2. Model Architectures
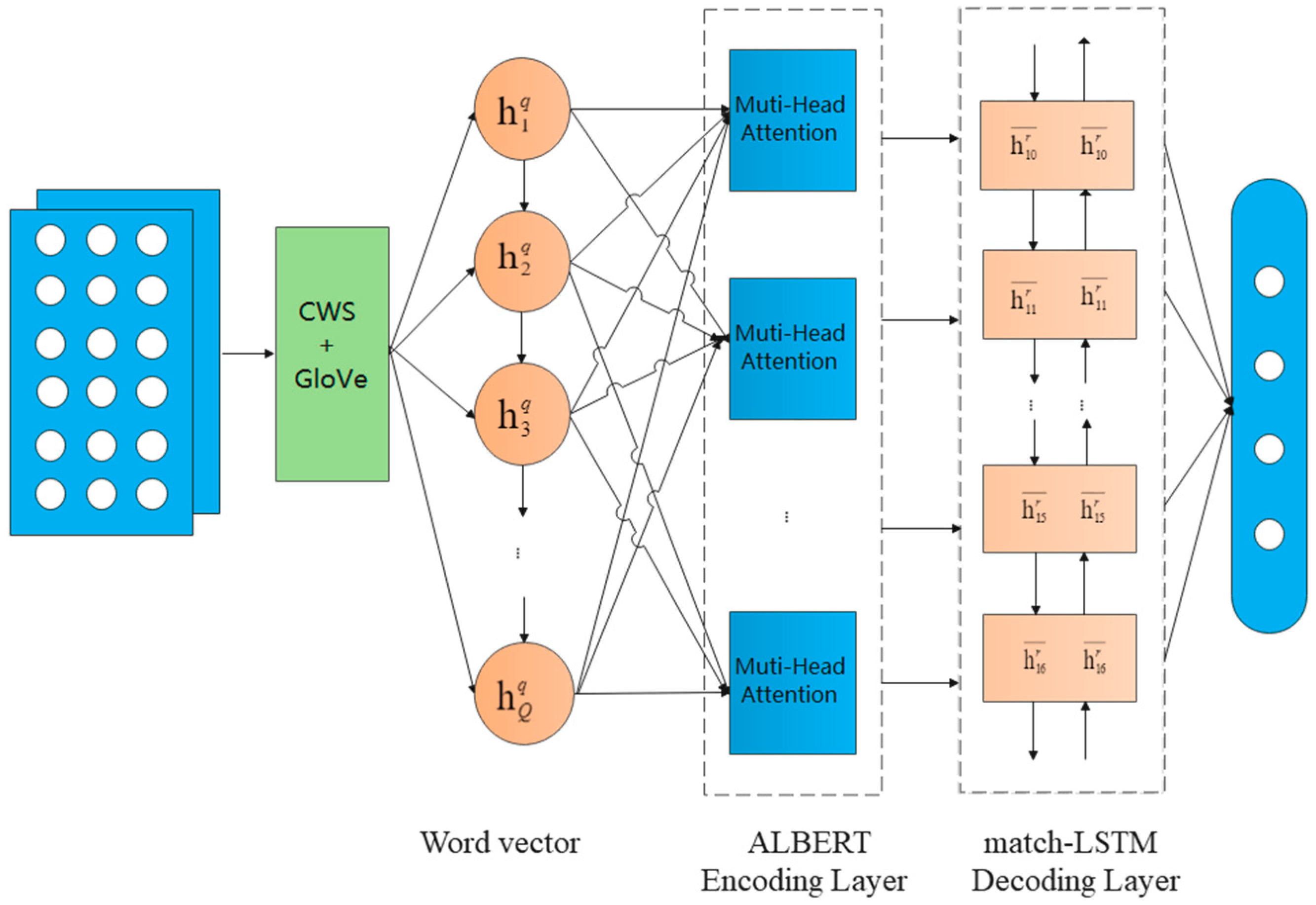
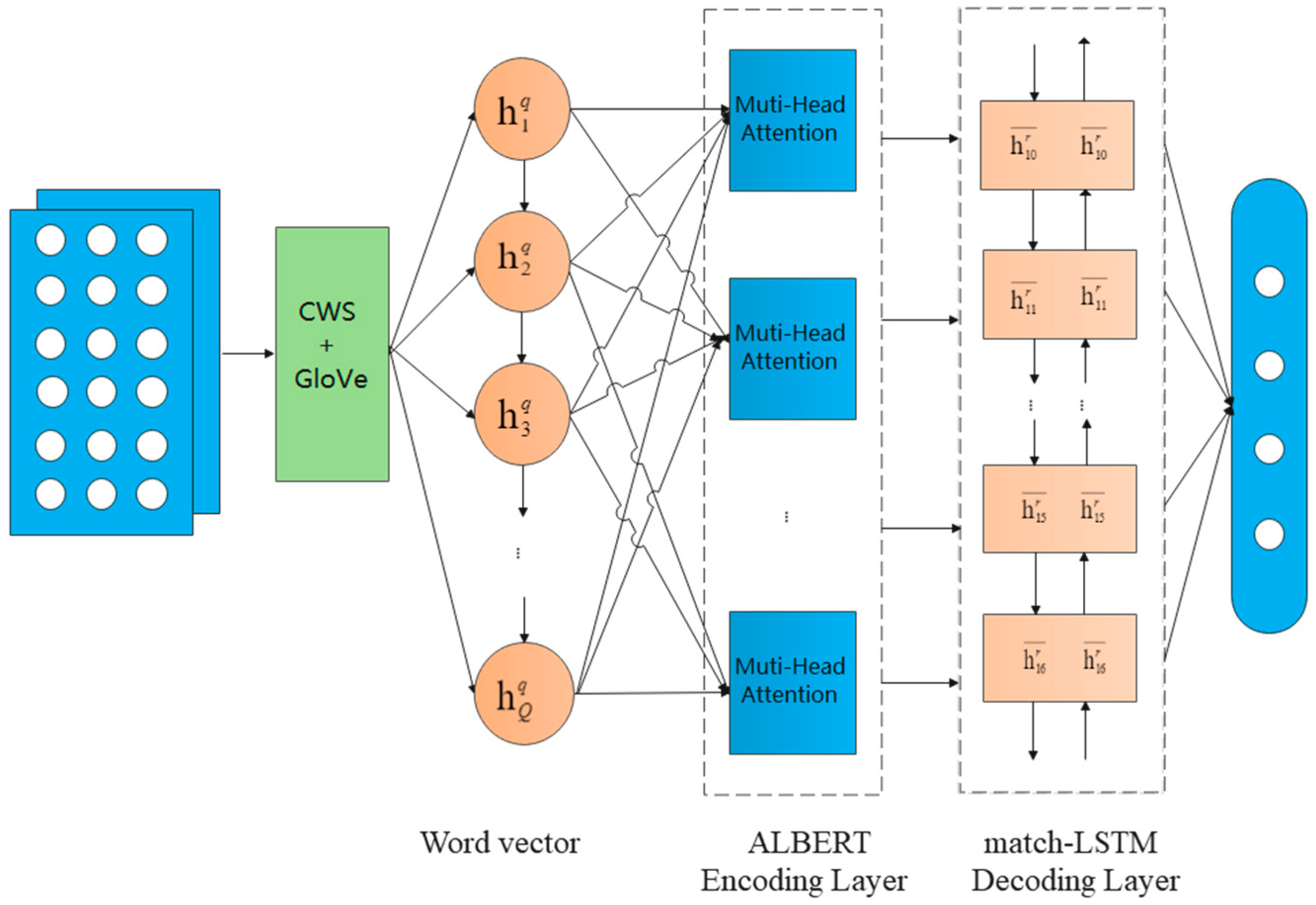
Our end-to-end architecture for text classification is illustrated in
Figure 1. The model consists of four parts: text preprocessing layer, ALBERT layer, match-LSTM layer and interactive classification layer. For pre-processing, we employ an efficient and precise model proposed by Duan et al. [
31] for Chinese word segmentation (CWS). Based on the stereotype in most NLP tasks, attention is strong in catching the “important” features and distribution of the input, employing multi-head attention. A recurrent network encoder is engaged to build representation for questions and answers separately; thus, we pre-train the data with the ALBERT model, which is a lighter and faster version of BERT, as it cuts down the parameters to reduce the memory consumption and speed up the BERT training model. After that, the match-LSTM model will be used to find the correct category of the question (as illustrated in
Figure 1 in more detail), by collecting information from questions and answers.
2.1. Chinese Word Segmentation
As Chinese text cannot be taken directly as the input for the classification model, it is necessary to convert them into vector. To preserve as much as possible the integrity and comprehensiveness of the semantic meaning of a sentence, we first preprocess the sentence with de-noising and word segmentation and vectorization, and then use the GloVe method to transform the word segmentation results into word vectors.
