1. Introduction
Food security remains a critical global concern, increasingly challenged by rapid urbanization, climate change, soil salinization, and arable land degradation, all of which exert mounting pressure on agricultural production [
1]. As a major contributor to and beneficiary of global agricultural production and consumption [
2], China relies heavily on stable crop yields to safeguard national food security. Winter wheat is one of the most important staple crops, contributing more than 20% to the national grain-sowing area and total yield. The North China Plain functions as the primary zone for its cultivation. Rapid and accurate identification of winter wheat distribution is thus essential for agricultural monitoring, crop management, and structural optimization [
3].
Remote sensing has proven to be an effective and economical approach for large-scale crop mapping, owing to its extensive spatial coverage, frequent temporal observations, and inherent objectivity [
4]. However, traditional classification approaches typically rely on imagery from the full growing period or from specific phenological stages [
5], leading to substantial delays in the availability of crop distribution information—often until harvest or later. For instance, the USDA’s Crop Data Layer (CDL) was generally released five months after harvest, limiting its application for real-time decision-making [
6]. To overcome this limitation, early-season crop mapping was proposed to enable the timely identification of crop types during the growing period [
7]. This approach supported numerous applications, including disaster response, agricultural insurance, precision farming, yield estimation, and environmental monitoring [
8].
Unlike traditional post-season classification, early-season mapping presents several unique challenges. One of the primary issues is the lack of timely training samples, as early-season survey sample collection is labor-intensive, time-consuming, and often delayed beyond the optimal mapping window. To address this, researchers developed a variety of automated sample generation methods. Among them, sample transfer became widely used, whereby early-season samples were generated from historical labeled remote sensing data and applied to current classification tasks [
8]. To improve this method’s adaptability to sowing date variations, the Time-Weighted Dynamic Time Warping (TWDTW) technique was incorporated [
9]. This method automatically matches historical samples to current crop growth conditions by comparing the similarity of temporal curves and has proven effective in early-season sample generation.
Another challenge stems from the heavy dependence on early-season satellite observations, which are essential for capturing key phenological and spectral traits. However, data quality during this period is often compromised by frequent cloud cover. To mitigate it, time-series interpolation techniques can be employed to reconstruct complete temporal datasets across the crop growth cycle, improving data continuity and usability [
10]. Based on the reconstructed time-series feature dataset, feature selection has become a crucial step for improving model performance. It enhances model simplicity, computational efficiency, and classification accuracy. Researchers have typically constructed time-series features spanning the entire growth period to represent spectral responses throughout crop development and to compensate for missing key phenological stages [
11]. However, due to the high dimensionality and redundancy in raw features, it was necessary to perform dimensionality reduction before feature ranking [
12]. For example, a study in the Huaihe Basin extracted time-series features such as the Normalized Difference Vegetation Index (NDVI), Enhanced Vegetation Index (EVI), Normalized Difference Red Edge Index (NDRDI), and Land Surface Water Index (LSWI), and used the Random Forest (RF) algorithm to evaluate their importance, achieving an early-season accuracy of 91% [
13]. Another study in Henan Province selected eight representative spectral indices, including the Land Surface Water Index (LSWI), Green Chlorophyll Vegetation Index (GCVI), Red Edge 2, Inverted Red Edge Chlorophyll Index (IRECI), and others, further improving classification performance [
14].
Despite considerable progress in early-season crop mapping, large-scale applications remain challenging due to spatial heterogeneity and environmental variability. In Shandong Province, several studies have reported an underestimation of winter wheat distribution during the overwintering period [
5,
15], primarily attributed to inconsistent phenological development driven by topographic and climatic differences. In warmer and wetter zones, winter wheat resumes growth earlier, while in colder areas with limited sunlight, its growth remains dormant for extended periods. Consequently, early detection requires zone-specific adaptation to phenological and environmental differences. To mitigate spatial inconsistency, some studies incorporated phenological information into mapping frameworks. For example, rice distribution in Northeast Asia was effectively mapped using flood signal phenology combined with vegetation indices [
16]. However, environmental factors such as rainfall, temperature, and elevation exhibited substantial spatial variability, making it challenging to fully capture zonal differences based solely on phenological features. Thus, zone-specific threshold adjustments were still necessary to maintain classification stability across diverse zones [
17].
Subdividing the study area into finer zones was recognized as an effective strategy to enhance zonal adaptability. Systems such as Agroecological Zones (AEZs) and Agricultural Climatic Zones (ACZs) were widely adopted to support zonal classification and improve large-scale mapping accuracy. For instance, the classification accuracy of winter wheat significantly improved after Jiangsu Province was divided into four AEZs and mapped separately [
18]. Nevertheless, predefined zones often failed to reflect real-time planting conditions within a given year, limiting their effectiveness for early-season mapping. Therefore, future zoning strategies require dynamic integration of phenological and environmental information to improve robustness and adaptability.
To tackle these challenges, this study proposes a zonal-based early-season mapping approach that integrates phenological and environmental factors. Zone-specific optimal identification times in Shandong Province are determined using Sentinel-1/2 time-series data processed on the Google Earth Engine (GEE) platform. This study aims to (1) construct and assess an integrated approach to enhance both the timeliness and accuracy of large-area winter wheat mapping at early growth periods; (2) identify the earliest feasible identification time for winter wheat within each defined zone; and (3) develop zone-specific classification strategies that account for environmental heterogeneity.
3. Methods
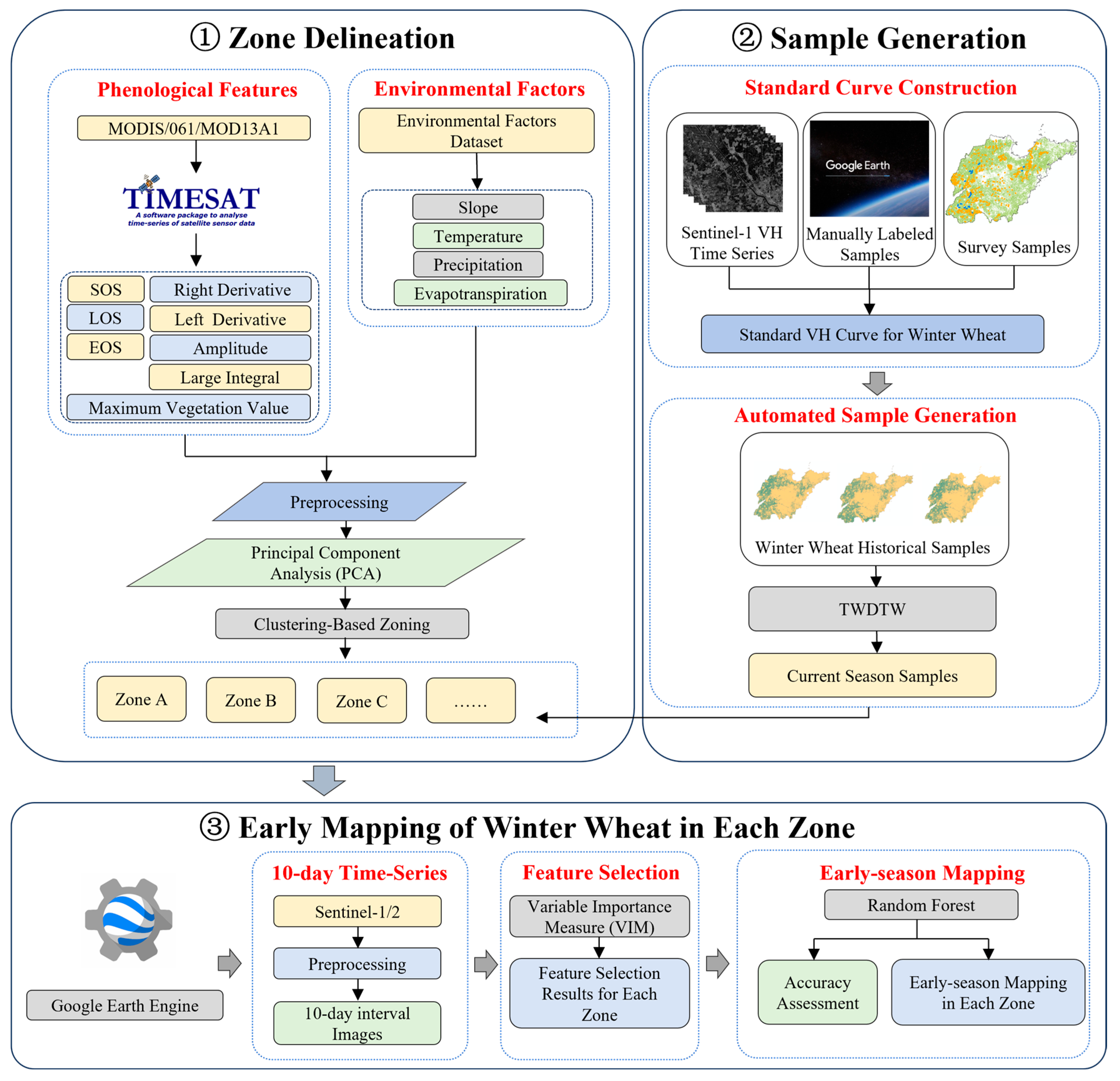
The flowchart is illustrated in
Figure 2. The primary objective of the study was to accurately determine the earliest identification time of winter wheat across different zones in Shandong Province, following three main steps:
(1) Zoning Shandong Province based on a comprehensive analysis of phenological features and environmental factors.
