Asymmetric Attributional Word Similarity Measures to Detect the Relations of Textual Generality



Abstract
1. Introduction
1.1. Defining Textual Entailment
- Semantic Subsumption—T and H express the same fact, but the situation described in T is more specific than the situation in H. The specificity of T is expressed through one or more semantic operations. For example, in the sentential pair:
- H: The cat eats the mouse.
- T: The cat devours the mouse.
T is more specific than H, as eating is a semantic generalization of devouring. - Syntactic Subsumption – T and H express the same fact, but the situation described in T is more specific than the situation in H. The specificity of T is expressed through one or more syntactic operations. For example, in the pair:
- H: The cat eats the mouse.
- T: The cat eats the mouse in the garden.
T contains a specializing prepositional phrase. - Direct Implication—H expresses a fact that is implied by a fact in T. For example:
- H: The cat killed the mouse.
- T: The cat devours the mouse.
H is implied by T, as it is supposed that killed is a precondition for devouring. In [1] syntactic subsumption roughly corresponds to the restrictive extension rule, while the direct implication and semantic subsumption to the axiom rule.
- Semantic Subsumption;
- Syntactic Subsumption;
- Or a combination of both—Semantic Subsumption + Syntactic Subsumption;
- T textually entails H relative to group G, if a member of G reading T would be justified in inferring the proposition expressed by H from the proposition expressed by T.
1.2. Textual Entailment by Generality
- :
- Mexico City has a terrible pollution problem because the mountains around the city act as walls and block in dust and smog.
- :
- Poor air circulation out of the mountain-walled Mexico City aggravates pollution.
1.3. Asymmetric Association
2. Related Work
2.1. Recognizing Textual Entailment
- T: In the end, defeated, Antony committed suicide and so did Cleopatra, according to legend, by putting an asp to her breast.
- H: Cleopatra committed suicide.
2.2. Unsupervised Language-Independent Methodologies for RTE
3. Asymmetric Similarity
4. Detect Relations of Textual Generality
