Robust Cochlear-Model-Based Speech Recognition


Abstract
1. Introduction
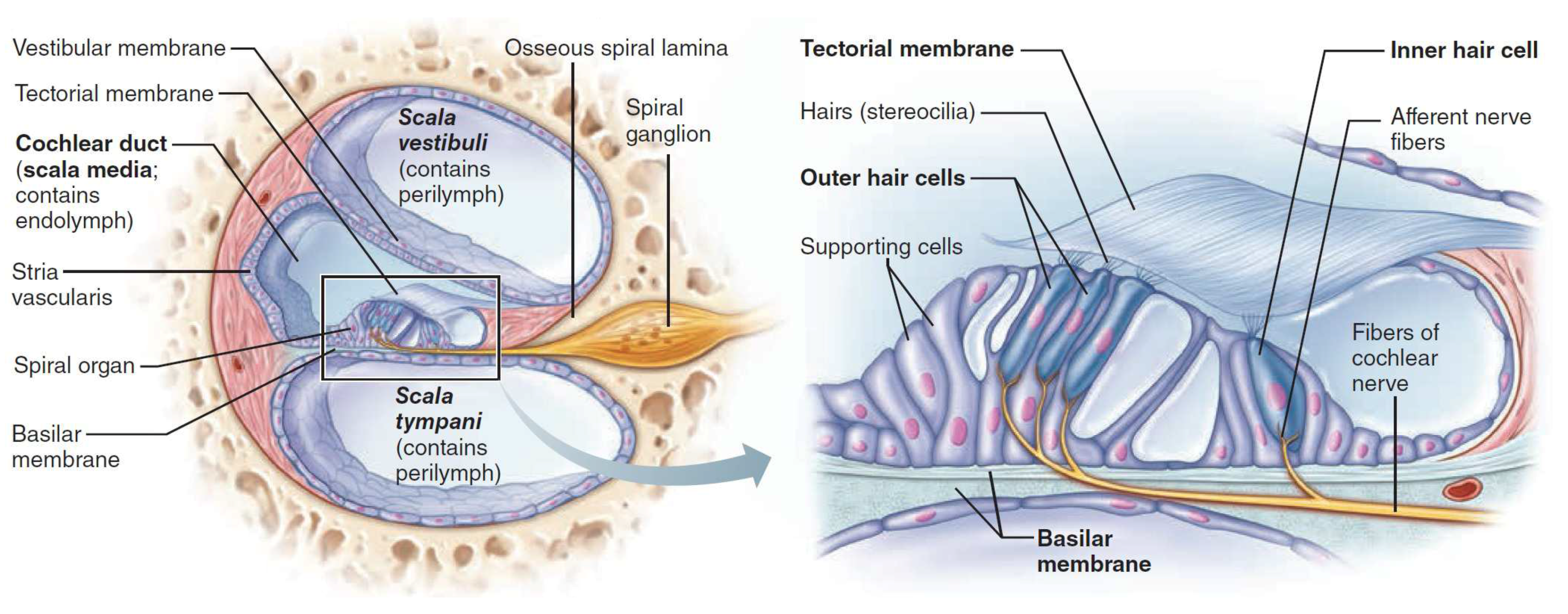
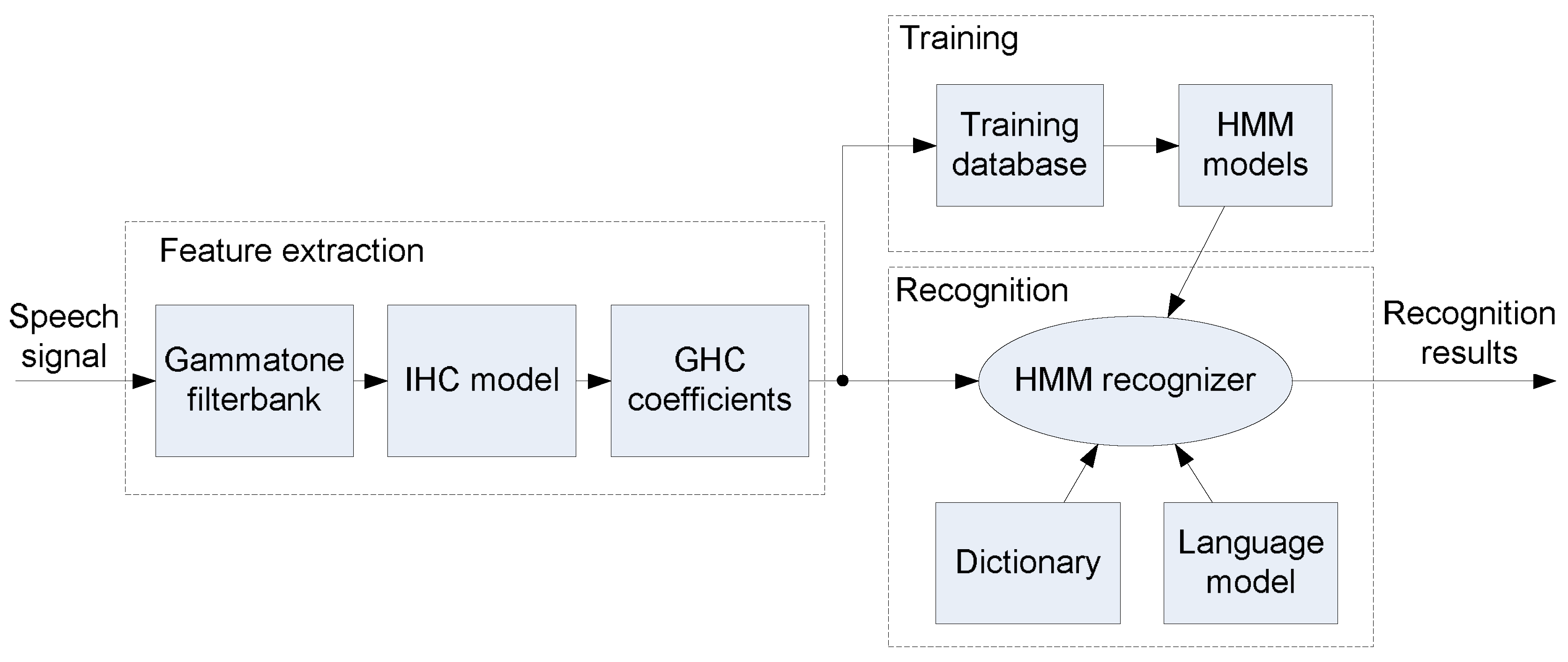
2. Cochlear-Based Processing for ASR
2.1. Gammatone Filterbank
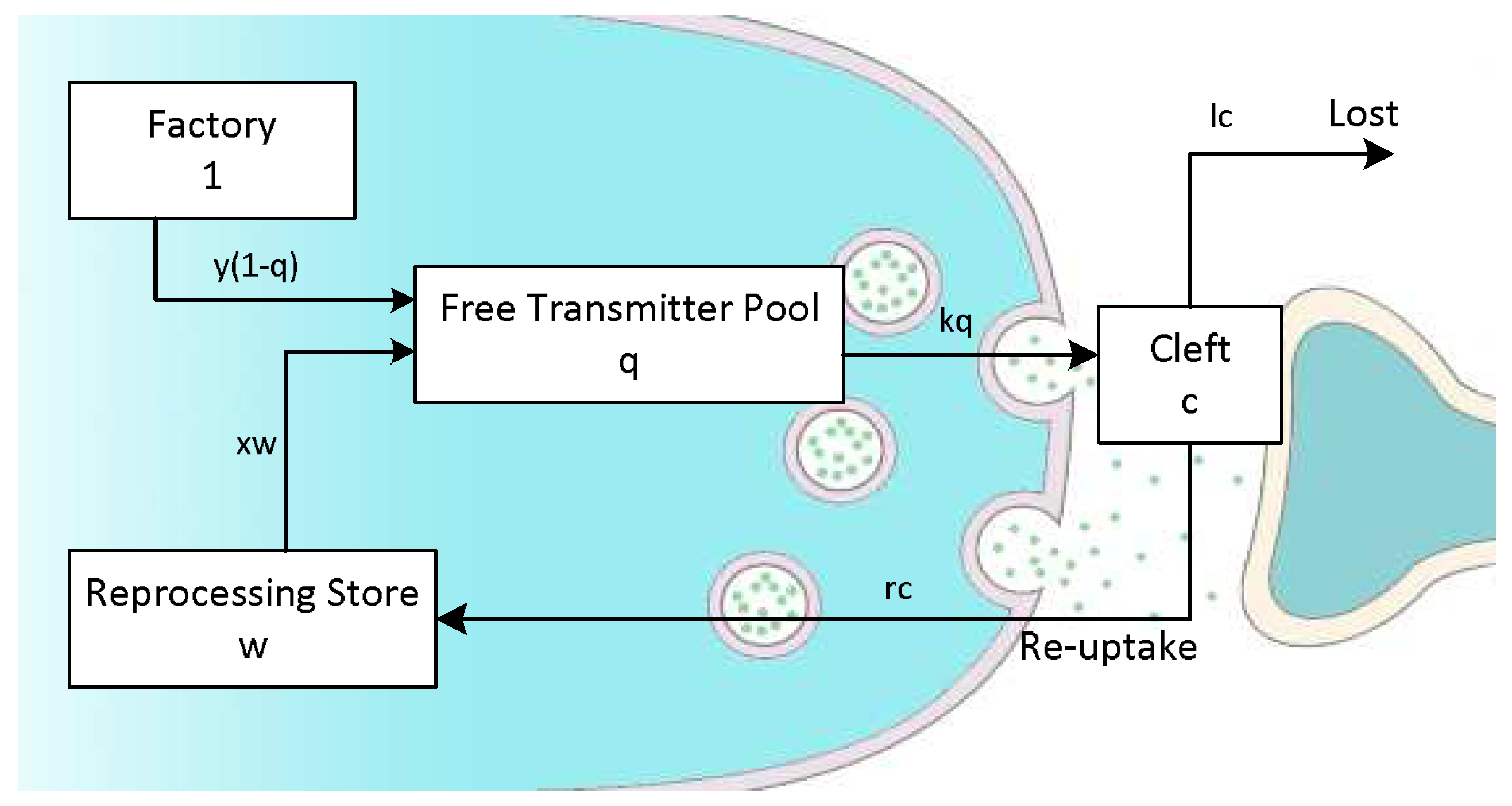
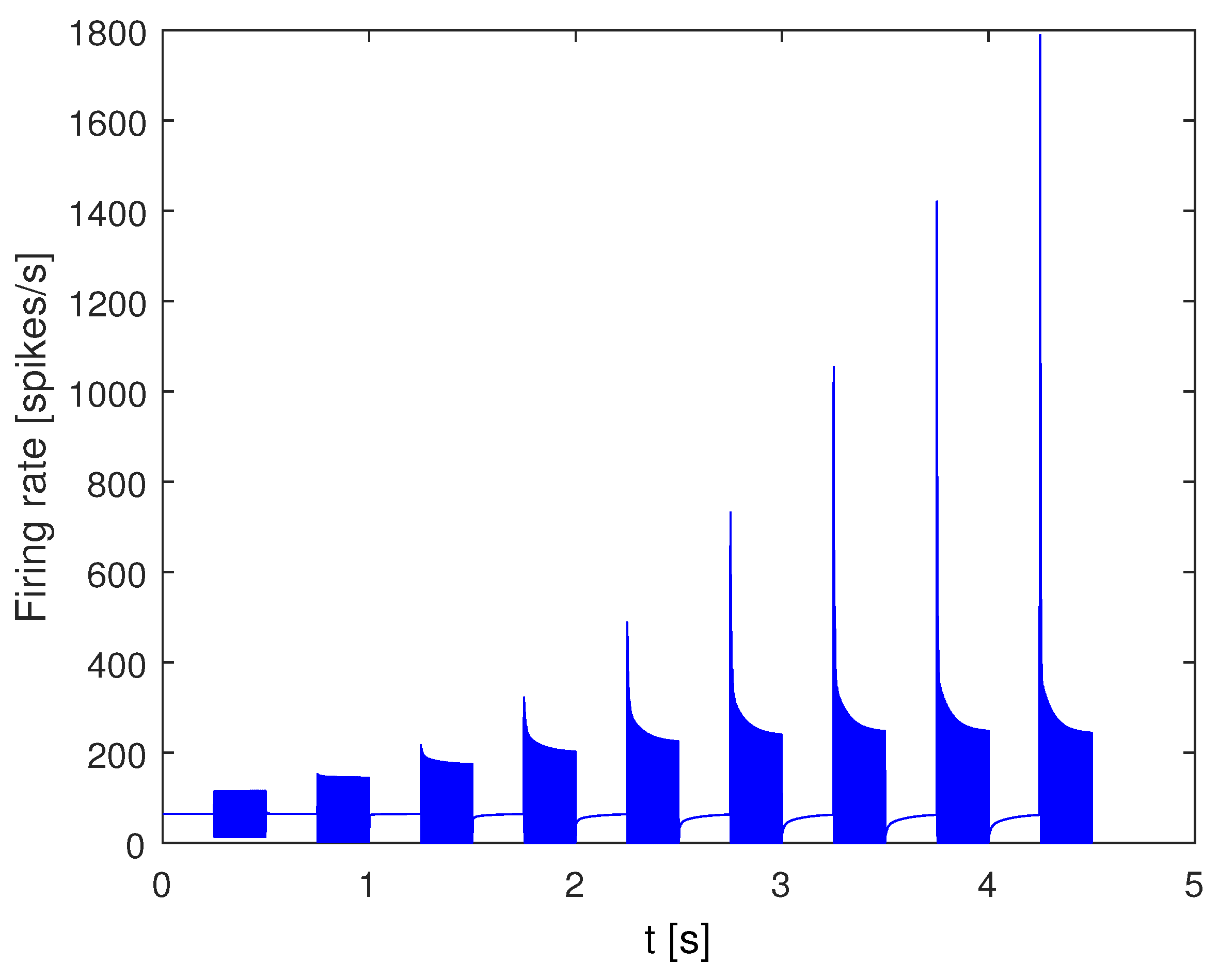
2.2. IHC Model
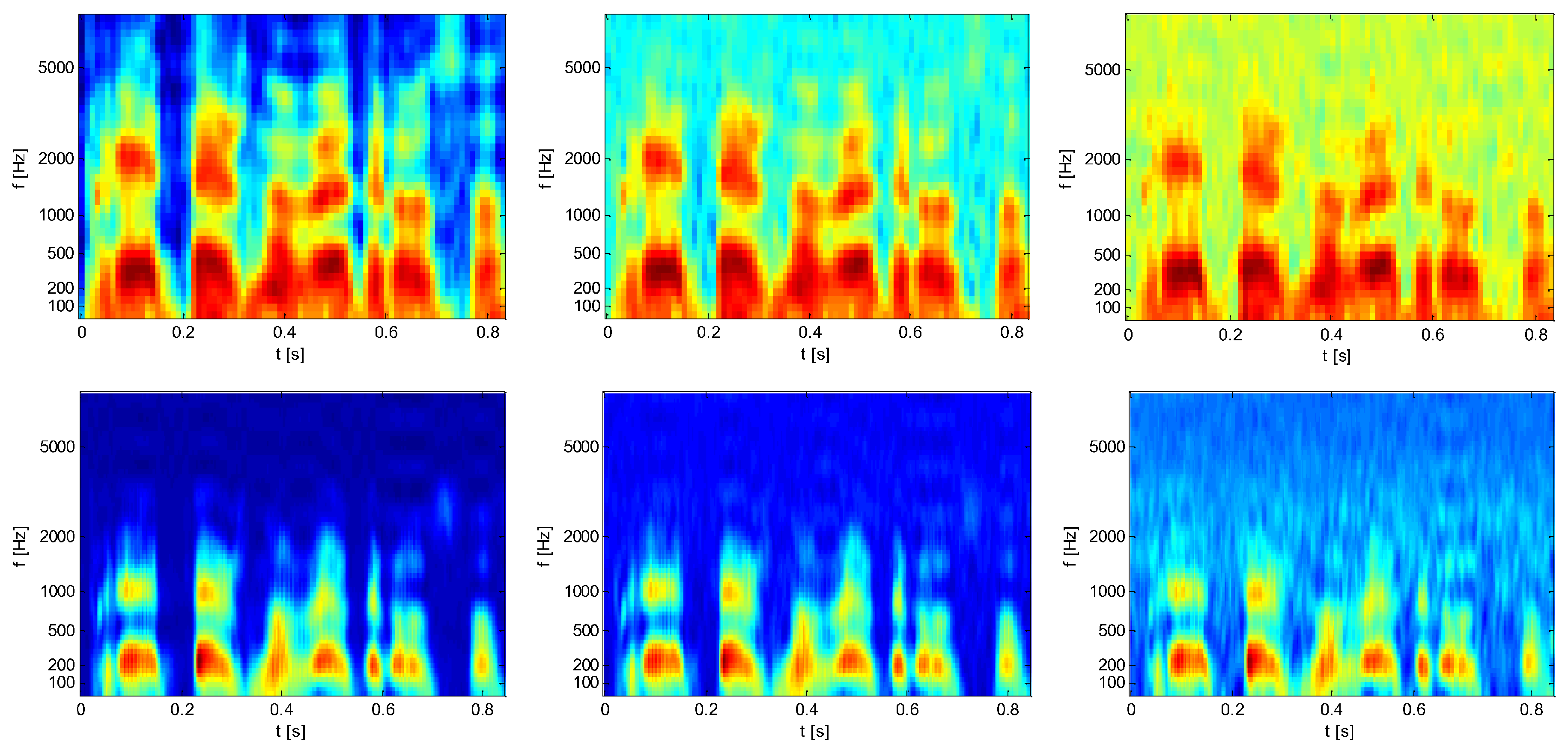
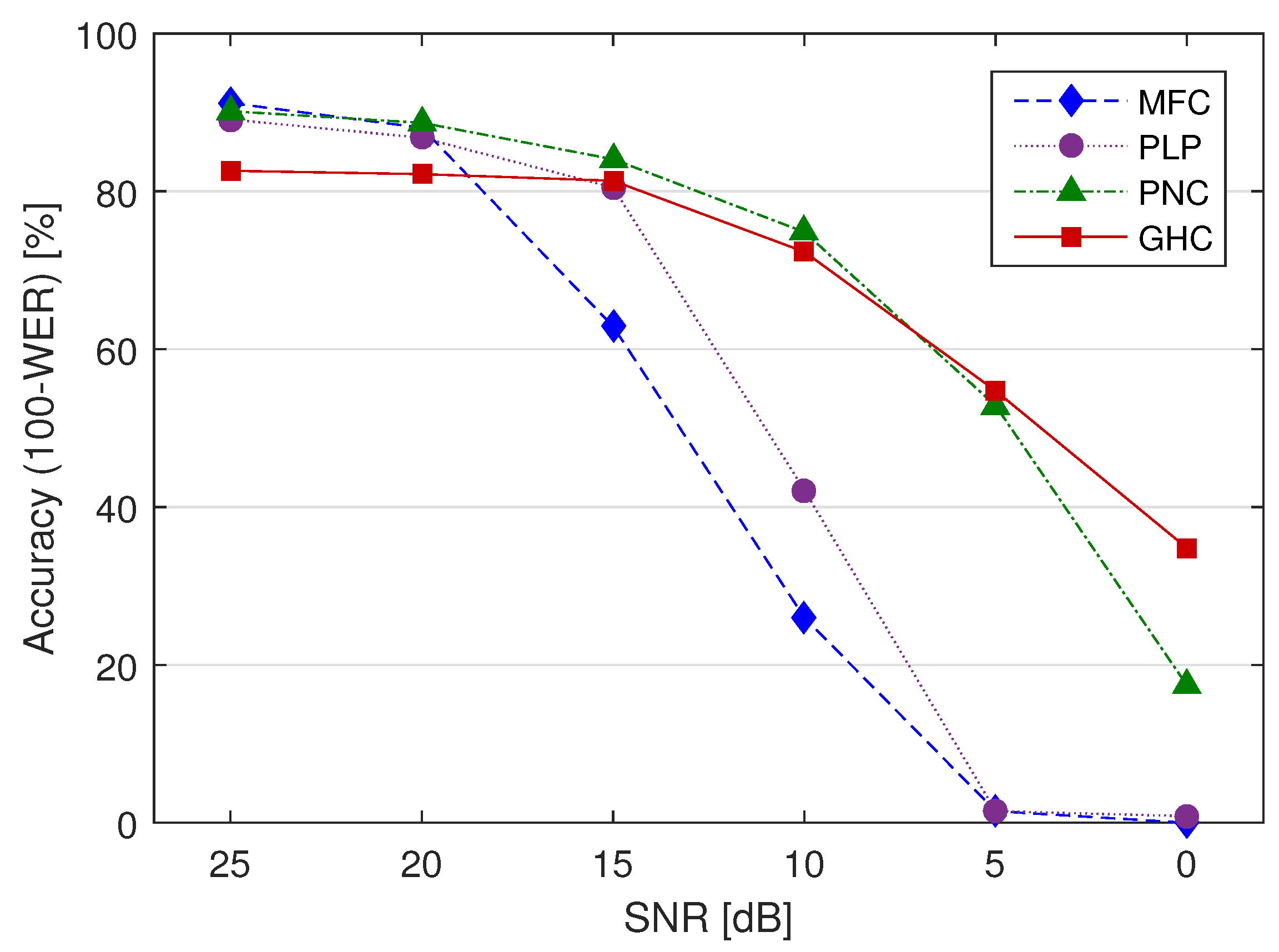
3. Speech Recognition Experiments
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fletcher, H. The nature of speech and its interpretation. J. Franklin Inst. 1922, 193, 729–747. [Google Scholar] [CrossRef]
- Davis, K.; Biddulph, R.; Balashek, S. Automatic recognition of spoken digits. J. Acoust. Soc. Am. 1952, 24, 637–642. [Google Scholar] [CrossRef]
- Gong, Y.F. Speech recognition in noisy environments—A survey. Speech Comm. 1995, 16, 261–291. [Google Scholar] [CrossRef]
- Ceidaite, G.; Telksnys, L. Analysis of factors influencing accuracy of speech recognition. Elektron. Ir Elektrotech. 2010, 9, 69–72. [Google Scholar]
- Tan, Z.H.; Lindberg, B. Mobile Multimedia Processing; Springer: New York, UY, USA, 2010. [Google Scholar]
- Li, W.; Takeda, K.; Itakura, F. Robust in-car speech recognition based on nonlinear multiple regressions. EURASIP J. Adv. Sig. Process. 2007, 2007, 5. [Google Scholar] [CrossRef]
