1. Introduction
Recently, with the rapid development of machine learning and the increasing accumulation of data through the internet, various methods of analyzing data using past techniques have been difficult to apply to modern big data problems, and various data preprocessing techniques have been developed. Among them, feature selection is a process of selecting a set of features (variables, attributes) that meet the purpose of analysis for a high-dimensional dataset having thousands or tens of thousands of features. Analysts can benefit from a selection of features, including better performance of predictive models, and faster and more efficient data analysis. The advantages of feature selection are as follows:
- (a)
reduces the dimension of the dataset and therefore reduces the cost of computing resources
- (b)
improves classification model performance by reducing data noise
- (c)
facilitates data visualization and understanding
The main purpose of the general feature selection is to determine a set of related features that is of interest regarding particular events or phenomena. This feature selection is usually divided into filtering methods and wrapper methods, depending on how the relevant features are searched [
1,
2,
3,
4]. Filter techniques assess the relevance of features by evaluating only the intrinsic properties of the data [
1]. In most cases, relevance scores between each feature and class vector are calculated, and high-scored features are selected. Filter techniques are simple, fast, and easy to understand. However, they do not consider redundancy and interaction between features; they assume features are independent from each other. To capture the interactions between features, wrapper methods embed a classification model within the feature subset evaluation. However, as the space of feature subsets grows exponentially with the number of features, heuristic search methods such as forward search and backward elimination are used to guide the search toward an optimal subset [
1]. Feature selection can be categorized into supervised, unsupervised, and semisupervised [
5,
6,
7]. Supervised feature selection algorithms consider features’ relevance by evaluating their correlation with the class information whereas unsupervised feature selection algorithms may exploit data variance or data distribution in its evaluation of features’ relevance without labels. Semisupervised feature selection algorithms use a small amount of labeled data as additional information to improve unsupervised feature selection [
5]. Minimum Redundancy Maximum Relevance (mRMR) and the proposed method belong to the supervised method.
Ding and Hanchuan [
8,
9] suggested the mRMR measure to reduce redundant features during the feature selection process. They tried to measure both redundancy among features and relevance between features and class vector for a given set of features. Their redundancy and relevance measures are based on mutual information as follows:
In the Equation (1),
x and
y are feature vector or class vector, and
p() represents probability. Suppose
S is a given set of features and
h is a class variable. The redundancy of
S is measured by Equation (2):
In Equation (2), |
S| is the number of features in
S. The relevance of
S is measured by Equation (3):
There are two types of methods to evaluate
S:
In many cases, MIQ (Mutual Information Quotient) shows better performance than MID (Mutual Information Difference). We cannot test all subsets of features S for a given dataset, so the mRMR algorithm adopts a forward search in its implementation. The procedure is described in Algorithm 1.
| Algorithm 1: Forward search |
| /* |
| M: size of feature subset S that we want to get |
| S: set of selected features |
| F: whole set of features of target dataset |
| */ |
| |
| S ← ∅ |
| REPEAT UNTIL |S| < M |
| Find fi∈F that maximize MID/MIQ of S ∪{ fi }; |
| S ← S ∪{ fi }; |
| Remove fi from F; |
| END REPEAT |
| RETURNS; |
In the context of statistics or information theory, the term ‘variable’ is used instead of ‘feature’. We will use ‘variable’ and ‘feature’ as compatible terms according to their context. Mutual information can be only applied on two categorical variables (
x,
y). Therefore, if a dataset has continuous variables, they need to be converted into categorical variables before performing mRMR. The performance of mRMR depends on the quality of redundancy and relevancy measures. If we can improve the measures, we can enhance the performance of mRMR. Several studies [
2,
10,
11] have attempted to improve redundancy measure WI by introducing equations of joint mutual information I(
x1,
x2,..
xn). Auffarth et al. [
12] compared various redundancy and relevance measures, and suggested ‘Fit Criterion’ and ‘Value Difference Metric’ as best measures. These measures, however, can be applied to only two-class datasets. mRMR is widely used in bioinformatics including gene selection and disease diagnosis [
8,
13,
14,
15].
In this study, we propose new measures for redundancy and relevancy. We suggest Pearson’s correlation coefficient [
16] as a redundancy measure and the R-value [
17] as a relevance measure. The R-value and correlation coefficient can be designed for continuous variables whereas mutual information implies categorical variables. We also implement advanced mRMR (AmRMR) using new measures. Details of the new measures and AmRMR are provided in the next section.
