1. Introduction
With the rapid growth of ecommerce platforms for online shopping, more and more customers share their opinions about products on the internet. This fact has generated a huge amount of opinion data within the platform [
1]. The opinion data has then emerged as a valuable and objective source of product information for both customers and companies. For customers, it helps them by recommending that they buy a certain product [
2]. For companies, it can help them in evaluating the design of a product [
3] based on the analysis of user generated content (UGC), i.e., product reviews describing the user’s experience [
4]. With the quantity of the data, manual processing is not an efficient task. Alternatively, a big data analytics technique is necessary [
5]. Sentiment Analysis (SA) has arisen in response to the necessity of processing the huge data in speed [
6]. SA is a computational technique to automate the extraction of subjective information, i.e., opinion of customers with respect to a product [
7]. For that reason, this study is important.
One of the most popular methods employed for SA tasks is the machine learning (ML)-based method [
8], i.e., a supervised approach employing an ML algorithm. Although the role of the ML algorithm is important, it is not yet the only factor that determines the performance of SA. As a text classification task, another important factor influencing the SA result is the employed text features [
9]. Semantic features are considered important for augmenting the result of SA tasks [
10] by providing correct sense of a word according to its local context, i.e., sentence. Providing the correct sense of words means providing correct sentiment value that is important in extracting a robust feature set for supervised SA. The best we know, recent lexicon based approaches of SA studies that concern semantics of words, like the work of [
11] and [
10], have not been evaluated in a supervised environment.
Saif [
11] has considered semantics of words by proposing a method called Contextual Semantics. The study introduced SentiCircle, which adheres to the distributional hypothesis that words that appear in similar contexts share identical meanings. This method has outperformed baseline methods when experimented and evaluated in several different sentiment lexicons, i.e., SentiWordNet [
12], Multi-Perspective Question Answering (MPQA) subjectivity lexicon [
13], and Thelwall-Lexicon [
14] using several Twitter datasets, i.e., Obama McCain Debate (OMD), Health Care Reform (HCR), and Stanford Sentiment Gold Standard (STS-Gold).
Another work, [
10], has also concerned semantic of words. The study provided extension for [
11] by assigning prior sentiment value based on the context of the word using a graph-based Word Sense Disambiguation (WSD) technique. The work has also introduced a similarity-based technique to determine pivot words used in [
11]. Tested in several product review domains, i.e., automotive, beauty, books, electronics, and movies, the result of this study has outperformed baselines in several performance metrics, i.e., precision, recall, and F-Measure. The result of [
11] and [
10] have highlighted the importance of semantics in SA tasks.
Meanwhile, other studies using the supervised approach commonly utilize the bag-of-words (BoW) feature or its extension as the base of the classification task. In this paper, we extend the previous lexicon-based approach presented in [
10] to generate a set of sentiment features that is capable of capturing the semantics of words. The feature set was evaluated in a supervised environment.
Referring to the previously described research gap, the purposes for this study comprised:
In assigning the correct sense of the words in a review sentence, an adapted WSD method was used. In this method, the sense is picked from the WordNet lexical database. To calculate the numeric value of the feature, one of three sentiment values of the sense, i.e., positivity, negativity, and objectivity, is then picked from the SentiWordNet database [
12]. Employing several WordNet similarity algorithms, we present a method to generate a semantic feature set of words. To evaluate the performance of our proposed semantic features, several ML algorithms and feature selection methods were employed. The employed ML algorithms and feature selection methods are implemented in WEKA, an open source tool containing algorithms for data mining applications [
15]. The results of these experiments using 10-fold cross-validation indicated that our proposed semantic features favorably enhanced the performance of SA in terms of precision, recall, and F-Measure. The rest of this manuscript is organized in the following sections.
Section 2 explores the most recent related study that has previously been done.
Section 3 describes the method for extracting semantic features of words, including the formulas that are introduced. We explain the scenario of the experiments and the results in
Section 4. The results of the experiments are discussed in
Section 4. Finally, we highlight the effectiveness of our proposed method in
Section 5.
