
An Approach for Detecting Tomato Under a Complicated Environment

Abstract
1. Introduction
2. Materials and Methods
2.1. Experimental Dataset
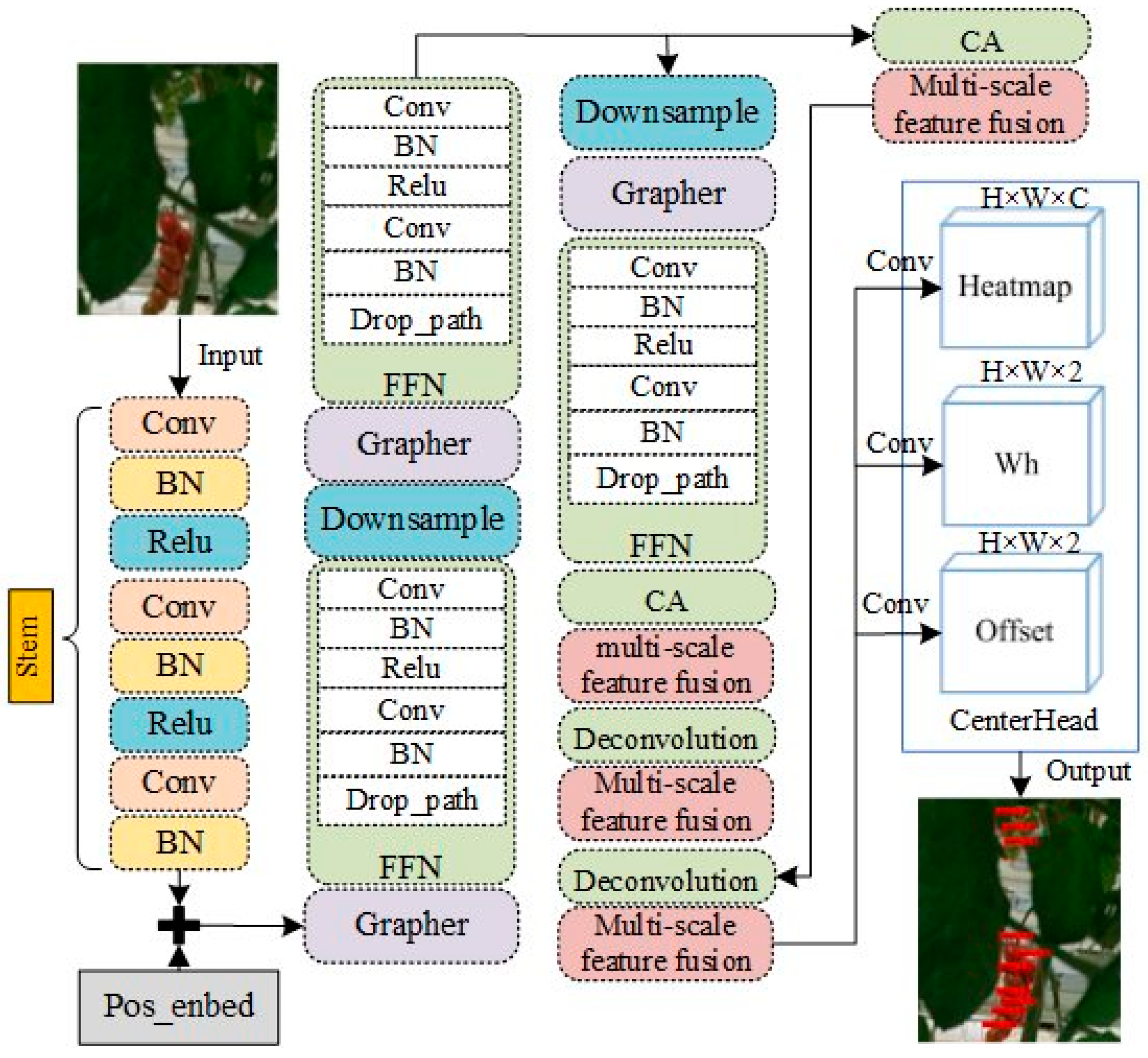
2.2. Construction of Graph-CenterNet Tomato Detection Model
2.2.1. Improvements of Backbone Networks
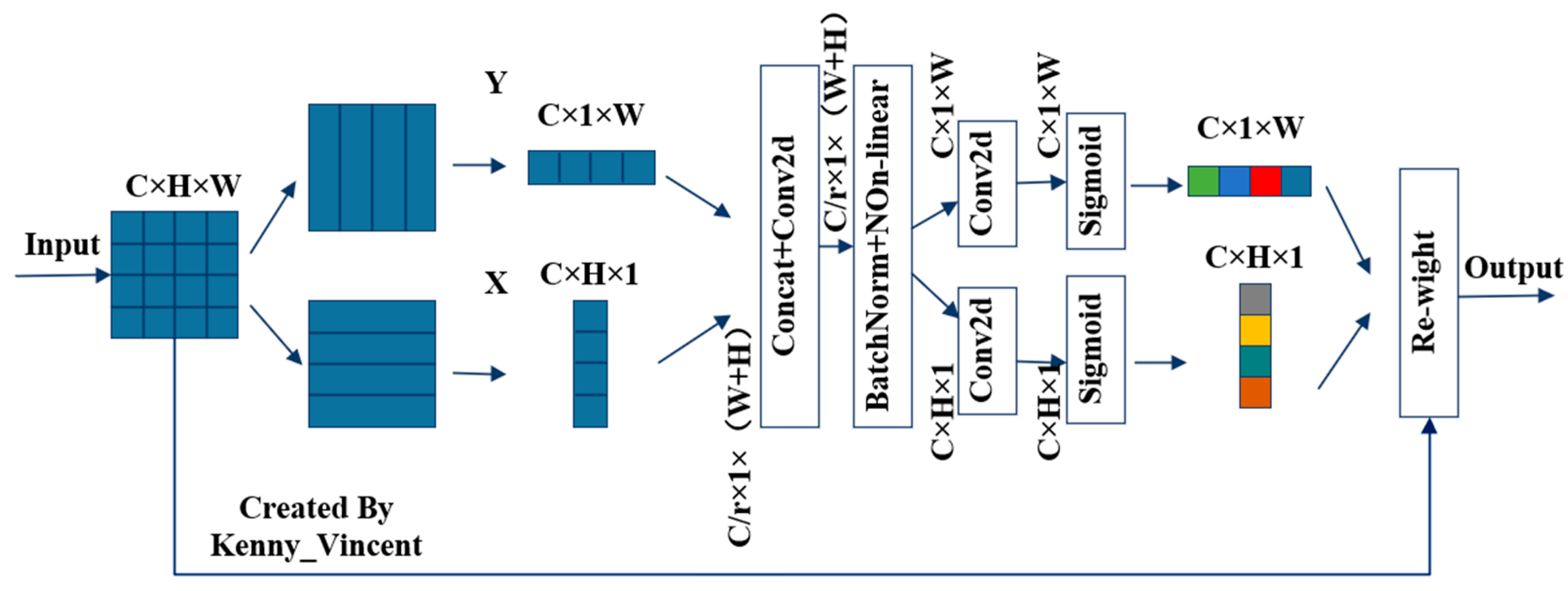
2.2.2. Embedded in the CA Mechanism
2.2.3. Add Multiscale Feature Fusion and Deconvolution
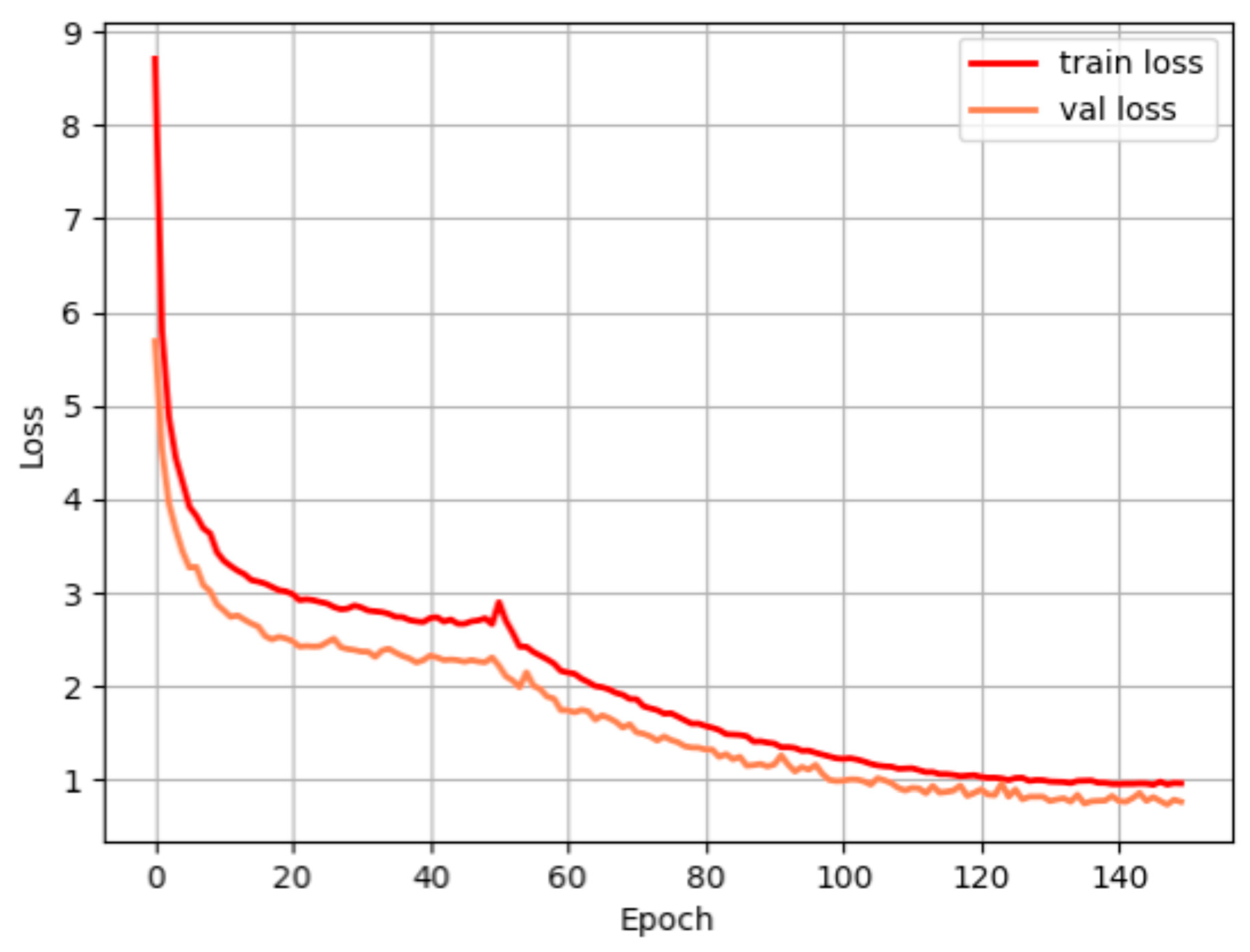
3. Model Training and Experiment
3.1. Experimental Platform
3.2. Evaluating Indicator
3.3. Ablation Experiments and Analysis
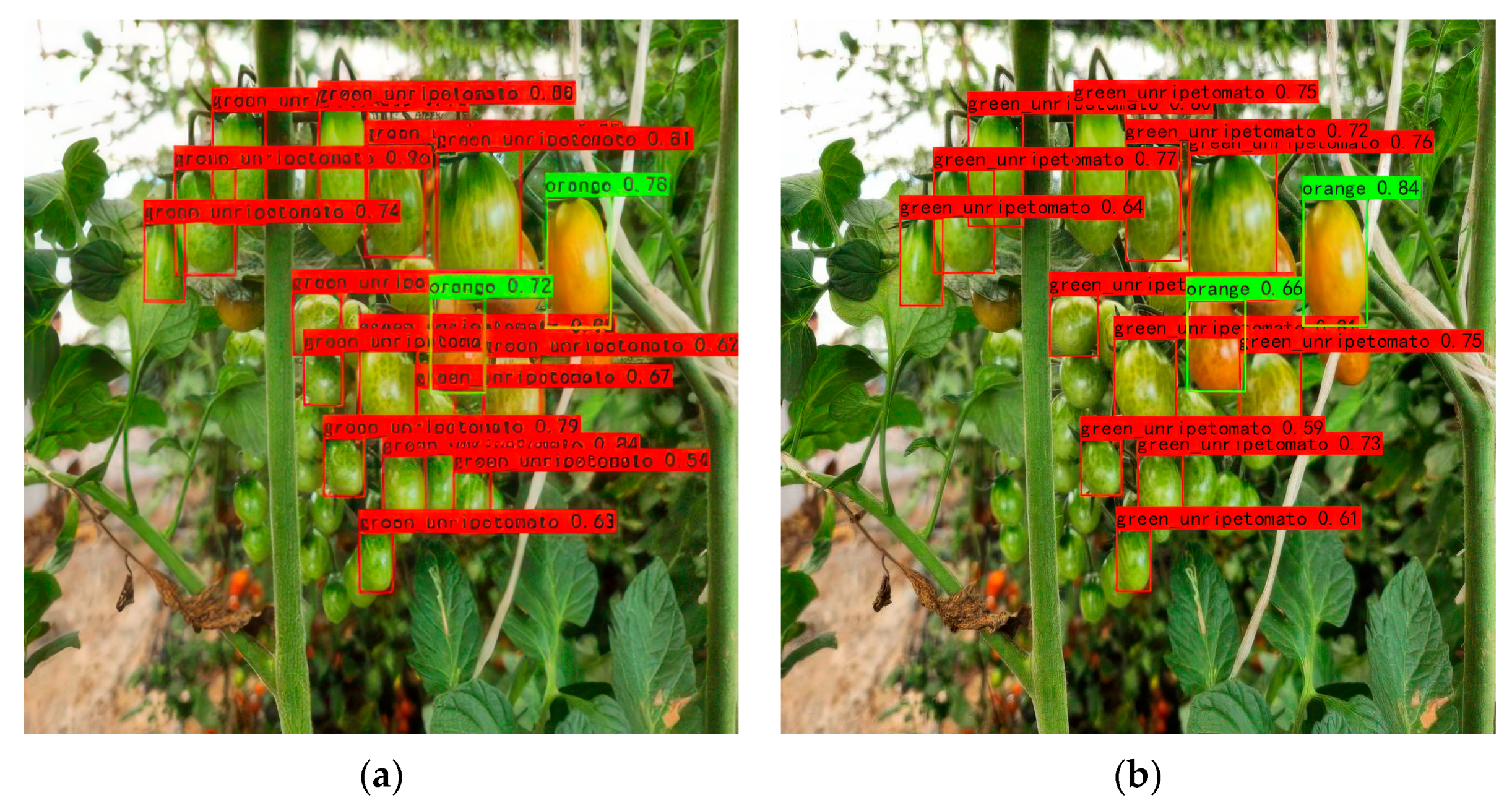
3.4. Contrast the Experiment and the Analysis
3.5. Generalization Experiments
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Costa, J.M.; Heuvelink, E.P. The global tomato industry. In Tomatoes; CABI: Wallingford, UK, 2018; pp. 1–26. [Google Scholar]
- Amirahmadi, E.; Ghorbani, M.; Moudrý, J.; Konvalina, P.; Kopecký, M. Impacts of environmental factors and nutrients management on tomato grown under controlled and open field conditions. Agronomy 2023, 13, 916. [Google Scholar] [CrossRef]
- Li, T.; Sun, M.; He, Q.; Zhang, G.; Shi, G.; Ding, X.; Lin, S. Tomato recognition and location algorithm based on improved YOLOv5. Comput. Electron. Agric. 2023, 208, 107759. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, X.; Au, W.; Kang, H.; Chen, C. Intelligent robots for fruit harvesting: Recent developments and future challenges. Precis. Agric. 2022, 23, 1856–1907. [Google Scholar] [CrossRef]
