1. Introduction
Soybeans are one of the world’s important grain and oil crops and a primary source of high-quality protein for humans [
1]. Soybean pods, as homologous organs of leaves, are crucial factors in determining grain yield and quality. Obtaining morphological measurement phenotypic parameters of soybean pods is essential for soybean breeding and yield estimation, making it a critical aspect of soybean cultivation [
2]. Soybean yield depends on four main factors: the number of plants per unit area, the number of pods per plant, the number of seeds per pod, and the weight of the individual soybeans. Among these, the number of seeds per pod is the least affected by environmental factors [
3,
4,
5]. Therefore, in the process of soybean variety selection and breeding, the number of seeds per soybean pod can be used as an indicator to assess the quality of the soybean variety and the health of the soybean plants [
6]. Hence, it is crucial to develop an intelligent and accurate method for automatic pod typing based on the number of seeds it has. This has significant practical implications for improving breeding efficiency and increasing soybean yield. Exploring such a method addresses the substantial need to alleviate the labor burden on breeding researchers.
The traditional process of collecting pod-type statistics is mostly carried out manually. Breeding experts detach pods, classify them, and record data, making the process labor-intensive and inefficient. Additionally, the data are prone to errors and cannot be accurately assessed. Electronic seed counting devices, using vibration-sorting and photoelectric sensors, usually have slow counting speeds and are costly and complex [
7]. In contrast, digital image-processing technology combined with machine learning has been proposed as a promising solution for automatic crop phenotype detection and measurement [
8,
9,
10]. For example, Sharma et al. [
11] used image processing to discover the relationship between wheat weight and area. Zhang et al. [
12] developed an image-processing algorithm to detect and count citrus fruits. Bu et al. [
13] proposed a novel classification model based on residual networks (ResNets) to evaluate the freshness of soybeans. Paulo et al. [
14] compared feature extraction-based algorithms with those not requiring them, finding that VGG-16 is the most effective in distinguishing corn and soybeans. Classical image-processing techniques are limited by their sensitivity to texture and lighting, resulting in restricted stability, effectiveness, and generalization in recognition tasks [
15,
16].
With the rapid development of deep learning technology in recent years, the integration of artificial intelligence and big data in plant phenotyping research has accelerated the progress of crop individual plant phenotypic measurements [
17]. Since pod type is a critical phenotype, many researchers have already achieved significant research outcomes in this area. Lu et al. [
18] improved the standard YOLOv3 model to detect soybean pod types, achieving an accuracy of 90.3% and providing insights into the application of YOLO series models in the pod-type detection task. Uzal et al. [
19] proposed a Convolutional Neural Network (CNN)-based classification model to identify the number of seeds in pods. This model was tested on a dataset of scattered pod images and achieved an accuracy of 86.2%. Yan et al. [
20] compared different network models to identify and classify individual pods. The results showed that the VGG-16 network combined with the Adam optimizer performed the best. Image segmentation was used to divide the whole image into individual pod images. However, the model’s ability to distinguish easily confused pods was not strong enough, i.e., the accuracies in identifying two-seed pods and three-seed pods were the lowest.
Apart from accuracy, efficiency is another significant factor for real-world applications. Deep neural networks with more layers and nodes make the computational process more complex, requiring more time and hardware resources to operate. For example, the aforementioned VGG-16-based models are well known for their high demands in computational costs. Early object detection models such as YOLOv3 [
21] and YOLOv4 [
22], although having made significant progress in real-time performance and accuracy, may experience declines in detection accuracy when handling dense scenes, leading to missed detections or false positives [
23]. Moreover, these models perform poorly when dealing with targets that have complex structures or subtle features [
24]. This is because they tend to divide the entire image into larger grids, which may result in the neglect or insufficient processing of local information, thereby affecting the accuracy and stability of pod detection.
Hence, this paper aims to improve detection accuracy, especially for easily confused pod types, and detection speed and reduce the model size in pod detection by designing a pod-type identification algorithm based on an improved YOLOv5s model—FEI-YOLO. Three improvements to the model structure are proposed in this paper:
Introducing the EMA [
25] module to focus on important regions that are relevant to the different target types in the image. This optimization enhances the model’s performance in handling local information, thereby increasing the accuracy and robustness of soybean pod-type detection.
Incorporating the FasterNet [
26] model into the YOLOv5s model to enable model lightweighting and reduce computational load and the number of parameters, thus enhancing model speed. This paper proposes to replace the BottleNeck modules in the YOLOv5s model’s C3 module with the FasterNet Block modules from FasterNet. With this substitution, the number of parameters and computational load is significantly reduced while the model’s effectiveness in extracting important and representative features is retained.
Combining the Inner-IoU loss function [
27] with the CIoU loss function, resulting in the combined loss function Inner-CIoU. With the Inner-IoU loss function, FEI-YOLO learns to control the size of the auxiliary bounding boxes through the scale factor ratio, while retaining the focus on the target’s center, enhancing the model’s generalization capability to different yet confusing pod types.
2. Methodology
2.1. FEI-YOLO
The YOLO (You Only Look Once) series models [
28] are state-of-the-art models with relatively good performance in general object detection tasks. This series of models uses a regression method for bounding box detection and classification. Among them, the YOLOv5 model performs relatively well and is stable.
Yet it usually needs task-specific adaption to obtain optimal performance. YOLOv5 is mainly divided into four parts: Input, Backbone, Neck, and Head. The Input section standardizes image input sizes and performs data augmentation. The Backbone section discards the Focus structure used in previous series models and employs a traditional 64 × 64 convolutional layer to reduce the number of parameters. Although the Neck layer in YOLOv5 and YOLOv4 both use the Feature Pyramid Network (FPN) [
29] and the Path Aggregation Network (PAN) [
30], YOLOv5 employs the CSP2 structure based on Cross Stage Partial Networks (CSPNet) [
31], which effectively enhances the network’s feature fusion capability. The Head section is used to predict and output the extracted and learned features on the image.
