1. Introduction
Web applications have become indispensable to a growing number of business organizations today as they now form an integral part of their business strategies [
1]. Considering this point of view, it is essential that web applications be maintainable so as to have a long lifecycle. However, achieving this objective is not a trivial task. As large-scale web applications become increasingly complex, the quality of such systems decreases. Of all the quality attributes, maintainability is one of the most important attributes that should be taken into consideration during the development of web applications. Maintaining the quality of large-scale web applications after they have been built can be very challenging. One of the approaches to decrease the maintainability effort is by managing the complexity of applications. Another approach is to predict code bug [
2] or smells [
3] thus contributing to prolonging the lifecycle of programs too. Software complexity is measured in order to, among other things, be able to predict the maintainability and reliability of software given that code metrics can serve as indicators of software defects [
4]. A good number of complexity metrics have been proposed to measure software programs. In many cases, these metrics are based on cognitive informatics [
5]—an approach to evaluating the complexity of software based on cognitive weights [
6,
7,
8].
Metrics have been suggested for both procedural (or functional) and object-oriented languages [
9]. Notable metrics for procedural languages includes the Halstead complexity measure [
10], McCabe’s cyclomatic complexity [
11], and Lines of Code (LoC) for functional/procedural languages, and Chidamber and Kemerer (CK) Metric Suite [
12] for object-oriented languages. In comparison to programming languages however, little work has been done in proposing metrics for other notation systems such as metaprograms [
13], or style sheet languages. Recently, complexity metrics were suggested for the web application domain, including Extensible Markup Language (XML) schema documents [
14], Web Services [
15,
16], and Document Type Definition (DTDs) [
17]. These components are a requisite part of contemporary web applications. Several complexity metrics have been proposed for XML. For example, Feuerlicht and Hartman [
18] proposed a Service Entropy Metric (SEM) that estimates the complexity of XML message structures on which web service interfaces are based. Pušnik et al. [
19] suggested a full set of composite metrics based on the 25 properties of XML documents for assessing an XML Schema’s quality. An overview of complexity metrics for XML schema languages is presented in Reference [
20].
Cascading Style Sheets (CSS) are another important part of web applications. It is a style sheet language that is used to structure the presentation of web pages written in markup languages, such as Wireless Markup Language (WML), Hyper Text Markup Language (HTML), and eXtensible HTML (XHTML), for implementing user-friendly and aesthetically attractive web interfaces. The main advantage that CSS offers is separation of the content aspects from the presentation aspects as suggested by the ‘separation of concerns’ paradigm [
21]. Despite this advantage, users perceive CSS as over-complex and this has hampered its far-reaching adoption. While CSS are perceived as complex, the domain of style sheets remains under-researched and no metric has been proposed to measure CSS complexity [
22]. Keller and Nussbaumer [
23] proposed a quality metric based on abstractness factor in order to understand why CSS codes written by humans were better than those automatically generated by tools. The goal of his research was to use the result of the metric as a benchmark for improving CSS authoring tools. The work however did not deal with measuring complexity of CSS. Mesbah and Mirshokraie [
24] in their work began by identifying the inheritance and cascading features of CSS as the main factors that make CSS code difficult to maintain. They went on to propose an automated method to aid CSS code maintenance by analyzing the performance dependencies between the CSS rules and Document Object Model (DOM) elements in a web application and detecting overridden declaration properties, unmatched and ineffective selectors, and undefined class values. A key significance of their approach is that it can help to ensure a clean code base by reporting unused code, which can then be deleted. This will in turn reduce complexity of the CSS code. Selecting high-quality CSS templates for website design can increase website maintainability and reduce work effort required in the future.
In our previous work [
25], we presented structural factors that contribute to complexity in CSS documents. While evaluating the complexity of CSS, it was identified that size, number of blocks, reuse of rule blocks, cohesion and attribute definition are the factors responsible for increasing the complexity. The study proceeded to propose metrics based on these factors. The metrics proposed include: Rule length (size); number of rule blocks (size); entropy (variety in rule block structure); number of extended rule blocks (rule block reuse); number of attributes defined per rule block (attribute definition in rule blocks); and number of cohesive rule blocks (cohesion). The metrics were validated using a practical framework. The validation results showed that the metrics were useful and applicable. The work however did not perform theoretical validation. Additionally, empirical validation of the metrics was not carried out. These aspects form the focus of this article.
The ultimate objective of this study is to carry out the theoretical and empirical validation on CSS metrics previously proposed in Reference [
25]. The structure of the remaining parts of the article is as follows. In
Section 2, we describe the proposed metric suite. The methodology adopted comprising of theoretical and empirical analysis as well as risk assessment is conducted in
Section 3.
Section 4 presents the results obtained and discusses the threats to validity.
Section 5 concludes the work.
2. Definition and Demonstration of Proposed Metrics
“The greater the size of a CSS the more complex the CSS will be. Since size is an important measure, we are proposing rule length metric which is similar to lines of code in procedural programming and number of rule block metric which is similar to the number of modules in structured programming.
Also, the more dissimilar the rule blocks in a CSS are to one another, the more complex it will be to understand. Since variety in rule block structure is an important measure, we are proposing entropy metric.
The smaller the number of modules that are reused in CSS increases the complexity of the CSS. Since reuse is an important measure, we are proposing number of extended rule blocks metric.
Furthermore, cohesion plays a vital role in the complexity of CSS as the lower the level of cohesion among rule blocks, the more complex the CSS. Since cohesion is an important measure, we are proposing number of cohesive rule blocks as metric.
In addition, the more the attributes defined for a rule block the more complex it will be. Since attribute definition in rule blocks is an important measure, we are pro- posing number of attributes defined per rule block as metric. In the paragraphs that follow, we describe the proposed metrics in detail” [
25].
