
Vernacular Names and Genetics of Cultivated Coffee (Coffea arabica) in Yemen


Abstract
1. Introduction
2. Materials and Methods
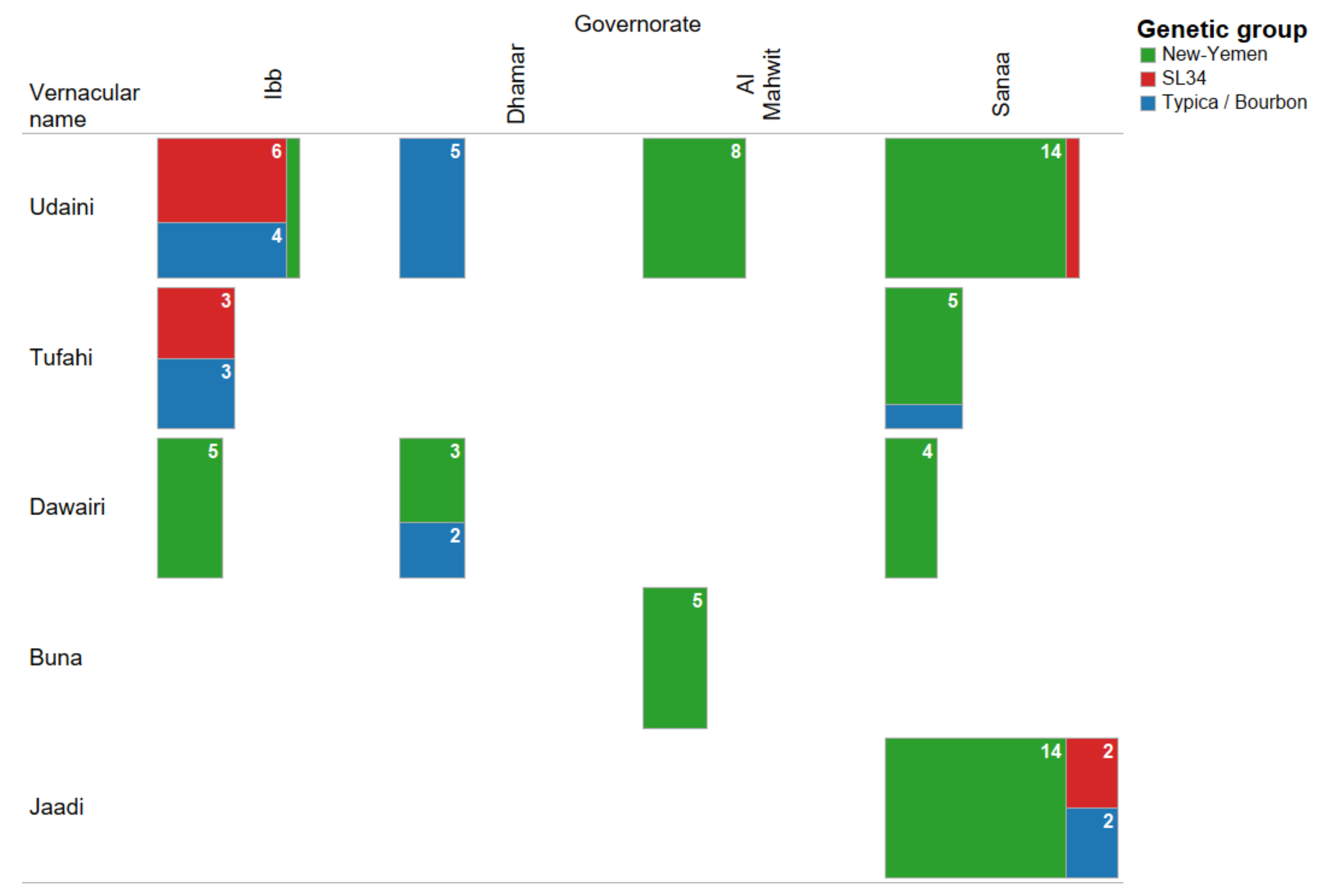
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Davis, A.P.; Gole, T.W.; Baena, S.; Moat, J. The impact of climate change on indigenous arabica coffee (Coffea arabica): Predicting future trends and identifying priorities. PLoS ONE 2012, 7, e47981. [Google Scholar] [CrossRef]
- Krishnan, S.; Pruvot-Woehl, S.; Davis, A.P.; Schilling, T.; Moat, J.; Solano, W.; Al Hakimi, A.; Montagnon, C. Validating South Sudan as a Center of Origin for Coffea arabica: Implications for Conservation and Coffee Crop Improvement. Front. Sustain. Food Syst. 2021, 5, 445. [Google Scholar] [CrossRef]
- De La Roque, J. Voyage de l’Arabie Heureuse, par l’Océan Oriental, et le Détroit de la Mer Rouge: Fait par les François Pour la Première Fois, Dans Les Années 1708, 1709 et 1710; André Cailleau: Paris, France, 1716; Available online: https://play.google.com/books/reader?id=3fsOAAAAQAAJ&hl=fr&num=10&printsec=frontcover&pg=GBS.PP7 (accessed on 1 July 2022).
