
A Heterogeneous Image Registration Model for an Apple Orchard

Abstract
1. Introduction
1.1. Related Works
1.2. Highlights
- (1)
- In the feature point extraction module, we adopt the Visual Geometry Group (VGG) network to process the information of the input image. Through stacking multiple convolutional layers and pooling layers, it can gradually extract different levels of features of the image.
- (2)
- The feature point encoder adds a residual module mechanism, allowing the Multi-Layer Perceptron (MLP) to show more significant advantages in fitting complex function mappings. The position encoding is embedded into neural networks to help the model better understand the spatial relationships between feature points.
- (3)
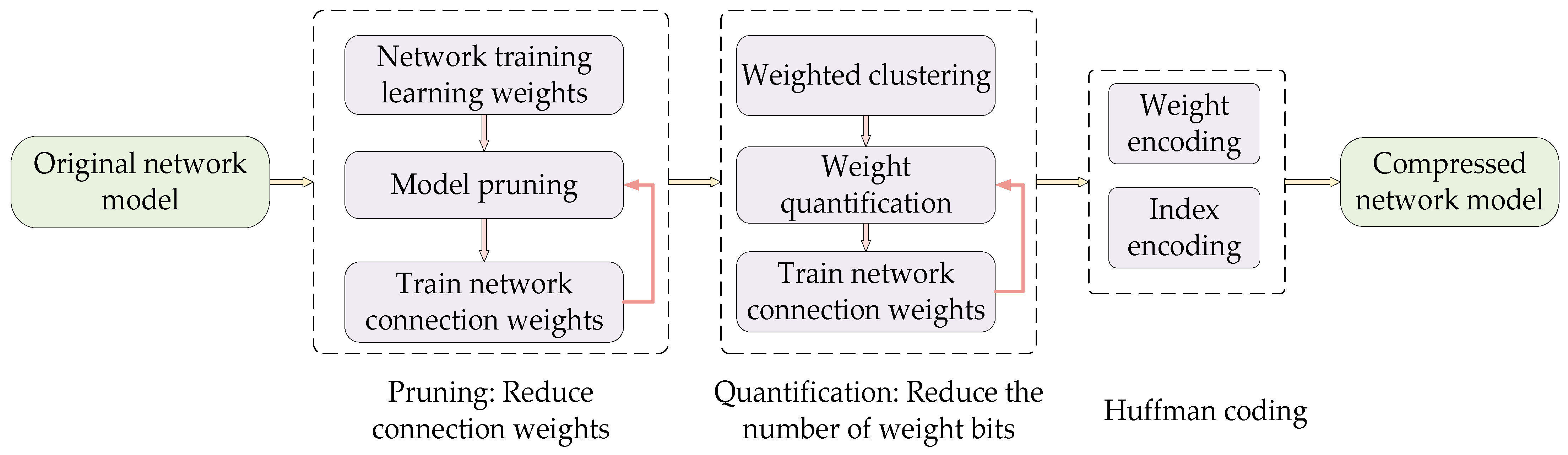
- We use the Sinkhorn AutoDiff algorithm for adaptive inference and solving optimization transmission problems. It is used to perform model pruning and network parameter compression on the network module of feature point matching to reduce computational complexity.
