Preimplantation Genetic Testing for Polygenic Disease Relative Risk Reduction: Evaluation of Genomic Index Performance in 11,883 Adult Sibling Pairs

 ,
,
Abstract
1. Introduction
2. Materials and Methods
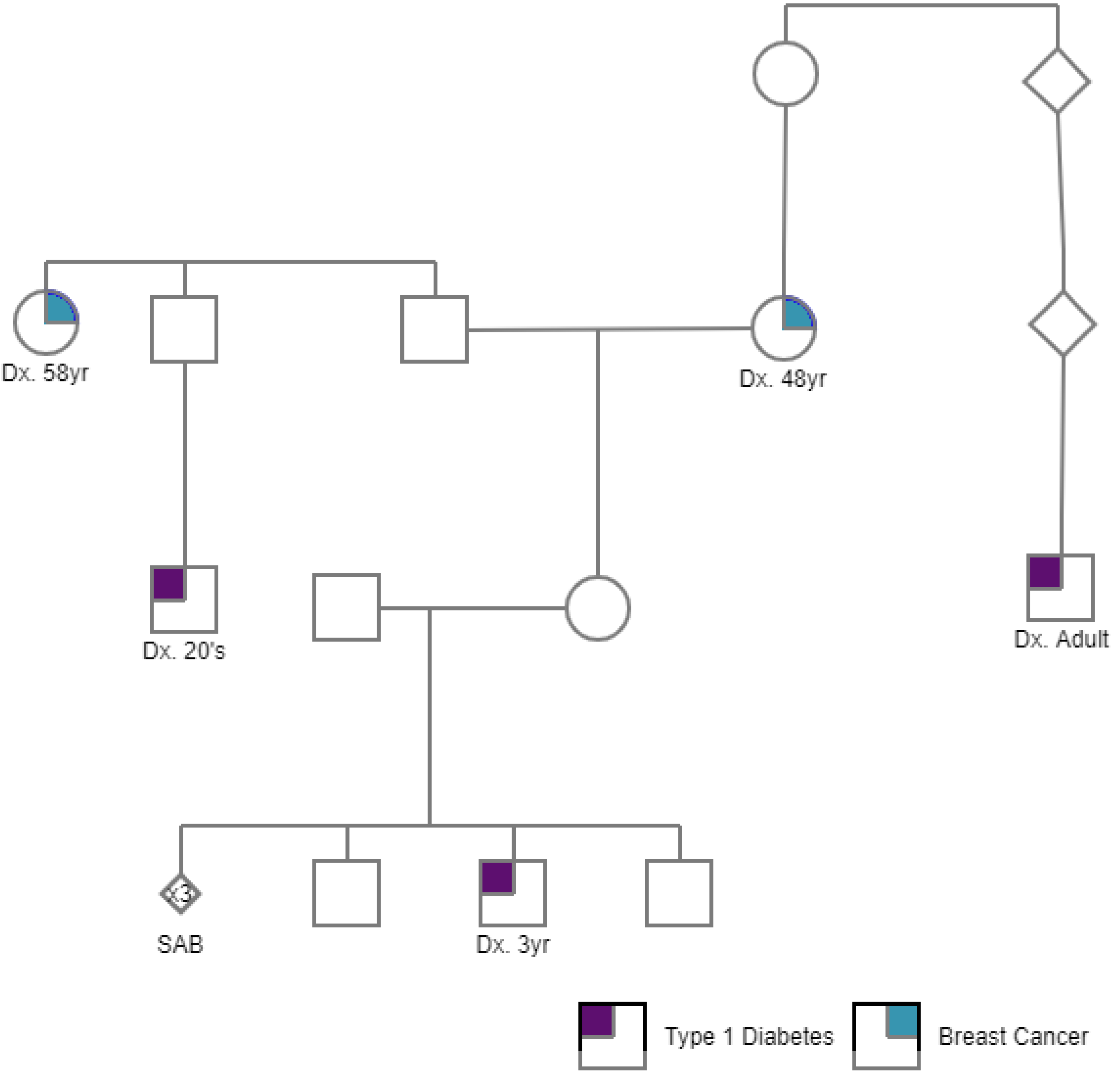
