Abstract
In the current study, we were inspired by sparse analysis signal representation theory to propose a novel single-image super-resolution method termed “sparse analysis-based super resolution” (SASR). This study presents and demonstrates mapping between low and high resolution images using a coupled sparse analysis operator learning method to reconstruct high resolution (HR) images. We further show that the proposed method selects more informative high and low resolution (LR) learning patches based on image texture complexity to train high and low resolution operators more efficiently. The coupled high and low resolution operators are used for high resolution image reconstruction at a low computational complexity cost. The experimental results for quantitative criteria peak signal to noise ratio (PSNR), root mean square error (RMSE), structural similarity index (SSIM) and elapsed time, human observation as a qualitative measure, and computational complexity verify the improvements offered by the proposed SASR algorithm.
1. Introduction
1.1. Background
Super resolution (SR) is a remarkable topic related to digital-image processing research. A hardware upgrade is the traditional solution to enhancing resolution, but is expensive in almost all cases. As a software-based technology, SR is an inexpensive and effective image processing technique. Many SR techniques have been proposed, including single-image super-resolution (SISR), which reconstructs a single low resolution (LR) image into a high resolution (HR) output image.
Conventional SISR techniques can be categorized into three classes. The first are interpolation-based techniques [1,2], which are the simplest solutions to the SISR problem. Bi-cubic and bilinear algorithms are the most well-known techniques in this category. Although their ringing and blocking effects are remarkable, simple structure and low complexity implementation are their main advantages. The second category comprises reconstruction-based techniques [3,4,5,6]. They deal with SR as an inverse problem. Their cost function has a general term for adapting HR and LR images and a regularization scheme to ensure better matching between the HR and LR images. Suresh et al. [6] used an adaptive edge detector as a regularization term in order to preserve edges and sharp image details. In a similar approach, Chen et al. [7] used a Tikhonov regularization term. Although most existing efforts in this category have worked well for small magnification factors, their performance decreases at larger magnification factors.
The third category of SISR algorithms is learning-based techniques [8,9,10,11,12,13]. These use a training dataset that includes HR–LR image pairs, and are based on a construction scheme for HR–LR databases called a dictionary. The extracted HR–LR image patches that have common features feed the dictionary. In HR image reconstruction, the LR patch closest to the input LR patch is found in the LR learned database. Its corresponding HR patch is then extracted and the resulting HR patches are merged to reconstruct the desired HR output image. These methods offer improved performance at a wide range of magnification factors and better quality in some image classes.
Training an effective HR–LR dictionary is a crucial stage in such algorithms. The sparse decomposition model has been used to propose SR algorithms based on dictionary learning techniques [10,11,12,13]. The sparse synthesis model assumes that each HR–LR image patch is composed of a few atoms from a learned HR–LR dictionary. The alternative sparse analysis model has been rarely examined for use in the SR field. In this study, we propose sparse analysis HR–LR operator learning and present a new approach to SISR.
1.2. Prior Work
Many SISR techniques have been proposed based on sparse coding and dictionary learning [10,11,12,13,14,15,16]. Yang et al. [11] proposed the first algorithm, which is known as SCSR. Their method was based on the sparse-synthesis model, which relies on the same sparse representation vector for each HR image patch and its corresponding LR patch in the HR–LR dictionary. HR–LR dictionary learning and HR image reconstruction were two main stages of these algorithms. In the first stage, the K-SVD dictionary learning method [17] has been modified for the HR–LR dictionary pair leaning by many authors. K-SVD is a dictionary learning algorithm based on K-means clustering and SVD matrix decomposition. It stands for K-means in addition to singular value decomposition [17].
Yang et al. proposed joint dictionary learning [12] and coupled dictionary learning [10] for the SCSR technique. Zeyde et al. [13] modified the SCSR algorithm to reduce the computational complexity and simplify HR dictionary learning using a single-image scale-up technique (SISU). Zhang et al. [14] proposed a dual dictionary-learning SR algorithm consisting of primary dictionary learning and residual dictionary learning to restore the main frequency detail and the residual frequency detail, respectively.
