kNN Prototyping Schemes for Embedded Human Activity Recognition with Online Learning †



Abstract
1. Introduction
- Use of various substitution schemes in the context of both standard kNN implementations and an LSH-based kNN implementation;
- Analysis, in terms of energy consumption and execution time, of the various approaches considered.
2. Related Work
3. kNN Substitution Schemes
- Default: In the kNN used (present in the MOA library [51]) when the instance limit is reached, whenever a new training instance arrives and needs to be stored, it replaces the oldest instance stored, regardless of its activity;
- SS1: randomly selects an instance of the class of the new instance and replaces it with the new instance;
- SS2: selects the oldest instance of the class of the new instance and replaces it with the new instance;
- SS3: classifies the new instance. If the new instance is incorrectly classified, SS1 is applied. Otherwise the new instance is discarded;
- SS4: classifies the new instance. If the new instance is incorrectly classified, SS2 is applied. Otherwise the new instance is discarded;
- SS5: classifies the new instance. If the new instance is correctly classified, the scheme randomly selects to apply SS1 or to discard the new instance. If the instance is classified incorrectly it applies SS1;
- SS6: classifies the new instance. If the new instance is correctly classified, the scheme randomly selects to apply SS2 or to discard the new instance. If the instance is classified incorrectly it applies SS2;
- SS7: classifies the new instance. If the new instance is incorrectly classified, the new instance replaces its nearest neighbor;
- SS8: classifies the new instance. If the new instance is correctly classified, the scheme randomly does one of these two options, (1) it replaces the nearest neighbor of the new instance by the new instance, or (2) it discards the new instance. If the new instance is incorrectly classified, the new instance replaces its nearest neighbor.
