
Integrating Stride Attention and Cross-Modality Fusion for UAV-Based Detection of Drought, Pest, and Disease Stress in Croplands

Abstract
1. Introduction
- A novel stride–cross-attention mechanism tailored for agricultural disaster detection is proposed for the first time, enabling simultaneous modeling of multi-scale and multi-directional image features. Compared with traditional attention mechanisms, restricted to fixed directions or full connectivity, this method demonstrates superior feature capture capabilities in scenarios involving ambiguous disaster boundaries, strong surface texture heterogeneity, and multimodal fusion. Moreover, it provides improved lightweight inference performance suitable for edge deployment.
- A fully deployable UAV agricultural disaster monitoring system is designed and implemented, integrating high-resolution image acquisition, real-time geometric correction, multimodal data preprocessing, feature extraction, disaster recognition, and alert modules. Unlike most existing systems that are validated only in offline or laboratory environments, this system supports real-time recognition and rapid response in field operation conditions.
- Extensive field trials were conducted across multiple stages and scenarios in Ordos City, Inner Mongolia, covering various crops (e.g., wheat, maize), multiple growth stages, and representative disaster types (e.g., drought, pest infestation). The experiments demonstrate the robustness and adaptability of the proposed approach in real agricultural environments, providing practical support for scalable deployment in high-risk zones.
- The algorithm and system design take into account edge-device constraints and engineering feasibility, incorporating techniques such as quantization-aware training, ONNX model export, and TensorRT acceleration. These efforts enable efficient operation on embedded platforms such as NVIDIA Jetson AGX Xavier, making the system more suitable for localized disaster monitoring tasks under limited computational resources, particularly in rural areas, compared to traditional approaches reliant on high-performance GPUs or cloud platforms.
2. Related Work on Attention Mechanisms
2.1. Attention Mechanisms in General Vision Tasks