Chen et al. [7] took into account the differences in the structure of the patches and proposed the classified SR technique for smooth and non-smooth regions. They used bi-cubic interpolation for the smooth regions, and SR was implemented using the dictionary learning method for the non-smooth regions. Dong et al. [18] proposed the non-locally centralized sparse representation (NCSR) model to suppress the sparse coding noise in image restoration algorithms, such as SR [18]. Timofte et al. [19] combined sparse learned dictionaries with the neighbor embedding method and proposed the anchored neighborhood regression (ANR)method. Zhang et al. [20] proposed the adaptive mixed samples ridge regression (AMSRR) to effectively optimize learned dictionaries. Lu et al. [21] utilized the sparse domain selection method and achieved accurate and stable HR image recovery. Naderahmadian et al. modified the dictionary update step in online dictionary learning [22]. Other algorithms that have been proposed include classified dictionaries [23], sub-dictionary learning [24], and solo dictionary learning [25].
These SR algorithms are based on the assumption that each patch of the image can be restored as a linear combination of a few columns from a trained over-complete dictionary. Recently, a different model, sparse analysis, has been proposed [26] as a powerful alternative model for signal processing problems. Extensive research has focused on the high competency of the sparse analysis model [27,28,29]. Ning et al. [30] proposed an SR algorithm using iterative refinement and the analysis sparsity model in the Lab color space. Hawe et al. [31] proposed an algorithm for learning an analysis operator based on lp-norm minimization on the set of full rank matrices and implementation of the conjugate gradient method on manifolds. They considered the importance of suitable sparse analysis operators on output image quality. Nevertheless, it seems that the sparse analysis model has more potential for SR problems and requires further attention.
1.3. Contribution
Although synthesis-based sparse HR–LR dictionary learning methods have been studied extensively in SR algorithms, the analysis-based sparse model is an alternative model. We propose a coupled HR–LR sparse analysis operator that exploits mapping between HR–LR image patches. In addition to the use of patch-ordering total variation measures, we propose a novel sparse analysis operator learning method in the patch selection phase. In this way, the HR–LR patch pairs are trained based on image texture complexity, resulting in more-efficient HR–LR sparse analysis operators being trained.
We show that the proposed approach improves the quality of reconstructed HR images, as well as reducing the complexity of dictionary learning. Our experimental results show that the proposed method is comparable to state-of-the-art methods, both qualitatively and quantitatively. The main contributions of this paper are:
- a novel SR technique is proposed for mapping between HR–LR patches based on HR–LR sparse analysis operators;
- a new sparse operator learning method is proposed in the patch selection stage that considers image texture complexity;
- the computational complexity of the algorithm is less than in previous approaches;
- the proposed SASR results perform better in comparison with state-of-the-art and classic interpolation-based methods (bicubic SR, SCSR [12], SISU [13], ANR [19], GR [19], NE + LS [19] and GOAL [31], AMSRR [20], and SDS [21]).
1.4. Organization
The remainder of the paper is organized as follows. The proposed sparse analysis SR method is described in detail in Section 2. Section 3 presents experiments on the performance of the proposed SASR method in comparison with the bi-cubic SR, SCSR [12], SISU [13], ANR [19], GR [19], NE + LS [19], GOAL [31], AMSRR [20], and SDS [21] methods. The paper is concluded in Section 4.
2. Proposed Sparse Analysis-Based SR Algorithm (SASR)
This work aims at establishing a SR algorithm based on sparse analysis theory. We initially modify the sparse analysis operator learning algorithm by selection of an informative patch from learning images and then propose a novel SR algorithm based on coupled sparse analysis operators.
2.1. Sparse Analysis Model
In the conventional sparse synthesis model, image patch is said to be “k-sparse” if it can be represented by a linear combination of k atoms from the over-complete dictionary as
where is the sparse synthesis representation of .
In the sparse analysis model, as an alternative model to the sparse synthesis model, an image patch is said to be l-cosparse if it produces a sparse vector when it is analyzed with a sparse analysis operator :
While is square and invertible, the two models are equivalent. In contrast, for a long time, the over-complete case of and were confused and were even considered to be equivalent. Elad et al. [26] considered the algebraic similarity between the two models, and showed that there is a surprising difference between them for over-complete dictionaries and operators.