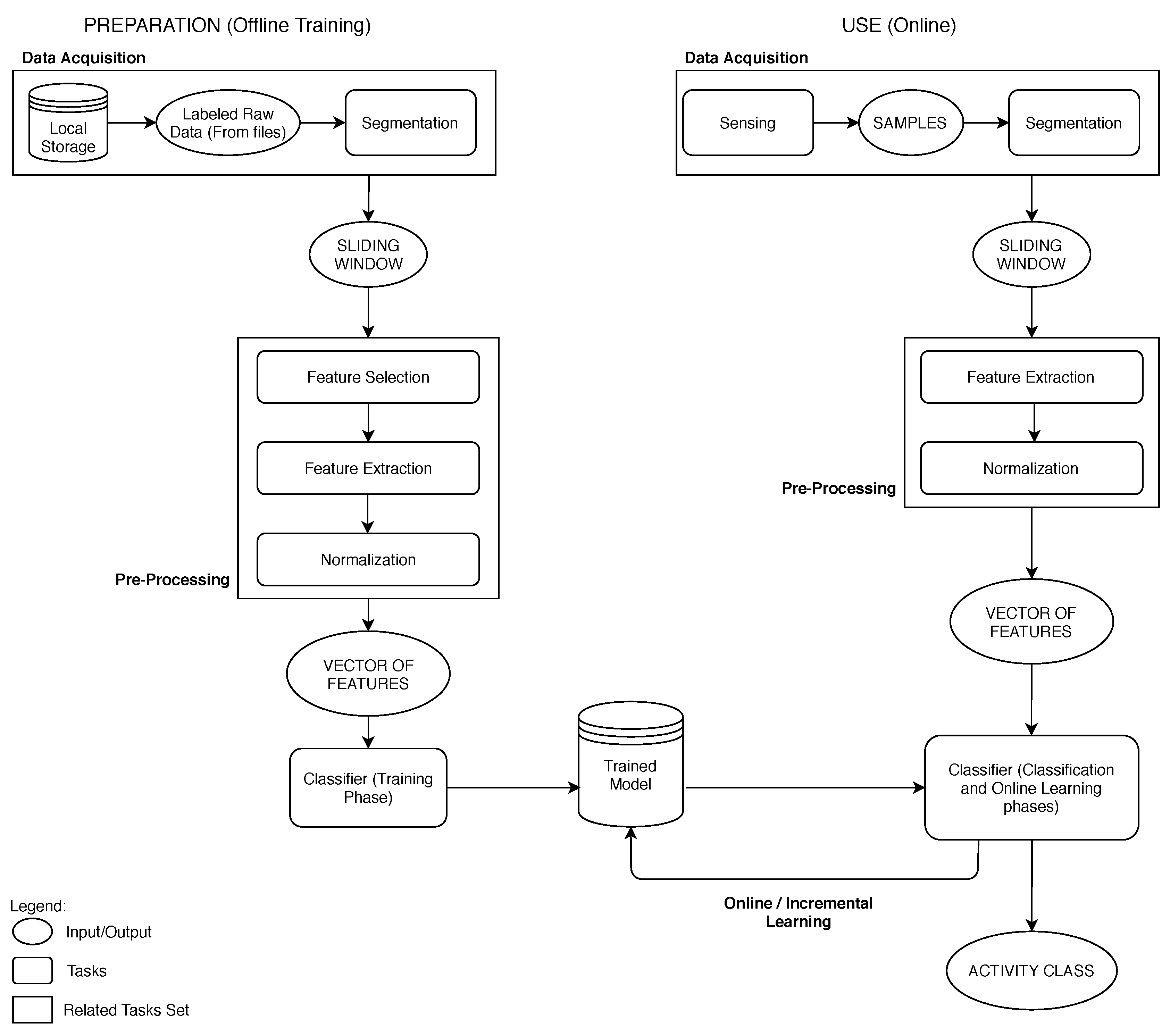
4. Experimental Setup
4.1. Prototypes
4.2. Datasets
4.3. Feature Extraction
4.4. Dataset Sampling
4.5. Instance Limits and Instance Reduction
4.6. Experiments Description
4.6.1. Without Online Learning
4.6.2. With Online/Incremental Learning
4.6.3. Impact of Online Learning
5. Results and Discussion
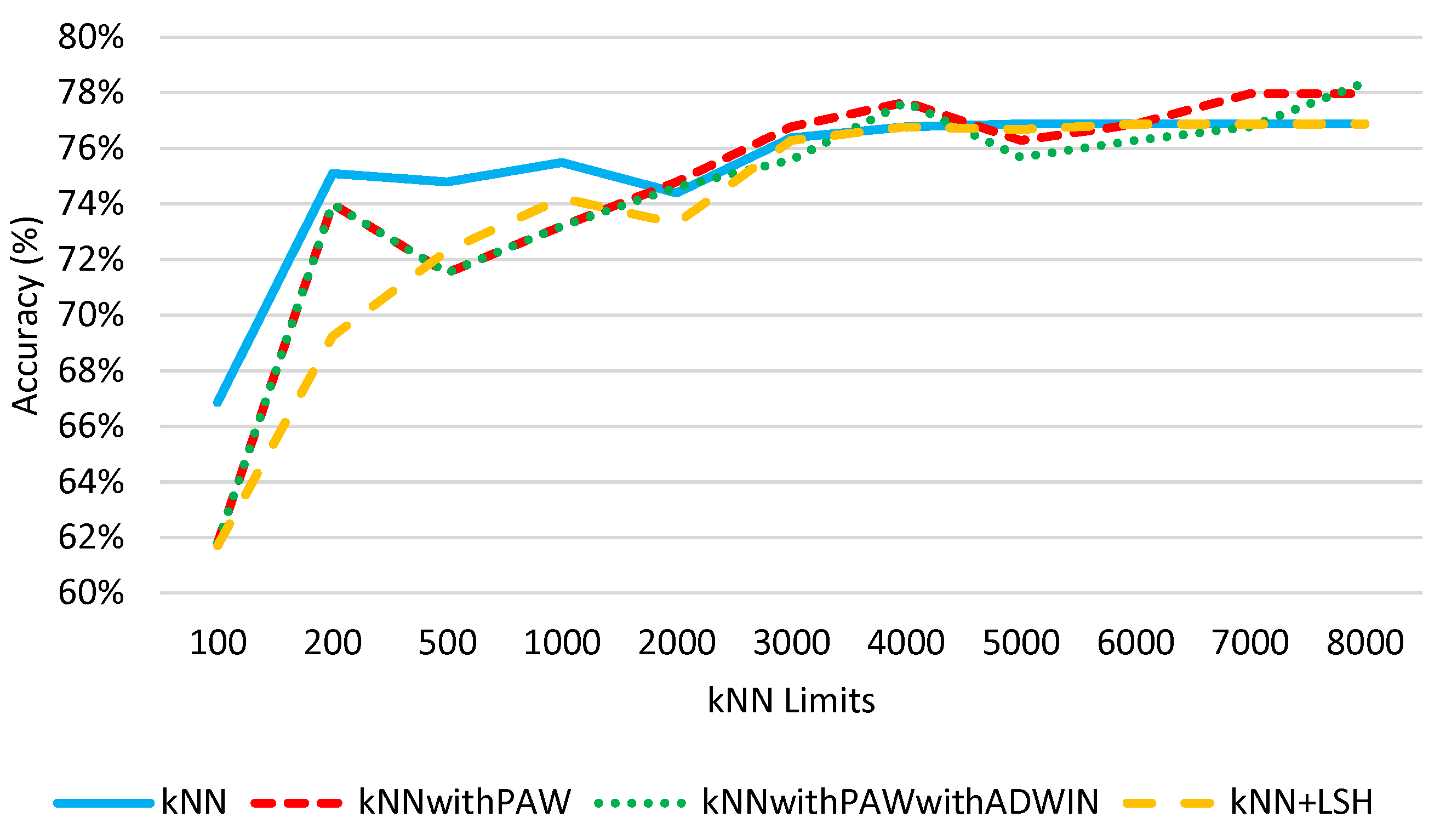
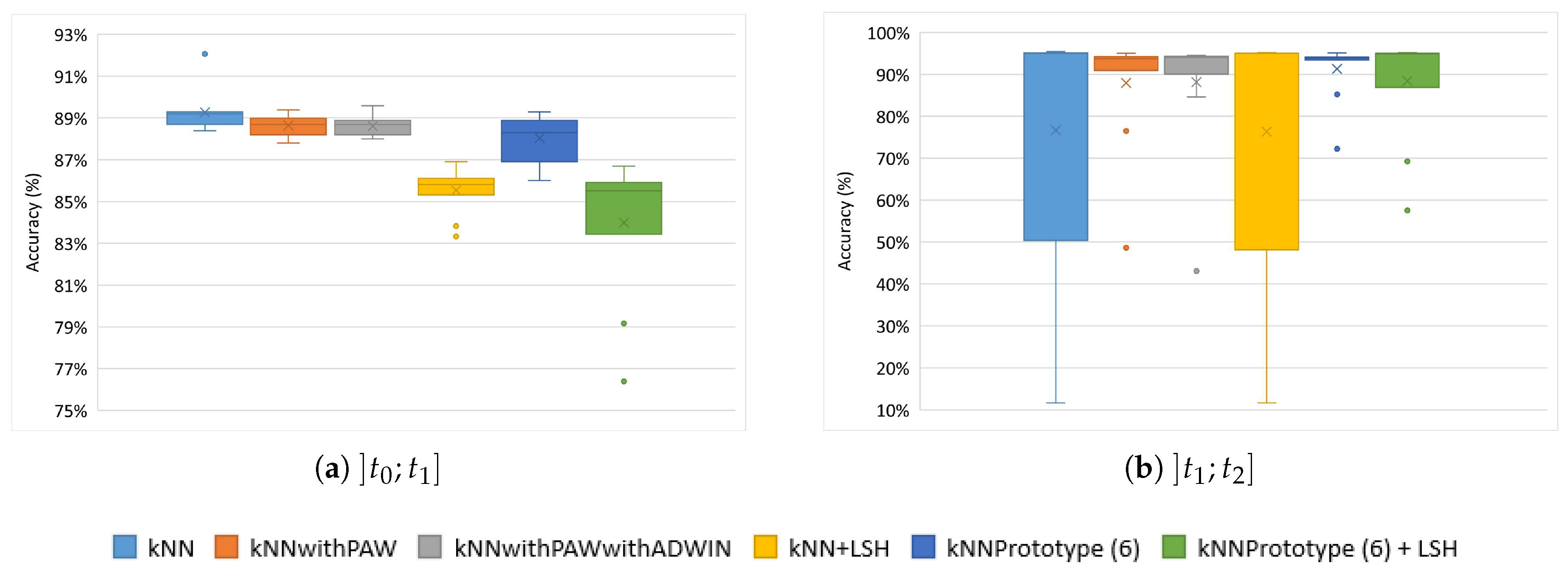
5.1. Comparison between the kNN Methods without Online Learning
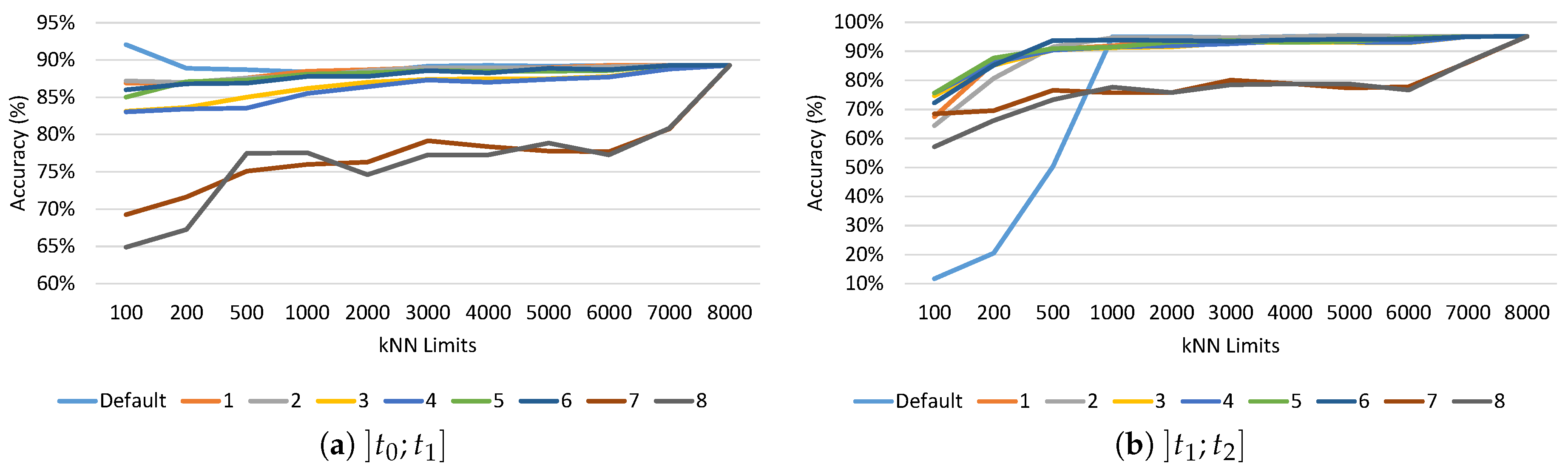
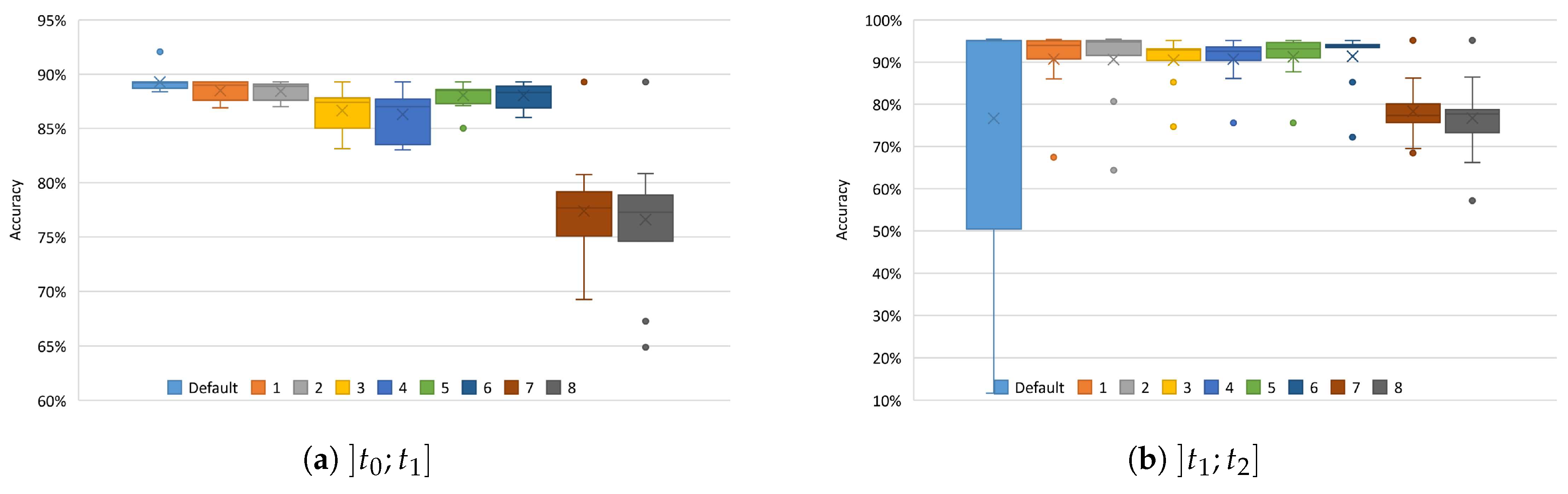
5.2. Substitution Schemes Comparison
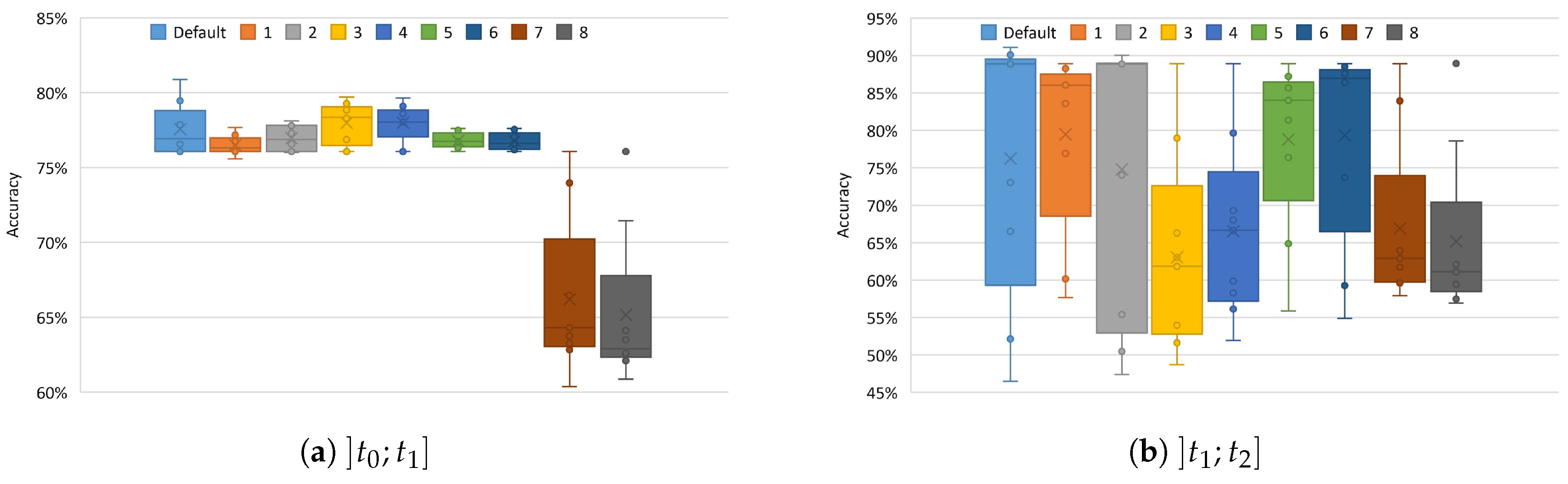
5.2.1. PAMAP2 Dataset
5.2.2. WISDM Dataset
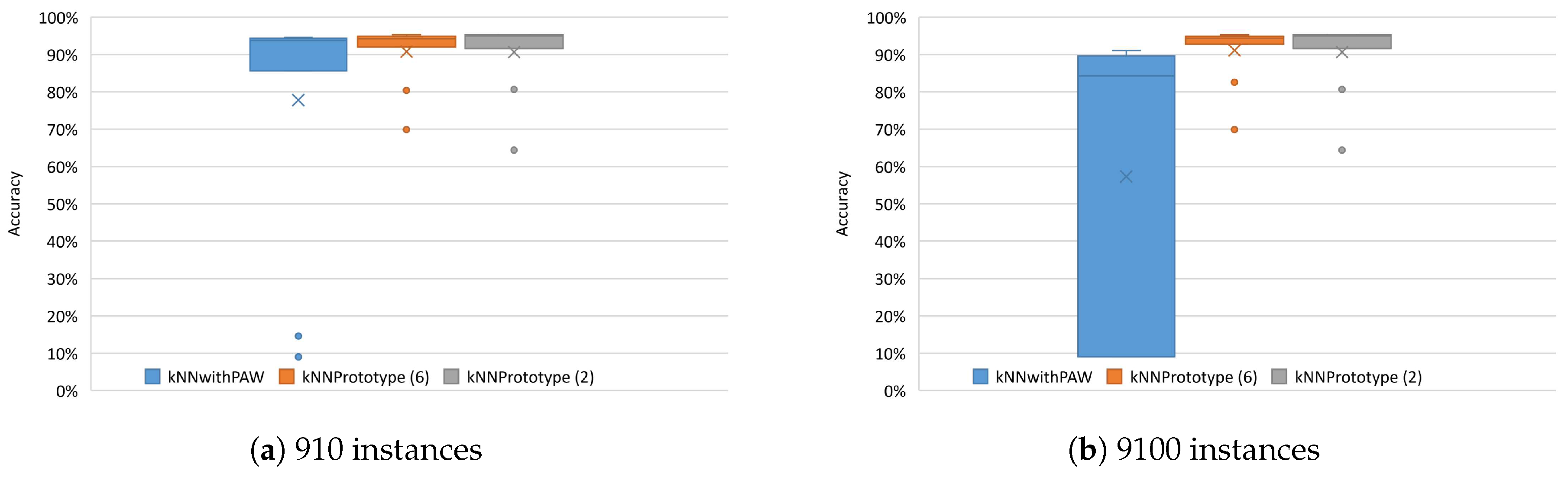
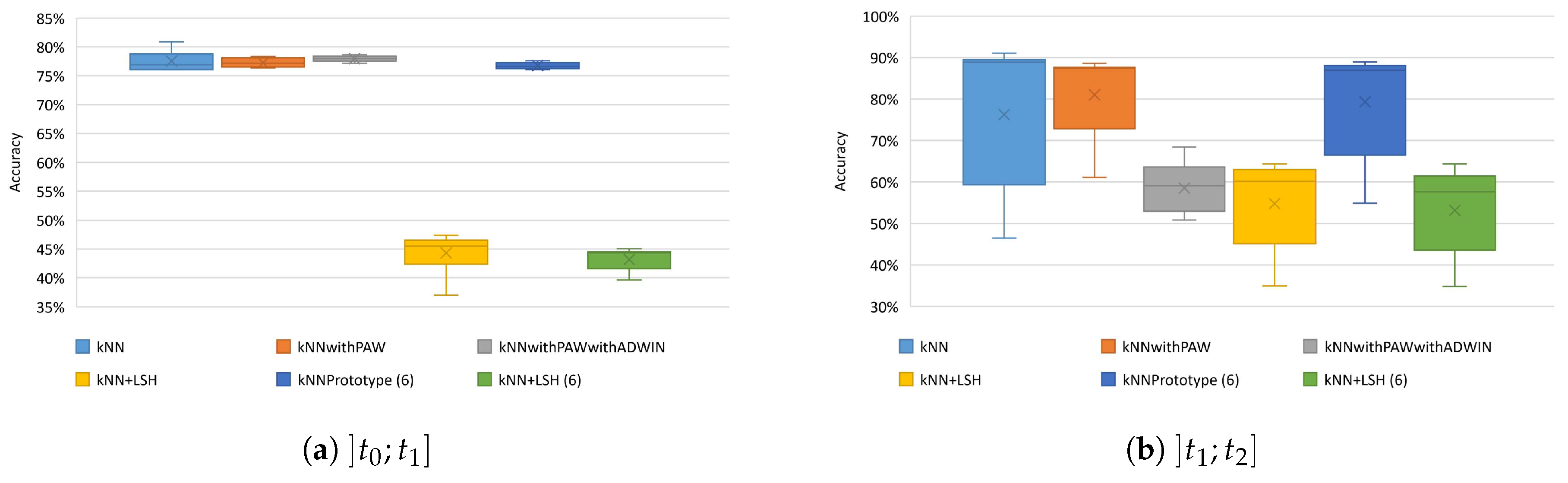
5.3. Comparison between the Various kNN Methods with Online Learning
5.3.1. PAMAP2 Dataset
5.3.2. WISDM Dataset
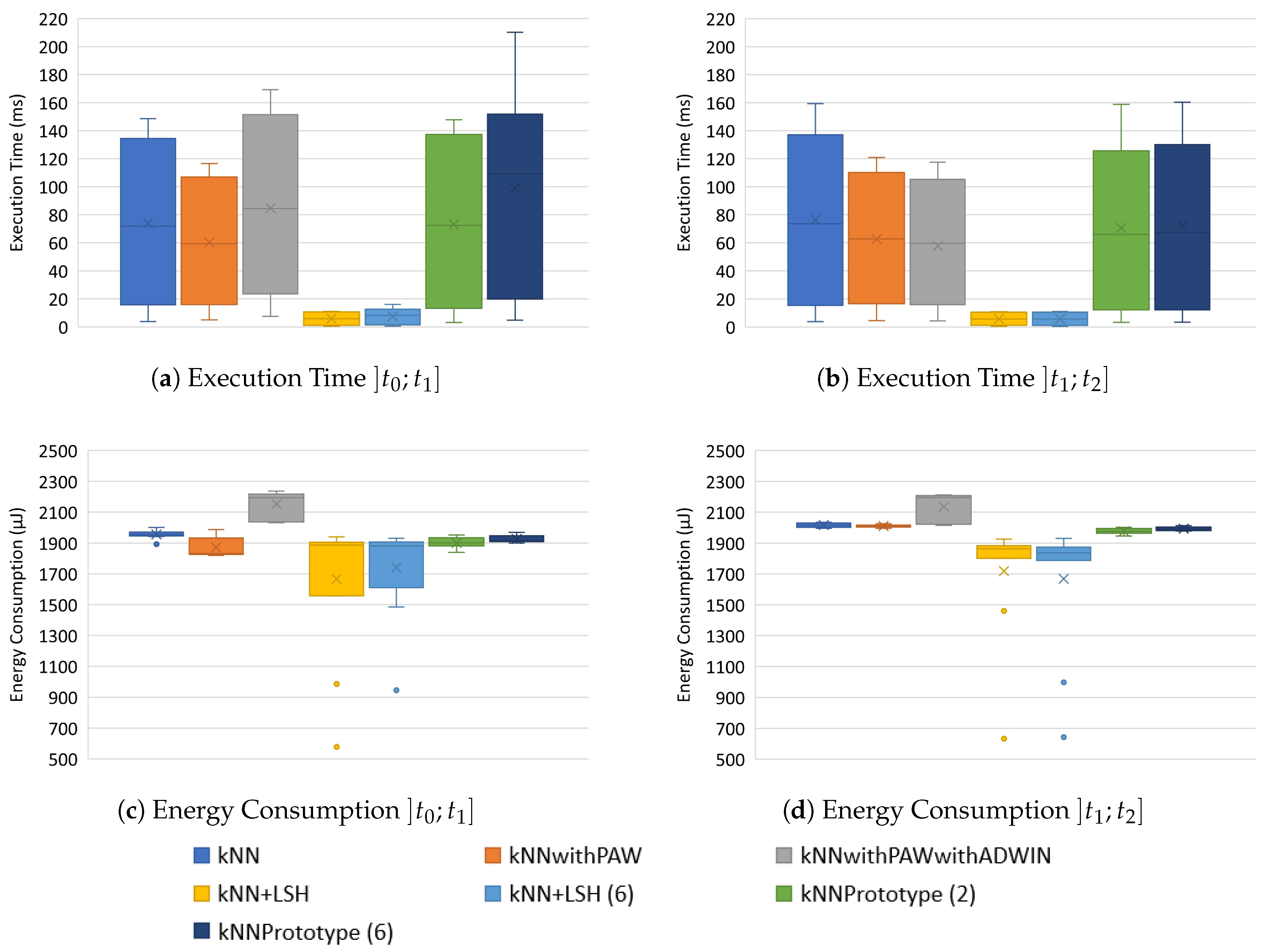
5.4. Execution Time and Energy Consumption
5.4.1. Execution Time
5.4.2. Energy Consumption
5.5. Analysis of Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HAR | Human Activity Recognition |
| kNN | k-Nearest Neighbour |
| ML | Machine Learning |
| LSH | Locality-Sensitive Hashing |
References
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutorials 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. A Survey of Online Activity Recognition Using Mobile Phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.; Scholten, H.; Havinga, P. Complex human activity recognition using smartphone and wrist-worn motion sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef]
- Chen, Y.; Shen, C. Performance analysis of smartphone-sensor behavior for human activity recognition. IEEE Access 2017, 5, 3095–3110. [Google Scholar] [CrossRef]
- Dobbins, C.; Rawassizadeh, R.; Momeni, E. Detecting physical activity within lifelogs towards preventing obesity and aiding ambient assisted living. Neurocomputing 2017, 230, 110–132. [Google Scholar] [CrossRef]