In this section, the various metrics are demonstrated using the following CSS example:
/* CSS Code Listing 1 */
* {
padding: 0;
margin: 0;
}
a {
text-decoration: underline;
color: #FFF;
}
a:hover {
text-decoration: none;
}
body {
background: #281525 url(images/bg0.jpg) top center no-repeat;
background-size: 100%;
line-height: 1.75em;
color: #CCB7C0;
font-size: 12pt;
}
h2 {
font-size: 1.75em;
}
h2,h3,h4 {
color: #FFF;
font-family: Abel, sans-serif;
margin-bottom: 1em;
}
h3 {
font-size: 1.5em;
}
h4 {
font-size: 1.25em;
}
#content {
padding: 0;
width: 765px;
float: left;
}
#footer {
text-align: center;
margin: 40px 0 80px 0;
color: #543E51;
text-shadow: 1px 1px 1px rgba(0,0,0,0.75);
}
2.1. Rule Length (RL)
A CSS document consists of a list of rules described according to the World Wide Web Consortium (W3C) specifications. The Rule Length (RL) metric counts the number of lines of rules in a CSS, while excluding white spaces or comment lines as comments and white spaces are not executable. The value of the RL metric is computed as the number of rule statements in a CSS file. Here, a rule statement can be any of the elements of a CSS file presented as follows:
Selector attribute(s) finishing with a semicolon “;”, e.g., “color: #00FF00”;
Selector(s) and an opening brace of a rule block “{”, e.g., “body {” as well as
A closing brace of a rule block represented by “}”
From the given CSS Code Listing 1, there are 43 lines aside comments and line spaces hence the RL metric has 43 lines.
2.2. Number of Rule Blocks (NORB)
Number of Rule Blocks (NORB) is calculated as the number of rule blocks in a CSS file. A rule block refers to a selector and its attributes (properties). This is illustrated by the following syntax:
/* Syntax of a rule block */
selector [, selector2, …] [:pseudo-class] {
property: value;
property2: value2;
…
propertyN: valueN;
}
Usually, a CSS document has at least one rule block.
In the CSS Code Listing 1, there are 10 rule blocks hence the value of NORB is 10.
2.3. Entropy Metric (E)
The concept of entropy is one that has been adopted for software measurements on different occasions [
2,
3,
14]. The entropy of a CSS file with
unique classes of elements can be computed using their frequency of occurrence as an unbiased estimate of their probability
. The frequency of the equivalence classes of the CSS file is the number of corresponding elements divided by the total number of CSS rule blocks. The unique class of elements means that elements with the same structural complexity are categorized to the same equivalence class (
). The entropy value is computed by first finding the equivalence classes by grouping similar rule blocks, which have the same number of attributes.
Finally, the Entropy (E) metric is calculated as follows:
There are seven similar classes as follows:
C1 = {*, a} = 2 elements
C2 = {a:hover} = 1 element
C3 = {body} = 1 element
C4 = {h2, h3, h4} = 3 elements
C5 = {{h2, h3, h4}} = 1 element
C6 = {#content} = 1 element
C7 = {#footer} = 1 element
Applying the formula we have:
E(CSS) = (2/10)log2(2/10) + (1/10)log2(1/10) + (1/10)log2(1/10) + (3/10)log2(3/10) + (1/10)log2(1/10) + (1/10)log2(1/10) + (1/10)log2(1/10)
= 0.3219 + 0.2303 + 0.2303 + 0.3612 + 0.2303 + 0.2303 + 0.2303
= 1.8346
2.4. Number of Extended Rule Blocks (NERB)
The Number of Extended Rule Blocks (NERB) metric calculates the number of rule blocks that are extended in a CSS file. For instance, in the CSS Code Listing 1 example, rule block a{…} is extended to give a:hover{…}. Hence, the value of NERB is one.
2.5. Number of Attributes Defined per Rule Block (NADRB)
The Number of Attributes Defined per Rule Block (NADRB) metric calculates the average number of attributes defined in the CSS rule blocks. It is calculated as the total number of attributes in all rule blocks divided by the total number of rule blocks.
From the CSS Code Listing 1 example, there are 23 attributes in all the rule blocks combined and there are 10 rule blocks in all, as already established. Hence,
NADRB = 23/10 = 2.3
2.6. Number of Cohesive Rule Blocks (NCRB)
The Number of Cohesive Rule Blocks (NCRB) metric counts all CSS rule blocks having only one attribute.
From the CSS Code Listing 1 example, there are four rule blocks that fulfill this criterion namely: a:hover, h2, h3, and h4. They all possess single attributes within their rule blocks.
3. Validation of the Proposed Metrics
We carry out both theoretical and empirical validation in order to evaluate our proposed CSS metrics. For the theoretical validation, we evaluate the CSS metrics against formal Weyuker’s properties [
26,
27]. Weyuker’s properties [
28] are measures that must be satisfied by every complexity measure in order to be considered as a good and acceptable one. Furthermore, Weyuker’s properties are straightforward and easy to understand [
29]. In addition, Weyuker’s properties have been proved as an appropriate measure for evaluation of new complexity measures [
29].
We present the description of Weyuker’s properties in the following subsection.
3.1. Theoretical Validation by Weyuker’s Properties
Property 1 implies that a measure should not rank all CSS documents as having an equal complexity:
Property 1. hereandare programs.
Property 2. Letbe a non-negative number then there is only a finite number of programs, which have complexity .
Property 3 implies that two distinct CSS files can have the same complexity value.
Property 3. There are distinct programs andsuch that
Property 4 implies that there can be two equivalent CSS rules achieving the same goal yet having distinct complexity values.
Property 4. Property 5 states that any subset of a CSS rule is always less than or equal to the value of the entire rule set.
Property 5. Properties 6a and 6b seek to find out if there are any three CSS rules (, , and ) such that has the same complexity value as and when is joined to each of them they produce different complexity values.
