1. Introduction
Polyethylene as a thermoplastic has received the uppermost popularity in a vast variety of applied contexts. In spite of the need for considerable financial investment for producing polyethylene, the end consumer might receive a very inexpensive and throwaway product. Therefore, improvements in polymer fabrication procedures aiming at reducing manufacturing expenses remain as an investigational, developmental, and process expansion topic [
1].
High-quality, low-cost petrochemical products are increasingly in demand for many applications including modernistic HDPE (high-density polyethylene) marketplaces [
2]. Polyethylene is manufactured using common process technologies including high-pressure autoclave, high-pressure tubular, slurry (suspension), gas phase, and solution. The gas phase process in particular is one of the typical and frequently used technologies in the production of HDPE and other polyolefins. Various reactors are applied in ethylene polymerizations ranging from simple autoclaves and steel piping to CSTR (continuously stirred tank reactors) and vertical fluidized beds [
3]. The main incentives for this innovation include the elimination of the necessity for removing the catalyst following the reaction and making the product in a style appropriate for manipulation and reposition. In the gas phase reactors, polymerization occurs at the surface of the catalyst and the polymer matrix, which is inflated with monomers throughout the polymerization [
4].
Although catalysts for polymerizing ethylene are often heterogeneous, homogeneous catalysts are also used in some processes. Currently, four kinds of catalysts exist for polymerizing ethylene: Ziegler–Natta, Phillips, metallocenes, and late transition metal catalysts [
2]. Only the first three types have commercial applications while the last one is yet to undergo examination and a developing phase. Ziegler–Natta catalysts vary greatly but are usually TiCl
4 supported on MgCl
2 and commonly employed for the polyethylene production in the industry [
5].
In HDPE production practices, the ethylene index (EIX) is the critical controlling variable that indicates product characteristics. It is necessary to preserve the uniform features of HDPE throughout grade change practices to fulfill the different and strict requirements for HDPE products, including the EIX.
There are several approaches regarding polyethylene production estimation and correlation in the literature. Khare et al. [
6] introduced steady-state and dynamic models for the HDPE slurry polymerization procedure for industrial applications. The authors utilized parallel reactors data to model the reactors in series order. They set the kinetic parameters by initial consideration of a single site catalyst followed by using the outcomes to optimize the kinetic parameters for multi-site-type catalyst. Neto et al. [
7] designed a dynamic model for the LLDPE polymerization process on the basis of a multi-site catalyst that underwent development merely for a single slurry reactor.
Considering a myriad of studies for improving polyethylene productivity, modeling approaches stand superior to experiments due to several key factors, including time and running costs, test feasibility, and safety (without hazards) concerns [
8,
9,
10,
11,
12]. As denoted in previous publications, modeling approaches comprise of regression models, mathematical models, and artificial intelligence models. Nevertheless, the accurate function of mathematical models is dubious, in particular, once these models deal with very uncertain polyethylene manufacture. Regression models, however, can still well predict the means of production systems per month. As it is necessary to accurately model the productive status of such systems, artificial neural network (ANN) models have been used to achieve this objective due to their ability to handle great uncertainty of such data. ANNs integrate industrial data for predicting the rate of production, but only a few investigations have been successful in utilizing the ANN models for such systems by integrating a diverse range of techniques such as the MLPNN (multi-layer perceptron), CFNN (cascaded forward), RBFNN (radial basis function), and GRNN (general regression) neural networks [
13,
14], among others.
MLP is a neural model with the highest prediction applicability, consisting of multiple layers, namely input, hidden layer(s), and output. Hidden layer(s) can also be set more precisely as having layers of nodes [
15]. The MLPNN as the prime and plainest topology of the ANN, employed for updating the weight links through the learning step.
RBFNN is a common feedforward neural network, which has been demonstrated to be capable of global estimation without local minima problem. Besides, it possesses a plain construct and a rapid learning algorithm in comparison with other neural networks [
16]. Despite the availability of multiple activation functions for radial basis neurons, the Gaussian function has received the uppermost popularity. Training is necessary before applying an RBF ANN, which is commonly achievable in two stages. Choosing centers among the data applied is in the first stage of the training. The second stage is to utilize the normal least squares for linear estimation of one weighting vector. The self-organized center election is the widespread learning approach employed for selecting RBF centers.
The input and output neurons begin the production of the CFNN topology. The output neurons are present in the neural network in advance; thus, novel neurons are provided for the network, as a result of which the network, in turn, attempts to increase the correlation level between the outputs and inputs by comparing the network residue with the novel measured error. This procedure goes ahead until reaching a smaller error value in the network, which explains the reasoning that it is labeled as a cascade [
17]. CFNN generally comprises three major layers namely, input, hidden, and output layers. The variables in hidden layers are multiplied by the bias (1.0) and the weight (computed in the creation phase to decline the prediction error) followed by addition to the sum entering the neuron. The resultant value from this procedure will cross a transfer function to present the output value.