2. Materials and Methods
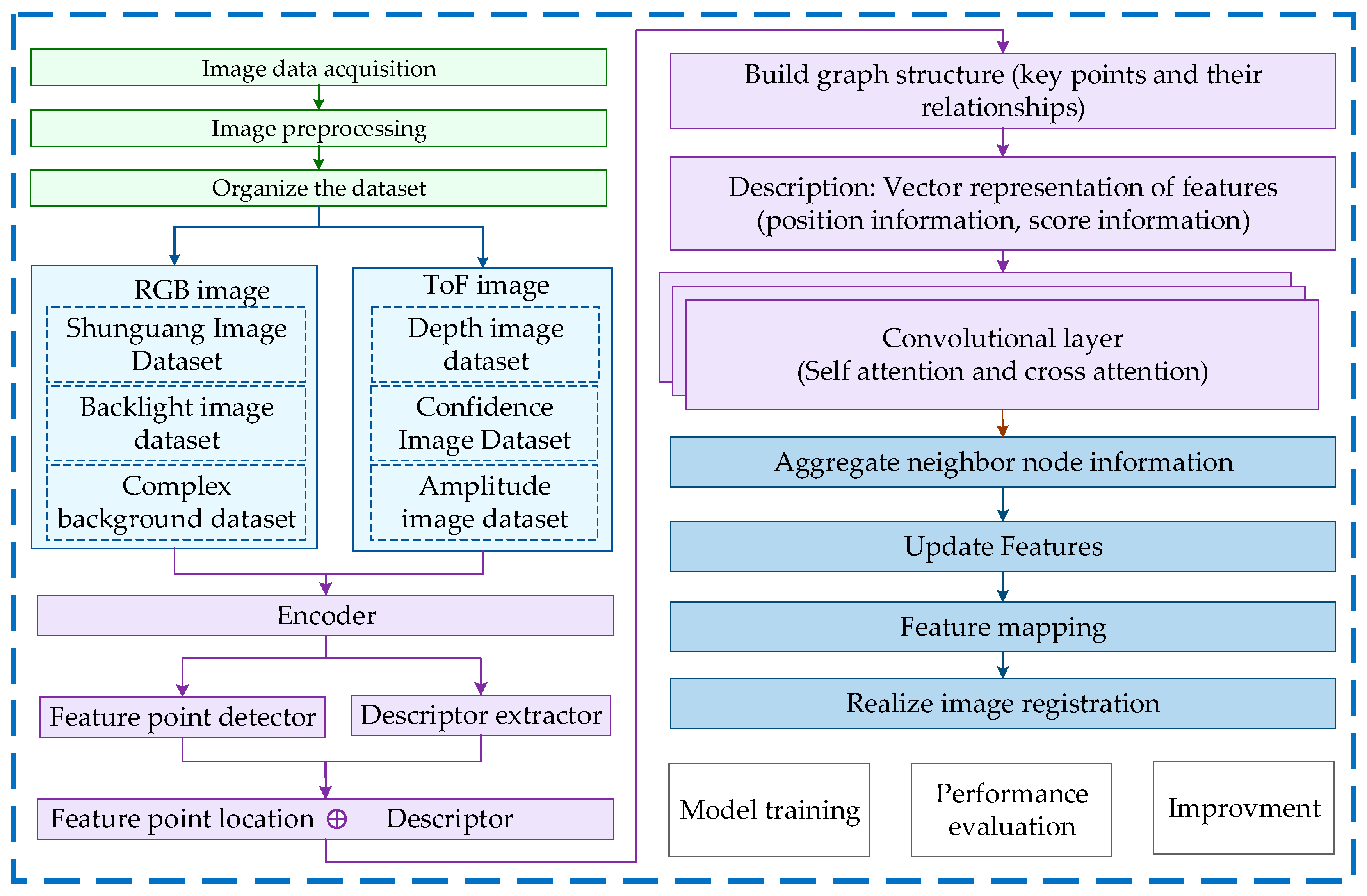
2.1. Materials and Datasets
2.2. Model
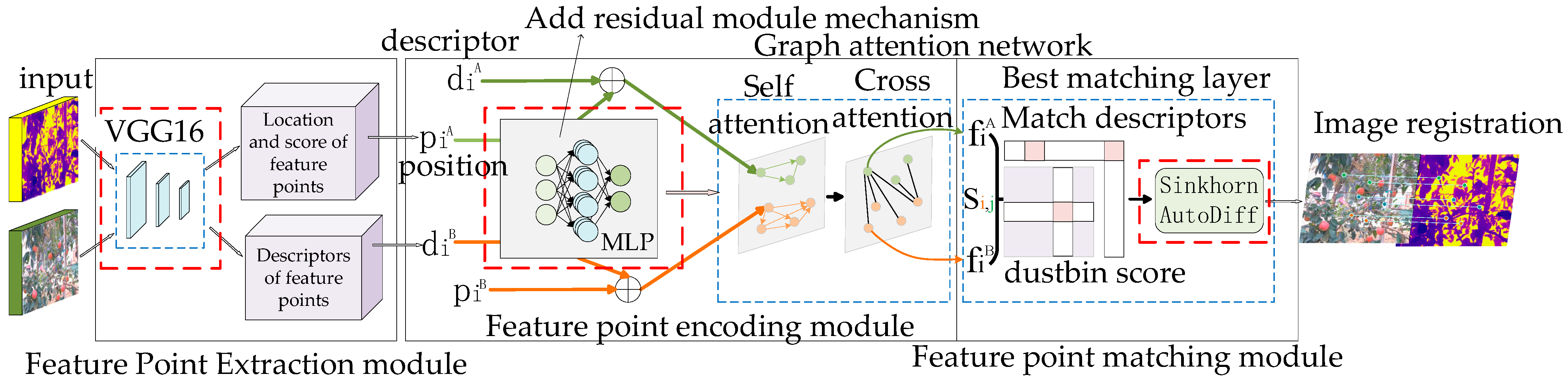
2.2.1. Overall Framework of the Model
2.2.2. Modules
- (1)
- Feature point extraction module
- (2)
- Feature point Encoding Module
- (3)
- Feature point matching module
2.2.3. Improvement in Sinkhorn AutoDiff Algorithm
2.3. Algorithm
| Algorithm 1: Image registration algorithm based on AD-ResSug | |
| Input: kpts0, kpts1, desc0, desc1, data | |
| Output: matches0, matches1, matchingscores0, matchingscores1, loss, | |
| 1. | Begin |
| 2. | Input feature points and descriptors |
| 3. | Normalize feature points |
| 4. | Encode descriptors |
| 5. | Perform feature propagation |
| 6. | Perform graph neural network computation |
| 7. | Calculate the optimal transmission score |
| 8. | Obtain matching results based on the score threshold |
| 9. | Loss value calculation |
| 10. | End |
3. Results
3.1. Comparative Experiment
3.1.1. Test on Public Datasets
3.1.2. Application Task Test on Self-Built Datasets
3.2. Comprehensive Evaluation Experiment of Model Performance
3.3. Ablation Experiment
3.3.1. Feature Point Detection Ablation Experiment
3.3.2. Improved Model Ablation Experiment
3.4. Model Performance Analysis
4. Discussion
4.1. Comparative Algorithm Analysis
4.1.1. Discussion of Test on Public Datasets
4.1.2. Discussion of Application Task Test
4.2. Discussion of Ablation Experiment
4.3. Summary of Experiment’s Results
5. Conclusions
- (1)
- In the feature point extraction module, we adopt the Visual Geometry Group (VGG) network to process the information of the input image. Through stacking multiple convolutional layers and pooling layers, it can gradually extract different levels of features of the image. Compared with other methods, AD-ResSug has significant performance improvements in feature matching and image registration tasks and can effectively handle the relationships between feature points. The public test results in Table 3 shows that the AD-ResSug model has further improved in several key indicators, such as root mean square error, peak signal-to-noise ratio, and relative global accuracy error.
- (2)
- The Sinkhorn AutoDiff algorithm is used to perform model pruning and network parameter compression on the network module of feature point matching to reduce computational complexity. From the ablation experiment results of Table 5 and Table 6, optimizing the matching process through global contextual information can effectively improve the accuracy and robustness of heterogeneous image matching and perform well in handling complex scenes. After adding a residual mechanism to the feature point encoding module, a larger number of key points were ultimately extracted. After adopting automatic differentiation processing technology for the Sinkhorn algorithm, the performance was better in calculating the optimal transmission problem. It can maintain high matching accuracy, even in the presence of occlusion and repeated textures.
