1. Introduction
With the improvement of living standards, people’s requirements for the quality of tea have increased [
1]. The surge in demand for high-quality tea has led to innovations in tea production and harvesting processes [
2]. Tea picking methods can be classified into two kinds, i.e., manual picking and mechanized picking [
3,
4]. Although manual picking can accurately pick out the tea buds, it is inefficient, requiring a large amount of manpower and easily causing the waste of resources. Mechanized picking can improve picking efficiency and reduce costs, yet it destroys the integrity of tea shoots, and the mixing of old leaves and broken leaves affects the quality of tea [
5]. Therefore, the picking of premium and high-quality tea mainly relies on manual picking. Thus, it is of great significance to study the technology of identifying tea shoots. Computer vision is used to accurately identify young shoots so as to improve the picking quality of tea [
6,
7].
At present, the automatic identification of tea shoots has become the key to improving the efficiency and quality of tea picking [
8,
9]. In the early research, traditional image processing methods [
10] were mainly used to identify tea shoots through color space analysis [
11] and edge detection [
12]. Zhao et al. used the HSV spatial transformation method to segment the tea bud image after RGB analysis of the tea bud image, and successfully extracted the tea bud image by setting the threshold and combining the three-channel component method [
13]. Although the traditional method can separate the tea buds from the old leaves, it has poor robustness in complex scenarios such as light changes and branch and leaf shading, and it is difficult to meet the practical application needs.
The tea shoot recognition method based on deep learning can better adapt to the recognition tasks in complex environments through the automatic extraction of multi-level features [
14,
15,
16]. Sun et al. presented a detection method for key organs in Tomato based on deep migration learning in a complex background [
17]. Peng et al. proposed a comparative study of semantic segmentation models for identification of grape with different varieties [
18].
Meanwhile, the YOLO series of algorithms [
19], with their end-to-end object detection framework, can quickly identify tea buds in complex backgrounds with high detection accuracy and strong real-time performance, and is widely applied in the field of tea bud recognition. Yang et al. improved the YOLOV3 network by introducing the residual network block structure and using convolution instead of the fully connected layer, combined with the K-means clustering algorithm to achieve end-to-end tea target recognition [
20]. Ji et al. presented apple recognition method in complex environment based on improved YOLOv4 [
21]. Zhou et al. presented an improved field obastacle detection algorithm based on YOLOv8 [
22].
In terms of tea picking, there is currently an urgent need for a tender shoot recognition technology with both high accuracy and real-time performance, so as to adapt to the complex natural environment and meet the requirements of lightweight deployment of picking robots. However, the existing techniques still have limitations. Traditional image processing methods rely on manual feature design, and the segmentation accuracy drops sharply when the illumination is uneven or the target is overlapping, which is hard to apply in dynamic farmland scenes. Although deep learning-based instance segmentation algorithms can improve adaptability through multi-level feature extraction, their application is still limited because of their high computation complexity and low recognition accuracy in complex natural environment. The research gaps can be summarized as follows.
- (1)
The recognition accuracy of tender tea shoots needs to be improved. The existing models have not been optimized for the features of tender tea shoots, resulting in insufficient distinction between tender shoots and similar background areas, as well as confusion during fine-grained classification. The tea plant environment is complex and changeable, and the models are prone to false positives and false negatives in conditions such as shadows and overlaps. Enhancing the feature extraction capability, especially in capturing the unique characteristics of tender tea shoots, is the key to improving recognition accuracy.
- (2)
The combination of object detection and segmentation algorithms affects the real-time performance of the system. The existing methods (such as Faster R-CNN [
17] and DeepLabV3+ [
18]) that integrate object detection and semantic segmentation for identifying tea buds are effective but computationally intensive, which impacts real-time performance. Therefore, while optimizing computational efficiency with high segmentation accuracy, how to enhance the stability and real-time performance of the system are also key research focuses in the current task of identifying tea buds.
