
Lightweight Mulberry Fruit Detection Method Based on Improved YOLOv8n for Automated Harvesting

Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset Production
2.2. Model Architecture
2.2.1. YOLOv8 Model
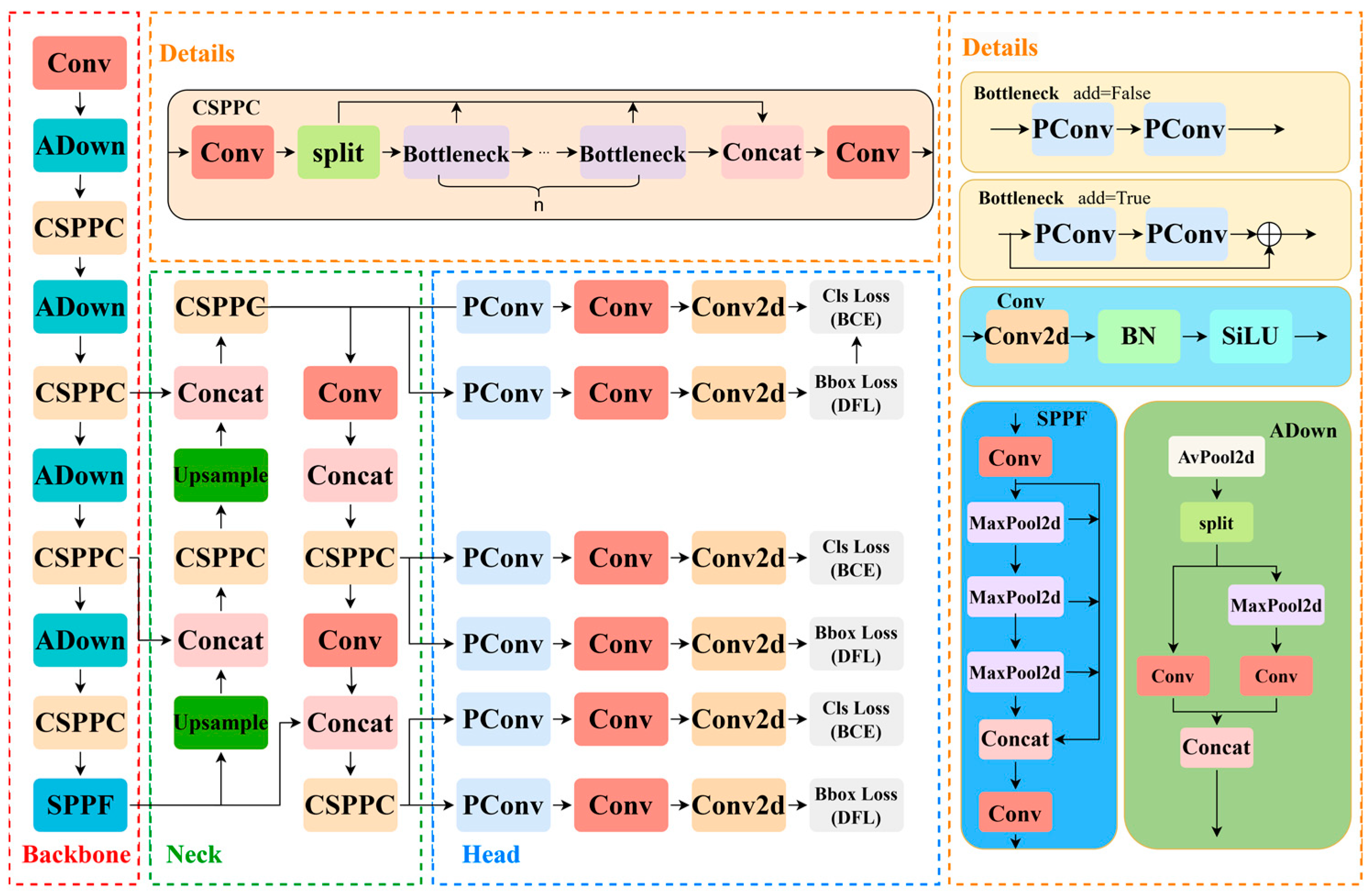
2.2.2. Improved YOLOv8 for Mulberry Detection
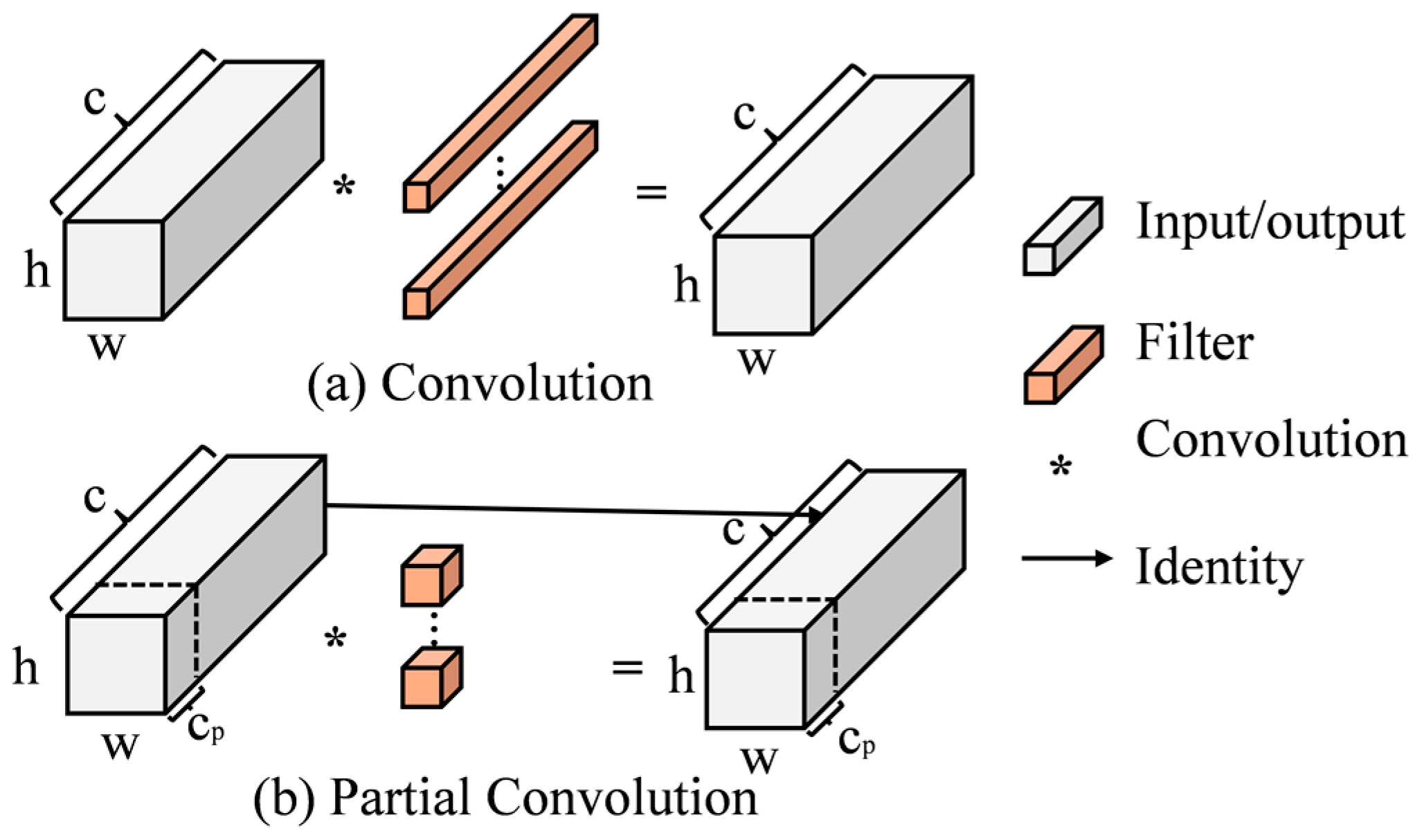
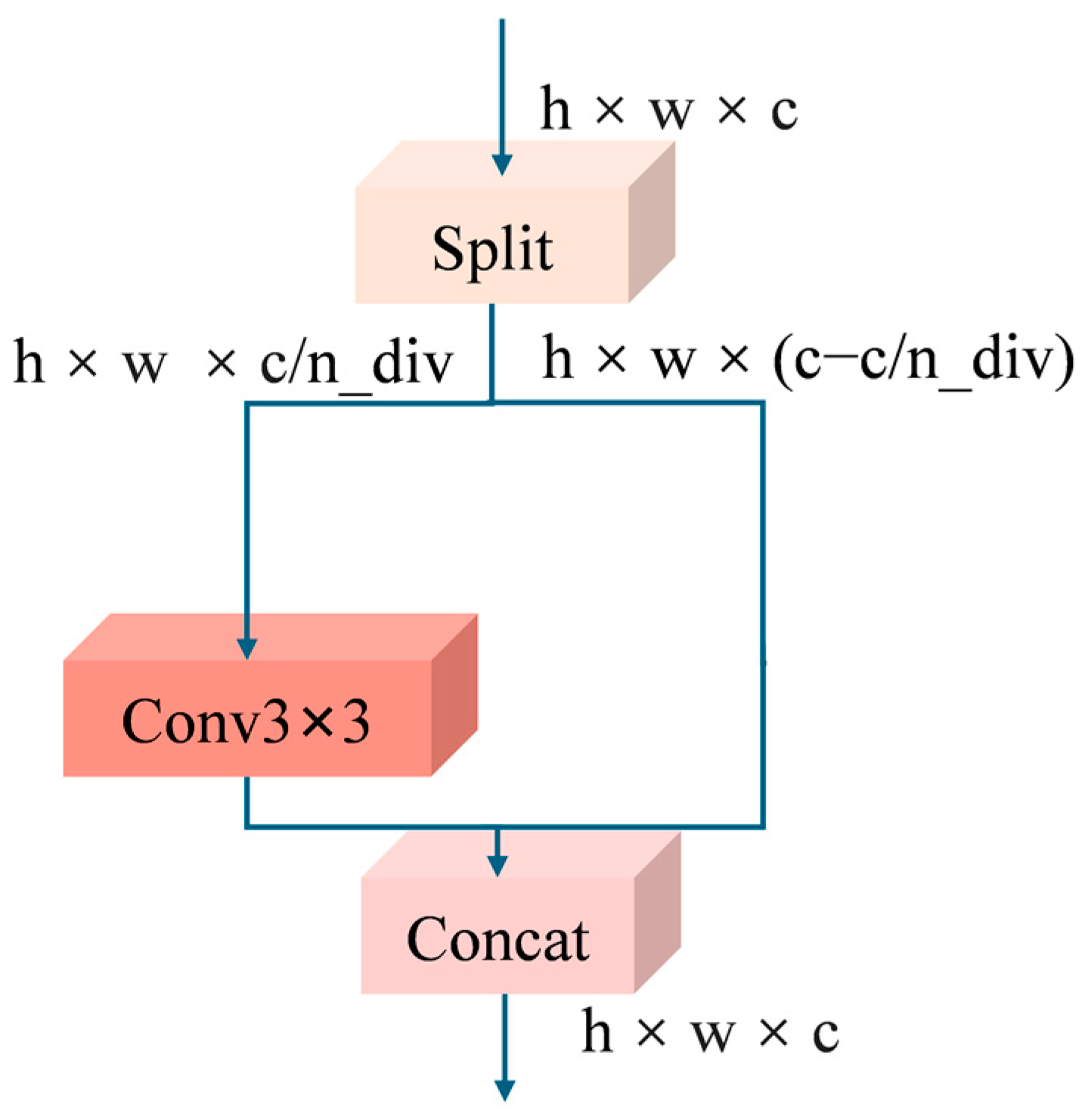
2.2.3. C2f Improvement
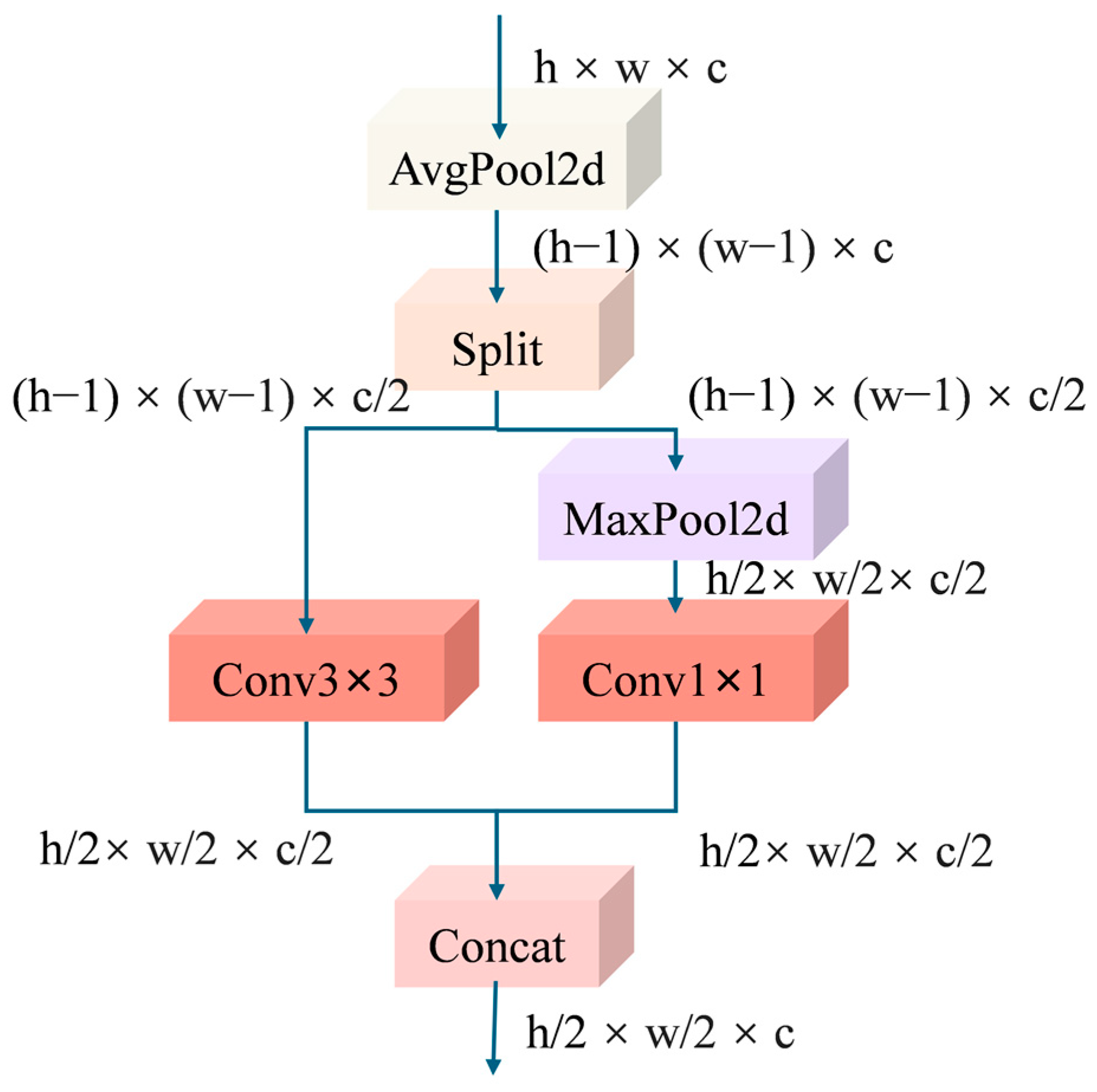
2.2.4. Improvements in the Downsampling Module
2.2.5. Detection Head Module Improvements
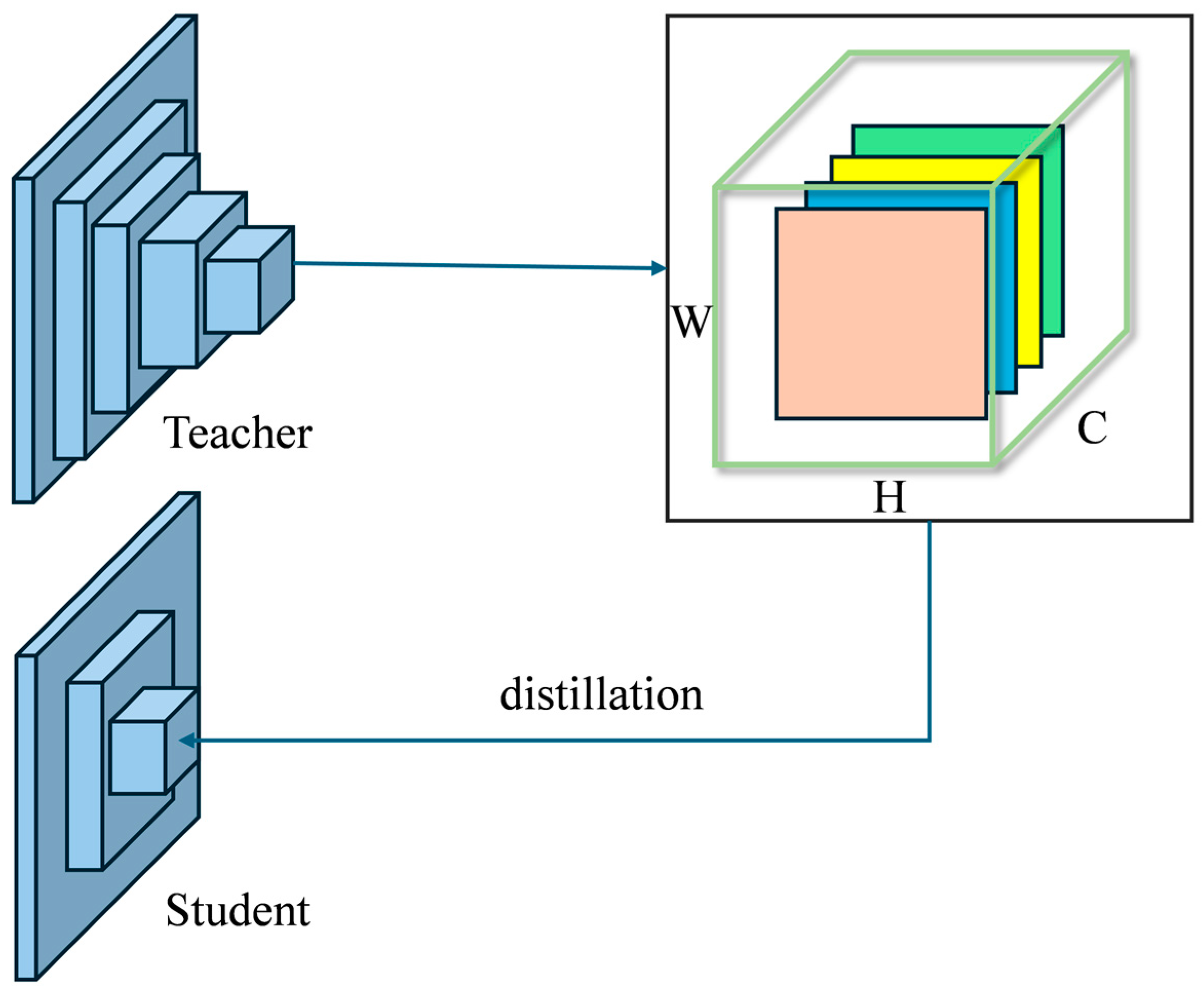
2.2.6. Channel-Wise Knowledge Distillation
2.3. Training Environment and Parameter Configuration
2.4. Evaluation Metrics
3. Results and Discussion
3.1. Performance Evaluation and YOLOv8 Model Selection
3.2. CSPPC Module Ablation Results
3.3. Improved C2f Structure with Different Lightweight Methods
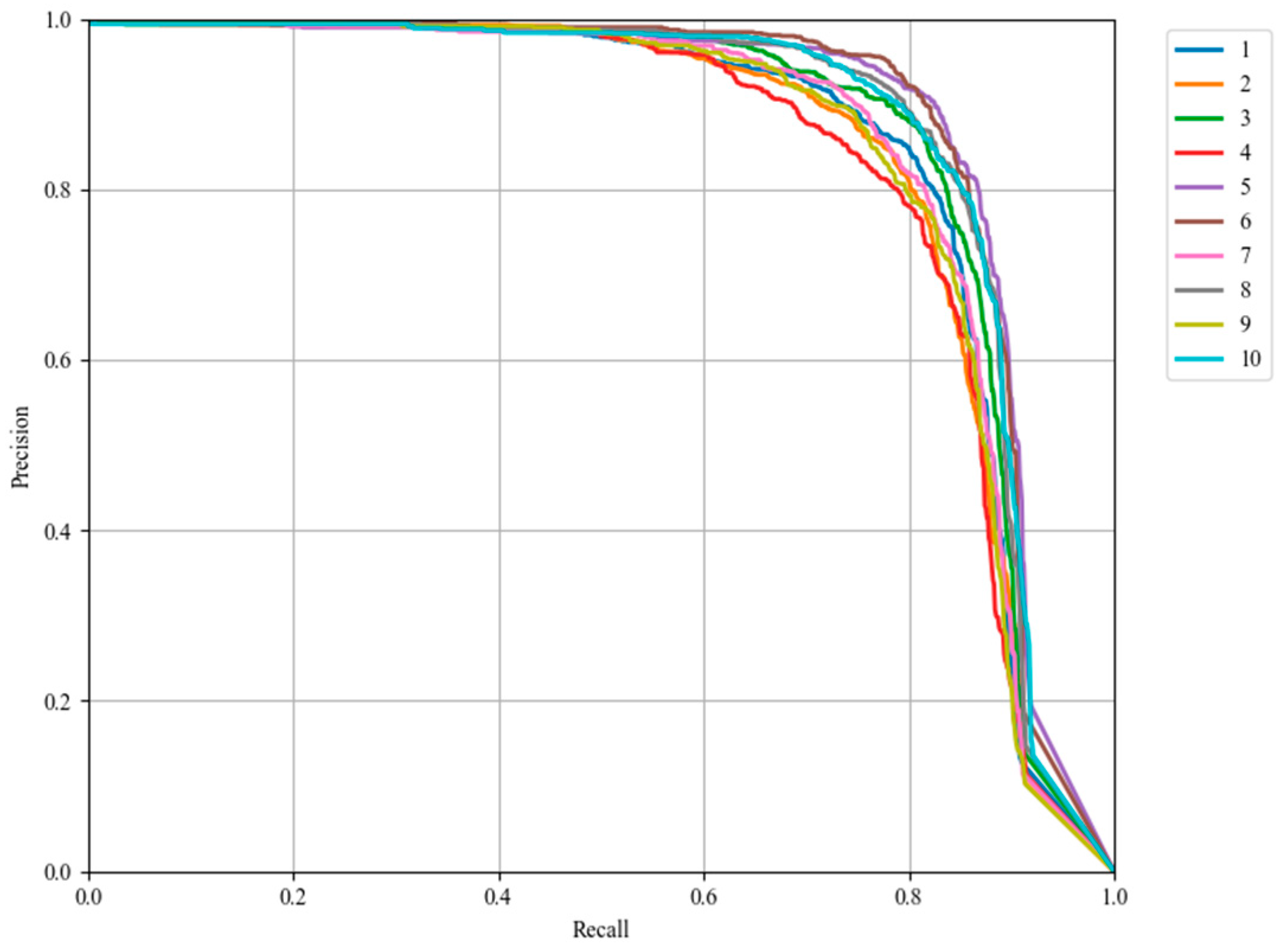
3.4. Ablation Experiment
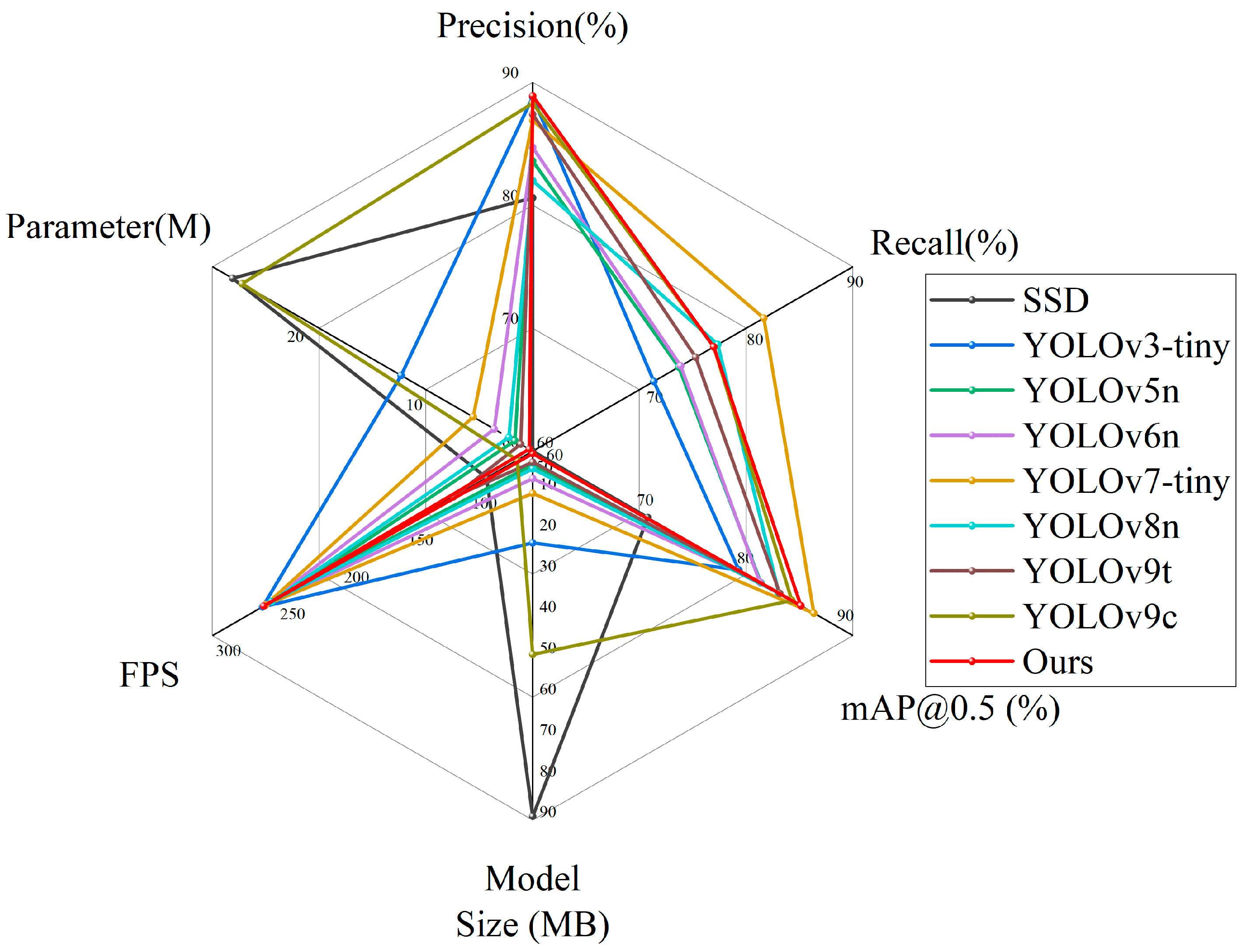
3.5. Contrast Experiment
3.6. Testing Our Model on Jetson
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yan, Z.; Xin, L.I.; Hao, D.; Lingling, L.I.; Yuxing, L.I.U.; Wanting, Y.; Shaobo, C.; Guogang, C. Optimization of the Production Process and Quality Evaluation of Mulberry-Purple Potato Compound Freeze-Dried Fruit Blocks. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2024, 40, 276–285. [Google Scholar] [CrossRef]