- (3)
- More importantly, the AD-ResSug model is more suitable for heterogeneous registration, especially for the color and ToF heterogeneous images. The results of the discussion on self-built datasets in Table 8 suggest that the AD-ResSug model overcomes the problem of low accuracy in heterogeneous image registration exhibited by other models. It shows the model is more suitable for the actual application scene.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, D.; Yan, Y.; Liang, D.; Du, S. MSFormer: Multi-scale transformer with neighborhood consensus for feature matching. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Xia, Y.; Ma, J. Locality-guided global-preserving optimization for robust feature matching. IEEE Trans. Image Process. 2022, 31, 5093–5108. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; You, Y.; Li, C.; Liu, J. TSK: A Trustworthy Semantic Keypoint Detector for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–20. [Google Scholar] [CrossRef]
- Bellavia, F. SIFT matching by context exposed. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2445–2457. [Google Scholar] [CrossRef]
- Kumar, A. SURF feature descriptor for image analysis. Imaging Radiat. Res. 2023, 6, 5643. [Google Scholar] [CrossRef]
- Chen, Q.; Yao, L.; Xu, L.; Yang, Y.; Xu, T.; Yang, Y.; Liu, Y. Horticultural image feature matching algorithm based on improved ORB and LK optical flow. Remote Sens. 2022, 14, 4465. [Google Scholar] [CrossRef]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Kim, S.H.; Choi, H.L. Convolutional neural network for monocular vision-based multi-target tracking. Int. J. Control Autom. Syst. 2019, 17, 2284–2296. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Corso, G.; Stark, H.; Jegelka, S.; Jaakkola, T.; Barzilay, R. Graph neural networks. Nat. Rev. Methods Primers 2024, 4, 17. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, J.; Yang, K.; Peng, K.; Stiefelhagen, R. Matchformer: Interleaving attention in transformers for feature matching. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 2746–2762. [Google Scholar]
- Xie, T.; Dai, K.; Wang, K.; Li, R.; Zhao, L. Deepmatcher: A deep transformer-based network for robust and accurate local feature matching. Expert Syst. Appl. 2024, 237, 121361. [Google Scholar]
- Sarlin, P.E.; Detone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 4938–4947. [Google Scholar]
- Lindenberger, P.; Sarlin, P.E.; Pollefeys, M. Lightglue: Local feature matching at light speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 17627–17638. [Google Scholar]
- Viniavskyi, O.; Dobko, M.; Mishkin, D.; Dobosevych, O. OpenGlue: Open source graph neural net based pipeline for image matching. arXiv 2022, arXiv:2204.08870. [Google Scholar]
