
Counting Crowded Soybean Pods Based on Deformable Attention Recursive Feature Pyramid


Abstract
:1. Introduction
2. Materials and Methods
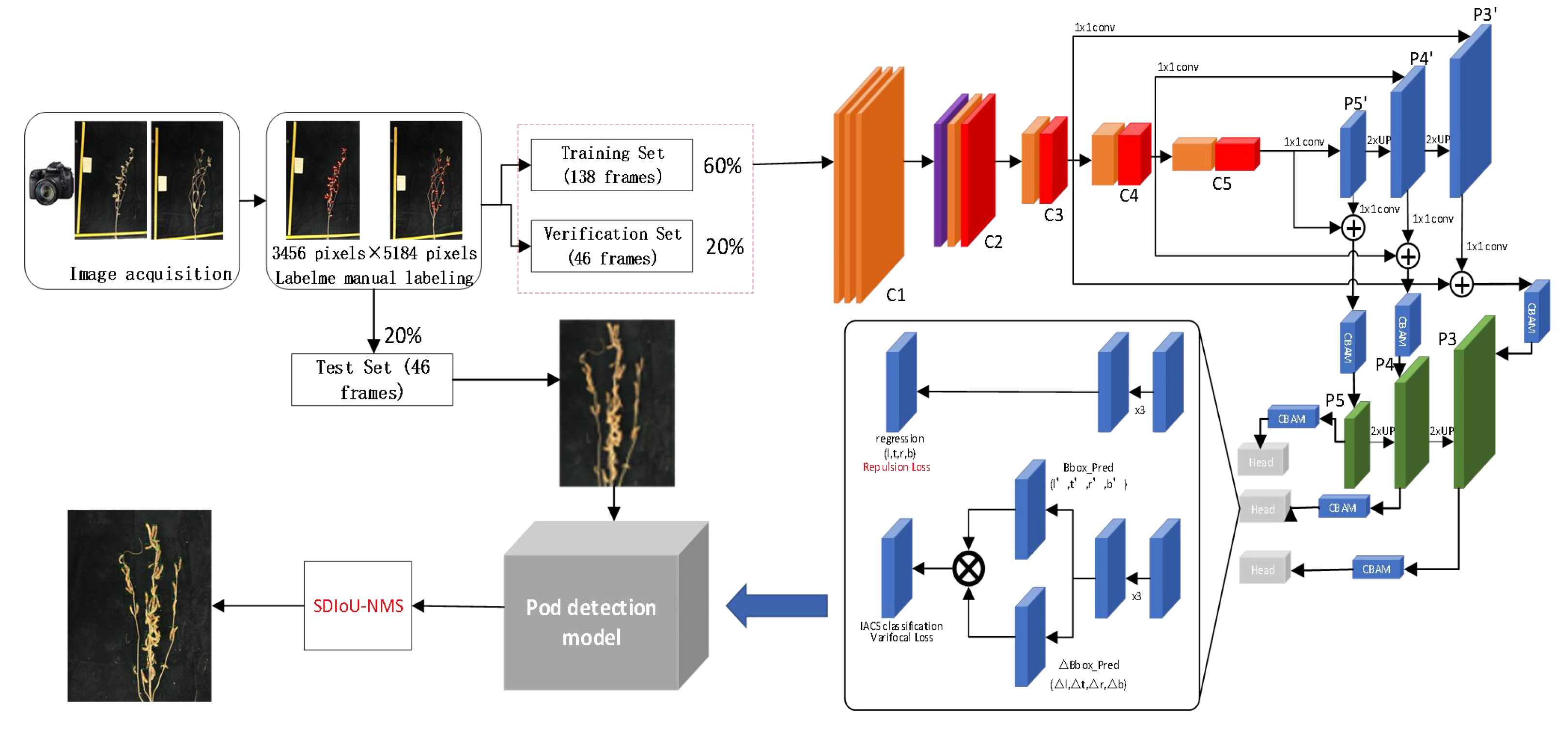
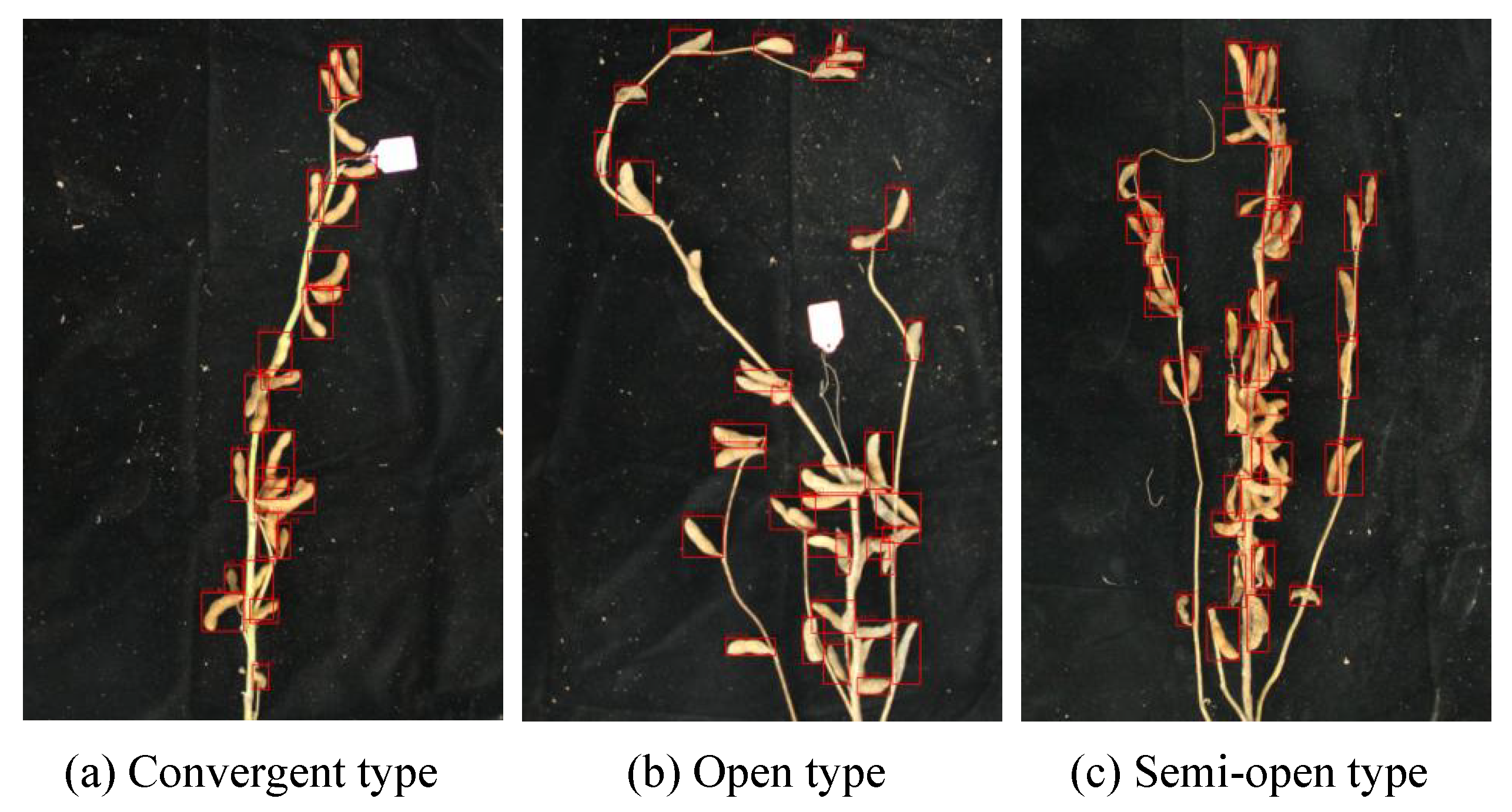
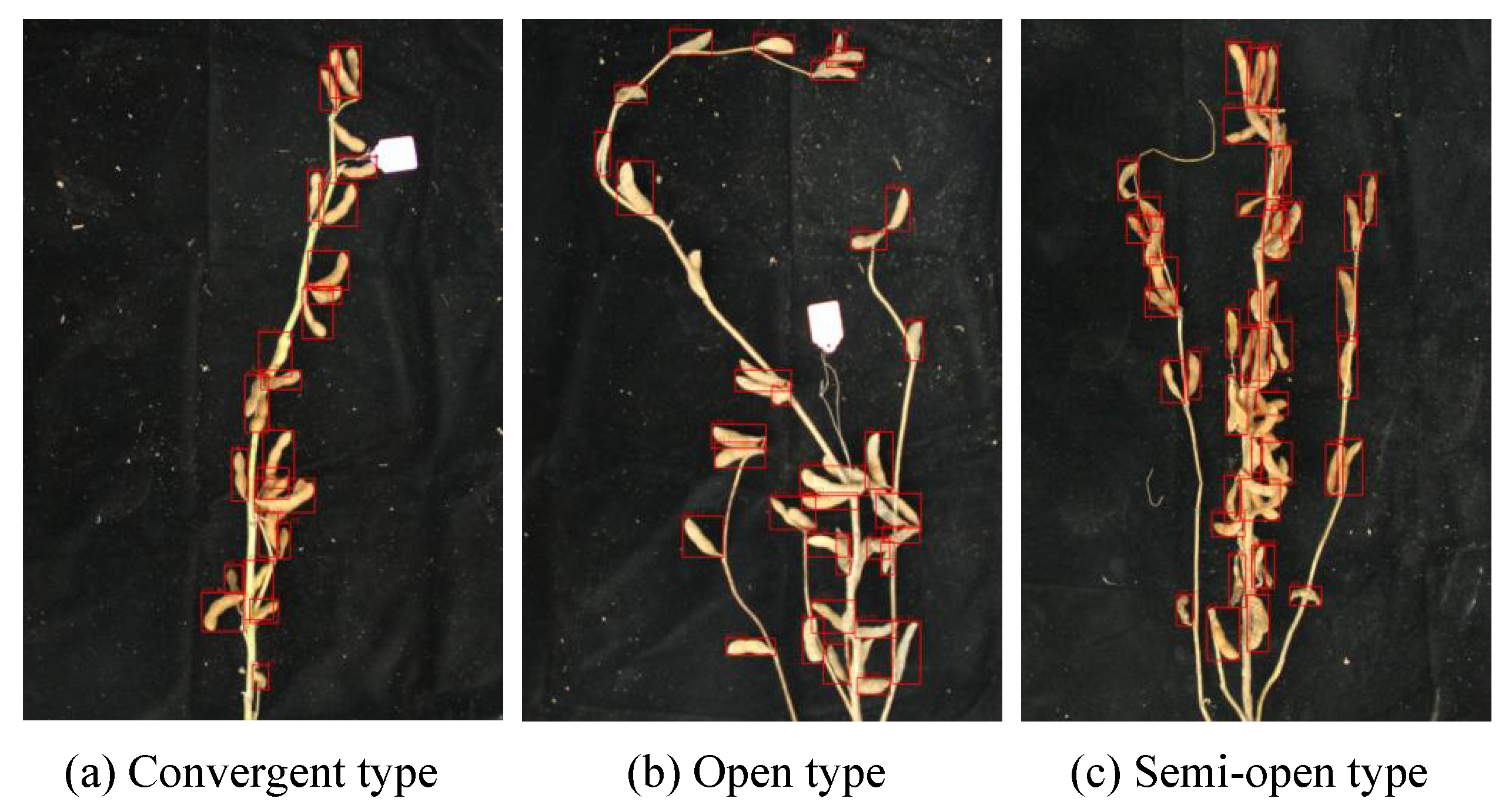
2.1. Image Acquisition and Annotation
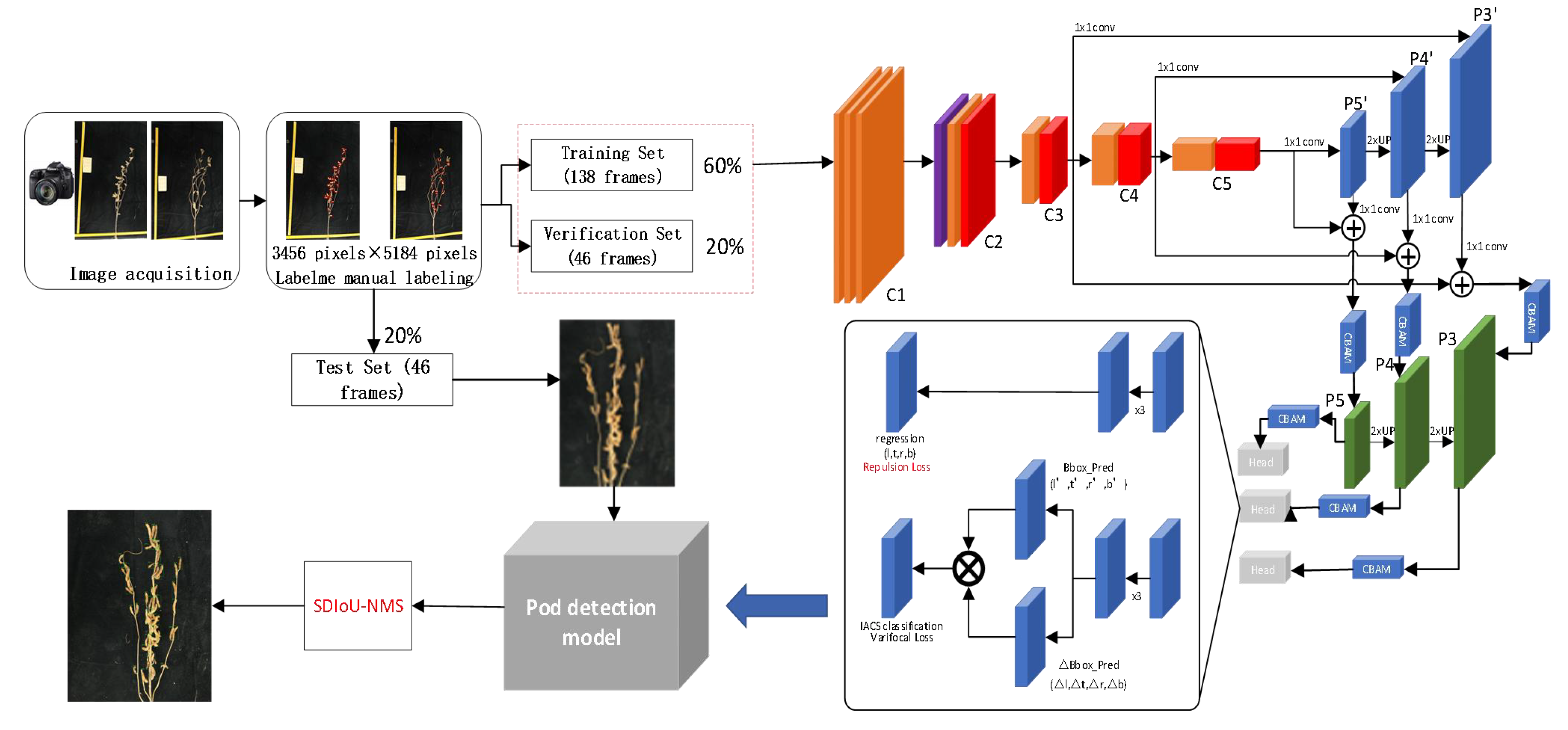
2.2. Design of DARFP-SD
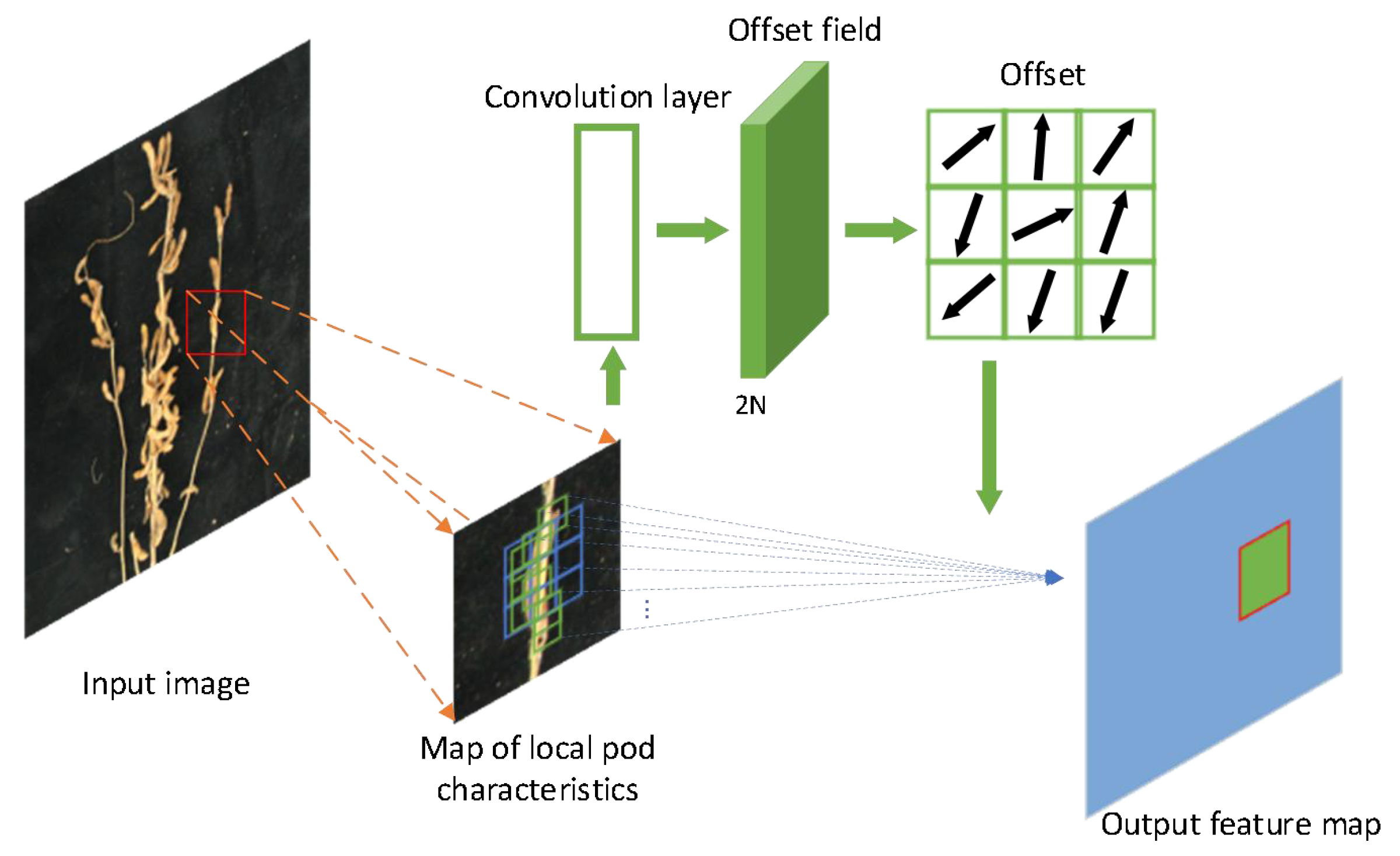
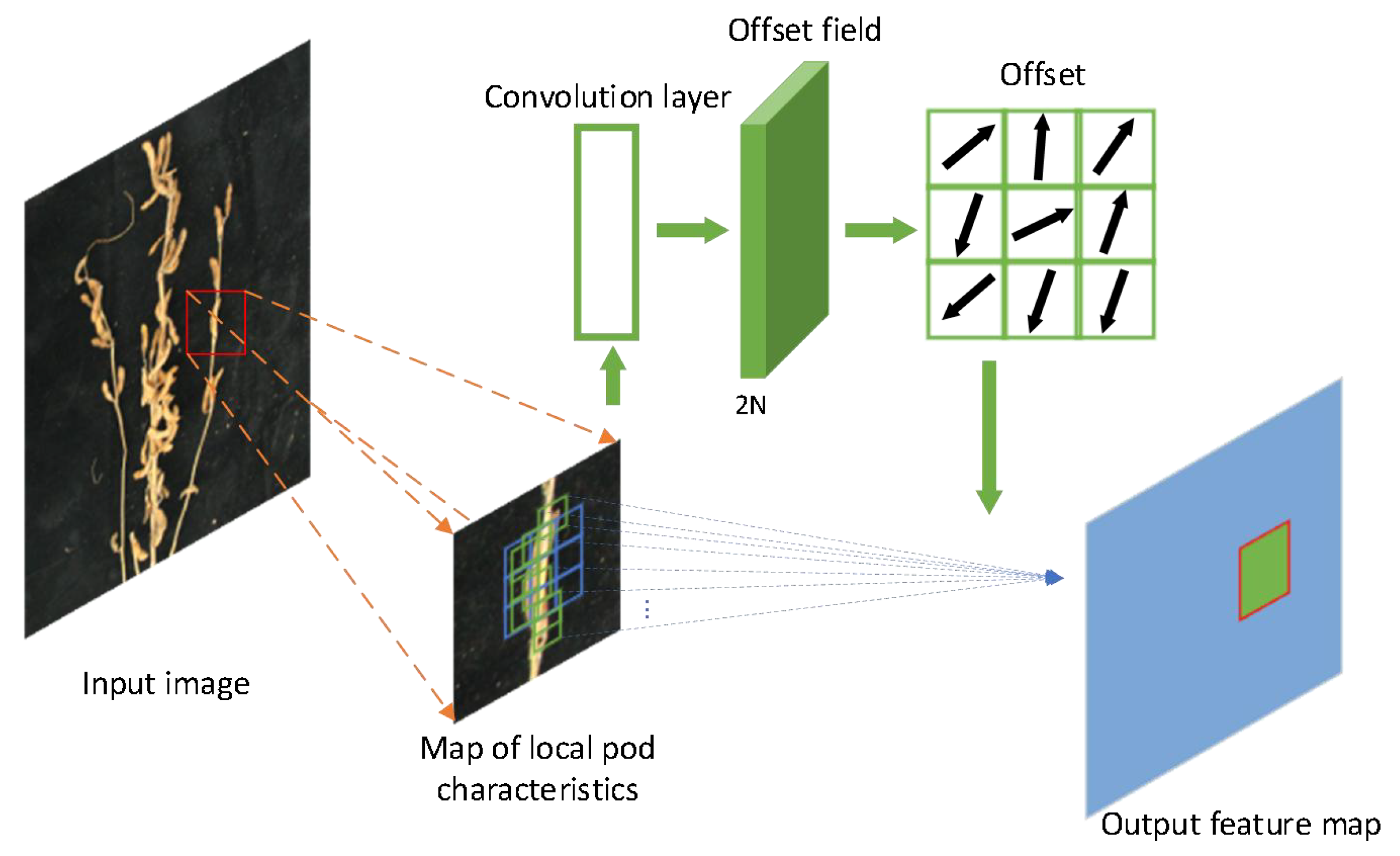
2.2.1. Deformable Attention Recursive Feature Pyramid
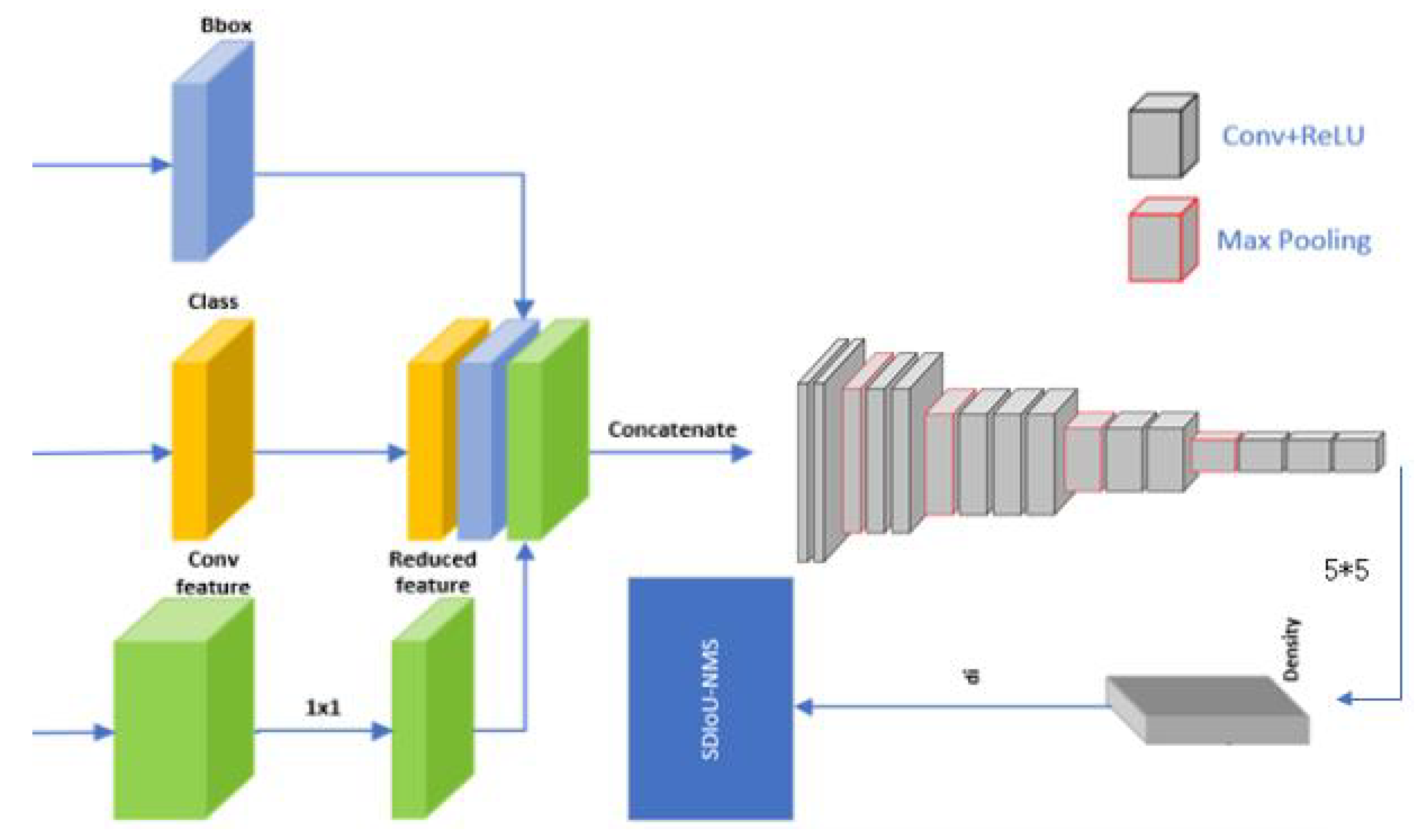
2.2.2. Bounding Box Refinement
2.2.3. Loss Function
2.3. Counting Pods Based on DARFP-SD
3. Results
3.1. Evaluation Index
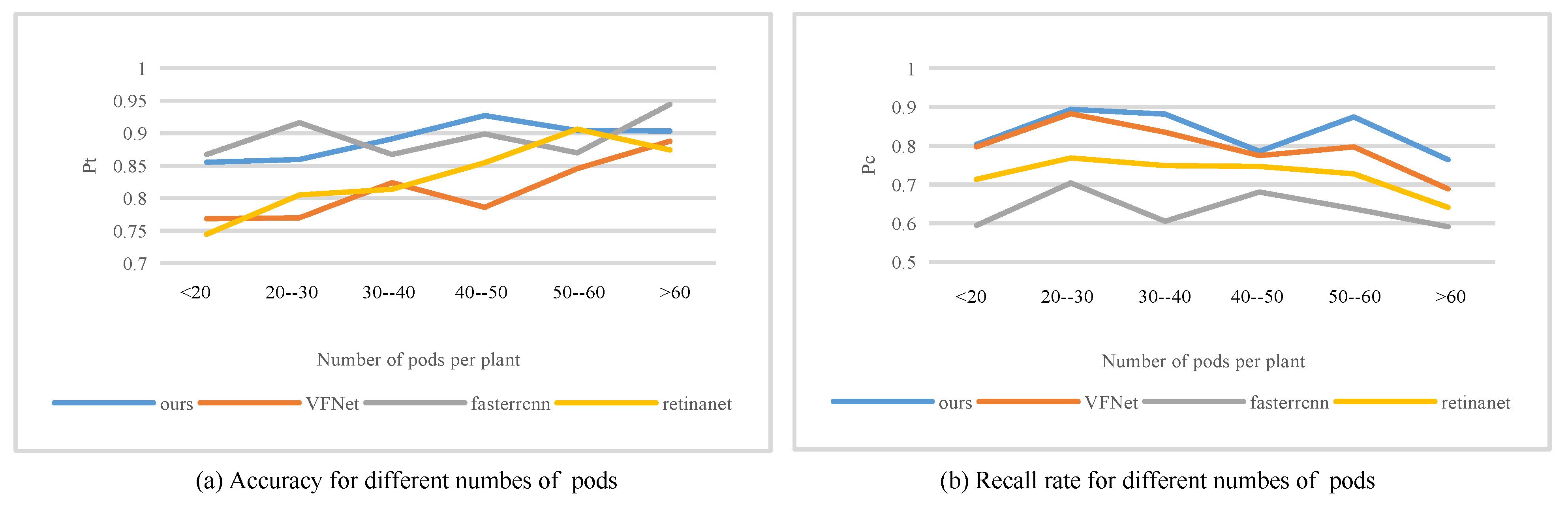
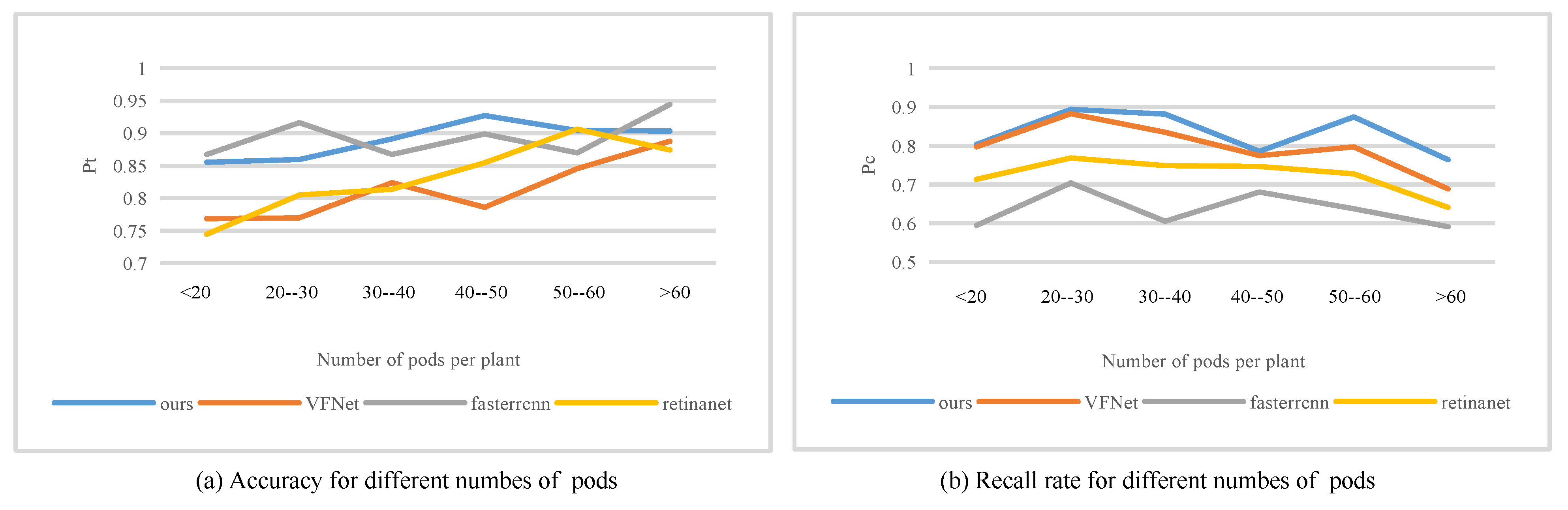
3.2. Comparison with SOTA Methods
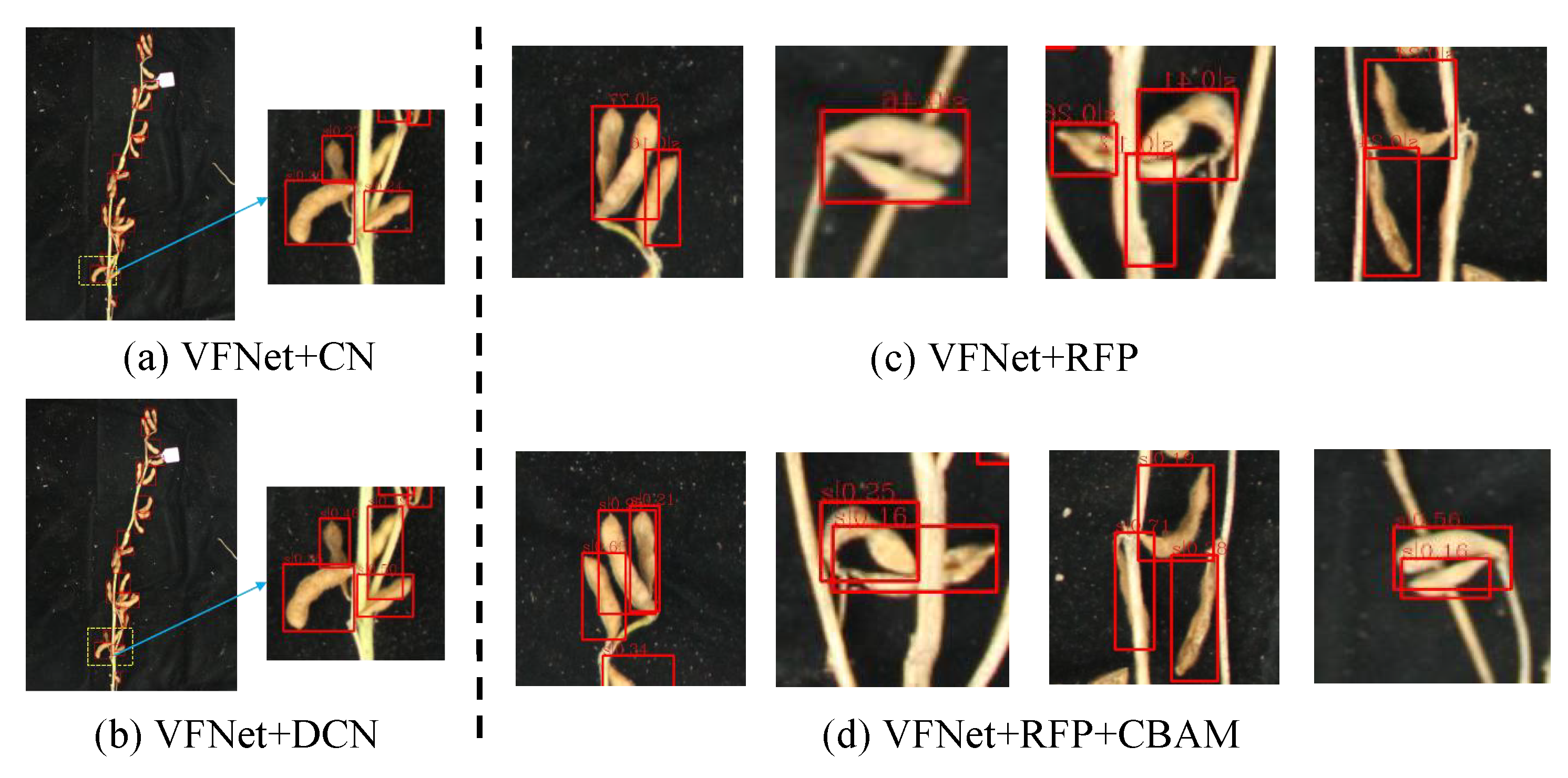
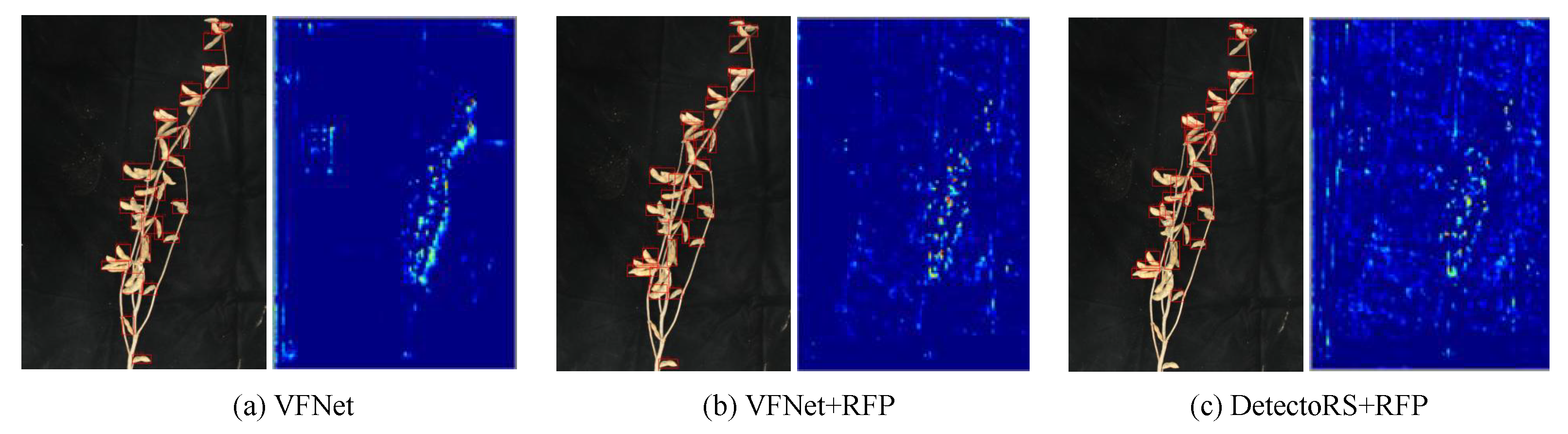
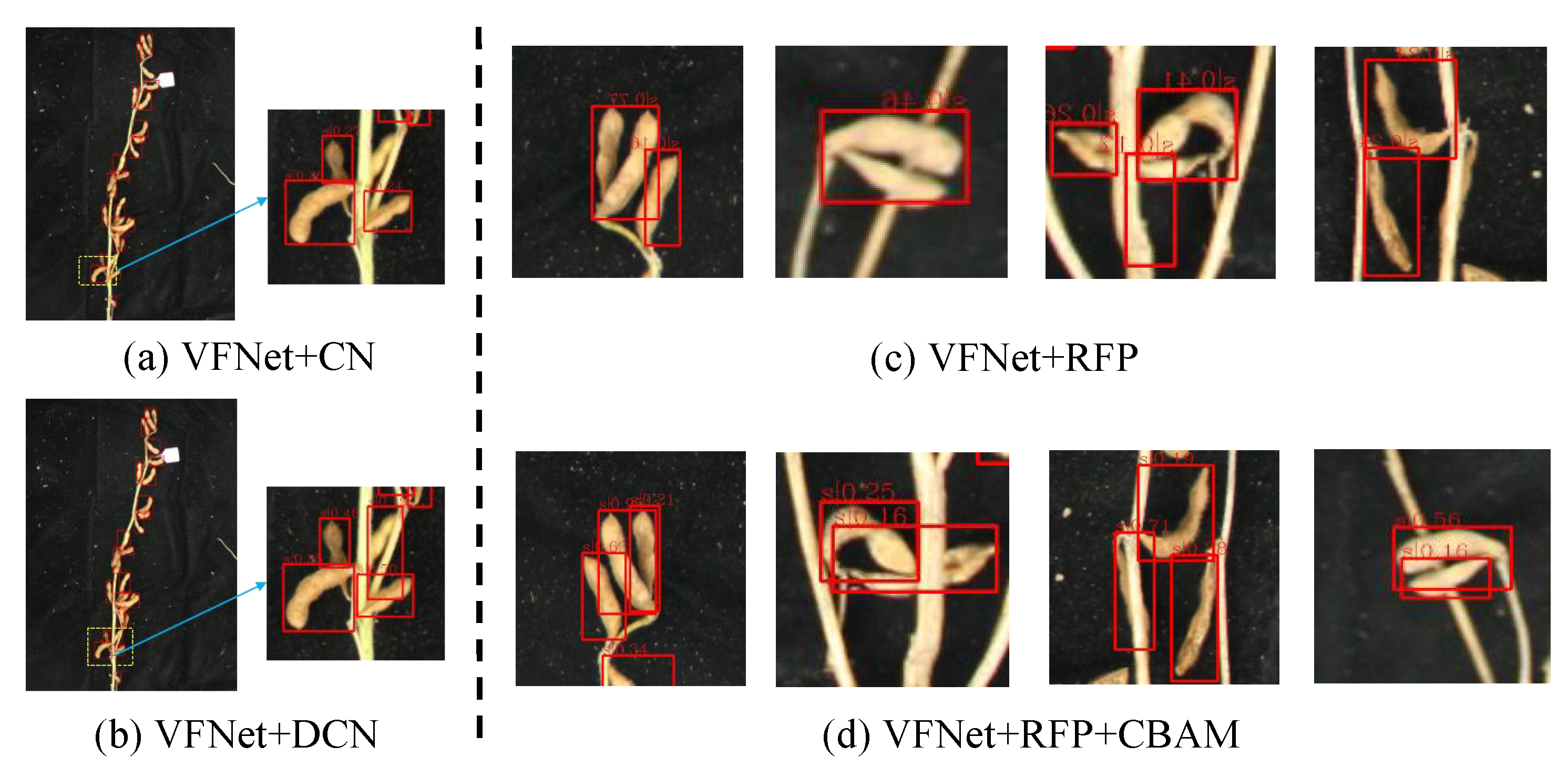
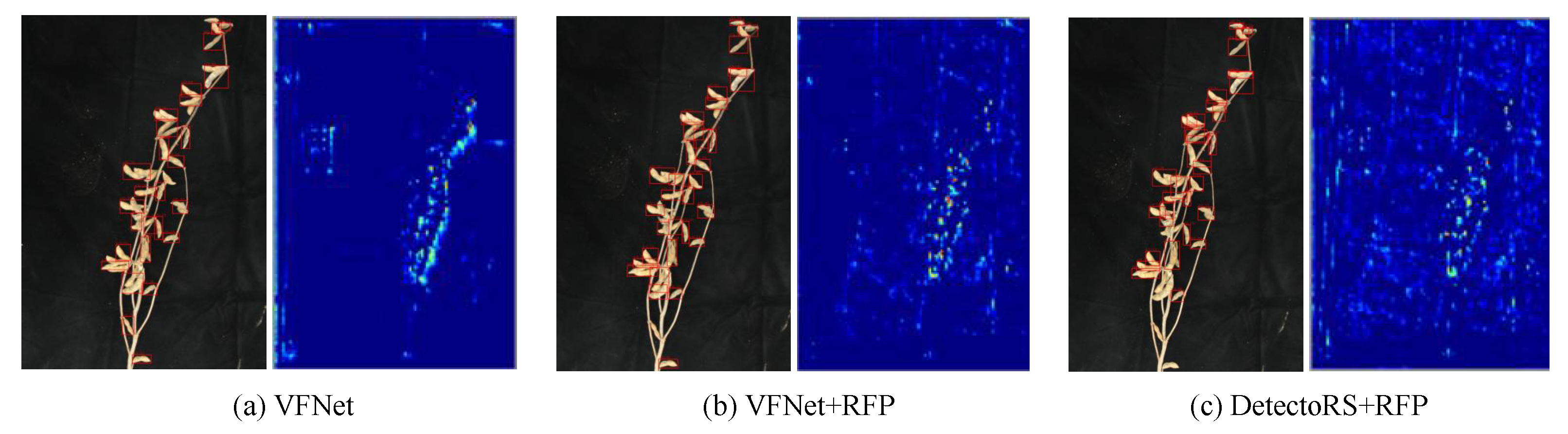
3.3. Effectiveness Analysis of ARFP
3.4. Effectiveness Analysis of BR
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Razfar, N.; True, J.; Bassiouny, R.; Venkatesh, V.; Kashef, R. Weed detection in soybean crops using custom lightweight deep learning models. J. Agric. Food Res. 2022, 8, 100308. [Google Scholar] [CrossRef]