- Ding, H.X.; Li, M.T.; Peng, J.; Liu, Z.J. Experimental Study on the Vibration Parameters of Mulberry Picking. J. Agric. Mech. Res 2016, 10, 183–186. [Google Scholar] [CrossRef]
- Lu, J.; Chen, P.; Yu, C.; Lan, Y.; Yu, L.; Yang, R.; Niu, H.; Chang, H.; Yuan, J.; Wang, L. Lightweight Green Citrus Fruit Detection Method for Practical Environmental Applications. Comput. Electron. Agric. 2023, 215, 108205. [Google Scholar] [CrossRef]
- Zhonghua, M.; Yichou, S.; Xiaohua, W.; Xiaofeng, Z.; Chengliang, L. Image Recognition Algorithm and Experiment of Overlapped Fruits in Natural Environment. Nongye Jixie Xuebao/Trans. Chin. Soc. Agric. Mach. 2016, 47, 21–26. [Google Scholar] [CrossRef]
- Zhuang, J.J.; Luo, S.M.; Hou, C.J.; Tang, Y.; He, Y.; Xue, X.Y. Detection of Orchard Citrus Fruits Using a Monocular Machine Vision-Based Method for Automatic Fruit Picking Applications. Comput. Electron. Agric. 2018, 152, 64–73. [Google Scholar] [CrossRef]
- Jia, W.; Meng, H.; Ma, X.; Zhao, Y.; Ji, Z.; Zheng, Y. Efficient Detection Model of Green Target Fruit Based on Optimized Transformer Network. J. Agric. Eng. 2021, 37, 163–170. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep Learning in Agriculture: A Survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- He, F.; Guo, Y.; Gao, C.; Chen, J. Image Segmentation of Ripe Mulberries Based on Visual Saliency and Pulse Coupled Neural Network. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2017, 33, 148–155. [Google Scholar] [CrossRef]
