Toward Smart Lockdown: A Novel Approach for COVID-19 Hotspots Prediction Using a Deep Hybrid Neural Network




Abstract
1. Introduction
- We propose a novel prediction framework that forecasts potential hotspots by exploiting the benefits of different deep learning models.
- The framework utilizes a unique CNN model to extract multi-time scale features that incorporate short, medium, and long dependencies in time-series data.
- From the experiment results, we demonstrate that the proposed framework achieves state-of-the-art performance in comparison to other existing methods.
2. Related Work
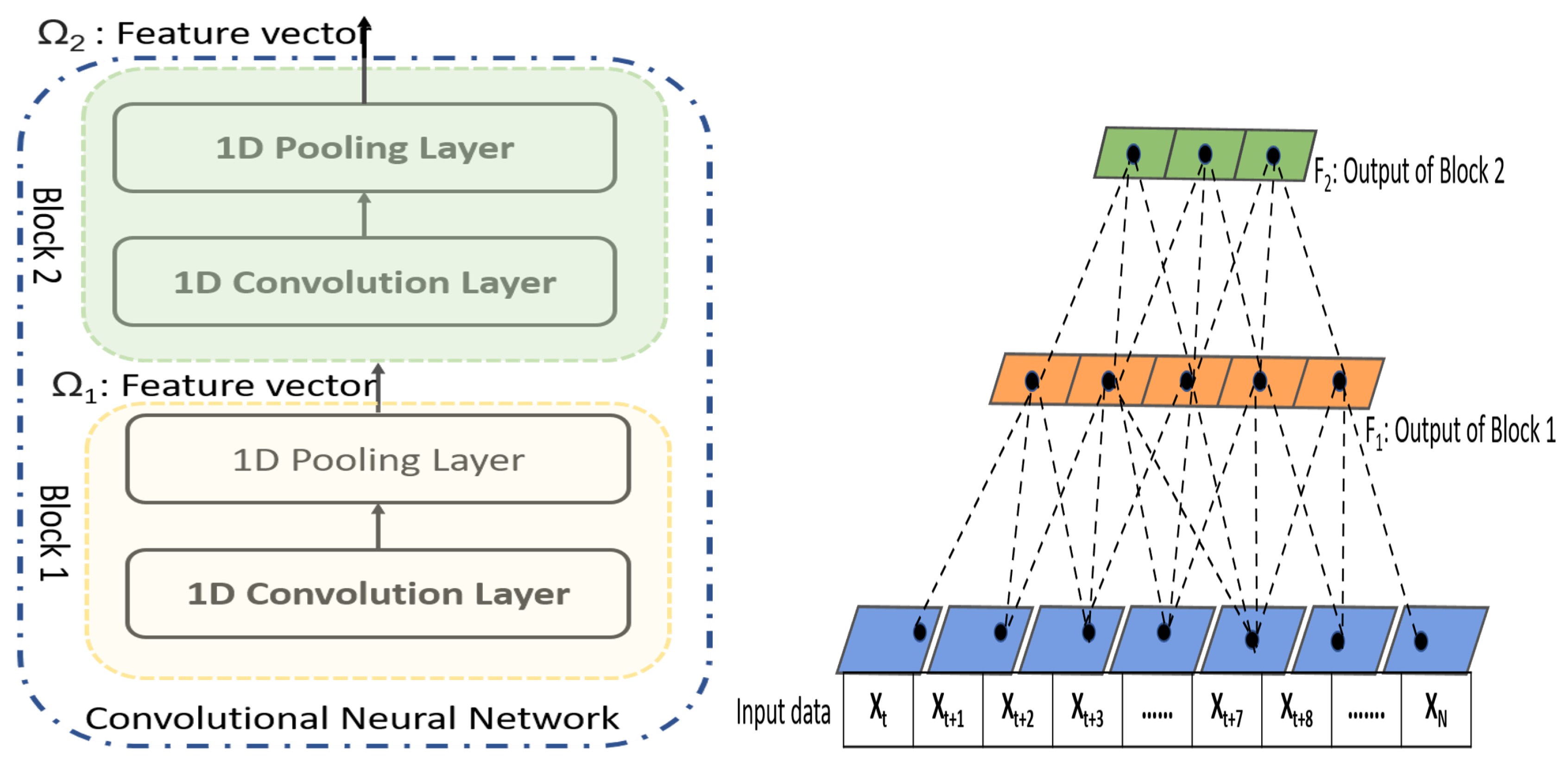
- The CNN network of existing hybrid neural utilizes the features from the last convolutional layer that represents the information of a single time-scale. In our work, we exploit CNN in an innovative way and extract features from different layers of CNN that represent different time-scale features which are vital for prediction process.
- The existing hybrid networks use LSTM that utilizes single time-scale features obtained from CNN to learn temporal dependencies. In the proposed framework, LSTMs take input from different convolutional layers of the CNN, to learn short, medium, and long time series dependencies.
