
Spatial and Temporal Variability in Yield Maps Can Localize Field Management—A Case Study with Corn and Soybean

 ,
,  , and
, and
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Sites and Data Sets
2.2. Protocol of Data Analysis
2.3. Exploratory Data Analysis
2.3.1. Data Normalization and Creation of Choropleth Maps
2.3.2. Yield Performance Index
2.3.3. Data Interpolation
2.3.4. Data Clustering, Rectification, and Evaluation of the Management Zones
- (i)
- Analysis of variance (ANOVA) using the Tukey test at 0.05% significance to identify whether sub-regions within the MZs designed show significant differences in the mean value of the variable of interest;
- (ii)
- Variance Reduction (VR%) [19]: measures the reduction in the sum of the MZs data variances;
- (iii)
- Fuzziness Performance Index (FPI) [29]: evaluates the degree of fuzziness in a classification;
- (iv)
- Modified Partition Entropy (MPE) [29]: evaluates the uncertainty in cluster assignments;
- (v)
- (vi)
- Smoothness Index (SI%) [19]: characterizes the smoothness of the boundary curves of MZs;
- (vii)
- Fragmentation index (FI%) [19]: characterizes the division of land into smaller, often irregularly shaped parcels, which can impact land management strategies;
- (viii)
- Global Quality Index (GQI) [1]: it looks to find the optimum number of classes during MZ delineation, considering all indices together.
- (i)
- ANOVA: This procedure was performed to verify if the mean values of the YPI (target variable) in each class were statistically distinct [19] using Tukey’s range test (0.05 level).
- (ii)
- Choosing the best GQI (the lowest), which contains all the remaining ones (FPI, MPE, VR%, ICVI, SI%, and FI%).
3. Results
3.1. Summary Statistics
- The 2003 soybean in Field A, 2002 corn in Field A, 2012 corn in Field B, and 2012 soybean in Field C presented very high SCV% (>30%);
- Notably, low minimum yield values were seen for the 1999 soybean in Field A, the 2003 soybean in Field A, and the 2002 corn in Field B;
- The highest weighted spatial variability (WSCV%) was found for corn in Field A (26.3%) and the lowest for soybeans in Field A (17.5%).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Year/Crop | Original Yield (Sampling Data) (t ha−1) | SSD | SCV% | WSSD | WSCV% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Soybean or Corn | Mean | Soybean or Corn | Mean | |||||||||
