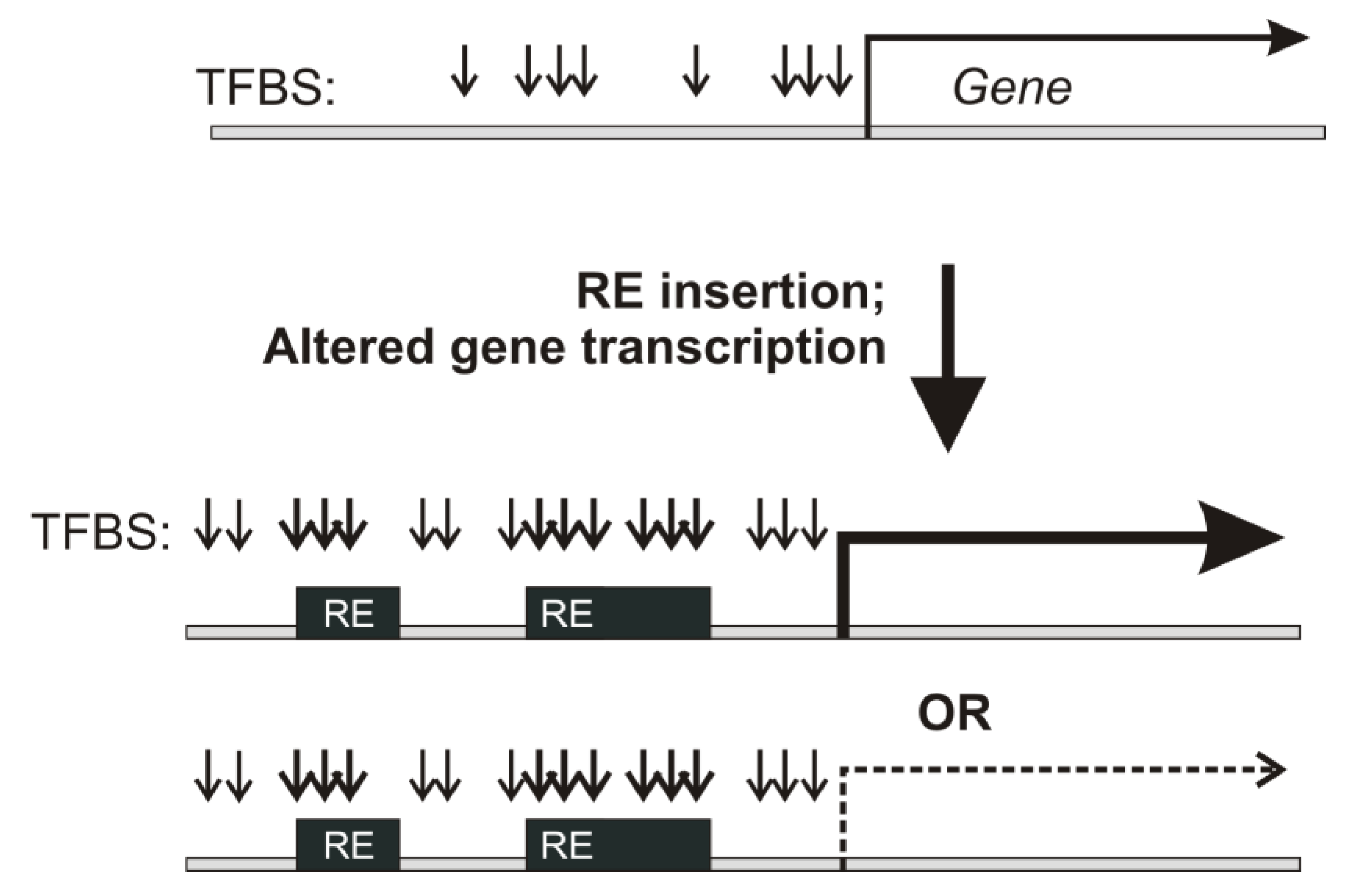
3.1. Mapping of RE-Specific TFBS
From the ENCODE project repository, we extracted experimental TFBS data based on the sequencing of immunoprecipitated DNA for 563 transcription factor proteins [
6,
58,
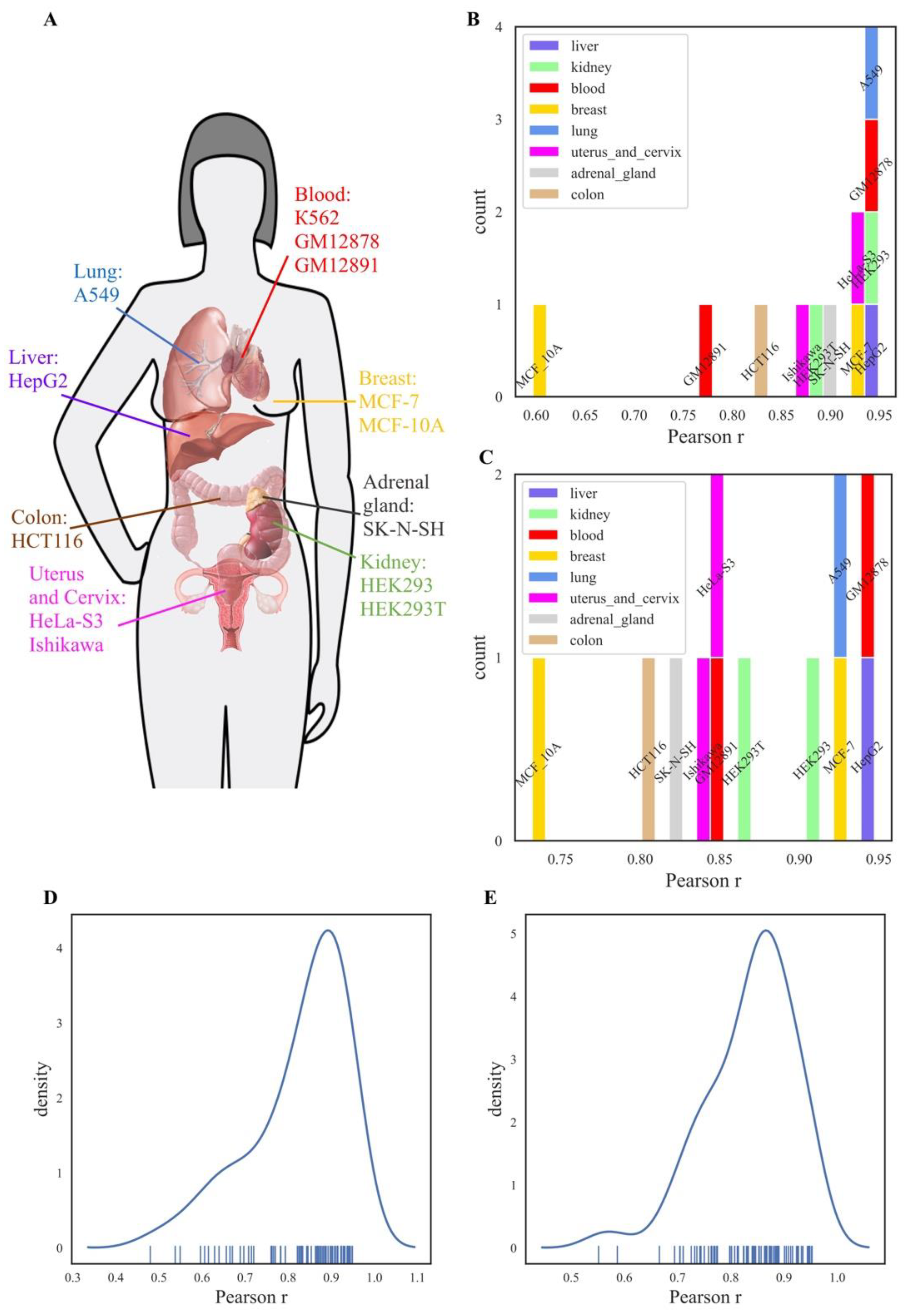
59]. The sufficient amount of data including mapping TFBS for at least three transcription factors was available for 13 human cell lines (
Supplementary file 2): myelogenous leukemia K562, transformed B cells GM12891, transformed lymphoblasts GM12878, cervix adenocarcinoma HeLa S3, endometrial adenocarcinoma Ishikawa, original and transformed human embryonal kidney HEK293 and HEK293T, breast cancer MCF-7 and MCF-10A, lung adenocarcinoma A549, hepatocyte carcinoma HepG2, colon carcinoma HCT116, and neuroblastoma SK-N-SH. These cell lines, therefore, represented eight cancerous or transformed human tissues/organs: blood, cervix, kidney, adrenal gland, mammary gland, lung, liver, and colon. Statistics for the TFBS data extracted and mapped on REs for these cell lines is shown in
Table 1.
In total, 277,187,723 TFBS hits could be mapped on the human genome for all these cell lines. Of them, 55.5% overlapped with the RE sequences, thus confirming that REs serve as the major source of TFBS in human cells.
Considering previous reports, this proportion may seem high [
60]. However, in our analysis, all multimapped TFBS reads were filtered out according to the standard ENCODE ChIP-seq mapping and filtering pipeline [
