Dissolved Gases Forecasting Based on Wavelet Least Squares Support Vector Regression and Imperialist Competition Algorithm for Assessing Incipient Faults of Transformer Polymer Insulation

 ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. Wavelet Least Squares Support Vector Machine
3. Using the Imperialist Competition Algorithm to Optimize Hyper-Parameters
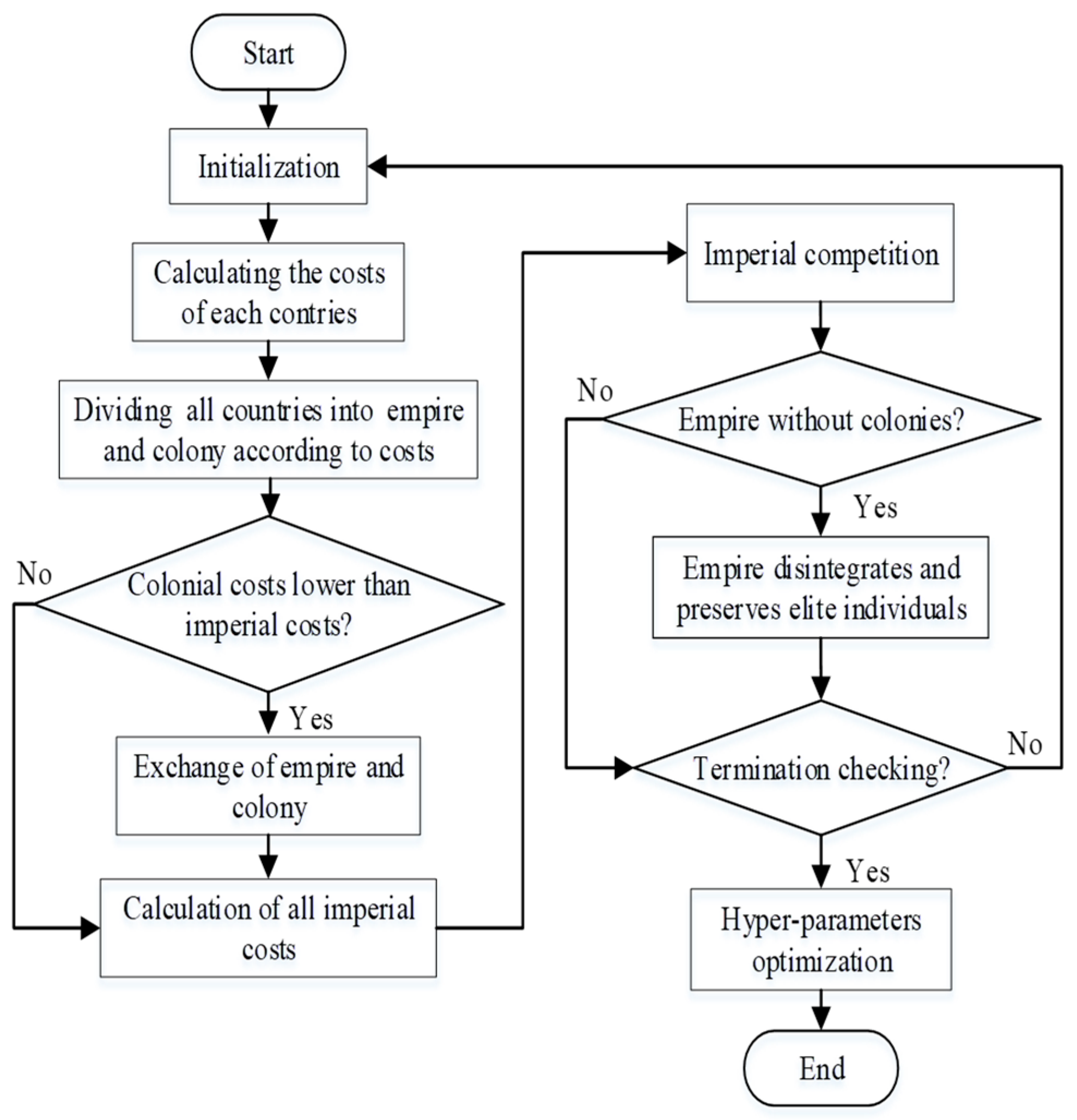
3.1. The Imperialist Competition Algorithm
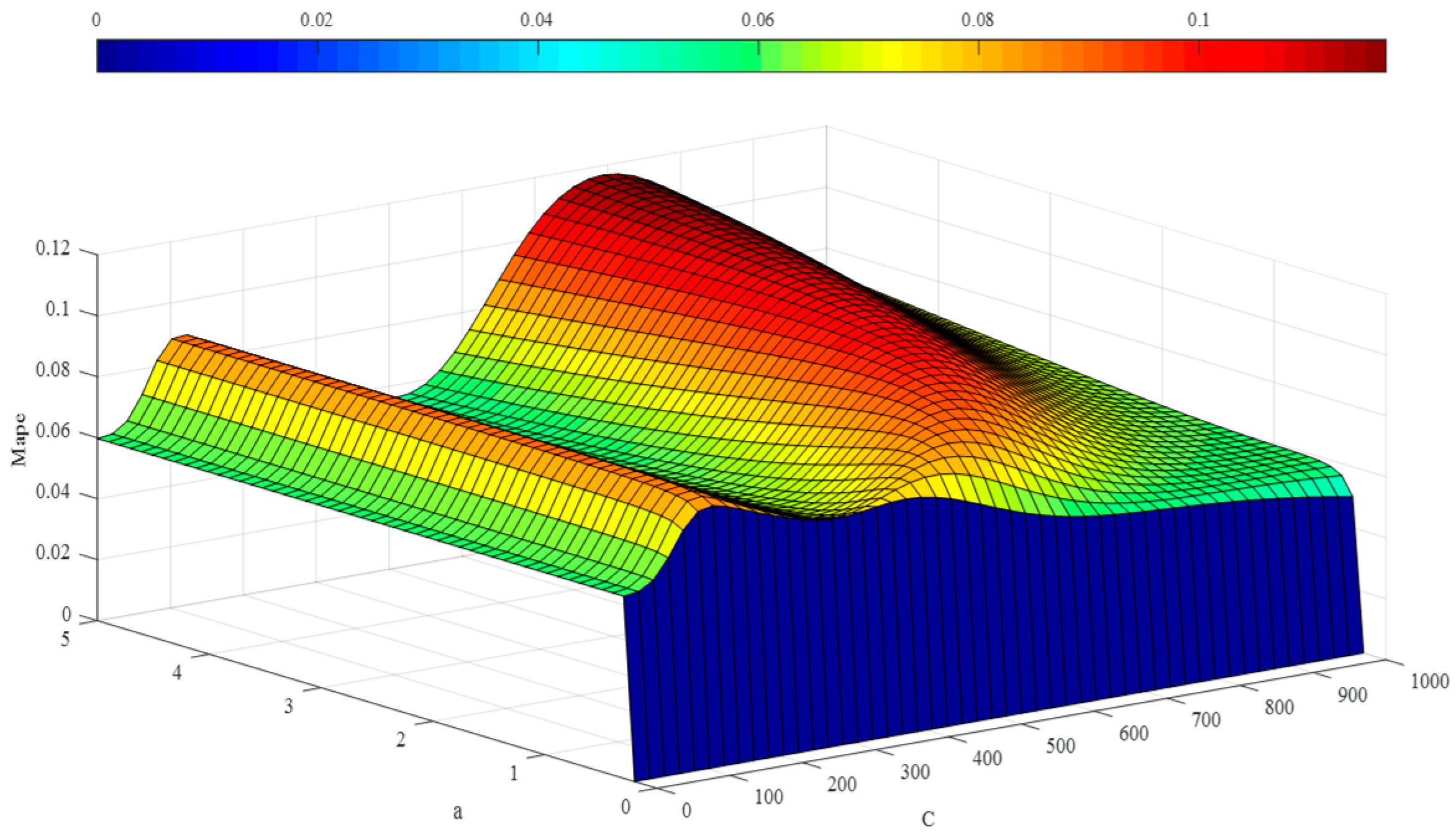
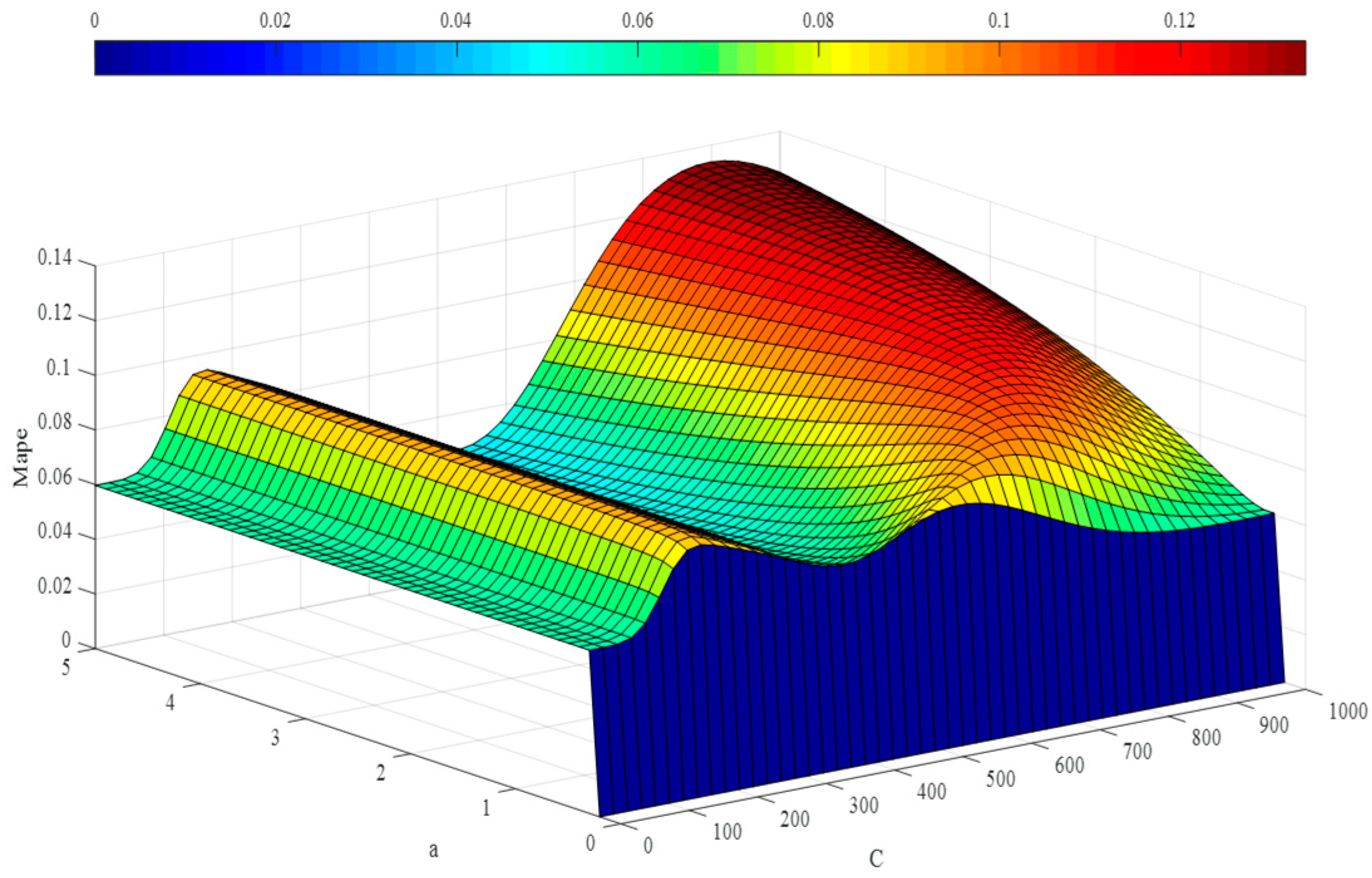
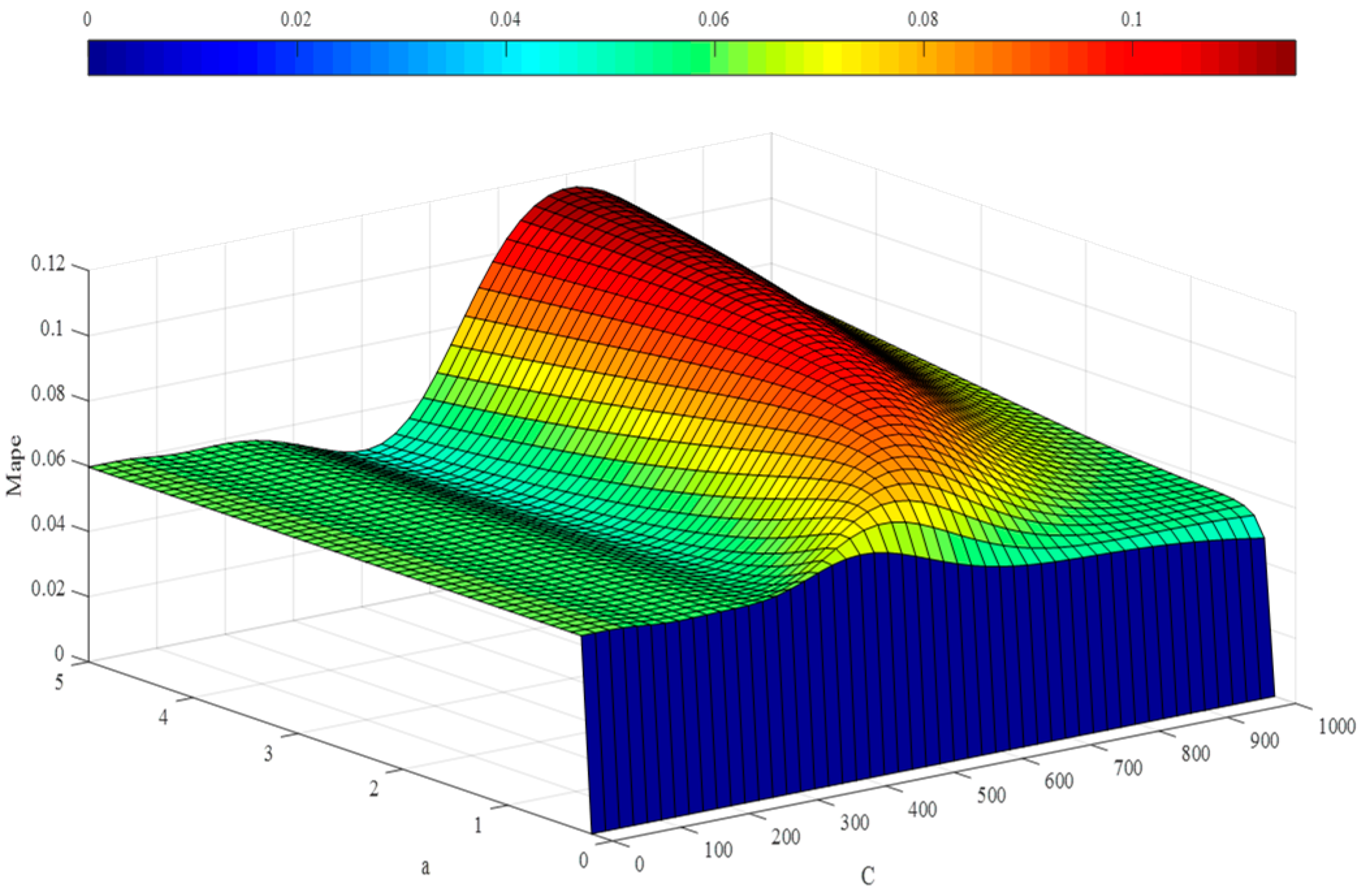
3.2. Hyper-Parameter Optimization
- (1)
- The location of the united empire is the expected solution to the optimal problem because the unique empire controls all empires and colonies.
