
Machine Learning Approach to Simulate Soil CO2 Fluxes under Cropping Systems



Abstract
:1. Introduction
1.1. Review of Previous Studies
1.2. Rationale for ML Study of Soil CO2
1.3. Purpose of Study
2. Materials and Methods
2.1. Description of the Database
2.2. Preprocessing
2.3. Machine Learning Implementation
2.4. Computational Software
2.5. Machine Learning Techniques
3. Results and Discussion
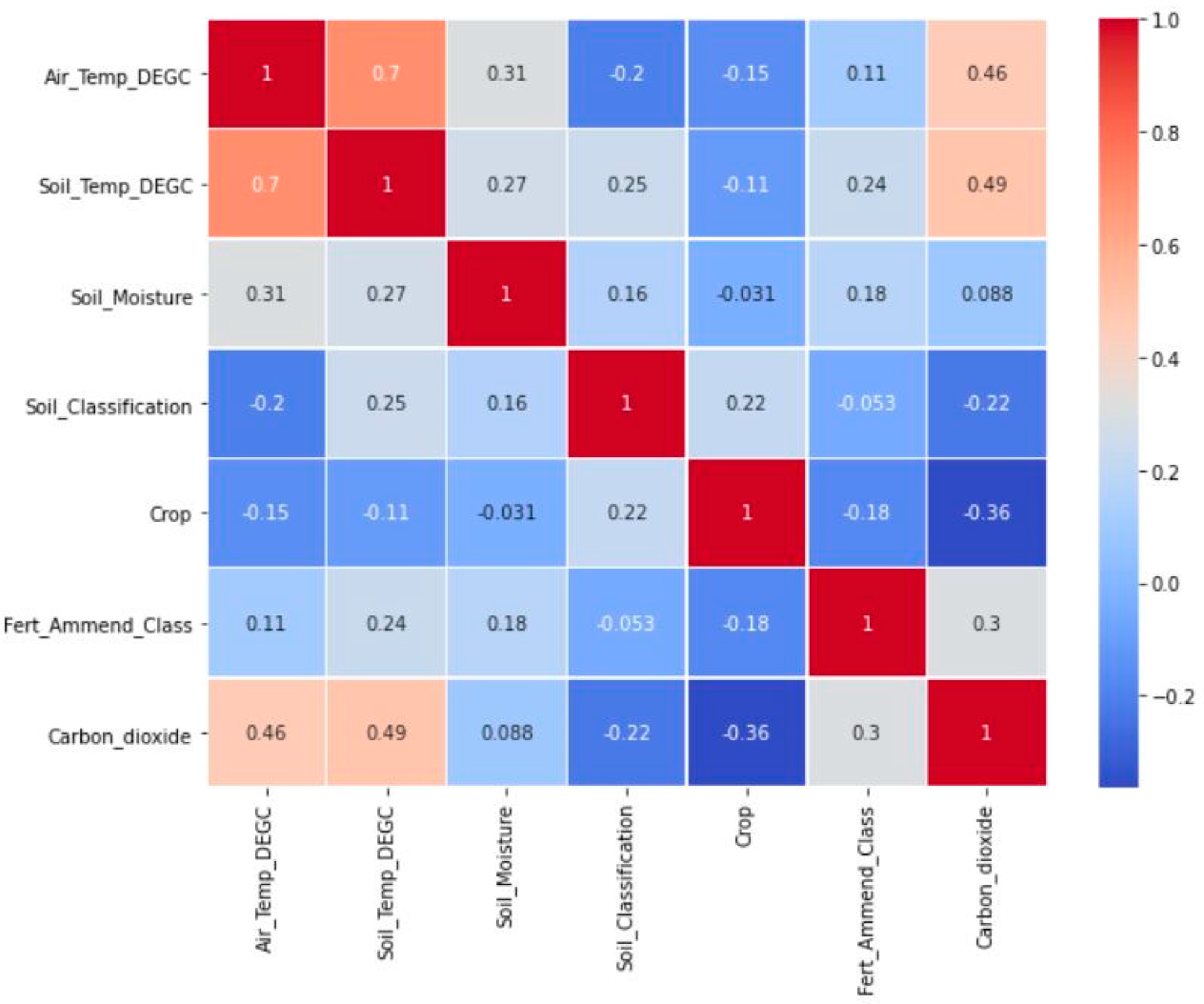
3.1. Feature Selection
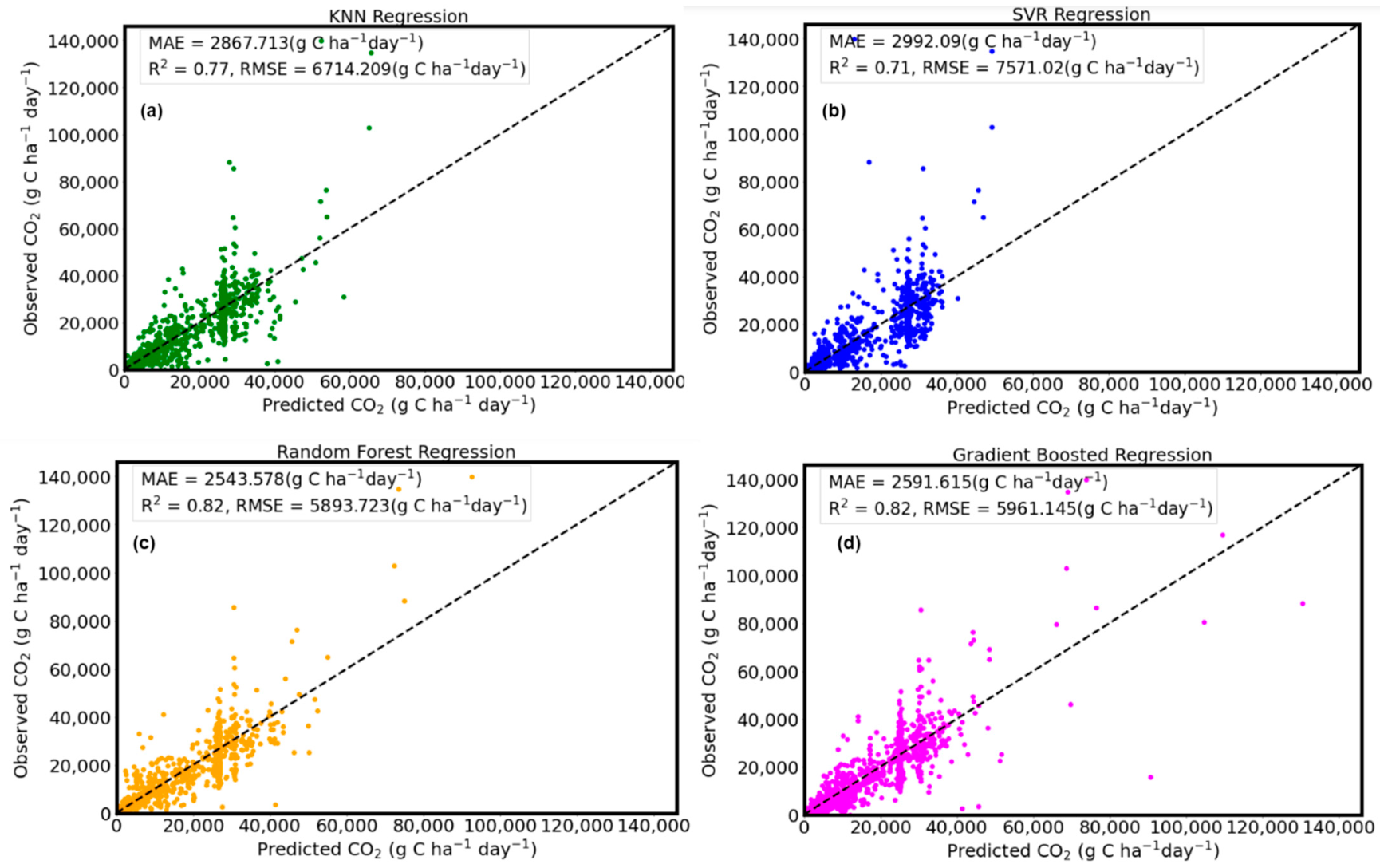
3.2. Model Performance Assessment
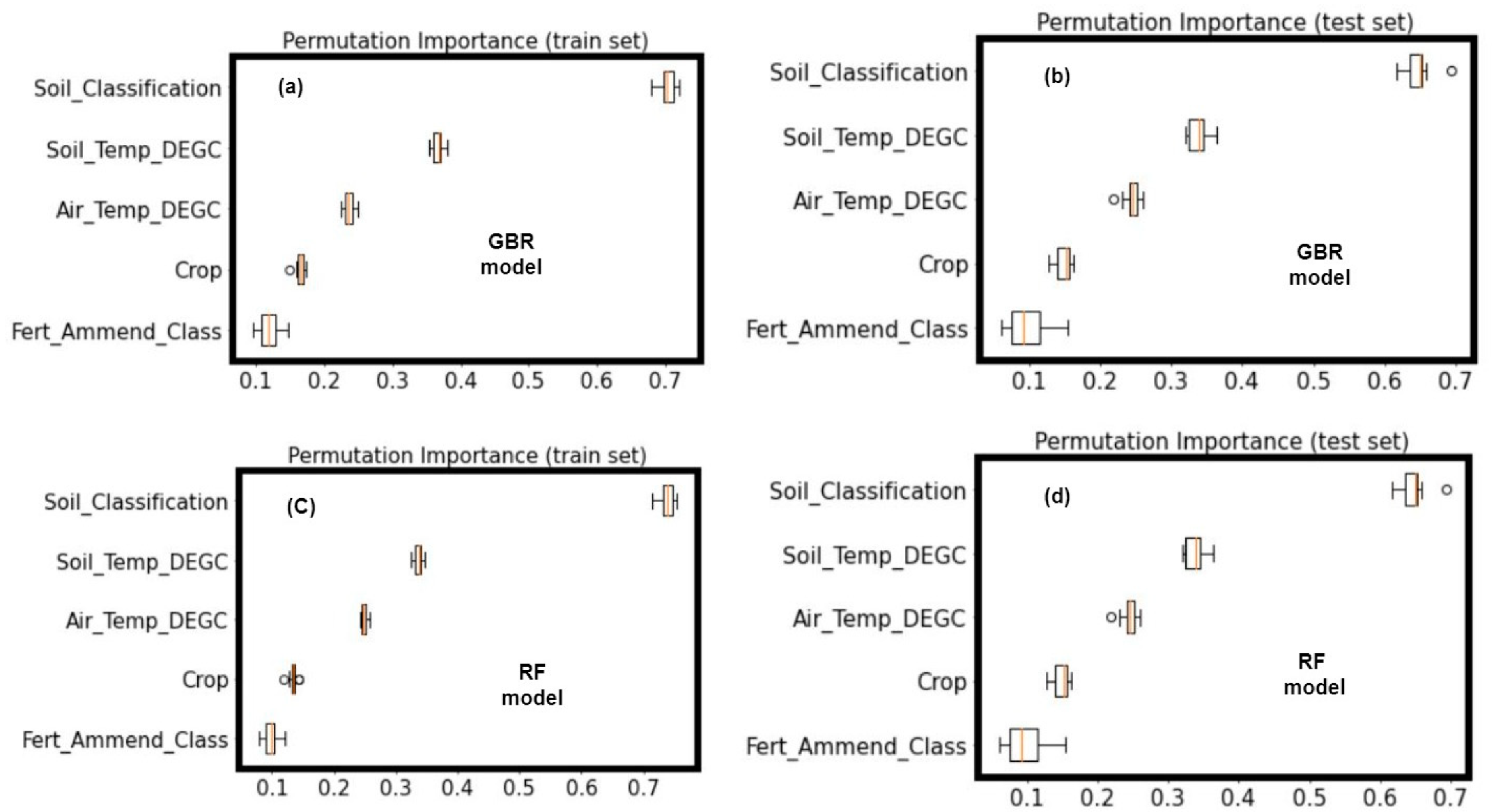
3.3. Important Model Predictors for Estimating Soil CO2 Fluxes
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shabani, E.; Hayati, B.; Pishbahar, E.; Ghorbani, M.A.; Ghahremanzadeh, M. A novel approach to predict CO2 emission in the agriculture sector of Iran based on Inclusive Multiple Model. J. Clean. Prod. 2021, 279, 123708. [Google Scholar] [CrossRef]
- EPA U.S. Overview of Greenhouse Gases. Available online: https://www.epa.gov/ghgemissions/overview-greenhouse-gases (accessed on 30 May 2021).
