
CLT-YOLOX: Improved YOLOX Based on Cross-Layer Transformer for Object Detection Method Regarding Insect Pest

Abstract
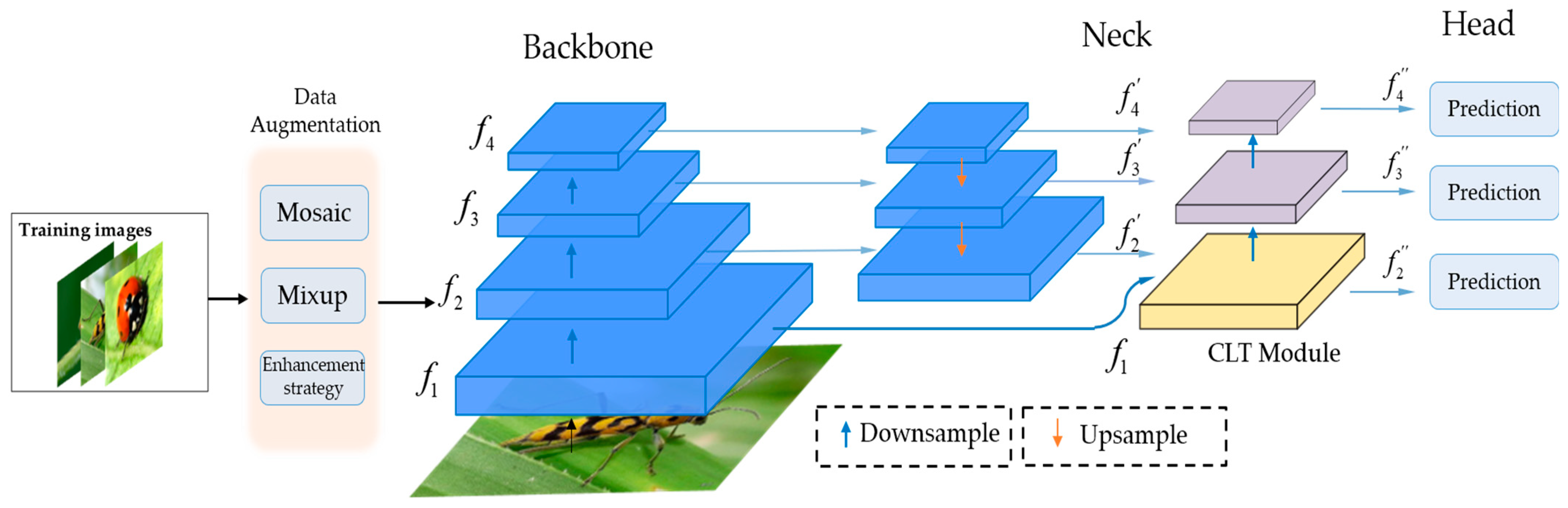
1. Introduction
- Addressing the scarcity of real pest image data: To overcome the limited availability of real pest image data in the field, we employed Mosaic and Mixup data augmentation techniques. These techniques effectively augment the dataset, allowing for a better model generalization. Additionally, a novel data enhancement strategy was introduced to further improve the model’s performance.
- Cross-Layer Transformer (CLT) module: Our proposed CLT (Cross-Layer Transformer) module incorporates cross-layer information, enabling the extraction of fine-grained features more effectively. By leveraging this cross-layer information, our model achieves improved detection results compared to the original YOLOX algorithm.
- Enhancements to the C3 module and integration of CBAM: We enhanced the C3 module within the PFPN structure by removing the convolution operation before the upsampling stage. Additionally, we integrated the Convolutional Block Attention Module (CBAM) to capture attention in complex scenes. These modifications enhance the recognition ability for multi-scale targets while managing the trade-off between computational requirements and accuracy.
- Performance improvements: The improved YOLOX algorithm proposed in this paper achieved an average precision (AP) of 57.7% on the public IP102 dataset. This performance is 2.2% higher than the original YOLOX model. Notably, the APsmall value increased by 2.2%, demonstrating the effectiveness of our enhancements in detecting small targets.
2. Related Work
2.1. Data Augmentation
2.2. Pest Identification
3. Materials and Methods
3.1. Data Enhancement
3.2. Backbone
- Focus module: The focus module slices an image by taking a value for each pixel at an interval (similar to adjacent down sampling). This process integrates information from the width (W) and height (H) dimensions into the channel space. The output channel is expanded by four times, resulting in a spliced image with 12 channels. This increase in channels benefits subsequent calculations. Figure 4 illustrates the concept of the focus module.
- SPP module: The SPP module is inspired by the idea of Spatial Pyramid Pooling. It utilizes a pooling layer composed of three convolutional kernels with different sizes (5 × 5, 9 × 9, 13 × 13) to fuse local features and global features. This enriches the expression capability of the final feature map. The SPP module enhances the network’s ability to capture features at different scales, improving the overall performance. Figure 4 provides an illustration of the SPP module.
