Method
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yan, B.; Yan, J.; Shi, W.; Li, Y. Study on the comprehensive comparative advantages of pig production and development in China based on geographic information system. Clean Technol. Environ. Policy 2020, 22, 105–117. [Google Scholar] [CrossRef]
- Goddard, M.E.; Kemper, K.E.; MacLeod, I.M.; Chamberlain, A.J.; Hayes, B.J. Genetics of complex traits: Prediction of phenotype, identification of causal polymorphisms and genetic architecture. Proc. R. Soc. B Boil. Sci. 2016, 283, 20160569. [Google Scholar] [CrossRef]
- Hayes, B.J.; Lewin, H.A.; Goddard, M.E. The future of livestock breeding: Genomic selection for efficiency, reduced emissions intensity, and adaptation. Trends Genet. 2013, 29, 206–214. [Google Scholar] [CrossRef]
- Hayes, B.; Bowman, P.; Chamberlain, A.; Goddard, M. Invited review: Genomic selection in dairy cattle: Progress and challenges. J. Dairy Sci. 2009, 92, 433–443. [Google Scholar] [CrossRef] [PubMed]
- Lund, M.S.; Su, G.; Janss, L.; Guldbrandtsen, B.; Brøndum, R.F. Genomic evaluation of cattle in a multi-breed context. Livest. Sci. 2014, 166, 101–110. [Google Scholar] [CrossRef]
- Koivula, M.; Strandén, I.; Su, G.; Mäntysaari, E. Different methods to calculate genomic predictions—Comparisons of BLUP at the single nucleotide polymorphism level (SNP-BLUP), BLUP at the individual level (G-BLUP), and the one-step approach (H-BLUP). J. Dairy Sci. 2012, 95, 4065–4073. [Google Scholar] [CrossRef]
- Pérez-Enciso, M.; Zingaretti, L.M. A Guide on Deep Learning for Complex Trait Genomic Prediction. Genes 2019, 10, 553. [Google Scholar] [CrossRef] [PubMed]
- Moeinizade, S.; Kusmec, A.; Hu, G.; Wang, L.; Schnable, P. Multi-trait Genomic Selection Methods for Crop Improvement. Genetics 2020, 215, 931–945. [Google Scholar] [CrossRef] [PubMed]
- Meuwissen, T.H.E.; Hayes, B.J.; Goddard, M.E. Prediction of Total Genetic Value Using Genome-Wide Dense Marker Maps. Genetics 2001, 157, 1819–1829. [Google Scholar] [CrossRef]
- Habier, D.; Fernando, R.L.; Kizilkaya, K.; Garrick, D.J. Extension of the bayesian alphabet for genomic selection. BMC Bioinform. 2011, 12, 186. [Google Scholar] [CrossRef]
- Yi, N.; Xu, S. Bayesian LASSO for quantitative trait loci mapping. Genetics 2008, 179, 1045–1055. [Google Scholar] [CrossRef]
- Zeng, J.; Pszczola, M.; Wolc, A.; Strabel, T.; Fernando, R.L.; Garrick, D.J.; Dekkers, J.C.M. Genomic breeding value prediction and QTL mapping of QTLMAS2011 data using Bayesian and GBLUP methods. BMC Proc. 2012, 6 (Suppl. 2), S7. [Google Scholar] [CrossRef] [PubMed]
- Teng, J.; Gao, N.; Zhang, H.; Li, X.; Li, J.; Zhang, H.; Zhang, X.; Zhang, Z. Performance of whole genome prediction for growth traits in a crossbred chicken population. Poult. Sci. 2019, 98, 1968–1975. [Google Scholar] [CrossRef]
