1. Introduction
Game-theoretic approach to population dynamics developed by Maynard Smith [
1,
2] and many other authors (see, for example, Reference [
3]) assumes that individual fitness results from payoffs received during pairwise interactions that depend on individual phenotypes or strategies.
The approach to studying strategy-dependent payoffs in the case of a finite number of strategies is as follows. Assume
is the payoff received by an individual using strategy
against one using strategy
. If there is a finite number of possible strategies (or traits), then
is an entry of the payoff matrix. Alternatively, the number of strategies may belong to a continuous rather than discrete set of values. The case when individuals in the population use strategies that are parameterized by a single real variable
x that belongs to a closed and bounded interval
was studied in [
4,
5,
6,
7,
8,
9,
10] as well as many others. A brief survey of recent results on continuous state games can be found in Reference [
6].
Specifically, the case of quadratic payoff function was considered in References [
11,
12] and some others.
Taylor and Jonker [
13] offered a dynamical approach for game analysis known as replicator dynamics that allows tracing evolution of a distribution of individual strategies/traits. Typically, it is assumed that every individual uses one of finitely many possible strategies parameterized by real numbers; in this case, the Taylor-Jonker equation can be reduced to a system of differential equations and solved using well-developed methods, subject to practical limitations stemming from possible high dimensionality of the system.
Here, I extend the approach of studying games with strategies that are parameterized by a continuous set of values to study the evolution of strategy (trait) distributions over time. Specifically, I develop a method that allows computing the current distribution for games with quadratic, as well as several more general payoff, functions at any time and for any initial distribution. The approach is close to the HKV (after
hidden
keystone
variables) method developed in References [
14,
15,
16] used for modeling evolution of heterogeneous populations and communities. It allows generation of more general results than have previously been possible.
2. Results
2.1. Master Model
Consider a closed inhomogeneous population, where every individual is characterized by a qualitative trait (or strategy) , where is a subset of real numbers. X can be a closed and bounded interval , a positive set of real numbers or the total set of real numbers R. Parameter x describes an individual’s inherited invariant properties; it remains unchanged for any given individual but varies from one individual to another. The fitness (per capita reproduction rate) of an individual depends on the strategy x and on interactions with other individuals in the population.
Let be population density at time t with respect to strategy x; informally, is the number of individuals that use x-strategy.
Assuming overlapping generations and smoothness of
in
t for each
, the population dynamics can be described by the following general model:
where
is the total population size and
is the pdf of the strategy distribution at time
t. The initial pdf
and the initial population size
are assumed to be given.
Let
be the payoff of an
x-individual when it plays against a
y-individual. Following standard assumptions of evolutionary game theory, assume that individual fitness
is equal to the expected payoff that the individual receives as a result of a random pairwise interaction with another individual in the population, that is,
Equations (1) and (2) make up the master model.
Here our main goal is to study the evolution of the pdf over time. To this end, it is necessary to compute population density and total population size , which will be done in the following section.
2.2. Evolution of Strategy Distribution in Games with Quadratic Payoff Function
Assume that the payoff
has the form
where
is the “background” fitness term that depends on the total population size
but does not depend on individuals’ traits and interactions;
are constant coefficients.
Then
where expected value is notated as
.
Now population dynamics is defined by the equation
In order to solve this equation, apply the version of HKV method [
14,
15,
16]. Introduce auxiliary variables
, such that
Notice that
depends neither on
nor on
Therefore, if one is interested in the distribution of strategies and how it changes over time rather than the density of x-individuals, then one can replace the reproduction rate given by Equation (4) by the reproduction rate
Equivalently, one can use the payment function (3) in a simplified form
The model (1) with payoff function (10) and reproduction rate (9) has the same distribution of strategies as model (1) with payoff (3) and reproduction rate (4).
Next, using Equation (8), one can write
in the form
Now define the following function
, such that
can now be expressed as
It is now possible to write the explicit equation for the auxiliary variable as
The moment generation function (mgf) of the current distribution of strategies as given by Equation (8) is
Equations (8)–(16) now provide a tool for studying the evolution of the distribution of strategies of the quadratic payment model over time for any initial distribution.
2.3. Initial Normal Distribution
The evolution of normal distribution in games with the quadratic payoff function has already been mostly studied; as shown by Oechssier and Riedel [
6,
8] and Cressman and Hofbauer [
5], the class of normal distributions is invariant with respect to replicator dynamics in games with quadratic payoff functions (3) with positive parameter
.
This statement immediately follows from Equation (8) for the current distribution of traits. Additionally, the class of normal distributions truncated in a (finite or infinite) interval
is also invariant, see
Section 2.6 for details and examples.
Now consider the dynamics of initial normal distributions in detail.