To meet these research gaps, this study proposes the instance segmentation algorithm YOLOv8-TEA, which contains three main parts, i.e., the backbone feature extraction network, the feature fusion network, and the high-precision instance segmentation head. Firstly, in terms of feature extraction network, the MobileViT Block (MVB) was innovatively combined with the C2PSA module to replace some C2f modules in the original feature extraction network, making full use of the advantages of convolutional neural network (CNN) and Transformer. The ability to capture local texture features and global context information is enhanced, and the feature extraction effect of the model for tender tea shoots in complex environments is improved. Secondly, in the feature fusion network, the learnable dynamic upsampling methods DySample and CoTAttention modules are introduced to replace the traditional sampling method, which effectively solves the problem of loss of details in traditional methods and improves the segmentation accuracy in the scene of branches and leaves occlusion. Finally, in the segmentation head part, the depthwise separable convolution reconstruction was used to reduce the amount of parameter interaction and meet the real-time requirements of the picking robot.
Through the above improvements, this study not only significantly improves the segmentation accuracy, but also effectively reduces the number of model parameters, and reduces the GFLOPs to 52.7, which fills the shortcomings of existing studies in accuracy and real-time performance, and provides new ideas and methods for the development of tea tender shoot recognition technology.
The main contents of this paper are as follows:
Section 2 describes the related research work of tender tea shoot recognition, instance segmentation algorithms, and the contribution of this study.
Section 3 introduces the proposed YOLOv8-seg method in detail.
Section 4 discusses ablation experiments and comparative experimental results. Finally, suggestions for future research are made.
3. Methods
3.1. Overall Model Structure of YOLOv8-TEA
The overall process of YOLOv8-TEA is shown in
Figure 1a. After the input image, the image features are extracted by adding the feature extraction network of the MVB and C2PSA modules. Secondly, the image features are fused by the network that adds the Dy_Sample module and the CoTAttention mechanism. Then, the feature map is processed by the segmentation head that fuses the DWConv module.
The overall framework of the proposed instance segmentation model YOLOv8-TEA is shown in
Figure 1b, which mainly contains three parts: the feature extraction backbone network (module A), the feature fusion network (module B), and the segmentation head (module C). In the feature extraction stage, MobileVit Block (MVB) is used to replace part of the C2f module in the original feature extraction network, and the C2PSA module is added in the last layer. The feature fusion section uses dynamic upsampling Dysamples to replace the traditional upsampling method, while the CoTAttention attention mechanism was introduced in the process. The segmentation header part inherits the design idea of YOLACT, which processes the input feature map separately through independent detection and segmentation branches, and combines the bounding box and segmentation mask in the post-processing stage to finally output the complete instance segmentation result.
3.2. The Improved Feature Extraction Network Based on MobileViT
As one of the basic networks of the YOLO series, Darknet53 ensures the feature extraction capability of the network by introducing more convolutional layers and residual blocks. The original feature extraction network, CSPDarknet of the YOLOv8-seg model, introduces CSPNet and SPPF structures on the basis of Darknet53, which not only ensures efficient computing, but also ensures the feature extraction ability. CSPNet [
45] is composed of two main branches, namely the backbone branch that realizes deep feature extraction through deep convolution calculation via Dense Block and the shortcut branch that directly passes part of the input features to the final fusion layer, which optimizes the gradient information transfer and reduces the computational cost through cross-stage feature distribution. However, SPPF uses recursive pooling instead of multi-scale pooling, which significantly reduces the computational effort while maintaining a large receptive field.