- Sang, V.N.T.; Thang, N.D.; Van Toi, V.; Hoang, N.D.; Khoa, T.Q.D. Human Activity Recognition and Monitoring Using Smartphones. In Proceedings of the 5th International Conference on Biomedical Engineering, Ho Chi Minh, Vietnam, 16–18 June 2014; pp. 481–485. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 16th IEEE International Symposium on Wearable Computers (ISWC), Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Banos, O.; Garcia, R.; Holgado-Terriza, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A novel framework for agile development of mobile health applications. In International Workshop on Ambient Assisted Living; Springer: Belfast, UK, 2014; pp. 91–98. [Google Scholar]
- Lara, O.D.; Labrador, M.A. A mobile platform for real-time human activity recognition. In Proceedings of the 2012 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012; pp. 667–671. [Google Scholar]
- Liang, Y.; Zhou, X.; Yu, Z.; Guo, B.; Yang, Y. Energy Efficient Activity Recognition Based on Low Resolution Accelerometer in Smart Phones. In Advances in Grid and Pervasive Computing; Li, R., Cao, J., Bourgeois, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 122–136. [Google Scholar]
- Siirtola, P.; Röning, J. Ready-to-use activity recognition for smartphones. In Proceedings of the 2013 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Singapore, 16–19 April 2013; pp. 59–64. [Google Scholar]
- Martín, H.; Barbolla, A.; Iglesias, J.; Casar, J. Activity Logging Using Lightweight Classification Techniques in Mobile Devices. Pers. Ubiquitous Comput. 2013, 17, 675–695. [Google Scholar] [CrossRef]
- Das, B.; Seelye, A.M.; Thomas, B.L.; Cook, D.J.; Holder, L.B.; Schmitter-Edgecombe, M. Using smart phones for context-aware prompting in smart environments. In Proceedings of the 2012 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012; pp. 399–403. [Google Scholar]
