1. Introduction
Online users use different online social network (OSN) services such as Facebook, Twitter, WhatsApp, and others for different purposes, varying from using them as informal communication channels with family and friends to considering them as formal communication channels in a work environment. The extensive consumption of OSN services raises several concerns and challenges at the user privacy level [
1].
The high volume of user-generated content exposes users to different kinds of content that can be harmful or unwanted. According to our previous work [
2], 83% of online users receive annoying and duplicate content via WhatsApp messenger, and around 80% would prefer to have the control to block certain content from being seen or received in their social space.
This exposure to unwanted content can negatively impact the privacy requirements desired for each individual [
3]. Several studies proposed privacy protection mechanisms and policies to protect users from seeing or receiving such unwanted content in their social space. However, these proposals assumed that all users have the same level of privacy requirements [
1,
4,
5]. Mostly, they ignored the fact that different users have different perceptions of what is considered as unwanted.
Therefore, it is essential to provide a personalized privacy protection technique that adapts to users’ perceptions of unwanted content. Various studies proposed predicting what users dislike based on explicit feedback gathered from users [
6,
7] or implicit feedback derived from user content consumption patterns [
8,
9]. However, the consistency between a user attitude and a user behavior needs further investigation to constitute a ground truth of the validity of using users’ behaviors as indicators of their attitudes. This study examines whether users’ behaviors in OSN services are suitable predictors of users’ actual attitudes towards certain topics among users from the Makkah region in Saudi Arabia. Specifically, it was hypothesized that there is a relationship between users’ implicit attitudes derived from users’ behaviors and users’ actual attitudes towards unwanted content.
In this paper, we investigate the applicability and effectiveness of considering behavioral factors to detect a user’s actual attitude towards unwanted content. A user analytics study that involved a population from the Makkah region in Saudi Arabia was conducted to collect, capture, and analyze users’ explicit attitudes towards pre-defined topics and compare them with users’ implicit attitudes derived from their behaviors. In addition, we propose a new attitude measure, called the semi-explicit attitude measure, which adopts an example-driven modeling approach [
8] to model users’ explicit attitudes using user-selected examples. The research question we aim to answer in this work is: do the behavioral factors of users reflect their actual attitudes towards unwanted content among users from the Makkah region in Saudi Arabia? Answering this question will help to decide if users’ behavioral attributes are reliable for use as indicators of their actual attitudes towards certain topics for our sample of users.
The contributions of this work are twofold. First, we investigate the relationship between user attitude, represented by the explicit and semi-explicit attitude measures, and user behavior, represented by the implicit attitude measure. Second, we propose a new user attitude measure, which is the semi-explicit attitude measure that relies on user-selected examples to infer user attitude. The results reported in this work can be used as evidence of the applicability of behavioral factors as indicators of user attitude within our selected population.
This paper is organized as follows.
Section 2 discusses some related work regarding the consistency between user attitude and user behavior. The data collection and analysis processes are demonstrated in
Section 3, highlighting all phases included in the processes.
Section 4 shows the user attitude capturing phase. Results and discussion are reported in
Section 5 and
Section 6, respectively. Finally,
Section 7 concludes the work discussed in this paper and addresses future work.
2. Related Work
There has been a considerable amount of studies that investigate attitude–behavior consistency, especially in the social psychology field. They were motivated by the insight that attitude is a predictor of a person’s behavior and actions. Therefore, attitude–behavior consistency was defined by [
9] as the degree to which an individual’s attitude can predict his/her behavior [
9].
The Theory of Reasoned Action developed by Fishbein and Ajzen [
10] in 1975, which was extended later as a Technology Acceptance Model, consists of three main concepts: attitude, behavior, and intention. The main goal of this theoretical model is to determine the psychological process that mediates the association between attitude, behavior, and intention. In this theory, Fishbein and Ajzen [
11] argued that behavior is affected by attitude through intention [
11]. Based on their theory, the authors of [
12] defined social attitude as a psychological state that is expressed by evaluating a person, object, or event with a favorable or disfavorable degree [
12]. According to [
13], social attitude is modeled through three main components: affective, behavioral, and cognitive. The affective component represents an individual’s feelings about an object/person/event; the behavioral component represents the impact of an individual’s attitude on their actions; and the cognitive component is demonstrated by an individual’s beliefs and knowledge about an object/person/event [
13].