Let the initial distribution be normal with the mean
and variance
,
Denoting for brevity
, one can compute the function
Then, according to Equation (5), the following explicit equation for auxiliary keystone variable emerges:
This equation can be solved analytically as follows:
Now it is possible to compute the mean, variance, and current distribution of strategies using Equations (12)–(15). In the case of normal initial distribution, the simplest way to do so is to use Equation (16) for the current mgf.
Indeed, using formula (16) and after simple algebra, one can write the current mgf as
It is exactly the mgf of the normal distribution (18) with the mean and variance .
Remembering that
and using Equation (22), after some algebra the mean of the current strategy distribution takes the form
Proposition 1. Let the initial distribution of strategies in model (1), (9) be normal
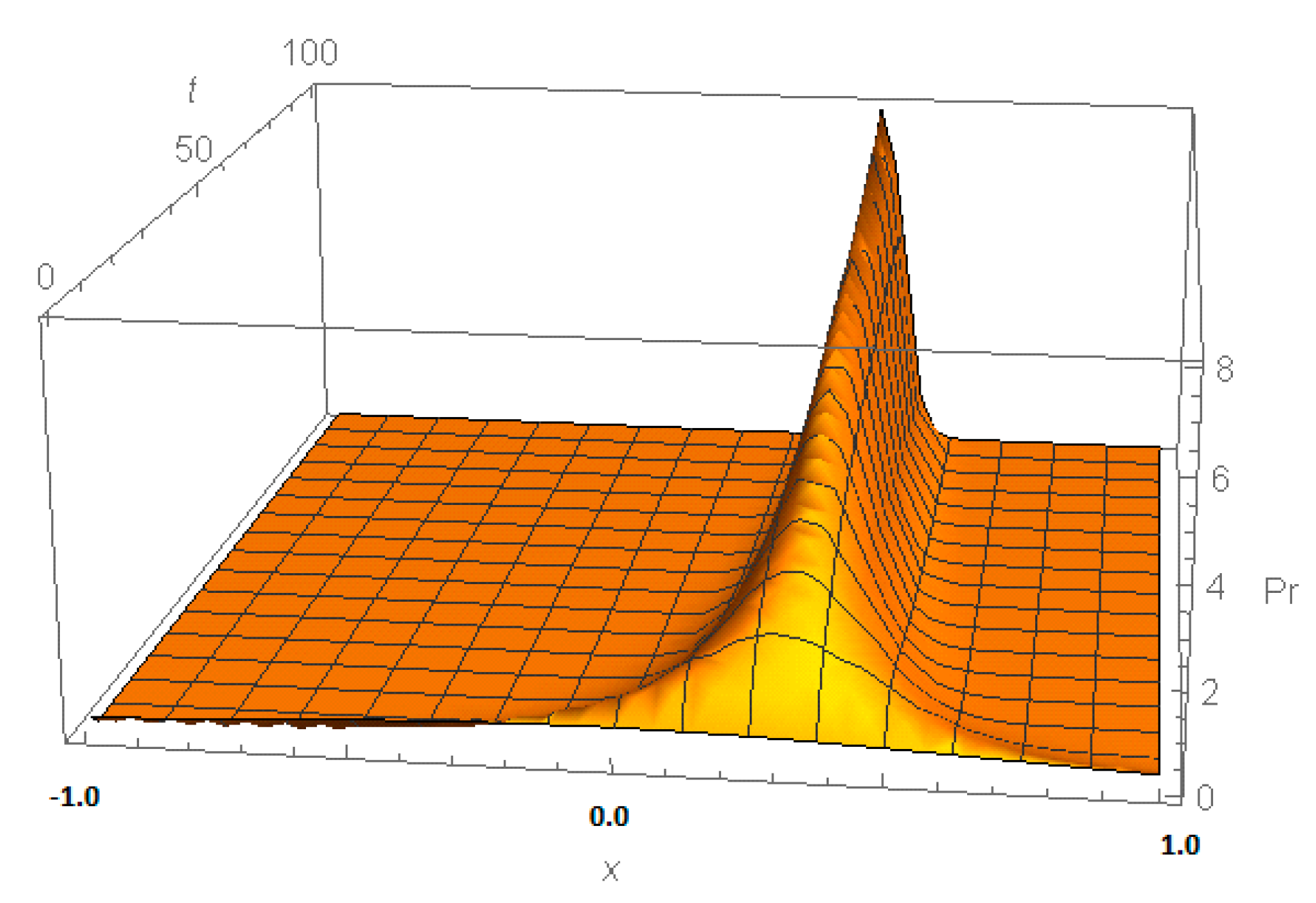
Then the distribution of strategies at any time t is normal with the mean given by Equation (23) and variance .