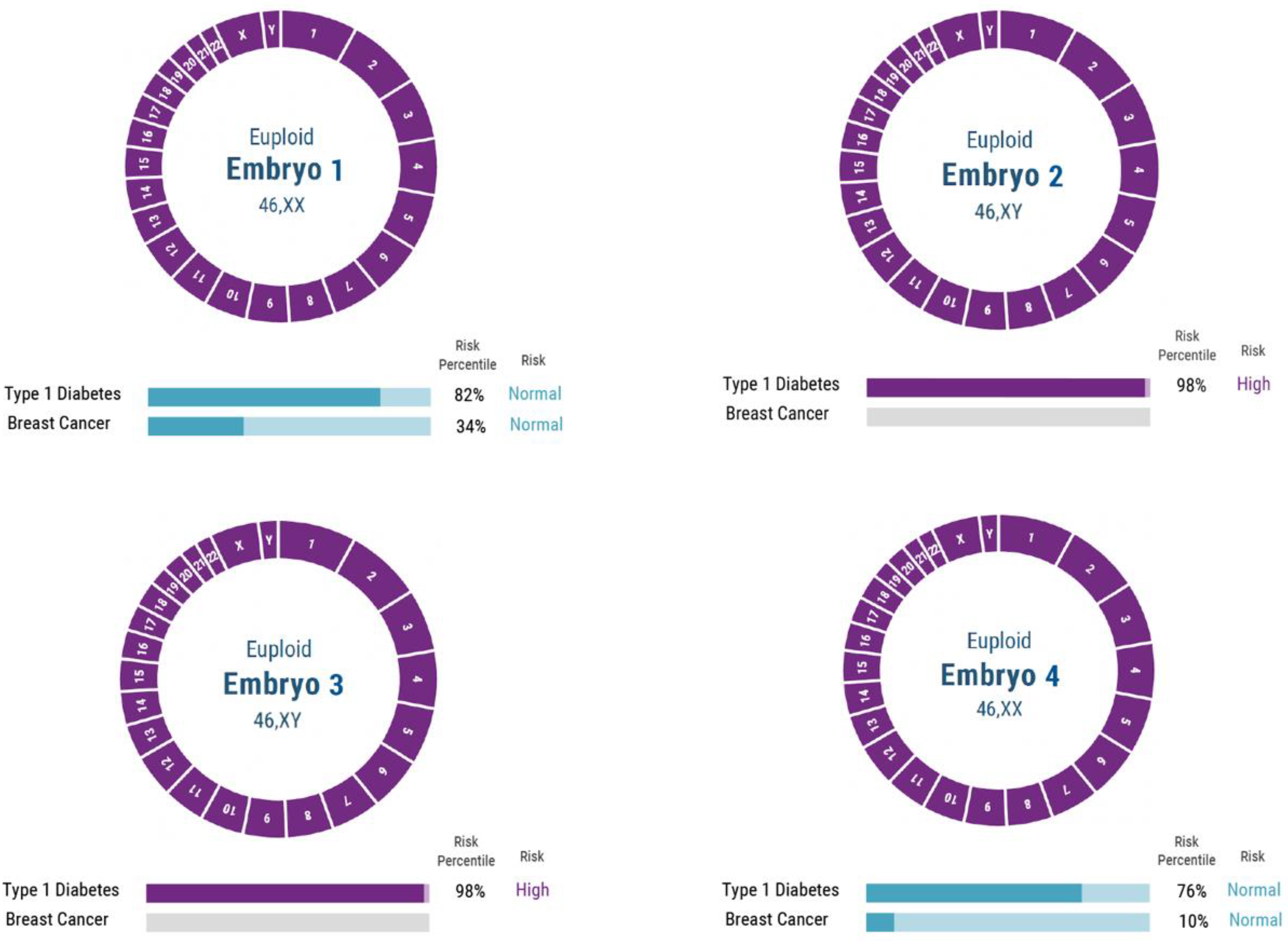
2.1. PGT-P Case with First Degree Affected Family History
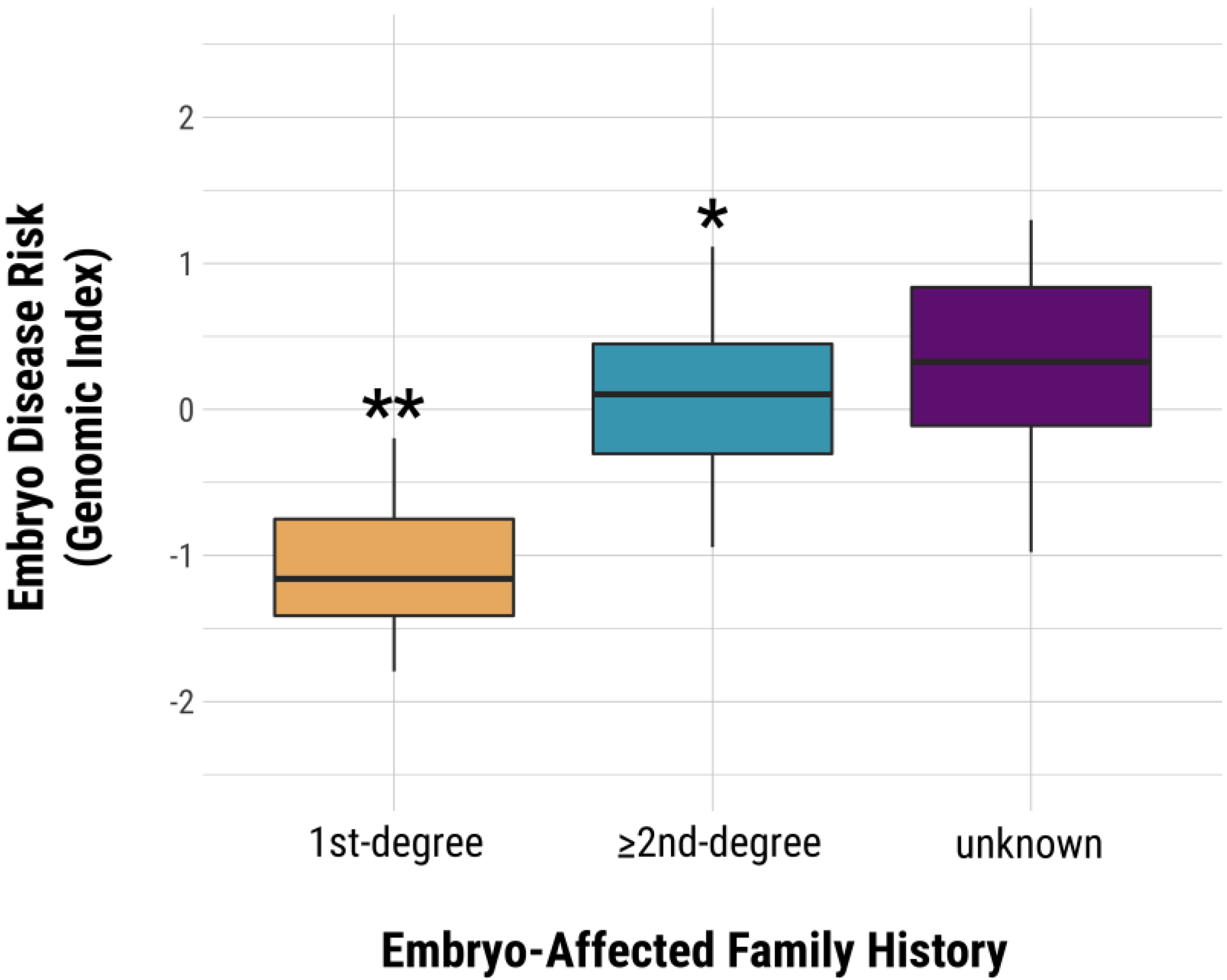
2.2. PGT-P Case Series including Unknown Family History
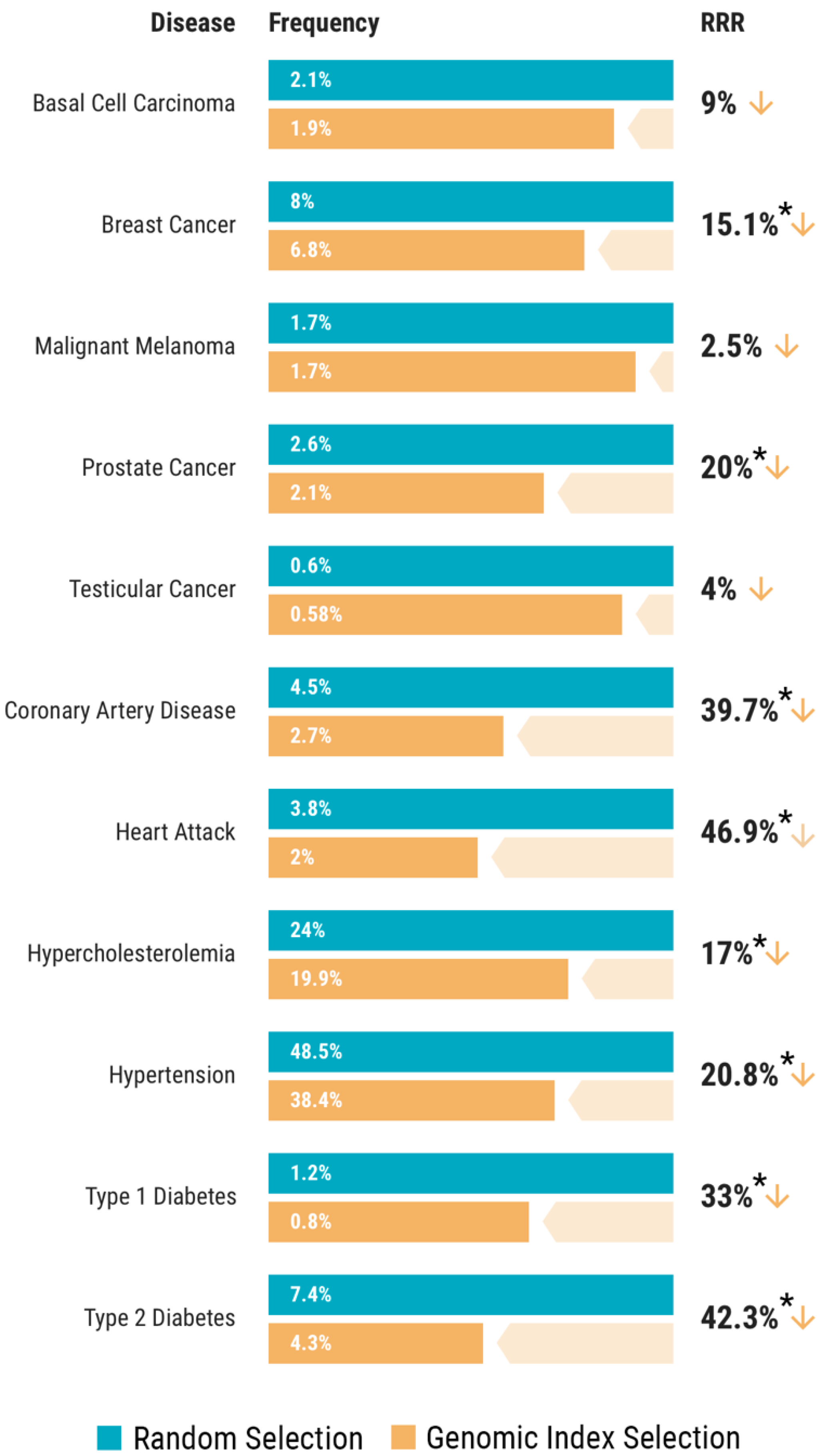
2.3. PGT-P in 11,883 Adult Sibling Pairs
3. Results
3.1. PGT-P Case with First-Degree Affected Family History
3.2. PGT-P Case Series Including Unknown Family History
3.3. Genomic Index Selection in 11,883 Adult Sibling Pairs
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- SART. Preliminary National Summary Report for 2018. Available online: https://www.sartcorsonline.com/rptCSR_PublicMultYear.aspx?reportingYear=2018 (accessed on 14 April 2020).