42], so the results represented uniquely mapped TFBS reads. To confirm this TFBS proportion, we also validated the method used by parallel mapping of all human RE sequences extracted from USCS Genome Browser [
55] on the human genome. In a good agreement with previously published data [
1], REs mapped by the same approach occupied ~45% of human DNA, genome assembly hg19. We therefore found no technological drawbacks here and suggest that the proportion of 55.5% RE-linked TFBS is correct at least for the ENCODE primary cell culture datasets used.
However, this proportion was somewhat lower for the TFBS mapped in a 10-kb neighborhood of gene transcriptional start sites (TSS): among 43,042,026 totally mapped TFBS, only 47% overlapped with REs. This overall trend was representative for all cell lines under investigation (
Table 2). The TSS-proximal TFBS hits were unevenly distributed among the major classes of REs: ~30% were attributed to SINEs; ~17%–to LINEs and ~7%–to LTR retrotransposons and endogenous retroviruses. For the total fraction of RE-linked TFBS hits (not only gene-proximal), these proportions were, respectively, 28%, 26% and 12%.
These data evidence that TSS-proximal TFBS are peculiar because they have a ~1,2-fold lower proportion of RE-linked hits (
Table 1).
The distribution of TFBS hits for the different transcriptional factor proteins varied among the different cell lines (
Supplementary file 6, color scale shows depth of TFBS mapping; blank spaces mean an absence of TFBS data for the respective transcriptional factor in the context of a given cell line in the ENCODE dataset).