- Ou, W.; Gao, W.; Li, Z.; Zhang, S.; Wang, Q. Application of keywords speech recognition in agricultural voice information system. In Proceedings of the 2010 Second International Conference on Computational Intelligence and Natural Computing, Wuhan, China, 13–14 September 2010; pp. 197–200. [Google Scholar]
- Zhu, L.; Chen, L.; Zhao, D.; Zhou, J.; Zhang, W. Emotion recognition from chinese speech for smart affective services using a combination of SVM and DBN. Sensors 2017, 17, 1694. [Google Scholar] [CrossRef] [PubMed]
- Noriega-Linares, J.E.; Navarro Ruiz, J.M. On the application of the raspberry Pi as an advanced acoustic sensor network for noise monitoring. Electronics 2016, 5, 74. [Google Scholar] [CrossRef]
- Al-Rousan, M.; Assaleh, K. A wavelet-and neural network-based voice system for a smart wheelchair control. J. Franklin Inst. 2011, 348, 90–100. [Google Scholar] [CrossRef]
- McLoughlin, I.; Sharifzadeh, H.R. Speech Recognition, Technologies and Applications; I-Tech Education and Publishing: Vienna, Austria, 2008; pp. 477–494. [Google Scholar]
- Glowacz, A. Diagnostics of rotor damages of three-phase induction motors using acoustic signals and SMOFS-20-EXPANDED. Arch. Acoust. 2016, 41, 507–515. [Google Scholar] [CrossRef]
- Glowacz, A. Fault diagnosis of single-phase induction motor based on acoustic signals. Mech. Syst. Signal Process. 2019, 117, 65–80. [Google Scholar] [CrossRef]