- Zhao, J.; Yan, J.; Xue, T.; Wang, S.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W.; Zhang, X. A deep learning method for oriented and small wheat spike detection (OSWSDet) in UAV images. Comput. Electron. Agric. 2022, 198, 107087. [Google Scholar] [CrossRef]
- Shafi, U.; Mumtaz, R.; Shafaq, Z.; Zaidi, S.M.H.; Kaifi, M.O.; Mahmood, Z.; Zaidi, S.A.R. Wheat rust disease detection techniques: A technical perspective. J. Plant Dis. Prot. 2022, 129, 489–504. [Google Scholar] [CrossRef]
- Liu, C.; Wang, K.; Lu, H.; Cao, Z. Dynamic color transform networks for wheat head detection. Plant Phenomics 2022, 2022, 9818452. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Jiang, H.; Yuen, P.; Ahmad, K.Z.; Chen, Y. MHW-PD: A robust Rice Panicles Counting Algorithm based on Deep Learning and Multi-scale Hybrid Window. Comput. Electron. Agric. 2020, 173, 105375. [Google Scholar] [CrossRef]
- Tseng, H.H.; Yang, M.D.; Saminathan, R.; Hsu, Y.C.; Yang, C.Y.; Wu, D.H. Rice seedling detection in UAV images using transfer learning and machine learning. Remote Sens. 2022, 14, 2837. [Google Scholar] [CrossRef]