| No.S | Min. | Mean | Median | Max. | (t ha−1) | (%) | (t ha−1) | (%) | ||||
| A | 1996 Soybean | 1209 | 1.80 | 3.07 | 3.10 | 4.32 | 0.41 | 13.3 | 0.41 | 0.87 | 17.5 | 24.0 |
| 1998 Soybean | 1207 | 1.59 | 2.53 | 2.57 | 3.25 | 0.30 | 12.0 | |||||
| 1999 Soybean | 1213 | 0.29 | 1.39 | 1.36 | 2.66 | 0.42 | 29.9 | |||||
| 2001 Soybean | 1202 | 1.28 | 2.49 | 2.50 | 3.67 | 0.38 | 15.3 | |||||
| 2003 Soybean * | 1216 | 0.26 | 1.55 | 1.57 | 2.95 | 0.49 | 31.6 | |||||
| 2004 Soybean | 1192 | 1.46 | 2.94 | 2.99 | 4.09 | 0.43 | 14.6 | |||||
| 1997 Corn | 1216 | 1.17 | 6.41 | 6.56 | 11.85 | 1.90 | 29.6 | 1.40 | 26.3 | |||
| 2000 Corn | 1191 | 6.31 | 9.27 | 9.39 | 11.42 | 0.85 | 9.2 | |||||
| 2002 Corn | 1212 | 0.06 | 3.06 | 3.11 | 6.73 | 1.23 | 40.2 | |||||
| B | 2011 Corn | 455 | 6.59 | 9.28 | 9.44 | 11.42 | 0.90 | 9.7 | 1.60 | 19.7 | ||
| 2012 Corn | 455 | 0.86 | 6.33 | 6.67 | 10.78 | 2.07 | 32.7 | |||||
| 2013 Corn | 454 | 4.63 | 8.85 | 9.35 | 11.72 | 1.61 | 18.2 | |||||
| C | 2012 Soybean | 1585 | 0.63 | 2.58 | 2.46 | 4.82 | 0.96 | 37.1 | 0.67 | 18.1 | ||
| 2013 Soybean | 1575 | 2.12 | 4.15 | 4.14 | 6.13 | 0.66 | 15.9 | |||||
| 2015 Soybean * | 1572 | 3.24 | 4.72 | 4.71 | 6.13 | 0.47 | 10.0 | |||||
| 2016 Soybean | 1566 | 2.00 | 3.45 | 3.41 | 5.02 | 0.49 | 14.1 | |||||
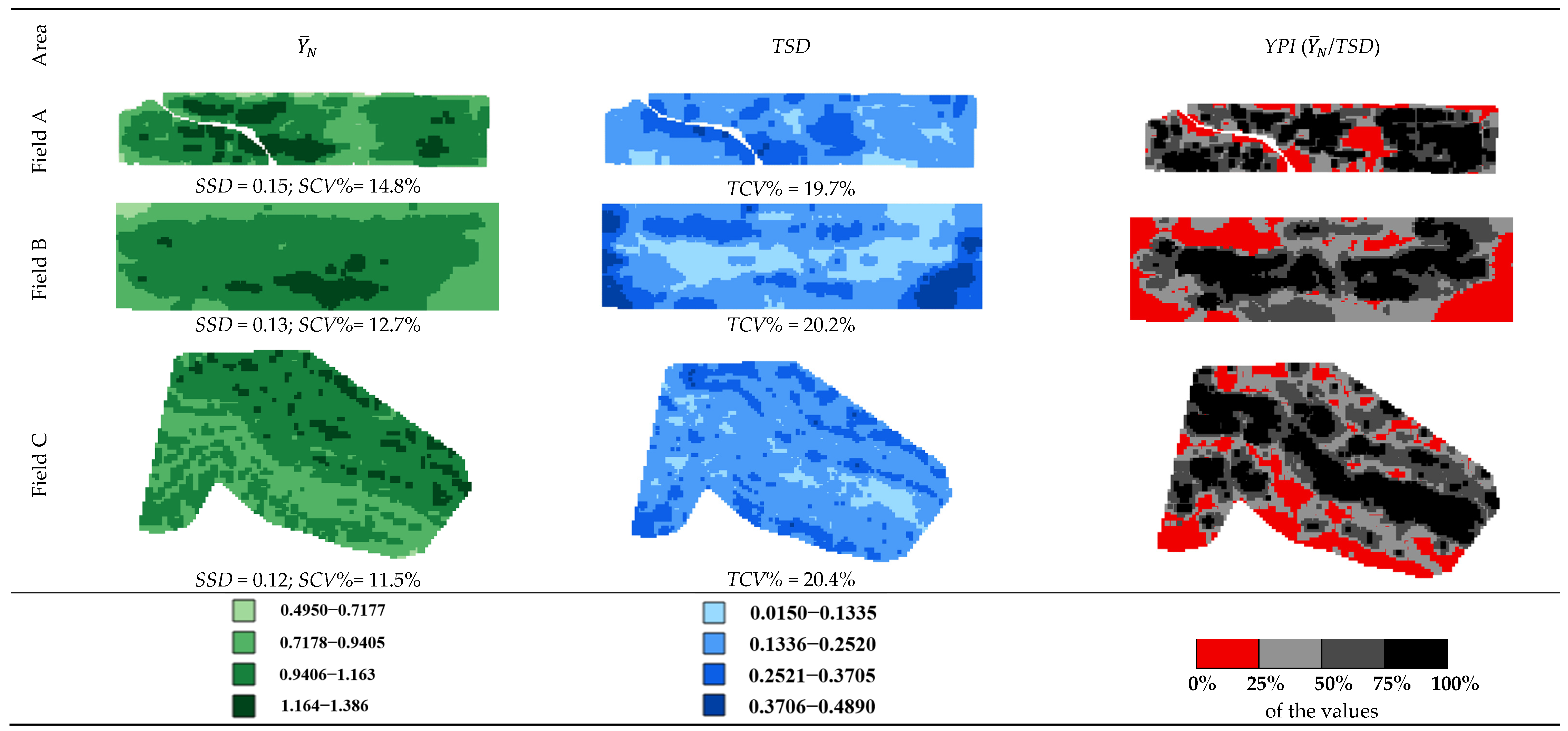
3.2. Yield, Temporal Variability, and Yield Performance Index Maps
3.3. Management Zones
4. Discussion
- The highest yields () correspond to regions that could benefit from a differentiated treatment that takes advantage of their high productive potential. However, these regions do not always correspond to low TSD (blue maps in Figure 3), so temporal yield stability must be considered before implementing a treatment plan.
- The large part of the area with higher TSD coincides with low . Although corn and soybean were planted in these fields in rotation, the time-dependent variations in normalized yield may be due to plant growth response to heat, precipitation, soil water, and plant nitrogen availability. Reducing TSD is a challenge that can be effectively achieved through precision agriculture, soil conservation practices, crop rotation, and advanced data analysis techniques, as remarked by Yost et al. [30].