- Kunicki, M.; Cichoń, A. Application of a Phase Resolved Partial Discharge Pattern Analysis for Acoustic Emission Method in High Voltage Insulation Systems Diagnostics. Arch. Acoust. 2018, 43, 235–243. [Google Scholar]
- Mika, D.; Józwik, J. Advanced time-frequency representation in voice signal analysis. Adv. Sci. Technol. Res. J. 2018, 12. [Google Scholar] [CrossRef]
- Ono, K. Review on structural health evaluation with acoustic emission. Appl. Sci. 2018, 8, 958. [Google Scholar] [CrossRef]
- Zou, L.; Guo, Y.; Liu, H.; Zhang, L.; Zhao, T. A method of abnormal states detection based on adaptive extraction of transformer vibro-acoustic signals. Energies 2017, 10, 2076. [Google Scholar] [CrossRef]
- Yang, H.; Wen, G.; Hu, Q.; Li, Y.; Dai, L. Experimental investigation on influence factors of acoustic emission activity in coal failure process. Energies 2018, 11, 1414. [Google Scholar] [CrossRef]
- Mokhtarpour, L.; Hassanpour, H. A self-tuning hybrid active noise control system. J. Franklin Inst. 2012, 349, 1904–1914. [Google Scholar] [CrossRef]
- Lee, S.C.; Wang, J.F.; Chen, M.H. Threshold-based noise detection and reduction for automatic speech recognition system in human-robot interactions. Sensors 2018, 18, 2068. [Google Scholar] [CrossRef] [PubMed]