4.1. Asymmetric Association Measures
4.2. Asymmetric Attributional Word Similarities
5. TEG Corpus
Building Methodology—Quantitative Analysis
- Textual Entailment by Generality (TEG),
- Textual Entailment, without Generality (TEnG),
- Other,
6. Experimentation
6.1. Levels of Word Granularity
Sample of Calculation for Identify Entailment by Generality
“<pair id=“217” entailment=“YES” task=“IR” length=“short” ><t>Pierre Beregovoy, apparently left no message when he shot himself with a borrowed gun.</t><h>Pierre Beregovoy commits suicide.</h>< /pair>”
7. Evaluating the Performance
7.1. Measures to Evaluate the Performance
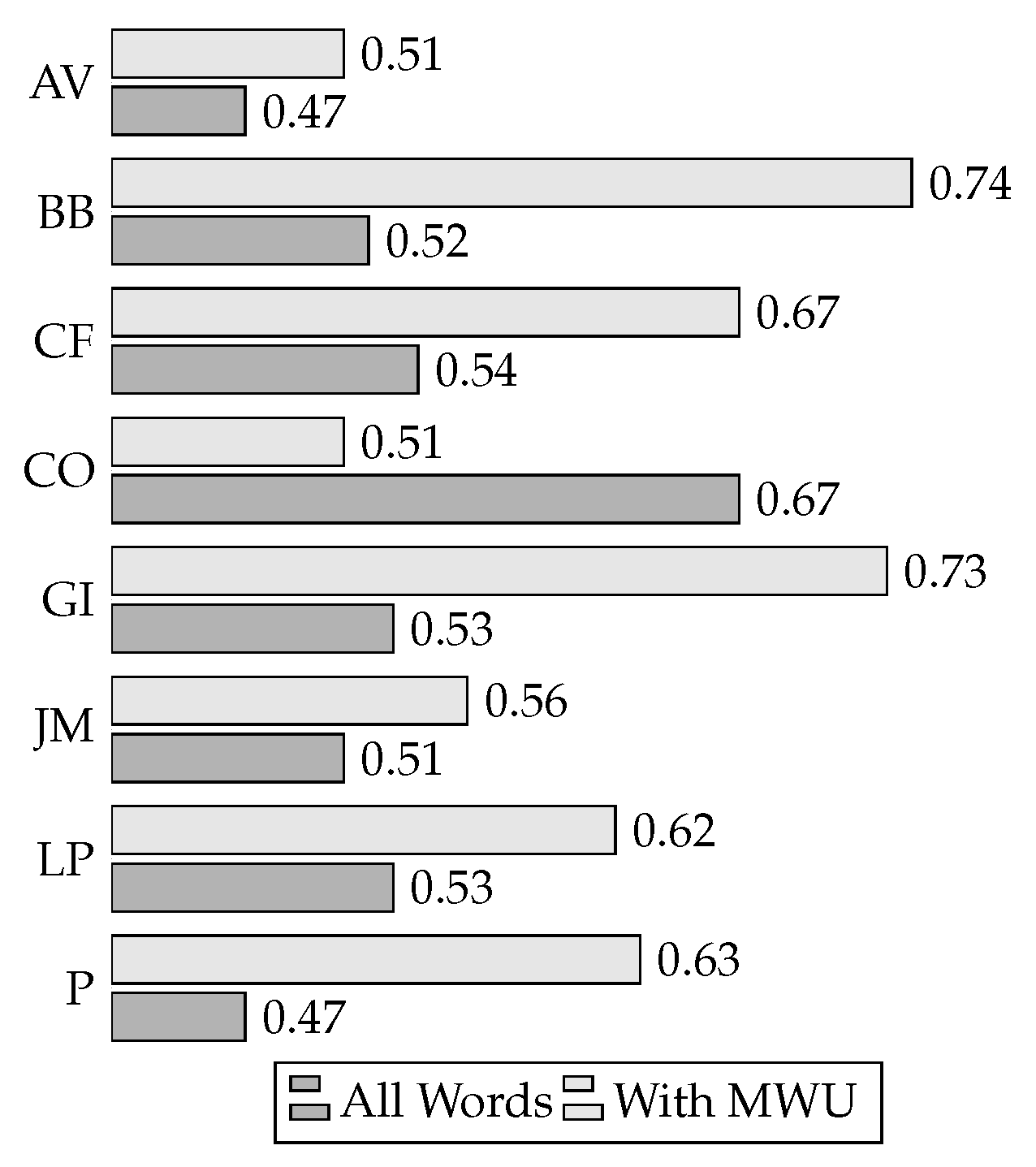
7.2. Results in TEG Corpus
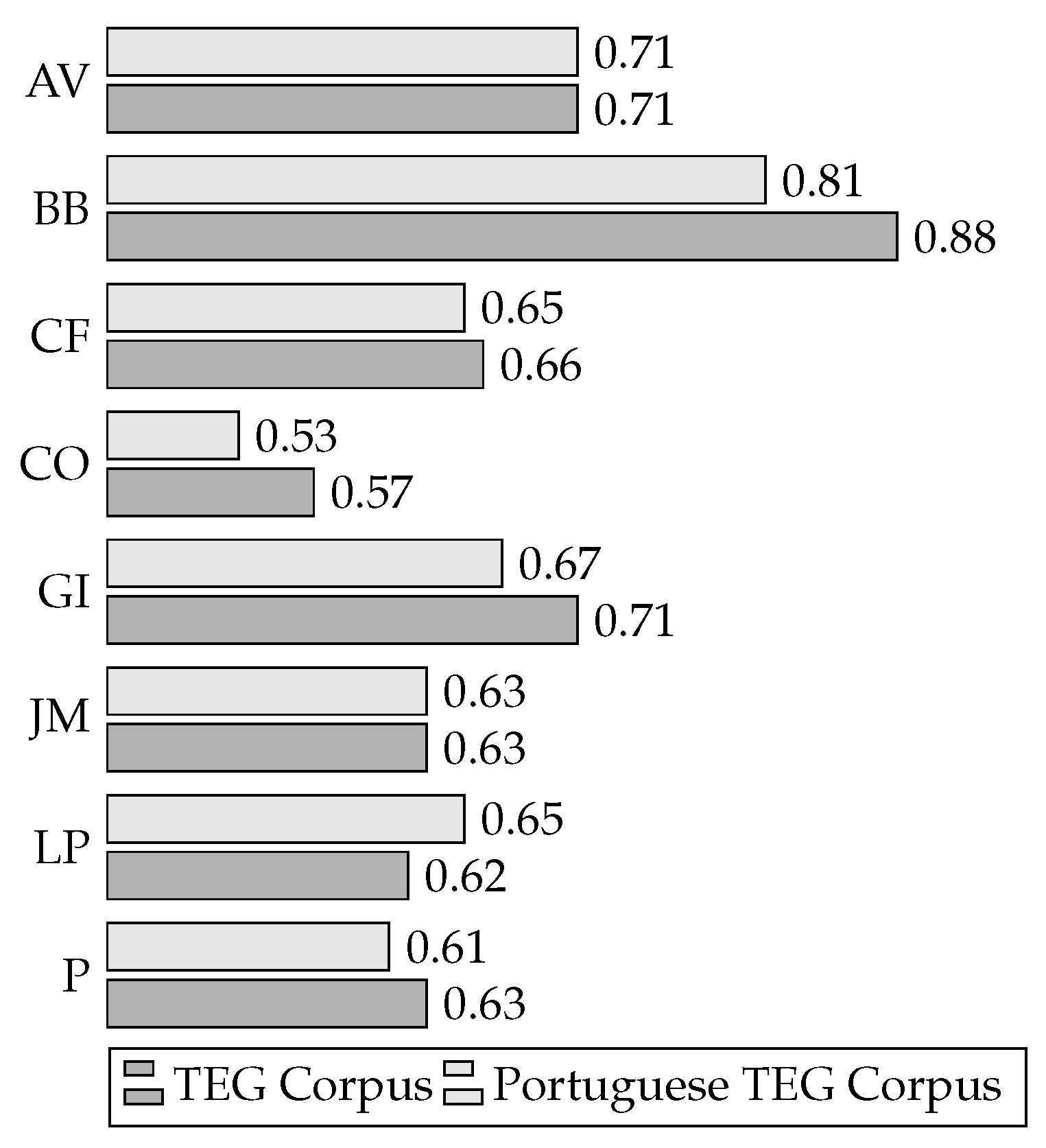
7.3. Results in Portuguese TEG Corpus
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix A.1. RTE Challenges
Appendix A.1.1. Evaluation Measures
Appendix A.1.2. First Challenge
Appendix A.1.3. Second Challenge
Appendix A.1.4. Third Challenge
Appendix A.1.5. Fourth Challenge
Appendix A.1.6. Fifth Challenge

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RTE-1 | RTE-2 | RTE-3 | RTE-4 | RTE-5 | |||||
|---|---|---|---|---|---|---|---|---|---|
| Participants | Accuracy | Participants | Accuracy | Participants | Accuracy | Participants | Accuracy | Participants | Accuracy |
| [49] | 0.606 | [51] | 0.754 | [56] | 0.800 | [63] | 0.746 | [68] | 0.735 |
| [24] | 0.586 | [52] | 0.738 | [57] | 0.723 | [64] | 0.721 | [69] | 0.685 |
| [22] | 0.586 | [53] | 0.639 | [59] | 0.691 | [65] | 0.706 | [70] | 0.670 |
| [48] | 0.566 | [54] | 0.626 | [61] | 0.670 | [66] | 0.659 | [71] | 0.662 |
| [50] | 0.559 | [55] | 0.616 | [62] | 0.669 | [67] | 0.608 | [72] | 0.643 |
References
- Dagan, I.; Glickman, O. Probabilistic Textual Entailment: Generic Applied Modeling of Language Variability. In Proceedings of the Workshop on Learning Methods for Text Understanding and Mining, Grenoble, France, 26–29 January 2004. [Google Scholar]
- Dagan, I.; Roth, D.; Sammons, M.; Zanzotto, F.M. Recognizing Textual Entailment: Models and Applications. Synth. Lect. Hum. Lang. Technol. 2013, 6, 1–220. [Google Scholar] [CrossRef]