- Oertel, C.; Matschullat, J.; Zurba, K.; Zimmermann, F.; Erasmi, S. Greenhouse gas emissions from soils—A review. Chem. Der Erde Geochem. 2016, 76, 327–352. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zheng, H.; Chen, F.; Li, R.; Yang, M.; Ouyang, Z.; Lan, J.; Xiang, X. Impact of nitrogen fertilization on soil–Atmosphere greenhouse gas exchanges in eucalypt plantations with different soil characteristics in southern China. PLoS ONE 2017, 12, e0172142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Post, W.M.; Emanuel, W.R.; Zinke, P.J.; Stangenberger, A.G. Soil carbon pools and world life zones. Nature 1982, 298, 156–159. [Google Scholar] [CrossRef]
- Yousaf, B.; Liu, G.; Wang, R.; Abbas, Q.; Imtiaz, M.; Liu, R. Investigating the biochar effects on C-mineralization and sequestration of carbon in soil compared with conventional amendments using the stable isotope (δ13C) approach. GCB Bioenergy 2017, 9, 1085–1099. [Google Scholar] [CrossRef]
- Paustian, K.; Lehmann, J.; Ogle, S.; Reay, D.; Robertson, G.P.; Smith, P. Climate-smart soils. Nature 2016, 532, 49–57. [Google Scholar] [CrossRef] [Green Version]
- Li, C. Quantifying greenhouse gas emissions from soils: Scientific basis and modeling approach. Soil Sci. Plant Nutr. 2007, 53, 344–352. [Google Scholar] [CrossRef] [Green Version]
- Liang, N.; Nakadai, T.; Hirano, T.; Qu, L.; Koike, T.; Fujinuma, Y.; Inoue, G. In situ comparison of four approaches to estimating soil CO2 efflux in a northern larch (Larix kaempferi Sarg.) forest. Agric. For. Meteorol. 2004, 123, 97–117. [Google Scholar] [CrossRef]
- Heinemeyer, A.; McNamara, N.P. Comparing the closed static versus the closed dynamic chamber flux methodology: Implications for soil respiration studies. Plant Soil 2011, 346, 145–151. [Google Scholar] [CrossRef]
- Gargiulo, O.; Morgan, K.T. Procedures to Simulate Missing Soil Parameters in the Florida Soils Characteristics Database. Soil Sci. Soc. Am. J. 2015, 79, 165–174. [Google Scholar] [CrossRef]
- Li, C.; Frolking, S.; Frolking, T.A. A model of nitrous oxide evolution from soil driven by rainfall events: 1. Model structure and sensitivity. J. Geophys. Res. Atmos. 1992, 97, 9759–9776. [Google Scholar] [CrossRef]
- Herbst, M.; Hellebrand, H.J.; Bauer, J.; Huisman, J.A.; Šimůnek, J.; Weihermüller, L.; Graf, A.; Vanderborght, J.; Vereecken, H. Multiyear heterotrophic soil respiration: Evaluation of a coupled CO2 transport and carbon turnover model. Ecol. Model. 2008, 214, 271–283. [Google Scholar] [CrossRef]
- Del Grosso, S.J.; Parton, W.J.; Adler, P.R.; Davis, S.C.; Keough, C.; Marx, E. DayCent model simulations for estimating soil carbon dynamics and greenhouse gas fluxes from agricultural production systems. In Managing Agricultural Greenhouse Gases; Liebig, M.A., Franzluebbers, A.J., Follett, R.F., Eds.; Elsevier: Amsterdam, The Netherlands, 2012; pp. 341–353. [Google Scholar]
- Del Grosso, S.J.; Ojima, D.S.; Parton, W.J.; Stehfest, E.; Heistemann, M.; Deangelo, B.; Rose, S. Global scale DAYCENT model analysis of greenhouse gas emissions and mitigation strategies for cropped soils. Glob. Planet. Change 2009, 67, 44–50. [Google Scholar] [CrossRef]
- Ahuja, L.; Rojas, K.; Hanson, J.D. Root Zone Water Quality Model: Modelling Management Effects on Water Quality and Crop Production; Water Resources Publication: Littleton, CO, USA, 2000.