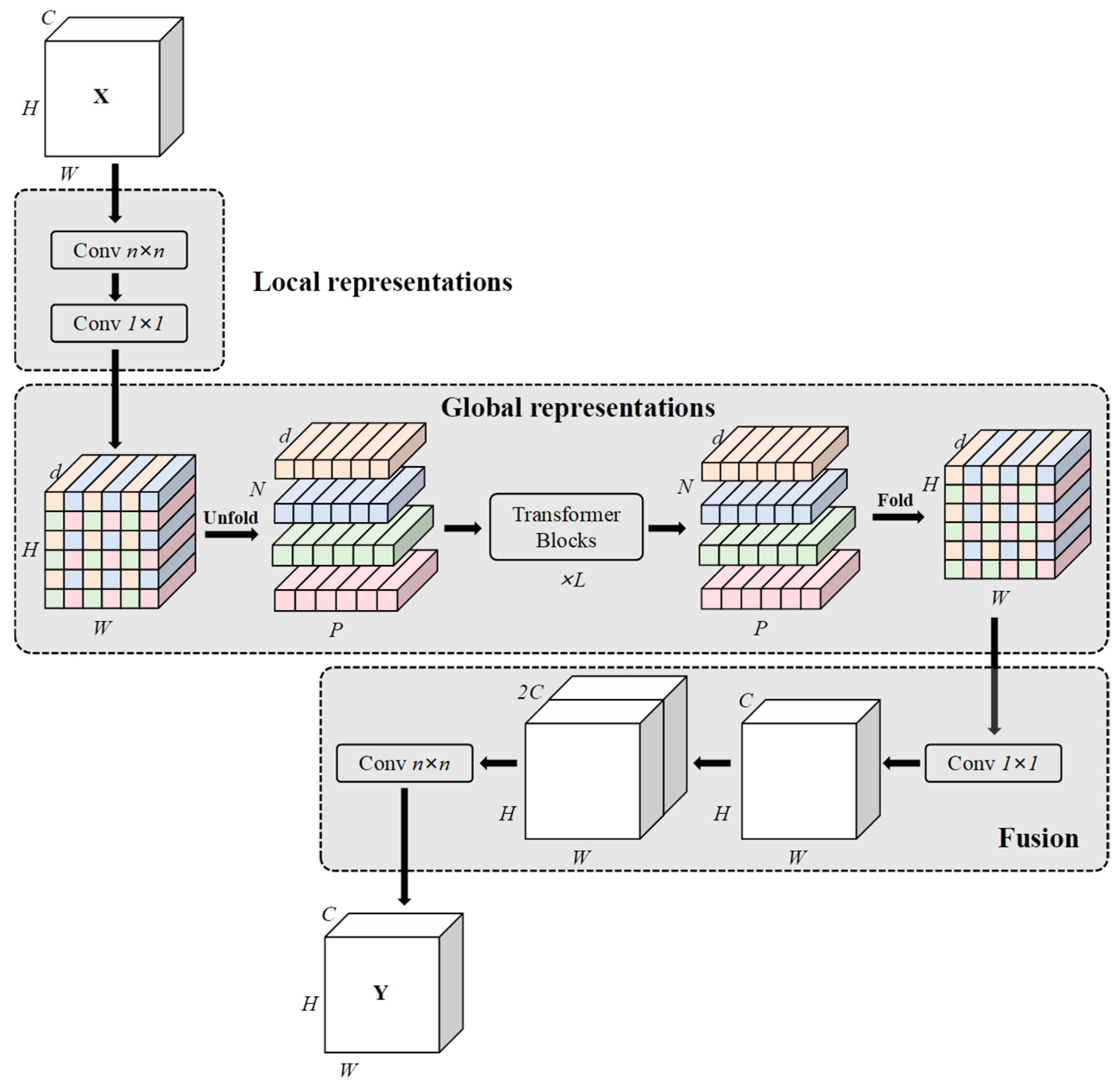
In this study, based on the original feature extraction network CSPDarknet, some C2f modules in the original feature extraction network are replaced with MobileVit Block (MVB) [
46], which combines the advantages of the convolutional neural network (CNN) and Transformer, and the C2PSA module following the Spatial Pooling Pyramid (SPPF), to combine convolution with attention mechanism to further improve the feature extraction ability, as shown in
Figure 2. MobileViT is a model architecture that combines the advantages of convolutional neural networks (CNN) and Vision Transformers (ViT). It is able to capture long-distance dependency information through the self-attention mechanism, so as to extract features in the image more effectively. In contrast, the traditional C2f block may be slightly insufficient in the richness of feature extraction and the ability to capture complex semantic information.
Replacing specific C2f blocks with MobileViT can introduce a more powerful feature extraction mechanism, which helps the model to better understand the objects in the image, improve the representation ability of different objects and scenes, and then improve the segmentation accuracy. If other C2f blocks were changed to MobileVit, it would cause training instability. Changing the model structure may break the original training balance, especially when fine-tuning the pre-trained model, which may require more fine hyperparameter tuning; otherwise, it may lead to training instability, such as gradient explosion or disappearance. Replacing all C2f blocks with MobileVit may result in a substantial increase in computational resource requirements. Due to the relatively high computational complexity of MobileViT, total replacement will dramatically increase the number of parameters and calculation of the model and greatly increase the requirements for hardware resources, which may mean that it would not be able to run in real-time on resource-constrained devices.