- Pook, T.; Schlather, M.; Simianer, H. MoBPS—Modular Breeding Program Simulator. G3 Genes Genomes Genet. 2020, 10, 1915–1918. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Teng, J.; Diao, S.; Xu, Z.; Ye, S.; Qiu, D.; Zhang, Z.; Pan, Y.; Li, J.; Zhang, Q. Insights into the architecture of human-induced polygenic selection in Duroc pigs. J. Anim. Sci. Biotechnol. 2022, 13, 99. [Google Scholar] [CrossRef]
- Giuffra, E.; Tuggle, C.K. FAANG Consortium Functional Annotation of Animal Genomes (FAANG): Current Achievements and Roadmap. Annu. Rev. Anim. Biosci. 2019, 7, 65–88. [Google Scholar] [CrossRef]
- Tao, J.; Qin, Z.-Q.; Tao, Y.; Wen, L.; Shu, X.-S.; Wang, Z.-C.; Liu, X.-W.; Li, W.-J.; Hu, W.-X. Genetic relationships among Chinese pigs and other pig populations from Hunan Province, China. Anim. Genet. 2007, 38, 417–420. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Chen, Z.; Teng, J.; Liu, S.; Lin, Q.; Gao, Y.; Bai, Z.; Consortium, T.F.; Li, B.; Liu, G.; et al. FarmGTEx TWAS-server: An interactive web server for customized TWAS analysis in both human and farm animals. bioRxiv 2023. bioRxiv:2023.02.03.527092. [Google Scholar] [CrossRef]
- Zhou, Z.-Y.; Li, A.; Otecko, N.O.; Liu, Y.-H.; Irwin, D.M.; Wang, L.; Adeola, A.C.; Zhang, J.; Xie, H.-B.; Zhang, Y.-P. PigVar: A database of pig variations and positive selection signatures. Database 2017, 2017, bax048. [Google Scholar] [CrossRef]
- González-Diéguez, D.; Tusell, L.; Carillier-Jacquin, C.; Bouquet, A.; Vitezica, Z.G. SNP-based mate allocation strategies to maximize total genetic value in pigs. Genet. Sel. Evol. 2019, 51, 55. [Google Scholar] [CrossRef]
- González-Diéguez, D.; Tusell, L.; Bouquet, A.; Legarra, A.; Vitezica, Z.G. Purebred and Crossbred Genomic Evaluation and Mate Allocation Strategies To Exploit Dominance in Pig Crossbreeding Schemes. G3 Genes Genomes Genet. 2020, 10, 2829–2841. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Henryon, M.; Sørensen, A.C. Mating strategies with genomic information reduce rates of inbreeding in animal breeding schemes without compromising genetic gain. Animal 2017, 11, 547–555. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Generation | F1 | F2 | G1 | G2 | G3 | G4 | G5 |
|---|---|---|---|---|---|---|---|
| Method | |||||||
| KIS | 55.068 B | 56.049 A | 57.165 B | 58.196 B | 59.318 B | 60.396 B | 61.446 B |
| Negative control | 45.003 A | 53.809 A | 53.958 A | 54.179 A | 53.873 A | 54.262 A | 54.011 A |
| GBLUP | 53.685 A | 55.624 A | 56.949 A | 57.648 A | 58.585 A | 59.396 B | 60.199 B |
| BayesB | 53.952 A | 55.665 A | 56.638 A | 57.594 A | 58.583 A | 59.136 B | 59.930 B |