- Hamrani, A.; Akbarzadeh, A.; Madramootoo, C.A. Machine learning for predicting greenhouse gas emissions from agricultural soils. Sci. Total Environ. 2020, 741, 140338. [Google Scholar] [CrossRef] [PubMed]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Twarakavi, N.K.C.; Šimůnek, J.; Schaap, M.G. Development of Pedotransfer Functions for Estimation of Soil Hydraulic Parameters using Support Vector Machines. Soil Sci. Soc. Am. J. 2009, 73, 1443–1452. [Google Scholar] [CrossRef] [Green Version]
- Baker, R.E.; Peña, J.-M.; Jayamohan, J.; Jérusalem, A. Mechanistic models versus machine learning, a fight worth fighting for the biological community? Biol. Lett. 2018, 14, 20170660. [Google Scholar] [CrossRef]
- Saha, D.; Basso, B.; Robertson, G.P. Machine learning improves predictions of agricultural nitrous oxide (N2O) emissions from intensively managed cropping systems. Environ. Res. Lett. 2021, 16, 024004. [Google Scholar] [CrossRef]
- Ebrahimi, M.; Sarikhani, M.R.; Safari Sinegani, A.A.; Ahmadi, A.; Keesstra, S. Estimating the soil respiration under different land uses using artificial neural network and linear regression models. CATENA 2019, 174, 371–382. [Google Scholar] [CrossRef]
- Abbasi, N.A.; Hamrani, A.; Madramootoo, C.A.; Zhang, T.; Tan, C.S.; Goyal, M.K. Modelling carbon dioxide emissions under a maize-soy rotation using machine learning. Biosyst. Eng. 2021, 212, 1–18. [Google Scholar] [CrossRef]
- Freitas, L.P.; Lopes, M.L.; Carvalho, L.B.; Panosso, A.R.; Júnior, N.L.S.; Freitas, R.L.; Minussi, C.R.; Lotufo, A.D. Forecasting the spatiotemporal variability of soil CO2 emissions in sugarcane areas in southeastern Brazil using artificial neural networks. Environ. Monit. Assess. 2018, 190, 741. [Google Scholar] [CrossRef]
- Philibert, A.; Loyce, C.; Makowski, D. Prediction of N2O emission from local information with Random Forest. Environ. Pollut. 2013, 177, 156–163. [Google Scholar] [CrossRef]
- Tavares, R.L.M.; Oliveira, S.R.D.M.; Barros, F.M.M.D.; Farhate, C.V.V.; Souza, Z.M.D.; Scala Junior, N.L. Prediction of soil CO2 flux in sugarcane management systems using the Random Forest approach. Sci. Agric. 2018, 75, 281–287. [Google Scholar] [CrossRef] [Green Version]
- Gauder, M.; Butterbach-Bahl, K.; Graeff-Hönninger, S.; Claupein, W.; Wiegel, R. Soil-derived trace gas fluxes from different energy crops - results from a field experiment in Southwest Germany. GCB Bioenergy 2012, 4, 289–301. [Google Scholar] [CrossRef]
- Adjuik, T.; Rodjom, A.M.; Miller, K.E.; Reza, M.T.M.; Davis, S.C. Application of Hydrochar, Digestate, and Synthetic Fertilizer to a Miscanthus x giganteus Crop: Implications for Biomass and Greenhouse Gas Emissions. Appl. Sci. 2020, 10, 8953. [Google Scholar] [CrossRef]
- Snyder, C.S.; Bruulsema, T.W.; Jensen, T.L.; Fixen, P.E. Review of greenhouse gas emissions from crop production systems and fertilizer management effects. Agric. Ecosyst. Environ. 2009, 133, 247–266. [Google Scholar] [CrossRef]
- Davis, S.C.; Parton, W.J.; Dohleman, F.G.; Smith, C.M.; Grosso, S.D.; Kent, A.D.; DeLucia, E.H. Comparative Biogeochemical Cycles of Bioenergy Crops Reveal Nitrogen-Fixation and Low Greenhouse Gas Emissions in a Miscanthus × giganteus Agro-Ecosystem. Ecosystems 2009, 13, 144–156. [Google Scholar] [CrossRef]
- Don, A.; Osborne, B.; Hastings, A.; Skiba, U.; Carter, M.S.; Drewer, J.; Flessa, H.; Freibauer, A.; Hyvönen, N.; Jones, M.B.; et al. Land-use change to bioenergy production in Europe: Implications for the greenhouse gas balance and soil carbon. GCB Bioenergy 2012, 4, 372–391. [Google Scholar] [CrossRef] [Green Version]
- Jawson, M.; Shafer, S.; Franzluebbers, A.; Parkin, T.; Follett, R. GRACEnet: Greenhouse gas reduction through agricultural carbon enhancement network. Soil Tillage Res. 2005, 83, 167–172. [Google Scholar] [CrossRef]
- Del Grosso, S.J.; White, J.W.; Wilson, G.; Vandenberg, B.; Karlen, D.L.; Follett, R.F.; Johnson, J.M.F.; Franzluebbers, A.J.; Archer, D.W.; Gollany, H.T.; et al. Introducing the GRACEnet/REAP Data Contribution, Discovery, and Retrieval System. J. Environ. Qual. 2013, 42, 1274–1280. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kotsiantis, S.B.; Kanellopoulos, D.; Pintelas, P.E. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Lakshminarayan, K.; Harp, S.A.; Samad, T. Imputation of missing data in industrial databases. Appl. Intell. 1999, 11, 259–275. [Google Scholar] [CrossRef]