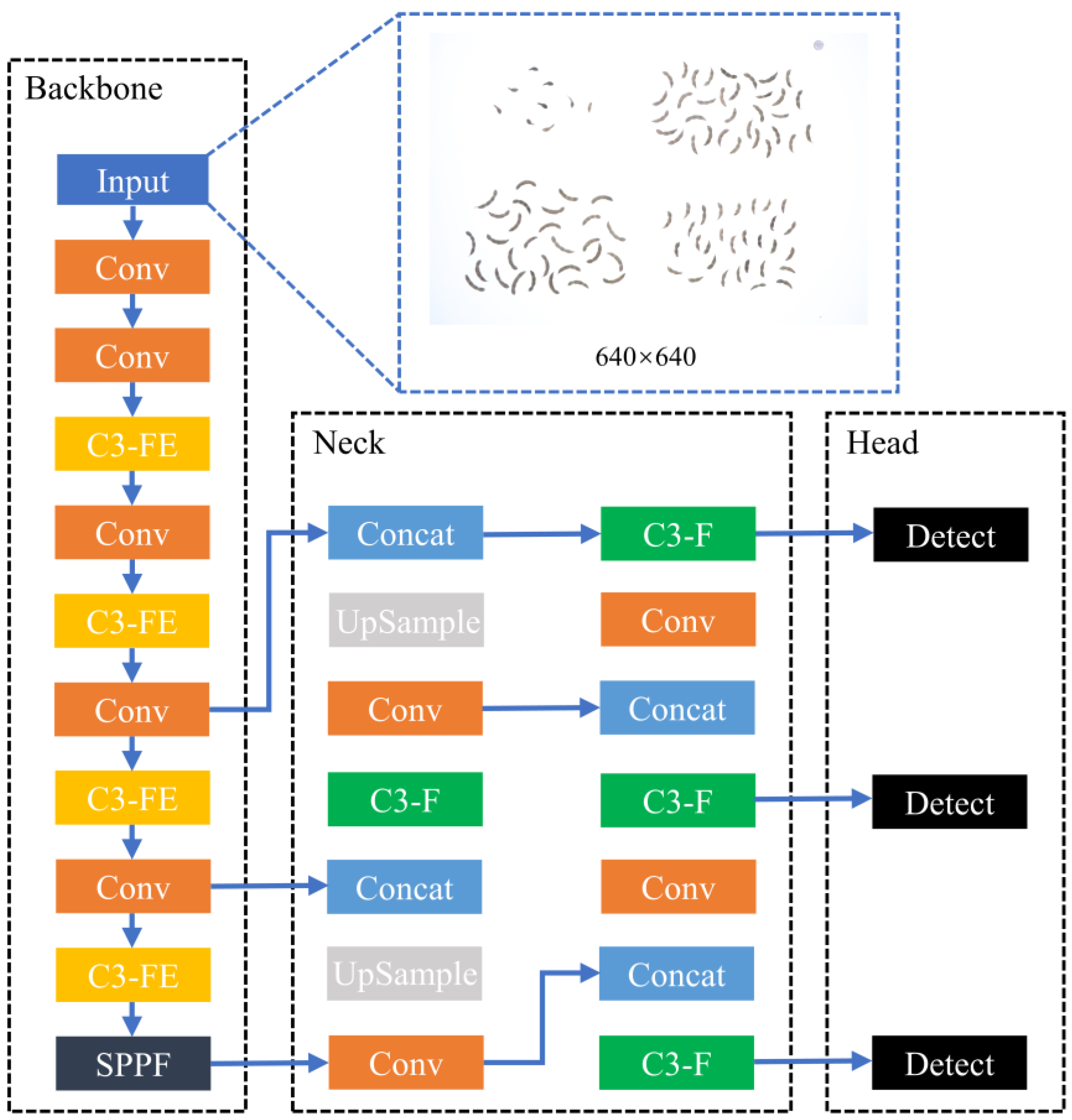
To improve the detection accuracy of pod types and enhance detection speed, this paper proposes to improve the YOLOv5s model from three aspects. Firstly, the C3 modules in the backbone and neck networks are enhanced using the FasterNet structure since they are the most costly and important components. Then, the EMA is incorporated into the C3 modules within the backbone network to optimize the model’s detection performance of the easily confused pod types. Finally, Inner-IoU loss with the CIoU standard loss is carried out to further improve the detection accuracy and generalization of the model. The overall structure of FEI-YOLO is shown in
Figure 1.
2.2. Model Lightweighting with FasterNet
The original C3 module in YOLOv5 contains one or more BottleNeck modules, each comprising a 1 × 1 convolution and a 3 × 3 convolution layer. Although this design enables the C3 module to learn rich feature representations, it also increases the computational load and complexity of the model.
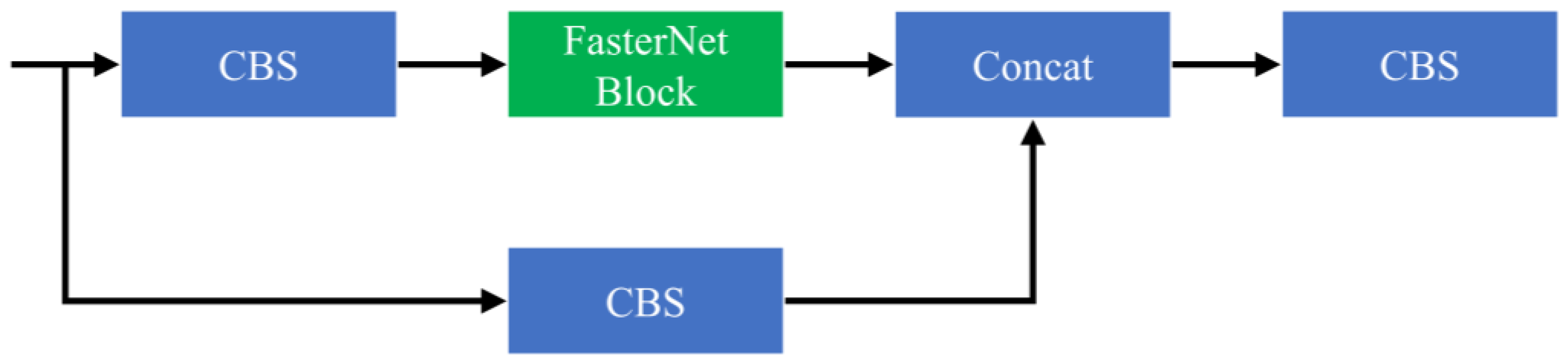
To lightweight the model and enhance detection speed, this paper replaces the BottleNeck modules in the C3 module with the FasterNet Block modules from FasterNet, resulting in the C3-F module, as shown in
Figure 1. With this substitution, we significantly reduce the number of parameters and computational load while maintaining the model’s effectiveness in extracting important and representative features, thereby accelerating the inference speed of the original network. The detailed structure of the C3-F module is shown in
Figure 2.
