In the following, we will use uppercase letters to define random variables and sets. Vectors are printed in bold-face. We will write X∼F if a random variable X is distributed according to a probability distribution F. Distributions on finite ordered sets are described using probability vectors , which represent the probability mass function of the underlying random variable. It is assumed that the random variable follows a discrete distribution, hence it has a density w.r.t. the counting measure. We will use the notation to express that an element d was sampled from the set with distribution ; i.e., if d is the i-th element in the ordered set .
2.2. Costs for Playing Mixed Strategies
The
damage that is minimized as the first objective is modeled by a utility function
:
,
that descries the expected damage depending on both players actions. For simplicity we assume
is a constant matrix.
The second goal is
switching cost minimization: by our definition, a switch from strategy
to strategy
will cause cost
for player 1. Note that the cost of switching strategies only depends on player 1’s actions, i.e., on his past and present strategy which we denote by
and
respectively, and
denotes the
t-th gameplay. Thus, we can employ a first order Markov chain to describe the switching behavior. As the player’s switching costs, and therefore his next move, only depend on the present state the switching process is a first order Markov process. As any stochastic process is fully determined by its finite dimensional distribution, we can describe the switching behavior by specifying the joint probability distribution (jpd) of
and
,
. As we assume the switching costs are constant over time, the optimal jpd that determines the mode of changing strategies will be constant over time as well. Thus, the resulting, optimal switching policy joint probability distribution of
can be modeled as a time-homogeneous process, i.e., it holds
. Homogeneity implies that expected switching cost can be described by
We now model the simultaneous optimization of damage and cost as a multi-objective game (MOG). In a MOG, each player
i can have
utility functions
,
defined over
, where
denotes the strategy space of the remaining players. In our two-player zero-sum game we have 2 objectives and both players have vector-valued payoffs
, which yields the two-player zero sum MOG
. For this situation the following definition is convenient.
Definition 1 (Pareto-Nash Equilibrium).
In game with a minimizing player 1, a Pareto-Nash equilibrium is a strategy profile that fulfillswhere means that there exists at least one coordinate i for which holds, regardless of the other coordinates. Lozovanu, Solomon and Zelikovsky [
13] have studied the computation of Pareto-Nash equilibria by scalarizing the utility vector. To this end, each player
i defines weights
,
to scalarize his utilities via
. In [
13] it was proven that the Nash equilibria of so scalarized games are exactly the Pareto-Nash equilibria in the original multi-objective game.
Letting the defender prioritize a set of two goals by assigning weights
and
, the scalarized payoff for the defender is
For readability we will drop the coefficients and as we can just include them in the constant matrices and .
2.3. The Switching Cost Model (SCM)
The model introduced in [
1] assumes that the switching of strategies is performed independently of the current strategy, i.e.,
. Thus, any future change in strategy is not predictable with more accuracy when the current system state is known. Hence the utility function
can be written as
This way, the whole behavior of the system can be described using only the marginal probability vectors
:
with constant payoff matrices
as well as
. We stress the fact that
need not be a symmetric matrix. As a simple example consider a security guard driving to different assets
i and
j where
j is on top of a mountains and
i in the valley. The ascend from
i to
j will certainly take up more resources (e.g., fuel) than the decent from
j to
i. Thus,
holds indeed. Yet, we assume that
(remaining in the current strategy does not incur any switching costs).
In absence of an accurate adversary model [
14], we may strive for a worst-case analysis and assume that the attacker will always try to cause as much damage as possible, i.e., they aim to maximize over
:
Note that for player 2 the expression
is constant. Thus
, where
denotes the
i-th coordinate unit vector. By substituting
, the resulting problem can be described through the following optimization problem.
