Network Intrusion Detection with a Hashing Based Apriori Algorithm Using Hadoop MapReduce

 ,
,
Abstract
1. Introduction
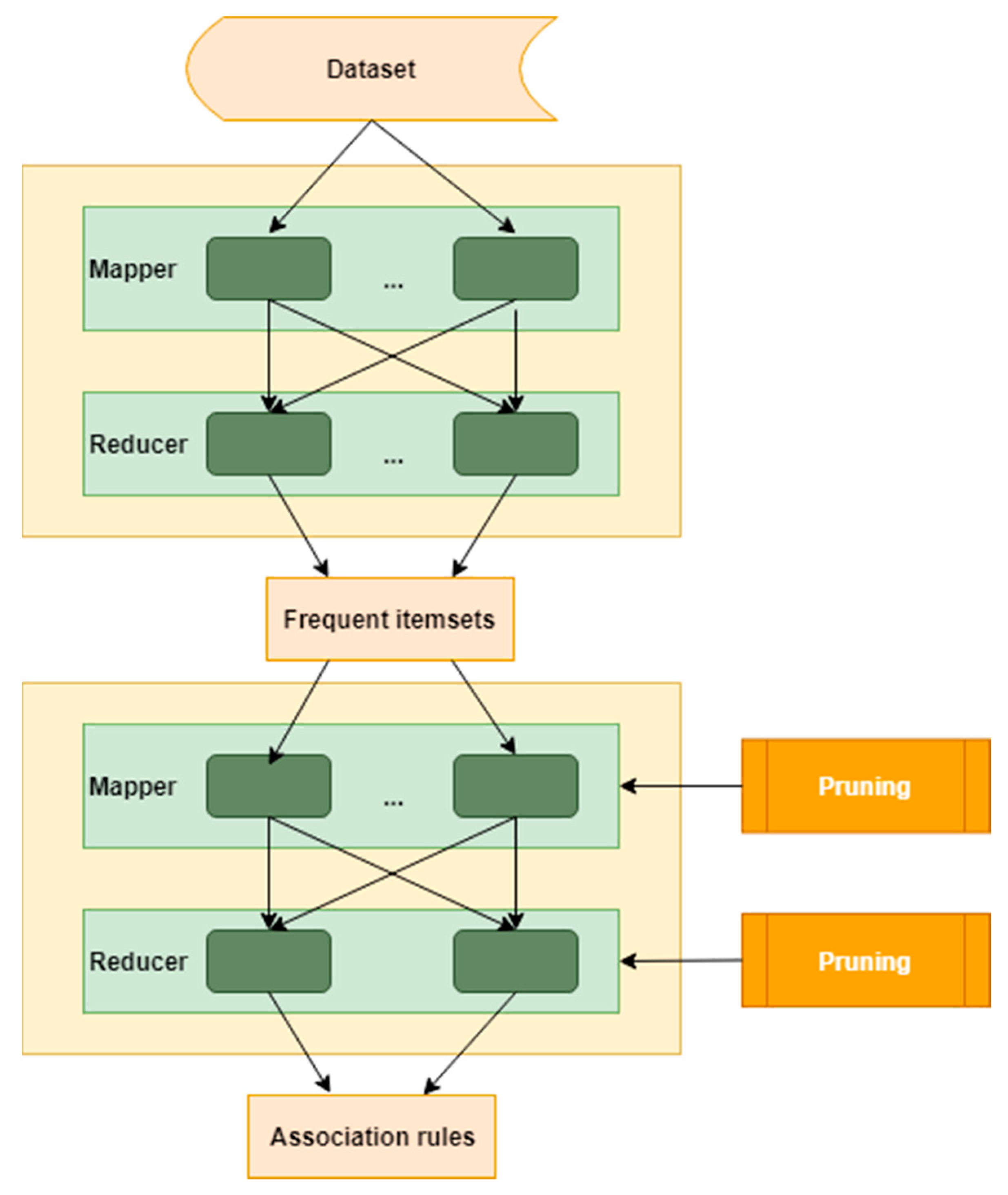
2. Methodology
2.1. Apriori Algorithm
| Algorithm 1: Apriori algorithm |
| Variables: Ck is a candidate itemset of size k Lk is a frequent itemset of size k BEGIN Find frequent set Lk−1 Generate Ck by using Cartesian product of Lk-1, i.e. Lk−1 x Lk−1 Perform pruning: remove any k−1 size itemsets that are not frequent Return frequent set Lk END |
| Algorithm 2: Find frequent itemsets |
| BEGIN END |
2.2. Dataset
2.3. Evaluation
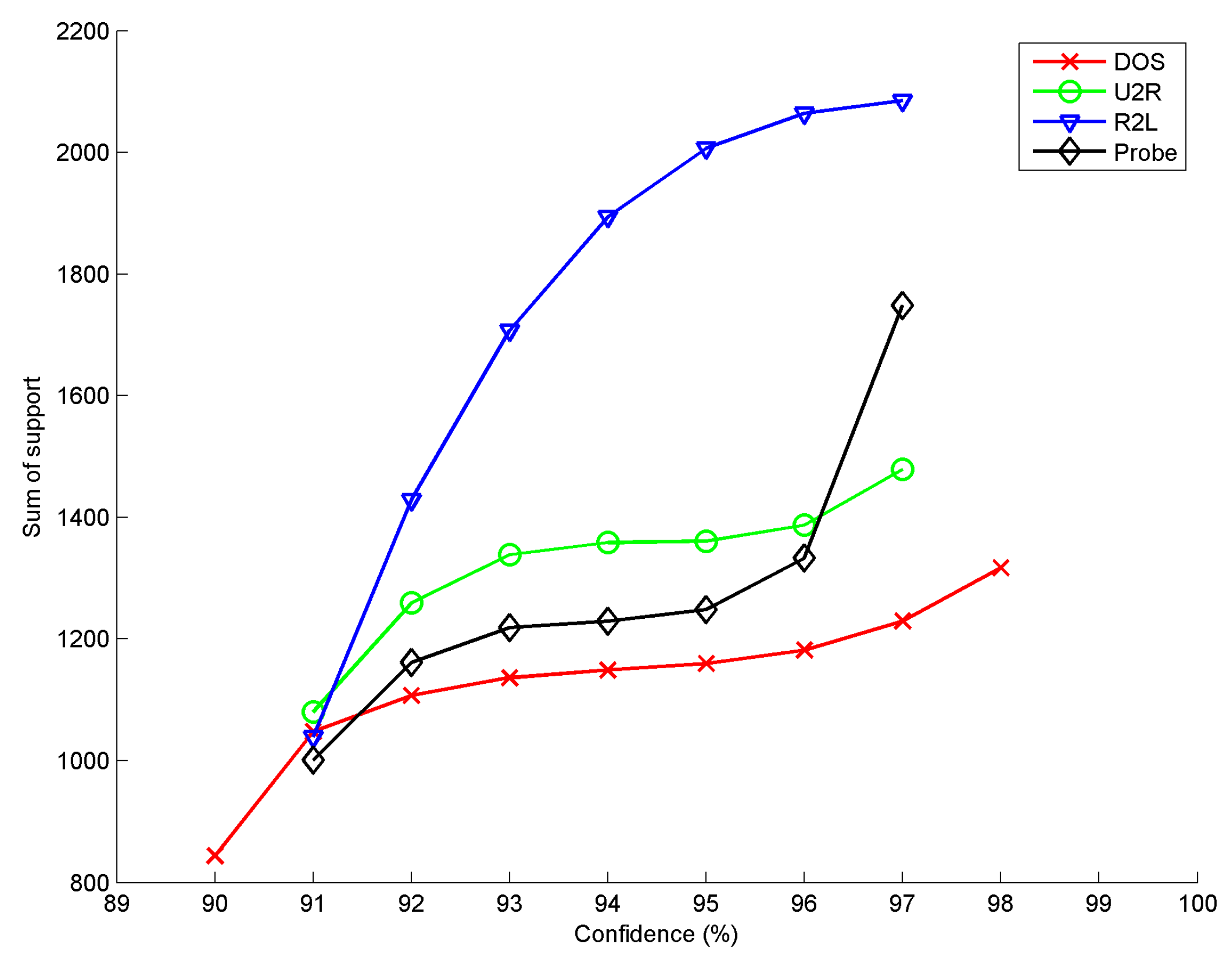
3. Results
4. Evaluation
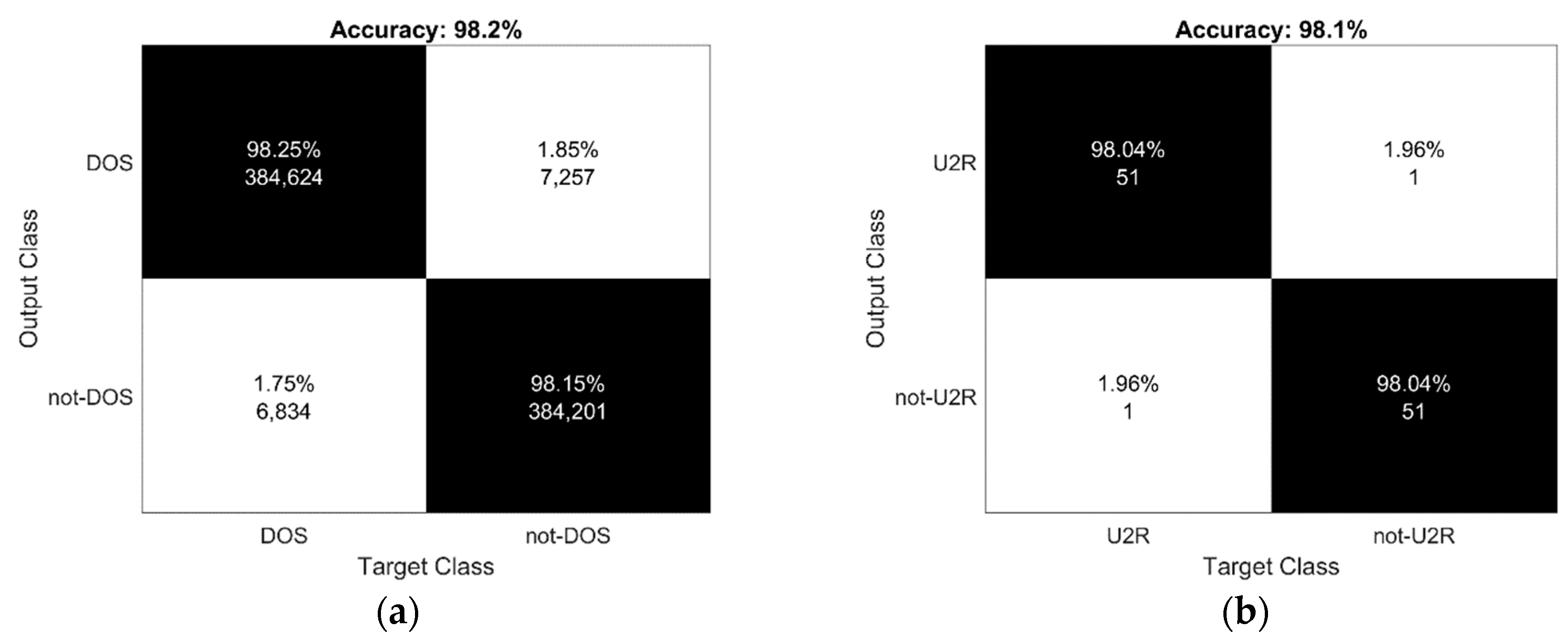
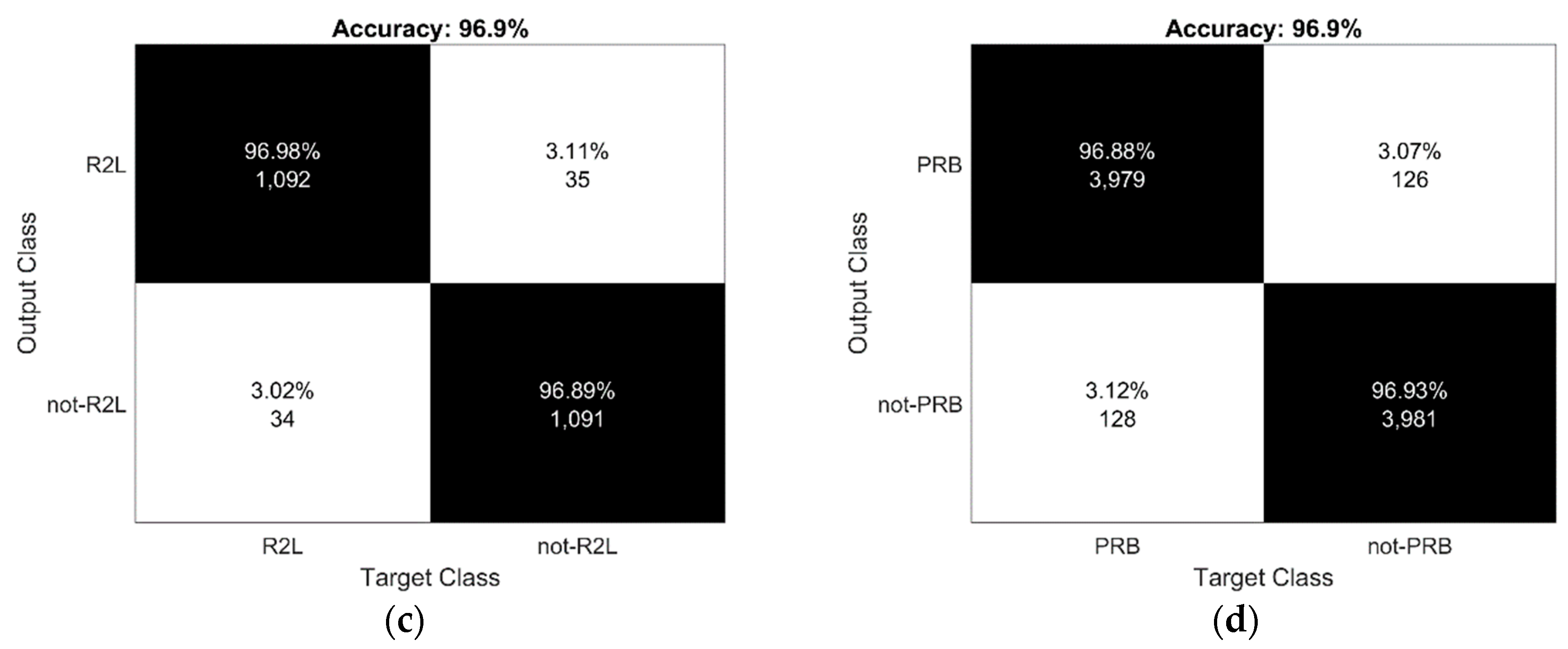
4.1. Accuracy
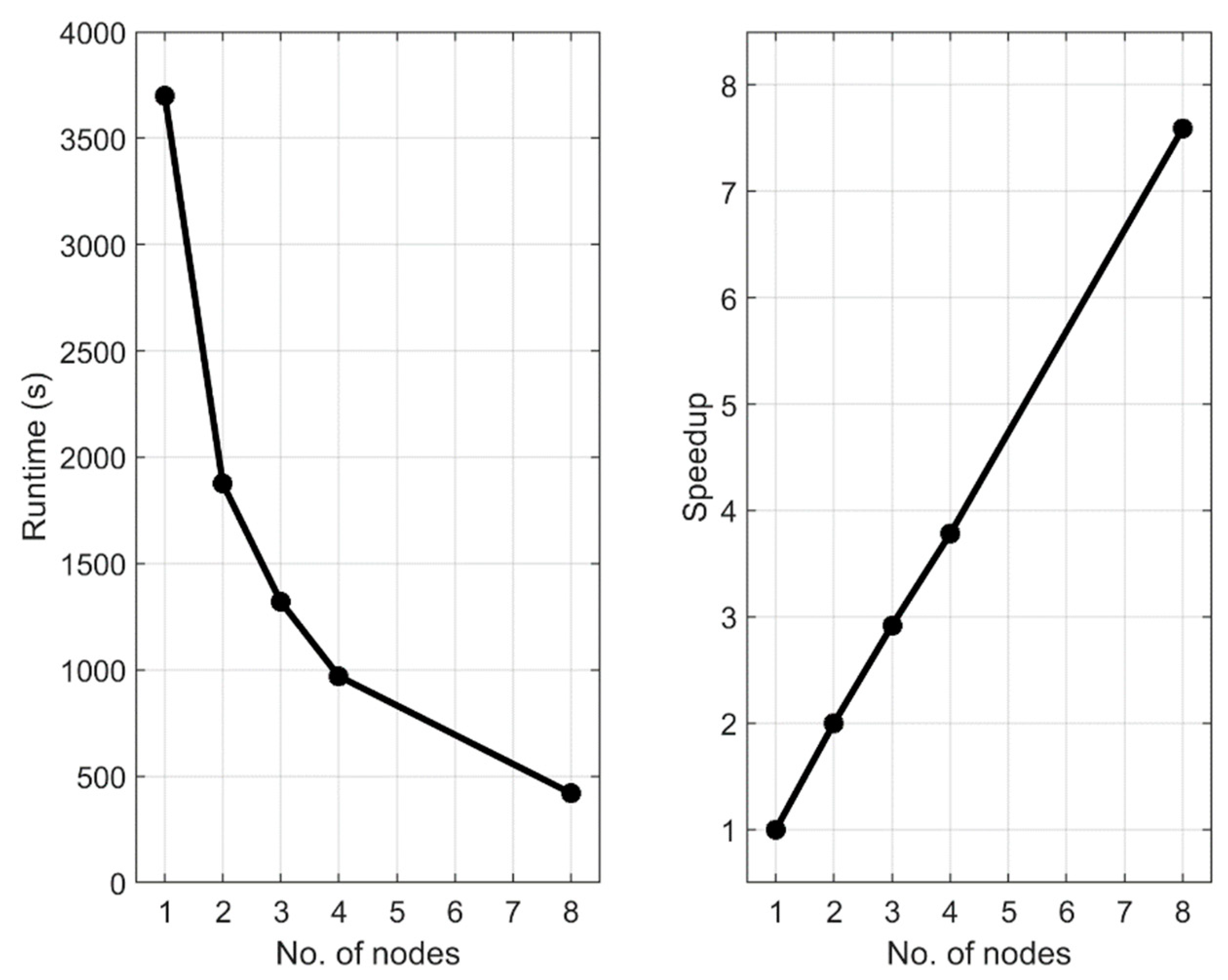
4.2. Scalability
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Amor, N.; Benferhat, S.; Elouedi, Z. Naïve Bayes vs. decision trees in intrusion detection systems. In Proceedings of the 2004 ACM Symposium on Applied Computing, New York, NY, USA, 14–17 March 2004; pp. 420–424. [Google Scholar]
- Odusami, M.; Abayomi-Alli, O.; Misra, S.; Shobayo, O.; Damasevicius, R.; Maskeliunas, R. Android malware detection: A survey. In Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2018; pp. 255–266. [Google Scholar] [CrossRef]
- Odun-Ayo, I.; Geteloma, V.; Misra, S.; Ahuja, R.; Damasevicius, R. Systematic Mapping Study of Utility-Driven Platforms for Clouds. In Proceedings of ICETIT 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 762–774. [Google Scholar] [CrossRef]
- An, X.; Su, J.; Lü, X.; Lin, F. Hypergraph clustering model-based association analysis of DDOS attacks in fog computing intrusion detection system. Eurasip J. Wirel. Commun. Netw. 2018, 1. [Google Scholar] [CrossRef]
- Venčkauskas, A.; Morkevicius, N.; Jukavičius, V.; Damaševičius, R.; Toldinas, J.; Grigaliūnas, Š. An Edge-Fog Secure Self-Authenticable Data Transfer Protocol. Sensors 2019, 19, 3612. [Google Scholar] [CrossRef] [PubMed]
- Wei, W.; Woźniak, M.; Damaševičius, R.; Fan, X.; Li, Y. Algorithm research of known-plaintext attack on double random phase mask based on WSNs. J. Internet Technol. 2019, 201, 39–48. [Google Scholar] [CrossRef]