| KIS | 55.068 A | 56.049 A | 57.165 A | 58.196 A | 59.318 A | 60.396 AB | 61.446 AB |
| TBV | 55.207 A | 57.896 A | 59.439 A | 60.858 A | 62.190 A | 63.410 A | 64.576 A |
| Generation | F1 | F2 | G1 | G2 | G3 | G4 | G5 |
|---|---|---|---|---|---|---|---|
| False Negative Rates | |||||||
| 0% (equal) | 55.068 A | 56.049 A | 57.165 A | 58.196 A | 59.318 A | 60.396 A | 61.446 A |
| 10% (equal) | 55.014 A | 56.242 A | 57.620 A | 58.552 A | 59.498 A | 60.633 A | 61.768 A |
| 20% (equal) | 54.887 A | 56.222 A | 57.497 A | 58.702 A | 59.665 A | 60.559 A | 61.536 A |
| 30% (equal) | 55.137 A | 56.462 A | 57.636 A | 58.582 A | 59.462 A | 60.473 A | 61.499 A |
| 0% (weight) | 55.807 A | 57.131 A | 58.755 A | 60.199 A | 61.466 A | 62.903 A | 64.040 A |
| 10% (weight) | 54.789 A | 55.891 A | 56.724 A | 57.622 A | 58.589 A | 59.534 AB | 60.148 AB |
| 20% (weight) | 54.765 A | 55.707 A | 56.476 A | 57.594 A | 58.342 A | 59.278 AB | 59.843 B |
| 30% (weight) | 54.936 A | 55.739 A | 56.601 A | 57.490 A | 58.252 A | 59.106 B | 59.954 B |
| Generation | F1 | F2 | G1 | G2 | G3 | G4 | G5 |
|---|---|---|---|---|---|---|---|
| Pseudo-Positive Test | |||||||
| 0% | 55.068 A | 56.049 A | 57.165 A | 58.196 A | 59.318 A | 60.396 A | 61.446 A |
| 10% | 55.109 A | 56.088 A | 57.146 A | 58.155 A | 59.193 A | 60.087 A | 60.780 A |
| 20% | 54.733 A | 56.124 A | 57.032 A | 57.928 A | 58.946 A | 59.749 A | 60.649 A |
| 30% | 54.641 A | 55.666 A | 56.673 A | 57.777 A | 58.757 A | 59.703 A | 60.646 A |
| GBLUP | 53.685 A | 55.624 A | 56.949 A | 57.648 A | 58.585 A | 59.396 B | 60.199 B |
| BayesB | 53.952 A | 55.665 A | 56.638 A | 57.594 A | 58.583 A | 59.136 B | 59.930 B |
| KIS (30%) | 54.641 A | 55.666 A | 56.673 A | 57.777 A | 58.757 A | 59.703 B | 60.646 B |
| TBV | 55.207 A | 57.896 A | 59.439 A | 60.858 A | 62.190 A | 63.410 A | 64.576 A |
| Generation | F1 | F2 | G1 | G2 | G3 | G4 | G5 |
|---|---|---|---|---|---|---|---|
| QTL Quantitative Gradients | |||||||
| GBLUP (QTL 100-350) | 48.941 A | 51.324 A | 52.115 A | 53.249 A | 54.355 A | 55.065 A | 56.156 AB |
| BayesB (QTL 100-350) | 49.161 A | 51.138 A | 52.353 A | 53.312 A | 53.979 A | 54.609 A | 55.551 B |
| KIS (QTL 100-350) | 50.320 A | 51.661 A | 52.970 A | 54.012 A | 55.304 A | 56.204 A | 57.185 AB |
| TBV (QTL 100-350) | 50.372 A | 53.380 A | 54.931 A | 56.339 A | 57.617 A | 58.834 A | 59.977 A |
| GBLUP (QTL 150-400) | 52.4935 A | 53.8096 B | 54.6248 B | 55.8352 B | 56.4513 B | 57.2635 B | 58.1057 B |
| BayesB (QTL 150-400) | 52.5697 A | 53.9613 B | 54.6381 B | 55.6529 B | 56.6019 B | 57.3517 B | 57.8415 B |
| KIS (QTL 150-400) | 53.6179 A | 54.5528 AB | 55.5732 B | 56.5278 B | 57.4771 B | 58.5359 B | 59.4759 B |