2.4. Extension of SCM–Taking into Account Information Delay
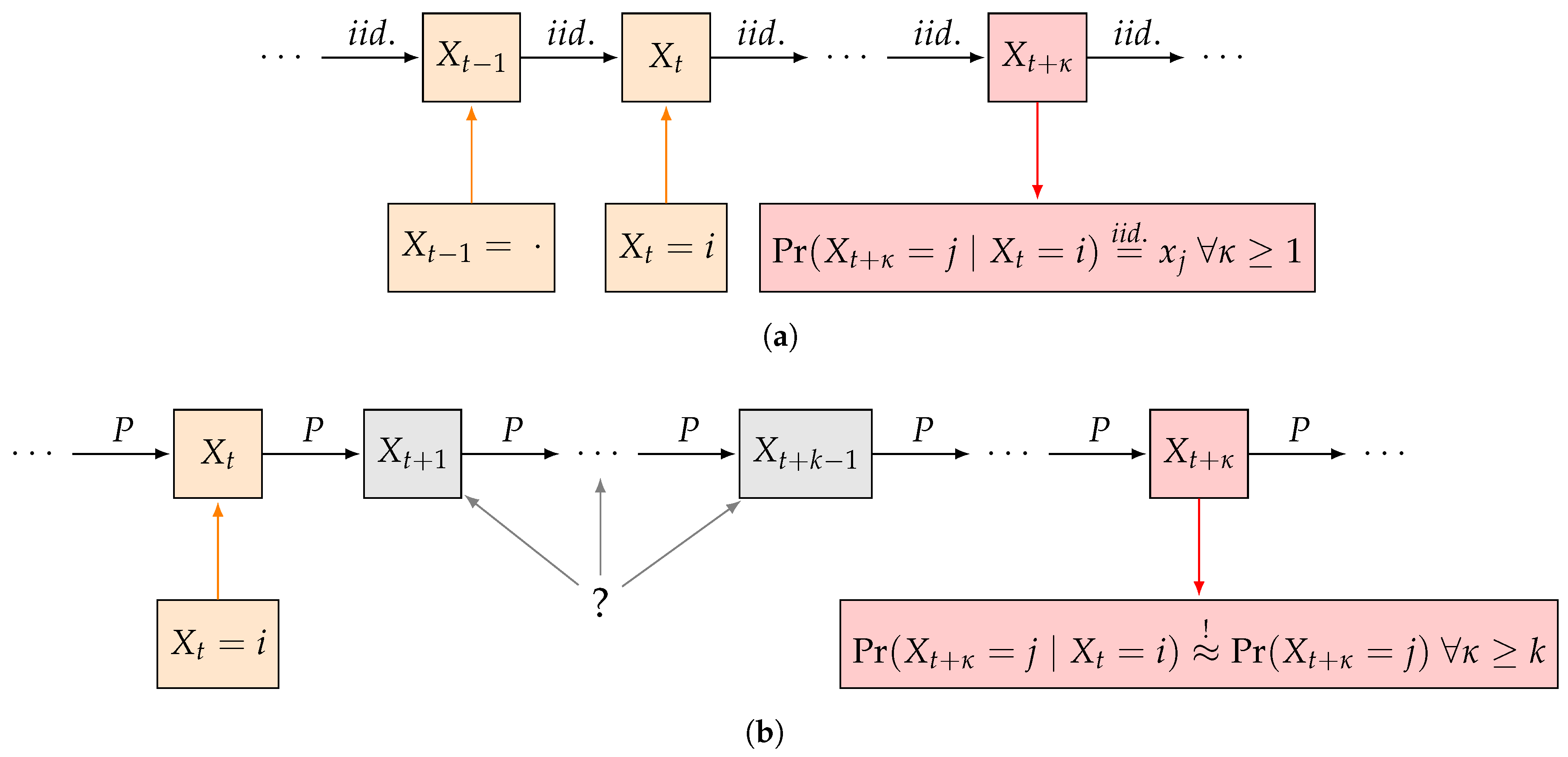
In this paper we extend the switching cost model by relaxing the independence assumption, i.e., we let the choice of the next pure strategy depend on the current state . Thus, we want to model the switching behavior as a Markov process. In order to reduce the switching costs, we may add some inertia to player 1 by increasing the conditional probability to remain in the current strategy for each state. Will control the amount of inertia in a way that we can guarantee the distribution of the system after a predetermined amount of gameplays k conditional on the last observed state to be almost the same as the unconditional distribution.
Hence, we demand the resulting marginal distribution after a fixed number
k of consecutive repetitions of the game to be “almost independent” of the initial state, i.e., the conditional and unconditional probabilities after
k or more steps need to be almost the same, that is we require
where
is the sum of absolute deviations of the two probability vectors. We call
k the
information delay that specifies the length of the period an attacker is not able to gain insight into a system prior to attacking (see
Figure 1). Furthermore we call
the
maximum deviation of independence. In a seemingly alternative view, one could propose wrapping up a lot of
rounds of the game that are interdependent in a single “larger” round, yet such an approach could be flawed for two reasons: first, this would impose an independence assumption between any two batch of round in the game. Second, the timing of the game rounds may be naturally induced by the “periodicity” of the business as such (e.g., work hours per day, shifts, or similar).
In this dynamic framework we need to redefine the objective function
. Obviously, there is a conflict in notation and conceptualization here when optimizing over
plus
, as
is a function with arguments
and
, i.e., the arguments are the marginal distributions each players assign to his set of pure strategies, but
(in contrast to the formulation in (
3)) is a function of the joint probability distribution of player 1’s strategies. Yet, there is a direct connection between
and
: as we are dealing with mixed strategies, the defender will often switch pure strategies and by law of large numbers the distribution over pure strategies
will converge to
after an infinitude of gameplays. Accordingly, the dynamic (i.e., switching) behavior of player 1, which is described using a homogeneous discrete Markov chain (HDMC) needs to have
as a stationary as well as the unique limiting distribution in order for the two objective goals to be consistent.
