1. Introduction
Cooperation is central to successful human interaction, and research demonstrates that a key mechanism for promoting cooperation is repetition: when people interact repeatedly, the “shadow of the future” can make cooperation pay off in the long run [
1]. In recent years, there has been considerable interest in examining experimental play in indefinitely repeated Prisoner’s Dilemmas (RPDs) in the laboratory [
2,
3,
4,
5,
6,
7]. This experimental work has indicated that, holding the stage game payoffs constant, cooperation tends to increase with the continuation probability—and, more generally, that cooperation increases with the extent to which the cooperative strategy “Grim”, which starts out cooperating but defects forever once one defect is observed, risk-dominates the non-cooperative strategy “Always Defect” [
3,
8].
Beyond asking how the game parameters affect cooperation within a setting, research has begun to ask how cooperation in one setting affects play in subsequent strategically-distinct settings—that is, how play under one set of incentives “spills over” to influence play under other sets of incentives. For example, Peysakhovich and Rand [
9] found that participants who played a series of RPDs where “Grim” strongly risk-dominated “Always Defect” gave more in a subsequent Dictator Game (DG) compared to participants who played a series of RPDs where “Grim” was not an equilibrium. They explain this observation using the “social heuristics hypothesis” [
10,
11], which argues that people internalize rules of thumb for social interactions that prescribe behaviors that are typically payoff-maximizing. By this logic, RPD environments that incentivize cooperation lead participants to develop “habits of prosociality”, which then spill over to promote giving in the subsequent DG (and the opposite for RPD environments which incentivize defection). Further evidence of such spillovers comes from Stagnaro et al. [
12], who find greater DG giving following a repeated Public Goods Game with centralized punishment relative to a Public Goods Game with no punishment. In both of these examples, behavior developed in a more socially- and strategically-complex game spills over to a subsequent simple one-shot anonymous allocation decision.
There is less evidence, however, regarding how play spills over between two equivalently complex interaction settings that differ in their strategic nature—for example, between RPDs with high versus low continuation probabilities. In this article, we directly investigate this issue by comparing cooperation in RPDs that transition from a long continuation probability where the cooperative strategy “Grim” is risk-dominant over “Always Defect” (i.e., an environment where we expect participants to learn to cooperate) to a short one where “Grim” is not an equilibrium (i.e., an environment where we expect participants to learn to defect), and vice versa.
We also examine the correlation between RPD cooperation and giving in DGs played before and after the RPD, seeking to replicate and extend the findings of Dreber et al. [
13], who argue that social preferences only help to explain RPD play in the absence of cooperative equilibria. Finally, we ask whether play in the subsequent DG varies based on RPD condition and whether play in a game is related to the time participants take to reach a decision.
We do find some evidence of spillovers when participants switch from the long RPD games to the short RPD games, with relatively high cooperation in the initial rounds of the short games. However, cooperation quickly declines as participants adjust to the short games (and lack of cooperative equilibria). Interestingly, we observe the same cooperative transient at the beginning of the condition in which the short games are played first, suggesting that the transition from daily life to short RPDs is similar to the transition from long RPDs to short RPDs. Conversely, when switching from short games to long games, participants immediately begin to cooperate at a high level. We therefore observe some evidence of a bias in favor of cooperation. We also note that cooperation in the short RPDs declines to a lower level in the condition where short RPDs are preceded by long RPDs, compared to the condition where short RPDs are played first—perhaps because having just played long RPDs makes it more explicit/salient to participants that cooperation cannot be supported in short RPDs.
With respect to DG giving, we replicate Dreber et al. [
13]’s finding that DG giving correlates positively with RPD cooperation in short games (where “Grim” is not an equilibrium) but not in long games (where “Grim” risk-dominates “Always Defect”); and we find that this is true for both the DG played before the RPD and the DG played after the RPD. We also find that giving in the post-RPD DG is lower than in the pre-RPD DG, regardless of the order of the long versus short RPDs.
We also explore the relationship between response time and decisions made in RPDs and DGs. We find that, on average, deciding to cooperate takes less time than to defect, and that participants take more time on average to reach a decision in the short RPDs. We also find that participants typically slow down when switching between conditions, except for those who gave in the DG and shifted towards an environment with long RPDs games, suggesting a bias in favor of cooperation among those participants.
