
Artificial-Intelligence-Based Time-Series Intervention Models to Assess the Impact of the COVID-19 Pandemic on Tomato Supply and Prices in Hyderabad, India

 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
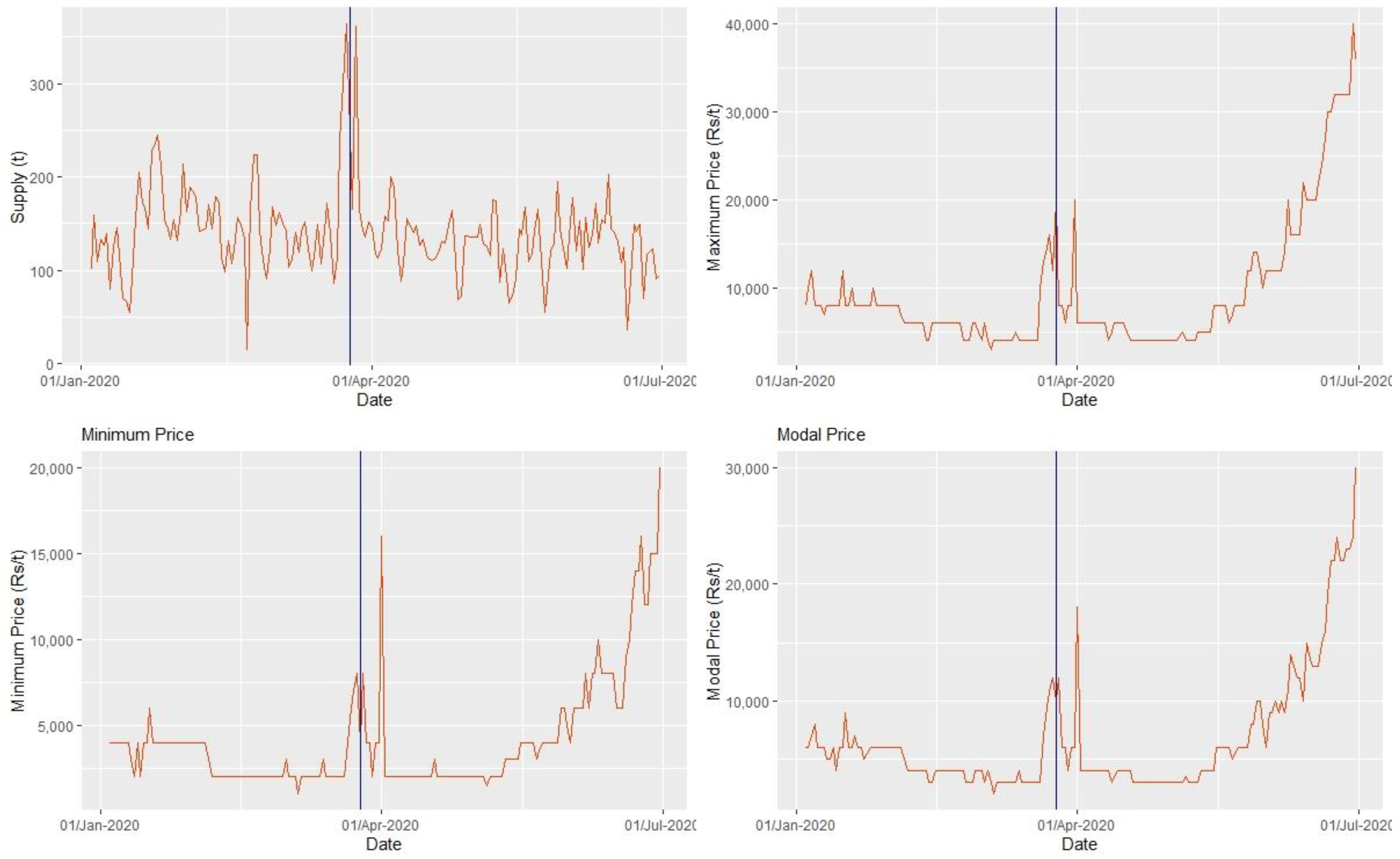
2.1. Data Description
2.2. ARIMA Model
2.3. ARIMA Intervention Model
2.4. Support Vector Regression (SVR) Model
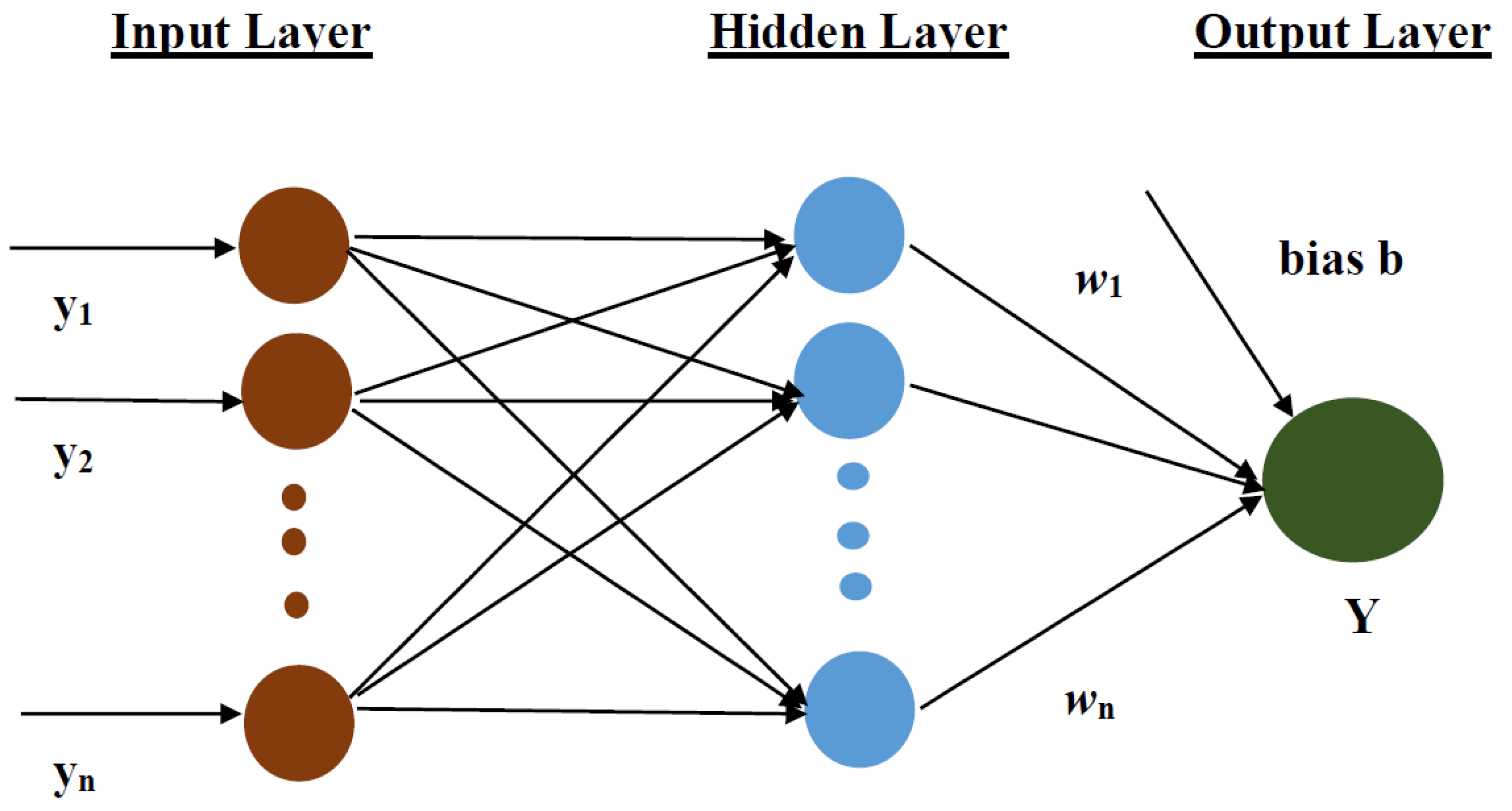
2.5. Artificial Neural Network (ANN) Model
2.6. Artificial Intelligence (AI)-Based Intervention Models
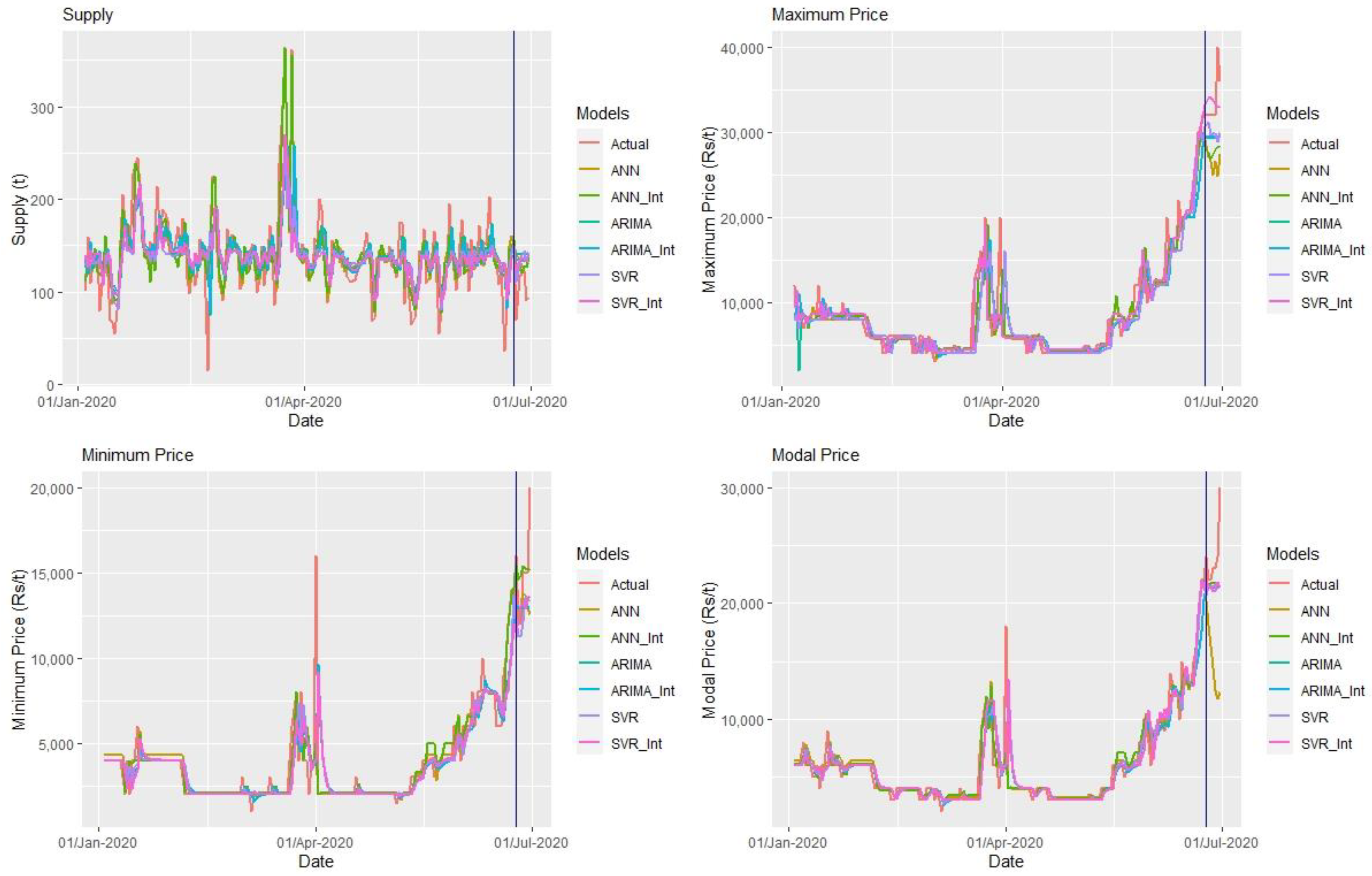
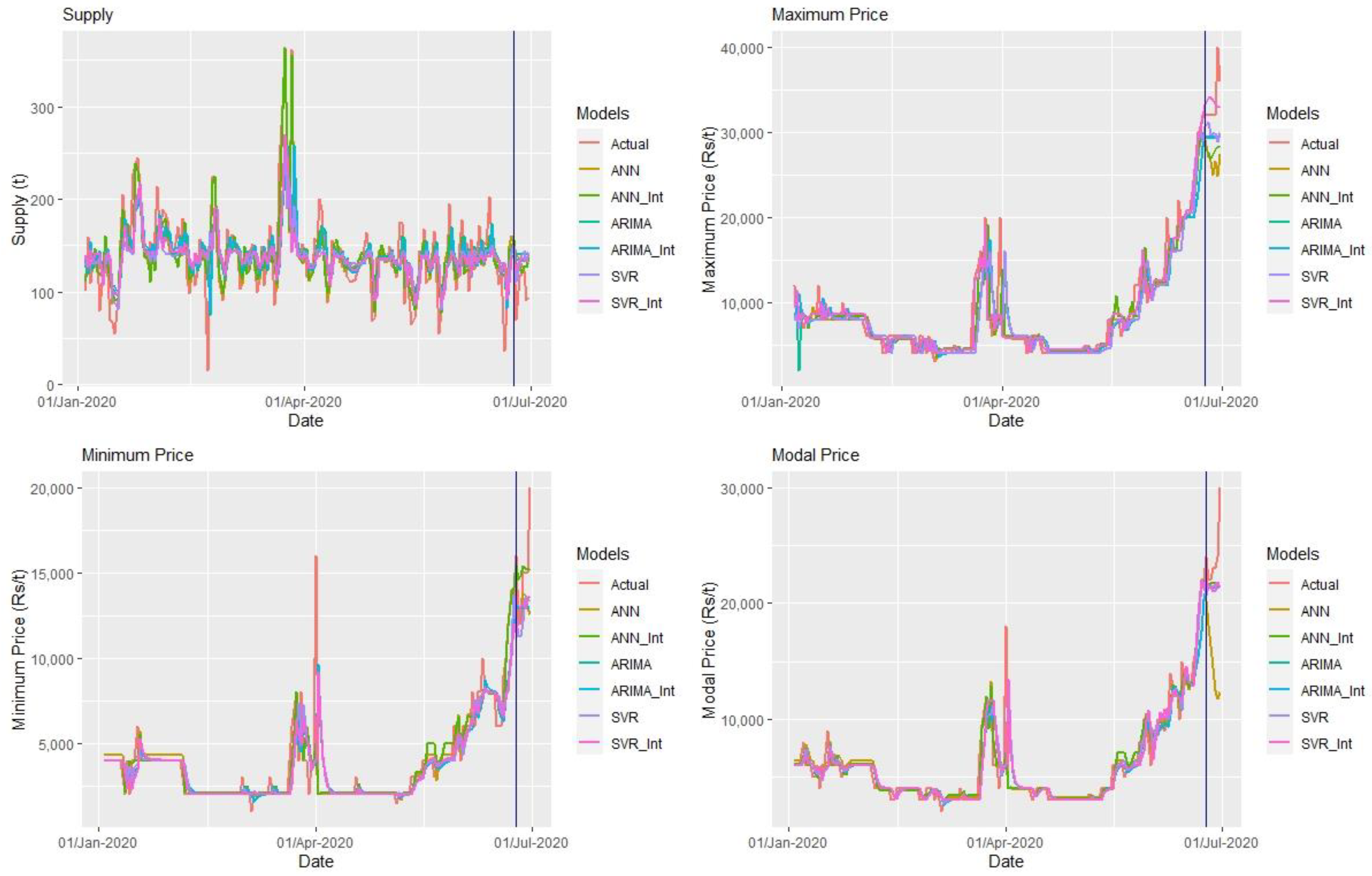
3. Results
3.1. Results of ARIMA Models
3.2. Results ARIMA Intervention Models
3.3. Results of SVR and SVR Intervention Models
3.4. Results of ANN and ANN Intervention Model
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- National Horticultual Boad; Ministry of Agriculture and Farmers Welfare; Governament of India. Horticultural Statistics at a Glance. 2018. Available online: http://nhb.gov.in/statistics/Publication/Horticulture%20Statistics%20at%20a%20Glance-2018.pdf (accessed on 12 September 2020).