- Kuo, S.M.; Peng, W.M. Principle and applications of asymmetric crosstalk-resistant adaptive noise canceler. J. Franklin Inst. 2000, 337, 57–71. [Google Scholar] [CrossRef]
- Hung, J.W.; Lin, J.S.; Wu, P.J. Employing Robust Principal Component Analysis for Noise-Robust Speech Feature Extraction in Automatic Speech Recognition with the Structure of a Deep Neural Network. Appl. Syst. Innov. 2018, 1, 28. [Google Scholar] [CrossRef]
- Lippmann, R.P. Speech recognition by machines and humans. Speech Commun. 1997, 22, 1–15. [Google Scholar] [CrossRef]
- Allen, J.B. How do humans process and recognize speech? IEEE Trans. Speech Audio Process. 1994, 2, 567–577. [Google Scholar] [CrossRef]
- Haque, S.; Togneri, R.; Zaknich, A. Perceptual features for automatic speech recognition in noisy environments. Speech Commun. 2009, 51, 58–75. [Google Scholar] [CrossRef]
- Hermansky, H. Perceptual linear predictive (PLP) analysis of speech. J. Acoust. Soc. Am. 1990, 87, 1738–1752. [Google Scholar] [CrossRef] [PubMed]
- Holmberg, M.; Gelbart, D.; Hemmert, W. Automatic speech recognition with an adaptation model motivated by auditory processing. IEEE Trans. Audio Speech Lang Process. 2006, 14, 43–49. [Google Scholar] [CrossRef]
- Kim, C.; Stern, R.M. Power-normalized cepstral coefficients (PNCC) for robust speech recognition. In Proceedings of the 37th International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4101–4104. [Google Scholar]
