
LCFANet: A Novel Lightweight Cross-Level Feature Aggregation Network for Small Agricultural Pest Detection


Abstract
1. Introduction
- (1)
- Small pests often exhibit a low resolution and high morphological similarity, leading to a weak feature extraction and misclassification. Standard CNNs struggle to balance large receptive fields and fine-grained details required for small pests, resulting in poor localization [30].
- (2)
- To enhance small-scale object detection accuracy, current research predominantly adopts network parameter scaling strategies. However, increasing parameters significantly slows down inference speed. Real-time constraints in agricultural drones or edge devices make such models impractical for field deployment.
- (1)
- LCFANet is proposed to achieve small pest object detection in insect trapping devices. Extensive evaluations on public Pest24 and our private datasets demonstrated its capability to accurately classify similar-feature pests and reliably detect objects with a small scale and debris, ultimately achieving SOTA detection performance.
- (2)
- We propose a Dual Temporal Feature Aggregation C3k2 (DTFA-C3k2) architecture, a Cross-Level Hierarchical Feature Pyramid (CLHFP), and a Multi-Scale Adaptive Spatial Fusion (MSASF) method in LCFANet. By integrating spatial-channel fusion, hierarchical feature interactions, and adaptive multi-scale fusion, these approaches maintain critical fine-grained details and structural hierarchies of small pests, significantly enhancing detection precision in agricultural scenarios.