- Bai, Y.; Kobayashi, H. Intrusion detection system: Technology and developments. In Proceedings of the 17th International Conference on Advanced Information Networking and Application, 2003. AINA 2003, Xi’an, China, 29 March 2003; p. 710. [Google Scholar]
- Chaabouni, N.; Mosbah, M.; Zemmari, A.; Sauvignac, C.; Faruki, P. Network intrusion detection for IoT security based on learning techniques. IEEE Commun. Surv. Tutor. 2019, 213, 2671–2701. [Google Scholar] [CrossRef]
- da Costa, K.A.P.; Papa, J.P.; Lisboa, C.O.; Munoz, R.; de Albuquerque, V.H.C. Internet of things: A survey on machine learning-based intrusion detection approaches. Comput. Netw. 2019, 151, 147–157. [Google Scholar] [CrossRef]
- Kwon, D.; Kim, H.; Kim, J.; Suh, S.C.; Kim, I.; Kim, K.J. A survey of deep learning-based network anomaly detection. Clust. Comput. 2019, 22, 949–961. [Google Scholar] [CrossRef]
- Uddin, M.; Rehman, A.A.; Uddin, N.; Memon, J.; Alsaqour, R.; Kazi, S. Signature-based multi-layer distributed intrusion detection system using mobile agents. Int. J. Netw. Secur. 2013, 15, 97–105. [Google Scholar]
- Patcha, A.; Park, J. An overview of anomaly detection techniques: Existing solutions and latest technological trends. Comput. Netw. 2007, 51, 3448–3470. [Google Scholar] [CrossRef]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Network anomaly detection: Methods, systems and tools. IEEE Commun. Surv. Tutor. 2014, 16, 303–336. [Google Scholar] [CrossRef]
- Liu, M.; Xue, Z.; Xu, X.; Zhong, C.; Chen, J. Host-based intrusion detection system with system calls: Review and future trends. ACM Comput. Surv. 2019, 51. [Google Scholar] [CrossRef]
- Debar, H.; Dacier, M.; Wespi, A. A Revised Taxonomy for Intrusion Detection Systems; Springer International Publishing: Cham, Switzerland, 2000; pp. 361–378. [Google Scholar]
- Abadeh, M.; Habibi, J. A Hybridization of Evolutionary Fuzzy Systems and Ant Colony Optimization for Intrusion Detection; Sharif University of Technology: Tehran, Iran, 2010. [Google Scholar]
- Al Haddad, Z.; Hanoune, M.; Mamouni, A. A collaborative network intrusion detection system (C-NIDS) in cloud computing. Int. J. Commun. Netw. Inf. Secur. 2016, 8, 130–135. [Google Scholar]