- Gomes, J.B.; Krishnaswamy, S.; Gaber, M.M.; Sousa, P.A.C.; Menasalvas, E. MARS: A Personalised Mobile Activity Recognition System. In Proceedings of the 2012 IEEE 13th International Conference on Mobile Data Management, Bengaluru, India, 23–26 July 2012; pp. 316–319. [Google Scholar]
- Mannini, A.; Intille, S.S.; Rosenberger, M.; Sabatini, A.M.; Haskell, W. Activity recognition using a single accelerometer placed at the wrist or ankle. Med. Sci. Sports Exerc. 2013, 45, 2193. [Google Scholar] [CrossRef]
- Siirtola, P.; Röning, J. Recognizing Human Activities User-independently on Smartphones Based on Accelerometer Data. Int. J. Interact. Multimed. Artif. Intell. 2012, 1, 38–45. [Google Scholar] [CrossRef]
- Xu, C.; Chai, D.; He, J.; Zhang, X.; Duan, S. InnoHAR: A Deep Neural Network for Complex Human Activity Recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Ignatov, A. Real-time human activity recognition from accelerometer data using Convolutional Neural Networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep learning models for real-time human activity recognition with smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Hassan, M.; Uddin, M.Z.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2017, 81, 307–313. [Google Scholar] [CrossRef]
- Mohamad, S.; Sayed-Mouchaweh, M.; Bouchachia, A. Online active learning for human activity recognition from sensory data streams. Neurocomputing 2020, 390, 341–358. [Google Scholar] [CrossRef]
- Dearo Garcia, K.; de Carvalho, A.; Mendes-Moreira, J. A cluster based prototype reduction for online classification. In Intelligent Data Engineering and Automated Learning—IDEAL 2018; Yin, H., Camacho, D., Novais, P., Tallón-Ballesteros, A., Eds.; Lecture Notes in Computer Science; Springer: Madrid, Spain, 21–23 November 2018; pp. 603–610. [Google Scholar] [CrossRef]
- Bhat, G.; Deb, R.; Chaurasia, V.V.; Shill, H.; Ogras, U.Y. Online Human Activity Recognition using Low-Power Wearable Devices. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar]