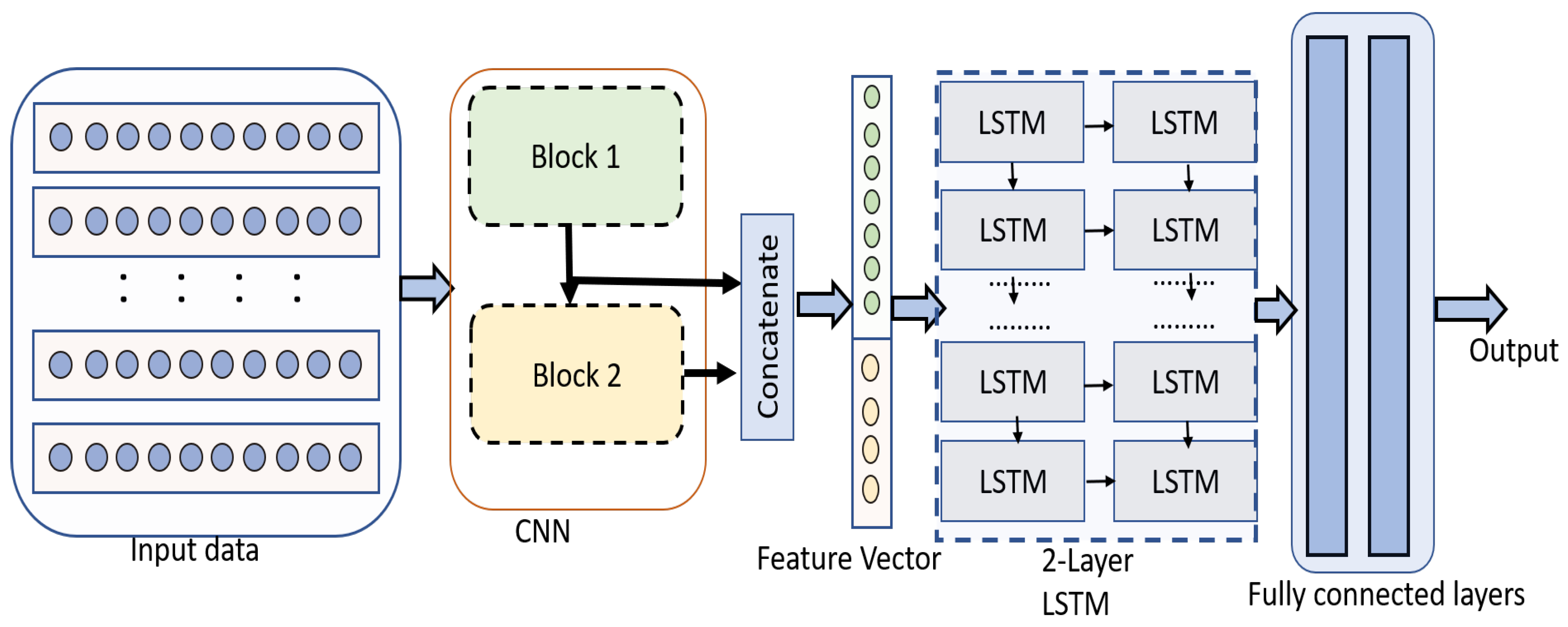
3. Proposed Framework
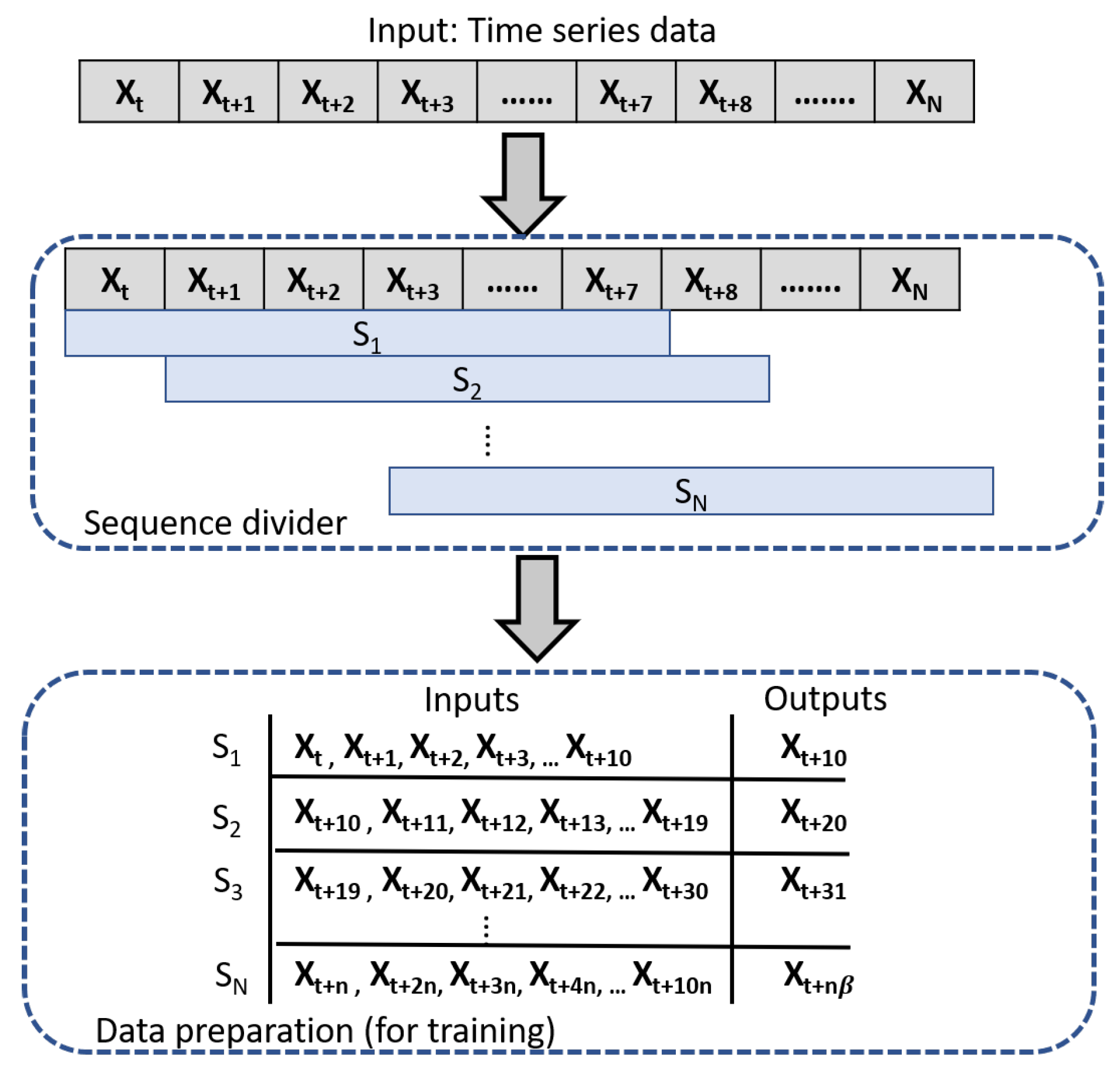
3.1. Data Pre-Processing
3.2. Convolutional Neural Network
3.3. Long Short-Term Memory
4. Experiment Results
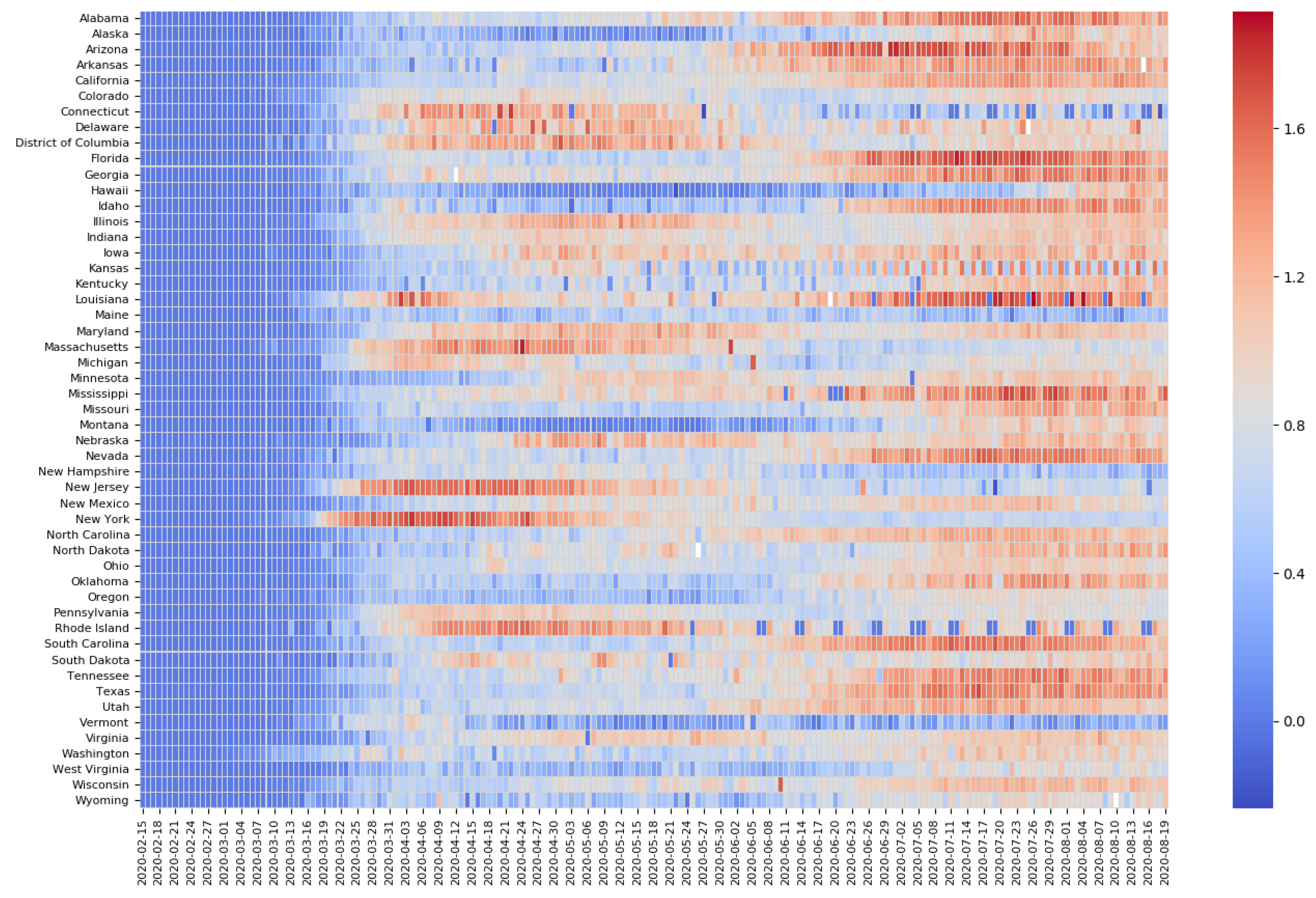
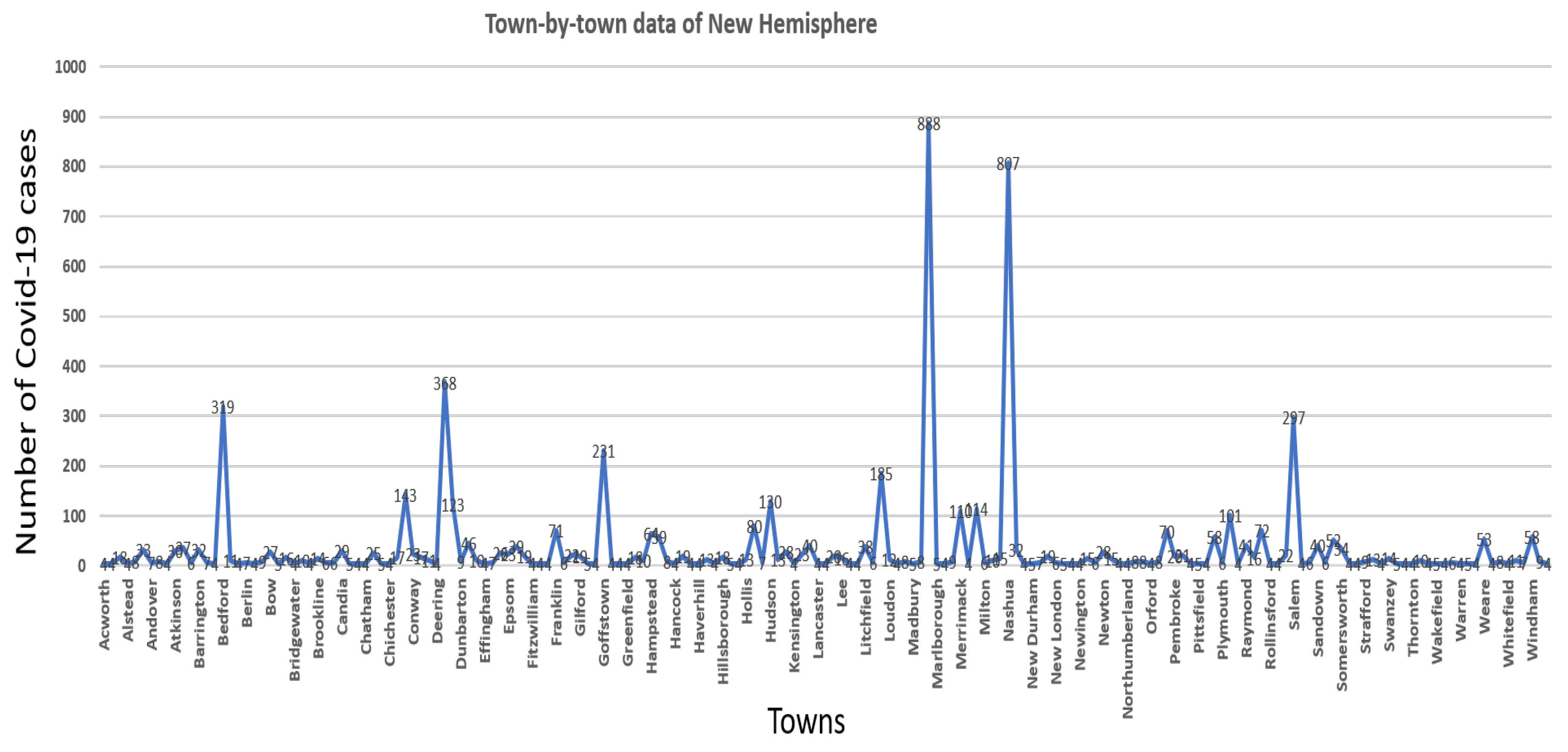
4.1. Experimental Data
4.2. Hyper Parameters of CNN
4.3. Hyper Parameters of LSTM
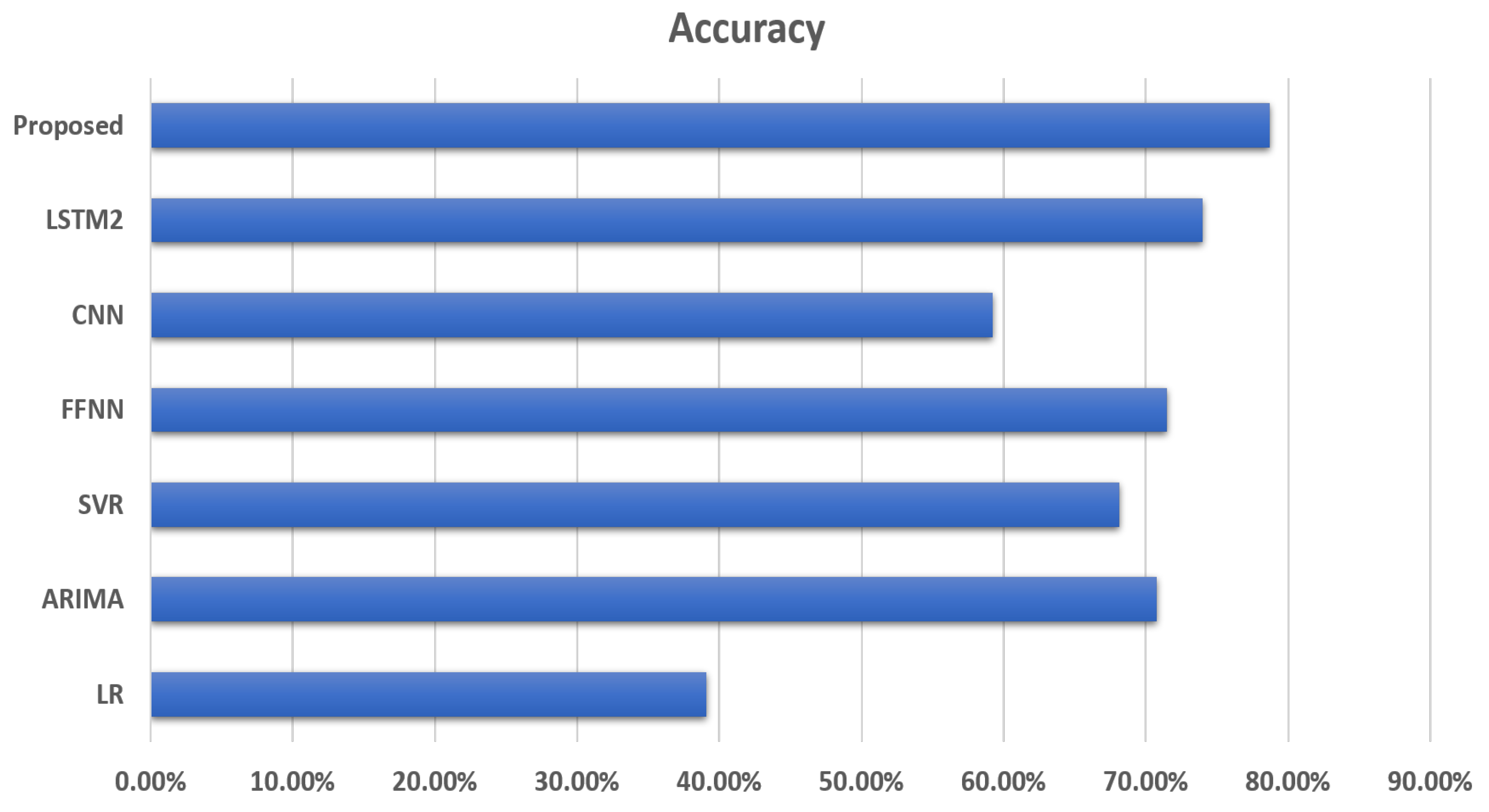
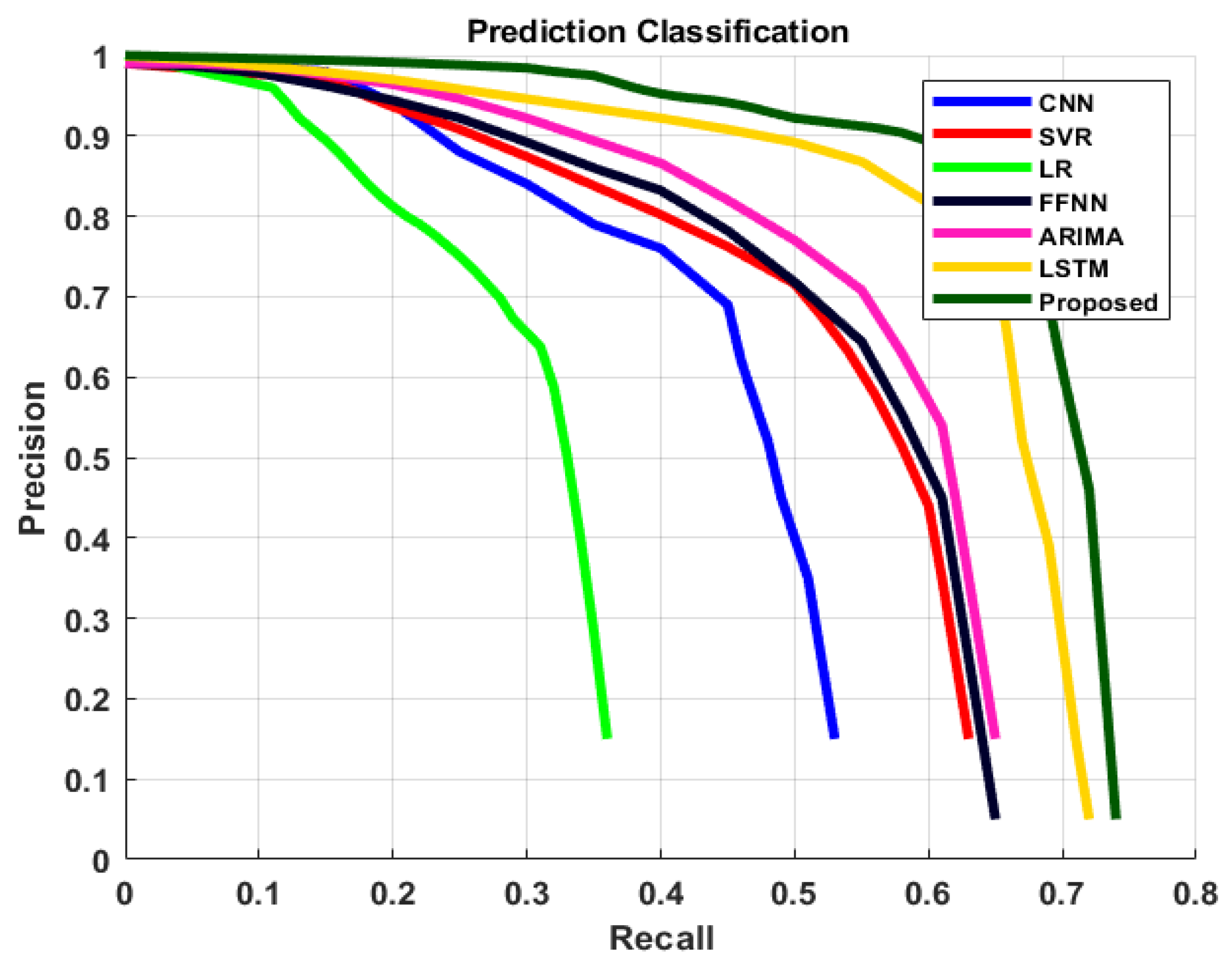
4.4. Comparison of Results
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Karin, O.; Bar-On, Y.M.; Milo, T.; Katzir, I.; Mayo, A.; Korem, Y.; Dudovich, B.; Yashiv, E.; Zehavi, A.J.; Davidovich, N.; et al. Adaptive cyclic exit strategies from lockdown to suppress COVID-19 and allow economic activity. medRxiv 2020. [Google Scholar] [CrossRef]
- Nabipour, M.; Nayyeri, P.; Jabani, H.; Mosavi, A.; Salwana, E.; Shahab, S. Deep learning for stock market prediction. Entropy 2020, 22, 840. [Google Scholar] [CrossRef] [PubMed]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN-LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Wang, J.; Yu, L.C.; Lai, K.R.; Zhang, X. Dimensional sentiment analysis using a regional CNN-LSTM model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 225–230. [Google Scholar]
- Askari, M.; Askari, H. Time series grey system prediction-based models: Gold price forecasting. Trends Appl. Sci. Res. 2011, 6, 1287. [Google Scholar] [CrossRef]
- Guha, B.; Bandyopadhyay, G. Gold price forecasting using ARIMA model. J. Adv. Manag. Sci. 2016, 4, 117–121. [Google Scholar]