Property 6a. Property 6b. Property 7. If a programis formed by permuting the order of the statements of program, then.
Property 8 means that if semantic renaming of symbols, variables or program does not change the complexity, then this property is satisfied.
Property 8. Ifis constructed by the renaming of, then.
Property 9 allows for the possibility that as the number of the CSS rules grow, additional complexity is introduced.
Property 9. 3.2. Empirical Validation
Empirical validation is vital to prove the practical usefulness of any metric. According to Reference [
30], it is the only way through which researchers can assist industry in selecting a new technology. In order to interpret and comprehend software metrics, calculating appropriate ranges and thresholds of metrics is imperative [
31]. Moreover, well-defined thresholds have good relation to software quality [
32]. Therefore, researchers have proposed to use statistical characteristics of metrics to obtain their ranges and thresholds [
33]. Although, most of software metrics do not follow the normal distribution, normality of distribution is a desired property as it provides more flexibility in calculating metric thresholds [
34].
To assess normality of metric values, we follow the recommendations presented in Reference [
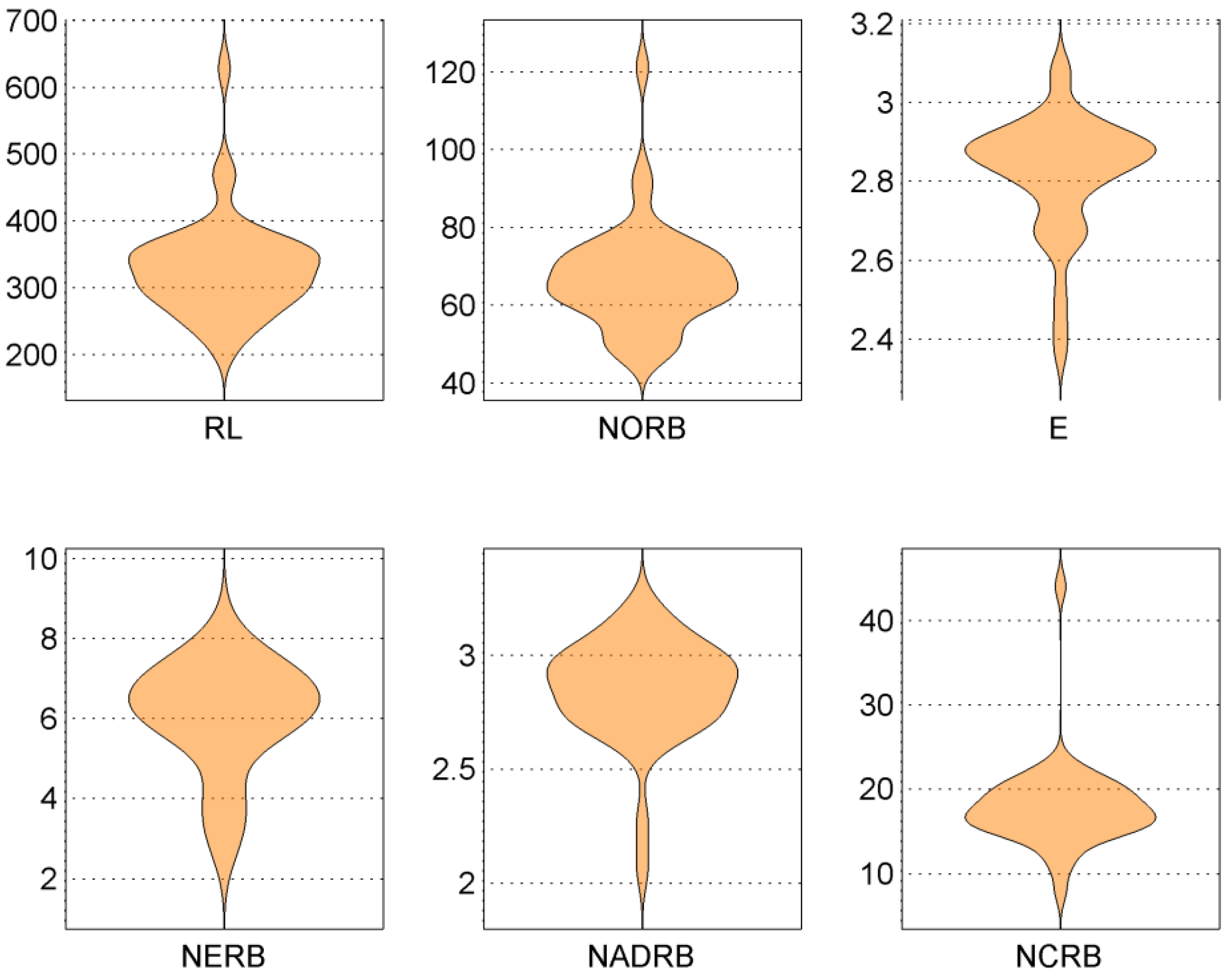
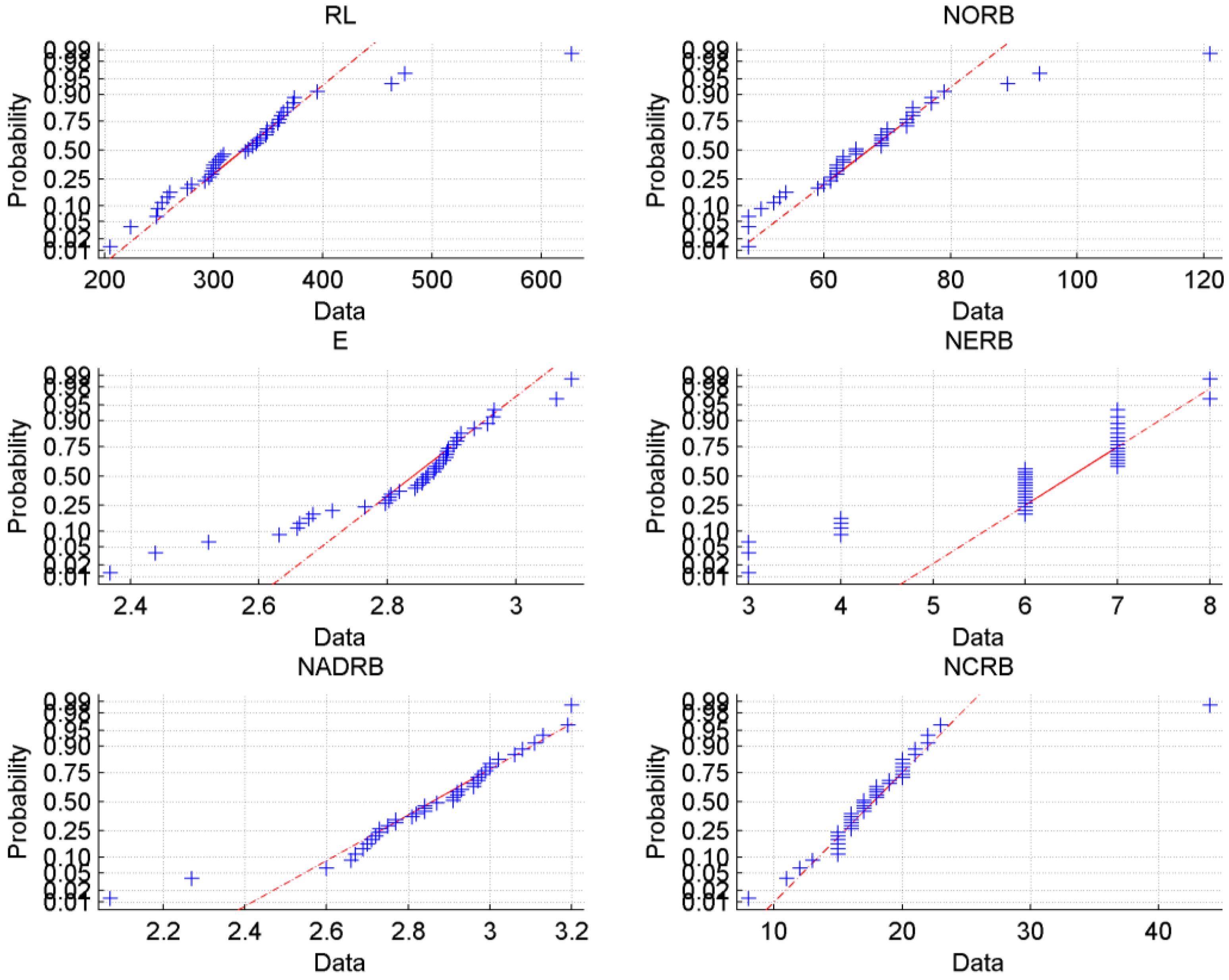
35]. We use the Q-Q (quantile-quantile) plot graphs the quantiles (i.e., values that divide a data set into equal parts) of the data for checking normality visually. We also use a violin plot (a specific case of a boxplot). A symmetric plot with the median value of the data set placed at approximately the center of the plot suggests that the data may have originated from a Gaussian distribution.
The statistical normality tests are an additional tool to the visual assessment of normality. Here we use the Chi-square test and Lilliefors corrected Kolmogorov-Smirnov (KS) test, as also suggested in Reference [
35]. The tests provide a decision for the null hypothesis that the tested data originates from a normal distribution at the 0.05 level of significance.
To assess reliability of metrics, we use the method described in Reference [
36]. We divide the metric values randomly into two groups. To compare the distribution of values among both groups, we apply Kruskal Wallis and Mann-Whitney U tests [