- Ashtiani, S.H.M.; Javanmardi, S.; Jahanbanifard, M.; Martynenko, A.; Verbeek, F.J. Verbeek Detection of Mulberry Ripeness Stages Using Deep Learning Models. IEEE Access 2021, 9, 100380–100394. [Google Scholar] [CrossRef]
- Wang, L.; Qin, M.; Lei, J.; Wang, X.; Tan, K. Blueberry Maturity Recognition Method Based on Improved YOLOv4-Tiny. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 170–178. [Google Scholar] [CrossRef]
- Gai, R.; Chen, N.; Yuan, H. A Detection Algorithm for Cherry Fruits Based on the Improved YOLO-v4 Model. Neural Comput. Appl. 2023, 35, 13895–13906. [Google Scholar] [CrossRef]
- Gao, C.; Jiang, H.; Liu, X.; Li, H.; Wu, Z.; Sun, X.; He, L.; Mao, W.; Majeed, Y.; Li, R.; et al. Improved Binocular Localization of Kiwifruit in Orchard Based on Fruit and Calyx Detection Using YOLOv5x for Robotic Picking. Comput. Electron. Agric. 2024, 217, 108621. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, J.; Zhang, F.; Gao, J.; Yang, C.; Song, C.; Rao, W.; Zhang, Y. Greenhouse Tomato Detection and Pose Classification Algorithm Based on Improved YOLOv5. Comput. Electron. Agric. 2024, 216, 108519. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1577–1586. [Google Scholar]
- Vadera, S.; Ameen, S. Methods for Pruning Deep Neural Networks. IEEE Access 2022, 10, 63280–63300. [Google Scholar] [CrossRef]