- Box, G.; Jenkins, G. Time Series Analysis: Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1970. [Google Scholar]
- Naveena, K.; Rathod, S.; Shukla, G.; Yogish, K.J. Forecasting of coconut production in India: Suitable time series models. Int. J. Agric. Eng. 2014, 7, 190–193. [Google Scholar]
- Jalikatti, V.N.; Raghavendra, C.; Ahmad, D.G.; Shreya, A.; Sheikh, S. Forecasting the prices of onion in belgaum market of northern Karnataka using ARIMA technique. Int. J. Agric. Econ. 2014, 5, 153–159. [Google Scholar] [CrossRef]
- Jeong, M.; Lee, Y.J.; Choe, Y. Forecasting agricultural commodity price: The case of onion. J. Res. Humanit. Soc. Sci. 2017, 5, 78–81. [Google Scholar]
- Kaur, L.; Dhaliwal, T.; Rangi, P.S.; Singh, N. An economic analysis of tomato arrivals and prices in Punjab. Indian J. Agril. Mktg. 2005, 19, 61–67. [Google Scholar]
- Rathod, S.; Singh, K.N.; Arya, P.; Ray, M.; Mukherjee, A.; Sinha, K.; Kumar, P.; Shekhawat, R.S. Forecasting maize yield using ARIMA-Genetic Algorithm approach. J. Outlook Agr. 2017, 46, 265–271. [Google Scholar] [CrossRef]