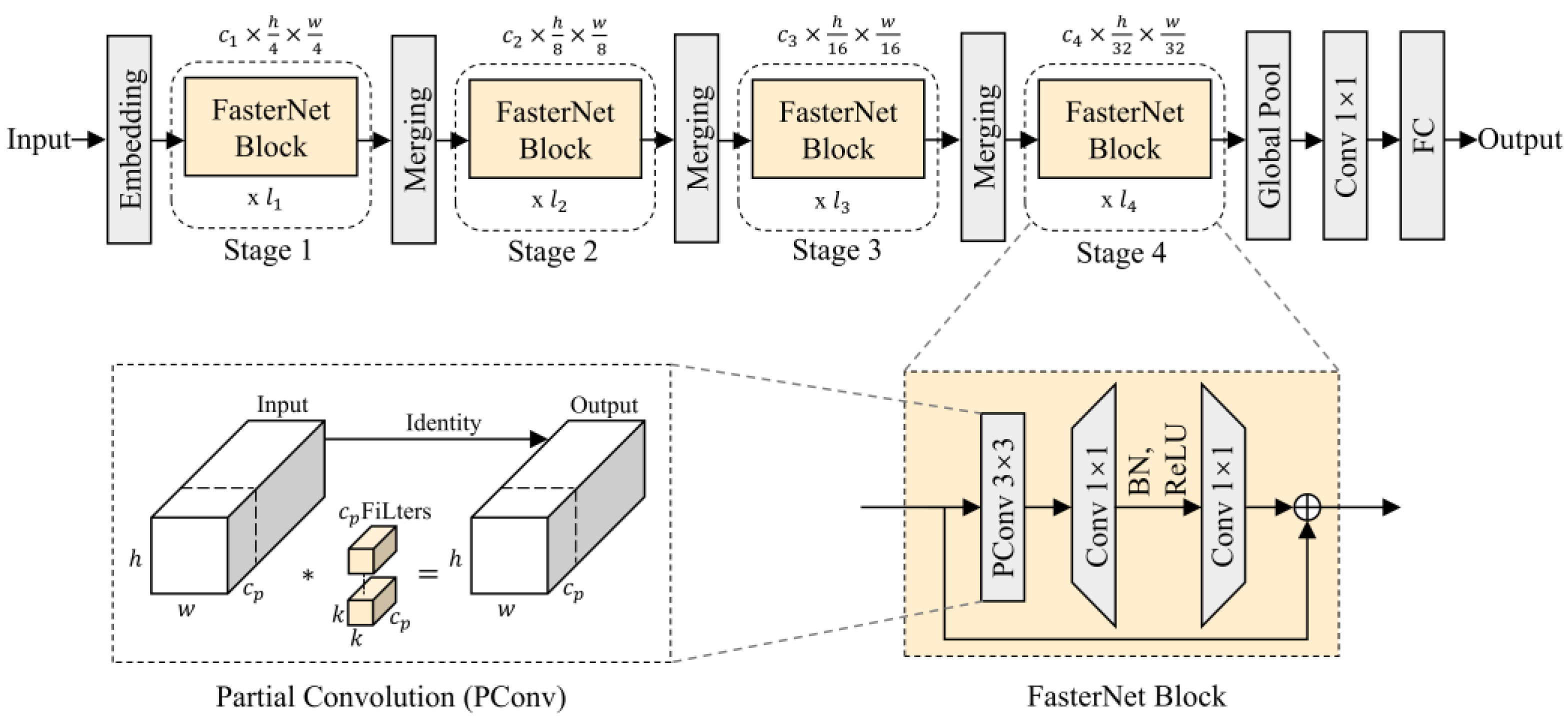
FasterNet [
26] is a new neural network structure for visual tasks proposed in 2023. This network structure offers faster operation speed without compromising the accuracy of various tasks. The structure of FasterNet is shown in
Figure 3.
The most significant modification introduced by FasterNet is the Partial Convolution (PConv) module, which applies standard convolution to only a proportion of the input channels to extract spatial features, instead of all the channels. PConv is highly parallelizable, allowing all pixels to be processed simultaneously, which enables efficient acceleration on GPUs. By using fewer operations to achieve the same accuracy, it reduces redundant computations and memory access, thereby improving the extraction of target features. For continuous memory access, only the first or last consecutive
channels are used to represent the entire feature map. Without loss of generality, we only consider the case where the input and output feature maps have the same number of channels. The floating-point operations (FLOPs) calculation for PConv is shown in Equation (1), and the memory usage calculation is shown in Equation (2), where
and
are the height and width of the feature map, and
is the size of the convolution kernel.
When using the common value , meaning only 1/4 of the channels undergo partial convolution, the FLOPs of PConv are only 1/16 of those of a standard convolution, and the memory access is 1/4 of that of a standard convolution.
As shown in
Figure 3, the FasterNet Block consists of one PConv module and two Pointwise Convolution (PWConv) modules, with normalization layers and activation functions placed between the two PWConv modules to maintain feature diversity and achieve low latency. PWConv is used to restore the number of channels in the feature map and can encode the relationships between channels. This integration of spatial and channel information generated by PConv enhances the network’s expressive capability. Finally, the input feature map is added to the output feature map to obtain the final output result. The PWConv module contains only 1 × 1 convolutional kernels, which changes the number of feature channels without altering the size of the feature map, effectively reducing computational complexity.