- Seltzer, M.L.; Yu, D.; Wang, Y. An investigation of deep neural networks for noise robust speech recognition. In Proceedings of the 38th International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Vancouver, Canada, 26–31 May 2013; pp. 7398–7402. [Google Scholar]
- Maas, A.L.; Le, Q.V.; O’Neil, T.M.; Vinyals, O.; Nguyen, P.; Ng, A.Y. Recurrent neural networks for noise reduction in robust ASR. In Proceedings of the 13th Annual Conference of the International Speech Communication Association, Oregon, Poland, 9–13 September 2012. [Google Scholar]
- Wollmer, M.; Schuller, B.; Eyben, F.; Rigoll, G. Combining long short-term memory and dynamic bayesian networks for incremental emotion-sensitive artificial listening. IEEE J. Sel. Top. Sign. Process. 2010, 4, 867–881. [Google Scholar] [CrossRef]
- Zhang, Z.; Geiger, J.; Pohjalainen, J.; Mousa, A.E.D.; Jin, W.; Schuller, B. Deep learning for environmentally robust speech recognition: An overview of recent developments. ACM Trans. Intell. Syst. Technol. 2018, 9, 49. [Google Scholar] [CrossRef]
- Jankowski, C.R., Jr.; Vo, H.D.H.; Lippmann, R.P. A comparison of signal processing front ends for automatic word recognition. IEEE Trans. Speech Audio Process. 1995, 3, 286–293. [Google Scholar] [CrossRef]