2. Materials and Methods
2.1. Pearson’s Correlation Coefficient and R-Value
Pearson’s correlation coefficient is a measure of the linear correlation between two variables
x and
y, and it is defined by Equation (6):
It has a value range [−1, +1]. If an absolute value of the correlation coefficient is near 1, the variables (x, y) have strong correlation. In the context of feature selection, if two features (x, y) represent similar values, then the correlation coefficient of (x, y) will be high; this means that the correlation coefficient can be used to measure redundancy. If two features (a, b) have strong negative correlation, their values will be different. However, from the point of view of information theory, the amount of information in a and b is similar, and they can be considered redundant features.
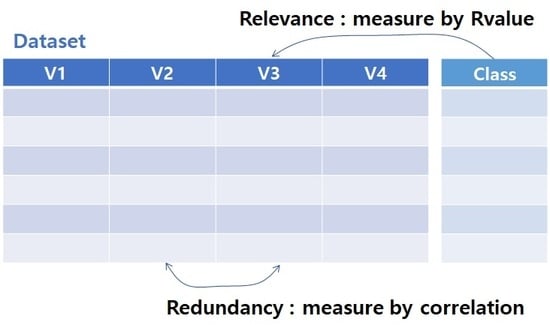
The R-value is proposed as an evaluation measure for datasets [
17,
18]. The motivation for using the R-value is that the quality of the dataset has a profound effect on classification accuracy, and overlapping areas among classes in a dataset have a strong relationship that determines the quality of the dataset. For example, dataset D
1 produces higher classification accuracy than dataset D
2 in
Figure 1. Overlapping area is a region where samples from different classes are gathered closely to one another. If an unknown sample is located in the overlapping area, it is difficult to determine its class label. Therefore, the size of overlapping areas may be a criterion to measure the quality of features or of the entire dataset [
19]. The R-value captures overlapping areas among classes in a dataset. The R-value uses a k-nearest neighbor algorithm to define overlapping areas. If an instance has many neighbors that have different class values, then it may belong to an overlapping area. Suppose
DS is a given dataset,
S is a subset of features, and
C is a class vector. Algorithm 2 describes the procedure to calculate the R-value of
S. The R-value has range [0, 1], and if the R-value of
S is near 1, then
S may produce lower classification accuracy.
| Algorithm 2:Rvalue(S,C) |
| //K: number of nearest neighbor |
| |
| Derive dataset DSs of S from DS; |
| OV ← 0; // |
| N ← number of instances of DSs[]; |
| |
| FOR each instance in DSs[i] DO |
| |
| Find K nearest neighbor values for DSs[i] and store their instance ID to KNV; |
| Count the number of elements in KNV that have class value different from C[i], and add it to OV; |
| |
| END FOR |
| |
| Rvalue ← OV/(K*N); |
| |
| RETURNRvalue; |
2.2. Formal Description of AmRMR
Suppose we evaluate a feature set
S that has
m features. The new relevancy measure
VR for
S is simply defined using the
Rvalue:
If a feature set S produces a high Rvalue, it means that large overlapping areas exist between classes and may cause lower classification accuracy. Therefore, the lower the Rvalue obtained, the better the classification. We define the new relevancy measure as 1 − Rvalue to give a higher score to a lower Rvalue.
To develop a better redundancy measure, we replace mutual information with a correlation coefficient. The original redundancy measure,
WI, is simply the mean of the mutual information for a pair of features in
S. From several experiments, we found that the value of a specific pair of features is more important than the mean of all pairs if the value is high. Therefore, we calculate a maximum (
maxC) and a mean (
meanC) of the correlation coefficient, and choose
maxC as a new redundant measure
WR if
maxC ≥ 0.5, otherwise
WR =
meanC. If the absolute value of correlation coefficient of variables (
x,
y) ≥ 0.5, we accept that they have meaningful correlation. In Equations (8) and (9),
Cor() is a correlation coefficient function,
abs() is an absolute value function, and
max() is a maximum value function.
From the new definition of relevance measure
VR and redundant measure
WR, we redefine
MID and
MIQ as
RVD and
RVQ, respectively.
RVD is similar to
MID. We define
RVQ in a more sophisticated manner. In evaluation function
RVQ,
VR indicates benefit and
WR indicates penalty. Therefore, (
VR/
WR) cannot be larger than
VR. However, 0 ≤
VR,
WR ≤ 1 in our equation, and sometimes (
VR/
WR) >
VR. Therefore, we adjust for this discrepancy in Equation (12).