3.4. Genes and Molecular Pathways Enriched or Deficient in all RE-Linked TFBS Regulation
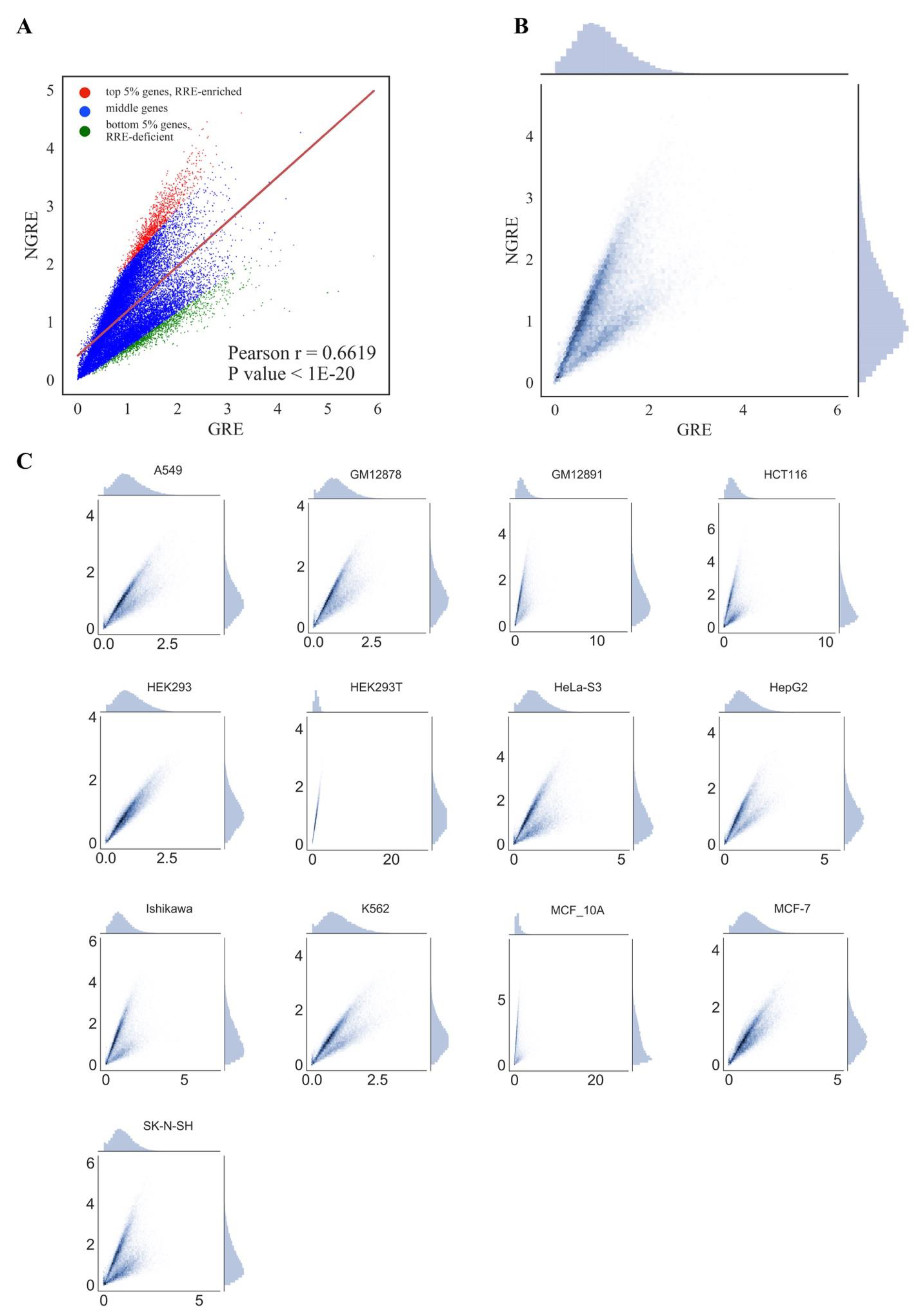
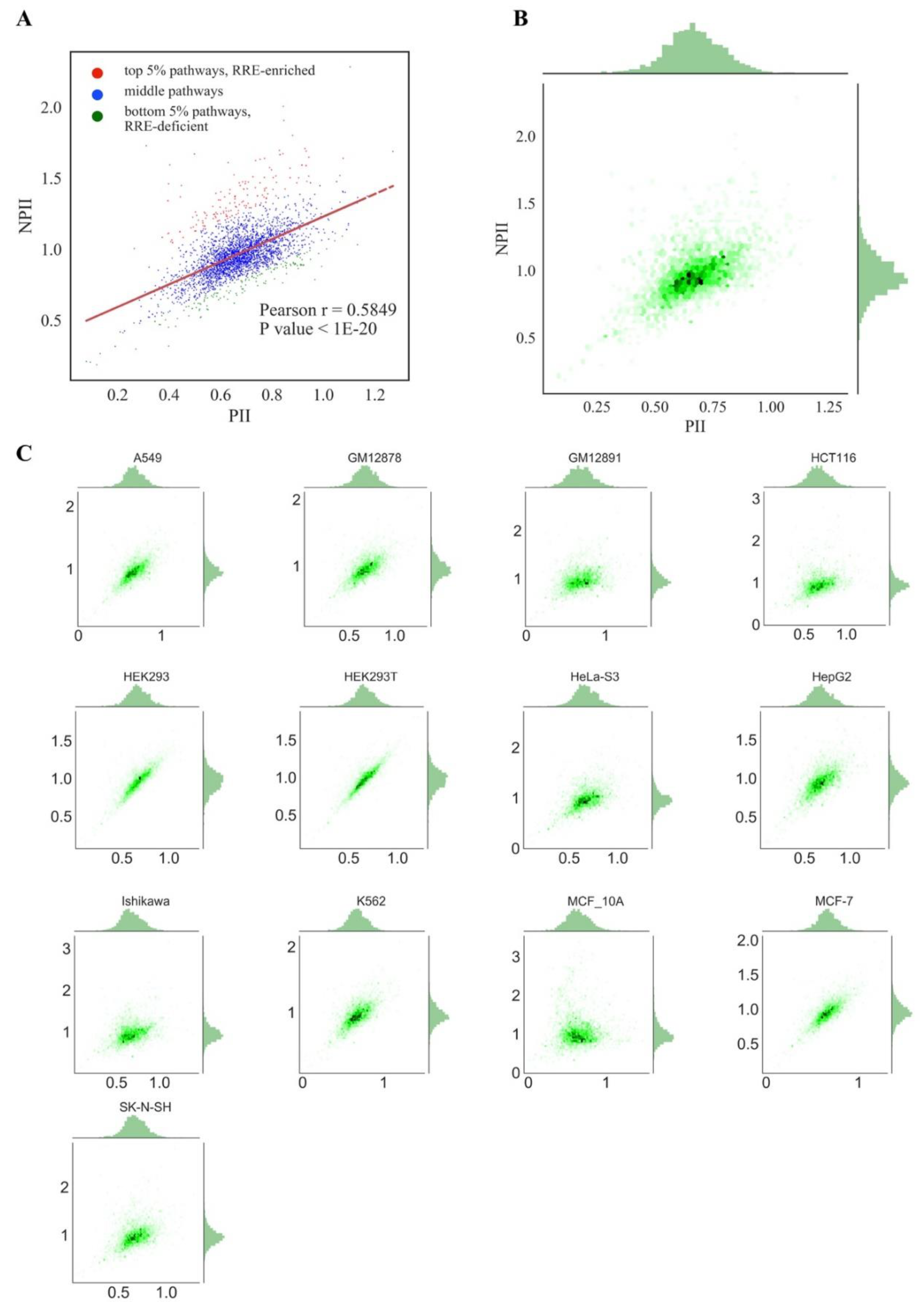
We next attempted to identify genes and molecular pathways enriched or deficient in RE-linked TFBS regulation (
RRE-enriched and
RRE-deficient genes/pathways). To this end, 24,389 human genes and 3123 pathways under investigation were examined respectively on scatter plots with an
abscissa axis showing the
GRE score for genes or
PII for pathways, and, respectively,
ordinate axis showing the
NGRE score for genes and
NPII for pathways (
Figure 3 and
Figure 4, respectively). This kind of presentation enables to visually distinguish genes/pathways that have a higher or lower
RRE impact. Among the entries with the same
GRE /
