

Downregulation of Ribosomal Protein Genes Is Revealed in a Model of Rat Hippocampal Neuronal Culture Activation with GABA(A)R/GlyRa2 Antagonist Picrotoxin

 , and
, and
Abstract
1. Introduction
2. Materials and Methods
2.1. Primary Hippocampal Neuron Cultures and Their Activation with PTX
2.2. Immunocytochemistry, Fluorescent Microscopy, and Image Processing
2.3. RNA Isolation and Reverse Transcription
2.4. RT-qPCR
- 95 °C for 5 min (once)
- 95 °C for 30 s, 63 °C for 30 s, 72 °C for 30 s (41 cycle)
- Melt curve (65 °C to 95 °C, increment 0.5 °C for 5 s)
2.5. Full-Length Enriched cDNA Library Preparation for Oxford Nanopore Sequencing
2.6. MinION Sequencing and Data Processing
2.7. Read Acquisition and Quality Control
2.8. Read Alignment and Counting
2.9. Transcriptome Assembly and Annotation
2.10. Differential Gene Expression Analysis, Visualization and Gene Ontology Analysis, and Differential Transcript Usage Analysis
2.11. Digital PCR
- 95 °C for 2 min—PCR initial heat activation; once
- 95 °C for 30 s, 60 °C for 30 s—amplification for 45 cycles
- 40 °C for 5 min—cooling; once
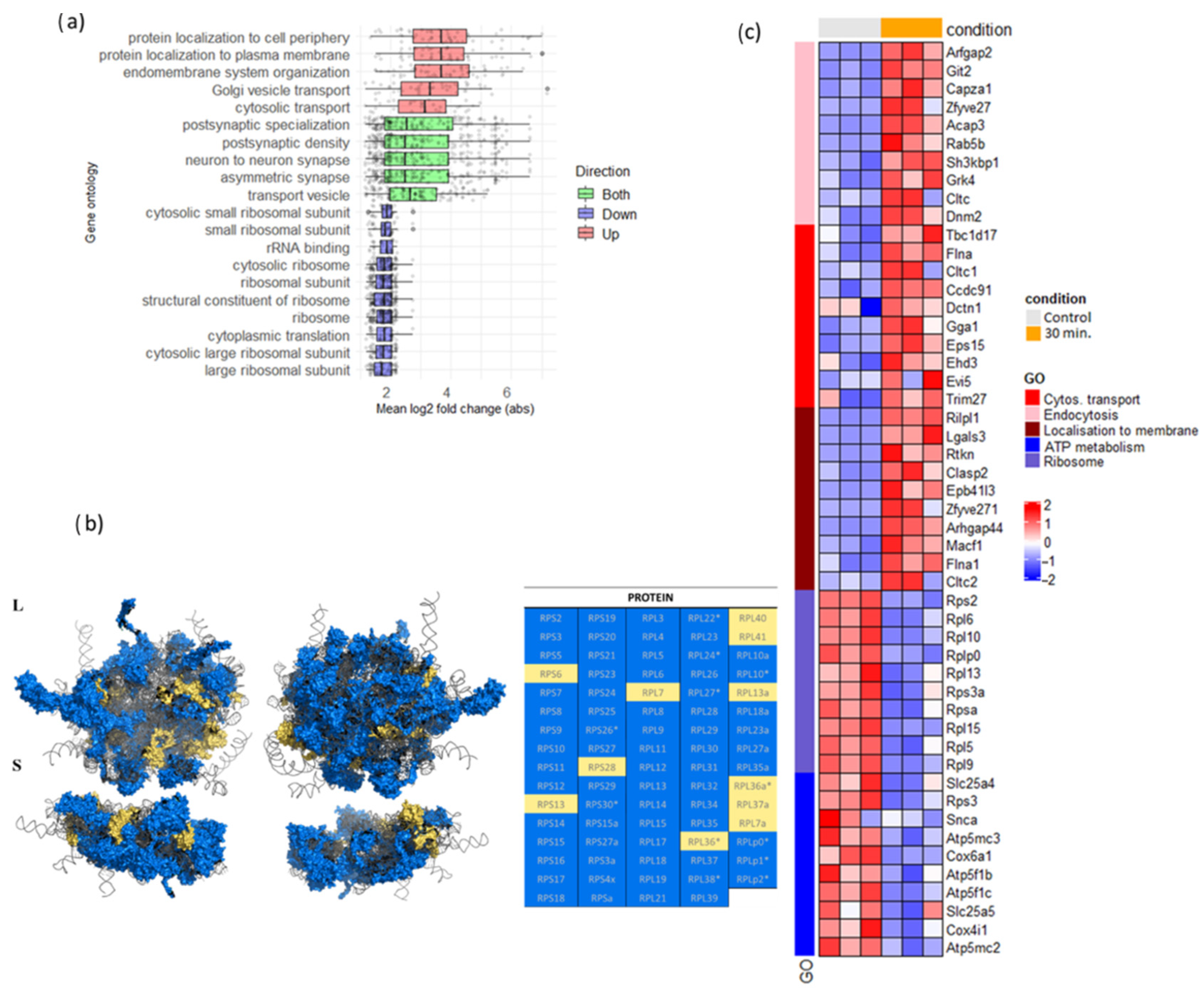
3. Results
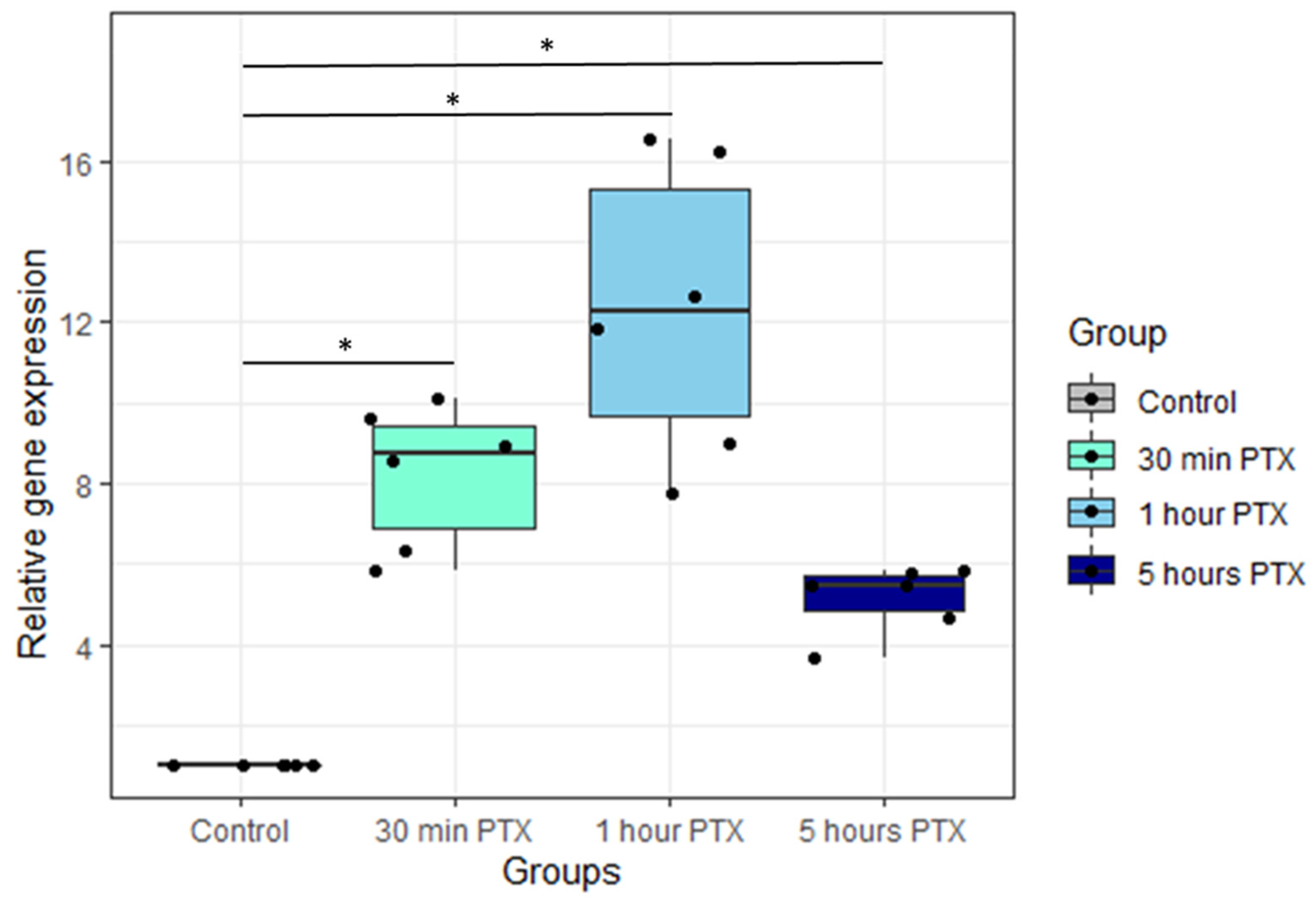
3.1. Fos Expression Level Increases after the PTX Application
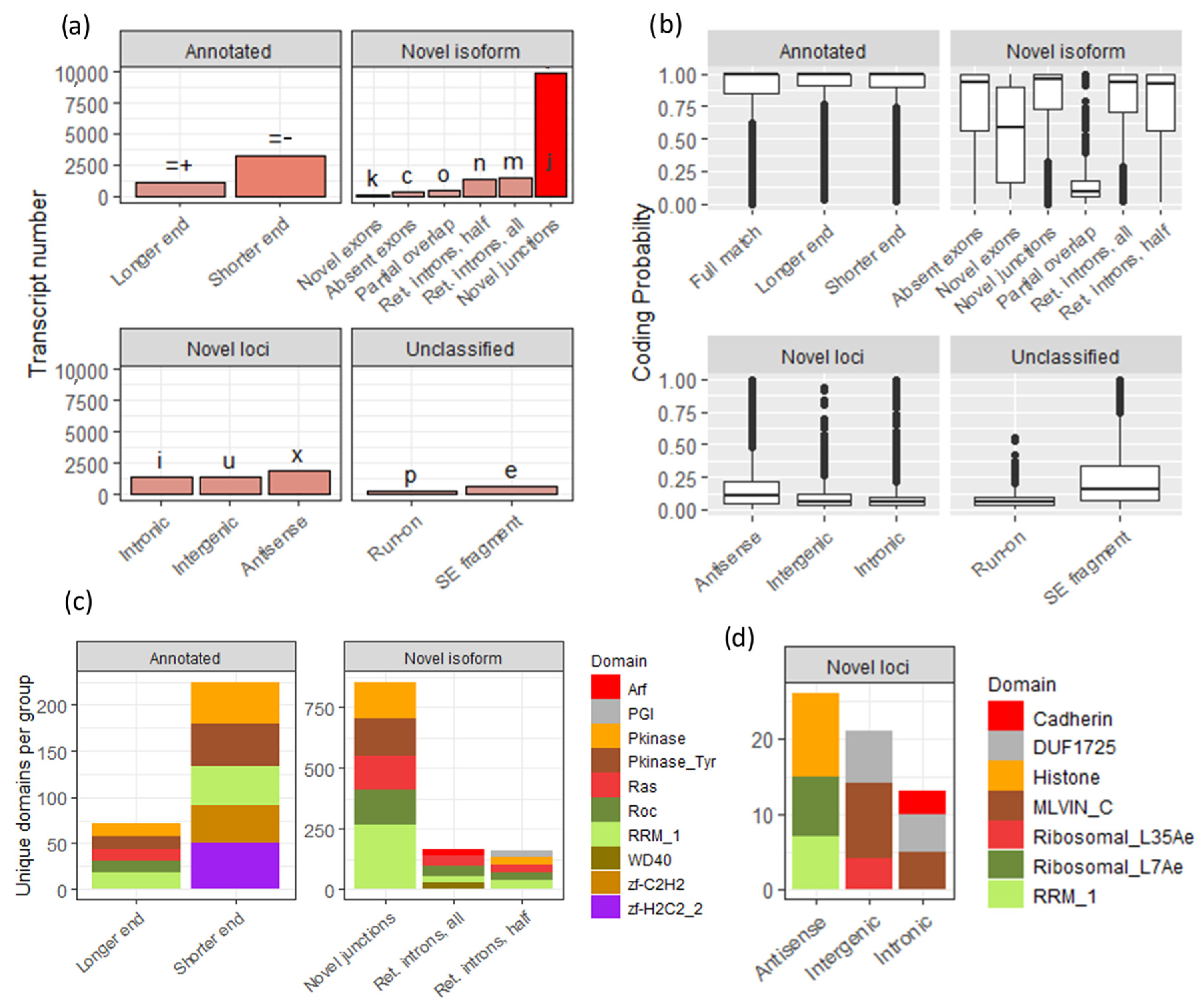
3.2. Custom Transcriptiome Assembly Based on the Sequencing Data
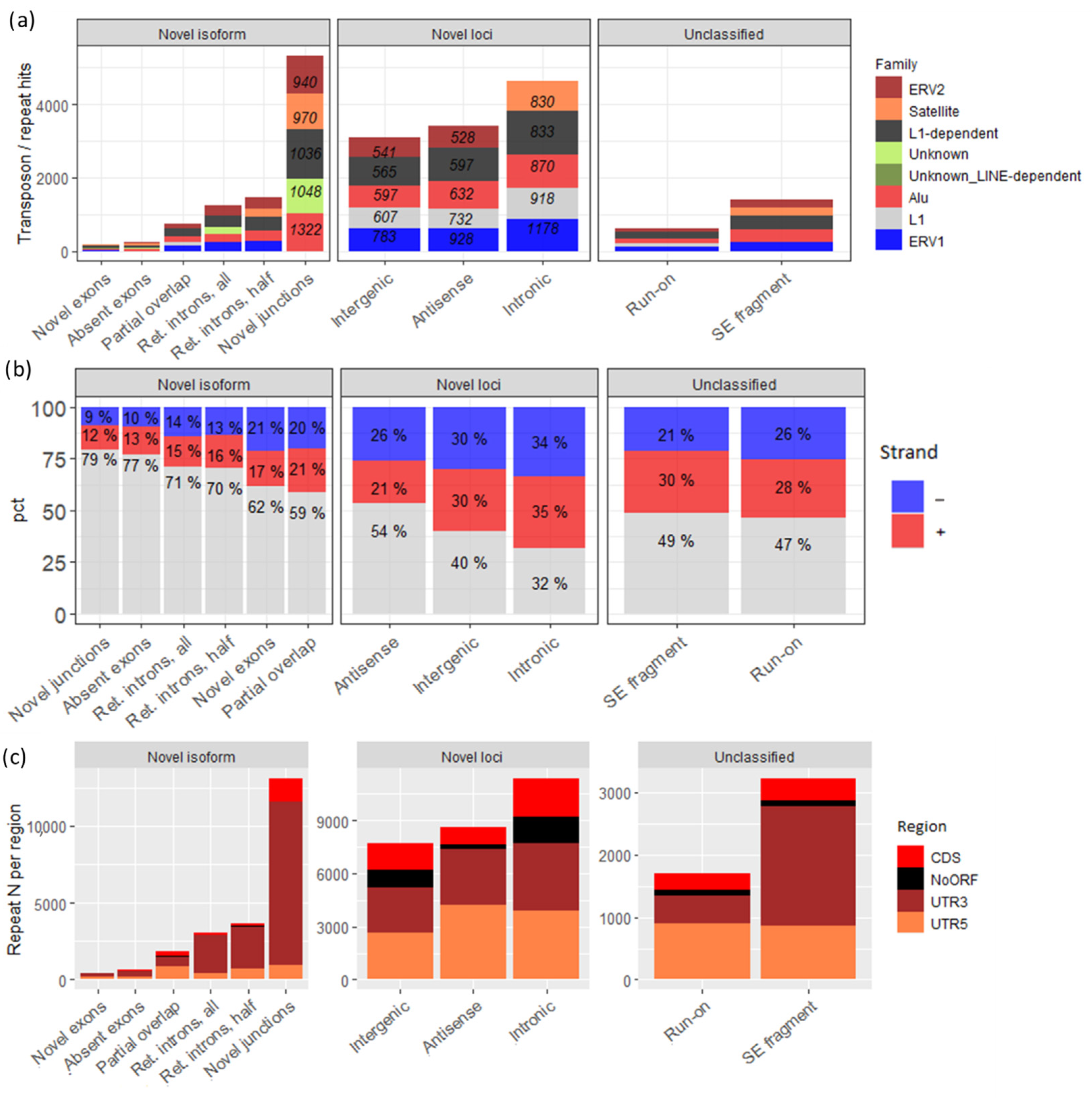
3.3. The Majority of Novel Loci Transcripts Are Transposon-Related
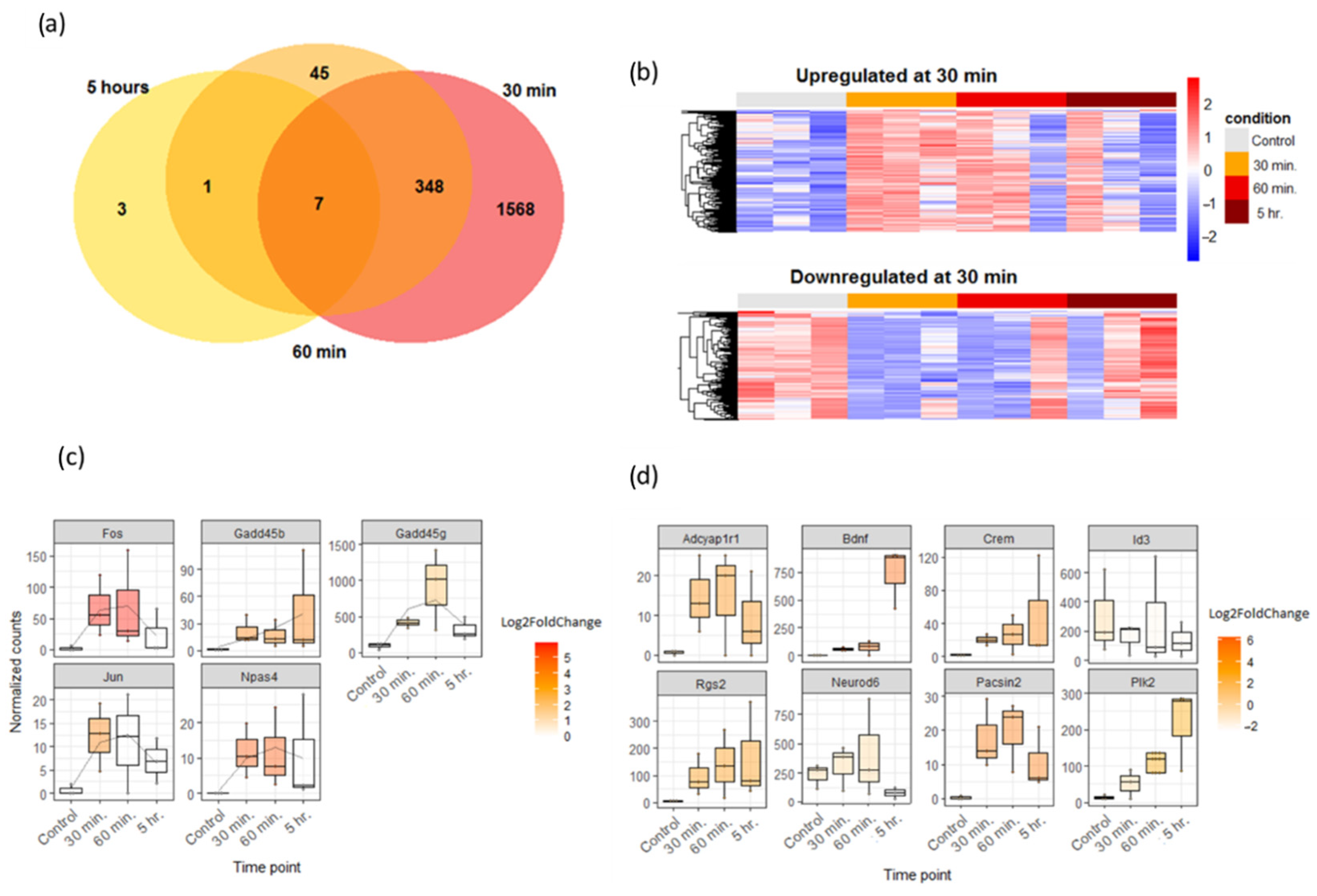
3.4. 30-Minute PTX Incubation Leads to Massive Ribosomal Gene Downregulation in Neuronal Cultures
3.5. 30-Minute PTX Incubation Does Not Cause Notable Increase in Alternative Splicing
4. Discussion
4.1. Limitations of the Study
4.2. Possible Glycine Receptors Target Side Effects and Perspectives for Future Research
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Uhlén, M.; Fagerberg, L.; Hallström, B.M.; Lindskog, C.; Oksvold, P.; Mardinoglu, A.; Sivertsson, Å.; Kampf, C.; Sjöstedt, E.; Asplund, A.; et al. Proteomics. Tissue-based map of the human proteome. Science 2015, 347, 1260419. [Google Scholar] [CrossRef]