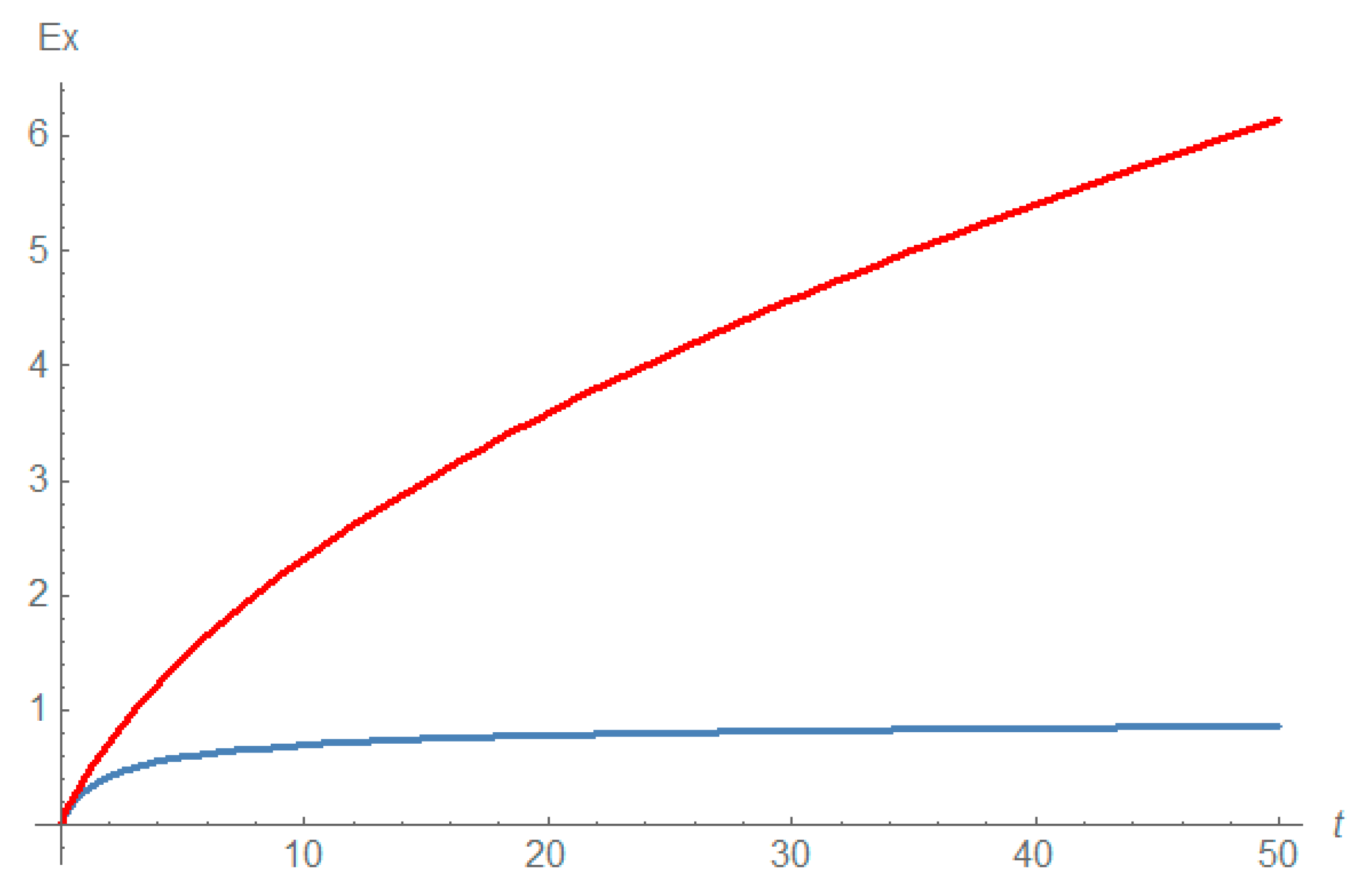
It is easy to see that if , then and as ; if , then therefore if and if as .
Notice that as , so if .
Figure 1 shows the dynamics of the mean of current distribution of traits.
Figure 2 shows the evolution of the distribution of traits over time. The variance of the current distribution
tends to 0; therefore, the distribution of traits over time tends to a distribution concentrated at the point
for
.
2.4. Exponential Initial Distributions
Let the initial distribution be exponential in
,
. Then
where
.
Equation (24) for any
describes the density of the normal distribution with the mean
and variance
truncated on
. Notably, the mean of the truncated normal distribution (24) is not equal to
, and its variance is not equal to
. Instead, the mean of distribution (24) is
In order to compute the mean given by Equation (25) and the current distribution (24) as a function of time one needs to solve for the auxiliary variable
that can be done using the function
:
Then, according to Equation (14),
This equation can be solved numerically. Using the solution , we can compute the distribution (24) and all its moments.