2.3. Enhancing Type-Distinctive Representation with EMA
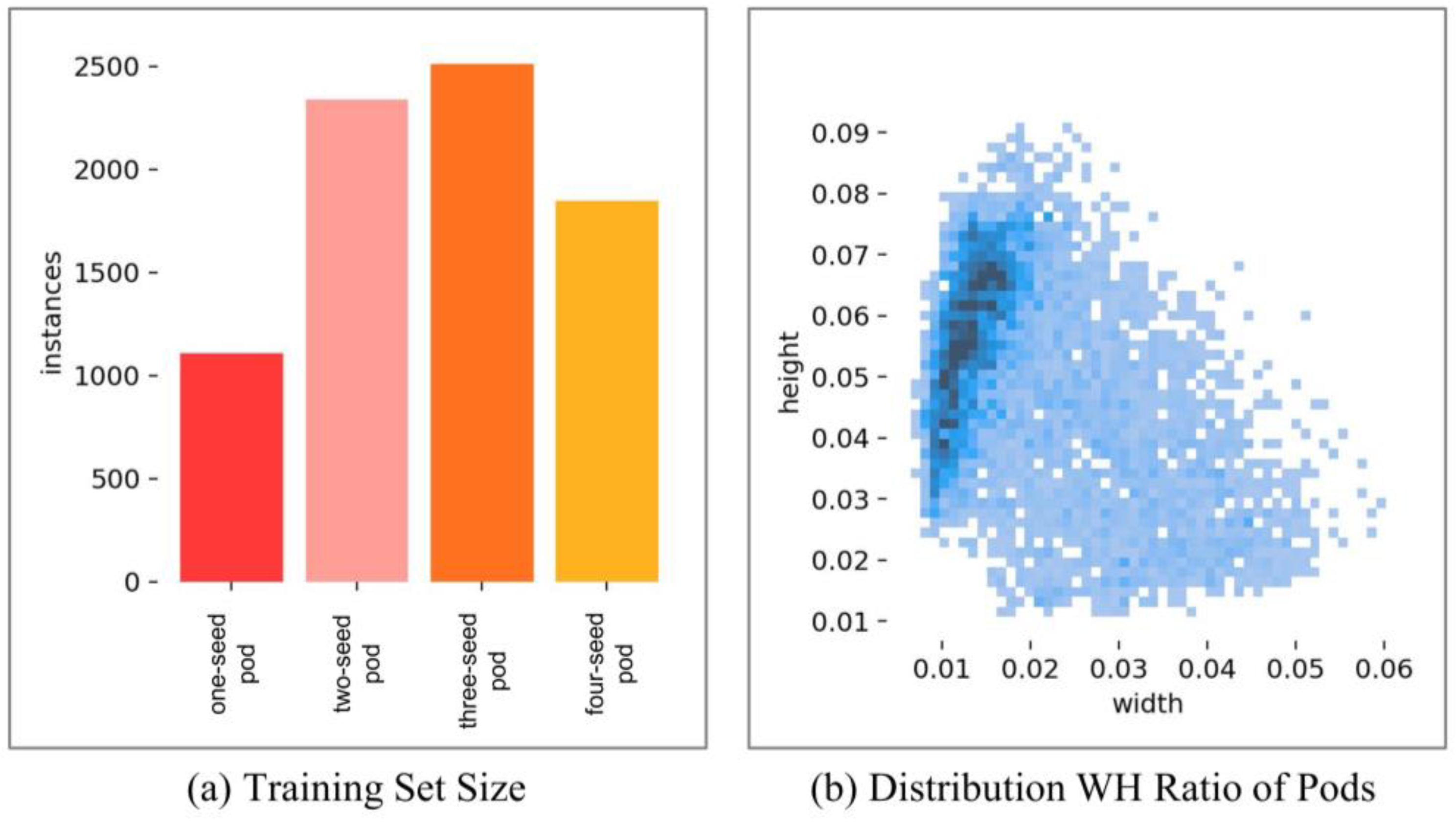
There is a significant difference in the number of pods with various numbers of seeds. Pods with two seeds and three seeds are the majority, yet they are also the most confusing pod types. Moreover, their visual phenotypic features can vary across different soybean plant varieties. The sample distribution of the dataset is shown in
Figure 4, where
Figure 4a represents the type distribution in the training set, and
Figure 4b shows the width-to-height (WH) ratio of the target objects to the entire image.
As shown in
Figure 4a, there exists a significant imbalance between different pod types. The number of three-seed pod samples is the highest, approximately 2.5 times the number of one-seed pod samples. As shown in
Figure 4b, due to the different pod types, the size of the detection boxes is also unbalanced. Most pods have a width-to-image ratio between 0.01 and 0.02, and a height-to-image ratio between 0.05 and 0.07. However, many pods still have a wide range of width-to-height ratios, which is unfavorable for model training.
Therefore, to adapt to changes in image scale and capture the distinguishing features of different types of pods, this paper introduces the Efficient Multi-Scale Attention (EMA) [
25] module. This module ensures the retention of information in each channel without the need for dimensionality reduction and reduces the computational burden. It can reconfigure a portion of the channels into batch dimensions and group them into multiple sub-features, ensuring uniform spatial semantic feature distribution within each feature group. Compared to the alternative Squeeze-and-Excitation (SE), Convolutional Block Attention Module (CBAM), and Coordinate Attention (CA) mechanisms, the EMA module not only offers better performance but is also more efficient in terms of required parameters. This paper incorporates the EMA module into the C3 module of the backbone network, combining it with the previously mentioned C3-F to form C3-FE. The structure is illustrated in
Figure 5. This structure retains the advantages of the C3-F module in processing local features while incorporating the strengths of the EMA module in capturing global contextual information. This improvement enhances the model’s ability to focus on target-specific features, enabling it to more accurately extract characteristic information from the target objects in the image.