The originally used C2f module in YOLOv8-seg mainly consists of four parts: a 1 × 1 convolution for dimensionality reduction; a split module that divides the convolution output into two parts, one directly entering the final concatenation and the other entering the DarknetBottleneck for computation; multiple DarknetBottleneck modules; and a 1 × 1 convolution to adjust the number of channels of the concatenated features. While this structure improves the efficiency of feature reuse, it also tends to cause a lack of global information interaction and the loss of small object details due to its heavy reliance on DarknetBottleneck.
The MVB module combines the advantages of a convolutional neural network (CNN) and a transformer to capture both the local features and global context information of an image, as shown in
Figure 3. The MVB module fuses convolutional features and Transformer features—the convolutional layer is responsible for efficiently extracting local features and the Transformer processes the global context information through the self-attention mechanism—and finally fuses the two through residual connections to generate feature representations that contain both local details and global dependencies so that the model can better understand the structure and relationship of the image, thereby improving the effect of detection and segmentation.
The C2PSA module refers to the method of improving the performance of the model through a partial self-attention mechanism in YOLOv10, which introduces the improved multi-head attention mechanism into the C2f structure, replaces the Darknet Bottleneck layer, and discards the output results of the middle layer, so as to realize the effective combination of convolutional blocks and attention mechanism, as shown in
Figure 4. The C2PSA module first receives the input feature map and converts the number of channels from
c1 to 2 ×
c using a 1 × 1 convolution. Here,
c is the number of hidden channels calculated from
c1 and the extended scale
e. Secondly, the output is divided into two parts,
a and
b, by means of the Split function, and the number of channels in each part is
c. Output
b is then processed using multiple PSABlock modules.
As shown in
Figure 5, the PSABlock module incorporates a multi-head attention mechanism and a feedforward neural network (FFN). It first processes input features through the attention mechanism, then further enhances these features via the FFN layer. Finally, it decides whether to apply a shortcut connection by adding the input and output to maintain information flow and mitigate issues like gradient vanishing. The processed features (B) and the original features (A) are combined through channel concatenation to form a new feature map. A 1 × 1 convolution is applied to the concatenated feature map to adjust the channel dimension from 2 ×
c back to the input channel number
c1, after which the features are output to the next layer.
3.3. An Improved Feature Fusion Network Integrating Dysample and CoTAttention
FPN is a feature fusion network of the original algorithm of Oriented R-CNN, which fuses the features of multi-scale feature maps output by different layers of the feature extraction network through a top-down structure with horizontal connections. Specifically, FPN realizes the effective integration of multi-scale features by combining feature maps of different scales; that is, the detailed information is obtained from the lower layer of the feature extraction network and then upsampled through the top-down path and fused layer by layer to obtain a high-dimensional feature map containing rich semantic information. Based on the fusion strategy of FPN, PAFPN proposes a more efficient secondary fusion strategy. PAFPN not only adds a bottom-up structure to the top-down structure of the FPN, but also further integrates the characteristics of each layer. Bottom-up helps convey more detailed information and spatial location features, while top-down conveys more semantic features. Through this bidirectional feature transfer, PAFPN can integrate multi-scale features more comprehensively, improve the ability to express features, and capture details.
Although PAFPN has achieved good results in image feature fusion, it adopts the nearest neighbor interpolation method without feature learning ability in the upsampling process, which directly enlarges the image by “copying” the adjacent pixel values, which limits the learning ability of the feature fusion network to a certain extent. In order to improve the learning ability of PAFPN, the traditional upsampling method is replaced by a learnable dynamic upsampling method, and the CoTAttention attention module is added, as shown in
Figure 6.
DySample replaces the traditional upsampling method by introducing a dynamic range factor and optimizing the initial sampling position, thereby generating high-quality upsampling feature maps more flexibly and efficiently [
47]. Unlike the traditional fixed-grid sampling, DySample adopts a dynamic sampling strategy, enabling the upsampling process to adaptively adjust and better capture feature details to enhance reconstruction accuracy.
First, DySample generates a sampling set through a sampling point generator, as shown in
Figure 7. The input feature map selects specific points through a grid sampling function and extracts values from them to achieve resampling. In this process, the input features, upsampled features, generated offsets, and the original grid are represented by X, X’,
o, and
g, respectively. In the sampling set generator, the sampling set is the sum of the generated offsets and the positions of the original grid, and it has two different implementation methods, as shown in
Figure 8. One is a static range factor version that generates offsets through a linear layer; the other is a dynamic range factor version that first generates a dynamic range factor and then modulates the offsets, where σ is an S-shaped activation function used to dynamically adjust the sampling range factor. Different from the traditional method, DySample optimizes the initial position distribution through bilinear initialization, which effectively avoids the problem of an uneven sampling position that may exist in the traditional method. In order to better handle the boundary problem, reduce the overlap of sampling locations, and avoid artifacts, DySample dynamically adjusts the offset range to ensure that the theoretical marginal condition is met between the overlapping and non-overlapping sampling locations.