- Dubey, A.D. Gold price prediction using support vector regression and ANFIS models. In Proceedings of the 2016 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 7–9 January 2016; pp. 1–6. [Google Scholar]
- Li, J.; Dai, Q.; Ye, R. A novel double incremental learning algorithm for time series prediction. Neural Comput. Appl. 2019, 31, 6055–6077. [Google Scholar] [CrossRef]
- Liu, D.; Li, Z. Gold price forecasting and related influence factors analysis based on random forest. In Proceedings of the Tenth International Conference on Management Science and Engineering Management, Baku, Azerbaijan, 30 August–2 September 2016; pp. 711–723. [Google Scholar]
- Makridou, G.; Atsalakis, G.S.; Zopounidis, C.; Andriosopoulos, K. Gold price forecasting with a neuro-fuzzy-based inference system. Int. J. Financ. Eng. Risk Manag. 2 2013, 1, 35–54. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef]
- Ai, Y.; Li, Z.; Gan, M.; Zhang, Y.; Yu, D.; Chen, W.; Ju, Y. A deep learning approach on short-term spatiotemporal distribution forecasting of dockless bike-sharing system. Neural Comput. Appl. 2019, 31, 1665–1677. [Google Scholar] [CrossRef]
- Zheng, J.; Fu, X.; Zhang, G. Research on exchange rate forecasting based on deep belief network. Neural Comput. Appl. 2019, 31, 573–582. [Google Scholar] [CrossRef]
- Zou, W.; Xia, Y. Back propagation bidirectional extreme learning machine for traffic flow time series prediction. Neural Comput. Appl. 2019, 31, 7401–7414. [Google Scholar] [CrossRef]