- Cho, J.; Yu, N.-K.; Choi, J.-H.; Sim, S.-E.; Kang, S.J.; Kwak, C.; Lee, S.-W.; Kim, J.-I.; Choi, D.I.; Kim, V.N.; et al. Multiple repressive mechanisms in the hippocampus during memory formation. Science 2015, 350, 82–87. [Google Scholar] [CrossRef]
- Bal, N.V.; Susorov, D.; Chesnokova, E.; Kasianov, A.; Mikhailova, T.; Alkalaeva, E.; Balaban, P.M.; Kolosov, P. Upstream Open Reading Frames Located in the Leader of Protein Kinase Mζ mRNA Regulate Its Translation. Front. Mol. Neurosci. 2016, 9, 103. [Google Scholar] [CrossRef]
- Sharangdhar, T.; Sugimoto, Y.; Heraud-Farlow, J.; Fernández-Moya, S.M.; Ehses, J.; Ruiz de Los Mozos, I.; Ule, J.; Kiebler, M.A. A retained intron in the 3′-UTR of Calm3 mRNA mediates its Staufen2- and activity-dependent localization to neuronal dendrites. EMBO Rep. 2017, 18, 1762–1774. [Google Scholar] [CrossRef]
- Paolantoni, C.; Ricciardi, S.; De Paolis, V.; Okenwa, C.; Catalanotto, C.; Ciotti, M.T.; Cattaneo, A.; Cogoni, C.; Giorgi, C. Arc 3′ UTR Splicing Leads to Dual and Antagonistic Effects in Fine-Tuning Arc Expression Upon BDNF Signaling. Front. Mol. Neurosci. 2018, 11, 145. [Google Scholar] [CrossRef]
- Bodea, G.O.; McKelvey, E.G.Z.; Faulkner, G.J. Retrotransposon-induced mosaicism in the neural genome. Open Biol. 2018, 8, 180074. [Google Scholar] [CrossRef]
- Muotri, A.R.; Chu, V.T.; Marchetto, M.C.N.; Deng, W.; Moran, J.V.; Gage, F.H. Somatic mosaicism in neuronal precursor cells mediated by L1 retrotransposition. Nature 2005, 435, 903–910. [Google Scholar] [CrossRef]
- Faulkner, G.J.; Garcia-Perez, J.L. L1 Mosaicism in Mammals: Extent, Effects, and Evolution. Trends Genet. 2017, 33, 802–816. [Google Scholar] [CrossRef] [PubMed]
- Kuwabara, T.; Hsieh, J.; Muotri, A.; Yeo, G.; Warashina, M.; Lie, D.C.; Moore, L.; Nakashima, K.; Asashima, M.; Gage, F.H. Wnt-mediated activation of NeuroD1 and retro-elements during adult neurogenesis. Nat. Neurosci. 2009, 12, 1097–1105. [Google Scholar] [CrossRef] [PubMed]