Duan et al. report a Chinese word segmentation (CWS) model—called attention is all you need for CWS (AAY_CWS)—which achieves state-of-the-art performance. Compared with Python’s Jieba word base, Duan’s CWS model is a more advanced greedy decoding segmentation algorithm, which employs a transformer-like method—Gaussian-masked Directional (GD) transformer. For smoother training, it consumes two highway connections: one is GD multi-head attention and the other is GD attention. The Python implementation of AAY_CWS can be found at
https://github.com/akibcmi/SAMS (accessed on 6 October 2020).
The segmentation results of Chinese sentences are greatly influenced by semantics and context. To improve the precision of segmentation, the stop words table is loaded before segmentation, which can reduce the adverse effect of the disabled words, special characters and spaces with little or no contributions to feature extraction in the sentence.
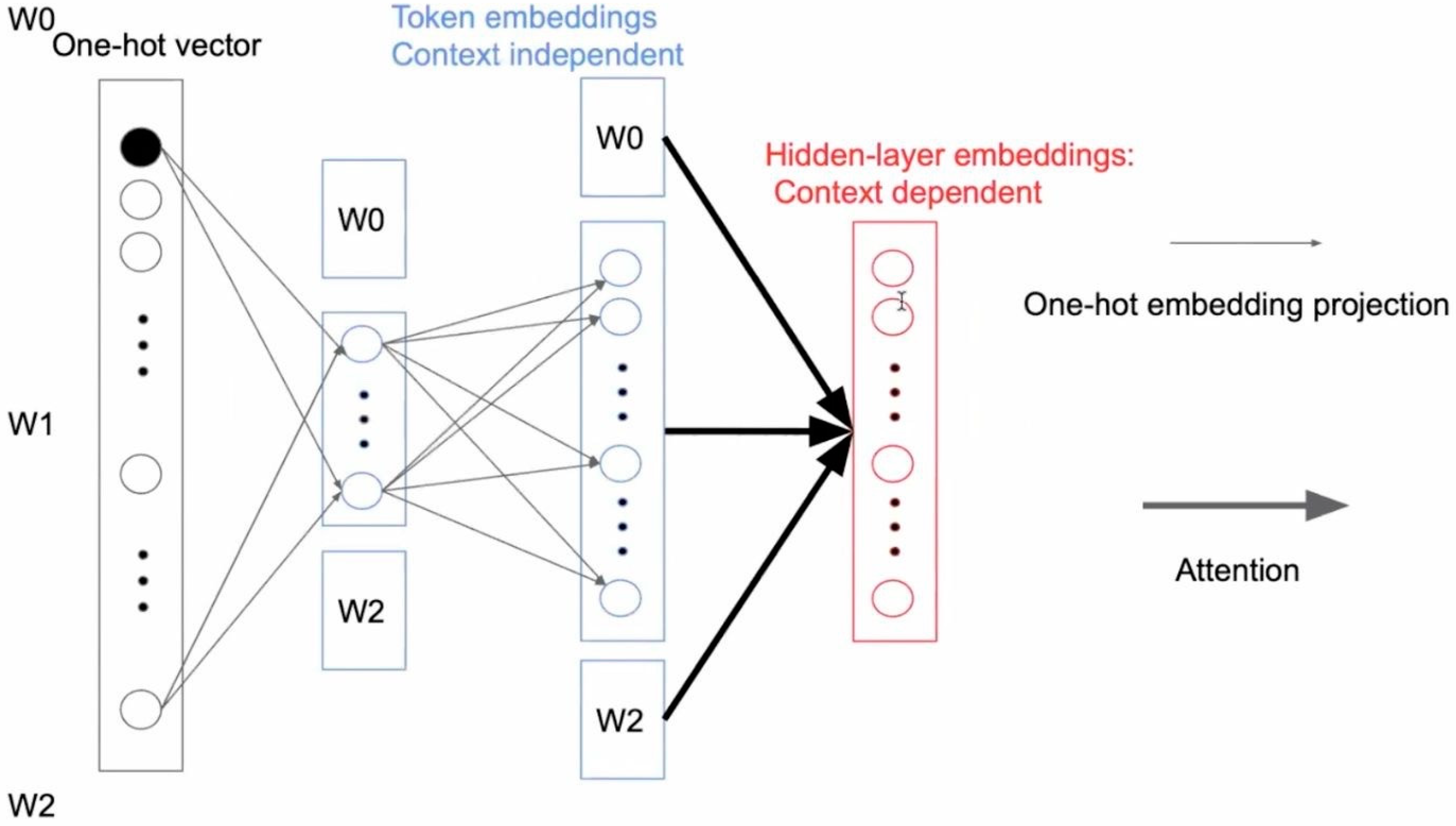
The attention mechanism has achieved great success in many fields. Most competitive neural sequence transduction models have an encoder and decoder layer. Using attention to connect the encoder and decoder performs well, since attention represents the relationship between words. The encoder maps the input sequence denoted as X to a sequence Z; given Z, the decoder then produces an output sequence Y.