- Ferreira, P.J.S.; Magalhães, R.M.C.; Garcia, K.D.; Cardoso, J.M.P.; Mendes-Moreira, J. An Efficient Scheme for Prototyping kNN in the Context of Real-Time Human Activity Recognition. In Intelligent Data Engineering and Automated Learning–IDEAL 2019; Yin, H., Camacho, D., Tino, P., Tallón-Ballesteros, A.J., Menezes, R., Allmendinger, R., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 486–493. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. In Proceedings of the Fourth International Workshop on Knowledge Discovery from Sensor Data, Washington, DC, USA, 4–30 May 2010; pp. 10–18. [Google Scholar]
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and Smartwatch-Based Biometrics Using Activities of Daily Living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Bifet, A.; Pfahringer, B.; Read, J.; Holmes, G. Efficient Data Stream Classification via Probabilistic Adaptive Windows. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 801–806. [Google Scholar] [CrossRef]
- Bifet, A.; Gavalda, R. Learning from time-changing data with adaptive windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, Minnesota, 26–28 April 2007; Volume 7, pp. 443–448. [Google Scholar]
- Indyk, P.; Motwani, R. Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 23–26 May 1998; pp. 604–613. [Google Scholar] [CrossRef]
- Datar, M.; Immorlica, N.; Indyk, P.; Mirrokni, V.S. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the 20th Annual Symposium on Computational Geometry—SCG’04, Brooklyn, NY, USA, 9–11 June 2004; p. 253. [Google Scholar] [CrossRef]
- Nanni, L.; Lumini, A. Prototype reduction techniques: A comparison among different approaches. Expert Syst. Appl. 2011, 38, 11820–11828. [Google Scholar] [CrossRef]
- Garcia, S.; Derrac, J.; Cano, J.; Herrera, F. Prototype Selection for Nearest Neighbor Classification: Taxonomy and Empirical Study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 417–435. [Google Scholar] [CrossRef]