- Chesnokova, E.A.; Kolosov, P.M. Local Protein Synthesis in Dendritic Terminals and Its Regulation in Normal Conditions and during Plastic Changes. Neurosci. Behav. Physiol. 2017, 47, 595–607. [Google Scholar] [CrossRef]
- Fusco, C.M.; Desch, K.; Dörrbaum, A.R.; Wang, M.; Staab, A.; Chan, I.C.W.; Vail, E.; Villeri, V.; Langer, J.D.; Schuman, E.M. Neuronal ribosomes exhibit dynamic and context-dependent exchange of ribosomal proteins. Nat. Commun. 2021, 12, 6127. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Boenigk, S.; Boehm, V.; Gehring, N.H.; Altmueller, J.; Dieterich, C. Single cell transcriptome sequencing on the Nanopore platform with ScNapBar. RNA 2021, 27, 763–770. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Guan, L.; Ge, L.; Liu, G.; Bai, Y.; Liu, X. Nanopore-based full-length transcriptome sequencing of Muscovy duck (Cairina moschata) ovary. Poult. Sci. 2021, 100, 101246. [Google Scholar] [CrossRef] [PubMed]
- O’Neill, K.; Brocks, D.; Hammell, M.G. Mobile genomics: Tools and techniques for tackling transposons. Philos. Trans. R. Soc. B Biol. Sci. 2020, 375, 20190345. [Google Scholar] [CrossRef] [PubMed]
- Sessegolo, C.; Cruaud, C.; Da Silva, C.; Cologne, A.; Dubarry, M.; Derrien, T.; Lacroix, V.; Aury, J.-M. Transcriptome profiling of mouse samples using nanopore sequencing of cDNA and RNA molecules. Sci. Rep. 2019, 9, 14908. [Google Scholar] [CrossRef] [PubMed]
- Uszczynska-Ratajczak, B.; Lagarde, J.; Frankish, A.; Guigó, R.; Johnson, R. Towards a complete map of the human long non-coding RNA transcriptome. Nat. Rev. Genet. 2018, 19, 535–548. [Google Scholar] [CrossRef] [PubMed]
- Quick, J.; Grubaugh, N.D.; Pullan, S.T.; Claro, I.M.; Smith, A.D.; Gangavarapu, K.; Oliveira, G.; Robles-Sikisaka, R.; Rogers, T.F.; Beutler, N.A.; et al. Multiplex PCR method for MinION and Illumina sequencing of Zika and other virus genomes directly from clinical samples. Nat. Protoc. 2017, 12, 1261–1276. [Google Scholar] [CrossRef] [PubMed]
- Massaiu, I.; Songia, P.; Chiesa, M.; Valerio, V.; Moschetta, D.; Alfieri, V.; Myasoedova, V.A.; Schmid, M.; Cassetta, L.; Colombo, G.I.; et al. Evaluation of Oxford Nanopore MinION RNA-Seq Performance for Human Primary Cells. Int. J. Mol. Sci. 2021, 22, 6317. [Google Scholar] [CrossRef]
