Toward a Theory of Play: A Logical Perspective on Games and Interaction

Abstract
: Logic and game theory have had a few decades of contacts by now, with the classical results of epistemic game theory as major high-lights. In this paper, we emphasize a recent new perspective toward “logical dynamics”, designing logical systems that focus on the actions that change information, preference, and other driving forces of agency. We show how this dynamic turn works out for games, drawing on some recent advances in the literature. Our key examples are the long-term dynamics of information exchange, as well as the much-discussed issue of extensive game rationality. Our paper also proposes a new broader interpretation of what is happening here. The combination of logic and game theory provides a fine-grained perspective on information and interaction dynamics, and we are witnessing the birth of something new which is not just logic, nor just game theory, but rather a Theory of Play.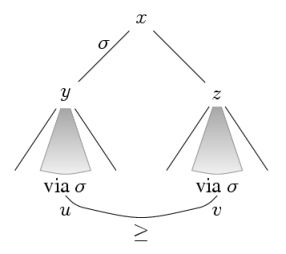
{kind=link}
{kind=link}
{kind=link}
{kind=link}
For many contemporary logicians, games and social interaction are important objects of investigation. Actions, strategies and preferences are central concepts in computer science and philosophical logic, and their combination raises interesting questions of definability, axiomatization and computational complexity [1–4]. Epistemic game theory, c.f. [5], has added one more element to this mix, again familiar to logicians: the role of factual and higher-order information. This much is well-understood, and there are excellent sources, that we need not reproduce here, though we will recall a few basics in what follows.
In this paper we will take one step further, assuming that the reader knows the basics of logic and game theory. We are going to take a look at all these components from a dynamic logical perspective, emphasizing actions that make information flow, change beliefs, or modify preferences—in ways to be explained below. For us, understanding social situations as dynamic logical processes where the participants interactively revise their beliefs, change their preferences, and adapt their strategies is a step towards a more finely-structured theory of rational agency. In a simple phrase that sums it up, this joint off-spring “in the making” of logic and game theory might be called a Theory of Play instead of a theory of games.
The paper starts by laying down the main components of such a theory, a logical take on the dynamics of actions, preferences, and information (Sections 1 and 2). We then show that this perspective has already shed new light on the long-term dynamics of information exchange, Section 3, as well as on the question of extensive game rationality, Section 4. We conclude with general remarks on the relation between logic and game theory, pleading for cross-fertilization instead of competition. This paper is introductory and programmatic throughout. Our treatment is heavily based on evidence from a number of recent publications demonstrating a variety of new developments.
1. An Encounter Between Logic and Games
A first immediate observation is that games as they stand are natural models for many existing logical languages: epistemic, doxastic and preference logics, as well as conditional logics and temporal logics of action. We do not aim at encyclopedic description of these systems—[2] is a relatively up-to-date overview. This section just gives some examples setting the scene for our later more detailed dynamic-logic analyses.
1.1. Strategic Games
Even simple strategic games call for logical analysis, with new questions arising at once. To a logician, a game matrix is a semantic model of a rather special kind that invites the introduction of well-known languages. Recall the main components in the definition of a strategic game for a set of n players N: (1) a nonempty set Ai of actions for each i ∈ N, and (2) a utility function or preference ordering on the set of outcomes. For simplicity, one often identifies the outcomes with the set S = ∏i∈NAi of strategy profiles. As usual, given a strategy profile σ ∈ S with σ = (a1, …, an), σi denotes the ith projection (i.e., σi = ai) and σ−i denotes the choices of all agents except agent i:σ−i = (a1, …, ai−1, ai+1, …, an).
Games as models
Now, from a logical perspective, it is natural to treat the set S of strategy profiles as a universe of “possible worlds”.1 These worlds then carry three natural relations, that are entangled in various ways. For each σ, σ′ ∈ S, define for each player i ∈ N:
σ ≥i σ′ iff player i prefers the outcome σ at least as much as outcome σ′,
σ ∼i σ′ iff : this epistemic relation represents player i's “view of the game” at the ex interim stage where i's choice is fixed but the choices of the other players' are unknown,
σ ≈i σ′ iff σ−i = σ−i: this relation of “action freedom” gives the alternative choices for player i when the other players' choices are fixed.2
This can all be packaged in a relational structure
Matching modal game languages
The next question is what is the “right” logical language to reason about these structures? The goal here is not simply to formalize standard game-theoretic reasoning. That could be done in a number of ways, often in the first-order language of these relational models. Rather, the logician will aim for a well-behaved language, with a good balance between the level of formalization and other desirable properties, such as perspicuous axiomatization, low computational complexity of model checking and satisfiability, and the existence of an elegant meta-theory for the system. In particular, the above game models suggest the use of modal languages, whose interesting balance of expressive power and computational complexity has been well-researched over the last decades.3
Our first key component—players' desires or preferences—has been the subject of logical analysis since at least the work of [10].4 Here is a modern take on preference logic [12,14]. A modal betterness model for a set N of players is a tuple = 〈W, {≥i}i∈N, V〉 where W is a nonempty set of states, for each i ∈ N, ≥i ⊆ W × W is a preference ordering, and V is a valuation function V : At → ℘(W) (At is a set of atomic propositions describing the ground facts about the situation being modeled). Precisely which properties ≥i should have has been the subject of debate in philosophy: in this paper, we assume that the relation is reflexive and transitive. For each ≥i, the corresponding strict preference ordering is written >i.
A modal language to describe betterness models uses modalities 〈≥i〉φ saying that “there is a world at least as good as the current world satisfying φ”, and likewise for strict preference:
, w ⊨ 〈≥i〉φ iff there is a v with v ≥i w and , v ⊨ φ
, w ⊨ 〈≥i〉φ iff there is a v with v ≥i w, w ≱i v, and , v ⊨ φ
Standard techniques in modal model theory apply to definability and axiomatization in this modal preference language: we refer to ([9], Chapter 3) and [13] for details. Both [12] and [13] show how this language can also define “lifted” generic preferences between propositions, i.e., properties of worlds.
Next, the full modal game language for the above models must also include modalities for the relations that we called the “view of the game” and the “action freedom”. But this is straightforward, as these are even closer to standard notions studied in epistemic and action logics.
Again, we start with a set At of atomic propositions that represent basic facts about the strategy profiles.5 Now, we add obvious modalities for the other two relations to get a full modal logic of strategic games:
σ ⊨ [∼i]φ iff for all σ′, if σ ∼i σ′ then σ′ ⊨ φ.
σ ⊨ [≈i]φ iff for all σ′, if σ ≈iσ′ then σ′ ⊨ φ.
σ ⊨ 〈≥i〉φ iff there exists σ′ such that σ′ ≥iσ and σ′ ⊨ φ.
σ ⊨ 〈>i〉φ iff there is a σ′ with σ′ ≥i σ, σ ≱ σ′, and σ′ ⊨ φ
Some issues in modal game logic for strategic games
A language allows us to say things about structures. But what about a calculus of reasoning: what is the logic of our modal logic of strategic games? For convenience, we restrict attention to 2-player games. First, given the nature of our three relations, the separate logics are standard: modal S4 for preference, and modal S5 for epistemic outlook and action freedom. What is of greater interest, and logical delicacy, is the interaction of the three modalities. For instance, the following combination of two modalities makes φ true in each world of a game model:
Thus, the language also has a so-called “universal modality”. Moreover, this modality can be defined in two ways, since we also have that:
the equivalence [∼i][≈i]φ↔ [≈i][∼i]φ is valid 6 in game models.
This validity depends on the geometrical “grid property” of game matrices that if one can go x ∼i y ≈i z, then there exists a point u with x≈ i u ∼i z.
This may look like a pleasant structural feature of matrices, but its logical effects are delicate. It is well-known that the general logic of such a bi-modal language on grid models is not decidable, and not even axiomatizable: indeed, it is “ ”.7 In particular, satisfiability in grid-like models can encode computations of Turing machines on their successive rows, or alternatively, they can encode geometrical “tiling problems” whose complexity is known to be high. From a logical point of view, simple-looking strategic matrix games can be quite complex computational structures.
However, there are two ways in which these complexity results can be circumvented. One is that we have mainly looked at finite games, where additional validities hold8 —and then, the complexity may be lower. Determining the precise modal logic of finite game matrices appears to be an open problem.
Here is another interesting point. It is known that the complexity of such logics may go down drastically when we allow more models, in particular, models where some strategy profiles have been ruled out. One motivation for this move has to do with dependence and independence of actions.9 Full matrix models make players' actions independent, as reflected in the earlier grid property. By contrast, general game models omitting some profiles can represent dependencies between players' actions: changing a move for one may only be possible by changing a move for another. The general logic of game models allowing dependencies does not validate the above commutation law. Indeed, it is much simpler: being just multi-agent modal S5. Thus, complexity of logics matches interesting decisions on how we view players: as independent, or correlated.
Against this background of available actions, information, and freedom, the preference structure of strategic games adds further interesting features. One benchmark for modal game logics has been the definition of the strategy profiles that are in Nash Equilibrium. And this requires defining the usual notion of best response for a player. One can actually prove10 that best response is not definable in the language that we have so far. One extension that would do the job is taking an intersection modality:
Then the best response for player i is defined as ¬〈≈i⋂>i〉T.
Questions of complexity and complete axiomatization then multiply. But we can also deal with preference structure in other ways. Introduce proposition letters “Best(i)” for players i saying that the profiles where they hold are best responses for i in the game model. Then one finds interesting properties of such models reflected in the logic. One example is that each finite game model has a cycle of points where (for simplicity assume there are only two players i and j):
Our main point with this warm-up discussion for our logical Theory of Play it that the simple matrix pictures that one sees in a beginner's text on game theory are already models for quite sophisticated logics of action, knowledge and preference. Thus, games of even the simplest sort have hidden depths for logicians: there is much more to them than we might think, including immediate open problems for logical research.12
1.2. Extensive Games
Just like strategic games, interactive agency in the more finely-structured extensive games offers a natural meeting point with logic. We will demonstrate this with a case study of Backwards Induction, a famous benchmark at the interface, treated in a slightly novel way. Our treatment in this section will be rather classical, that is static and not information-driven. However, in Section 4 we return to the topic, giving it a dynamic, epistemic twist.
Dynamic logic of actions and strategies
The first thing to note is that the sequential structure of players' actions in an extensive game lends itself to logical analysis. A good system to use for this purpose is propositional dynamic logic (PDL), originally designed to analyze programs and computation (see [27] for the original motivation and subsequent theory). Let Act be a set of primitive actions. An action model is a tuple = 〈W, {Ra | a ∈ Act}, V〉 where W is an abstract set of states, or stages in an extensive game, and for each a ∈ Act, Ra ⊆ W × W is a binary transition relation describing possible transition from states w to w′ by executing the action a. On top of this atomic repertoire, the tree structure of extensive games supports complex action expressions, constructed by the standard regular operations of “indeterministic choice” (∪), “sequential composition” (;) and “unbounded finitary iteration” (*: Kleene star)
This syntax recursively defines complex relations in action models:
Rα∪β := Rα ∪ Rβ
Rα;β := Rα ∘ Rβ
(the identity relation) and .
The key dynamic modality [α]φ now says that “after the move described by the program expression α is taken, φ is true”:
PDL has been used for describing solution concepts on extensive games by many authors [2,4,28]. An extended discussion of logics that can explicitly define strategies in extensive games is found in [29].
Adding preferences: the case of Backwards Induction
As before, a complete logical picture must bring in players' preferences on top of PDL, along the lines of our earlier modal preference logic. To show how this works, we consider a key pilot example: the Backwards Induction (BI) algorithm. This procedure marks each node of an extensive game tree with values for the players (assuming that distinct end nodes have different utility values):13
BI Algorithm
At end nodes, players already have their values marked. At further nodes, once all daughters are marked, the player to move gets her maximal value that occurs on a daughter, while the other, non-active player gets his value on that maximal node.
The resulting strategy for a player selects the successor node with the highest value. The resulting set of moves for all players (still a function on nodes given our assumption on end nodes) is the “bi strategy”.
Relational strategies and set preference
But to a logician, a strategy is best viewed as a subrelation of the total move relation. It is an advice to restrict one's next choice in some way, similar to the more general situation where our plans constrain our choices. Mathematically, this links up with the usual way of thinking about programs and procedures in computational logic, in terms of the elegant algebra of relations and its logic PDL as defined earlier.