GRNN is a type of supervised network that works on the basis of the probabilistic model and is able to produce continuous outputs. It is a robust instrument for non-linear regression analysis based on the approximation of probability density functions using the Parzen window technique [
18]. The GRNN architecture basically does not need an iterative process to simulate such results as back-propagation learning algorithms. GRNN is capable of estimating arbitrary functions among output and input datasets directly from training data.
The main uses of the RBF and GRNN topologies are with a rather small size of input data. Despite the common topology of neural networks, every neuron depends on the entire prior layer neurons in the CFNN. Additionally, the CFNN is able to carry on to a broad extent in case the input data possess a sizable memory capacity.
As revealed by a literature review, the ANN model has applications in predicting the performance of production rate. Nonetheless, only the MLP model was utilized to forecast the production rate [
19]. The novelty of the present study is to utilize and compare the performance of several models including the GRNN and RBF models, which were not previously used for predicting the production rate. Accordingly, the current research mainly aims to introduce and assess a model for predicting the rate of polyethylene fabrication. The novelty of our model is characterized by its capability in predicting system productivity by taking the uncertainty issue into account.
3. Results and Discussion
This section summarizes the actual databank gathered from the industrial polyethylene petrochemical company, by considering the significant independent variables and by utilizing the Pearson correlation matrix. Furthermore, this section deals with determining the best structures of different models and comparing the precisions of different models. The present section concludes by selecting the best model and analyzing the results.
3.1. Industrial Database
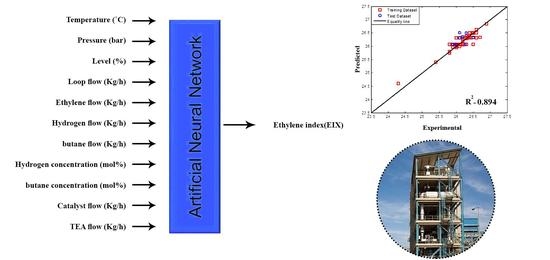
To investigate the EIX, eleven independent sets of input data namely, temperature, operating pressure, level, loop flow, ethylene flow, hydrogen flow, 1-butane flow, hydrogen concentration, 1-butane concentration, catalyst flow, and TEA (triethylaluminium) flow (i.e., inputs 1 to 11 denoted, respectively, by X1 to X11), and the EIX response (denoted by Y) are collected.
Table 1 presents the information summary of the industrial data used in this work.
According to the industrial databank, 93 data points were gathered at the steady-state conditions. The trained neural network needs validation for determining the precision of the introduced model. The network performance can be analyzed by cross-validation of an unidentified dataset. The network is validated through preserving a fraction of the dataset (e.g., 15%) for validation and the rest of the dataset is used for training. After the training phase, the data forecasted through the ANN topology and the measured data undergo a correlation analysis.
All ANN models were developed in MATLAB
® with the Levenberg–Marquardt optimization algorithm. Besides, the choice of training algorithm and neuron transfer function has a major contribution to model precision. As researchers have shown, the Levenberg–Marquardt (LM) algorithm produces quicker responses for regression-type problems in overall facets of neural networks [
31,
32]. Most often, the LM training algorithm was reported to have the highest significant efficiency, fast convergence, and accuracy compared with other training algorithms.
3.2. Scaling the Data
To enhance the rate of convergence in the training step as well as to avoid parameter saturation in the intended ANNs, the entire actual data were subjected to mapping within the interval [0.01 0.99]. Data were normalized by Equation (6):
where
denotes an independent or dependent variable,
represents the normal value,
is the maximum, and
is the minimum value of each variable.
3.3. Independent Variable Selection
Mathematical investigation for the dependency of two variables is possible through the correlation matrix study, the coefficients of which are usually measured from −1 to +1. This indicates that the two variables are correlated directly or indirectly given the signs of these coefficients, whereas the magnitude defines the robustness of their association. Our research surveyed a multivariate AI-based method with the Pearson correlation test for estimating the degree of relationship between each two variables [
23].
Figure 3 displays the correlation coefficient values’ given probable pairs of variables.
The Pearson correlation coefficient as the variable ranking is described in choosing appropriate inputs for the neural network [
33,
34]. Values delivered by the Pearson method reveal the type and intensity of the association between every variable pair, with a value between −1 and +1 representing the uppermost converse relationship and the highest direct association, respectively. The coefficient takes a zero value in cases where the given variables do not have any association. Independent variables take non-zero correlation coefficients that verify their choices. The highest consideration is devoted to absolute average values because they have important strong associations. The values of Pearson correlation coefficient for each input are presented in
Table 2.