- Huang, M.L.; Wu, Y.S. GCS-YOLOV4-Tiny: A lightweight group convolution network for multi-stage fruit detection. Math. Biosci. Eng. 2023, 20, 241–268. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Zhou, H.; Wang, H.; Zhang, Y. Fruit detection and positioning technology for a Camellia oleifera C. Abel orchard based on improved YOLOv4-tiny model and binocular stereo vision. Expert Syst. Appl. 2023, 211, 118573. [Google Scholar] [CrossRef]
- Gao, F.; Fang, W.; Sun, X.; Wu, Z.; Zhao, G.; Li, G.; Li, R.; Fu, L.; Zhang, Q. A novel apple fruit detection and counting methodology based on deep learning and trunk tracking in modern orchard. Comput. Electron. Agric. 2022, 197, 107000. [Google Scholar] [CrossRef]
- Lyu, S.; Li, R.; Zhao, Y.; Li, Z.; Fan, R.; Liu, S. Green citrus detection and counting in orchards based on YOLOv5-CS and AI edge system. Sensors 2022, 22, 576. [Google Scholar] [CrossRef] [PubMed]
- Mamat, N.; Othman, M.F.; Abdulghafor, R.; Alwan, A.A.; Gulzar, Y. Enhancing Image Annotation Technique of Fruit Classification Using a Deep Learning Approach. Sustainability 2023, 15, 901. [Google Scholar] [CrossRef]
- Gulzar, Y. Fruit Image Classification Model Based on MobileNetV2 with Deep Transfer Learning Technique. Sustainability 2023, 15, 1906. [Google Scholar] [CrossRef]