The remainder of the paper is structured as follows. In
Section 2, we review the related experimental literature. In
Section 3, we introduce the experimental methods. In
Section 4, we analyze our experimental results and their relationship with previous findings in the literature. Finally, in
Section 5, we make concluding remarks.
2. Related Experimental Literature
Several researchers have investigated the role of time horizon on RPD play since the influential work by Rapoport and Chammah [
14]. Notably, Roth and Murninghan [
15] brought the concept of a stochastic continuation rule for repeated games to the lab and found more cooperative responses as the probability increased. Dal Bó and Frechette [
3] investigated the evolution of cooperation and found that experience leads to repeated defection in environments where cooperation is not an equilibrium, but that in environments where cooperation
is an equilibrium experience does not always lead to cooperation.
Dal Bó [
2] compared finite and indefinite games with similar expected length and found higher cooperation rates in the latter. However, Normann and Wallace [
16], and Lugovskyy et al. [
17] with a different game and setup also compared finite and indefinite continuation rules and found no difference in terms of cooperation; on the other hand, Bigoni et al. [
18], using a collection of continuous-time RPDs, reported higher cooperation rates with deterministic horizons. Overall, however, meta-analyses of Rand and Nowak [
8] and Dal Bó and Fréchette [
5] show that cooperation in infinitely repeated games increases with the continuation probability.
However, evidence of spillovers between two RPDs that vary their strategic nature is scarce. Duffy and Ochs [
19] investigate the effect of switching from partner matching to stranger matching or vice versa (which is essentially the same as repeated to one-shot or vice versa). They show that, in fixed pairings (partner matching), a cooperative norm emerges as players gain more experience, and that such norm quickly disappears (albeit with a brief transient of cooperation) when switching to one-shot games without cooperative equilibria. Moreover, not only does a cooperative norm not emerge in treatments where participants are first matched randomly (stranger matching), but players engage in cooperative norms immediately after they switch to a partner matching environment.
Fréchette and Yuksel [
20] modify the stage game payoffs of their RPD experiment such that cooperation is risk-dominant in the first part but not in the second. They also find brief cooperative transients when switching from games with cooperative equilibria to games without, but they do not vary the order in which these games are played.
Finally, evidence on cooperative transients or spillovers is also suggestive in other games. In an experiment on collusion in Bertrand oligopolies where participants are exposed to communication and no-communication conditions (or vice versa), Fonseca and Normann [
21] find a
hysteresis effect in which participants are much better at colluding without communication if this condition is preceded by the communication phase. Hence, collusion (i.e., cooperation) spills over from environments where communication is conducive to cooperation. Bednar et al. [
22] also investigate behavioral spillovers by having participants play two distinct games simultaneously with different opponents. They find that, when participants play Prisoner’s Dilemmas in conjunction with Hawk–Dove games, participants cooperate less than when they play the Prisoner’s Dilemma alone.
3. Methods
Our workhorse for this study is the indefinitely repeated Prisoner’s Dilemma with stage game payoffs determined as follows: one Monetary Unit (MU) for mutual defection, four MUs for mutual cooperation, five MUs for defecting while the other cooperates, and zero MUs for cooperating while the other defects. We used a neutral labeling for the strategies in the experiment (“A” for cooperation and “B” for defection”) and participants were provided with the payoff information in every round. As can be seen
Table 1, this is a standard two-player Prisoner’s Dilemma game with a static Nash equilibrium in mutual defection {“B”, “B”}.
To incorporate an indefinitely repeated nature into the experiment, we let participants continue playing for another round with the same partner with either a continuation probability of δ = 7/8 (average game length of eight rounds; “Grim” strongly risk-dominates “Always Defect” such that we expect participants to learn to cooperate) or δ = 1/8 (average game length of 1.14 rounds; “Grim” is not an equilibrium, such that we expect participants to learn to defect) [
9].
3.1. Treatments
Our experimental manipulation was the order in which the games were played: either a series of δ = 7/8 games followed by a series of δ = 1/8 games (δ = 7/8 → δ = 1/8), or vice versa (δ = 1/8 → δ = 7/8). To avoid cross-treatment noise introduced by stochastic variations in game lengths and time allotted per session, we followed the procedure of prior work [
4,
6,
7] and predetermined the number of rounds (50) and interactions (6 for δ = 7/8 and 21 for δ = 7/8) in each treatment according to their geometric distribution
1.
In every interaction, participants were randomly assigned to play with another partner in the room. To avoid cross-session noise caused by different probabilities of meeting with another person, we restricted the number of participants to 12 per session.