When the above algorithm is modified to a relational setting—we can now drop assumptions about unicity at end-points—we find an interesting new feature: special assumptions about players. For instance, it makes sense to take a minimum value for the passive player at a node over all highest-value moves for the active player. But this is a worst-case assumption: my counter-player does not care about my interests after her own are satisfied. But we might also assume that she does, choosing a maximal value for me among her maximum nodes. This highlights an important feature: solution methods are not neutral, they encode significant assumptions about players.
One interesting way of understanding the variety that arises here has to do with the earlier modal preference logic. We might say in general that the driving idea of Rationality behind relational BI is the following:
I do not play a move when I have another whose outcomes I prefer.
But preferences between moves that can lead to different sets of outcomes call for a notion of “lifting” the given preference on end-points of the game to sets of end-points. As we said before, this is a key topic in preference logic, and here are many options: the game-theoretic rationality behind BI has a choice point. One popular version in the logical literature is this:
This says that we choose a move with the highest maximal value that can be achieved. A more demanding notion of preference for a set Y over X in the logical literature [10] is the ∀∀ clause that
Here is what relational BI looks like when we follow the latter stipulation, which makes Rationality less demanding, and hence the method more cautious:
First mark all moves as active. Call a move a dominated if it has a sibling move all of whose reachable endpoints via active nodes are preferred by the current player to all reachable endpoints via a itself. The second version of the BI algorithm works in stages:
At each stage, mark dominated moves in the ∀∀ sense of preference as passive, leaving all others active.
Here “reachable endpoints” by a move are all those that can be reached via a sequence of moves that are still active at this stage.
We will analyze just this particular algorithm in our logics to follow, but our methods apply much more widely.
Defining Backwards Induction in logic
Many logical definitions for the BI strategy have been published [cf. again the survey in 2, Section 3]. Here is a modal version combining the logics of action and preferences presented earlier—significantly, involving operator commutations between these:
Theorem 1.1 ([30])
For each extensive game form, the strategy profile σ is a backward induction solution iff a is played at the root of a tree satisfying the following modal axiom for all propositions p and players i:
Here movei = ∪a is an i-move a, turni is a propositional variable saying that it is i's turn to move, and end is a propositional variable true at only end nodes. Instead of a proof, we merely develop the logical notions involved a bit further.
The meaning of the crucial axiom follows by a modal frame correspondence ([9], Chapter 3).14 Our notion of Rationality reappears:
Fact 1.2
A game frame makes (turni Λ [σ*] (end → p)) → [movei] 〈σ*〉(end Λ 〈pre fi 〉p) true for all i at all nodes iff the frame has this property for all i:
RAT
No alternative move for the current player i guarantees outcomes via further play using σ that are all strictly better for i than all outcomes resulting from starting at the current move and then playing σ all the way down the tree.
A typical picture to keep in mind here, and also later on in this paper, is this:
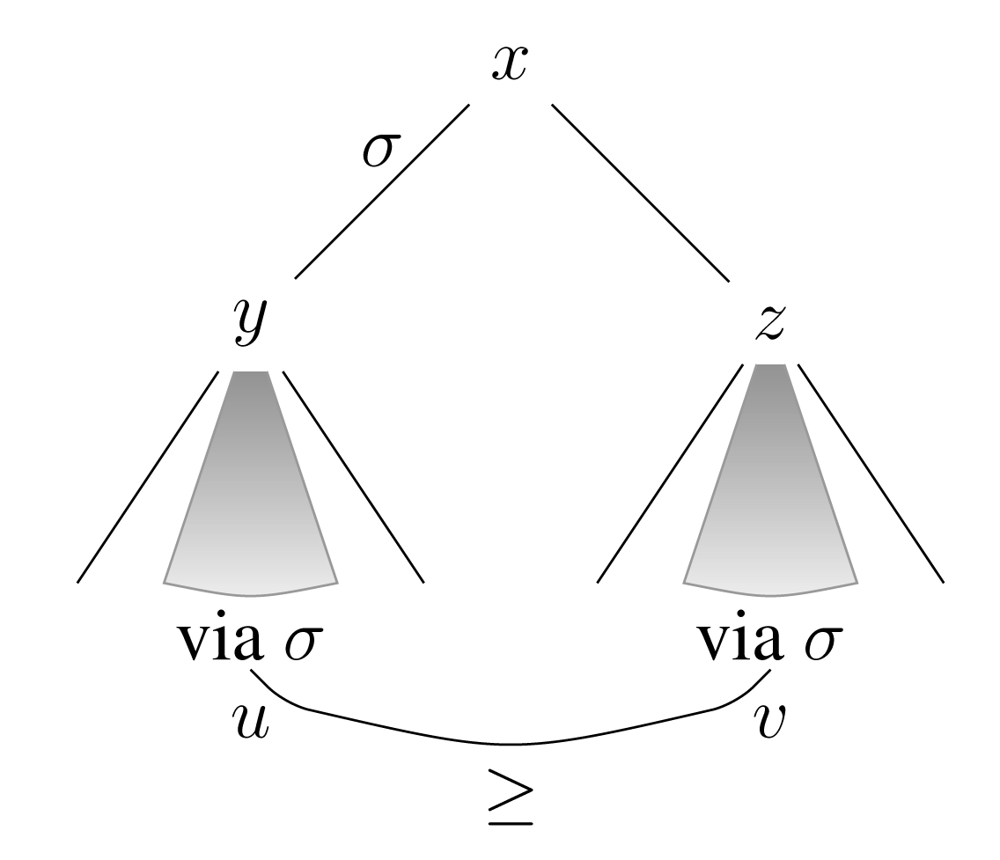
More formally, RAT is this confluence property for action and preference:
Now, a simple inductive proof on the depth of finite game trees shows for our cautious algorithm that:
Theorem 1.3
BI is the largest subrelation S of the move relation in a game with (a) S has a successor at each intermediate node, (b) S satisfies CF.
This result is not very deep, but it opens a door to a whole area of research.
The general view: fixed-point logics for game trees
We are now in the realm of a well-known logic of computation, viz. first-order fixed-point logic LFP(FO) [31]. The above analysis really tells us:
Theorem 1.4
The BI relation is definable as a greatest-fixed-point formula in the logic LFP(FO).
Here is the explicit definition in LFP(FO):
The crucial feature making this work is a typical logical point: the occurrences of the relation S in the property CF are syntactically positive, and this guarantees upward monotonic behaviour. We will not go into technical details of this connection here, except for noting the following.
Fixed-point formulas in computational logics like this express at the same time static definitions of the bi relation, and procedures computing it.15 Thus, fixed-point logics are an attractive language for extensive games, since they analyze both the statics and dynamics of game solution.
This first analysis of the logic behind extensive games already reveals the fruitfulness of putting together logical and game-theoretical perspectives. But it still leaves untouched the dynamics of deliberation and information flow that determine players' expectations and actual play as a game unfolds, an aspect of game playing that both game theorists and logicians have extensively studied in the last decades. In what follow we make these features explicit, deploying the full potential of the fine-grained Theory of Play that we propose.
2. Information Dynamics
The background to the logical systems that follow is a move that has been called a “Dynamic Turn” in logic, making informational acts of inference, but also observations, or questions, into explicit first-class citizens in logical theory that have their own valid laws that can be brought out in the same mathematical style that has served standard logic so well for so long. The program has been developed in great detail in [19,33] drawing together a wide range of relevant literature, but we will only use some basic components here: single events of information change and, later on in this paper, longer-term interactive processes of information change. Towards the end of the paper, we will also briefly refer to other dynamic components of rational agency, with dynamic logics for acts of strategy change, or even preference change.
Players' informational attitudes can be broadly divided into two categories: hard and soft information [34,35].16 Hard information, and its companion attitude, is information that is veridical and not revisable. This notion is intended to capture what agents are fully and correctly certain of in a given game situation. So, if an agent has hard information that some fact φ is true, then φ really is true. In absence of better terminology and following common usage in the literature, we use the term knowledge to describe this very strong type of informational attitude. By contrast, soft information is, roughly speaking, anything that is not “hard”: it is not necessarily veridical, and it is revisable in the presence of new information. As such, it comes much closer to beliefs or more generally attitudes that can be described as “regarding something as true” [36]. This section introduces some key logical systems for describing players' hard and soft information in a game situation, and how this information can change over time.
2.1. Hard Information and Public Announcements
Recall that N is the set of players, and At a set of atomic sentences p describing ground facts, such as “player i choose action a” or “the red card is on the table”. A non-empty set W of worlds or states then represent possible configurations of plays for a fixed game. Typically, players have hard information about the structure of the game—e.g., which moves are available, and what are their own preferences and choices, at least in the ex interim stage of analysis.
Static epistemic logic
Rather than directly representing agents' information in terms of syntactic statements, in this paper, we use standard epistemic models for “semantic information” encoded by epistemic “indistinguishability relations”. Setting aside some conceptual subtleties for the purpose of exposition, we will assume that indistinguishability is an equivalence relation. Each agent has some “hard information” about the situation being modeled, and agents cannot distinguish between any two states that agree on this information. This is essentially what we called the player's “view of the game” in Section 1. Technically, we then get well-known structures:
Definition 2.1
[Epistemic Model] An epistemic model = 〈W, {∼i}i∈N, V〉 has a non-empty set of worlds W; for each i ∈ N, ∼i⊆ W × W is reflexive, transitive and symmetric; and V: At → ℘(W) is a valuation map.
A simple modal language describes properties of these structures. Formally, EL is the set of sentences generated by the grammar:
Definition 2.2
Let = 〈W, {∼i}i∈N, V〉 be an epistemic model. For each w ∈ W, φ is true at state w, denoted , w ⊨ φ, is defined by induction:
, w ⊨ p iff w ∈ V(p)
, w ⊨ ¬φ iff , w ⊭ φ
, w ⊨ φΛψ iff , w ⊨ φ and , w ⊨ φ
, w ⊨ Kiφ iff for all v ∈ W, if w∼i v then , v ⊨ φ
We call φ satisfiable if there is a model = 〈W, {∼i}i∈N, V〉 and w ∈ W with , w ⊨ φ, and say φ is valid in , denoted ⊨ φ, if , w ⊨ φ for all w ∈ W.
Given the definition of the dual of Ki, it is easy to see that:
This says that “φ is consistent with agent i's current hard information”.
Information update
Now comes a simple concrete instance of the above-mentioned “Dynamic Turn”. Typically, hard information can change, and this crucial phenomenon can be added to our logic explicitly.
The most basic type of information change is a public announcement [37,38]. This is an event where some proposition φ (in the language of EL) is made publicly available, in full view, and with total reliability. Clearly, the effect of such an event should be to remove all states that do not satisfy φ: new hard information shrinks a current range of uncertainty.
Definition 2.3
[Public Announcement.] Let = 〈W, {∼i}i∈N, V〉 be an epistemic model and φ an epistemic formula. The model updated by the public announcement of φ is the structure where Wφ = {w ∈ W | , w ⊨ φ}, for each i ∈ N, , and for all atomic proposition p, Vφ(p) = V(p) ∩ Wφ.
Clearly, if is an epistemic model then so is φ. The two models describe two different moments in time, with the current information state of the agents and xφ the information state after the information that φ is true has been incorporated in . This temporal dimension can be represented explicitly in our logical language:
Let PAL extend EL with expressions of the form [φ]ψ with φ ∈ EL. The intended interpretation of [φ]ψ is “ψ is true after the public announcement of φ” and truth is defined as , w ⊨ [φ]ψ iff if , w ⊨ φ then φ, w ⊨ ψ.
Now, in the earlier definition of public announcement, we can also allow formulas from the extended language PAL: the recursion will be in harmony. As an illustration, a formula like ¬Kiψ Λ [φ]Kiψ says that “agent i currently does not know ψ but after the announcement of φ, agent i knows ψ”. So, the language of PAL describes what is true both before and after the announcement while explicitly mentioning the informational event that achieved this.
While this is a broad extension of traditional conceptions of logic, standard methods still apply. A fundamental insight is that there is a strong logical relationship between what is true before and after an announcement, in the form of so-called reduction axioms:
Theorem 2.4
On top of the static epistemic base logic, the following reduction axioms completely axiomatize the dynamic logic of public announcement:
| [φ]p | ↔ | φ → p, where p ∈ At |
| [φ]¬ψ | ↔ | φ → ¬ [φ]ψ |
| [φ] (ψ Λ χ) | ↔ | [φ] ψ Λ [φ]χ |
| [φ] [ψ]χ | ↔ | [φ Λ [φ] ψ] χ |
| [φ]Kiφ | ↔ | φ → Ki(φ → [φ]ψ) |
Going from left to right, these axioms reduce syntactic complexity in a stepwise manner. This recursive style of analysis has set a model for the logical analysis of informational events generally. Thus, information dynamics and logic form a natural match.