- Seneff, S. A computational model for the peripheral auditory system: Application of speech recognition research. In Proceedings of the ICASSP ’86. IEEE International Conference on Acoustics, Speech, and Signal Processing, Tokyo, Japan, 7–11 April 1986; pp. 1983–1986. [Google Scholar]
- Ghitza, O. Auditory models and human performance in tasks related to speech coding and speech recognition. IEEE Trans. Speech Audio Process. 1994, 2, 115–132. [Google Scholar] [CrossRef]
- Qi, J.; Wang, D.; Jiang, Y.; Liu, R. Auditory features based on gammatone filters for robust speech recognition. In Proceedings of the 2013 IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013; pp. 305–308. [Google Scholar]
- Yin, H.; Hohmann, V.; Nadeu, C. Acoustic features for speech recognition based on Gammatone filterbank and instantaneous frequency. Speech Commun. 2011, 53, 707–715. [Google Scholar] [CrossRef]
- Shao, Y.; Jin, Z.; Wang, D.; Srinivasan, S. An auditory-based feature for robust speech recognition. In Proceedings of the 34th International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Taipei, Taiwan, 19–24 April 2009; pp. 4625–4628. [Google Scholar]
- Menon, A.; Kim, C.; Stern, R.M. Robust Speech Recognition Based on Binaural Auditory Processing. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 3872–3876. [Google Scholar]