- The information presented in the YPI shows the ratio of mean normalized yield () to the TSD, having two particular cases: (i) the black areas correspond to consistently high yields with low variability; (ii) the red areas have low yields with high variability. This information is more visible than when presented separately as and TSD and can help define parts of the field that should receive particular attention.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Acronym | Description |
| ASC | Average Silhouette Coefficient |
| CV% | Coefficient of Variation |
| FI% | Fragmentation index |
| FPI | Fuzziness Performance Index |
| GA | Global Accuracy |
| GQI | Global Quality Index |
| ICVI | Improved Cluster Validation Index |
| IDW | Inverse Distance Weighted Interpolation |
| Kappa | Kappa Coefficient |
| MGQI | Modified Global Quality Index |
| MPE | Modified Partition Entropy |
| Mean Yield | |
| Mean Normalized Yield | |
MZ | Mean of Mean Normalized Yield Management Zone |
| NC SCV% | Number of classes Spatial Coefficient of Variation; |
| SD | Standard Deviation |
| SI% | Smoothness Index |
| SSD | Spatial Standard Deviation; |
| TCV% | Temporal Coefficient of Variation |
| TM | Thematic Map |
| TSD | Temporal Standard Deviation |
| VR% | Variance Reduction |
| WSSD | Weighted Standard Deviation |
| Y | Yield |
| Normalized Yield | |
| YPI | Yield Performance Index |
Appendix A
Appendix A.1. The Weighted Standard Deviation
Appendix A.2. The Interpolation Selection Index
Appendix A.3. Evaluation Indices of Management Zones’ Quality
References
- Aikes, J., Jr.; Souza, E.G.; Bazzi, C.L.; Sobjak, R. Thematic Maps and Management Zones for Precision Agriculture: Systematic Literature Study, Protocols, and Practical Cases; Poncã: Curitiba, Brazil, 2021. [Google Scholar]
- Stafford, J.; Ambler, B.; Lark, R.; Catt, J. Mapping and interpreting the yield variation in cereal crops. Comput. Electron. Agric. 1996, 14, 101–119. [Google Scholar] [CrossRef]
- Pennington, D. The Importance of Collecting Accurate Yield Monitoring Data. Michigan State University Extension. 2016. Available online: https://www.no-tillfarmer.com/articles/6103-the-importance-of-collecting-accurate-yield-monitoring-data (accessed on 14 January 2025).
