Emulators of a Physical Model for Estimating Leaf Wetness Duration


Abstract
1. Introduction
2. Theoretical Background
2.1. Penman–Monteith Model for LW Estimation
2.2. Candidate ML Algorithms of the PM Emulator for LW Prediction
2.2.1. Extreme Learning Machine
2.2.2. Random Forest
2.2.3. Support Vector Machine
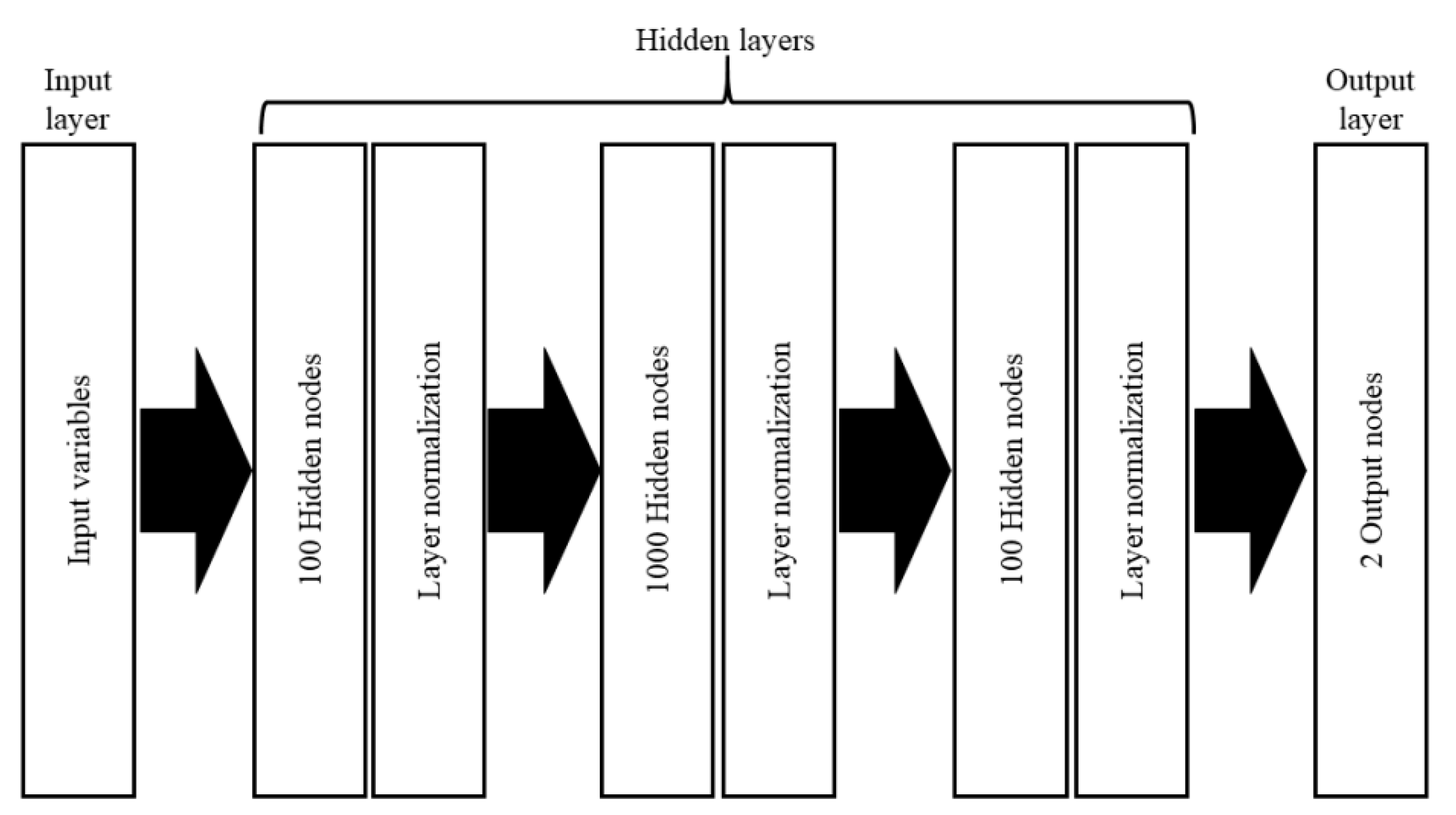
2.2.4. Deep Neural Network
2.3. Input Variable Sets for Emulators Based on the PM Model
2.4. Evaluation Measures
3. Simulation Study for Building Emulators Using Generated Data
3.1. Simulation Design
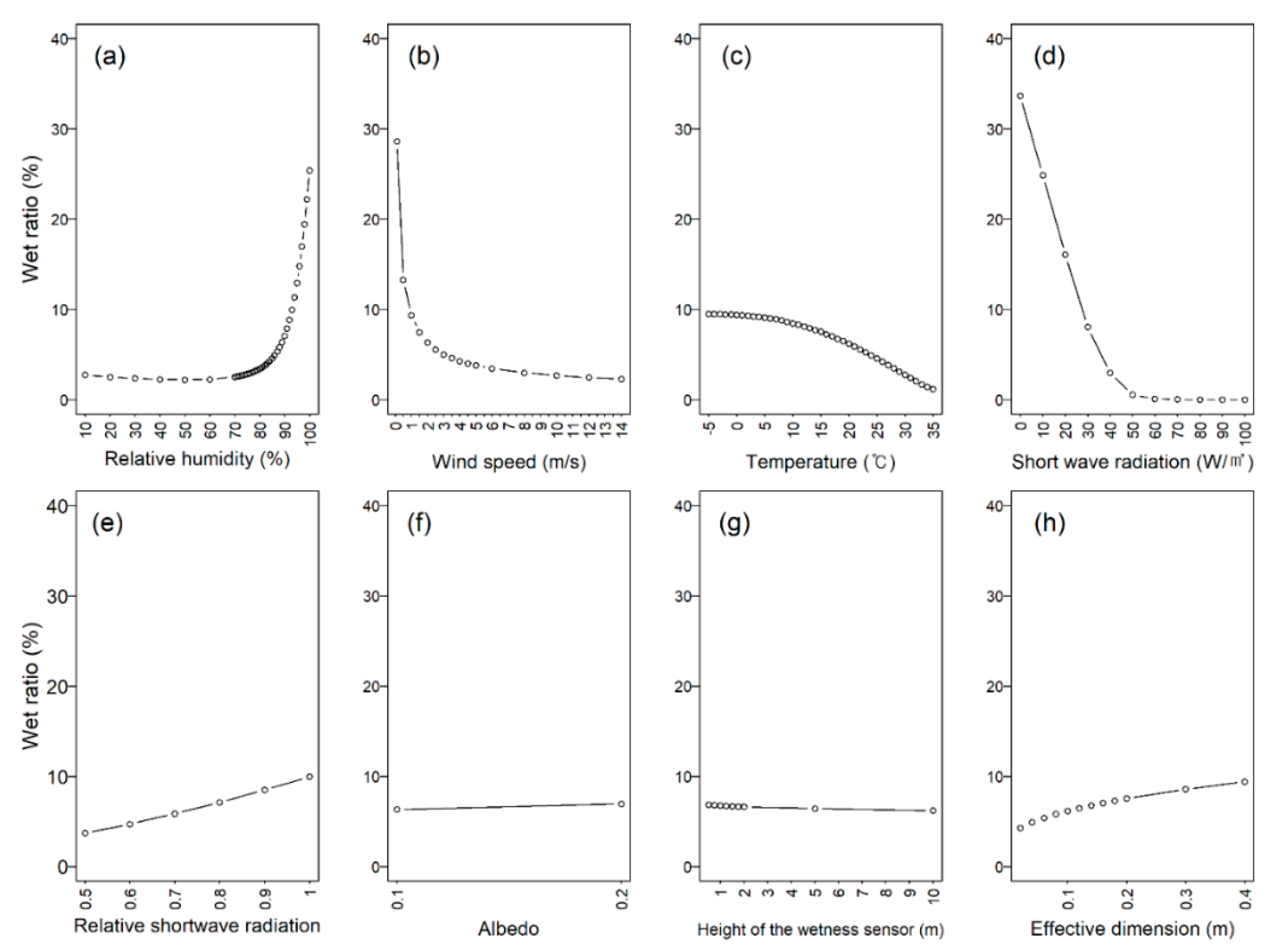
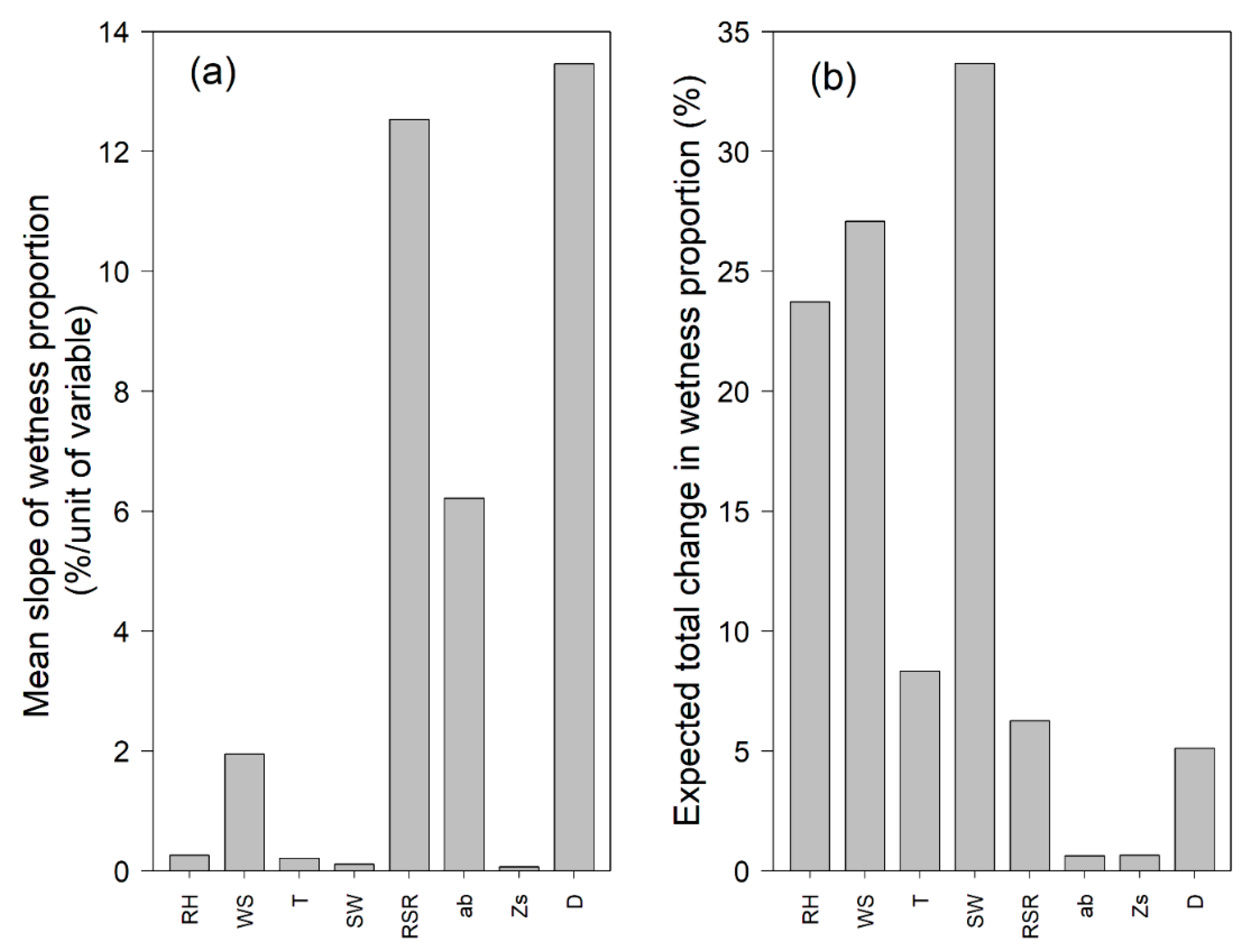