- Lloret, E.; Ferrández, O.; Munoz, R.; Palomar, M. A Text Summarization Approach under the Influence of Textual Entailment. In Proceedings of the International Workshop on Natural Language Processing and Cognitive Science, NLPCS, Bercelona, Spain, 12 June 2008; pp. 22–31. [Google Scholar]
- Gupta, A.; Kaur, M.; Mirkin, S.; Singh, A.; Goyal, A. Text summarization through entailment-based minimum vertex cover. In Proceedings of the Third Joint Conference on Lexical and Computational Semantics (* SEM 2014), Birmingham, UK, 16–17 November 2014; pp. 75–80. [Google Scholar]
- Padó, S.; Galley, M.; Jurafsky, D.; Manning, C. Robust machine translation evaluation with entailment features. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; Volume 1, pp. 297–305. [Google Scholar]
- Nevěřilová, Z. Paraphrase and textual entailment generation. In Proceedings of the International Conference on Text, Speech, and Dialogue, Pilsen, Czech Republic, 14–17 September 2014; Springer: Berlin, Germany, 2014; pp. 293–300. [Google Scholar]
- Almansor, E.H.; Hussain, F.K. Survey on Intelligent Chatbots: State-of-the-Art and Future Research Directions. In Proceedings of the Conference on Complex, Intelligent, and Software Intensive Systems, Sydney, Australia, 1–3 July 2019; Springer: Berlin, Germany, 2019; pp. 534–543. [Google Scholar]
- Pazienza, M.T.; Pennacchiotti, M.; Zanzotto, F.M. A Linguistic Inspection of Textual Entailment. In Proceedings of the 9th Conference on Advances in Artificial Intelligence, AI*IA’05, Milan, Italy, 21–23 September 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 315–326. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Korman, D.Z.; Mack, E.; Jett, J.; Renear, A.H. Defining textual entailment. J. Assoc. Inf. Sci. Technol. 2018, 69, 763–772. [Google Scholar] [CrossRef]
- Dagan, I.; Glickman, O.; Magnini, B. The PASCAL Recognising Textual Entailment Challenge. Machine Learning Challenges, Evaluating Predictive Uncertainty, Visual Object Classification and Recognizing Textual Entailment. In Proceedings of the First PASCAL Machine Learning Challenges Workshop, MLCW 2005, Southampton, UK, 11–13 April 2005; Revised Selected Papers. Candela, J.Q., Dagan, I., Magnini, B., d Alché-Buc, F., Eds.; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2005; Volume 3944, pp. 177–190. [Google Scholar] [CrossRef]