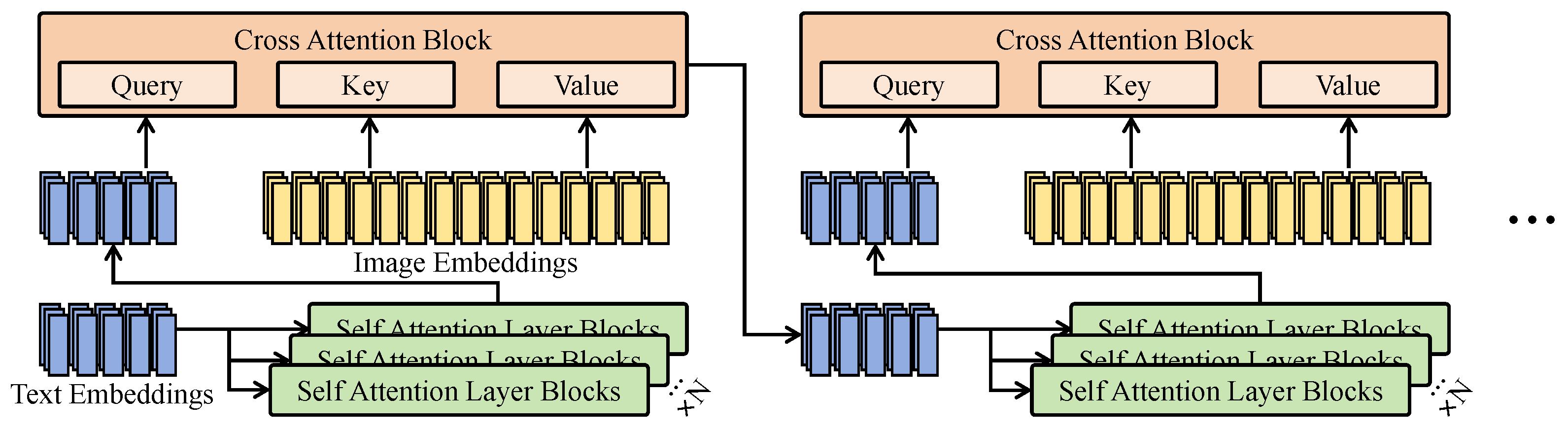
2.2. Attention Mechanisms in Multimodal Vision and Remote Sensing
2.3. Applications of Attention Mechanisms in Agricultural Remote Sensing
2.4. Challenges and Motivation
3. Materials and Method
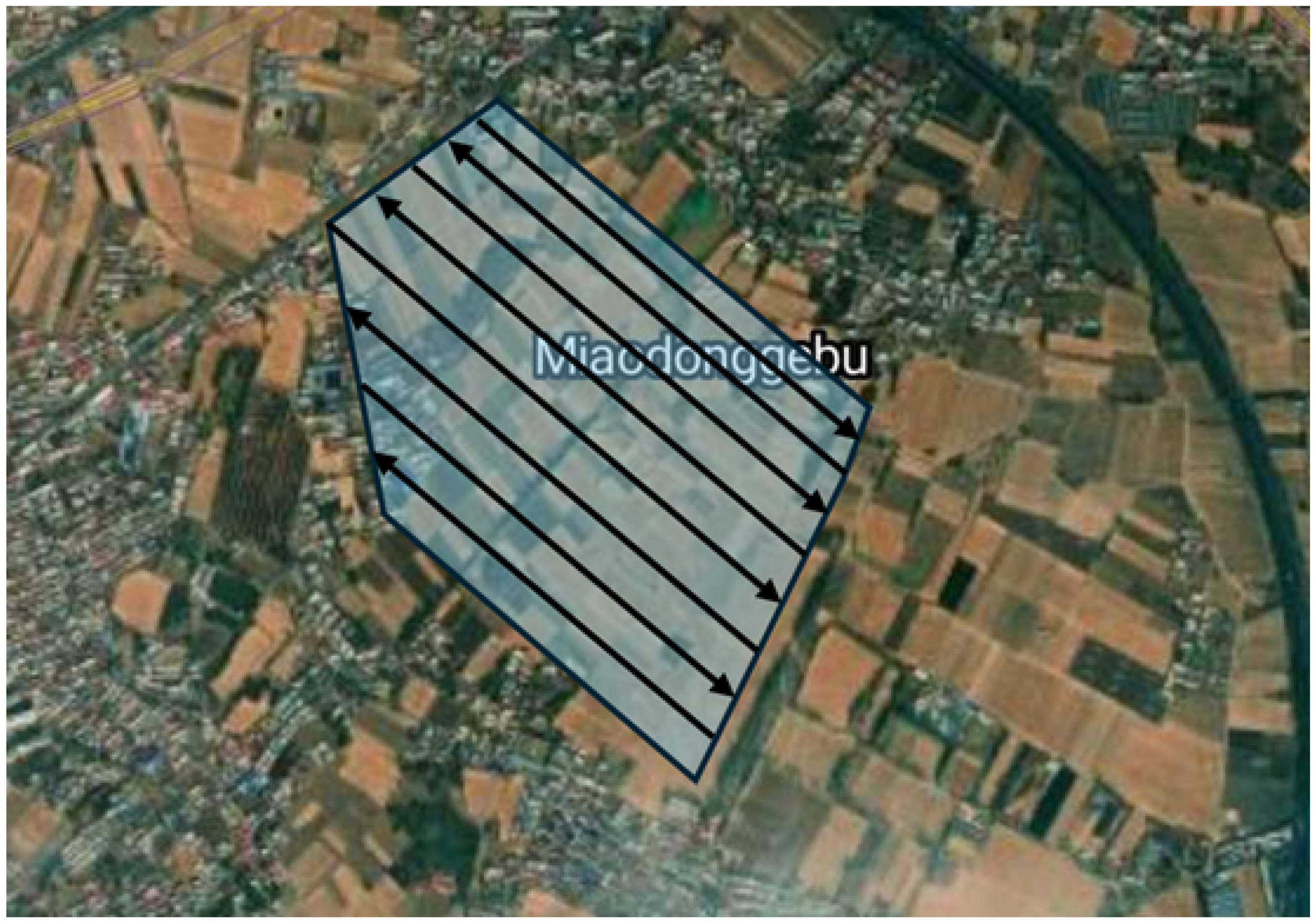
3.1. Data Collection
| Algorithm 1 UAV Attitude Control and Disturbance Compensation Algorithm. |
|
3.2. Dataset Annotation and Enhancement
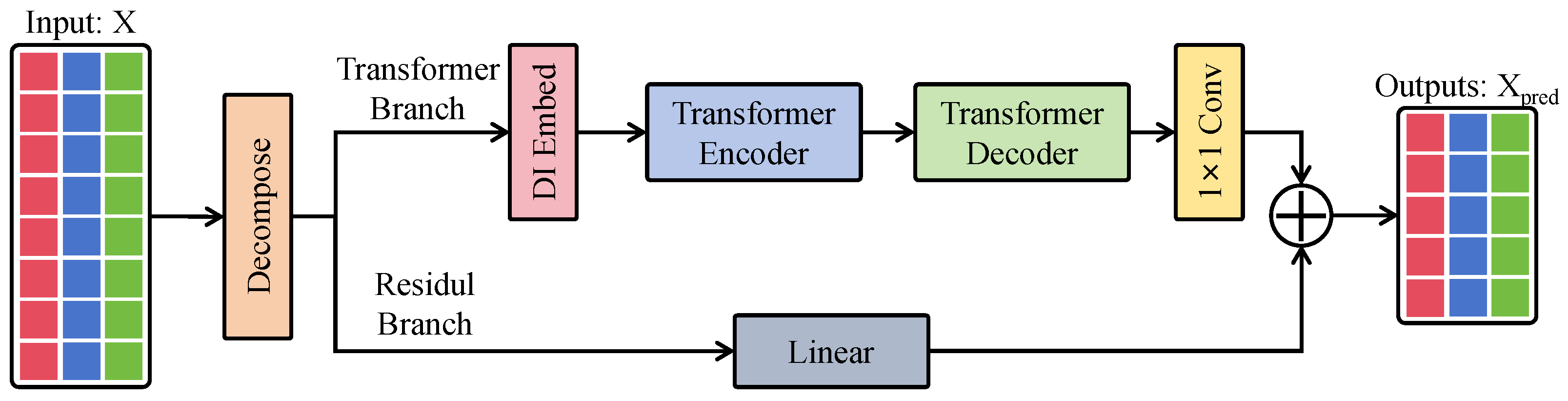
3.3. Proposed Method
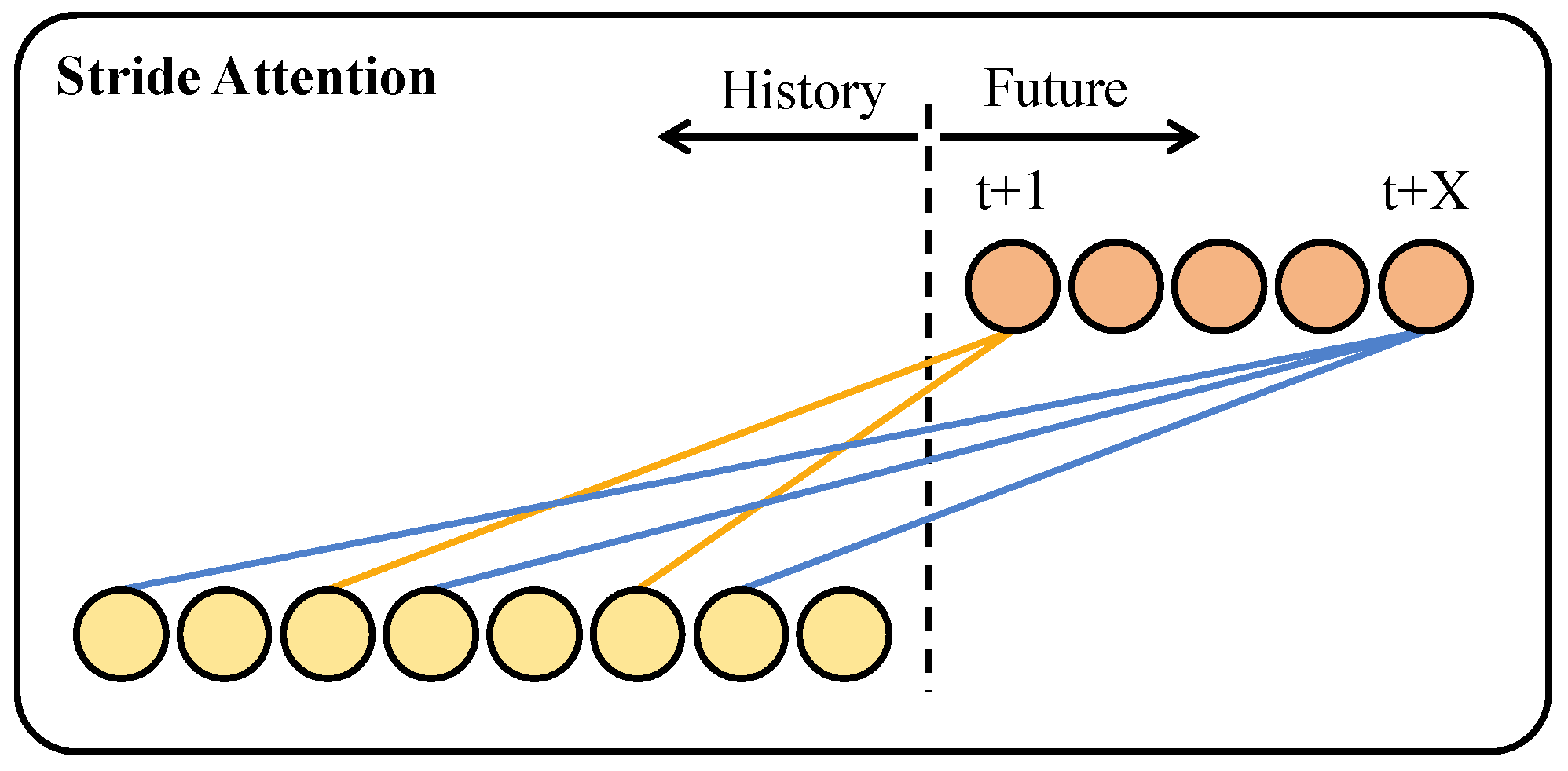
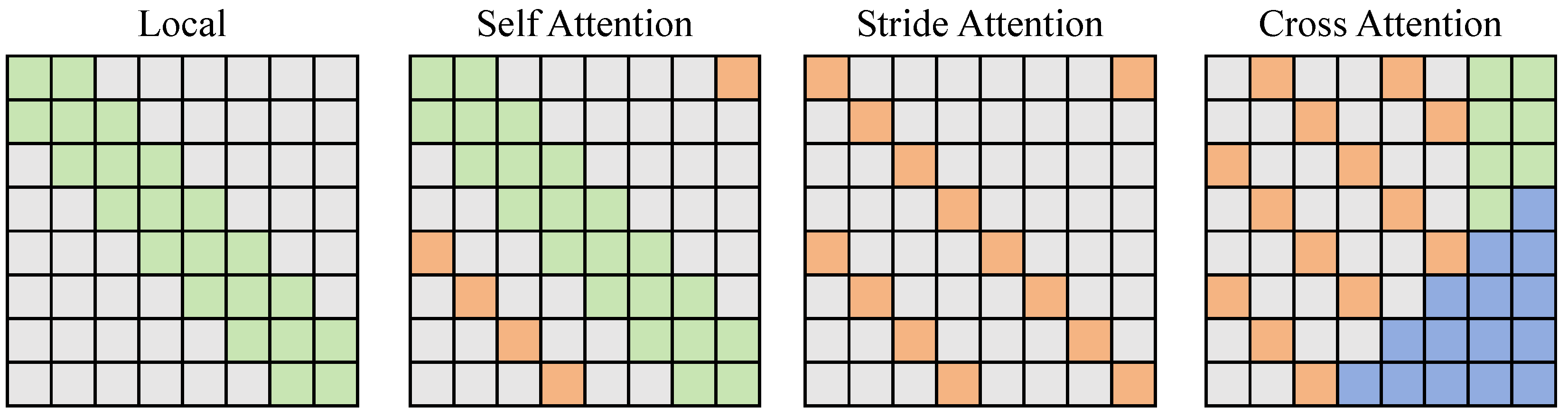
3.3.1. Dual Branch and Cross-Attention
3.3.2. Disaster Classification and Recognition Network
3.3.3. Implementation Details
| Algorithm 2 Proposed Model Inference Flow. |
|
3.4. Experimental Setup
3.4.1. Hardware and Software Platform
3.4.2. Dataset Construction
3.4.3. Evaluation Metrics
3.5. Baseline
4. Results and Discussion
4.1. Performance Comparison of Different Models in Agricultural Disaster Detection Tasks
4.2. Performance Comparison of Different Models on Weed Detection in Soybean Crops
4.3. Ablation Study on the Cross-Attention Module
4.4. Ablation Study on Classifier Architecture Variants
4.5. Ablation Study on Stride Setting
4.6. Discussion on Lightweight Strategies
4.7. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gullino, M.L.; Albajes, R.; Al-Jboory, I.; Angelotti, F.; Chakraborty, S.; Garrett, K.A.; Hurley, B.P.; Juroszek, P.; Lopian, R.; Makkouk, K.; et al. Climate change and pathways used by pests as challenges to plant health in agriculture and forestry. Sustainability 2022, 14, 12421. [Google Scholar] [CrossRef]
- Wang, C.; Wang, X.; Jin, Z.; Müller, C.; Pugh, T.A.; Chen, A.; Wang, T.; Huang, L.; Zhang, Y.; Li, L.X.; et al. Occurrence of crop pests and diseases has largely increased in China since 1970. Nat. Food 2022, 3, 57–65. [Google Scholar] [CrossRef]
- Wang, C.; Gao, Y.; Aziz, A.; Ogunmola, G.A. Agricultural disaster risk management and capability assessment using big data analytics. Big Data 2022, 10, 246–261. [Google Scholar] [CrossRef]
- Su, Y.; Wang, X. Innovation of agricultural economic management in the process of constructing smart agriculture by big data. Sustain. Comput. Inform. Syst. 2021, 31, 100579. [Google Scholar] [CrossRef]