2. Related Work
The expansion of online shopping has triggered consumer to express their opinion about a product they have purchased on ecommerce platform. SA is an efficient text mining technique to extract the opinion from online product reviews [
16]. Two types of approaches that is commonly employed to perform SA task, i.e., supervised approach and lexicon based approach [
17]. Supervised approaches make use of labeled training data to learn the model. Using an ML algorithm, the model is then performed to test the dataset. Using Hybrid ML approach, Al Amrani [
18] performed SA on an Amazon review dataset. A number of decision trees at randomly selected features were firstly picked to forecast the class of test dataset. Support Vector Machine (SVM) was then used to maximize the margin that separates two classes. Since RF was not sensitive to input, the default parameters were used for each classifier. The method was applied to the Amazon review dataset.
To optimize the SA task, Singh [
19] employed four ML classifiers, i.e., Naïve Bayes, J48, BFTree, and OneR. NLTK and bs4 libraries were used for preprocessing of raw text. Using three manually annotated datasets, i.e., Woodlan’s wallet, digital camera reviews, and movie reviews from IMDB, the robustness of the classifiers was compared. WEKA 3.8 was used for implementing the classifiers. The results of the experiment confirmed that OneR was the most prominent in accuracy.
Conditional Random Field (CRF) and SVM was employed for sentiment classification of online reviews [
16]. CRF was used to extract emotional fragment of the review from a Unigram features of the text. SVM transformed data that is not linearly separable into linearly separable dataset in the feature space through nonlinear mapping. The proposed method was evaluated using Chinese online reviews from Autohome and English online reviews from Amazon. To segment the review, the jieba library of Python was employed. The results of the experiment indicated that average accuracy achieved was 90%.
A study formed a classifier ensemble consisting of Multinomial Naïve Bayes, SVM, Random Forest, and Logistic Regression to improve the accuracy of SA. The utilized feature was BoW represented by a table in which the column represents the term of the document, and the values represent their frequencies. The sentiment orientation was determined using majority voting and the average class probability of each classifier. Using four benchmarks of the Twitter dataset, i.e., Sanders, Stanford, Obama–McCain Debate, and HCR, the experiment revealed that the method can improve the accuracy of SA tasks on Twitter.
Mukherjee [
20] optimized the SA approach for product reviews by developing a system to extract both potential product features and the associated opinion words. In terms of SA tasks, product features extracted in this work are actually aspect. The pair of product features and their associated opinion words was extracted by making use of grammatical relation provided by the Stanford Dependency Parser. The evaluation was conducted using two datasets from [
21,
22]. The system outperformed several baseline systems. Using two scenarios of the experiment, i.e., rule-based classification and supervised classification using SVM, the results of the study confirmed that the supervised classification significantly outperformed the Naïve rule-based classification.
Meanwhile, a lexicon-based SA approach relies on a pre-built Sentiment Lexicon, i.e., a pre-built list of sentiment terms with their associated sentiment value that is publicly available, e.g., Opinion Lexicon, General Inquirer, and SentiWordNet [
12]. The sentiment of the term’s overall document is then aggregated to determine its sentiment orientation. The main challenge of the lexicon-based approach is to improve a term’s sentiment value with respect to a specific context [
23] since the same term can have different sentiment values when it appears in different contexts [
24].
In that regard, Saif [
11] has proposed a method to learn sentiment orientation of words from their contextual semantics. Based on a hypothesis that words appearing in similar contexts tend to share similar meanings, the work proposed a method called SentiCircle. The method was tested on several benchmarks of the Twitter dataset. The results of the experiment indicated that SentiCircle outperformed several baseline methods.
A study has improved the implementation of SentiCircle in the online review dataset by considering semantics of words [
10]. The study argued that the result of SentiCircle is valid only if the prior sentiment value of words is also valid so that
of SentiCircle will adjust sentiment value of words in the right direction. Semantics of words is extracted using a WSD technique. The sentiment value of words was picked from SentiWordNet. The method has been proven more robust against several baseline methods.