- Pais, S.; Dias, G.; Wegrzyn-Wolska, K.; Mahl, R.; Jouvelot, P. Textual Entailment by Generality. Procedia Soc. Behav. Sci. 2011, 27, 258–266. [Google Scholar] [CrossRef]
- Dias, G.; Pais, S.; Wegrzyn-Wolska, K.; Mahl, R. Recognizing Textual Entailment by Generality Using Informative Asymmetric Measures and Multiword Unit Identification to Summarize Ephemeral Clusters. In Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology—Volume 01, WI-IAT ’11, Lyon, France, 22–27 August 2018; IEEE Computer Society: Washington, DC, USA, 2011; pp. 284–287. [Google Scholar] [CrossRef]
- Pecina, P.; Schlesinger, P. Combining Association Measures for Collocation Extraction. In Proceedings of the Joint Conference of the International Committee on Computational Linguistics and the Association for Computational Linguistics (COLING/ACL 2006), Sydney, Australia, 17–22 July 2006; pp. 651–658. [Google Scholar]
- Tan, P.N.; Kumar, V.; Srivastava, J. Selecting the Right Objective Measure for Association Analysis. Inf. Syst. 2004, 29, 293–313. [Google Scholar] [CrossRef]
- Michelbacher, L.; Evert, S.; Schütze, H. Asymmetric Association Measures. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2007), Borovets, Bulgaria, 27–29 September 2007; pp. 1–6. [Google Scholar]
- Sanderson, M.; Croft, B. Deriving concept hierarchies from text. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’99, Berkeley, CA, USA, 15–19 August 1999; ACM: New York, NY, USA, 1999; pp. 206–213. [Google Scholar] [CrossRef]
- Dias, G.; Mukelov, R.; Cleuziou, G. Unsupervised Graph-Based Discovery of General-Specific Noun Relationships from Web Corpora Frequency Counts. In Proceedings of the 12th International Conference on Natural Language Learning (CoNLL 2008), Manchester, UK, 16–17 August 2008. [Google Scholar]
- Sanderson, M.; Lawrie, D. Building, Testing, and Applying Concept Hierarchies. Adv. Inf. Retr. 2000, 7, 235–266. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Texts. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2004), Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Glickman, O. APPLIED TEXTUAL ENTAILMENT: A Generic Framework to Capture Shallow Semantic Inference; VDM Verlag: Saarbrücken, Germany, 2009. [Google Scholar]