3.3. Improved Neck
3.3.1. Improved C3 Module
3.3.2. Convolutional Block Attention Module (CBAM)
3.3.3. Cross-Layer Transformers Module
| Algorithm 1: Cross-Layer Transformer |
| Input: input feature maps, Q, K, V |
| ←K, Q, ←V |
| Output: output Fout |
|
3.4. Head
3.4.1. Decoupled Head
3.4.2. Anchor Free
3.4.3. SimOTA
3.4.4. Loss Function
4. Experiments
4.1. Implementation Details
4.1.1. Datasets
4.1.2. Experimental Environment
4.1.3. Network Parameter
4.1.4. Evaluation Metrics
4.2. Contrast Result
4.2.1. Comparison Experiments of Different Models
4.2.2. Comparative Experiment of Freezing Training
4.3. Ablation Experiment
4.3.1. Added Module Ablation Experiments
4.3.2. Comparative Experiment of Freezing Training
4.4. Result Visualization
4.4.1. Qualitative Visualization of Detection Results
4.4.2. Visualization Comparison of the Thermal Characteristic Maps
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lindeberg, T. Scale Invariant Feature Transform. Scholarpedia 2012, 7, 10491. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A Comparative Study of Texture Measures with Classification Based on Featured Distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2564–2571. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up Robust Features. Lect. Notes Comput. Sci. 2006, 3951, 404–417. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support Vector Machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Peterson, L.E. K-Nearest Neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hinton, G.E. Deep Belief Networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Hopfield, J.J. Hopfield Network. Scholarpedia 2007, 2, 1977. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing between Capsules. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wu, X. Study on Identification of Pests Based on Machine Vision. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2016. [Google Scholar]
- Wang, L.; Sun, J.; Wu, X.; Shen, J.; Lu, B.; Tan, W. Identification of Crop Diseases Using Improved Convolutional Neural Networks. IET Comput. Vis. 2020, 14, 538–545. [Google Scholar] [CrossRef]
- Huang, M.-L.; Chuang, T.-C.; Liao, Y.-C. Application of Transfer Learning and Image Augmentation Technology for Tomato Pest Identification. Sustain. Comput. Inform. Syst. 2022, 33, 100646. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Cui, Y.; Yang, L.; Liu, D. Dynamic Proposals for Efficient Object Detection. arXiv 2022, arXiv:2207.05252. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. Up-Detr: Unsupervised Pre-Training for Object Detection with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1601–1610. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; NanoCode012; ChristopherSTAN; Liu, C.; Laughing; tkianai; Hogan, A.; lorenzomammana; et al. Ultralytics/Yolov5: V3.1-Bug Fixes and Performance Improvements. 2020. Available online: https://zenodo.org/record/4154370 (accessed on 20 June 2019).
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv4-5D: An Effective and Efficient Object Detector for Autonomous Driving. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-Shot Image Semantic Segmentation with Prototype Alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Hassan, S.N.; Rahman, N.S.; Win, Z. Automatic Classification of Insects Using Color-Based and Shape-Based Descriptors. Int. J. Appl. Control Electr. Electron. Eng. 2014, 2, 23–35. [Google Scholar]
- Zheng, C.-H.; Pei, W.-J.; Yan, Q.; Chong, Y.-W. Pedestrian Detection Based on Gradient and Texture Feature Integration. Neurocomputing 2017, 228, 71–78. [Google Scholar] [CrossRef]
- Shen, Y.; Zhou, H.; Li, J.; Jian, F.; Jayas, D.S. Detection of Stored-Grain Insects Using Deep Learning. Comput. Electron. Agric. 2018, 145, 319–325. [Google Scholar] [CrossRef]
- Rani, R.U.; Amsini, P. Pest Identification in Leaf Images Using SVM Classifier. Int. J. Comput. Intell. Inform. 2016, 6, 248–260. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-Level Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13039–13048. [Google Scholar]