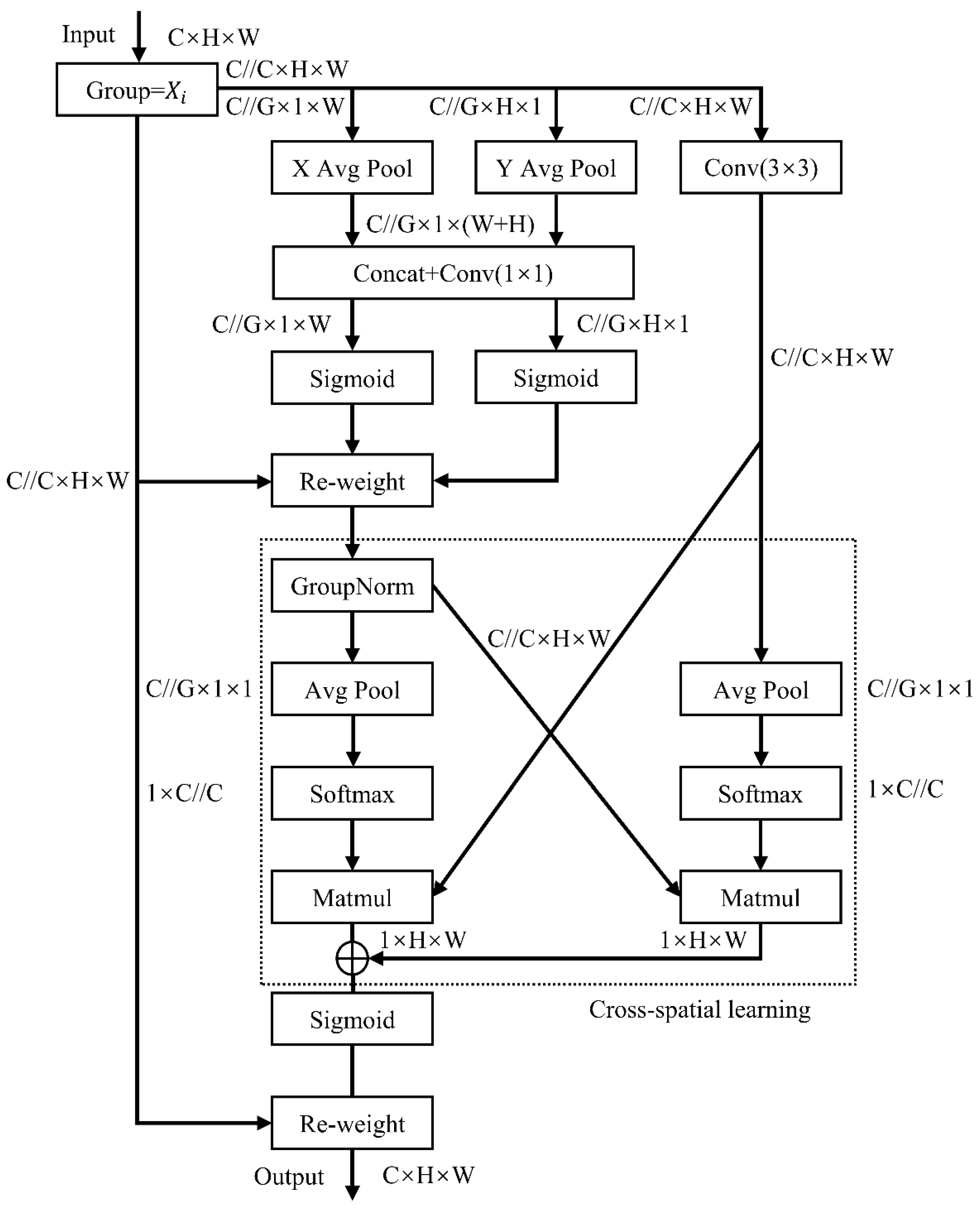
The detailed structure of the EMA module is shown in
Figure 6. Let
represents the number of channels,
represents the number of groups,
the height,
the width, ‘
’ indicates much less than, and ‘
’ indicates floor division. For the input feature
, the EMA module first divides it into
sub-features along the channel dimension
, where
, with
. Each sub-feature
is enhanced through learned attention weights. For each sub-feature, the EMA module extracts the attention weights of the grouped feature maps through three parallel branches. The first two branches include 1 × 1 convolutions and use adaptive global average pooling to encode the channels along the
and
directions, respectively. The two encoded features are then concatenated, and a shared 1 × 1 convolution is applied, followed by linear fitting using the Sigmoid activation function. The third branch includes a 3 × 3 convolution aimed at capturing multi-scale feature representations. In the cross-spatial learning section, the EMA module aggregates cross-spatial information from different spatial dimensions. First, the global information output by the 1 × 1 branch is normalized. Next, 2D global average pooling is used to encode the global spatial information from both the 1 × 1 and 3 × 3 branches. The Softmax function is then employed to fit a linear transformation, directly converting the channel features of the branch with the smallest output into the corresponding dimensional shape to achieve cross-spatial information aggregation. Finally, the cross-spatial interaction module aggregates the two-channel attention weight values, capturing pixel-level pairwise relationships. The features are output through the Sigmoid activation function, thereby enhancing the original input features and producing the final output feature map.
2.4. Enhancing CIoU with Inner-IoU
Loss function is the guide for a learning model. Models for the target detection typically use the Intersection over Union (IoU) [
32] loss function, which is a crucial component of mainstream loss functions. The IoU is defined as follows:
and
represent the predicted box and the ground truth (GT) box, respectively.
The bounding box regression loss function family based on the IoU have continuously evolved, including variants such as the Generalized IoU (GIoU), Distance IoU (DIoU), Complete IoU (CIoU), Extended IoU (EIoU), and Scalable IoU (SIoU).
The default loss function used by YOLOv5 is the CIoU, a loss function commonly used in classification problems [
33]. It measures the accuracy of object detection models in terms of detecting the position and size of the target, effectively handling the overlap and misalignment between bounding boxes, thereby improving the performance evaluation of the model.
The CIoU is defined as follows: Let
and
represent the predicted box and the GT box, respectively.
represents the distance between their center points. The greater the distance, the higher the penalty. This mechanism ensures that the predicted box not only overlaps in area but is also positioned closer to the ground truth box. The term
represents the aspect ratio consistency penalty mechanism. The greater the difference, the higher the penalty. This mechanism ensures that the predicted box matches the shape of the ground truth box as closely as possible.
includes the aspect ratio to be predicted, and
is a positive weighting parameter.
and
denote the width and height of the ground truth box, while
and
denote the width and height of the predicted box.
The CIoU has certain limitations. On one hand, it has a weaker ability to evaluate objects with large aspect ratios and irregular shapes. On the other hand, it cannot adaptively adjust to various detection tasks and targets, and it does not account for the balance between different samples. When there is substantial variability among samples, it can also constrain the convergence speed of the model [
32,
34].
In this dataset, the
and
of the pods are relatively small with significant ratio differences, which increases the aspect ratio consistency penalty term in the CIoU, thereby reducing the CIoU value. This causes the CIoU to fail to reflect the real situation and may optimize similarity in an unreasonable way. To address these limitations, this paper introduces the Inner-IoU [
27] loss function based on auxiliary bounding boxes. The Inner-IoU is a more detailed and target-center-focused performance evaluation metric. By using the scale of auxiliary bounding boxes, it enhances the accuracy and efficiency of object detection tasks, aligning well with practical needs. In the Inner-IoU, the scale factor ratio is introduced to control the size of the auxiliary bounding boxes. Calculating the IoU using smaller-scale auxiliary bounding boxes aids in the regression of high-IoU samples, accelerating convergence. Using larger-scale auxiliary bounding boxes for IoU loss calculation speeds up the regression process of low-IoU samples. Employing auxiliary bounding boxes of different scales for different datasets and detectors overcomes the limitations of existing methods in terms of generalization capability.