- Glickman, O.; Dagan, I. Web based probabilistic textual entailment. In Proceedings of the 1st Pascal Challenge Workshop, Southampton, UK, 11–13 April 2005; pp. 33–36. [Google Scholar]
- Perez, D.; Alfonsecaia, E.; Rodríguez, P. Application of the Bleu algorithm for recognising textual entailments. In Proceedings of the Recognising Textual Entailment Pascal Challenge, Southampton, UK, 11–13 April 2005. [Google Scholar]
- Bayer, S.; Burger, J.; Ferro, L.; Henderson, J.; Yeh, E. Mitre’s submission to the eu pascal rte challenge. In Proceedings of the First Challenge Workshop, Recognizing Textual Entailment, PASCAL, Southampton, UK, 11–13 April 2005; pp. 41–44. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, Pennsylvania, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Och, F.J.; Ney, H. A systematic comparison of various statistical alignment models. Comput. Linguist. 2003, 29, 19–51. [Google Scholar] [CrossRef]
- Rosch, E. Natural Categories. Cogn. Psychol. 1973, 4, 265–283. [Google Scholar] [CrossRef]
- Cleuziou, G.; Buscaldi, D.; Levorato, V.; Dias, G. A Pretopological Framework for the Automatic Construction of Lexical-Semantic Structures from Texts; CIKM; Macdonald, C., Ounis, I., Ruthven, I., Eds.; ACM: New York, NY, USA, 2011; pp. 2453–2456. [Google Scholar]
- Dias, G.; Alves, E.; Lopes, J. Topic Segmentation Algorithms for Text Summarization and Passage Retrieval: An Exhaustive Evaluation. In Proceedings of the 22nd Conference on Artificial Intelligence (AAAI 2007), Vancouverm, BC, Canada, 22–26 July 2007; pp. 1334–1340. [Google Scholar]
- Cleuziou, G.; Dias, G.; Levorato, V. Modélisation Prétopologique pour la Structuration Sémantico-Lexicale. In Proceedings of the 17èmes Rencontres de la Société Francophone de Classification (SFC 2010), Stockholm, Sweden, 15–16 October 2010. [Google Scholar]
- Dias, G. Information Digestion. 2010. Available online: https://tel.archives-ouvertes.fr/tel-00669780/document (accessed on 10 October 2020).