37] using the 0.05 level of confidence (i.e.,
p-value < 0.05). Both tests are non-parametric statistical tests that do not assume a Gaussian distribution of data values. We apply the Bonferroni correction to adjust the threshold
p-value by dividing it by the number of tests executed. If there is a statistically significant difference (i.e.,
p-value < 0.05/number of tests), we reject the null hypothesis and report that the division into groups (i.e., the sampling strategy) affects the distribution of values, i.e., the metric is not reliable.
We also use a non-parametric measure of effect size, Cliff’s delta [
38], which estimates the probability that a randomly selected value from one group is larger than a randomly selected value from another group, minus the reverse probability as follows:
here
and
are values within group 1 and group 2, respectively,
and
are the sizes of groups, and
is the Iverson operator. Cliff’s delta values range from 1 to −1, whereas fully overlapping distributions have a Cliff’s delta of 0.
To assess the relationship between metric values and document size, and between the metrics, we use Pearson’s correlation. Following the suggestions presented in Reference [
39], values exceeding 0.7 are considered as strong, while values exceeding 0.4 are considered as moderate, while the significance is evaluated using the
p-value.
3.3. Assessment of Risk
To evaluate the risk categories of CSS documents associated with their high complexity/low maintainability, we follow the approach presented in [
34] (see
Table 1).
The 70%, 80%, and 90% percentiles of the metric’s values are used as thresholds to assign the categories of low, moderate, and high risk. The low risk category is assigned a risk value of 0, the moderate risk category is assigned a risk value of 0.5, and the high risk category is assigned a risk value of 1. Finally, the aggregate risk is calculated as an average of risk values across all metrics.
4. Results
4.1. Dataset
For the empirical validation of our proposed metrics, we analyzed a dataset of forty CSS documents randomly downloaded from a popular CSS template site—
https://templated.co/.
Table A1 in
Appendix A shows the links to all the CSS files used in this evaluation. A tool was developed to analyze and retrieve the RL, NORB, NADRB, and NCRB metric values of the CSS dataset files.