- Triguero, I.; Derrac, J.; Garcia, S.; Herrera, F. A Taxonomy and Experimental Study on Prototype Generation for Nearest Neighbor Classification. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 86–100. [Google Scholar] [CrossRef]
- Hart, P. The condensed nearest neighbor rule (Corresp.). IEEE Trans. Inf. Theory 1968, 14, 515–516. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. The Feature Selection Problem: Traditional Methods and a New Algorithm. In Proceedings of the Tenth National Conference on Artificial Intelligence, San Jose, CA, USA, 12–16 July 1992; pp. 129–134. [Google Scholar]
- Gallego, A.J.; Calvo-Zaragoza, J.; Valero-Mas, J.J.; Rico-Juan, J.R. Clustering-based k-nearest neighbor classification for large-scale data with neural codes representation. Pattern Recognit. 2018, 74, 531–543. [Google Scholar] [CrossRef]
- Athitsos, V.; Potamias, M.; Papapetrou, P.; Kollios, G. Nearest Neighbor Retrieval Using Distance-Based Hashing. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; pp. 327–336. [Google Scholar] [CrossRef]
- He, J.; Chang, S.; Radhakrishnan, R.; Bauer, C. Compact hashing with joint optimization of search accuracy and time. In Proceedings of the CVPR, Colorado Springs, CO, USA, 20–25 June 2011; pp. 753–760. [Google Scholar] [CrossRef]
- Andoni, A.; Indyk, P. Near-Optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions. Commun. ACM 2008, 51, 117–122. [Google Scholar] [CrossRef]
- Magalhães, R.M.C.; Cardoso, J.M.P.; Mendes-Moreira, J. Energy Efficient Smartphone-Based Users Activity Classification. In Proceedings of the 19th EPIA Conference on Artificial Intelligence, Vila Real, Portugal, 3–6 September 2019; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Losing, V.; Hammer, B.; Wersing, H. KNN Classifier with Self Adjusting Memory for Heterogeneous Concept Drift. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 291–300. [Google Scholar] [CrossRef]