PII scores, those having higher
NGRE /
NPII metrics will be enriched in
RRE, end vice versa: Those with lower
NGRE /
NPII will be
RRE-
deficient.
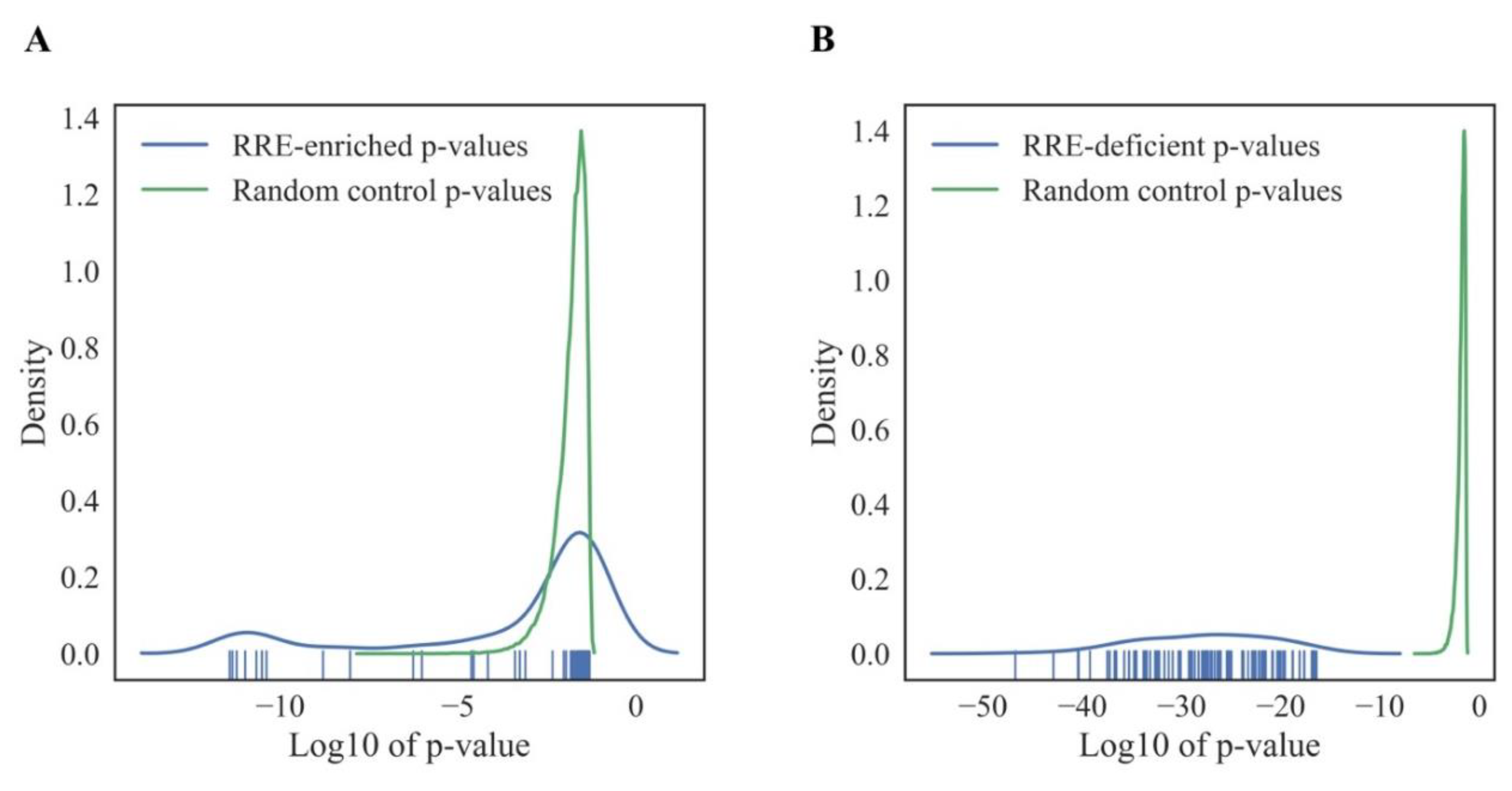
For both types of graphs, we observed very similar distribution trends among the different cell lines (
Figure 3 and
Figure 4). At the pathway level,
PII and
NPII scores were statistically significantly correlated for all the cell lines (Pearson r~0.58;
Figure 4). Correlation was also strong at the gene level (
GRE /
NGRE), but in 12/13 of the cell lines tested we observed unusual yet very similar V-shaped distributions (
Figure 3). This shape was remarkable and represented two rays of higher and lower slope coming from a zero point. The upper and lower rays accumulated, respectively, in relatively
RRE-enriched and
RRE-deficient genes.
