
Factors in Learning Dynamics Influencing Relative Strengths of Strategies in Poker Simulation


Abstract
:1. Introduction
1.1. Previous Work
1.2. Evolutionary Game Theory
1.3. Poker
1.4. Erev and Roth Learning
2. Materials and Methods
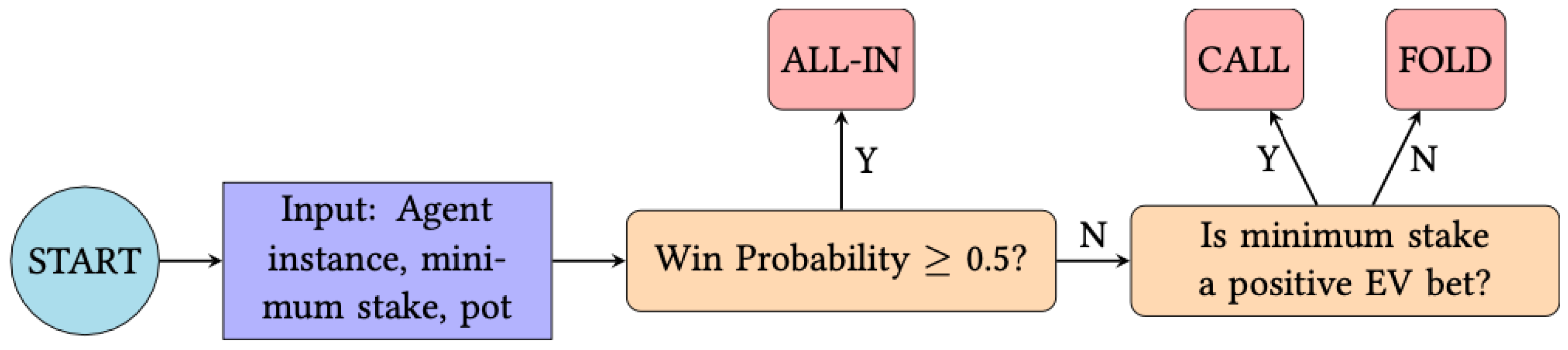
2.1. Rational and Random Strategies
2.2. Relative Strengths of Strategies with No Learning
2.3. Learning Dynamics
2.3.1. Unweighted Learning
2.3.2. Win Oriented Learning
2.3.3. Holistic Learning
2.3.4. Holistic Learning with Recency
2.4. Simplified Poker
2.5. Simulation Structure
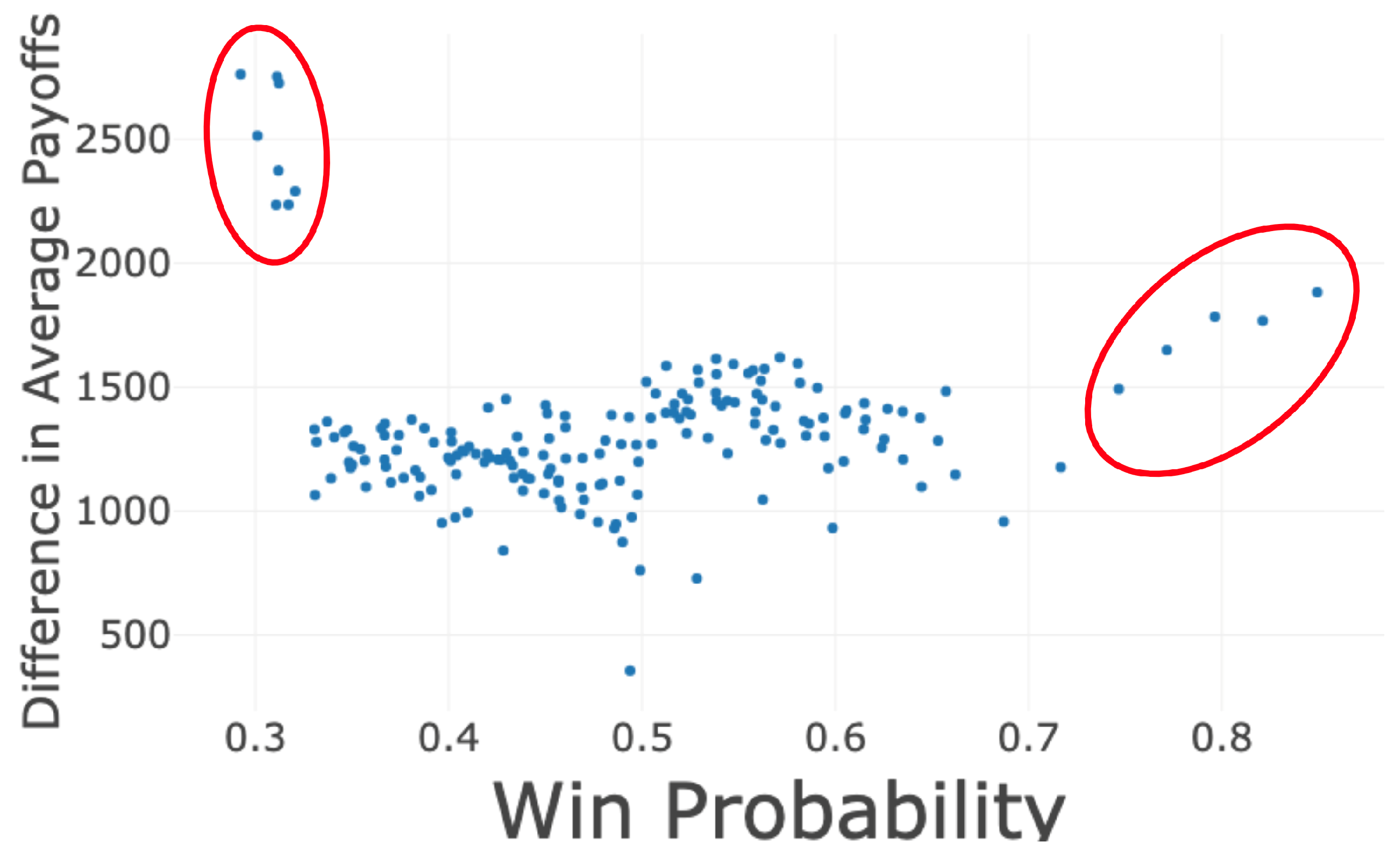
3. Results
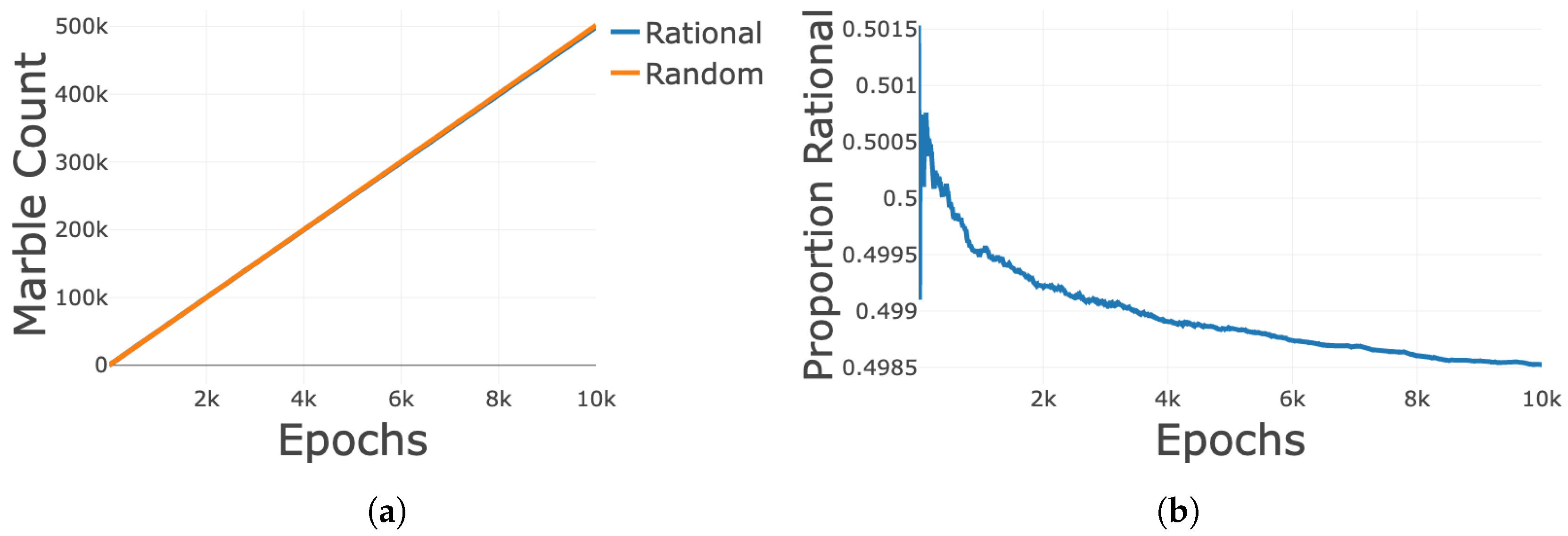
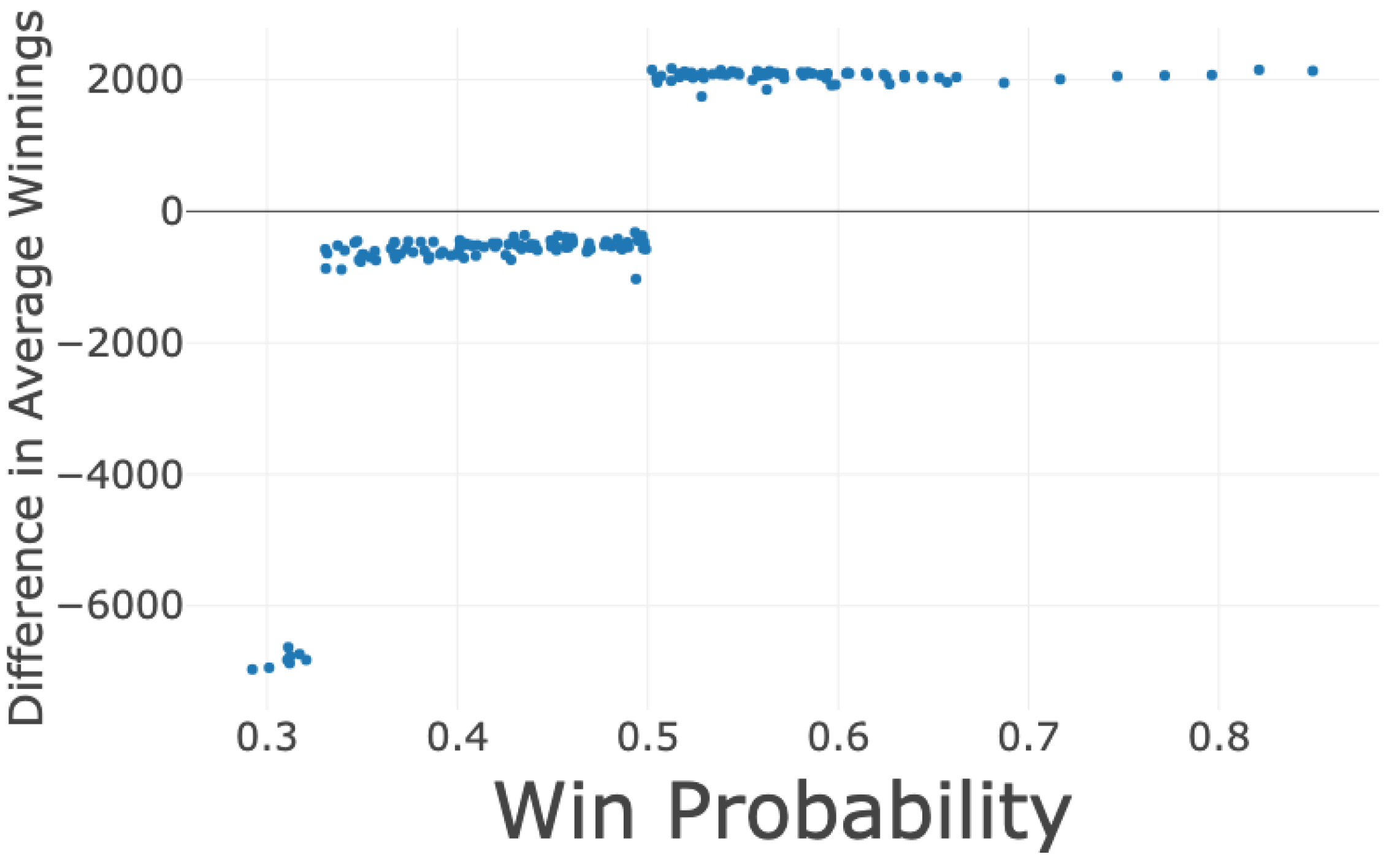
3.1. Relative Strength with No Learning
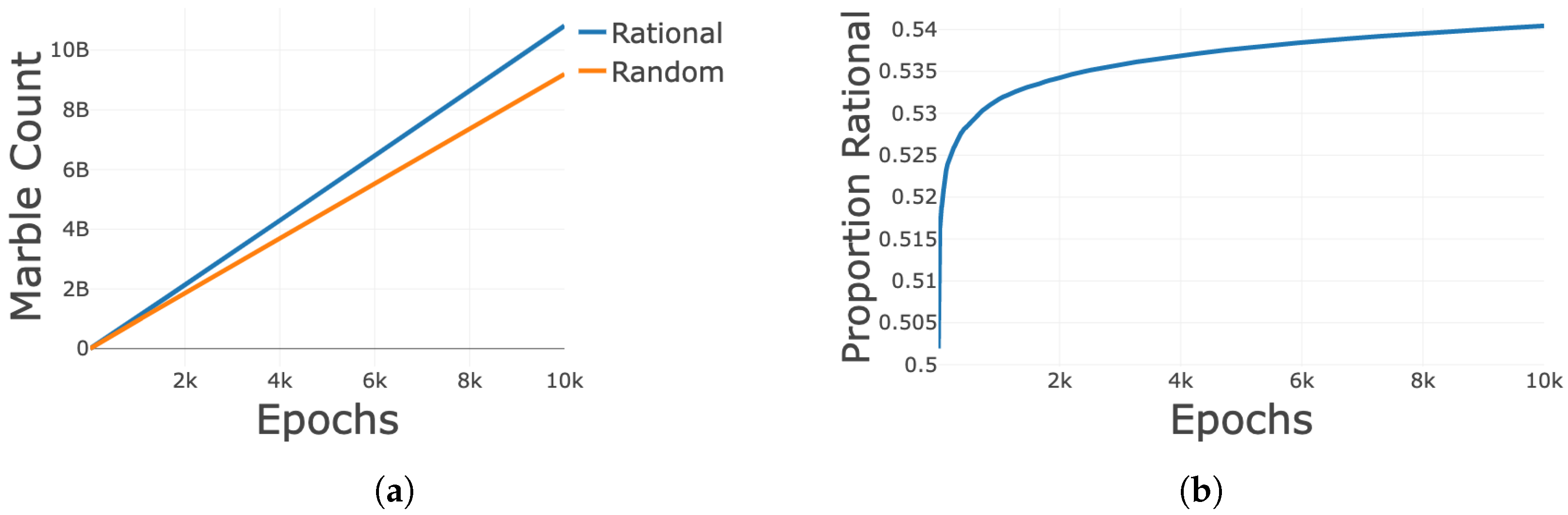
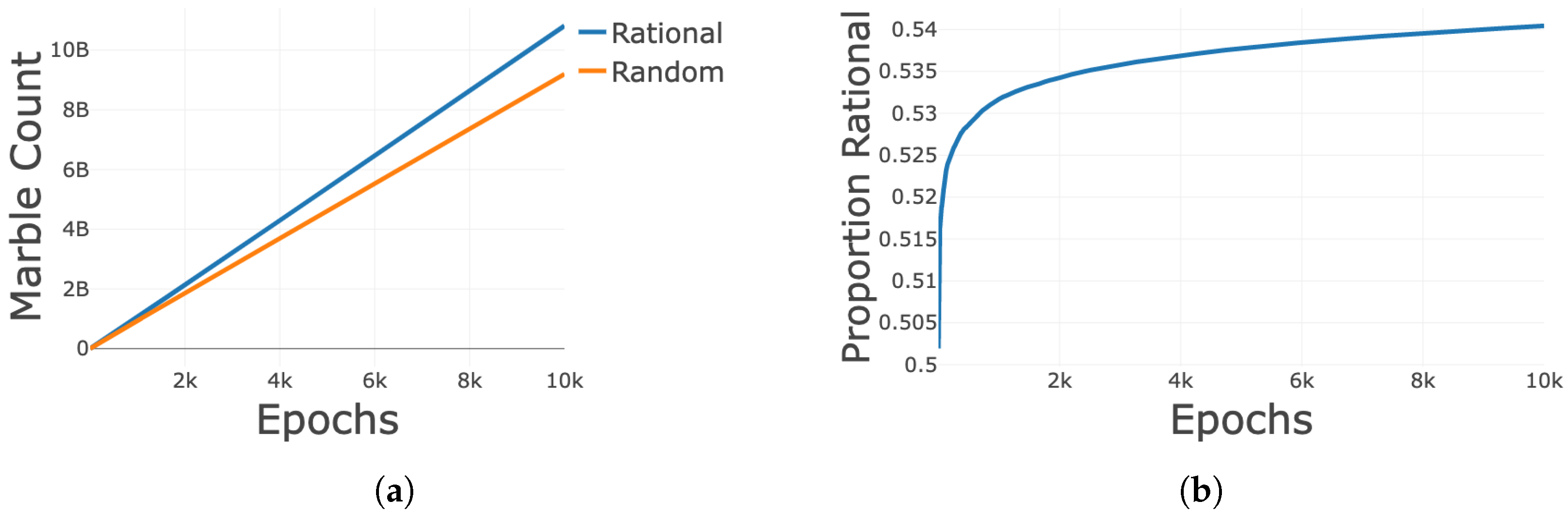
3.2. Unweighted Learning
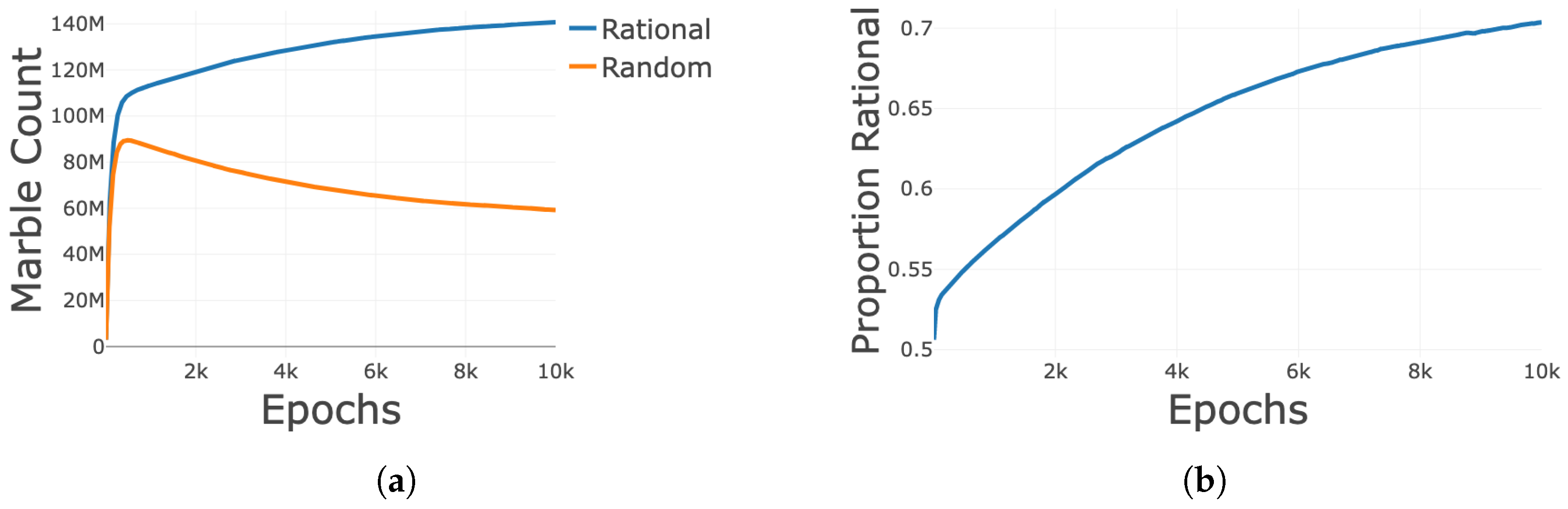
3.3. Win Oriented Learning
3.4. Holistic Learning
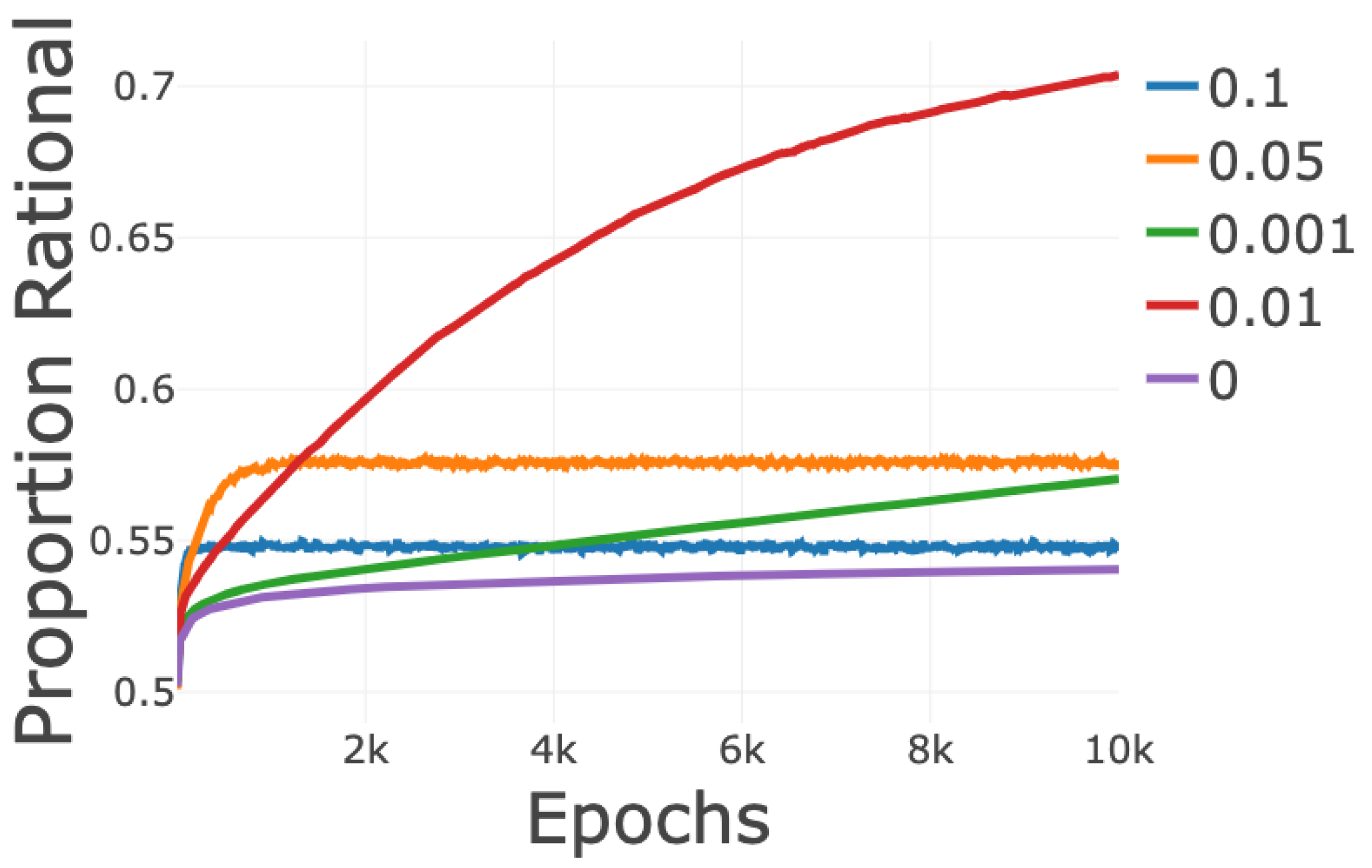
3.5. Holistic Learning with Recency
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
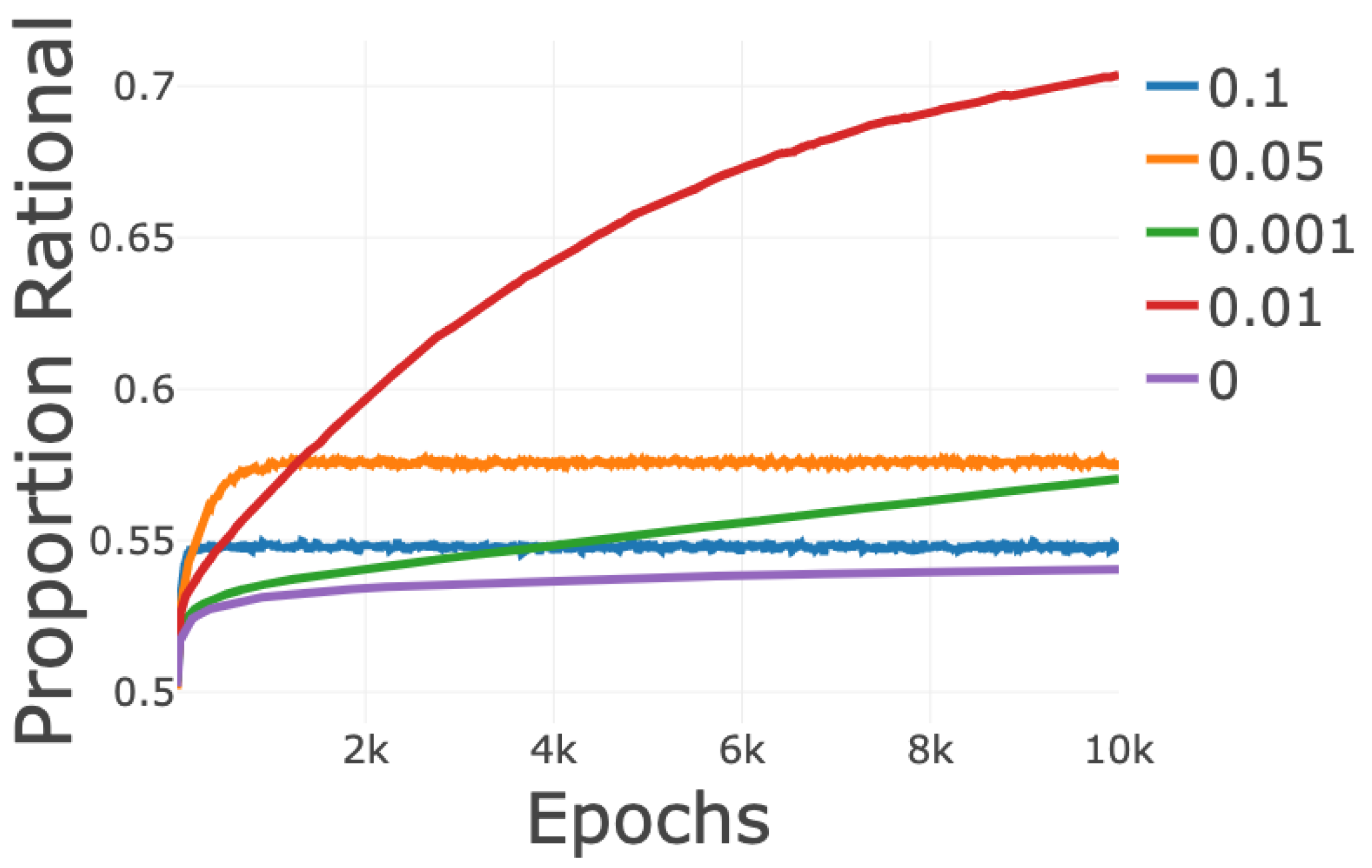
Appendix A. Investigation of ϕ
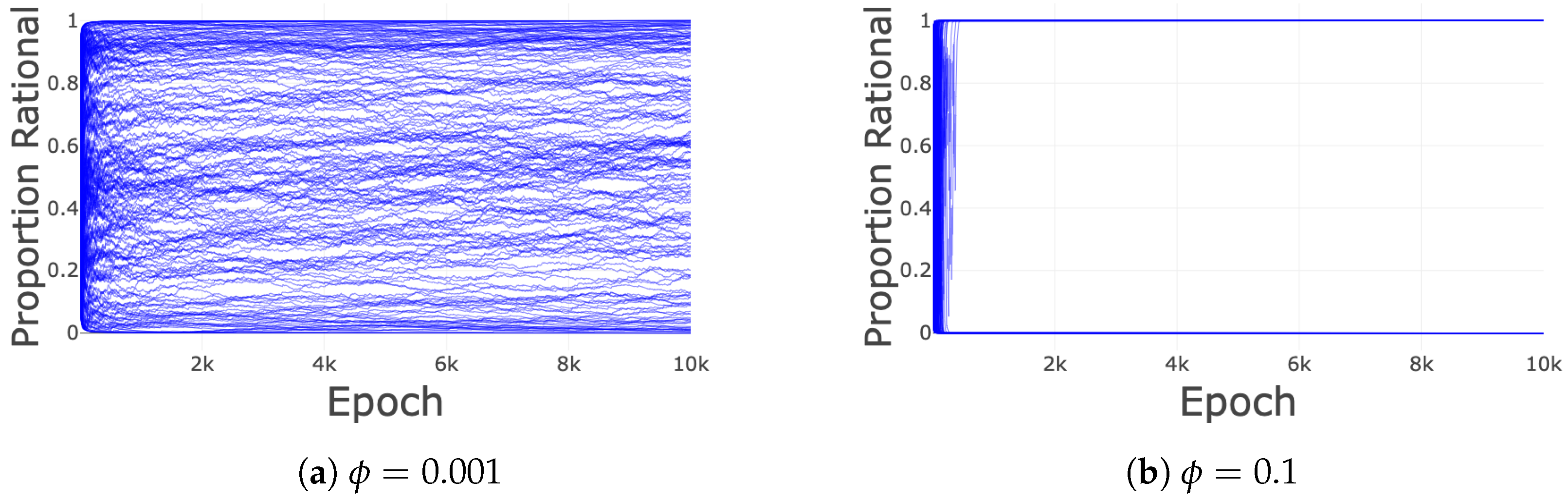
Appendix B. Other Tested Dynamics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dynamic | Description |
|---|---|
| Complete Information Weighted Learning | Agents learn to play like their opponent, and the extent to which they learn depends on the outcome. Each agent maintains a confidence level in the various playable strategies. On a loss the amount of confidence an agent will lose in the strategy they just used is proportional to the amount of money lost. That confidence is placed in the strategy played by the opponent. The winning agent does not learn. |