- Das, A.; Nguyen, D.; Zambreno, J.; Memik, G.; Choudhary, A. An FPGA-based network intrusion detection architecture. IEEE Trans. Inf. Forensics Secur. 2008, 3, 118–132. [Google Scholar] [CrossRef]
- Huang, J.; Chen, C. Integration of rough sets and support vector machines for network intrusion detection. J. Ind. Prod. Eng. 2014, 31, 425–432. [Google Scholar] [CrossRef]
- Khamphakdee, N.; Benjamas, N.; Saiyod, S. Improving intrusion detection system based on snort rules for network probe attacks detection with association rules technique of data mining. J. ICT Res. Appl. 2015, 8, 234–250. [Google Scholar] [CrossRef][Green Version]
- Kola Sujatha, P.; Suba Priya, C.; Kannan, A. Network intrusion detection system using genetic network programming with support vector machine. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics, ACM International Conference Proceeding Series, New York, NY, USA, 3–5 August 2012; pp. 645–649. [Google Scholar] [CrossRef]
- Hashem, S.H. Enhance network intrusion detection system by exploiting br algorithm as an optimal feature selection. In Handbook of Research on Threat Detection and Countermeasures in Network Security; Information Science Reference: Hershey, PA, USA, 2014; pp. 17–32. [Google Scholar] [CrossRef]
- Gao, J.; Chai, S.; Zhang, B.; Xia, Y. Research on Network Intrusion Detection Based on Incremental Extreme Learning Machine and Adaptive Principal Component Analysis. Energies 2019, 12, 1223. [Google Scholar] [CrossRef]
- Abdulhammed, R.; Musafer, H.; Alessa, A.; Faezipour, M.; Abuzneid, A. Features Dimensionality Reduction Approaches for Machine Learning Based Network Intrusion Detection. Electronics 2019, 8, 322. [Google Scholar] [CrossRef]
- Al Tobi, A.M.; Duncan, I. Improving Intrusion Detection Model Prediction by Threshold Adaptation. Information 2019, 10, 159. [Google Scholar] [CrossRef]
- Prasenna, P.; Kumar, R.K.; Ramana, A.V.T.; Devanbu, A. Network programming and mining classifier for intrusion detection using probability classification. In Proceedings of the International Conference on Pattern Recognition, Informatics and Medical Engineering (PRIME-2012), Salem, Tamilnadu, India, 21–23 March 2012; pp. 204–209. [Google Scholar]
