SoS TextVis: An Extended Survey of Surveys on Text Visualization



Abstract
1. Introduction and Motivation
- the first focus Survey of Surveys (SoS) in text visualization,
- a novel classification of text surveys in the reviewed literature,
- helpful survey meta-data in order to facilitate comparison of the surveys, and
- a unique, valuable starting point and comprehensive overview for both newcomers and experienced researchers in text visualization.
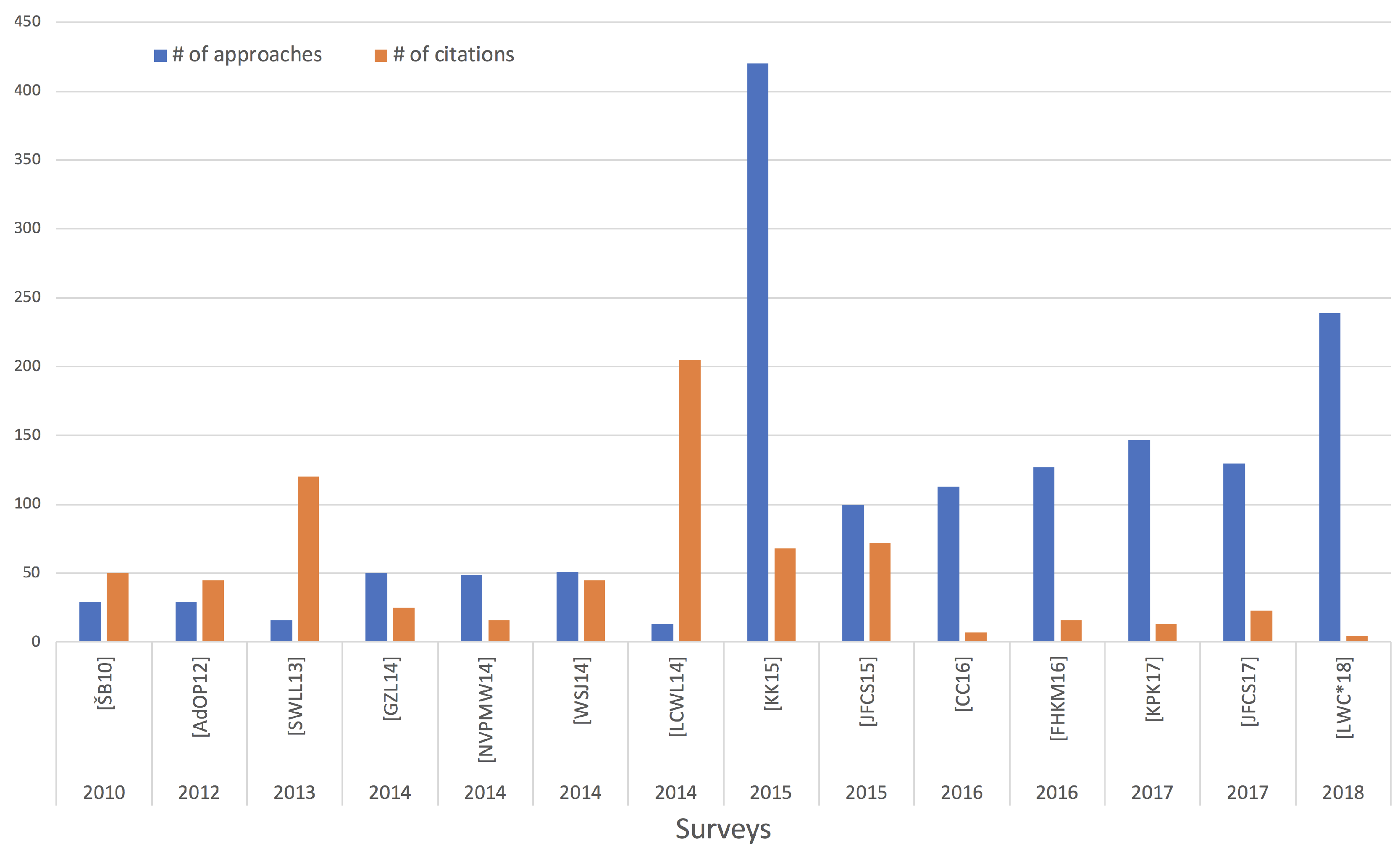
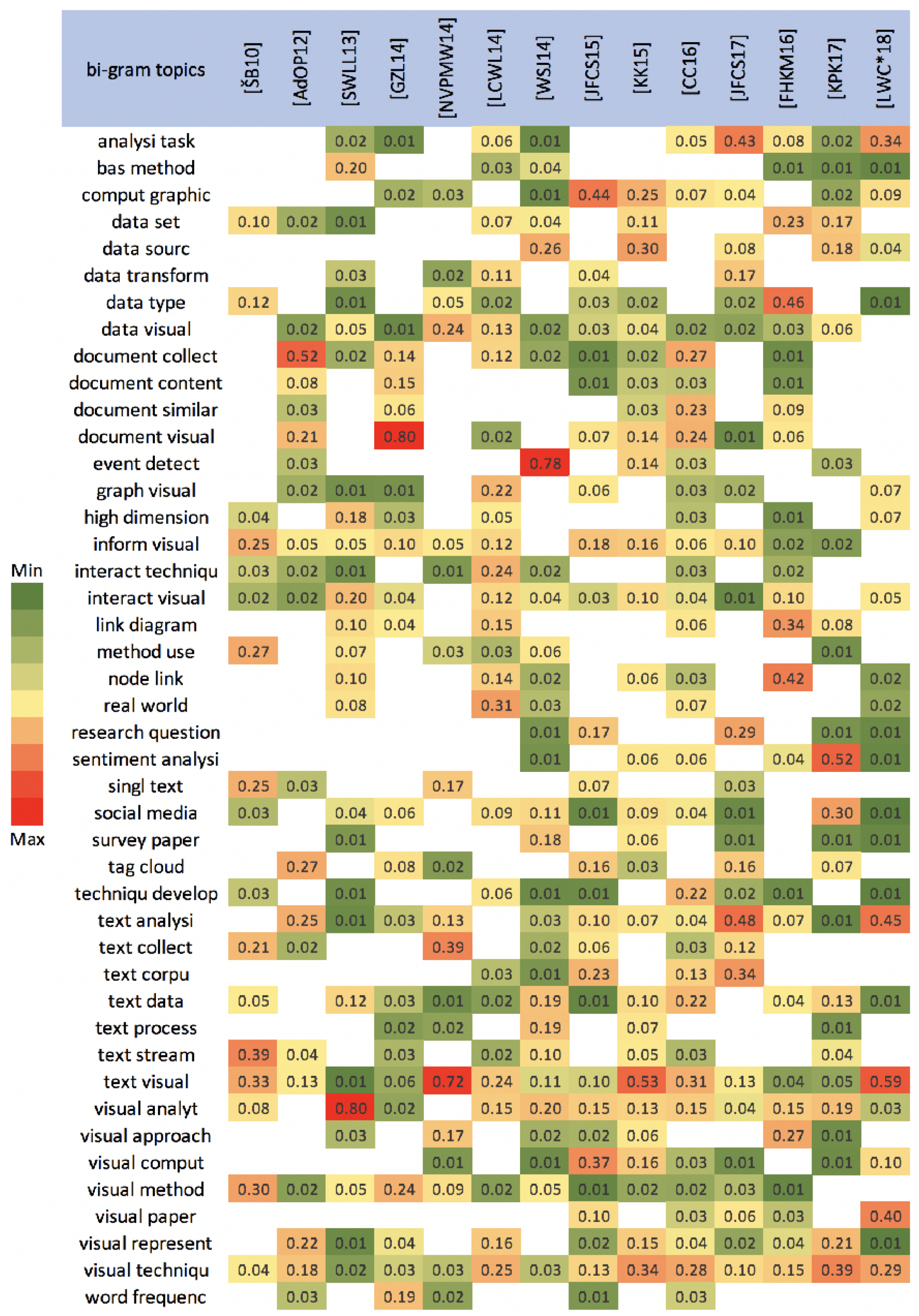
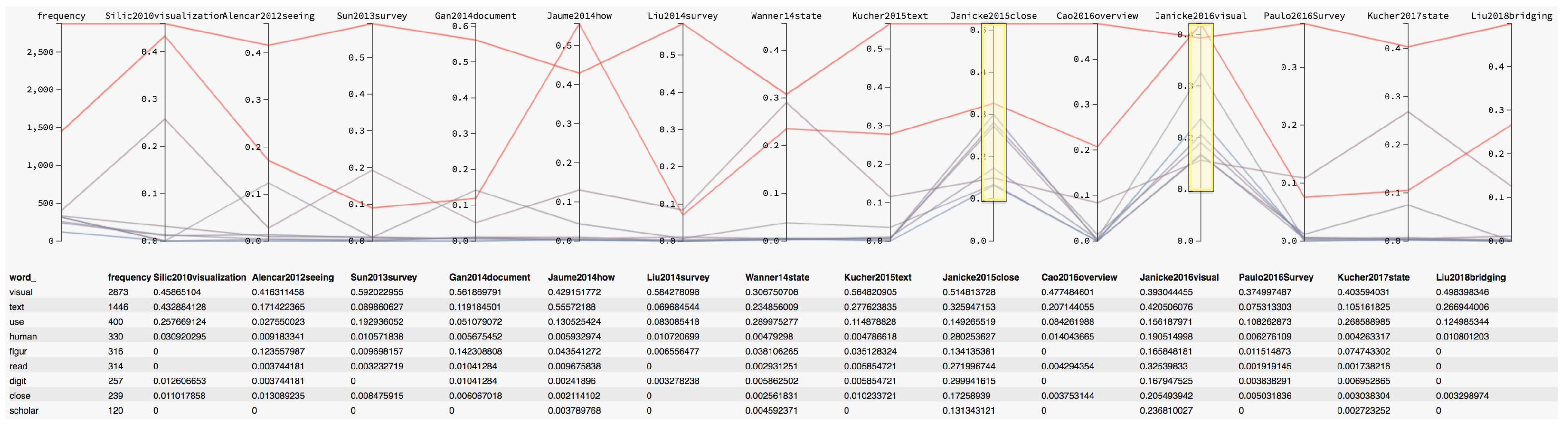
1.1. Literature Search Methodology
1.2. Survey Scope
1.3. Related Work
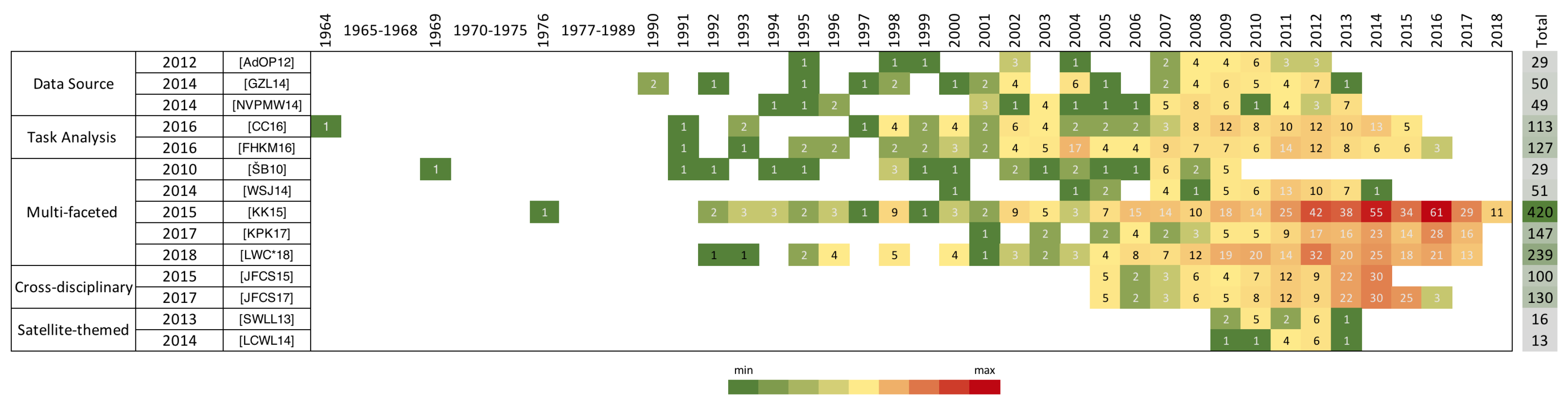
1.4. Survey Classification
- Data source: We place all surveys that derive their classification based on the underlying text source in this group; e.g., single text or text stream.
- Task analysis: We group surveys that mainly categorize their related literature based on the task analysis; e.g., showing similarities between texts.
- Multi-faceted: Here are surveys that categorize related literature into multi-faceted classifications. In this case, the survey may propose multiple classifications based on a variety of characteristics; e.g., presentation and underlying data mining technique.
- Cross-disciplinary: We collect surveys that survey visualization techniques to support Digital Humanities.
- Satellite-themed: This group contains surveys that review existing information visualization literature. We include surveys that only include text visualization as a sub-section within their classification.
2. Summary and Comparison of Surveys
2.1. Document-Centered Surveys
- Text characteristics depicted as word concordances, semantic relations, contents, or document relations.
- Design principles satisfied, which refers to the Type by Task Taxonomy (TTT) that Shneiderman proposes [37]. He includes seven tasks which are: Overview, zoom, filter, details-on-demand, relate, history, and extract.
- Requirements for a document to suit this visual design, such as arbitrary text documents or sequence-based documents.
- Main features such as interactivity and versatility (designing general visualization models for different tasks).
- The sub-divisions for individual texts:
- (a)
- Whole or sub-sets: The visualization process includes the whole text or part of it.