- Eghball, B.; Varvel, G.E. Fractal analysis of temporal yield variability of crop sequences: Implications for site-specific management. Agron. J. 1997, 89, 851–855. [Google Scholar] [CrossRef]
- Jaynes, D.B.; Colvin, T.S. Spatiotemporal variability of corn and soybean yield. Agron. J. 1997, 89, 30–37. [Google Scholar] [CrossRef]
- Robinson, T.; Metternicht, G. Comparing the performance of techniques to improve the quality of yield maps. Agric. Syst. 2005, 85, 19–41. [Google Scholar] [CrossRef]
- Sudduth, K.A.; Drummond, S.T. Yield editor: Software for removing errors from crop yield maps. Agron. J. 2007, 99, 1471–1482. [Google Scholar] [CrossRef]
- Lyle, G.; Bryan, B.A.; Ostendorf, B. Post-processing methods to eliminate erroneous grain yield measurements: Review and directions for future development. Precis. Agric. 2013, 15, 377–402. [Google Scholar] [CrossRef]
- Sun, W.; Whelan, B.; McBratney, A.B.; Minasny, B. An integrated framework for software to provide yield data cleaning and estimation of an opportunity index for site-specific crop management. Precis. Agric. 2013, 14, 376–391. [Google Scholar] [CrossRef]
- Moharana, P.C.; Jena, R.K.; Pradhan, U.K.; Nogiya, M.; Tailor, B.L.; Singh, R.S.; Singh, S.K. Geostatistical and fuzzy clustering approach for delineation of site-specific management zones and yield-limiting factors in irrigated hot arid environment of India. Precis. Agric. 2020, 21, 426–448. [Google Scholar] [CrossRef]
- Li, X.; Pan, Y.-C.; Ge, Z.-Q.; Zhao, C.-J. Delineation and scale effect of precision agriculture management zones using yield monitor data over four years. Agric. Sci. China 2007, 6, 180–188. [Google Scholar] [CrossRef]
- Blackmore, S. The interpretation of trends from multiple yield maps. Comput. Electron. Agric. 2000, 26, 37–51. [Google Scholar] [CrossRef]
- Blackmore, S.; Godwin, R.J.; Fountas, S. The analysis of spatial and temporal trends in yield map data over six years. Biosyst. Eng. 2003, 84, 455–466. [Google Scholar] [CrossRef]
- Maestrini, B.; Basso, B. Drivers of within-field spatial and temporal variability of crop yield across the US Midwest. Sci. Rep. 2018, 8, 14833. [Google Scholar] [CrossRef] [PubMed]
- Maestrini, B.; Basso, B. Predicting spatial patterns of within-field crop yield variability. Field Crops Res. 2018, 219, 106–112. [Google Scholar] [CrossRef]
- Kharel, T.P.; Maresma, A.; Czymmek, K.J.; Oware, E.K.; Ketterings, Q.M. Combining spatial and temporal corn silage yield variability for management zone development. Agron. J. 2019, 111, 2703–2711. [Google Scholar] [CrossRef]
- Taylor, J.; Wood, G.; Earl, R.; Godwin, R. Soil factors and their influence on within-field crop variability, part II: Spatial analysis and determination of management zones. Biosyst. Eng. 2003, 84, 441–453. [Google Scholar] [CrossRef]
- Li, Y.; Shi, Z.; Li, F.; Li, H.-Y. Delineation of site-specific management zones using fuzzy clustering analysis in a coastal saline land. Comput. Electron. Agric. 2007, 56, 174–186. [Google Scholar] [CrossRef]
- Sobjak, R.; de Souza, E.G.; Bazzi, C.L.; Schenatto, K.; Betzek, N.M.; Gavioli, A. Incorporation of computational routines in a microservice architecture in AgDataBox platform. Sustain. Comput. Informatics Syst. 2024, 44, 101038. [Google Scholar] [CrossRef]
- Kitchen, N.; Sudduth, K.; Myers, D.; Drummond, S.; Hong, S. Delineating productivity zones on claypan soil fields using apparent soil electrical conductivity. Comput. Electron. Agric. 2005, 46, 285–308. [Google Scholar] [CrossRef]
- Jamison, V.C.; Smith, D.D.; Thornton, J.F. Soil and Water Research on a Claypan Soil; USDA-ARS Technical Bulletin 1379; US Government Printing Office: Washington, DC, USA, 1967. [Google Scholar]
- Soil Survey Division Staff. Soil Survey Manual; Soil Conservation Service. US. Department of Agriculture Handbook 18; US Department of Agriculture: Washington, DC, USA, 2017. Available online: https://www.nrcs.usda.gov/sites/default/files/2022-09/The-Soil-Survey-Manual.pdf (accessed on 14 July 2024).