We concluded, therefore, that different cell lines demonstrate highly similar patterns of RE-linked TFBS regulation at both the gene and pathway levels, as also suggested by the strong correlations among the cell lines (previous section). To operate with the universal values representing all cell lines tested, we next introduced the aggregated scores equal to the mean
GRE,
NGRE, PII and
NPII values for all cell lines investigated, respectively (
Figure 3A,B,
Figure 4A,B). The distributions of the aggregated values were similar to those for the individual cell lines (
Figure 3 and
Figure 4).
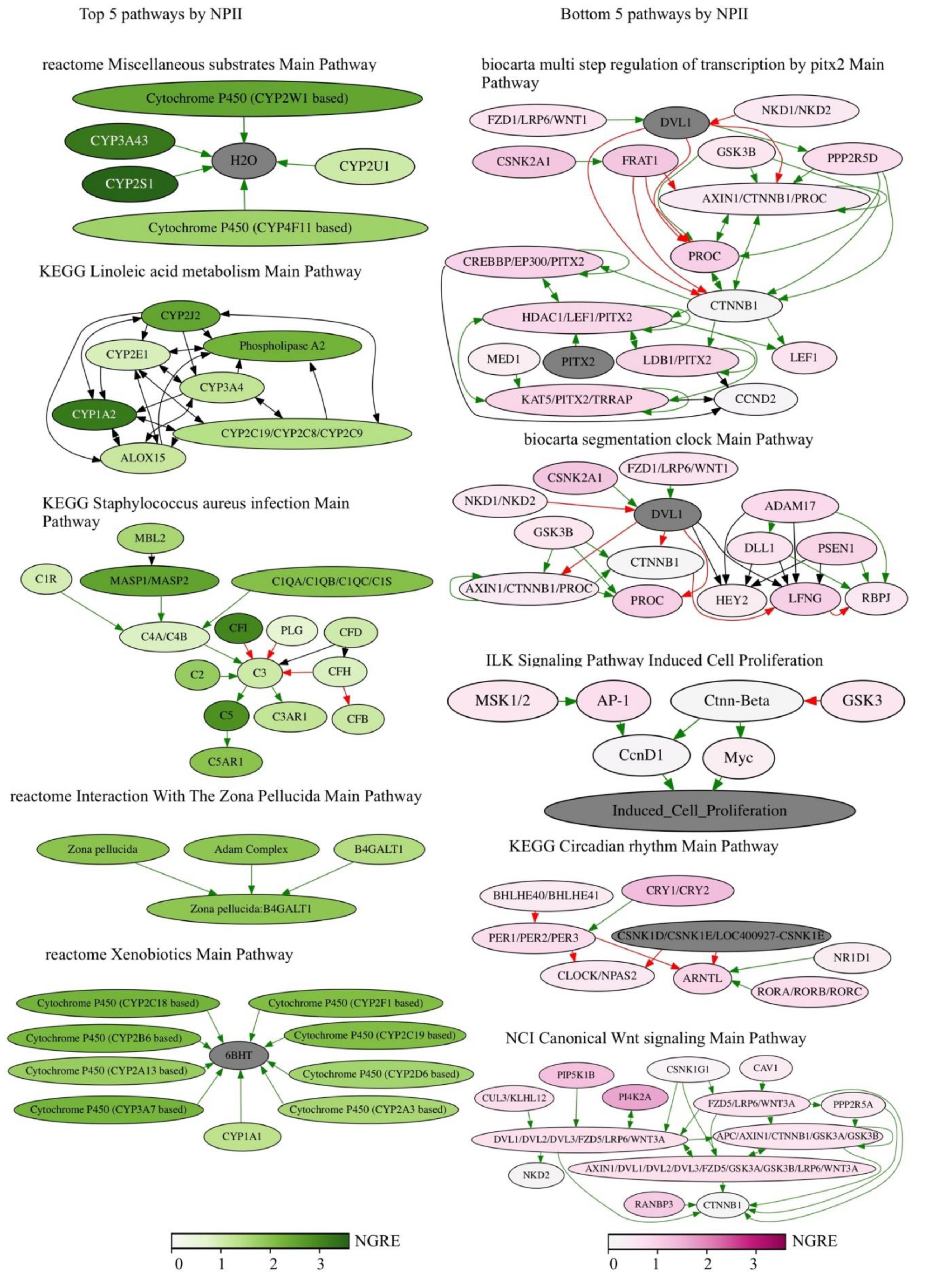
To formalize the identification of the top
RRE-
enriched and
deficient genes and pathways, we did the following. For the gene level, 1000 random sets each containing 500 genes were examined and a regression line (polynomial curve of first degree) was calculated using the Least Squares method [
61]. Then two regression lines with the highest and lowest slope were selected. Then, 5% (1219) genes lying above the highest slope regression line with the maximal Euclidean distance to this regression line were considered as
RRE-
enriched. Similarly, 5% of the genes lying below the lowest slope regression line with maximal Euclidean distance from it were considered as
RRE-
deficient (
Figure 3).