- Sun, J.; Yang, K.; Chen, C.; Shen, J.; Yang, Y.; Wu, X.; Norton, T. Wheat head counting in the wild by an augmented feature pyramid networks-based convolutional neural network. Comput. Electron. Agric. 2022, 193, 106705. [Google Scholar] [CrossRef]
- Uzal, L.C.; Grinblat, G.L.; Namías, R.; Larese, M.G.; Bianchi, J.S.; Morandi, E.N.; Granitto, P.M. Seed-per-pod estimation for plant breeding using deep learning. Comput. Electron. Agric. 2018, 150, 196–204. [Google Scholar] [CrossRef]
- Guo, R.; Yu, C.; He, H.; Zhao, Y.; Yu, H.; Feng, X. Detection method of soybean pod number per plant using improved YOLOv4 algorithm. Trans. Chin. Soc. Agric. Eng. 2021, 37, 179–187. [Google Scholar]
- Li, S.; Yan, Z.; Guo, Y.; Su, X.; Cao, Y.; Jiang, B.; Yang, F.; Zhang, Z.; Xin, D.; Chen, Q.; et al. SPM-IS: An auto-algorithm to acquire a mature soybean phenotype based on instance segmentation. Crop J. 2022, 10, 1412–1423. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 764–773. [Google Scholar]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion loss: Detecting pedestrians in a crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7774–7783. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10213–10224. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Guayaquil, Ecuador, 4–7 July 2006; Volume 3, pp. 850–855. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Gulzar, Y.; Hamid, Y.; Soomro, A.B.; Alwan, A.A.; Journaux, L. A convolution neural network-based seed classification system. Symmetry 2020, 12, 2018. [Google Scholar] [CrossRef]
- Aggarwal, S.; Gupta, S.; Gupta, D.; Gulzar, Y.; Juneja, S.; Alwan, A.A.; Nauman, A. An Artificial Intelligence-Based Stacked Ensemble Approach for Prediction of Protein Subcellular Localization in Confocal Microscopy Images. Sustainability 2023, 15, 1695. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Training Set | Val Set | Test Set | Total |
|---|---|---|---|---|
| Convergent type | 48 | 16 | 16 | 80 |
| Semi-open type | 12 | 4 | 4 | 20 |
| Open type | 78 | 26 | 26 | 130 |
| Total | 138 | 46 | 46 | 230 |
| Method | TP | FP | % | ||
|---|---|---|---|---|---|
| Faster R-CNN | 1136 | 141 | 88.95 | 64.34 | 74.67 |
| RetinaNet | 1301 | 259 | 82.70 | 74.10 | 78.17 |
| YOLO V4 | 1327 | 253 | 83.50 | 75.69 | 79.40 |
| YOLO V5 | 1408 | 733 | 66.70 | 84.76 | 74.13 |
| VFNet | 1422 | 345 | 81.04 | 81.53 | 81.28 |