2.2. Group Knowledge
Both game theorists and logicians have extensively studied a next phenomenon after the individual notions considered so far: group knowledge and belief.17 We assume that the reader is familiar with the relevant notions, recalling just the merest basics. For a start, the statement “everyone in the (finite) group G ⊆ N knows φ” can be defined as follows:
Following [41]18, the intended interpretation of “it is common knowledge in G that φ” (CGφ) is the infinite conjunction:
In general, we need to add a new operator CGφ to the earlier epistemic language for this. It takes care of all iterations of knowledge modalities by inspecting all worlds reachable through finite sequences of epistemic accessibility links for arbitrary agents. Let = 〈W, {∼i}i∈N, V〉 be an epistemic model, with w ∈ W. Truth of formulas of the form Cφ is defined by:
Fixed-Point Axiom: CGφ→EGCGφ
Induction Axiom: φ Λ CG(φ → EGφ) → CGφ
Studying group knowledge is just a half-way station to a more general move in current logics of agency Common knowledge is a notion of group information that is definable in terms of what the individuals know about each others. But taking collective agents—a committee, a scientific research community—seriously as logical actors in their own right brings us beyond this reductionist perspective.
Finally, what about dynamic logics for group modalities? Baltag, Moss and Solecki [44] proved that the extension of EL with common knowledge and public announcement operators is strictly more expressive than with common knowledge alone. Nonetheless, a technical reduction axiom-style recursive analysis is still possible, as carried out in [45].
2.3. Soft Information and Soft Announcements
But rational agents are not just devices that keep track of hard information, and produce indubitable knowledge all the time. What seems much more characteristic of intelligent behaviour, as has been pointed out by philosophers and psychologists alike, is our creative learning ability of having beliefs, perhaps based on soft information, that overshoot the realm of correctness. And the dynamics of that is found in our skills in revising those beliefs when they turn out to be wrong. Thus, the dynamics of “correction” is just as important to rational agency as that of “correctness”.
Models of belief via plausibility
While there is an extensive literature on the theory of belief revision, starting with [46], truly logical models of the dynamics of beliefs, hard and soft information have only been developed recently. For a start, we need a static base, extending epistemic models with softer, revisable informational attitudes. One appealing approach is to endow epistemic ranges with a plausibility ordering for each agent: a pre-order (reflexive and transitive) w ≼iv that says “player i considers world v at least as plausible as w.” As a convenient notation, for X ⊆ W, we set Min≼i(X) = {v ∈ W | v ≼iw for all w ∈ X }, the set of minimal elements of X according to ≼i. The plausibility ordering ≼i represents which possible worlds an agent considers more likely, encoding soft information. Such models representing have been used by logicians [35,47,48], game theorists [49], and computer scientists [50,51]:
Definition 2.5
(Epistemic-Doxastic Models). An epistemic-doxastic model is a tuple:
plausibility implies possibility: if w ≼i v then w ∼i v.
locally-connected: if w ∼i v then either w ≼i v or v ≼i w.21
These richer models can define many basic soft informational attitudes:
Belief: , w ⊨ Biφ iff for all v ∈ Min≼i ([w]i), , v ⊨ φ.
This is the usual notion of belief which satisfies standard properties,
Safe Belief: , w ⊨ Biφ iff for all v, if v ≼i w then , v ⊨ φ.
Thus, φ is safely believed if φ is true in all states the agent considers more plausible. This stronger notion of belief has also been called certainty by some authors ([52], Section 13.7).22
Soft attitudes in terms of information dynamics
As noted above, a crucial feature of soft informational attitudes is that they are defeasible in light of new evidence. In fact, we can characterize these attitudes in terms of the type of evidence which can prompt the agent to adjust them. To make this precise, consider the natural notion of a conditional belief in a epistemic-doxastic model . We say i believes φ given ψ, denoted , if
Safe belief can be similarly characterized by restricting the admissible evidence:
, w ⊨ Bi□ iff , w ⊨ for all ψ with , w ⊨ ψ.
i.e., i safely believes φ iff i continues to believe φ given any true formula.
Baltag and Smets [55] give an elegant logical characterization of all these notions by adding the safe belief modality □i to the epistemic language EL.
Belief change under hard information
Let us now turn to the systematic logical issue of how beliefs change under new hard information, i.e., the logical laws governing [φ]Biψ. One might think this is taken care of by conditional belief , and indeed they are when ψ is a ground formula not containing any modal operators. But in general, they are different.
Example 2.6
[Dynamic Belief Change versus Conditional Belief] Consider state w1 in the following epistemic-doxastic model:
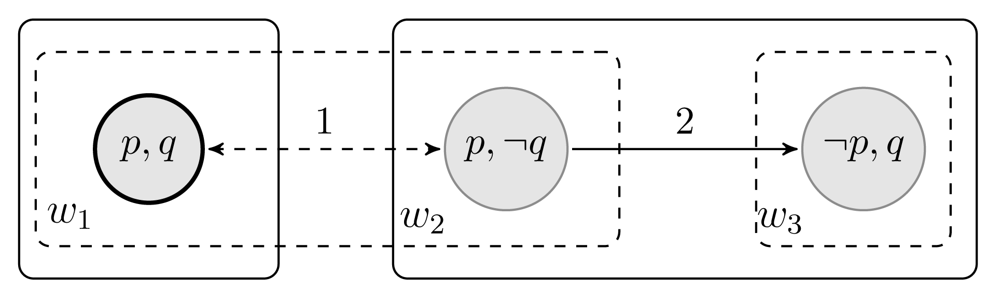
In this model, the solid lines represent agent 2′s hard and soft information (the box is 2′s hard information ∼2 and the arrow represent 2′s soft information ≼2) while the dashed lines represent 1′s hard and soft information. Reflexive arrows are not drawn to keep down the clutter in the picture. Note that at state w1, agent 2 knowsp and q (e.g., w1 ⊨ K2(p ⋀ q)), and agent 1 believes p but not q (w1 ⊨ B1p ⋀ ¬B1q). Now, although agent 1 does not know that agent 2 knows p, agent 1 does believe that agent 2 believes q (w1 ⊨ B1B2q). Furthermore, agent 1 maintains this belief conditional on p: . However, public announcing the true fact p, removes state w3 and so we have w1 ⊨ [p] ¬B1B2q. Thus a belief in ψ conditional on φ is not the same as a belief in ψ after the public announcement of φ. The reader is invited to check that is satisfiable but [!p]Bi(p ⋀ ¬Kip) is not satisfiable.24
The example is also interesting as the announcement of a true fact misleads agent 1 by forcing her to drop her belief that agent 2 believes q ([33], pg. 182). Despite these intricacies, the logical situation is clear: The dynamic logic of changes in absolute and conditional beliefs under public announcement is completely axiomatizable by means of the static base logic of belief over plausibility models plus the following complete reduction axiom:
Belief change under soft information
Public announcement assumes that agents treat the source of the incoming information as infallible. But in many scenarios, agents trust the source of the information up to a point. This calls for softer announcements, that can also be brought under our framework. We only make some introductory remarks: see ([33], Chapter 7) and [55] for more extensive discussion.
How to incorporate less-than-conclusive evidence that φ is true into an epistemic-doxastic model ? Eliminating worlds is too radical for that. It makes all updates irreversible. What we need for a soft announcement of a formula φ is thus not to eliminate worlds altogether, but rather modify the plausibility ordering that represents an agent's current hard and soft information state. The goal is to rearrange all states in such a way that φ is believed, and perhaps other desiderata are met. There are many “policies” for doing this [57], but here, we only mention two, that have been widely discussed in the literature on belief revision. The following picture illustrates the setting:
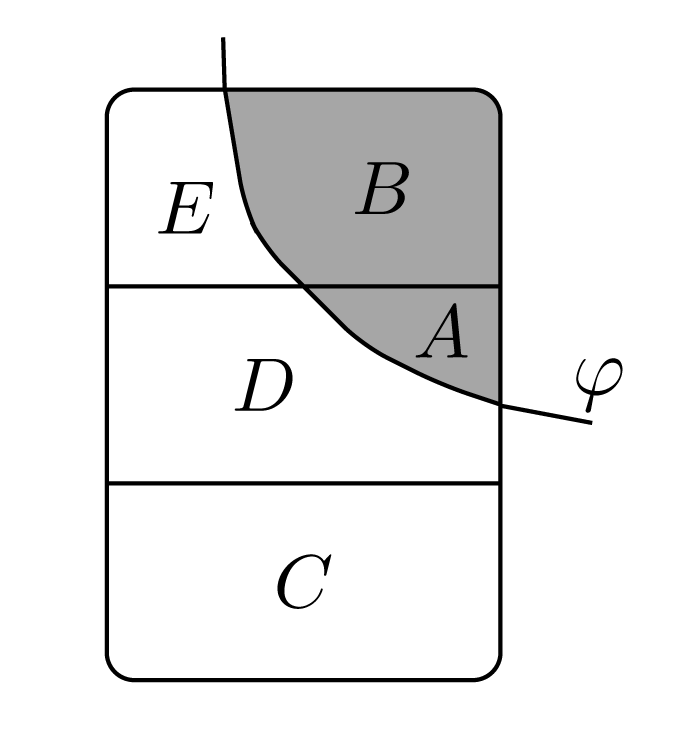
Suppose the agent considers all states in C as least as plausible as all states in A ∪ D, which she, in turns, considers at least as plausible as all states in B ∪ E. If the agent gets evidence in favor of φ from a source that she barely thrusts. How is she to update her plausibility ordering?
Perhaps the most ubiquitous policy is conservative upgrade, which lets the agent only tentatively accept the incoming information φ by making the best φ the new minimal set and keeping the old plausibility ordering the same on all other worlds. In the above picture a conservative upgrade with φ results in the new ordering A ≺i C ≺i D ≺i B ∪ E. The general logical idea here is this: “plausibility upgrade is model reordering”.25 This view can be axiomatized in a dynamic logic in the same style as we did with earlier scenarios ([33], Chapter 7 for details).
In what follows, we will focus on a more radical policy for belief upgrade, between the soft conservative upgrade and hard public announcements. The idea behind such radical upgrade is to move all φ worlds ahead of all other worlds, while keeping the order inside these two zones the same. In the picture above, a radical upgrade by φ would result in A ≺i B ≺i C ≺i D ≺i E.
The precise definition of radical upgrades goes as follow. Let (where [w]i is the equivalence class of w under ∼i) denote this set of φ worlds:
Definition 2.7
(Radical Upgrade.). Given an epistemic-doxastic model = 〈W, {∼i}i∈N, {≺i}i∈N, V〉 and a formula φ, the radical upgrade of with φ is the model with W⇑φ = W, for each i, , V⇑φ = V and finally, for all i ∈ N and w ∈ W⇑φ:
for all x and, set,
for all x,y, set y iff x ≼i y, and
for all x, y, set x y iff x ≼i y.
A logical analysis of this type of information change uses modalities [⇑iφ]ψ meaning “after i's radical upgrade of φ, ψ is true”, interpreted as follows:
Here is how belief revision under soft information can be treated:
Theorem 2.8
The dynamic logic of radical upgrade is completely axiomatized by the complete static epistemic-doxastic base logic plus, essentially, the following recursion axiom for conditional beliefs:
This result is from [58], and its proof shows how revision policies as plausibility transformations really give agents not just new beliefs, but also new conditional beliefs – a point sometimes overlooked in the literature.
2.4. The General Logical Dynamics Program
Our logical treatment of update with hard and soft information reflects a general methodology, central to the Theory of Play that we advocate here. Information dynamics is about steps of model transformation, either in their the universe of worlds, or their relational structure, or both.
Other dynamic actions and events
These methods work much more generally than we are able to show here, including model update with information that may be partly private, but also for various other relevant actions, such as inference manipulating finer syntactic information, or questions modifying a current agenda of issues for investigation. These methods even extend beyond the agents' informational attitudes, such as the dynamics of preferences expressing their “evaluation” of the world.27
From local to global dynamics
One further important issue is this. Most information flow only makes sense in a longer-term temporal setting, where agents can pursue goals and engage in strategic interaction. This is the realm of epistemic-doxastic temporal logics that describe a “Grand Stage” of histories unfolding over time. By now, there are several studies linking up between the dynamic logics of local informational step that we have emphasized, and abstract long-term temporal logics. We refer to [33,59] for these new developments, that are leading to complete logics of information dynamics with “protocols” and what may be called procedural information that agents have about the process they are in. Obviously, this perspective is very congenial to extensive games, and in the rest of this paper, it will return in many places, though always concretely28
3. Long-term Information Dynamics
We now discuss a first round of applications of the main components of the Theory of Play outlined in the previous sections. We leave aside games for the moment, and concentrate on the dynamic of information in interaction. These applications have in common that they use single update steps, but then iterate them, according to what might be called “protocols” for conversation, learning, or other relevant processes. It is the resulting limit behavior that will mainly occupy us in this section.