- Ukers, M.A. All about Coffee; The Tea and Coffee Trade Journal: New York, NY, USA, 1922. [Google Scholar]
- Chevalier, A. Les caféiers du globe. I. In Généralités sur les Caféiers. Encyclopédie Biologique; Paul Lechevalier: Paris, France, 1929. [Google Scholar]
- Cramer, P.J.S. A Review of Literature of Coffee Research in Indonesia (from about 1602 to 1945); IICA: Turrialba, Costa Rica, 1957. [Google Scholar]
- Haarer, A.E. Modern coffee production. In Ebenezer Baylis and Son; The Trinity Press: London, UK, 1958. [Google Scholar]
- Meyer, F.G. Notes on wild Coffea arabica from Southwestern Ethiopia, with some historical considerations. Econ. Bot. 1965, 19, 136–151. [Google Scholar] [CrossRef]
- Koehler, J. Where the Wild Coffee Grows: The Untold Story of Coffee from the Cloud Forests of Ethiopia to Your Cup; Bloomsbury Publishing: New York, NY, USA, 2017. [Google Scholar]
- Anthony, F.; Bertrand, B.; Quiros, O.; Wilches, A.; Lashermes, P.; Berthaud, J.; Charrier, A. Genetic diversity of wild coffee (Coffea arabica L.) using molecular markers. Euphytica 2001, 118, 53–65. [Google Scholar] [CrossRef]
- Anthony, F.; Combes, M.C.; Astorga, C.; Bertrand, B.; Graziosi, G.; Lashermes, P. The origin of cultivated Coffea arabica L. varieties revealed by AFLP and SSR markers. Theor. Appl. Genet. 2002, 104, 894–900. [Google Scholar] [CrossRef]
- Silvestrini, M.; Junqueira, M.G.; Favarin, A.C.; Guerreiro-Filho, O.; Maluf, M.P.; Silvarolla, M.B.; Colombo, C.A. Genetic diversity and structure of Ethiopian, Yemen and Brazilian Coffea arabica L. accessions using microsatellites markers. Genet. Resour. Crop Evol. 2007, 54, 1367–1379. [Google Scholar] [CrossRef]
- Scalabrin, S.; Toniutti, L.; Di Gaspero, G.; Scaglione, D.; Magris, G.; Vidotto, M.; Pinosio, S.; Cattonaro, F.; Magni, F.; Jurman, I.; et al. A single polyploidization event at the origin of the tetraploid genome of Coffea arabica is responsible for the extremely low genetic variation in wild and cultivated germplasm. Sci. Rep. 2020, 10, 4642. [Google Scholar] [CrossRef]
- Montagnon, C.; Mahyoub, A.; Solano, W.; Sheibani, F. Unveiling a unique genetic diversity of cultivated Coffea arabica L. in its main domestication center: Yemen. Genet. Resour. Crop Evol. 2021, 68, 2411–2422. [Google Scholar] [CrossRef]
- Browning, D. How Many Coffee Farms Are There in the World? In Proceedings of the ASIC Conference, Portland, OR, USA, 16–20 September 2018; Available online: https://www.youtube.com/watch?v=vKaeDkpqPSg (accessed on 1 July 2022).