From the previously described recent related works, several insights can be highlighted as follows:
BoW is a common text features utilized for supervised SA tasks. To show the robustness of our proposed features against BoW, we will compare the performance of our proposed features with two baselines of BoW, i.e., Unigram (Baseline 1) and Bigram (Baseline 2).
Since semantics has the potential to enhance the performance of SA, we extent a lexicon-based method [
10] to extract text features that capture semantics of words based on its local context, i.e., sentence to provide correct sentiment value of words. We evaluate the performance in a supervised environment. We train the model for several ML algorithms, i.e., Naïve Bayes, Naïve Bayes Multinomial, Logistic, Simple Logistic, Decision Tree, and Random Forest.
We also apply the feature selection method to find the best set of our features.
3. Proposed Method
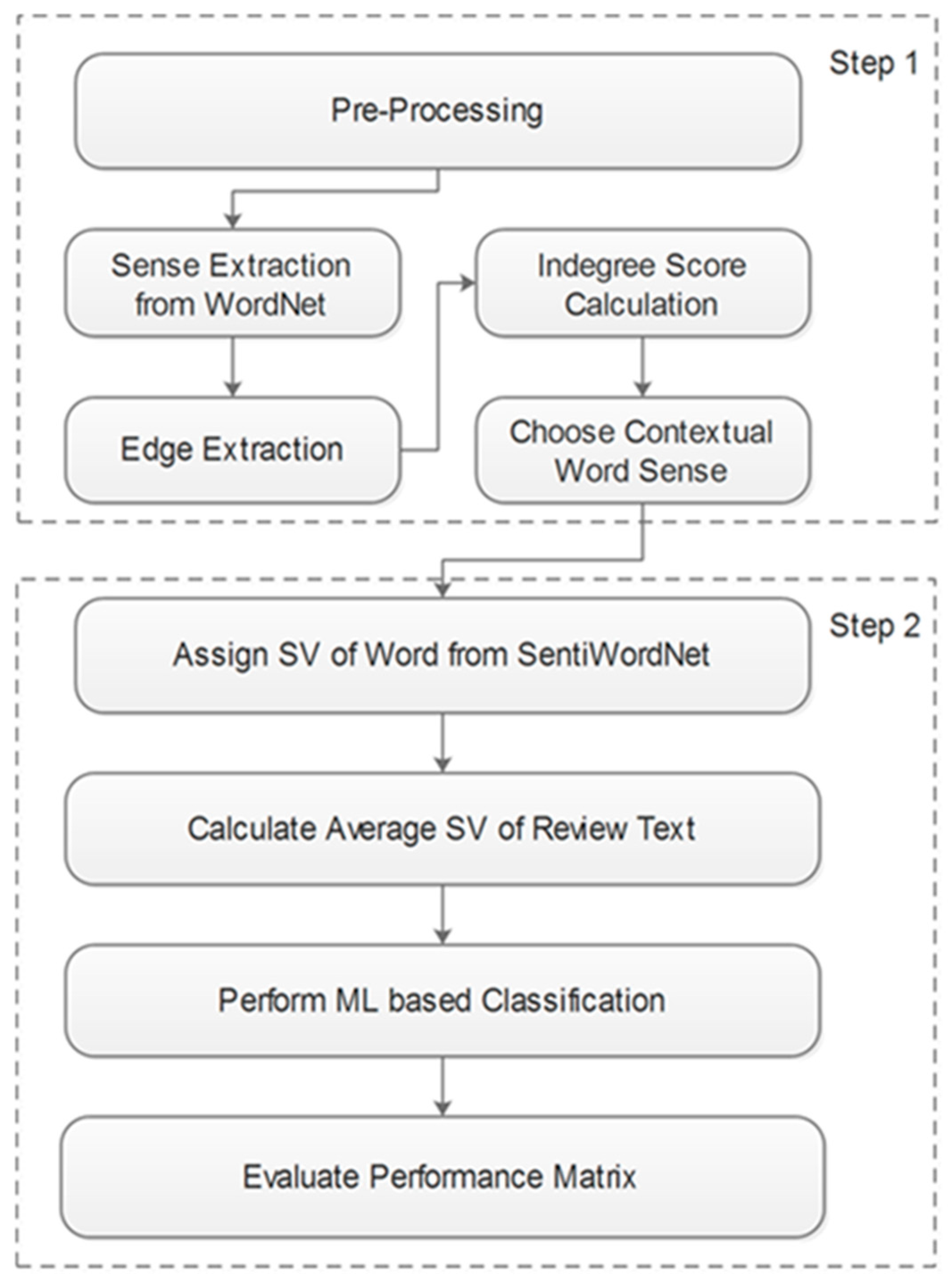
All steps carried out in this study are described in
Figure 1. Step 1 was adopted from [
13], which is an extension of [
14]. This technique is called WSD. The aim of Step 1 was to assign a correct sentiment value to the words according to their contextual sense related to different neighboring words since the same words can appear in different parts of a text and may reveal different meanings, depending on the neighboring words. This problem is called polysemy. As shown in
Figure 2, polysemy is a word with the same word form (WF) but a different meaning (WS). Some examples of polysemy can be seen in
Table 1.