Bearing in mind that the limiting behavior of any HDMC can be described using a one-step transition matrix
of dimension
and an initial distribution
that describes the starting state of the process, we will make use of the following theorems for our results:
Theorem 1. (Limit [15]) Every aperiodic irreducible HDMC with finite state space has a unique limiting state π. So if we are dealing with aperiodic irreducible homogeneous discrete Markov chains with finite state space
we can ensure the existence of a unique limiting state
, which is always a stationary state. Additionally, it can be shown that the limiting distribution
of a such a stochastic process is independent of the initial distribution
. Moreover, by the following ergodic theorem, it is possible to specify the speed of convergence to the limit state for an aperiodic irreducible HDMC with finite state space
and transition matrix
. Let
denote the transition probability from state
to
after
k steps. Note that the following theorem is a consequence of the Perron-Frobenius Theorem.
1Theorem 2. (Geometric Ergodicity [16]) Let the transition matrix of an irreducible, aperiodic Markov chain with finite state space . Then for all probability vectors if holds , for all and π is the only solution to Moreover, the speed of convergence to the limiting state π is geometric, i.e., there exists a constant (that depends on only) such that is the row vector with all ones, denotes the second largest eigenvalue of in terms of absolute values.
The following proof is from [
17]. We will limit ourself tho the case when
is diagonalizable, which is the case for our construction of
.
Proof. An irreducible aperiodic Markov chain has a positive transition matrix . Let , , denote the right eigenvectors of and , , the left eigenvectors of .
By Perron-Frobenius Theorem the largest eigenvalue
is unique and possesses a strictly positive left eigenvector. For stochastic matrices like
it additionally holds that the largest eigenvalue is
, the right eigenvector to
is
and its left eigenvector is the one that fulfills (
5). Thus,
.
Now we can write
in its spectral representation
where
. As
if
and
if
, we have
As
we have
Now for all initial states
i and resulting states
j the absolute difference of the components of
and the corresponding entries in
(i.e.,
) is bounded by
where
denotes the respective entry of
,
.
Finally
yields
Finally, taking
we get the Expression (
6). ☐
Geometric ergodicity means that the absolute difference of the steady state to the marginal distribution after
k steps given any initial distribution is bounded by
. Subsequently,
determines the speed of convergence to the steady state distribution given an arbitrary initial distribution
: The smaller
, the faster the convergence to the steady state. Considering Equation (
4) it is obvious, that if we want the distributions of
and
for an arbitrary instantiation of
to differ by
at maximum
, we need to control the second largest eigenvalue of
, i.e.,
.
Now we want construct an irreducible aperiodic HDMC described by a transition probability matrix of a for which it holds
In (
8) have seen that
-convergence can be achieved by controlling the second largest eigenvalue of the conditional probability matrix. The following result will help construct the sought transition matrix for the intended convergence control:
Theorem 3. (Sklar [18]) Every cumulative distribution function of a random vector can be expressed by its marginal distributions and a copula such that . Note that we are dealing with first order HDMCs and that the whole behaviour of the chain is determined by one single two-dimensional joint distribution function for all
, i.e.,
. For brevity, we will abbreviate
by
. As we require both the marginal probabilities of
and
to equal the Nash-Equilibrium-solution from (
3), the joint distribution of the random vector
can be constructed using the marginal distribution of
only, i.e.,
.
Using Sklar’s Theorem and the fact that we are only considering absolutely continuous discrete random variables with -finite measures , the first order Markov Process has not only a joint cdf, but also a discrete density . Thus, there exists an , for which it holds that for all : , for all j and for all i. Therefore, the discrete density, which is represented by , has marginals prescribed by and we hereafter write to denote this dependency. As such , is not necessarily a function of , but rather chosen in a way constrained by regarding the marginals.
Under the above-mentioned prerequisites, we are able to redefine
so that it only depends on
:
for the just defined joint probability matrix
,
.
Note that it is necessary to specify parametric functions
to model the jpd, as
parameters are not estimable given the number of constraints. It is not possible to directly optimize the individual
over
. Therefore, we need to constrain
f to a parametric family of functions, i.e.,
, where the optimization is performed by adjusting the parameter vector
. Then, given
which represents, the respective one step transition matrix
can directly be computed via
where
is a diagonal matrix. Unfortunately, even when using parametric families of functions for
f in most cases controlling the value of
from
will be difficult. For reversible Markov chains one could compute upper bounds via Cheeger’s and Poincare’s inequality [
19], yet we will work with a direct construction scheme for
for which it is possible to obtain
exact control of
.



{kind=link}