The measures of the analyzed CSS documents are given in
Table 2.
4.2. Performance of the Measures against Weyuker’s Properties
Table 2 gives the summary of the performance of the proposed CSS metrics against formal Weyuker’s properties. Here, ‘*’ means that a measure satisfies a Weyuker property, and ‘-’ means that the measure does not satisfy a Weyuker property.
As we can see from
Table 2, different CSS documents have different RL, NORB, E, NERB, NADRB and NCRB values. Though some of the CSS documents had similar values for some metric, it was not the case for all the CSS documents. Hence, Property 1 is satisfied by our metrics suite.
Property 3 implies that it is possible for two distinct CSS files to have the same complexity value. As can be observed in
Table 2, different CSS documents have the same RL (e.g., CSS documents 4 and 16), NORB (e.g., CSS documents 1, 9 and 17), E (e.g., CSS documents 11 and 16), NERB (CSS documents 1, 29 and 40), NADRB (e.g., CSS documents 3 and 12), and NCRB values (e.g., 1, 25, 27, 35, 38, and 40) and hence Property 3 is also satisfied by all the proposed measures.
All the proposed metrics are independent of the arrangement or rearrangement of rule blocks in a CSS rule. In other words, permuting the order of the rule blocks in the CSS will not cause a change in the measures. Therefore, none of our metrics satisfy property 7.
Property 8 means that if semantic renaming of symbols, variables or program does not change the complexity, then this property is satisfied. Renaming of CSS documents does not modify the metric value. As a result, Property 8 is satisfied by all our metrics.
Therefore, all the proposed CSS metrics satisfy properties 1, 2, 3, 5, 8; while none of our metrics satisfy properties 4, 7, and 9 (
Table 3).
Our metrics satisfy five out of nine Weyuker’s properties which indicates that our measure is a good measure. It is worth mentioning that for a measure to be rated as good and acceptable, it is not mandatory to fulfill all the properties [
40].
4.3. Empirical and Statistical Evaluation Results
To assess distribution of the metric values we used the visual approach: the violin plots of the metric values are presented in
Figure 1 while the Q-Q plots are presented in