- Bunn, C.; Läderach, P.; Jimenez, J.G.P.; Montagnon, C.; Schilling, T. Multiclass classification of agro-ecological zones for Arabica coffee: An improved understanding of the impacts of climate change. PLoS ONE 2015, 10, e0140490. [Google Scholar] [CrossRef]
- Ovalle-Rivera, O.; Läderach, P.; Bunn, C.; Obersteiner, M.; Schroth, G. Projected shifts in Coffea arabica suitability among major global producing regions due to climate change. PLoS ONE 2015, 10, e0124155. [Google Scholar] [CrossRef]
- USAID. Moving Yemen Coffee Forward. In Assessment of the Coffee Industry in Yemen to Sustainably Improve Incomes and Expand Trades; USAID: Washington, DC, USA, 2005. Available online: https://pdf.usaid.gov/pdf_docs/Pnadf516.pdf (accessed on 12 July 2022).
- Al-Zaidi, A.A.; Baig, M.B.; Shalaby, M.Y.; Hazber, A. Level of knowledge and its application by coffee farmers in the Udeen Area, Governorate of IBB-Republic of Yemen. J. Anim. Plant Sci. 2016, 26, 1797–1804. [Google Scholar]
- Cambrony, H.R.; Vincent, J.C.; Wierer, C. Caféiculture au Yémen 1975. In Problèmes Révélés à L’occasion d’une Mission d’étude de la Production du Traitement et de la Commercialisation, Suggestions Pour une Réhabilitation; Gerdad-IFCC: Montpellier, France, 1975. [Google Scholar]
- Robinson, J.B.D. Coffee in Yemen: A practical guide. In Rural Development Project Al-Mahwit Province; Klaus Schwarz Verlag: Berlin, Germany, 1993. [Google Scholar]
- Ebrahim, N.; Shibli, R.; Makhadmeh, I.; Shatnawi, M.; Abu-Ein, A. In vitro propagation and in vivo acclimatization of three coffee cultivars (Coffea arabica L.) from Yemen. World Appl. Sci. J. 2007, 2, 142–150. [Google Scholar]
- Al-Azab, A.; Habib, S.; Hussein, M.; El-Sherif, F. Micropropagation of Four Coffee Cultivars (Coffea arabica L.) from Yemen through Shoot Tip Culture. Hortsci. J. Suez Canal Univ. 2015, 4, 25–31. [Google Scholar]
- Hussein, M.A.; Al-Azab, A.; Habib, S.; El Sherif, F.M.; El-Garhy, H.A. Genetic Diversity, Structure and DNA Fingerprint for Developing Molecular IDs of Yemeni Coffee (Coffea Arabica L.) Germplasm Assessed by SSR Markers. Egypt. J. Plant Breed. 2017, 203, 713–736. [Google Scholar]
- Combes, M.C.; Andrzejewski, S.; Anthony, F.; Bertrand, B.; Rovelli, P.; Graziosi, G.; Lashermes, P. Characterization of microsatellite loci in Coffea arabica and related coffee species. Mol. Ecol. 2002, 9, 1178–1180. [Google Scholar] [CrossRef]
- Pruvot-Woehl, S.; Krishnan, S.; Solano, W.; Schilling, T.; Toniutti, L.; Bertrand, B.; Montagnon, C. Authentication of Coffea arabica Varieties through DNA Fingerprinting and its Significance for the Coffee Sector. J. AOAC Int. 2020, 103, 325–334. [Google Scholar] [CrossRef]
- Sham, P.C.; Curtis, D. Monte Carlo tests for associations between disease and alleles at highly polymorphic loci. Ann. Hum. Genet. 1995, 59, 97–105. [Google Scholar] [CrossRef]
- Addinsoft. XLSTAT Statistical and Data Analysis Solution; Addinsoft: Paris, France, 2022; Available online: https://www.xlstat.com/fr (accessed on 12 July 2022).
- Perrier, X.; Jacquemoud-Collet, J.P. DARwin Software. 2006. Available online: http://darwin.cirad.fr/darwin (accessed on 12 July 2022).
- Murray, D.G. Tableau Your Data!: Fast and Easy Visual Analysis with Tableau Software; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- International Plant Genetic Resources Institute. Descriptors for Coffee (Coffea spp. and Psilanthus spp.); IPGRI: Paris, France, 1996; Available online: https://www.bioversityinternational.org/fileadmin/user_upload/online_library/publications/pdfs/365.pdf (accessed on 12 July 2022).