- Derksen, S.; Keselman, H.J. Backward, forward and stepwise automated subset selection algorithms: Frequency of obtaining authentic and noise variables. Br. J. Math. Stat. Psychol. 1992, 45, 265–282. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations; Acm Sigmod Record: Cambridge, MA, USA, 2002; Volume 31, pp. 76–77. [Google Scholar]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- McKinney, W. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython; O’Reilly Media, Inc.: Newton, MA, USA, 2012. [Google Scholar]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.E.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.B.; Grout, J.; Corlay, S. Jupyter Notebooks-a Publishing Format for Reproducible Computational Workflows; IOS Press: Amsterdam, The Netherlands, 2016; Volume 2016. [Google Scholar]
- Raschka, S. MLxtend: Providing machine learning and data science utilities and extensions to Python’s scientific computing stack. J. Open Source Softw. 2018, 3, 638. [Google Scholar] [CrossRef]
- Ayodele, T.O. Types of machine learning algorithms. New Adv. Mach. Learn. 2010, 3, 19–48. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. In Real Word AI Systems with Applications in eHealth, Hci, Information Retrieval and Pervasive Technologies; IOS Press: Amsterdam, The Netherlands; Washington, DC, USA, 2007; Volume 160, pp. 3–24. [Google Scholar]
- Achieng, K.O. Modelling of soil moisture retention curve using machine learning techniques: Artificial and deep neural networks vs support vector regression models. Comput. Geosci. 2019, 133, 104320. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support Vector Regression. In Efficient Learning Machines; Apress: Berkeley, CA, USA, 2015; pp. 67–80. [Google Scholar]
- Üstün, B.; Melssen, W.J.; Buydens, L.M. Facilitating the application of support vector regression by using a universal Pearson VII function based kernel. Chemom. Intell. Lab. Syst. 2006, 81, 29–40. [Google Scholar] [CrossRef]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2016. [Google Scholar]
- Imandoust, S.B.; Bolandraftar, M. Application of k-nearest neighbor (knn) approach for predicting economic events: Theoretical background. Int. J. Eng. Res. Appl. 2013, 3, 605–610. [Google Scholar]
- Ray, S. A Quick Review of Machine Learning Algorithms. In Proceedings of the International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (Com-IT-Con), Faridabad, India, 14–16 February 2019; p. 5. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Horning, N. Random Forests: An algorithm for image classification and generation of continuous fields data sets. In Proceedings of the International Conference on Geoinformatics for Spatial Infrastructure Development in Earth and Allied Sciences, Osaka, Japan, 9–11 December 2010. [Google Scholar]
- Zhang, H.; Nettleton, D.; Zhu, Z. Regression-enhanced random forests. arXiv 2019, arXiv:1904.10416. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Molnar, C.; König, G.; Herbinger, J.; Freiesleben, T.; Dandl, S.; Scholbeck, C.A.; Casalicchio, G.; Grosse-Wentrup, M.; Bischl, B. Pitfalls to avoid when interpreting machine learning models. arXiv 2020, arXiv:2007.04131. [Google Scholar]
- Sandri, M.; Zuccolotto, P. Variable Selection Using Random Forests. In Data Analysis, Classification and the Forward Search; Springer: Berlin/Heidelberg, Germany, 2006; pp. 263–270. [Google Scholar]
- O’Brien, R.M. A Caution Regarding Rules of Thumb for Variance Inflation Factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Chandra, B. Gene Selection Methods for Microarray Data. In Applied Computing in Medicine and Health; Elsevier: Amsterdam, The Netherlands, 2016; pp. 45–78. [Google Scholar]
- Elbisy, M.S. Support vector machine and regression analysis to predict the field hydraulic conductivity of sandy soil. KSCE J. Civ. Eng. 2015, 19, 2307–2316. [Google Scholar] [CrossRef]