- Lund, K.; Burgess, C.; Atchley, R. Semantic and Associative Priming in High Dimensional Semantic Space. In Proceedings of the 17th Annual Conference of the Cognitive Science Society, Pittsburgh, PA, USA, 22–25 July 1995; pp. 660–665. [Google Scholar]
- Freitag, D.; Blume, M.; Byrnes, J.; Chow, E.; Kapadia, S.; Rohwer, R.; Wang, Z. New Experiments in Distributional Representations of Synonymy. In Proceedings of the 9th Conference on Computational Natural Language Learning (CoNLL 2005), Ann Arbor, MI, USA, 29–30 June 2005; pp. 25–32. [Google Scholar]
- Kullback, S.; Leibler, R. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Menéndez, M.; Pardo, J.; Pardo, L.; Pardo, M. The Jensen-Shannon Divergence. J. Frankl. Inst. 1997, 334, 307–318. [Google Scholar] [CrossRef]
- Marcus, M.P.; Marcinkiewicz, M.A.; Santorini, B. Building a large annotated corpus of English: The penn treebank. Comput. Linguist. 1993, 19, 313–330. [Google Scholar]
- Palmer, M.; Gildea, D.; Kingsbury, P. The Proposition Bank: An Annotated Corpus of Semantic Roles. Comput. Linguist. 2005, 31, 71–106. [Google Scholar] [CrossRef]
- Pustejovsky, J.; Hanks, P.; Sauri, R.; See, A.; Gaizauskas, R.; Setzer, A.; Radev, D.; Sundheim, B.; Day, D.; Ferro, L.; et al. The TIMEBANK Corpus. In Proceedings of the Corpus Linguistics, Lancaster, UK, 28–31 March 2003; pp. 647–656. [Google Scholar]
- Baker, C.F.; Fillmore, C.J.; Lowe, J.B. The Berkeley FrameNet Project. In Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics—Volume 1, ACL ’98, Montreal, QC, Canada, 10–14 August 1998; Association for Computational Linguistics: Stroudsburg, PA, USA, 1998; pp. 86–90. [Google Scholar] [CrossRef]
- Miller, G.A.; Leacock, C.; Tengi, R.; Bunker, R.T. A semantic concordance. In Proceedings of the Workshop on Human Language Technology, HLT ’93, Plainsboro, NJ, USA, 21–24 March 1993; Association for Computational Linguistics: Stroudsburg, PA, USA, 1993; pp. 303–308. [Google Scholar] [CrossRef]
- Banko, M.; Brill, E. Scaling to very very large corpora for natural language disambiguation. In Proceedings of the 39th Annual Meeting on Association for Computational Linguistics, ACL ’01, Toulouse, France, 6–11 July 2001; Association for Computational Linguistics: Stroudsburg, PA, USA, 2001; pp. 26–33. [Google Scholar] [CrossRef]
- Callison-Burch, C.; Dredze, M. Creating speech and language data with Amazon’s Mechanical Turk. In Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, CSLDAMT ’10, Los Angeles, CA, USA, 6 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 1–12. [Google Scholar]
- Choueka, Y.; Klein, T.; Neuwitz, E. Automatic Retrieval of Frequent Idiomatic and Collocation Expressions in a Large Corpus. J. Lit. Linguist. Comput. 1983, 4, 34–38. [Google Scholar]
- Dias, G. Extraction Automatique d’Associations Lexicales à Partir de Corpora. Ph.D. Thesis, Univeristy of Orléans and New University of Lisbon, Orleans, France, Lisbon, Portugal, 2002. [Google Scholar]
- Gross, G. Les Expressions Figées en Français; Ophrys: Paris, France, 1996. [Google Scholar]
- Dias, G.; Guilloré, S.; Lopes, J. Language Independent Automatic Acquisition of Rigid Multiword Units from Unrestricted Text Corpora. In Proceedings of the 6ème Conférence Annuelle sur le Traitement Automatique des Langues Naturelles (TALN 1999), Cargese, France, 12–17 July 1999; pp. 333–339. [Google Scholar]
- Manning, C.D.; Schütze, H. Foundations of Statistical Natural Language Processing; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Herrera, J.; Peñas, A.; Verdejo, F. Textual entailment recognition based on dependency analysis and wordnet. In Proceedings of the First PASCAL Challenges Workshop on Recognising Textual Entailment, Southampton, UK, 11–13 April 2005. [Google Scholar]