- Niu, X. Vulnerability Assessment of Water Resources in Bayannur City based on Entropy Power Method. Sci. J. Econ. Manag. Res. 2023, 5, 2. [Google Scholar]
- Deepika, P.; Kaliraj, S. A survey on pest and disease monitoring of crops. In Proceedings of the 2021 3rd International Conference on Signal Processing and Communication (ICPSC), Coimbatore, India, 13–14 May 2021; pp. 156–160. [Google Scholar]
- Pettorelli, N.; Vik, J.O.; Mysterud, A.; Gaillard, J.M.; Tucker, C.J.; Stenseth, N.C. Using the satellite-derived NDVI to assess ecological responses to environmental change. Trends Ecol. Evol. 2005, 20, 503–510. [Google Scholar] [CrossRef]
- Garbulsky, M.F.; Peñuelas, J.; Gamon, J.; Inoue, Y.; Filella, I. The photochemical reflectance index (PRI) and the remote sensing of leaf, canopy and ecosystem radiation use efficiencies: A review and meta-analysis. Remote Sens. Environ. 2011, 115, 281–297. [Google Scholar] [CrossRef]
- Gonenc, A.; Ozerdem, M.S.; Acar, E. Comparison of NDVI and RVI vegetation indices using satellite images. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Istanbul, Turkey, 16–19 July 2019; pp. 1–4. [Google Scholar]
- Ahad, M.T.; Li, Y.; Song, B.; Bhuiyan, T. Comparison of CNN-based deep learning architectures for rice diseases classification. Artif. Intell. Agric. 2023, 9, 22–35. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 2961–2969. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 10–17 October 2021; pp. 558–567. [Google Scholar]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-accuracy detection of maize leaf diseases CNN based on multi-pathway activation function module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Zhang, Y.; He, S.; Wa, S.; Zong, Z.; Lin, J.; Fan, D.; Fu, J.; Lv, C. Symmetry GAN detection network: An automatic one-stage high-accuracy detection network for various types of lesions on CT images. Symmetry 2022, 14, 234. [Google Scholar] [CrossRef]
- Li, Q.; Ren, J.; Zhang, Y.; Song, C.; Liao, Y.; Zhang, Y. Privacy-Preserving DNN Training with Prefetched Meta-Keys on Heterogeneous Neural Network Accelerators. In Proceedings of the 2023 60th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 9–13 July 2023; pp. 1–6. [Google Scholar]