The traditional self-attention module dynamically learns the interaction between each element in the sequence by computing the relationship among Query, Key, and Value, thereby capturing long-range dependencies, enabling parallelization, and providing strong context modeling capabilities. However, due to the need to store the attention matrix and intermediate results, it incurs relatively high memory consumption when processing high-resolution images or long texts. In contrast, CoTAttention combines convolution operations with the attention mechanism. It generates Keys and Values through convolution and then weights the Values via the attention mechanism to enhance the representativeness of the output feature map, allowing the model to capture richer context information across different positions. The structure is shown in
Figure 9.
Let the input be X ∈ R
H×W×C, and the Query, Key, and Value are defined as K = X, Q = X, and V =
XWv, respectively. First, to provide more context information for each key, a k × k group convolution is applied to all adjacent keys within a k × k grid to obtain the Key K
1 ∈ R
H×W×C, which represents the static context relationship between adjacent keys and is regarded as the static context representation of the input X. Then, K
1 and the Query are concatenated, and a context attention matrix A is calculated through two consecutive 1 × 1 convolutions.
Here, W
θ is equipped with a ReLU activation function, while W
δ has no activation function. Next, all values are aggregated according to the contextual attention matrix A to obtain the final dynamic context K
2.
Finally, the weighted features are restored to the same size as the input, and then the static context K
1 and dynamic context K
2 are fused through the self-attention mechanism to obtain the final output Y.
The CoTAttention attention mechanism realizes the fusion of local information and global information by combining convolution operation and attention mechanism so that the features of each position can be adjusted according to the contextual information of other positions, and the model expression ability is improved while maintaining high computational efficiency.
3.4. Improved Segmentation Head Combined with DWConv
The YOLOv8-seg segmentation head inherits the architecture of the YOLACT segmentation head and introduces a segmentation branch alongside the object detection branch [
48]. The detection branch comprises a regression head—responsible for predicting the coordinates and dimensions of object bounding boxes—and a classification head—tasked with predicting object categories. The regression head utilizes two convolutional layers and an output layer to generate bounding box-associated parameters, primarily including the distribution of center coordinates and size metrics for each pixel point. The classification head adopts a parallel architecture, employing two depthwise separable convolutional layers (DWConv) to compute category probabilities for each pixel point, as illustrated in
Figure 10.
The branch splitting approach transforms the instance segmentation problem into a weighted combination problem by introducing mask prototypes and a coefficient generation mechanism. Here, mask prototypes serve as the basic templates for generating segmentation masks, representing universal and fixed templates of different parts or shapes of the target objects. Meanwhile, each layer of the input feature map generates mask coefficients through convolutional layers, which control the way the mask prototypes are combined with the feature maps of the input image and determine the segmentation effect of each target. The segmentation mask for each target is achieved by multiplying the mask prototypes with the corresponding mask coefficients and performing a weighted combination. The mask coefficients determine the weight of each prototype, while the prototypes define the shape of the mask. The combination method is as follows:
where mask
i is the segmentation mask of target i, mc
i,k is the k-th mask coefficient corresponding to target i, proto
k is the k-th mask prototype, and the final mask is the weighted sum of these prototypes.
4. Experiment
4.1. Datasetss and Evaluation Metrics
The experimental images were collected from the Juyuanchun tea garden in Yizheng, Yangzhou, Jiangsu Province, with the target variety being “Longjing 34”. During the research, RGB images of the tender tea shoots of tea plants were captured from multiple angles in April and August 2023. The used camera was the rear camera of iPhone 13 Pro. To ensure the generalization and robustness of the model, the impact of different shooting angles and methods on the subsequent extraction of tea bud picking points was studied, and the diversity of collected samples was ensured. The image collection process included different lighting scenarios such as early morning, noon, and evening, and samples were collected from vertical, oblique downward, backlight, and light-reversal angles. Data augmentation [
49] was performed on all samples, which not only enriched the samples and improved the accuracy of the algorithm but also restored the real shooting environment of machine picking. The storage format was JPG. In order to ensure the interference of the dataset quality on the detection effect of the model, the image was visually evaluated, and the image with blurred target, no tea tender tip target, and tea tender tip was seriously occluded, and the image with clear shooting outline and visible picking point was retained.