- Forman, E.J.; Hong, K.H.; Ferry, K.M.; Tao, X.; Taylor, D.; Levy, B.; Treff, N.R.; Jr, R.T.S. In vitro fertilization with single euploid blastocyst transfer: A randomized controlled trial. Fertil. Steril. 2013, 100, 100–107. [Google Scholar] [CrossRef] [PubMed]
- Juneau, C.; Franasiak, J.; Treff, N. Challenges facing contemporary preimplantation genetic screening. Curr. Opin. Obstet. Gynecol. 2016, 28, 151–157. [Google Scholar] [CrossRef] [PubMed]
- Gardner, D.K.; Meseguer, M.; Rubio, C.; Treff, N.R. Diagnosis of human preimplantation embryo viability. Hum. Reprod. Updat. 2015, 21, 727–747. [Google Scholar] [CrossRef]
- World Health Organization. Global Status Report on Roncommunicable Riseases 2014; World Health Organization: Geneva, Switzerland, 2014. [Google Scholar]
- Forouzanfar, M.H.; Afshin, A.; Alexander, L.T.; Anderson, H.R.; A Bhutta, Z.; Biryukov, S.; Brauer, M.; Burnett, R.; Cercy, K.; Charlson, F.J.; et al. Global, regional, and national comparative risk assessment of 79 behavioural, environmental and occupational, and metabolic risks or clusters of risks, 1990–2015: A systematic analysis for the Global Burden of Disease Study 2015. Lancet 2016, 388, 1659–1724. [Google Scholar] [CrossRef]
- Cedars, M.I.; Taymans, S.E.; DePaolo, L.V.; Warner, L.; Moss, S.B.; Eisenberg, M.L. The sixth vital sign: What reproduction tells us about overall health. Proceedings from a NICHD/CDC workshop. Hum. Reprod. Open 2017, 2017, hox008. [Google Scholar] [CrossRef]
- Khera, A.V.; Chaffin, M.D.; Aragam, K.G.; Haas, M.E.; Roselli, C.; Choi, S.H.; Natarajan, P.; Lander, E.S.; Lubitz, S.A.; Ellinor, P.T.; et al. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nat. Genet. 2018, 50, 1219–1224. [Google Scholar] [CrossRef]
- Torkamani, A.; E Wineinger, N.; Topol, E.J. The personal and clinical utility of polygenic risk scores. Nat. Rev. Genet. 2018, 19, 581–590. [Google Scholar] [CrossRef]
- Treff, N.; Zimmerman, R.; Bechor, E.; Hsu, J.; Rana, B.; Jensen, J.; Li, J.; Samoilenko, A.; Mowrey, W.; Van Alstine, J.; et al. Validation of concurrent preimplantation genetic testing for polygenic and monogenic disorders, structural rearrangements, and whole and segmental chromosome aneuploidy with a single universal platform. Eur. J. Med Genet. 2019, 62, 103647. [Google Scholar] [CrossRef]
- Duncan, L.; Shen, H.; Gelaye, B.; Meijsen, J.; Ressler, K.; Feldman, M.; Peterson, R.; Domingue, B.W. Analysis of polygenic risk score usage and performance in diverse human populations. Nat. Commun. 2019, 10, 3328. [Google Scholar] [CrossRef]
- Treff, N.; Eccles, J.; Lello, L.; Bechor, E.; Hsu, J.; Plunkett, K.; Zimmerman, R.; Rana, B.; Samoilenko, A.; Hsu, S.; et al. Utility and First Clinical Application of Screening Embryos for Polygenic Disease Risk Reduction. Front. Endocrinol. 2019, 10, 845. [Google Scholar] [CrossRef]
- Alexander, D.H.; Novembre, J.; Lange, K. Fast model-based estimation of ancestry in unrelated individuals. Genome Res. 2009, 19, 1655–1664. [Google Scholar] [CrossRef]
- Gibbs, R.A.; Belmont, J.W.; Hardenbol, P.; Willis, T.D.; Yu, F.; Yang, H.; Ch’ang, L.-Y.; Huang, W.; Liu, B.; Shen, Y.; et al. The International HapMap Project. Nature 2003, 426, 789–796. [Google Scholar] [CrossRef]