- Rathod, S.; Singh, K.N.; Patil, S.G.; Naik, R.H.; Ray, M.; Meena, V.S. Modelling and forecasting of oilseed production of India through artificial intelligence techniques. Indian J. Agric. Sci. 2018, 88, 22–27. [Google Scholar]
- Tatarintsev, M.; Korchagin, S.; Nikitin, P.; Gorokhova, R.; Bystrenina, I.; Serdechnyy, D. Analysis of the Forecast Price as a Factor of Sustainable Development of Agriculture. Agronomy 2021, 11, 1235. [Google Scholar] [CrossRef]
- Box, G.E.P.; Tiao, G.C. Intervention analysis with application to Economic and Environmental Problems. J. Am. Stat. Assoc. 1995, 70, 70–79. [Google Scholar] [CrossRef]
- Bianchi, L.; Jeffrey, J.; Choudary, H.R. Improving forecasting for telemarketing centres by ARIMA modelling with intervention. Int. J. Forecast. 1998, 14, 497–504. [Google Scholar] [CrossRef] [Green Version]
- Ray, M.; Ramasubramanian, V.; Anil, R. Applications of time series intervention modelling for modelling and forecasting cotton yield. Stat. Appl. 2014, 12, 61–70. [Google Scholar]
- Ramasubramanian, V.; Ray, M. Power computation-based performance assessment of ARIMA intervention modelling. J. Indian Soc. Agric. Stat. 2019, 73, 233–242. [Google Scholar]
- Jeffrey, E.J.; Kyner, E. ARIMA modelling with intervention to forecast and analyse Chinese stock prices. Int. J. Agric. Mark. 2011, 3, 53–58. [Google Scholar] [CrossRef]
- Corchuelo Martínez-Azúa, B.; López-Salazar, P.E.; Sama-Berrocal, C. Impact of the COVID-19 Pandemic on Agri-Food Companies in the Region of Extremadura (Spain). Agronomy 2021, 11, 971. [Google Scholar] [CrossRef]
- Di Marcantonio, F.; Twum, E.K.; Russo, C. Covid-19 Pandemic and Food Waste: An Empirical Analysis. Agronomy 2021, 11, 1063. [Google Scholar] [CrossRef]
- Zhang, G.P.; Patuwo, E.; Hu, Y.M. Forecasting with Artificial Neural Networks: The State of the Art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Rathod, S.; Mishra, G.C. Statistical Models for Forecasting Mango and Banana Yield of Karnataka. India. J. Agric. Sci. Technol. 2018, 20, 803–816. Available online: https://jast.modares.ac.ir/article-23-19768-en.html (accessed on 10 September 2021).