- Kaingo, J.; Tumbo, S.D.; Kihupi, N.I.; Mbilinyi, B.P. Prediction of Soil Moisture-Holding Capacity with Support Vector Machines in Dry Subhumid Tropics. Appl. Environ. Soil Sci. 2018, 2018, 9263296. [Google Scholar] [CrossRef] [Green Version]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Interpretable machine learning: Definitions, methods, and applications. arXiv 2019, arXiv:1901.04592. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wadoux, A.M.-C.; Molnar, C. Beyond prediction: Methods for interpreting complex models of soil variation. Geoderma 2021. [Google Scholar] [CrossRef]
- Casalicchio, G.; Molnar, C.; Bischl, B. Visualizing the feature importance for black box models. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; pp. 655–670. [Google Scholar]
- Wachiye, S.; Merbold, L.; Vesala, T.; Rinne, J.; Räsänen, M.; Leitner, S.; Pellikka, P. Soil greenhouse gas emissions under different land-use types in savanna ecosystems of Kenya. Biogeosciences 2020, 17, 2149–2167. [Google Scholar] [CrossRef] [Green Version]
- Schaufler, G.; Kitzler, B.; Schindlbacher, A.; Skiba, U.; Sutton, M.A.; Zechmeister-Boltenstern, S. Greenhouse gas emissions from European soils under different land use: Effects of soil moisture and temperature. Eur. J. Soil Sci. 2010, 61, 683–696. [Google Scholar] [CrossRef]
- Schindlbacher, A.; Zechmeister-Boltenstern, S.; Butterbach-Bahl, K. Effects of soil moisture and temperature on NO, NO2, and N2O emissions from European forest soils. J. Geophys. Res. Atmos. 2004, 109, D17. [Google Scholar] [CrossRef]
- Lloyd, J.; Taylor, J.A. On the Temperature Dependence of Soil Respiration. Funct. Ecol. 1994, 8, 315. [Google Scholar] [CrossRef]
- Ni, X.; Liao, S.; Wu, F.; Groffman, P.M. Short-term precipitation pulses stimulate soil CO2 emission but do not alter CH4 and N2O fluxes in a northern hardwood forest. Soil Biol. Biochem. 2019, 130, 8–11. [Google Scholar] [CrossRef]
- Nemes, A.; Rawls, W.J.; Pachepsky, Y.A. Use of the nonparametric nearest neighbor approach to estimate soil hydraulic properties. Soil Sci. Soc. Am. J. 2006, 70, 327–336. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | ML Method Used | Key Highlight |
|---|---|---|
| Hamrani et al. [17] | FNN, RBFNN, ExNN, LSTM, DBN, CNN, LASSO, RFR, and SVR | LSTM model predicted the highest accuracy metrics on CO2 fluxes with (R2 = 0.87 and RMSE = 30.3 mg·m−2·h−1). |
| Saha et al. [21] | RF | RF model explained 51% of variation in daily N2O fluxes upon coupling with a cropping systems model used to predict daily soil nitrogen availability. |
| Ebrahimi et al. [22] | ANN, LR | ANN model could predict basal respiration with R2 = 0.66 and substrate induced respiration with R2 = 0.52 respectively. |
| Abbasi et al. [23] | SVM, RF, LASSO, FNN, RBFNN, and ELM | RF attained optimal performance on predicting CO2 emissions with R2 = 0.86 and RMSE = 3.05 Kg ha−1 d−1. |
| Freitas et al. [24] | ANN | The ANN model predicted CO2 fluxes with R2 = 0.80; mean absolute percentage error (MAPE) = 12.0591. |
| Philibert et al. [25] | RF | RF model predicted soil N2O fluxes with Root mean square error of prediction (RMSE) of 2.99 kg N ha−1 year−1). |
| Tavares et al. [26] | RF | RF model predicted soil CO2 fluxes with R2 = 0.80. |
| Technique | Operating Principle | Pros | Cons |
|---|---|---|---|
| Support vector regression (SVR) | SVR works by regressing a dependent variable on an independent variable according to a weight vector and a bias term. Regression functions are learned by mapping data onto a high-dimensional feature space known as kernelling [47,48] | Excellent generalization capability, with high prediction accuracy. Performs well for data with high dimensions [48]. | Choosing appropriate hyperparameters, especially kernel functions, is a difficult task [49]. Inefficient when dealing with large datasets. |
| K-Nearest Neighbor regression (KNN) | The KNN regression model is an adaptation of the KNN classification algorithm whereby predictions for new instances are made based on the average of the values of its “K” nearest (most similar) neighbors in the training dataset [50]. | Relatively easy to implement because you only need to specify two parameters i.e., K and the distance function. Robust to noisy training data and works effectively with large training data [51]. | Computationally expensive when data is large because the algorithm computes distances of each query instance to all training samples [51]. Sensitive to missing data and outliers which can lead to reduction in accuracy [52]. |