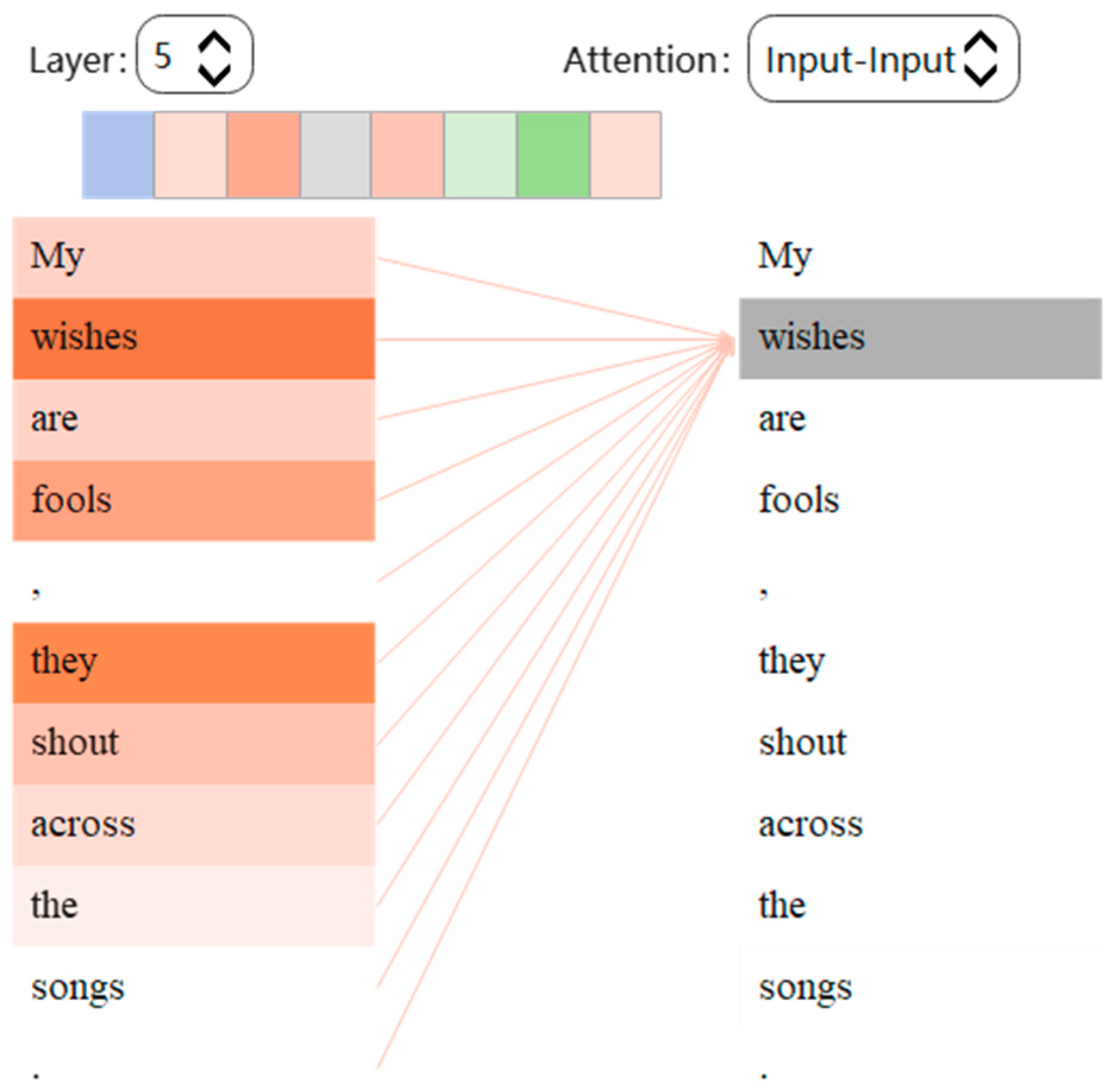
An attention model maps a query vector Q and a set of key–value (K, V) vector pairs as (Q, K, V) to an output vector. As shown in
Figure 2, we can visualize the attention relationship between words with colors. The deeper the color, the closer the relationship between the word “wishes” and others. As shown in the table, “they” has the deepest color with “wishes”, which means the model finds that “they” refers to “wishes”.
2.2. Global Word Vector
Semantic vector space models of language represent each word with a real-valued vector, and these vectors are useful as features in a variety of applications, such as information retrieval [
12], document classification [
32], question answering and named entity recognition [
33,
34].