- Krug, C.A.; Mendes, J.E.T.; Carvalho, A. Taxonomia de Coffea arabica L.: II-Coffea arabica L. Var. Caturra e sua forma Xanthocarpa. Bragantia 1949, 9, 157–163. [Google Scholar]
- Carvalho, A. Genética de Coffea: IV. Instabilidade do par de alelos Na-na de Coffea arabica L. Bragantia 1941, 1, 453–466. [Google Scholar]
- Carvalho, A.; Filho, H.P.M.; Fazuoli, L.C.; Costa, W.M.D. Genética de Coffea: XXVI. Hereditariedade do porte reduzido do cultivar Caturra. Bragantia 1984, 43, 443–458. [Google Scholar]
- Krug, C.A. Mutações em Coffea arabica L. Bragantia 1949, 9, 1–10. [Google Scholar] [CrossRef]
- Lécolier, A.; Besse, P.; Charrier, A.; Tchakaloff, T.N.; Noirot, M. Unraveling the origin of Coffea arabica ‘Bourbon pointu’ from La Réunion: A historical and scientific perspective. Euphytica 2009, 168, 1–10. [Google Scholar] [CrossRef]
- Eskes, A.B. Identification, Description and Collection of Coffee Types in P.D.R. Yemen; Technical Report of Mission 15 April–7 May 1989; IRCC-CIRAD: Montpellier, France, 1989; Available online: http://agritrop.cirad.fr/359247/1/ID359247.pdf (accessed on 1 July 2022).
- Benti, T.; Gebre, E.; Tesfaye, K.; Berecha, G.; Lashermes, P.; Kyallo, M.; Yao, N.K. Genetic diversity among commercial arabica coffee (Coffea arabica L.) varieties in Ethiopia using simple sequence repeat markers. J. Crop Improv. 2021, 35, 147–168. [Google Scholar] [CrossRef]
- Hill, T.; Bekele, G. A Reference Guide to Ethiopian Coffee Varieties; Counter Culture Coffee: Durham, NC, USA, 2018. [Google Scholar]
- Tesfaye, K.; Oljira, T.; Govers, K.; Belkele, E.; Borsh, T. Genetic diversity and population structure of wild Coffea arabica populations in Ethiopia using molecular markers. In Coffee Diversity and Knowledge; Adugna, G., Bellachew, B., Taye, E., Kufa, T., Eds.; Ethiopian Institute of Agricultural Research: Jimma, Ethiopia, 2008; pp. 35–44. [Google Scholar]