| Death | Agents that do not have the money required to play are removed from the population. Money is taken as an indicator of fitness, so when the agents run out of money they have effectively died. |
| Holistic Learning | Strategies are determine by sampling a marble at random from each urn. Upon the conclusion of the hand, both agents return their selected marble to their urn. Both agents then add marbles to their urn equal to their change in stack from the hand minus the minimum possible payoff (−10,000). |
| Holistic Learning with Recency | Strategies are determine by sampling a marble at random from their urn. Upon the conclusion of the hand, both agents return their selected marble to their urn. Before adding marbles, their previous propensities for each strategy is multiplied by where is small. Then, agents add marbles to their urn equal to their change in stack from the hand minus the minimum possible payoff (−10,000). |
| Incomplete Information Weighted Learning | Similar to complete information weighted learning, except the losing agent does not place their loss of confidence in the strategy played by their opponent. Instead, they uniformly distribute the confidence between the strategies they did not play. The winning agent does not learn. |
| Pólya Urn Complete Information Learning | Both winning and losing agent learn. Agent has propensities for each strategy. When choosing their strategy for a hand, they randomly select their strategy, weighted by propensities. The winner increments the propensity for the strategy used by one while the loser increments the strategy their opponent played by one. |
| Pólya Urn Incomplete Information Learning | Again, both the winning and losing agents update after the hand. Strategies are determined at the start of the hand in the same manner as for Pólya Urn complete information learning and the winner updates in the same manner. However, the losing agent randomly picks one of the propensities for a strategy they did not play and increments that propensity by one rather than the one their opponent played. |
| Unweighted Learning | Strategies are determine by sampling a marble at random from their urn. Upon the conclusion of the hand, both agents return their selected marble to each urn. Only the winning agent learns, and they do so by adding one marble for the strategy used. |
| Win Oriented Learning | Strategies are determine by sampling a marble at random from their urn. Upon the conlcusion of the hand, both agents return their selected marble to their urn. Only the wining agent learns, and they do so by adding a number of marbles equal to the chips won on the hand. |
References
- Leonard, R.J. From Parlor Games to Social Science: Von Neumann, Morgenstern, and the Creation of Game Theory 1928–1944. J. Econ. Lit. 1995, 33, 730–761. [Google Scholar]
- Kuhn, H.W.; Bohnenblust, H.F.; Brown, G.W.; Dresher, M.; Gale, D.; Karlin, S.; Kuhn, H.W.; Mckinsey, J.C.C.; Nash, J.F.; Neumann, J.V.; et al. A simplified two-person poker. In Contributions to the Theory of Games (AM-24), Volume I; Princeton University Press: Princeton, NJ, USA, 1952; pp. 97–104. [Google Scholar]