- Gholami, A.; Kim, S.; Zhen, D.; Yao, Z.; Mahoney, M.; Keutzer, K. A Survey of Quantization Methods for Efficient Neural Network Inference. In Low-Power Computer Vision; Chapman and Hall/CRC: New York, NY, USA, 2022; pp. 291–326. ISBN 978-1-00-316281-0. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight Tomato Real-Time Detection Method Based on Improved YOLO and Mobile Deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Wu, X.; Tang, R.; Mu, J.; Niu, Y.; Xu, Z.; Chen, Z. A Lightweight Grape Detection Model in Natural Environments Based on an Enhanced YOLOv8 Framework. Front. Plant Sci. 2024, 15, 1407839. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Du, C.; Li, Y.; Mudhsh, M.; Guo, D.; Fan, Y.; Wu, X.; Wang, X.; Almodfer, R. YOLO-Granada: A Lightweight Attentioned Yolo for Pomegranates Fruit Detection. Sci. Rep. 2024, 14, 16848. [Google Scholar] [CrossRef]
- Liu, Z.; Rasika, D.; Abeyrathna, R.M.; Mulya Sampurno, R.; Massaki Nakaguchi, V.; Ahamed, T. Faster-YOLO-AP: A Lightweight Apple Detection Algorithm Based on Improved YOLOv8 with a New Efficient PDWConv in Orchard. Comput. Electron. Agric. 2024, 223, 109118. [Google Scholar] [CrossRef]
- Xie, T.; Cheng, X.; Wang, X.; Liu, M.; Deng, J.; Zhou, T.; Liu, M. Cut-Thumbnail: A Novel Data Augmentation for Convolutional Neural Network. In Proceedings of the 29th ACM International Conference on Multimedia, Online, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1627–1635. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics, v. 8.0.0; Ultralytics: Los Angeles, CA, USA, 2023; Available online: https://github.com/ultralytics/ultralytics (accessed on 26 November 2024).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 12021–12031. [Google Scholar]