- Khan, T.; Sherazi, H.H.R.; Ali, M.; Letchmunan, S.; Butt, U.M. Deep Learning-Based Growth Prediction System: A Use Case of China Agriculture. Agronomy 2021, 11, 1551. [Google Scholar] [CrossRef]
- Niazkar, H.R.; Niazkar, M. Application of artificial neural networks to predict the COVID-19 outbreak. Glob. Health Res. Policy 2020, 5, 50. [Google Scholar] [CrossRef]
- Niazkar, M. Assessment of artificial intelligence models for calculating optimum properties of lined channels. J. Hydroinformatics 2020, 22, 1410–1423. [Google Scholar] [CrossRef]
- Niazkar, M.; Talebbeydokthi, N.; Afzali, S.H. Bridge backwater estimation: A comparison between artificial intelligence models and explicit equations. Sci. Iran. 2020, 28, 573–585. [Google Scholar] [CrossRef]
- Xun, Z.; Yu, L.; Wang, S. Assessing potentiality of support vector machine method in crude oil price forecasting. EURASIA J. Math. Sci. Technol. Educ. 2017, 13, 7893–7904. [Google Scholar] [CrossRef]
- Harini, S.; Nathan, H.; Jhonson, A.; Anthony, L.C.; Peter, S.; Marzyeh, G. Clinical intervention prediction understanding with deep neural networks. In Proceedings of the 2nd Machine Learning for Healthcare Conference, PMLR, Boston, MA, USA, 19–20 August 2017; Volume 68, pp. 322–337. Available online: https://arxiv.org/abs/1705.08498v1 (accessed on 23 May 2017).
- Hu, Z.; Ge, Q.; Shudi, L.; Boerwinkle, E.; Jin, L.; Xiong, M. Forecasting and Evaluating Multiple Interventions for COVID-19 Worldwide. Front. Artif. Intell. 2020, 3, 41. [Google Scholar] [CrossRef]
- Jha, G.K.; Sinha, K. Agricultural Price Forecasting using Neural Network Model: An Innovative Information Delivery System. Agric. Econ. Res. Rev. 2013, 26, 229–239. [Google Scholar] [CrossRef] [Green Version]
- Kuan, C.M.; White, H. Artificial Neural Networks: An Economic Perspective. Econom. Rev. 1994, 13, 1–91. [Google Scholar] [CrossRef]
- Pai, P.F.; Lin, C.S. A Hybrid ARIMA and Support Vector Machines model in Stock Price Forecasting. Int. J. Manag. Sci. 2004, 33, 497–505. [Google Scholar] [CrossRef]
- Shelke, R.D.; Kalyanker, S.C. Pattern of Market Arrivals of Tomato in Parbhani District of Maharashtra State. Int. J. Agric. Econ. 1998, 53, 423–425. [Google Scholar]
- Bejo, K.S.; Mustaffha, S.; Ismail, I.W. Application of Artificial Neural Network in Predicting the Crop Yield: A Review. J. Food Sci. Eng. 2014, 4, 1–9. [Google Scholar]
- Jhee, W.C.; Lee, K.C. A Neural Network Approach for the Identification of the Box-Jenkins Model. Comput. Neural Syst. 2009, 3, 323–339. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar] [CrossRef]
- Smola, A.J.; Scholkopf, B.A. Tutorial on support vector regression, statistical computing. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- White, H. Learning in Artificial Neural Networks: A Statistical Perspective. Neural Comput. 1989, 1, 425–464. [Google Scholar] [CrossRef]
- Brock, W.; Scheinkman, J.A.; Dechert, W.D.; LeBaron, B. A test for independence based on the correlation dimension. Econom. Rev. 1996, 15, 197–235. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R.S. Comparing predictive accuracy. J. Bus. Econ. Stats. 1995, 13, 253–263. Available online: http://www.jstor.org/stable/1392185 (accessed on 10 September 2021).