Based on the assumption that an image patch can be restored as a linear combination of atoms from an over-complete dictionary, many algorithms have been proposed that aim to solve inverse problems regularized with the sparse-synthesis model. Given the observation that , where is a linear observation matrix, the optimization formulation of these two inverse problems can be represented as
and
Elad et al. [26] showed that if (the pseudo-inverse of ), the solutions of both the synthesis and analysis models are substantially different in the general over-complete case. In addition, they showed that the two formulations refer to very different models, and the analysis is much richer and may lead to better performance in various applications.
2.2. Image SR Using Coupled Sparse Analysis Operators
Sparsity has been used as an effective regulator for the ill-posed SISR problem. The core of traditional sparse representation-based SR is employment of the same sparse synthesis vector for corresponding HR and LR patches over the HR and LR learned dictionaries. Whereas sparse analysis has been successfully applied to many inverse problems in signal processing, we applied it to the SR problem. In our setting, we work with two coupled sparse analysis operators: for high resolution patches, and for low resolution ones. Because the basic assumption is the same sparse analysis vector for both HR and LR patches with respect to their analysis operators, the sparse analysis vector for LR patches is used directly to recover the corresponding high resolution patches for the HR analysis operator. Learning the HR–LR patch pair selection is the first step in the operator learning phase, and learning patch pair selection plays an important role in such methods. In this way, all patches extracted from each image are ordered based on structural similarity using a greedy algorithm. Next, the total variation measure is used to evaluate texture complexity and select a number of informative patches in each learning image. Figure 1 summarizes the proposed SASR algorithm.
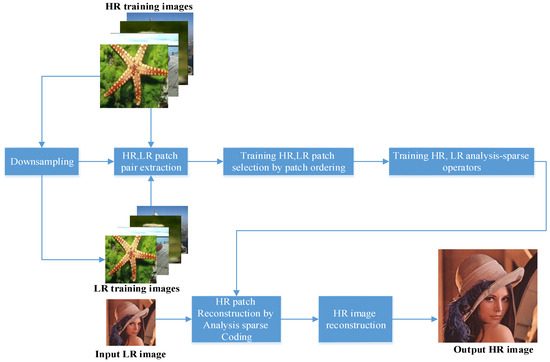
Figure 1.
Architecture of proposed sparse analysis-based super-resolution algorithm.
2.2.1. Coupled Sparse Analysis Operator Learning
(a) Patch Selection Based on Ordering
Let Y be an image of size and indicate the kth overlapping patch having size . In the first stage, we extract all possible patches from the image. Assuming that each patch is a point in space , the goal is to reorder the patches so as to minimize the total variance (TV) measure:
The smoothness of the ordered patches can be measured using the TV. Minimizing the results in the ordering of all extracted patches based on a structural similarity measure. We chose a simple approximate solution, which was to start from a random point and then continue from each patch to its nearest neighbor with a Euclidean distance similarity measure. TV minimization of patches using the proposed patch ordering is summarized in Algorithm 1.
| Algorithm 1: Proposed patch ordering based on structural similarity |
| Task: Reorder the image patches Parameters: We are given image patches and distance function ω. Let be the set of indices of all overlapping patches extracted from the image. Initialization: Choose random index . Set , . Main iteration: For Find as the nearest neighbor to If and Set Otherwise: Find as the nearest neighbor to such that . Set . Output: Set Ω holds the proposed patch-based patch ordering. |
We then calculate the total variation of and using Equation (5). After calculating the TV measure for each image in the database, we assign the number of patches for each image proportional to its TV to the total TV of images as
where M is the total number of training patches and is the number of patches extracted from the ith image. After this step, we uniformly choose patches from each ordered image patch. Figure 2 shows examples of training images, and the results for the calculated TV measure, sampling step, and number of patches extracted for each image are shown in Table 1.

Figure 2.
Examples of training images used for patch selection. (a) Penguin, (b) boats, (c) old woman, (d) ladybug, and (e) girls.

Table 1.
Total variance (TV) measure, sampling step, and number of extracted patches for sample images in Figure 2 (total number of training patches is 50,000).
