
Compressive Strength Estimation of Steel-Fiber-Reinforced Concrete and Raw Material Interactions Using Advanced Algorithms

 , , , and
, , , and 
Abstract
:1. Introduction
2. Methodology
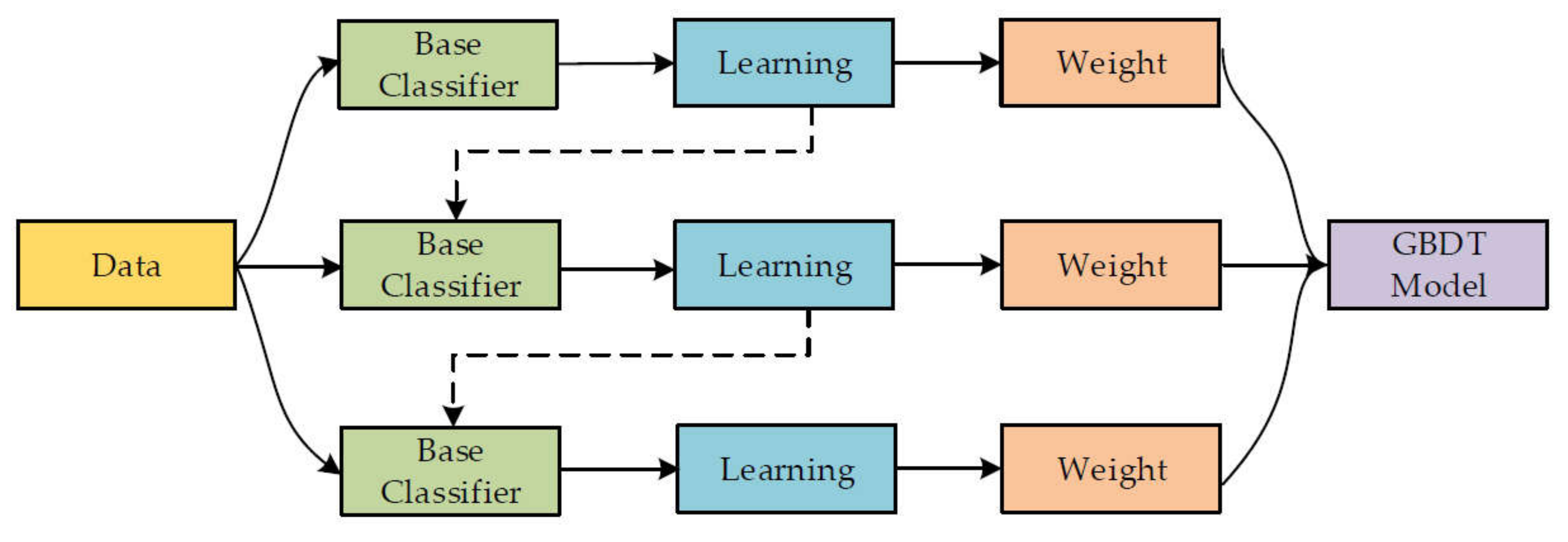
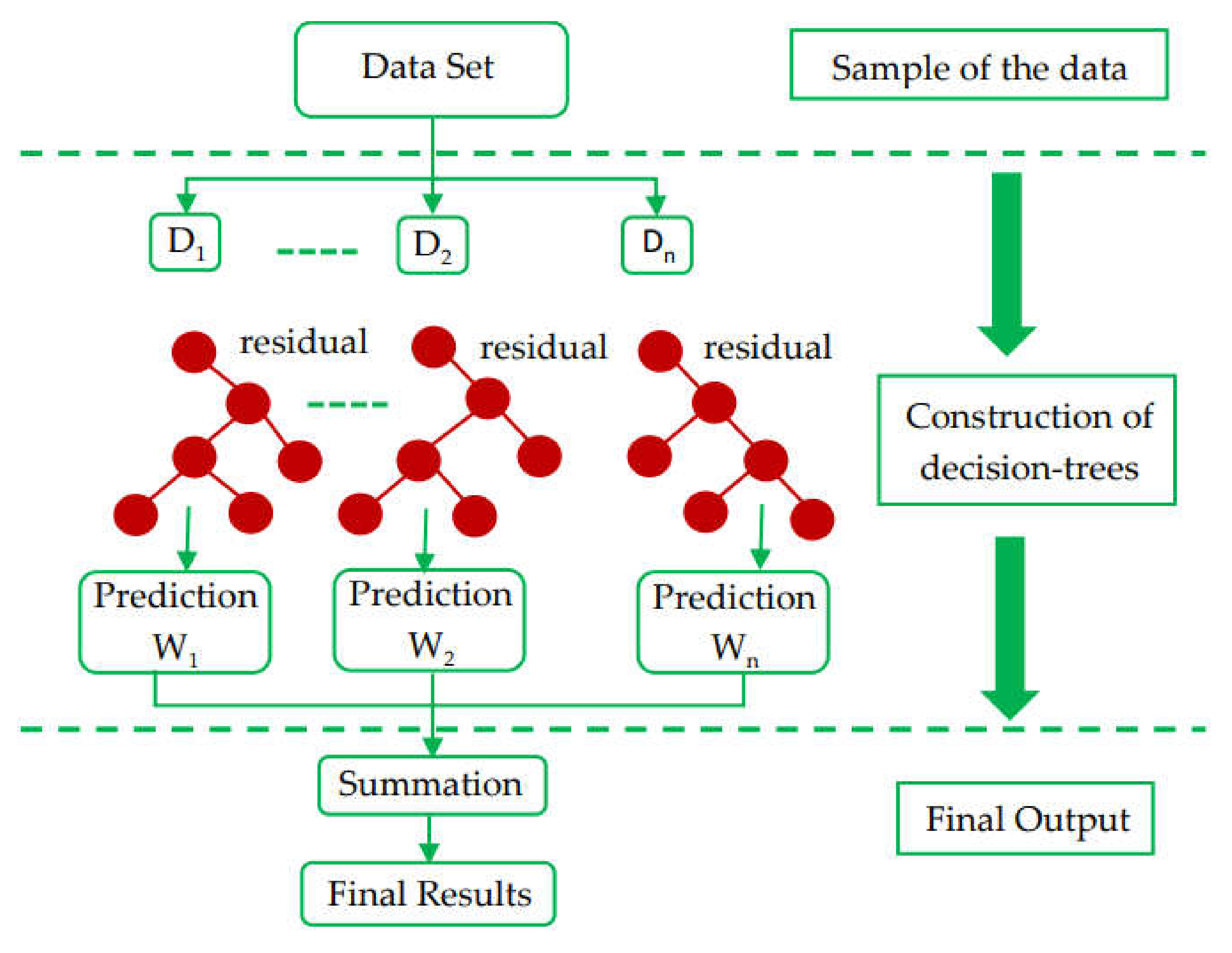
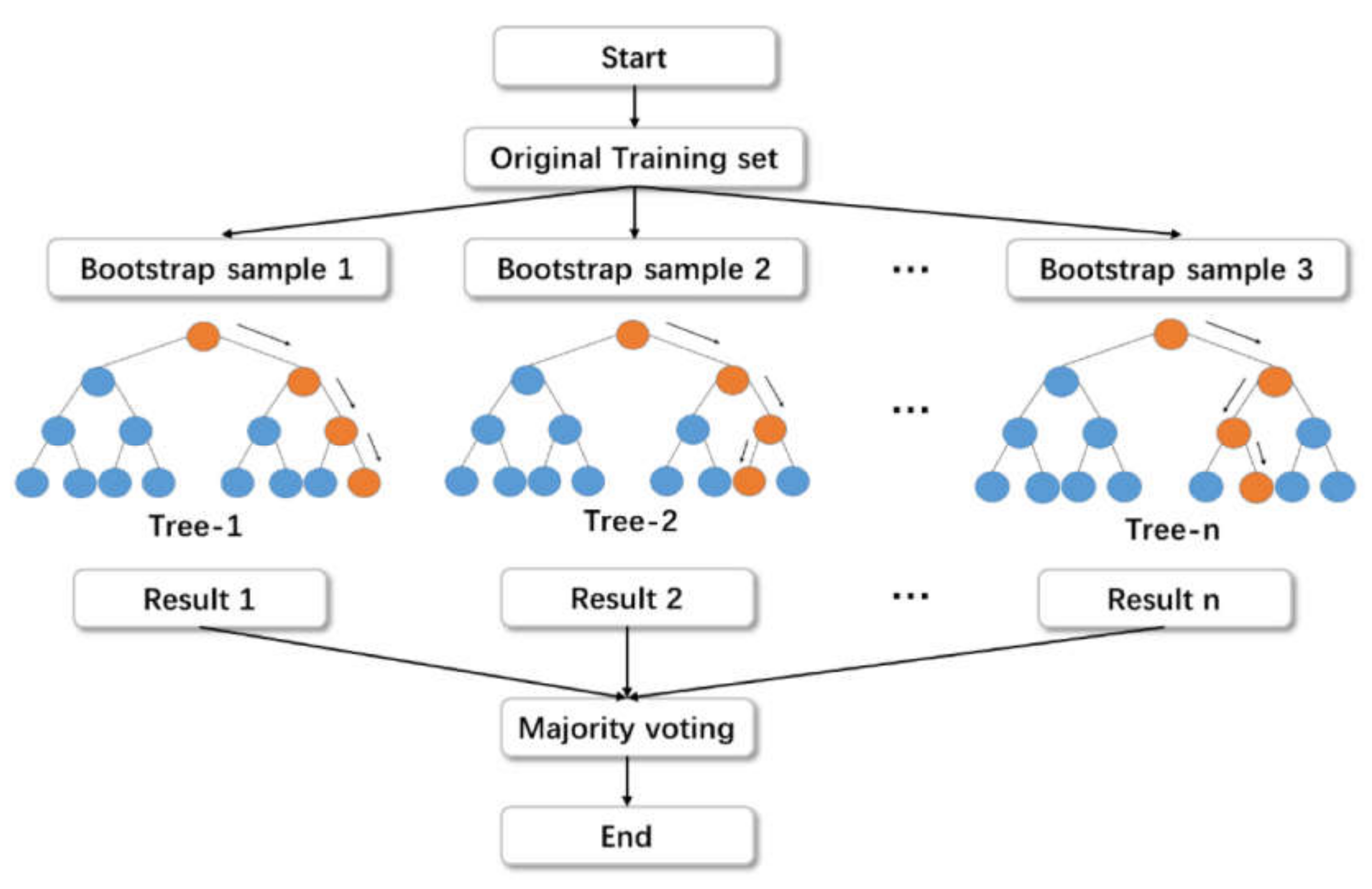
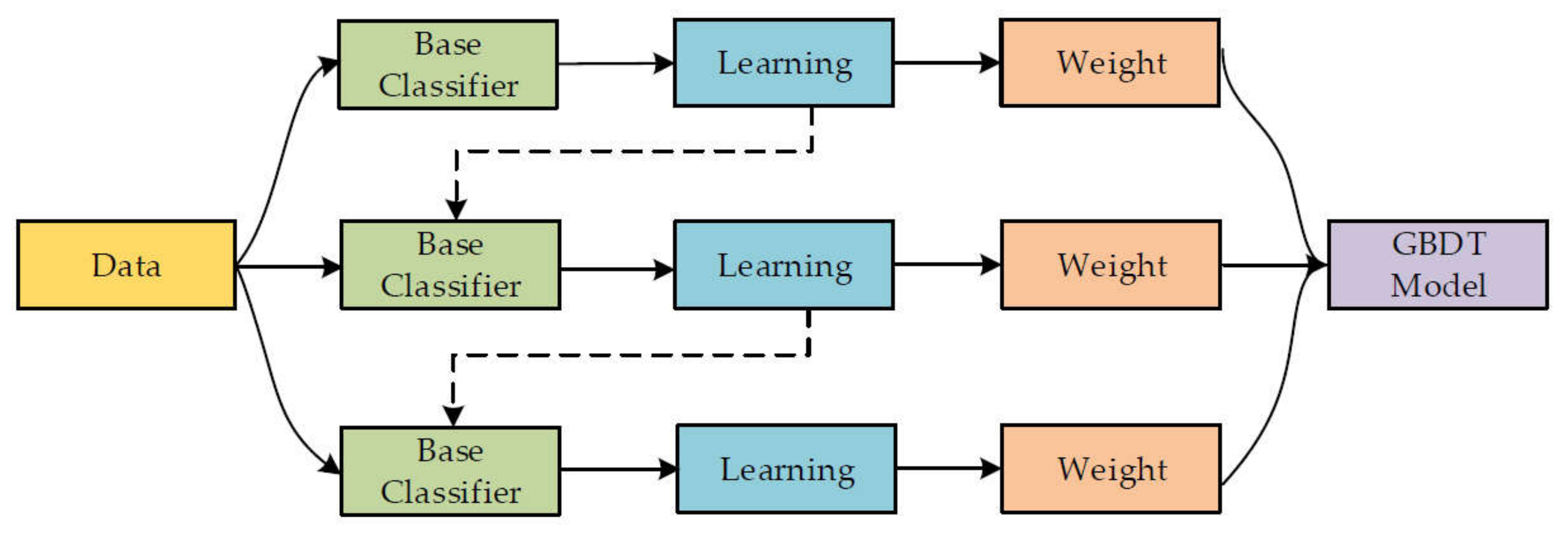
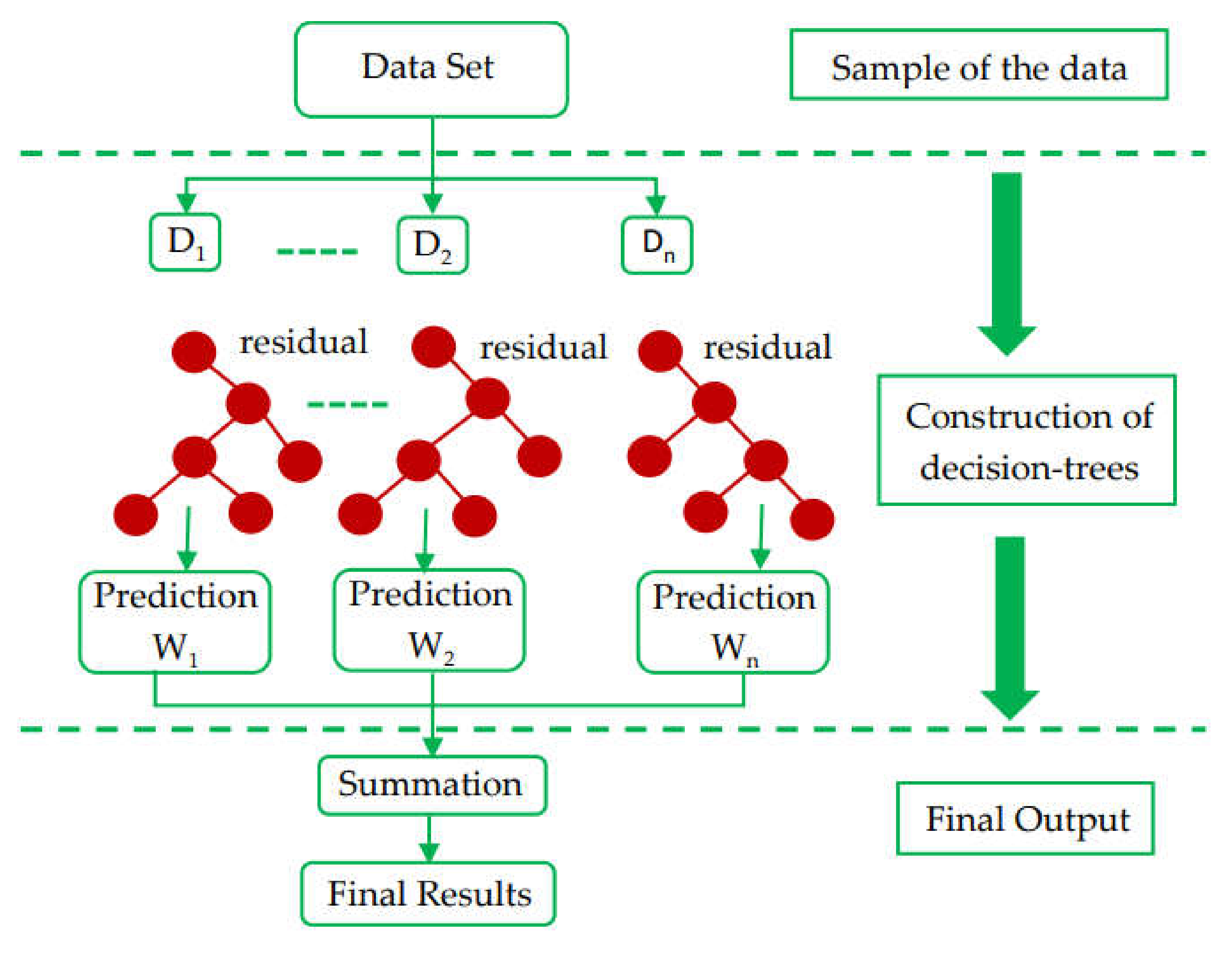
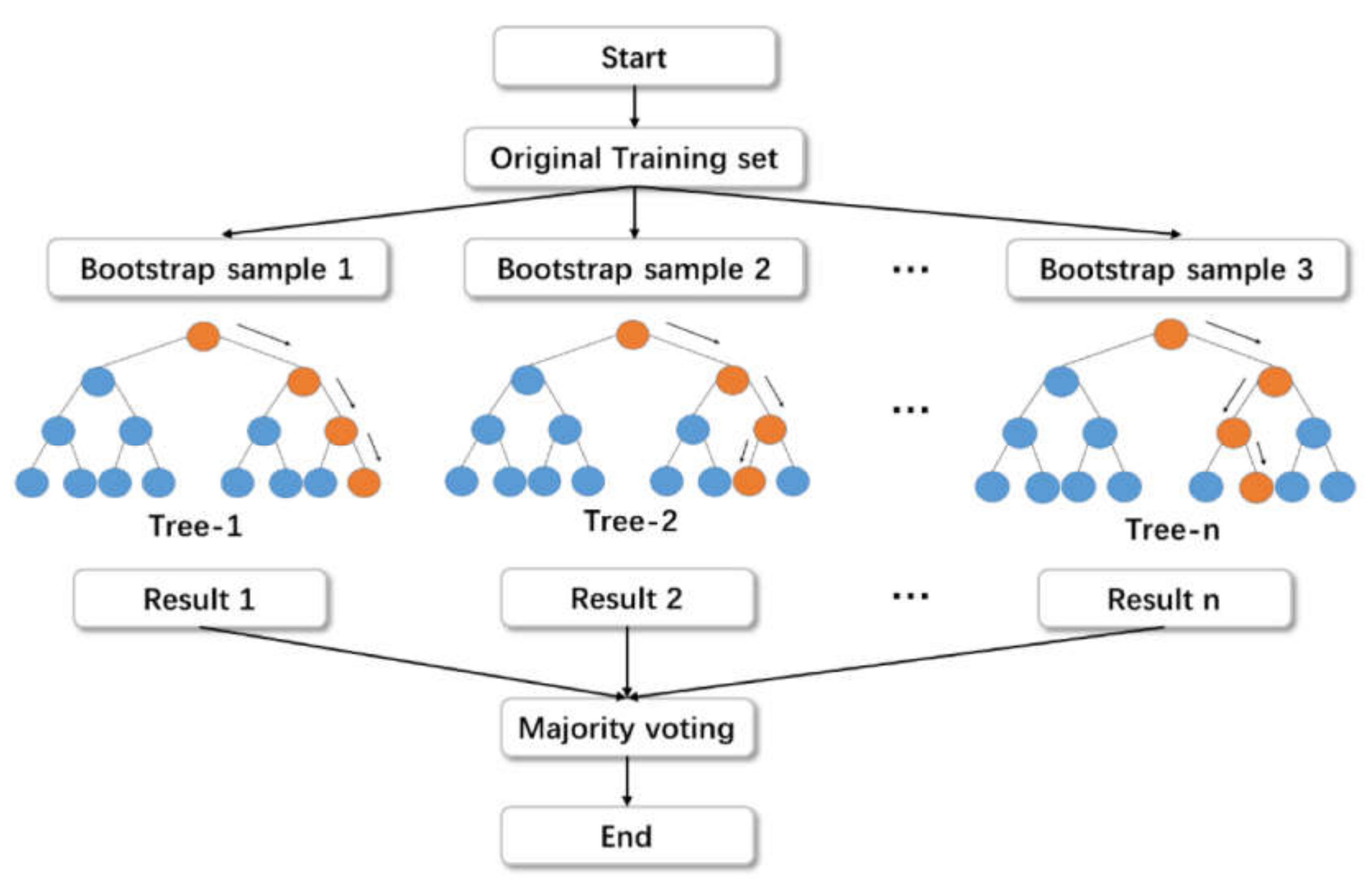
2.1. Machine-Learning Techniques
- S is the feature subset;
- is the feature j;
- p is the feature number in the model.