- (2)
- Reaching the maximum generations.
4. Procedure for Forecasting Key Gas Contents with Wavelet Least Squares Support Vector Machine Regression and Imperialist Competition Algorithm
5. Results and Comparisons
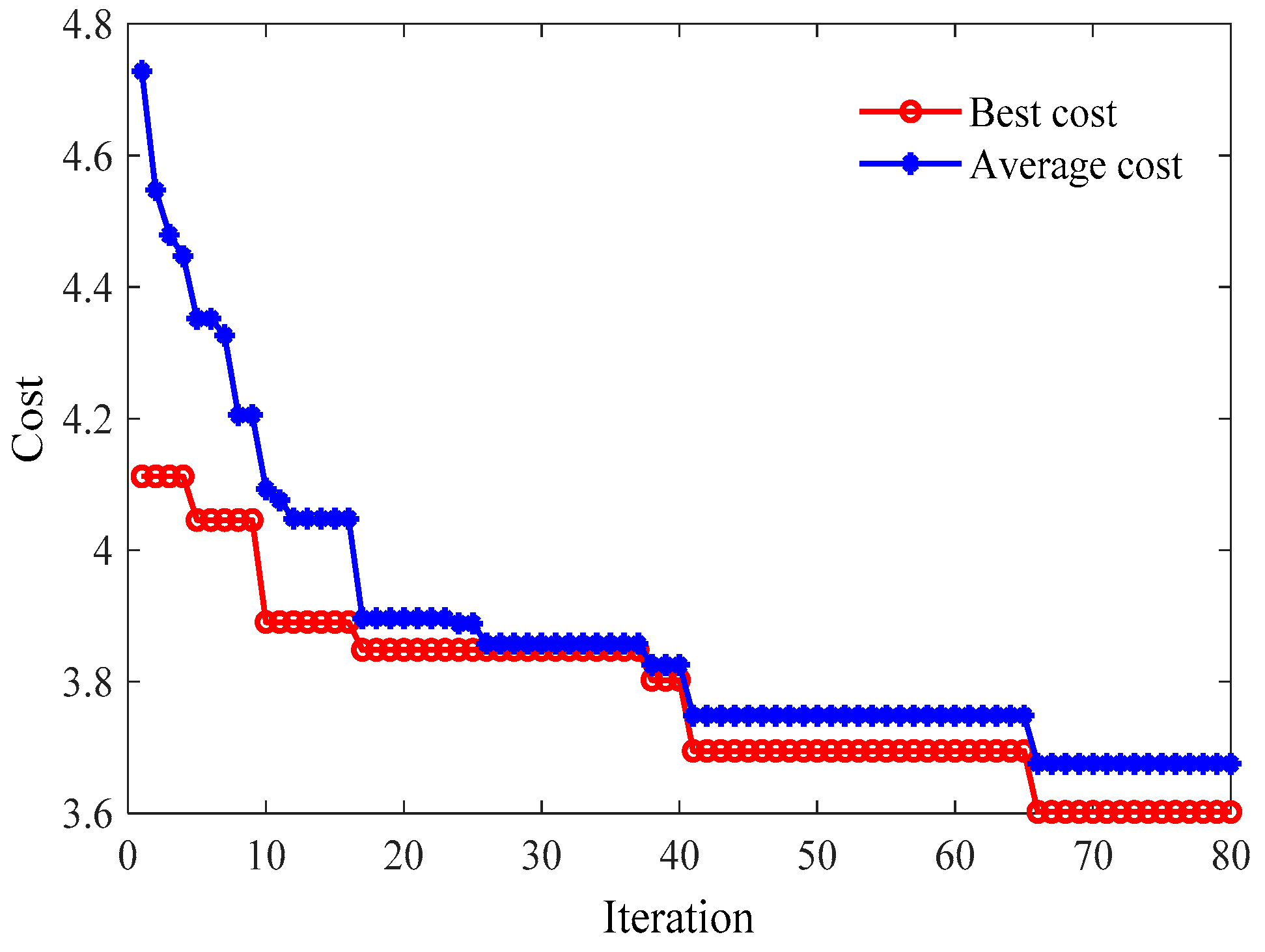
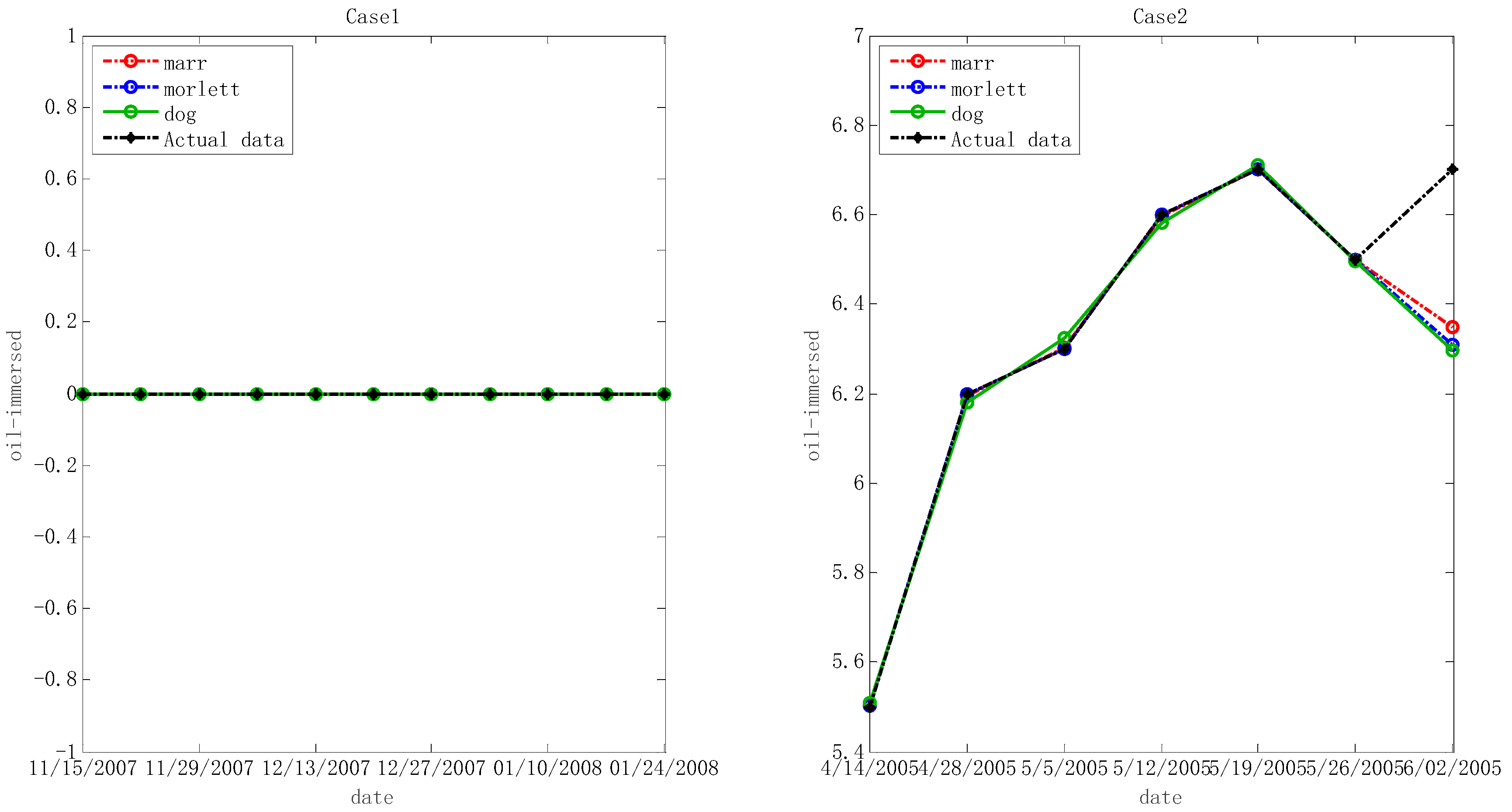
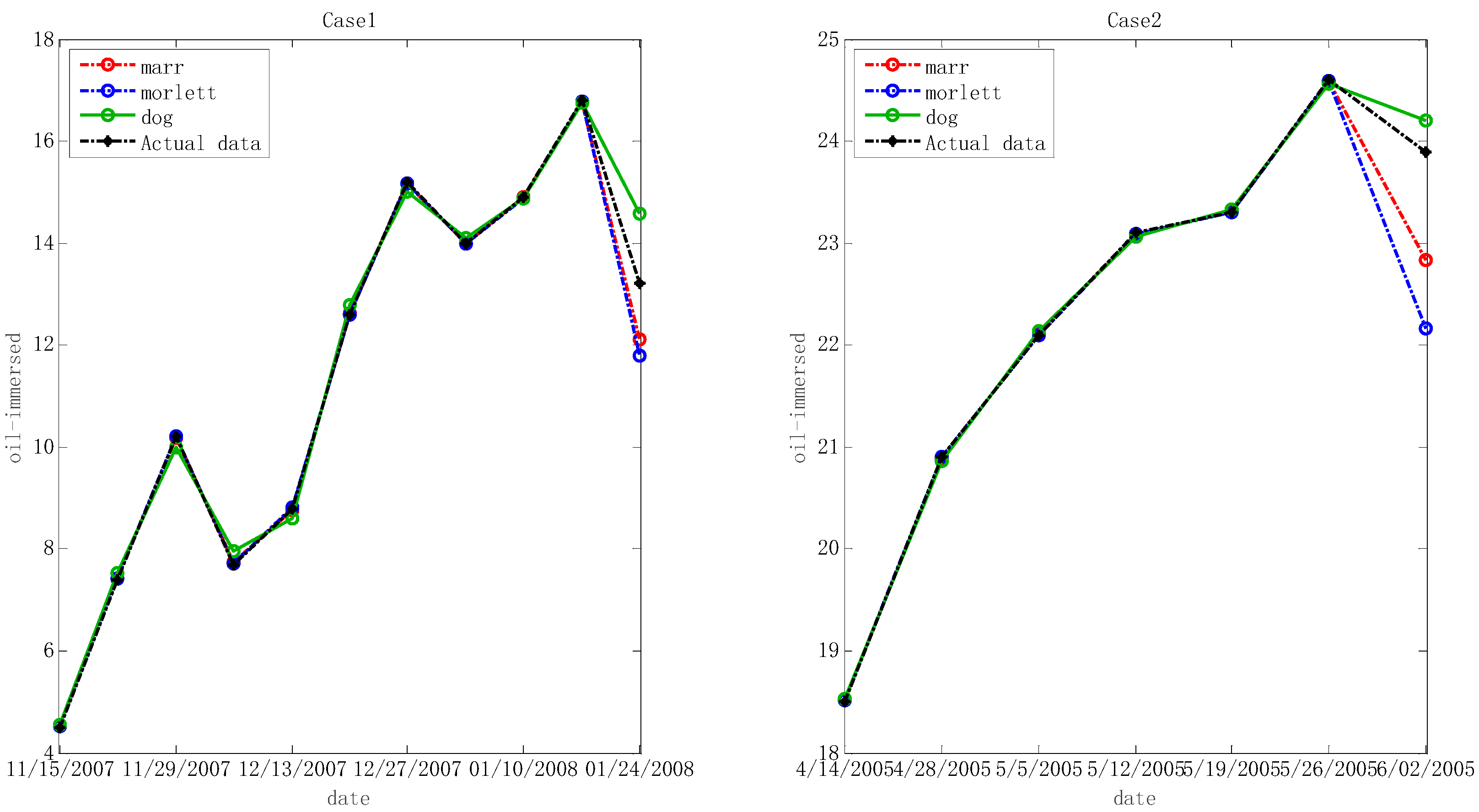