- Nash, J.F.; Shapley, L.S.; Bohnenblust, H.F.; Brown, G.W.; Dresher, M.; Gale, D.; Karlin, S.; Kuhn, H.W.; Mckinsey, J.C.C.; Nash, J.F.; et al. A simple three-person poker game. In Contributions to the Theory of Games (AM-24), Volume I; Princeton University Press: Princeton, NJ, USA, 1952; pp. 105–116. [Google Scholar]
- Rapoport, A.; Erev, I.; Abraham, E.V.; Olson, D.E. Randomization and Adaptive Learning in a Simplified Poker Game. Organ. Behav. Hum. Decis. Process. 1997, 69, 31–49. [Google Scholar] [CrossRef]
- Seale, D.A.; Phelan, S.E. Bluffing and betting behavior in a simplified poker game. J. Behav. Decis. Mak. 2010, 23, 335–352. [Google Scholar] [CrossRef]
- Hausken, K.; Moxnes, J.F. Behaviorist stochastic modeling of instrumental learning. Behav. Process. 2001, 56, 121–129. [Google Scholar] [CrossRef]
- Fudenberg, D.; Levine, D. Learning in games. Eur. Econ. Rev. 1998, 42, 631–639. [Google Scholar] [CrossRef]
- Findler, N.V. Studies in machine cognition using the game of poker. Commun. ACM 1977, 20, 230–245. [Google Scholar] [CrossRef]
- Findler, N.V. Computer Model of Gambling and Bluffing. IRE Trans. Electron. Comput. 1961, EC-10, 97–98. [Google Scholar] [CrossRef]
- Bowling, M.; Burch, N.; Johanson, M.; Tammelin, O. Heads-up limit hold’em poker is solved. Science 2015, 347, 145–149. [Google Scholar] [CrossRef]
- Billings, D.; Burch, N.; Davidson, A.; Holte, R.; Schaeffer, J.; Schauenberg, T.; Szafron, D. Approximating Game-Theoretic Optimal Strategies for Full-Scale Poker. In Proceedings of the 18th International Joint Conference on Artificial Intelligence, IJCAI’03, Acapulco, Mexico, 9–15 August 2003; pp. 661–668. [Google Scholar]