- is the input feature number;
- is the constant without any information (i.e., no input).
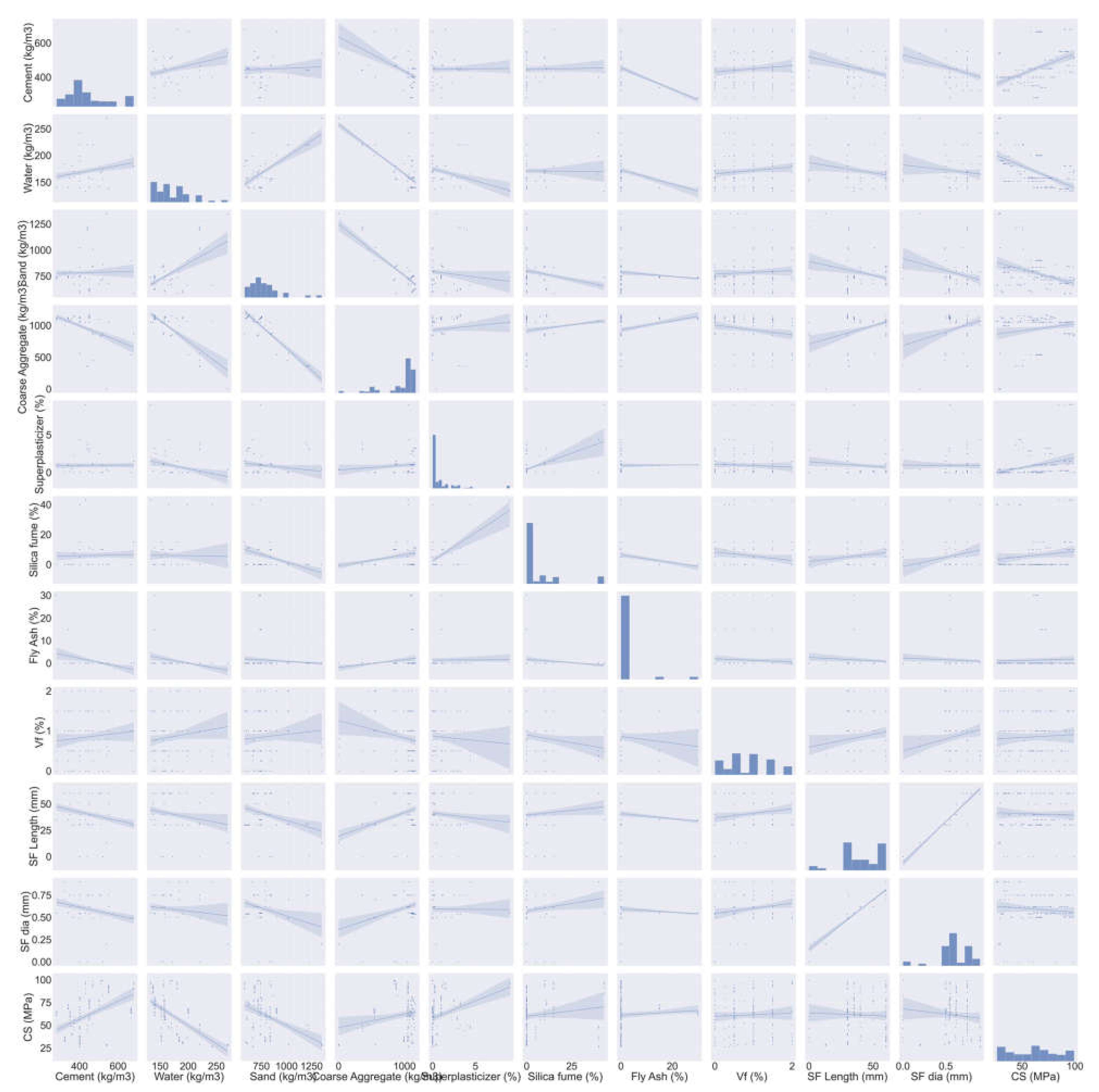
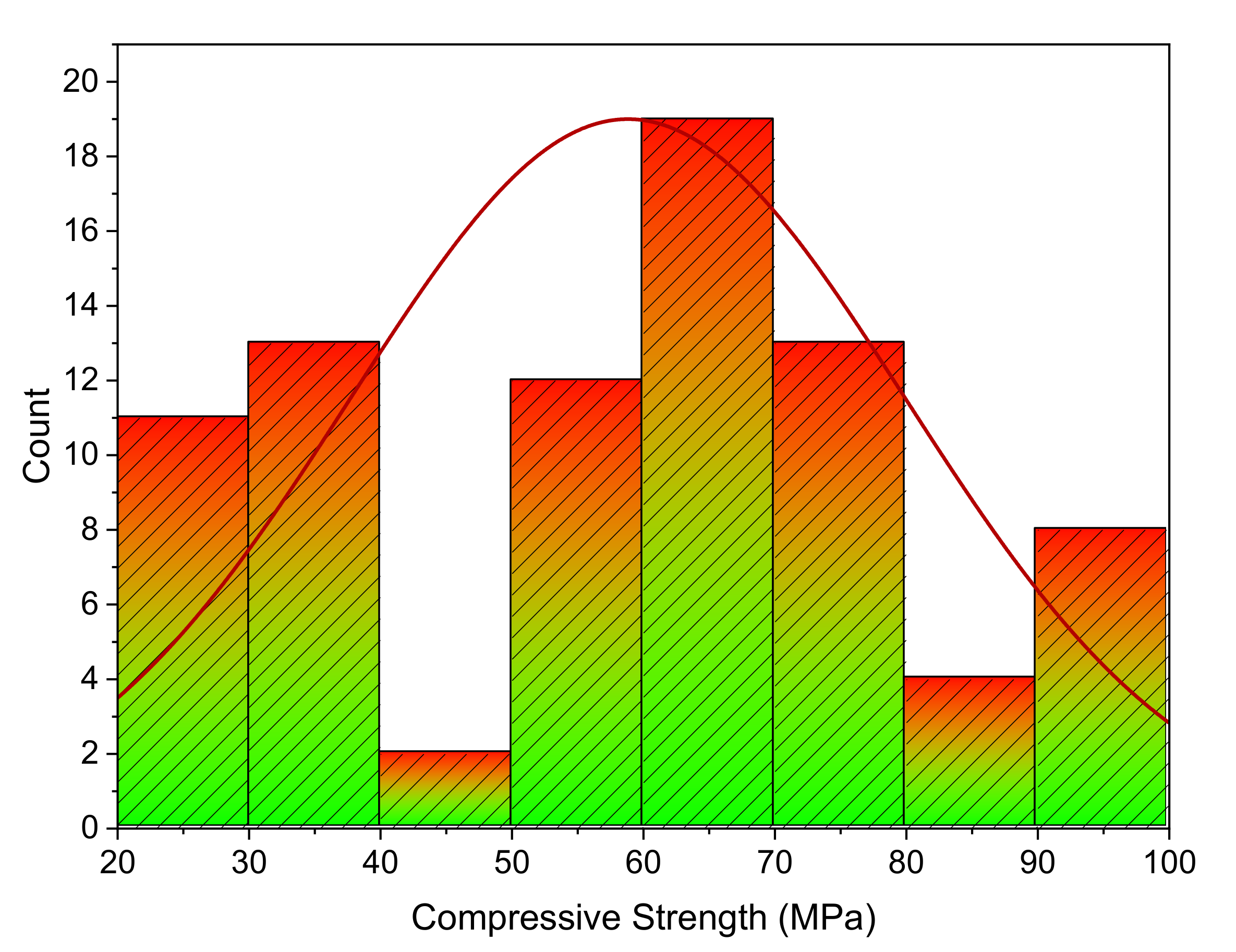
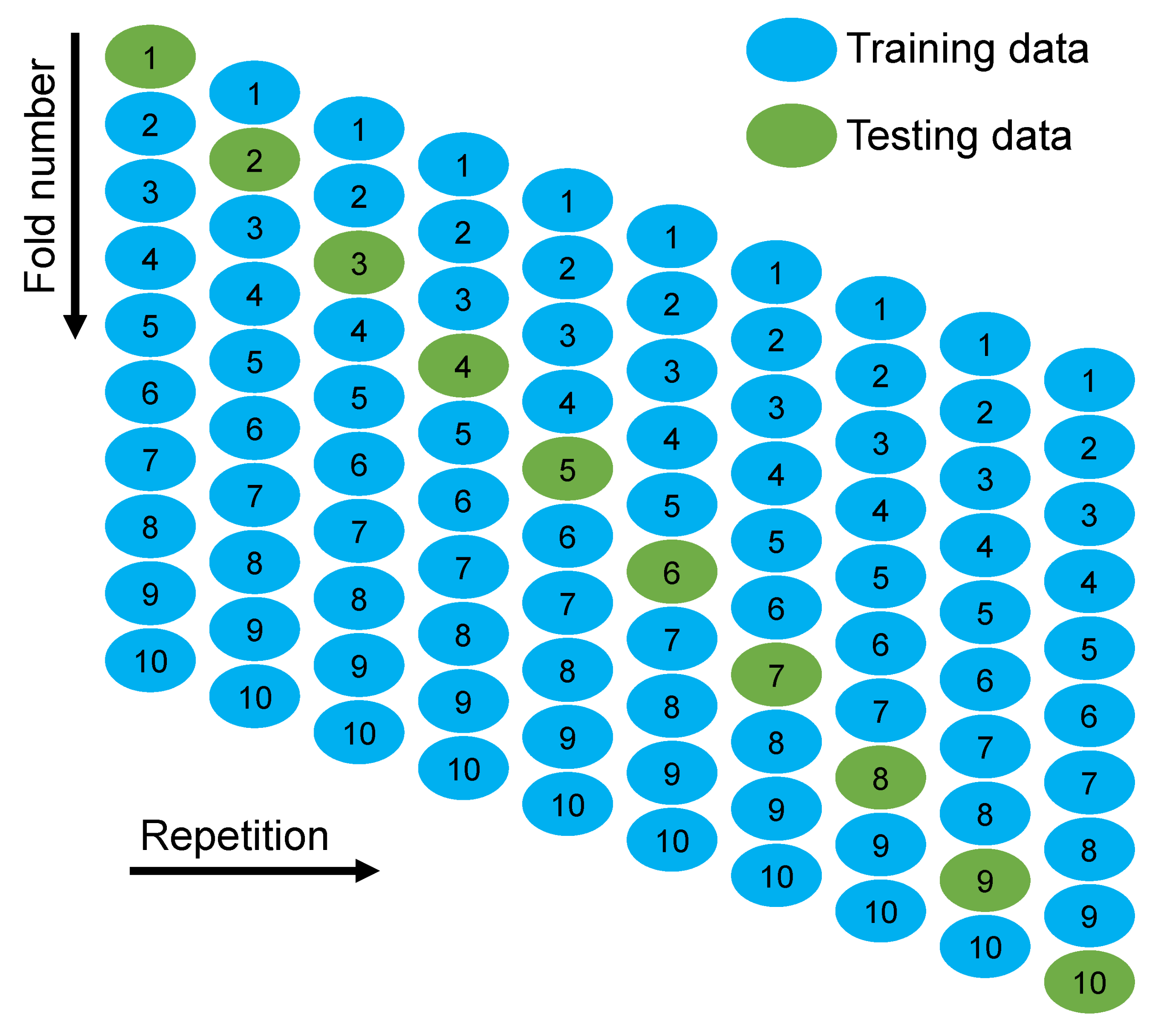
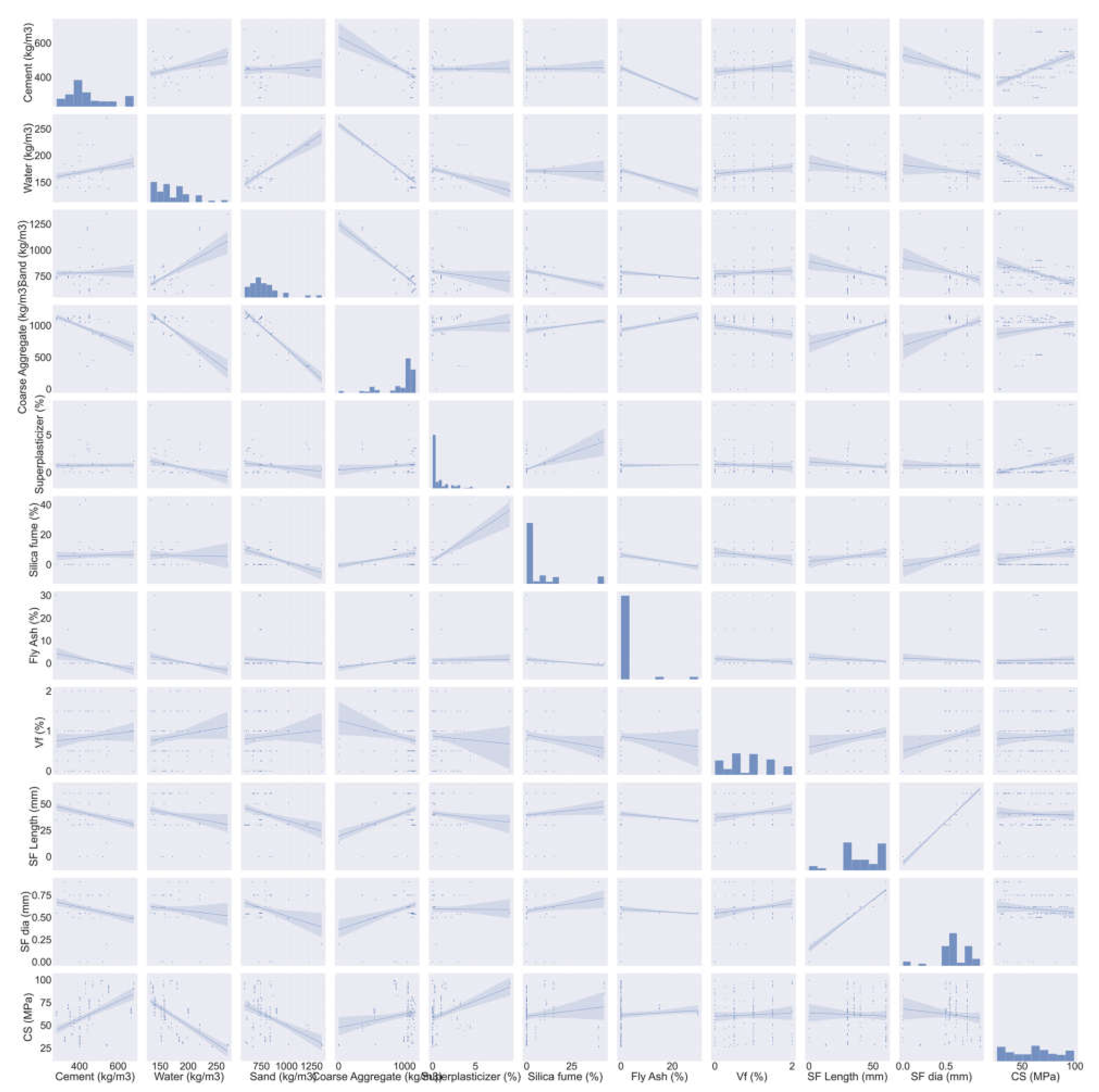
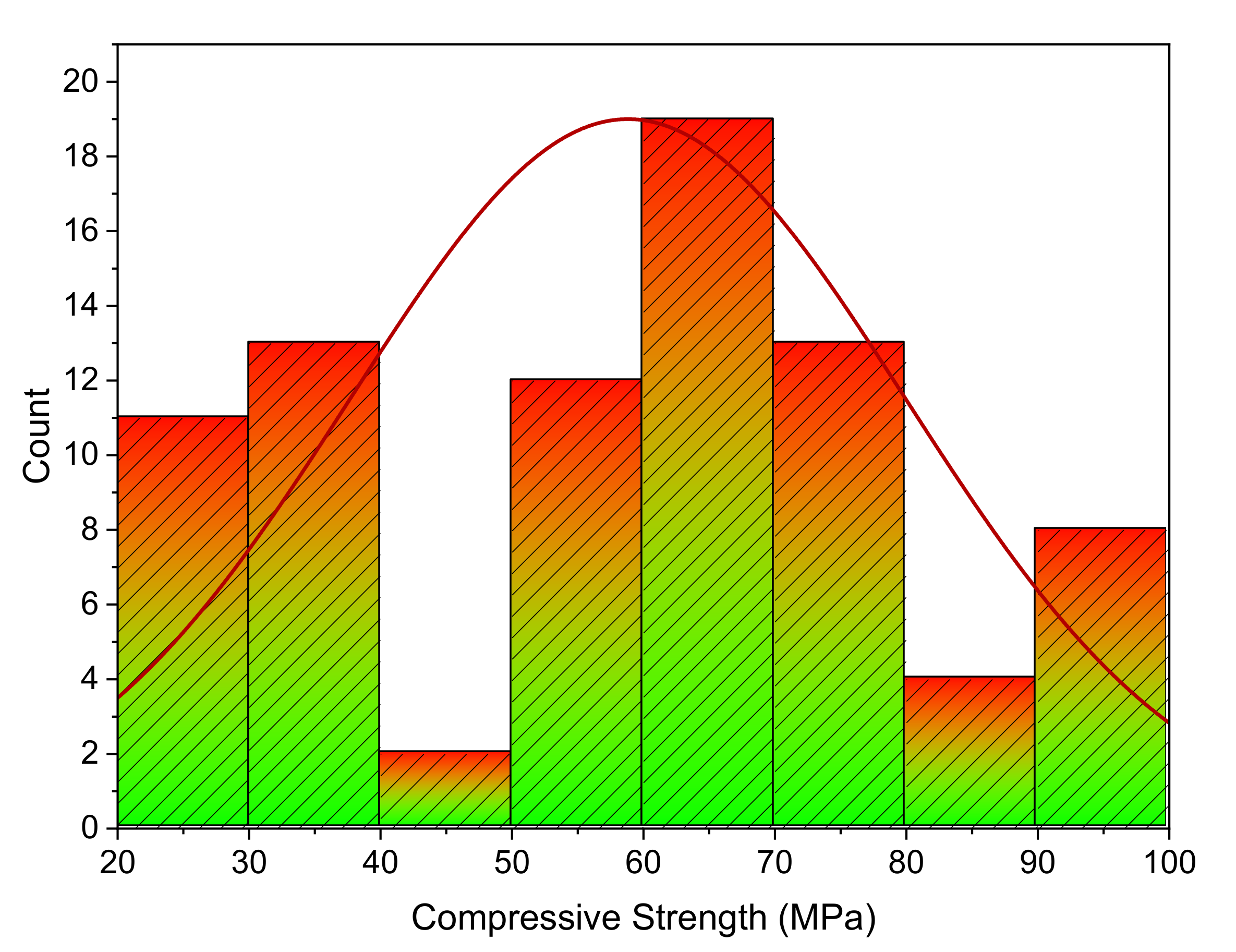
2.2. Dataset Description
3. Results and Discussion
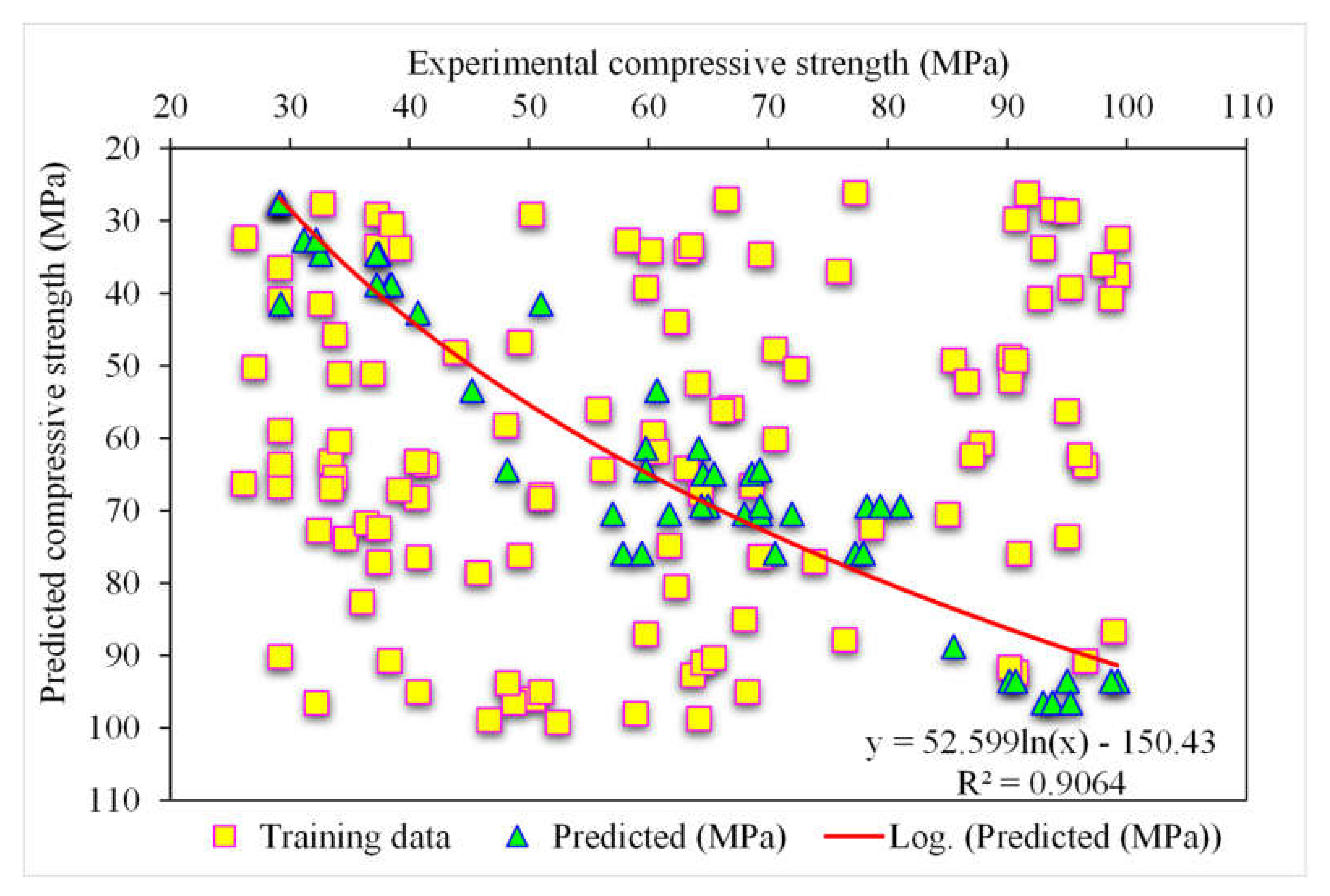