- (3)
- To address the challenge in model lightweighting, we incorporate the Aggregated Downsampling Convolution (ADown-Conv) module into both the feature extraction and fusion stages of the LCFANet. ADown-Conv provides an effective downsampling solution for real-time object detection models through its lightweight design and structural flexibility.
2. Materials and Methods
2.1. Construction of Agricultural Pest Image Datasets
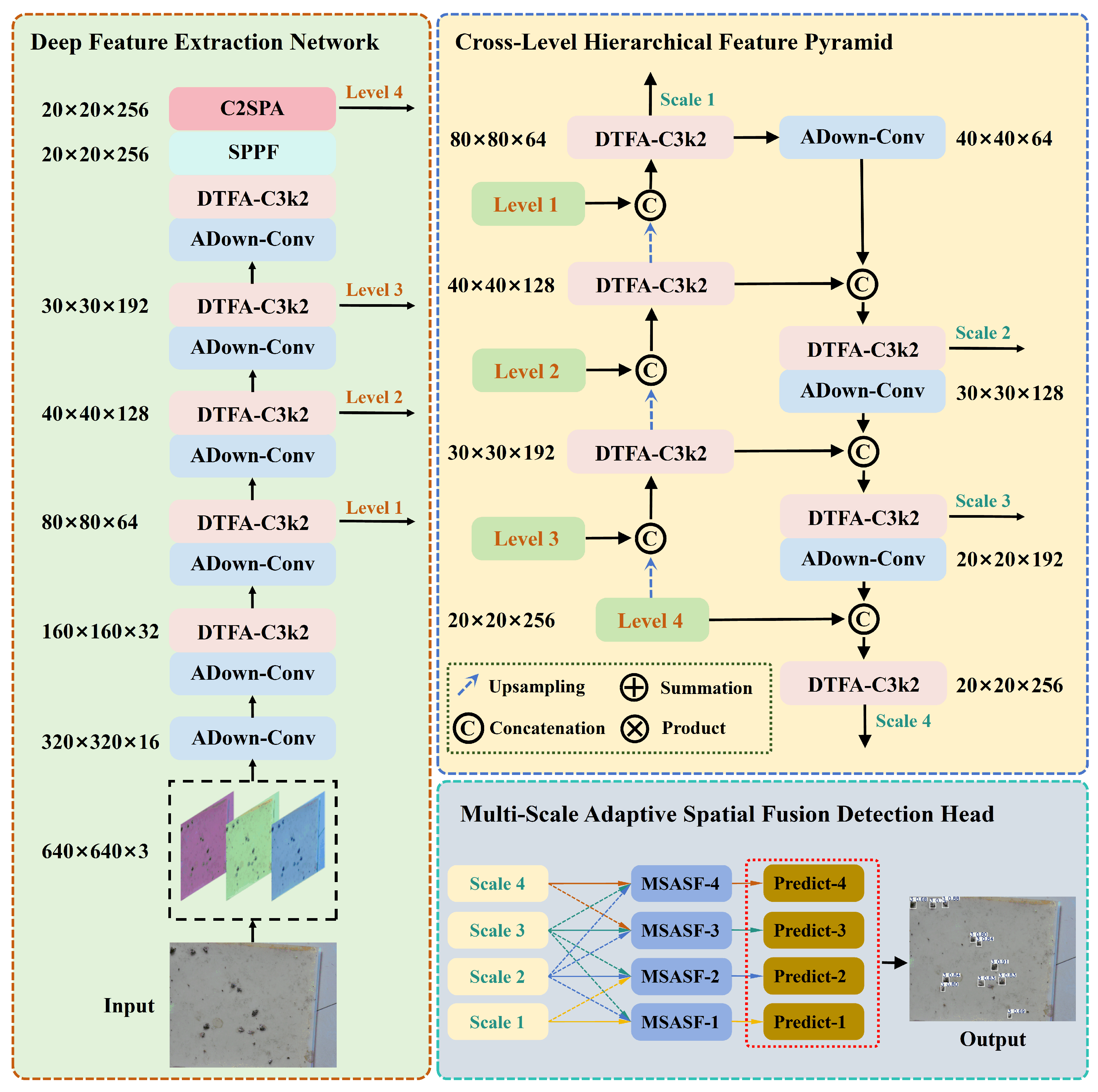
2.2. Construction of the Lightweight Cross-Level Feature Aggregation Network
2.2.1. Deep Feature Extraction Network
| Algorithm 1 ADown-Conv Forward Propagation |
|
2.2.2. Cross-Level Hierarchical Feature Pyramid