3.2. Experimental Procedures
All the experimental sessions took place at the Kellogg School of Management between February and April 2016. The games were programmed in z-Tree [
23], and a total of 168 people participated in 14 sessions (of 12 participants each)
2. The average age was 20.7 years (±0.12 standard error of the mean (SEM)) and 60 percent were female.
At the start of each session, participants were randomly allocated to a cubicle in the laboratory and asked to play a one-shot Dictator game (DG1) with another participant in their session. Roles in the DG were assigned randomly and neither participant was informed of which role they had. Both players were asked how many MUs, out of 100, they would give to the recipient if they were assigned to be the Dictator. This allowed us to maximize the number of observations collected for the role of Dictator (instructions were presented on screen and a copy can be found in the
Appendix A).
Upon completion of the first task, participants received a printed copy of the instructions for the RPD (also included in the
Appendix A). The instructions were read out by the same experimenter through all the sessions and participants’ understanding was tested by having them individually answer a series of comprehension questions. To allow participants to familiarize themselves further with the game, the experiment proceeded with a one-shot trial interaction of the RPD with no consequences in terms of payoffs. Once this practice round was completed, the experimental treatments actually started with a collection of either 21
short interactions or six
long interactions, totaling 25 rounds
3.
A new set of instructions was administered right after the first part of the treatment had ended containing the details of the new games with a different continuation probability (either δ = 7/8 or δ = 1/8). Participants were informed about the existence of a second part to the experiment, but did not learn any of its details until the first part was completed. Similar to the first part, instructions were read out and a series of comprehension questions were administered, but this time no practice round was offered. Participants then played for another set of interactions that lasted for 25 rounds of combined play.