- Lalli, M.; Palanisamy, V. Filtering framework for intrusion detection rule schema in mobile ad hoc networks. Int. J. Control Theory Appl. 2016, 9, 195–201. [Google Scholar]
- Jie, X.; Wang, H.; Fei, M.; Du, D.; Sun, Q.; Yang, T.C. Anomaly behavior detection and reliability assessment of control systems based on association rules. Int. J. Crit. Infrastruct. Prot. 2018, 22, 90–99. [Google Scholar] [CrossRef]
- Yan, S.; Chen, Y.; Song, Y.; Zhu, M. Frequent attack sequences-based network log mining. J. Phys. Conf. Ser. 2019, 1176. [Google Scholar] [CrossRef]
- Ohrui, M.; Kikuchi, H.; Rosyid, N.R.; Terada, M. Mining botnet coordinated attacks using apriori-prefixspan hybrid algorithm. J. Inf. Process. 2013, 21, 607–616. [Google Scholar] [CrossRef][Green Version]
- Zeng, X.; Lv, J.; Li, J.; Luo, W. An optimized apriori algorithm based on sparse matrix for intrusion detection. Open Cybern. Syst. J. 2014, 8, 8–11. [Google Scholar]
- Khalili, A.; Sami, A. SysDetect: A systematic approach to critical state determination for industrial intrusion detection systems using apriori algorithm. J. Process Control 2015, 32, 154–160. [Google Scholar] [CrossRef]
- Zheng, J.; Yang, L. Research on the improvement of apriori algorithm and its application in intrusion detection system. In Proceedings of the 2015 IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 10–11 October 2015; pp. 105–108. [Google Scholar] [CrossRef]
- Chiba, Z.; Abghour, N.; Moussaid, K.; El Omri, A.; Rida, M. A cooperative and hybrid network intrusion detection framework in cloud computing based on snort and optimized back propagation neural network. Procedia Comput. Sci. 2016, 83, 1200–1206. [Google Scholar] [CrossRef]
- Odusami, M.; Misra, S.; Adetiba, E.; Abayomi-Alli, O.; Damasevicius, R.; Ahuja, R. An improved model for alleviating layer seven distributed denial of service intrusion on webserver. J. Phys. Conf. Ser. 2019, 1235. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, C.; Niu, X.; Yang, Y. Building an Effective Intrusion Detection System Using the Modified Density Peak Clustering Algorithm and Deep Belief Networks. Appl. Sci. 2019, 9, 238. [Google Scholar] [CrossRef]