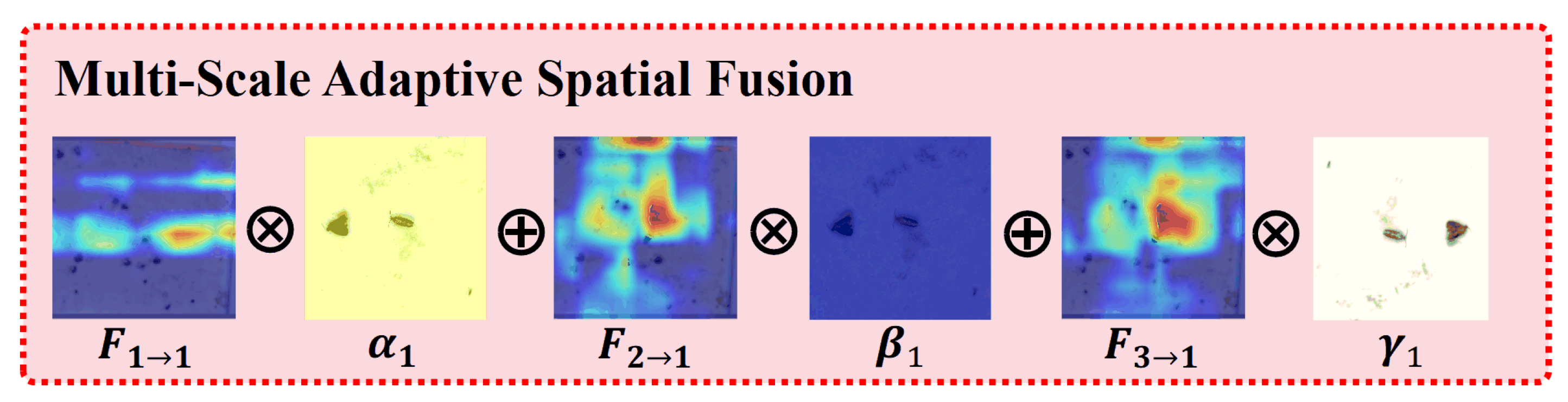
2.2.3. Multi-Scale Adaptive Spatial Fusion Detection Head
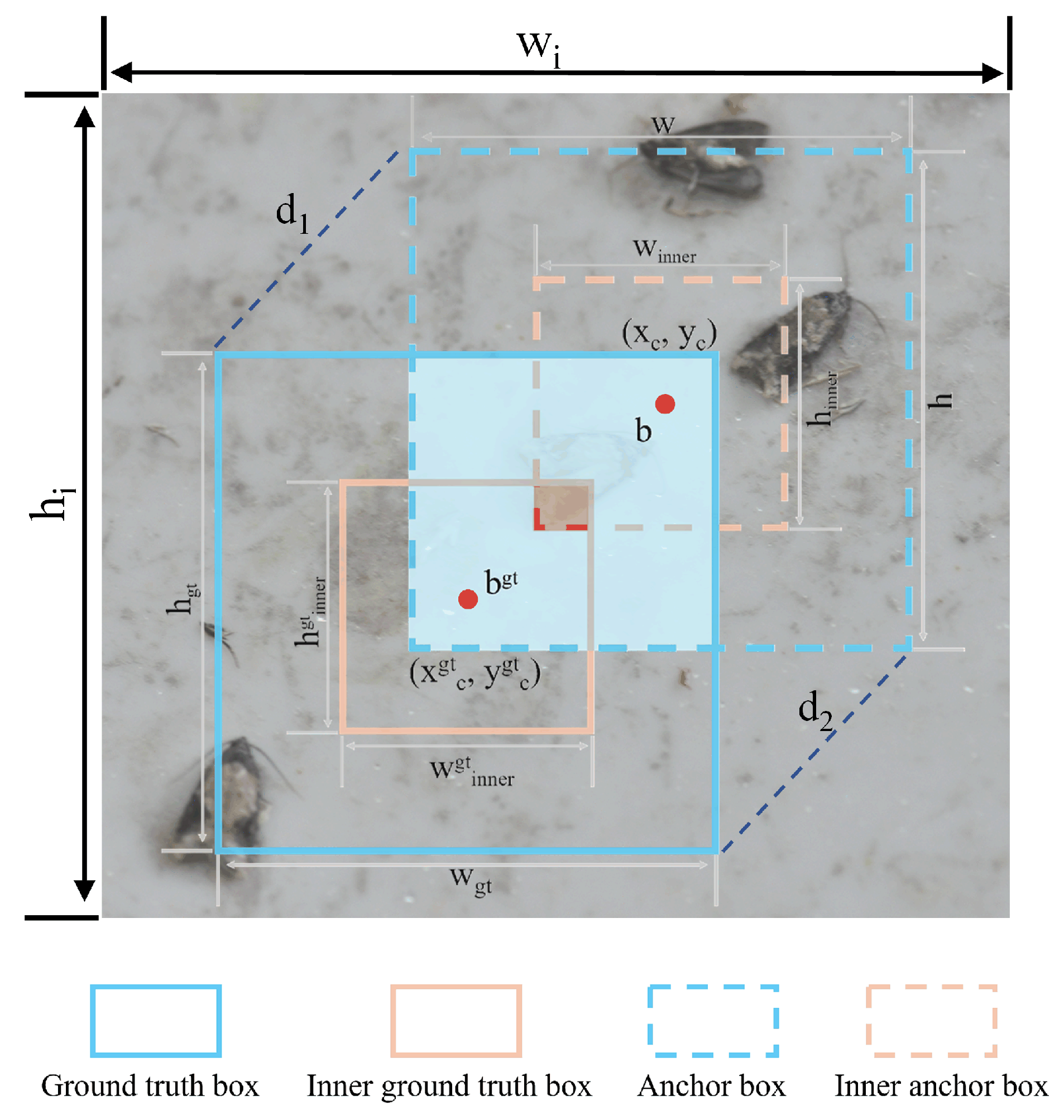
2.2.4. MPDINIoU Loss Function
3. Results
3.1. Model Training Parameters and Evaluation Metrics
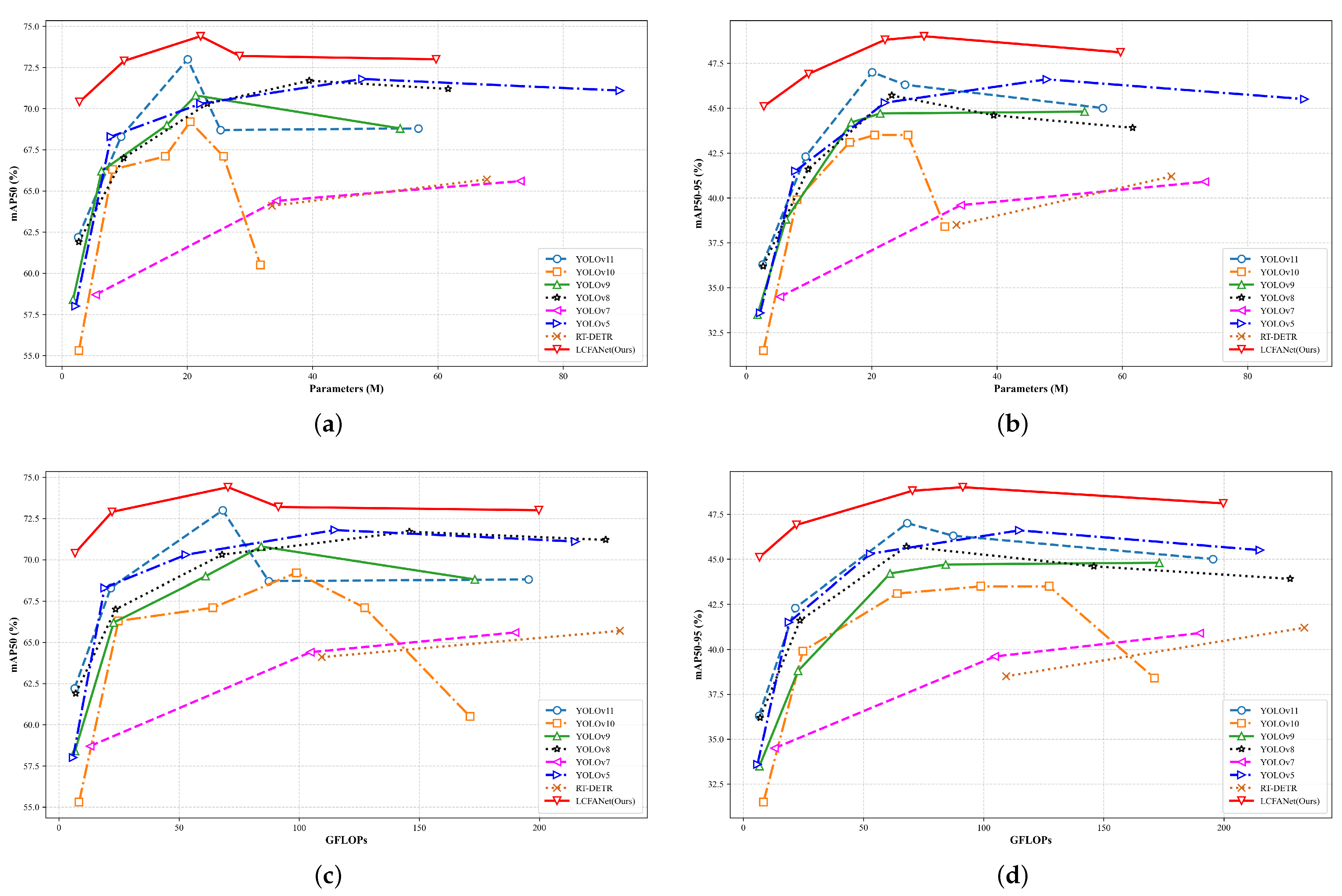
3.2. Detection Performance and Generalization Experiments of LCFANet
3.3. Comparison Experiments
3.4. Ablation Experiments
4. Discussion
4.1. Experimental Results’ Discussion
4.2. Limitations and Future Works
5. Conclusions
- (1)
- The proposed DTFA-C3k2 module effectively handles scale variations through the spatiotemporal fusion of multi-receptive-field features, preserving cross-scale fine-grained textures and structural details to enhance detection accuracy.