- Xin, H.; He, X.; Li, J.; Guan, X.; Liu, X.; Wang, Y.; Niu, L.; Qiu, D.; Wu, X.; Wang, H. Profiling of the full-length transcriptome in abdominal aortic aneurysm using nanopore-based direct RNA sequencing. Open Biol. 2022, 12, 210172. [Google Scholar] [CrossRef]
- Wang, D.S.; Mangin, J.M.; Moonen, G.; Rigo, J.M.; Legendre, P. Mechanisms for picrotoxin block of alpha2 homomeric glycine receptors. J. Biol. Chem. 2006, 281, 3841–3855. [Google Scholar] [CrossRef]
- Rienecker, K.D.A.; Poston, R.G.; Saha, R.N. Merits and Limitations of Studying Neuronal Depolarization-Dependent Processes Using Elevated External Potassium. ASN Neuro 2020, 12, 1759091420974807. [Google Scholar] [CrossRef] [PubMed]
- Hardingham, G.E.; Fukunaga, Y.; Bading, H. Extrasynaptic NMDARs oppose synaptic NMDARs by triggering CREB shut-off and cell death pathways. Nat. Neurosci. 2002, 5, 405–414. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, T.; Takagi, R.; Kawashima, K. Picrotoxin increased acetylcholine release from rat cultured embryonic septal neurons. Neurosci. Lett. 2004, 356, 57–60. [Google Scholar] [CrossRef] [PubMed]
- Kaech, S.; Banker, G. Culturing hippocampal neurons. Nat. Protoc. 2006, 1, 2406–2415. [Google Scholar] [CrossRef] [PubMed]
- Moutin, E.; Hemonnot, A.-L.; Seube, V.; Linck, N.; Rassendren, F.; Perroy, J.; Compan, V. Procedures for Culturing and Genetically Manipulating Murine Hippocampal Postnatal Neurons. Front. Synaptic Neurosci. 2020, 12, 19. [Google Scholar] [CrossRef] [PubMed]
- Chomczynski, P. A reagent for the single-step simultaneous isolation of RNA, DNA and proteins from cell and tissue samples. BioTechniques 1993, 15, 532–534, 536–537. [Google Scholar] [PubMed]
- Toni, L.S.; Garcia, A.M.; Jeffrey, D.A.; Jiang, X.; Stauffer, B.L.; Miyamoto, S.D.; Sucharov, C.C. Optimization of phenol-chloroform RNA extraction. MethodsX 2018, 5, 599–608. [Google Scholar] [CrossRef] [PubMed]
- Pfaffl, M.W. A new mathematical model for relative quantification in real-time RT-PCR. Nucleic Acids Res. 2001, 29, e45. [Google Scholar] [CrossRef]