The opposite direction of attitude–behavior consistency needs further investigation to examine the degree to which users’ behaviors can predict users’ attitudes. This type of consistency is important in computing fields to determine the applicability of using behavioral analysis as an indicator of user attitude. Several theoretical and practical solutions have been proposed to investigate user attitude towards certain systems, services, or topics. For instance, various studies were conducted to infer user attitudes towards mobile advertisements, such as [
14,
15]. The relationship between attitude and behavior has been investigated by [
16] in the context of mobile advertisements. The authors defined four factors that impact a user’s attitude towards mobile advertisements, showing that entertainment is the most significant factor followed by creditability and irritation [
16]. They declared in their work that there is a direct relationship between a user’s attitude and his behavior, where the user attitude was collected explicitly using a survey instrument [
16].
Another context that concentrates on the relationship between attitude and behavior is the privacy paradox. It is defined as the inconsistency between a user’s privacy attitude and behavior [
17]. Several explanations of the privacy paradox have been proposed to determine factors that impact users’ behaviors towards privacy. For example, the authors of [
18] constructed an experimental study to find factors that affect users’ behaviors towards privacy. They found that internet users have inaccurate perceptions of their knowledge about privacy [
18]. The study revealed that trust marks and the existence of a privacy policy are significant factors in impacting users’ privacy behaviors [
18]. It is important to show a consistent relationship between a user’s expressed protective attitude towards privacy and their actual protective behavior. Many users show a substantial interest in their privacy and express favorable attitudes towards privacy protection behaviors; however, they rarely show actual protective behavior towards their privacy [
19,
20,
21,
22].
One major gap in the previous work is the examination of the validity of considering a user behavior as an indicator of the user attitude to determine if the attitude is a driver of the behavior or vice versa.
3. Data Collection and Analysis
In most cases, collecting data is a time-consuming process because it involves several phases and requires a reasonable amount of effort to ensure data reliability. In this section, we describe our methodology to collect, capture, and analyze both explicit and implicit user attitudes towards pre-defined topics to predict unwanted content for each individual. Both data collection and analysis processes, and attitude-capturing measures are addressed in this section.
This paper makes use of a dataset sample that was produced in our previous work [
21]. The data includes about 80,000 tweets from the timelines of 30 Twitter users. The users were selected from different demographics and backgrounds, although they are all Saudi users from the Makkah region in Saudi Arabia. Their mother language is Arabic, and the sample consists of 21 females (65.6%) and 11 males (34.3%). The average number of comments for men was 52%, while it was 47.9% for women. The average number of likes for women was 51.75%, while it was 48.24% for men. Our selection of users was restricted to the Makkah region in Saudi Arabia as we considered it a case study for our work. All results will be reported within the selected population.
We selected the Twitter API as our source of data because it is a freely available API for developers who need to explore and analyze real-world data. The timeline of each user contains posts/tweets he/she posts and comments on self-posted tweets or tweets posted by others. Our focus is on users’ commenting and liking behaviors as possible indicators of their implicit attitudes towards pre-defined topics. Thus, our data collection and analysis process consists of the four main phases described in the following subsections.
3.1. Reply Acquisition Phase
In the reply acquisition phase, we extracted users’ comments and ended up with 6807 comments for the 30 users, with an average of 226 comments per user. The next step in the reply acquisition phase is to associate each comment with its original tweet. This was achieved by creating another extractor that sends the in-reply-tweet-id attribute to retrieve the original text of the tweet. This process is needed because the timeline of each user doesn’t include the original tweets that a user has commented on.
3.2. Liked Tweets Acquisition Phase
Because tweets that a user has liked do not appear in the extracted timelines, we had to extract liked tweets independently. We retrieved 66,576 liked tweets, with an average of 2219 tweets for each user.
3.3. Filtering Phase
In this phase, both the original tweets of users’ comments and users’ liked tweets were exposed to the same filtering process. The filtering process includes removing extra spaces, removing prepositions, removing meaningless Arabic words, and removing URLs. URLs are considered noise because most of the embedded URLs in tweets are references to media files and our focus is on textual content. The filtered data are saved and used for the purposes of analysis.
Table 1 shows some examples of the filtering actions performed.
3.4. Topic Classification Phase
In this work, we specified five pre-defined topics in the classification phase, which are health, sport, politics, technology, and social content. For each category, a set of 20 words/phrases was specified to represent the category. We collected these keywords by crawling Arabic tweets using the Twitter API for accounts related to that topic and filtered them manually. We then performed the same preprocessing to get the most 20 frequent terms in each defined topic. Examples of these keywords with their associated categories are shown in
Table 2.