- (2)
- The CLHFP architecture systematically reorganizes multi-scale feature representations from the backbone network, overcoming challenges posed by target scale diversity and complex background interference.
- (3)
- The MSASF module implements learnable adaptive fusion of four-scale features from CLHFP, significantly improving detection performance.
- (4)
- The ADown-Conv modules in both feature extraction and fusion networks achieve model compression, reducing parameters by and computational costs by while maintaining detection accuracy.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Luo, Y.; Wang, L.; Sun, D.; Wang, Y.; Zhou, J.; Luo, B.; Liu, H.; Yan, R.; Wang, L. Advancements in Life Tables Applied to Integrated Pest Management with an Emphasis on Two-Sex Life Tables. Insects 2025, 16, 261. [Google Scholar] [CrossRef]
- Guo, B.; Wang, J.; Guo, M.; Chen, M.; Chen, Y.; Miao, Y. Overview of Pest Detection and Recognition Algorithms. Electronics 2024, 13, 3008. [Google Scholar] [CrossRef]
- Wang, S.; Xu, D.; Liang, H.; Bai, Y.; Li, X.; Zhou, J.; Su, C.; Wei, W. Advances in Deep Learning Applications for Plant Disease and Pest Detection: A Review. Remote Sens. 2025, 17, 698. [Google Scholar] [CrossRef]
- Paymode, A.S.; Malode, V.B. Transfer Learning for Multi-Crop Leaf Disease Image Classification Using Convolutional Neural Network VGG. Artif. Intell. Agric. 2022, 6, 23–33. [Google Scholar] [CrossRef]
- Khan, D.; Waqas, M.; Tahir, M.; Islam, S.U.; Amin, M.; Ishtiaq, A.; Jan, L. Revolutionizing Real-Time Object Detection: YOLO and MobileNet SSD Integration. J. Comput. Biomed. Inform. 2023, 6, 41–49. [Google Scholar]
- Hussain, M.; Khanam, R. In-Depth Review of YOLOv1 to YOLOv10 Variants for Enhanced Photovoltaic Defect Detection. Solar 2024, 4, 351–386. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Badgujar, C.M.; Poulose, A.; Gan, H. Agricultural object detection with You Only Look Once (YOLO) Algorithm: A bibliometric and systematic literature review. Comput. Electron. Agric. 2024, 223, 109090. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, S.; Li, E.; Yang, G.; Liang, Z.; Tan, M. MD-YOLO: Multi-scale Dense YOLO for small target pest detection. Comput. Electron. Agric. 2023, 213, 108233. [Google Scholar] [CrossRef]
- Xu, W.; Xu, T.; Thomasson, J.A.; Chen, W.; Karthikeyan, R.; Tian, G.; Shi, Y.; Ji, C.; Su, Q. A lightweight SSV2-YOLO based model for detection of sugarcane aphids in unstructured natural environments. Comput. Electron. Agric. 2023, 211, 107961. [Google Scholar] [CrossRef]
- Wang, C.; Wang, L.; Ma, G.; Zhu, L. CSF-YOLO: A Lightweight Model for Detecting Grape Leafhopper Damage Levels. Agronomy 2025, 15, 741. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 24 October 2024).