The session ended with a final round of the Dictator game (DG2), which was similar to the one administered earlier but played with a different participant in their session. Participants then completed a survey on their basic demographics and received payment for their participation in cash (the MUs earned throughout the session were converted into dollars at a rate of 30 MUs per dollar). A graphic summary of the experimental design is depicted in
Table 2.
Overall, sessions lasted approximately 60 min and participants were paid an average of $19.22 (±0.08 SEM). Finally, statistical tests and analyses of RPD cooperation use logistic regression because it is a binary outcome, whereas analyses of DG giving and (log-transformed) response time use linear regression because it is a continuous outcome, both with robust standard errors clustered by session.
5. Discussion
This article investigated play in the indefinitely repeated Prisoner’s Dilemma—in particular the effects on cooperation of transitioning from a long continuation probability to a short one and vice versa, as well as the relationship between RPD play and Dictator Game giving.
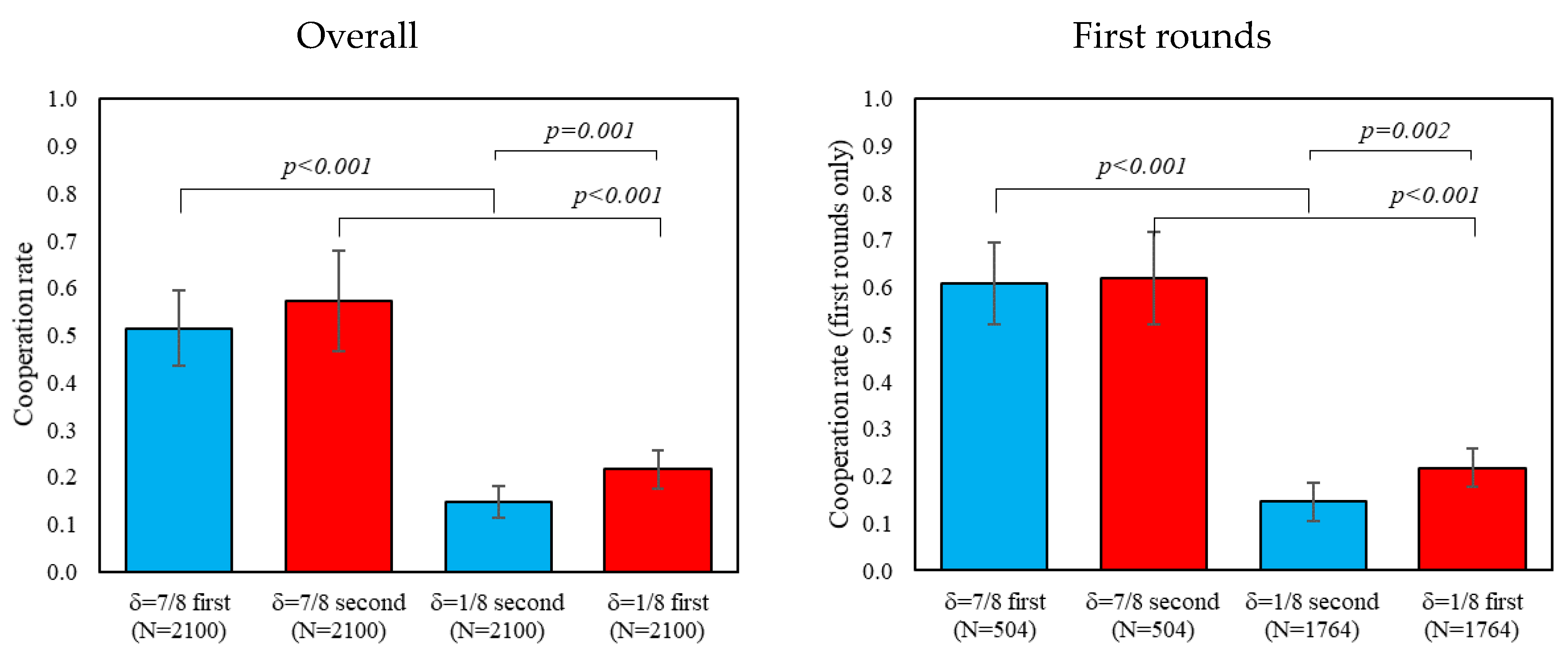
Consistent with prior work on the RPD (e.g., [
5,
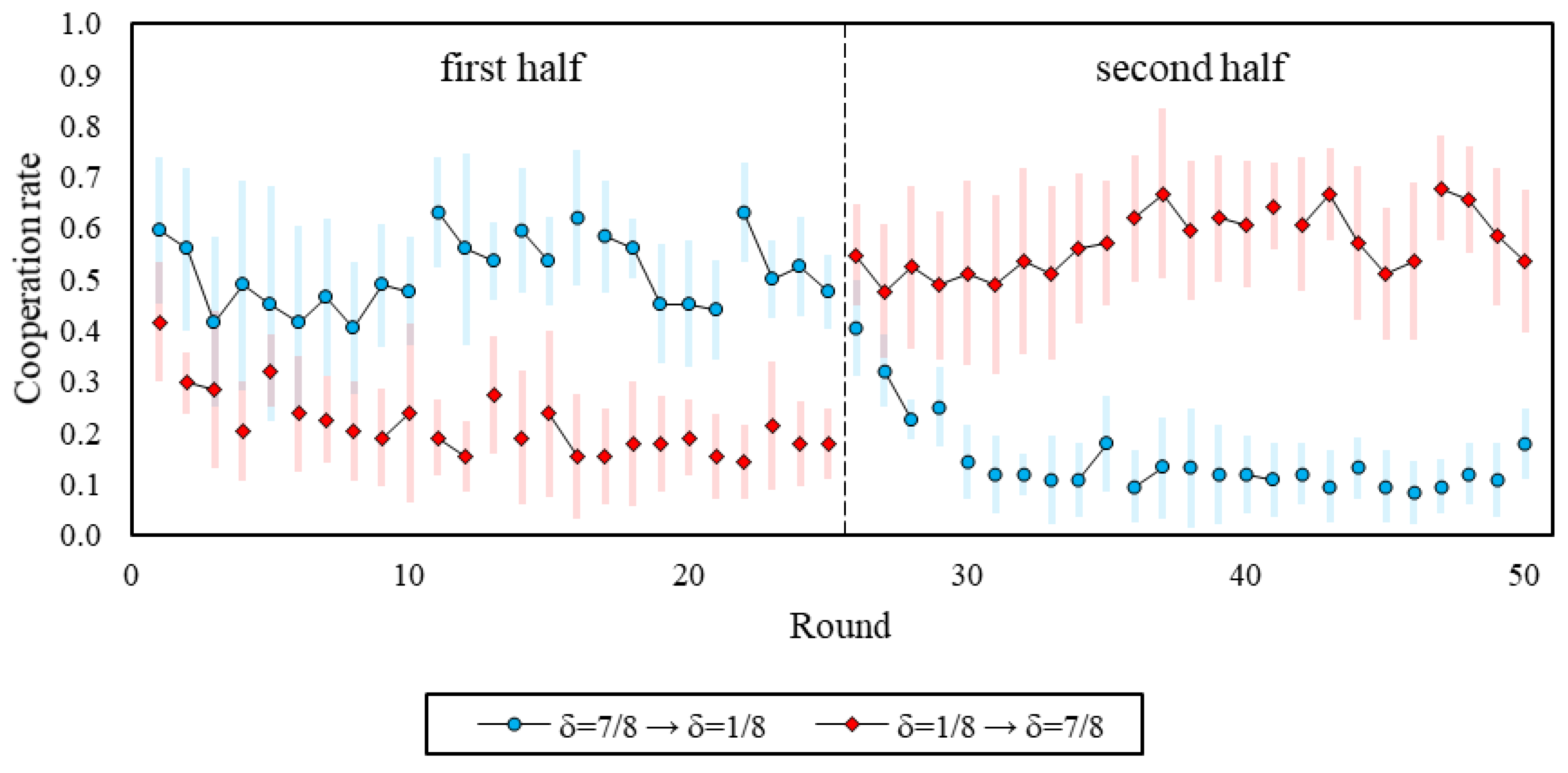
8]), we found substantially higher cooperation rates, and use of cooperative strategies, in the high continuation probability games where δ = 7/8 (such that “Grim” risk-dominates “Always Defect”) compared to the low continuation probability games, where δ = 1/8 (such that “Grim” is not an equilibrium). When transitioning from δ = 7/8 to δ = 1/8, we observe that cooperation remained somewhat high in the initial rounds of δ = 1/8, but then quickly declined with experience.