We first consider agreement theorems, well known to game theorists, showing how repeated conditioning and public announcements lead to consensus in the limit. This opens the door a general analysis of fixed-points of repeated attitude changes, raising new questions for logic as well as for interactive epistemology. Next we discuss underlying logical issues, including extensions to scenarios of belief merge and formation of group preferences in the limit. Finally we return to a concrete illustration: viz. learning scenarios, a fairly recent chapter in logical dynamics, at the intersection of logic, epistemology, and game theory.
3.1. Agreement Dynamics
Agreement Theorems, introduced in [60], show that common knowledge of disagreement about posterior beliefs is impossible given a common prior. Various generalizations have been given to other informational attitudes, such as probabilistic common belief [61] and qualitative non-negatively introspective “knowledge” [62]. These results naturally suggest dynamic scenarios, and indeed [63] have shown that agreement can be dynamically reached by repeated Bayesian conditioning, given common prior beliefs.
The logical tools introduced above provide a unifying framework for these various generalizations, and allow to extend them to other informational attitudes. For the sake of conciseness, we will not cover static agreement results in this paper. The interested reader can consult [64,65].
For a start, we will focus on a comparison between agreements reached via conditioning and via public announcements, reporting the work of [65]. In the next section, we show how generalized scenarios of this sort can also deal with softer forms of information change, allowing for diversity in update policies within groups.
Repeated Conditioning Lead to Agreements
The following example, inspired by a recent Hollywood production, illustrates how agreements are reached by repeated belief conditioning:
Example 3.1
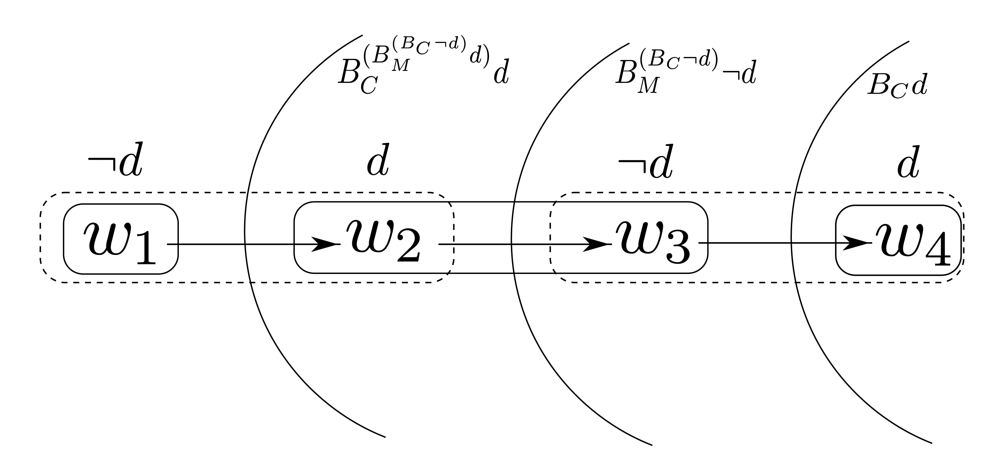
Cobb and Mal are standing on a window ledge, arguing whether they are dreaming or not. Cobb needs to convince Mal, otherwise dreadful consequences will ensue. For the sake of the example, let us assume that Cobb knows they are not dreaming, but Mal mistakenly believes that they are: state w1 in Figure 1. The solid and dashed rectangles represent, respectively, Cobb's and Mal's hard information. The arrow is their common plausibility ordering.
With some thinking, Mal can come to agree with Cobb. The general procedure for achieving this goes as follows: A sequence of simultaneous belief conditioning acts starts with the agents' simple belief about φ, i.e. for all i, the first element 𝔹1i, in the sequence is Biφ if , w ⊨ Biφ, and ¬Biφ otherwise. Agent i′s beliefs about φ at a successor stage are defined by taking her beliefs about φ, conditional upon learning the others' belief about φ at that stage. Formally, for two agents i,j then: if , and otherwise.29
Following the zones marked with an arc in Figure 1, the reader can check that, at w1, Mal needs three rounds of conditioning to switch her belief about their waking, and thus reach an agreement with Cobb. Her belief stays the same upon learning that Cobb believes that they are not dreaming. Let us call this fact φ. The turning point occurs when she learns that Cobb would not change his mind even if he would learn φ. Conditional on this, she now believes that they are indeed not dreaming. Note that Cobb's beliefs stay unchanged throughout, since he knows the true state at the outset.
Iterated conditioning thus leads to agreement, given common priors. Indeed, conditioning induces a decreasing map from subsets to subsets, which guarantees the existence of a fixed points, where all agent's conditional beliefs stabilize. Once the agents have reached this fixed-point, they have eliminated all higher-order uncertainties concerning the posteriors beliefs about φ of the others. Their posteriors beliefs are now common knowledge:
Theorem 3.2 ([65])
At the fixed-point n of a sequence of simultaneous conditioning acts on φ, for all w ∈W and i ∈ I, we have that:
The reader accustomed to static agreement theorems will see that we are now only a small step away from concluding that sequences of simultaneous conditionings lead to agreements, as it is indeed the case in our example. Since common prior and common belief of posteriors suffice for agreement, we get:
Corollary 3.3
Take any sequence of conditioning acts for a formula φ, as defined above, in a finite model with common prior. At the fixed point of this sequence, either all agents believe φ or they all don't believe φ.
This recasts, in our logical framework, the result of [63], showing how “dialogs” lead to agreements. Still, belief conditioning has a somewhat private character.30 In the example above, Cobb remains painfully uncertain of Mal's thinking process until he sees her changing her mind, that is until she makes the last step of conditioning. Luckily for Cobb, they can do better, as we will now proceed to show.
Repeated Public Announcements Lead to Agreements
Figure 2 shows another scenario, where Cobb and Mal publicly and repeatedly announce their beliefs at w1. They keep announcing the same thing, but each time, this induces important changes in both agents' higher-order information. Mal is led stepwise to realize that they are not dreaming, and crucially, Cobb also knows that Mal receives and processes this information. As the reader can check, at each step in the process, Mal's beliefs are common knowledge.
One again, Figure 2 exemplifies a general fact. We first define a dialogue about φ as a sequence of public announcements. Let , w be a finite pointed
epistemic-doxastic model.31 Now let , i′s original belief state at w, be Biφ if this formula holds at w, and ¬Biφ, otherwise. Agent i′s n + 1 belief state, written is defined as if , and as otherwise. Intuitively, a dialogue about φ is a process in which all agents in a group publicly and repeatedly announce their posterior beliefs about φ, while updating with the information received in each round.
In dialogues, just like with belief conditioning, iterated public announcements induce decreasing maps between epistemic-doxastic models, and thus are bound to reach a fixed point, where no further discussion is needed. At this point, the protagonists are guaranteed to have reached consensus:
Theorem 3.4 ([65])
At the fixed-point n, w of a public dialogue about φ among agents in a group I:
Corollary 3.5 ([65])
For any public dialogue about φ, if there is a common prior that is a well-founded plausibility order, then at the fixed-point n, w, either all agents believe φ or all do not believe φ.
As noted in the literature [63,64], the preceding dynamics of agreement is one of higher-order information. In the examples above, Mal's information about the ground facts of dreaming or not dreaming, does not change until the very last round of conditioning or public announcement. The information she gets by learning about Cobb's beliefs affects her higher-order beliefs, i.e., what she believes about Cobb's information. This importance of higher-order information flow is a general phenomenon, well-known to epistemic game theorists, which the present logical perspective treats in a unifying way.
Agreements and Dynamics: Further Issues
Here are a few points about the preceding scenarios that invite generalization. Classical agreement results require the agents to be “like-minded” [66]. Our analysis of agreement in dynamic-epistemic logic reveals that this like-mindedness extends beyond the common prior assumption: it also requires the agents to process the information they receive in the same way.32 One can easily find counter-examples to the agreement theorems when the update rule is not the same for all agents. Indeed, the issue of “agent diversity” is largely unexplored in our logics (but see [12] for an exception).
A final point is this. While agreement scenarios seem special, to us, they demonstrate a general topic, viz. how different parties in a conversation, say a “Skeptic” and an ordinary person, can modify their positions interactively. In the epistemological literature, this dynamic conversational feature has been neglected—and the above, though solving things in a general way, at least suggests that there might be interesting structure here of epistemological interest.
3.2. Logical Issues about Hard and Soft Limit Behavior
One virtue of our logical perspective is that we can study the above limit phenomena in much greater generality.
Hard information
For a start, for purely logical reasons, iterated public announcement of any formula φ in a model must stop at a limit model lim(, φ) where φ has either become true throughout (it has become common knowledge), or its negation is true throughout.33 This raises an intriguing open model-theoretic problem of telling, purely from syntactic form, when a given formula is uniformly “self-fulfilling” (the case where common knowledge is reached), or when “self-refuting” (the case where common knowledge is reached of the negation). Game-theoretic assertions of rationality tend to be self-fulfilling, as we shall see in Section 4 below. But there is no stigma attached to the self-refuting case: e.g., the ignorance assertion in the famous Muddy Children puzzle is self-refuting in the limit. Thus, behind our single scenarios, there is a whole area of limit phenomena that have not yet been studied systematically in epistemic logic.34
In addition to definability, there is complexity and proof. Van Benthem [4] shows how announcement limit submodels can be defined in various known epistemic fixed-point logics, depending on the syntactic shape of φ. Sometimes the resulting formalisms are decidable, e.g., when the driving assertion φ has “existential positive form”, as in the mentioned Muddy Children puzzle, or simple rationality assertions in games.
But these scenarios are still quite special, in that the same assertion gets repeated. There is large variety of further long-term scenarios in the dynamic logic literature, starting from the “Tell All” protocols in [69-71] where agents tell each other all they know at each stage, turning the initial distributed knowledge of the group into explicit common knowledge.
Soft information
In addition to the limit dynamics of knowledge under hard information, there is the limit behavior of belief, making for more realistic dialog scenarios. This allows for more interesting phenomena in the earlier update sequences. An example is iterated hard information dovetailing agents' opinions, flipping sides in the disagreement until the very last steps of the dialogue (cf. [33] and [72], p.110-111). Such disagreement flips can occur until late in the exchange, but as we saw above, they are bound to stop at some point.
All these phenomena get even more interesting mathematically with dialogs involving soft announcements [⇑φ], when limit behavior can be much more complex, as we will see in the next section. Some relevant observations can be found in [71], and in Section 4 below. First, there need not be convergence at all, the process can oscillate:
Example 3.6
Suppose that φ is the formula (r ∨ (B¬rq Λ p) ∨ (B¬rp ∧ q)) and consider the one agent epistemic-doxastic models pictured below. Since , we have Furthermore, , so . Since, 3 is the same model as 1, we have a cycle:
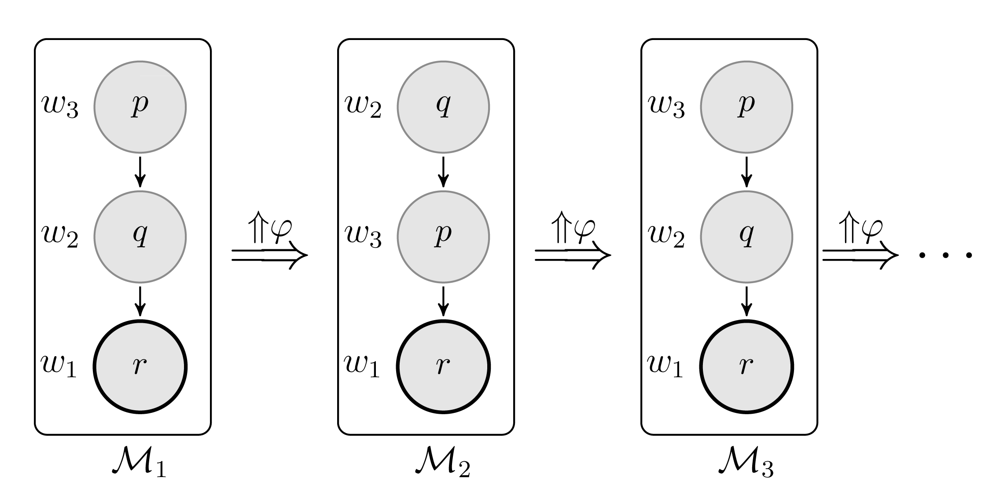
In line with this, players' conditional beliefs may keep changing along the stages of an infinite dialog.35 But still, there is often convergence at the level of agents' absolute factual beliefs about that the world is like. Indeed, here is a result from [71]:
Theorem 3.7
Every iterated sequence of truthful radical upgrades stabilizes all simple non-conditional beliefs in the limit.