- Huang, Y.; Liu, Z.; Zhao, H.; Tang, C.; Liu, B.; Li, Z.; Wan, F.; Qian, W.; Qiao, X. YOLO-YSTs: An Improved YOLOv10n-Based Method for Real-Time Field Pest Detection. Agronomy 2025, 15, 575. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Feng, H.; Chen, X.; Duan, Z. LCDDN-YOLO: Lightweight Cotton Disease Detection in Natural Environment, Based on Improved YOLOv8. Agriculture 2025, 15, 421. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Mu, J.; Sun, L.; Ma, B.; Liu, R.; Liu, S.; Hu, X.; Zhang, H.; Wang, J. TFEMRNet: A Two-Stage Multi-Feature Fusion Model for Efficient Small Pest Detection on Edge Platforms. AgriEngineering 2024, 6, 4688–4703. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, K.-R.; Duan, L.-J.; Deng, Y.-J.; Liu, J.-L.; Long, C.-F.; Zhu, X.-H. Pest Detection Based on Lightweight Locality-Aware Faster R-CNN. Agronomy 2024, 14, 2303. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Guan, B.; Wu, Y.; Zhu, J.; Kong, J.; Dong, W. GC-Faster RCNN: The Object Detection Algorithm for Agricultural Pests Based on Improved Hybrid Attention Mechanism. Plants 2025, 14, 1106. [Google Scholar] [CrossRef]
- Koay, H.V.; Chuah, J.H.; Chow, C.; Chang, Y. Detecting and recognizing driver distraction through various data modality using machine learning: A review, recent advances, simplified framework and open challenges (2014–2021). Eng. Appl. Artif. Intell. 2022, 115, 105309. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 1, 2, 4, 6. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2021, arXiv:2010.04159. [Google Scholar]
- Liu, H.; Zhan, Y.; Sun, J.; Mao, Q.; Wu, T. A transformer-based model with feature compensation and local information enhancement for end-to-end pest detection. Comput. Electron. Agric. 2017, 138, 200–209. [Google Scholar] [CrossRef]
- Zhang, H.; Gong, Z.; Hu, C.; Chen, C.; Wang, Z.; Yu, B.; Suo, J.; Jiang, C.; Lv, C. A Transformer-Based Detection Network for Precision Cistanche Pest and Disease Management in Smart Agriculture. Plants 2025, 14, 499. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Lv, C. TinySegformer: A lightweight visual segmentation model for real-time agricultural pest detection. Comput. Electron. Agric. 2024, 218, 180740. [Google Scholar] [CrossRef]
- Bottou, L.; Curtis, F.E.; Fang, L.; Nocedal, J. Optimization Methods for Large-Scale Machine Learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, S.; Dong, S.; Zhang, G.; Yang, J.; Li, R.; Wang, H. Pest24: A large-scale very small object data set of agricultural pests for multi-target detection. Comput. Electron. Agric. 2020, 175, 105585. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOV11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Zhang, Z.; Bao, L.; Xiang, S.; Xie, G.; Gao, R. B2CNet: A Progressive Change Boundary-to-Center Refinement Network for Multitemporal Remote Sensing Images Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 11322–11338. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More Effective Intersection over Union Loss with Auxiliary Bounding Box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Ma, S.; Xu, Y. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Lv, W.; Zhao, Y.; Xu, S.; Wei, J.; Wang, G.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. DETRs Beat YOLOs on Real-time Object Detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Test Images | Test Instances | Precision (%) | Recall (%) | mAP50(%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|
| Pest24 [31] | 5075 | 38,666 | 71.7 | 68.5 | 70.4 | 45.1 |
| Our Dataset | 189 | 2985 | 92.4 | 91.7 | 86.8 | 54.7 |
| Category | Test Images | Test Instances | Precision (%) | Recall (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|
| Grapholita molesta | 65 | 1084 | 91.3 | 90.5 | 84.9 | 52.1 |
| Anarsia lineatella | 60 | 987 | 92.5 | 91.3 | 87.2 | 55.0 |
| Cydia pomonella | 64 | 914 | 93.1 | 92.7 | 88.4 | 57.6 |
| Overall | 189 | 2985 | 92.4 | 91.7 | 86.8 | 54.7 |
| Model | Params (M) | GFLOPs | Precision (%) | Recall (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|
| YOLOv5-n | 2.19 | 5.9 | 52.6 | 62.5 | 58.0 | 33.6 |
| YOLOv7-tiny | 5.39 | 13.0 | 62.9 | 52.6 | 58.7 | 34.5 |
| YOLOv8-n | 2.69 | 7.0 | 63.6 | 56.0 | 61.9 | 36.2 |
| YOLOv9-t | 1.99 | 6.7 | 57.9 | 57.1 | 58.4 | 33.5 |
| YOLOv10-n | 2.71 | 8.4 | 55.6 | 56.4 | 55.3 | 31.5 |
| YOLOv11-n | 2.59 | 6.5 | 58.2 | 64.3 | 62.2 | 36.3 |
| LCFANet-n (Ours) | 2.78 | 6.7 | 71.7 | 68.5 | 70.4 | 45.1 |
| YOLOv5-s | 7.83 | 19.0 | 76.0 | 63.1 | 68.3 | 41.5 |
| YOLOv8-s | 9.84 | 23.6 | 63.5 | 68.8 | 67.0 | 41.6 |
| YOLOv9-s | 6.32 | 22.8 | 71.7 | 67.4 | 66.2 | 38.8 |
| YOLOv10-s | 8.08 | 24.8 | 73.0 | 61.4 | 66.3 | 39.9 |
| YOLOv11-s | 9.43 | 21.6 | 63.9 | 74.1 | 68.3 | 42.3 |
| LCFANet-s (Ours) | 9.91 | 22.1 | 78.0 | 70.0 | 72.9 | 46.9 |
| YOLOv5-m | 22.14 | 52.9 | 64.8 | 70.3 | 70.3 | 45.3 |
| YOLOv8-m | 23.22 | 67.9 | 72.3 | 63.7 | 70.3 | 45.7 |
| YOLOv9-m | 16.73 | 61.1 | 66.0 | 68.5 | 69.0 | 44.2 |
| YOLOv10-m | 16.50 | 64.1 | 61.9 | 66.7 | 67.1 | 43.1 |
| YOLOv11-m | 20.06 | 68.2 | 66.5 | 71.8 | 73.0 | 47.0 |
| LCFANet-m (Ours) | 22.12 | 70.4 | 73.9 | 71.5 | 74.4 | 48.8 |
| YOLOv5-l | 47.96 | 114.9 | 68.1 | 69.7 | 71.8 | 46.6 |
| YOLOv7 | 34.24 | 104.7 | 65.2 | 56.0 | 64.4 | 39.6 |
| YOLOv8-l | 39.47 | 145.9 | 70.7 | 67.7 | 71.7 | 44.6 |
| YOLOv9-c | 21.37 | 84.2 | 66.3 | 69.3 | 70.8 | 44.7 |
| YOLOv10-b | 20.47 | 98.8 | 68.1 | 63.1 | 69.2 | 43.5 |
| YOLOv10-l | 25.79 | 127.3 | 65.1 | 63.1 | 67.1 | 43.5 |
| YOLOv11-l | 25.32 | 87.3 | 69.6 | 65.4 | 72.0 | 46.3 |
| RT-DETR-l | 33.53 | 109.4 | 63.3 | 65.2 | 64.1 | 38.5 |
| SSD | 23.37 | 90.3 | 64.6 | 61.0 | 61.6 | 37.3 |
| Faster R-CNN | 32.45 | 90.2 | 67.1 | 69.6 | 68.7 | 42.1 |