- Billings, D. Algorithms and Assessment in Computer Poker. Ph.D. Thesis, University of Alberta, Edmonton, AB, Canada, 2006. [Google Scholar]
- Brown, N.; Sandholm, T. Libratus: The Superhuman AI for No-Limit Poker. In Proceedings of the Twenty-Sixth International Joint Conference onArtificial Intelligence, IJCAI-17, Melbourne, Australia, 19–25 August 2017; pp. 5226–5228. [Google Scholar] [CrossRef]
- Brown, N.; Sandholm, T.; Amos, B. Depth-Limited Solving for Imperfect-Information Games. arXiv 2018, arXiv:1805.08195. [Google Scholar]
- Quek, H.; Woo, C.; Tan, K.; Tay, A. Evolving Nash-optimal poker strategies using evolutionary computation. Front. Comput. Sci. China 2009, 3, 73–91. [Google Scholar] [CrossRef]
- Nash, J.F. Equilibrium Points in n-Person Games. Proc. Natl. Acad. Sci. USA 1950, 36, 48–49. [Google Scholar] [CrossRef]
- Bankes, S.C. Agent-based modeling: A revolution? Proc. Natl. Acad. Sci. USA 2002, 99, 7199–7200. [Google Scholar] [CrossRef]
- Perc, M.; Grigolini, P. Collective behavior and evolutionary games—An introduction. Chaos Solitons Fractals 2013, 56, 1–5. [Google Scholar] [CrossRef]
- Oliehoek, F.; Vlassis, N.; de Jong, E. Coevolutionary Nash in poker games. BNAIC 2005, 1, 188–193. [Google Scholar]
- Javarone, M.A. Poker as a Skill Game: Rational versus Irrational Behaviors. J. Stat. Mech. 2015, 2015, P03018. [Google Scholar] [CrossRef]
- Javarone, M.A. Modeling Poker Challenges by Evolutionary Game Theory. Games 2016, 7, 39. [Google Scholar] [CrossRef]