Figure 2. We can see that although the distribution of all metric values is skewed, they are still similar to normal distribution as they have a single maxima and tails. The observation is confirmed by the Q-Q plots, which clearly show a linear relationship between quantile values of metrics.
The statistical tests of Chi-square and Liliefors rejected the normality hypothesis for the RL, E, NERB and NCRB metrics, while the results for the NORB and NADRB metric were mixed (hypothesis not rejected but the p-values exceeded a threshold value of 0.05). The results suggest the need for applying normalization transform to the values of metrics to make them more usable.
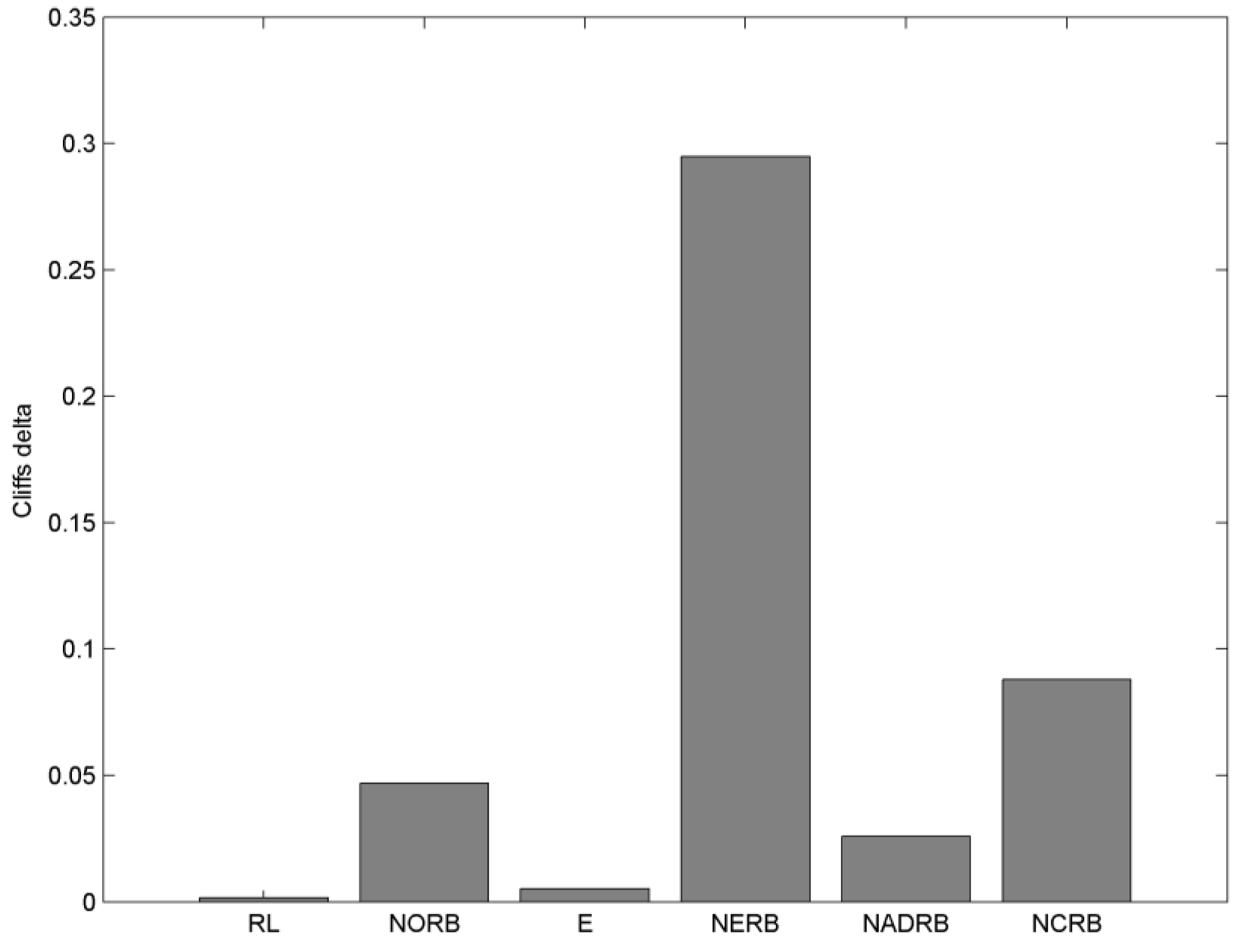
The results of Cliff’s delta are presented in
Figure 3. Following the rule-of-thumb given in [
41] the metric values smaller than 0.1 are considered as acceptable. In our case, only the NERB metric has exceeded the value of 0.1
Following the suggestions presented in [
42], complexity metrics should not be confused to size metrics, because correlation to size can produce a wrong impression that some metrics are valid. Moreover, asserted size has a confounding effect on the metric validity [
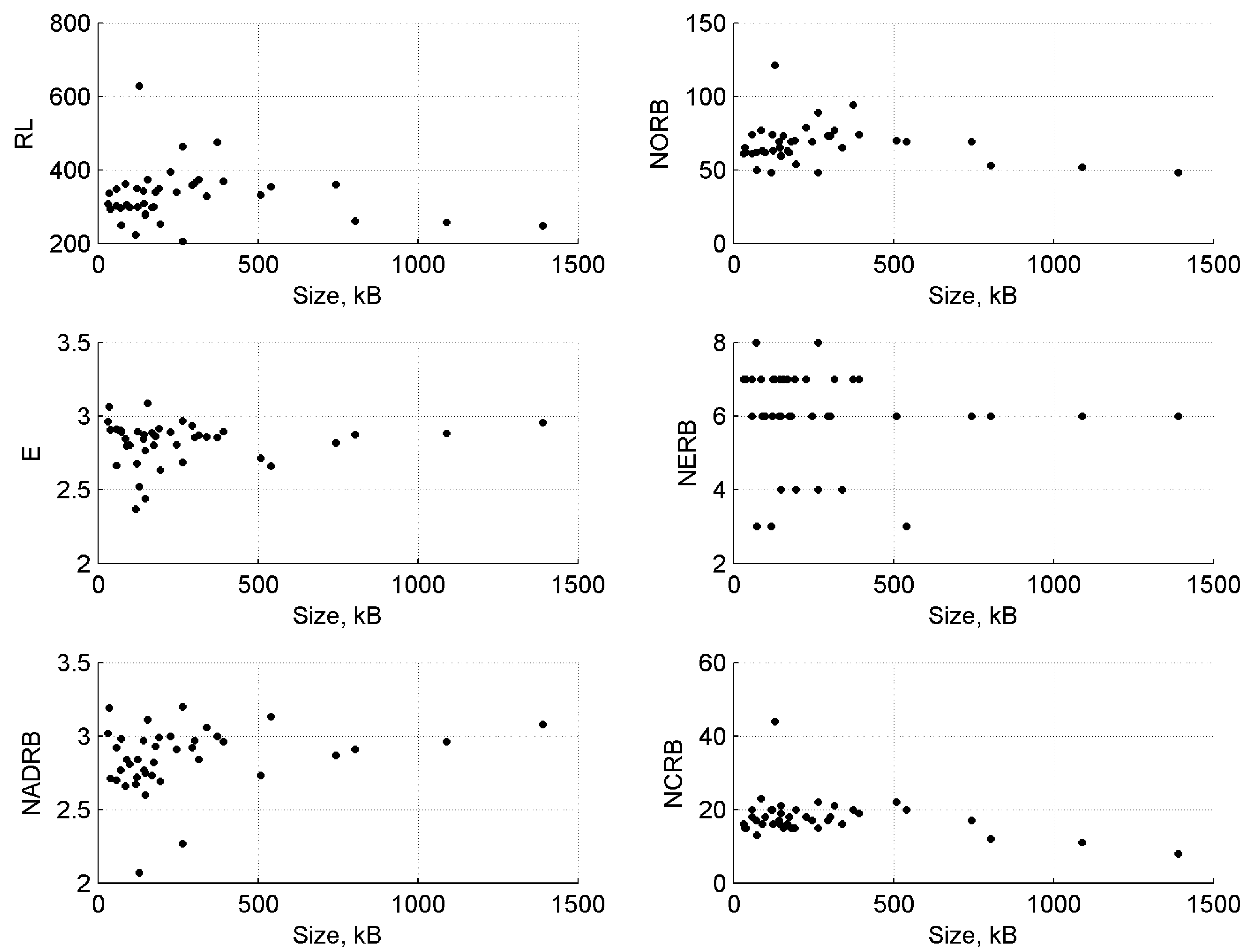
43]. To check for the absence of correlations, we employed both a visual approach (see
Figure 4) as well as calculated Pearson correlation between CSS metric values and the CSS document sizes (in kB) (see
Figure 5).
From visual inspection, we can observe small effects of the size of the CSS documents on the values of CSS complexity metrics. The results are confirmed by the Pearson correlation values, which show insignificant correlation to metric values (RL, NORB, NERB NCRB metrics—negative correlation; E, NADRB—positive correlation). In all cases, the coefficient of determination was insignificant ().
Correlation between metric values in the metric suite is considered bad as correlated metrics, e.g., can skew the results of some applications such as defect prediction, while removing correlated metrics from the metric suite improves the consistency [
44]. From the correlation matrix presented in
Figure 5 we can see that strong correlations are observed between the RL and NORB metrics (
), NORB and NCRB (
), RL and NCRB (
). Moderate correlations are observed between E and NADRB (
), E and NERB (
), NADRB and NCRB (
), E and NCRB (
), NORB and NERB (
), RL and NERB (
).