- Baxter, S. World Reference Base for Soil Resources. World Soil Resources Report 103. Rome: Food and Agriculture Organization of the United Nations (2006), pp. 132. ISBN 92-5-10511-4. Exp. Agric. 2007, 43, 264. [Google Scholar] [CrossRef]
- Córdoba, M.A.; Bruno, C.I.; Costa, J.L.; Peralta, N.R.; Balzarini, M.G. Protocol for multivariate homogeneous zone delineation in precision agriculture. Biosyst. Eng. 2016, 143, 95–107. [Google Scholar] [CrossRef]
- Pimentel-Gomes, F.; Garcia, G.H. Estatística Aplicada a Experimentos Agronômicos e Florestais. Statistics Applied to Agronomic and Forestry Experiments; Biblioteca de Ciências Agrárias Luiz de Queiroz: Piracicaba, Brazil, 2002; 307p. [Google Scholar]
- Molin, J.P. Definição de unidades de Manejo a partir de mapas de produtividade. Definition of management units from productivity maps. Eng. Agrícola 2002, 22, 83–92. [Google Scholar]
- Milillo, T.M.; Gardella, J.A., Jr. Spatial Analysis of Time of Flight− Secondary Ion Mass Spectrometric Images by Ordinary Kriging and Inverse Distance Weighted Interpolation Techniques. Anal. Chem. 2008, 80, 4896–4905. [Google Scholar] [CrossRef] [PubMed]
- Du, K.L. Clustering: A neural network approach. Neural Netw. 2010, 23, 89–107. [Google Scholar] [CrossRef]
- Boydell, B.; McBratney, A.B. Identifying potential within-field management zones from cotton-yield estimates. Precis. Agric. 2002, 3, 9–23. [Google Scholar] [CrossRef]
- Yost, M.A.; Kitchen, N.R.; Sudduth, K.A.; Sadler, E.J.; Drummond, S.T.; Volkmann, M.R. Long-term impact of a precision agriculture system on grain crop production. Precis. Agric. 2017, 18, 823–842. [Google Scholar] [CrossRef]
- Nawar, S.; Corstanje, R.; Halcro, G.; Mulla, D.; Mouazen, A.M. Delineation of soil management zones for variable-rate fertilization: A review. Adv. Agron. 2017, 143, 175–245. [Google Scholar] [CrossRef]
 ) (adapted from [1]). FPI: Fuzziness Performance Index; MPE: Modified Partition Entropy; VR%: Variance Reduction; ICVI: Improved Cluster Validation Index; ASC: average silhouette coefficient; SI%: Smoothness Index; FI%: Fragmentation index; and GQI: Global Quality Index; MGQI: Modified Global Quality Index; Kappa: Kappa coefficient; GA: Global accuracy.