(b) Coupled Sparse Analysis Operator Learning
In this section, we introduce the proposed sparse analysis operator learning method, which trains the coupled and operators for the HR and LR patches. Sample set contains training image patch pairs , where are the selected high resolution patches and are the corresponding low resolution patches. At this stage, the main goal is to learn coupled sparse analysis operators , so that the sparse analysis vector of each high resolution patch is the same as the sparse analysis vector of the corresponding low resolution patch:
The analysis K-SVD algorithm is applied to train the low resolution sparse analysis operator . In this operator training algorithm, Robinstein et al. [25] supposed that given training set as K clean vectorized patches of the LR images, is a noisy version of the patches contaminated with additive zero-mean white Gaussian noise. They proposed the analysis K-SVD algorithm to find which forces the sparse analysis vector to be sparse for each . They formulated an optimization task for the learning process as:
Considering the constraint that each HR patch and its corresponding LR patch has the same sparse analysis vector with respect to the HR and LR sparse analysis operators, the LR training patches are analyzed by to obtain the sparse analysis vectors by . Therefore, for high resolution sparse analysis operator , we should have:
The solution of the problem is given by the following pseudo-inverse expression:
where matrix is constructed with the selected high resolution training patches as its columns, and A contains sparse analysis vector for paired low resolution patches over as its columns.
2.2.2. HR Image Reconstruction
Given LR image , we establish an SR sparse analysis method for reconstructing HR image , where is the magnification scale. First, we extract all LR patches by raster scanning , where is the size of the LR patches. Because sparse analysis vectors for high and low resolution patch pairs must have the same corresponding operators, we have:
In order to restore from , the LR sparse analysis operator is first applied to the LR patch to obtain vector . Next, is applied to the HR sparse analysis operator to obtain HR image patch using . After recovering all the HR image patches, a complete HR image can be constructed by merging all these HR image patches by averaging the overlapping regions between adjacent patches. Because of the noise, and according to Equation (11), the reconstructed HR image may not exactly satisfy the observation model between the HR and LR images (), where is a linear observation model for downsampling and blurring. In order to enhance the output HR image, the regression output is refined as follows:
where is the initial reconstructed HR image, the first term represents the reconstruction error and the second term recovers an image close to . Using gradient descent, optimal solution can be obtained as the final recovered HR image [12] as
where is the estimate of the high-resolution image after the t-th iteration and is the step size of the gradient descent.
3. Experimental Results
3.1. Test Setup
To evaluate the efficiency of the proposed SASR algorithm, it was compared with the following classic and state-of-the-art methods: bicubic interpolation, SCSR [12], SISU [13], ANR [19], GR [19], NE + LS [19] GOAL [31], AMSRR [20], and SDS [21]. All the source codes of the competing methods are publicly available on their authors’ webpages. For fair comparison, care was taken to ensure that the parameters used in the methods were similar. Because the first step in all learning-based SR algorithms is to select a dataset, all algorithms were tested on the same dataset. The HR and LR sparse analysis operators were trained using the dataset proposed by Yang et al. [12] (http://www.ifp.illinois.edu/~jyang29/). These HR images were down-sampled by bicubic interpolation to generate HR–LR image pairs for the training phase. To test the proposed algorithm, we took two standard datasets, SET14 (number of images = 14) and SET5 (number if images = 5), as testing images, which are two commonly used benchmark datasets in super-resolution literature. These images contain a nice mixture of details, flat regions, shading and texture. All testing was performed at a 3× magnification factor to validate the effectiveness of the proposed method. For patch selection in both the training and testing phases, our algorithm used 3 × 3 HR–LR patches with a two-pixel overlap.
All of the experiments were performed using MATLAB R2014a on an Intel (R) Core (TM) i5-M 460 @2.53 GHz machine with 4 GB of RAM.
The performance of the proposed algorithm was evaluated for root mean square error (RMSE), peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and running time between the luminance channels of the original and restored images. PSNR is defined as
where X is the original HR image of size , is reconstructed HR image, and ) denotes the mean square error between , which is defined as
RMSE is the square root of the MSE of Equation (14). Although, these two criteria have been very often used by SR researchers, they do not represent the human visual system very well. Therefore, another form of measure, such as structural similarity measure (SSIM), has also been used in SR algorithms. SSIM measure is defined as:
where and are constants, and are the mean of and , respectively, and and are the standard deviation of original and reconstructed images, respectively.