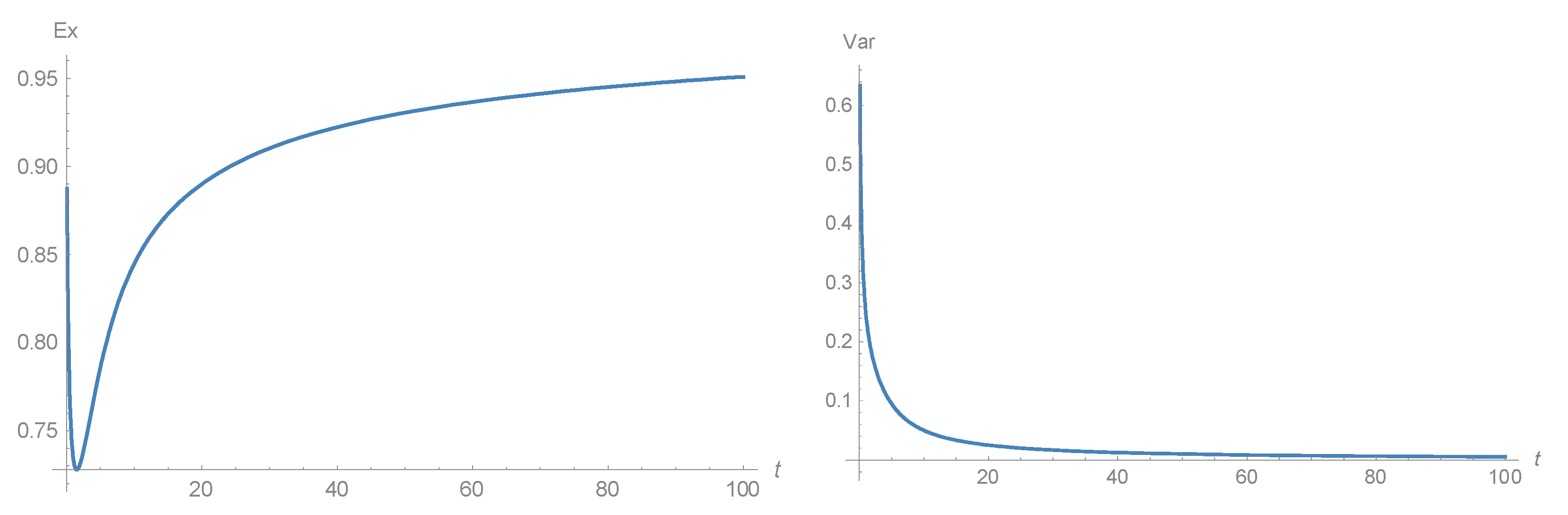
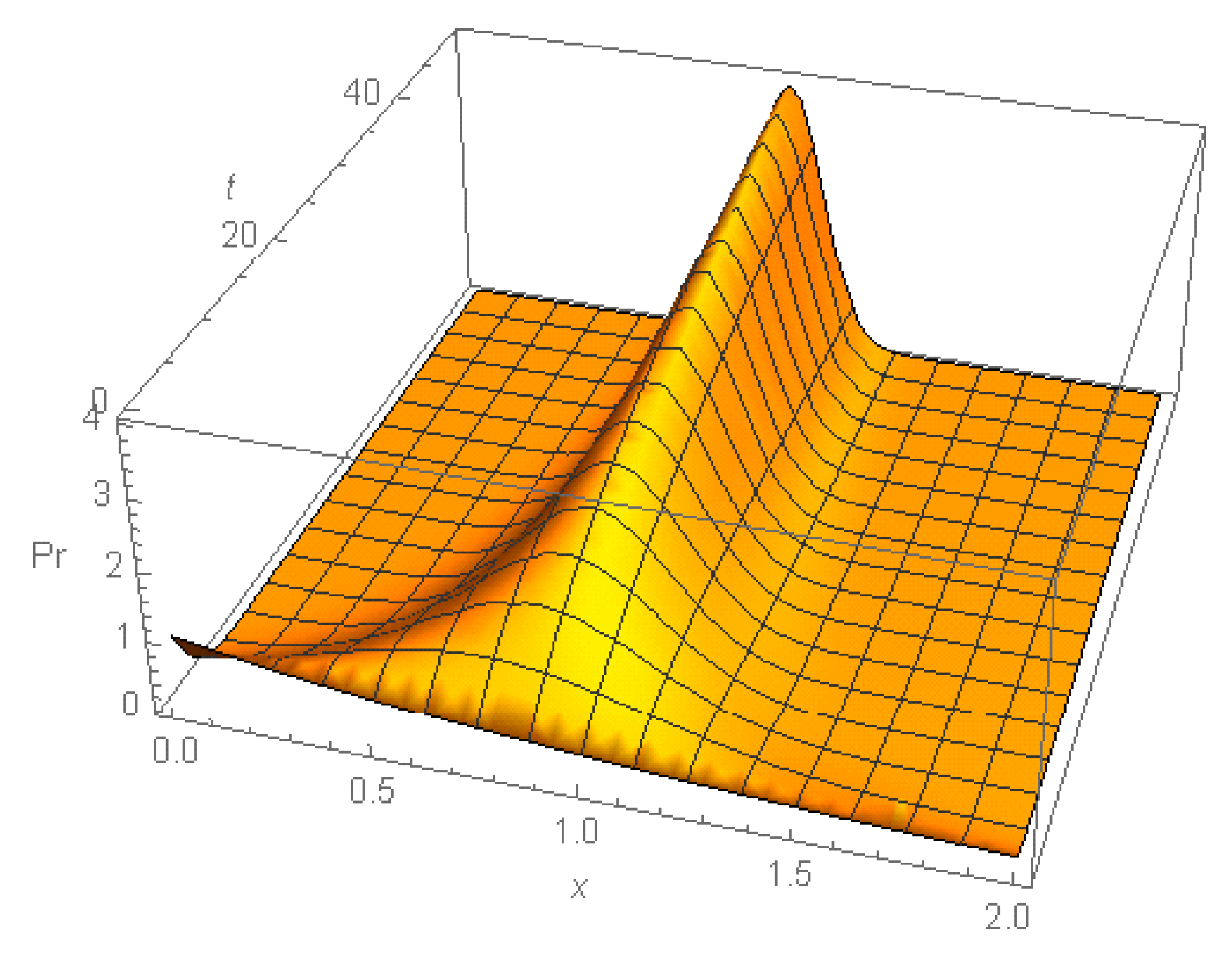
It follows from Equation (25), that as . One can show that therefore . The variance of the current distribution tends to 0, so the limit distribution tends to a distribution concentrated in the point . This proves the following proposition.