- Aga, E.; Bekele, E.; Bryngelsson, T. Inter-simple sequence repeat (ISSR) variation in forest coffee trees (Coffea arabica L.) populations from Ethiopia. Genetica 2005, 124, 213–221. [Google Scholar] [CrossRef]
- Dida, G.; Bantte, K.; Disasa, T. Molecular characterization of Arabica Coffee (Coffea arabica L.) germplasms and their contribution to biodiversity in Ethiopia. Plant Biotechnol. Rep. 2021, 15, 791–804. [Google Scholar] [CrossRef]
- Carvalho, A.; Krug, C.A. Agentes de polinizacao da flor do cafeeiro (Coffea arabica L.). Bragantia 1949, 9, 11–24. [Google Scholar] [CrossRef]
- Castillo-Zapata, J. Tasa de polinization cruzada del café arabigo en la region de Chinchina. Cenicafe 1976, 27, 78–88. [Google Scholar]
- Berecha, G.; Aerts, R.; Vandepitte, K.; Van Glabeke, S.; Muys, B.; Roldán-Ruiz, I.; Honnay, O. Effects of forest management on mating patterns, pollen flow and intergenerational transfer of genetic diversity in wild Arabica coffee (Coffea arabica L.) from Afromontane rainforests. Biol. J. Linn. Soc. 2014, 112, 76–88. [Google Scholar] [CrossRef]
- Peroni, N.; Kageyama, P.Y.; Begossi, A. Molecular differentiation, diversity, and folk classification of “sweet” and “bitter” cassava (Manihot esculenta) in Caiçara and Caboclo management systems (Brazil). Genet. Resour. Crop Evol. 2007, 54, 1333–1349. [Google Scholar] [CrossRef]
- Birmeta, G.; Nybom, H.; Bekele, E. RAPD analysis of genetic diversity among clones of the Ethiopian crop plant Ensete ventricosum. Euphytica 2002, 124, 315–325. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
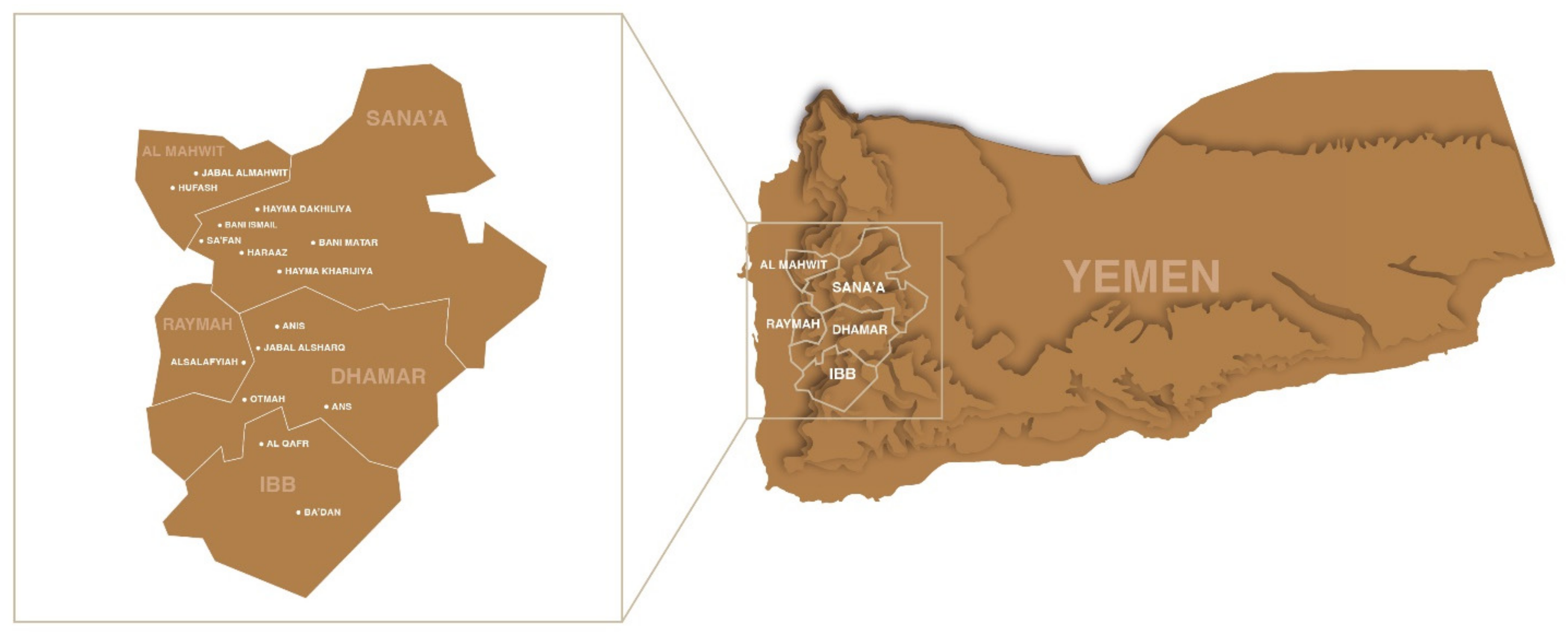
| Indication of Vernacular Names | # Samples for Genotyping for Main Vernacular Names | ||||||
|---|---|---|---|---|---|---|---|
| Governorate | Region | # Farms | Udaini | Dawairi | Buna | Jaadi | Tufahi |
| Al Mahwit | Hufash | 8 | |||||
| Jabal Almahwit | 22 | 8 | 5 | ||||
| Total | 30 | ||||||
| Dhamar | Anis | 4 | |||||
| Ans | 13 | 5 | 5 | ||||