Because the human visual system is more sensitive to changes in the luminance channel, an LR color image first was transformed to YCbCr color space, then all SR methods were only applied to the luminance channel. The chromatic channels were reconstructed by bicubic interpolation, as is commonly performed in SR algorithms.
3.2. Results
We quantitatively and qualitatively evaluated the performance of the proposed method in comparison with bicubic interpolation, the SCSR [12], SISU [13], ANR [19], GR [19], NE + LS [19], GOAL [29], AMSRR [20], and SDS [21] methods. The sparse representation-based methods (SCSR [12] SISU [13]) and regression-based methods (ANR [19], GR [19], and NE + LS [19]) were used as for baseline methods. Three methods (AMSRR [20], SDS [21], and GOAL [29]) were used as for the state-of-the-art methods. Table 2, Table 3 and Table 4 show the quantitative comparison for the PSNR, RMSE, and SSIM measures. These tables reveal that the proposed SASR method can possess better performance compared with some state-of-the-art methods, and gained average improvements of 0.07 dB in PSNR, 0.14 in RMSE, and 0.0007 in the SSIM criteria.
Table 2.
PSNR (dB) of the reconstructed HR images with a magnification factor of m = 3.
Table 3.
RMSE of the reconstructed HR images with a magnification factor of m = 3.
Table 4.
SSIM of the reconstructed HR images with a magnification factor of m = 3.
Figure 3 and Figure 4 show the effectiveness of the proposed method. Figure 3 and Figure 4 present the image super-resolution results of all methods for the “Butterfly” and “Face” images at 3× magnification. For more precise comparison, specific zoomed scenes are provided. We observed that the bicubic and GR [19] methods tended to generate blocking and ringing artifacts. Although the SCSR [12], SISU [13], ANR [19], NE + LS [19], GOAL [29], AMSRR [20], and SDS [21] methods improved the visual details and edges, it can be seen that the proposed SASR algorithm had more acceptable performance when reconstructing sharp edges, and showed more detail compared to the other algorithms.
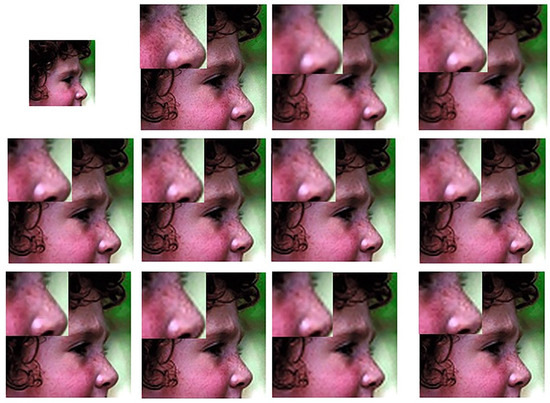
Figure 3.
SR results of the “Face” image with a magnification factor of 3X. Images from left to right and top to bottom: LR input image, original HR image, bicubic, SCSR [12], SISU [13], GR [19], ANR [19], NE + LS [19], GOAL [29], AMSRR [20], SDS [21], and our proposed SASR.

Figure 4.
SR results of the “Butterfly” image with a magnification factor of 3X. Images from left to right and top to bottom: LR input image, original HR image, bicubic, SCSR [12], SISU [13], GR [19], ANR [19], NE + LS [19]), GOAL [29], AMSRR [20], SDS [21], and our proposed SASR.
Although the objective quality of a few HR images obtained by the proposed method had a slight advantage over the other methods, the average quantitative evaluations of the proposed method are competitive to those of the others.
According to Table 5, the elapsed time of our algorithm is comparable with GR [19] and ANR [19], while its performance was much faster than other compared algorithms. Although in terms of elapsed time our proposed algorithm was not the fastest method, it achieved satisfactory results. According to Table 5, in terms of elapsed time, the proposed method was faster than SCSR [12], SISU [13], NE + LS [19], and AMSRR [20], while it was comparable with GR [19].
Table 5.
Average elapsed time of the reconstructed HR images with a magnification factor of m = 3.