At the level of molecular pathways, a regression line (polynomial curve of first degree) was calculated using the Least Squares method [
61] for the entire set of 3123 molecular pathways. Five percent (156) of pathways with maximal Euclidean distance lying above the regression line were considered as
RRE-enriched, and 5% with maximal Euclidean distance lying below the regression line were considered as
RRE-deficient pathways (
Figure 4). We, therefore, identified 1219 top and 1219 bottom genes and 156 top and 156 bottom molecular pathways according to a measured aggregated RE-linked TFBS regulation in all13 human cell lines tested (
Supplementary dataset 9 and 10).
3.5. Functional Characteristics of Top RRE-Enriched and Deficient Genes (all REs)
For the selected 1219 top and 1219 bottom genes, we performed Gene Ontology (GO) analysis using DAVID software [
62,
63] to identify if they are enriched by the clusters of genes included in any biological processes. The data on the top GO annotation clusters with a p-value < 0.05 are shown in
Supplementary dataset 11. In total, 141 GO annotation terms were identified for the
RRE-enriched genes, versus as much as 1022 (~7 times more) terms for the fraction of
RRE-deficient genes. This finding may represent a phenomenon that more biological processes in human cells are evolutionary conserved than quickly evolving.
We manually curated the identified annotation terms and could classify them into 27 major groups (
Table 3). The significantly
RRE-enriched groups of the processes dealt with the metabolism of amino acids, lipids and metals, detoxication and response to xenobiotics, with sensory perception, neurotransmission and fertilization. The
RRE-deficient groups of processes were more numerous and featured protein translation, RNA transcription, intracellular signaling, cell adhesion and interaction, cell cycle progression, programmed cell death, metabolism of nucleic acids, carbohydrates, response to phorbol acetate, protein modifications, stress response and general virus response mechanisms, maintaining chromatin organization, electron transfer chain, and mitochondria functioning.
Fifty annotation terms were linked with immunity; they were distributed differently depending on their functional roles. For example, immune cells migration/activation and cellular immune response by T- and NK cells were
RRE-enriched, whereas B cells-related terms were
RRE-deficient (
Table 4).
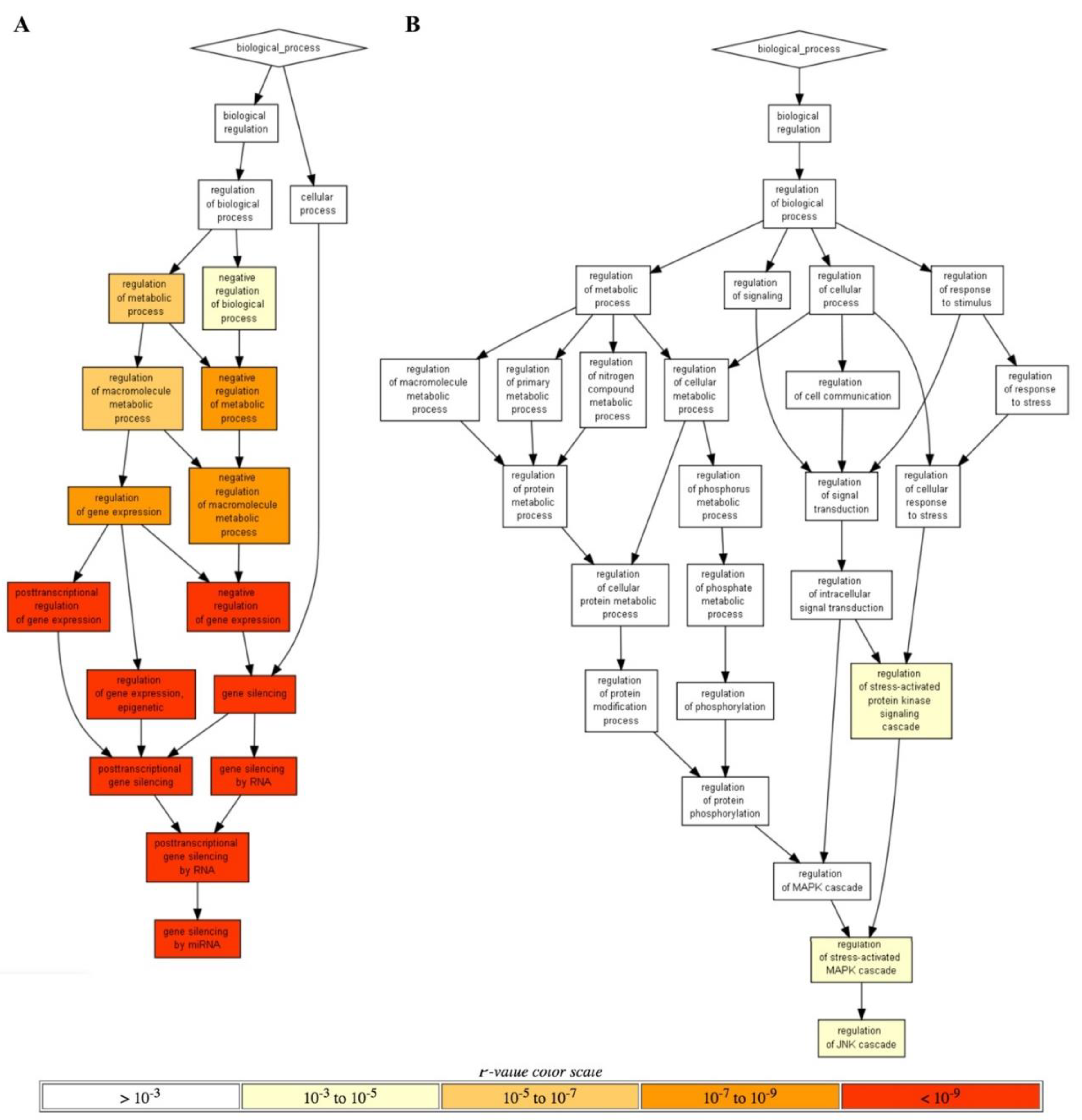
In addition, another line of GO data analysis performed using Gorilla software [
64] returned only the annotation terms that could pass significantly more stringent threshold. In this way, a unique yet extremely strongly statistically significant
RRE-enriched annotation cluster (p < 10
−9;
Figure 5A) was for gene silencing by microRNAs, whereas the top two
RRE-deficient processes were for the Regulation of stress-activated MAPK cascade and Regulation of JNK cascade (p < 10
−3;
Figure 5B).