- Chang, L.C.; Chen, P.A.; Chang, F.J. Reinforced two-step-ahead weight adjustment technique for online training of recurrent neural networks. IEEE Trans. Neural Networks Learn. Syst. 2012, 23, 1269–1278. [Google Scholar] [CrossRef] [PubMed]
- ur Sami, I.; Junejo, K.N. Predicting Future Gold Rates using Machine Learning Approach. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 92–99. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Lipton, Z.C.; Kale, D.C.; Elkan, C.; Wetzel, R. Learning to diagnose with LSTM recurrent neural networks. arXiv 2015, arXiv:1511.03677. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Punia, S.; Nikolopoulos, K.; Singh, S.P.; Madaan, J.K.; Litsiou, K. Deep learning with long short-term memory networks and random forests for demand forecasting in multi-channel retail. Int. J. Prod. Res. 2020, 58, 4964–4979. [Google Scholar] [CrossRef]
- Bao, W.; Yue, J.; Rao, Y. A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 2017, 12, e0180944. [Google Scholar] [CrossRef]
- Sirignano, J.; Cont, R. Universal features of price formation in financial markets: Perspectives from deep learning. Quant. Financ. 2019, 19, 1449–1459. [Google Scholar] [CrossRef]
- Tsantekidis, A.; Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Using deep learning to detect price change indications in financial markets. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 2511–2515. [Google Scholar]
- Huang, J.; Kingsbury, B. Audio-visual deep learning for noise robust speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7596–7599. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar] [CrossRef]