As shown in
Table 1, the same sentiment word that appears in different review sentences potentially has a different sentiment orientation or value. This issue may interfere with the result of the SA. To address this problem, we employed a general purpose sentiment lexicon, namely SentiWordNet [
4]. SentiWordNet specifies three sentiment values, namely positivity, negativity, and objectivity, to each synset of WordNet. More about SentiWordNet can be found at
https://github.com/aesuli/sentiwordnet.
In the pre-processing step, stopword removal, stemming, part of speech (POS) tagging, and filtering were conducted. In the implementation, the Stanford POS tagger library was used. POS tagging is necessary to pick the correct sense of the words from the WordNet collection. In the filtering step, we left in only verbs, adjectives, and nouns. The local neighborhood used as the context for the words was a review sentence. Therefore, the processing step of WSD was done on a sentence basis.
After pre-processing (stop word removal, stemming, POS tagging, and filtering), the sense of the words from the WordNet collection was picked. As an example of the calculation of the proposed feature, consider the review sentence “I love the screen of the camera”. The result of the pre-processing step can be seen in
Table 2.
After filtering, the left term is assigned to
. In the case of the example, we have
, and
. We then pick the senses of
from the WordNet database, indicated as
, as shown in
Table 3.
In terms of the weighted graph, the senses of the words serve as the vertices of the graph. Adopting [
25], the edges are then generated by calculating the similarity between the vertices using WordNet similarity measures from Wu and Palmer (WUP) [
26], Leacock and Chodorow (LCH) [
27], Resnik (RES) [
28], Jiang and Conrath (JCN) [
29], and Lin (LIN) [
30]. Adapted Lesk [
31] was incorporated to improve the result.
Suppose
is the similarity between
and
. All possible similarities between the word senses of the different words are calculated as shown in
Table 4. For the implementation of WordNet similarity, the ws4j algorithm from Hideki Shima was adapted. The tool can be downloaded at
https://ws4jdemo.appspot.com/. To select the contextual sense, the indegree score of each sense was computed using the indegree algorithm. For example, the indegree score of
in
Table 4, i.e.,
, is calculated as follows:
+
+
+
. In general, the indegree score of
is computed using Equation (1). The notation used in Equation (1) is described in
Table 5. In
Table 4, the similarity highlights with red are the similarities between word senses on the left side of
, and the similarity highlighted with green is the similarity of the word senses on the right side of
. The indegree scores of all
are calculated, and the selected (contextual) sense is the sense of the word with the highest indegree score. The contextual sentiment value of a word, i.e.,
, is determined using Equation (2), where
assigns three sentiment values from SentiWordNet, called
,
, and
. In Equation (3),
is the number of words in the processed review sentence.
where:
At the sentence level, three average sentiment values are calculated using Equations (4)–(6), respectively.