We next compared the microRNA (miR) contents of the
RRE-enriched and
-deficient gene sets (
Table 5). The
enriched group had 177 miR genes versus only 72 miR genes in the
deficient group. Provided that the total content of miR genes in the human genome is 1865, a hypothesis can be accepted that the
RRE-enriched group is also enriched in microRNA genes (p < 10
−17) and that the
RRE-deficient group is not enriched (p = 0.01). Similarly, the content of long non-coding RNA (lncRNA) genes also differed significantly among the gene sets (150 in the
enriched versus only 18 in the
deficient group;
Table 5). With the total number of 1505 lncRNA genes in the human genome, this statistically supports the hypothesis that the
RRE-enriched group is also enriched in lncRNA genes (p < 10
−16) and that the
RRE-deficient group is not enriched (p < 10
−15). These findings clearly suggest that the regulation by RE-linked TFBS was particularly strongly recruited in the recent evolution of microRNA- and lncRNA-related mechanisms.
3.7. Consensus Molecular Processes according to Gene- and Pathway- Based Assays (all REs)
Comparison of the results obtained at the gene and molecular pathway levels is outlined in
Table 3. As mentioned above, the results obtained using these two alternative methods were highly congruent. The following molecular processes showed consensus regulation patterns using both types of data analysis. Processes with the
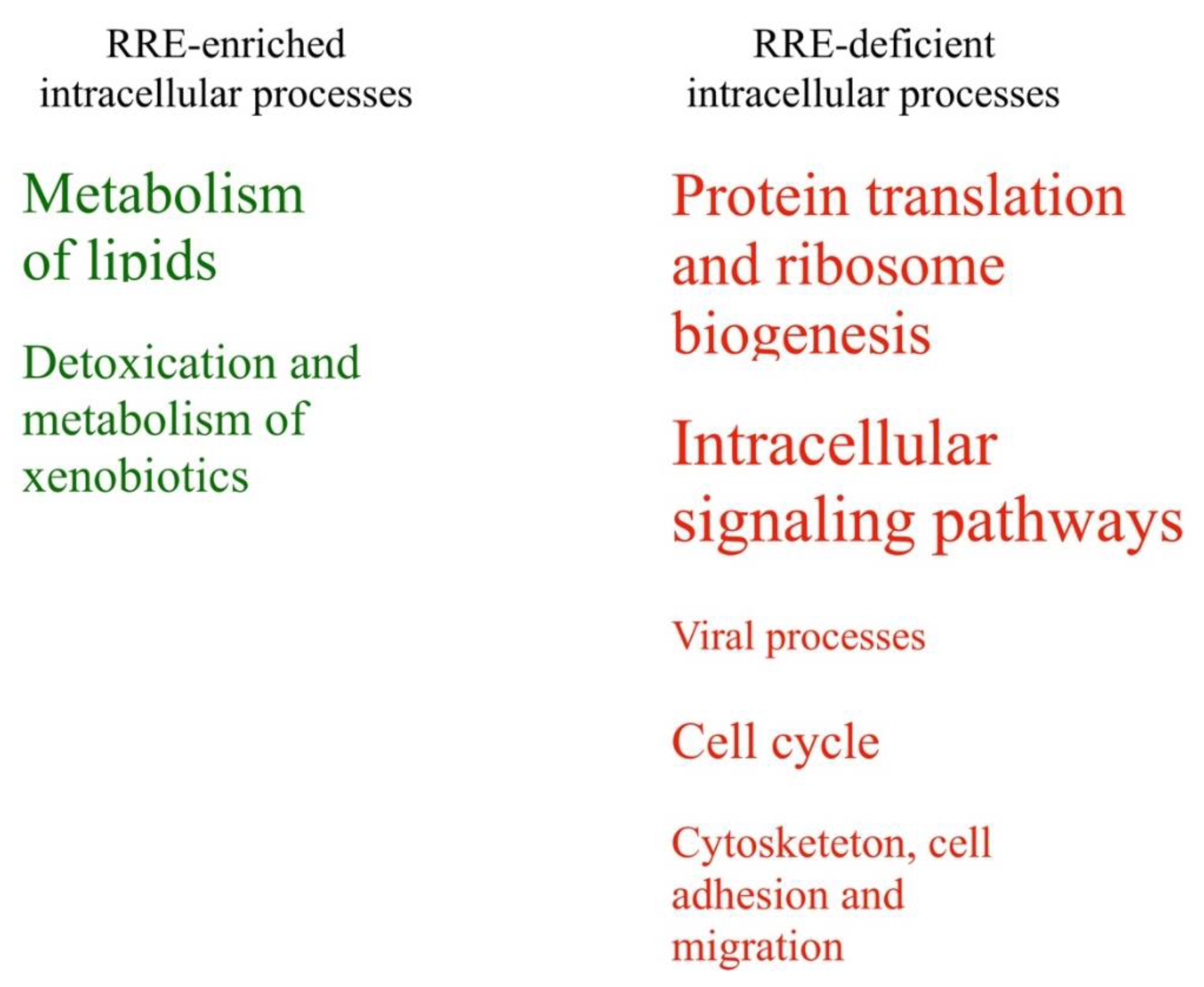
RRE-enriched regulation: (1) posttranscriptional silencing by small RNAs; (2) DNA repair; metabolism of (3) amino acids and (4) lipids; (5) detoxication and metabolism of xenobiotics; (6) sensory perception and neurotransmission; (7) fertilization; (8) T- and NK-cellular immune response.