- Ferrer, M.; Ruiz-Hidalgo, J.; Gregorio, E.; Vilaplana, V.; Morros, J.R.; Gené-Mola, J. Simultaneous fruit detection and size estimation using multitask deep neural networks. Biosyst. Eng. 2023, 233, 63–75. [Google Scholar]
- Gené-Mola, J.; Vilaplana, V.; Rosell-Polo, J.R.; Morros, J.-R.; Ruiz-Hidalgo, J.; Gregorio, E. Multi-modal Deep Learning for Fruit Detection Using RGB-D Cameras and their Radiometric Capabilities. Comput. Electron. Agric. 2019, 162, 689–698. [Google Scholar]
- Xu, W.; Liu, L. PCNN orchard heterogeneous image fusion with semantic segmentation of significance regions. Comput. Electron. Agric. 2024, 216, 108454. [Google Scholar]
- Yang, H.; Ni, J.; Gao, J.; Han, Z.; Luan, T. A novel method for peanut variety identification and classification by Improved VGG16. Sci. Rep. 2021, 11, 15756. [Google Scholar] [CrossRef]
- Feng, M.; Lu, H.; Yu, Y. Residual learning for salient object detection. IEEE Trans. Image Process. 2020, 29, 4696–4708. [Google Scholar]
- Luise, G.; Rudi, A.; Pontil, M.; Ciliberto, C. Differential properties of sinkhorn approximation for learning with wasserstein distance. Adv. Neural Inf. Process. Syst. 2018, 31, 1467–5463. [Google Scholar]
- Lee, S.; Lim, J.; Suh, I.H. Progressive feature matching: Incremental graph construction and optimization. IEEE Trans. Image Process. 2020, 29, 6992–7005. [Google Scholar]
- Poiesi, F.; Boscaini, D. Learning general and distinctive 3D local deep descriptors for point cloud registration. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3979–3985. [Google Scholar]
- Jiang, Q.; Liu, Y.; Yan, Y.; Deng, J.; Fang, J.; Li, Z.; Jiang, X. A contour angle orientation for power equipment infrared and visible image registration. IEEE Trans. Power Deliv. 2020, 36, 2559–2569. [Google Scholar]
- Xu, S.; Chen, S.; Xu, R.; Wang, C.; Lu, P.; Guo, L. Local feature matching using deep learning: A survey. Inf. Fusion 2024, 107, 102344. [Google Scholar]
- Chen, J.; Li, G.; Zhang, Z.; Zeng, D. EFDCNet: Encoding fusion and decoding correction network for RGB-D indoor semantic segmentation. Image Vis. Comput. 2024, 142, 104892. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- Choy, C.B.; Gwak, J.; Savarese, S.; Chandraker, M. Universal correspondence network. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 467–483. [Google Scholar]
- Verdie, Y.; Yi, K.; Fua, P.; Lepetit, V. Tilde: A temporally invariant learned detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5279–5288. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative learning of deep convolutional feature point descriptors. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 118–126. [Google Scholar]
- Detone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 224–236. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Dataset | Image Number | Original Image | Image Size | Image Type | Usage |