In order to improve the generalization ability and robustness of the model, a variety of data augmentation techniques are used in the data preprocessing process so that the model can adapt to different illumination, angle, and background changes, so as to improve the accuracy and stability of picking point detection.
Firstly, in the aspect of geometric transformation, the original image is rotated randomly to simulate the changes of different shooting angles and improve the adaptability of the model to rotation transformation. At the same time, the horizontal flip and vertical flip are used to enhance the direction diversity of the data and prevent the model from overfitting the specific direction features. In addition, the main feature area was retained by random clipping and the sample variation was increased so that the model could still effectively identify the picking point of tea tender shoots in the case of local information changes.
Secondly, in terms of illumination and color adjustment, in order to adapt to the light conditions of different periods of time such as early morning, noon, and evening, the brightness of the image is adjusted to ensure that the model can maintain good robustness in different lighting environments. At the same time, the contrast and saturation are adjusted to optimize the visual difference between the young shoots and the background so as to improve the adaptability of the model under various light conditions. In addition, the color shift technology is used to simulate the changes of environmental light sources to further improve the stability of the model in complex natural environments.
Finally, in order to enhance the adaptability of the model to occlusion, random occlusion is used in the enhancement of background interference to simulate the situation that the tender tea shoot is occluded by some leaves or external objects so that the model can maintain high recognition accuracy in the case of missing local information.
To effectively harvest tea buds, tea picking robots usually need to identify the picking points on the tender shoots of tea plants. Based on the growth conditions of tea plants and the national standard GB/T18650-2008 [
50], the tender shoots with single buds and one bud with one leaf are defined as the picking targets. During the data annotation process, Labelme is used to precisely annotate the collected tea plant images to ensure that the subsequent model can accurately learn the feature information of the key areas. The annotation tool interface and label information are shown in
Figure 11. In order to improve the generalization ability of the model, the instance segmentation dataset was split in a ratio of 7:2:1, with 6230 images in the training set, 1780 images in the validation set, and 890 images in the test set.
To evaluate the performance of this method, the mean average precision (mAP) is utilized to assess the detection accuracy of the rotated object detection model. We use AP and mAP to measure the model’s performance. The relevant calculation formulas are as follows:
where P is the precision, R is the recall, TP is the number of positive samples correctly predicted by the model, and FP is the number of negative samples that the model is wrongly predicted.
4.2. Experimental Environment and Training Parameter Settings
The YOLOv8-TEA model was built using Pytorch 1.12 and trained and tested on a computer equipped with an AMD Ryzen 5 5600 6-Core Processor as the CPU and an NVIDIA GeForce RTX 3070 as the GPU. The development environment was specifically Python 3.8, CUDA 11.3, and CuDNN 8.3.2.
The training loop type based on Epoch is adopted, with a total of 300 epochs for training and a batch size of 16. The Stochastic Gradient Descent (SGD) optimizer is used, with a learning rate of 0.0025, a momentum of 0.9, and a weight decay of 0.0001. A stepwise learning rate decay strategy is employed, which includes a warm-up stage and several stepwise decay stages [
51]. The warm-up stage uses a linear decay strategy with 500 iterations and a warm-up ratio of 1/3. The parameter list for stepwise decay is [48,192,264]. All input images are cropped to a size of 640 × 640.
4.3. Ablation Experiments
To verify the effectiveness of the different improved modules in the model, seven groups of experiments were designed, as shown in
Table 1, to test whether to replace some C2f modules in the backbone feature extraction network with MVB modules, whether to add C2PSA modules to the backbone feature extraction network, whether to replace the ordinary upsampling method in the feature fusion network with dynamic upsampling, whether to add the CoTAttention mechanism to the feature fusion network, and whether to insert depthwise separable convolution in the detection branch of the segmentation head. The accuracy (P-B), recall (R-B), mean average precision (mAP-B) of the detection boxes, the accuracy (P-M), recall (R-M), mean average precision (mAP-M) of the segmentation masks, and the number of parameters (GFLOPs) of the model were evaluated on the test set, respectively. The specific results are shown in
Table 2.