(2) Automatically generating current-season training samples for winter wheat and non-winter wheat using the TWDTW method.
(3) Selecting optimal features for each zone and employing the Random Forest classifier to determine the earliest identification time of winter wheat.
3.1. Clustering Zone Generation Based on Phenological and Environmental Factors
3.1.1. Phenological and Environmental Factors Preparation
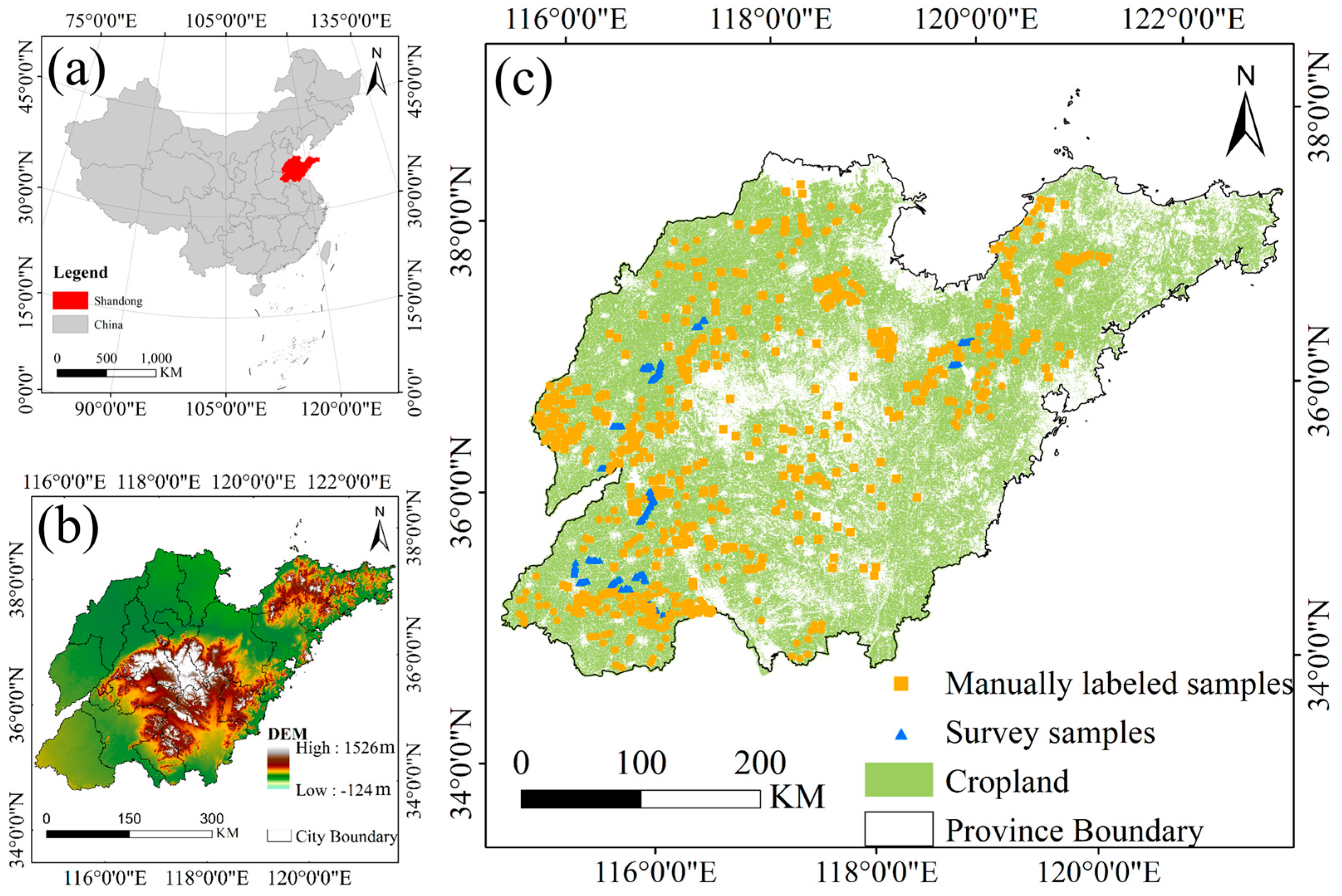
In this study, zonal delineation across the study area was based on phenological features and environmental factors, with detailed descriptions provided in
Table 2. To avoid multicollinearity among these factors, the Spearman correlation coefficients were first calculated, and variables with a correlation greater than 0.9 were excluded [
25]. Specifically, amplitude and maximum vegetation value (MVV) exhibited a high degree of correlation, and thus, MVV was removed.
Secondly, Principal Component Analysis (PCA) was employed to condense the dimensionality of the selected phenological and environmental factors. Prior to analysis, all variables were standardized using Z-score normalization to eliminate the influence of scale differences among indicators, as defined by the following formula:
where
refers to the standardized form of the variable, computed as the deviation from the mean
, normalized by the standard deviation
.
Subsequently, principal components were extracted, and an orthogonal rotation was applied to optimize the loading matrix structure, thereby enhancing the interpretability of each principal component. In accordance with the commonly used eigenvalue criterion, only components with eigenvalues exceeding 1 were preserved [
26], as these accounted for the majority of the variance within the dataset. Each principal component was expressed as a linear combination of standardized variables, formulated as
where
represents the
-th principal component,
are the corresponding coefficients, and
represent the standardized indicator values.
Through this approach, complex phenological and environmental factors were transformed into a limited number of comprehensive principal components. This not only reduced data dimensionality, but also more clearly revealed the dominant variations among indicators and their internal relationships.
3.1.2. Zone Delineation Using K-Means Clustering Method
In this study, the K-means clustering algorithm was applied to group and analyze the composite indicators obtained through PCA. As a widely adopted unsupervised learning method, K-means delineates spatially homogeneous zones by assigning each sample to the nearest cluster centroid, thereby minimizing the total within-cluster sum of squares.
This clustering approach effectively delineates zones with similar feature characteristics, enabling a reduction in internal heterogeneity across large-scale research areas. K-means was selected not only for its computational efficiency and scalability but also due to its unsupervised nature, which avoids reliance on manually selected training samples and minimizes human subjectivity. Instead, it clusters samples based solely on their intrinsic feature separability. Similar strategies have been successfully employed in previous studies involving time-series remote sensing data for crop phenology and zonal mapping, further demonstrating the method’s robustness and suitability for large-scale agricultural applications [
25,
27].
During the clustering process, the similarity between samples was quantified using the Euclidean distance, as defined by the following formula:
where
quantifies the dissimilarity between two samples
and
,
and
represent the values of the
-th feature for each sample, and
is the total number of features. Based on this distance metric, each sample was iteratively assigned to the closest cluster center.