- He, Y.; Zhou, Z.; Tian, L.; Liu, Y.; Luo, X. Brown Rice Planthopper (Nilaparvata Lugens Stal) Detection Based on Deep Learning. Precis. Agric. 2020, 21, 1385–1402. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point Set Representation for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9657–9666. [Google Scholar]
- Huang, J.; Huang, Y.; Huang, H.; Zhu, W.; Zhang, J.; Zhou, X. An Improved YOLOX Algorithm for Forest Insect Pest Detection. Comput. Intell. Neurosci. 2022, 2022, 5787554. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, B.; Lyu, S.; Wang, C.; Zhang, H. TPH-YOLOv5++: Boosting Object Detection on Drone-Captured Scenarios with Cross-Layer Asymmetric Transformer. Remote Sens. 2023, 15, 1687. [Google Scholar] [CrossRef]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient Long-Range Attention Network for Image Super-Resolution. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 649–667. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Setting |
|---|---|
| Pretrained weights | COCO-Train2017-yolox_s.pth |
| mosaic_prob | 0.5 |
| mixup_prob | 0.5 |
| special_aug_ratio | 0.7 |
| Freeze_Epoch | 50 |
| Freeze_batch_size | 32 |
| UnFreeze_Epoch | 150 |
| Unfreeze_batch_size | 16 |
| Learning rate | 0.01 |
| Minimum learning rate | 0.0001 |
| Learning rate decay | lr×Batch_Size/64 |
| Evaluation Index | Explanation |
|---|---|
| AP | AP at IOU = 0.50:0.05:0.95 (primary challenge metric) |
| = 0.50 | AP at IOU = 0.50 (Pascal VOC metric) |
| = 0.75 | AP at IOU = 0.75 (strict metric) |
| FPN | 28.10 | 54.93 | 23.30 | — | — | — |
| SSD300 | 21.49 | 47.21 | 16.57 | — | — | — |
| RefineDet | 22.84 | 49.01 | 16.82 | — | — | — |
| YOLOv3 | 25.67 | 50.64 | 21.79 | — | — | — |
| YOLOv5 | 34.1 | 56.2 | 36.8 | — | — | — |
| Faster R-CNN | 28.4 | 48.0 | 30.2 | 17.8 | 29.0 | 29.4 |
| Dynamic R-CNN | 29.4 | 50.7 | 30.3 | 14.6 | 25.9 | 30.4 |
| PAA | 25.2 | 42.7 | 26.1 | 18.6 | 27.1 | 26.1 |
| TOOD | 26.5 | 43.9 | 28.7 | 19.0 | 28.3 | 27.4 |
| YOLOX | 31.6 | 55.5 | 31.8 | 22.9 | 28.1 | 32.7 |
| CLT-YOLOX | 33.2 | 57.7 | 33.6 | 25.1 | 31.5 | 33.9 |
| Augmentation Ratios (a, b) | |||||
|---|---|---|---|---|---|
| a = 0, b = 0 | a = 0.2, b = 0.2 | a = 0.5, b = 0.5 | a = 0.7, b = 0.7 | a = 1, b = 1 | |
| 27.9 | 31.4 | 33.2 | 32.4 | 31.6 | |
| 50.3 | 55.3 | 57.7 | 57.0 | 55.5 | |
| 28.0 | 31.4 | 33.6 | 31.8 | 31.8 | |
| Params | GFLOPS | FPS | |||||||
|---|---|---|---|---|---|---|---|---|---|
| YOLOX | 31.6 | 55.5 | 31.8 | 22.9 | 28.1 | 32.7 | 8.977 M | 26.974 G | 68.4 |
| YOLOX + ES | 31.8 | 56.3 | 32.5 | 23.1 | 29.4 | 32.8 | 8.977 M | 26.974 G | 67.3 |
| YOLOX + ES + CBAM + C2F | 32.6 | 56.9 | 33.5 | 23.6 | 30.3 | 33.3 | 10.101 M | 29.496 G | 63.3 |
| YOLOX + ES + CBAM + C2F + CLT | 33.2 | 57.7 | 33.6 | 25.1 | 31.5 | 33.9 | 10.504 M | 35.355 G | 61.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Cui, H.; Sun, J.; Li, Z.; Wang, H.; Li, D. CLT-YOLOX: Improved YOLOX Based on Cross-Layer Transformer for Object Detection Method Regarding Insect Pest. Agronomy 2023, 13, 2091. https://doi.org/10.3390/agronomy13082091
Zhang L, Cui H, Sun J, Li Z, Wang H, Li D. CLT-YOLOX: Improved YOLOX Based on Cross-Layer Transformer for Object Detection Method Regarding Insect Pest. Agronomy. 2023; 13(8):2091. https://doi.org/10.3390/agronomy13082091
Chicago/Turabian StyleZhang, Lijuan, Haibin Cui, Jiadong Sun, Zhiyi Li, Hao Wang, and Dongming Li. 2023. "CLT-YOLOX: Improved YOLOX Based on Cross-Layer Transformer for Object Detection Method Regarding Insect Pest" Agronomy 13, no. 8: 2091. https://doi.org/10.3390/agronomy13082091
APA StyleZhang, L., Cui, H., Sun, J., Li, Z., Wang, H., & Li, D. (2023). CLT-YOLOX: Improved YOLOX Based on Cross-Layer Transformer for Object Detection Method Regarding Insect Pest. Agronomy, 13(8), 2091. https://doi.org/10.3390/agronomy13082091