5.1. Experimental Results Based upon Wavelet Least Squares Support Vector Machine Regression and the Imperialist Competition Algorithm
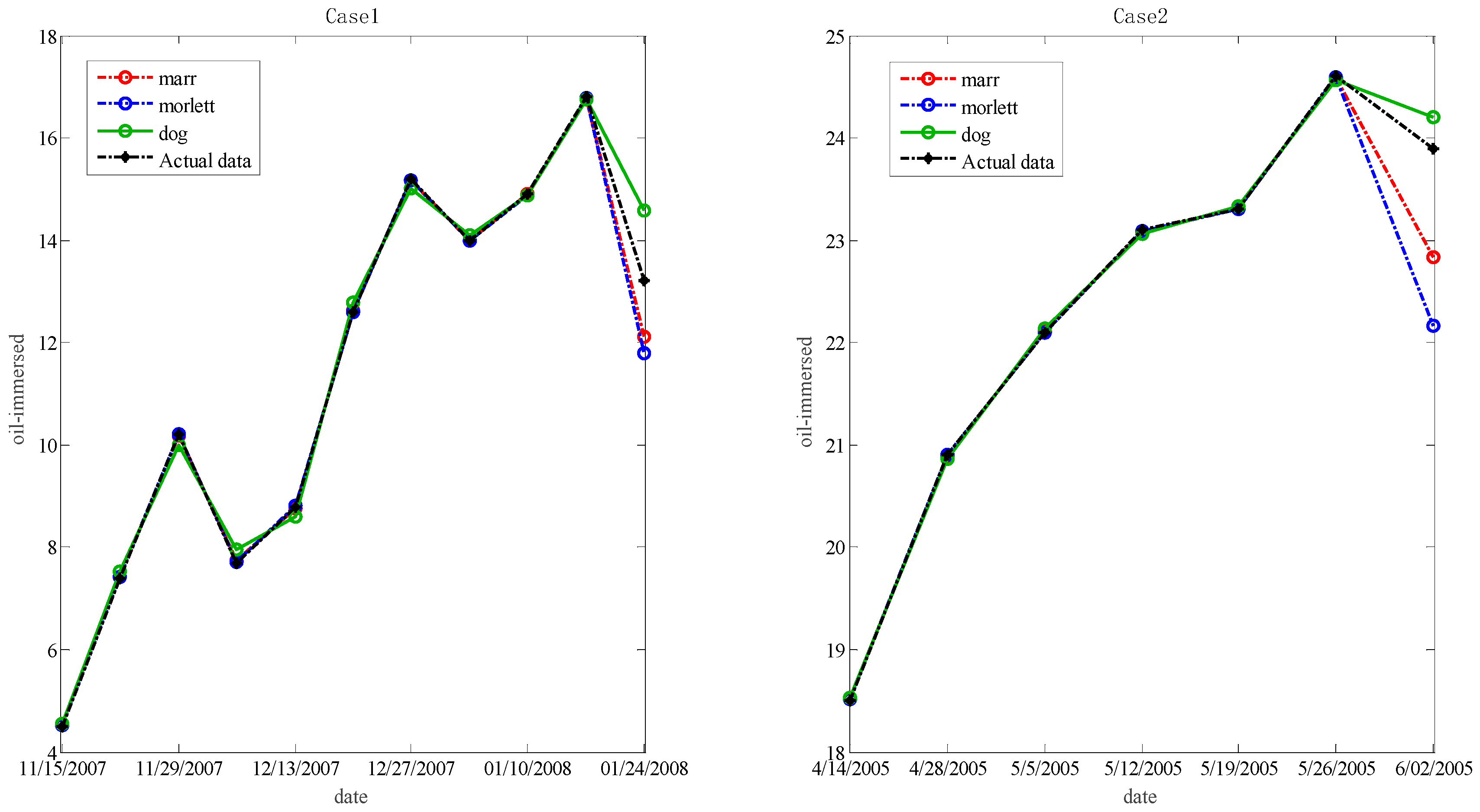
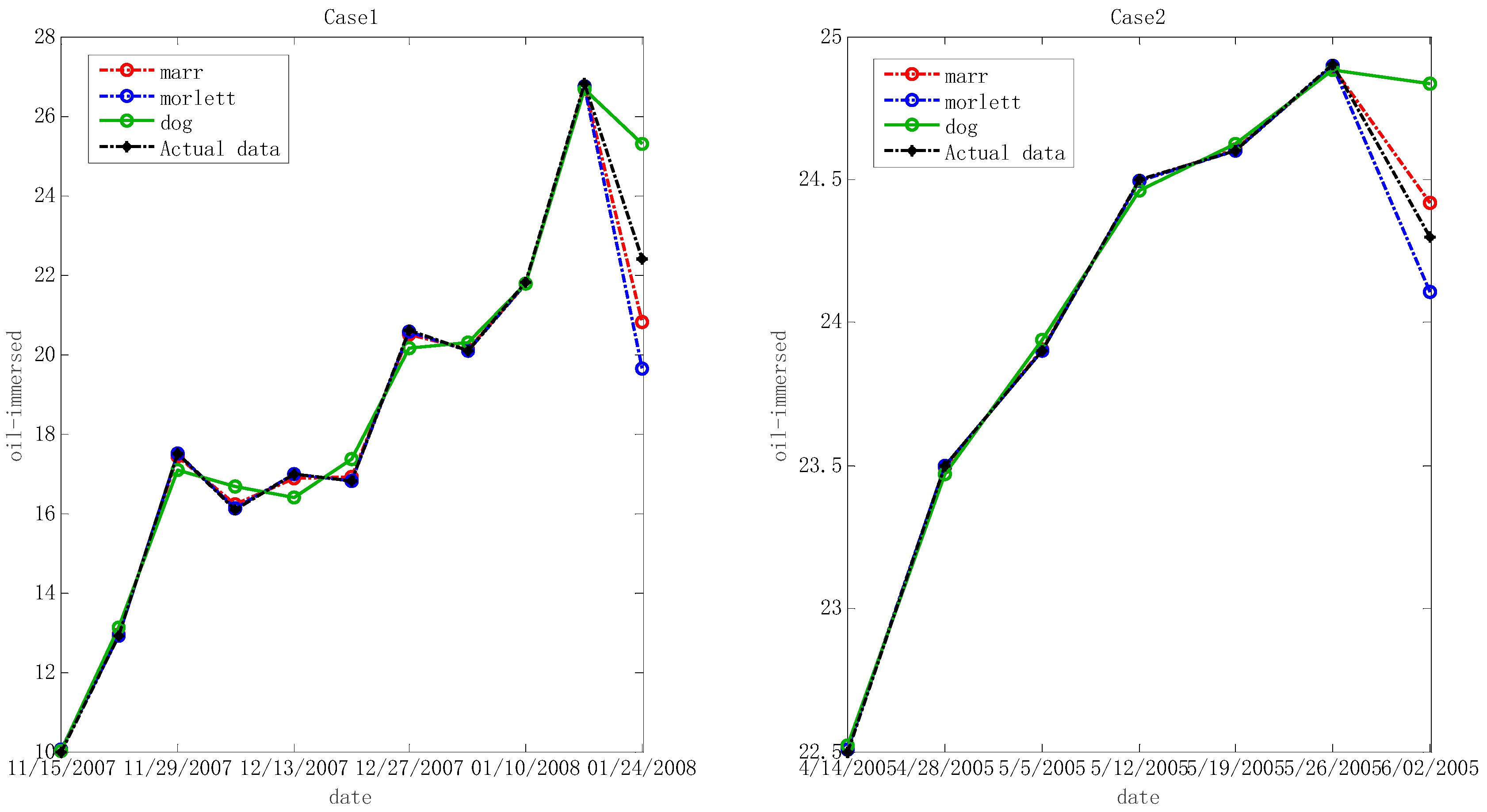
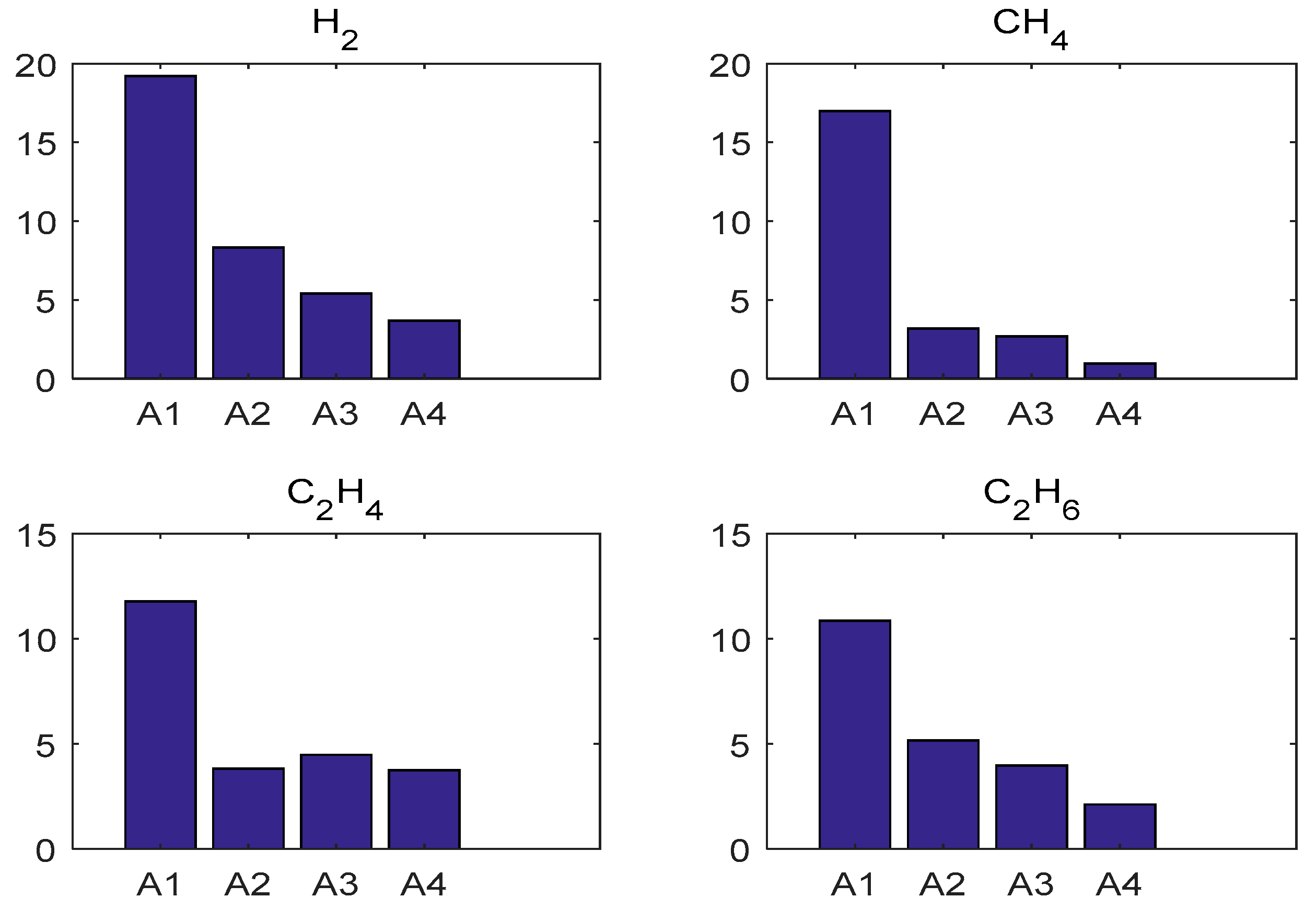
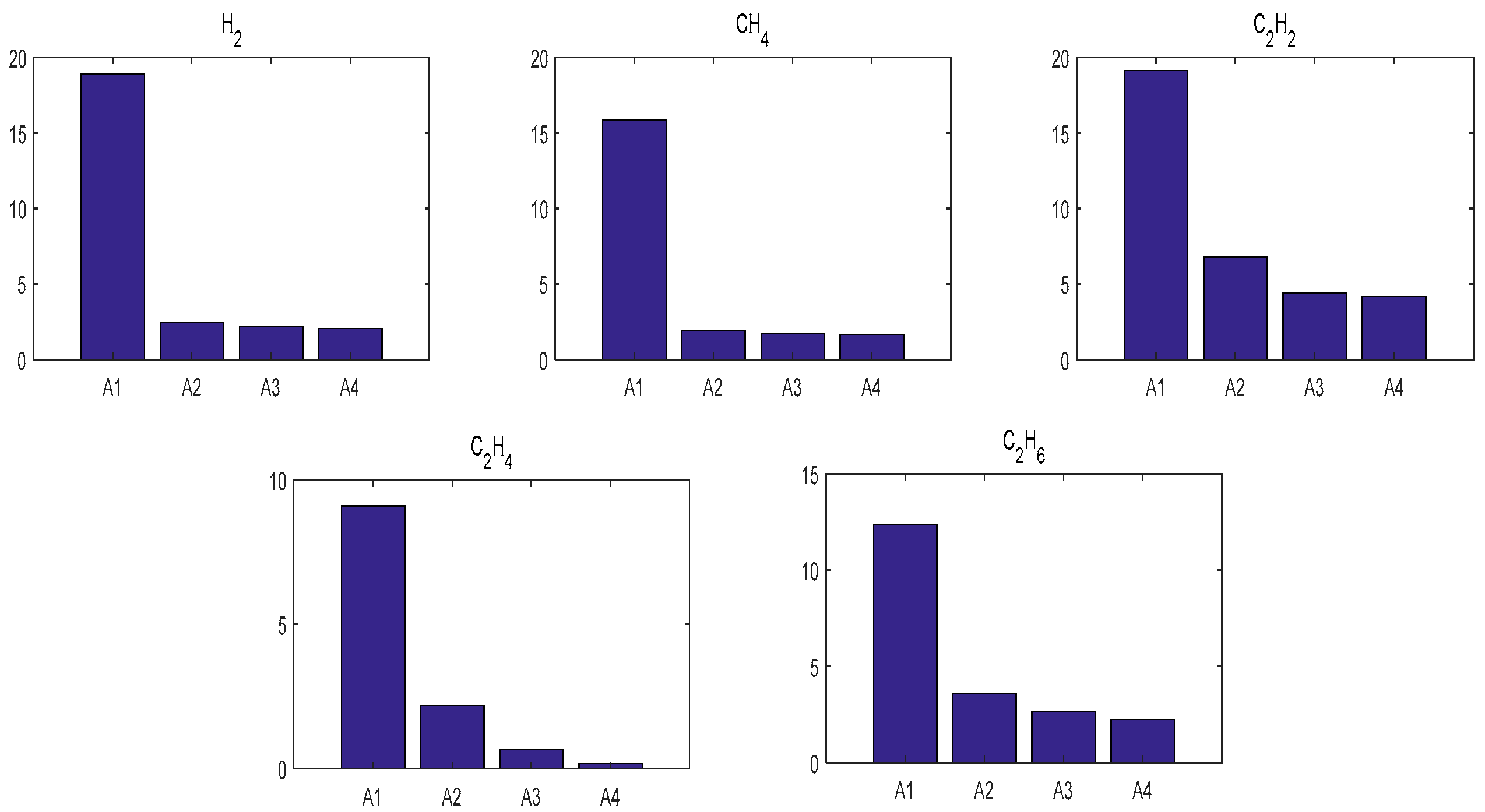
5.2. Comparisons
6. Conclusions
- In theory, arbitrary curves can be approximated in L2 (RN) space by the wavelet function that is known as a set of bases. Therefore, the wavelet technique is combined with LS-SVM to find a new forecasting method in this study. The results of the analysis infer that the admissible wavelet kernels, including Morlet, Marr and DOG wavelet kernels exist.
- Simply, only two parameters need to be chosen in W-LSSVR as compared to the standard SVM regression. Moreover, the optimal hyper-parameters are available by applying the imperialist competition algorithm.
- In many cases, the given forecasting procedure is effective to predict the useful gas contents in oil-dissolved transformers. The ICA based W-LSSVR has outstanding predicting ability for actual limited samples, and this is better than that of SVR, PSO-W-LSSVR and BPNN.
