
YOLOv8n-CA: Improved YOLOv8n Model for Tomato Fruit Recognition at Different Stages of Ripeness



Abstract
1. Introduction
2. Materials and Methods
2.1. Image Acquisition
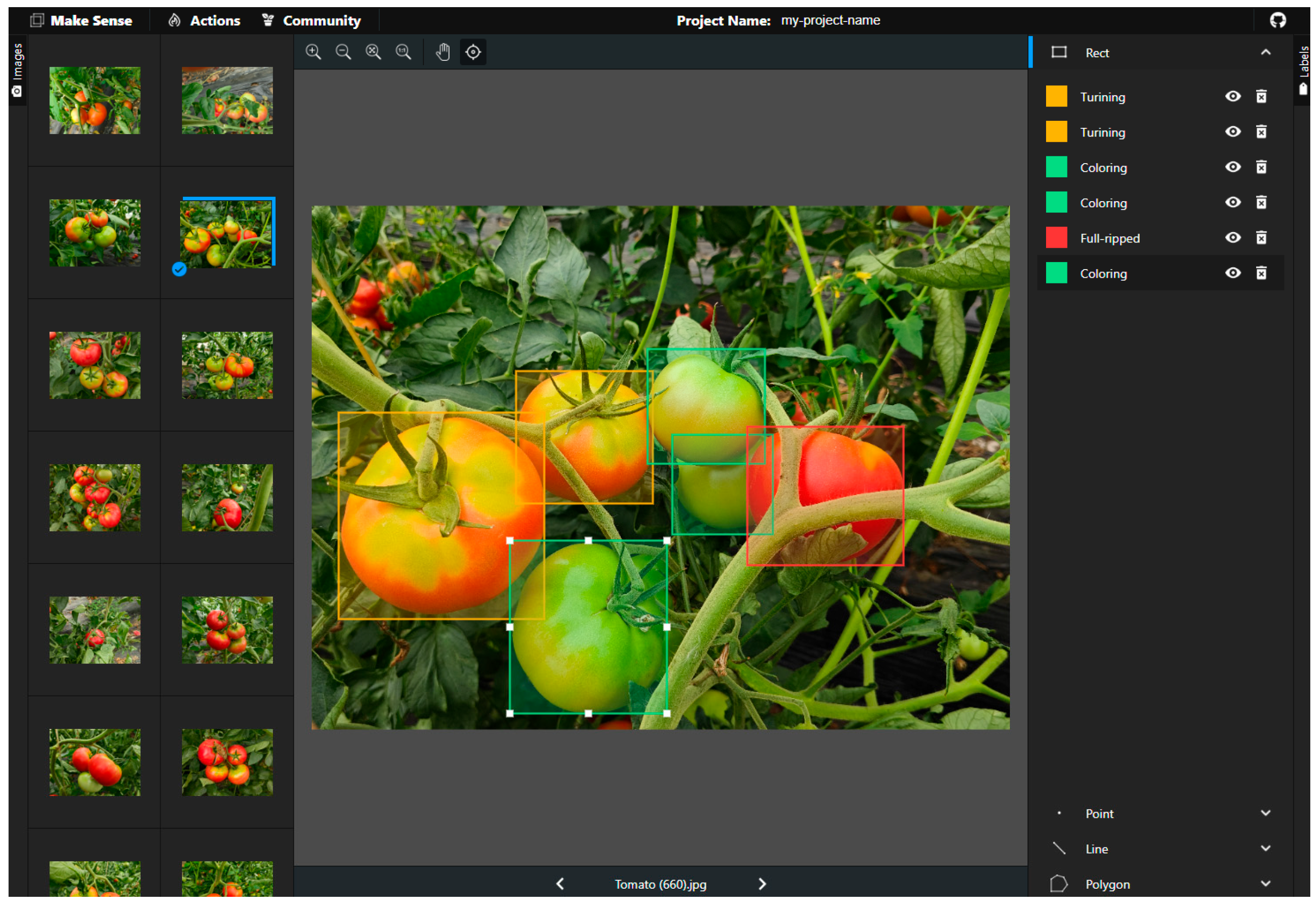
2.2. Dataset Construction
3. Experimental Methods