3.2. Sensitivity Analysis of PM Model and Performance Evaluation Results
4. Case Study for Evaluation Based on Real-World Data
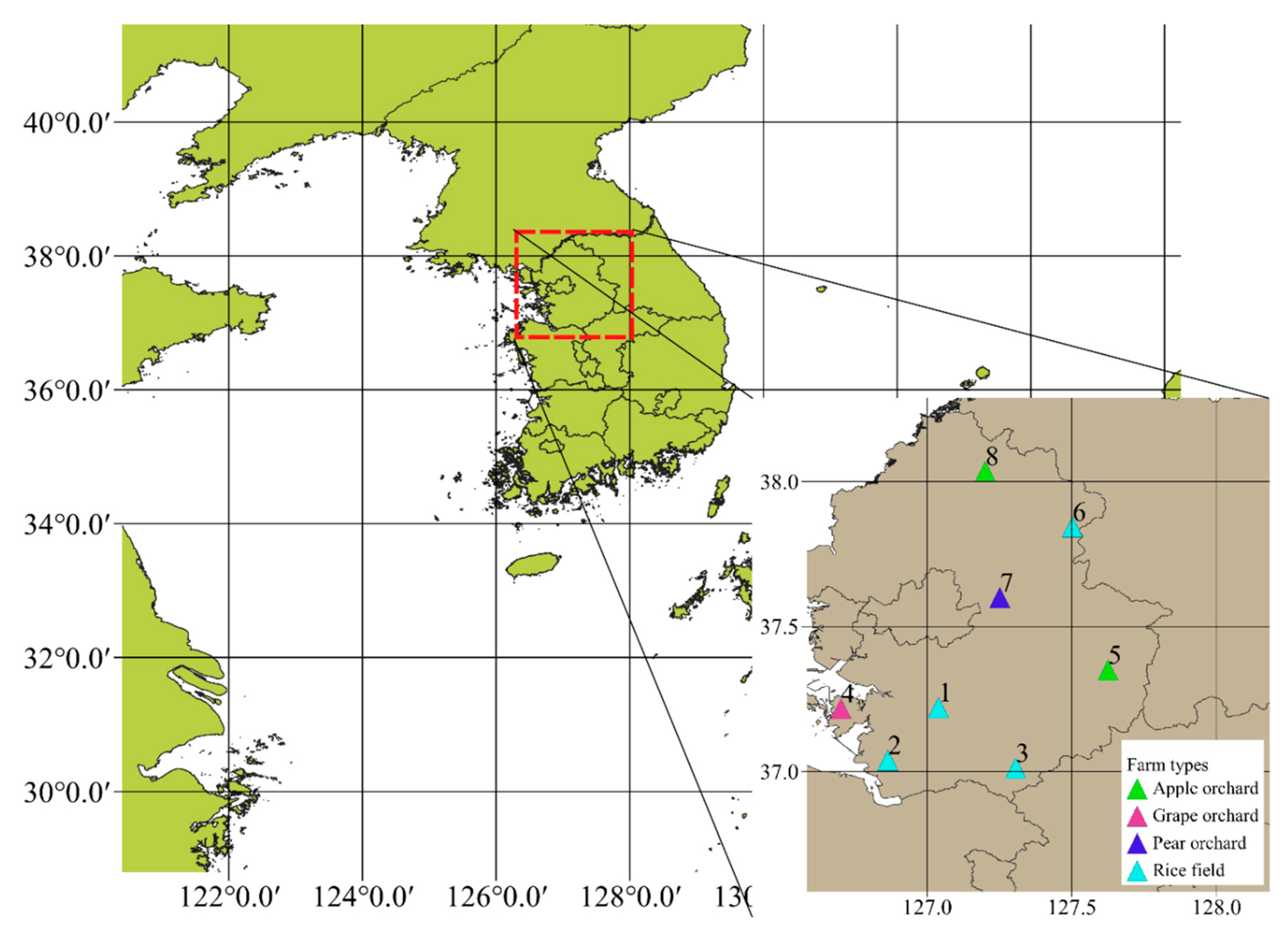
4.1. Data Description
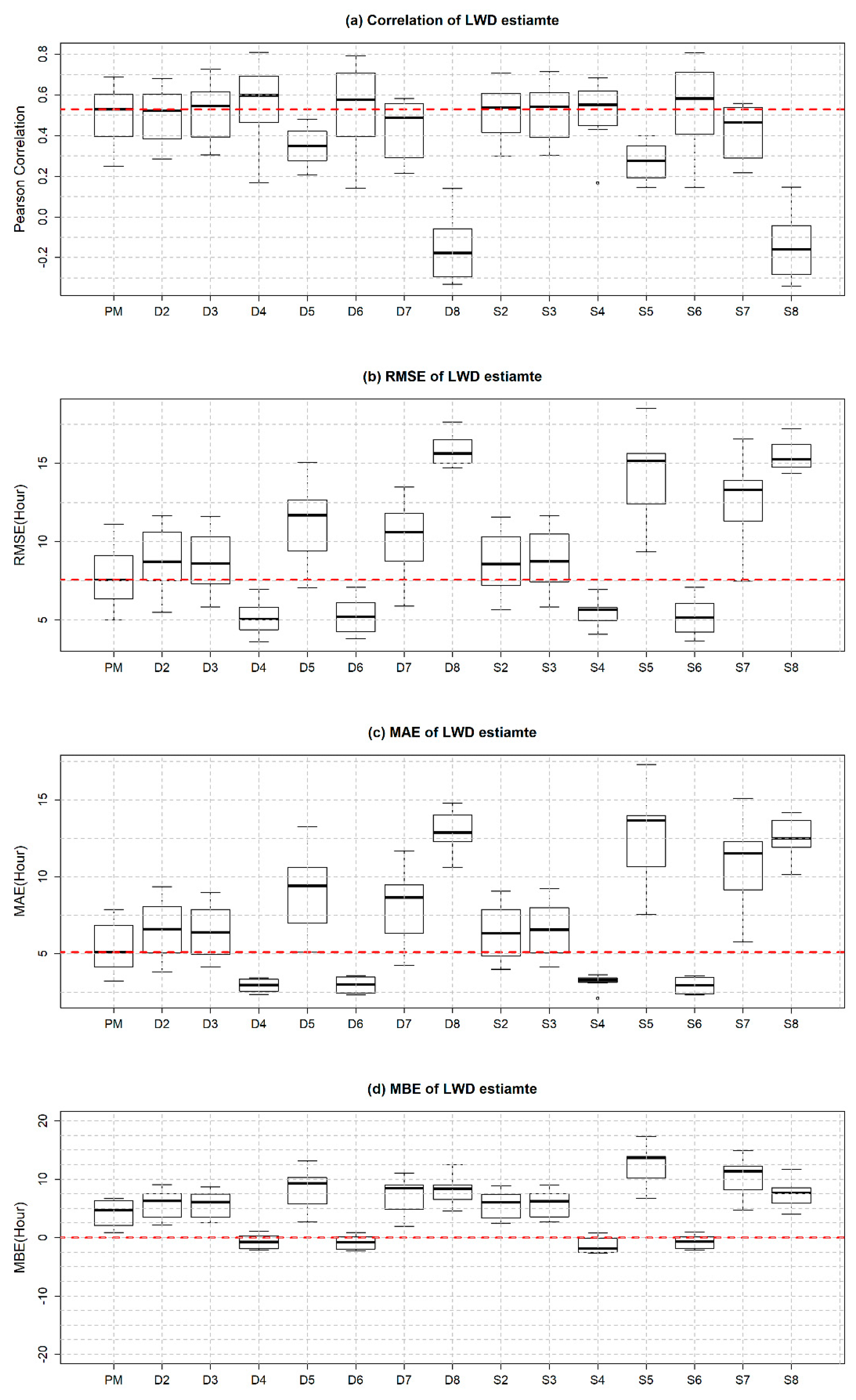
4.2. Results
5. Discussion
6. Conclusions
- (1)
- The emulators for the physical model can be applicable for LW and LWD estimation. The emulators using RH, WS, T, Z_s, and D provide approximately 84% ACC of the PM model for LW estimation. In addition, the emulators using RH, WS, Z_s, and D provide approximately 81% ACC of the PM model.
- (2)
- Some emulators that use RH for input variable realize better performances than the PM model in the case study for LW and LWD estimations. The emulator using RH, T, Z_s, and D leads to the best performance based on the case study. The discrepancy between the simulation and case studies may be induced by the uncertainty in the observed data.