Regarding the utilized WordNet similarity algorithm, the average value of every contextual sense in the review document was then calculated and assigned as a feature of the review document. Three average sentiment scores from SentiWordNet were assigned to each document review. Hence, a set of 15 contextual features was provided as the basis for the classification task. A detailed description of the features is presented in
Table 6.
For assessing the proposed features, an experiment was performed using five ML algorithms, namely Naïve Bayes, Logistic, Simple Logistic, Decision Tree, and Random Forest. We also applied five different feature selection methods, i.e., correlation-based feature selection (CFS), correlation attribute evaluator, information gain attribute evaluator, one rule attribute evaluator and principle component analysis, in order to test the performance of the proposed feature set in various different optimized combinations. For the implementation of the ML algorithms and the attribute selection methods, we used WEKA from the University of Waikato. The toolkit can be found at
https://www.cs.waikato.ac.nz/ml/weka/. The employed attribute selection methods are briefly overviewed in the following paragraphs.
3.1. Correlation Feature Selection (CFS)
CFS argues that representative features are features that are highly correlated with the class, yet uncorrelated to each other. Therefore, it measures the individual predictive ability of each subset along with the degree of redundancy between them. CFS presents a measure called the ‘merit’ of the feature subsets. It predicts the correlation between a composite test consisting of the summed components and the outside variable using the standardized Pearson’s correlation coefficient [
32], as shown in Equation (7).
In Equation (7), is defined as the correlation between the summed components and the outside variable, is the number of components, is the average of the correlation between the components and the outside variable, and is the average inter-correlation between the components.
3.2. Correlation Attribute Evaluator
This method calculates the weighted average of the overall Pearson correlation coefficient between an attribute and its class as an indicator for ranking a set of attributes. For
and
, where
is the feature subset and
is the class, and Pearson’s correlation coefficient is given by Equation (8).
3.3. Information Gain Attribute Evaluator
Information gain, also called mutual information, can also reveal dependency between features by calculating the level of impurity in a group of samples. This technique provides a ranking of attributes by evaluating the information gain of an attribute with respect to the class. The information gain of
for
is the class, and
is the attribute subset given by Equation (9).
3.4. OneR Attribute Evaluator
The one rule attribute evaluator rates the values of the attributes based on a simple yet accurate classifier called the one rule classifier [
33], which classifies a dataset based on a single attribute, i.e., a one-level decision tree. OneR chooses the rule with the smallest error rate from previously built rules for every attribute in the training data.
3.5. Principle Components
The algorithm attempts to find the axis of greatest variance of the data. In the implementation, this attribute evaluator calculates the eigenvector of the covariance matrix of the data and filters out the attributes with the worst eigenvectors.
4. Result and Discussion
In the experiment, we used three product review datasets from Amazon Review Data provided by Julian McAuley [
23], i.e., Beauty, Books, and Movies. The dataset can be downloaded from
http://jmcauley.ucsd.edu/data/amazon/. For building the ground truth, we assigned a label of three sentiment categories, i.e., positive, negative, and neutral, for every product review document by taking the ‘overall’ score from the metadata of the dataset (see the sample review in
Figure 3.). The datasets with an ‘overall’ score of 1–2 were labeled as negative reviews. Meanwhile, the datasets with an ‘overall’ score of 4–5 were labeled as positive. The rest was labeled as neutral.
We present the results of the experiment using the three Jean McAuley Amazon datasets in
Table 7,
Table 8 and
Table 9. Our proposed features were evaluated using Naïve Bayes, Naïve Bayes, Logistic, Simple Logistic, J48, and Random Forest. The combination of features was optimized using CFS, correlation attribute evaluator, information gain attribute evaluator, one-rule attribute evaluator, and principle component analysis, and then we compared the results with the full feature set. The performance metrics of the selected features were evaluated using 10-fold cross-validation.