We applied the term frequency TF-IDF feature engineering method [
22] to convert each filtered tweet into several tokens and search for matching keywords for each category by counting how many times a word has appeared in user social space.
4. Capturing User Attitudes
Attitude as a term can be generally defined as a cognitive evaluation of a person, object, event, or behavior [
23]. It also represents an individual’s thoughts and opinions that determine their choices and actions [
9,
24]. In this paper, our focus is on capturing both the implicit and explicit attitudes of a user towards certain topics to determine the association between the user behavior and the user’s actual attitude. This will help to detect unwanted content for each user via his/her behaviors to prevent this kind of content from being seen or received in the user’s social space.
Generally, attitude can be captured using implicit attitude measures and explicit attitude measures. We propose a new attitude measure called the semi-explicit attitude measure. It detects the explicit attitude of a user by using an example-driven modeling approach [
8].
We elaborate on each attitude measure considered in this paper as follows:
Explicit Attitude Measure: This measurement is used to detect users’ explicit attitudes towards certain topics. Thus, a user survey was conducted asking the 30 users in our sample to order the five pre-defined topics based on their preferences from the most preferred topic to the least preferred one. Then, each topic is given a weight to represent the users’ preferences.
Semi-Explicit Attitude Measure: We propose this measure to detect the users’ explicit attitudes by adopting user-selected examples. Therefore, in the same user survey conducted to detect explicit attitudes, we also provided a set of tweets representing the five pre-defined topics and asked users how likely they would be to like/comment on each of them. Their selections are used as indicators of users’ semi-explicit attitudes.
Implicit Attitude Measure: This measurement is used to detect the implicit attitudes of a user towards certain topics by utilizing both commenting and liking behaviors. Commenting behavior is used without any considerations of its sentiment. The purpose of this representation is to compare the implicit attitudes derived from both behaviors with the explicit and semi-explicit attitudes discussed previously. The association among them will help in reflecting the effectiveness of tracking users’ behaviors to perceive users’ attitudes towards certain topics.
Table 3 demonstrates each attitude measure considered in this paper and highlights the indications of each measure.
5. Results
The main goal of our analytics study is to determine whether implicit attitudes derived from users’ behavioral factors are consistent with users’ explicit attitudes collected explicitly from the users about certain topics to predict unwanted content for each user in the selected population. The state of consistency or inconsistency between user attitude and behavior towards unwanted content would imply the applicability and effectiveness of considering behavioral factors to predict a user’s attitude. Thus, we conducted a descriptive statistical analysis and a correlation statistical test to examine the association among the different attitude measures.
5.1. Descriptive Statistical Analysis
It is of substantial importance to conduct a descriptive statistical analysis of our dataset to gain solid insights about the nature and distribution of our data. We calculated the mean, median, and standard deviation for users’ commenting behavior and users’ liking behavior, which are indicators of users’ implicit attitudes towards the topics in
Table 2. In addition, the same attributes were calculated for users’ explicit attitudes and users’ semi-explicit attitudes towards the same topics.
Table 4 illustrates the results of the descriptive analysis performed on our dataset.
From the above descriptive analysis, the following conclusions can be drawn from the bold values in the table:
Users’ implicit attitudes derived from liking behavior show more relaxed attitudes, which indicates that users show less conservative behavior when they like a post on Twitter (indication from the mean values).
Commenting on a post is a less frequent behavior than liking a post in our dataset sample (indication from the median values).
The disliking attitude is highly detected in commenting behavior and self-reported preferences. Users show conservative behavior more frequently when they are asked to report their preferences explicitly or when they comment on a post (indication from the mode values).
The distribution of the data in semi-explicit attitude, explicit attitude, and implicit attitude derived from commenting behavior differs from normal distribution to the left by positive skew values, while the distribution of the data in implicit attitude derived from liking behavior differs from normal distribution to the right by negative skew values. This observation indicates that liking behavior is a common behavior in our dataset sample (indication from skewness values).
5.2. Correlation Statistical Analysis
A coefficient statistical test was performed to examine the relationship between implicit attitude derived from liking and commenting behaviors, semi-explicit attitude derived from user-selected examples, and the explicit attitude of a user. To investigate the association between the three types of attitude measures, we performed a correlation test to examine how each type of attitude is associated with the others. We used the R programming and analytics tool to perform the data analysis and correlation test.