Proposition 2. Let the initial distribution of strategies be exponential. Then the current distribution is normal at any time
that tends to a distribution concentrated in the point .
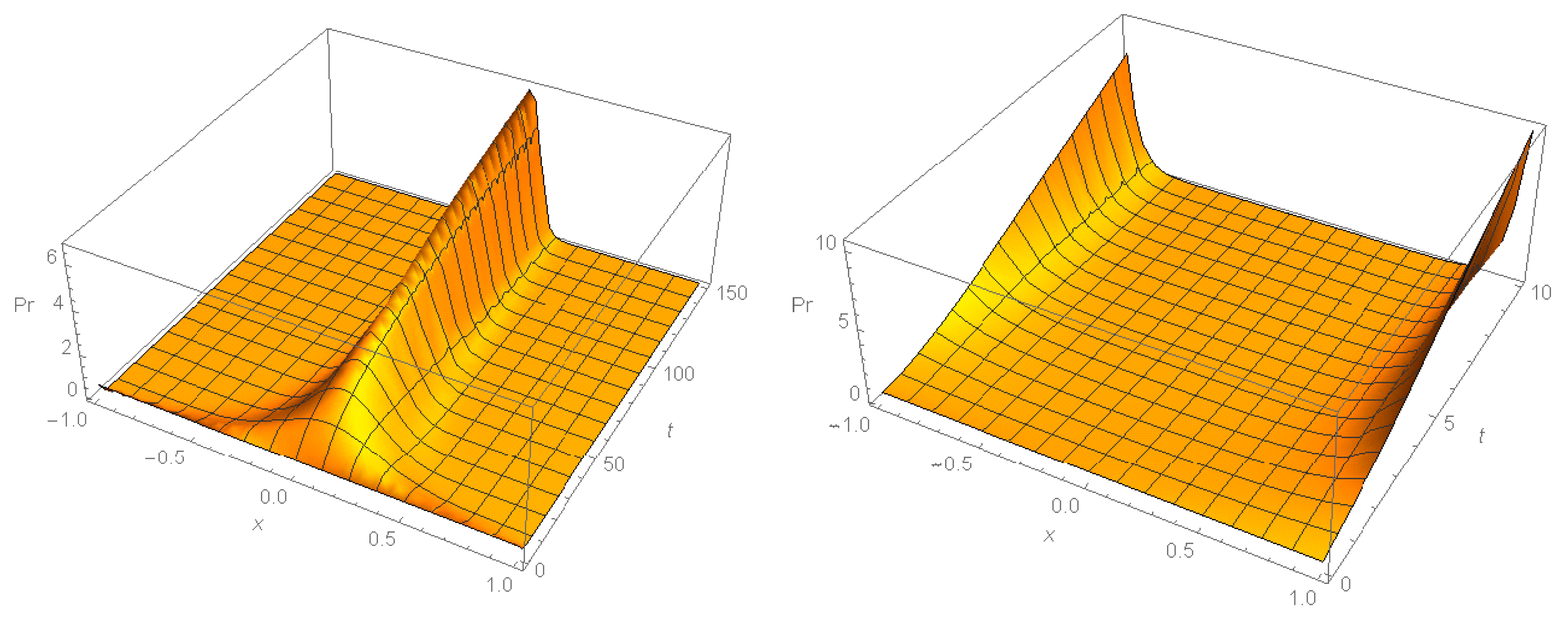
An example of the dynamics of the current mean and variance is given on
Figure 3.