| DARFP-SD + VGG16 | 1335 | 300 | 80.52 | 82.23 | 81.36 |
| DARFP-SD + AlexNet | 1250 | 314 | 79.05 | 76.63 | 77.15 |
| DARFP-SD + DarkNet53 | 595 | 117 | 83.23 | 39.07 | 51.05 |
| DARFP-SD + MobilenetV3 | 841 | 214 | 79.03 | 51.79 | 60.26 |
| DARFP-SD + ResNet(ours) | 1502 | 179 | 90.35 | 85.59 | 87.90 |
| VFNet | DCN | RFP | CBAM | % | % | % | % | % | % |
|---|---|---|---|---|---|---|---|---|---|
| √ | × | × | × | 81.04 | 81.53 | 81.28 | / | / | / |
| √ | √ | × | × | 81.84 | 84.23 | 83.02 | +0.80 | +2.7 | +1.74 |
| √ | × | √ | × | 85.67 | 83.87 | 84.76 | +4.63 | +2.34 | +3.48 |
| √ | × | √ | √ | 87.09 | 84.67 | 85.86 | +6.05 | +3.14 | +4.58 |
| √ | √ | √ | √ | 87.57 | 85.06 | 86.30 | +6.53 | +3.53 | +5.02 |
| × | × | √ | × | 79.46 | 78.28 | 78.87 | −1.58 | −3.25 | −2.41 |
| Methods | Backbone | Loss Function | Post Processing | % | % | % |
|---|---|---|---|---|---|---|
| VFNet | ResNet50 + FPN | GIoU Loss | NMS | 81.04 | 81.53 | 81.28 |
| VFNet | ResNet50 + FPN | DIoU Loss | NMS | 82.37 | 81.62 | 81.99 |
| VFNet | ResNet50 + FPN | Repulsion Loss | NMS | 86.69 | 81.59 | 84.06 |
| Faster R-CNN | ResNet50 + FPN | GIoU Loss | NMS | 88.95 | 64.34 | 74.67 |
| Faster R-CNN | ResNet50 + FPN | Repulsion Loss | NMS | 89.82 | 64.78 | 75.28 |