) (adapted from [1]). FPI: Fuzziness Performance Index; MPE: Modified Partition Entropy; VR%: Variance Reduction; ICVI: Improved Cluster Validation Index; ASC: average silhouette coefficient; SI%: Smoothness Index; FI%: Fragmentation index; and GQI: Global Quality Index; MGQI: Modified Global Quality Index; Kappa: Kappa coefficient; GA: Global accuracy.
) (adapted from [1]). FPI: Fuzziness Performance Index; MPE: Modified Partition Entropy; VR%: Variance Reduction; ICVI: Improved Cluster Validation Index; ASC: average silhouette coefficient; SI%: Smoothness Index; FI%: Fragmentation index; and GQI: Global Quality Index; MGQI: Modified Global Quality Index; Kappa: Kappa coefficient; GA: Global accuracy.
) (adapted from [1]). FPI: Fuzziness Performance Index; MPE: Modified Partition Entropy; VR%: Variance Reduction; ICVI: Improved Cluster Validation Index; ASC: average silhouette coefficient; SI%: Smoothness Index; FI%: Fragmentation index; and GQI: Global Quality Index; MGQI: Modified Global Quality Index; Kappa: Kappa coefficient; GA: Global accuracy.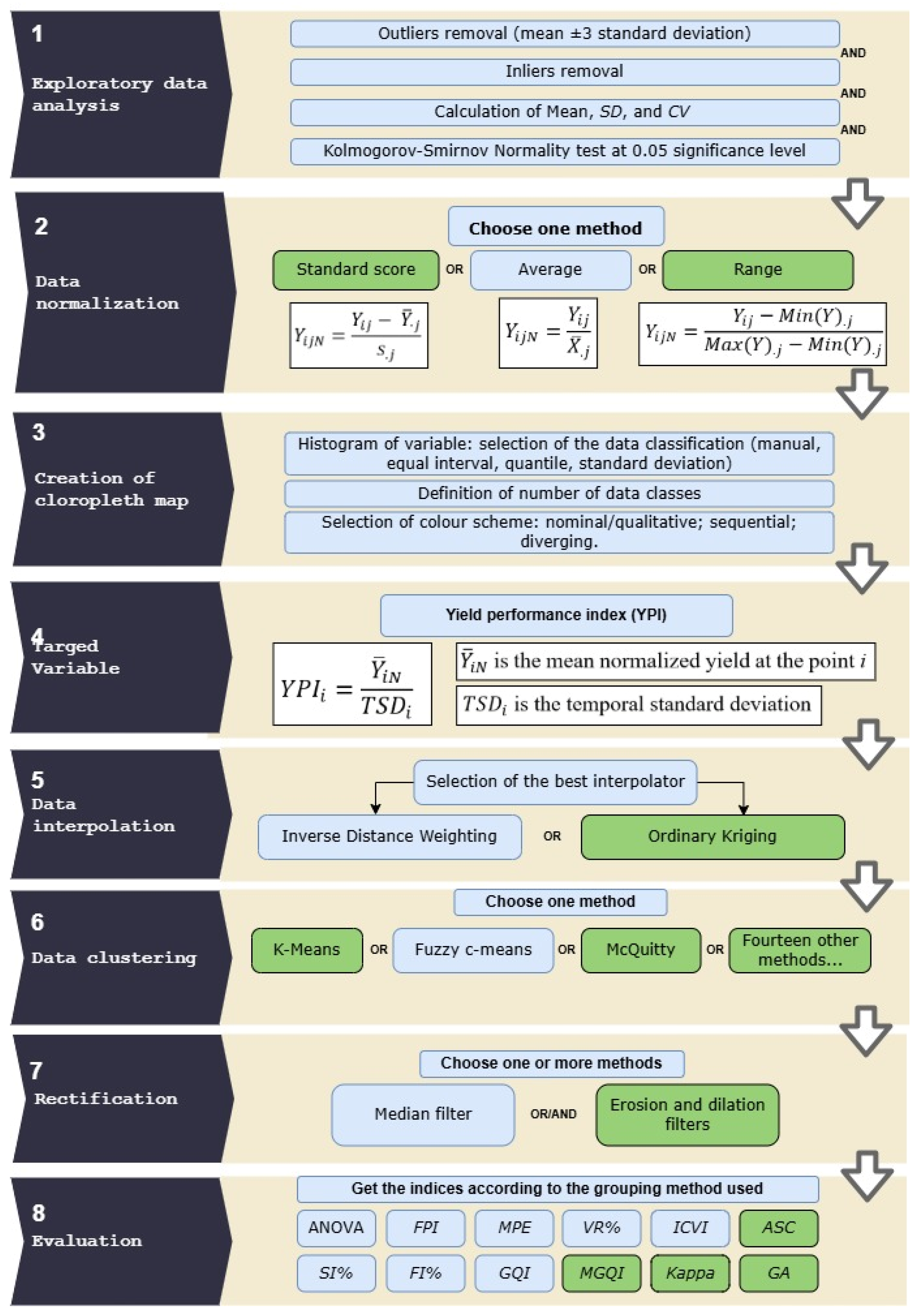


| Field | A | B | C |
|---|---|---|---|
| Latitude | 39.2347 | 40.6659 | −25.1092 |
| Longitude | −92.1466 | −104.9981 | −53.8319 |
| Area (ha) | 13 | 4.7 | 15.6 |
| Municipality | Centralia | Denver | Céu Azul |
| State | Missouri | Colorado | Paraná |
| Country | US | US | BR |
| Soil type | Claypan (Alfisol) | Kim Loam | Rhodic Ferralsol |
| Tillage | No tillage | No tillage | No tillage |
| Crop | Field A | Field B | Field C | |||
|---|---|---|---|---|---|---|
| Year | Equipment | Year | Equipment | Year | Equipment | |
| Corn Yield | 97, 00, 02 | Gleaner R42 combine harvester | 11, 12, 13 | Case IH 1660 combine harvester | ||