We have described a new evaluation measure for feature subset S. As we mentioned earlier, we cannot evaluate all instances of S for a given dataset; thus, a heuristic approach is required. We implemented AmRMR based on mRMR code. It applies a forward search to reduce the search space. Algorithm 3 describes the pseudo code for AmRMR. We only consider the case of RVQ.
| Algorithm 3: AmRMR(DS,C,M) |
| /* |
| DS: target dataset |
| C: class vector of DS |
| M: size of feature subset S that we want to get |
| F: set of features in DS |
| */ |
| |
| Find fi ∈ F that produces max(R-value( fi,C)); |
| S ← {fi}; |
| Remove fi from F; |
| |
| REPEAT UNTIL |S| < M |
| max_eval ← 0; |
| max_idx ← 0; |
| FOR each fj ∈ F DO |
| Target ← S ∪ {fi}; |
| Calculate RVQ for Target; |
| IF RVQ > max_eval THEN |
| max_eval ← RVQ; |
| max_idx ← j; |
| END IF |
| END FOR |
| S ← S ∪{fmax_idx}; |
| Remove fj from F; |
| END REPEAT |
| |
| RETURNS; |
3. Result
To compare mRMR and AmRMR algorithms, we collected several types of datasets that have different numbers of features, classes, and instances.
Table 1 summarizes the datasets. We obtained GDS2546, GDS2547, and GDS3715 from the NCBI Gene Expression Omnibus [
20], and arcene and madelon from NPIS2003’s challenge of feature selection [
21], and others were obtained from the UCI Machine Learning Repository [
22]. We took 5–25 features using mRMR and AmRMR, and performed classification tests using k-nearest neighbor (KNN), support vector machine (SVM), C5.0 (C50), and random forest (RF). To avoid an overfitting problem, we adopted a k-fold cross-validation, where k is 10. In the case of arcene and madelon, we took feature set from the training dataset and performed classification tests using validation datasets because they support separated training/validation datasets.
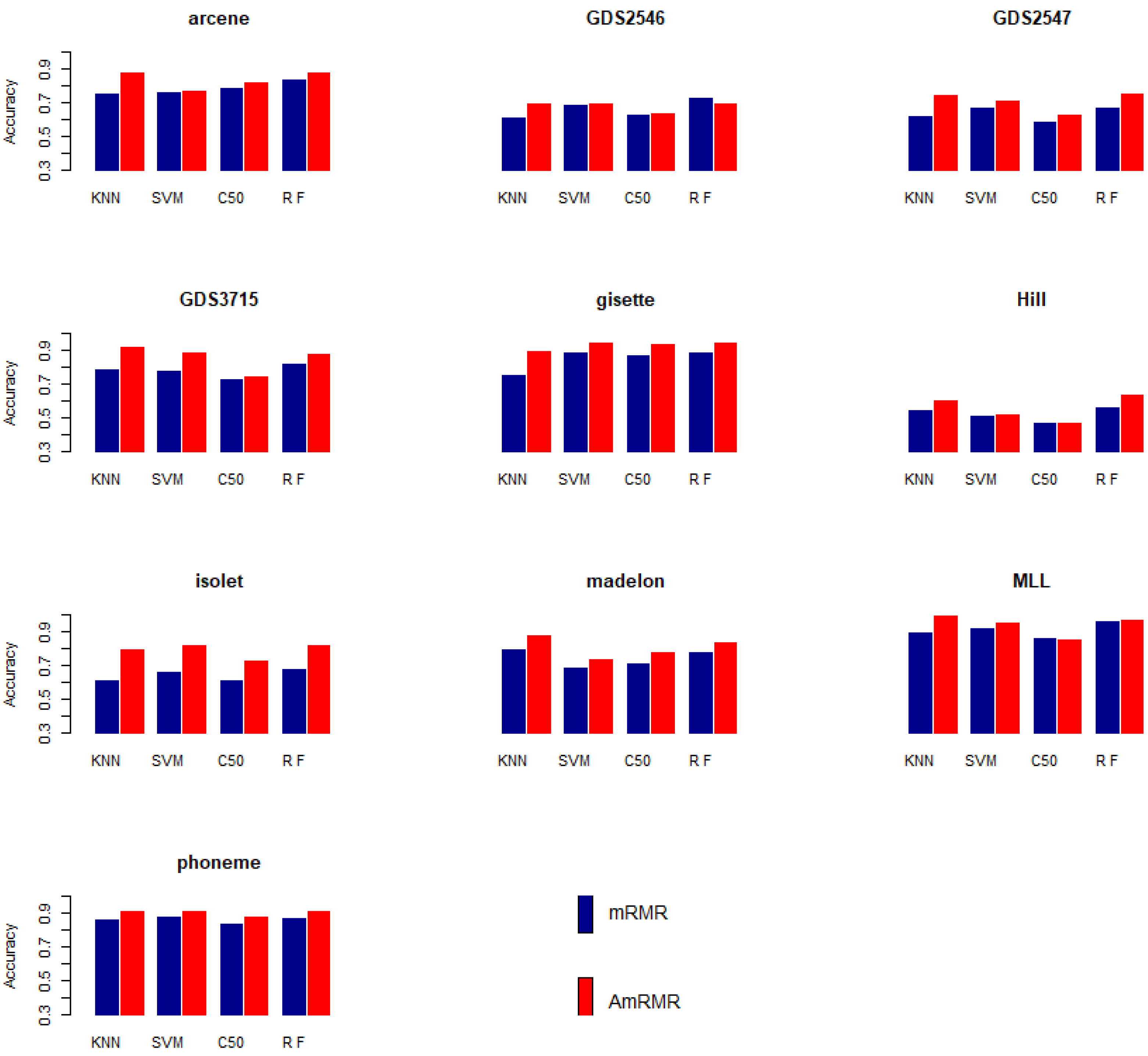
Table 2,
Table 3,
Table 4 and
Table 5 summarize the results. In most of the cases, AmRMR produces better performance than mRMR.