| Jabal Alsharq | 2 | ||||||
| Otmah | 4 | ||||||
| Total | 23 | ||||||
| Ibb | Alqafr | 25 | 11 | 5 | 6 | ||
| Ba’dan | 6 | ||||||
| Total | 31 | ||||||
| Raymah | Alsalafyiah | 5 | |||||
| Total | 5 | ||||||
| Sanaa | Bani Ismail | 5 | |||||
| Bani Matar | 3 | 2 | 1 | 1 | |||
| Hayma Dakhiliya | 12 | 4 | |||||
| Hayma Kharijiya | 11 | 13 | 3 | 3 | |||
| Haraaz | 28 | 13 | 3 | ||||
| Total | 59 | ||||||
| Grand Total | 148 | 39 | 14 | 5 | 18 | 12 | |
| Code of Microsatellite | Primer Sequence Forward | Primer Sequence Reverse | Size Product (bp) |
|---|---|---|---|
| Sat-11 | ACCCGAAAGAAAGAACCAA | CCACACAACTCTCCTCATTC | 143–145 |
| Sat-207 | CAATCTCTTTCCGATGCTCT | GAAGCCGTTTCAAGCC | 83–93 |
| Sat-225 | CATGCCATCATCAATTCCAT | TTACTGCTCATCATTCCGCA | 283–317 |
| Sat-235 | TCGTTCTGTCATTAAATCGTCAA | GCAAATCATGAAAATAGTTGGTG | 245–278 |
| Sat-24 | GGCTCGAGATATCTGTTTAG | TTTAATGGGCATAGGGTCC | 167–181 |
| Sat-244 | GCATACTAAGGAATTATCTGACTGCT | GCATGTGCTTTTTGATGTCGT | 178–306 |
| Sat-254 | ATGTTCTTCGCTTCGCTAAC | AAGTGTGGGAGTGTCTGCAT | 221–237 |
| Sat-29 | GACCATTACATTTCACACAC | GCATTTTGTTGCACACTGTA | 137–154 |
| Sat-32 | AACTCTCCATTCCCGCATTC | CTGGGTTTTCTGTGTTCTCG | 119–125 |
| Sat-47 | TGATGGACAGGAGTTGATGG | TGCCAATCTACCTACCCCTT | 135–169 |
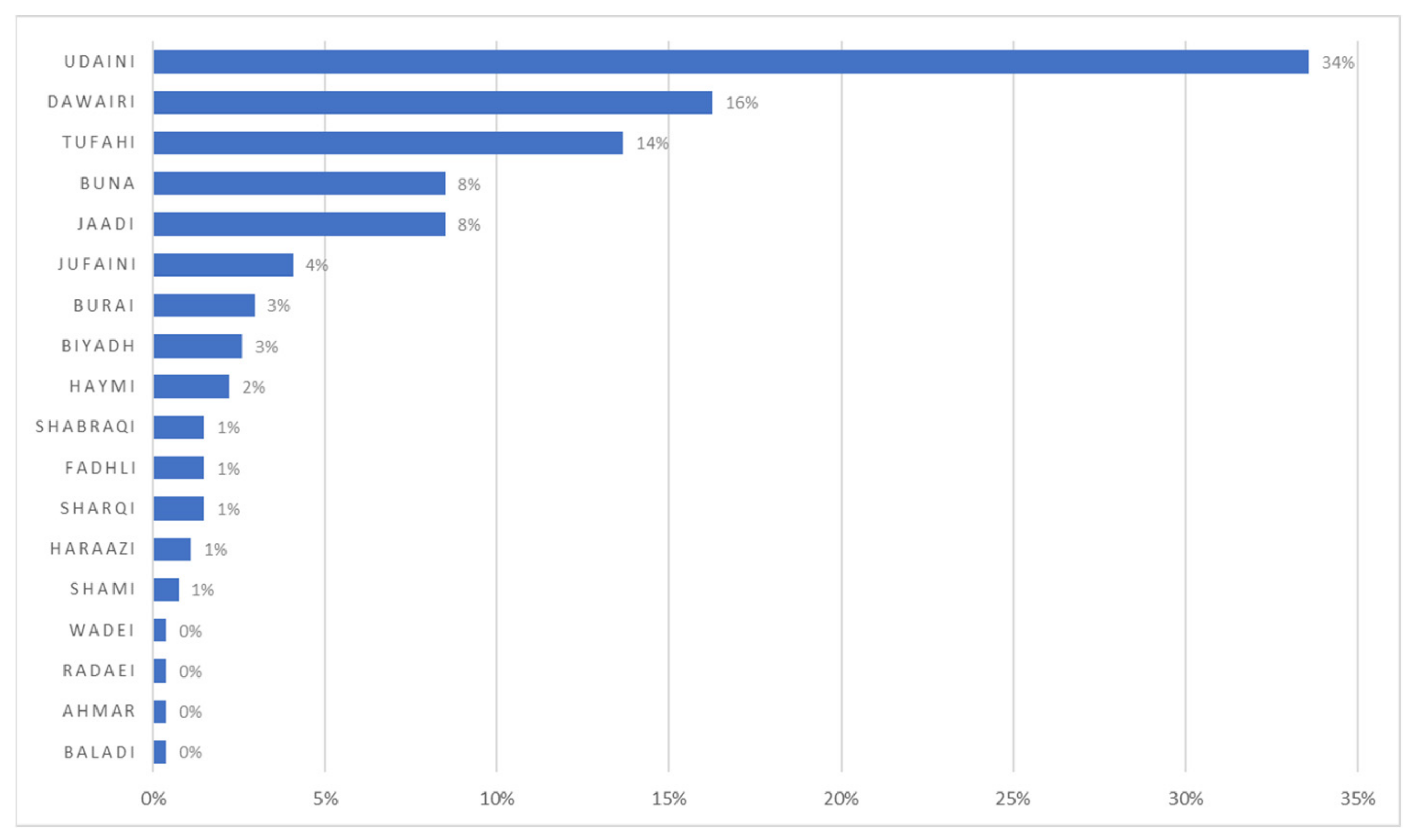
| Variety | Frequency | Named after a Region of Origin | Named after a Specific Visible Trait | Comments |
|---|---|---|---|---|
| Udaini | 34% | Al Udaini | ||
| Dawairi | 16% | Tree shape | “Dawairi” means “rounded” in Arabic, possibly related to bushy shape | |
| Tufahi | 14% | Coffee cherries are apple-shaped | ||
| Jaadi | 8% | Clustered cherries—close together | “Jadi” in Arabic can be translated to “curly” or “rough”. Some farmers state it refers to curly leaves, others state it refers to rough cherry clusters that are difficult to pick. | |