|---|---|---|---|---|---|---|
| 1 | papple dataset | 3925 images | 1300 × 1300 | 1025 × 769 | Depth with color | For testing |
| 2 | kfuji dataset | 967 images | 1920 × 1080 | 1025 × 769 | Depth with color | For testing |
| 3 | early stage | 568 images | 640 × 480 | 640 × 480 | ToF Confdence with color | For application |
| 4 | fruit swelling period | 434 images | 640 × 480 | 640 × 480 | ToF Confdence with color | For application |
| 5 | maturation period | 668 images | 640 × 480 | 640 × 480 | ToF Confdence with color | For application |
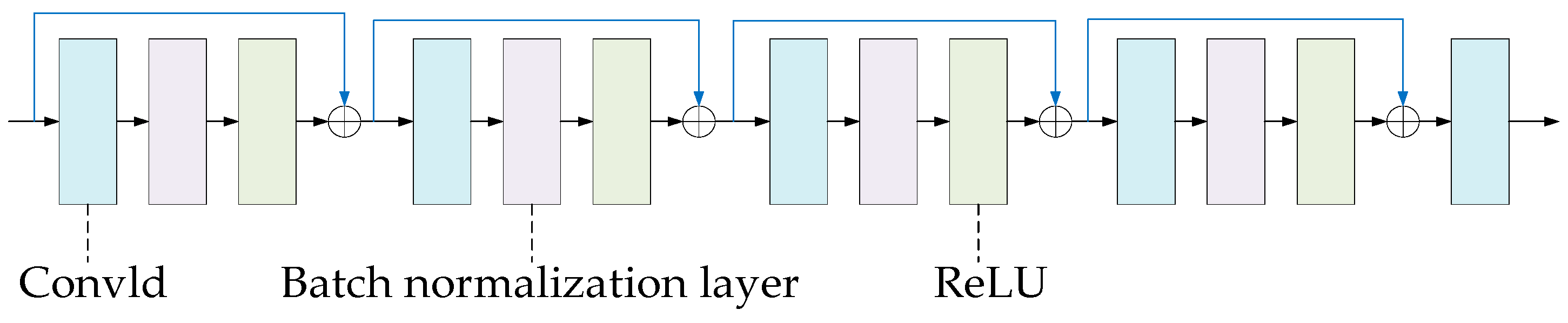
| Number of Layers | Network Layer | Number of Input Channels | Number of Output Channels | Convolutional Kernel Size | Step Length | Epsilon Value | Momentum Value | Affine Parameter | Track_Running_Stats Parameter |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Convolutional Layer | 3 | 32 | 1 | 1 | ||||
| 2 | Batch normalization layer | 32 | 1 × 10−5 | 0.1 | True | True | |||
| 3 | activation function | ||||||||
| 4 | Convolutional Layer | 32 | 64 | 1 | 1 | ||||
| 5 | Batch normalization layer | 64 | 1 × 10−5 | 0.1 | True | True | |||
| 6 | activation function | ||||||||
| 7 | Convolutional Layer | 64 | 128 | 1 | 1 | ||||
| 8 | Batch normalization layer | 128 | 1 × 10−5 | 0.1 | True | True | |||
| 9 | activation function | ||||||||
| 10 | Convolutional Layer | 128 | 256 | 1 | 1 | ||||
| 11 | Batch normalization layer | 256 | 1 × 10−5 | 0.1 | True | True | |||
| 12 | activation function | ||||||||
| 13 | Convolutional Layer | 256 | 256 | 1 | 1 |
| Model | PSNR | SSIM | RMSE | UQI |
|---|---|---|---|---|
| SIFT [4] | 12.72 | (0.297, 0.347) | 58.95 | 0.651 |
| SURF [5] | 11.43 | (0.26, 0.32) | 62.31 | 0.39 |
| ORB [6] | 9.99 | (0.192, 0.261) | 80.71 | 0.607 |
| LoFTR [28] | 7.11 | (0.219, 0.278) | 79.13 | 0.671 |
| MatchFormer [12] | 10.32 | (0.224, 0.281) | 57.76 | 0.583 |
| SuperGlue [14] | 12.65 | (0.11, 0.14) | 52.16 | 0.42 |
| LightGlue [15] | 12.89 | (0.327, 0.398) | 32.75 | 0.489 |
| Ours | 14.34 | (0.285, 0.326) | 26.24 | 0.674 |
| Datasets | AUC@5 | AUC@10 | AUC@20 | Prec | MScore |
|---|---|---|---|---|---|
| Dataset1 | 25.31 | 45.38 | 60.44 | 69.99 | 88.63 |
| Dataset 2 | 16.87 | 30.25 | 40.29 | 68.4 | 83.67 |
| Dataset 3 | 19.67 | 32.46 | 43.38 | 68.61 | 85.72 |
| Dataset 4 | 21.38 | 35.33 | 48.72 | 69.53 | 86.49 |
| Dataset 5 | 24.86 | 38.42 | 51.09 | 67.5 | 87.36 |
| Feature Extraction Algorithm | Descriptor | Single Network | Complete Image Input | Time (s) |
|---|---|---|---|---|
| SIFT [4] | √ | 3.21 | ||
| ORB [6] | √ | 2.89 | ||
| UCN [29] | √ | √ | 3.62 | |
| LIFT [30] | √ | 3.08 | ||
| TILDE [31] | 2.17 | |||
| DeepDesc [32] | √ | 1.23 | ||
| SuperPoint [33] | √ | √ | √ | 0.82 |
| Ours | √ | √ | √ | 0.75 |
| Model | Keypoints | Matches | Times | PSNR | RMSE |
|---|---|---|---|---|---|