To determine the optimal number of clusters, both the Elbow Method and the Silhouette Coefficient were adopted. The Elbow Method involved plotting the ratio of the between-cluster sum of squares (BSS) to total sum of squares (TSS) across varying values of
, and identifying the point at which the rate of increase in this ratio began to level off. The ratio was computed using the following formula:
where
represents the total sample size,
represents the number of clusters,
is the feature vector of the
th sample,
denotes the overall mean,
is the centroid of cluster
, and
indicates the number of samples in the cluster [
28].
Moreover, the Silhouette Coefficient was employed to assess the clustering quality by simultaneously considering the cohesion within clusters and the separation between different clusters. It provides an effective metric for evaluating the overall clustering structure, and has been widely applied in ecological and remote sensing studies due to its balance between intra-cluster compactness and inter-cluster distinctiveness [
25]. It was calculated as
where
denotes the mean distance between sample
and all other members of the same cluster, whereas
refers to the average distance between sample
and the samples in the closest adjacent cluster. The coefficient varied between −1 and 1, with values approaching 1 indicating stronger and more distinct clustering.
Finally, the results of both evaluation metrics were jointly considered to determine the optimal number of clusters. This ensured that the final zonal delineation achieved both internal homogeneity and external distinctiveness across the delineated zones.
3.2. Automated Sample Generation Using the TWDTW Method
To obtain representative winter wheat training samples with strong adaptability and robustness, winter wheat pixels were first extracted from historical datasets corresponding to 2018, 2019 and 2020, and then their spatial intersection was calculated. To further refine the sample quality, an area-based filtering step was subsequently applied. Specifically, winter wheat patches were ranked by area, and the smallest 50% were excluded. This allowed the retention of only relatively large and spatially consistent zones, from which training samples were selected.
Subsequently, a standard winter wheat time-series curve was constructed based on both survey samples and manually labeled samples. The TWDTW algorithm was then applied to calculate the TWDTW distance between candidate pixels and the standard curve. Pixels with TWDTW distances below a predefined threshold were selected as training samples.
The selection of an appropriate input variable is critical to the effectiveness of TWDTW in sample generation. Common vegetation indices like NDVI and EVI exhibited constrained effectiveness in differentiating winter wheat from other co-occurring winter crops. In contrast, a significant discrepancy in VH backscatter coefficients between winter wheat and other winter crops in Shandong Province was reported, indicating the potential of the VH band to enhance class separability [
20]. Therefore, VH time-series data were employed as inputs to the TWDTW algorithm to facilitate the automated extraction of training samples.
3.3. Winter Wheat Early-Season Mapping
3.3.1. Feature Selection
This study integrated both spectral and radar features to enhance the discrimination among crop types and mitigate the adverse effects caused by spectral similarity on classification performance. Spectral features captured the physiological and biochemical characteristics of vegetation, whereas radar features provided complementary information related to surface structure and backscattering properties. The fusion of these heterogeneous data sources significantly improved the robustness and accuracy of crop classification.
Specifically, spectral features were derived from ten multispectral bands of Sentinel-2 imagery, alongside vegetation indices that reflect crop growth conditions [
29]. Radar features included the VV and VH polarization bands extracted from Sentinel-1 data [
30], which are sensitive to surface roughness and structural variations. The detailed list of spectral bands and vegetation indices used in this study is provided in
Table 3.
To identify the most discriminative features for classification within each zone, the RF algorithm was employed to calculate the Variable Importance Measure (VIM) scores (
Section 3.3.2). An ensemble of decision trees was constructed, and the averaged feature importance scores were used to identify the most relevant variables, thereby optimizing the overall classification performance.
3.3.2. Winter Wheat Early-Season Mapping and Accuracy Assessment
The RF algorithm was utilized in this study to facilitate the early-season identification of winter wheat. RF has been widely applied to land cover monitoring tasks on the GEE platform [
38], including dynamic land cover mapping, detection of croplands and irrigated areas, and crop type classification [
39]. Within the framework of ensemble learning, RF enhanced model diversity and reduced generalization error by incorporating bootstrap aggregation (bagging) and random feature subset selection. Moreover, it allowed for the evaluation of variable importance when determining class labels. During the classification process, final outputs were determined by majority voting across all decision trees. Previous studies have demonstrated that RF outperformed several traditional classifiers, including maximum likelihood classification and shallow neural networks, in terms of robustness, accuracy, and computational efficiency [
12,
40]. Given its strong capability in handling high-dimensional data and its robustness to collinearity and redundancy, RF was well suited to the needs of this study.
The number of trees in the RF was set to 100, and the minimum number of samples per leaf node was set to 10, while all remaining hyperparameters were kept at their default values.
Early-season winter wheat mapping was conducted for each zone based on the optimal strategy identified for that specific zone. Classification performance was assessed based on confusion matrices, from which evaluation metrics including overall accuracy (OA), user’s accuracy (
UA), producer’s accuracy (
PA), and the
F1 score were derived.
4. Results
4.1. Clustering Zone Results and Analysis
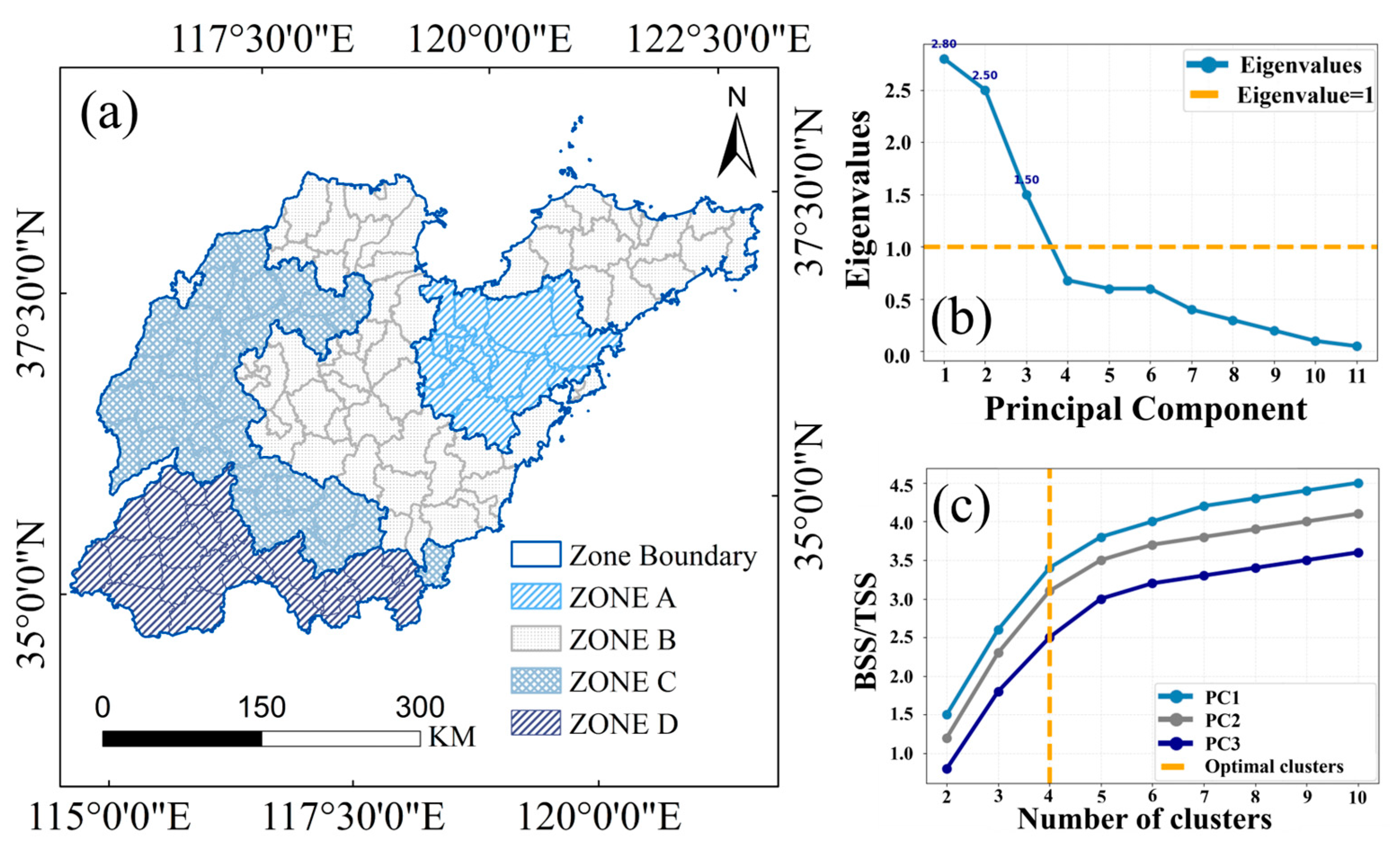
In this study, a total of eleven principal components were extracted through PCA. The eigenvalues of the first three principal components were 2.80, 2.50, and 1.50, respectively, cumulatively explaining 86.9% of the total variance (PC1: 40.5%; PC2: 27.7%; PC3: 18.7%). The eigenvalues of these components were significantly greater than 1, whereas those of subsequent components declined rapidly and remained stable, indicating their relatively minor contribution to overall variability (
Figure 3b).