- Duan, X.; Zhang, B.; Deng, Q.; Ma, H.; Yang, B. Research on Small Objects Detection Algorithm of UAV Photography Based on Improved YOLOv7. Preprint 2024. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In European Conference on Computer Vision; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2025; pp. 1–21. [Google Scholar]
- Shu, C.; Liu, Y.; Gao, J.; Yan, Z.; Shen, C. Channel-Wise Knowledge Distillation for Dense Prediction. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 5291–5300. [Google Scholar]
- Lin, J.-D.; Wu, X.-Y.; Chai, Y.; Yin, H.-P. Structure Optimization of Convolutional Neural Networks: A Survey. Acta Autom. Sin. 2020, 46, 24–37. [Google Scholar] [CrossRef]
- Keqi, C.; Zhiliang, Z.; Xiaoming, D.; Cuixia, M.; Hongan, W. Deep Learning for Multi-Scale Object Detection: A Survey. J. Softw. 2021, 32, 1201–1227. [Google Scholar] [CrossRef]
- Singh, P.; Verma, V.K.; Rai, P.; Namboodiri, V.P. HetConv: Heterogeneous Kernel-Based Convolutions for Deep CNNs. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4830–4839. [Google Scholar]
- Zhong, J.; Chen, J.; Mian, A. DualConv: Dual Convolutional Kernels for Lightweight Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 9528–9535. [Google Scholar] [CrossRef] [PubMed]
- Han, K.; Wang, Y.; Guo, J.; Wu, E. ParameterNet: Parameters Are All You Need for Large-Scale Visual Pretraining of Mobile Networks. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 15751–15761. [Google Scholar]
