Sweet corn (
Zea mays var.
saccharata) is a subspecies of maize whose milky stage is rich in sugar, various amino acids, vitamins, minerals and dietary fiber. Based on its high nutritional and edible value [
1,
2,
3], the economic benefit of sweet corn is twice that of ordinary corn. It has been reported that the planting area of sweet corn in China has gradually expanded, which accounted for approximately 25% of the world’s planting area in 2018 [
4]. To meet the yield and quality requirements for crop production, the safety, high quality and reliability of seeds are important for planting. However, the mixing of different cultivars during the cultivation, harvest, transportation and storage of seeds can occur, especially with the widespread adoption of hybrid seed techniques. The optimal harvest period of sweet corn occurs in an extremely short time, and the corn quality changes rapidly after harvest [
5]. In particular, the sweet corns are generally harvested at milk-ripe stage, about 20–22 days after pollinaiton, and the immature sweet kernel of ear endosperm is the main product; thus, pure seed is essential for uniform harvesting time, uniform maturity, appropriate shelf-life and timely consumption. Moreover, the economic value, nutritional value and pest resistance of sweet corn are related to the properties of the cultivars. To control seed quality and avoid repeat cultivation, rapid and accurate methods to measure the purity of sweet corn seed are highly important for industrial production of sweet corn.
Morphological identification, physical and chemical analyses, and molecular identification are the conventional methods for identifying plant cultivars [
6,
7,
8]. However, these methods generally require the use of protein electrophoresis or DNA molecular markers, both of which are time consuming, expensive and destructive [
9]. Therefore, these methods are generally used to measure a small number of sampled seeds. To develop accurate and nondestructive classification of a large number of seed samples, a series of research methods have been proposed by scholars, among which spectral imaging and optical imaging technology are widely used [
10,
11,
12,
13].
Spectral technology has been applied to seed feature analysis and cultivar classification by many scholars [
14,
15,
16]. For example, in Qiu et al. (2019), a feature wavelength was selected for two sweet corn seed cultivars via a genetic algorithm (GA), and the classification models based on full spectral wavelengths were compared with models based on feature wavelengths; it was indicated that the model complexity could be reduced and the classification accuracy was still high after the feature wavelength selection [
17]. In Zhao et al. (2018), 12,900 seeds of three maize cultivars were studied, and a radial basis function neural network based on the optimal wavelength selected by principal component analysis (PCA) was established. The experiment showed that the results of the small-size calibration model based on feature wavelengths were similar to those of the large-sample-size calibration model [
18]. To enable an increased number of feature combinations, in Xia et al. (2019), spectral features and texture features were extracted from 1632 seeds of 17 different maize cultivars, and the optimal features were selected via uninformative variable elimination (UVE), the successive projections algorithm (SPA) and multilinear discriminant analysis (MLDA). The results showed that the least squares-support vector machine (LSSVM) classification model based on the features selected via MLDA gained the best performance, achieving the highest classification accuracy (99.13%) [