Interestingly, exactly the same pattern was observed when the δ = 1/8 games were played first—suggesting that coming into the lab and playing with δ = 1/8 involved making a transition from daily life (where δ is high) in the same way that playing δ = 1/8 after δ = 7/8 involves a transition. This pattern is indicative of a spillover effect: when people are used to cooperating (either outside the lab, or in the δ = 7/8 games), they continue to cooperate at a relatively high level when they first switch to δ = 1/8, and it takes several interactions for them to adjust. The fact that this happens to a similar extent in δ = 1/8 regardless of the order is at least consistent with the suggestion that δ = 7/8 is a reasonable model of the conditions participants experience outside the lab (and brought to bear at the outset of the δ = 1/8 to δ = 7/8 order). We do not have a clear explanation for why cooperation ultimately declines to a lower level in δ = 1/8 s compared to δ = 1/8 first, but it may be that making the transition from long to short games explicit leads participants to realize more fully that cooperation cannot be supported when δ = 1/8.
When considering δ = 7/8, conversely, we do not see much initial adjustment. Whether coming in from cooperating outside the lab or switching from a low level of cooperation in δ = 1/8, participants cooperate at a comparatively high level even in the very first round of δ = 7/8. Thus, there is an interesting asymmetry between cooperation and defection that is suggestive of a bias in favor of cooperation: when switching from δ = 7/8 to δ = 1/8, there is an adjustment lag in which participants initially try to cooperate before learning to defect, whereas no such lag occurs when switching from δ = 1/8 to δ = 7/8. This bias could be the result of an intuitive predisposition towards cooperation (e.g., [
10,
24]), or the result of explicit reasoning about, for example, efficiency.
Alternatively, our findings could also be interpreted there, being no spillovers whatsoever, and merely that participants play randomly at first, and then slowly transition towards their preferred choices as they gain more experience with the games—still, we observe some order differences that challenge this interpretation. For example, we identify a positive trend in cooperation when δ = 7/8 is played after δ = 1/8, but not when δ = 7/8 is played before δ = 1/8, and also note that cooperation in δ = 7/8 is consistently higher than in δ = 1/8 at the outset.