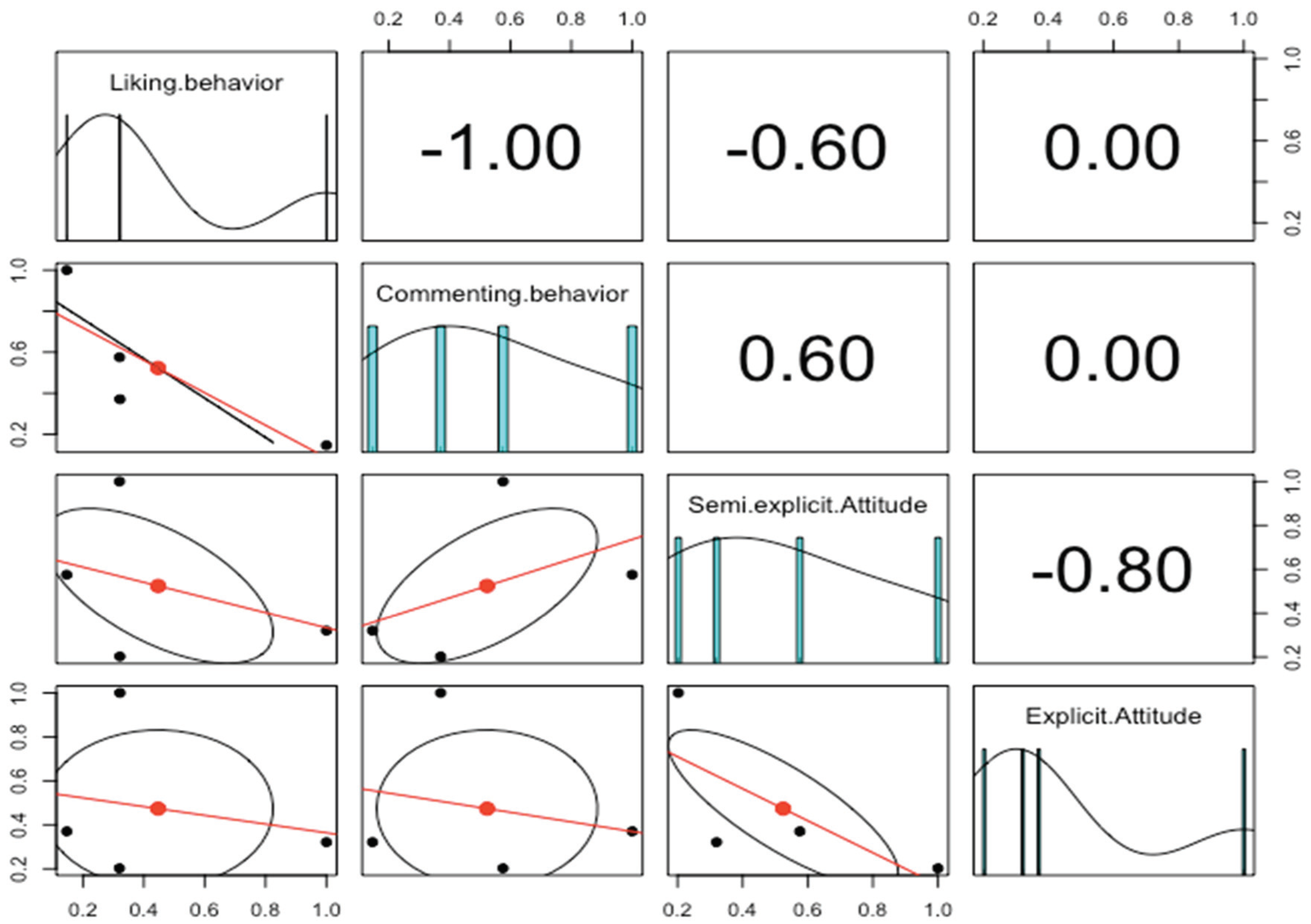
Figure 1 shows the data distribution of each factor and correlation values plus the significance levels. Spearman’s correlation was run to determine the relationship between user behavior and user attitude (12 pairs of variables). There was a strong positive correlation between commenting behavior and semi-explicit attitude (r = 0.57). In addition, it is shown that the data in both commenting behavior and semi-explicit attitude are distributed in the same direction.