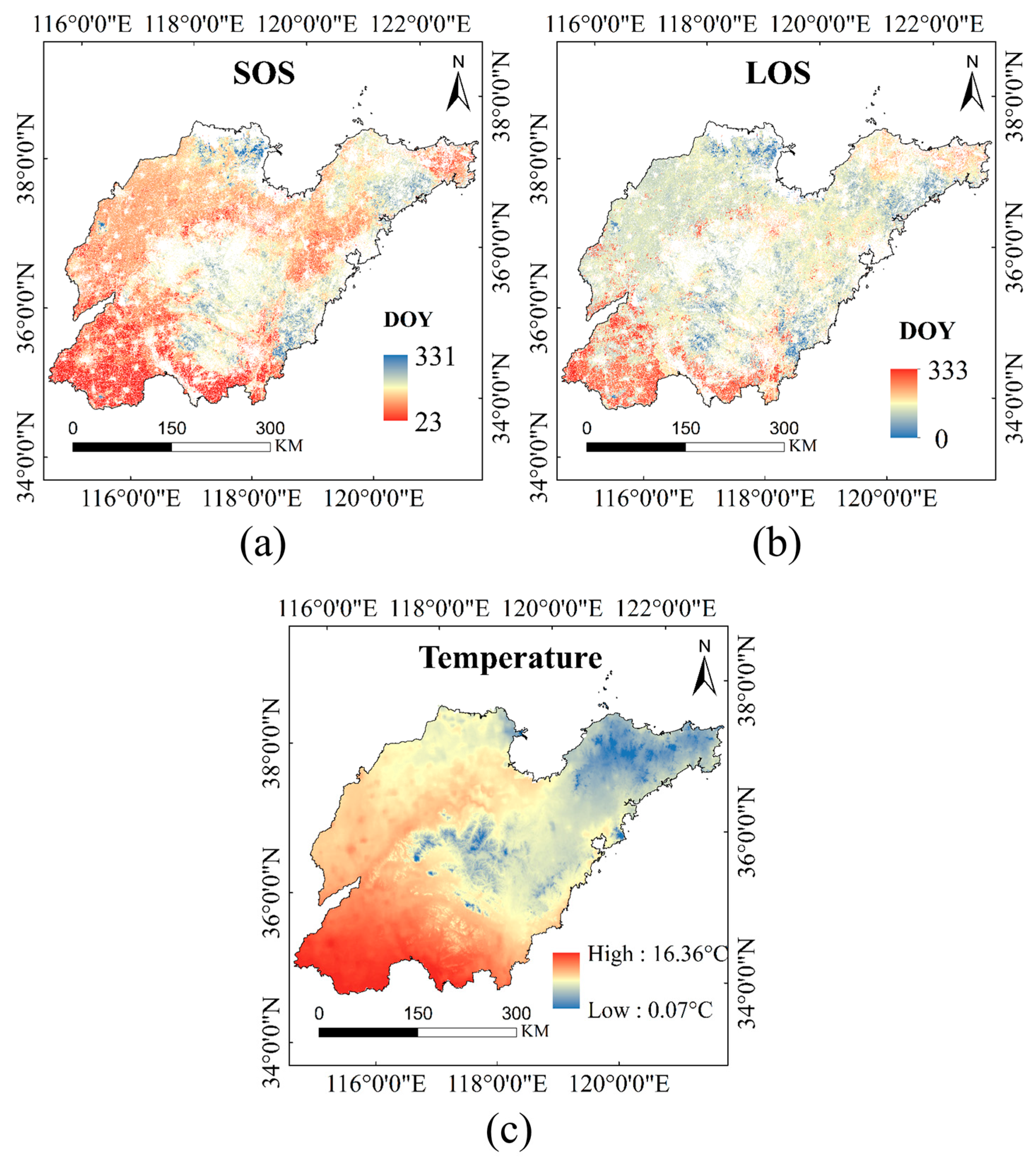
PC1 exhibited a strong correlation with the SOS. The spatial distribution of the SOS ranged from 23 to 331 days across the study area, with earlier onset observed in southern Shandong and later dates in northern and mountainous zones (
Figure 4a). PC2 was closely associated with temperature during the growing period. Temperature values ranged from 0.07 °C to 16.36 °C, with higher temperatures mainly concentrated in the southwestern part of the province (
Figure 4c). PC3 was strongly correlated with the LOS, which revealed substantial zonal differences in crop development periods. In particular, southern areas experienced longer growing seasons due to warmer climatic conditions (
Figure 4b).
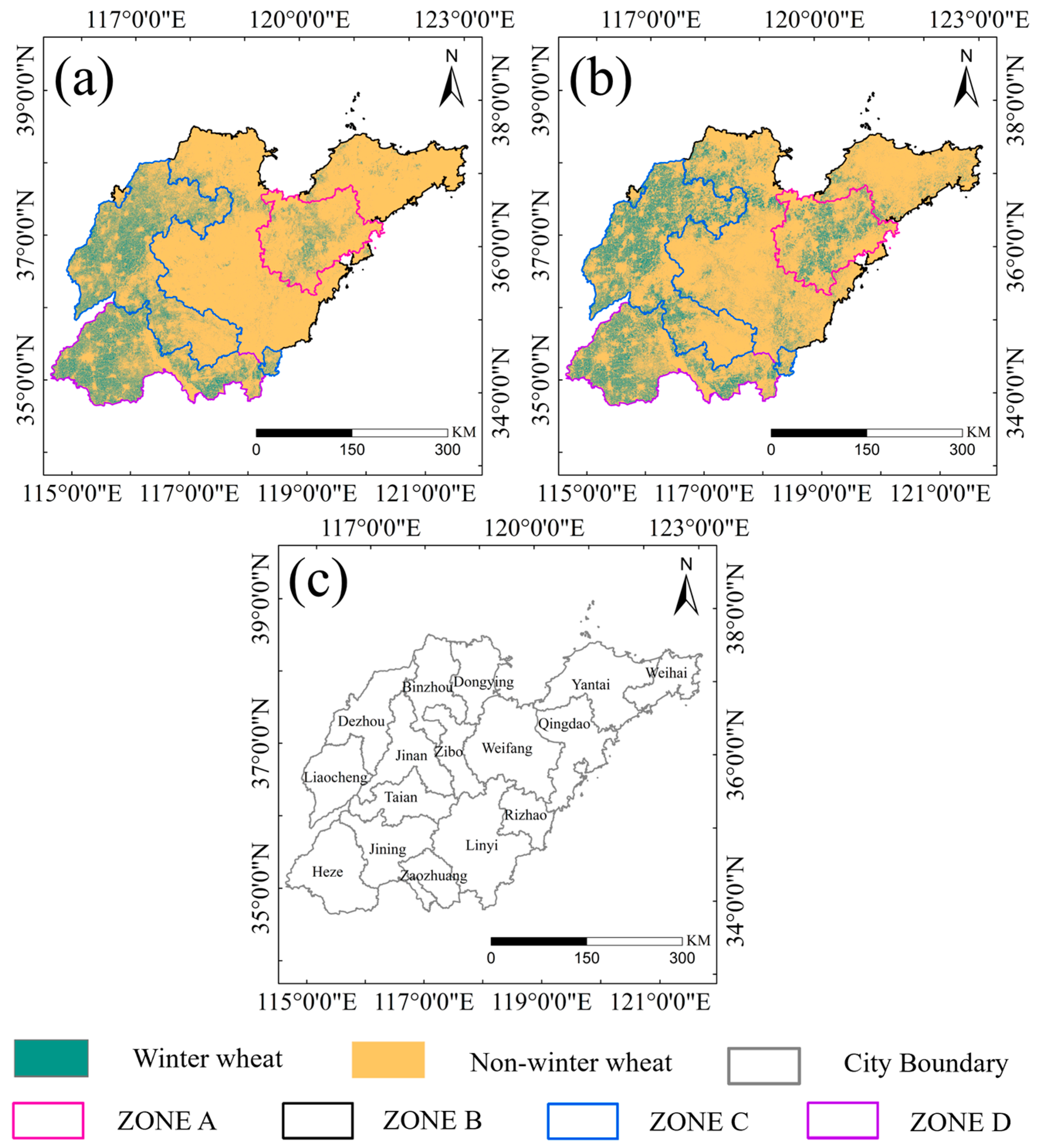
The optimal number of clusters was determined as four using the Elbow Method, which involved evaluating the total within-cluster sum of squares alongside the explanatory power of principal components under varying cluster configurations (
Figure 3). The final clustering results delineated the study area into four distinct zones (Zone A, Zone B, Zone C, and Zone D), each exhibiting unique phenological and environmental characteristics (
Figure 3a).