- Le, T.-T.-H.; Kim, Y.; Kim, H. Network Intrusion Detection Based on Novel Feature Selection Model and Various Recurrent Neural Networks. Appl. Sci. 2019, 9, 1392. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules in Large Databases. In Proceedings of the 20th International Conference on Very Large Data Bases, VLDB, San Francisco, CA, USA, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Tribhuvan, S.A.; Gavai, N.R.; Vasgi, B.P. Frequent Itemset Mining Using Improved Apriori Algorithm with MapReduce. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 17–18 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Jayalakshmi, N.; Vidhya, V.; Krishnamurthy, M.; Kannan, A. Frequent Itemset Generation using Double Hashing Technique. Procedia Eng. 2012, 38, 1467–1478. [Google Scholar] [CrossRef]
- Bera, D.; Pratap, R. Frequent-Itemset Mining Using Locality-Sensitive Hashing. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 143–155. [Google Scholar] [CrossRef]
- Wen, Y.; Huang, J.; Chen, M. Hardware-enhanced association rule mining with hashing and pipelining. IEEE Trans. Knowl. Data Eng. 2008, 20, 784–795. [Google Scholar] [CrossRef]
- Dean, J. Experiences with MapReduce, an abstraction for large-scale computation. In Proceedings of the 15th International Conference on Parallel Architectures and Compilation Techniques, Seattle, Washington, DC, USA, 16–20 September 2006; p. 1. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, D.; Wang, X. Improvement of Apriori-Pro Algorithm Based on MapReduce. In Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2019; pp. 1257–1265. [Google Scholar] [CrossRef]
- Zhao, F.; Zhao, J.; Niu, X.; Luo, S.; Xin, Y. A Filter Feature Selection Algorithm Based on Mutual Information for Intrusion Detection. Appl. Sci. 2018, 8, 1535. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Hadri, A.; Chougdali, K.; Touahni, R. Identifying intrusions in computer networks using robust fuzzy PCA. In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; pp. 1261–1268. [Google Scholar]