- Tong, Z.; Zhang, S.; Yu, J.; Zhang, X.; Wang, B.; Zheng, W. A Hybrid Prediction Model for CatBoost Tomato Transpiration Rate Based on Feature Extraction. Agronomy 2023, 13, 2371. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision And Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Huang, Y.P.; Wang, T.H.; Basanta, H. Using fuzzy mask R-CNN model to automatically identify tomato ripeness. IEEE Access 2020, 8, 207672–207682. [Google Scholar] [CrossRef]
- Li, K.R.; Duan, L.J.; Deng, Y.J.; Liu, J.L.; Long, C.F.; Zhu, X.H. Pest detection based on lightweight locality-aware faster R-CNN. Agronomy 2024, 14, 2303. [Google Scholar] [CrossRef]
- Hu, C.; Liu, X.; Pan, Z.; Li, P. Automatic detection of single ripe tomato on plant combining faster R-CNN and intuitionistic fuzzy set. IEEE Access 2019, 7, 154683–154696. [Google Scholar] [CrossRef]
- Magalhães, S.A.; Castro, L.; Moreira, G.; Dos Santos, F.N.; Cunha, M.; Dias, J.; Moreira, A.P. Evaluating the single-shot multibox detector and YOLO deep learning models for the detection of tomatoes in a greenhouse. Sensors 2021, 21, 3569. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-tomato: A robust algorithm for tomato detection based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Chen, Z.; Bao, R.; Zhang, C.; Wang, Z. Recognition of dense cherry tomatoes based on improved YOLOv4-LITE lightweight neural network. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 270–278. [Google Scholar]
- Li, T.; Sun, M.; Ding, X.; Li, Y.; Zhang, G.; Shi, G.; Li, W. Tomato recognition method at the ripening stage based on YOLO v4 and HSV. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 183–190. [Google Scholar]
- Mingbo, L.; Yule, L.; Zhimin, M.; Junwang, G.; Yong, W.; Dongyue, R.; Jishen, J.; Zezhong, W.; Yuhong, L. Tomato Fruit Recognition Based on YOLOX-L-TN Model. J. Agric. Sci. Technol. 2024, 26, 97–105. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 11. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to feature extraction. In Feature Extraction: Foundations and Applications; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–25. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Mustafa, H.T.; Yang, J.; Zareapoor, M. Multi-scale convolutional neural network for multi-focus image fusion. Image Vis. Comput. 2019, 85, 26–35. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Lang, I.; Manor, A.; Avidan, S. Samplenet: Differentiable point cloud sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7578–7588. [Google Scholar]
- Bebis, G.; Georgiopoulos, M. Feed-forward neural networks. IEEE Potentials 1994, 13, 27–31. [Google Scholar] [CrossRef]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. Deepgcns: Can gcns go as deep as cnns? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9267–9276. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and deep graph convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6027–6037. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, G.; Ge, W.; Yu, Y. GraphFPN: Graph feature pyramid network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2763–2772. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Experimental Configuration |
|---|---|
| Operating System | Windows10 Operating System |
| CPU | 12th Gen Intel(R) Core(TM) i9-12900K CPU @ 3.20 GHz |
| GPU | NVIDIA GeForce RTX 4090 Memory 24G |
| Programming Language | Python3.7 |
| Name | Value |
|---|---|
| Initial learning rate | 5 × 10−4 |
| Input shape | 512 × 512 |
| Momentum | 0.9 |
| Confidence threshold | 0.5 |
| Batch size | 4 |
| Optimizer | Adam |
| Freeze epoch | 50 |
| Un-Freeze epoch | 150 |
| Number of Multiscale Fusion Layers | Tomato AP (%) | F1 | Recall (%) | Precision (%) |
|---|---|---|---|---|
| 3 layer | 91.53 | 0.88 | 79.04 | 98.08 |
| 2 layer | 96.53 | 0.96 | 92.76 | 99.01 |
| Whether to Add the CA Module | Whether to Add Two Layers Multiscale Feature Fusion | Tomato AP (%) | F1 | Recall (%) | Precision (%) |