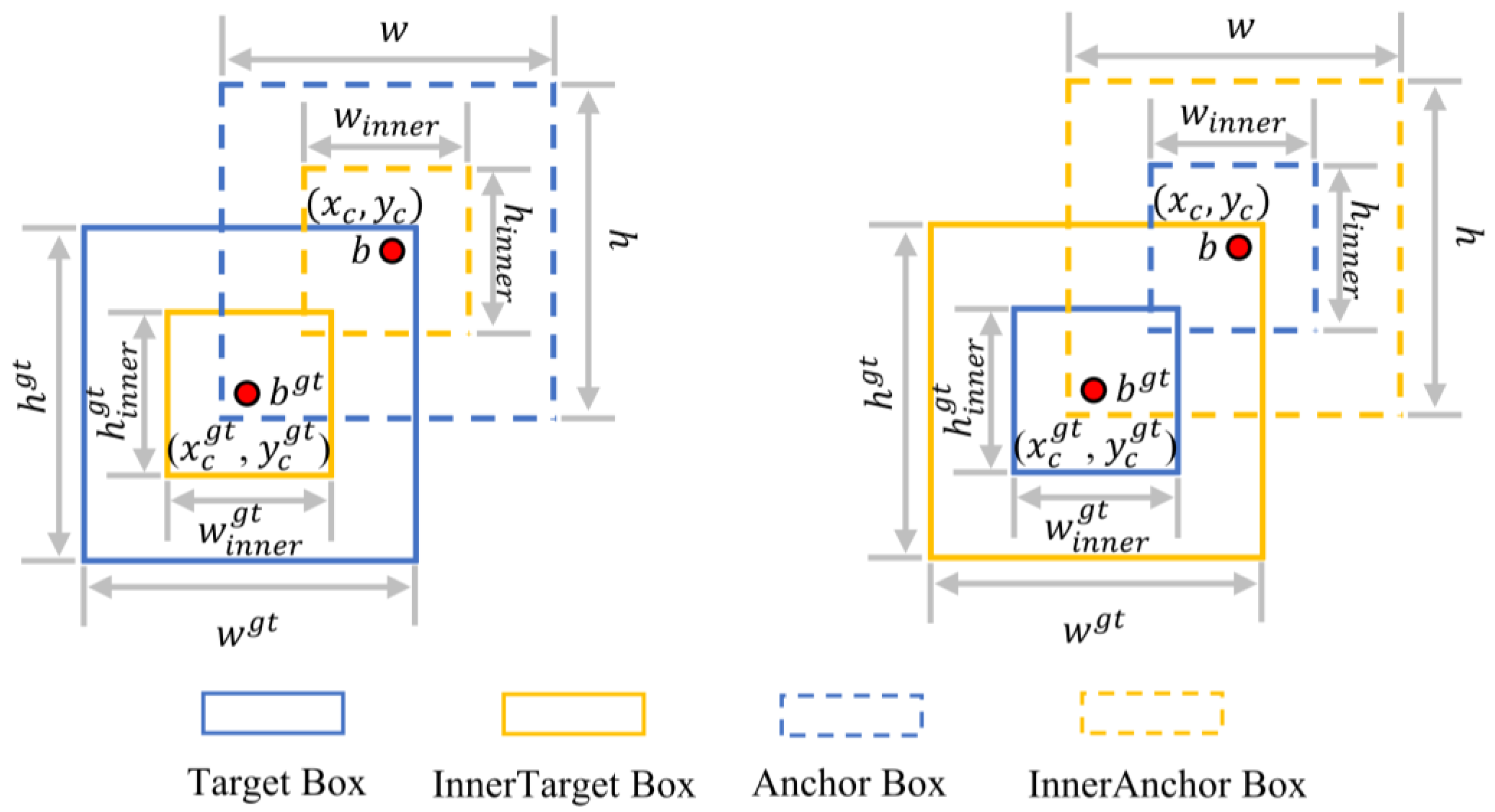
The Inner-IoU is defined as follows:
and
represent the predicted box and the GT box, respectively, as illustrated in
Figure 7.
and
are the width and height of the predicted box, and
and
are the width and height of the GT box, respectively.
represents the center point of the predicted box, and
represents the center point of the GT box. The variable ratio corresponds to the scale factor, typically ranging from [0.5, 1.5].
This paper applies the Inner-IoU to the CIoU, resulting in the loss function Inner-CIoU. This loss function not only retains the advantages of the CIoU but also controls the size of the auxiliary bounding boxes through the scale factor ratio, enhancing the model’s generalization ability. By allowing the model to focus more on the target center, it effectively mitigates the issue of the CIoU value reduction due to significant aspect ratio differences in pods, thereby improving detection accuracy.
2.5. Dataset
The soybean plant samples used in this study were obtained from the experimental field of the College of Agriculture at Yangtze University. The plants were planted in June 2023 and harvested in October 2023, with a maturity period of 82 to 126 days.
To obtain the characteristic information of soybean pods, the LabelImg data annotation tool was used to label the pods in each image. Pods were categorized as one-seed pods, two-seed pods, three-seed pods, and four-seed pods according to the number of seeds they have. An example from each pod type is shown in
Figure 8. The collected data were then randomly divided into training, validation, and test sets in a 7:2:1 ratio. The number of targets for each label is shown in
Table 1. There are a total of 11,076 pod targets. Two-seed pods and three-seed pods are the majority, with 3347 and 3567 targets, respectively. This is followed by the four-seed pod type with 2591 targets. The one-seed pod type has the fewest targets, with 1571 targets.
2.6. Experimental Setup
All experiments in this paper were conducted on the same platform. The operating system was Windows 10, with Python 3.9, PyTorch 2.0.1, CUDA 11.8, an Intel i5-12600KF CPU, an NVIDIA RTX 3090Ti GPU, and 32 GB of memory. Both the original and improved models used the same hyperparameters, as shown in
Table 2. The hyperparameters of this experiment are all set by default.
2.7. Performance Indicator
To evaluate the stability and recognition performance of the network model, this study employs classic object detection performance metrics, including Precision (
), Recall (
), and mean Average Precision (
).
Positive samples: pod types correctly identified by the model; negative samples: pod types incorrectly identified by the model. True Positives (): correctly identified as positive samples. True Negatives (): correctly identified as negative samples. False Positives (): incorrectly identified as positive samples. False Negatives (): incorrectly identified as negative samples. represents the number of images, represents the average precision for the current type, and denotes the number of types in the detection task.