To investigate the role of semantic features in enhancing the result of the supervised SA method, the performance of our proposed features was compared with a baseline feature. For the baseline, we applied Unigram features, i.e., common features used for text classification, extracted using an unsupervised filter from StringtoWordVector in WEKA. In the experiment, we also applied the same feature selection method for the baseline. For the performance metrics, precision, recall, and F-Measure were employed. The whole experiment was conducted using 10-fold cross-validation with WEKA. The results of the experiment are presented in
Table 7,
Table 8 and
Table 9. We compared the result of experiment with two baseline methods, i.e., Unigram (Baseline 1) and Bigram (Baseline 2), of BoW that are commonly adopted for supervised SA tasks.
In
Table 7,
Table 8 and
Table 9, we provide the experiment results for the three product review datasets, i.e., Beauty, Books, and Movies dataset. In each table, we compare the performance of the proposed features with two baselines, namely Unigram and Bigram, that are commonly employed for text classification tasks. The results are grouped based on the employed feature selection method. For every feature selection method, we applied all used ML algorithms. To indicate the best performance achieved for precision, recall, and F-Measure, we used the asterisk symbol as presented in the Tables. For the Beauty dataset, the best performance of the proposed features is 0.897, 1.000, and 0.945 for precision, recall, and F-Measure, respectively. For the Books dataset, Principal Component Analysis (PCA) achieved the best performance by 0.916, 0.882, and 0.895 for precision, recall, and F-Measure, respectively. Meanwhile, for the Movies dataset, features selected using CFS reached the best performance by 0.943, 1.000, and 0.970 for precision, recall, and F-Measure, respectively.
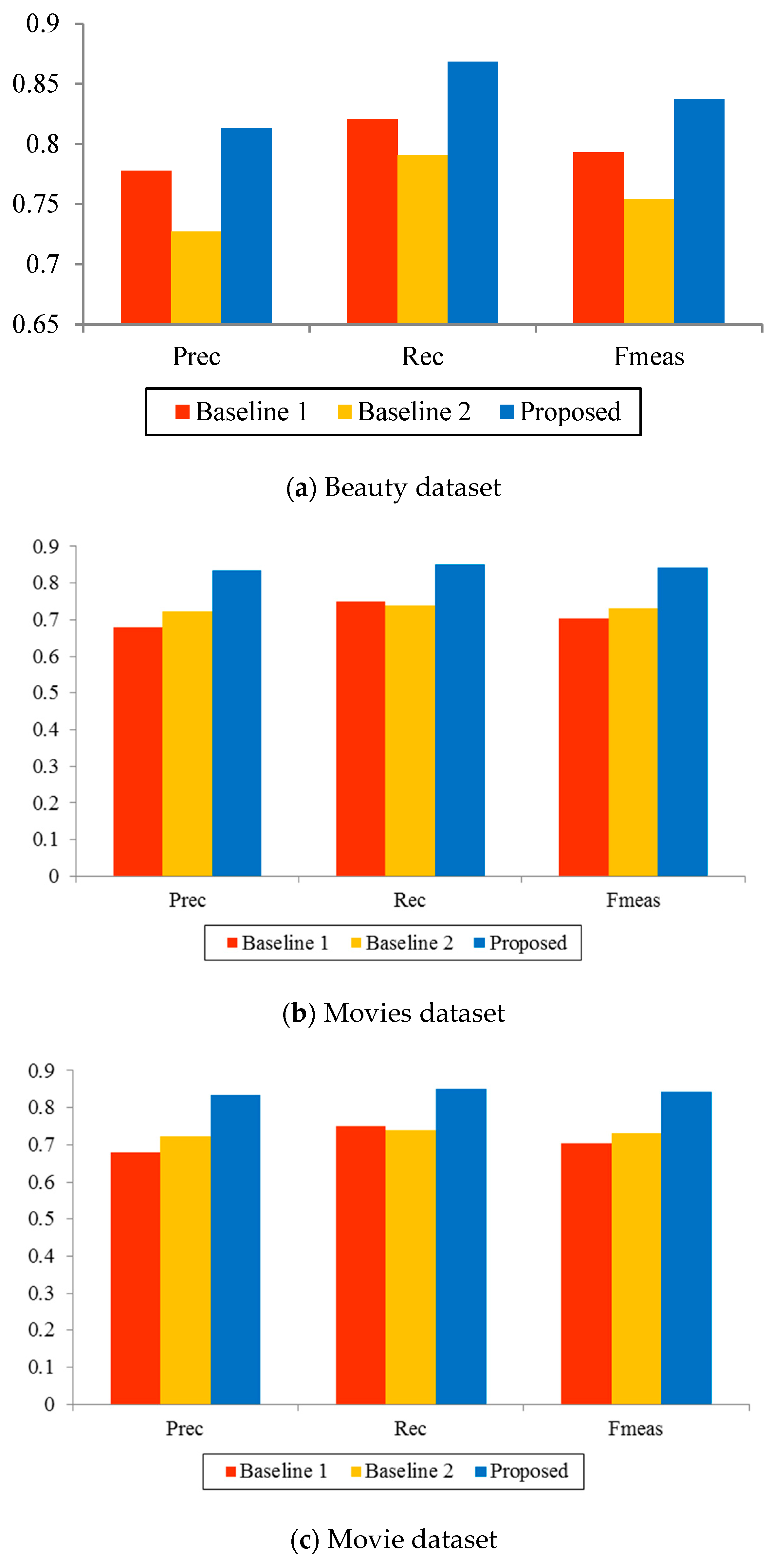
In