Belief and Preference Merge
Finally, we point at some further aspects of the topics raised here. Integrating agents' orderings through some prescribed process has many similarities with other areas of research. One is belief merge where groups of agents try to arrive at a shared group plausibility rder, either as a way of replacing individual orders, or as a way of creating a further group agent that is a most reasonable amalagam of the separate components. And this scenario is again much like those of social choice theory, where individual agents have to aggregate preference orders into some optimal public ordering. This naturally involves dynamic analysis of the processes of delberation that lead to the eventual act of voting.36 Thus, the technical issues raised in this section have much wider impact. We may be seeing the contours of a systematic logical study of conversation, deliberation and related social processes.
3.3. Learning
We conclude this section with one concrete setting where many of the earlier themes come together, viz. formal learning theory: see [76–78]. The paradigm we have in mind is identification in the limit of correct hypotheses about the world (cf. [79] on language learning), though formal learning theory in epistemology has also studied concrete learning algorithms for inquiry of various sorts.
The learning setting shows striking analogies with the dynamic-epistemic logics that we have presented in this paper. What follows is a brief summary of recent work in [80,81], to show how our logics link up with learning theory. For broader philosophical backgrounds in epistemology, we refer to [82]. The basic scenario of formal learning theory is one of an agent trying to formulate correct and informative hypotheses about the world, on the basis of an input stream of evidence (in general, an infinite history) whose totality describes what the world is like. At each finite stage of such a sequence, an agent outputs a current hypothesis about the world, which can be modified as new evidence comes in. Success of such a learning function in recognition can be of two kinds: either a correct hypothesis is identified uniformly on all histories by some finite stage (the strong notion of “finite identifiability”), or more weakly, each history reaches a point where a correct hypothesis is stated, but when that is may vary according to the history (“identifiability in the limit”). There is a rich mathematical theory of learning functions and what classes of hypotheses can, and cannot, be described by them.
Now, it is not hard to recognize many features here of the logical dynamics that we have discussed. The learning function outputs beliefs, that get revised as new hard information comes in (we think of the observation of the evidence stream as a totally reliable process). Indeed, it is possible to make very precise connections here. We can take the possible hypotheses as our possible worlds, each of which allows those evidence streams (histories of investigation) that satisfy that hypothesis. Then observing successive pieces of evidence is a form of public announcement allowing us to prune the space of worlds. The beliefs involved can be modeled as we did before, by a plausibility ordering on the set of worlds for the agent, which may be modified by successive observations.
On the basis of this simple analogy, [83] prove results like the following, making connections very tight:
Theorem 3.8
Public announcement-style eliminative update is a universal method: for any learning function, there exists a plausibility order that encodes the successive learning states as current beliefs. The same is true, taking observations as events of soft information, for radical upgrade of plausibility orders.
Theorem 3.9
When evidence streams may contain a finite amount of errors, public announcement-style update is no longer a universal learning mechanisms, but radical upgrade still is.
With these bridges in place, one can also introduce logical languages in the learning-theoretic universe. [80] show how many notions in learning theory then become expressible in dynamic-epistemic or epistemic-temporal languages, say convergence in the limit as necessary future truth of knowledge of a correct hypothesis about the world. 37 Thus, we seem to be witnessing the beginning of merges between dynamic logic, belief revision theory and learning theory.
Such combinations of dynamic epistemic logic and learning theory also invite comparison with game theory Learning, for instance, to coordinate on a Nash equilibrium in repeated games, has been extensively studied, with many positive and negative results—see, for example, [84].38
This concludes our exploration of long-term information dynamics in our logical setting. We have definitely not exhausted all possible connections, but we hope to have shown how a general Theory of Play fits in naturally with many different areas, providing a common language between them.
4. Solution Dynamics on Extensive Games
We now return to game theory proper, and bring our dynamic logic perspective to bear on an earlier benchmark example: Backwards Induction. This topic has been well-discussed already by eminent authors, but we hope to add a number of new twists suggesting broader ramifications in the study of agency.
In the light of logical dynamics, the main interest of a solution concept is not its “outcome”, its set of strategy profiles, but rather its “process”, the way in which these outcomes are reached. Rationality seems largely a feature of procedures we follow, and our dynamic logics are well-suited to focus on that.
4.1. First Scenario: Iterated Announcement of Rationality
Here is a procedural line on Backwards Induction as a rational process. We can take BI to be a process of prior off-line deliberation about a game by players whose minds proceed in harmony, though they need not communicate in reality. The treatment that follows was proposed by [22] (which mainly deals with strategic games), and studied in much greater detail by [85].
As we saw in Section 3, public announcements saying that some proposition φ is true transform an epistemic model into its submodel |φ whose domain consists of just those worlds in M that satisfy φ. Now the driving assertion for the Backwards Induction procedure is the following assertion. It states essentially the notion of Rationality discussed in our static analysis of Section 1. As before, at a turn for player i, a move a is dominated by a sibling b (a move available at the same node) if every history through a ends worse, in terms of i′s preference, than every history through b:
“at the current node, no player ever chose a strictly dominated move coming here” (rat)
This makes an informative assertion about nodes in a game tree, that can be true or false. Thus, announcing this formula rat as a fact about the players will in general make the current game tree smaller. But then we get a dynamics of iteration as in our scenarios of Section 3. In the new smaller game tree, new nodes may become dominated, and hence announcing rat again (saying that it still holds after this round of deliberation) makes sense, and so on. As we have seen, this process must reach a limit:
Example [Solving games through iterated assertions of Rationality.] Consider a game with three turns, four branches, and pay-offs for A, E in that order:
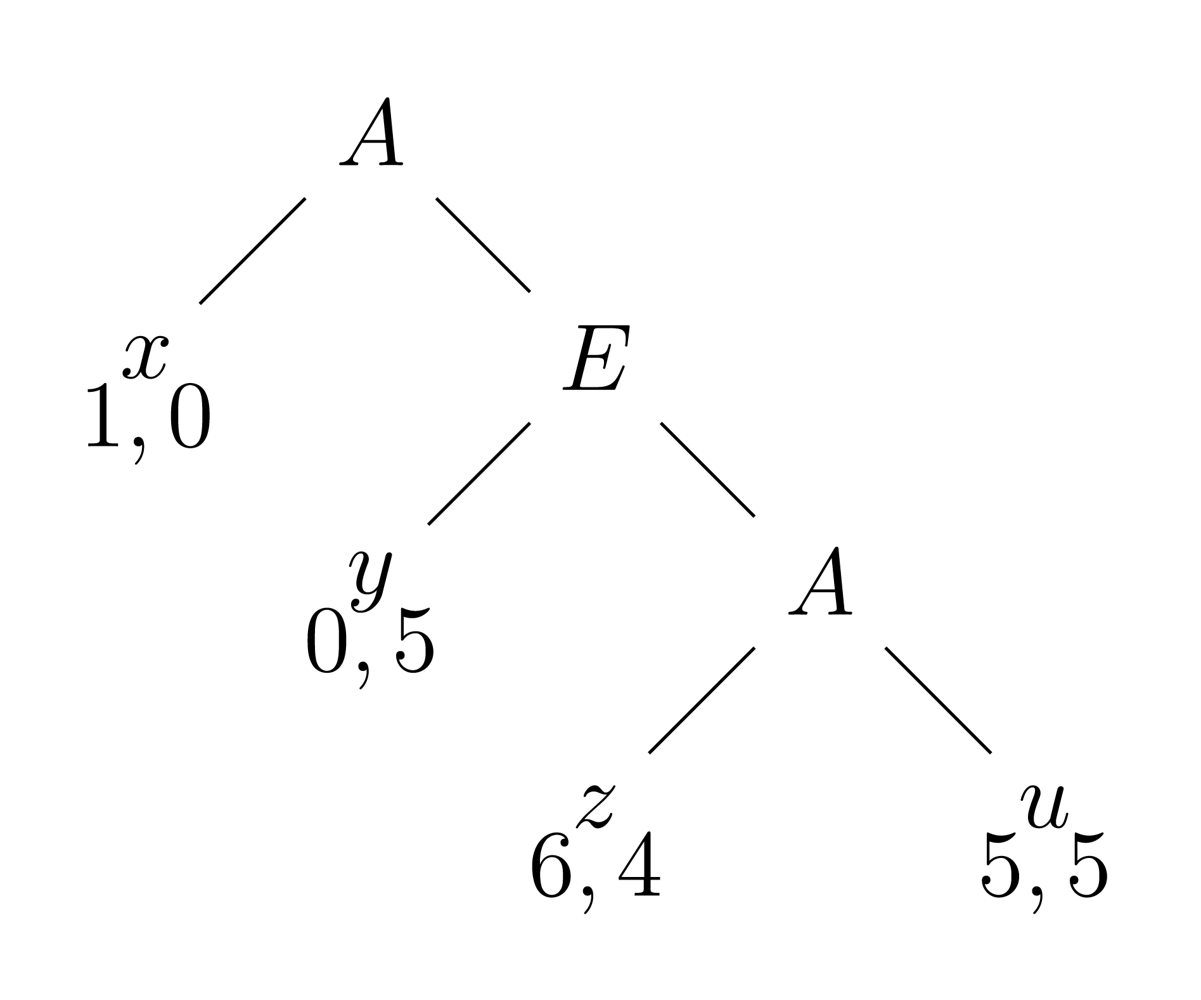
Stage 0 rules out u, the only point where rat fails, Stage 1 rules out z and the node above it (the new points where rat fails), and Stage 2 rules out y and the node above it. In the remaining game, Rationality reigns supreme:

We see how the BI solution emerges from the given game step by step. The general result follows from a simple correspondence between subrelations of the total move relation and sets of nodes ([85] has a precise proof with full details):
Theorem 4.1
In any game tree , the model (rat, )# is the actual subtree computed by the BI procedure.
The logical background here is just as we have seen earlier in our epistemic announcement dynamics. The actual BI play is the limit sub-model, where rat holds throughout. In terms of our earlier distinction, this means that Rationality is a “self-fulfilling” proposition: its announcement eventually makes it rue everywhere, and hence common knowledge of rationality emerges in the process. Thus, the algorithmic definition of the BI procedure in Section 1 and our iterated announcement scenario amount to the same thing. One might say then that our deliberation scenario is just a way of “conversationalizing” a mathematical fixed-point computation. Still, it is of independent interest. Viewing a game tree as an logical model, we see how repeated announcement of Rationality eventually makes this property true throughout the remaining model: it has made itself into common knowledge.
4.2. Second Scenario: Belief and Soft Plausibility Upgrade
Many foundational studies in game theory view Rationality as choosing a best action given what one believes about the current and future behaviour of the players. An appealing alternative take on the BI procedure does not eliminate any nodes of the initial game, but rather endows it with “progressive expectations” on how the game will proceeed. This is the plausibility dynamics that we studied in Section 3, now performing a soft announcement of rat, where the appropriate action is the “radical upgrade” studied earlier. The essential information produced by the algorithm is then in the binary plausibility relations that it creates inductively for players among end nodes in the game, standing for complete histories or “worlds”:
Example
[The BI outcome in a soft light.] A soft scenario does not remove nodes but modifies the plausibility relation. To implement this, we start with all endpoints of the game tree incomparable.39 Next, at each stage, we compare sibling nodes, using this notion:
A move x for player i dominates its sibling y in beliefs if the most plausible end nodes reachable after x along any path in the whole game tree are all better for the active player than all the most plausible end nodes reachable in the game after y.
Rationality* (rat*) says no player plays a move that is dominated in beliefs. Now we perform essentially a radical upgrade ⇑rat*:40
If game node x dominates node y in beliefs, make all end nodes reachable from x more plausible than those reachable from y, keeping the old order inside these zones.