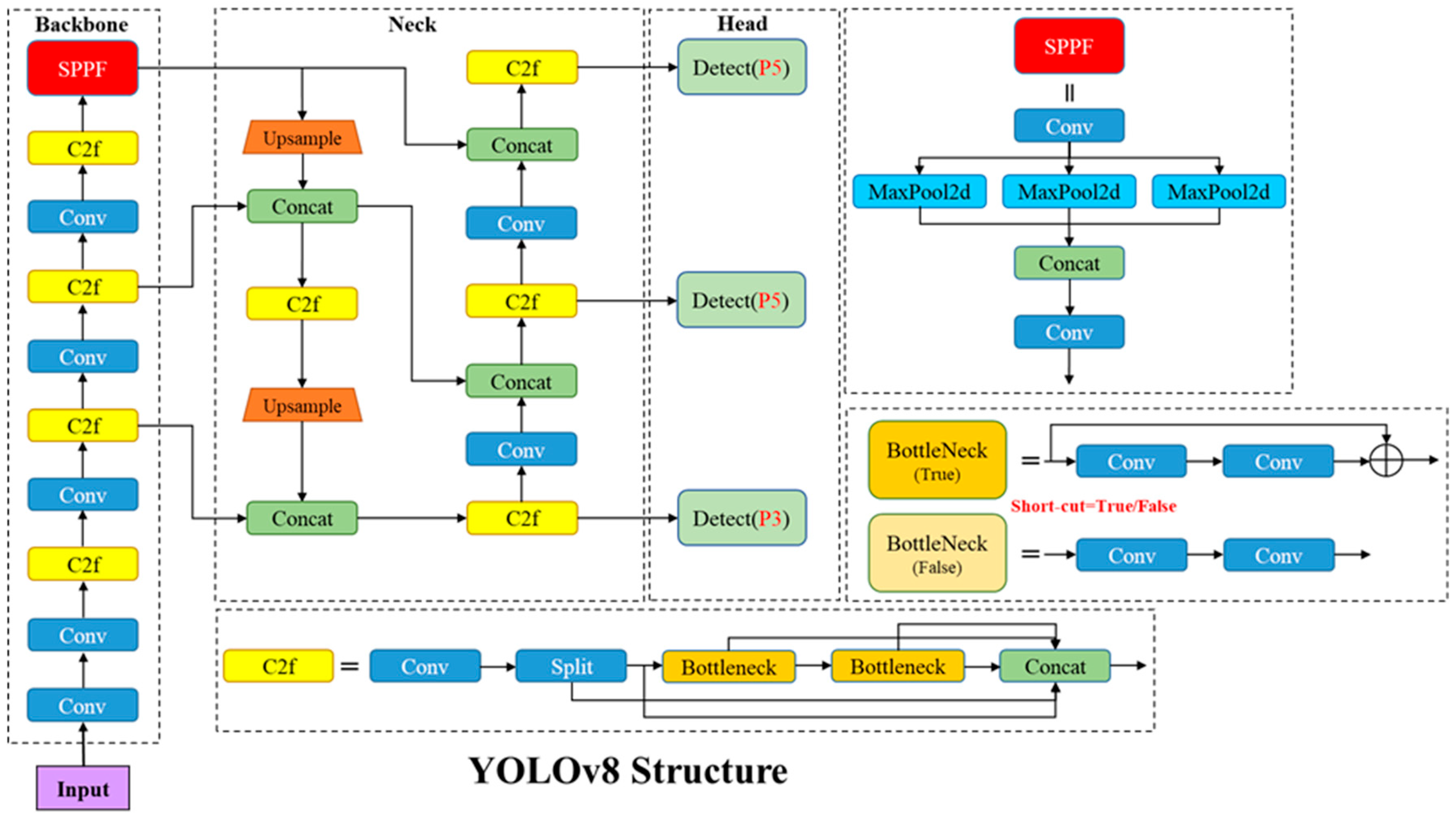
3.1. YOLOv8 Model
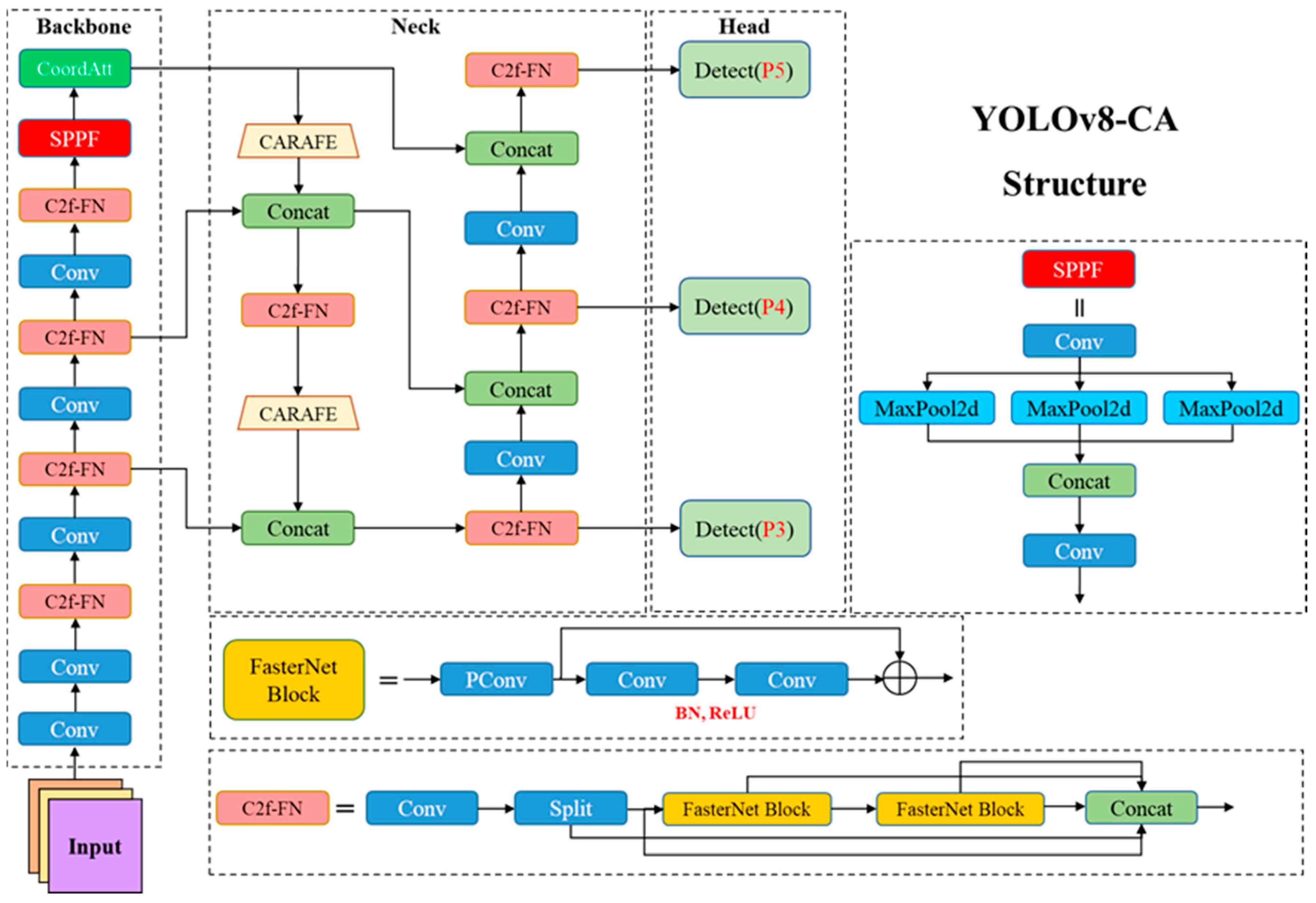
3.2. YOLOv8-CA Model
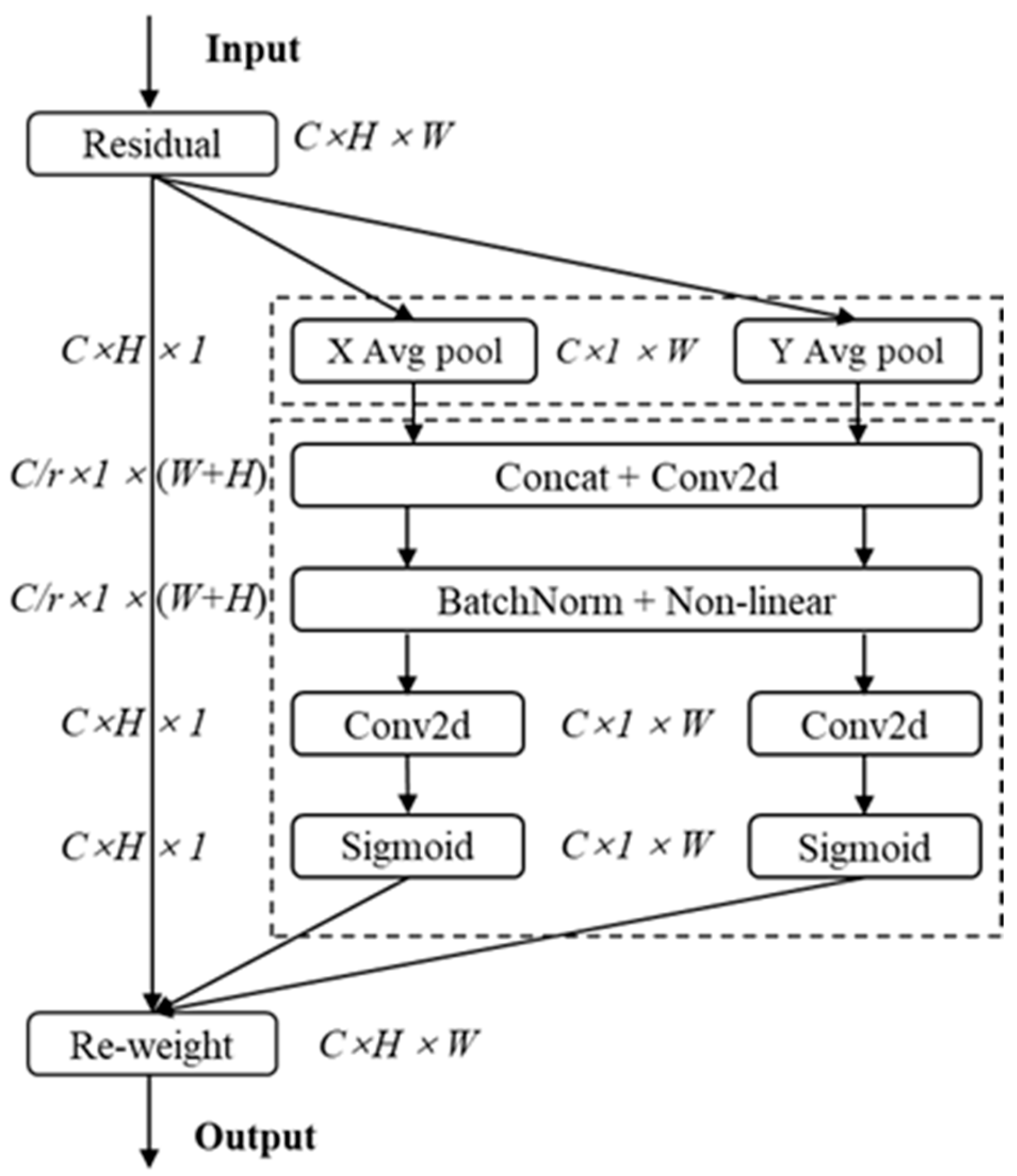
3.2.1. CA Mechanism
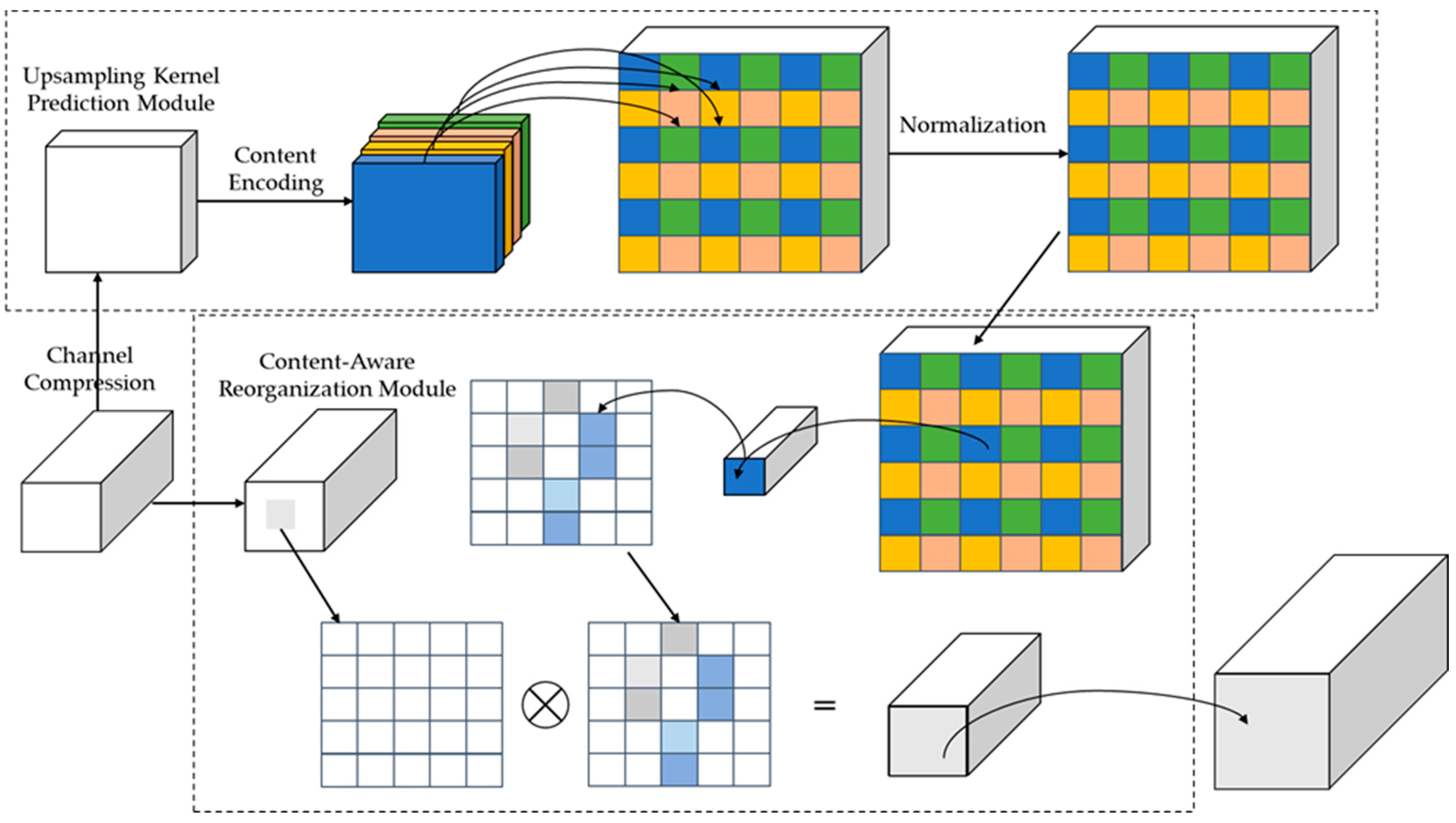
3.2.2. CARAFE Up-Sampling
3.2.3. C2f-FN Feature Extraction Module