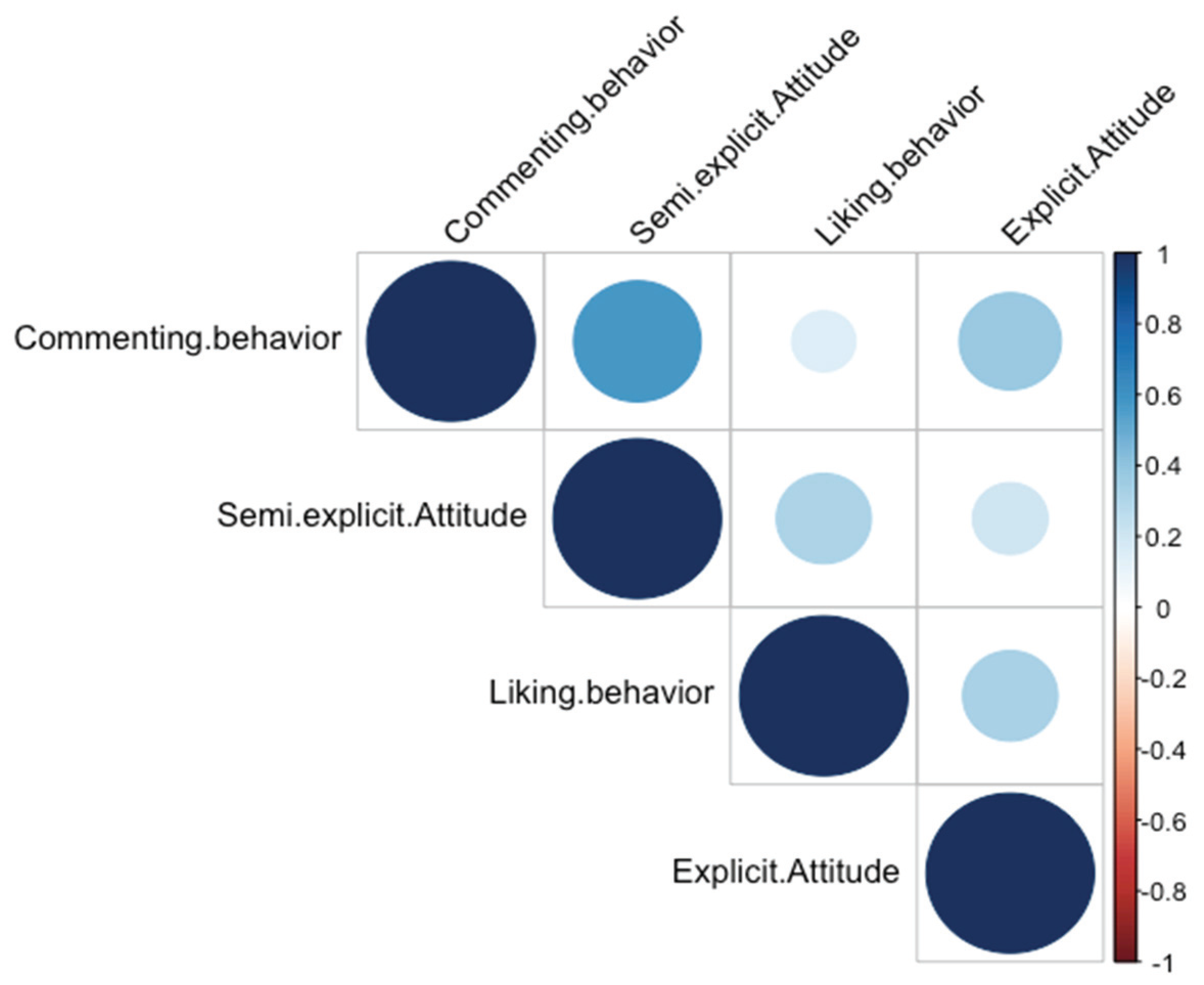
Figure 2 shows the correlation coefficients between the three types of attitudes. The color intensity and the size of the circle are proportional to the correlation coefficients where the blue color represents positive correlations and the red color represents negative correlations.