Therefore, based on our wide-coverage agricultural corpus, we employ GloVe for the global log bilinear regression model properties needed for such regularities. GloVe stands for Global Vectors, which uses global words statistics information.
First, GloVe provides annotation for word–word co-occurrence counts with matrix X, whose entries represents the number of times word i occurs in the context of probe word k. We take the final formula directly from the GloVe source:
This is one example of an equation:
represents the probability of word k occurring in the context of probe word i.
First, noting that the ratio
depends on three words
i,
j and
k, the most general model takes the form:
After a few variations, Pennington et al. proposed a new weighted least squares regression model that addresses these problems. Casting Equation (3) as a least squares problem and introducing a weighting function
into the cost function gives us the model:
The higher the co-occurrence of (
j,
k), the bigger the weight
, the assumption is reasonable—except for high-frequency words. Some high-frequency auxiliary words without actual meanings should be ignored. Therefore:
where
and
.
Take sheep and peach from our dataset as examples.
Table 1 shows these probabilities and their ratios for a large corpus, and the numbers confirm these expectations. Compared to the raw probabilities, the ratio is better able to distinguish relevant words (raise and pick) from irrelevant words (disease and radio) and it is also better able to discriminate between the two relevant words. This co-occurrence result shows that our word vectors are good word vectors, preserving the relevant features of words.
2.3. ALBERT
In 2018, Google proposed the BERT model [
35], which set a record in the 11 task tests at that time, bringing a landmark change to the development of natural language processing.
BERT is a seq2seq [
36] model of encoder–decode structure, while ALBERT is an improvement based on it. There are four methods to turn BERT to ALBERT.
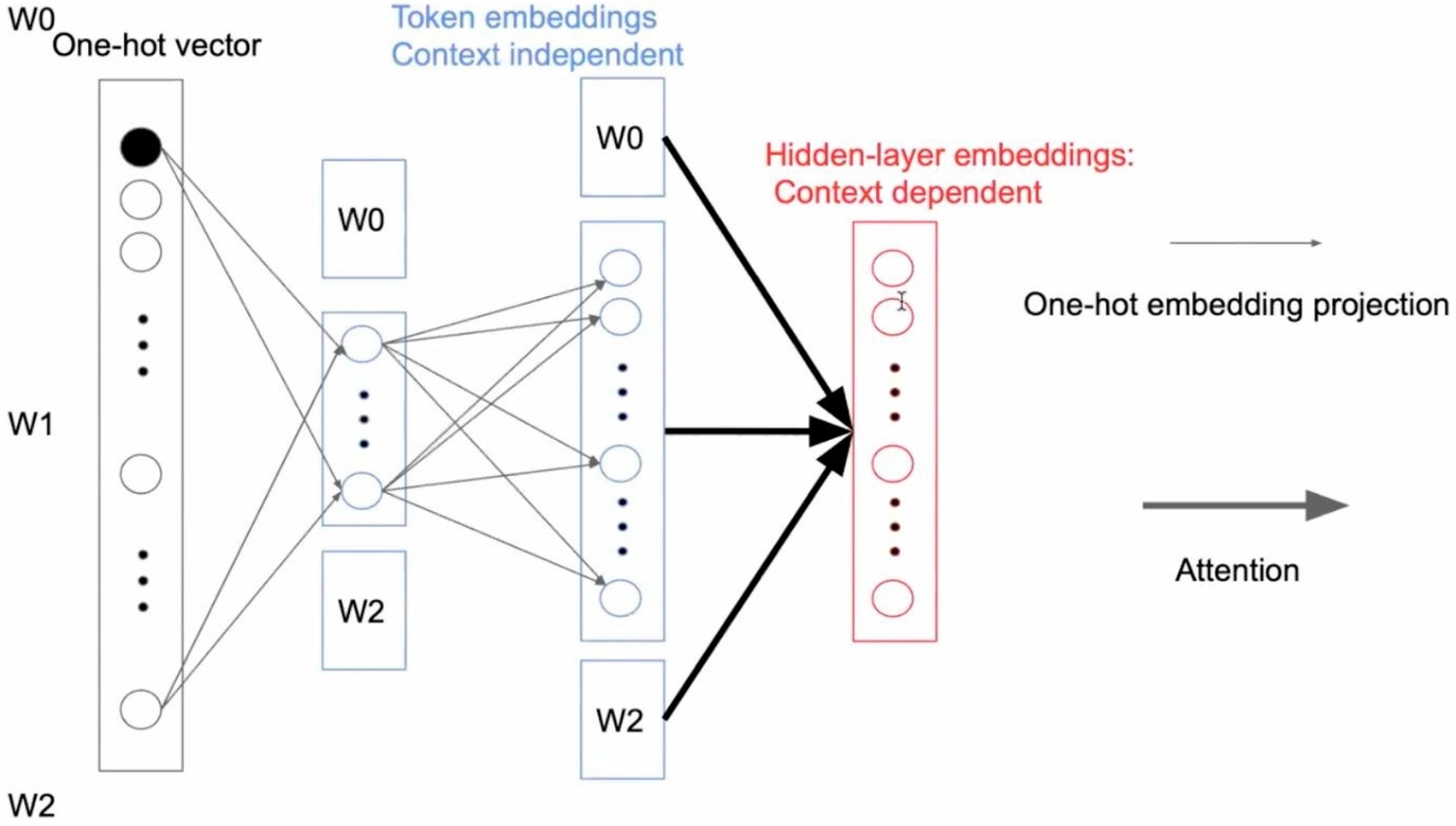
Figure 3 shows the structure of factorized embedding parameterization.
It can be seen from
Figure 3 that the encoder of the model contains two layers. The first layer is the multi-attention network layer, which can extract different features of the model, and the second layer is the feedforward network layer. Each layer contains a function of concatenation and standardization of input and output information.