To compare the computational cost of the proposed and SCSR [12] methods, an image patch size of was used for LR patches, and HR patches were obtained by implementing four feature extraction filters in order to extract high frequency details. Accordingly, after vectorization, LR patches with dimensions of and HR patches with dimensions of were obtained, leading to an LR dictionary with dimensions of and an HR dictionary with dimensions of . In the SISU method proposed by Zeyde et al. [13], the HR patch dimension decreased from to after implementing a dimension reduction algorithm. The ANR [19], GR [19], and NE + LS [19] methods followed Zeyde et al. [13].
GOAL [29] is based on a sparse analysis model and uses a geometric conjugate gradient method on the oblique manifold to solve the optimization task. The performance of the analysis approach can be further increased by learning the particular operator with regard to the specific problem or employing a specialized training set [31]. However, in the proposed SASR method, selected training patches were obtained from the patches having a size of , and they were ordered by the proposed simple algorithm, leading to LR and HR dictionaries with dimensions of . Therefore, the structure of the proposed SASR method was simpler in the learning phase. Moreover, because the patch extraction method should be the same at the learning and reconstruction phases, this difference can also be observed in the HR image reconstruction stage. In the reconstruction phase, other methods have used greedy algorithms, such as matching pursuit (MP) and orthogonal matching pursuit (OMP), to determine the sparse representation vectors for each low resolution image patch. In the proposed SASR method, sparse analysis vectors for LR image patches were obtained through two simple operations: calculation of the pseudo-inverse matrix and multiplication. Total evaluation for the quantitative criteria (PSNR, RMSE, SSIM), human observation as a qualitative measure, and elapsed time for computational complexity comparison verify the improvement of the proposed SASR algorithm.
4. Conclusions
We proposed a single-image super-resolution algorithm based on recent sparse analysis signal representation with coupled HR–LR sparse analysis operator learning. We showed that conventional sparse synthesis SR methods can be reformulated into sparse analysis operators. The proposed method, SASR, uses a new patch extraction method from the learning dataset with patch ordering and total variation measures. The proposed approach uses a new sparse matrix for analysis of the image, in contrast with other sparse super-resolution approaches, which are all synthesis-based approaches.
The experimental results show that the performance of the proposed algorithm is comparable to that of state-of the-art algorithms in terms of quantitative metrics and visual quality. Although in terms of elapsed time our proposed algorithm is not the fastest method, it achieves satisfactory results.
Although the performance improvement was revealed in the average results of empirical evaluation of our proposed method, there is a high potential for extending the theory of this approach in SR applications. In addition, the proposed method has the potential to be applied to de-noising and de-blurring problems. Further study will focus on optimizing the sparse analysis operator training process to improve reconstruction efficiency.
Author Contributions
V.A contributed conceptualizing, methodology and software, F.R and R.A. did validation and visualization.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Dai, S.; Han, M.; Xu, W.; Wu, Y.; Gong, Y. Soft edge smoothness prior for alpha channel super resolution. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Sun, J.; Xu, Z.; Shum, H. Image super-resolution using gradient profile prior. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Farsiu, S.; Robinson, M.D.; Elad, M.; Milanfar, P. Fast and robust multi-frame super resolution. IEEE Trans. Image Process. 2004, 13, 1327–1344. [Google Scholar] [CrossRef] [PubMed]
- Hardie, R.C.; Barnard, K.J.; Armstrong, E.E. Joint MAP registration and high-resolution image estimation using a sequence of under sampled images. IEEE Trans. Image Process. 1997, 6, 1621–1633. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Hu, R.; Han, Z.; Lu, T. Efficient single image super-resolution via graph-constrained least squares regression. Multimed. Tools Appl. 2014, 72, 2573–2596. [Google Scholar] [CrossRef]