Figure 2 summarizes the classification results in
Table 2,
Table 3,
Table 4 and
Table 5. Each accuracy means average classification accuracy from 5 to 25 features of datasets. Each graph clearly shows AmRMR chooses better features than mRMR.
4. Discussion
In general, the R-value is better than mutual information as a measure of relevance between features and class vector. Mutual information is a statistical measure and it needs categorical values to calculate probability. Therefore, if a target dataset contains continuous values, we need to discretize them before applying mRMR. Information loss is inevitable in discretization. The R-value does not need discretization and is more advantageous than mutual information when a dataset has continuous values. Another weak point of mutual information is that it can calculate I(fi, C) where fi is a feature and C is a class vector, but it cannot calculate I({f1, f2, f3}, C) because it is based on probability. Therefore, it uses (I(f1, C) + I(f2, C) + I(f3, C))/3 to calculate relevance between {f1, f2, f3} and C. This calculation cannot fully capture interactions among {f1, f2, f3}. In contrast, the R-value is a dimensionless distance-based measure so R-value({f1, f2, f3}, C) can be directly calculated.
mRMR and AmRMR output different feature sets from the same dataset, resulting in different classification accuracies.
Table 6 shows a list of 25 features from GDS3715 dataset evaluated by mRMR and AmRMR. In the case of Arcene, there is only one shared feature (9970) between