- Tao, W.; Wang, X.; Xue, J.H.; Su, W.; Zhang, M.; Yin, D.; Zhu, D.; Xie, Z.; Zhang, Y. Monitoring the damage of armyworm as a pest in summer corn by unmanned aerial vehicle imaging. Pest Manag. Sci. 2022, 78, 2265–2276. [Google Scholar] [CrossRef] [PubMed]
- Ren, C.; Liu, B.; Liang, Z.; Lin, Z.; Wang, W.; Wei, X.; Li, X.; Zou, X. An Innovative Method of Monitoring Cotton Aphid Infestation Based on Data Fusion and Multi-Source Remote Sensing Using Unmanned Aerial Vehicles. Drones 2025, 9, 229. [Google Scholar] [CrossRef]
- Zhou, X.G.; Zhang, D.; Lin, F. UAV Remote Sensing: An Innovative Tool for Detection and Management of Rice Diseases. In Diagnostics of Plant Diseases; IntechOpen: London, UK, 2021. [Google Scholar]
- Guo, W.; Gong, Z.; Gao, C.; Yue, J.; Fu, Y.; Sun, H.; Zhang, H.; Zhou, L. An accurate monitoring method of peanut southern blight using unmanned aerial vehicle remote sensing. Precis. Agric. 2024, 25, 1857–1876. [Google Scholar] [CrossRef]
- Ye, W.; Lao, J.; Liu, Y.; Chang, C.C.; Zhang, Z.; Li, H.; Zhou, H. Pine pest detection using remote sensing satellite images combined with a multi-scale attention-UNet model. Ecol. Inform. 2022, 72, 101906. [Google Scholar] [CrossRef]
- Pansy, D.L.; Murali, M. UAV hyperspectral remote sensor images for mango plant disease and pest identification using MD-FCM and XCS-RBFNN. Environ. Monit. Assess. 2023, 195, 1120. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yang, X.; Liu, Y.; Zhou, J.; Huang, Y.; Li, J.; Zhang, L.; Ma, Q. A time-series neural network for pig feeding behavior recognition and dangerous detection from videos. Comput. Electron. Agric. 2024, 218, 108710. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Y.; Ren, J.; Li, Q.; Zhang, Y. You Can Use But Cannot Recognize: Preserving Visual Privacy in Deep Neural Networks. arXiv 2024, arXiv:2404.04098. [Google Scholar]
- Tian, H.; Wang, P.; Tansey, K.; Han, D.; Zhang, J.; Zhang, S.; Li, H. A deep learning framework under attention mechanism for wheat yield estimation using remotely sensed indices in the Guanzhong Plain, PR China. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102375. [Google Scholar] [CrossRef]