- Papamartzivanos, D.; Gómez Mármol, F.; Kambourakis, G. Dendron: Genetic trees driven rule induction for network intrusion detection systems. Future Gener. Comput. Syst. 2018, 79, 558–574. [Google Scholar] [CrossRef]
- Elhag, S.; Fernández, A.; Altalhi, A.; Alshomrani, S.; Herrera, F. A multi-objective evolutionary fuzzy system to obtain a broad and accurate set of solutions in intrusion detection systems. Soft Comput. 2017, 1–16. [Google Scholar] [CrossRef]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Aljarah, I.; Ludwig, S.A. MapReduce intrusion detection system based on a particle swarm optimization clustering algorithm. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 955–962. [Google Scholar] [CrossRef]
- Rathinasabapathy, R.; Bhaskaran, R. Performance Comparison of Hashing Algorithm with Apriori. In Proceedings of the 2009 International Conference on Advances in Computing, Control, and Telecommunication Technologies (ACT 2009), Trivandrum, Kerala, India, 28–29 December 2009. [Google Scholar] [CrossRef]
- Shakya, S.; Singh, A.; Singh, D. A Survey on Hash based A-priori Algorithm for Web Log Analysis. Int. J. Comput. Appl. 2013, 76, 47–50. [Google Scholar] [CrossRef]
- Lin, C.-C.; Li, W.-C.; Chen, J.-C.; Chung, W.-Y.; Chung, S.-H.; Lin, K.W. A Distributed Algorithm for Fast Mining Frequent Patterns in Limited and Varying Network Bandwidth Environments. Appl. Sci. 2019, 9, 1859. [Google Scholar] [CrossRef]
- Maitrey, S.; Jha, C.K. MapReduce: Simplified Data Analysis of Big Data. Procedia Comput. Sci. 2015, 57, 563–571. [Google Scholar] [CrossRef]
- Veiga, J.; Exposito, R.R.; Pardo, X.C.; Taboada, G.L.; Tourifio, J. Performance evaluation of big data frameworks for large-scale data analytics. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 424–431. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
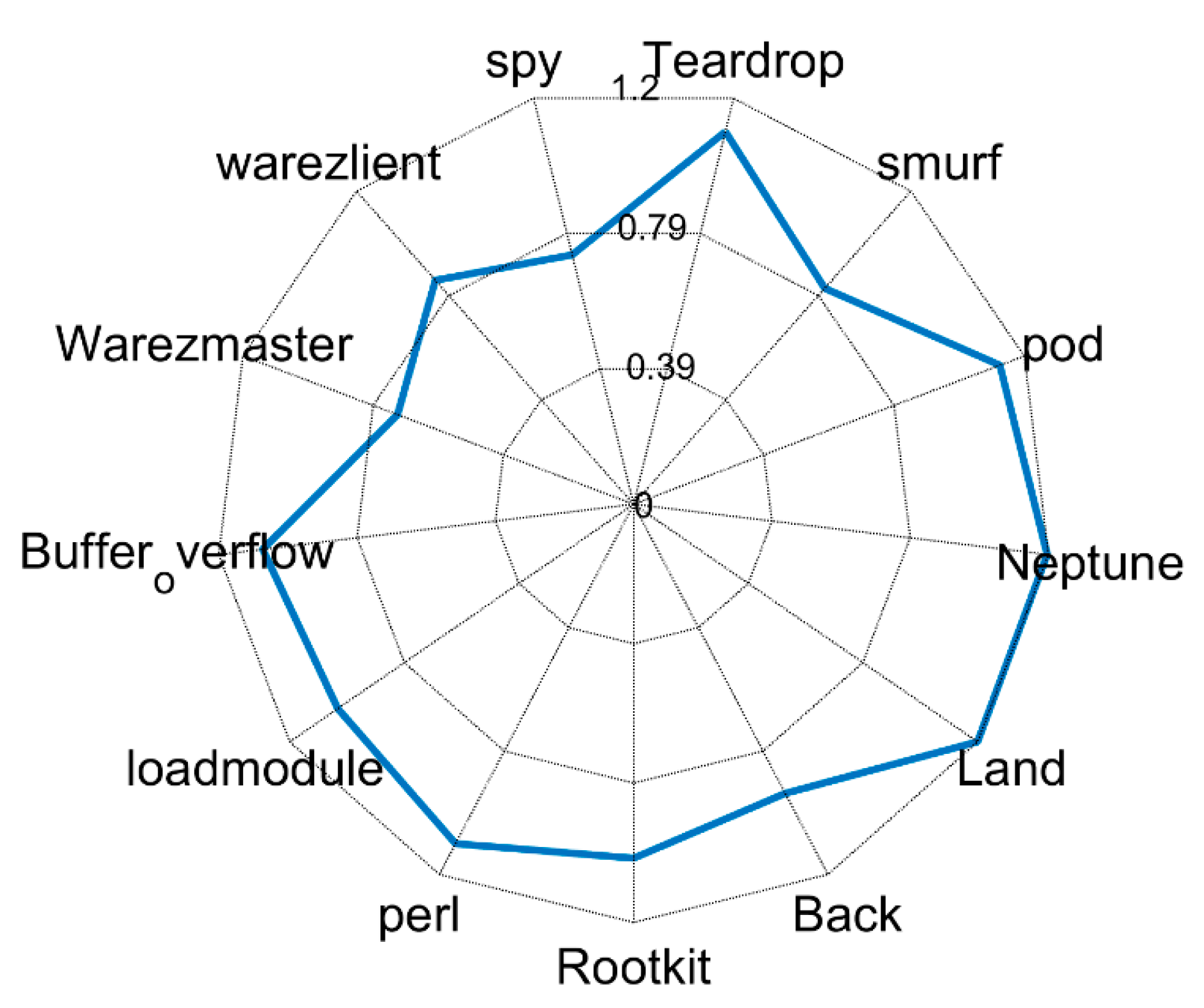
| Class | Description | Number of Records | Attack Types |
|---|---|---|---|
| DOS | denial of services (DoS), | 391,458 | Teardrop, smurf, pod, Neptune, Land, Back |
| U2R | unauthorized access to local supervisor privileges | 52 | Rootkit, perl, loadmodule, Buffer_overflow, |
| R2L | unauthorized access from a remote machine | 1126 | Warezmaster, warezlient, spy, phf, multihop, imap, guess_passwd, ftp_write |