- (3)
- DNN and SVM algorithms can be good techniques for emulating the PM model in LW and LWD estimation. The two techniques provide slightly better performances than other used ML algorithms, particularly in applications with a larger number of input variables.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sentelhas, P.C.; Gillespie, T.J.; Gleason, M.L.; Monteiro, J.E.B.A.; Helland, S.T. Operational exposure of leaf wetness sensors. Agric. For. Meteorol. 2004, 126, 59–72. [Google Scholar] [CrossRef]
- Huber, L.; Gillespie, T.J. Modeling Leaf Wetness in Relation to Plant Disease Epidemiology. Annu. Rev. Phytopathol. 1992, 30, 553–577. [Google Scholar] [CrossRef]
- Schmitz, H.F.; Grant, R.H. Precipitation and dew in a soybean canopy: Spatial variations in leaf wetness and implications for Phakopsora pachyrhizi infection. Agric. For. Meteorol. 2009, 149, 1621–1627. [Google Scholar] [CrossRef]
- Jesperson, G.D.; Sutton, J.C. Evaluation of a forecaster for downy mildew of onion (Allium cepa L.). Crop Prot. 1987, 6, 95–103. [Google Scholar] [CrossRef]
- de Visser, C.L.M. Development of a Downy Mildew Advisory Model Based on Downcast. Eur. J. Plant Pathol. 1998, 104, 933–943. [Google Scholar] [CrossRef]
- Wang, H.; Sanchez-Molina, J.A.; Li, M.; Berenguel, M. Development of an empirical tomato crop disease model: A case study on gray leaf spot. Eur. J. Plant Pathol. 2020, 156, 477–490. [Google Scholar] [CrossRef]
- Magarey, R.D.; Russo, J.M.; Seem, R.C. Simulation of surface wetness with a water budget and energy balance approach. Agric. For. Meteorol. 2006, 139, 373–381. [Google Scholar] [CrossRef]
- Pedro, M.J.; Gillespie, T.J. Estimating dew duration. II. Utilizing standard weather station data. Agric. Meteorol. 1981, 25, 297–310. [Google Scholar] [CrossRef]
- Pedro, M.J.; Gillespie, T.J. Estimating dew duration. I. Utilizing micrometeorological data. Agric. Meteorol. 1981, 25, 283–296. [Google Scholar] [CrossRef]
- Kim, K.S.; Taylor, S.E.; Gleason, M.L. Development and validation of a leaf wetness duration model using a fuzzy logic system. Agric. For. Meteorol. 2004, 127, 53–64. [Google Scholar] [CrossRef]
- Marta, A.D.; De Vincenzi, M.; Dietrich, S.; Orlandini, S. Neural network for the estimation of leaf wetness duration: Application to a Plasmopara viticola infection forecasting. Phys. Chem. Earth 2005, 30, 91–96. [Google Scholar] [CrossRef]
- Sentelhas, P.C.; Dalla Marta, A.; Orlandini, S.; Santos, E.A.; Gillespie, T.J.; Gleason, M.L. Suitability of relative humidity as an estimator of leaf wetness duration. Agric. For. Meteorol. 2008, 148, 392–400. [Google Scholar] [CrossRef]
- Wilks, D.S.; Shen, K.W. Threshold Relative Humidity Duration Forecasts for Plant Disease Prediction. J. Appl. Meteorol. 1991, 30, 463–477. [Google Scholar] [CrossRef]
- Francl, L.J.; Panigrahi, S. Artificial neural network models of wheat leaf wetness. Agric. For. Meteorol. 1997, 88, 57–65. [Google Scholar] [CrossRef]
- Gillespie, T.J.; Srivastava, B.; Pitblado, R.E. Using Operational Weather Data to Schedule Fungicide Sprays on Tomatoes in Southern Ontario, Canada. J. Appl. Meteorol. 1993, 32, 567–573. [Google Scholar] [CrossRef]
- Gleason, M.; Taylor, S.; Loughin, T.; Koehler, K. Development and validation of an empirical model to estimate the duration of dew periods. Plant Dis. 1994. [Google Scholar] [CrossRef]
- Rao, P.S.; Gillespie, T.J.; Schaafsma, A.W. Estimating wetness duration on maize ears from meteorological observations. Can. J. Soil Sci. 1998, 78, 149–154. [Google Scholar] [CrossRef]
- Sentelhas, P.C.; Gillespie, T.J.; Gleason, M.L.; Monteiro, J.E.B.M.; Pezzopane, J.R.M.; Pedro, M.J. Evaluation of a Penman–Monteith approach to provide “reference” and crop canopy leaf wetness duration estimates. Agric. For. Meteorol. 2006, 141, 105–117. [Google Scholar] [CrossRef]