The calculation formula of multi-head attention is as follows:
In the above formula,
represents the additional weight of Formula
M,
Concat represents the logical concatenation and
represents the attention mechanism, as follows:
where
Q,
K,
V represent a query vector
Q and a set of key–value (
K,
V) vector pairs as in the Attention model and
,
,
represent the corresponding weight matrix. The formula of the Attention mechanism is as follows:
where
denotes the transpose of k vector and
is the vector dimension of
q. Softmax is a normalization function as follows:
As a lighter version of BERT, the ALBERT model transformed Next Sentence Prediction (NSP, ref. [
35]) to Sentence Order Prediction (SOP), which improves the downstream effect of multi-sentence input. Compared to BERT, the ALBERT model reduces the number of parameters and enhances the ability of semantic comprehension.
2.4. Decoder Layer
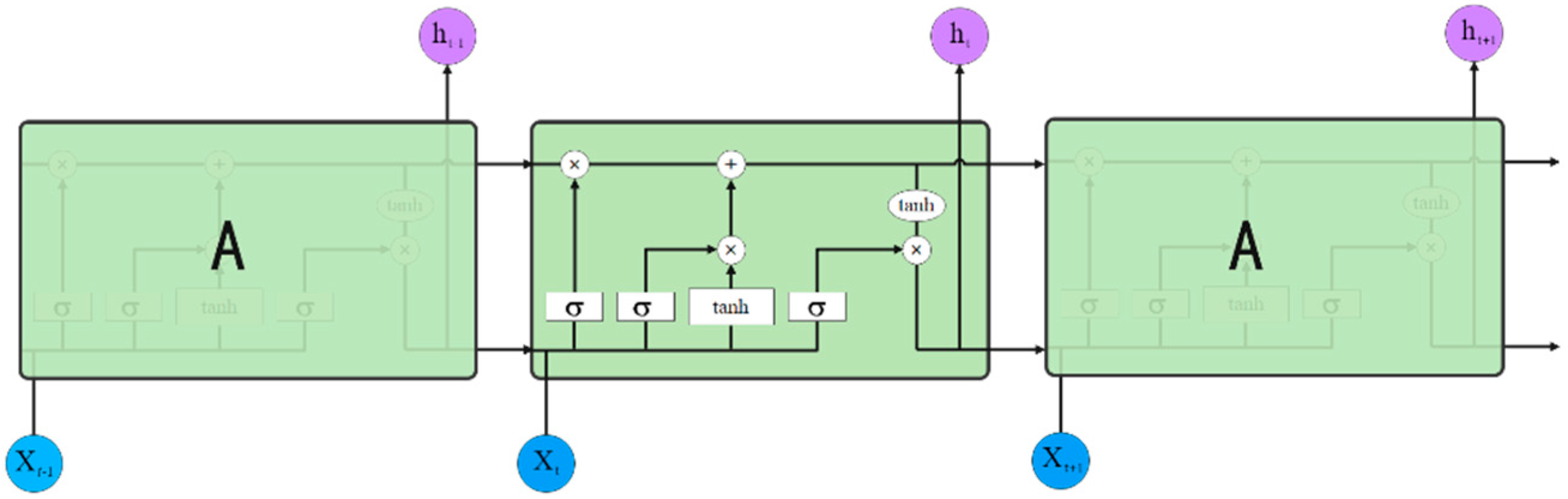
For decoder layer, match-LSTM is employed; to help understand the model, LSTM is explained. The long short-term memory network (LSTM) [
37] is a special type of recurrent neural network (RNN), which solves the problems of RNN, such as the disappearance of feedback and the long interval and delay of prediction sequence. The LSTM model includes three gate structures: forget gate, input gate and output gate. The three gates act on the cell unit to form the hidden middle layer of the LSTM model. The so-called gate is actually a mapping representation of the data model, which determines whether to connect or close through the combination operation of sigmoid function and matrix multiplication, and controls whether the current time node information is added to the cell unit. The key to LSTMs is the horizontal line running through the top of the diagram.
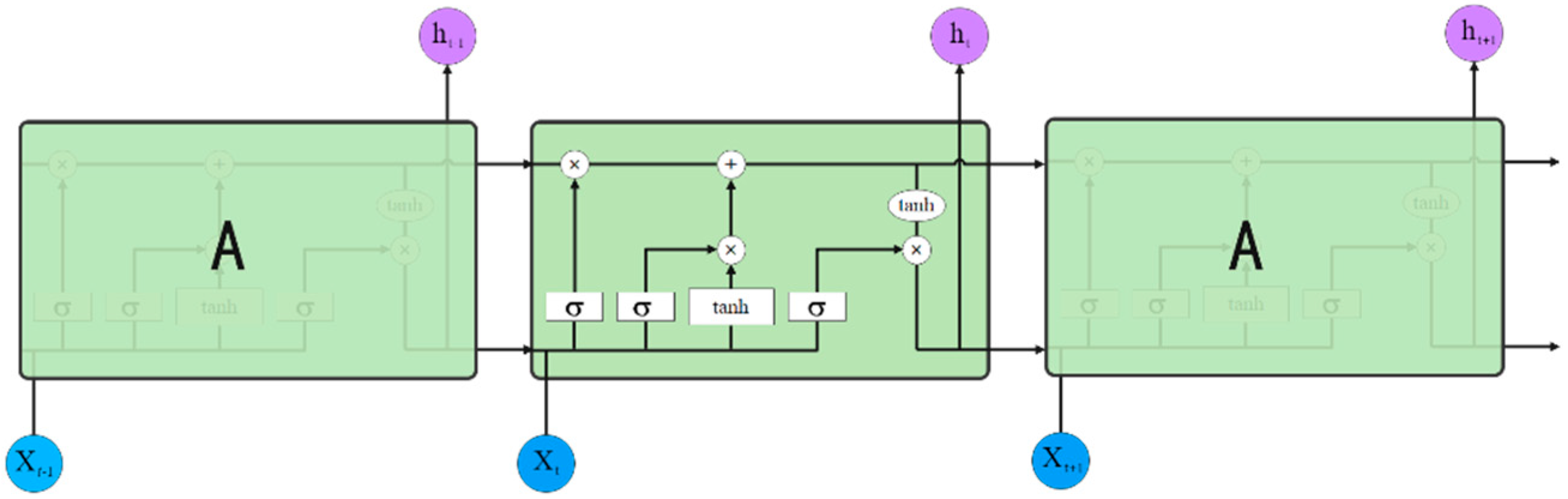
The working mode of LSTM is basically the same as that of RNN network, and its network structure is shown in
Figure 4. (All the annotation used in
Figure 4 is explained in
Figure 5.)