|---|---|---|---|---|---|
| - | - | 89.68 | 0.94 | 89.76 | 98.88 |
| √ | - | 95.24 | 0.94 | 89.14 | 98.97 |
| - | √ | 95.41 | 0.94 | 89.63 | 98.88 |
| √ | √ | 96.53 | 0.96 | 92.76 | 99.01 |
| Models | Tomato AP (%) | F1 | Recall (%) | Precision (%) |
|---|---|---|---|---|
| Faster RCNN | 88.59 | 0.73 | 93.29 | 59.42 |
| CenterNet | 85.95 | 0.83 | 71.45 | 98.17 |
| YOLOv8 | 95.29 | 0.90 | 86.60 | 94.57 |
| Graph-CenterNet | 96.53 | 0.96 | 92.76 | 99.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Long, C.-F.; Yang, Y.-J.; Liu, H.-M.; Su, F.; Deng, Y.-J. An Approach for Detecting Tomato Under a Complicated Environment. Agronomy 2025, 15, 667. https://doi.org/10.3390/agronomy15030667
Long C-F, Yang Y-J, Liu H-M, Su F, Deng Y-J. An Approach for Detecting Tomato Under a Complicated Environment. Agronomy. 2025; 15(3):667. https://doi.org/10.3390/agronomy15030667
Chicago/Turabian StyleLong, Chen-Feng, Yu-Juan Yang, Hong-Mei Liu, Feng Su, and Yang-Jun Deng. 2025. "An Approach for Detecting Tomato Under a Complicated Environment" Agronomy 15, no. 3: 667. https://doi.org/10.3390/agronomy15030667
APA StyleLong, C.-F., Yang, Y.-J., Liu, H.-M., Su, F., & Deng, Y.-J. (2025). An Approach for Detecting Tomato Under a Complicated Environment. Agronomy, 15(3), 667. https://doi.org/10.3390/agronomy15030667