- Guppy. Nanopore Community. Available online: https://community.nanoporetech.com/docs/prepare/library_prep_protocols/Guppy-protocol/v/gpb_2003_v1_revj_14dec2018 (accessed on 9 February 2024).
- Porechop. Adapter Trimmer for Oxford Nanopore Reads. Available online: https://github.com/rrwick/Porechop (accessed on 9 February 2024).
- De Coster, W.; D’Hert, S.; Schultz, D.T.; Cruts, M.; Van Broeckhoven, C. NanoPack: Visualizing and processing long-read sequencing data. Bioinformatics 2018, 34, 2666–2669. [Google Scholar] [CrossRef]
- Li, H. Minimap2: Pairwise alignment for nucleotide sequences. Bioinformatics 2018, 34, 3094–3100. [Google Scholar] [CrossRef]
- Pipeline-Transcriptome-de. Pipeline for Differential Gene Expression (DGE) and Differential Transcript Usage (DTU) Analysis Using Long Reads. Available online: https://github.com/nanoporetech/pipeline-transcriptome-de (accessed on 9 February 2024).
- Soneson, C.; Yao, Y.; Bratus-Neuenschwander, A.; Patrignani, A.; Robinson, M.D.; Hussain, S. A comprehensive examination of Nanopore native RNA sequencing for characterization of complex transcriptomes. Nat. Commun. 2019, 10, 3359. [Google Scholar] [CrossRef]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R. The Sequence Alignment/Map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef]
- Patro, R.; Duggal, G.; Love, M.I.; Irizarry, R.A.; Kingsford, C. Salmon provides fast and bias-aware quantification of transcript expression. Nat. Methods 2017, 14, 417–419. [Google Scholar] [CrossRef]
- Soneson, C.; Love, M.I.; Robinson, M.D. Differential analyses for RNA-seq: Transcript-level estimates improve gene-level inferences. F1000Research 2015, 4, 1521. [Google Scholar] [CrossRef] [PubMed]
- Liao, Y.; Smyth, G.K.; Shi, W. featureCounts: An efficient general purpose program for assigning sequence reads to genomic features. Bioinformatics 2014, 30, 923–930. [Google Scholar] [CrossRef] [PubMed]
- Pysam. Available online: https://github.com/pysam-developers/pysam (accessed on 9 February 2024).