- Ismail, Z.; Suhartono, S.; Yahaya, A.; Efend, R. Intervention Model for Analysing the Impact of Terrorism to Tourism Industry. J. Math. Stat. 2009, 5, 322–329. [Google Scholar]
- Omolola, M.A.; Joel, O.B.; Abiodum, M.A.; Abubeker, H.; Christina, M.B.; Daniel, D.; Eyob, T. Application of Artificial Neural Network for Predicting Maize Production in South Africa. Agronomy 2019, 11, 1145. [Google Scholar] [CrossRef] [Green Version]
- Rathod, S.; Mishra, G.; Singh, K.N. Hybrid time series models for forecasting banana production in Karnataka state, India. J. Indian Soc. Agric. Stat. 2017, 71, 193–200. [Google Scholar]
- Kurumatani, K. Time Series Forecasting of Agricultural Product Prices Based on Recurrent Neural Networks and its Evaluation method. SN Appl. Sci. 2020, 2, 1434. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neuro. Comput. 2003, 50, 159–175. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistic | Supply (t) | Maximum Price (Rs/t) | Minimum Price (Rs/t) | Modal Price (Rs/t) |
|---|---|---|---|---|
| Observation | 179 | 179 | 179 | 179 |
| Mean | 139.74 | 9346.37 | 4127.78 | 6612.60 |
| Median | 137.4 | 6000 | 3000 | 4500 |
| Mode | 164.2 | 4000 | 2000 | 4000 |
| Standard Deviation | 46.42 | 7335.47 | 3310.34 | 5079.42 |
| Minimum | 15.15 | 3000 | 1000 | 2000 |
| Maximum | 363.8 | 40,000 | 20,000 | 30,000 |
| Skewness | 1.47 | 2.15 | 2.33 | 2.24 |
| Kurtosis | 5.84 | 4.32 | 5.75 | 5.07 |
| Coefficient of Variation (%) | 31.22 | 78.48 | 80.20 | 76.81 |
| Time Series | Eps (1) | Eps (2) | Eps (3) | Eps (4) | ||||
|---|---|---|---|---|---|---|---|---|
| Statistic at m = 2 | Statistic at m = 3 | Statistic at m = 2 | Statistic at m = 3 | Statistic at m = 2 | Statistic at m = 3 | Statistic at m = 2 | Statistic at m = 3 | |
| Supply | 4.19 (p < 0.001) | 4.65 (p < 0.001) | 5.44 (p < 0.001) | 5.55 (p < 0.001) | 6.69 (p < 0.001) | 6.92 (p < 0.001) | 7.48 (p < 0.001) | 7.83 (p < 0.001) |
| Maximum Price | 20.47 (p < 0.001) | 25.81 (p < 0.001) | 16.13 (p < 0.001) | 16.86 (p < 0.001) | 14.58 (p < 0.001) | 14.36 (p < 0.001) | 16.15 (p < 0.001) | 15.27 (p < 0.001) |
| Minimum Price | 27.02 (p < 0.001) | 39.03 (p < 0.001) | 15.07 (p < 0.001) | 15.86 (p < 0.001) | 13.53 (p < 0.001) | 13.66 (p < 0.001) | 12.38 (p < 0.001) | 11.55 (p < 0.001) |
| Modal Price | 20.51 (p < 0.0001) | 25.15 (p < 0.001) | 16.31 (p < 0.001) | 17.07 (p < 0.001) | 14.35 (p < 0.001) | 14.55 (p < 0.001) | 13.48 (p < 0.001) | 12.55 (p < 0.001) |
| Time Series | Model | Parameters | Estimation | S. E | Z Value | p Value | Model Fitting | Box–Pierce Non-Correlation Test | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Original | Residuals | |||||||||
| Supply | ARIMA (1,0,0) | AR1 | 0.53 | 0.06 | 8.33 | <0.001 | Log-likelihood | −1292.85 | X-squared = 51.378 (p = 0.0001) | X-squared = 0.152 (p = 0.61) |
| AIC | 2591.7 | |||||||||
| BIC | 2601.19 | |||||||||
| Maximum Price | ARIMA (0,1,1) | MA1 | −0.37 | 0.072 | −5.059 | <0.001 | Log-likelihood | −1180.29 | X-squared = 144.61 (p = 0.0001) | X-squared = 0.06 (p = 0.81) |
| AIC | 2364.58 | |||||||||
| BIC | 2370.9 | |||||||||
| Minimum Price | ARIMA (0,1,1) | MA1 | −0.54 | 0.07 | −7.24 | <0.001 | Log-likelihood | −1117.4 | X-squared = 115.34 (p = 0.0001) | X-squared = 0.001 (p = 0.97) |
| AIC | 2238.8 | |||||||||
| BIC | 2245.12 | |||||||||
| Modal Price | ARIMA (0,1,1) | MA1 | −0.38 | 0.07 | −4.90 | <0.001 | Log-likelihood | −1140.81 | X-squared = 138.85 (p = 0.0001) | X-squared = 0.0003 (p = 0.98) |
| AIC | 2285.62 | |||||||||
| BIC | 2291.93 | |||||||||