Figure 4 shows the dynamics of the initial exponential distribution that turns to a truncated normal distribution with its variance tending to 0. Therefore, the current distribution tends to a distribution concentrated in the point
as
.
2.5. Uniform Initial Distribution
Now assume that the initial distribution is uniform in the interval [−1, 1]. Then
and the current distribution
The auxiliary variable
can be computed using Equation (14), or, equivalently, directly using the expression (29) for the current pdf:
For a positive parameter
, the distribution
is normal with the mean
and variance
truncated in the interval
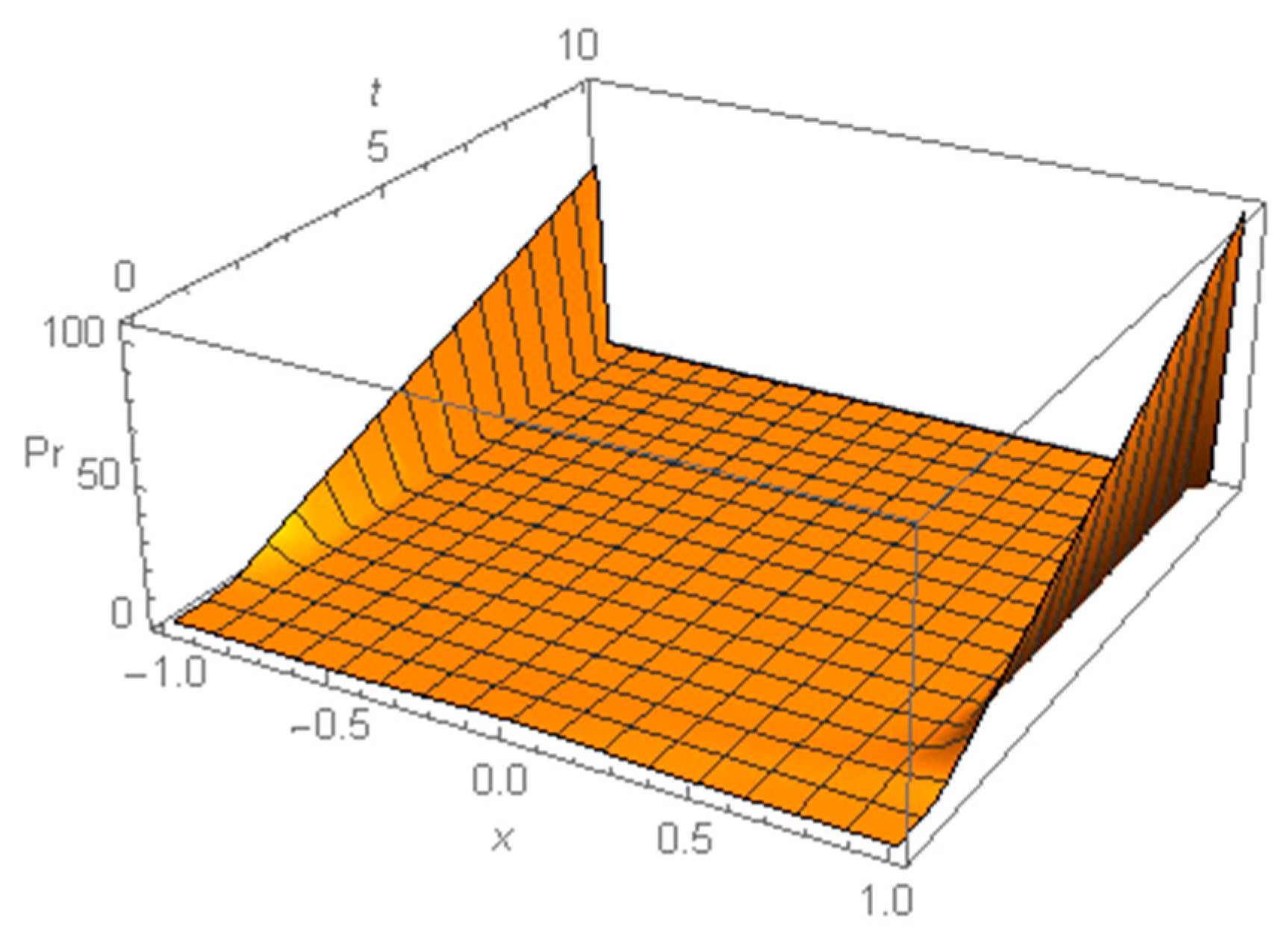
. However, for negative values of parameter
the distribution (29) is not normal; more specifically, if parameter
b is also negative, then the initial distribution evolves towards a U-shaped distribution, as can be seen
Figure 5 (right).