- Liu, T.; Luo, R.; Xu, L.; Feng, D.; Cao, L.; Liu, S.; Guo, J. Spatial channel attention for deep convolutional neural networks. Mathematics 2022, 10, 1750. [Google Scholar] [CrossRef]
- Han, K.J.; Huang, J.; Tang, Y.; He, X.; Zhou, B. Multi-Stride Self-Attention for Speech Recognition. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Zhang, Y.; Wu, R.; Dascalu, S.M.; Harris, F.C. Sparse transformer with local and seasonal adaptation for multivariate time series forecasting. Sci. Rep. 2024, 14, 15909. [Google Scholar] [CrossRef]
- Kim, S.; Ahn, D.; Ko, B.C. Cross-Modal Learning with 3D Deformable Attention for Action Recognition. arXiv 2023, arXiv:2212.05638. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. arXiv 2021, arXiv:2102.12122. [Google Scholar]
- Yu, J.; Wang, Z.; Vasudevan, V.; Yeung, L.; Seyedhosseini, M.; Wu, Y. Coca: Contrastive captioners are image-text foundation models. arXiv 2022, arXiv:2205.01917. [Google Scholar]
- Liu, M.; Jiang, X.; Zhang, X. CADFormer: Fine-Grained Cross-modal Alignment and Decoding Transformer for Referring Remote Sensing Image Segmentation. arXiv 2025, arXiv:2503.23456. [Google Scholar]
- Yang, Z.; Zheng, N.; Wang, F. DSSFN: A Dual-Stream Self-Attention Fusion Network for Effective Hyperspectral Image Classification. Remote Sens. 2023, 15, 3701. [Google Scholar] [CrossRef]
- Zhang, Y.; Lai, Z.; Zhang, T.; Fu, Y.; Zhou, C. Unaligned RGB Guided Hyperspectral Image Super-Resolution with Spatial-Spectral Concordance. arXiv 2025, arXiv:2505.02109. [Google Scholar]
- Yu, H.; Li, X.; Yu, Y.; Sui, Y.; Zhang, J.; Zhang, L.; Qi, J.; Zhang, N.; Jiang, R. A dual-branch multimodal model for early detection of rice sheath blight: Fusing spectral and physiological signatures. Comput. Electron. Agric. 2025, 231, 110031. [Google Scholar] [CrossRef]
- Kang, H.; Ai, L.; Zhen, Z.; Lu, B.; Man, Z.; Yi, P.; Li, M.; Lin, L. A Novel Deep Learning Model for Accurate Pest Detection and Edge Computing Deployment. Insects 2023, 14, 660. [Google Scholar] [CrossRef]
- Zhang, Y.; Lv, C. TinySegformer: A lightweight visual segmentation model for real-time agricultural pest detection. Comput. Electron. Agric. 2024, 218, 108740. [Google Scholar] [CrossRef]