- Bonfield, J.K.; Marshall, J.; Danecek, P.; Li, H.; Ohan, V.; Whitwham, A.; Keane, T.; Davies, R.M. HTSlib: C library for reading/writing high-throughput sequencing data. GigaScience 2021, 10, giab007. [Google Scholar] [CrossRef] [PubMed]
- Lawrence, M.; Huber, W.; Pagès, H.; Aboyoun, P.; Carlson, M.; Gentleman, R.; Morgan, M.T.; Carey, V.J. Software for Computing and Annotating Genomic Ranges. PLoS Comput. Biol. 2013, 9, e1003118. [Google Scholar] [CrossRef] [PubMed]
- Tang, A.D.; Soulette, C.M.; van Baren, M.J.; Hart, K.; Hrabeta-Robinson, E.; Wu, C.J.; Brooks, A.N. Full-length transcript characterization of SF3B1 mutation in chronic lymphocytic leukemia reveals downregulation of retained introns. Nat. Commun. 2020, 11, 1438. [Google Scholar] [CrossRef] [PubMed]
- Tian, L.; Jabbari, J.S.; Thijssen, R.; Gouil, Q.; Amarasinghe, S.L.; Voogd, O.; Kariyawasam, H.; Du, M.R.M.; Schuster, J.; Wang, C.; et al. Comprehensive characterization of single-cell full-length isoforms in human and mouse with long-read sequencing. Genome Biol. 2021, 22, 310. [Google Scholar] [CrossRef]
- Kovaka, S.; Zimin, A.V.; Pertea, G.M.; Razaghi, R.; Salzberg, S.L.; Pertea, M. Transcriptome assembly from long-read RNA-seq alignments with StringTie2. Genome Biol. 2019, 20, 278. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Sim, A.; Wan, Y.K.; Yeo, K.; Lee, J.J.X.; Ling, M.H.; Love, M.I.; Göke, J. Context-Aware Transcript Quantification from Long Read RNA-Seq data with Bambu. bioRxiv 2022, 20, 1187–1195. [Google Scholar] [CrossRef] [PubMed]
- Pertea, G.; Pertea, M. GFF Utilities: GffRead and GffCompare. F1000Research 2020, 9, 304. [Google Scholar] [CrossRef]
- Storer, J.; Hubley, R.; Rosen, J.; Wheeler, T.J.; Smit, A.F. The Dfam community resource of transposable element families, sequence models, and genome annotations. Mob. DNA 2021, 12, 2. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Park, H.J.; Dasari, S.; Wang, S.; Kocher, J.P.; Li, W. CPAT: Coding-Potential Assessment Tool using an alignment-free logistic regression model. Nucleic Acids Res. 2013, 41, e74. [Google Scholar] [CrossRef]
- Love, M.I.; Huber, W.; Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 2014, 15, 550. [Google Scholar] [CrossRef]
- Yu, G.; Wang, L.G.; Han, Y.; He, Q.Y. clusterProfiler: An R package for comparing biological themes among gene clusters. Omics A J. Integr. Biol. 2012, 16, 284–287. [Google Scholar] [CrossRef]
- Luo, W.; Pant, G.; Bhavnasi, Y.K.; Blanchard, S.G., Jr.; Brouwer, C. Pathview Web: User friendly pathway visualization and data integration. Nucleic Acids Res. 2017, 45, W501–W508. [Google Scholar] [CrossRef]
- Gu, Z.; Eils, R.; Schlesner, M. Complex heatmaps reveal patterns and correlations in multidimensional genomic data. Bioinformatics 2016, 32, 2847–2849. [Google Scholar] [CrossRef]
- Chen, H.; Boutros, P.C. VennDiagram: A package for the generation of highly-customizable Venn and Euler diagrams in R. BMC Bioinform. 2011, 12, 35. [Google Scholar] [CrossRef]
- Vitting-Seerup, K.; Sandelin, A. The Landscape of Isoform Switches in Human Cancers. Mol. Cancer Res. 2017, 15, 1206–1220. [Google Scholar] [CrossRef]
- Anders, S.; Reyes, A.; Huber, W. Detecting differential usage of exons from RNA-seq data. Genome Res. 2012, 22, 2008–2017. [Google Scholar] [CrossRef]
- Filipkowski, R.K.; Rydz, M.; Berdel, B.; Morys, J.; Kaczmarek, L. Tactile experience induces c-fos expression in rat barrel cortex. Learn. Mem. 2000, 7, 116–122. [Google Scholar] [CrossRef]
- PFAM. Available online: https://pfam.xfam.org/ (accessed on 9 February 2024).
- Punta, M.; Coggill, P.C.; Eberhardt, R.Y.; Mistry, J.; Tate, J.; Boursnell, C.; Pang, N.; Forslund, K.; Ceric, G.; Clements, J.; et al. The Pfam protein families database. Nucleic Acids Res. 2012, 40, D290–D301. [Google Scholar] [CrossRef] [PubMed]
- Kaczmarek, L.; Chaudhuri, A. Sensory regulation of immediate-early gene expression in mammalian visual cortex: Implications for functional mapping and neural plasticity. Brain Res. Brain Res. Rev. 1997, 23, 237–256. [Google Scholar] [CrossRef] [PubMed]
- Saha, R.N.; Wissink, E.M.; Bailey, E.R.; Zhao, M.; Fargo, D.C.; Hwang, J.Y.; Daigle, K.R.; Fenn, J.D.; Adelman, K.; Dudek, S.M. Rapid activity-induced transcription of Arc and other IEGs relies on poised RNA polymerase II. Nat. Neurosci. 2011, 14, 848–856. [Google Scholar] [CrossRef] [PubMed]
- Panja, D.; Bramham, C.R. BDNF mechanisms in late LTP formation: A synthesis and breakdown. Neuropharmacology 2014, 76 Pt C, 664–676. [Google Scholar] [CrossRef]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef] [PubMed]
- Gene Ontology Consortium. The Gene Ontology resource: Enriching a GOld mine. Nucleic Acids Res. 2021, 49, D325–D334. [Google Scholar] [CrossRef]
- Kanehisa, M.; Furumichi, M.; Sato, Y.; Ishiguro-Watanabe, M.; Tanabe, M. KEGG: Integrating viruses and cellular organisms. Nucleic Acids Res. 2021, 49, D545–D551. [Google Scholar] [CrossRef]
- PDB:4v6x. Available online: https://www.rcsb.org/structure/4v6x (accessed on 9 February 2024).