- Chen, C.T.; Chen, A.P.; Huang, S.H. Cloning strategies from trading records using agent-based reinforcement learning algorithm. In Proceedings of the 2018 IEEE International Conference on Agents (ICA), Singapore, 28–31 July 2018; pp. 34–37. [Google Scholar]
- Sezer, O.B.; Ozbayoglu, A.M. Algorithmic financial trading with deep convolutional neural networks: Time series to image conversion approach. Appl. Soft Comput. 2018, 70, 525–538. [Google Scholar] [CrossRef]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Li, C.; Wang, P.; Wang, S.; Hou, Y.; Li, W. Skeleton-based action recognition using LSTM and CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 585–590. [Google Scholar]
- Zhao, Y.; Yang, R.; Chevalier, G.; Xu, X.; Zhang, Z. Deep residual bidir-LSTM for human activity recognition using wearable sensors. Math. Probl. Eng. 2018, 2018, 1–13. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Rehg, J.M. Multi-object tracking with neural gating using bilinear lstm. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 200–215. [Google Scholar]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Gong, X.; Yang, Y.; Horng, S.J. Traffic flow forecasting based on hybrid deep learning framework. In Proceedings of the 2017 12th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Nanjing, China, 24–26 November 2017; pp. 1–6. [Google Scholar]