Zone A (mainly encompassing parts of Weifang and Qingdao) was characterized by early greening and moderate thermal accumulation, creating favorable conditions for winter wheat cultivation. Zone B (including Yantai, Dongying, and portions of Weifang and Zibo) featured higher elevation, resulting in a noticeable delay in phenological development. Zone C (primarily including Liaocheng and parts of Dezhou and Jining) displayed intermediate phenological and meteorological conditions. Zone D (covering Heze and parts of Jining and Zaozhuang) had SOS values predominantly between 45 and 100 days, with an average of 64 days, indicating a significantly earlier growing season onset compared to other zones. This zone’s distinctiveness lay in its early SOS combined with suitable thermal conditions, making its phenological profile notably different from the rest.
4.2. Training Sample Generation
To train zone-specific RF classification models for early-season winter wheat mapping, high-confidence training samples were generated using the TWDTW algorithm with historical data. In this study, the distribution of training samples was relatively balanced, with sufficient quantity and category representation to support reliable model training in each zone.
Using the TWDTW algorithm, the similarity between the standard VH time-series curve of winter wheat for each zone and the corresponding historical sample curves was computed. To determine the optimal threshold, the Otsu automatic thresholding method was applied, resulting in an average threshold value of 1.73 for sample generation across the four zones. The winter wheat and non-winter wheat samples selected under this threshold were then used for zone-specific crop classification training.
A total of 2423 winter wheat samples and 1022 non-winter wheat samples were collected, resulting in a combined dataset of 3445 samples. Among all zones, Zone C contributed the largest number of training samples, with 1415 in total—comprising 956 winter wheat and 459 non-winter wheat samples. This was primarily due to the extensive and representative winter wheat cultivation areas in this region, which enabled efficient and effective sample extraction. Zone D followed with 1009 samples, while Zones B and A contributed 719 and 302 samples, respectively (
Table 4).
4.3. Winter Wheat Early-Season Mapping Results
4.3.1. Feature Selection Results
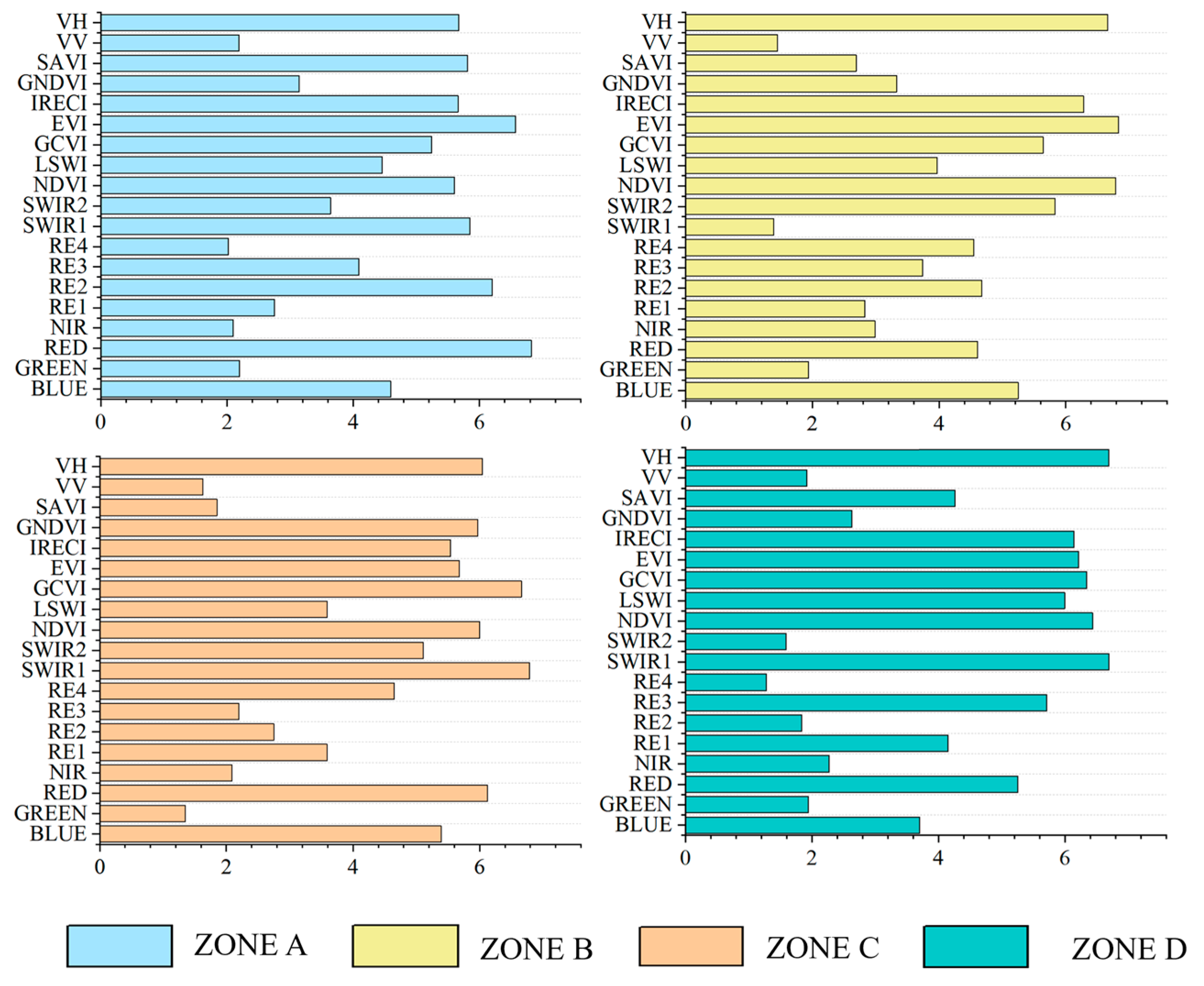
As illustrated in
Figure 5, several spectral bands and vegetation indices—particularly SWIR1, EVI, NDVI, VH, and GCVI—consistently exhibited high VIMs across all four delineated zones, indicating their strong and stable relevance for early-season winter wheat identification.
Despite this overall consistency, notable differences were observed in the importance rankings of features among the individual zones, reflecting the spatial heterogeneity in remote sensing responses. Specifically, the top six features in Zone A were RED, EVI, RE2, SWIR1, SAVI, and VH, while Zone B emphasized EVI, NDVI, VH, IRECI, SWIR1, and GCVI. In Zone C, the most important features included SWIR1, GCVI, RED, VH, NDVI, and GNDVI. For Zone D, SWIR1, VH, NDVI, GCVI, EVI, and RE3 were most relevant.