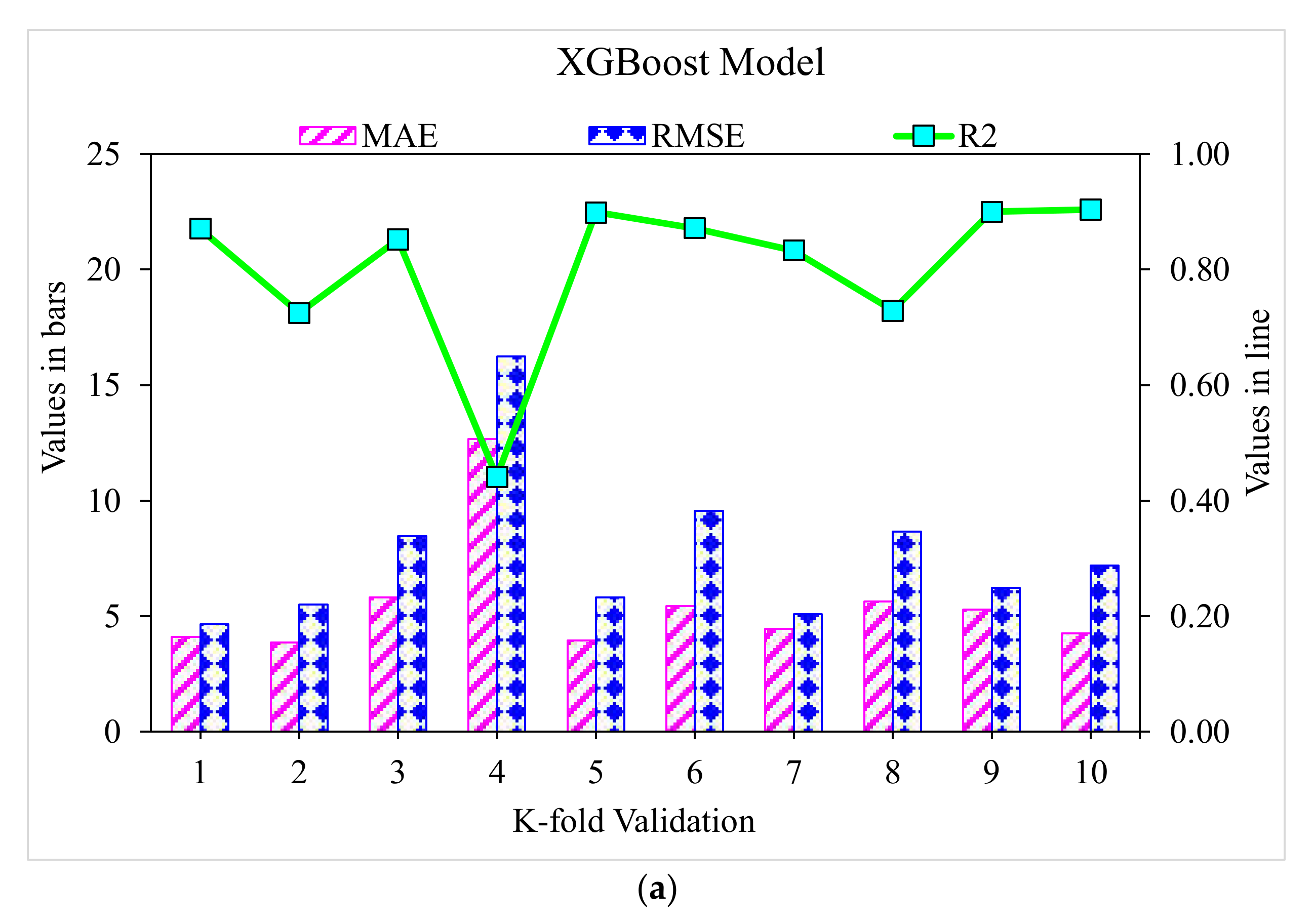
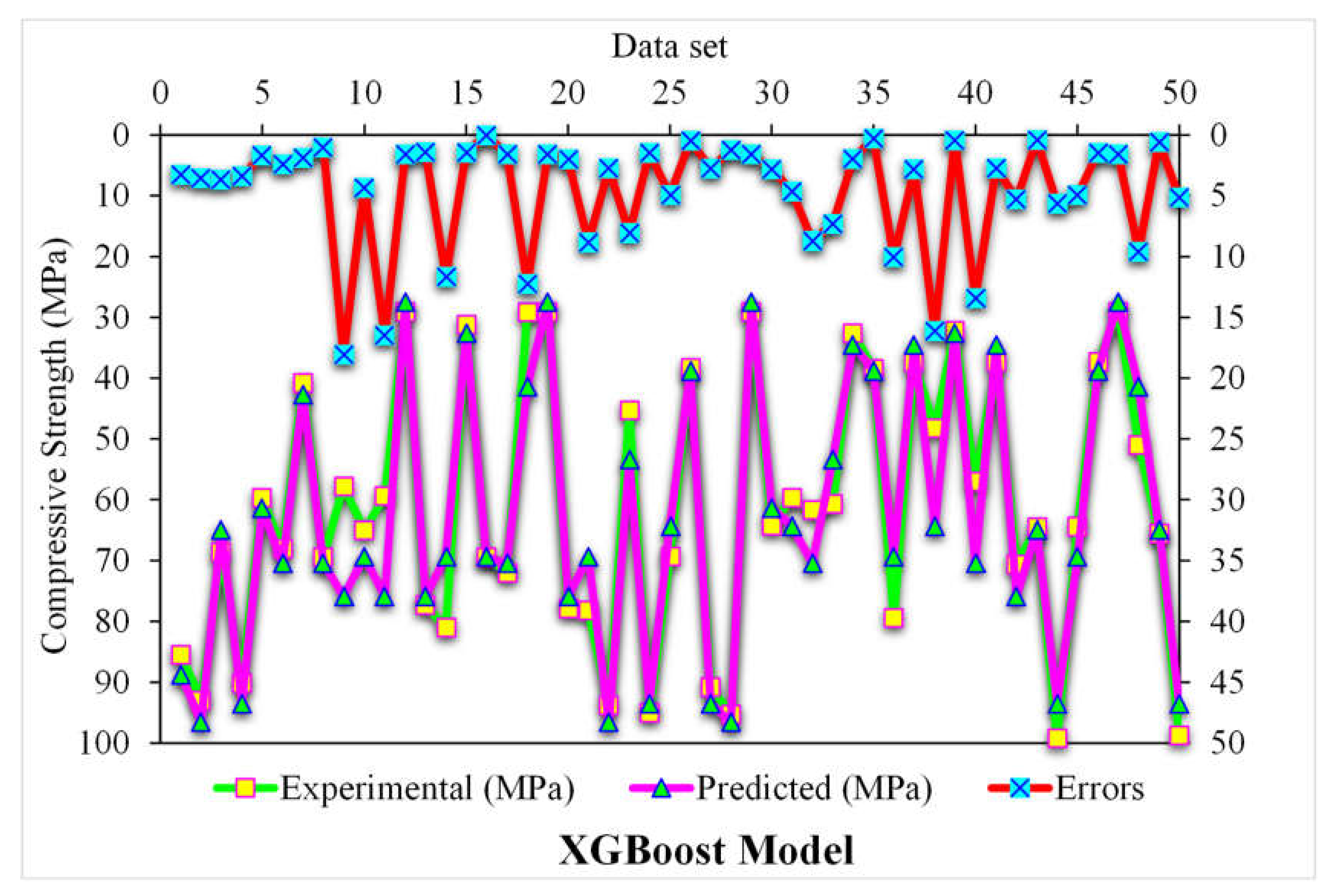
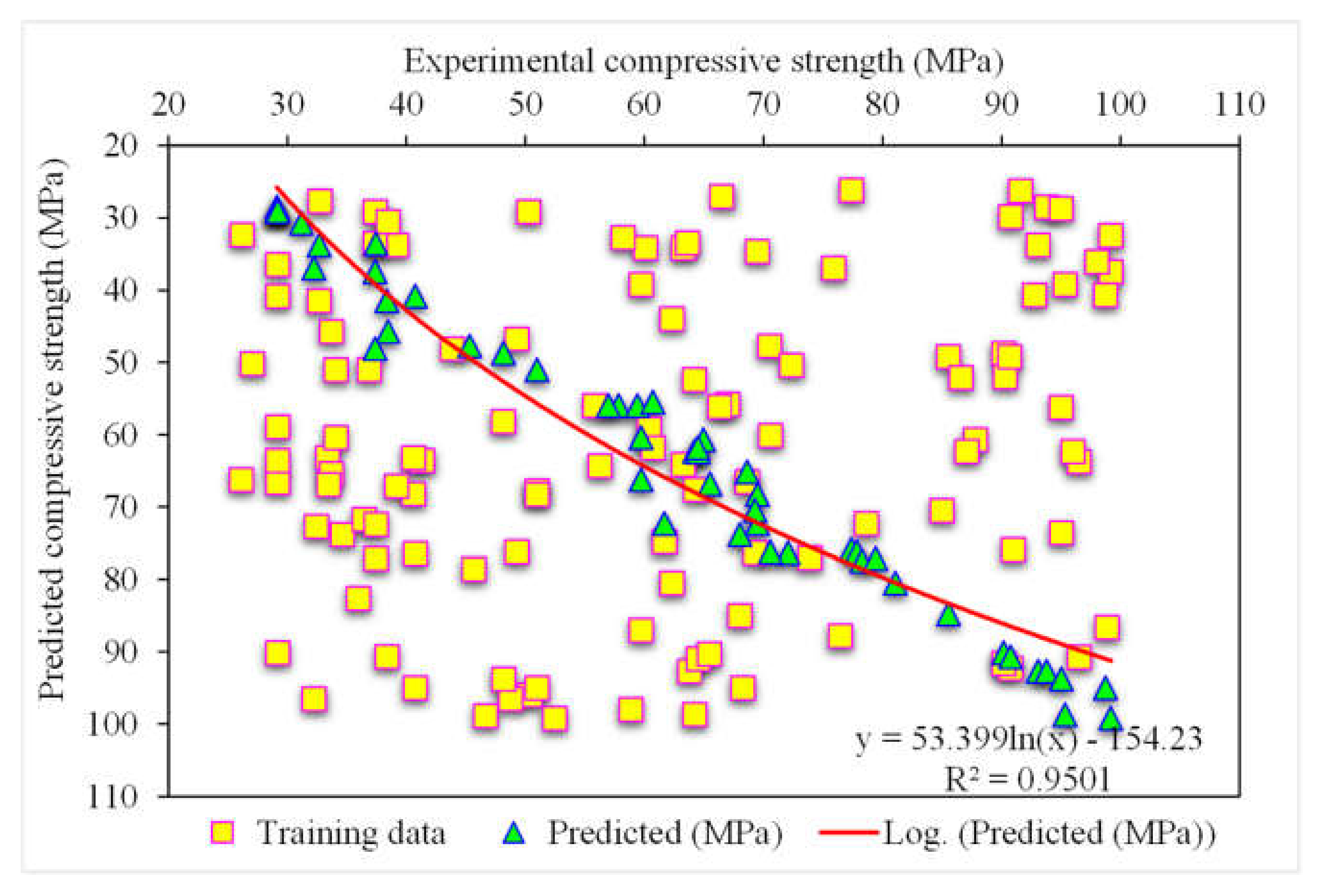
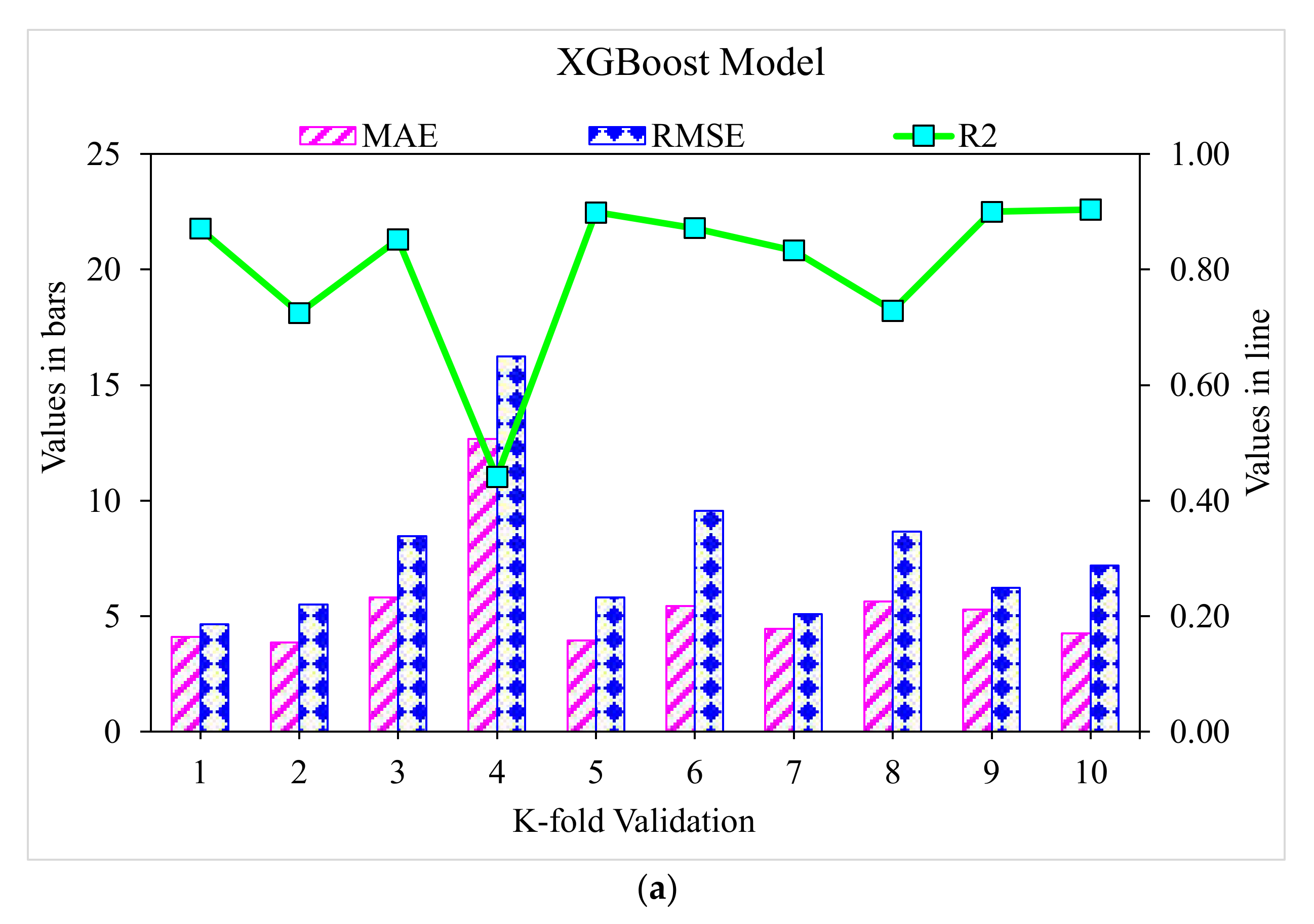
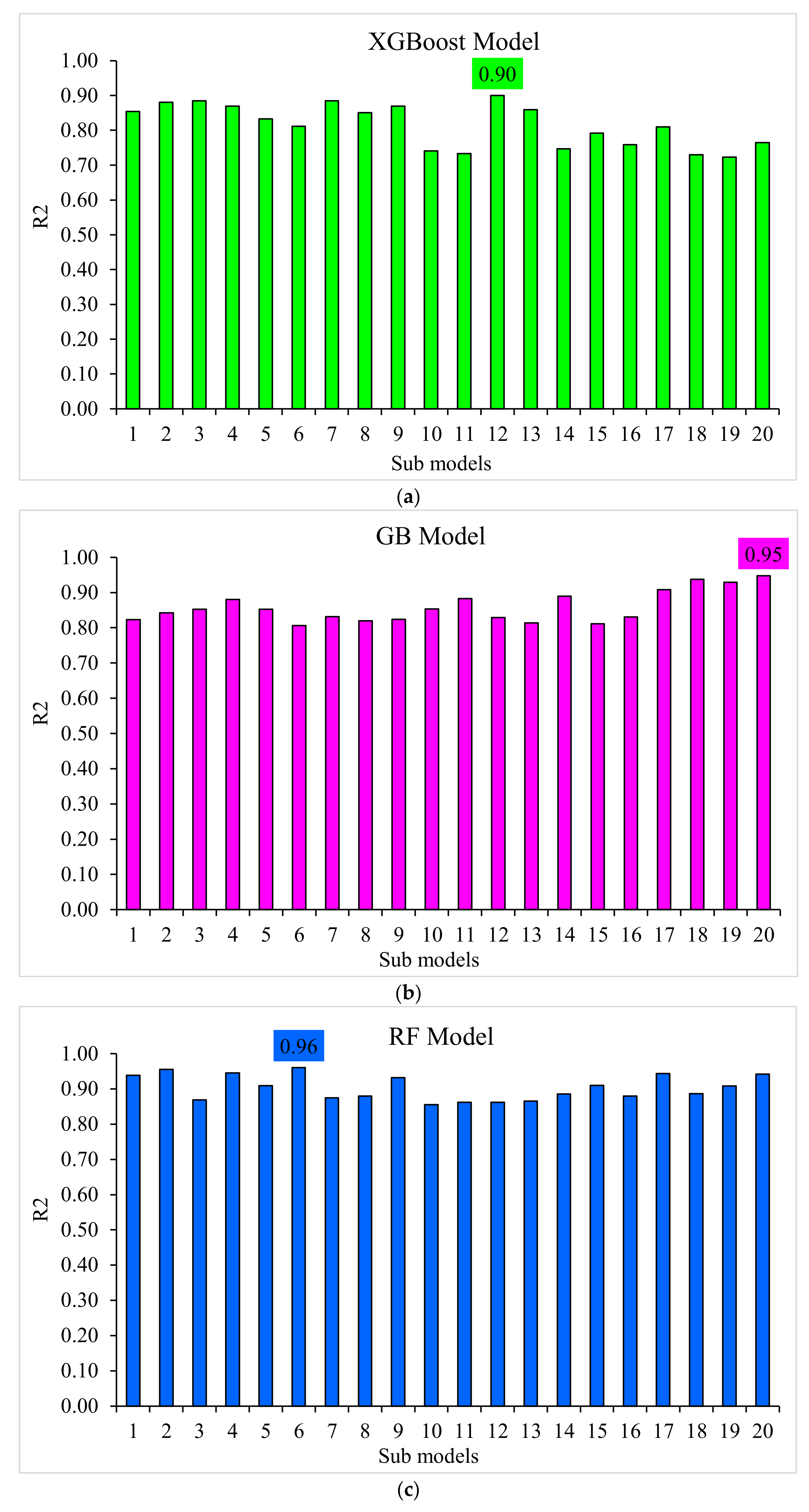
3.1. XGBoost
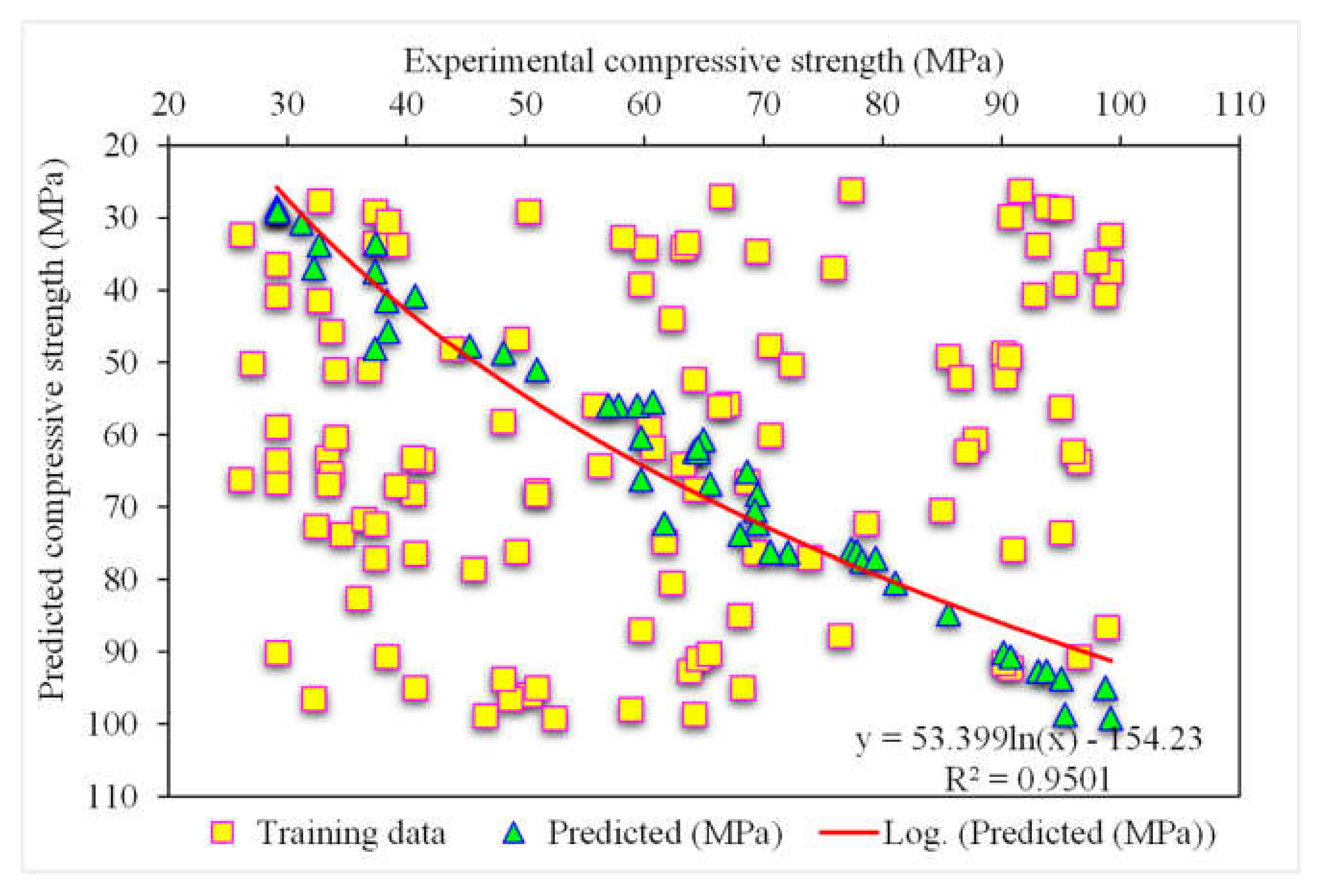
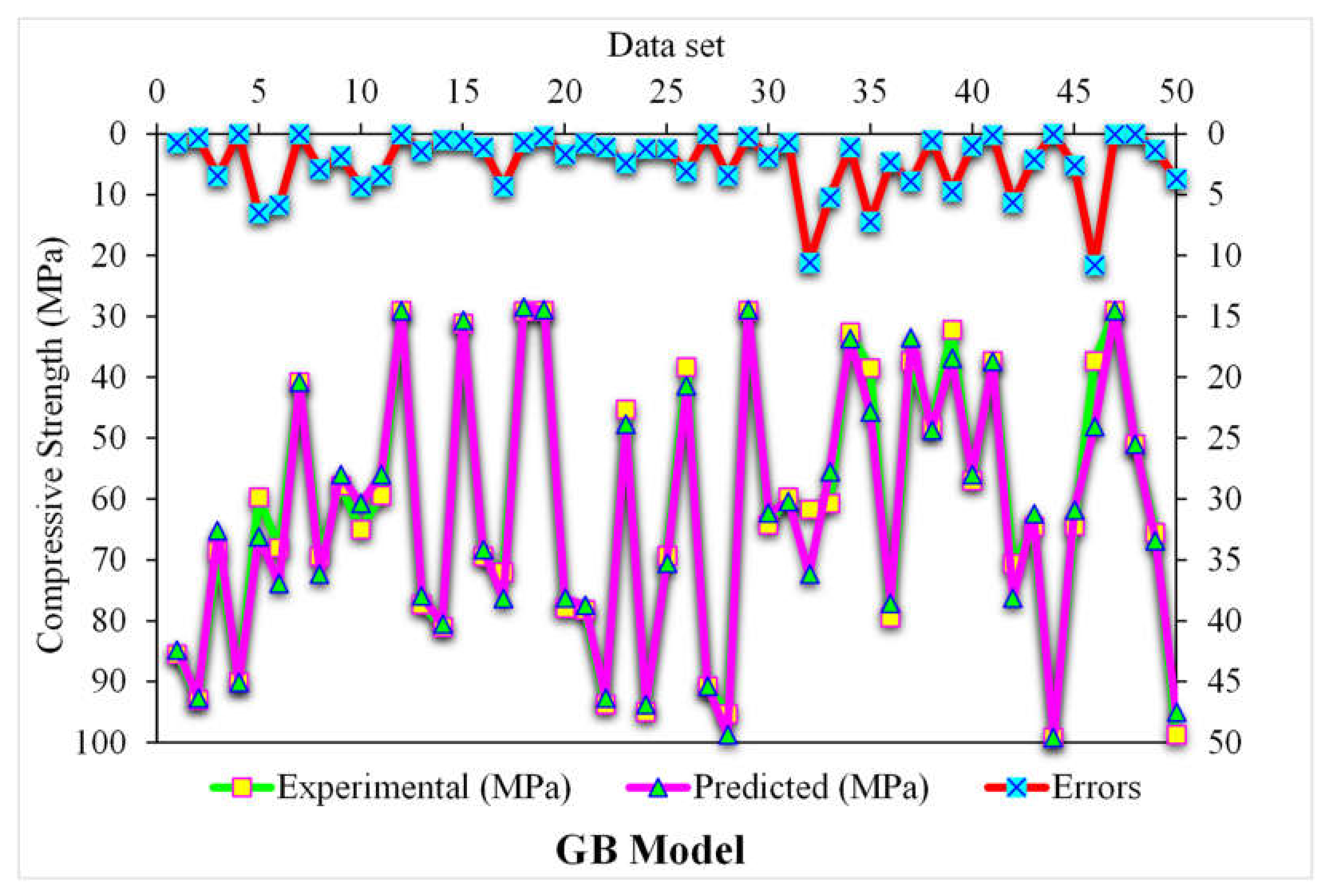
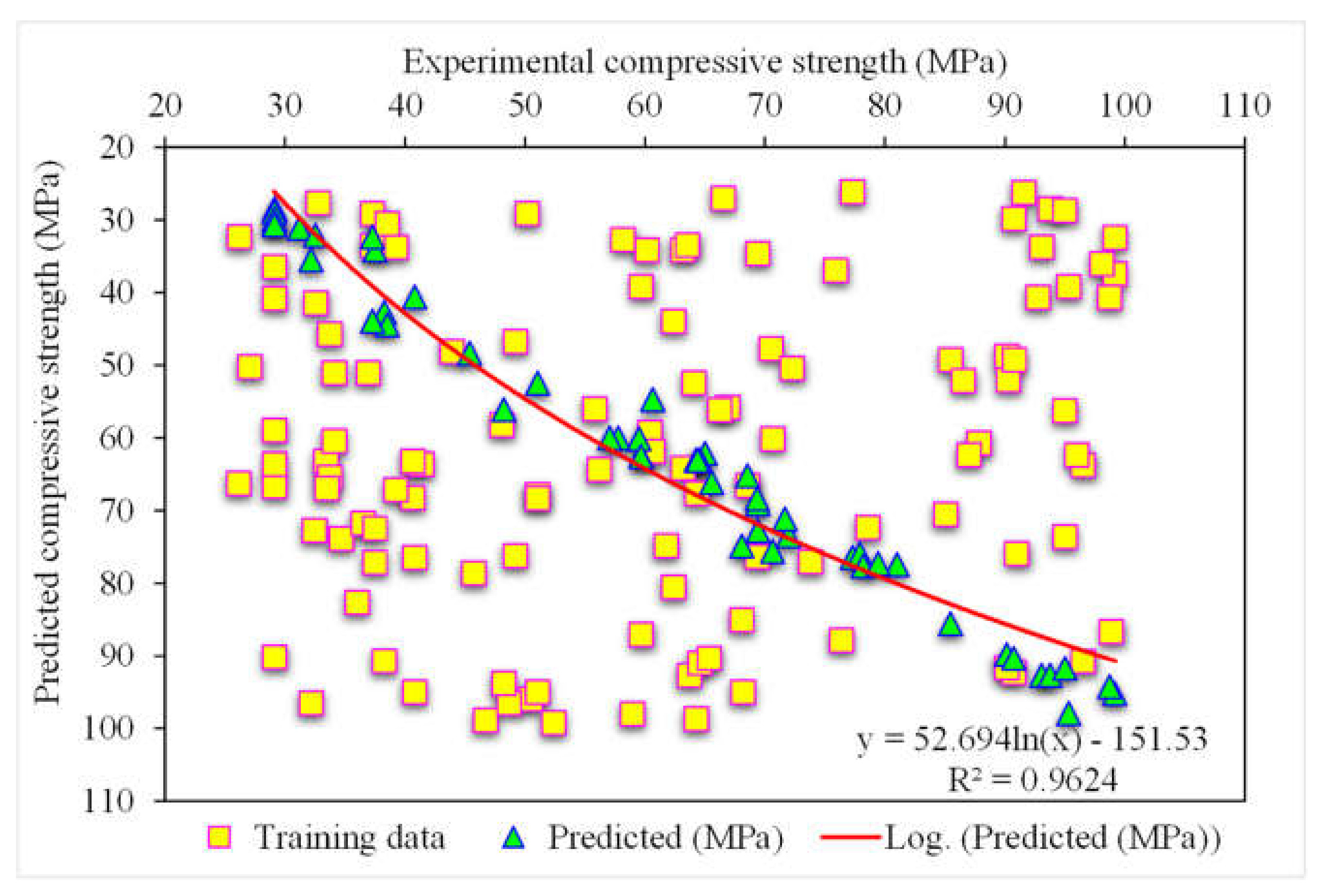
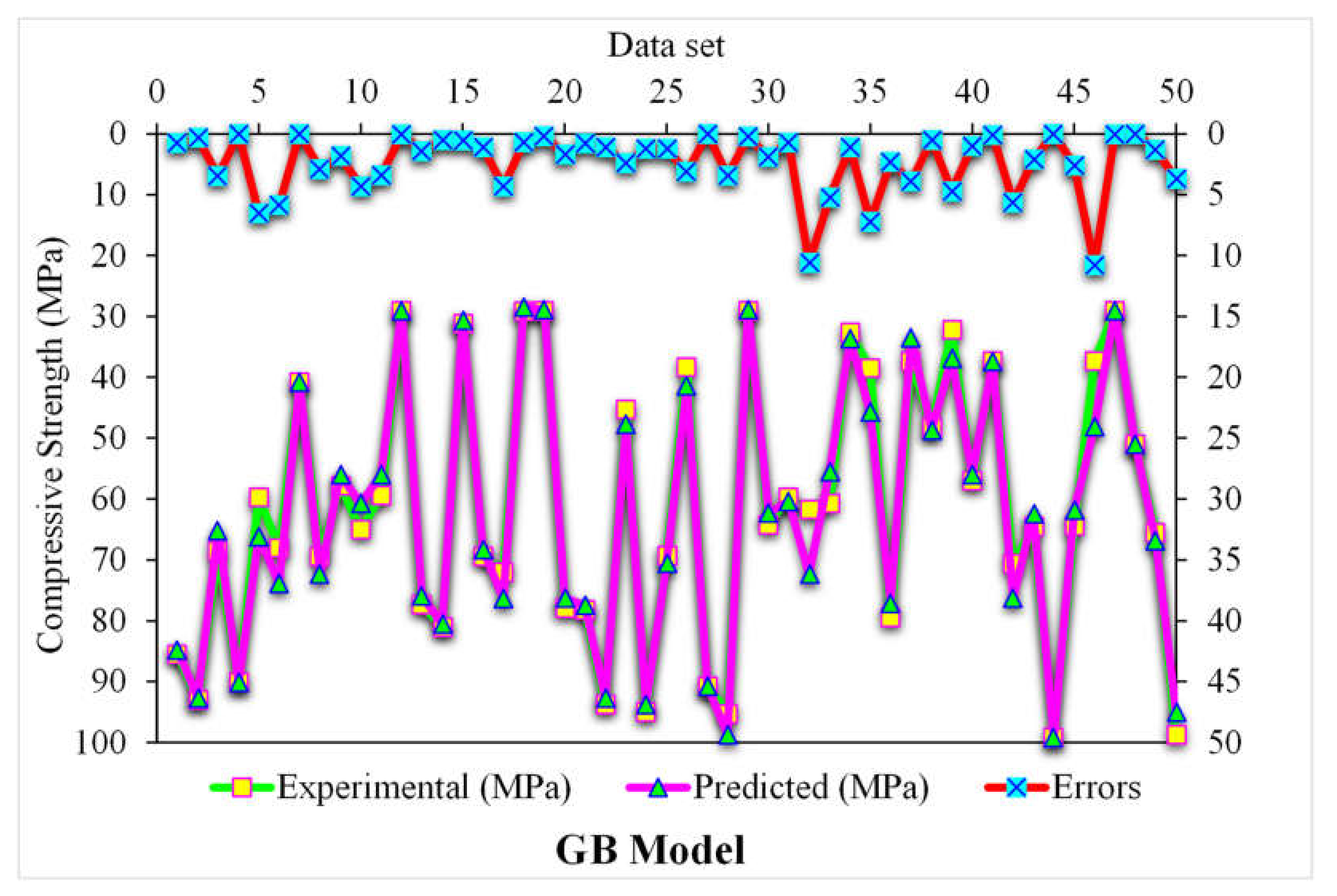
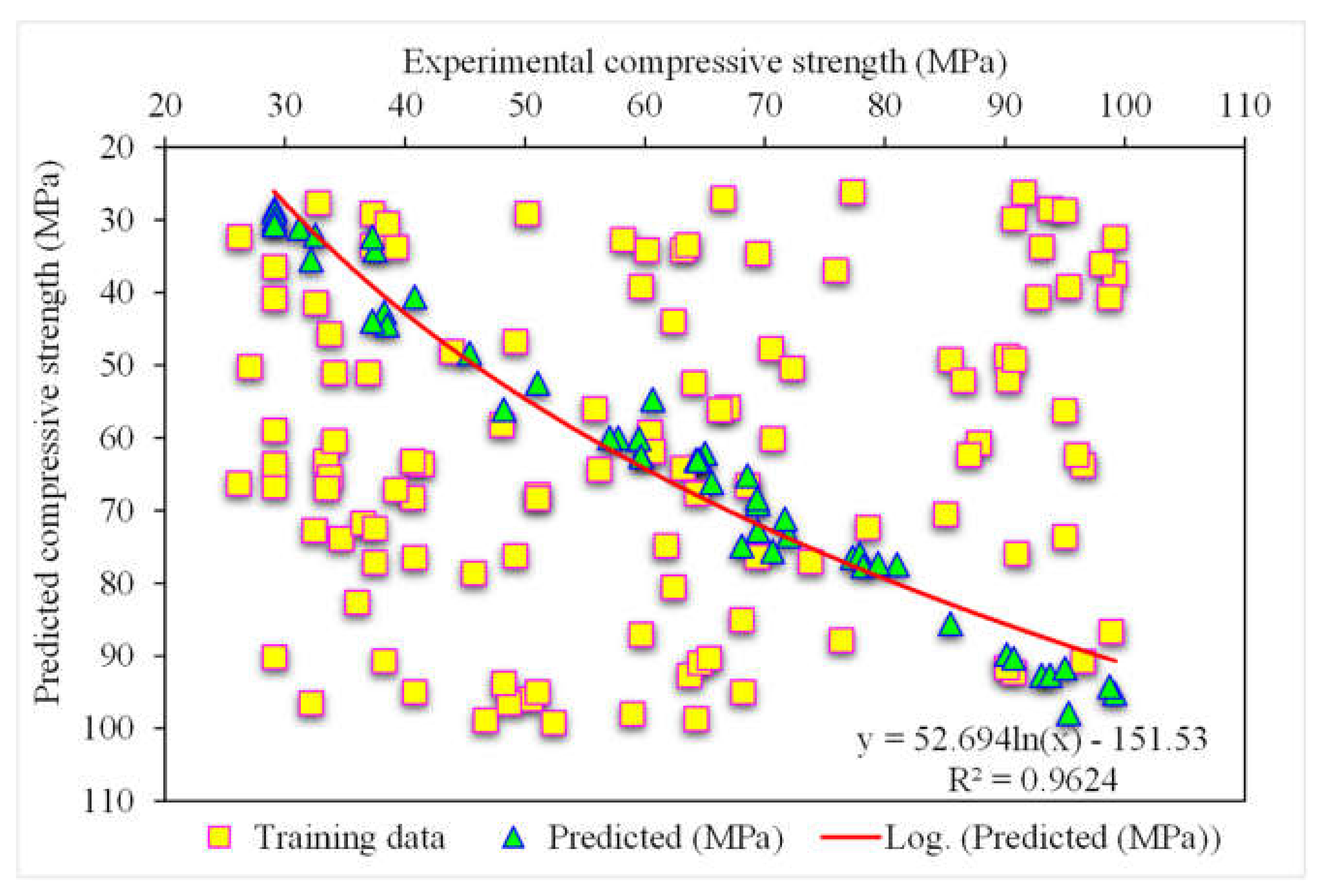