| SuperGlue | 786 | 306 | 3.7 | 12.56 | 82.36 |
| AD | 1003 | 637 | 3.6 | 12.48 | 52.11 |
| Res | 1196 | 649 | 3.6 | 13.87 | 67.42 |
| NP | 1469 | 782 | 2.7 | 13.21 | 57.34 |
| AD + Res | 1981 | 798 | 3.4 | 14.19 | 30.99 |
| PE + NP | 1598 | 773 | 3.0 | 14.57 | 30.63 |
| Res + NP | 1602 | 964 | 3.0 | 14.74 | 30.87 |
| AD-ResSug | 1792 | 825 | 1.3 | 15.86 | 25.22 |
| Model | Params(M) | Runtime(s) |
|---|---|---|
| LoFTR [28] | 28.11 | 0.39 |
| MatchFormer [12] | 21.32 | 0.57 |
| SuperGlue [14] | 15.65 | 0.25 |
| LightGlue [15] | 9.89 | 0.28 |
| Ours | 11.34 | 0.17 |
| Model | PSNR (dB) | SSIM | RMSE | UQI |
|---|---|---|---|---|
| SIFT [4] | 14.28 | (0.235, 0.293) | 65.32 | 0.523 |
| SURF [5] | 18.76 | (0.24, 0.28) | 61.87 | 0.487 |
| ORB [6] | 16.37 | (0.186, 0.254) | 76.23 | 0.636 |
| LoFTR [28] | 19.39 | (0.221, 0.264) | 77.86 | 0.618 |
| MatchFormer [12] | 11.01 | (0.217, 0.265) | 56.49 | 0.609 |
| SuperGlue [14] | 12.76 | (0.51, 0.66) | 50.99 | 0.543 |
| LightGlue [15] | 22.68 | (0.57, 0.65) | 33.86 | 0.495 |
| Ours | 37.29 | (0.61, 0.72) | 24.89 | 0.655 |
| Model | Advantages | Disadvantages |
|---|---|---|
| SIFT | Rotation, scale, and brightness remain unchanged, suitable for detecting corners and edges | Large computational load, sensitive to occlusion |
| SURF | High computational efficiency, suitable for detecting large-area features | Sensitive to rotation |
| ORB | Stable number of feature points | Scale sensitive |
| LoFTR | Adopting Transformer architecture, strong robustness | The model is large and requires high computing resources |
| MatchFormer | Proficient in capturing long-distance dependencies and effectively handling global information | High computational cost, slow speed, and large number of parameters |
| SuperGlue | Has good robustness to changes in lighting and occlusion | Large computational load, slow speed, not suitable for processing heterogeneous image registration |
| LightGlue | Fast speed, lightweight | The accuracy is slightly low, and the robustness needs to be improved |
| Ours | Reducing the number of parameters while ensuring registration accuracy | suitable for registration of color and ToF heterogeneous images |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, D.; Liu, L. A Heterogeneous Image Registration Model for an Apple Orchard. Agronomy 2025, 15, 889. https://doi.org/10.3390/agronomy15040889
Huang D, Liu L. A Heterogeneous Image Registration Model for an Apple Orchard. Agronomy. 2025; 15(4):889. https://doi.org/10.3390/agronomy15040889
Chicago/Turabian StyleHuang, Dongfu, and Liqun Liu. 2025. "A Heterogeneous Image Registration Model for an Apple Orchard" Agronomy 15, no. 4: 889. https://doi.org/10.3390/agronomy15040889
APA StyleHuang, D., & Liu, L. (2025). A Heterogeneous Image Registration Model for an Apple Orchard. Agronomy, 15(4), 889. https://doi.org/10.3390/agronomy15040889