- Li, J.; Wen, Y.; He, L. SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 6153–6162. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Categories | Parameter Settings |
|---|---|
| Optimizer | SGD |
| Batch size | 16 |
| Epochs | 200 |
| Input size | 640 × 640 |
| Initial learning rate | 0.01 |
| Momentum | 0.937 |
| Weight decay rate | 0.0005 |
| Model | Precision (%) | Recall (%) | mAP@0.5 (%) | Parameter (M) | Model Size (MB) |
|---|---|---|---|---|---|
| YOLOv8l | 91.9 | 85.2 | 91.4 | 4.36 × 107 | 85.6 |
| YOLOv8m | 89.7 | 84.2 | 90.1 | 2.59 × 107 | 50.8 |
| YOLOv8s | 88 | 82.3 | 88.4 | 1.11 × 107 | 22 |
| YOLOv8n | 82 | 78.5 | 84.6 | 3.01 × 106 | 6.3 |
| Model | Backbone | Neck | P (%) | R (%) | mAP@0.5 (%) | Parameter | Model Size (MB) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | 83 | 78.3 | 84.7 | 3.01 × 106 | 6.3 | 8.2 | 253.9 |
| 2 | ✓ | × | 85.1 | 77.1 | 84.8 | 2.56 × 106 | 5.2 | 6.9 | 283 |
| 3 | × | ✓ | 85.2 | 75.5 | 84.3 | 2.58 × 106 | 5.4 | 7.3 | 267 |
| 4 | ✓ | ✓ | 83.2 | 75.8 | 83.3 | 2.12 × 106 | 4.3 | 6.0 | 280 |
| Model | P (%) | R (%) | mAP@0.5 (%) | Parameter | Model Size (MB) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 83 | 78.3 | 84.7 | 3.01 × 106 | 6.3 | 8.2 | 253.9 |
| YOLOv8n + CSPHet | 84.2 | 76.4 | 84.2 | 2.38 × 106 | 5.1 | 6.6 | 58 |
| YOLOv8n + C2f_SCConv | 85.5 | 75 | 84.3 | 2.71 × 106 | 5.7 | 7.5 | 76.1 |
| YOLOv8n + C2f_Ghost | 83.1 | 75.3 | 82.8 | 2.19 × 106 | 4.6 | 5.8 | 140.9 |