- Packer, B.R. SNP500Cancer: A public resource for sequence validation, assay development, and frequency analysis for genetic variation in candidate genes. Nucleic Acids Res. 2006, 34, 617–621. [Google Scholar] [CrossRef][Green Version]
- Yong, S.Y.; Raben, T.; Lello, L.; Hsu, S.D.H. Genetic Architecture of Complex Traits and Disease Risk Predictors. bioRxiv 2020. [Google Scholar] [CrossRef]
- Torrance, G.W.; Feeny, D. Utilities and Quality-Adjusted Life Years. Int. J. Technol. Assess. Heal. Care 1989, 5, 559–575. [Google Scholar] [CrossRef]
- Lello, L.; Raben, T.; Yong, S.Y.; Tellier, L.C.A.M.; Hsu, S.D.H. Genomic Prediction of 16 Complex Disease Risks Including Heart Attack, Diabetes, Breast and Prostate Cancer. Sci. Rep. 2019, 9, 1–16. [Google Scholar] [CrossRef]
- Franco, O.H.; Peeters, A.; Bonneux, L.; De Laet, C. Blood Pressure in Adulthood and Life Expectancy With Cardiovascular Disease in Men and Women. Hypertens. 2005, 46, 280–286. [Google Scholar] [CrossRef]
- Yang, J.; Liu, Y.N.; Liu, J.M.; Zeng, X.Y.; Zhao, Y.F.; Wang, Z.Q.; Zhou, M.G. The effect of high total cholesterol on life expectancy in 2013 in China. Zhonghua Liu Xing Bing Xue Za Zhi 2017, 38, 1017–1021. [Google Scholar] [CrossRef]
- Grundtvig, M.; Hagen, T.P.; Amrud, E.S.; Reikvam, Å. Reduced life expectancy after an incident hospital diagnosis of acute myocardial infarction — Effects of smoking in women and men. Int. J. Cardiol. 2013, 167, 2792–2797. [Google Scholar] [CrossRef]
- Capocaccia, R.; Gatta, G.; Maso, L.D. Life expectancy of colon, breast, and testicular cancer patients: An analysis of US-SEER population-based data. Ann. Oncol. 2015, 26, 1263–1268. [Google Scholar] [CrossRef]
- Livingstone, S.J.; Levin, D.; Looker, H.C.; Lindsay, R.S.; Wild, S.H.; Joss, N.; Leese, G.; Leslie, P.; McCrimmon, R.J.; Metcalfe, W.; et al. Estimated life expectancy in a Scottish cohort with type 1 diabetes, 2008-2010. JAMA 2015, 313, 37–44. [Google Scholar] [CrossRef] [PubMed]
- Syriopoulou, E.; Bower, H.; Andersson, T.M.-L.; Lambert, P.C.; Rutherford, M.A. Estimating the impact of a cancer diagnosis on life expectancy by socio-economic group for a range of cancer types in England. Br. J. Cancer 2017, 117, 1419–1426. [Google Scholar] [CrossRef] [PubMed]
- Hollestein, L.M.; De Vries, E.; Aarts, M.J.; Schroten, C.; Nijsten, T.E. Burden of disease caused by keratinocyte cancer has increased in The Netherlands since 1989. J. Am. Acad. Dermatol. 2014, 71, 896–903. [Google Scholar] [CrossRef]
- Chang, C.C.; Chow, C.C.; Tellier, L.C.A.M.; Vattikuti, S.; Purcell, S.M.; Lee, J.J. Second-generation PLINK: Rising to the challenge of larger and richer datasets. GigaScience 2015, 4, 7. [Google Scholar] [CrossRef] [PubMed]
- Bycroft, C.; Freeman, C.; Petkova, D.; Band, G.; Elliott, L.T.; Sharp, K.; Motyer, A.; Vukcevic, D.; Delaneau, O.; O’Connell, J.; et al. The UK Biobank resource with deep phenotyping and genomic data. Nature 2018, 562, 203–209. [Google Scholar] [CrossRef]
- Rojas, K.; Stuckey, A. Breast Cancer Epidemiology and Risk Factors. Clin. Obstet. Gynecol. 2016, 59, 651–672. [Google Scholar] [CrossRef]
- Hariri, S.; Yoon, P.W.; Qureshi, N.; Valdez, R.; Scheuner, M.T.; Khoury, M.J. Family history of type 2 diabetes: A population-based screening tool for prevention? Genet. Med. 2006, 8, 102–108. [Google Scholar] [CrossRef]