- Delmonte, R.; Tonelli, S.; Boniforti, A.P.; Bristot, A.; Pianta, E. VENSES—A Linguistically-Based System for Semantic Evaluation. In Proceedings of the First PASCAL Challenges Workshop on Recognising Textual Entailment, Southampton, UK, 11–13 April 2005; pp. 49–52. [Google Scholar]
- Kouylekov, M.; Magnini, B. Recognizing Textual Entailment with Tree Edit Distance Algorithms. In Proceedings of the First PASCAL Challenges Workshop on Recognising Textual Entailment, Southampton, UK, 11–13 April 2005; pp. 17–20. [Google Scholar]
- Hickl, A.; Bensley, J.; Williams, J.; Roberts, K.; Rink, B.; Shi, Y. Recognizing textual entailment with lcc’s groundhog system. In Proceedings of the Second PASCAL Challenges Workshop, Venice, Italy, 10–12 April 2006. [Google Scholar]
- Tatu, M.; Iles, B.; Slavick, J.; Novischi, A.; Moldovan, D. COGEX at the second recognizing textual entailment challenge. In Proceedings of the 2nd PASCAL Challenges Workshop on Recognising Textual Entailment, Venice, Italy, 10–12 April 2006. [Google Scholar]
- Zanzotto, F.M.; Moschitti, A.; Pennacchiotti, M.; Pazienza, M.T. Learning textual entailment from examples. In Proceedings of the 2nd PASCAL Challenges Workshop on Recognising Textual Entailment, Venice, Italy, 10–12 April 2006; pp. 50–55. [Google Scholar]
- Adams, R.; Nicolae, G.; Nicolae, C.; Harabagiu, A. Textual Entailment Through Extended Lexical Overlap. In Proceedings of the RTE-2 Workshop, Venice, Italy, 10–12 April 2006. [Google Scholar]
- Bos, J.; Markert, K. When logical inference helps determining textual entailment (and when it doesn’t). In Proceedings of the Second PASCAL Challenges Workshop on Recognizing Textual Entailment, Venice, Italy, 10–12 April 2006. [Google Scholar]
- Hickl, A.; Bensley, J. A discourse commitment-based framework for recognizing textual entailment. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing, Prague, Czech Republic, 28–29 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 171–176. [Google Scholar]
- Tatu, M.; Moldovan, D. COGEX at RTE3. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing, Prague, Czech Republic, 28–29 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 22–27. [Google Scholar]
- Harabagiu, S.M.; Miller, G.A.; Moldovan, D.I. WordNet 2—A Morphologically and Semantically Enhanced Resource. In Proceedings of the SigLex99: Standardizing Lexical Resources, College Park, MD, USA, 21–22 June 1999; pp. 1–8. [Google Scholar]
- Iftene, A.; Balahur-Dobrescu, A. Hypothesis transformation and semantic variability rules used in recognizing textual entailment. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing, Prague, Czech Republic, 28–29 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 125–130. [Google Scholar]
- Lin, D.; Pantel, P. DIRT—Discovery of Inference Rules from Text. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 323–328. [Google Scholar]
- Adams, R.; Nicolae, G.; Nicolae, C.; Harabagiu, S. Textual entailment through extended lexical overlap and lexico-semantic matching. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing, Prague, Czech Republic, 28–29 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 119–124. [Google Scholar]
- Wang, R.; Neumann, G. Recognizing textual entailment using sentence similarity based on dependency tree skeletons. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing, Prague, Czech Republic, 28–29 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 36–41. [Google Scholar]