| RetinaNet | ResNet50 + FPN | GIoU Loss | NMS | 82.70 | 74.10 | 78.17 |
| RetinaNet | ResNet50 + FPN | Repulsion Loss | NMS | 84.57 | 75.78 | 79.94 |
| Methods | Backbone | Loss Function | Post Processing | % | % | % |
|---|---|---|---|---|---|---|
| VFNet | ResNet50 + FPN | GIoU Loss | NMS | 81.04 | 81.53 | 81.28 |
| VFNet | ResNet50 + FPN | GIoU Loss | Soft-NMS | 80.91 | 81.83 | 81.37 |
| VFNet | ResNet50 + FPN | GIoU Loss | SDIoU-NMS | 82.44 | 83.10 | 82.77 |
| VFNet | ResNet50 + FPN | GIoU Loss | Adaptive SDIoU-NMS | 82.83 | 84.33 | 83.57 |
| Faster R-CNN | ResNet50 + FPN | GIoU Loss | NMS | 88.95 | 64.34 | 74.67 |
| Faster R-CNN | ResNet50 + FPN | GIoU Loss | SDIoU-NMS | 89.06 | 64.51 | 74.82 |
| Faster R-CNN | ResNet50 + FPN | GIoU Loss | Adaptive SDIoU-NMS | 89.51 | 64.98 | 75.30 |
| RetinaNet | ResNet50 + FPN | GIoU Loss | NMS | 82.70 | 74.10 | 78.17 |
| RetinaNet | ResNet50 + FPN | GIoU Loss | SDIoU-NMS | 83.86 | 75.32 | 79.36 |
| RetinaNet | ResNet50 + FPN | GIoU Loss | Adaptive SDIoU-NMS | 84.04 | 76.24 | 79.95 |
| Methods | Convergent | Open | Semi-Open | ||||||
|---|---|---|---|---|---|---|---|---|---|
| % | |||||||||
| Faster R-CNN | 88.49 | 65.30 | 75.15 | 88.55 | 65.68 | 75.42 | 89.30 | 63.54 | 74.25 |