19]. Miao et al. (2018) introduced t-distributed stochastic neighborhood embedding (t-SNE) for the classification of seeds from eight different waxy maize cultivars and found that the classification accuracy of the t-SNE models was improved by procrustes analysis (PA) preprocessing, and the models using the nonembryo-side data were more accurate than those using the embryo-side data [
20]. In Liu et al. (2014), multispectral imaging technique was used to discriminate the non-transgenic seeds and transgenic rice seeds by combining with four chemometrics methods. By comparing the discrimination performance of different chemometrics methods, the best model for classifying the rice seeds was obtained [
21]. In Shrestha et al. (2016), the classification model was investigated by multispectral imaging technique with the wavelengths ranging from 375 nm to 970 nm for five cultivars of tomato seeds, and a good classification accuracy for two independent test sets was obtained for all tomato cultivars irrespective of chemometric methods [
22]. Hu et al. (2020) used multispectral imaging technology to separate sweet clover seeds from alfalfa seed. The performance of multispectral imaging with object-wise multivariate image analysis was evaluated, and the results demonstrated that the linear discriminant analysis (LDA) model based on a combination of spectral and morphological data showed the best classification performance, with an accuracy of up to 99% [
23]. Seed cultivar classification can be achieved via spectral technology, but the spectral system requires stringent experimental conditions, and the computational complexity of the data processing is high. As economical, convenient and easily adoptable methods, many optical imaging technique-based seed classification methods have been proposed. These methods have been successfully applied to the seed cultivar identification of rice, wheat, corn and other crop species [
24,
25,
26]. For example, to study the influence of different optical properties on the classification of rice seed cultivars, a neural network-based classification model based on the texture, shape and the combination of the two properties was proposed by Chaugule et al. (2014) [
27], and a positive classification result based on seed shape features was reported. Wu et al. (2018) used digital image processing techniques to extract six typical kinds of optical shape features, such as the area, perimeter and rectangularity of ordinary corn seeds, and developed many kinds of classification models. Their results showed that, based on shape features, a support vector machine (SVM) classification model combining GA and particle swarm optimization (PSO) could effectively classify different cultivars of maize seeds [
28]. Kiratiratanapruk et al. (2011) investigated the extraction problems associated with key optical attribute features and compared the performance of color (those based on red-green-blue (RGB) and hue-saturation-value (HSV) color histograms) and texture features (those based on a gray level co-occurrence matrix and local binary patterns) to classify maize seeds, and the results showed that the color and texture features combined gained the best classification performance [
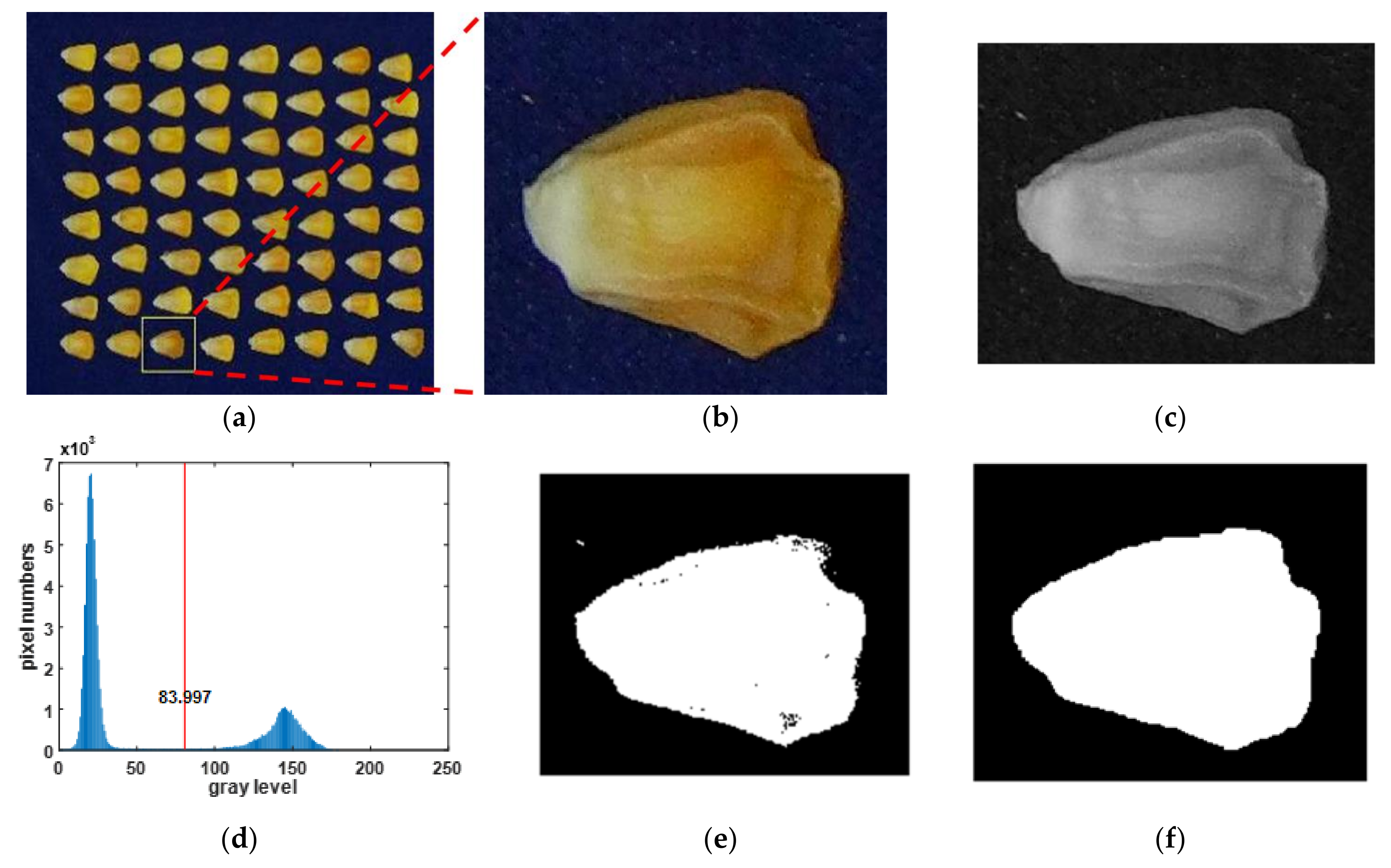