These results suggest that the metric suite is redundant and one or two metrics could be removed without the significant loss of information.
4.4. Threats to Validity
We follow guidelines provided in Reference [
45] in discussing the threats to validity of our study.
Threats to internal validity involve selection of systems and analysis methods. We randomly have sampled 40 CSS documents from the templated.co CSS repository. As a result, our findings might be definitive to CSS documents hosted on
https://templated.co/ only.
Threats to external validity involve the generalization power of our results. Our findings might not be directly applicable to other types of style sheet languages. Yet our approach can be useful for benchmarking quality and maintainability of web applications.
Threats to reliability validity include the ability to replicating this study. We have attempted to report all the necessary information to allow replication of our study.
Threats to conclusion validity address the relation between the selection of the dataset and the result. As noted by Gil and Lalouche [
4], code metrics are context dependent and the distribution of their values in different projects varies. The selection of CSS documents involved arbitrary decisions. Including other CSS documents may have changed the statistical properties of the calculated metric values.
4.5. Discussion
Software metrics are important for evaluation of software maintainability. Developing software programs that are less complex and more maintainable means that these programs (or programming artefacts, such as data files or specifications as CSS, in general) have a lower probability of bugs, are more stable and have a longer prospective lifecycle [
46]. Having the ability to evaluate maintainability early enough by calculation of software metrics can help to avoid costly repairs in the future as well as to improve the availability of critical software systems [
47] such as, for example, online banking systems, which among other heavily use and depend upon CSS documents. The primary role of the proposed metrics suite is, therefore, to be a part of the risk assessment process when evaluating and predicting the risk of failure of online systems and websites [
48]. Software metrics that indicate potential software failures, are in high demand in the areas of software testing and maintenance, when developing complex software-intensive systems.