| Soybean Yield | 96, 98, 99, 01, 03, 04 | 12, 13, 14, 16 | Case IH 2388 combine harvester | |||
| Number Of Crop-Years | Mean Normalized Yield | SSD | SCV% | TSV | Relation TSV/SSD | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Dimensionless) | ||||||||||||
| Field | No.S | Corn | Soybean | Min. | Mean | Median | Max. | Range | (%) | (%) | ||
| A | 1216 | 3 | 6 | 0.49 | 1.00 | 1.01 | 1.39 | 0.89 | 0.15 | 14.8 | 19.7 | 1.33 |
| B | 455 | 3 | - | 0.64 | 1.00 | 1.02 | 1.31 | 0.67 | 0.13 | 12.7 | 20.2 | 1.59 |
| C | 1585 | - | 4 | 0.69 | 1.00 | 1.00 | 1.29 | 0.60 | 0.12 | 11.5 | 20.4 | 1.77 |
| Mean | 0.13 | 13.0 | 20.1 | 1.57 | ||||||||
| Field (Area) | NC | Tukey’s Test | FPI | MPE | VR% | ICVI | SIr% | MZs | FIr% | GQI | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | |||||||||||
| 2 | YPI | 5.38 a | 9.37 b | 0.086 | 0.103 | 30.7 | 0.73 | 94.7 | 7 | 250 | 2.71 | |||
| Area (ha) | 10.39 | 2.61 | ||||||||||||
| %Area | 79.9% | 20.1% | ||||||||||||
| A | 3 | YPI | 4.23 a | 7.12 b | 10.6 c | 0.080 | 0.081 | 37.4 | 0.58 | 90.8 | 12 | 300 | 2.56 | |
| (13.0 ha) | Area (ha) | 5.13 | 7.12 | 0.75 | ||||||||||
| %Area | 39.5% | 54.8% | 5.8% | |||||||||||
| 4 | YPI | 4.01 a | 6.77 b | 10.1 c | *** | 0.078 | 0.069 | 38.3 | 0.53 | 89.9 | 16 | 300 | 2.34 | |
| Area (ha) | 4.27 | 7.52 | 1.22 | |||||||||||
| %Area | 32.8% | 57.8% | 9.4% | |||||||||||
| 2 | YPI | 9.14 a | 110 b | 0.011 | 0.013 | 29.8 | 0.30 | 99.6 | 2 | 0 | 0.30 | |||
| Area (ha) | 4.70 | 0.042 | ||||||||||||
| %Area | 99.1% | 0.9% | ||||||||||||
| B | 3 | YPI | 6.14 a | 23.4 b | 129 c | 0.046 | 0.047 | 48.4 | 0.66 | 95.7 | 6 | 100 | 1.37 | |
| (4.7 ha) | Area (ha) | 3.86 | 0.84 | 0.031 | ||||||||||
| %Area | 81.5% | 17.8% | 0.7% | |||||||||||
| 4 | YPI | 5.17 a | 16.9 b | 41.1 c | 153 d | 0.048 | 0.043 | 49.0 | 0.64 | 94.5 | 6 | 50 | 1.01 | |