This changes the plausibility order, and hence the pattern of dominance-in-belief, so that iteration makes sense. Here are the stages in our earlier example, where letters x, y, z stand for the end nodes of the game:
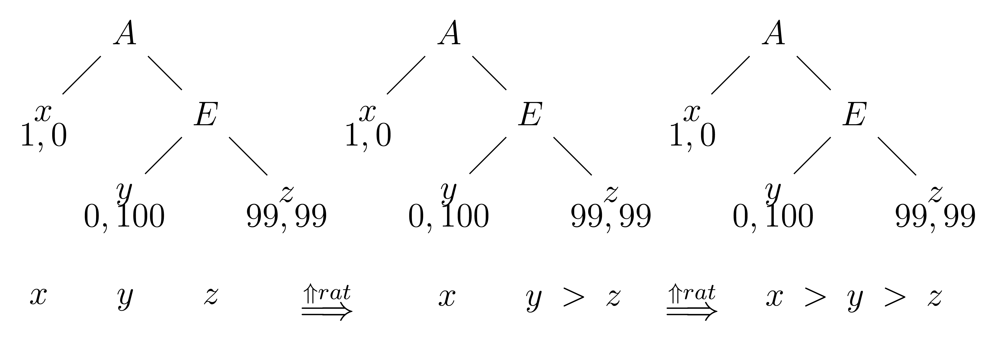
In the first game tree, going right is not yet dominated in beliefs for A by going left. rat* only has bite at E′s turn, and an upgrade takes place that makes (0, 100) more plausible than (99, 99). After this upgrade, however, going right has now become dominated in beliefs, and a new upgrade takes place, making A's going left most plausible. Here is the general result [33,85]:
Theorem 4.2
On finite trees, the Backwards Induction strategy is encoded in the plausibility order for end nodes created by iterated radical upgrade with rationality-in-belief.
Again this is “self-fulfilling”: at the end of the procedure, the players have acquired common belief in rationality. An illuminating way of proving this uses an idea from [86]:
Strategies as plausibility relations
Each sub-relation R of the total move relation induces a total plausibility order ord(R) on endpoints of a game:
x ord(R) y iff, looking up at the first node z where the histories of x,y diverged, if x was reached via an R move from z, then so is y.
More generally, relational strategies correspond one-to-one with “move-compatible” total orders of endpoints. In particular, conversely, each such order ≤ induces a strategy rel(≤). Now we can relate the computation in our upgrade scenario for belief and plausibility to the earlier relational algorithm for BI in Section 1:
Fact 4.3
For any game tree and any k, rel ((⇑rat*)k, )) = BIk.
Thus, the algorithmic view of Backwards Induction and its procedural doxastic analysis in terms of forming beliefs amount to the same thing. Still, as with our iterated announcement scenario, the dynamic logical view has interesting features of its own. One is that it yields fine-structure to the plausibility relations among worlds that are usually taken as primitive in doxastic logic. Thus games provide an underpinning for the possible worlds semantics of belief that seems of interest per se.
4.3. Logical Dynamic Foundations of Game Theory
We have seen how several dynamic approaches to Backwards Induction amount to the same thing. To us, this means that the notion is logically stable. Of course, extensionally equivalent definitions can still have interesting intensional differences. For instance, the above analysis of strategy creation and plausibility change seems the most realistic description of the “entanglement” of belief and rational action in the behaviour of agents. But as we will discuss soon, a technical view in terms of fixed-point logics may be the best mathematical approach linking up with other areas.
No matter how we construe them, one key feature of our dynamic announcement and upgrade scenarios is this. Unlike the usual epistemic foundation results, common knowledge or belief of rationality is not assumed, but produced by the logic. This reflects our general view that rationality is primarily a property of procedures of deliberation or other logical activities, and only secondarily a property of outcomes of such procedures.
4.4. Logics of of Game Solution: General Issues
Our analysis does not just restate existing game-theoretic results, it also raises new issues in the logic of rational agency. Technically, all that has been said in Sections 2 an 3 can be formulated in terms of existing fixed-point logics of computation, such as the modal “μ-calculus” and the first-order fixed-point logic LFP(FO). This link with a well-developed area of computational logic is attractive, since many results are known there, and we may use them to investigate game solution procedures that are quite different from Backwards Induction.41 But the analysis of game solutions also brings some new logical issues to this area.
Game solution and fragments of fixed-point logics
Game solution procedures need not use the full power of fixed-point languages for recursive procedures. It makes sense to use small decidable fragments where appropriate. Still, it is not quite clear right now what the best fragments are. In particular, our earlier analysis intertwines two different relations on trees: the move relation of action and computation, and the preference relations for players on endpoints. And the question is what happens to known properties of computational logics when we add such preference relations:
The complexity of rationality
In combined logics of action and knowledge, it is well-known that apparently harmless assumptions such as Perfect Recall for agents make the validities undecidable, or non-axiomatizable, sometimes even -complete [15]. The reason is that these assumptions generate commuting diagrams for actions move and epistemic uncertainty ∼ satisfying a “confluence property”
These patterns serve as the basic grid cells in encodings of complex “tiling problems” in the logic.42 Thus, the logical theory of games for players with perfect memory is more complex than that of forgetful agents [15,18]. But now consider the non-epistemic property of rationality studied above, that mixes action and preference. Our key property CF in Section 1 had a confluence flavour, too, with a diagram involving action and preference:
So, what is the complexity of fixed-point logics for players with this kind of regular behaviour? Can it be that Rationality, a property meant to make behaviour simple and predictable, actually makes its theory complex?
Zooming in and zooming out: modal logics of best action
The main trend in our analysis has been toward making dynamics explicit in richer logics than the usual epistemic-doxastic-preferential ones, in line with the program in [33]. But in logical analysis, there are always two opposite directions intertwined: getting at important reasoning patterns by making things more explicit, or rather, by making things less explicit!
In particular, in practical reasoning, we are often only interested in what are our best actions without all details of their justification. As a mathematical abstraction, it would then be good to extract a simple surface logic for reasoning with best actions, while hiding most of the machinery:
Can we axiomatize the modal logic of finite game trees with a move relation and its transitive closure, turns and preference relations for players, and a new relation best computed by Backwards Induction?
Further logical issues in our framework concern extensions to infinite games games with imperfect information, and scenarios with diverse agents. See [12,72,87] for some first explorations.
4.5. From Games to Their Players
We end by high-lighting a perhaps debatable assumption of our analysis so far. It has been claimed that the very Backwards Induction reasoning that ran so smoothly in our presentation, is incoherent when we try to “replay” it in the opposite order, when a game is actually played.43
Example [The ‘Paradox of Backwards Induction'.] Recall the style of reasoning toward a Backward Induction solution, as in our earlier simple scenario:
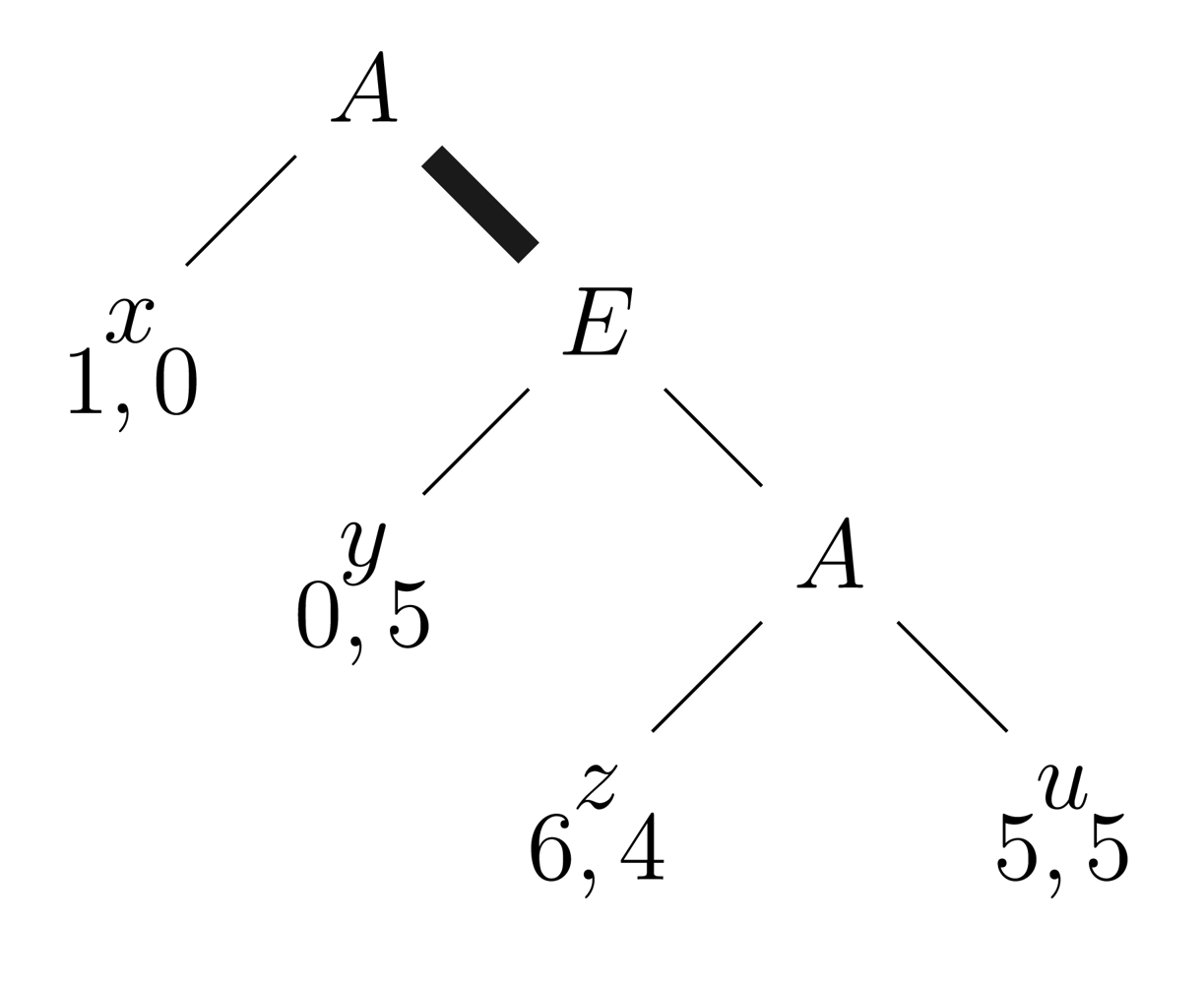
Backwards Induction tells us that A will go left at the start, on the basis of logical reasoning that is available to both players. But then, if A plays right (as marked by the thick black line) what should E conclude? Does not this mean that A is not following the BI reasoning, and hence that all bets are off as to what he will do later on in the game? It seems that the very basis for the computations in our earlier sections collapses.44
Responses to this difficulty vary. Many game-theorists seem under-impressed. The characterization result of [89] assumes that players know that rationality prevails throughout.45 One can defend this behaviour by assuming that the other player only makes isolated mistakes. Baltag, Smets and Zvesper [86] essentially take the same tack, deriving the BI strategy from an assumption of “stable true belief” in rationality, a gentler form of stubbornness stated in terms of dynamic-epistemic logic.
Players' revision policies
We are more inclined toward the line of [91,92]. A richer analysis should add an account of the types of agent that play the game. In particular, we need to represent the belief revision policies of the players, that determine what they will do when making a surprising observation contradicting their beliefs in the course of a game. There are many different options for such policies in the above example, such as “It was just an error, and A will go back to being rational”, “A is telling me that he wants me to go right, and I will be rewarded for that”, “A is an automaton with a general rightward tendency”, and so on.46 Our analysis so far has omitted this type of information about players of the game, since our algorithms made implicit uniform assumptions about their prior deliberation, as well as what they are going to do as the game proceeds.
This matching up of two directions of thought: backwards in “off-line dynamics” of deliberation, and forwards in “on-line dynamics” of playing the actual game, is a major issue in its own right, beyond specific scenarios. Belief revision policies and other features of players must come in as explicit components of the theory, in order to deal with the dynamics of how players update knowledge and revise beliefs as a game proceeds.
But all this is exactly what the logical dynamics of Section 2 is about. Our earlier discussion has shown how acts of information change and belief revision can enter logic in a systematic manner. Thus, once more, the richer setting that we need for a truly general theory of game solution is a perfect illustration for the general Theory of Play that we have advocated.
5. Conclusion
Logic and game theory form a natural match, since the structures of game theory are very close to being models of the sort that logicians typically study. Our first illustrations reviewed existing work on static logics of game structure, drawing attention to the fixed-point logic character of game solution methods. This suggests a broader potential for joining forces between game theory and computational logic, going beyond specific scenarios toward more general theory. To make this more concrete, we then presented the recent program of “logical dynamics” for information-driven agency, and showed how it throws new light on basic issues studied in game theory, such as agreement scenarios and game solution concepts.
What we expect from this contact is not the solution of problems afflicting game theory through logic, or vice versa, remedying the aches and pains of logic through game theory. Of course, game theorists may be led to new thoughts by seeing how a logician treats (or mistreats) their topics, and also, as we have shown, logicians may see interesting new open problems through the lense of game theory.