The observed discrepancies in feature importance can be explained by zonal agroecological variability, such as sowing dates, topographic conditions, and accumulated thermal time across zones. Therefore, the development of zone-specific feature selection strategies is essential to accommodate zonal variability in crop growth patterns and spectral characteristics, ultimately enhancing classification accuracy and generalization. Based on these insights, the top six features in each zone were selected to support subsequent classification tasks.
4.3.2. Zonal Early-Season Mapping Results and Analysis
Based on the optimized feature combinations and zone-specific RF, winter wheat classification was conducted across the four delineated zones. The classification model was trained using samples generated through TWDTW and Otsu thresholding (
Table 4), while the classification accuracy was assessed using validation samples derived from a combination of survey samples and manually labeled samples based on high-resolution Google Earth imagery (
Table 1). The validation samples were evenly distributed across different zones and categories (winter wheat and non-winter wheat) to ensure both reliability and spatial representativeness.
The classification accuracy including
UA,
PA, and OA for each zone is presented in
Table 5, which was derived from a confusion matrix by comparing classification results with the validation samples. Specifically, the confusion matrix was constructed by counting the number of correctly and incorrectly classified validation samples in each category (i.e., winter wheat and non-winter wheat). The diagonal elements of the matrix represent the number of correctly classified samples for each class, while the off-diagonal elements correspond to misclassifications.
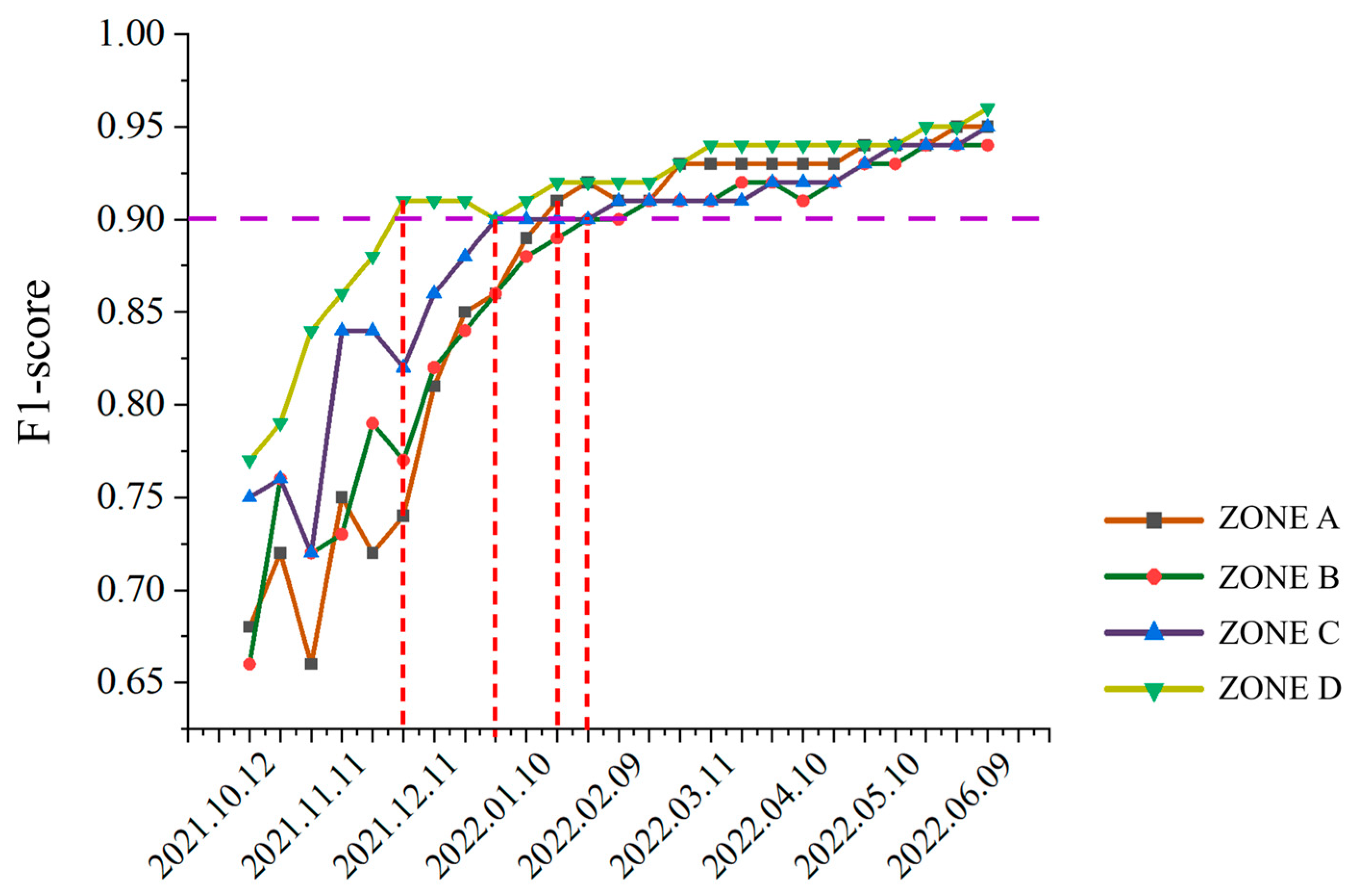
The criterion for the earliest identification time was set as the first time point at which the F1 score for winter wheat classification exceeded 0.9. Based on the preceding experiments, the maximum F1 score achieved in Zone A and Zone C was 0.95, while the remaining two zones reached 0.94 and 0.96, respectively. Therefore, an F1 score threshold of 0.9 was adopted as the criterion for determining the earliest identification time.
The earliest identification dates were derived from the temporal trends shown in
Figure 6. The results indicated that the earliest identification time for winter wheat was 1 December in Zone D, 31 December in Zone C, 2 January in Zone A, and 30 January in Zone B, corresponding to the first occurrence of an
F1 score exceeding 0.9. These findings highlight the spatial variability in phenological development across zones and validate the effectiveness of the proposed zone-specific classification strategy for achieving timely and accurate winter wheat identification.
4.3.3. Comparison Between Zonal and Non-Zonal Mapping Approaches
In this study, early-season winter wheat mapping results derived from the proposed zonal strategy were systematically compared with those obtained using a non-zonal approach in Shandong Province (
Table 6 and
Figure 7). The results indicated that the zonal classification strategy significantly increased OA and improved the spatial consistency of the classification outcomes.
In terms of classification accuracy, the non-zonal method achieved an OA of 94.03%. In contrast, the zonal method yielded a markedly improved OA of 97.63%, with higher accuracies observed across all zones. Specifically, Zone C, where the planting area of winter wheat was extensive and winter crop types were relatively homogeneous, attained the highest OA of 98.94%. In Zone A, although the OA was comparatively lower at 95.76%, it still outperformed the non-zonal approach. The detailed accuracy assessments conducted for each zone provided additional evidence supporting the robustness and effectiveness of the proposed method: in Zone A (20 January), the UA and PA for winter wheat were 93.44% and 97.44%, respectively; in Zone B (30 January), these values reached 95.73% and 99.09%; in Zone C (31 December), they were 97.65% and 99.49%; and in Zone D (1 December), the PA reached 99.32%, with an OA of 97.02%.
Regarding identification timeliness, the non-zonal method typically recognizes winter wheat around mid-January. However, the zonal method allowed for earlier and zone-specific identification, which better aligned with local phenological development. Although Shandong Province lies entirely within the warm temperate zone, intra-provincial climatic variability—driven by topography and maritime influence—led to significant differences in the greening periods of winter wheat. For instance, in Zone D, located in the southwestern and northwestern inland zones (e.g., Heze and Liaocheng), winter wheat was sown earlier, and the greening stage was reached as early as 1 December. In contrast, the eastern coastal zones, such as Zone A (e.g., Qingdao and Yantai), experienced slower warming due to maritime regulation, and early identification was only feasible by 20 January. These findings demonstrated that the zonal strategy effectively accommodated zonal phenological variability, thereby improving both the accuracy and timeliness of early-season winter wheat identification.