- Bensley, J.; Hickl, A. Workshop: Application of LCC’s GROUNDHOG System for RTE-4. In Proceedings of the Text Analysis Conference, Gaithersburg, MD, USA, 17–19 November 2008. [Google Scholar]
- Iftene, A. UAIC Participation at RTE4. In Proceedings of the Text Analysis Conference (TAC 2008) Workshop—RTE-4 Track, Gaithersburg, MD, USA, 17–19 November 2008; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2008; pp. 17–19. [Google Scholar]
- Wang, R.; Neumann, G. An divide-and-conquer strategy for recognizing textual entailment. In Proceedings of the Text Analysis Conference, Gaithersburg, MD, USA, 17–19 November 2008. [Google Scholar]
- Li, F.; Zheng, X.; Tang, Y.; Bu, F.; Ge, R.; Zhang, X.; Zhu, X.; Huang, M. Thu quanta at tac 2008 qa and rte track. In Proceedings of the First Text Analysis Conference (TAC 2008), Gaithersburg, MD, USA, 17–19 November 2008. [Google Scholar]
- Balahur, R.; Lloret, E.; Ferrández, Ó.; Montoyo, A.; Palomar, M.; Muñoz, R. The DLSIUAES team’s participation in the tac 2008 tracks. In Proceedings of the Text Analysis Conference, Gaithersburg, MD, USA, 17–19 November 2008. [Google Scholar]
- Iftene, A.; Moruz, M.A. UAIC Participation at RTE5. In Proceedings of the TAC 2009, Gaithersburg, MD, USA, 16–17 November 2009. [Google Scholar]
- Wang, R.; Zhang, Y.; Neumann, G. A Joint Syntactic-Semantic Representation for Recognizing Textual Relatedness. In Proceedings of the TAC/RTE-5, Gaithersburg, MD, USA, 16–17 November 2009. [Google Scholar]
- Li, F.; Zheng, Z.; Bu, F.; Tang, Y.; Zhu, X.; Huang, M. THU QUANTA at TAC 2009 KBP and RTE Track. In Proceedings of the Text Analysis Conference, Gaithersburg, MD, USA, 16–17 November 2009. [Google Scholar]
- Mehdad, Y.; Moschitti, R.; Zanzotto, F.M. SemKer: Syntactic/semantic kernels for recognizing textual entailment. In Proceedings of the Text Analysis Conference, Gaithersburg, MD, USA, 16–17 November 2009. [Google Scholar]
- Sammons, M.; Vydiswaran, V.G.V.; Vieira, T.; Johri, N.; Chang, M.W.; Goldwasser, D.; Srikumar, V.; Kundu, G.; Tu, Y.; Small, K.; et al. Relation Alignment for Textual Entailment Recognition. In Proceedings of the TAC, Gaithersburg, MD, USA, 16–17 November 2009. [Google Scholar]










| Challenge | Accuracy Average |
|---|---|
| RTE-1 | 0.581 |
| RTE-2 | 0.675 |
| RTE-3 | 0.711 |
| RTE-4 | 0.688 |
| RTE-5 | 0.679 |
| # Input Pairs | 2000 (RTE-1: 400 + RTE-2: 400 + RTE-3: 400 + RTE-4: 500 + RTE-5: 300) |
| # Pairs to Launch | 1740 |
| # Gold Pairs | 260 |
| # Output Pairs | 1203 |
| # Discarded Pairs | 797 |
| Evaluation Time | ≈43 days |
| # Trusted “Turkers” | 2308 |
| # Trusted Judgments | 5220 (1740*3) |
| # Untrusted Judgments | 60,482 |
| YES Is Correct | NO Is Correct | |
|---|---|---|
| YES was assigned | TP | FP |
| NO was assigned | FN | TN |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pais, S.; Dias, G. Asymmetric Attributional Word Similarity Measures to Detect the Relations of Textual Generality. Computers 2020, 9, 81. https://doi.org/10.3390/computers9040081
Pais S, Dias G. Asymmetric Attributional Word Similarity Measures to Detect the Relations of Textual Generality. Computers. 2020; 9(4):81. https://doi.org/10.3390/computers9040081
Chicago/Turabian StylePais, Sebastião, and Gaël Dias. 2020. "Asymmetric Attributional Word Similarity Measures to Detect the Relations of Textual Generality" Computers 9, no. 4: 81. https://doi.org/10.3390/computers9040081
APA StylePais, S., & Dias, G. (2020). Asymmetric Attributional Word Similarity Measures to Detect the Relations of Textual Generality. Computers, 9(4), 81. https://doi.org/10.3390/computers9040081