- Cao, L.; Wang, Y.; Zhang, B.; Jin, Q.; Vasilakos, A.V. GCHAR: An efficient Group-based Context—Aware human activity recognition on smartphone. J. Parallel Distrib. Comput. 2018, 118, 67–80. [Google Scholar] [CrossRef]
- Zheng, L.; Wu, D.; Ruan, X.; Weng, S.; Peng, A.; Tang, B.; Lu, H.; Shi, H.; Zheng, H. A Novel Energy-Efficient Approach for Human Activity Recognition. Sensors 2017, 17, 2064. [Google Scholar] [CrossRef]
- Yan, Z.; Subbaraju, V.; Chakraborty, D.; Misra, A.; Aberer, K. Energy-Efficient Continuous Activity Recognition on Mobile Phones: An Activity-Adaptive Approach. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 17–24. [Google Scholar] [CrossRef]
- Liang, Y.; Zhou, X.; Yu, Z.; Guo, B. Energy-Efficient Motion Related Activity Recognition on Mobile Devices for Pervasive Healthcare. Mob. Netw. Appl. 2014, 19, 303–317. [Google Scholar] [CrossRef]
- Yang, T.; Cao, L.; Zhang, C. A Novel Prototype Reduction Method for the K-Nearest Neighbor Algorithm with K ≥ 1. In Proceedings of the 14th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining—Volume Part II, Hyderabad, India, 21–24 June 2010 2010; pp. 89–100. [Google Scholar] [CrossRef]
- Muja, M.; Lowe, D.G. Scalable Nearest Neighbor Algorithms for High Dimensional Data. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2227–2240. [Google Scholar] [CrossRef]
- Vieira, J.; Duarte, R.P.; Neto, H.C. kNN-STUFF: kNN STreaming Unit for Fpgas. IEEE Access 2019, 7, 170864–170877. [Google Scholar] [CrossRef]
- Ito, T.; Itotani, Y.; Wakabayashi, S.; Nagayama, S.; Inagi, M. A Nearest Neighbor Search Engine Using Distance-Based Hashing. In Proceedings of the 2018 International Conference on Field-Programmable Technology (FPT), Naha Okinawa, Japan, 11–15 December 2018; pp. 150–157. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Kirkby, R.; Pfahringer, B. MOA: Massive Online Analysis. J. Mach. Learn. Res. 2010, 11, 1601–1604. [Google Scholar]
- Baek, I.H.; Liu, X. Power and Energy Analysis on Odroid-XU+ E and Adaptive Power Model; University of California Los Angeles: Los Angeles, CA, USA, 2017. [Google Scholar]