According to the experimental data in
Table 2, after replacing the C2f module in the backbone network with the MVB module, the computational cost GFLOPs was significantly reduced from 111. 7 to 51. 5, while the map50 for detection and segmentation improved by 1.3% and 1.2%, respectively. Adding the C2PSA module increased the map50 for detection and segmentation by 1.4% and 2.2%, respectively. Replacing the ordinary upsampling with dynamic upsampling improved the map50 for detection and segmentation by 2.1% and 2.2%, respectively. Introducing the CoTAttention mechanism increased the map50 for detection and segmentation by 1.2% and 2.1%, respectively. Replacing the ordinary convolution in the segmentation head with depthwise separable convolution improved the map50 for detection and segmentation by 1.8% and 1.3%, respectively. The model TOLOv8-TEA, which integrates all the above improvements, reduced the computational cost by 53% while improving the mAP50 for detection and segmentation by 2.9% and 2.2%, respectively, compared to the original YOLOv8m-seg, fully verifying the effectiveness of the improvement methods.
As shown in
Figure 12, the mAP (Box) and mAP (Mask) of YOLOv8m-seg and YOLOv8-TEA both steadily increased with the increase in the number of iterations and eventually converged. In the early stage of training, the accuracy difference between the two models was small, but as the iterations continued, the performance gap between them gradually widened, and the improved model demonstrated higher accuracy in both detection and segmentation tasks. Finally, the recognition and segmentation effects of the model on images were further tested. As shown in
Figure 13, the proposed instance segmentation model YOLOv8-TEA can accurately recognize and segment tea shoot images under different lighting conditions and with different numbers of tea shoots.
4.4. Comparative Experiments
To further evaluate the recognition and segmentation performance of the algorithm on the tea shoot dataset, the following were selected for comparison: YOLOv5m-seg, YOLOv7m-seg, YOLOv11m-seg, YOLACT, and SOLO. Due to the essential differences in bounding box dependency and mask prediction mechanisms among different methods, mAP (Mask) can more accurately measure the performance of the segmentation task, avoiding the interference of detection box accuracy, and thus ensuring the fairness and rationality of the comparison results. In this study, the COCO standard [
52] mAP calculation method is used, where mAP50 refers to the IoU threshold of 0.5 as the judgment criterion, which reflects the performance of the model under the relaxed overlap requirement. mAP50-95 is the average precision calculated for IoU thresholds ranging from 0.5 to 0.95 (with a step size of 0.05), which comprehensively evaluates the robustness of the model at different levels of stringency. Although mAP50 (IoU = 0.5) can intuitively reflect the practicality of the model in common scenarios, the introduction of MAP50-95 (IoU = 0.5:0.95) further verifies the potential of the model in high-precision localization tasks.
As shown in
Table 3, the proposed model YOLOv8-TEA performs best in terms of segmentation accuracy. Compared with YOLOv11m-seg, YOLOv7m-seg, YOLOv5m-seg, YOLACT, and SOLO, its mAP50 has increased by 4.3%, 10.4%, 15.4%, 25.7%, and 28.9%, respectively, and its mAP50-95 has increased by 12.0%, 17.0%, 22.5%, 29.1%, and 34.8%, respectively. Additionally, the computational complexity of YOLOv8-TEA is only 52.7 GFLOPs, significantly lower than the 129.3 GFLOPs of YOLOv11m-seg and 153.5 GFLOPs of SOLO, further verifying its efficiency. The experimental results show that YOLOv8-TEA significantly reduces the computational cost while maintaining high accuracy, demonstrating stronger practical application value. At the same time, the inference speed of YOLOv8-TEA is 74.1FPS, which is significantly higher than the industrial real-time standard (≥30 FPS). The high FPS of YOLOv8-TEA not only meets the requirements of real-time operation, but also shows significant advantages in computing speed and actual scene adaptation. These results strongly demonstrate the model’s robustness and practical deployment potential.