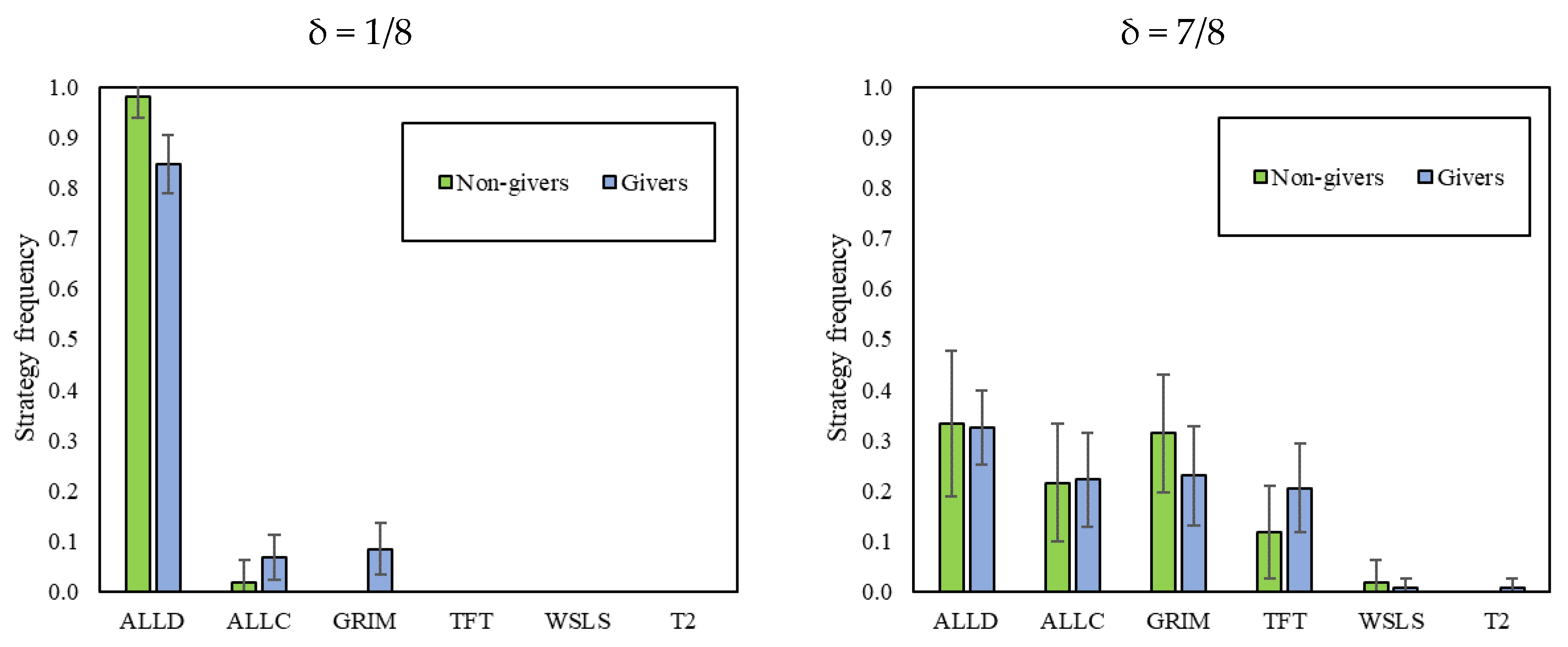
The strategy distributions found in this paper have some interesting parallels with the ones observed in Dal Bó and Fréchette [
3], and provide additional insights. First, in both cases, defecting strategies describe the data better in the environments where cooperation is not an equilibrium. Second, in both cases, the cooperative strategy that is most often identified is “Tit-for-tat” (especially when δ = 7/8 is played after δ = 1/8). However, while “Grim” is not significantly present in [
3], it is in our data (especially when δ = 7/8 is played first). In both cases, accounting only for “Always Defect”, “Grim” and “Tit-for-tat” can explain most of the data.