As can be seen from
Figure 4, for the set represented by a listed input sequence x, the calculation formula of hidden state
is as follows:
While the “model” in the
Figure 4 represents
f, which is a non-linear function,
represents the hidden state at time
t − 1. Taking the sample
X as input of the model, a set of hidden state {
,
} will be calculated, where
represents the final state of the sequence transferred to the end of the neural network. It can be understood that any input
in the middle will interact with the hidden state of the secondary
t − 1, and thus the self-loop form on the left side of
Figure 4 can be equivalent to the expression on the right side.
The first step in our LSTM is to decide what information we are going to throw away from the cell state. This decision is made by a sigmoid layer called the “forget gate layer”.
where
w is the weight matrix and
is the bias unit.
The input gate layer is as follows:
The output gate layer is calculated as follows:
The cell state is calculated as follows, where
represents the new memory cell or temporary memory cell and
represents the final cell at time
t:
The hidden state at time
t is as follows:
In 2016, Wang and Jiang proposed a match-LSTM sequence-to-sequence model for predicting textual entailment, which is a widely used and well-explored method for RC tasks. Based on different answer pointer layer, Wang proposed two types of match-LSTM mode: sequence and boundary models. In the case of textual entailment, two sentences, a premise–hypothesis pair, are specified. In our case, a question–answer pair is given. To find whether the answer matches the question, we will practice the boundary match-LSTM model. After the output of ALBERT, the results will be sent to the match-LSTM to get multiple candidates, and the n-best re-rank model will be used. Among them, the top four results (or there could be less or only one result) will be sent to users, and the users will decide which result is the correct one.
The boundary model consists of an LSTM Preprocessing Layer, a match-LSTM layer and an answer Pointer layer; the detailed formula can be found in the paper of Wang and Jiang.
3. Datasets and Experimental Setup
3.1. Data: 20,000 Questions
We use NQuAD to conduct our experiments. Python’s regular expression is employed to clean and filter the obtained text data to remove useless information.
We used a random sample of two thousand QA pairs of NQuAD, and these 20,000 peach-related questions were classified into 12 categories (shown in
Table 2): marketing, plant diseases and pests, animal disease, cultivation management, breeding management, fertilizer science, nutrition, harvest process, agricultural equipment, storage and transportation, slaughtering process and “OTHERS”. Sample questions are shown in
Table 3. From
Table 2, we can see that the distribution is not a uniform distribution—there are more than 6000 questions for plant diseases and pests, while only 28 for slaughtering process, which is a challenge for our classification task.