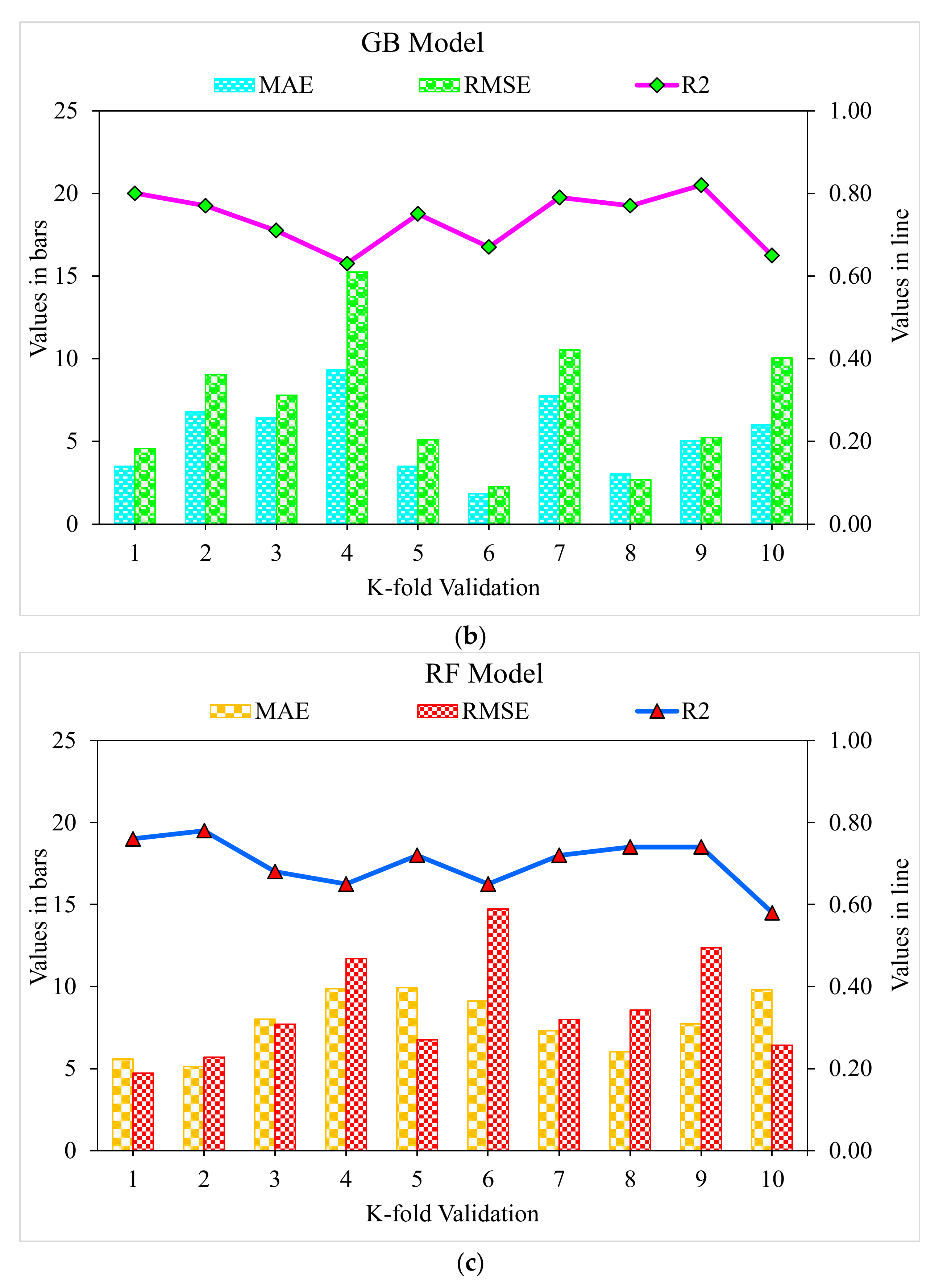
3.2. Gradient Boosting
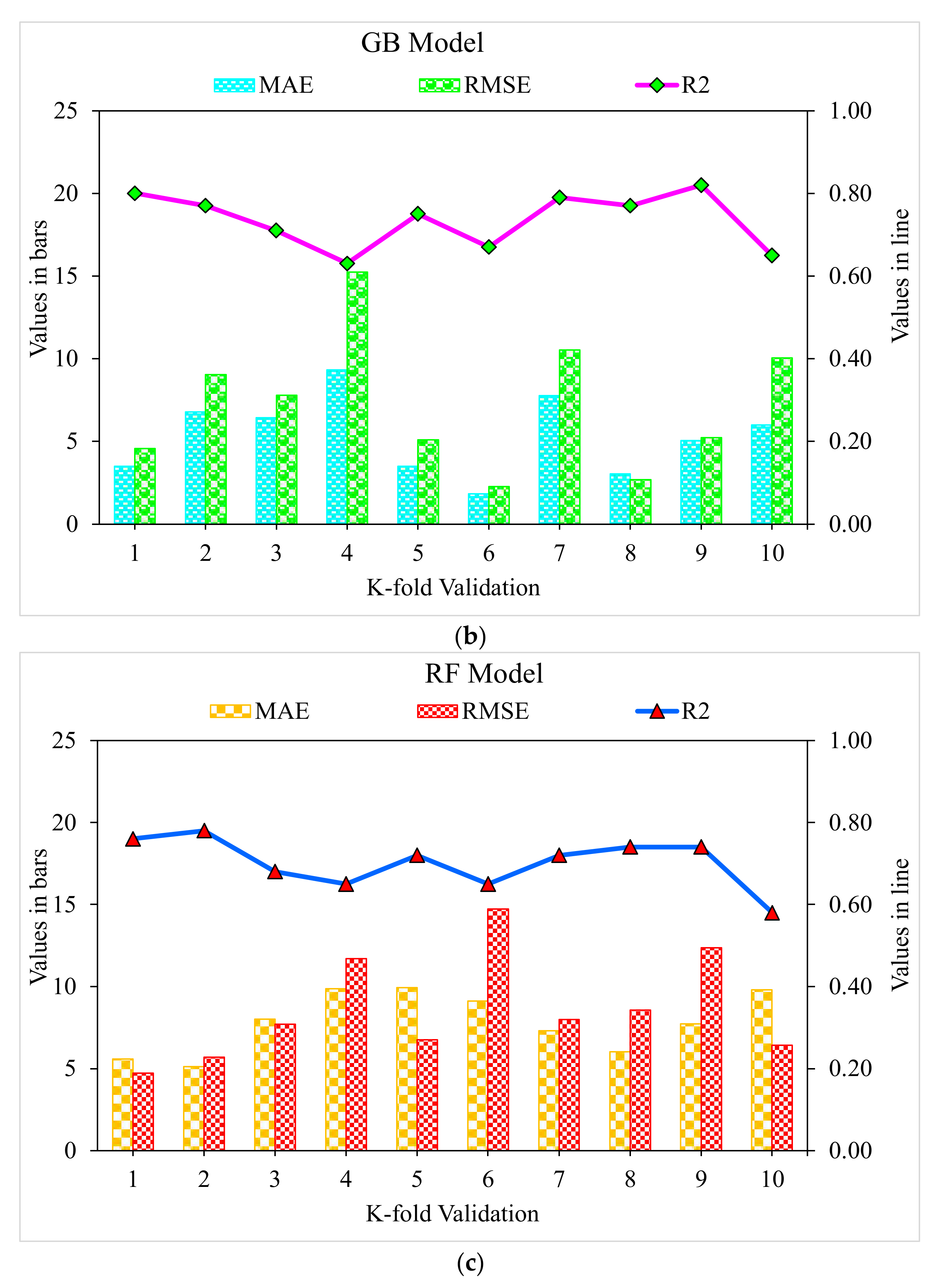
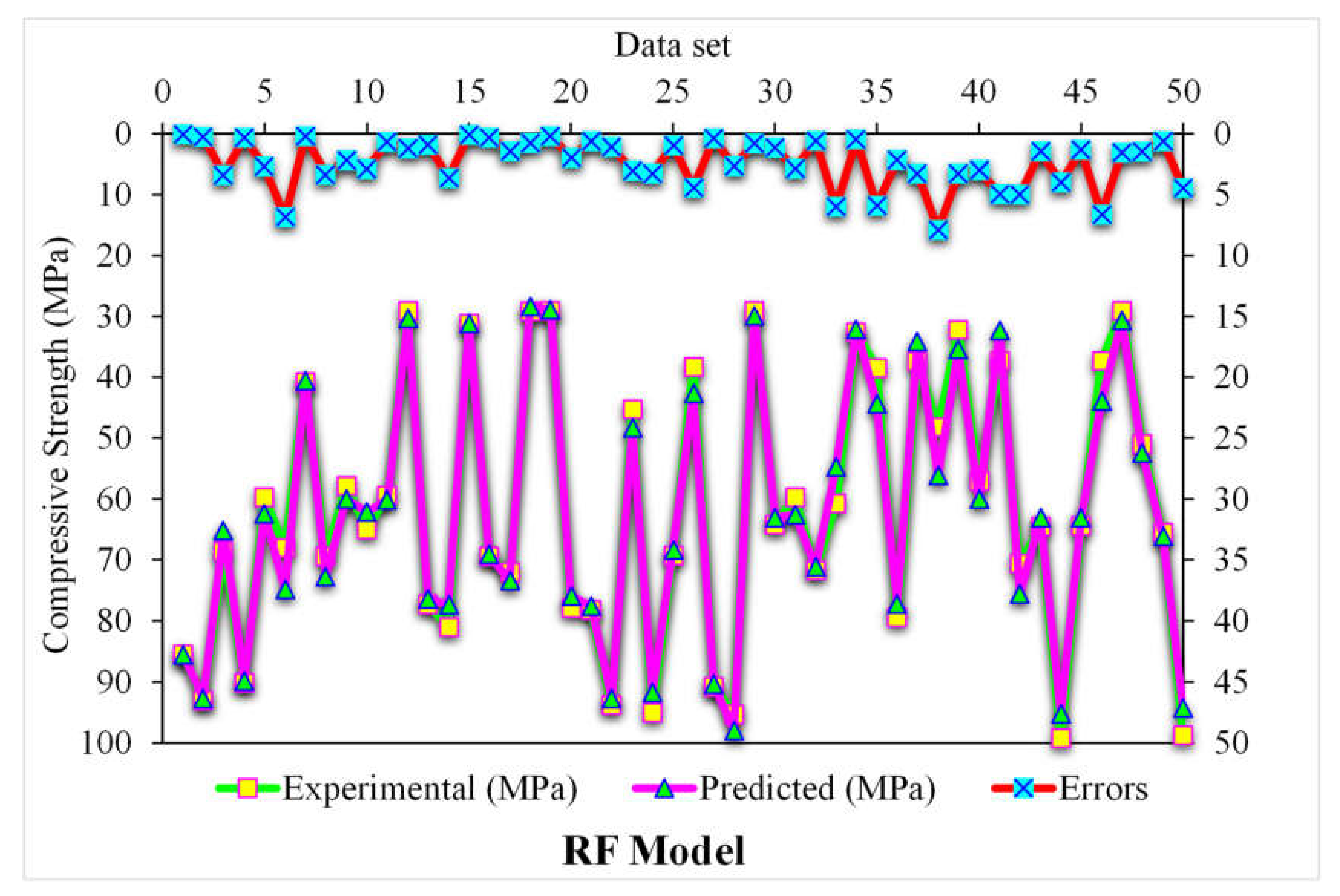
3.3. Random Forest
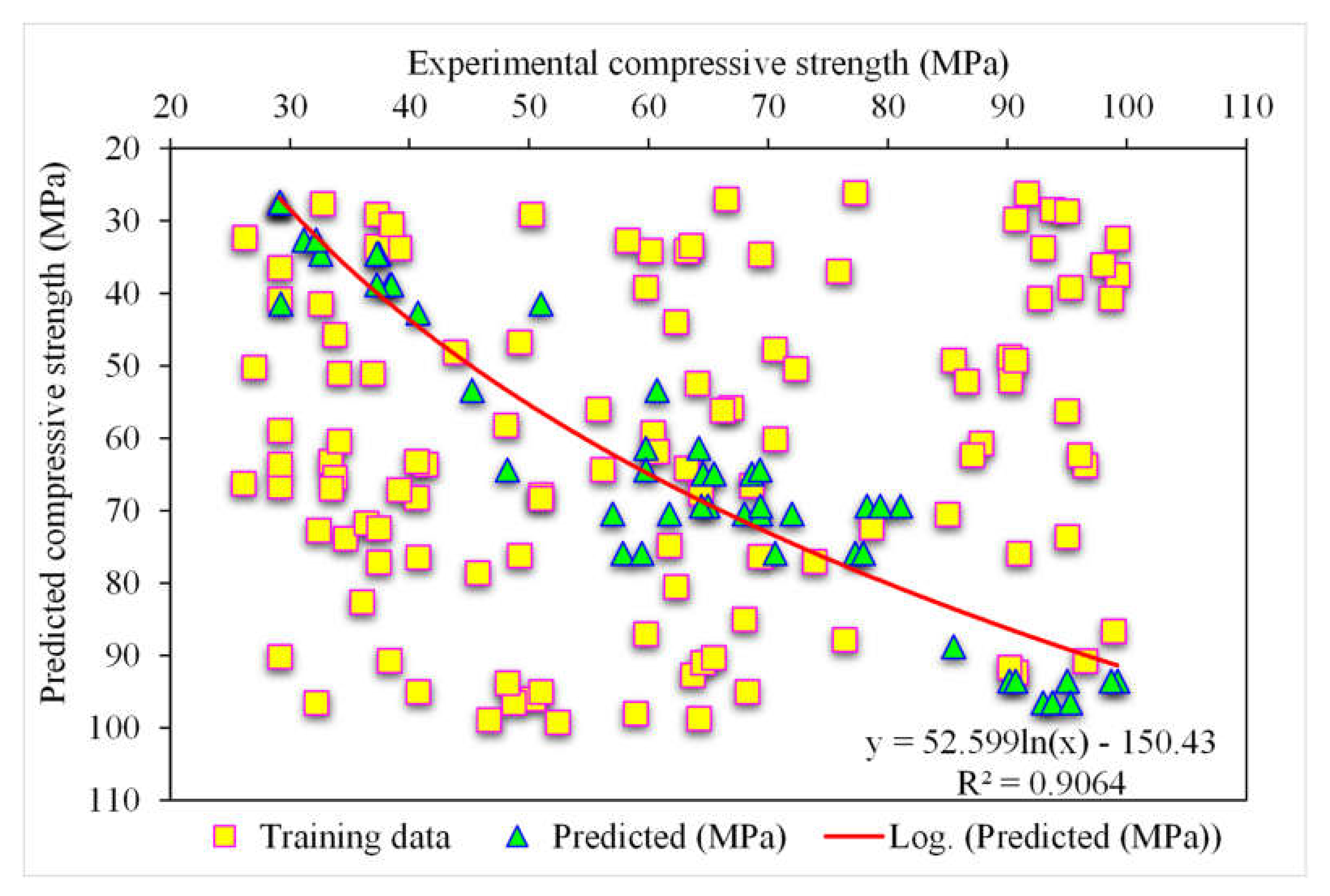
3.4. Comparison of All Models
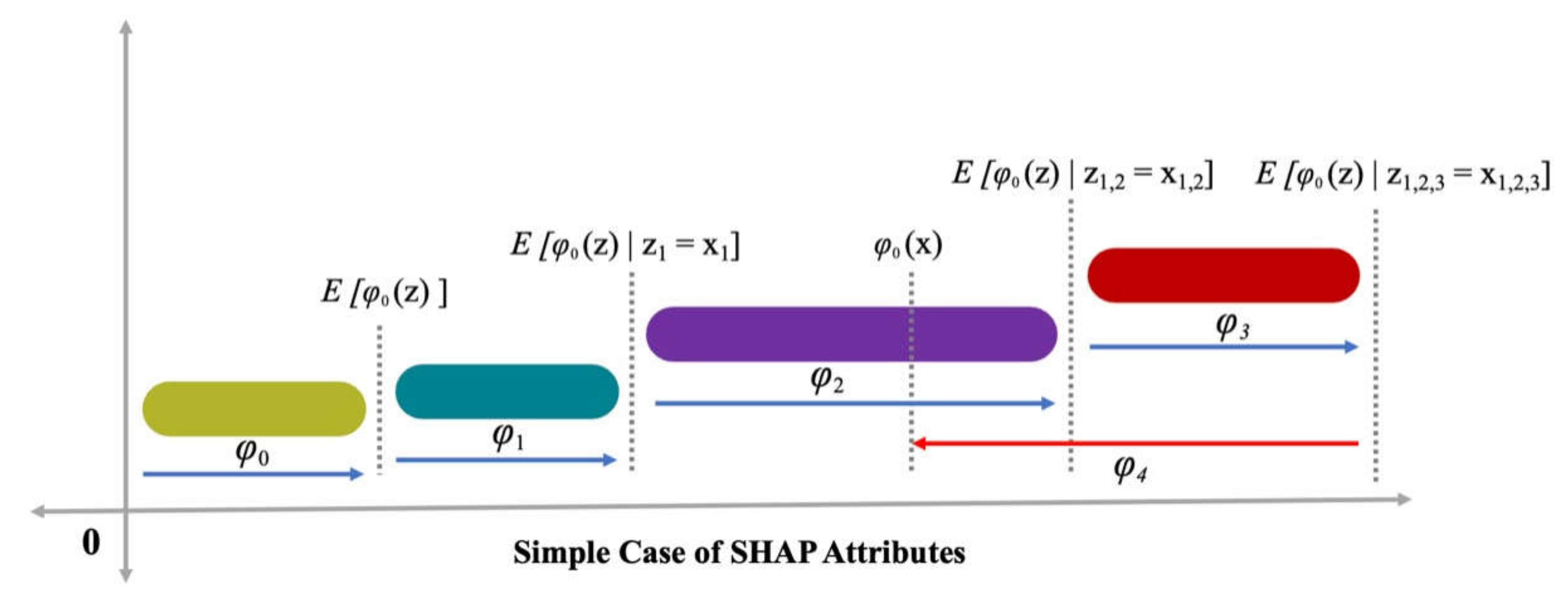
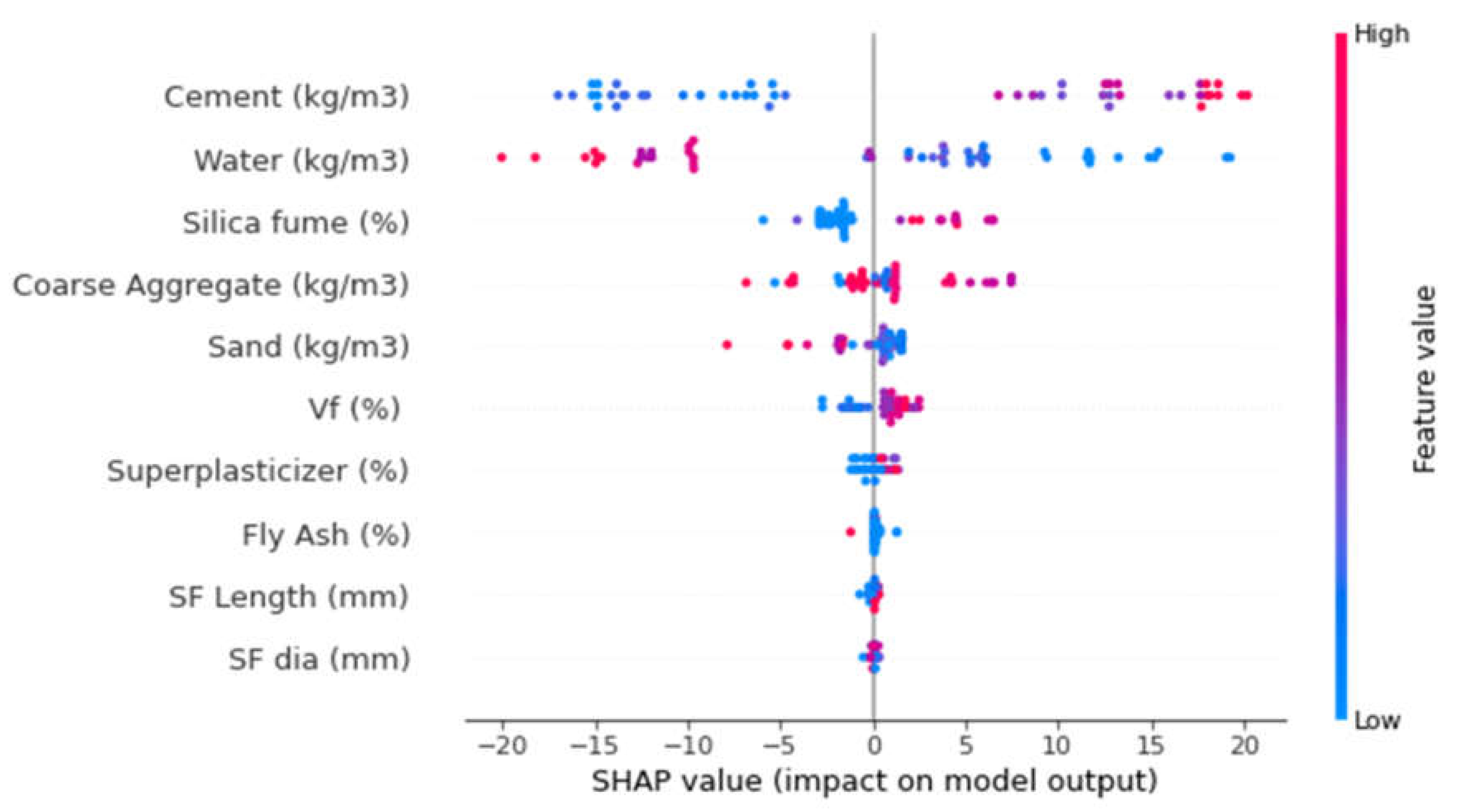
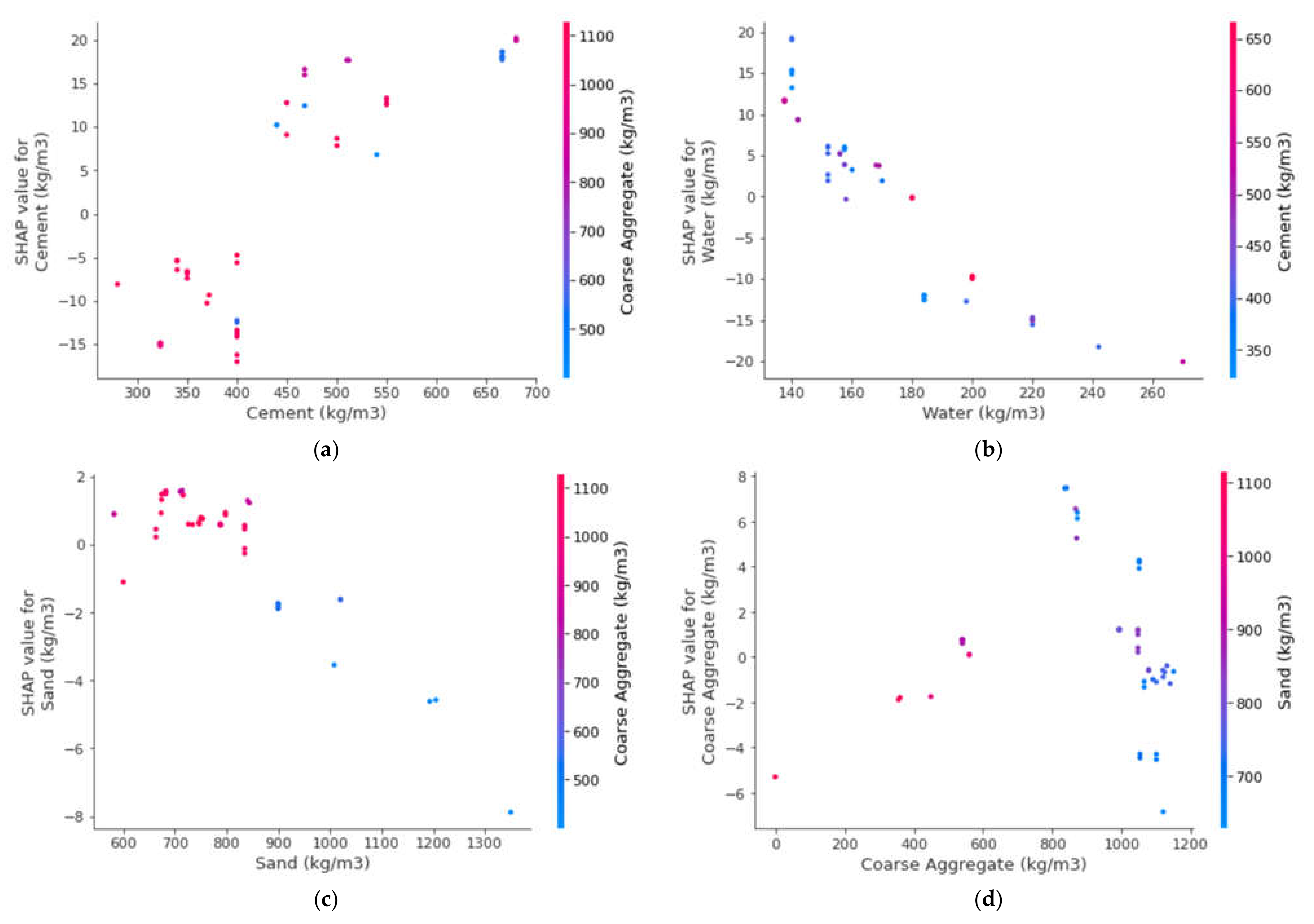
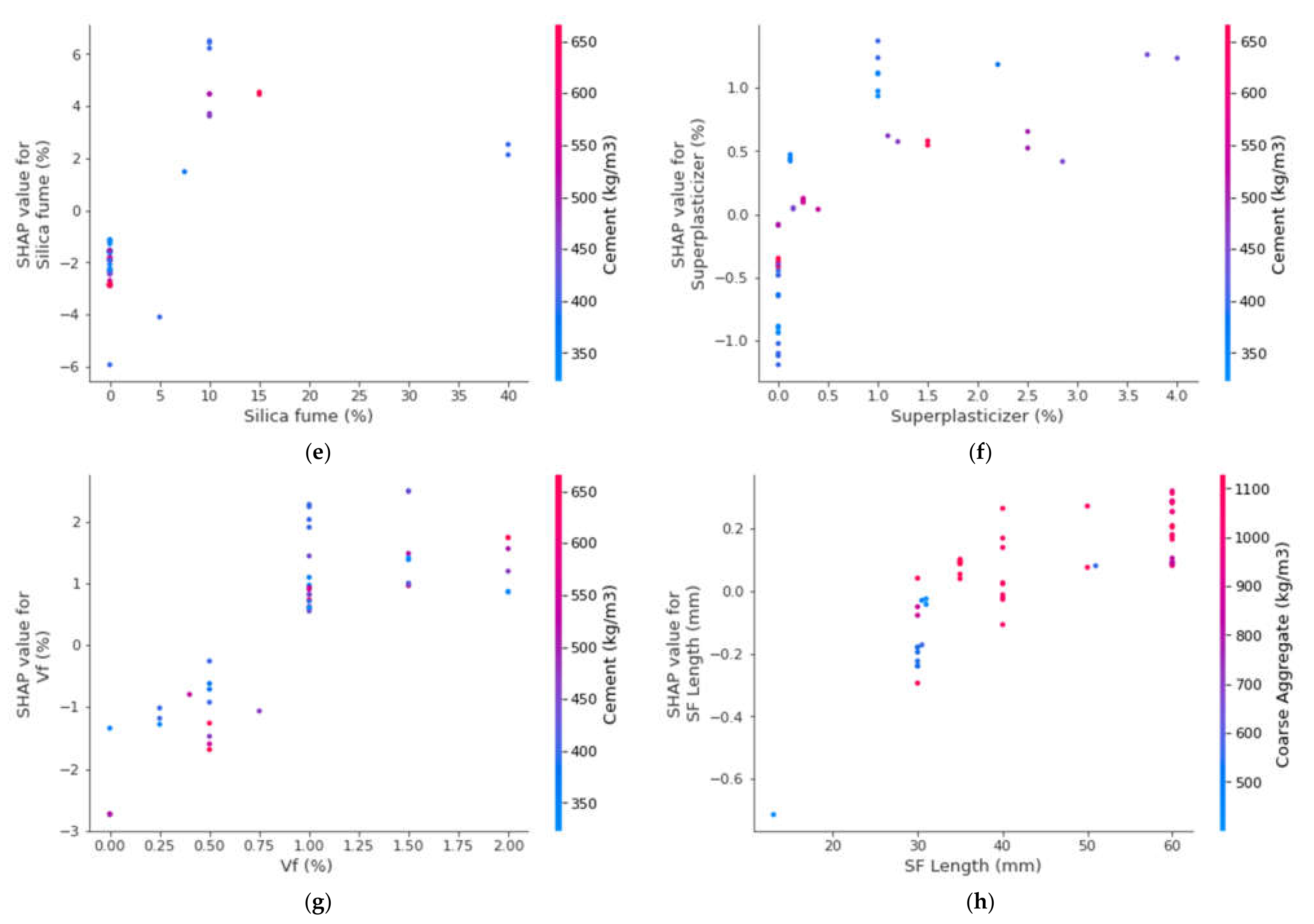