- Lin, T.; Guo, T.; Aberer, K. Hybrid neural networks for learning the trend in time series. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2273–2279. [Google Scholar]
- Xue, N.; Triguero, I.; Figueredo, G.P.; Landa-Silva, D. Evolving Deep CNN-LSTMs for Inventory Time Series Prediction. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 1517–1524. [Google Scholar]
- Kitapcı, O.; Özekicioğlu, H.; Kaynar, O.; Taştan, S. The effect of economic policies applied in Turkey to the sale of automobiles: Multiple regression and neural network analysis. Procedia-Soc. Behav. Sci. 2014, 148, 653–661. [Google Scholar] [CrossRef]
- Kheirkhah, A.; Azadeh, A.; Saberi, M.; Azaron, A.; Shakouri, H. Improved estimation of electricity demand function by using of artificial neural network, principal component analysis and data envelopment analysis. Comput. Ind. Eng. 2013, 64, 425–441. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef]
- Hao, Y.; Gao, Q. Predicting the Trend of Stock Market Index Using the Hybrid Neural Network Based on Multiple Time Scale Feature Learning. Appl. Sci. 2020, 10, 3961. [Google Scholar] [CrossRef]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adam, M.; Gertych, A.; San Tan, R. A deep convolutional neural network model to classify heartbeats. Comput. Biol. Med. 2017, 89, 389–396. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep neural network ensembles for time series classification. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–6. [Google Scholar]