mRMR and AmRMR. In the case of Madelon, there are five shared features. It means that mRMR and AmRMR have different evaluation criteria for feature selection.
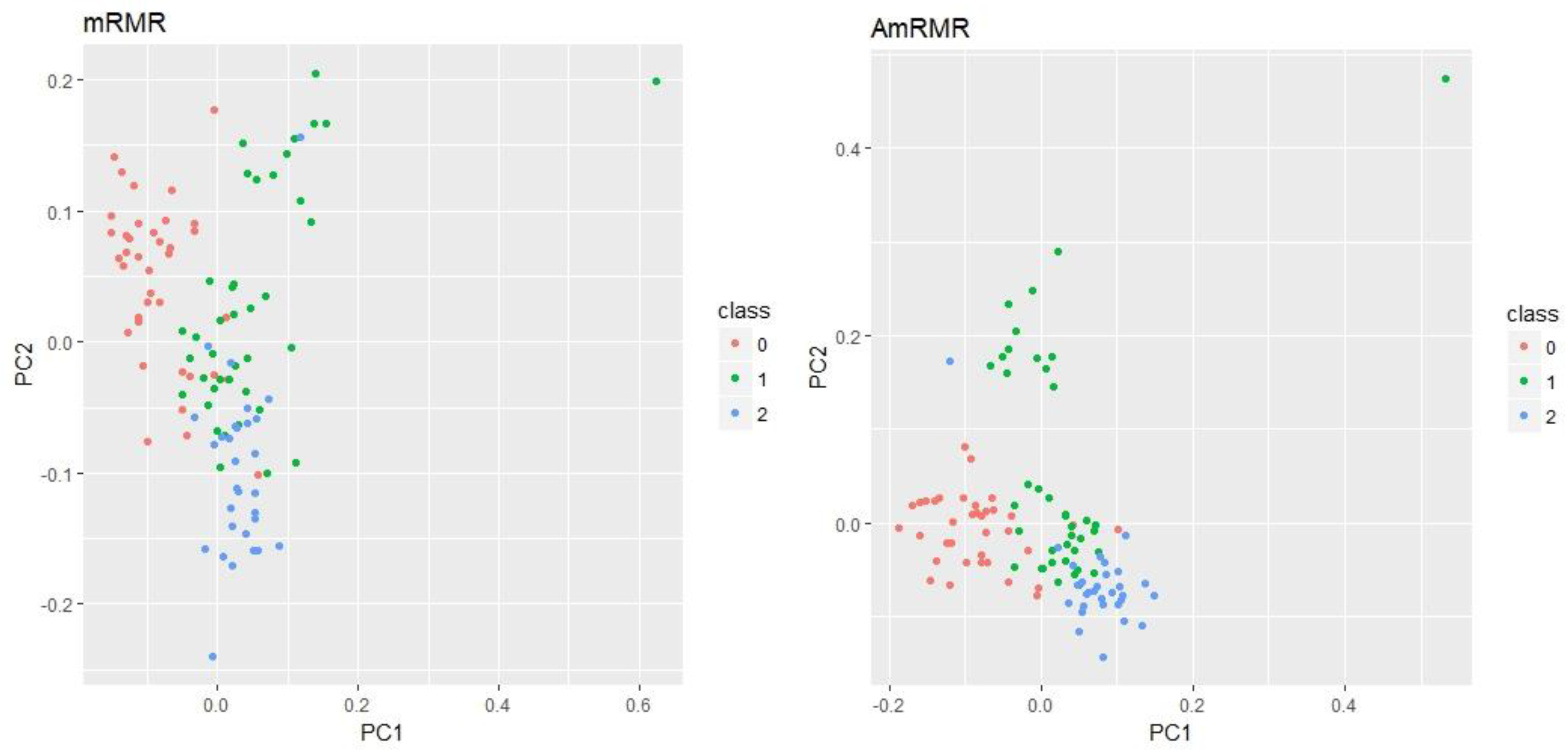
Figure 3 shows PCA (Principal Component Analysis) plots for Arcene and Madelon using five features by mRMR and AmRMR. As we can see, PCA plots of AmRMR show a clearer distribution of class instances than mRMR. It explains why the feature set of AmRMR produces better classification accuracy than the one used by mRMR.
Table 7 shows averages of the improved classification accuracy for 10 datasets. In the four classifiers, 4–10% of accuracies are improved. This result indicates that the proposed new redundancy and relevance measures enhance performance compared to