| Probe | surveillance and other probing | 4107 | satan, portsweep, nmap, IPsweep |
| Class | Selected Features |
|---|---|
| DoS | count, dst_bytes, dst_host_count, dst_host_serror_rate, dst_host_srv_count, dst_host_srv_serror_rate, flag, protocol type, serror_rate, service, src_bytes, srv_count, srv_serror_rate. |
| Probe | count, diff_srv_rate, dst_bytes, dst_host_count, dst_host_diff_srv_rate, dst_host_rerror_rate, dst_host_same_src_port_rate, dst_host_same_srv_rate, dst_host_srv_count, dst_host_srv_diff_host_rate, dst_host_srv_rerror_rate, dst_host_srv_serror_rate, duration, flag, protocol_type, rerror_rate, same_srv_rate, service, src_bytes, srv_count, srv_diff_host_rate, srv_rerror_rate, srv_serror_rate. |
| R2L | count, dst_host_count, dst_host_diff_srv_rate, dst_host_same_src_port_rate, dst_host_same_srv_rate, dst_host_srv_count, dst_host_srv_diff_host_rate, flag, hot, is_guest_login, logged_in, same_srv_rate, services. |
| U2R | count, dst_bytes, dst_host_count, dst_host_same_src_port_rate, dst_host_same_srv_rate, dst_host_srv_count, duration, flag, hot, logged_in, num_compromised, num_file_creations, num_root, num_shells, protocol_type, root_shell, same_srv_rate, service, src_bytes, srv_count. |
| Antecedent | Consequent | Support (%) | Confidence (%) |
|---|---|---|---|
| "same_srv_rate = true" - "dst_host_same_src_port_rate = true" | "src_bytes = true" | 69.646 | 97.988 |
| "srv_count = true" - "same_srv_rate = true" - "dst_host_same_src_port_rate = true" | "src_bytes = true" | 69.646 | 97.988 |
| "same_srv_rate = true" - "src_bytes = true" | "srv_count = true" - "dst_host_same_src_port_rate = true" | 69.646 | 90.860 |
| "count = true" - "dst_host_same_src_port_rate = true" | "same_srv_rate = true" - "src_bytes = true" | 69.646 | 97.979 |
| "same_srv_rate = true" - "src_bytes = true" | "count = true" - "dst_host_same_src_port_rate = true" | 69.646 | 90.860 |
| "srv_count = true" - "dst_host_same_src_port_rate = true" | "same_srv_rate = true" - "src_bytes = true" | 69.646 | 97.979 |
| "dst_host_same_src_port_rate = true" | "dst_host_count = true" - "same_srv_rate = true" - "src_bytes = true" | 69.646 | 97.979 |