- Roth, A.E.; Erev, I. Learning in extensive-form games: Experimental data and simple dynamic models in the intermediate term. Games Econ. Behav. 1995, 8, 164–212. [Google Scholar] [CrossRef]
- Conlisk, J. Why Bounded Rationality? J. Econ. Lit. 1996, 34, 669–700. [Google Scholar]
- Arthur, W.B. Designing Economic Agents that Act like Human Agents: A Behavioral Approach to Bounded Rationality. Am. Econ. Rev. 1991, 81, 353–359. [Google Scholar]
- Skyrms, B. Learning to Signal with Two Kinds of Trial and Error. In Foundations and Methods for Mathematics to Neuroscience: Essays Inspired by Patrick Suppes; Center for the Study of Language and Information: Stanford, CA, USA, 2014. [Google Scholar]
- Kalai, E.; Lehrer, E. Rational Learning Leads to Nash Equilibrium. Econometrica 1993, 61, 1019–1045. [Google Scholar] [CrossRef]
- Javarone, M.A. Is poker a skill game? New insights from statistical physics. Europhys. Lett. 2015, 110, 58003. [Google Scholar] [CrossRef]
- Ponsen, M.; Tuyls, K.; Jong, S.; Ramon, J.; Croonenborghs, T.; Driessens, K. The dynamics of human behaviour in poker. In Proceedings of the Belgian/Netherlands Artificial Intelligence Conference, Enschede, The Netherlands, 30–31 October 2008. [Google Scholar]
- Ponsen, M.; Tuyls, K.; Kaisers, M.; Ramon, J. An evolutionary game-theoretic analysis of poker strategies. Entertain. Comput. 2009, 1, 39–45. [Google Scholar] [CrossRef]
- Barone, L.; While, L. An adaptive learning model for simplified poker using evolutionary algorithms. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Washington, DC, USA, 6–9 July 1999; Volume 1, pp. 153–160. [Google Scholar] [CrossRef]