More specifically, the posttranscriptional silencing by small RNAs (1) was represented by a single pathway and one GO term featuring gene regulation by microRNAs. Note also that according to GO analysis, the microRNA regulation was statistically the most strongly enriched cluster in the RRE-enriched subset. The content of microRNA and long non-coding (lnc) RNA genes in this subset was statistically also significantly enriched (p < 10−16).
The DNA repair (2) cluster was represented by the Protein kinase pathway in nonhomologous end joining and by the GO terms of Mitotic recombination, DNA synthesis involved in DNA repair, Meiosis, and Strand displacement.
The metabolism of amino acids (3) was represented by the pathways of D-arginine and D-ornithine metabolism, aspartate, asparagine, lysine, diphtamide, carnitine biosynthesis and cysteine, proline, hydroxyproline, beta-alanine, tryptophan and L-kynurenine catabolism, glutamate removal from folates, and conjugation of salicylate and benzoate with glycine. The GO terms were for the proline metabolic and tryptophan catabolic processes.
The metabolism of lipids (4) had pathways of bile secretion, bile salt and organic anion SLC transporters, fatty acids cycling pathway, acyl-CoA hydrolysis, alpha-linolenic acid metabolism, alpha-oxidation of phytanate, beta-oxidation of unsaturated fatty acids, lipoxin biosynthesis, ether lipid metabolism pathway, synthesis of (16–20)–hydroxyeicosatetraenoic, epoxyeicosatrienoic and dihydroxyeicosatrienoic acids, and phosphatidylinositol acyl chain remodeling pathway. The GO terms were for lipid catabolic process, carboxylic ester hydrolase activity, arachidonic acid metabolism, epoxygenase and monooxygenase activity, and lipase activity.
The detoxication and metabolism of xenobiotics (5) cluster included pathways of CYP2E1 reactions, drug metabolism by cytochrome P450, nicotine, heme and bupropion degradation, caffeine metabolism, flavin-containing monooxygenase (FMO) oxidation of nucleophiles, formaldehyde oxidation, S-reticuline metabolism, aflatoxin activation and detoxification. The GO terms were for cellular response to xenobiotic stimulus, xenobiotic metabolic process and epoxygenase P450 pathway.
The cluster of sensory perception and neurotransmission (6) processes has molecular pathways involved in olfactory signaling and transduction, visual signal perception via cones and GABA A (rho) receptor activation, dopamine receptors pathway and mechanism of acetaminophen activity, and toxicity pathway. The GO terms here were for the sensory perception of smell, odorant binding and olfactory receptor activity.
The fertilization (7) was represented by a unique pathway of interaction with the zona pellucida and by several GO terms: fertilization, sperm-egg recognition, sperm flagellum, positive regulation of sperm motility, binding of sperm to zona pellucida, and single fertilization.
The T- and NK-cellular immune response (8) pathways regulated the phosphorylation of CD3 and T-cellular receptor zeta chains, downstream signaling in naive CD8 T-cells (alpha, beta T-cell proliferation), and CD28 co-stimulation in T-cell homeostasis. The GO terms were for the regulation of leukocyte-mediated cytotoxicity, natural killer cell-mediated immunity and its regulation.
Finally, the processes with the RRE-deficient regulation were: (9) nucleotide and DNA metabolism; (10) maintenance and modulation of chromatin structure; (11) protein translation and ribosome biogenesis; (12) intracellular signaling pathways; and (13) cellular mechanisms of antiviral response.
Here, the nucleotide and DNA metabolism (9) pathways controlled adenine and adenosine salvage, cleavage of the damaged purines, UMP biosynthesis, UDP-N-acetyl-D-galactosamine biosynthesis, GDP-L-fucose biosynthesis from GDP-D-mannose, and NADH repair. The GO terms were found for ATP metabolism, adenine transport, GTP binding, purine nucleosides and ribonucleotides metabolism, and pyrimidine binding.
The maintenance and modulation of chromatin structure (10) clade comprised pathways of PRC2 methylation of histones and DNA, HDACs histone deacetylation, arginine methyltransferases (RMTs) methylation of histone arginine residues, G2/M DNA damage checkpoint, and HDAC proteasomal degradation. The GO terms were found for the CENP-dependent centromere formation, for telomere formation and capping, lamin binding with chromatin, purine NTP-dependent helicase activity, histone exchange, histone lysine H3-K4 and H3-K9 methylation, acetylation and deacetylation, and for signal transduction in response to DNA damage.
The protein translation and ribosome biogenesis (11) pathways account for ribosomal and transfer RNA transcription, processing including RNA modifications such as wybutosine and 7-3-amino-3-carboxypropyl-wyosine biosynthesis, spliceosomal biogenesis and assembly, ribosomal assembly, tRNA aminoacetylation, ribosomal scanning, initiation, elongation and termination of translation for nonsense mediated decay. The identified GO terms fully functionally matched these molecular pathways.
The
intracellular signaling pathways (12) formed the biggest group of molecular processes including 94 various pathways and 48 GO terms. These included all major aspects of human intracellular signaling (
Table 3).
The cellular mechanisms of antiviral response (13) included pathways of host cell interaction with retroviruses, including APOBEC3-mediated resistance to HIV-1 infection. The GO terms were related to the assembly of viral capsids, viral transcription and translation, and IRES-dependent and cap-independent viral translational initiation.
All these categories were represented by different numbers of enclosed pathways and GO terms (
Table 3). Schematically, these processes linked with enriched or deficient RRE-regulation are shown in
Figure 7 in relation with the number of enclosed features. Fourteen other groups of processes (50%) were identified as either RRE-enriched or deficient using only one of the methods used (either
gene- or
pathway-based), and only one group (~4% of the total amount of groups considered) for the metabolism of carbohydrates showed ambiguous trends in these two types of analyses (
Table 3).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}