the original mRMR measures. KNN classifier shows remarkably improved result (10.7%). The reason is in the R-value, which is a measure of relevance. Both KNN and R-value are based on k-nearest neighbor. Therefore, a set of features with good R-value may produce good classification accuracy by KNN. The relationship between R-value and KNN is similar to the relationship between the classifier and the feature evaluation measure in the wrapper method.
The proposed new redundancy and relevance measures are tailored to datasets that have continuous values. This means that they are not suitable for datasets that have categorical values. The mutual information measure in the original mRMR method is more suitable for categorical datasets. Nevertheless, AmRMR is useful, because there exist many high-dimensional continuous datasets such as microarray data, diagnosed diseases data, image analysis data, and so on.
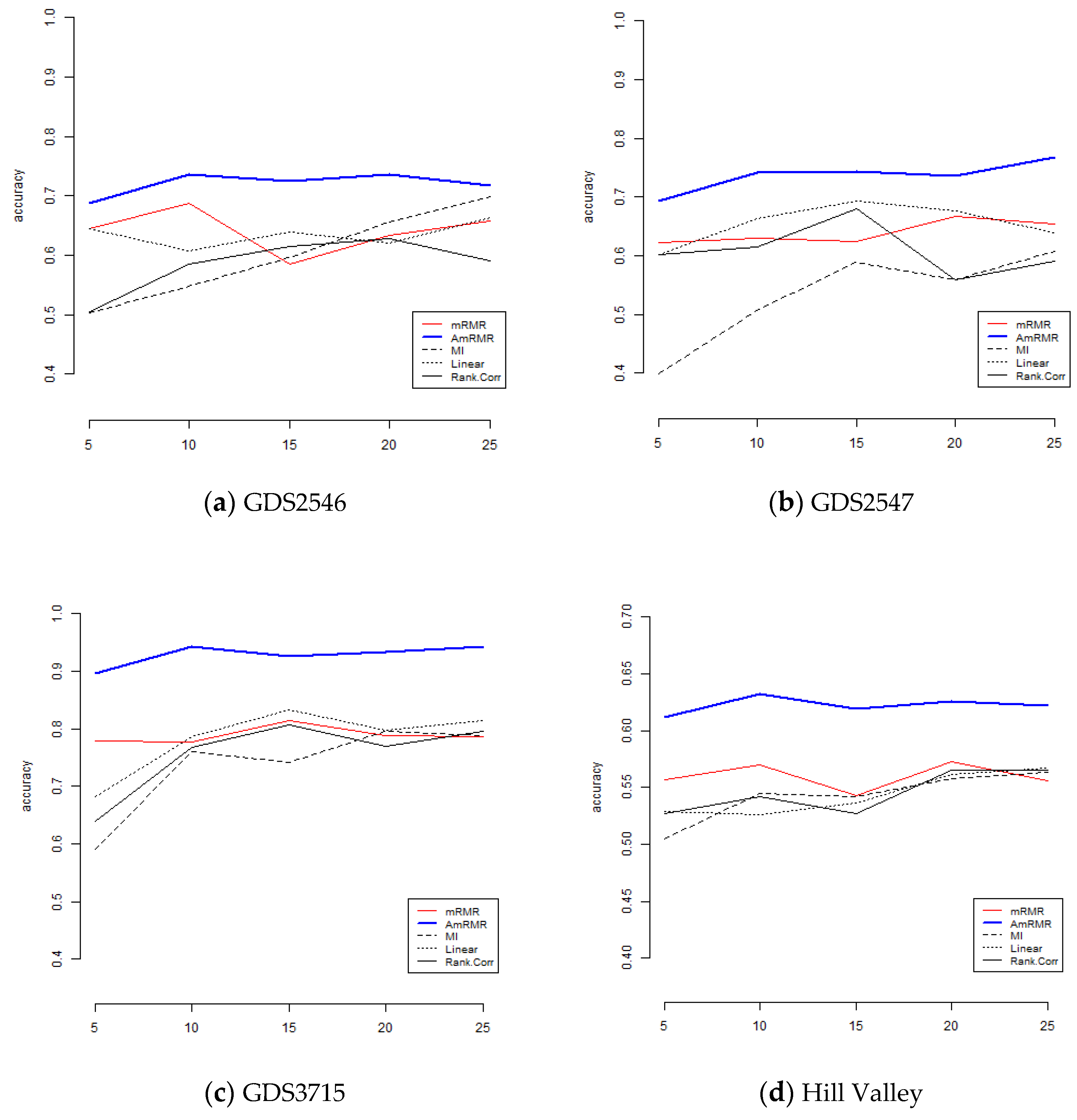
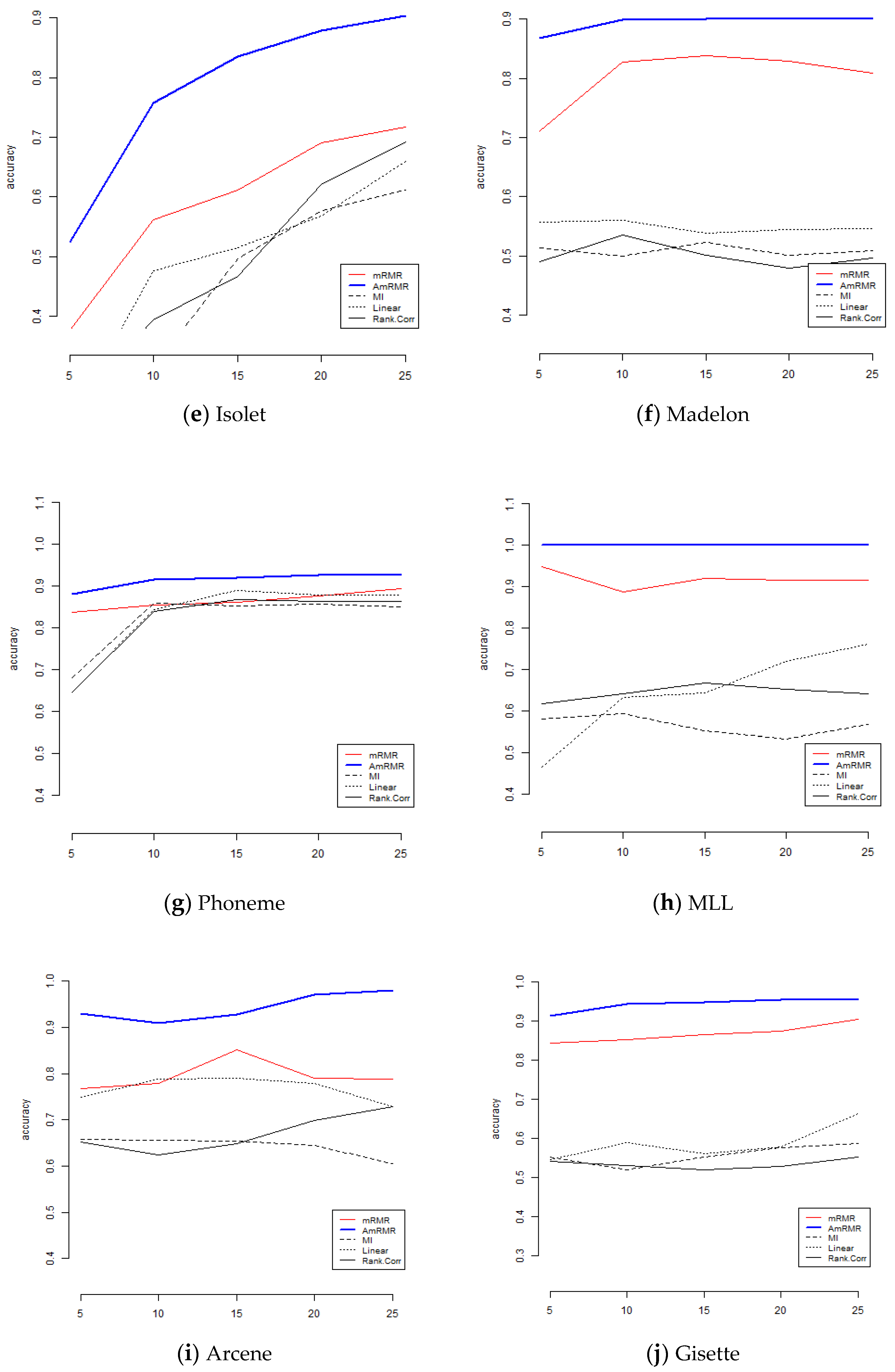
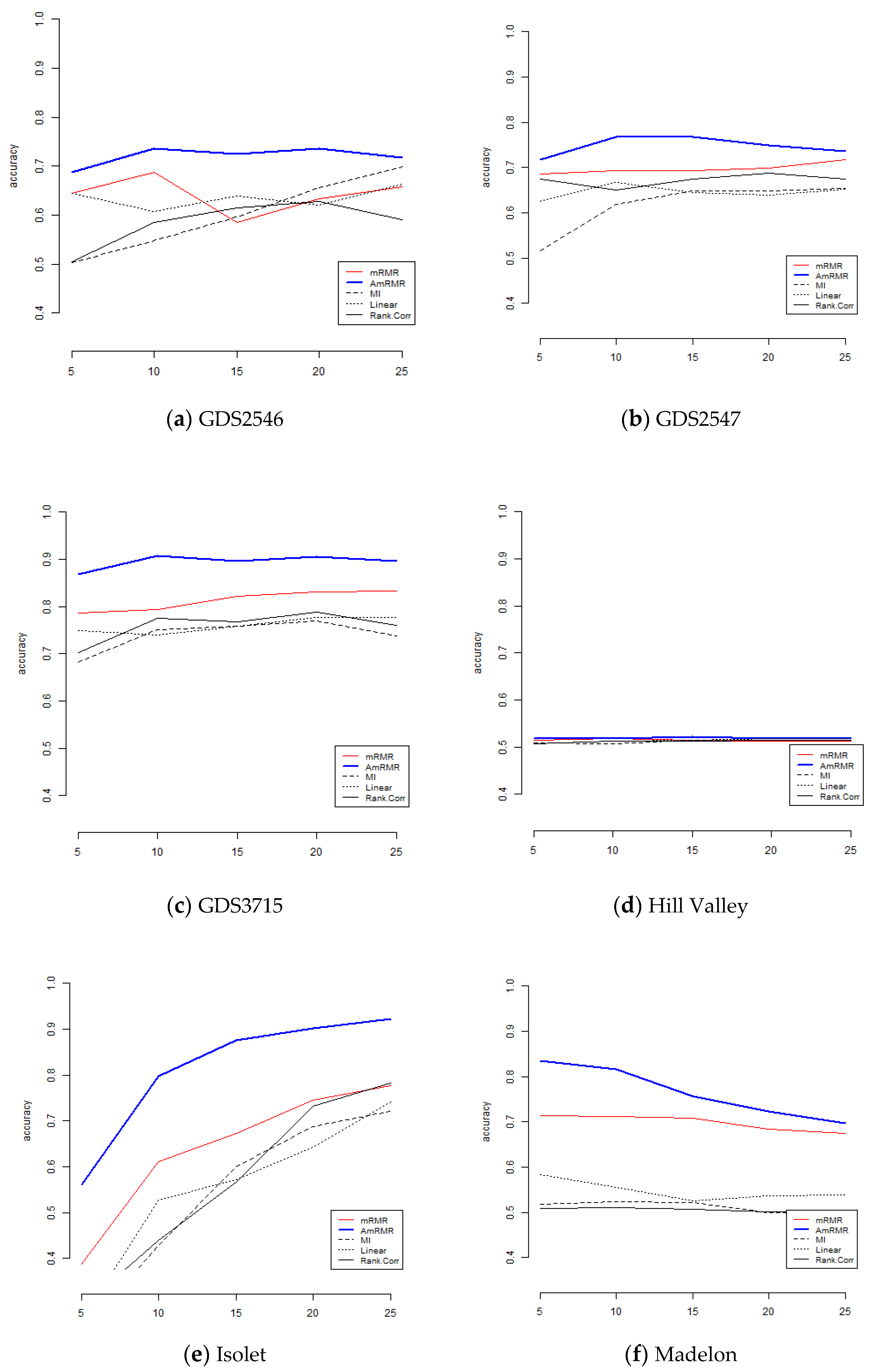
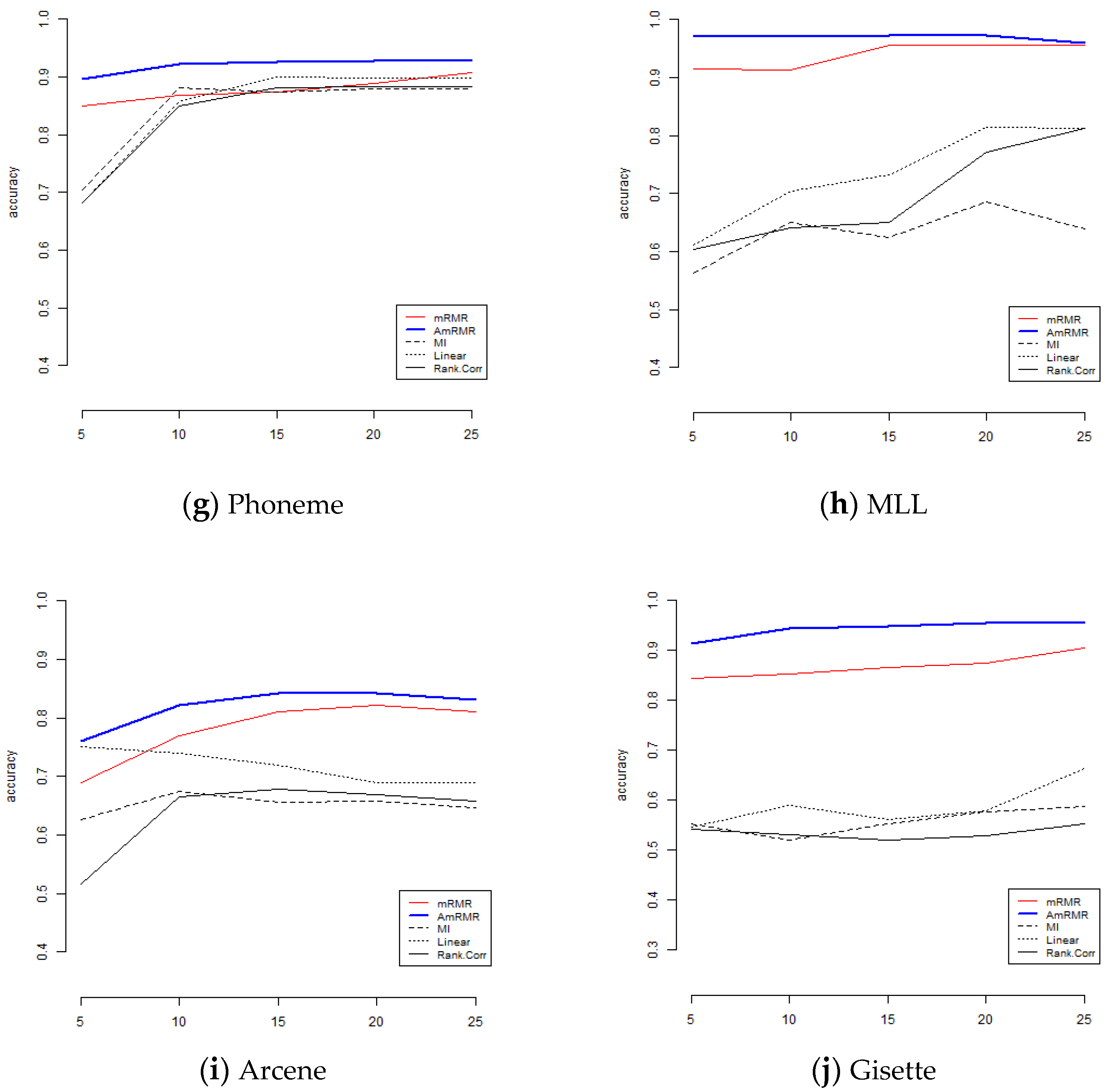
To show the effect of AmRMR, we compare it with three filter feature selection methods such as mutual information (MI), linear correlation (Linear), and rank correlation (Rank.Corr). The condition of comparison is the same as for the case of mRMR. For simplicity, we test KNN and SVM.
Figure 4 and
Figure 5 are the results of comparison. We can see AmRMR produces the highest performance of all the methods.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}