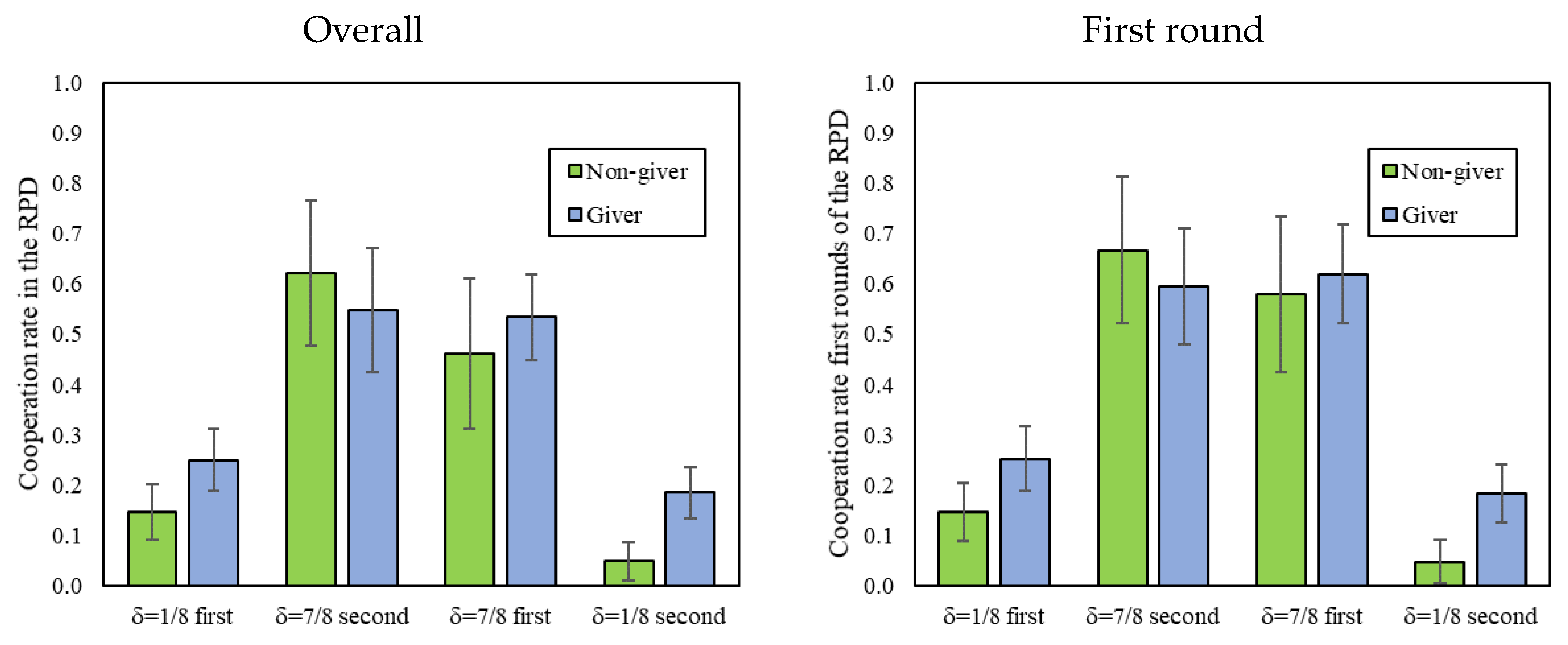
In line with Dreber et al. [
13], we find that DG giving in the final stage of the experiment is correlated with cooperation in the δ = 1/8 environment, but not in δ = 7/8. Crucially, we also find the same relationship when considering giving in the DG played
before the RPD. This shows that the correlation observed in [
13] was not an artifact of the DG coming after the RPD (e.g., because of income effects). Instead, our results provide robust evidence that those whose social preferences drive them to give in the DG cooperate more in RPDs where cooperation is not an equilibrium. However, RPD cooperation in the presence of cooperative equilibria is not associated with social preference-based giving in the DG. That is, cooperation does not depend on social preferences in games where there is a self-interested reason to cooperate.
When comparing giving in the DGs played pre-RPD and post-RPD, we find that experiencing a combination of δ = 1/8 and δ = 7/8 reduces the degree of prosociality among participants, and that the order in which the environments are introduced does not affect such levels. This observation is potentially interesting in light of the evidence in Peysakhovich and Rand [
9] suggesting that participants who experience an environment with δ = 7/8 are subsequently more prosocial than those who experience an environment with δ = 1/8. A possible explanation is that experiencing δ = 1/8 has a negative effect on prosociality beyond the positive one induced by δ = 7/8—that is, that “bad is stronger than good” [
26]. Alternatively, the relative lack of positive spillovers in our study may have been due to the fact that the level of cooperation achieved in the δ = 7/8 condition of our experiment (roughly 55%) was much lower than in [
9] (roughly 90%)—such that, even in δ = 7/8 in our experiment, a prosocial habit was not created.