2.6. Normal Initial Distribution Truncated in the Interval [−1, 1]
Now assume the initial distribution is normal with zero mean, truncated in the interval [−1, 1]:
with normalization constant
.
Using the theory developed in
Section 2.3, Equation (8), one can show that the current distribution of strategies is given by the formula
The distribution (32) is again normal truncated in the interval [−1, 1]. The current mean value that defines Equation (14) for the auxiliary variable
can be computed using Equation (13) or using the expression (32) for the current pdf. This way one can obtain a (rather bulky) equation for
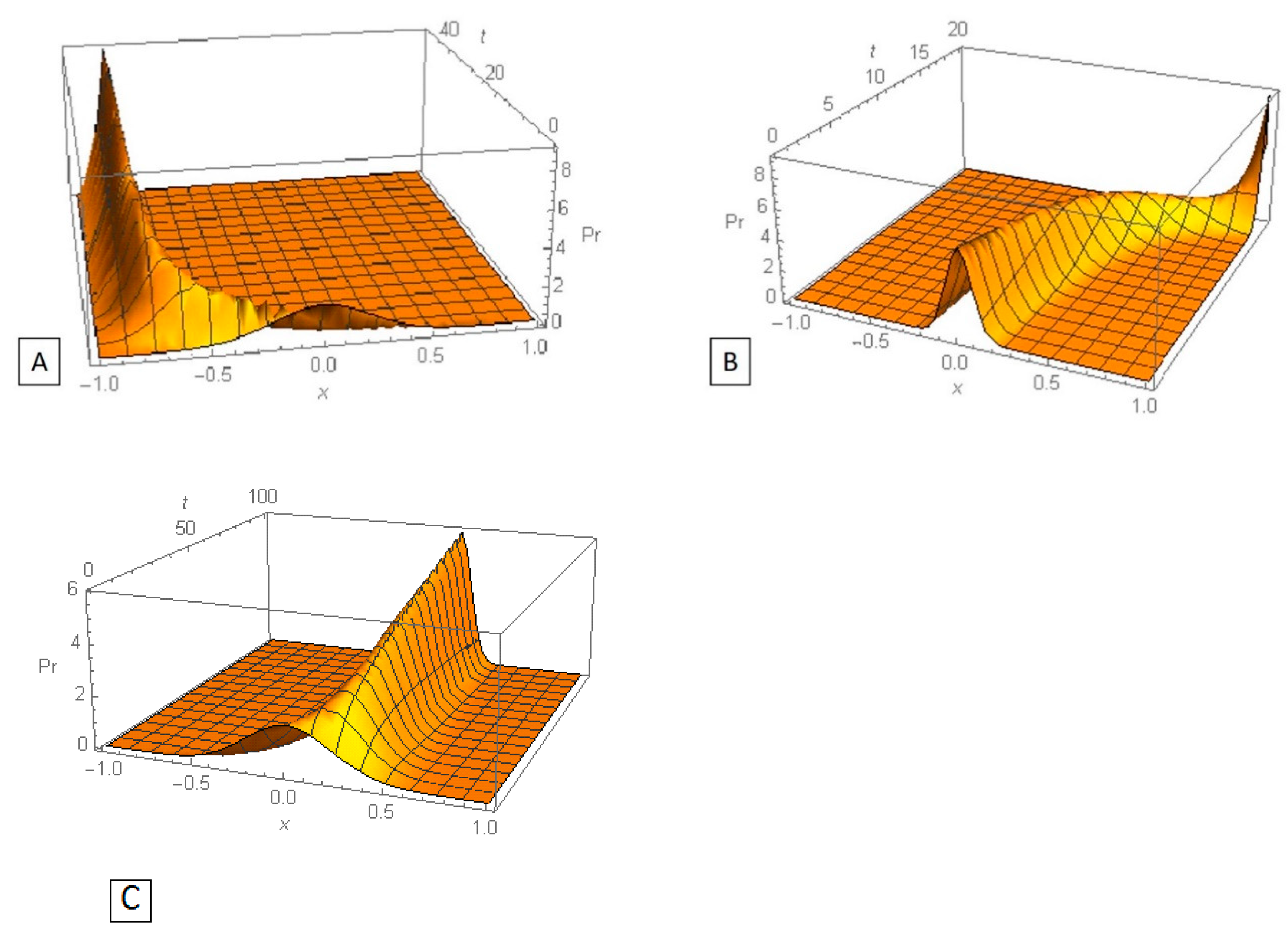
that can be solved numerically. With this solution, one can trace the evolution of the initial truncated normal distribution. It can be shown that for
the variance of the current distribution tends to 0; therefore, the current distribution tends to a distribution concentrated in the point
at
. The value of
depends on model parameters. Three examples of the evolution of strategy distribution are given in
Figure 6.