- Kendall, G.; Willdig, M. An Investigation of an Adaptive Poker Player. In Proceedings of the AI 2001: Advances in Artificial Intelligence; Stumptner, M., Corbett, D., Brooks, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 189–200. [Google Scholar]
- Traulsen, A.; Glynatsi, N.E. The future of theoretical evolutionary game theory. Philos. Trans. R. Soc. B Biol. Sci. 2023, 378, 20210508. [Google Scholar] [CrossRef] [PubMed]
- Friedman, D. Evolutionary Games in Economics. Econometrica 1991, 59, 637–666. [Google Scholar] [CrossRef]
- Hazra, T.; Anjaria, K. Applications of game theory in deep learning: A survey. Multimed. Tools Appl. 2022, 81, 8963–8994. [Google Scholar] [CrossRef] [PubMed]
- Keller, L.; Ross, K. Selfish genes: A green beard in the red fire ant. Nature 1998, 394, 573–575. [Google Scholar] [CrossRef]
- Weber, R.A. ‘Learning’ with no feedback in a competitive guessing game. Games Econ. Behav. 2003, 44, 134–144. [Google Scholar] [CrossRef]
- Sarin, R.; Vahid, F. Predicting How People Play Games: A Simple Dynamic Model of Choice. Games Econ. Behav. 2001, 34, 104–122. [Google Scholar] [CrossRef]
- Sarin, R.; Vahid, F. Payoff Assessments without Probabilities: A Simple Dynamic Model of Choice. Games Econ. Behav. 1999, 28, 294–309. [Google Scholar] [CrossRef]
- Blackburn, J.M. The Acquisition of Skill: An Analysis of Learning Curves; IHRB Report 73; H.M. Stationery Office: Singapore, 1936. [Google Scholar]
- Newell, A.; Rosenbloom, P. Mechanisms of skill acquisition and the law of practice. In Cognitive Skills and Their Acquisition; Psychology Press: New York, NY, USA, 1993; Volume 1. [Google Scholar]