| LCFANet-l (Ours) | 28.35 | 91.3 | 72.7 | 70.4 | 73.2 | 49.0 |
| YOLOv5-x | 89.06 | 215.0 | 69.9 | 65.5 | 71.1 | 45.5 |
| YOLOv7-x | 73.20 | 189.9 | 67.0 | 57.5 | 65.6 | 40.9 |
| YOLOv8-x | 61.64 | 227.6 | 68.7 | 68.3 | 71.2 | 43.9 |
| YOLOv9-e | 53.98 | 173.1 | 67.5 | 70.5 | 68.8 | 44.8 |
| YOLOv10-x | 31.68 | 171.1 | 58.4 | 62.0 | 60.5 | 38.4 |
| YOLOv11-x | 56.89 | 195.5 | 66.5 | 65.9 | 68.8 | 45.0 |
| RT-DETR-x | 67.83 | 233.5 | 64.2 | 66.6 | 65.7 | 41.2 |
| LCFANet-x (Ours) | 59.73 | 199.8 | 66.4 | 73.9 | 73.0 | 48.1 |
| Model | Params (M) | GFLOPs | Precision (%) | Recall (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|
| YOLO-YSTs [13] | 6.5 | 13.8 | 62.5 | 64.4 | 64.8 | 37.9 |
| CSF-YOLO [11] | 3.7 | 8.8 | 68.7 | 62.9 | 65.2 | 39.4 |
| SSV2-YOLO [10] | 13.7 | 16.3 | 63.9 | 62.4 | 63.3 | 34.7 |
| LLA-RCNN [21] | 6.4 | 74.5 | 65.7 | 66.5 | 66.8 | 38.1 |
| LCFANet-n (Ours) | 2.78 | 6.7 | 71.7 | 68.5 | 70.4 | 45.1 |
| DTFA -C3k2 | ADown -Conv | CLHFP | MSASF Module | MPDINIoU Loss | Params (M) | GFLOPs | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|---|---|
| 2.59 | 6.5 | 62.2 | 36.3 | |||||
| ✓ | 2.61 (↑ 0.02) | 6.5 | 63.8 (↑ 1.6) | 38.4 (↑ 2.1) | ||||
| ✓ | 1.98 (↓ 0.61) | 5.5 (↓ 1.0) | 61.8 (↓ 0.4) | 36.0 (↓ 0.3) | ||||
| ✓ | 3.44 (↑ 0.85) | 7.6 (↑ 1.1) | 66.4 (↑ 4.2) | 39.9 (↑ 3.6) | ||||
| ✓ | 2.84 (↑ 0.25) | 6.9 (↑ 0.4) | 65.6 (↑ 3.4) | 39.1 (↑ 2.8) | ||||
| ✓ | 2.59 | 6.5 | 63.4 (↑ 1.2) | 37.8 (↑ 1.5) | ||||
| 2.59 | 6.5 | 62.2 | 36.3 | |||||
| ✓ | 2.84 (↑ 0.25) | 6.9 (↑ 0.4) | 65.6 (↑ 3.4) | 39.1 (↑ 2.8) | ||||
| ✓ | ✓ | 3.57 (↑ 0.73) | 7.8 (↑ 0.9) | 67.9 (↑ 2.3) | 41.7 (↑ 2.6) | |||
| ✓ | ✓ | ✓ | 3.58 (↑ 0.01) | 7.9 (↑ 0.1) | 68.7 (↑ 0.8) | 43.3 (↑ 1.6) | ||
| ✓ | ✓ | ✓ | ✓ | 2.78 (↓ 0.8) | 6.7 (↓ 1.2) | 68.2 (↓ 0.5) | 42.9 (↓ 0.4) | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 2.78 | 6.7 | 70.4 (↑ 2.2) | 45.1 (↑ 2.2) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Tian, Y.; Tan, Y.; Liang, Z. LCFANet: A Novel Lightweight Cross-Level Feature Aggregation Network for Small Agricultural Pest Detection. Agronomy 2025, 15, 1168. https://doi.org/10.3390/agronomy15051168
Huang S, Tian Y, Tan Y, Liang Z. LCFANet: A Novel Lightweight Cross-Level Feature Aggregation Network for Small Agricultural Pest Detection. Agronomy. 2025; 15(5):1168. https://doi.org/10.3390/agronomy15051168
Chicago/Turabian StyleHuang, Shijian, Yunong Tian, Yong Tan, and Zize Liang. 2025. "LCFANet: A Novel Lightweight Cross-Level Feature Aggregation Network for Small Agricultural Pest Detection" Agronomy 15, no. 5: 1168. https://doi.org/10.3390/agronomy15051168
APA StyleHuang, S., Tian, Y., Tan, Y., & Liang, Z. (2025). LCFANet: A Novel Lightweight Cross-Level Feature Aggregation Network for Small Agricultural Pest Detection. Agronomy, 15(5), 1168. https://doi.org/10.3390/agronomy15051168