| TBV (QTL 150-400) | 53.4380 A | 56.2417 A | 57.8186 A | 59.1561 A | 60.5100 A | 61.7221 A | 62.9629 A |
| GBLUP (QTL 200-500) | 60.5938 A | 62.6374 A | 63.8198 B | 64.7000 B | 65.5406 B | 66.1291 B | 66.6235 B |
| BayesB (QTL 200-500) | 60.5819 A | 62.8641 A | 63.9442 B | 64.6765 B | 65.7173 B | 66.5116 B | 67.1417 B |
| KIS (QTL 200-500) | 61.8339 A | 63.2821 A | 64.4985 AB | 65.5540 AB | 66.4141 B | 67.6554 B | 68.6712 B |
| TBV (QTL 200-500) | 61.9914 A | 64.5347 A | 66.2707 A | 67.4954 A | 68.9448 A | 70.3415 A | 71.4575 A |
| Generation | F1 | F2 | G1 | G2 | G3 | G4 | G5 |
|---|---|---|---|---|---|---|---|
| Simulation Test | |||||||
| Popsize 2000 | 55.391 A | 56.751 A | 58.575 A | 60.159 A | 61.646 A | 63.016 A | 64.532 A |
| Popsize 1000 | 55.363 A | 56.690 A | 58.272 A | 59.692 A | 60.943 A | 62.250 A | 63.591 AB |
| Popsize 500 | 55.130 A | 56.260 A | 57.748 A | 58.893 A | 60.252 A | 61.464 A | 62.400 AB |
| Popsize 200 | 55.068 A | 56.049 A | 57.165 A | 58.196 A | 59.318 A | 60.396 A | 61.446 AB |
| Popsize 100 | 54.641 A | 55.911 A | 56.907 A | 57.583 A | 58.345 A | 59.235 A | 60.039 B |
| SI_3_10 | 55.411 A | 56.738 A | 57.999 A | 59.044 A | 60.615 A | 61.564 A | 62.152 A |
| SI_5_20 | 55.068 A | 56.049 A | 57.165 A | 58.196 A | 59.318 A | 60.396 A | 61.446 A |
| SI_10_30 | 55.219 A | 56.186 A | 57.222 A | 58.179 A | 59.157 A | 59.483 A | 60.948 A |
| SI_15_40 | 55.051 A | 56.009 A | 56.810 A | 57.689 A | 58.574 A | 59.483 A | 60.184 A |
| SI_20_50 | 54.978 A | 55.899 A | 56.666 A | 57.329 A | 57.968 A | 58.675 A | 59.303 A |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, J.; Guo, J.; Zhang, Z.; Xu, Y.; Qadri, Q.R.; Zhang, Z.; Wang, Z.; Wang, Q.; Pan, Y. Molecular Design-Based Breeding: A Kinship Index-Based Selection Method for Complex Traits in Small Livestock Populations. Genes 2023, 14, 807. https://doi.org/10.3390/genes14040807
Gu J, Guo J, Zhang Z, Xu Y, Qadri QR, Zhang Z, Wang Z, Wang Q, Pan Y. Molecular Design-Based Breeding: A Kinship Index-Based Selection Method for Complex Traits in Small Livestock Populations. Genes. 2023; 14(4):807. https://doi.org/10.3390/genes14040807
Chicago/Turabian StyleGu, Jiamin, Jianwei Guo, Zhenyang Zhang, Yuejin Xu, Qamar Raza Qadri, Zhe Zhang, Zhen Wang, Qishan Wang, and Yuchun Pan. 2023. "Molecular Design-Based Breeding: A Kinship Index-Based Selection Method for Complex Traits in Small Livestock Populations" Genes 14, no. 4: 807. https://doi.org/10.3390/genes14040807
APA StyleGu, J., Guo, J., Zhang, Z., Xu, Y., Qadri, Q. R., Zhang, Z., Wang, Z., Wang, Q., & Pan, Y. (2023). Molecular Design-Based Breeding: A Kinship Index-Based Selection Method for Complex Traits in Small Livestock Populations. Genes, 14(4), 807. https://doi.org/10.3390/genes14040807