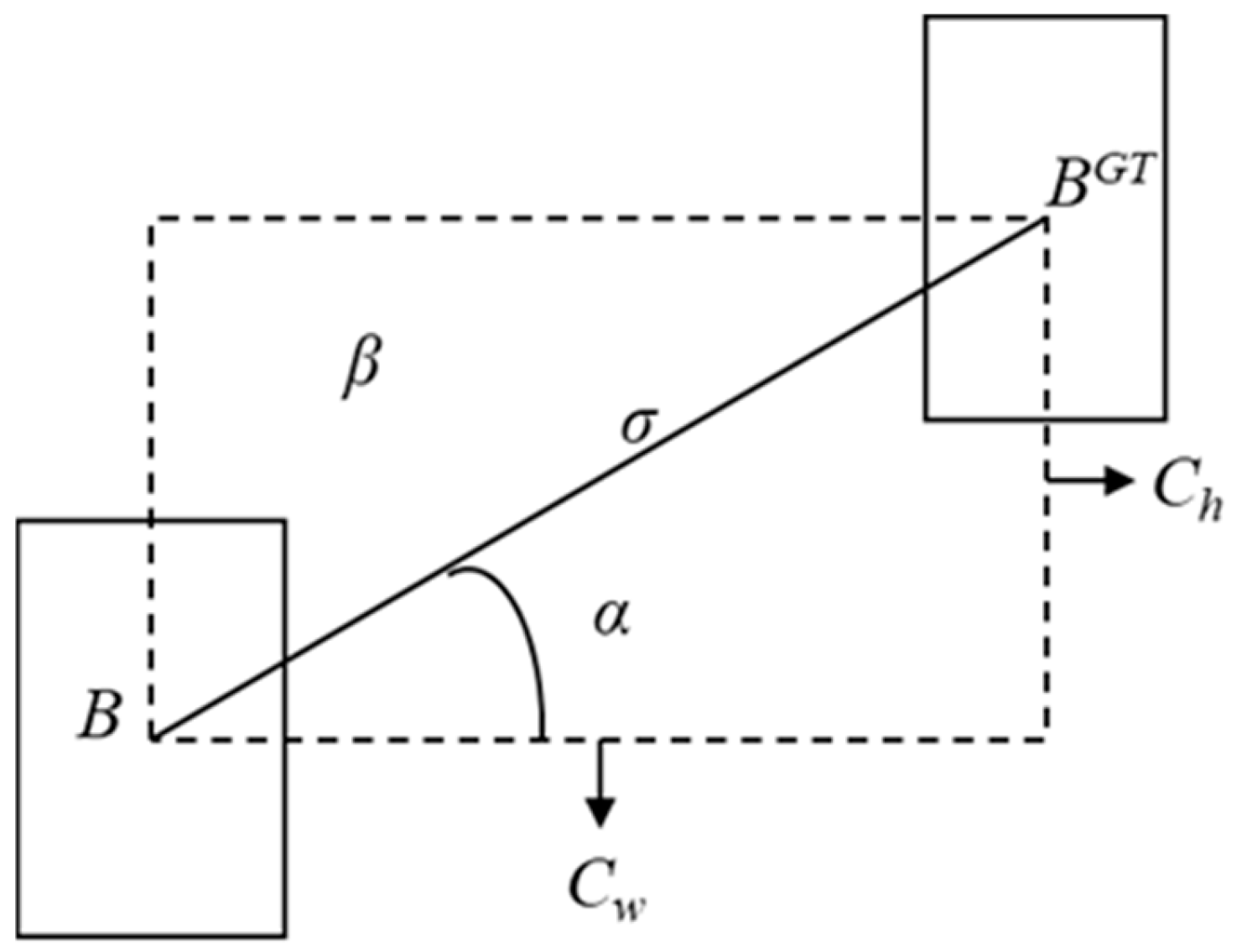
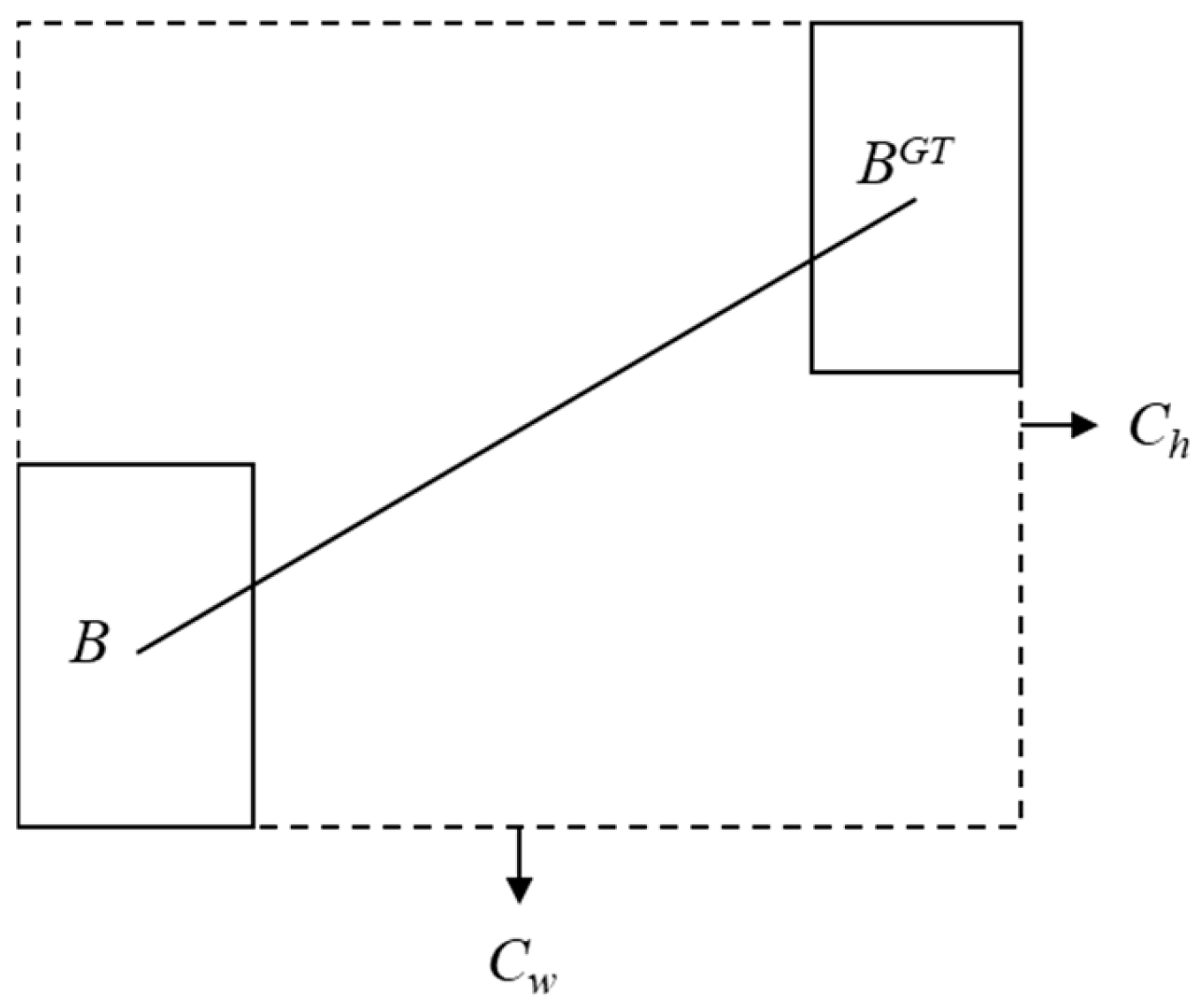
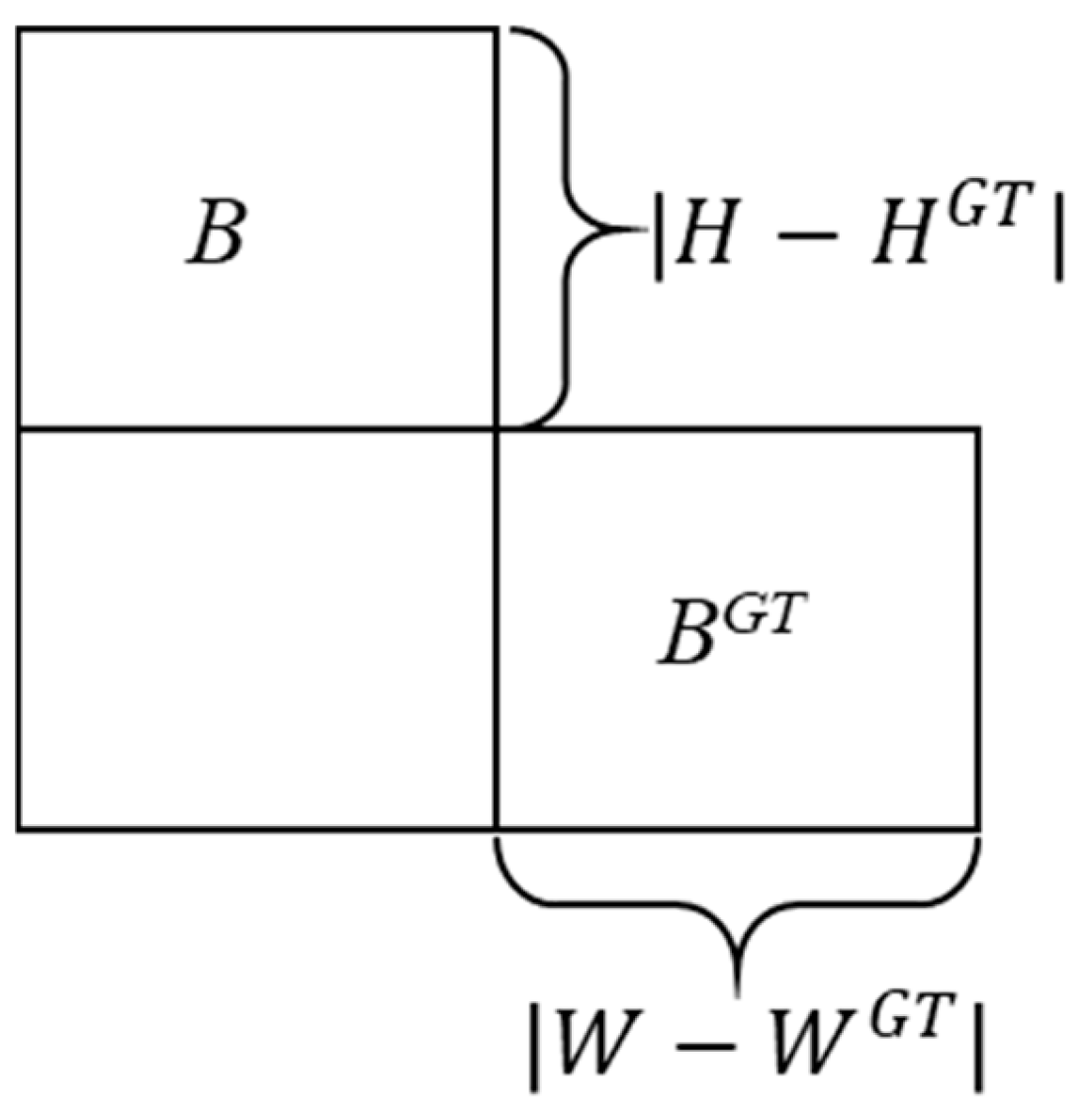
3.2.4. SIoU Loss Function
4. Experimental Results
4.1. Experimental Parameters and Evaluation Metrics
4.2. Experimental Results and Analysis