Figure 4, we calculated the average performance of our proposed features in terms of precision, recall, and F-Measure. Compared with the baseline feature that is commonly employed in the supervised SA task, i.e., BOW, the extracted semantics features have favorably increased all performance metrics of the supervised SA task, i.e., precision, recall, and F-Measure, as indicated in
Figure 4. In the figure, we present average evaluation metrics for the three datasets. The figure indicates that the proposed semantic features outperform both Unigram and Bigram in all performance metrics. On average, the proposed features increased precision, recall, and F-Measure by 10.9%, 9.2%, and 10.6% of those compared to baseline methods.
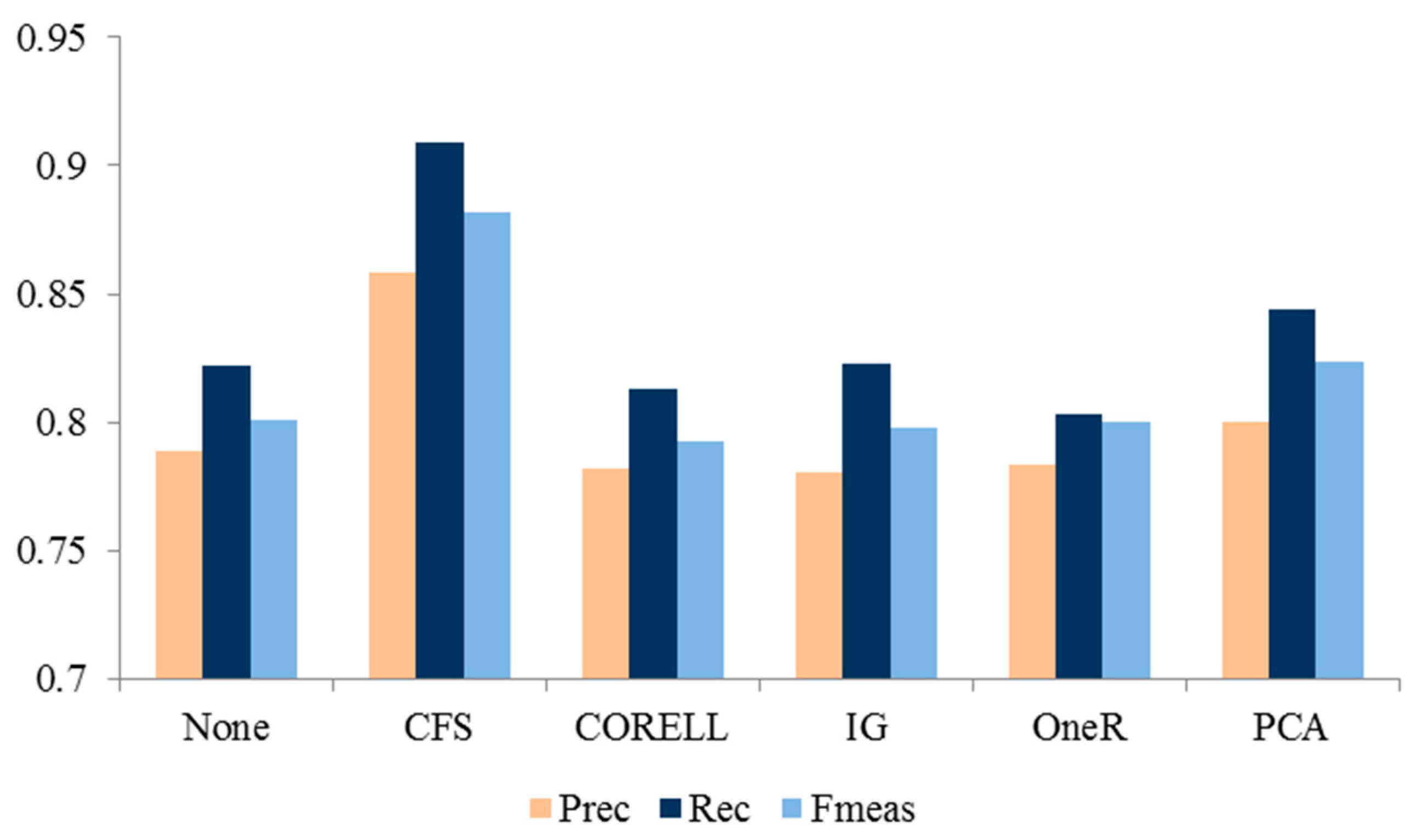
To find the best set of the features, we calculated the average performance of our semantic features for every feature selection method, as presented in
Figure 5. The results of the experiment presented in
Figure 5 confirmed that the best semantic feature set is one that is selected using CFS, i.e., F1–6. Features selected using PCA are in second place. We also highlight that the employed WordNet similarity algorithms have a dominant role in determining the correct sentiment value of a term. Assigning incorrect sentiment values results in extracting contextual features that potentially lead to misclassification.
The limitation of this study is that the performance of the adopted similarity algorithm is not what was expected. As an example, we calculate semantic similarity of love#v#1, hate#v#1, and like#v#1 using
and
. Naturally, we expected that love#v#1 and like#v#1 should have greater semantic similarity than love#v#1 and hate#v#1. Sense of those words can be seen in
Table 10. Yet, the result was not what we wished, as indicated in
Table 11. In the future, we plan to propose a robust similarity algorithm to augment the result of a supervised SA task.
Implications