It is noticeable from the above figure that positive correlations were detected between all types of attitudes and no negative correlations were found. Interestingly, there is a strong positive correlation (correlation coefficient r = 0.57) between implicit attitude derived from commenting behavior and semi-explicit attitude derived from user-selected examples. This type of correlation indicates that there is a statistically significant relationship between commenting behavior and semi-explicit attitude derived from user-selected examples. In addition, weak positive correlations were detected between semi-explicit attitude and both explicit attitude (correlation coefficient = 0.20) and implicit attitude derived from liking behavior (correlation coefficient r = 0.31). Therefore, the semi-explicit attitude derived from user-selected examples can be used as a representation of a user’s actual attitude for users of the Makkah region in Saudi Arabia. From this result, we can conclude that example-driven modeling is an effective approach to predict unwanted content for users based on their pre-specified examples. The correlation results support our stated hypothesis that there is a relationship between users’ implicit attitudes derived from users’ behaviors and users’ actual attitudes towards unwanted content in our selected population.
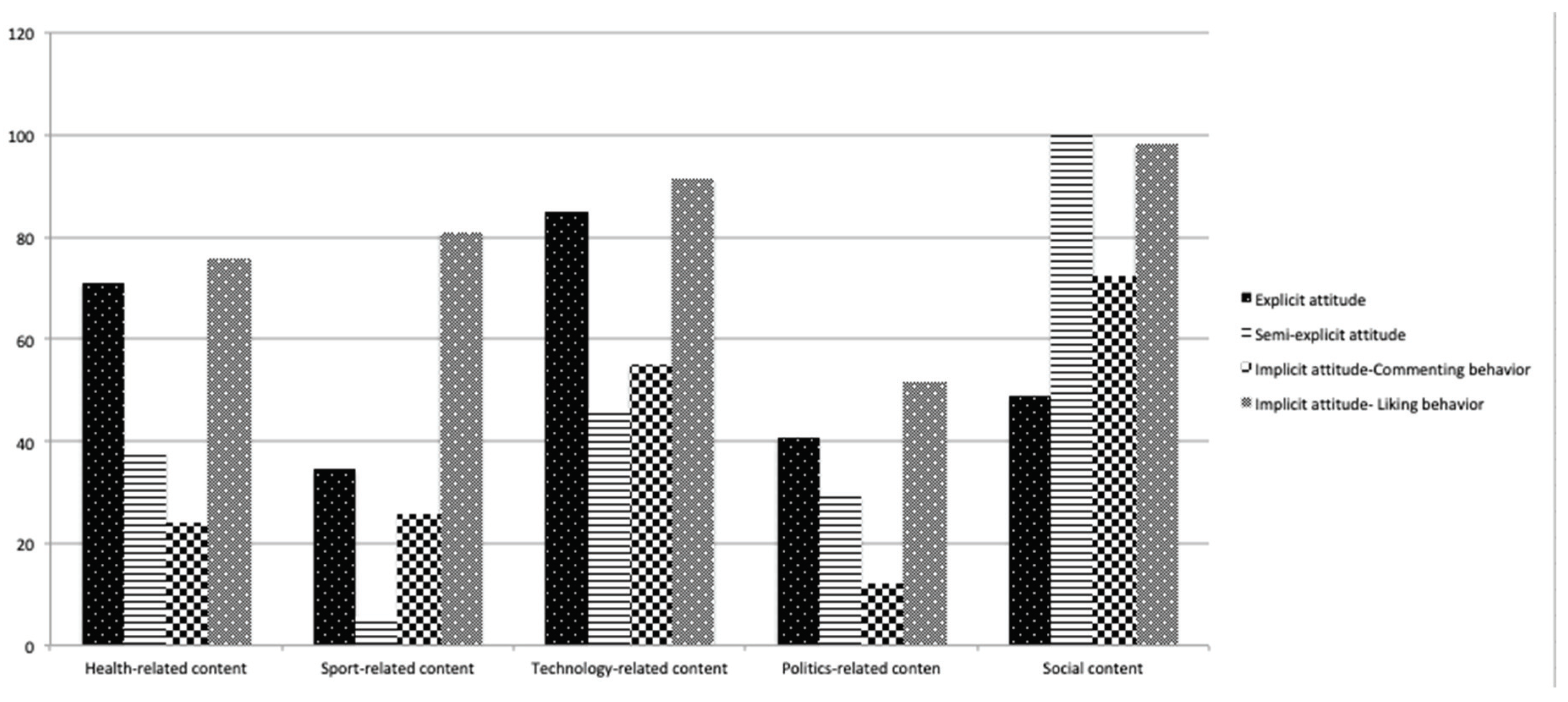
To illustrate how implicit attitude derived from commenting and liking behavior is associated with semi-explicit and explicit attitudes,
Figure 3 shows a topic-based comparison analysis between the three types of attitudes. The purpose of the comparison is to show how implicit attitude derived from liking or commenting behavior is consistent with explicit or semi-explicit attitude in terms of the preferred topics. For three topics, namely, health, technology, and politics, an implicit attitude derived from liking behavior is consistent with users’ explicit attitude, which indicates that tracking users’ liking behavior is sufficient to detect unwanted content for individuals. On the other hand, implicit attitude derived from commenting behavior is consistent with semi-explicit attitude derived from user-selected examples.