| RetinaNet | 83.02 | 74.84 | 78.72 | 86.34 | 76.62 | 81.19 | 81.96 | 73.26 | 77.37 |
| VFNet | 83.39 | 81.57 | 82.47 | 88.98 | 75.34 | 81.60 | 78.38 | 82.42 | 80.35 |
| DARFP-SD (Ours) | 88.87 | 86.37 | 87.60 | 90.53 | 83.93 | 87.10 | 89.07 | 84.81 | 86.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Lu, Y.; Jiang, H.; Liu, S.; Ma, Y.; Zhao, T. Counting Crowded Soybean Pods Based on Deformable Attention Recursive Feature Pyramid. Agronomy 2023, 13, 1507. https://doi.org/10.3390/agronomy13061507
Xu C, Lu Y, Jiang H, Liu S, Ma Y, Zhao T. Counting Crowded Soybean Pods Based on Deformable Attention Recursive Feature Pyramid. Agronomy. 2023; 13(6):1507. https://doi.org/10.3390/agronomy13061507
Chicago/Turabian StyleXu, Can, Yinhao Lu, Haiyan Jiang, Sheng Liu, Yushi Ma, and Tuanjie Zhao. 2023. "Counting Crowded Soybean Pods Based on Deformable Attention Recursive Feature Pyramid" Agronomy 13, no. 6: 1507. https://doi.org/10.3390/agronomy13061507
APA StyleXu, C., Lu, Y., Jiang, H., Liu, S., Ma, Y., & Zhao, T. (2023). Counting Crowded Soybean Pods Based on Deformable Attention Recursive Feature Pyramid. Agronomy, 13(6), 1507. https://doi.org/10.3390/agronomy13061507