- GB/T 32136-2015; Agricultural Drought Grade. National Standards of the People’s Republic of China. General Administration of Quality Supervision, Inspection and Quarantine of China (AQSIQ) and Standardization Administration of China (SAC): Beijing, China, 2015.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2010, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; Volume 9, pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Type | Quantity (Sets) | Resolution and Band Information |
|---|---|---|
| Multispectral images | 320 | 1280 × 960, red/green/blue/red edge/NIR |
| Visible-light images | 420 | 4000 × 3000, RGB (three channels) |
| Orthomosaic stitched images | 95 | Approx. 8000 × 6000, RGB + multispectral fusion (resolution standardized after cropping; original sizes vary by area) |
| Date | RGB Images | Multispectral Images | Orthomosaic Images |
|---|---|---|---|
| 10 June 2024 | 20 | 15 | 4 |
| 15 June 2024 | 18 | 13 | 3 |
| 20 June 2024 | 15 | 14 | 3 |
| 25 June 2024 | 17 | 15 | 3 |
| 1 July 2024 | 19 | 16 | 5 |
| 6 July 2024 | 16 | 13 | 4 |
| 11 July 2024 | 18 | 14 | 4 |
| 16 July 2024 | 20 | 15 | 5 |
| 21 July 2024 | 22 | 17 | 6 |
| 26 July 2024 | 18 | 14 | 4 |
| 1 August 2024 | 16 | 13 | 4 |
| 6 August 2024 | 20 | 16 | 5 |
| 11 August 2024 | 19 | 15 | 5 |
| 16 August 2024 | 18 | 14 | 4 |
| 21 August 20241 | 17 | 13 | 4 |
| 26 August 2024 | 18 | 14 | 5 |
| 1 September 2024 | 20 | 16 | 5 |
| 6 September 2024 | 22 | 18 | 6 |
| 11 September 2024 | 19 | 15 | 4 |
| 16 September 2024 | 20 | 16 | 5 |
| 21 September 2024 | 19 | 15 | 3 |
| 26 September 2024 | 20 | 15 | 4 |
| Total | 420 | 320 | 95 |
| Image Type | Original Count | Augmented Count |
|---|---|---|
| RGB | 420 | 2100 |
| Multispectral | 320 | 1600 |
| Orthomosaic | 95 | 380 |
| Module | Description |
|---|---|
| Input | RGB + MS image |
| Patch Embedding | Conv2D (7 × 7, stride = 4) + Flatten + Linear Projection |
| Feature Size after Embedding | |
| Transformer Encoder | 6 Transformer blocks (MHA + MLP + LayerNorm) |
| Feature Size after Encoder | |
| Transformer Decoder | 6 Transformer blocks (Cross-Attention + MLP) |
| Feature Size after Decoder | |
| Upsampling Module | Conv2D (3 × 3) + PixelShuffle to |
| Residual Fusion | Linear projection of auxiliary branch + Element-wise addition |