But fruitful human relations are usually not therapeutic: they lead to new facts, in the form of shared offspring. In particular, one broad trend behind much of what we have discussed here is this. Through the fine-structure offered by logic, we can see the dynamics of games as played in much more detail, making them part of a general analysis of agency that also occurs in many other areas, from “multi-agent systems” in computer science to social epistemology and the philosophy of action. It is our expectation that the offspring of this contact might be something new, neither fully logic nor game theory: a Theory of Play, rather than just a theory of games.

References and Notes
- Epsitemic Logic and the Theory of Games and Decisions; Bacharach, M., Gerard-Varet, L., Mongin, P., Shin, H., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1997.
- Van der Hoek, W.; Pauly, M. Modal logic for games and information. In Handbook of Modal Logic; Blackburn, P., van Benthem, J., Wolter, F., Eds.; Elsevier: Amsterdam, The Netherlands, 2006; pp. 1077–1148. [Google Scholar]
- Bonanno, G. Modal logic and game theory: Two alternative approaches. Risk Decis. Policy 2002, 7, 309–324. [Google Scholar]
- Van Benthem, J. Games in dynamic epistemic logic. Bull. Econ. Res. 2001, 53, 219–248. [Google Scholar]
- Brandenburger, A. The power of paradox: Some recent developments in interactive epistemology. Int. J. Game Theory 2007, 35, 465–492. [Google Scholar]
- Aumann, R. Interactive epistemology I: Knowledge. Int. J. Game Theory 1999, 28, 263–300. [Google Scholar]
- Seligman, J. Hybrid logic for analyzing games. Presented at the Workshop Door to Logic, Beijing, China, May 2010.
- Van Benthem, J. Modal Logic for Open Minds; CSLI Publications: Stanford, CA, USA, 2010. [Google Scholar]
- Blackburn, P.; de Rijke, M.; Venema, Y. Modal Logic; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Von Wright, G.H. The Logic of Preference; University of Edinburgh Press: Edinburgh, UK, 1963. [Google Scholar]
- Hansson, S.O.; Grüne-Yanoff, T. Preferences. In The Stanford Encyclopedia of Philosophy, Spring 2009 ed.; Zalta, E.N., Ed.; Stanford University: Stanford, CA, USA, 2009. [Google Scholar]
- Liu, F. Changing for the Better: Preference Dynamics and Agent Diversity. Ph.D Thesis, Institute for Logic, Language and Computation (DS-2008-02), University of Amsterdam, Amsterdam, The Netherlands, 2008. [Google Scholar]
- Van Benthem, J.; Girard, P.; Roy, O. Everything Else Being Equal: A Modal Logic for Ceteris Paribus Preferences. J. Phil. Logic 2009, 38, 83–125. [Google Scholar]
- Girard, P. Modal Logic for Belief and Preference Change. Ph.D Thesis, Stanford University, Stanford, CA, USA, 2008. [Google Scholar]
- Halpern, J.; Vardi, M. The complexity of reasoning about knowledge and time. J. Comput. Syst. Sci. 1989, 38, 195–237. [Google Scholar]
- Marx, M. Complexity of modal logic. In Handbook of Modal Logic; Blackburn, P., van Benthem, J., Wolter, F., Eds.; Elsevier: Amsterdam, The Netherlands, 2006; pp. 139–189. [Google Scholar]
- Gabbay, D.; Kurucz, A.; Wolter, F.; Zakharyaschev, M. Many-Dimensional Modal Logics: Theory and Applications; Elsevier: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Van Benthem, J.; Pacuit, E. The tree of knowledge in action: Towards a common perspective. Proceedings of Advances in Modal Logic Volume 6, Queensland, Australia, 25–28 September 2006; Governatori, G., Hodkinson, I., Venema, Y., Eds.; King's College Press: London, UK, 2006; pp. 87–106. [Google Scholar]
- Van Benthem, J. Exploring Logical Dynamics; CSLI Press: Stanford, CA, USA, 1996. [Google Scholar]
- Aumann, R.J. Correlated equilibrium as an expression of bayesian rationality. Econometrica 1987, 55, 1–18. [Google Scholar]
- Brandenburger, A.; Friedenberg, A. Intrinsic correlations in games. J. Econ. Theor. 2008, 141, 28–67. [Google Scholar]
- Van Benthem, J. Rational dynamics and epistemic logic in games. Int. J. Game Theory Rev. 2007, 9, 13–45. [Google Scholar]
- De Bruin, B. Explaining Games: The Epsitemic Programme in Game Theory; Springer: Berlin, Germany, 2010. [Google Scholar]
- Bonanno, G. A Syntactic Approach to Rationality in Games with Ordinal Payoffs. In Logic and the Foundations of Game and Decision Theory; Bonanno, G., van der Hoek, W., Wooldridge, M., Eds.; Amsterdam University Press: Amsterdam, The Netherlands, 2008; pp. 59–86. [Google Scholar]
- Van Benthem, J. Open problems in logic and games. In We Will Show Them! Essays in Honour of Dov Gabbay; Artemov, S., Barringer, H., d'Avila Garcez, A., Lamb, L., Woods, J., Eds.; College Publications: London, UK, 2005. [Google Scholar]
- Lorini, E.; Schwarzentruber, F.; Herzig, A. Epistemic games in modal logic: Joint actions, knowledge and preferences all together. Proceedings of LORI-II: Workshop on Logic, Rationality and Interaction, Chongqing, China; He, X., Horty, J., Pacuit, E., Eds.; Springer-Verlag: Berlin, Germany; pp. 212–226.
- Harel, D.; Kozen, D.; Tiuryn, J. Dynamic Logic; The MIT Press: Cambridge, UK, 2000. [Google Scholar]
- Harrenstein, B.; van der Hoek, W.; Meyer, J.J.; Witteveen, C. A modal characterization of Nash Equilibrium. Fund. Inform. 2003, 57, 281–321. [Google Scholar]
- Van Benthem, J. In Praise of Strategies. In Technical report, PP-2008-03; Institute for Logic, Language and Computation: Amsterdam, The Netherlands, 2008. [Google Scholar]
- Van Benthem, J.; van Otterloo, S.; Roy, O. Preference logic, conditionals, and solution concepts in games. In Modality Matters: Twenty-Five Essays in Honour of Krister Segerberg; Lagerlund, H., Lindström, S., Sliwinski, R., Eds.; Uppsala University Press: Uppsala, Sweden, 2006; Volume 53. [Google Scholar]
- Ebbinghaus, H.D.; Flum, J. Finite Model Theory; Springer: Berline, Germany, 1995. [Google Scholar]
- Gheerbrant, A. Fixed-Point Logics on Trees. Ph.D Thesis, Institute for Logic, Language and Information, University of Amsterdam, Amsterdam, The Netherlands, 2010. [Google Scholar]
- Van Benthem, J. Logical Dynamics of Information and Interaction; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Van Benthem, J. Rational Animals: What is ‘KRA’? Presented at ESSLLI Summer School, Malaga, Spain; 2006. [Google Scholar]
- Baltag, A.; Smets, S. Conditional Doxastic Models: A Qualitative Approach to Dynamic Belief Revision. In Electronic Notes in Theoretical Computer, Proceedings of the 13th Workshop on Logic, Language, Information and Computation (WoLLIC 2006), Stanford University, CA, USA, 18–21 July 2006; Mints, G., de Queiroz, R., Eds.; Elsevier: Amsterdam, The Netherlands, 2006; 165, pp. 5–21. [Google Scholar]
- Schwitzgebel, E. Belief. In The Stanford Encyclopedia of Philosophy, Fall 2008 ed.; Zalta, E.N., Ed.; Stanford University: Stanford, CA, USA, 2008. [Google Scholar]
- Plaza, J. Logics of public communications. Proceedings of the 4th International Symposium on Methodologies for Intelligent Systems, Charlotte, NC, USA; Emrich, M.L., Pfeifer, M.S., Hadzikadic, M., Ras, Z., Eds.; 1989; pp. 201–216. [Google Scholar]
- Gerbrandy, J. Bisimulations on Planet Kripke. Ph.D Thesis, Institute for Logic, Language and Computation, University of Amsterdam, Amsterdam, The Netherlands, 1999. [Google Scholar]
- Fagin, R.; Halpern, J.; Moses, Y.; Vardi, M. Reasoning about Knowledge; The MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Vanderschraaf, P.; Sillari, G. Common knowledge. In The Stanford Encyclopedia of Philosophy, Spring 2009 ed.; Zalta, E.N., Ed.; Stanford University: Stanford, CA, USA, 2009. [Google Scholar]
- Lewis, D. Convention; Harvard University Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Cubitt, R.P.; Sugden, R. Common knowledge, salience and convention: A reconstruction of David Lewis' game theory. Econ. Phil. 2003, 19, 175–210. [Google Scholar]
- Van Benthem, J. Modal frame correspondences and fixed-points. Studia Logica 2006, 83, 133–155. [Google Scholar]
- Baltag, A.; Moss, L.; Solecki, S. The Logic of Common Knowledge, Public Announcements and Private Suspicions. Proceedings of the 7th Conference on Theoretical Aspects of Rationality and Knowledge (TARK 98), Evanston, IL, USA; Gilboa, I., Ed.; Morgan Kaufmann Publishers: San Francisco, CA, USA; pp. 43–56.
- Van Benthem, J.; van Eijck, J.; Kooi, B. Logics of communication and change. Inform. Comput. 2006, 204, 1620–1662. [Google Scholar]
- Alchourrón, C.E.; Gärdenfors, P.; Makinson, D. On the logic of theory change: Partial meet contraction and revision functions. J. Symbolic Logic 1985, 50, 510–530. [Google Scholar]
- Van Benthem, J. Dynamic logic for belief revision. J. Appl Non Classical Logics 2004, 14, 129–155. [Google Scholar]
- van Ditmarsch, H. Prolegomena to dynamic logic for belief revision. Synthese: Knowl. Ration. Action 2005, 147, 229–275. [Google Scholar]
- Board, O. Dynamic interactive epistemology. Games Econ. Behav. 2004, 49, 49–80. [Google Scholar]
- Boutilier, C. Conditional Logics for Default Reasoning and Belief Revision. Ph.D Thesis, University of Toronto, Toronto, Canada, 1992. [Google Scholar]
- Lamarre, P.; Shoham, Y. Knowledge, Certainty, Belief and Conditionalisation. Proceedings of the 4th International Conference on Principles of Knowledge Representation and Reasoning (KR'94), Bonn, Germany, 24–27 May; Doyle, J., Sandewall, E., Torasso, E., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1994; pp. 415–424. [Google Scholar]
- Shoham, Y.; Leyton-Brown, K. Multiagent Systems; Cambridge University Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Stalnaker, R. Iterated belief revision. Erkenntnis 2009, 70, 189–209. [Google Scholar]
- Battigalli, P.; Siniscalchi, M. Strong belief and forward induction reasoning. J. Econ. Theory 2002, 105, 356–391. [Google Scholar]
- Baltag, A.; Smets, S. ESSLLI 2009 course: Dynamic logics for interactive belief revision, Bordeaux, France, 2009. Available online: http://alexandru.tiddlyspot.com/ (accessed on 15 February 2011).
- Baltag, A.; Smets, S. A qualitative theory of dynamic interactive belief revision. In Logic and the Foundation of Game and Decision Theory (LOFT7); Bonanno, G., van der Hoek, W., Wooldridge, M., Eds.; Amsterdam University Press: Amsterdam, The Netherlands, 2008; Volume 3, pp. 13–60. [Google Scholar]
- Rott, H. Shifting priorities: Simple representations for 27 iterated theory change operators. In Modality Matters: Twenty-Five Essays in Honour of Krister Segerberg; Lagerlund, H., Lindström, S., Sliwinski, R., Eds.; Uppsala University Press: Uppsala, Sweden, 2006; Volume 53, pp. 359–384. [Google Scholar]
- Van Benthem, J. Dynamic logic for belief revision. J. Appl Non-Classical Logics 2007, 17, 129–155. [Google Scholar]
- Van Benthem, J.; Gerbrandy, J.; Hoshi, T.; Pacuit, E. Merging frameworks for interaction. J. Phil. Logic 2009, 38, 491–526. [Google Scholar]
- Aumann, R. Agreeing to disagree. Ann. Stat. 1976, 4, 1236–1239. [Google Scholar]
- Monderer, D.; Samet, D. Approximating common knowledge with common beliefs. Games Econ. Behav. 1989, 1, 170–190. [Google Scholar]
- Samet, D. Agreeing to disagree: The non-probabilistic case. Games Econ. Behav. 2010, 69, 169–174. [Google Scholar]
- Geanakoplos, J.; Polemarchakis, H. We can't disagree forever. J. Econ. Theory 1982, 28, 192–200. [Google Scholar]
- Bonanno, G.; Nehring, K. Agreeing to Disagree: A Survey. Document prepared of an invited lecture at the Workshop on Bounded Rationality and Economic Modeling, Firenze, Italy, 1–2 July 1997.