- Ju, X.; Cheng, M.; Xia, Y.; Quo, F.; Tian, Y. Support Vector Regression and Time Series Analysis for the Forecasting of Bayannur’s Total Water Requirement; ITQM: San Rafael, Ecuador, 2014; pp. 523–531. [Google Scholar]
- Fattah, J.; Ezzine, L.; Aman, Z.; El Moussami, H.; Lachhab, A. Forecasting of demand using ARIMA model. Int. J. Eng. Bus. Manag. 2018, 10, 1847979018808673. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, X.; Jiang, B.; Yang, W. Forecasting incidence of hemorrhagic fever with renal syndrome in China using ARIMA model. BMC Infect. Dis. 2011, 11, 218. [Google Scholar] [CrossRef] [PubMed]
- Nichiforov, C.; Stamatescu, I.; Făgărăşan, I.; Stamatescu, G. Energy consumption forecasting using ARIMA and neural network models. In Proceedings of the 2017 5th International Symposium on Electrical and Electronics Engineering (ISEEE), Galati, Romania, 20–22 October 2017; pp. 1–4. [Google Scholar]
- Adebiyi, A.A.; Adewumi, A.O.; Ayo, C.K. Comparison of ARIMA and artificial neural networks models for stock price prediction. J. Appl. Math. 2014, 2014, 1–7. [Google Scholar] [CrossRef]
- Merh, N.; Saxena, V.P.; Pardasani, K.R. A comparison between hybrid approaches of ANN and ARIMA for Indian stock trend forecasting. Bus. Intell. J. 2010, 3, 23–43. [Google Scholar]
- Sterba, J.; Hilovska, K. The implementation of hybrid ARIMA neural network prediction model for aggregate water consumption prediction. Aplimat J. Appl. Math. 2010, 3, 123–131. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Convolutional Neural Network | ||||
|---|---|---|---|---|
| Layer-1 | Layer-2 | |||
| Filter Size | # of Filters | Filter Size | # of Filters | Accuracy |