4.2.1. Comparison of Up-Sampling Modules
4.2.2. Ablation Test
4.2.3. Comparison with Other Object Detection Models
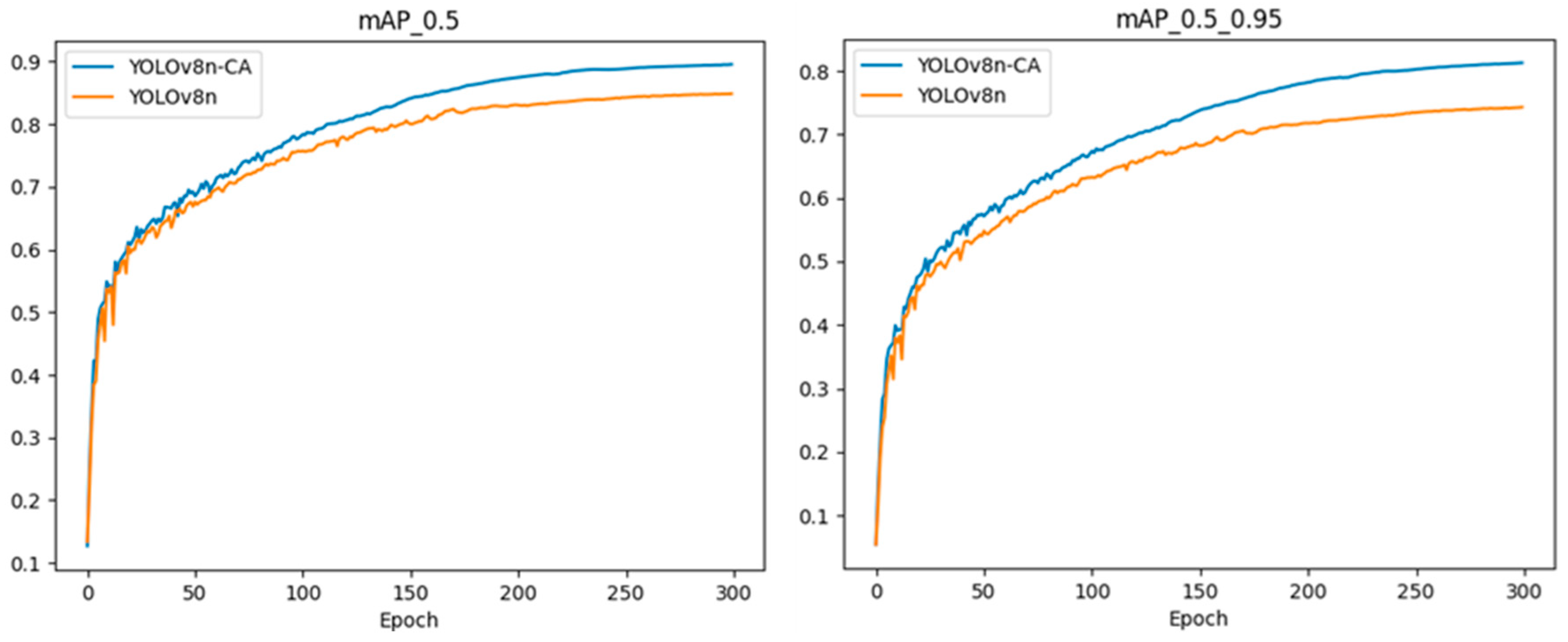
4.2.4. Performance Analysis of the YOLOv8n-CA Model
5. Conclusions
- (1)
- This study introduces the YOLOv8n-CA model, which integrates the CA mechanism by adding an attention layer following the SPPF. This modification enhances the model’s focus on detecting tomato fruits and mitigates the impact of complex environmental factors. Additionally, the CARAFE up-sampling operator is employed to enlarge the receptive field, thereby improving the model’s sensitivity to tomatoes. Lastly, the modified C2f-FN feature extraction module eliminates redundant and noisy information, prioritizing the extraction of key features related to tomato fruits.