The data are sampled as follows. For each category, 80% of the questions are sampled as a training set (with 16,000 questions), 10% as a test set (2000 questions) and the rest as a validation set (2000 questions).
3.2. Statistics of Our Data
We divide our NQuAD questions into six types, which are common in search logs, as shown in
Table 4. The statistics are illustrated in
Table 5. We set the dimension of word vector as 120, and max sentence length as 100 words.
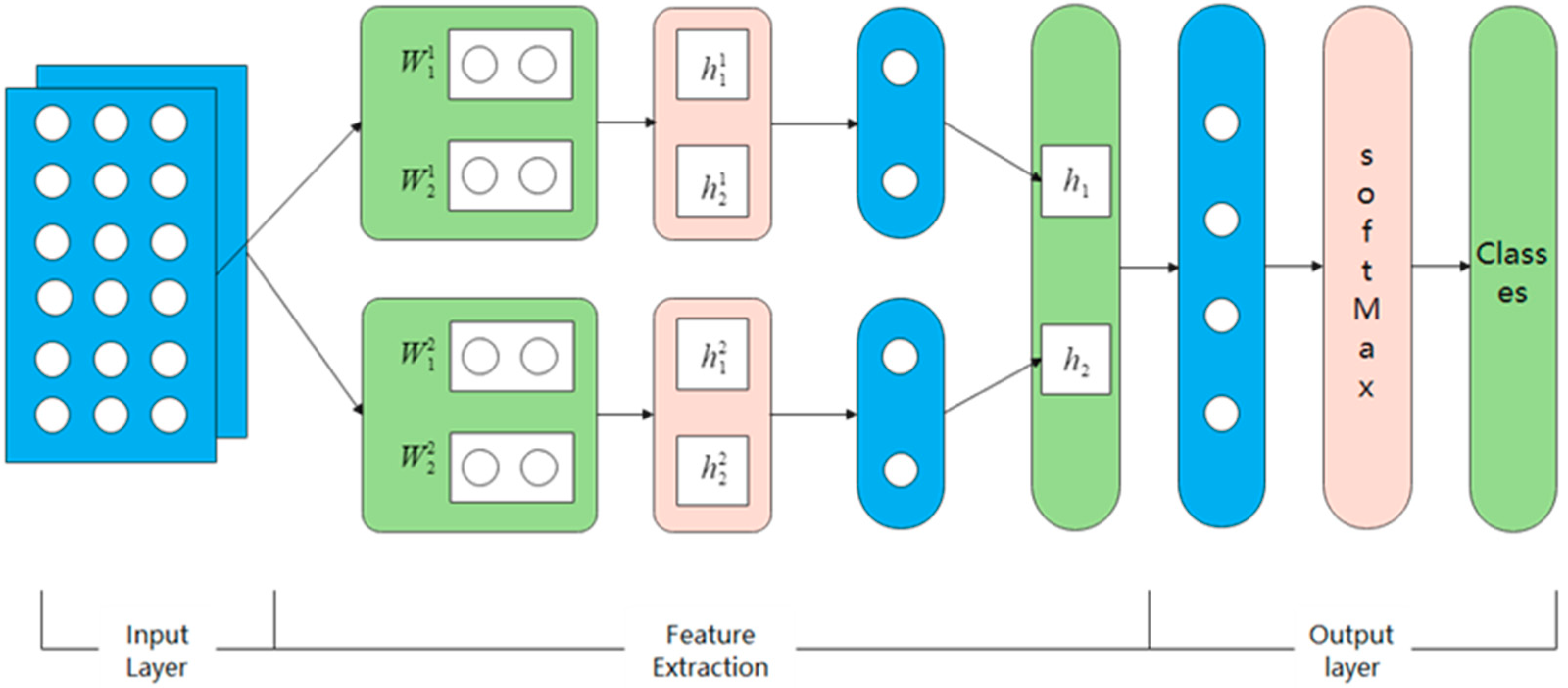
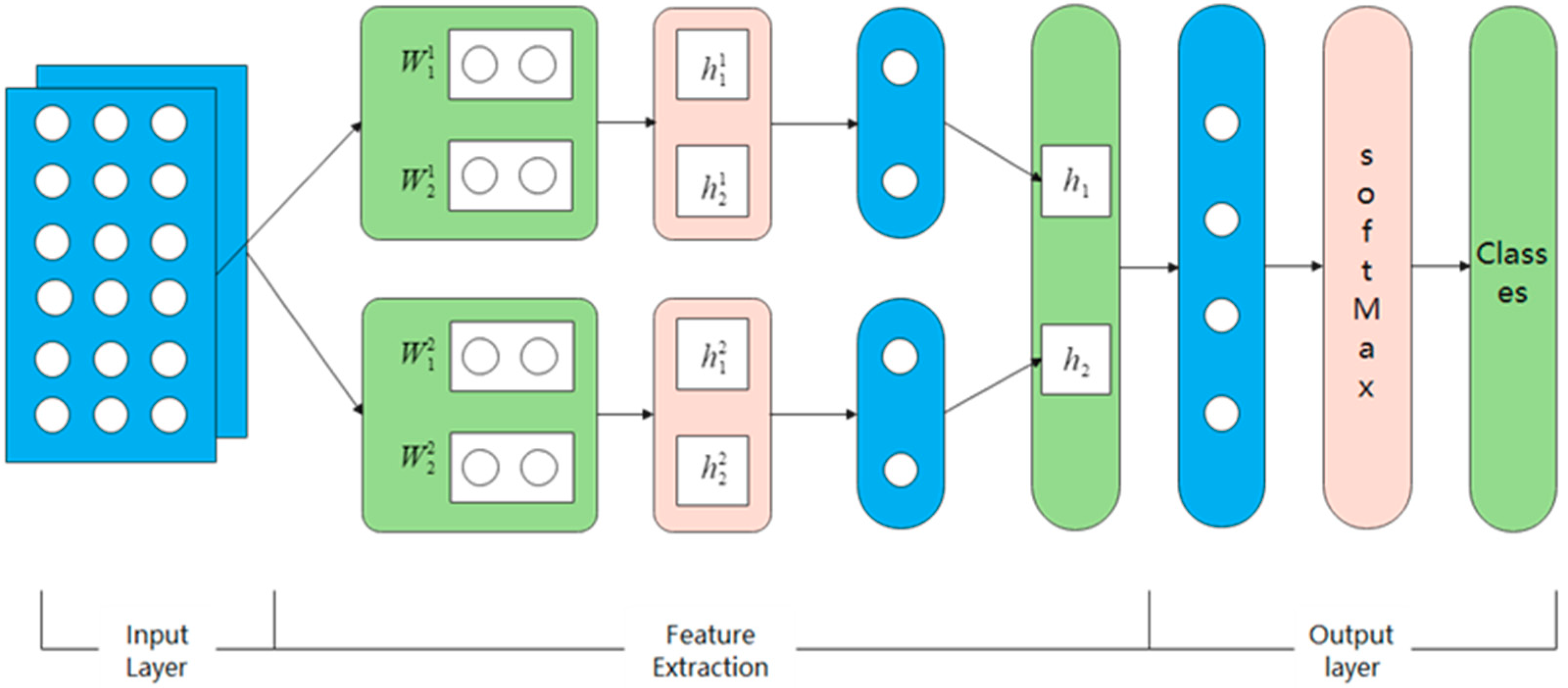
3.3. Flow Chart of Data Set Construction
The flow chart of our classification model based on ALBERT+match-LSTM is as follows (
Figure 6), which contains input layer, feature extraction and output layer.
CWS + GloVe → N*512-dimension word vectors, which is the input for our ALBERT+match-LSTM model.
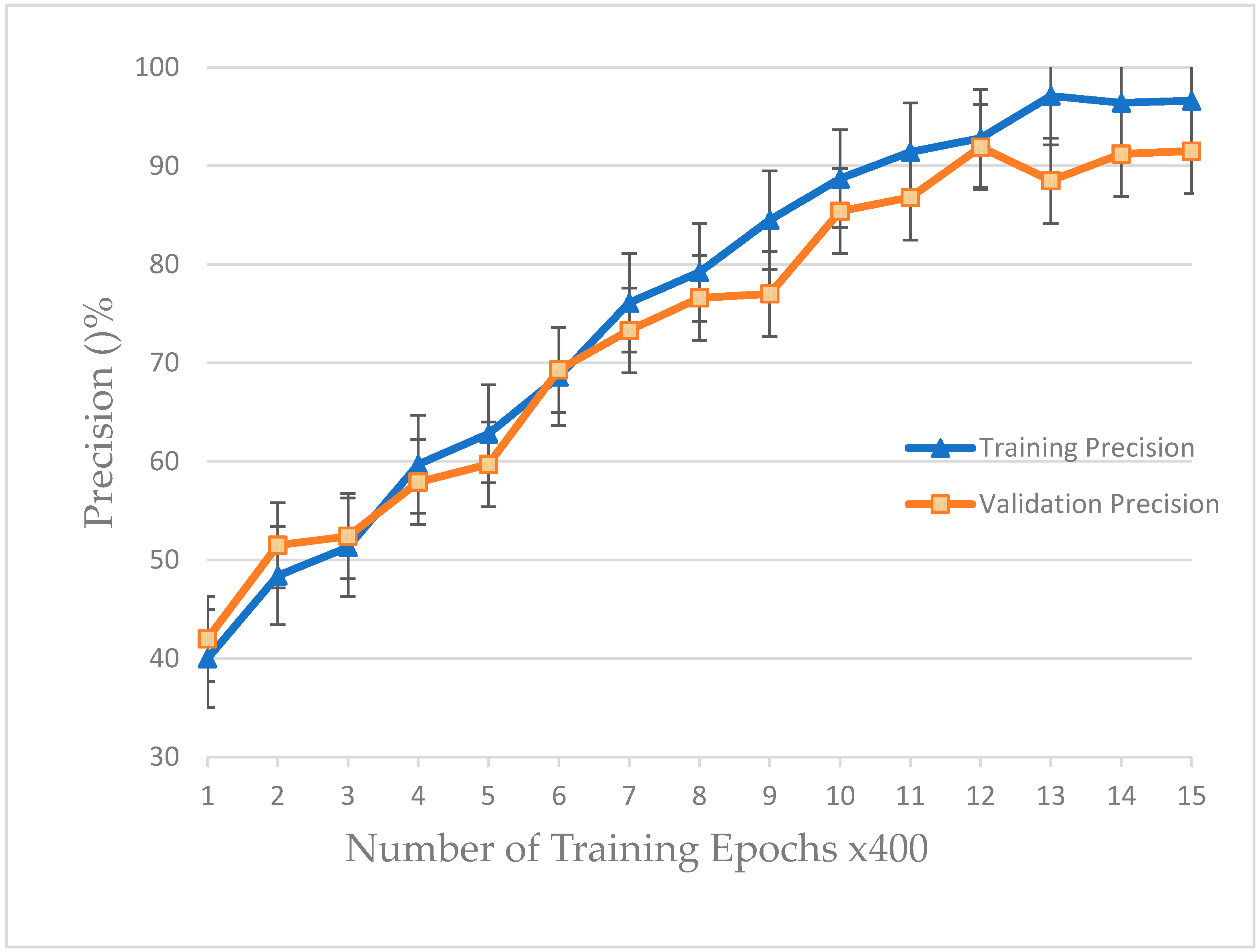
In this layer, parameters will be trained to extract the significant features. We set the feature dimension as 512, N = 128, and the initial weight is a Gaussian distribution The K-fold cross validation is employed to train our model and monitor the performance; 16,000 questions were selected as our training set and 2000 as validation set. Set batch size as 1000, in total 16 batches; set the epoch as 500, the sample will be validated every 400 epochs. Adam optimization algorithm is used with , . The dropout regularization is employed to avoid overfitting and the gradients are clipped to the maximum norm of 10.0.
After the features are extracted, all the feature vectors will be concatenated to be a one-dimension vector, and finally, the SoftMax function is used to obtain the feature vector output.
3.4. Hardware, Software Environment and Evaluation Indicators
This experiment’s software environment is Python 3.6.2 and TensorFlow 1.13.1, the server’s hardware environment is NVIDIA Corporation device 1e04 (Rev A1) and GPU is NVIDIA GeForce RTX 2080ti. In this study, the TensorFlow neural network framework is used to construct the neural network.
In the experiment, 20,000 problems are divided into the training set, verification set and test set according to a ratio of 8:1:1. The precision, recall rate and
F1 value are used as evaluation indexes in this paper. The formula is as follows:
5. Discussion and Conclusions
In this paper, to improve the performance of QA machines, we propose to use Duan’s Chinese word segmentation method to preprocess our data, utilize GloVe instead of word2vec to represent the words, and then employ ALBERT as an encoder and match-LSTM as a decoder, which treat the question as a premise and the answer as a hypothesis over multi-head attention (attention score).
Word2vec is predictive, while GloVe is count-based. GloVe can be implemented in parallel, which means it is faster than Word2vec to obtain to a set precision rate. Additionally, GloVe uses global corpus statistics, which contains more information.
In this paper, our attention-based method is compared with classic machine learning models (Multi-SVM and KNN), as well as convolution-kernel models (CNN, LSTM and match-LSTM).