3. Results and Analysis
3.1. Baseline Model Prior Experiments
To explore the best baseline model, this paper evaluates the performance of three versions of the YOLOv5 baseline model. In the metrics presented in
Table 3, floating-point operations (FLOPs) and the number of parameters (Params) are evaluation standards for lightweight models. FLOPs represent the number of floating-point operations required for a model to perform inference, reflecting the model’s computational complexity. Lower FLOPs indicate faster inference speeds. Params is a key metric for evaluating the model’s size; lower Params indicate that the model requires less memory space. Frames per second (FPS) is used to evaluate model speed. Higher FPS indicates a faster detection rate.
The experimental results indicate that, although the YOLOv5n model has the smallest computational load and the fastest detection speed, its average detection accuracy is considerably lower. While the YOLOv5m model shows some improvement in average detection accuracy, it has a significantly higher computational load and slower detection speed compared to the YOLOv5n and YOLOv5s models. Balancing these factors, the YOLOv5s model, despite sacrificing some detection speed, can largely maintain a high detection accuracy. Therefore, this paper adopts the YOLOv5s model as the baseline model.
3.2. Model Comparison Experiment
To further verify the detection performance of FEI-YOLO, it was compared with current mainstream object detection models, including SSD, Faster RCNN, YOLOv3, YOLOv5s, YOLOv7, YOLOv8s, YOLOv9s and YOLOv10s. The detection results of each model are shown in
Table 4.
As shown in the table, FEI-YOLO has significant advantages in detection accuracy and Params. Its and are 98.6% and 81.1%, respectively, the highest among all models, and its Params is 7.73 M, the smallest among all models. The FLOPs of FEI-YOLO is 21.4 G, which is slightly higher than YOLOv3’s 12.9 G but lower than the FLOPs of all other models. Its FPS reaches 127, second only to YOLOv3. Despite slightly higher FLOPs and lower FPS compared to YOLOv3, FEI-YOLO significantly outperforms it in detection accuracy. These results indicate that, compared to mainstream object detection models, FEI-YOLO can maintain detection accuracy while achieving model lightweighting. YOLOv7’s is 0.3% higher than YOLOv5s, but its FLOPs and Params are 4.4 times and 4.1 times those of YOLOv5s, respectively. This poses challenges for fast image processing and model deployment. Experiments show that YOLOv8s performs worse than YOLOv5s in both and , while its FLOPs and parameters are larger, and FPS is lower, making it a less favorable option. Although YOLOv9s is comparable to YOLOv5s in both and ; its FLOPs are 1.7 times higher, and it falls short in terms of parameters and FPS. As for YOLOv10s, it offers no advantage in detection accuracy compared to other models in the YOLO series, so it is not considered further. This paper chooses YOLOv5s as the baseline model, ensuring detection accuracy, achieving model lightweighting, and maintaining processing speed.
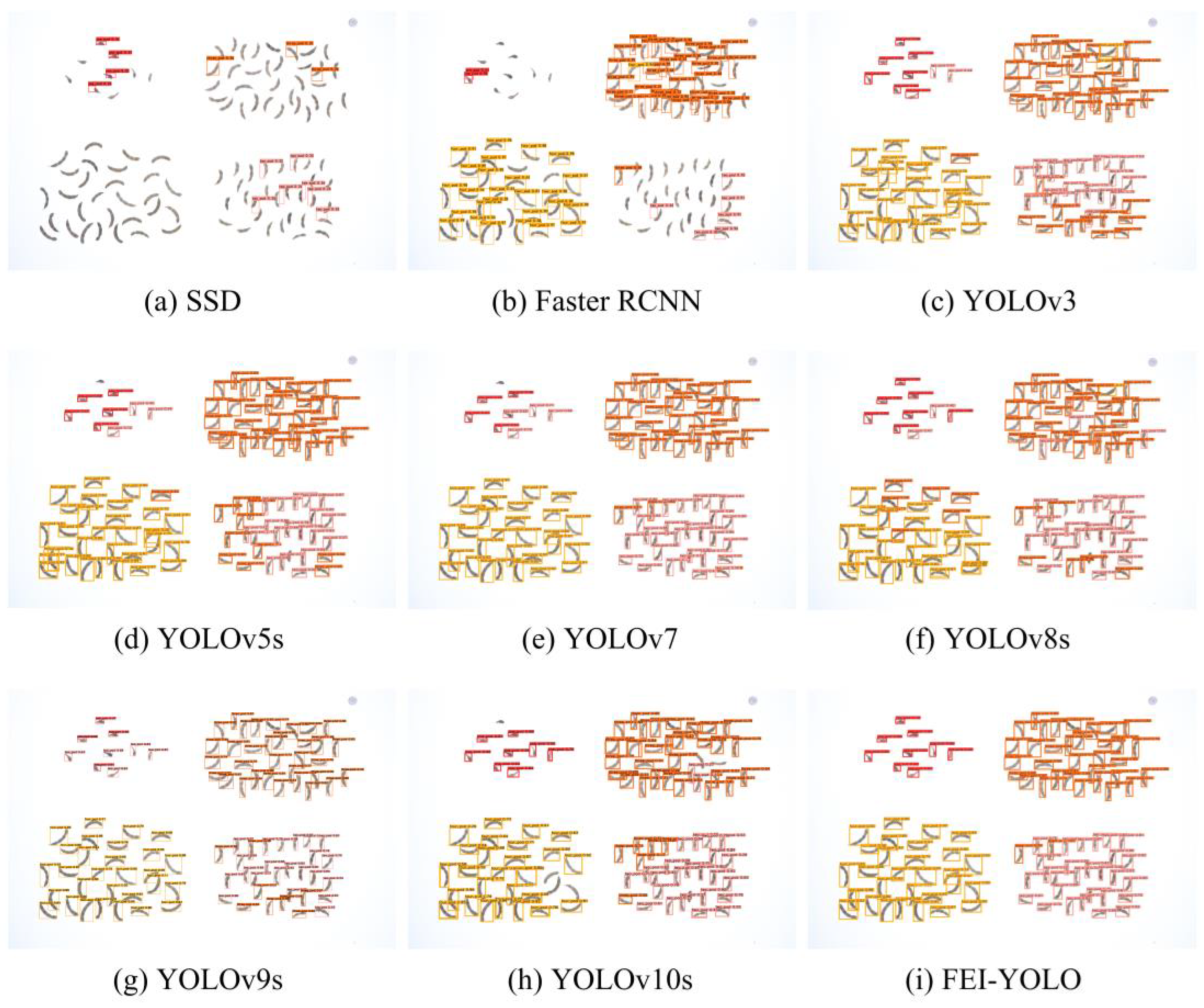
To intuitively display the detection performance of each model,
Figure 9 compares the detection results of various models on the same image. As shown in the figure, SSD has the worst detection performance, with a high miss detection rate for all pod types. This indicates that the SSD model may not have learned the corresponding features. Faster RCNN shows a significant improvement in detecting three-seed pod and four-seed pod types, but it remains insensitive to one-seed pod and two-seed pod features, failing to achieve a higher accuracy over all pod types. Although YOLOv3 can detect all types of pods, it has a relatively high error rate in classification, particularly for the two-seed pod type. YOLOv5s performs relatively well in terms of recognition, but there are some errors in one-seed pod and two-seed pod types. YOLOv7 and YOLOv9s have detection errors for one-seed pod types, with YOLOv9s also showing errors in the two-seed pod type. YOLOv8s and YOLOv10s exhibit errors in the detection of two-seed, three-seed, and four-seed pod types. Compared to the aforementioned YOLO series models, FEI-YOLO can accurately detect all pods in the one-seed pod type and shows significant improvement in the misdetection of two-seed pod and three-seed pod types.