- Monteith, J.L.; Unsworth, M.H. (Eds.) Principles of Environmental Physics. In Principles of Environmental Physics, 4th ed.; Academic Press: Boston, MA, USA, 2013; p. iii. [Google Scholar] [CrossRef]
- Allen, R.G.; Pereira, L.S.; Raes, D.; Smith, M. Crop Evapotranspiration-Guidelines for Computing Crop Water Requirements-FAO Irrigation and Drainage Paper 56; FAO: Rome, Italy, 1998; Volume 300, p. D05109. [Google Scholar]
- Walter, I.A.; Allen, R.G.; Elliott, R.; Jensen, M.E.; Itenfisu, D.; Mecham, B.; Howell, T.A.; Snyder, R.; Brown, P.; Echings, S.; et al. ASCE’s Standardized Reference Evapotranspiration Equation. In Watershed Management and Operations Management 2000; American Society of Civil Engineers: Reston, VA, USA, 2001. [Google Scholar] [CrossRef]
- Niazian, M.; Niedbała, G. Machine Learning for Plant Breeding and Biotechnology. Agriculture 2020, 10, 436. [Google Scholar] [CrossRef]
- Niedbała, G.; Kurasiak-Popowska, D.; Stuper-Szablewska, K.; Nawracała, J. Application of Artificial Neural Networks to Analyze the Concentration of Ferulic Acid, Deoxynivalenol, and Nivalenol in Winter Wheat Grain. Agriculture 2020, 10, 127. [Google Scholar] [CrossRef]
- Yin, H.; Gu, Y.H.; Park, C.-J.; Park, J.-H.; Yoo, S.J. Transfer Learning-Based Search Model for Hot Pepper Diseases and Pests. Agriculture 2020, 10, 439. [Google Scholar] [CrossRef]
- Park, J.; Shin, J.-Y.; Kim, K.R.; Ha, J.-C. Leaf Wetness Duration Models Using Advanced Machine Learning Algorithms: Application to Farms in Gyeonggi Province, South Korea. Water 2019, 11, 1878. [Google Scholar] [CrossRef]
- Shin, J.-Y.; Kim, B.-Y.; Park, J.; Kim, K.R.; Cha, J.W. Prediction of Leaf Wetness Duration Using Geostationary Satellite Observations and Machine Learning Algorithms. Remote Sens. 2020, 12, 3076. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Peña, M.; van den Dool, H. Consolidation of Multimodel Forecasts by Ridge Regression: Application to Pacific Sea Surface Temperature. J. Clim. 2008, 21, 6521–6538. [Google Scholar] [CrossRef]
- Huang, G.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Smith, A. Image segmentation scale parameter optimization and land cover classification using the Random Forest algorithm. J. Spat. Sci. 2010, 55, 69–79. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Wright, M.N.; Ziegler, A. ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. arXiv 2017, 77, 17. [Google Scholar] [CrossRef]
- Jung, K.; Shin, J.-Y.; Park, D. A new approach for river network classification based on the beta distribution of tributary junction angles. J. Hydrol. 2019, 572, 66–74. [Google Scholar] [CrossRef]
- Chen, P.-H.; Lin, C.-J.; Schölkopf, B. A tutorial on ν-support vector machines. Appl. Stoch. Model. Bus. 2005, 21, 111–136. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Granada, Spain, 12–14 December 2011; pp. 2546–2554. [Google Scholar]
- Tran, T.T.K.; Lee, T.; Shin, J.-Y.; Kim, J.-S.; Kamruzzaman, M. Deep Learning-Based Maximum Temperature Forecasting Assisted with Meta-Learning for Hyperparameter Optimization. Atmosphere 2020, 11, 487. [Google Scholar] [CrossRef]
- Xu, J.; Sun, X.; Zhang, Z.; Zhao, G.; Lin, J. Understanding and Improving Layer Normalization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 27–30 November 2019; pp. 4381–4391. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Magarey, R.D.; Isard, S.A. A Troubleshooting Guide for Mechanistic Plant Pest Forecast Models. J. Integr. Pest Manag. 2017, 8. [Google Scholar] [CrossRef]