More generally, one can consider the normal distribution truncated in a finite interval or in a half-line . Then it follows from Equation (8) that the current distribution is also normal truncated in that interval.
Proposition 3. The class of truncated normal distributions is invariant with respect to replicator dynamics in games with quadratic payoff functions (3) with positive parameter.
In contrast, one can observe another kind of evolution of the initial truncated normal distribution for
. Specifically, the current distribution has a U-shape and tends to a distribution concentrated in two extremal points of the interval where the initial distribution is defined, as can be seen in
Figure 7.
2.7. Generalization
The developed approach can be applied to a more general version of the payoff function:
In this case
where
.
Let us introduce auxiliary variables
One can see that the pdf does not depend on the variable and hence on the function .
It follows from (35) that
Then the equation
can be solved, at least numerically.
Another equivalent approach may also be useful. Define the function
This results in a closed equation for the auxiliary variable
Having the solution to equations (36) or (38), one can compute the current pdf (35) and all statistical characteristics of interest, such as the current mean and variance of strategies given any initial distribution.
Example 1 (see [12], Example 1). Let . Then .
Introduce the auxiliary variable using the equation
. Then
.
This equation can be solved numerically, allowing one to then compute the pdf according to Equation (39).
3. Discussion
Classical problems of evolutionary game theory are concentrated on studying equilibrium states (such as evolutionarily stable states and Nash equilibria). Notably, it takes indefinite time to reach any equilibrium when starting from a from non-trivial initial distribution of strategies in continuous-time models. Therefore, the evolution of a given initial distribution over time may be of great interest and potentially critical importance for studying real population dynamics.
Here I developed a method that allows extending the analysis of evolution of continuous strategy distributions in games with a quadratic payoff function. Specifically, the method described here allows us to answer the question: given an initial distribution of strategies in a game, how will it evolve over time? Typically, the dynamics of population distributions are governed by replicator equations, which appear both in evolutionary game theory, as well as in analysis of the dynamics of non-homogeneous populations and communities. The approach suggested here is based on the HKV (
hidden
keystone
variable) method developed in References [
9,
10,
11] for analysis of the dynamics of inhomogeneous populations and finding solutions of corresponding replicator equations. The method allows the computing of the current strategy distribution and all statistical characteristics of interest, such as current mean and variance, of the current distribution given any initial distribution at any time.
I looked at several specific examples of initial distributions:
- ⚬
Normal
- ⚬
Exponential
- ⚬
Uniform on [−1, 1]
- ⚬
Truncated normal on [−1, 1]
Through the application of the proposed method, I confirm the existing results given in References [
5,
6], that the family of normal distributions is invariant in a game with a quadratic payoff function with negative quadratic term. Additionally, I derive explicit formulas for the current distribution, its mean and variance. I show also that the class of truncated normal distributions is also invariant with respect to replicator dynamics in games with quadratic payoff functions; as an example, I consider in detail the case of initial normal distribution truncated in [−1, 1].
Notably and unexpectedly, in most cases, regardless of initial distribution, the current distribution of strategies in games with negative quadratic term is normal, standard or truncated. Over time it evolves towards a distribution concentrated in a single point that is equal to the limit values of the mean of the current normal distribution. This can have implications for a broad class of questions pertaining to evolution of strategies in games.
For instance, the question of whether the limit state of the population is mono - or polymorphic was discussed in the literature. Here I show that for games with a quadratic payoff function, the population tends to a monomorphic stable state if the quadratic term is negative. In contrast, if the quadratic term of the payoff function is positive and the initial distribution is concentrated in a finite interval, then the current distribution can have a U-shape, and then the population tends to a di-morphic state.
In the last section I extend the developed approach to games with payoff functions of the form . Formally, this framework can be applied to a very broad class of payoff functions, which include exponential or polynomial payoff functions; however, in many cases finding a solution to the equation for the auxiliary variable can be a difficult computational problem.
To summarize, the proposed method is validated against previously published results, and is then applied to a previously unsolvable class of problems. Application of this method could help expand the class of questions and answers that can now be obtained for a large class of problems in evolutionary game theory.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