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Li, J.S.; Zhou, H.W.; Meng, J.; Yang, Q.; Chen, B. Carbon emissions and their drivers for a typical urban economy from multiple perspectives: A case analysis for Beijing city. Appl. Energy 2018, 226, 1076–1086. [Google Scholar] [CrossRef]
- Liu, J.; Zheng, H.; Zhang, Y.; Wei, H.; Liao, R. Grey Relational Analysis for Insulation Condition Assessment of Power Transformers Based Upon Conventional Dielectric Response Measurement. Energies 2017, 10, 1526. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, J.; Zheng, H.; Wei, H.; Liao, R. Study on quantitative correlations between the ageing condition of transformer cellulose insulation and the large time constant obtained from the extended Debye model. Energies 2017, 10, 1842. [Google Scholar] [CrossRef]
- Liu, J.; Zheng, H.; Zhang, Y.; Zhou, T.; Zhao, J.; Li, J.; Liu, J.; Li, J. Comparative Investigation on the Performance of Modified System Poles and Traditional System Poles Obtained from PDC Data for Diagnosing the Ageing Condition of Transformer Polymer Insulation Materials. Polymers 2018, 10, 191. [Google Scholar] [CrossRef]
- Zhang, Y.; Wei, H.; Yang, Y.; Zheng, H.; Zhou, T.; Jiao, J. Forecasting of Dissolved Gases in Oil-immersed Transformers Based upon Wavelet LS-SVM Regression and PSO with Mutation ☆. Energy Procedia 2016, 104, 38–43. [Google Scholar] [CrossRef]
- Zheng, H.; Zhang, Y.; Liu, J.; Wei, H.; Zhao, J.; Liao, R. A novel model based on wavelet LS-SVM integrated improved PSO algorithm for forecasting of dissolved gas contents in power transformers. Electr. Power Syst. Res. 2018, 155, 196–205. [Google Scholar] [CrossRef]
- Tang, H.; Goulermas, J.Y.; Wu, H.; Richardson, Z.J.; Fitch, J. A probabilistic classifier for transformer dissolved gas analysis with a particle swarm optimizer. IEEE Trans. Power Del. 2008, 23, 751–759. [Google Scholar]
- Chatterjee, A.; Bhattacharjee, P.; Roy, N.K.; Kumbhakar, P. Usage of nanotechnology based gas sensor for health assessment and maintenance of transformers by DGA method. Int. J. Electr. Power Energy Syst. 2012, 45, 137–141. [Google Scholar] [CrossRef]
- Chatterjee, A.; Roy, N.K. Health monitoring of power transformers by dissolved gas analysis using regression method and study the effect of filtration on oil. World Acad. Sci. Eng. Technol. 2009, 59, 37–42. [Google Scholar]
- IEEE. IEEE Guide for the Interpretation of Gases Generated in Oil-Immersed Transformers; IEEE Std. C57; IEEE: Piscataway, NJ, USA, 2008. [Google Scholar]
- Duval, M.; Depablo, A. Interpretation of gas-in-oil analysis using new IEC publication 60599 and IEC TC 10 databases. IEEE Elect. Insul. Mag. 2001, 17, 31–41. [Google Scholar] [CrossRef]
- Wang, M. Grey-extension method for incipient fault forecasting of oil-immersed power transformer. Electr. Power Compon. Syst. 2004, 32, 959–975. [Google Scholar] [CrossRef]
- Hippert, H.S.; Pedreira, C.E.; Souza, R.C. Neural networks for short-term load forecasting: A review and evaluation. IEEE Trans. Power Syst. 2001, 16, 44–55. [Google Scholar] [CrossRef]
- Chang, F.; Chen, Y. Estuary water-stage forecasting by using radial basis function neural network. J. Hydrol. 2003, 270, 158–166. [Google Scholar] [CrossRef]
- Leung, M.T.; Chen, A.; Daouk, H. Forecasting exchange rates using general regression neural networks. Comput. Oper. Res. 2000, 27, 1093–1110. [Google Scholar] [CrossRef]
- Wang, M.; Hung, C. Novel grey model for the prediction of trend of dissolved gases in oil-filled power apparatus. Electr. Power Syst. Res. 2003, 67, 53–58. [Google Scholar] [CrossRef]
- Fei, S.; Sun, Y. Forecasting dissolved gases content in power transformer oil based on support vector machine with genetic algorithm. Electr. Power Syst. Res. 2008, 78, 507–514. [Google Scholar] [CrossRef]
- Li, Y.; Tong, S.; Li, T. Adaptive fuzzy output feedback control for a single-link flexible robot manipulator driven DC motor via backstepping. Nonlinear Anal. Real. 2013, 14, 483–494. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory. Technometrics 1997, 38, 409. [Google Scholar]
- Ganyun, L.V.; Cheng, H.; Zhai, H.; Dong, L. Fault diagnosis of power transformer based on multi-layer SVM classifier. Electr. Power Syst. Res. 2005, 75, 9–15. [Google Scholar] [CrossRef]
- Jardine, A.K.S.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Si, X.S.; Wangbde, W.; Zhouc, D.H. Remaining useful life estimation—A review on the statistical data driven approaches. Eur. J. Oper. Res. 2011, 213, 1–14. [Google Scholar] [CrossRef]
- Benmoussa, S.; Djeziri, M.A.; Benmoussa, S.; Djeziri, M.A.; Benmoussa, S.; Djeziri, M.A. Remaining useful life estimation without needing for prior knowledge of the degradation features. Iet Sci. Meas. Techno. 2017, 11, 1071–1078. [Google Scholar] [CrossRef]
- Djeziri, M.A.; Benmoussa, S.; Sanchez, R. Hybrid method for remaining useful life prediction in wind turbine systems. Renew. Energy 2017, 116, 173–187. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Gestel, T.V.; Brabanter, J.D.; Moor, B.D.; Vandewalle, J. Least Squares Support Vector Machines. Int. J. Circ. Theor. Appl. 2015, 27, 605–615. [Google Scholar] [CrossRef]
- Van Gestel, T.; Suykens, J.K.; Baestaens, D.E.; Lambrechts, A.; Lanckriet, G.; Vandaele, B.; Moor, D.B.; Vandewalle, J. Financial time series prediction using least squares support vector machines within the evidence framework. IEEE Trans. Neural Networ. 2001, 12, 809–821. [Google Scholar] [CrossRef] [PubMed]
- De Kruif, B.J.; De Vries, T.J.A. Pruning error minimization in least squares support vector machines. IEEE Trans. Neural Netw. 2003, 14, 696–702. [Google Scholar] [CrossRef] [PubMed]
- Gestel, T.V.; Suykens, J.A.K.; Baesens, B.; Viaene, S.; Vanthienen, J.; Dedene, G.; Moor, D.B.; Vandewalle, J. Benchmarking least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y. Traffic forecasting using least squares support vector machines. Transportmetrica 2009, 5, 193–213. [Google Scholar] [CrossRef]
- Yang, Z.; Gu, X.; Liang, X.; Ling, L. Genetic algorithm-least squares support vector regression based predicting and optimizing model on carbon fiber composite integrated conductivity. Mater. Des. 2010, 31, 1042–1049. [Google Scholar] [CrossRef]
- Zhang, Q.; Benveniste, A. Wavelet networks. IEEE Trans. Neural Netw. 1992, 3, 889–898. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Jiao, L. Wavelet support vector machine. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2004, 34, 34–39. [Google Scholar] [CrossRef]
- Wu, Q. The forecasting model based on wavelet v-support vector machine. Expert Syst. Appl. 2009, 36, 7604–7610. [Google Scholar] [CrossRef]
- Kaveh, A.; Talatahari, S. Optimum design of skeletal structures using imperialist competitive algorithm. Comput. Struct. 2010, 88, 1220–1229. [Google Scholar] [CrossRef]
- Chang, C.; Lin, C. LIBSVM—A Library for Support Vector Machines. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 1 January 2011).