- Li, J. Exploitability and Game Theory Optimal Play in Poker. Boletín De Matemáticas 2018, 1–11. Available online: https://math.mit.edu/~apost/courses/18.204_2018/Jingyu_Li_paper.pdf (accessed on 1 October 2023).
- Erev, I.; Roth, A.E. Predicting How People Play Games: Reinforcement Learning in Experimental Games with Unique, Mixed Strategy Equilibria. Am. Econ. Rev. 1998, 88, 848–881. [Google Scholar]
- Barrett, J.; Zollman, K.J. The role of forgetting in the evolution and learning of language. J. Exp. Theor. Artif. Intell. 2009, 21, 293–309. [Google Scholar] [CrossRef]
- Beggs, A. On the convergence of reinforcement learning. J. Econ. Theory 2005, 122, 1–36. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Foote, A.; Gooyabadi, M.; Addleman, N. Factors in Learning Dynamics Influencing Relative Strengths of Strategies in Poker Simulation. Games 2023, 14, 73. https://doi.org/10.3390/g14060073
Foote A, Gooyabadi M, Addleman N. Factors in Learning Dynamics Influencing Relative Strengths of Strategies in Poker Simulation. Games. 2023; 14(6):73. https://doi.org/10.3390/g14060073
Chicago/Turabian StyleFoote, Aaron, Maryam Gooyabadi, and Nikhil Addleman. 2023. "Factors in Learning Dynamics Influencing Relative Strengths of Strategies in Poker Simulation" Games 14, no. 6: 73. https://doi.org/10.3390/g14060073
APA StyleFoote, A., Gooyabadi, M., & Addleman, N. (2023). Factors in Learning Dynamics Influencing Relative Strengths of Strategies in Poker Simulation. Games, 14(6), 73. https://doi.org/10.3390/g14060073