| Time Series | Model | Parameters | Estimation | S. E | Z Value | p Value | Model Fitting | Box–Pierce Non- Correlation Test | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Original | Residuals | |||||||||
| Supply | ARIMA (1,0,0) | AR1 | 0.53 | 0.06 | 8.25 | <0.001 | Log-likelihood | −1292.74 | X-squared = 51.37 (p = 0.0001) | X-squared = 0.13 (p = 0.71) |
| Impact | −5.73 | 2.86 | −2.00 | 0.023 | AIC | 2593.49 | ||||
| BIC | 2606.15 | |||||||||
| Maximum Price | ARIMA (0,1,1) | MA1 | −0.36 | 0.07 | −4.86 | <0.001 | Log-likelihood | −1179.93 | X-squared = 144.61 (p = 0.0001) | X-squared = 0.04 (p = 0.83) |
| Impact | 171.29 | 90.10 | 1.90 | 0.39 | AIC | 2365.85 | ||||
| BIC | 2375.33 | |||||||||
| Minimum Price | ARIMA (0,1,1) | MA1 | −0.52 | 0.07 | −6.91 | <0.001 | Log-likelihood | −1116.43 | X-squared = 115.34 (p = 0.0001) | X-squared = 0.007 (p = 0.93) |
| Impact | 179.82 | 84.82 | 2.12 | 0.017 | AIC | 2238.86 | ||||
| BIC | 2248.34 | |||||||||
| Modal Price | ARIMA (0,1,1) | MA1 | −0.38 | 0.07 | −4.88 | <0.001 | Log-likelihood | −1140.49 | X-squared = 138.85 (p = 0.0001) | X-squared = 0.0005 (p = 0.98) |
| Impact | 124.88 | 70.91 | 1.76 | 0.039 | AIC | 2286.99 | ||||
| BIC | 2296.46 | |||||||||
| Parameter | Supply | Maximum Price | Minimum Price | Modal Price | ||||
|---|---|---|---|---|---|---|---|---|
| SVR | SVR Intervention | SVR | SVR Intervention | SVR | SVR Intervention | SVR | SVR Intervention | |
| Kernel Function | Radial | |||||||
| No. of S.Vs | 117 | 111 | 118 | 115 | 123 | 133 | 116 | 112 |
| Cost | 2.1 | 2.29 | 2.4 | 2.1 | 2 | 2 | 1.94 | 2.07 |
| Gamma | 1 | 0.5 | 1 | 0.5 | 1 | 0.5 | 1 | 0.5 |
| Epsilon | 0.01 | 0.001 | 0.0001 | 0.0001 | 0.001 | 0.001 | 0.0001 | 0.0001 |
| Box–pierce non-correlation test | 0.364 | 0.03 | 0.05 | 0.005 | 0.30 | 0.14 | 0.07 | |
| p-value | 0.827 | 0.721 | 0.963 | 0.654 | 0.782 | 0.985 | 0.924 | 0.754 |
| Parameter | Arrivals | Maximum Price | Minimum Price | Modal Price | ||||
|---|---|---|---|---|---|---|---|---|
| ANN | ANN Intervention | ANN | ANN Intervention | ANN | ANN Intervention | ANN | ANN Intervention | |
| Input Lag | 3 | 3 | 3 | 3 | 2 | 2 | 2 | 2 |
| Dependent/Output Variable | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Hidden Layers | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Hidden Nodes | 10 | 10 | 10 | 10 | 9 | 9 | 9 | 9 |
| Exogenous Variables | 1 | 7 | 1 | 7 | 1 | 7 | 1 | 7 |
| Model | 3:10S:1L | 4:10S:1L | 3:10S:1L | 4:10S:1L | 2:9S:1L | 3:9S:1L | 2:9S:1L | 3:9S:1L |
| Total Number of Parameters | 51 | 61 | 51 | 61 | 37 | 46 | 37 | 46 |
| Network Type | Feed Forward | |||||||
| Activation Function I:H | Sigmoidal | |||||||
| Activation Function H:O | Identity | |||||||
| Box–Pierce Non-Correlation Test for Residuals | 0.06 (p = 0.79) | 0.003 (p = 0.95) | 0.16 (p = 0.69) | 0.04 (p = 0.83) | 0.22 (p = 0.63) | 0.60 (p = 0.43) | 0.11 (p = 0.73) | 0.19 (p = 0.66) |
| Time Series | ARIMA | ARIMA Intervention | SVR | SVR Intervention | ANN | ANN Intervention | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | Training | Testing | Training | Testing | Training | Testing | |
| Supply | 25.52 | 37.86 | 25.20 | 31.81 | 23.98 | 33.12 | 24.16 | 29.02 | 18.4 | 29.86 | 16.52 | 27.84 |
| Maximum Price | 12.40 | 10.77 | 12.28 | 10.68 | 11.13 | 10.09 | 11.01 | 10.02 | 9.78 | 8.98 | 8.95 | 6.51 |
| Minimum Price | 17.24 | 16.04 | 16.78 | 15.78 | 16.24 | 15.35 | 15.87 | 15.04 | 12.03 | 13.28 | 11.16 | 11.18 |
| Modal Price | 13.04 | 10.14 | 12.96 | 10.04 | 12.81 | 9.78 | 12.35 | 9.67 | 10.77 | 9.76 | 9.83 | 8.52 |