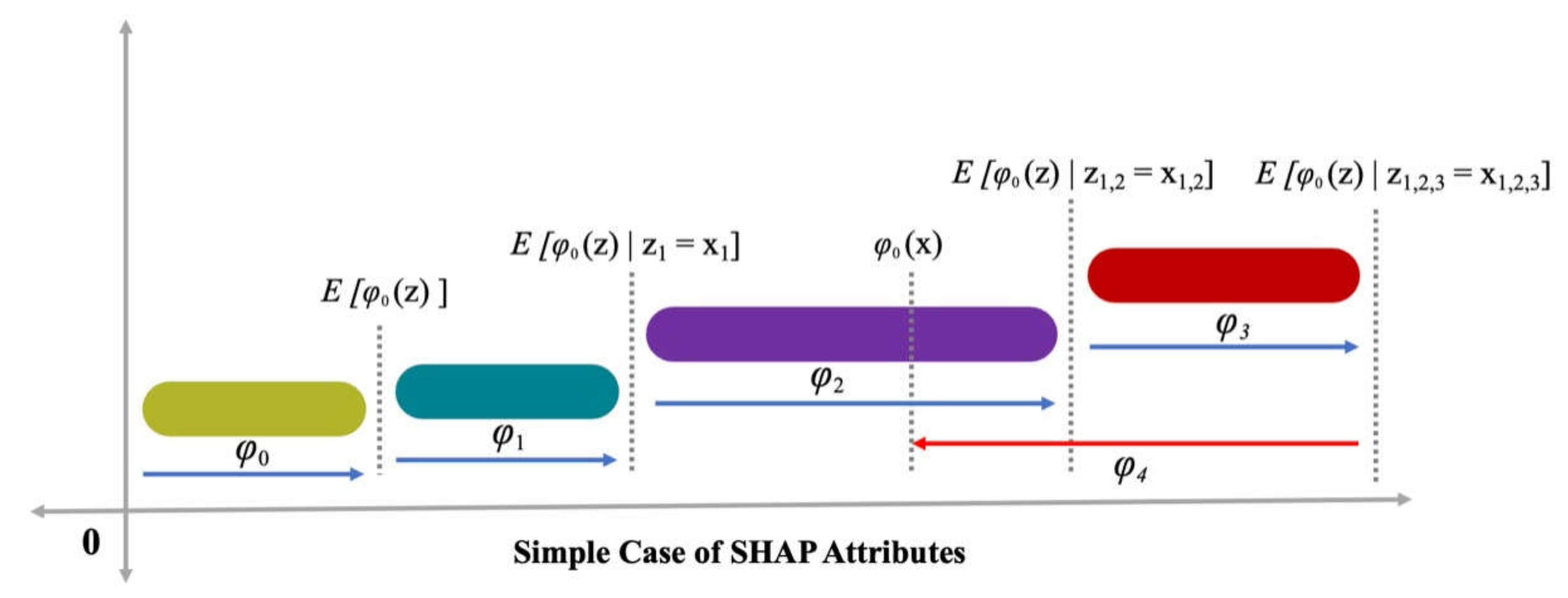
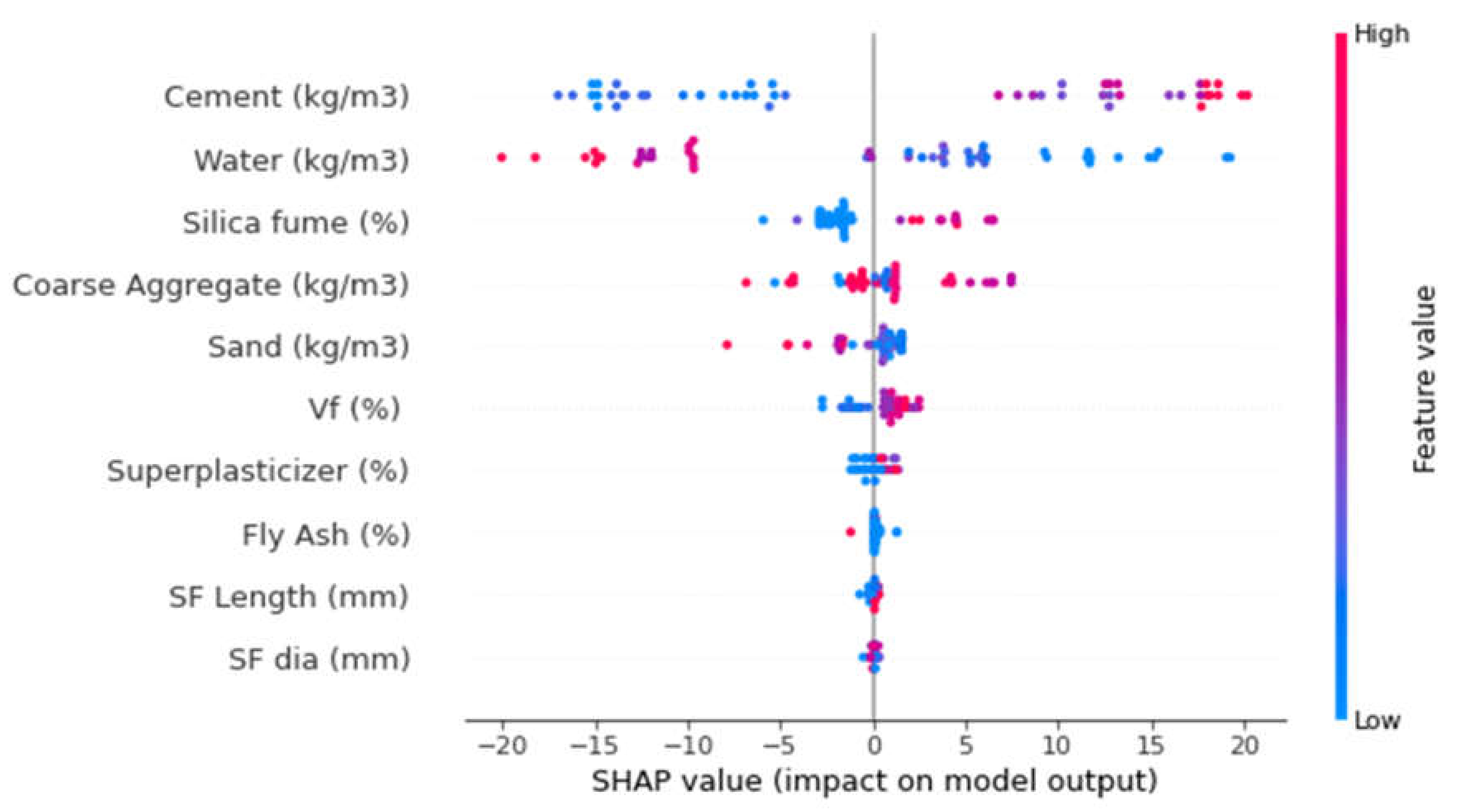
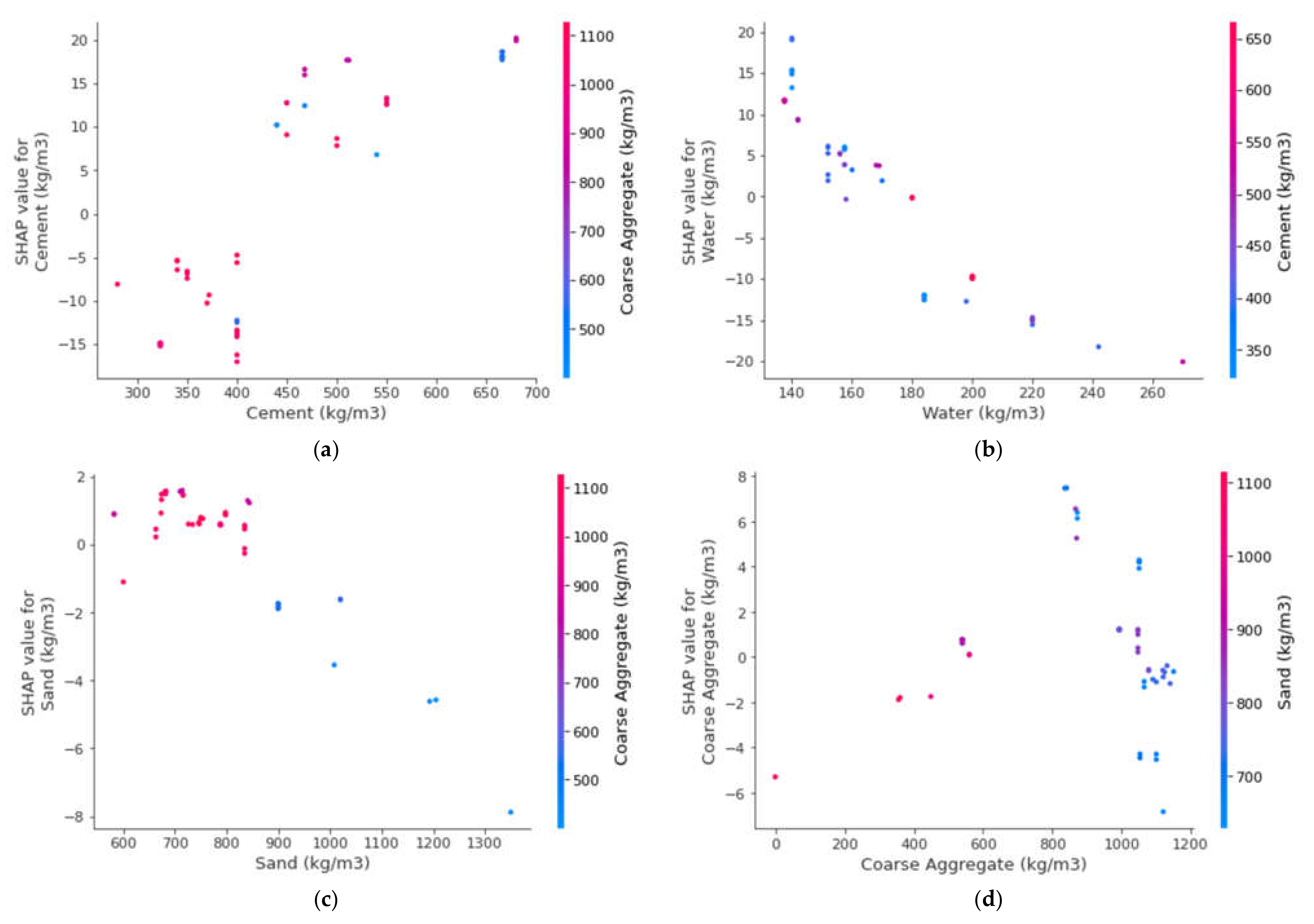
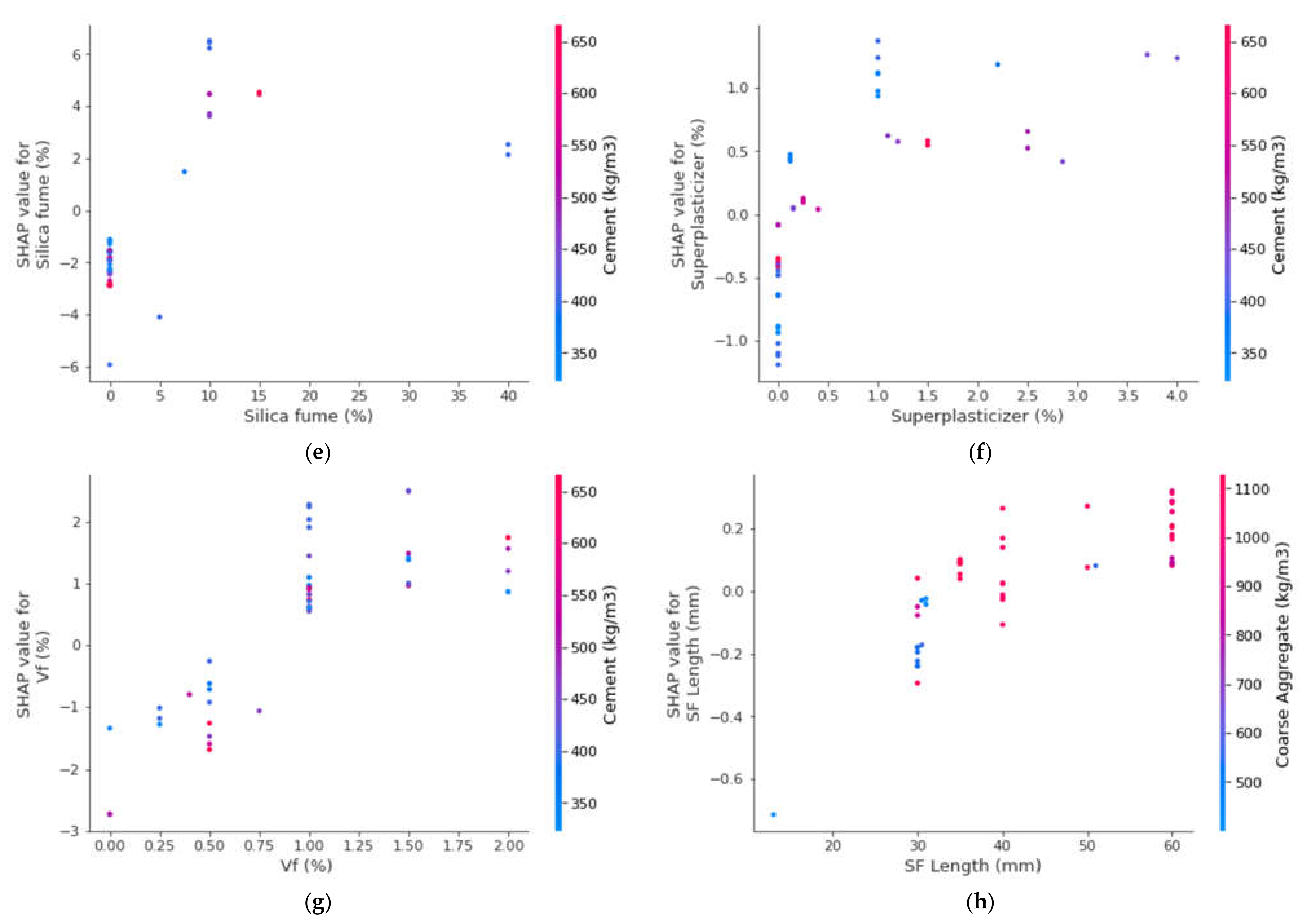
3.5. Enhanced Explainability of ML Models
4. Conclusions
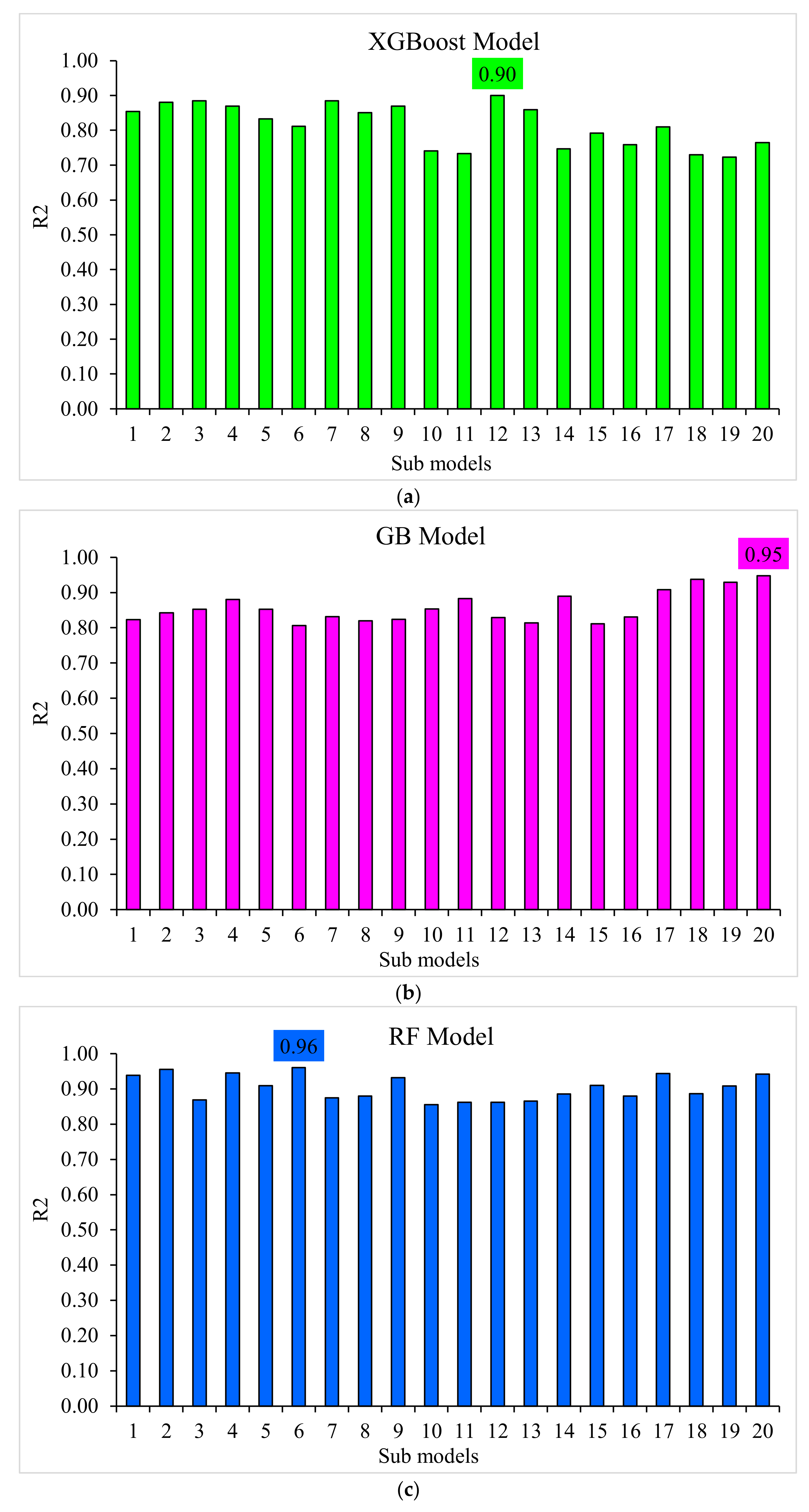
- The 0.96 R2 value in the case of the random forest model showed its accuracy in predicting SFRC compressive