In addition, the above figure shows that social-related content is the most preferred type of content among our subjects, which indicates that Saudi users especially those who are from the Makkah region are socially active and prefer to use social media to socially communicate with others. In addition, politics-related content is the least preferred content among our sample.
6. Discussion
To answer the research question of this paper, which is “do the behavioral factors of users reflect their attitudes towards unwanted content among users from the Makkah region in Saudi Arabia?” results show that users’ semi-explicit attitude is consistent with their implicit attitude, which indicates the effectiveness of using user-selected examples as a representation of a user’s actual attitude among users in the Makkah region in Saudi Arabia. In addition, the conclusion can be drawn from this result that users’ behavioral factors such as commenting and liking behaviors are positive indicators of users’ actual attitudes. However, the explicit attitude derived directly from self-reported attitude is insufficient in determining either the user’s actual attitude, since it does not match with users’ semi-explicit attitudes, or the user’s implicit attitude.
In addition, in this section, we address some threats to the external validity of our experimental study. External validity refers to which extent our results and findings are applicable to other groups of populations [
25]. In our study, we reported a possible threat to external validity that can be encountered, which is the interaction effect of the selection of our sample. Several factors controlled the selection of our experimentally accessible population. First, we needed to select users, instead of collecting them randomly, who are active on Twitter to examine their interaction factors and to test our hypothesis. Even though random sampling can increase the external validity of the study, it can cause an incomplete dataset or unreliable data in the context of our work. Second, we performed an in-depth analysis in which we collected users’ timelines from Twitter and ask the same users for their explicit attitude towards certain topics, and then infer their semi-explicit attitude through a survey instrument. Thus, to increase the external validity in terms of people-oriented generalization, our results can be generalized to/across different groups of people from the same target population, but future work is needed to enlarge the sample considering other groups from other cultures.
The main limitation of this work is the lack of behavioral factors considered in the study. Expanding our selected behaviors might lead to the reporting of different results. Another limitation in our work is the selection of random users. Recruiting random participants from the crowdsourcing platform, as one way to recruit random samples, has a privacy constraint since many workers are unwilling to share their real/personal Twitter accounts via online jobs. In terms of future work, reproducing the study using different populations from different cultures seems a promising research direction for researchers who are willing to study cross-cultural differences in the context of detecting unwanted content in OSN services.
Our results have both practical and design implications on the process of filtering unwanted content. In terms of personalized privacy protection practices, our findings can be used to better understand the factors that determine the personalized privacy requirements dedicated for each individual in the scope of users from the Makkah region in Saudi Arabia. Results of this work provide insights on designing effective user modeling approaches that rely on user-specified examples instead of self-reported preferences. This work is experimental evidence of the effectiveness of tracking a user commenting behavior as a predictor of the user’s actual attitude, which provides a research opportunity for researchers in both social and computing disciplines.
7. Conclusions and Future Work
Being exposed to unwanted content is a substantial problem that negatively impacts users’ browsing experiences while using OSN services. It is necessary to develop a personalized privacy protection technique that aims to provide the desired privacy level for each individual. This development requires accurate inference of a user’s attitude towards different kinds of content appearing in his/her social space. In this paper, we investigated the relationship between users’ explicit and semi-explicit attitudes and users’ behaviors within a sample from the Makkah region in Saudi Arabia. Our results show that behavioral factors, specifically commenting behavior, are a positive indicator of users’ actual attitudes in our selected population. In addition, results demonstrated the effectiveness of the new proposed attitude measure, semi-explicit attitude, in detecting users’ actual attitudes by the high correlation between it and other types of attitude measures across users from the selected sample. In future work, we will utilize sufficient behavioral factors, such as commenting behavior, to develop a personalized privacy protection policy. In addition, we are planning to improve the external validity of our results by considering a wider range of user behaviors.






{kind=link}
{kind=link}
{kind=link}