- (2)
- The optimized YOLOv8n-CA model consists of 2.45 × 10⁶ parameters, a computational complexity of 6.7 GFLOPs, and a model weight file size of 4.90 MB. In comparison to the YOLOv8n model, these values reflect reductions of 18.7%, 17.3%, and 18.1%, respectively. The mAP of the YOLOv8n-CA model is 97.3%, ensuring a consistent performance improvement while maintaining a lightweight design. This model effectively balances detection accuracy and computational efficiency.
- (3)
- The comparison of different models reveals that, despite certain numerical advantages, more recent algorithms do not always outperform their predecessors in detection effectiveness. This is due to the distinct architectural differences among the models, each of which exhibits unique characteristics when applied to the same detection task. Specifically, in the agricultural detection domain, only experimental validation can identify the most suitable algorithm for the task at hand.
6. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ninja, B.; Manuj, K.H. Maturity detection of tomatoes using transfer learning. Meas. Food. 2022, 7, 100038. [Google Scholar]
- Arad, B.; Balendonck, J.; Barth, R.; Ben-Shahar, O.; Edan, Y.; Hellström, T.; Hemming, J.; Kurtser, P.; Ringdahl, O.; Tielen, T.; et al. Development of a sweet pepper harvesting robot. Field Robot. 2020, 37, 1027–1039. [Google Scholar] [CrossRef]
- Lawal, M.O. Tomato detection based on modified YOLOv3 framework. Sci. Rep. 2021, 11, 1447. [Google Scholar] [CrossRef]
- Kanagasingham, S.; Ekpanyapong, M.; Chaihan, R. Integrating machine visionbased row guidance with gps and compass-based routing to achieve autonomous navigation for a rice field weeding robot. Precis. Agric. 2020, 21, 831–855. [Google Scholar] [CrossRef]
- Bonde, L.; Ouedraogo, O.; Traore, S.; Thiombiano, A.; Boussim, J.I. Impact of environmental conditions on fruit production patterns of shea tree (Vitellaria paradoxa CF Gaertn) in West Africa. Afr. J. Ecol. 2019, 57, 353–362. [Google Scholar] [CrossRef]
- Hoye, T.T.; Arhe, J.; Bjerge, K.; Hansen, O.L.P.; Iosifidis, A.; Leese, F.; Mann, H.M.R.; Meissner, K.; Melvad, C.; Raitoharju, J. Deep learning and computer vision will transform entomology. Proc. Natl. Acad. Sci. USA 2021, 118, e2002545117. [Google Scholar] [CrossRef] [PubMed]
- Ariza-Sentís, M.; Vélez, S.; Martínez-Peña, R.; Baja, H.; Valente, J. Object detection and tracking in Precision Farming: A systematic review. Comput. Electron. Agric. 2024, 219, 108757. [Google Scholar] [CrossRef]
- Das, A.K.; Esau, T.J.; Zaman, Q.U.; Farooque, A.A.; Schumann, A.W.; Hennessy, P.J. Machine vision system for real-time debris detection on mechanical wild blueberry harvesters. Smart Agric. Technol. 2024, 4, 100166. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. Real-time growth stage detection model for high degree of occultation using DenseNet-fused YOLOv4. Comput. Electron. Agric. 2022, 193, 106694. [Google Scholar] [CrossRef]
- Saman, M.O.; Kayhan, Z.G.; Shavan, K.A. Lightweight improved yolov5 model for cucumber leaf disease and pest detection based on deep learning. Signal Image Video Process. 2023, 18, 1329–1342. [Google Scholar]
- Cardellicchio, A.; Solimani, F.; Dimauro, G.; Petrozza, A.; Summerer, S.; Cellini, F.; Renò, V. Detection of tomato plant phenotyping traits using YOLOv5-based single stage detectors. Comput. Electron. Agric. 2023, 207, 107757. [Google Scholar] [CrossRef]
- Olisah, C.C.; Trewhella, B.; Li, B.; Smith, M.L.; Winstone, B.; Whitfield, E.C.; Fernández, F.F.; Duncalfe, H. Convolutional neural network ensemble learning for hyperspectral imaging-based blackberry fruit ripeness detection in uncontrolled farm environment. Eng. Appl. Artif. Intell. 2024, 132, 107945. [Google Scholar] [CrossRef]
- Tenorio, G.L.; Caarls, W. Automatic visual estimation of tomato cluster maturity in plant rows. Mach. Vis. Appl. 2021, 32, 78. [Google Scholar] [CrossRef]
- Tamilarasi, T.; Muthulakshmi, P. Machine vision algorithm for detection and maturity prediction of Brinjal. Smart Agric. Technol. 2024, 7, 100402. [Google Scholar]