The prediction results of a model are the most intuitive way to evaluate its performance.
Table 5 quantifies the detection results shown in
Figure 9 by comparing the corresponding number of
,
, and
for different models. This comparison provides an instance of the predictive performance of each model based on the counts of
,
, and
.
Table 6 compares the recognition performance of FEI-YOLO and YOLOv5s across different pod types. Compared to YOLOv5s, FEI-YOLO’s AP was improved by 1.1%, 1.5%, 2.3%, and 1.2% for one-seed pod, two-seed pod, three-seed pod, and four-seed pod types, respectively. Overall, the accuracy of all types was improved after the modifications. The most significant improvement was observed in the three-seed pod type, followed the by two-seed pod type. The reason for this is that these two types are easily confused. The inclusion of the EMA module in FEI-YOLO enhances the model’s ability to extract features from target regions more accurately. This leads to better feature acquisition of the targets to be detected, resulting in improved accuracy for smaller targets like the one-seed pod. Additionally, it becomes easier to distinguish between the easily confused two-seed pod and three-seed pod types, thereby improving the overall detection accuracy.
3.3. Ablation Experiment
To verify the effectiveness of the improvements made to the FEI-YOLO modules, ablation experiments were conducted using the YOLOv5s model as the baseline. The specific results are shown in
Table 7.
The data in the table lead to the following conclusions: In the ablation experiments of individual modules, replacing the CIoU with Inner-IoU improved the model’s detection accuracy, with both and increasing by 0.6%. By improving the YOLOv5s model’s C3 module with FasterNet, specifically using the C3-F module, the model’s FLOPs were reduced by 13% and Params by 13.5%, indicating a significant lightweighting effect. Meanwhile, increased by 0.3% and increased by 0.4%, ensuring the detection accuracy of the model. The improvement of the EMA module is based on the FasterNet-enhanced C3 module. After further enhancing the C3-F module in the backbone network with the EMA module, the model’s FLOPs and Params increased slightly, but improved by 0.8%, and improved by 0.7%, showing a clear improvement. On the premise of using the C3-F module, replacing CIoU with Inner-IoU resulted in an increase of 0.7% in and a 0.4% increase in .
The ablation experiments show that all three improvement methods are effective, each providing a certain degree of enhancement compared to the baseline YOLOv5s model. The FEI-YOLO model, compared to the YOLOv5s algorithm, achieves a 10.8% reduction in FLOPs, a 13.2% reduction in Params, a 1.5% increase in , a 1.4% increase in , and a 25.7% elevation in FPS, making it the optimal solution for both lightweighting and detection accuracy.
To comprehensively study the performance of FEI-YOLO,
Figure 10 shows the performance differences between FEI-YOLO and YOLOv5s under the same parameter settings. As shown in
Figure 10a, compared to YOLOv5s, FEI-YOLO not only has an improvement in detection accuracy but also converges faster. The
value of YOLOv5s stabilizes around 450 iterations, whereas the accuracy of FEI-YOLO stabilizes significantly before 400 iterations. The comparison in
Figure 10b between FEI-YOLO and YOLOv5s in terms of
further demonstrates that FEI-YOLO achieves higher detection accuracy and faster convergence.
5. Conclusions
This paper proposes the FEI-YOLO model based on soybean pod-type detection. By integrating FasterNet into the backbone and neck networks, the model achieves lightweighting by reducing the number of parameters while maintaining accuracy, thereby addressing the issue of slow detection speed. The incorporation of the EMA module into the backbone network enhances the model’s feature extraction capability, allowing it to more accurately identify pods with similar features. This solves the problem of confusion between two-seed pods and three-seed pods and improves the overall detection accuracy. Additionally, the loss function is replaced with the Inner-IoU, which accelerates the regression of bounding boxes using auxiliary boxes, leading to better convergence. This further enhances the model’s detection accuracy and generalization capability. Based on the analysis of the experimental results, the following conclusions can be drawn:
- 1.
Model Detection Accuracy: FEI-YOLO achieved and scores of 98.6% and 81.1%, respectively, which are the highest scores among all compared models. Compared to the baseline YOLOv5s model, FEI-YOLO’s detection accuracy obtained 1.5% and 1.4% increases, respectively. These results indicate that FEI-YOLO can infer more accurately than the baseline YOLOv5s model.
- 2.
Model Size and Detection Speed: While improving detection accuracy, FEI-YOLO successfully reduced the model size of the YOLOv5s, reducing the number of parameters by 13.2%. Meanwhile, FEI-YOLO also improved the detection speed, reducing FLOPs by 10.8% and increasing FPS by 25.7%. These results indicate that FEI-YOLO can infer faster and is a more lightweight model than the baseline YOLOv5s model.
Future work will focus on further enhancing the model’s generalization capability to ensure reliable performance across diverse environmental and background conditions, making it more applicable in real-world agricultural scenarios. However, challenges remain, such as difficulties in accurately detecting pods in complex situations, like occlusion or overlap. Future efforts will aim to improve the model’s robustness in these challenging conditions.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}