| Final Fused Feature |
| Layer | Description |
|---|---|
| Input Feature Map | |
| Conv1 | Conv2D (3 × 3, 128 channels) + BN + ReLU |
| Feature Size after Conv1 | |
| Conv2 | Conv2D (3 × 3, 64 channels) + BN + ReLU + MaxPool(2 × 2) |
| Feature Size after Conv2 | |
| Conv3 | Conv2D (3 × 3, 32 channels) + BN + ReLU (stride = 2) |
| Feature Size after Conv3 | |
| Global Average Pooling | Pool to |
| Fully Connected 1 | FC(32 → 128) + ReLU |
| Fully Connected 2 | FC(128 → C categories) + Softmax |
| Output | Disaster category probabilities |
| Item | Description / Value |
|---|---|
| Edge-device model | NVIDIA Jetson Xavier NX |
| FPS | 8–10 frames per second |
| Preprocessing time (per image) | 0.12 s |
| Estimated hourly power consumption | 18–22 W |
| Battery type and capacity | 6S Li-Po battery, 10,000 mAh |
| Estimated runtime per charge | Approximately 3.5 h |
| Alert trigger condition | Classification confidence > 90% or anomaly detection flag |
| Notification method | 4G LTE real-time push + onboard audible and visual alarms |
| Model | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|
| ResNet50 [44] | 88.3 | 87.6 | 86.1 | 88.9 |
| CNN+SE [30] | 88.9 | 88.1 | 87.4 | 88.6 |
| DenseNet121 [45] | 89.2 | 88.7 | 88.1 | 89.3 |
| MobileNetV2 [46] | 87.5 | 86.9 | 85.2 | 88.1 |
| EfficientNet-B0 [47] | 89.6 | 89.1 | 88.4 | 89.7 |
| ViT [31] | 90.1 | 89.5 | 89.3 | 89.6 |
| Swin-Transformer [32] | 90.8 | 90.3 | 90.0 | 90.6 |
| CSPDarknet+E-ELAN [48] | 90.2 | 89.7 | 89.1 | 90.4 |
| Improved CSPDarknet+E-ELAN [49] | 90.6 | 90.0 | 89.5 | 90.8 |
| CoCa [34] | 84.1 | 83.9 | 83.7 | 84.3 |
| Proposed method | 93.2 | 92.7 | 93.5 | 92.4 |
| Model | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|
| ResNet50 [44] | 86.2 | 85.9 | 86.5 | 85.3 |
| CNN+SE [30] | 86.5 | 86.1 | 86.8 | 85.6 |
| DenseNet121 [45] | 87.0 | 86.7 | 87.5 | 86.1 |
| MobileNetV2 [46] | 85.8 | 85.4 | 86.0 | 85.0 |
| EfficientNet-B0 [47] | 87.3 | 87.0 | 87.8 | 86.5 |
| ViT [31] | 88.2 | 87.8 | 88.5 | 87.2 |
| Swin-Transformer [32] | 88.7 | 88.3 | 88.9 | 88.0 |
| CSPDarknet+E-ELAN [48] | 89.0 | 88.7 | 89.2 | 88.4 |
| Improved CSPDarknet+E-ELAN [49] | 89.4 | 89.1 | 89.7 | 88.8 |
| Proposed method | 90.8 | 90.5 | 91.0 | 90.1 |