| Buna | 8% | For smaller trees and cherries | “Buna” is the feminine of “bun” which is “coffee” in Arabic. In Arabic sometimes, the feminine noun can be used to represent smaller size/structure; hence possibly related to smaller trees | |
| Jufaini | 4% | Shape of cherries—elongated | “Jufain” means “eyelids”—possibly related to the shape of the cherry and/or the bean, like almonds in shape. | |
| Burai | 3% | Bura | ||
| Biyadh | 3% | Cherries are lighter in colour | “Bayad” comes from the word “white” in Arabic | |
| Haymi | 2% | Hayma | ||
| Sharqi | 1% | Sharqi Haraaz | ||
| Fadhli | 1% | Bani Fadl | ||
| Shabraqi | 1% | Lowest branches fall rip apart as if they were naturally pruned | “Shobraq” means “ripped apart” in Arabic | |
| Harazi | 1% | Haraaz | ||
| Shami | 1% | Yellow cherries | The word “sham” can mean corn (which are yellow in colour), likely refering to the yellow cherry mutation | |
| Baladi | 0% | Local | “Baladi” means “local” in Arabic | |
| Ahmar | 0% | Red | “Ahmar” is translated literally to “red” | |
| Radaei | 0% | Radaa | ||
| Wadei | 0% | Yadi |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Montagnon, C.; Rossi, V.; Guercio, C.; Sheibani, F. Vernacular Names and Genetics of Cultivated Coffee (Coffea arabica) in Yemen. Agronomy 2022, 12, 1970. https://doi.org/10.3390/agronomy12081970
Montagnon C, Rossi V, Guercio C, Sheibani F. Vernacular Names and Genetics of Cultivated Coffee (Coffea arabica) in Yemen. Agronomy. 2022; 12(8):1970. https://doi.org/10.3390/agronomy12081970
Chicago/Turabian StyleMontagnon, Christophe, Veronica Rossi, Carolina Guercio, and Faris Sheibani. 2022. "Vernacular Names and Genetics of Cultivated Coffee (Coffea arabica) in Yemen" Agronomy 12, no. 8: 1970. https://doi.org/10.3390/agronomy12081970
APA StyleMontagnon, C., Rossi, V., Guercio, C., & Sheibani, F. (2022). Vernacular Names and Genetics of Cultivated Coffee (Coffea arabica) in Yemen. Agronomy, 12(8), 1970. https://doi.org/10.3390/agronomy12081970