strength. In the case of ensemble gradient-boosting and XGBoost ML models having 0.95 and 0.90 R2 values, respectively, the predicted SFRC compressive strength had less accuracy.
- The predicted SFRC compressive strength was optimized using twenty submodels with a range of 10 to 200 predictors. The ensemble random forest model produced a comparatively more precise prediction of SFRC compressive strength than all the other considered models.
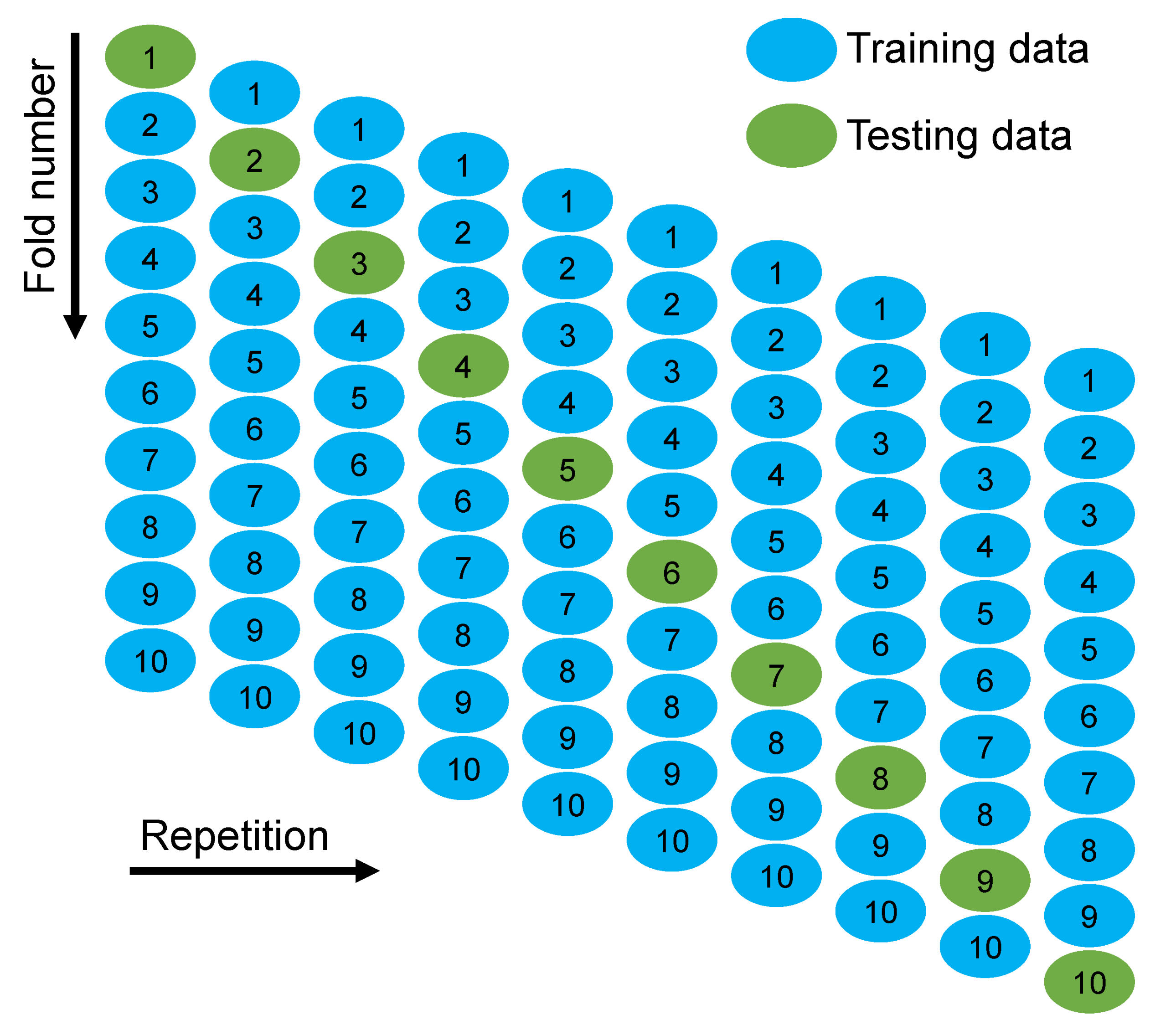
- As revealed from the k-fold cross-validation outcomes, the gradient-boosting and random forest models had higher R2 and lesser RMSE and MAE values for SFRC compressive strength than the other considered models, where the random forest model displayed the best accuracy for SFRC compressive strength prediction.