| Time Series | Data Type | M1, M2 | M1, M3 | M1, M4 | M1, M5 | M1, M6 | M2, M3 | M2, M4 | M2, M5 | M2, M6 | M3, M4 | M3, M5 | M3, M6 | M4, M5 | M5, M6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Supply | Training | 2.42 (0.016) | 0.73 (0.466) | 2.70 (0.007) | 1.77 (0.076) | 1.79 (0.075) | −2.31 (0.021) | 2.81 (0.003) | −2.78 (0.006) | −2.72 (0.007) | 2.60 (0.009) | 1.70 (0.090) | 1.82 (0.070) | −3.09 (0.002) | 0.33 (0.740) |
| Testing | 2.79 (0.031) | 3.36 (0.015) | 3.65 (0.01) | 1.28 (0.241) | 1.84 (0.107) | 2.36 (0.556) | −2.17 (0.073) | 0.47 (0.648) | 0.55 (0.597) | −3.20 (0.019) | 0.47 (0.649) | 0.61 (0.055) | 0.19 (0.855) | −0.30 (0.767) | |
| Maximum price | Training | 2.74 (0.006) | 0.27 (0.788) | 2.82 (0.005) | 1.78 (0.075) | 4.15 (<0.001) | −2.68 (0.008) | 0.41 (0.683) | −1.07 (0.285) | 2.66 (0.008) | 2.77 (0.006) | 1.62 (0.106) | 4.08 (<0.001) | −0.98 (0.323) | 3.70 (0.0002) |
| Testing | −7.10 (0.0004) | 3.27 (0.017) | −4.10 (0.006) | 1.24 (0.254) | 2.09 (0.074) | 7.08 (0.0004) | 7.09 (0.0003) | 2.71 (0.030) | 2.25 (0.058) | −4.11 (0.006) | 1.08 (0.314) | 2.07 (0.076) | 4.48 (0.002) | 1.49 (0.177) | |
| Minimum price | Training | 2.38 (0.015) | 0.43 (0.667) | 2.41 (0.017) | 0.44 (0.659) | 1.07 (0.284) | −2.18 (0.03) | 0.76 (0.448) | −2.73 (0.006) | −2.53 (0.012) | 2.23 (0.027) | 0.13 (0.899) | 0.66 (0.509) | −2.71 (0.007) | 0.31 (0.759) |
| Testing | 2.32 (0.06) | 2.02 (0.089) | 1.19 (0.28) | 0.81 (0.442) | 0.32 (0.757) | −0.03 (0.977) | 1.03 (0.339) | 0.03 (0.973) | −0.11 (0.918) | 1.13 (0.30) | 0.41 (0.690) | 0.06 (0.948) | −1.21 (0.265) | −0.24 (0.816) | |
| Modal price | Training | 2.34 (0.02) | 0.06 (0.54) | 2.31 (0.018) | 1.53 (0.128) | 1.60 (0.111) | −2.31 (0.022) | 0.45 (0.651) | 1.47 (0.143) | 1.51 (0.130) | 2.35 (0.02) | −2.17 (0.031) | −2.09 (0.037) | −2.33 (0.025) | 0.27 (0.787) |
| Testing | −4.83 (0.003) | 2.52 (0.045) | −3.20 (0.018) | 1.06 (0.324) | 1.11 (0.301) | 4.83 (0.003) | 4.81 (0.003) | 1.01 (0.346) | 1.01 (0.346) | −3.19 (0.018) | 2.57 (0.037) | 2.63 (0.033) | −1.69 (0.135) | −0.22 (0.830) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chitikela, G.; Admala, M.; Ramalingareddy, V.K.; Bandumula, N.; Ondrasek, G.; Sundaram, R.M.; Rathod, S. Artificial-Intelligence-Based Time-Series Intervention Models to Assess the Impact of the COVID-19 Pandemic on Tomato Supply and Prices in Hyderabad, India. Agronomy 2021, 11, 1878. https://doi.org/10.3390/agronomy11091878
Chitikela G, Admala M, Ramalingareddy VK, Bandumula N, Ondrasek G, Sundaram RM, Rathod S. Artificial-Intelligence-Based Time-Series Intervention Models to Assess the Impact of the COVID-19 Pandemic on Tomato Supply and Prices in Hyderabad, India. Agronomy. 2021; 11(9):1878. https://doi.org/10.3390/agronomy11091878
Chicago/Turabian StyleChitikela, Gayathri, Meena Admala, Vijaya Kumari Ramalingareddy, Nirmala Bandumula, Gabrijel Ondrasek, Raman Meenakshi Sundaram, and Santosha Rathod. 2021. "Artificial-Intelligence-Based Time-Series Intervention Models to Assess the Impact of the COVID-19 Pandemic on Tomato Supply and Prices in Hyderabad, India" Agronomy 11, no. 9: 1878. https://doi.org/10.3390/agronomy11091878
APA StyleChitikela, G., Admala, M., Ramalingareddy, V. K., Bandumula, N., Ondrasek, G., Sundaram, R. M., & Rathod, S. (2021). Artificial-Intelligence-Based Time-Series Intervention Models to Assess the Impact of the COVID-19 Pandemic on Tomato Supply and Prices in Hyderabad, India. Agronomy, 11(9), 1878. https://doi.org/10.3390/agronomy11091878