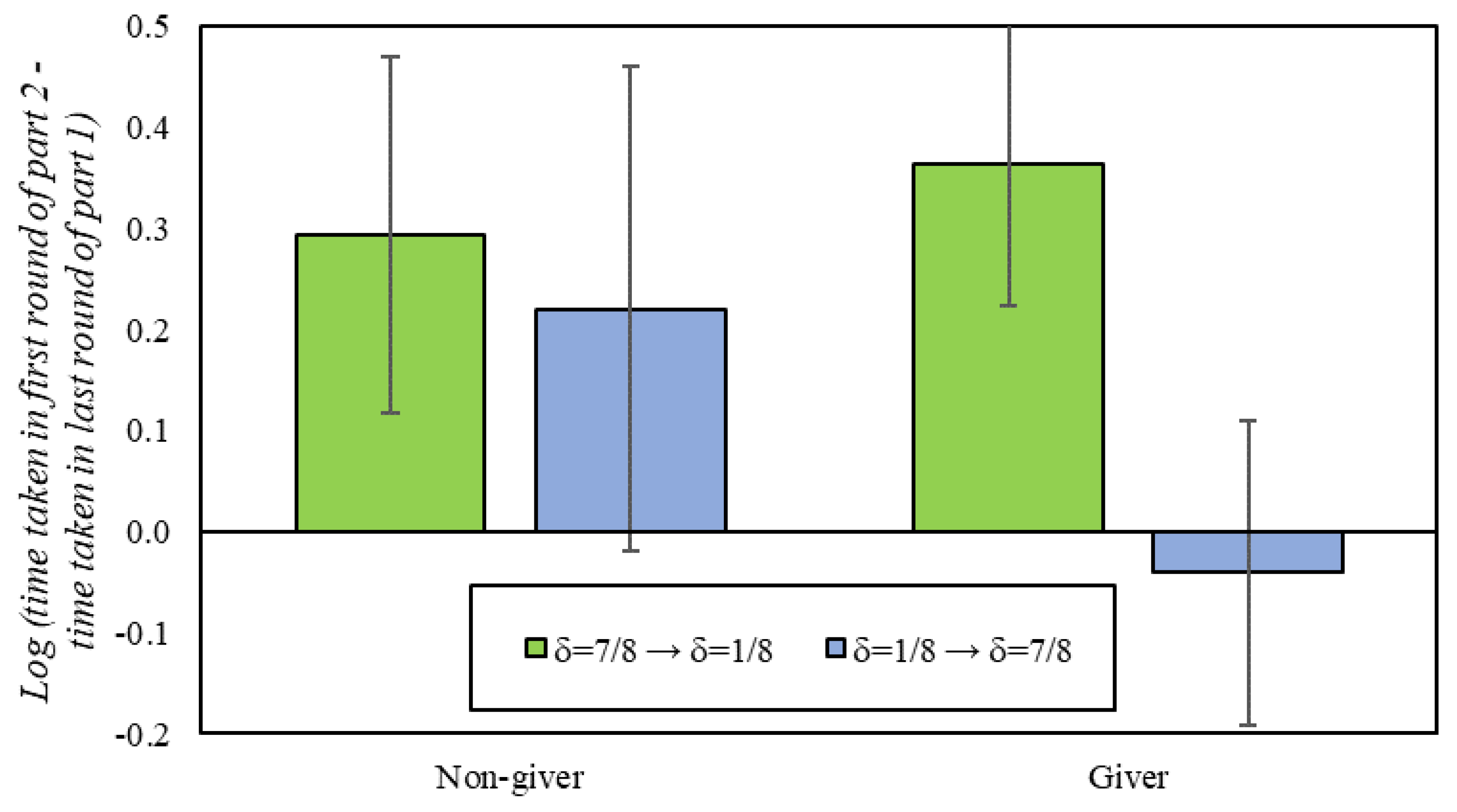
Although the experiment was not designed to investigate reaction times, this work also identified some evidence suggesting a bias in favor of cooperation among altruistic players. Unlike participants who typically take long pauses to determine play in the first round of a new set of RPDs, altruistic participants (who gave in the DG) who transition to scenarios with long RPDs do not slow down at all. This may be the reflection of the time participants need to deliberate in (un)familiar scenarios: non-givers weigh up the potential benefits of strategic cooperation, regardless of the sequence of RPDs experienced; givers, on the one hand, hesitate to start cooperating in an environment where cooperation is not an equilibrium, but, on the other, they are ready to enlist in cooperation when the scenario is favorable.
Future work should clarify these observations through further exploration of spillovers between RPD play and subsequent DG giving, as well as spillovers from other types of institutions (such as centralized punishment, see [
12]). In addition, new designs could also explore spillovers arising from environments where equilibrium selection is an issue. For instance, having participants play games with either low or high continuation probabilities in the first part of the experiment, and then play a constant stream of games that are conducive to stable cooperation in the second part. We would be surprised not to find spillovers in such scenarios.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