- Statistical checks such as RMSE and MAE were employed to evaluate the performances of the models. However, the higher determination coefficient and lower error value showed the superiority of the random forest model in the prediction of SFRC compressive strength.
- Among all the ML techniques, the random forest was the best approach to estimate SFRC compressive strength.
- The cement feature had the highest influence on the prediction of SFRC compressive strength, followed by water content, silica fume, coarse aggregates, sand, volumetric fiber content, and content of super-plasticizer, as revealed from SHAP analysis. However, the SFRC compressive strength was least influenced by the diameter of the steel fibers.
- SFRC compressive strength was positively influenced by cement content, as well as steel fiber volumetric content and length, as depicted from the feature interaction plots.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, M.; Mao, Y.; Khan, M.; Si, W.; Shen, S. Different testing methods for assessing the synthetic fiber distribution in cement-based composites. Constr. Build. Mater. 2018, 184, 128–142. [Google Scholar] [CrossRef]
- Khan, M.; Cao, M.; Hussain, A.; Chu, S. Effect of silica-fume content on performance of CaCO3 whisker and basalt fiber at matrix interface in cement-based composites. Constr. Build. Mater. 2021, 300, 124046. [Google Scholar] [CrossRef]
- Arshad, S.; Sharif, M.B.; Irfan-ul-Hassan, M.; Khan, M.; Zhang, J.-L. Efficiency of supplementary cementitious materials and natural fiber on mechanical performance of concrete. Arab. J. Sci. Eng. 2020, 45, 8577–8589. [Google Scholar] [CrossRef]
- Xie, C.; Cao, M.; Guan, J.; Liu, Z.; Khan, M. Improvement of boundary effect model in multi-scale hybrid fibers reinforced cementitious composite and prediction of its structural failure behavior. Compos. Part B Eng. 2021, 224, 109219. [Google Scholar] [CrossRef]
- Cao, M.; Khan, M. Effectiveness of multiscale hybrid fiber reinforced cementitious composites under single degree of freedom hydraulic shaking table. Struct. Concr. 2021, 22, 535–549. [Google Scholar] [CrossRef]
- Khan, U.A.; Jahanzaib, H.M.; Khan, M.; Ali, M. Improving the tensile energy absorption of high strength natural fiber reinforced concrete with fly-ash for bridge girders. In Key Engineering Materials; Trans Tech Publications: Freienbach, Switzerland, 2018; pp. 335–342. [Google Scholar]
- Khan, M.; Cao, M.; Ai, H.; Hussain, A. Basalt Fibers in Modified Whisker Reinforced Cementitious Composites. Period. Polytech. Civ. Eng. 2022, 66, 344–354. [Google Scholar] [CrossRef]
- Zhang, N.; Yan, C.; Li, L.; Khan, M. Assessment of fiber factor for the fracture toughness of polyethylene fiber reinforced geopolymer. Constr. Build. Mater. 2022, 319, 126130. [Google Scholar] [CrossRef]
- Khan, M.; Ali, M. Improvement in concrete behavior with fly ash, silica-fume and coconut fibres. Constr. Build. Mater. 2019, 203, 174–187. [Google Scholar] [CrossRef]
- Khan, M.; Cao, M.; Chu, S.; Ali, M. Properties of hybrid steel-basalt fiber reinforced concrete exposed to different surrounding conditions. Constr. Build. Mater. 2022, 322, 126340. [Google Scholar] [CrossRef]
- Li, L.; Khan, M.; Bai, C.; Shi, K. Uniaxial tensile behavior, flexural properties, empirical calculation and microstructure of multi-scale fiber reinforced cement-based material at elevated temperature. Materials 2021, 14, 1827. [Google Scholar] [CrossRef]
- Khan, M.; Cao, M.; Xie, C.; Ali, M. Hybrid fiber concrete with different basalt fiber length and content. Struct. Concr. 2022, 23, 346–364. [Google Scholar] [CrossRef]
- Khan, M.; Cao, M.; Xie, C.; Ali, M. Effectiveness of hybrid steel-basalt fiber reinforced concrete under compression. Case Stud. Constr. Mater. 2022, 16, e00941. [Google Scholar] [CrossRef]
- Wang, J.; Dai, Q.; Si, R. Experimental and Numerical Investigation of Fracture Behaviors of Steel Fiber–Reinforced Rubber Self-Compacting Concrete. J. Mater. Civ. Eng. 2022, 34, 04021379. [Google Scholar] [CrossRef]
- Su, P.; Dai, Q.; Li, M.; Ma, Y.; Wang, J. Investigation of the mechanical and shrinkage properties of plastic-rubber compound modified cement mortar with recycled tire steel fiber. Constr. Build. Mater. 2022, 334, 127391. [Google Scholar] [CrossRef]
- Khan, M.; Lao, J.; Dai, J.-G. Comparative study of advanced computational techniques for estimating the compressive strength of UHPC. J. Asian Concr. Fed. 2022, 8, 51–68. [Google Scholar] [CrossRef]
- Chaabene, W.B.; Flah, M.; Nehdi, M.L. Machine learning prediction of mechanical properties of concrete: Critical review. Constr. Build. Mater. 2020, 260, 119889. [Google Scholar] [CrossRef]
- Marani, A.; Nehdi, M.L. Machine learning prediction of compressive strength for phase change materials integrated cementitious composites. Constr. Build. Mater. 2020, 265, 120286. [Google Scholar] [CrossRef]
- Ramadan Suleiman, A.; Nehdi, M.L. Modeling self-healing of concrete using hybrid genetic algorithm–artificial neural network. Materials 2017, 10, 135. [Google Scholar] [CrossRef]
- Castelli, M.; Vanneschi, L.; Silva, S. Prediction of high performance concrete strength using genetic programming with geometric semantic genetic operators. Expert Syst. Appl. 2013, 40, 6856–6862. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, Y.; Aslani, F.; Ma, G.; Nener, B. A hybrid intelligent system for designing optimal proportions of recycled aggregate concrete. J. Clean. Prod. 2020, 273, 122922. [Google Scholar] [CrossRef]
- Han, Q.; Gui, C.; Xu, J.; Lacidogna, G. A generalized method to predict the compressive strength of high-performance concrete by improved random forest algorithm. Constr. Build. Mater. 2019, 226, 734–742. [Google Scholar] [CrossRef]
- Ali, B.; Kurda, R.; Ahmed, H.; Alyousef, R. Effect of recycled tyre steel fiber on flexural toughness, residual strength, and chloride permeability of high-performance concrete (HPC). J. Sustain. Cem.-Based Mater. 2022, 1–17. [Google Scholar] [CrossRef]
- Ali, B.; Raza, S.S.; Hussain, I.; Iqbal, M. Influence of different fibers on mechanical and durability performance of concrete with silica fume. Struct. Concr. 2021, 22, 318–333. [Google Scholar] [CrossRef]
- Ali, B. Development of environment-friendly and ductile recycled aggregate concrete through synergetic use of hybrid fibers. Environ. Sci. Pollut. Res. 2022, 29, 34452–34463. [Google Scholar] [CrossRef] [PubMed]
- Lauritsen, S.M.; Kristensen, M.; Olsen, M.V.; Larsen, M.S.; Lauritsen, K.M.; Jørgensen, M.J.; Lange, J.; Thiesson, B. Explainable artificial intelligence model to predict acute critical illness from electronic health records. Nat. Commun. 2020, 11, 3852. [Google Scholar] [CrossRef] [PubMed]
- Johnsen, P.V.; Riemer-Sørensen, S.; DeWan, A.T.; Cahill, M.E.; Langaas, M. A new method for exploring gene–gene and gene–environment interactions in GWAS with tree ensemble methods and SHAP values. BMC Bioinform. 2021, 22, 230. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Yao, M.; Zhu, Y.; Li, J.; Wei, H.; He, P. Research on predicting line loss rate in low voltage distribution network based on gradient boosting decision tree. Energies 2019, 12, 2522. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Amjad, M.; Ahmad, I.; Ahmad, M.; Wróblewski, P.; Kamiński, P.; Amjad, U. Prediction of Pile Bearing Capacity Using XGBoost Algorithm: Modeling and Performance Evaluation. Appl. Sci. 2022, 12, 2126. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, G.; Huang, Y.; Aslani, F.; Nener, B. Modelling uniaxial compressive strength of lightweight self-compacting concrete using random forest regression. Constr. Build. Mater. 2019, 210, 713–719. [Google Scholar] [CrossRef]
- Shaqadan, A. Prediction of concrete mix strength using random forest model. Int. J. Appl. Eng. Res. 2016, 11, 11024–11029. [Google Scholar]
- Xu, Y.; Ahmad, W.; Ahmad, A.; Ostrowski, K.A.; Dudek, M.; Aslam, F.; Joyklad, P. Computation of High-Performance Concrete Compressive Strength Using Standalone and Ensembled Machine Learning Techniques. Materials 2021, 14, 7034. [Google Scholar] [CrossRef] [PubMed]
- Guo, K.; Wan, X.; Liu, L.; Gao, Z.; Yang, M. Fault Diagnosis of Intelligent Production Line Based on Digital Twin and Improved Random Forest. Appl. Sci. 2021, 11, 7733. [Google Scholar] [CrossRef]
- Lundberg, S. A game theoretic approach to explain the output of any machine learning model. Github 2021. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Hussain, A.; Farooqi, M.U.; Deifalla, A.F. Artificial intelligence-based estimation of ultra-high-strength concrete’s flexural property. Case Stud. Constr. Mater. 2022, e01243. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Shen, Z.; Deifalla, A.F.; Kamiński, P.; Dyczko, A. Compressive Strength Evaluation of Ultra-High-Strength Concrete by Machine Learning. Materials 2022, 15, 3523. [Google Scholar] [CrossRef] [PubMed]
- Soulioti, D.; Barkoula, N.; Paipetis, A.; Matikas, T. Effects of fibre geometry and volume fraction on the flexural behaviour of steel-fibre reinforced concrete. Strain 2011, 47, e535–e541. [Google Scholar] [CrossRef]
- Yoo, D.-Y.; Yoon, Y.-S.; Banthia, N. Flexural response of steel-fiber-reinforced concrete beams: Effects of strength, fiber content, and strain-rate. Cem. Concr. Compos. 2015, 64, 84–92. [Google Scholar] [CrossRef]
- Lee, J.-H.; Cho, B.; Choi, E. Flexural capacity of fiber reinforced concrete with a consideration of concrete strength and fiber content. Constr. Build. Mater. 2017, 138, 222–231. [Google Scholar] [CrossRef]
- Köksal, F.; Altun, F.; Yiğit, İ.; Şahin, Y. Combined effect of silica fume and steel fiber on the mechanical properties of high strength concretes. Constr. Build. Mater. 2008, 22, 1874–1880. [Google Scholar] [CrossRef]
- Yoon, E.-S.; Park, S.-B. An experimental study on the mechanical properties and long-term deformations of high-strength steel fiber reinforced concrete. KSCE J. Civ. Environ. Eng. Res. 2006, 26, 401–409. [Google Scholar]
- Abbass, W.; Khan, M.I.; Mourad, S. Evaluation of mechanical properties of steel fiber reinforced concrete with different strengths of concrete. Constr. Build. Mater. 2018, 168, 556–569. [Google Scholar] [CrossRef]
- Yoo, D.-Y.; Yoon, Y.-S.; Banthia, N. Predicting the post-cracking behavior of normal-and high-strength steel-fiber-reinforced concrete beams. Constr. Build. Mater. 2015, 93, 477–485. [Google Scholar] [CrossRef]
- Lee, H.-H.; Lee, H.-J. Characteristic strength and deformation of SFRC considering steel fiber factor and volume fraction. J. Korea Concr. Inst. 2004, 16, 759–766. [Google Scholar] [CrossRef]
- Oh, Y.-H. Evaluation of flexural strength for normal and high strength concrete with hooked steel fibers. J. Korea Concr. Inst. 2008, 20, 531–539. [Google Scholar]
- Song, P.; Hwang, S. Mechanical properties of high-strength steel fiber-reinforced concrete. Constr. Build. Mater. 2004, 18, 669–673. [Google Scholar] [CrossRef]
- Jang, S.-J.; Yun, H.-D. Combined effects of steel fiber and coarse aggregate size on the compressive and flexural toughness of high-strength concrete. Compos. Struct. 2018, 185, 203–211. [Google Scholar] [CrossRef]
- Aldossari, K.; Elsaigh, W.; Shannag, M. Effect of steel fibers on flexural behavior of normal and high strength concrete. Int. J. Civ. Environ. Eng. 2014, 8, 22–26. [Google Scholar]
- Dinh, N.H.; Park, S.-H.; Choi, K.-K. Effect of dispersed micro-fibers on tensile behavior of uncoated carbon textile-reinforced cementitious mortar after high-temperature exposure. Cem. Concr. Compos. 2021, 118, 103949. [Google Scholar] [CrossRef]
- Thomas, J.; Ramaswamy, A. Mechanical properties of steel fiber-reinforced concrete. J. Mater. Civ. Eng. 2007, 19, 385–392. [Google Scholar] [CrossRef]
- Sivakumar, A.; Santhanam, M. Mechanical properties of high strength concrete reinforced with metallic and non-metallic fibres. Cem. Concr. Compos. 2007, 29, 603–608. [Google Scholar] [CrossRef]
- Afroughsabet, V.; Ozbakkaloglu, T. Mechanical and durability properties of high-strength concrete containing steel and polypropylene fibers. Constr. Build. Mater. 2015, 94, 73–82. [Google Scholar] [CrossRef]
- Atiş, C.D.; Karahan, O. Properties of steel fiber reinforced fly ash concrete. Constr. Build. Mater. 2009, 23, 392–399. [Google Scholar] [CrossRef]
- Ahmad, W.; Ahmad, A.; Ostrowski, K.A.; Aslam, F.; Joyklad, P.; Zajdel, P. Application of advanced machine learning approaches to predict the compressive strength of concrete containing supplementary cementitious materials. Materials 2021, 14, 5762. [Google Scholar] [CrossRef]
- Ahmad, A.; Ahmad, W.; Aslam, F.; Joyklad, P. Compressive strength prediction of fly ash-based geopolymer concrete via advanced machine learning techniques. Case Stud. Constr. Mater. 2021, 16, e00840. [Google Scholar] [CrossRef]
- Yuan, X.; Tian, Y.; Ahmad, W.; Ahmad, A.; Usanova, K.I.; Mohamed, A.M.; Khallaf, R. Machine Learning Prediction Models to Evaluate the Strength of Recycled Aggregate Concrete. Materials 2022, 15, 2823. [Google Scholar] [CrossRef]
- Shang, M.; Li, H.; Ahmad, A.; Ahmad, W.; Ostrowski, K.A.; Aslam, F.; Joyklad, P.; Majka, T.M. Predicting the Mechanical Properties of RCA-Based Concrete Using Supervised Machine Learning Algorithms. Materials 2022, 15, 647. [Google Scholar] [CrossRef]
- Wang, Q.; Ahmad, W.; Ahmad, A.; Aslam, F.; Mohamed, A.; Vatin, N.I. Application of Soft Computing Techniques to Predict the Strength of Geopolymer Composites. Polymers 2022, 14, 1074. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. Explainable AI for trees: From local explanations to global understanding. arXiv 2019, arXiv:1905.04610. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques | MAE (MPa) | RMSE (MPa) | R2 |
|---|---|---|---|
| XGBoost | 4.6 | 6.5 | 0.90 |
| Gradient boosting | 2.4 | 3.5 | 0.95 |
| Random forest | 2.4 | 3.1 | 0.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, K.; Ahmad, W.; Amin, M.N.; Ahmad, A.; Nazar, S.; Alabdullah, A.A. Compressive Strength Estimation of Steel-Fiber-Reinforced Concrete and Raw Material Interactions Using Advanced Algorithms. Polymers 2022, 14, 3065. https://doi.org/10.3390/polym14153065
Khan K, Ahmad W, Amin MN, Ahmad A, Nazar S, Alabdullah AA. Compressive Strength Estimation of Steel-Fiber-Reinforced Concrete and Raw Material Interactions Using Advanced Algorithms. Polymers. 2022; 14(15):3065. https://doi.org/10.3390/polym14153065
Chicago/Turabian StyleKhan, Kaffayatullah, Waqas Ahmad, Muhammad Nasir Amin, Ayaz Ahmad, Sohaib Nazar, and Anas Abdulalim Alabdullah. 2022. "Compressive Strength Estimation of Steel-Fiber-Reinforced Concrete and Raw Material Interactions Using Advanced Algorithms" Polymers 14, no. 15: 3065. https://doi.org/10.3390/polym14153065
APA StyleKhan, K., Ahmad, W., Amin, M. N., Ahmad, A., Nazar, S., & Alabdullah, A. A. (2022). Compressive Strength Estimation of Steel-Fiber-Reinforced Concrete and Raw Material Interactions Using Advanced Algorithms. Polymers, 14(15), 3065. https://doi.org/10.3390/polym14153065