- Sahlin, K.; Medvedev, P. Error correction enables use of Oxford Nanopore technology for reference-free transcriptome analysis. Nat. Commun. 2021, 12, 2. [Google Scholar] [CrossRef]
- Doucet, A.J.; Wilusz, J.E.; Miyoshi, T.; Liu, Y.; Moran, J.V. A 3′ Poly(A) Tract Is Required for LINE-1 Retrotransposition. Mol. Cell 2015, 60, 728–741. [Google Scholar] [CrossRef]
- Beaulieu, Y.B.; Kleinman, C.L.; Landry-Voyer, A.-M.; Majewski, J.; Bachand, F. Polyadenylation-Dependent Control of Long Noncoding RNA Expression by the Poly(A)-Binding Protein Nuclear 1. PLoS Genet. 2012, 8, e1003078. [Google Scholar] [CrossRef] [PubMed]
- Lynch, G.; Kramár, E.A.; Gall, C.M. Protein synthesis and consolidation of memory-related synaptic changes. Brain Res. 2015, 1621, 62–72. [Google Scholar] [CrossRef] [PubMed]
- Fioravante, D.; Byrne, J.H. Protein degradation and memory formation. Brain Res. Bull. 2011, 85, 14–20. [Google Scholar] [CrossRef] [PubMed]
- Tyssowski, K.M.; DeStefino, N.R.; Cho, J.H.; Dunn, C.J.; Poston, R.G.; Carty, C.E.; Jones, R.D.; Chang, S.M.; Romeo, P.; Wurzelmann, M.K.; et al. Different Neuronal Activity Patterns Induce Different Gene Expression Programs. Neuron 2018, 98, 530–546.e511. [Google Scholar] [CrossRef] [PubMed]
- Shigeoka, T.; Koppers, M.; Wong, H.H.; Lin, J.Q.; Cagnetta, R.; Dwivedy, A.; de Freitas Nascimento, J.; van Tartwijk, F.W.; Ströhl, F.; Cioni, J.M.; et al. On-Site Ribosome Remodeling by Locally Synthesized Ribosomal Proteins in Axons. Cell Rep. 2019, 29, 3605–3619.e3610. [Google Scholar] [CrossRef] [PubMed]
- Rashid, M.; Shah, S.G.; Natu, A.; Verma, T.; Rauniyar, S.; Gera, P.B.; Gupta, S. RPS13, a potential universal reference gene for normalisation of gene expression in multiple human normal and cancer tissue samples. Mol. Biol. Rep. 2021, 48, 7967–7974. [Google Scholar] [CrossRef]
- Cho, W.K.; Jayanth, N.; English, B.P.; Inoue, T.; Andrews, J.O.; Conway, W.; Grimm, J.B.; Spille, J.H.; Lavis, L.D.; Lionnet, T.; et al. RNA Polymerase II cluster dynamics predict mRNA output in living cells. eLife 2016, 5, e13617. [Google Scholar] [CrossRef]
- Pruunsild, P.; Bengtson, C.P.; Bading, H. Networks of Cultured iPSC-Derived Neurons Reveal the Human Synaptic Activity-Regulated Adaptive Gene Program. Cell Rep. 2017, 18, 122–135. [Google Scholar] [CrossRef]
- Zhang, S.J.; Steijaert, M.N.; Lau, D.; Schütz, G.; Delucinge-Vivier, C.; Descombes, P.; Bading, H. Decoding NMDA receptor signaling: Identification of genomic programs specifying neuronal survival and death. Neuron 2007, 53, 549–562. [Google Scholar] [CrossRef]
- Grabowska, A.; Sas-Nowosielska, H.; Wojtas, B.; Holm-Kaczmarek, D.; Januszewicz, E.; Yushkevich, Y.; Czaban, I.; Trzaskoma, P.; Krawczyk, K.; Gielniewski, B.; et al. Activation-induced chromatin reorganization in neurons depends on HDAC1 activity. Cell Rep. 2022, 38, 110352. [Google Scholar] [CrossRef]
- Kim, T.K.; Hemberg, M.; Gray, J.M.; Costa, A.M.; Bear, D.M.; Wu, J.; Harmin, D.A.; Laptewicz, M.; Barbara-Haley, K.; Kuersten, S.; et al. Widespread transcription at neuronal activity-regulated enhancers. Nature 2010, 465, 182–187. [Google Scholar] [CrossRef]
- Baudry, M.; Zhu, G.; Liu, Y.; Wang, Y.; Briz, V.; Bi, X. Multiple cellular cascades participate in long-term potentiation and in hippocampus-dependent learning. Brain Res. 2015, 1621, 73–81. [Google Scholar] [CrossRef]
- Mao, W.; Salzberg, A.C.; Uchigashima, M.; Hasegawa, Y.; Hock, H.; Watanabe, M.; Akbarian, S.; Kawasawa, Y.I.; Futai, K. Activity-Induced Regulation of Synaptic Strength through the Chromatin Reader L3mbtl1. Cell Rep. 2018, 23, 3209–3222. [Google Scholar] [CrossRef] [PubMed]
- Rajman, M.; Metge, F.; Fiore, R.; Khudayberdiev, S.; Aksoy-Aksel, A.; Bicker, S.; Ruedell Reschke, C.; Raoof, R.; Brennan, G.P.; Delanty, N.; et al. A microRNA-129-5p/Rbfox crosstalk coordinates homeostatic downscaling of excitatory synapses. EMBO J. 2017, 36, 1770–1787. [Google Scholar] [CrossRef] [PubMed]
- Zhu, T.; Niu, D.-K. Frequency of intron loss correlates with processed pseudogene abundance: A novel strategy to test the reverse transcriptase model of intron loss. BMC Biol. 2013, 11, 23. [Google Scholar] [CrossRef] [PubMed]
- Shagin, D.A.; Lukyanov, K.A.; Vagner, L.L.; Matz, M.V. Regulation of average length of complex PCR product. Nucleic Acids Res. 1999, 27, e23. [Google Scholar] [CrossRef] [PubMed]
- Xu, T.-L.; Gong, N. Glycine and glycine receptor signaling in hippocampal neurons: Diversity, function and regulation. Prog. Neurobiol. 2010, 91, 349–361. [Google Scholar] [CrossRef] [PubMed]
- Avila, A.; Nguyen, L.; Rigo, J.M. Glycine receptors and brain development. Front. Cell. Neurosci. 2013, 7, 184. [Google Scholar] [CrossRef]
- Lynch, J.W. Native glycine receptor subtypes and their physiological roles. Neuropharmacology 2009, 56, 303–309. [Google Scholar] [CrossRef]
- Aroeira, R.I.; Ribeiro, J.A.; Sebastião, A.M.; Valente, C.A. Age-related changes of glycine receptor at the rat hippocampus: From the embryo to the adult. J. Neurochem. 2011, 118, 339–353. [Google Scholar] [CrossRef] [PubMed]
- Allen Brain Atlas. Available online: https://celltypes.brain-map.org/rnaseq/mouse_ctx-hpf_smart-seq?selectedVisualization=Heatmap&colorByFeature=Cell+Type&colorByFeatureValue=Gad1 (accessed on 9 February 2024).