| "dst_host_srv_count = true" - "same_srv_rate = true" - "src_bytes = true" | "dst_host_same_src_port_rate = true" | 69.646 | 90.861 |
| "dst_host_count=true" - "same_srv_rate = true" - "src_bytes = true" | "dst_host_same_src_port_rate = true" | 69.646 | 90.861 |
| "dst_host_same_src_port_rate = true" | "dst_host_srv_count = true" - "same_srv_rate = true" - "src_bytes = true" | 69.646 | 97.979 |
| "same_srv_rate = true" - "src_bytes = true" | "dst_host_count = true" - "dst_host_same_src_port_rate = true" | 69.646 | 90.86 |
| "dst_host_count = true" - "dst_host_same_src_port_rate = true" | "same_srv_rate = true" - "src_bytes = true" | 69.646 | 97.979 |
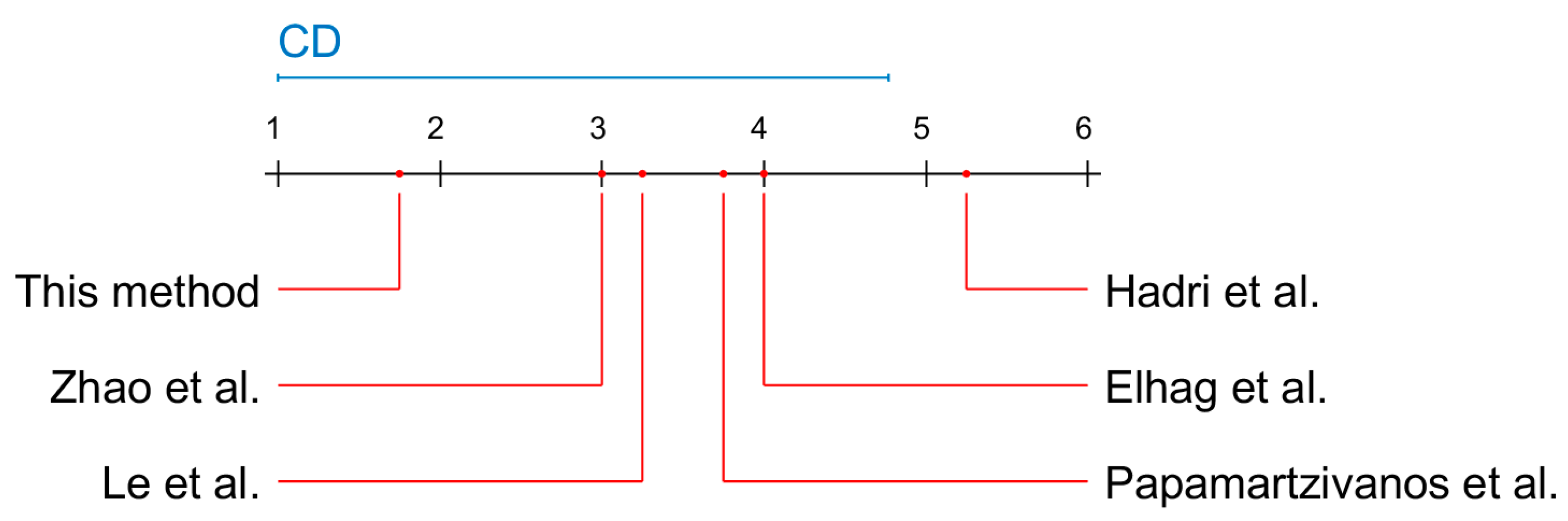
| Authors | Method | DOS | U2R | R2L | PRB |
|---|---|---|---|---|---|
| Hadri et al. [47] | Robust fuzzy PCA | 74.2 | 16.1 | 4.55 | 92.1 |
| Papamartzivanos et al. [48] | Genetic trees | 99.12 | 52.63 | 79.54 | 82.63 |
| Elhag et al. [49] | Evolutionary fuzzy | 90.28 | 42.31 | 92.77 | 67.15 |
| Le et al. [37] | Recurrent Neural Networks (RNN) | 88 | 85 | 81 | 100 |
| Zhao et al. [45] | SVM+RBF kernel | 99.77 | 96.19 | 91.07 | n/a |
| This method | Apriori | 98.2 | 98.1 | 96.9 | 96.9 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azeez, N.A.; Ayemobola, T.J.; Misra, S.; Maskeliūnas, R.; Damaševičius, R. Network Intrusion Detection with a Hashing Based Apriori Algorithm Using Hadoop MapReduce. Computers 2019, 8, 86. https://doi.org/10.3390/computers8040086
Azeez NA, Ayemobola TJ, Misra S, Maskeliūnas R, Damaševičius R. Network Intrusion Detection with a Hashing Based Apriori Algorithm Using Hadoop MapReduce. Computers. 2019; 8(4):86. https://doi.org/10.3390/computers8040086
Chicago/Turabian StyleAzeez, Nureni Ayofe, Tolulope Jide Ayemobola, Sanjay Misra, Rytis Maskeliūnas, and Robertas Damaševičius. 2019. "Network Intrusion Detection with a Hashing Based Apriori Algorithm Using Hadoop MapReduce" Computers 8, no. 4: 86. https://doi.org/10.3390/computers8040086
APA StyleAzeez, N. A., Ayemobola, T. J., Misra, S., Maskeliūnas, R., & Damaševičius, R. (2019). Network Intrusion Detection with a Hashing Based Apriori Algorithm Using Hadoop MapReduce. Computers, 8(4), 86. https://doi.org/10.3390/computers8040086