- Dégremont, C.; Roy, O. Agreement theorems in dynamic-epistemic logic. Proceedings of the 12th Conference on Theoretical Aspects of Rationality and Knowledge, Stanford, CA, USA; Heifetz, A., Ed.; ACM Digital Library: New York, NY, USA; pp. 91–98.
- Bacharach, M. Some extensions of a claim of Aumann in an axiomatic model of knowledge. J. Econ. Theory 1985, 37, 167–190. [Google Scholar]
- Baltag, A.; Smets, S. Talking Your Way into Agreement: Belief Merge by Persuasive Communication. Proceedings of the Second Multi-Agent Logics, Languages, and Organisations Federated Workshops, Turin, Italy, 7–10 September, 2009; Baldoni, M., Ed.; CEUR-WS.org: Tilburg, The Netherlands, 2009; 494, pp. 129–141. [Google Scholar]
- Holliday, W.; Icard, T. Moorean phenomena in epistemic logic. Proceedings of Advances in Modal Logic, Moscow, Russia; Beklemishev, L., Goranko, V., Shehtman, V., Eds.; College Publications: London, UK; 8, pp. 178–199.
- Van Benthem, J. One is a lonely number: On the logic of communication. Proceedings of the Annual European Summer Meeting of the Association for Symbolic Logic And Colloquium Logicum, Logic Colloquium'02, Munster, Germany, 3–11 August 2006; Chatzidakis, Z., Koepke, P., Pohlers, W., Eds.; A K Peters: Natick, MA, USA, 2006; 27, pp. 96–129. [Google Scholar]
- Roelofsen, F. Exploring Logical Perspectives on Distributed Information and Its Dynamics. Master Thesis, ILLC (LDC 2005-05). University of Amsterdam, Amsterdam, The Netherlands, 2005. [Google Scholar]
- Baltag, A.; Smets, S. Group Belief Dynamics under Iterated Revision: Fixed Points and Cycles of Joint Upgrades. Proceedings of the 12th Conference on Theoretical Aspects of Rationality and Knowledge, Stanford, CA, USA; Heifetz, A., Ed.; ACM Digital Library: New York, NY, USA, 2009; pp. 41–50. [Google Scholar]
- Dégremont, C. The Temporal Mind. Observations on the Logic of Belief Change in Interactive Systems. Ph.D Thesis, Institute for Logic, Language and Computation (DS-2010-03), University of Amsterdam, Amsterdam, The Netherlands, 2010. [Google Scholar]
- Gupta, A. Truth and Paradox. J. Phil. Logic 1982, 11, 1–60. [Google Scholar]
- Herzberger, H. Notes on naive semantics. J. Phil. Logic 1982, 11, 61–102. [Google Scholar]
- Visser, A. Semantics and the Liar Paradox. In Handbook of Philosophical Logic; Gabbay, D., Guenthner, F., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2004; Volume 11, pp. 149–240. [Google Scholar]
- Kelly, K. The Logic of Reliable Inquiry; Oxford University Press: Oxford, UK, 1996. [Google Scholar]
- Osherson, D.; Stob, M.; Weinstein, S. Systems that Learn; The MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Schulte, O. Formal Learning Theory. In The Stanford Encyclopedia of Philosophy, Winter 2008 ed.; Zalta, E.N., Ed.; Standford University: Stanford, CA, USA, 2008. [Google Scholar]
- Gold, E.M. Language identification in the limit. Inform. Control. 1967, 10, 447–474. [Google Scholar]
- Dégremont, C.; Gierasimczuk, N. Can Doxastic Agents Learn? On the Temporal Structure of Learning. Proceedings of LORI-II: Workshop on Logic, Rationality and Interaction, Chongqing, China, 6-11 October 2009; He, X., Horty, J., Pacuit, E., Eds.; Springer-Verlag: Berlin, Germany, 2009; pp. 90–104. [Google Scholar]
- Gierasimczuk, N. Knowing Ones Limits: Logical Analysis of Inductive Inference. Ph.D Thesis, Institute for Logic, Language and Computation, University of Amsterdam, Amsterdam, The Netherlands, 2011. [Google Scholar]
- Hendricks, V. Mainstream and Formal Epistemology; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Baltag, A.; Gierasimczuk, N.; Smets, S. Truth-tracking by belief revision. 2010. (Unpublished). [Google Scholar]
- Kalai, E.; Lehrer, E. Rational learning leads to Nash Equilibrium. Econometrica 1993, 61, 1019–1045. [Google Scholar]
- Van Benthem, J.; Gheerbrant, A. Game solution, epistemic dynamics and fixed-point logics. Fund. Inform. 2010, 100, 1–23. [Google Scholar]
- Baltag, A.; Smets, S.; Zvesper, J. Keep ‘hoping’ for rationality: A solution to the backward induction paradox. Synthese 2009, 169, 301–333. [Google Scholar]
- Zvesper, J. Playing with Information. Ph.D Thesis, Institute for Logic, Language and Computation, University of Amsterdam, Amsterdam, The Netherlands, 2010. [Google Scholar]
- Bicchieri, C. Self-refuting theories of strategic interaction: A paradox of common knowledge. Erkenntnis 1989, 30, 69–85. [Google Scholar]
- Aumann, R. Backward induction and common knowledge of rationality. Games Econ. Behav. 1995, 8, 6–19. [Google Scholar]
- Samet, D. Hypothetical knowledge and games with perfect information. Games Econ. Behav. 1996, 17, 230–251. [Google Scholar]
- Stalnaker, R. Knowledge, belief and counterfactual reasoning in games. Econ. Philos. 1996, 12, 133–163. [Google Scholar]
- Stalnaker, R. Substantive rationality and backward induction. Games Econ. Behav. 2001, 37, 425–435. [Google Scholar]
- Velázquez-Quesada, F.R. Small Steps in the Dynamics of Information. Ph.D Thesis, Institute for Logic, Language and Computation, University of Amsterdam, Amsterdam, The Netherlands, 2011. [Google Scholar]
- Plaza, J. Logics of public communications. Synthese: Knowl. Ration. Action 2007, 158, 165–179. [Google Scholar]
- 1We could also have more abstract worlds, carrying strategy profiles without being identical to them. This additional generality is common in epistemic game theory, see e.g. [6], but it is not needed in what follows.
- 2We have borrowed the appealing term “freedom” from [7].
- 3We cannot go into details of the modern modal paradigm here, but refer to the textbooks [8,9].
- 4See [11-13] for a contemporary discussion and references.
- 5For example, a proposition might say “agent i plays action a”.
- 6A formula is valid in a class of model whenever it is true at all states in all models of that class. C.f. [9, chap.1] for details.
- 7Cf. [15-18] for formal details behind the assertions in this paragraph.
- 8Cf. [4] for some concrete examples of modal “Gregorczyk axioms’.
- 9Cf. [19] for this, and what follows. Game theorists have also studied correlations extensively, c.f. [20,21]. The precise relation between our logical and their probabilistic approaches to correlations is still to be investigated.
- 10We omit the simple modal “bisimulation”-based argument here.
- 11Cf. [22] for technical details, including connections to epistemic “fixed-point logics” over game models, as well as applications to game solution procedures.
- 12For further illustrations of logics on strategic games, cf. [23-26].
- 13In what follows, we shall mainly work with finite games, though current dynamic and temporal logics can also deal with infinite games.
- 14"Game frames" here are extensive games extended with one more binary relation σ.
- 15One can use the standard defining sequence for a greatest fixed-point, starting from the total move relation, and see that its successive decreasing approximation stages Sk are exactly the ‘active move stages’ of the above algorithm. This and related connections have been analyzed in greater mathematical detail in [32].
- 16Note that the distinction “hard” versus “soft” information has to do with the way agents take an incoming new signal that some proposition is true. Despite a similarity in terms, this is orthogonal to the standard game-theoretic contrast between “perfect” and “imperfect” information, which is rather about how much players know about their position during a game. Players can receive both hard and soft information in both perfect and imperfect information games.
- 17[39] and [40] provide an extensive discussion.
- 18Cf. [42] for an alternative reconstruction.
- 19Cf. [43] for an easy way of seeing why the next principles do the job.
- 20Well-foundedness is only needed to ensure that for any set X, Min≼i (X) is nonempty. This is important only when W is infinite—and there are ways around this in current logics. Moreover, the condition of connectedness can also be lifted, but we use it here for convenience.
- 21We can even prove the following equivalence: w ∼i v iff w≼i v or v ≼i w.
- 22Another notion is Strong Belief iff there is a v with w ∼i v and , v ⊨ φ and where [w]i is the equivalence class of w under ∼i. This has been studied by [53,54].
- 23We can define belief Biφ as belief in φ given a tautology.
- 24The key point is stated in ([56], pg. 2): “ says that if agent i would learn φ, she would come to believe that ψ was true before the learning, while [!φ]Biψ says that after learning φ,i would come to believe that ψ is the case (after the learning).” This observation will be of importance in our analysis of Agreement Theorems later on.
- 25The most general dynamic point is this: “Information update is model transformation”.
- 26Conservative upgrade is the special case of radical upgrade with the modal formula besti(φ,w):= Min≼i([w]i ⋂{x | , x ⊨ φ}).
- 27See [12] on dynamic logics for agents' preference changes between worlds, triggered by commands or other actions with evaluative or moral force.
- 28In terms of the cited literature, we will now engage in concrete “logic of protocols”.
- 29This definition is meant to fix intuition only. Full details on how to deal with infinite scenarios, here and later, are in the cited paper.
- 30See the remarks on page 66 contrasting public announcement and belief conditioning.
- 31Our analysis also applies to infinite models: see the cited papers.
- 32Thanks to Alexandru Baltag for pointing out this feature to us.
- 33We omit some details with pushing the process through infinite ordinals. The final stage is discussed further in terms of “redundant assertions” in [67].
- 34Even in the single-step case, characterizing “self-fulfilling” public announcements has turned out quite involved [68].
- 35Infinite iteration of plausibility reordering is in general a non-monotonic process closer to philosophical theories of truth revision in the philosophical literature [73,74]. The technical theory developed on the latter topic in the 1980s may be relevant to our concerns here [75].
- 36Van Benthem [33], Chapter 12, elaborates this connection in more technical detail.
- 37The logical perspective can actually define many further refinements of learning desiderata, such as reaching future stages when the agent's knowledge becomes introspective, or when her belief becomes correct, or known.
- 38Many of these results live in a probabilistic setting, but dynamic logic and probability is another natural connection, that we have to forego in this paper.
- 39Other versions of our scenario would rather make them equi-plausible.
- 40We refer to [85] for technical details.
- 41See the dissertation [32] for details, linking up with computational logic.
- 42Recall our earlier remarks in Section 1 on the complexity of strategic games.
- 43There is a large literature focused on this “paradox” of backwards induction which we do not discuss here. See, for example, [88].
- 44The drama is clearer in longer games, when A has many comebacks toward the right.
- 45Samet [90] calls this “rationality no matter what”, a stubborn unshakable belief that players will act rationally later on, even if they have never done so up until now.
- 46One reaction to these surprise events might even be a switch to an entirely new style of reasoning about the game. That would require a more finely-grained syntax-based views of revision: cf. the discussion in [93].
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/.)
Share and Cite
Van Benthem, J.; Pacuit, E.; Roy, O. Toward a Theory of Play: A Logical Perspective on Games and Interaction. Games 2011, 2, 52-86. https://doi.org/10.3390/g2010052
Van Benthem J, Pacuit E, Roy O. Toward a Theory of Play: A Logical Perspective on Games and Interaction. Games. 2011; 2(1):52-86. https://doi.org/10.3390/g2010052
Chicago/Turabian StyleVan Benthem, Johan, Eric Pacuit, and Olivier Roy. 2011. "Toward a Theory of Play: A Logical Perspective on Games and Interaction" Games 2, no. 1: 52-86. https://doi.org/10.3390/g2010052
APA StyleVan Benthem, J., Pacuit, E., & Roy, O. (2011). Toward a Theory of Play: A Logical Perspective on Games and Interaction. Games, 2(1), 52-86. https://doi.org/10.3390/g2010052