Figure 8 presents a detailed comparison of identification results across different zones. In Zone B(a), characterized by complex mountainous terrain, the non-zonal method exhibited substantial sparsity and failed to accurately delineate the spatial distribution of winter wheat. By contrast, the zonal approach successfully incorporated spatial heterogeneity across zones, thereby substantially enhancing classification performance.
In the flat terrain of Zone B(b), the zonal method successfully corrected the misclassification issues observed in the global results. It not only enhanced the detection accuracy of winter wheat but also significantly suppressed salt-and-pepper noise, thereby improving the overall classification performance. In Zones A and C, the zonal method also demonstrated notable improvements in both classification accuracy and consistency compared with the non-zonal approach. By contrast, the performance gap in Zone D between the two methods was less pronounced, likely due to the similar early identification times under both strategies in this zone.
4.3.4. Comparison with Official Statistics
To further evaluate the reliability of the classification results, the early-season winter wheat area in Shandong Province was quantitatively estimated and compared with official planting area statistics from the Shandong Provincial Bureau of Statistics (2021). The relative error was −3.6%, indicating that the identified area was slightly smaller than the reported figure, thereby demonstrating a high level of classification accuracy.
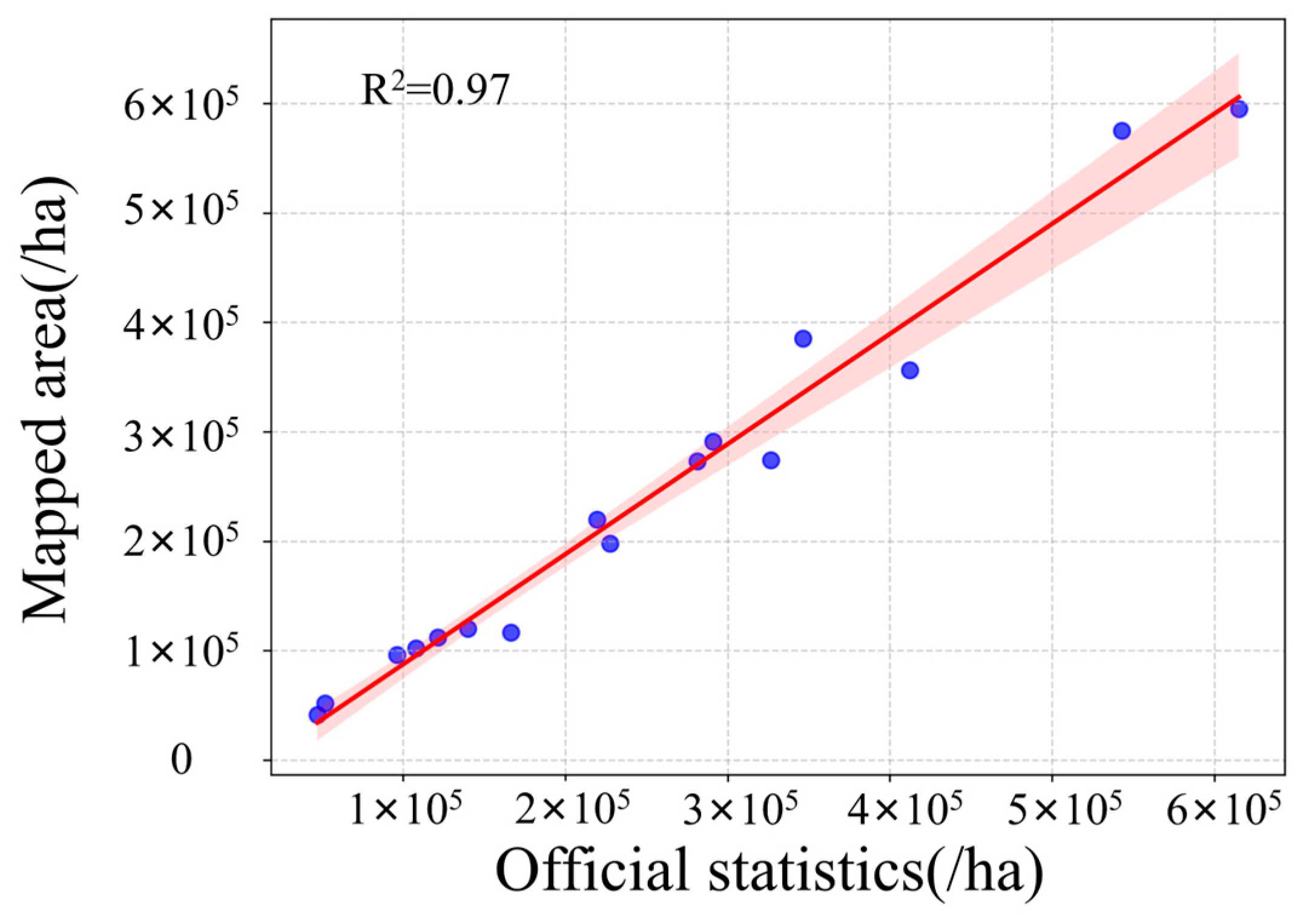
Moreover, to assess the spatial consistency of winter wheat classification, official statistics on planting areas from 16 prefecture-level cities in Shandong Province were gathered, and the mapped results were evaluated at the municipal level. The validation results (
Figure 9) revealed a strong agreement between the zonal early-season identification results and the official statistics, with an R
2 value of 0.97. This further confirmed the reliability and robustness of the zonal classification approach proposed in this study.
4.4. Confusion Analysis Between Winter Wheat and Garlic
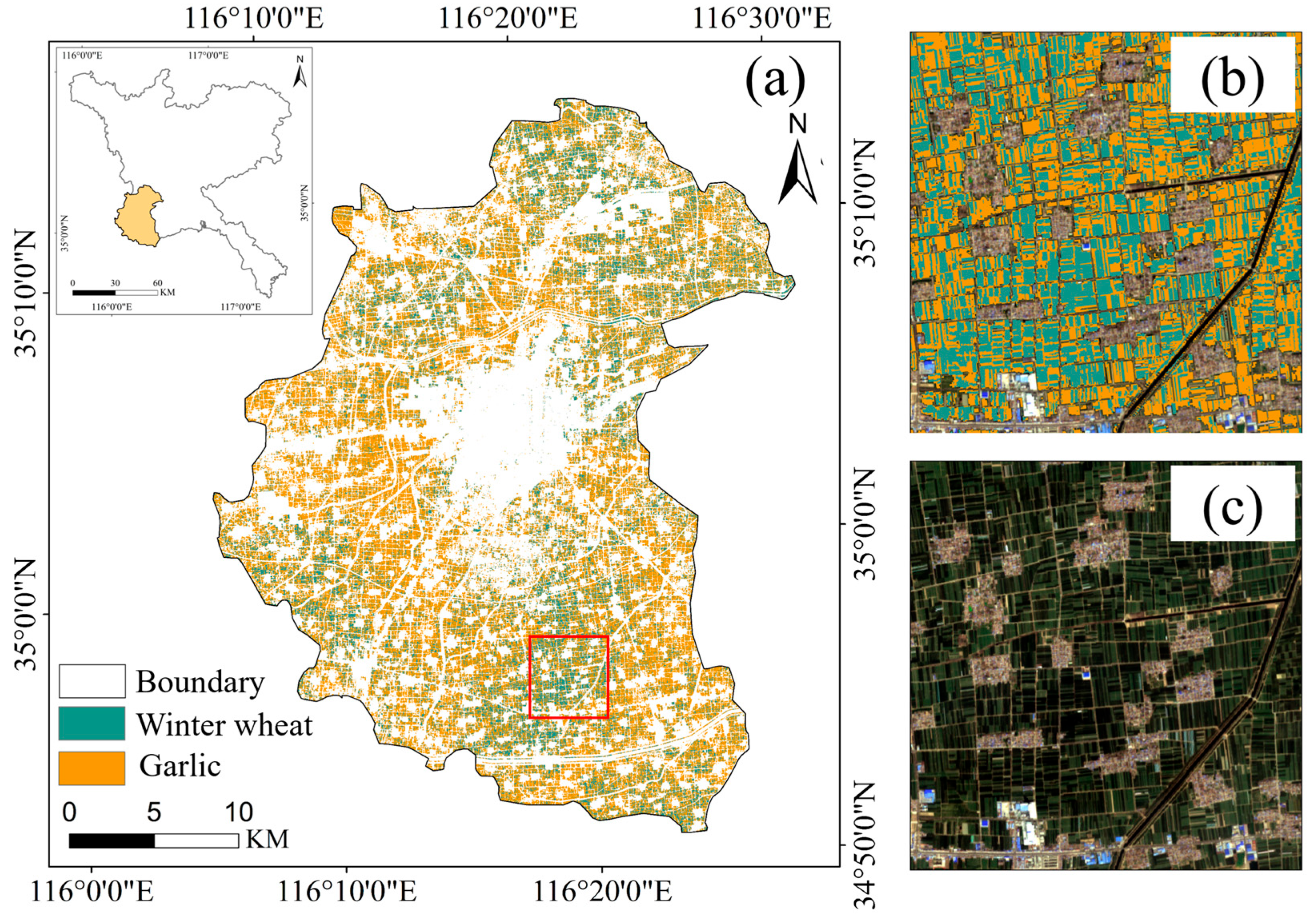
In Shandong Province, garlic is one of the primary confounding overwintering crops besides winter wheat, due to its high similarity in both phenological cycles and spectral characteristics. This issue was particularly prominent in key garlic cultivation zones, such as Jinxiang County in Jining City, where adjacent and interspersed fields posed challenges for accurate classification.