| Random forest regression (RF) | RF is an ensemble algorithm based on the decision tree algorithm whereby several decision trees are constructed during training of the data and outputting the mean prediction of the individual trees [53]. The dataset is split into several segments by posing a series of questions about the features of the dataset (predictors) and a final decision of the class of a new prediction is made based on the outcome of the individual trees [54]. | Reduces overfitting and variance unlike in decision trees since it creates several trees using a subset of the data to predict an output. Robust to missing values and outliers in a dataset [54]. | Tends to overestimate low values and underestimate high values because the output value of a prediction is the average of several decision trees [55]. Inefficient at extrapolating during prediction beyond the the range of the training dataset [56]. |
| Gradient boosted regression (GB) | GB uses the technique of boosting to combine many relatively simple regression tree models, predicting their pseudo residuals, and fitting new models based on the pseudo residuals. New regression trees are built based on the same predictors used to predict the residuals for all samples in the training dataset until further addition of trees does not significantly reduce the residuals [57]. | Prediction accuracy usually higher than other regression models. Has several hyperparameters that can be tuned to increase performance of models. | While it gives higher accuracy, GB does not necessarily yield intelligible parameters making interpretation of the model difficult [58]. Can be computationally expensive since it requires a large number of trees for optimal performance. |
| Best Predictor Combination | Number of Predictors Chosen | R2 |
|---|---|---|
| Soil classification | 1 | 0.63 |
| Air temperature, soil classification | 2 | 0.74 |
| Air temperature, soil classification, fertilization amendment class | 3 | 0.76 |
| Air temperature, soil classification, crop, and fertilization amendment class | 4 | 0.77 |
| Air temperature, soil temperature, soil classification, fertilization amendment class, crop | 5 | 0.76 |
| Air temperature, soil temperature, soil moisture, soil classification, fertilization amendment class, crop | 6 | 0.76 |
| Training Dataset | Testing Dataset | |||||
|---|---|---|---|---|---|---|
| Model | R2 | RMSE (g C ha−1 day−1) | MAE (g C ha−1 day−1) | R2 | RMSE (g C ha−1 day−1) | MAE (g C ha−1 day−1) |
| Support Vector Regression | 0.74 | 6708.81 | 2923.69 | 0.71 | 7571.02 | 2992.09 |
| KNN Regression | 0.80 | 5910.76 | 2679.03 | 0.77 | 6714.21 | 2867.71 |
| Random Forest | 0.87 | 4696.76 | 1968.07 | 0.82 | 5893.72 | 2543.58 |
| Gradient Boosted Regression | 0.88 | 4405.43 | 2177.89 | 0.82 | 5961.15 | 2591.61 |
| Learning Algorithm | Hyperparameter |
|---|---|
| K Nearest Neighbor Regression (KNN) | n_neighbors = 8, metric = “manhattan” |
| Support Vector Regression (SVR) | kernel = ‘rbf’, C = 4000, ε = 0.001, and γ = 1.2 |
| Gradient Boosted Regression (GB) | n_estimators = 50, learning rate = 0.1, max_depth = 10, loss = ‘huber’, alpha = 0.99 |
| Random Forest Regression (RF) | n_estimators = 80, max_depth = 30, max_features = ‘sqrt’ min_sample_leaf = 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adjuik, T.A.; Davis, S.C. Machine Learning Approach to Simulate Soil CO2 Fluxes under Cropping Systems. Agronomy 2022, 12, 197. https://doi.org/10.3390/agronomy12010197
Adjuik TA, Davis SC. Machine Learning Approach to Simulate Soil CO2 Fluxes under Cropping Systems. Agronomy. 2022; 12(1):197. https://doi.org/10.3390/agronomy12010197
Chicago/Turabian StyleAdjuik, Toby A., and Sarah C. Davis. 2022. "Machine Learning Approach to Simulate Soil CO2 Fluxes under Cropping Systems" Agronomy 12, no. 1: 197. https://doi.org/10.3390/agronomy12010197
APA StyleAdjuik, T. A., & Davis, S. C. (2022). Machine Learning Approach to Simulate Soil CO2 Fluxes under Cropping Systems. Agronomy, 12(1), 197. https://doi.org/10.3390/agronomy12010197