| YOLOv8n + C2f_Dual | 83.1 | 77.6 | 84.8 | 2.86 × 106 | 5.9 | 7.7 | 241.7 |
| YOLOv8n + CSPPC | 83.2 | 75.8 | 83.3 | 2.12 × 106 | 4.3 | 6.0 | 280 |
| CSPPC | ADown | P-Head | KD | P (%) | R (%) | mAP (%) | Parameter | Model Size (MB) | GFLOPs | FPS | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 82 | 78.5 | 84.6 | 3.01 × 106 | 6.3 | 8.2 | 253.9 |
| 2 | ✓ | × | × | × | 83.2 | 75.8 | 83.3 | 2.12 × 106 | 4.3 | 6.0 | 280 |
| 3 | × | ✓ | × | × | 85.6 | 78 | 85.1 | 2.73 × 106 | 5.7 | 7.5 | 247.7 |
| 4 | × | × | ✓ | × | 82.9 | 75.5 | 83.4 | 2.46 × 106 | 5.1 | 5.7 | 297.2 |
| 5 | × | × | × | ✓ | 88.8 | 81.9 | 88.1 | 3.01 × 106 | 6.3 | 8.2 | 247 |
| 6 | × | ✓ | × | ✓ | 90.7 | 80.1 | 88.2 | 2.73 × 106 | 5.7 | 7.5 | 249 |
| 7 | × | ✓ | ✓ | × | 86.9 | 76 | 84.4 | 2.14 × 106 | 4.5 | 4.9 | 288.4 |
| 8 | ✓ | × | × | ✓ | 89.7 | 78.5 | 86.9 | 2.12 × 106 | 4.5 | 6.0 | 258.0 |
| 9 | ✓ | ✓ | ✓ | × | 84.5 | 74.3 | 82.8 | 1.29 × 106 | 2.6 | 2.7 | 254.8 |
| 10 | ✓ | ✓ | ✓ | ✓ | 88.9 | 78.1 | 86.8 | 1.29 × 106 | 2.6 | 2.6 | 260 |
| Model | Precision (%) | Recall (%) | mAP@0.5 (%) | Parameter | Model Size (MB) | FPS |
|---|---|---|---|---|---|---|
| SSD | 80.6 | 59.6 | 71.5 | 2.63 × 107 | 91.1 | 86.02 |
| YOLOv3-tiny | 88.8 | 72.1 | 80.6 | 1.21 × 107 | 24.4 | 261 |
| YOLOv5n | 83.6 | 74.6 | 82.8 | 2.51 × 106 | 5.3 | 237 |
| YOLOv6n | 84.7 | 74.8 | 82.7 | 4.24 × 106 | 8.7 | 258.1 |
| YOLOv7-tiny | 86.9 | 83.1 | 88.1 | 6.02 × 106 | 12.3 | 258.6 |
| YOLOv8n | 82 | 78.5 | 84.6 | 3.01 × 106 | 6.3 | 253.9 |