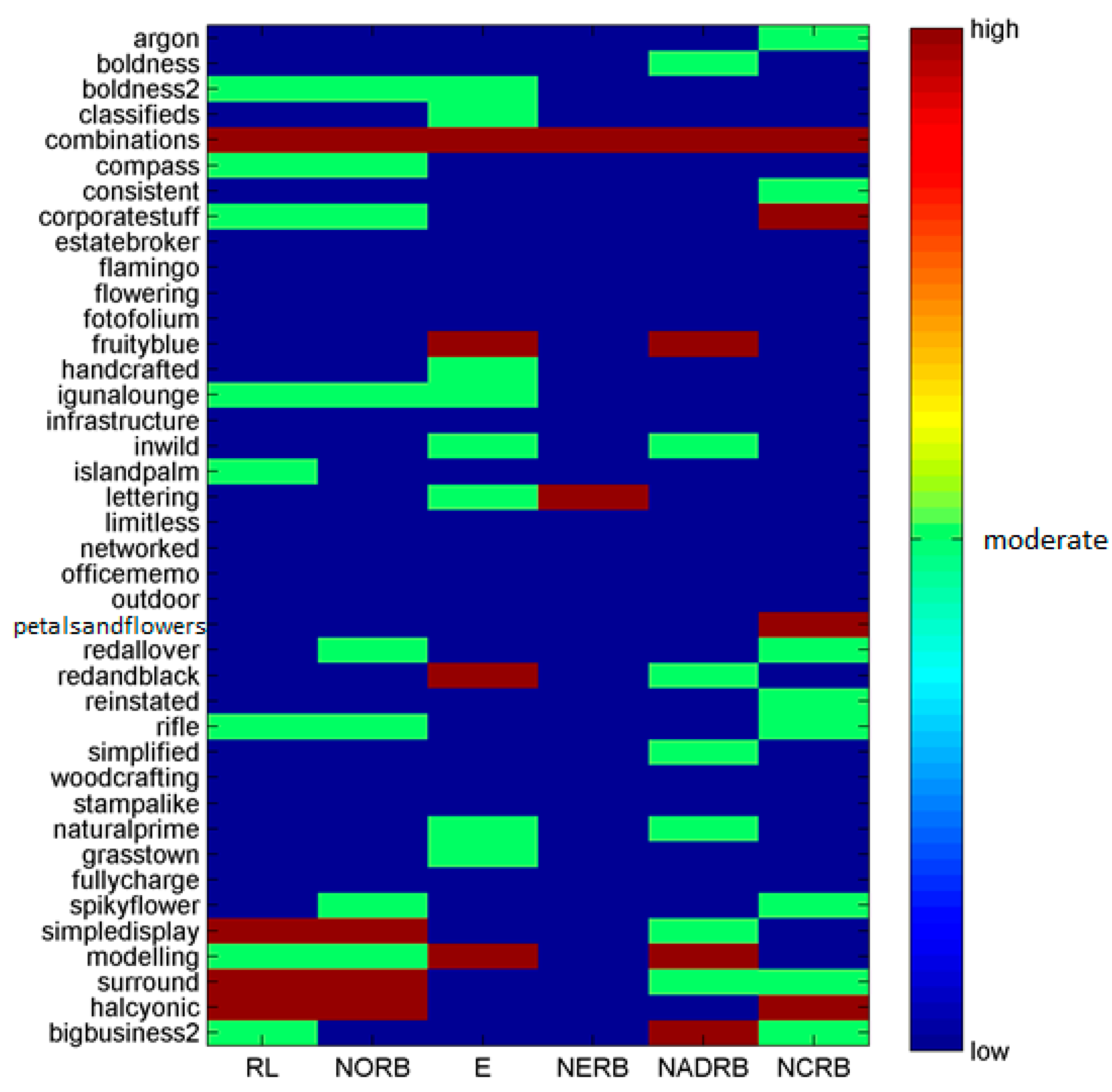
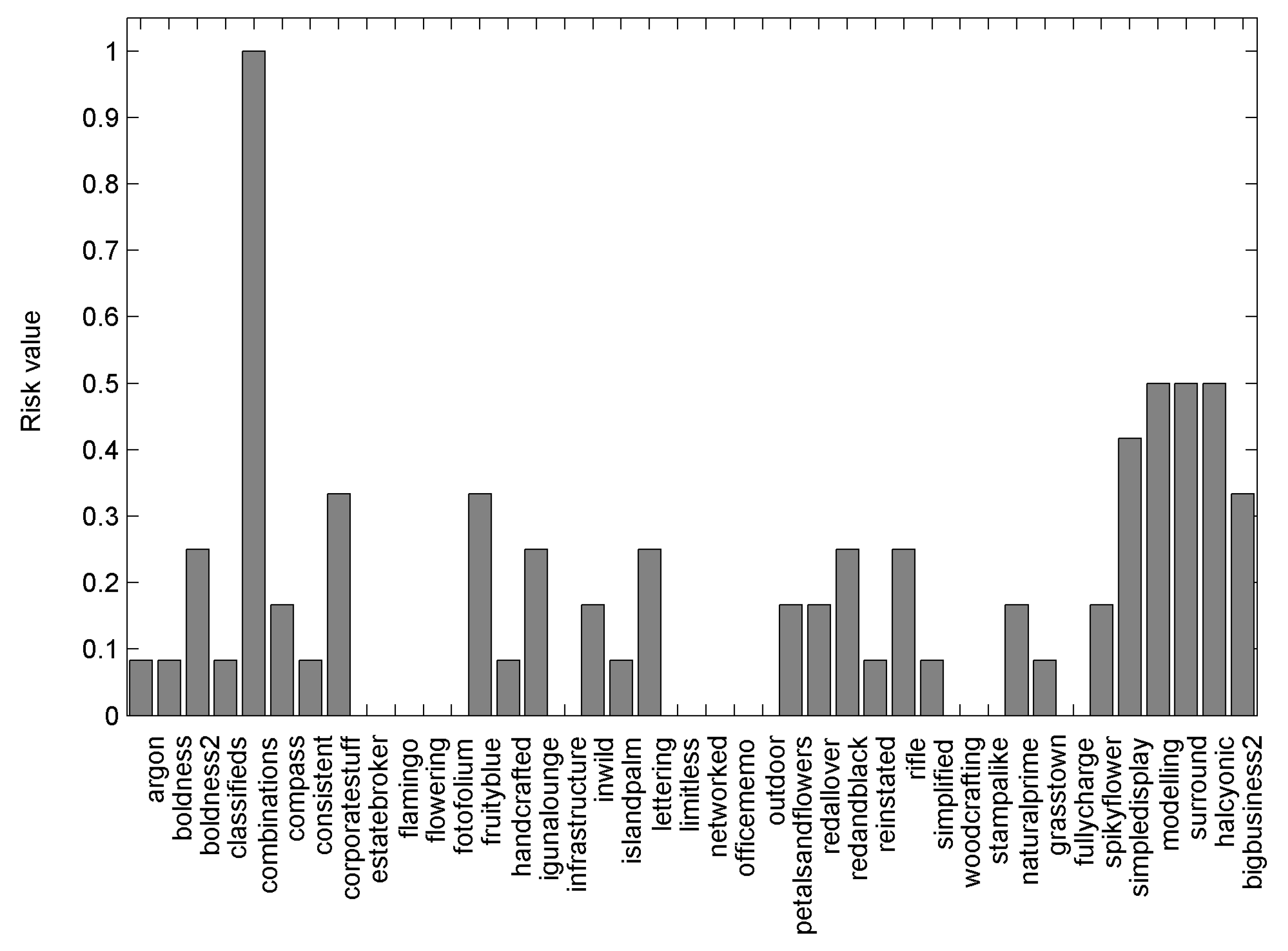
As an example, we present the risk assessment results in
Figure 6 and
Figure 7. The results show that the combinations component of the CSS dataset exceeds threshold values of all CSS metrics and is assigned to the high-risk category, suggesting the immediate need for attention by software maintainability personnel.
In future, we plan to develop a tool to estimate the various metrics as the other previous tools are not comprehensive and also integrate the suite into one comprehensive metric that can be used in estimating the complexity of CSS documents as well as documents written in other stylesheet languages such as Sass (Syntactically awesome style sheets) for web application developers in the context for risk assessment framework for online systems and applications.
5. Conclusions
In this article we have presented and analyzed six metrics—Rule Length (RL), Number of Rule Blocks (NORB), Entropy Metric (E), Number of Extended Rule Blocks (NERB), Number of Attributes Defined per Rule Block (NADRB), and Number of Cohesive Rule Blocks (NCRB), which can be used to assess complexity in Cascading Style Sheets (CSS).
These metrics were theoretically and empirically validated using Weyuker properties: five out of the nine metrics (56%) satisfy the Weyuker properties, except for the NADRB metric, which satisfies six out of nine (67%) properties. This qualifies them as good metrics from a formal viewpoint. In addition, the results from the empirical and statistical study show good statistical distribution characteristics (only the NERB metric exceed the rules-of-thumb threshold value of Cliff’s delta). The correlation between the metric values and the size of CSS documents was insignificant, suggesting that the presented metrics were indeed complexity rather than size metrics. However, the correlation analysis of metrics within the presented metric suite revealed cases of redundancy suggesting that the optimization of the suite by removing one or two metrics is possible.
The practical application of the presented CSS complexity metric suite is to assess the risk of CSS documents. The analysis of our CSS dataset allowed identification of the CSS file that would require immediate attention of the software maintenance personnel.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