| 2 | 5 | 3 | 7 | 0.64 |
| 3 | 10 | 4 | 15 | 0.57 |
| 5 | 20 | 6 | 25 | 0.43 |
| 6 | 25 | 3 | 30 | 0.39 |
| 2 | 32 | 2 | 64 | 0.74 |
| Number of Layers | Training Time (s) | Accuracy | |
|---|---|---|---|
| LSTM_1 | 1 | 350 | 0.64% |
| LSTM_2 | 2 | 795 | 0.72% |
| LSTM_3 | 3 | 1587 | 0.73% |
| Metrics | Models | ||||||
|---|---|---|---|---|---|---|---|
| LR | SVR | ARIMA | FFNN | CNN | LSTM | Proposed | |
| MAE | 476.41 | 310.23 | 201.75 | 115.03 | 276.95 | 120.76 | 74.27 |
| RMSE | 580.43 | 414.63 | 283.46 | 167.25 | 386.92 | 179.41 | 106.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, S.D.; Alarabi, L.; Basalamah, S. Toward Smart Lockdown: A Novel Approach for COVID-19 Hotspots Prediction Using a Deep Hybrid Neural Network. Computers 2020, 9, 99. https://doi.org/10.3390/computers9040099
Khan SD, Alarabi L, Basalamah S. Toward Smart Lockdown: A Novel Approach for COVID-19 Hotspots Prediction Using a Deep Hybrid Neural Network. Computers. 2020; 9(4):99. https://doi.org/10.3390/computers9040099
Chicago/Turabian StyleKhan, Sultan Daud, Louai Alarabi, and Saleh Basalamah. 2020. "Toward Smart Lockdown: A Novel Approach for COVID-19 Hotspots Prediction Using a Deep Hybrid Neural Network" Computers 9, no. 4: 99. https://doi.org/10.3390/computers9040099
APA StyleKhan, S. D., Alarabi, L., & Basalamah, S. (2020). Toward Smart Lockdown: A Novel Approach for COVID-19 Hotspots Prediction Using a Deep Hybrid Neural Network. Computers, 9(4), 99. https://doi.org/10.3390/computers9040099