To evaluate the feasibility of distinguishing garlic from winter wheat in remote sensing, this study selected Jinxiang County as a representative area. Multi-temporal remote sensing images from the 2021–2022 growing period were used to construct time-series features, and a total of 291 manually labeled garlic samples were obtained. Feature selection and classification experiments were subsequently conducted. The feature selection process identified that the top six features were VH, NDVI, IRECI, GCVI, RE2, and RED, three of which were also identified as key features in winter wheat classification within the same zone. This finding indicated that the proposed method exhibited a degree of feature universality when distinguishing crops with similar phenology and spectral responses.
Using the optimized time-series features for classification, an OA of 0.97 and an
F1 score of 0.94 were achieved, demonstrating that garlic and winter wheat remained distinguishable despite the close timing and similarity in feature expression. Recent studies have investigated the spatial mapping of winter wheat and garlic [
5,
13]. In this study, the proposed method achieved high classification accuracy, demonstrating its effectiveness in distinguishing between these spectrally and phenologically similar crops.
Additionally, distribution maps for winter wheat and garlic were generated to visually illustrate their spatial distribution characteristics in Jinxiang County (
Figure 10a), along with classification results (
Figure 10b) and detailed comparisons between imagery (
Figure 10c). The results indicated that the garlic planting area was significantly larger than that of winter wheat. Moreover, the classification method using optimized features yielded high accuracy even in cases of adjacent planting of winter wheat and garlic.
6. Conclusions
This study proposed a zonal early-season identification strategy to address the spatial heterogeneity in large-scale winter wheat mapping. By integrating phenological and environmental factors, Shandong Province was divided into four representative zones, each with tailored classification schemes. The results demonstrated significant improvements in accuracy, timeliness, and spatial consistency.
The main contributions are as follows:
(1) Zonal strategy effectiveness: Zoning based on phenological and environmental factors reduced large-scale heterogeneity and supported high classification accuracy.
(2) Optimized identification timing: Zone-specific identification windows were established. The earliest mapping occurred in Zone D in early December, with an OA of 97.02%. Zones A-C reached their optimal identification periods between late December and January, each attaining an OA above 95%.
(3) Reliability and comparison: Validation against official statistics showed a relative area error of –3.6% at the provincial level and an R2 of 0.97 across 16 municipalities. The zonal strategy improved overall accuracy by 3.6% over a non-zonal approach and outperformed public datasets such as ChinaWheat10 in spatial detail and classification precision.
(4) Feature adaptability: Zone-specific features enhanced classification. The method also successfully distinguished winter wheat from garlic, a spectrally similar crop, achieving an F1 score of 0.94, indicating strong generalization capability.
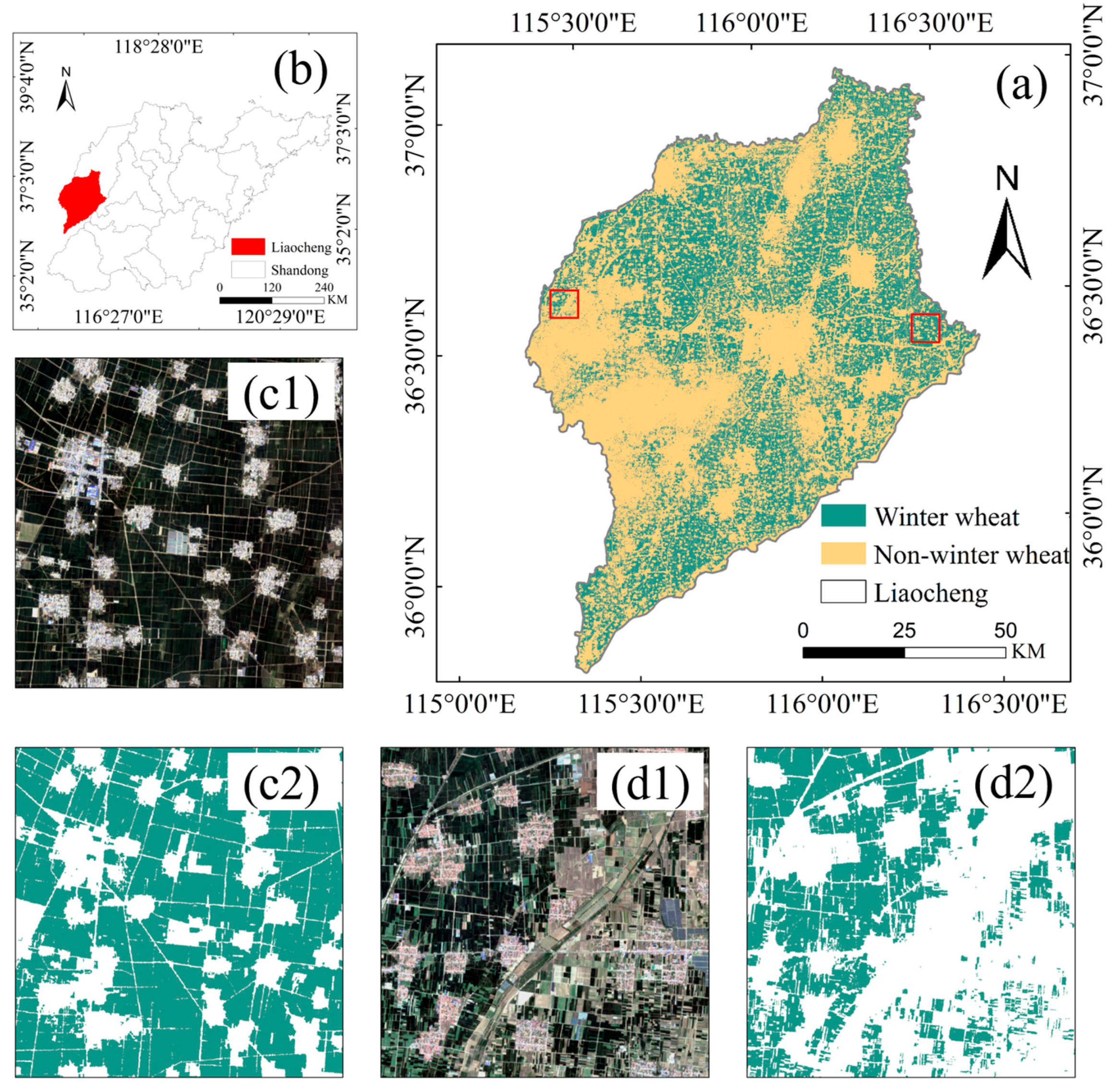
(5) Temporal robustness: Historical validation using 2017–2018 data in Liaocheng produced consistent results, with an OA of 98% and an F1 score of 0.96. The identification timing matches historical phenology.
In summary, the proposed zonal strategy proved accurate, robust, and adaptable for early-season winter wheat mapping at large zonal scales.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}