Figure 14 shows the real values of the model and the predicted results. In
Figure 14b, the boxes with different colors represent different types of buds and leaves predicted by the model. The verification process not only shows the visual results predicted by the model by comparing with the real tea image in
Figure 14a, but also shows the visual results predicted by the model. Moreover, the fit between the prediction and the real value is strictly tested through quantitative indicators, which effectively enhances the credibility of the model performance conclusion. To more intuitively display the segmentation effects of each algorithm,
Figure 15 shows the segmentation test results of each method on the same test image, where the poor segmentation results are circled in red boxes. All of these models have missed detection, and SOLO has a more serious level of missed detection. At the same time, YOLOv5m-seg and YOLOv7m-seg still have an incomplete segmentation of the boundary of tea shoots, YOLACT struggles to identify the segmentation boundary between some background regions and tea shoots, and YOLOv11m-seg has low segmentation accuracy for small-size shoots. In summary, it can be seen that YOLOv8-TEA not only leads in overall segmentation accuracy, but also is more accurate in edge detail processing.
5. Conclusions and Discussions
In this study, the instance segmentation algorithm YOLOv8-TEA is proposed by improving the YOLOv8-seg model, which uses MobileVit Block to replace part of the C2f modules in the original feature extraction network, and adds the C2PSA module in the last layer to enhance the local feature extraction ability. The lightweight dynamic upsampler Dysample, which simplifies the upsampling process by point sampling, replaces the original upsampling method that relies on dynamic convolution to achieve upsampling, which reduces the computational complexity and improves the inference speed. By adding the CoTAttention attention module, the advantages of context mining and self-attention learning were simultaneously used to improve the representation ability of the deep network. In the segmentation branch, the instance mask generation method of YOLACT is inherited, and the dilated convolution is added to the classification head to expand the receptive field so as to further improve the segmentation accuracy and speed. Secondly, an example segmentation dataset of tea shoots in natural scenes is constructed, including images of tea shoots under different growth states, different backgrounds, and different lighting conditions. At the same time, in order to improve the robustness and generalization ability of the model, data enhancement processing is performed on the dataset to ensure that it can effectively deal with various complex changes in the actual picking scene. Finally, the improved algorithm YOLOv8-TEA is experimentally verified using metrics such as P, R, mAP50, and GFLOPs. The results show that the mAP50 (Box) and mAP50 (Mask) of the improved model reach 86.9% and 86.8%, respectively, which are 2.9% and 2.2% higher than those of the base model. Comparative experiments with other instance segmentation algorithms verify the effectiveness of the model.
While our research is primarily focused on the agricultural domain, specifically tea picking, we recognize that the proposed methods and techniques have potential for wider applications. For example, in forestry management, it is very important to monitor the growth of trees. Our method can be used to identify and monitor tree shoots and new branches, thus helping foresters to better understand the growth status and health of forests. In industrial vision and defect detection, e.g., for millimeter-scale defects such as bearing roller cracks and circuit board solder joints, the model’s sensitivity to edge details (CoTAttention enhances local feature response) can achieve the accurate segmentation of defect contours. The lightweight design (52.7 GFLOPs) meets the high-speed inspection requirements of the production line (≥45 FPS), and supports real-time defect classification and location localization. In the detection of reflective surfaces such as glass and metal sheets, the global context modeling capability of the MVB module can suppress the interference of uneven illumination, and dynamic upsampling can avoid the misjudgment of defect boundaries caused by interpolation ambiguity, which provides technical support for high-precision quality control.
Although YOLOv8-TEA shows high accuracy and efficiency in the task of tea shoot recognition, there are still limitations: first, although the model performs well in the experimental dataset (multi-period of morning and dusk, multi-angle of backlight/light), the robustness of the model to extreme weather (such as heavy rain and fog) and severe occlusion scenes (branch coverage > 80%) still needs to be improved. Second, the ability to generalize across varieties is limited. The current model is based on the dataset of a single tea variety “Longjing 34” and does not cover the morphological differences in other tea varieties (such as Biluochun and Tieguanyin). Finally, there is the problem of the missing detection of small targets. For shoots smaller than 20 × 20 pixels (such as early bud tips), the boundary blurring phenomenon of the model segmentation mask is significant, and the missed detection rate is 8.2% higher than that of medium and large targets, which is directly related to the minimum receptive field (20 × 20) design of the feature fusion network.
Future research may focus on solving the occlusion problem of picking points for tender tea shoots and improving the generalization ability of the model. In the future, multi-modal data fusion technology, such as combining infrared information and multi-view images, can be considered to further improve the algorithm’s ability to segment objects in occlusion scenes.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}