The implications comprise practical implication for both online marketers and customers, as well as academic implications for the researcher in the field of text processing. The results of study affirm that our proposed SA technique can be employed to generate quantitative ratings from unstructured text data within the product review [
34]. The online marketers could, therefore, apply the technique to foresee consumer satisfaction toward a certain product [
35]. Meanwhile, for potential customers, a big data recommender system could possibly be built accordingly to provide recommendation about the intended product they want to purchase [
2]. The finding of this work could also be beneficial for researchers in the field of text processing to further explore more sophisticated semantic features of words. Previous work has also confirmed the robustness of semantic features [
10].
5. Conclusions
This paper proposed a set of contextual features for SA of product reviews, generated using an extended WSD method. Several ML algorithms were employed to evaluate the performance of the proposed features in a supervised SA task. To find the subset that provides the best performance metrics, several feature selection methods were applied, i.e., CFS, correlation attribute evaluator, information gain attribute evaluator, one-rule attribute evaluator, and principle component analysis.
This study contributes to improving the performance of supervised SA tasks by proposing a method to extract semantic features of the product review dataset. The results of the cross-validated experiment in a supervised environment using several ML algorithms and feature selection methods has confirmed that our proposed semantic features favorably augment the performance of SA in terms of precision, recall, and F-Measure. Another finding of this study summarizes the robustness of semantic feature set selected using CFS and PCA.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}