- Smola, A.J.; Schölkopf, B.; Müller, K.R. The connection between regularization operators and support vector kernels. Neural Netw. 1998, 11, 637–649. [Google Scholar] [CrossRef]
- Hadji, M.M.; Vahidi, B.A. Solution to the Unit Commitment Problem Using Imperialistic Competition Algorithm. IEEE Trans. Power Syst. 2012, 27, 117–124. [Google Scholar] [CrossRef]
- Liang, J.; Qin, A.; Suganthan, P.N.; Baskar, S. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions. IEEE Trans. Evol. Comput. 2006, 10, 281–295. [Google Scholar] [CrossRef]
- Talatahari, S.; Azar, B.F.; Sheikholeslami, R. Imperialist competitive algorithm combined with chaos for global optimization. Commun. Nonlinear Sci. 2012, 17, 1312–1319. [Google Scholar] [CrossRef]
- Atashpaz-Gargari, E.; Lucas, C. Imperialist competitive algorithm: An algorithm for optimization inspired by imperialistic competition. In Proceedings of the IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 4661–4667. [Google Scholar]
- Duan, Q.; Li, S.; Bao, F.; Twizell, E.H. Hermite interpolation by piecewise rational surface. Appl. Math. Comput. 2008, 198, 59–72. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case No. | Gas | Kernel | Hyper-Parameters | Testing | Ranking (1/2/3) | |
|---|---|---|---|---|---|---|
| C | a | MAPE (%) | ||||
| 1 | H2 | Morlet | 968.8347 | 10 | 4.0601 | ◇◇◆ |
| Marr | 563.8497 | 6.7185 | 3.6785 | ●○○ | ||
| DOG | 394.7711 | 6.4114 | 3.9803 | □■□ | ||
| CH4 | Morlet | 822.7634 | 7.5923 | 1.1321 | ◇◆◇ | |
| Marr | 837.9421 | 1.4713 | 0.9675 | ●○○ | ||
| DOG | 995.8278 | 2.0343 | 1.3872 | □□■ | ||
| C2H4 | Morlet | 210.927 | 1.8828 | 3.9879 | ◇◆◇ | |
| Marr | 251.5736 | 2.8453 | 3.7385 | ●○○ | ||
| DOG | 766.4636 | 7.8339 | 4.4210 | □□■ | ||
| C2H6 | Morlet | 985.8278 | 6.5617 | 2.6413 | ◇◇◆ | |
| Marr | 961.6398 | 3.7656 | 2.1140 | ●○○ | ||
| DOG | 995.8998 | 1.9911 | 2.3002 | □■□ | ||
| 2 | H2 | Morlet | 768.7547 | 8.9979 | 2.5740 | ◇◇◆ |
| Marr | 833.8758 | 5.8930 | 2.0665 | ○●○ | ||
| DOG | 394.7773 | 5.8830 | 1.8542 | ■□□ | ||
| CH4 | Morlet | 452.7316 | 7.8890 | 1.8003 | ◇◆◇ | |
| Marr | 797.8851 | 2.0754 | 1.6653 | ●○○ | ||
| DOG | 989.4299 | 1.8997 | 1.9899 | □□■ | ||
| C2H2 | Morlet | 517.8760 | 4.8877 | 4.3780 | ◇◆◇ | |
| Marr | 457.0041 | 8.5542 | 4.1681 | ●○○ | ||
| DOG | 486.1128 | 9.0411 | 5.2119 | □□■ | ||
| C2H4 | Morlet | 687.9904 | 2.0062 | 0.1949 | ◇◆◇ | |
| Marr | 774.8831 | 2.7831 | 0.1684 | ●○○ | ||
| DOG | 882.1139 | 7.5572 | 0.2120 | □□■ | ||
| C2H6 | Morlet | 456.1436 | 7.0032 | 2.4780 | ◇◇◆ | |
| Marr | 946.4432 | 3.6645 | 2.2409 | ○●○ | ||
| DOG | 890.3323 | 2.3210 | 1.9930 | ■□□ | ||
| Case No. | Gas | Training | Testing | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAPE (%) | r2 | MAPE (%) | |||||||||||
| BPNN | SVR | PSO-W-LSSVR | ICA-W-LSSVR | BPNN | SVR | PSO-W-LSSVR | ICA-W-LSSVR | BPNN | SVR | PSO-W-LSSVR | ICA-W-LSSVR | ||
| 1 | H2 | 14.9834 | 7.2456 | 0.1962 | 0.2446 | 0.7187 | 0.9168 | 0.9999 | 0.9999 | 19.2011 | 8.3248 | 5.4238 | 3.6785 |
| CH4 | 13.5612 | 2.6297 | 0.5499 | 0.5579 | 0.7479 | 0.968 | 0.9997 | 0.9995 | 16.98 | 3.198 | 2.6832 | 0.9675 | |
| C2H2 | / | / | / | / | / | / | / | / | / | / | / | / | |
| C2H4 | 9.9912 | 2.3216 | 0.3537 | 0.4932 | 0.8109 | 0.9999 | 0.9998 | 0.9995 | 11.7801 | 3.8227 | 4.4761 | 3.7385 | |
| C2H6 | 10.5412 | 3.2884 | 0.1899 | 12.113 | 0.8322 | 0.9485 | 0.9999 | 0.8925 | 10.8611 | 5.1541 | 3.9606 | 2.114 | |
| 2 | H2 | 16.1476 | 1.1292 | 0.4872 | 1.2039 | 0.7632 | 0.976 | 0.9999 | 0.9787 | 18.9187 | 2.4628 | 2.1567 | 2.0665 |
| CH4 | 14.0121 | 0.8325 | 0.3071 | 0.3112 | 0.81 | 0.9815 | 0.9999 | 0.9859 | 15.8601 | 1.9107 | 1.7543 | 1.6653 | |
| C2H2 | 18.1890 | 3.4673 | 0.5194 | 0.8878 | 0.7511 | 0.971 | 0.9998 | 0.9178 | 19.1222 | 6.7795 | 4.385 | 4.1681 | |
| C2H4 | 8.9832 | 0.5231 | 0.0871 | 0.97 | 0.8532 | 0.9785 | 0.9999 | 0.9303 | 9.1011 | 2.1942 | 0.6741 | 0.1684 | |
| C2H6 | 11.9867 | 1.3453 | 0.5184 | 0.4366 | 0.7765 | 0.9626 | 0.9998 | 0.9622 | 12.3901 | 3.609 | 2.6521 | 2.2409 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Zheng, H.; Zhang, Y.; Li, X.; Fang, J.; Liu, Y.; Liao, C.; Li, Y.; Zhao, J. Dissolved Gases Forecasting Based on Wavelet Least Squares Support Vector Regression and Imperialist Competition Algorithm for Assessing Incipient Faults of Transformer Polymer Insulation. Polymers 2019, 11, 85. https://doi.org/10.3390/polym11010085
Liu J, Zheng H, Zhang Y, Li X, Fang J, Liu Y, Liao C, Li Y, Zhao J. Dissolved Gases Forecasting Based on Wavelet Least Squares Support Vector Regression and Imperialist Competition Algorithm for Assessing Incipient Faults of Transformer Polymer Insulation. Polymers. 2019; 11(1):85. https://doi.org/10.3390/polym11010085
Chicago/Turabian StyleLiu, Jiefeng, Hanbo Zheng, Yiyi Zhang, Xin Li, Jiake Fang, Yang Liu, Changyi Liao, Yuquan Li, and Junhui Zhao. 2019. "Dissolved Gases Forecasting Based on Wavelet Least Squares Support Vector Regression and Imperialist Competition Algorithm for Assessing Incipient Faults of Transformer Polymer Insulation" Polymers 11, no. 1: 85. https://doi.org/10.3390/polym11010085
APA StyleLiu, J., Zheng, H., Zhang, Y., Li, X., Fang, J., Liu, Y., Liao, C., Li, Y., & Zhao, J. (2019). Dissolved Gases Forecasting Based on Wavelet Least Squares Support Vector Regression and Imperialist Competition Algorithm for Assessing Incipient Faults of Transformer Polymer Insulation. Polymers, 11(1), 85. https://doi.org/10.3390/polym11010085