- Suresh, K.V.; Rajagopalan, A. A discontinuity adaptive method for super-resolution of license plates. In Computer Vision, Graphics and Image Processing; Kalra, P.K., Peleg, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2006; Volume 4338, pp. 25–34. [Google Scholar]
- Chen, H.; Jiang, B.; Chen, B. Image super-resolution based on patches structure. In Proceedings of the 2011 IEEE International Congress Image and Signal Processing, Shanghai, China, 15–17 October 2011; pp. 1076–1080. [Google Scholar]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef]
- Gao, X.; Zhang, K.; Tao, D.; Li, X. Image super-resolution with sparse neighbor embedding. IEEE Trans. Image Process. 2012, 21, 3194–3205. [Google Scholar] [PubMed]
- Yang, J.; Wang, Z.; Lin, Z.; Cohen, S.; Huang, T. Coupled dictionary training for image super-resolution. IEEE Trans. Image Process. 2012, 21, 3467–3478. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the 7th International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2010; Volume 6920, pp. 711–730. [Google Scholar]
- Zhang, J.; Zhao, C.; Xiong, R.; Ma, S. Image super-resolution via dual-dictionary learning and sparse representation. In Proceedings of the 2012 IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Korea, 20–23 May 2012; pp. 1688–1691. [Google Scholar]
- Yeganli, F.; Nazzal, M.; Unal, M.; Ozkaramanli, H. Image super-resolution via sparse representation over coupled dictionary learning based on patch sharpness. In Proceedings of the 2012 IEEE European Modelling Symposium, Pisa, Italy, 21–23 October 2014; pp. 203–208. [Google Scholar]
- Wang, S.; Zhang, L.; Liang, Y.; Pan, Q. Semi-coupled dictionary learning with applications to image super-resolution and photo-sketch synthesis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2216–2223. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. A K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, L.; Shi, G.; LI, X. Nonlocally centralized sparse representation for image restoration. IEEE Trans. Image Process. 2013, 22, 1620–1630. [Google Scholar] [CrossRef] [PubMed]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored neighborhood regression for fast example-based super-resolution. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1920–1927. [Google Scholar]
- Zhang, H.; Liu, W.; Liu, J.; Liu, C.; Shi, C. Sparse representation and adaptive mixed samples regression for single image super-resolution. Signal Process Image Commun. 2018, 67, 79–89. [Google Scholar] [CrossRef]
- Lu, W.; Sun, H.; Wang, R.; He, L.; Jou, M.; Syu, S.; Li, J. Single image super resolution based on sparse domain selection. Neurocomputing 2017, 269, 180–187. [Google Scholar] [CrossRef]
- Naderahmadian, Y.; Beheshti, S.; Tinati, M.A. Correlation based online dictionary learning algorithm. IEEE Trans. Signal Process. 2016, 64, 592–602. [Google Scholar] [CrossRef]
- Zhu, X.; Tao, J.; Li, B.; Chen, X.; Li, Q. A novel image super-resolution reconstruction method based on sparse representation using classified dictionaries. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 776–780. [Google Scholar]
- Yang, W.; Yuan, T.; Wang, W.; Zhao, F.; Liao, Q. Single-Image Super-Resolution by Subdictionary Coding and Kernel Regression. IEEE Trans. Syst. Man Cybern. 2017, 47, 2478–2488. [Google Scholar] [CrossRef]
- Juefei-Xu, F.; Savvides, M. Single face image super-resolution via solo dictionary learning. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 2239–2243. [Google Scholar]
- Elad, M.; Milanfar, P.; Rubinstein, R. Analysis versus synthesis in signal priors. Inverse Problems 2007, 23, 947–953. [Google Scholar] [CrossRef]
- Rubinstein, R.; Peleg, T.; Elad, M. Analysis K-SVD: A dictionary-learning algorithm for the analysis sparse model. IEEE Trans. Signal Process. 2013, 61, 661–677. [Google Scholar] [CrossRef]
- Dong, J.; Wang, W.; Dai, W. Analysis SimCO algorithms for sparse analysis model based dictionary learning. IEEE Trans. Signal Process. 2016, 64, 417–431. [Google Scholar] [CrossRef]
- Seibert, M.; Wörmann, J.; Gribonval, R. Learning co-sparse analysis operators with separable structures. IEEE Trans. Signal Process. 2016, 64, 120–130. [Google Scholar] [CrossRef]
- Ning, Q.; Chen, K.; Yi, L. Image super-resolution via analysis sparse prior. IEEE Signal Process. Letters 2013, 20, 399–402. [Google Scholar] [CrossRef]
- Hawe, S.; Kleinsteuber, M.; Diepold, K. Analysis operator learning and its application to image reconstruction. IEEE Trans. Image Process. 2013, 22, 2138–2150. [Google Scholar] [CrossRef] [PubMed]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).