- Du, X.; Meng, Z.; Ma, Z.; Zhao, L.; Lu, W.; Cheng, H.; Wang, Y. Comprehensive visual information acquisition for tomato picking robot based on multitask convolutional neural network. J. Biosyst. Eng. 2024, 238, 51–61. [Google Scholar] [CrossRef]
- Liu, Z.; Abeyrathna, R.R.; Sampurno, R.M.; Nakaguchi, V.M.; Ahamed, T. Faster-YOLO-AP: A lightweight apple detection algorithm based on improved YOLOv8 with a new efficient PDWConv in orchard. Comput. Electron. Agric. 2024, 223, 109118. [Google Scholar] [CrossRef]
- Luo, L.; Yin, W.; Ning, Z.; Wang, J.; Wei, H.; Chen, W.; Lu, Q. In-field pose estimation of grape clusters with combined point cloud segmentation and geometric analysis. Comput. Electron. Agric. 2022, 200, 107197. [Google Scholar] [CrossRef]
- Bigal, E.; Galili, O.; van Rijn, I.; Rosso, M.; Cleguer, C.; Hodgson, A.; Scheinin, A.; Tchernov, D. Reduction of Species Identification Errors in Surveys of Marine Wildlife Abundance Utilising Unoccupied Aerial Vehicles (UAVs). Remote Sens. 2022, 14, 4118. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 13713–13722. [Google Scholar]
- Zhao, J.; Xi, X.; Shi, Y.; Zhang, B.; Qu, J.; Zhang, J.; Zhu, Z.; Zhang, R. An Online Method for Detecting Seeding Performance Based on Improved YOLOv5s Model. Agronomy 2023, 13, 2391. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Badgujar, C.M.; Poulose, A.; Gan, H. Agricultural object detection with You Only Look Once (YOLO) Algorithm: A bibliometric and systematic literature review. Comput. Electron. Agric. 2024, 223, 109090. [Google Scholar] [CrossRef]
- Xu, K.; Song, C.; Xie, Y.; Pan, L.; Gan, X.; Huang, G. RMT-YOLOv9s: An Infrared Small Target Detection Method Based on UAV Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 7002205. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Params (M) | GFLOPs | Model Size (M) | P (%) | R (%) | mAP@0.5 (%) |
|---|---|---|---|---|---|---|
| Other improvements—DySample | 2.32 | 6.3 | 4.67 | 93.3 | 93.1 | 96.4 |
| Other improvements—CARAFE | 2.45 | 6.7 | 4.90 | 94.3 | 92.5 | 97.3 |
| No. | Models | Params (M) | GFLOPs | Model Size (MB) | mAP@0.5 (%) |
|---|---|---|---|---|---|
| 1 | YOLOv8n | 3.01 | 8.1 | 5.98 | 96.0 |
| 2 | YOLOv8n-CA | 3.02 | 8.2 | 5.99 | 95.6 |
| 3 | YOLOv8n-CARAFE | 3.30 | 9.1 | 6.25 | 95.9 |
| 4 | YOLOv8n-C2f-FN | 2.31 | 6.5 | 4.67 | 95.7 |
| 5 | YOLOv8n-CA-C2f_Faster | 2.45 | 7.0 | 4.64 | 96.2 |
| 6 | YOLOv8n-CA-CARAFE | 3.16 | 8.5 | 6.27 | 96.1 |
| 7 | YOLOv8n-C2f_Faster-CARAFE | 2.45 | 6.6 | 4.92 | 96.5 |
| 8 | YOLOv8n-CA-C2f_FN-CARAFE-SIoU | 2.45 | 6.7 | 4.90 | 97.3 |
| Models | Params (M) | GFLOPs | Model Size (MB) | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5 (%) | Detect Times (ms) |
|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | 136.75 | 401.8 | 108.0 | 60.1 | 59.2 | 62.3 | 53.8 | 70.1 |
| YOLOv3s | 61.51 | 154.6 | 117 | 88.1 | 87.1 | 91.4 | 87.7 | 58.5 |
| YOLOv5s | 7.03 | 16.0 | 13.70 | 88.5 | 87.2 | 91.9 | 75.3 | 38.3 |
| YOLOv5m | 20.87 | 47.9 | 40.2 | 88.2 | 88.1 | 91.8 | 77.6 | 42.1 |
| YOLOv7 | 36.49 | 103.2 | 71.30 | 95.5 | 90.5 | 91.7 | 76.7 | 45.1 |
| YOLOv8n | 3.01 | 8.1 | 5.98 | 92.1 | 92.0 | 96.0 | 88.3 | 18.9 |
| YOLOv10s | 8.07 | 24.8 | 15.7 | 89.4 | 82.9 | 89.8 | 86.0 | 21.4 |
| YOLOv11n | 2.59 | 6.3 | 5.23 | 98.2 | 90.2 | 93.2 | 87.9 | 14.1 |
| YOLOv8n-CA | 2.45 | 6.7 | 4.90 | 94.3 | 92.5 | 97.3 | 88.8 | 17.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Ding, J.; Zhang, R.; Xi, X. YOLOv8n-CA: Improved YOLOv8n Model for Tomato Fruit Recognition at Different Stages of Ripeness. Agronomy 2025, 15, 188. https://doi.org/10.3390/agronomy15010188
Gao X, Ding J, Zhang R, Xi X. YOLOv8n-CA: Improved YOLOv8n Model for Tomato Fruit Recognition at Different Stages of Ripeness. Agronomy. 2025; 15(1):188. https://doi.org/10.3390/agronomy15010188
Chicago/Turabian StyleGao, Xin, Jieyuan Ding, Ruihong Zhang, and Xiaobo Xi. 2025. "YOLOv8n-CA: Improved YOLOv8n Model for Tomato Fruit Recognition at Different Stages of Ripeness" Agronomy 15, no. 1: 188. https://doi.org/10.3390/agronomy15010188
APA StyleGao, X., Ding, J., Zhang, R., & Xi, X. (2025). YOLOv8n-CA: Improved YOLOv8n Model for Tomato Fruit Recognition at Different Stages of Ripeness. Agronomy, 15(1), 188. https://doi.org/10.3390/agronomy15010188