- Bassimba, D.D.M.; Intrigliolo, D.S.; Dalla Marta, A.; Orlandini, S.; Vicent, A. Leaf wetness duration in irrigated citrus orchards in the Mediterranean climate conditions. Agric. For. Meteorol. 2017, 234–235, 182–195. [Google Scholar] [CrossRef]
- Gao, Z.; Shi, W.; Wang, X.; Cao, B.; Wang, Y. Comparison of the performance of leaf wetness duration models for rainfed jujube (Ziziphus jujuba Mill.) plantations in the loess hilly region of China using machine learning. Ecohydrology 2020, 13, e2237. [Google Scholar] [CrossRef]
- Gommes, R.; Challinor, A.; Das, H.; Dawod, M.; Mariani, L.; Tychon, B.; Krüger, R.; Otte, U.; Vega, R.; Trampf, W. Guide to Agricultural Meteorological Practices; World Meteorological Organization: Geneva, Switzerland, 2010; Volume 134. [Google Scholar]
- WMO. Guide to Instruments and Methods of Observation; World Meteorological Organisation: Geneva, Switzerland, 2018. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model # | Input Variables |
|---|---|
| 1 (M1) | RH, WS, T, SW, , D, ab, RSR |
| 2 (M2) | RH, WS, T, , D |
| 3 (M3) | RH, WS, , D |
| 4 (M4) | RH, T, , D |
| 5 (M5) | WS, T, , D |
| 6 (M6) | RH, , D |
| 7 (M7) | WS, , D |
| 8 (M8) | T, , D |
| Variables | Values |
|---|---|
| Relative humidity (RH, %) | 10, 20, 30, 40, 50, 60, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100 |
| Air temperature (T, °C) | −5, −4, −3, −2, −1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 |
| Short wave (SW, W/m2) | 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200, 300 |
| Wind speed (WS, m/s) | 0.01, 0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5, 6, 8, 10, 12, 14 |
| Height of the wetness sensor (, m) | 0.5, 0.75, 1, 1.25, 1.5, 1.75, 2, 5, 10 |
| Effective dimension (D, m) | 0.02, 0.04, 0.06, 0.08, 0.1, 0.12, 0.14, 0.16, 0.18, 0.2, 0.3, 0.4 |
| Albedo (ab) | 0.1, 0.2 |
| Relative shortwave radiation (RSR) | 0.5, 0.6, 0.7, 0.8, 0.9, 1 |
| Algorithms | M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 |
|---|---|---|---|---|---|---|---|---|
| ELM (E) | 0.9537 | 0.8332 | 0.8178 | 0.7112 | 0.6978 | 0.6898 | 0.6701 | 0.6078 |
| RF (R) | 0.9357 | 0.8167 | 0.7974 | 0.7100 | 0.6919 | 0.6854 | 0.6637 | 0.6001 |
| SVM (S) | 0.9937 | 0.8415 | 0.8163 | 0.7181 | 0.6938 | 0.6911 | 0.6715 | 0.6012 |
| DNN (D) | 0.9927 | 0.8393 | 0.8168 | 0.7145 | 0.6985 | 0.6922 | 0.6731 | 0.6020 |
| Site | Latitude (Degree) | Longitude (Degree) | Elevation (m) | Farm Type |
|---|---|---|---|---|
| 1 | 37.221 | 127.039 | 45 | Rice field |
| 2 | 37.039 | 126.864 | 24 | Rice field |
| 3 | 37.012 | 127.306 | 34 | Rice field |
| 4 | 37.217 | 126.702 | 6 | Grape orchard |
| 5 | 37.350 | 127.625 | 57 | Apple orchard |
| 6 | 37.844 | 127.502 | 68 | Rice field |
| 7 | 37.600 | 127.251 | 65 | Pear orchard |
| 8 | 38.036 | 127.201 | 101 | Apple orchard |
| Statistics | T | RH | SW | WS |
|---|---|---|---|---|
| Mean | 10.0 | 67.6 | 160.4 | 1.1 |
| Standard deviation | 11.8 | 22.3 | 239.6 | 1.3 |
| Minimum | −26.2 | 10.0 | 0.0 | 0.0 |
| Median | 10.5 | 70.3 | 2.8 | 0.5 |
| Maximum | 36.9 | 100.0 | 1027.9 | 10.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, J.-Y.; Park, J.; Kim, K.R. Emulators of a Physical Model for Estimating Leaf Wetness Duration. Agronomy 2021, 11, 216. https://doi.org/10.3390/agronomy11020216
Shin J-Y, Park J, Kim KR. Emulators of a Physical Model for Estimating Leaf Wetness Duration. Agronomy. 2021; 11(2):216. https://doi.org/10.3390/agronomy11020216
Chicago/Turabian StyleShin, Ju-Young, Junsang Park, and Kyu Rang Kim. 2021. "Emulators of a Physical Model for Estimating Leaf Wetness Duration" Agronomy 11, no. 2: 216. https://doi.org/10.3390/agronomy11020216
APA StyleShin, J.-Y., Park, J., & Kim, K. R. (2021). Emulators of a Physical Model for Estimating Leaf Wetness Duration. Agronomy, 11(2), 216. https://doi.org/10.3390/agronomy11020216