| Model Structure | Accuracy () | F1 Score () | Precision (P) | Recall (R) |
|---|---|---|---|---|
| RGB input only | 76.8 | 75.3 | 74.1 | 75.9 |
| Multimodal input | 84.6 | 83.1 | 82.7 | 83.8 |
| Full model (proposed) | 93.2 | 92.7 | 93.5 | 92.4 |
| Backbone Model | Accuracy Improvement | F1 Score Improvement |
|---|---|---|
| VGG-16 | +1.6 | +1.4 |
| ResNet50 | +1.9 | +2.0 |
| EfficientNet-B0 | +2.1 | +2.3 |
| ViT | +1.8 | +1.9 |
| Model Architecture | Accuracy () | F1 Score () | Precision (P) | Recall (R) |
|---|---|---|---|---|
| MLP classifier | 74.5 | 72.9 | 71.2 | 73.4 |
| Shallow CNN classifier | 82.1 | 80.6 | 79.8 | 81.3 |
| Random Forest classifier | 78.4 | 76.9 | 77.2 | 76.6 |
| XGBoost classifier | 80.2 | 78.7 | 79.0 | 78.4 |
| CNN classifier (proposed) | 93.2 | 92.7 | 93.5 | 92.4 |
| Stride Setting | Accuracy () | F1 Score () | Precision (P) | Recall (R) | FPS |
|---|---|---|---|---|---|
| Stride = 1 | 93.4 | 92.8 | 93.6 | 92.5 | 47.1 |
| Stride = 2 | 93.2 | 92.7 | 93.5 | 92.4 | 61.8 |
| Stride = 4 | 92.1 | 91.5 | 92.3 | 91.0 | 76.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wu, Y.; Wang, W.; Jin, H.; Wu, X.; Liu, J.; Hu, C.; Lv, C. Integrating Stride Attention and Cross-Modality Fusion for UAV-Based Detection of Drought, Pest, and Disease Stress in Croplands. Agronomy 2025, 15, 1199. https://doi.org/10.3390/agronomy15051199
Li Y, Wu Y, Wang W, Jin H, Wu X, Liu J, Hu C, Lv C. Integrating Stride Attention and Cross-Modality Fusion for UAV-Based Detection of Drought, Pest, and Disease Stress in Croplands. Agronomy. 2025; 15(5):1199. https://doi.org/10.3390/agronomy15051199
Chicago/Turabian StyleLi, Yan, Yaze Wu, Wuxiong Wang, Huiyu Jin, Xiaohan Wu, Jinyuan Liu, Chen Hu, and Chunli Lv. 2025. "Integrating Stride Attention and Cross-Modality Fusion for UAV-Based Detection of Drought, Pest, and Disease Stress in Croplands" Agronomy 15, no. 5: 1199. https://doi.org/10.3390/agronomy15051199
APA StyleLi, Y., Wu, Y., Wang, W., Jin, H., Wu, X., Liu, J., Hu, C., & Lv, C. (2025). Integrating Stride Attention and Cross-Modality Fusion for UAV-Based Detection of Drought, Pest, and Disease Stress in Croplands. Agronomy, 15(5), 1199. https://doi.org/10.3390/agronomy15051199