- Watanabe, K.; Stringer, S.; Frei, O.; Mirkov, M.U.; De Leeuw, C.A.; Polderman, T.J.; Van Der Sluis, S.; Andreassen, O.A.; Neale, B.M.; Posthuma, D. A global overview of pleiotropy and genetic architecture in complex traits. Nat. Genet. 2019, 51, 1339–1348. [Google Scholar] [CrossRef]
- Murray, C.J.; Lopez, A. Measuring the Global Burden of Disease. N. Engl. J. Med. 2013, 369, 448–457. [Google Scholar] [CrossRef]
- Devleesschauwer, B.; De Noordhout, C.M.; Smit, S.; Duchateau, L.; Dorny, P.; Stein, C.; Van Oyen, H.; Speybroeck, N. Quantifying burden of disease to support public health policy in Belgium: Opportunities and constraints. BMC Public Heal. 2014, 14, 1196. [Google Scholar] [CrossRef]
- Badano, J.; Katsanis, N. Beyond Mendel: An evolving view of human genetic disease transmission. Nat. Rev. Genet. 2002, 3, 779–789. [Google Scholar] [CrossRef] [PubMed]
- Do, C.B.; Hinds, D.A.; Francke, U.; Eriksson, N. Comparison of Family History and SNPs for Predicting Risk of Complex Disease. PLoS Genet. 2012, 8, e1002973. [Google Scholar] [CrossRef] [PubMed]
- Lazarin, G.A.; Haque, I.S.; Nazareth, S.; Iori, K.; Patterson, A.S.; Jacobson, J.L.; Marshall, J.R.; Seltzer, W.K.; Patrizio, P.; Evans, E.A.; et al. An empirical estimate of carrier frequencies for 400+ causal Mendelian variants: Results from an ethnically diverse clinical sample of 23,453 individuals. Genet. Med. 2012, 15, 178–186. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease. | Male | Female |
|---|---|---|
| Basal Cell Carcinoma | 0.0224 | 0.2655 |
| Breast Cancer | 0.0001 | |
| Malignant Melanoma | 0.3518 | 0.4661 |
| Prostate Cancer | 0.0224 | |
| Testicular Cancer | 0.5 | |
| Coronary Artery Disease | 9.53 × 10−16 | 3.09 × 10−7 |
| Heart Attack | 7.31 × 10−22 | 1.24 × 10−6 |
| Hypercholesterolemia | 4.73 × 10−10 | 1.21 × 10−11 |
| Hypertension | 3.03 × 10−25 | 3.08 × 10−33 |
| Type 1 Diabetes | 0.0019 | 0.0083 |
| Type 2 Diabetes | 1.64 × 10−17 | 2.09 × 10−21 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Treff, N.R.; Eccles, J.; Marin, D.; Messick, E.; Lello, L.; Gerber, J.; Xu, J.; Tellier, L.C.A.M. Preimplantation Genetic Testing for Polygenic Disease Relative Risk Reduction: Evaluation of Genomic Index Performance in 11,883 Adult Sibling Pairs. Genes 2020, 11, 648. https://doi.org/10.3390/genes11060648
Treff NR, Eccles J, Marin D, Messick E, Lello L, Gerber J, Xu J, Tellier LCAM. Preimplantation Genetic Testing for Polygenic Disease Relative Risk Reduction: Evaluation of Genomic Index Performance in 11,883 Adult Sibling Pairs. Genes. 2020; 11(6):648. https://doi.org/10.3390/genes11060648
Chicago/Turabian StyleTreff, Nathan R., Jennifer Eccles, Diego Marin, Edward Messick, Louis Lello, Jessalyn Gerber, Jia Xu, and Laurent C.A.M. Tellier. 2020. "Preimplantation Genetic Testing for Polygenic Disease Relative Risk Reduction: Evaluation of Genomic Index Performance in 11,883 Adult Sibling Pairs" Genes 11, no. 6: 648. https://doi.org/10.3390/genes11060648
APA StyleTreff, N. R., Eccles, J., Marin, D., Messick, E., Lello, L., Gerber, J., Xu, J., & Tellier, L. C. A. M. (2020). Preimplantation Genetic Testing for Polygenic Disease Relative Risk Reduction: Evaluation of Genomic Index Performance in 11,883 Adult Sibling Pairs. Genes, 11(6), 648. https://doi.org/10.3390/genes11060648