- Marieb, E.N.; Hoehn, K. Human anatomy & physiology; Benjamin Cummings: San Francisco, CA, USA, 2016. [Google Scholar]
- Purves, D.; Augustine, G.J.; Fitzpatrick, D.; Hall, W.C.; LaMantia, A.S.; McNamara, J.O.; Williams, S.M. Neuroscience; Sinauer Associates: Sunderland, MA, USA, 2004. [Google Scholar]
- Johannesma, P.I. The pre-response stimulus ensemble of neurons in the cochlear nucleus. In Proceedings of the Symposium of Hearing Theory, Eindhoven, The Netherland, 22–23 June 1972; pp. 58–69. [Google Scholar]
- Patterson, R.D.; Robinson, K.; Holdsworth, J.; McKeown, D.; Zhang, C.; Allerhand, M. Complex sounds and auditory images. In Proceedings of the 9th International Symposium on Hearing, Carcens, France, 9–14 June 1991; pp. 429–446. [Google Scholar]
- Patterson, R.D. Frequency Selectivity in Hearing; Auditory Filters and Excitation Patterns as Representations of Fre-Quency Resolution; Academic Press: Cambridge, MA, USA, 1986; pp. 123–177. [Google Scholar]
- Glasberg, B.R.; Moore, B.C. Derivation of auditory filter shapes from notched-noise data. Hear. Res. 1990, 47, 103–138. [Google Scholar] [CrossRef]
- Slaney, M. An Efficient Implementation of the Patterson-Holdsworth Auditory Filter Bank. 1993. Available online: https://engineering.purdue.edu/~malcolm/apple/tr35/PattersonsEar.pdf (accessed on 25 December 2018).