Accordingly, this examination confirmed that Input2, Input5, Input6, Input7, Input10, and Input11 had the uppermost direct dependency and that other inputs presented the lowermost indirect association. Hence, it is possible to model polyethylene as a function of pressure, ethylene flow, hydrogen flow, 1-butane, catalyst flow, and TEA flow. Therefore, we try to present a smart model to derive the following relation:
Consequently, in the case of maximizing the AAPC (average of absolute Pearson’s coefficient) for a specific transformation on the dependent variable, it is inferred that it yields an association between the dependent and independent variables with the highest reliability. Every input variable of differing models was selected with the Pearson correlation coefficient. The inputs of every model are presented in
Table 3.
From this table, it can be concluded that it is better to output to the power of 12 instead of modeling the output itself. Although, at last, by inverse transformation, the dependent variable is calculated to compare with the actual values.
3.4. Configuration Selection for Different ANN Approaches
In this work, the EIX is predicted using a proper ANN model obtained from a logical procedure. As mentioned earlier, the number of hidden neurons has a major contribution to network performance. The majority of related investigations obtain the number of neurons through the trial and error approach. Training and generalization errors may highly happen when the numbers of hidden neurons are less than the optimum numbers. On the other hand, larger numbers of hidden neurons may result in over-fitting and considerable variations. Therefore, it is necessary to calculate the optimum number of hidden neurons for achieving the best performance of the network.
Subsequently, the ANN approaches were developed and then, for example, the MLP network was compared in terms of performance with CF, RBF, and GR neural networks. The numerical validation associates with the observed AARD%, R
2, MSE, and RMSE between actual and estimated data. According to the literature, MLP network capability with one hidden layer was proven [
35]. As such, an MLP network with only a single hidden layer is used for the analysis.
It is noted that the training data points should be at least twice the number of bias and weights. As a result, for the MLP with one dependent and six independent variables, the hidden neuron is computed as:
Therefore, this number can change from 1 to 4 (the highest acceptable number) in this network, and is trained 50 times for each network. The best configuration of the hidden neurons in the MLP model is presented in
Table 4.
The MLP network with three hidden neurons and the structure of 6-3-1 was determined as the most appropriate model. The MSE values of the MLP network with various numbers of hidden layer neurons are presented in
Figure 4. The data reveal that the optimality of the three numbers of neurons owes to the uppermost value of R
2 (0.89413) and the lowermost value of MSE (0.02217).
According to
Figure 4, MSE is lowest (0.07184) in the total MLP model with the presence of a single neuron in the hidden layer. The MLP model possesses the least MSE (0.02217) once six neurons exist in the hidden layer. Moreover,
Figure 5 presents a comparison between the industrial datasets and the predicted values by the optimum MLP network. The fit performance was determined for every trained MLP with minimum MSE value on the basis of R
2 values.
3.5. Other Types of ANN
To find an appropriate model for evaluating the EIX, different topologies of artificial neural networks must be compare based on their performances. Therefore, the intended MLP approach developed with optimum configuration in terms of predictive accuracy was evaluated with other ANN models (GR, CF, and RBF). The sensitivity results for selecting the best number of hidden neurons are presented in
Table 5,
Table 6 and
Table 7. It should be pointed out that determination of the number of hidden neurons in the other ANNs was the same as for the MLP model.
In GR, hidden neurons were not significant and the spread value needed to be set up. Subsequently, the spread value for the GR changes from 0.1 to 10 with 0.1 steps and 50 different GRs were considered, with statistical indices. The MSE is minimum (0.10808) in the GR model when the spread value was 4.81.
Considering the task, the best model contains the lowest value for MSE and AARD%.
Table 8 clearly reveals that the MLP model can predict the EIX more accurately than other types of ANN models. Based on the statistical error values, the MSE for the MLP model (0.02217) is less than those for the MSE estimated with CF (0.03914), GR (0.10808), and RBF (0.09255) models, respectively. The above findings confirm that the MLP model is superior in the prediction of the EIX comparing to other ANN models.
The MLP model, trained by the Levenberg–Marquardt algorithm with 6-3-1 structure, has the logsig transfer function in the output and hidden layers. In fact, this model is chosen from 600 models (200 MLPNN models, 150 CFNN models, 50 GRNN models, and 200 RBFNN models). This selection is based on four statistical indices: AARD%, MSE, RMSE, and R2.
Table 9 summarizes the value of the weight and bias for the proposed MLP model. The MLP was trained using a training dataset by the adjustment of the biases and weights. The performance validity of the trained MLP was achieved according to the training and testing datasets (independent datasets). The optimal division ratio is 85:15 for segregating the data.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}