- Soria Morillo, L.; Gonzalez-Abril, L.; Ortega, J.; Álvarez de la Concepción, M. Low Energy Physical Activity Recognition System on Smartphones. Sensors 2015, 15, 5163–5196. [Google Scholar] [CrossRef]
- Youssef, A.; Aerts, J.; Vanrumste, B.; Luca, S. A Localised Learning Approach Applied to Human Activity Recognition. IEEE Intell. Syst. 2020. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Features | #Classes | Total Instances (#Windows) | Train Set Instances (#Windows) | Test Set Instances (#Windows) |
|---|---|---|---|---|---|
| WISDM | 43 | 6 | 5418 | 3793 | 1625 |
| PAMAP2 | 90 | 18 | 7194 | 6186 | 1008 |
| Activity | Instances | % |
|---|---|---|
| lying | 88 | 8.73 |
| sitting | 99 | 9.82 |
| standing | 82 | 8.13 |
| ironing | 123 | 12.20 |
| vacuum_cleaning | 90 | 8.93 |
| ascending_stairs | 53 | 5.26 |
| descending_stairs | 47 | 4.66 |
| walking | 119 | 11.81 |
| nordic_walking | 97 | 9.62 |
| cycling | 91 | 9.03 |
| running | 91 | 9.03 |
| rope_jumping | 28 | 2.78 |
| Total | 1008 | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferreira, P.J.S.; Cardoso, J.M.P.; Mendes-Moreira, J. kNN Prototyping Schemes for Embedded Human Activity Recognition with Online Learning. Computers 2020, 9, 96. https://doi.org/10.3390/computers9040096
Ferreira PJS, Cardoso JMP, Mendes-Moreira J. kNN Prototyping Schemes for Embedded Human Activity Recognition with Online Learning. Computers. 2020; 9(4):96. https://doi.org/10.3390/computers9040096
Chicago/Turabian StyleFerreira, Paulo J. S., João M. P. Cardoso, and João Mendes-Moreira. 2020. "kNN Prototyping Schemes for Embedded Human Activity Recognition with Online Learning" Computers 9, no. 4: 96. https://doi.org/10.3390/computers9040096
APA StyleFerreira, P. J. S., Cardoso, J. M. P., & Mendes-Moreira, J. (2020). kNN Prototyping Schemes for Embedded Human Activity Recognition with Online Learning. Computers, 9(4), 96. https://doi.org/10.3390/computers9040096