| YOLOv9t | 87.4 | 76.3 | 84.7 | 2.01 × 106 | 4.7 | 111.9 |
| YOLOv9c | 88.3 | 78.1 | 85.9 | 2.55 × 107 | 51.6 | 62 |
| Ours | 88.9 | 78.1 | 86.8 | 1.29 × 106 | 2.6 | 260 |
| Model | Computer FPS | Jetson Nano FPS | TensorRT FPS |
|---|---|---|---|
| SSD | 86.02 | 1.19 | 3.79 |
| YOLOv3-tiny | 261 | 3.7 | 11.02 |
| YOLOv5n | 237 | 5.5 | 16.65 |
| YOLOv6n | 258.1 | 3.9 | 16.65 |
| YOLOv7-tiny | 258.6 | 4.58 | 9.95 |
| YOLOv8n | 253.9 | 5.2 | 16.11 |
| YOLOv9t | 111.9 | 3.6 | 14.02 |
| Ours | 260 | 10 | 19.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, H.; Zhang, Q.; Li, J.; Rong, J.; Yang, Z. Lightweight Mulberry Fruit Detection Method Based on Improved YOLOv8n for Automated Harvesting. Agronomy 2024, 14, 2861. https://doi.org/10.3390/agronomy14122861
Qiu H, Zhang Q, Li J, Rong J, Yang Z. Lightweight Mulberry Fruit Detection Method Based on Improved YOLOv8n for Automated Harvesting. Agronomy. 2024; 14(12):2861. https://doi.org/10.3390/agronomy14122861
Chicago/Turabian StyleQiu, Hong, Qinghui Zhang, Junqiu Li, Jian Rong, and Zongpeng Yang. 2024. "Lightweight Mulberry Fruit Detection Method Based on Improved YOLOv8n for Automated Harvesting" Agronomy 14, no. 12: 2861. https://doi.org/10.3390/agronomy14122861
APA StyleQiu, H., Zhang, Q., Li, J., Rong, J., & Yang, Z. (2024). Lightweight Mulberry Fruit Detection Method Based on Improved YOLOv8n for Automated Harvesting. Agronomy, 14(12), 2861. https://doi.org/10.3390/agronomy14122861