- Human Protein Atlas. GLRA2 expression in Different Cell Types. Available online: https://www.proteinatlas.org/ENSG00000101958-GLRA2/single+cell+type (accessed on 12 February 2024).
- Human Protein Atlas. GLRA3 expression in Different Cell Types. Available online: https://www.proteinatlas.org/ENSG00000145451-GLRA3/single+cell+type (accessed on 12 February 2024).
- Li, P.; Slaughter, M. Glycine receptor subunit composition alters the action of GABA antagonists. Vis. Neurosci. 2007, 24, 513–521. [Google Scholar] [CrossRef] [PubMed]
- Kuhse, J.; Groeneweg, F.; Kins, S.; Gorgas, K.; Nawrotzki, R.; Kirsch, J.; Kiss, E. Loss of Extrasynaptic Inhibitory Glycine Receptors in the Hippocampus of an AD Mouse Model Is Restored by Treatment with Artesunate. Int. J. Mol. Sci. 2023, 24, 4623. [Google Scholar] [CrossRef] [PubMed]
- Pribilla, I.; Takagi, T.; Langosch, D.; Bormann, J.; Betz, H. The atypical M2 segment of the beta subunit confers picrotoxinin resistance to inhibitory glycine receptor channels. EMBO J. 1992, 11, 4305–4311. [Google Scholar] [CrossRef]
- Human Protein Atlas. GLRB Expression in Different Cell Types. Available online: https://www.proteinatlas.org/ENSG00000109738-GLRB/single+cell+type (accessed on 9 February 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene | Primer Pair Sequences |
|---|---|
| Osbp | F: 5′-TCC GGG AGA CTT TAC CTT CAC TT-3′ R: 5′-GTG TCA CCC TCT TAT CAA CCA CC-3′ |
| Fos | F: 5′-CAA AGT AGA GCA GCT ATC TCC-3′ R: 5′-CTC GTC TTC AAG TTG ATC TGT-3′ |
| Gene | Primer Pair Sequences |
|---|---|
| Rack1 | F: 5′-ATG ACC GAG CAA ATG ACC CT-3′ R: 5′-TCT CGT GGT AGT GCC CGT TG-3′ Probe: 5′-CCC GAA CAG CAG CAA CCC GCT TAT CAT-3′ |
| Rps8 | F: 5′-AAC CCT ACC ACA AGA AGC GG-3′ R: 5′-TAT TGC CTC CTC GAA CTC GG-3′ Probe: 5′-AGA TGG CTA TGT GCT CGA AGG CAA-3′ |
| Rps3a | F: 5′-CCG ATG GGT ATT TGC TCC GA-3′ R: 5′-CCA ATG CTG TCT GGA ATC AGT T-3′ Probe: 5′-ATC CTA TGC GCA GCA CCA GCA-3′ |
| Rpl15 | F: 5′-TTC AGT CTG TTG CTG AGG AGA G-3′ R: 5′-TGT CGT TGT GGA CTG GTT TG-3′ Probe: 5′-AGT CCT GAA TTC CTA CTG GGT TGG TGA AG-3′ |
| Hprt | F: 5′-CGT CGT GAT TAG TGA TGA TGA AC-3′ R: 5′-CAA GTC TTT CAG TCC TGT CCA TAA-3′ Probe: 5′-CCT GGT TCA TCA TCA CTA ATC ACG ACG C-3′ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beletskiy, A.; Zolotar, A.; Fortygina, P.; Chesnokova, E.; Uroshlev, L.; Balaban, P.; Kolosov, P. Downregulation of Ribosomal Protein Genes Is Revealed in a Model of Rat Hippocampal Neuronal Culture Activation with GABA(A)R/GlyRa2 Antagonist Picrotoxin. Cells 2024, 13, 383. https://doi.org/10.3390/cells13050383
Beletskiy A, Zolotar A, Fortygina P, Chesnokova E, Uroshlev L, Balaban P, Kolosov P. Downregulation of Ribosomal Protein Genes Is Revealed in a Model of Rat Hippocampal Neuronal Culture Activation with GABA(A)R/GlyRa2 Antagonist Picrotoxin. Cells. 2024; 13(5):383. https://doi.org/10.3390/cells13050383
Chicago/Turabian StyleBeletskiy, Alexander, Anastasia Zolotar, Polina Fortygina, Ekaterina Chesnokova, Leonid Uroshlev, Pavel Balaban, and Peter Kolosov. 2024. "Downregulation of Ribosomal Protein Genes Is Revealed in a Model of Rat Hippocampal Neuronal Culture Activation with GABA(A)R/GlyRa2 Antagonist Picrotoxin" Cells 13, no. 5: 383. https://doi.org/10.3390/cells13050383
APA StyleBeletskiy, A., Zolotar, A., Fortygina, P., Chesnokova, E., Uroshlev, L., Balaban, P., & Kolosov, P. (2024). Downregulation of Ribosomal Protein Genes Is Revealed in a Model of Rat Hippocampal Neuronal Culture Activation with GABA(A)R/GlyRa2 Antagonist Picrotoxin. Cells, 13(5), 383. https://doi.org/10.3390/cells13050383