| Area (ha) | 3.34 | 1.22 | 0.16 | 0.021 | ||||||||||
| %Area | 70.5% | 25.7% | 3.3% | 0.4% | ||||||||||
| 2 | YPI | 5.17 a | 9.53 b | 0.065 | 0.079 | 17.8 | 0.66 ¥ | 95.3 | 10 | 400 | 3.46 | |||
| Area (ha) | 12.43 | 3.18 | ||||||||||||
| %Area | 79.6% | 20.4% | ||||||||||||
| C | 3 | YPI | 4.79 a | 7.47 b | 12.8 c | 0.075 | 0.075 | 20.1 | 0.65 ¥ | 92.1 | 13 | 333 | 3.06 | |
| (15.6 ha) | Area (ha) | 9.47 | 5.51 | 0.63 | ||||||||||
| %Area | 60.7% | 35.3% | 4.0% | |||||||||||
| 4 | YPI | 4.55 a | 6.69 b | 9.48 c | 11.6 d | 0.074 | 0.066 | 17.8 | 0.65 ¥ | 90.0 | 13 | 225 | 2.33 | |
| Area (ha) | 7.56 | 6.06 | 1.62 | 0.37 | ||||||||||
| %Area | 48.5% | 38.8% | 10.3% | 2.4% | ||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Souza, E.G.d.; Khosla, R.; Sudduth, K.A.; Johann, J.A.; Bazzi, C.L. Spatial and Temporal Variability in Yield Maps Can Localize Field Management—A Case Study with Corn and Soybean. Agronomy 2025, 15, 1179. https://doi.org/10.3390/agronomy15051179
Souza EGd, Khosla R, Sudduth KA, Johann JA, Bazzi CL. Spatial and Temporal Variability in Yield Maps Can Localize Field Management—A Case Study with Corn and Soybean. Agronomy. 2025; 15(5):1179. https://doi.org/10.3390/agronomy15051179
Chicago/Turabian StyleSouza, Eduardo G. de, Raj Khosla, Kenneth A. Sudduth, Jerry A. Johann, and Claudio L. Bazzi. 2025. "Spatial and Temporal Variability in Yield Maps Can Localize Field Management—A Case Study with Corn and Soybean" Agronomy 15, no. 5: 1179. https://doi.org/10.3390/agronomy15051179
APA StyleSouza, E. G. d., Khosla, R., Sudduth, K. A., Johann, J. A., & Bazzi, C. L. (2025). Spatial and Temporal Variability in Yield Maps Can Localize Field Management—A Case Study with Corn and Soybean. Agronomy, 15(5), 1179. https://doi.org/10.3390/agronomy15051179