- Meddis, R. Simulation of mechanical to neural transduction in the auditory receptor. J. Acoust. Soc. Am. 1986, 79, 702. [Google Scholar] [CrossRef] [PubMed]
- McEwan, A.; Van Schaik, A. A silicon representation of the Meddis inner hair cell model. In Proceedings of the International Congress on Intelligent Systems and Applications (ISA’2000), Sydney, Australia, 12–15 December 2000. [Google Scholar]
- Wang, D.; Brown, G.J. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications; Wiley-IEEE Press: Hoboken, NJ, USA, 2006. [Google Scholar]
- Young, S.J.; Evermann, G.; Gales, M.J.F.; Hain, T.; Kershaw, D.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; Valtchev, V.; Woodland, P.C. The HTK Book, Edition 3.4 ed; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Kim, C.; Stern, R.M. Power-normalized cepstral coefficients (PNCC) for robust speech recognition. IEEE/ACM Trans. Audio, Speech Lang. Process. 2016, 24, 1315–1329. [Google Scholar] [CrossRef]
- Pagano, M.; Gauvreau, K. Principles of Biostatistics; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR (dB) | MFC | PLP | PNC | GHC | ||||
|---|---|---|---|---|---|---|---|---|
| Corr | Acc | Corr | Acc | Corr | Acc | Corr | Acc | |
| clean | 93.9 | 91.6 | 93.3 (0.69) | 90.2 (0.43) | 93.7 (0.89) | 91.4 (0.91) | 87.2 (0.00) | 82.6 (0.00) |
| 25 | 92.9 | 91.2 | 92.0 (0.62) | 89.1 (0.28) | 92.5 (0.8) | 90.2 (0.58) | 87.2 (0.00) | 82.6 (0.00) |
| 20 | 91.4 | 88.1 | 90.6 (0.65) | 86.8 (0.56) | 91.4 (1.0) | 88.7 (0.76) | 86.6 (0.02) | 82.2 (0.01) |
| 15 | 81.1 | 62.9 | 81.1 (1.0) | 80.5 (0.00) | 89.7 (0.00) | 84.1 (0.00) | 86.6 (0.02) | 81.3 (0.00) |
| 10 | 42.8 | 26.0 | 47.4 (0.15) | 42.1 (0.00) | 87.0 (0.00) | 74.8 (0.00) | 83.9 (0.00) | 72.3 (0.00) |
| 5 | 4.8 | 1.5 | 4.2 (0.64) | 1.5 (1.0) | 75.7 (0.00) | 52.8 (0.00) | 77.4 (0.00) | 54.7 (0.00) |
| 0 | 1.3 | 0.0 | 0.0 (0.01) | 0.8 (0.05) | 45.1 (0.00) | 17.4 (0.00) | 62.5 (0.00) | 34.8 (0.00) |
| Average | 58.3 | 51.6 | 58.4 (1) | 55.9 (0.19) | 82.1 (0.00) | 71.3 (0.00) | 81.6 (0.00) | 70.1 (0.00) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Russo, M.; Stella, M.; Sikora, M.; Pekić, V. Robust Cochlear-Model-Based Speech Recognition. Computers 2019, 8, 5. https://doi.org/10.3390/computers8010005
Russo M, Stella M, Sikora M, Pekić V. Robust Cochlear-Model-Based Speech Recognition. Computers. 2019; 8(1):5. https://doi.org/10.3390/computers8010005
Chicago/Turabian StyleRusso, Mladen, Maja Stella, Marjan Sikora, and Vesna Pekić. 2019. "Robust Cochlear-Model-Based Speech Recognition" Computers 8, no. 1: 5. https://doi.org/10.3390/computers8010005
APA StyleRusso, M., Stella, M., Sikora, M., & Pekić, V. (2019). Robust Cochlear-Model-Based Speech Recognition. Computers, 8(1), 5. https://doi.org/10.3390/computers8010005