SVM (here, multi-SVM is used) has been one of the most efficient machine learning algorithms since its introduction in the 1990s. However, the SVM algorithms for text classification are limited by the lack of transparency in results caused by a high number of dimensions, while KNN is limited by data storage constraints for large search problems to find nearest neighbors. Additionally, the performance of KNN is dependent on finding function, thus making this technique a very data-dependent algorithm.
CNN, LSTM (a modified RNN) and match-LSTM use multiple convolution kernels to extract text features, which are then inputted to the linear transformation layer followed by a sigmoid function to output the probability distribution over the label space.
ALBERT takes the advantage of attention mechanisms and convolution kernels, thus reaching the highest performance. Extensive experimental results show that the proposed methods outperform other models by a substantial margin (3.9%). Further analysis of experimental results demonstrates that our proposed methods not only find the adequate answers to the question, but also select the most informative words automatically when predicting different answers.
This model can be quite valuable in practice; as mentioned previously in the introduction, this agri-intelligent QA system is built on the NJTG platform. Currently, there are more than 10 million QA pairs collected and stored in the NJTG QA dataset (20,000 were used in this paper); what is more, end-users of the NJTG platform submit thousands of questions every day. With the application of this model, our QA system can identify the most adequate answers from the exact category (about 100 thousand QA pairs) instead of the whole NJTG QA dataset (10 million QA pairs). In other words, the time complexity decreases 100 times.
Regarding the drawback of this model, if one question sentence “what vitamin can be used for pig’s night blindness” can be classified into two categories (nutrition or animal disease), based on our current model, it can belong to only one category; there is a chance that the adequate answer cannot be identified but some constructive work can be done in a sense.
For future work, there is still a gap between the English and non-English (such as Chinese) intelligent QA systems. With the rapid development and high precision of current English QA models and machine translation (MT) models, can we take a detour? To bridge this gap, first there should be a built English-based dataset using MT models from non-English data; there are tons of well-built English-based datasets. Second, we should translate non-English questions into English using high precision MT models. Third, we should identify the adequate answers with a high precision method, and translate the answers back to the original language. It sounds like extra work, but with many ready-to-use models for both tasks, it might be worth the effort. Furthermore, this general method could be applied to all languages, not only Chinese. Based on this grand unification theory, English plays the role of a bridge—all we need are MT models and English-based models.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}