29]. With respect to the problem of adhesion between optical images of seeds, the foreground segmentation of a single typical corn seed is achieved by using the line contour segmentation algorithm in Li et al. (2019) [
30]. Moreover, on the basis of their color and shape, normal and damaged corn seeds are classified by the maximum likelihood estimation. In Abbaspourgilandeh et al. (2020), the color, shape and texture features from the optical images of different rice cultivars with nonlinear relationship were extracted, and the rice cultivar classification model was established by discriminant analysis (DA) and artificial neural network (ANN); the results indicated that ANN achieved a better identification accuracy than that of DA [
31].
The above classification models were generally established through feature extraction and classification algorithms; thus, features reduction algorithms and classification methods have a strong effect on identification accuracy, and improving these model components has been studied previously [
15,
16,
17,
18,
28]. As the feature expressions and classification methods have different effects on the accuracy of cultivar identification, a performance evaluation on these two aspects should be performed first to determine the feature space that is most beneficial to cultivar identification; however, this concept has not been studied in the above research. In addition, most current research focuses on the features from a random section or part of the seed (they do not distinguish between the embryo side and nonembryo side) [
12,
14,
15,
16,
18,
28,
29,
30] or only the embryo side [
17,
19] of maize seeds. Because of the presence of the germ, the characteristic information contained in the front (containing the embryo) and the back (not containing embryo) of corn seeds and its influence on the performance of cultivar classification differs. To improve the accuracy of cultivar classification and improve the stability of the model, the performance of feature information from the embryo side of seeds, the nonembryo side and both of them combined should be evaluated, with the optimal side subsequently used for feature analysis and classification modeling; however, this has not been investigated. To ensure the systematic nature and integrity of cultivar identification, it is especially important to establish a performance evaluation in feature analysis and processing methods for sweet corn seeds. Thus, in this paper, in view of the above problems, seed cultivar classification via image analysis was studied. Due to it being economical, convenient and easily adoptable, a charge-coupled device (CCD) camera (model H1600Cam) with 16 million pixel was used for image acquisition in this study. The optical image of seven cultivars of sweet corn seeds were collected and different optical features were generated to evaluate the performance of cultivar identification. Through optical property features, such as the color, shape and texture features of the embryo side and nonembryo side of seeds, cultivar separability of the different seed sides was achieved, and the optimal side was determined. The key features of seed images were obtained by different dimension reduction methods, and the performance of the different feature spaces was evaluated by four classification algorithms. The key optical feature expressions and classification methods that affect the identification model of sweet corn seed cultivars were ultimately determined.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}