- (b)
- Sequential or non-sequential: The visual layout preserves the same word sequence as that of the original text.
- (c)
- Discourse structure or syntactic structure: The visual design uses elements from discourse structure which refers to using actual parts of the text enabling the viewer to read through visualization or syntactic structure using intrinsic elements of the text such as words and phrases.
- (d)
- Search: The imagery results from a search query.
- (e)
- Time: Text that changes over time.
- The sub-divisions for collections of texts are:
- (a)
- Items or Aggregations: The items of the collection used individually or there is some aggregation visualized.
- (b)
- Pure data or landscape: The text data in the collection is accompanied by graphical content.
- (c)
- Search: Same as above 1d.
- (d)
- Time: Same as above 1e.
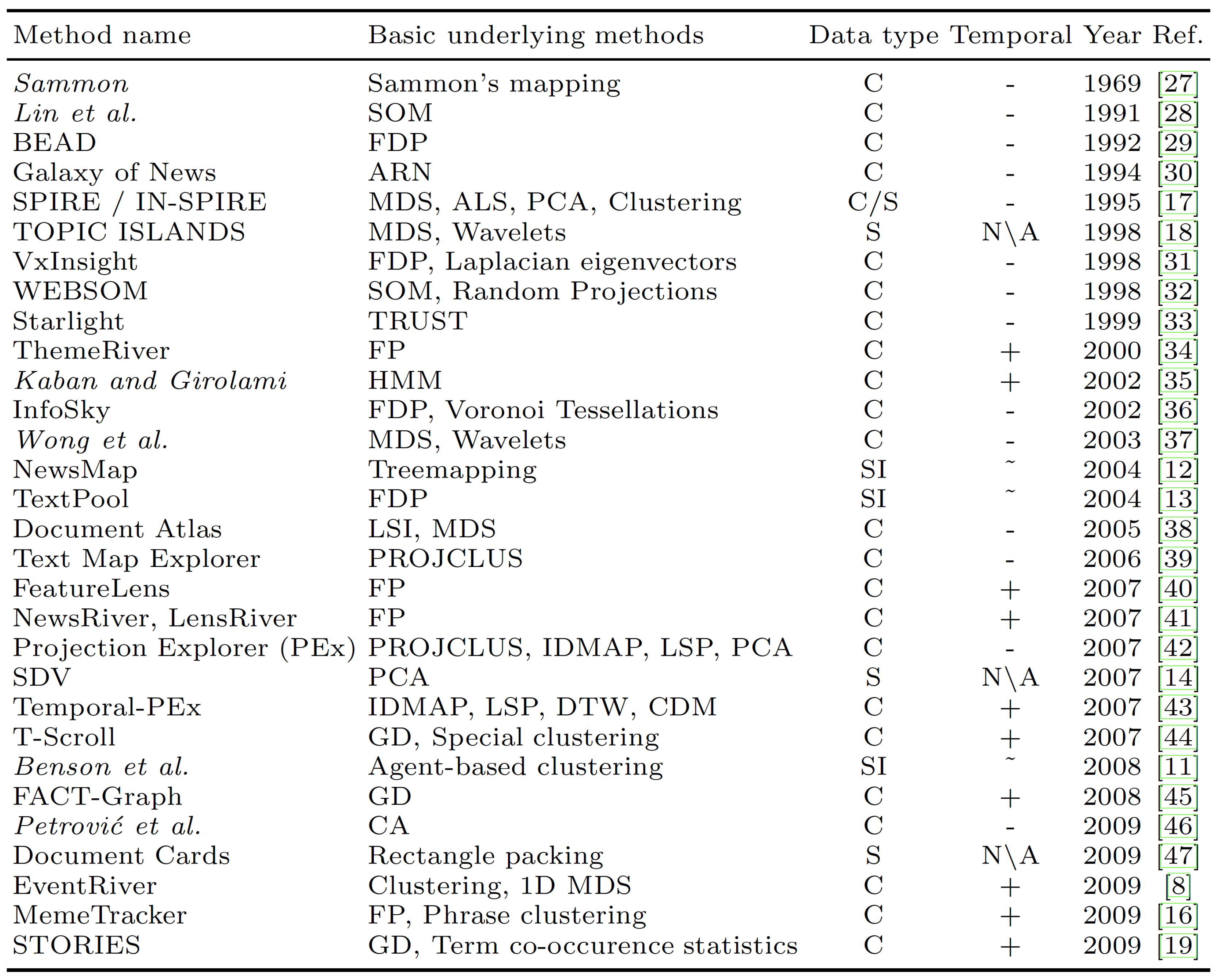
2.2. User Task Analysis Surveys
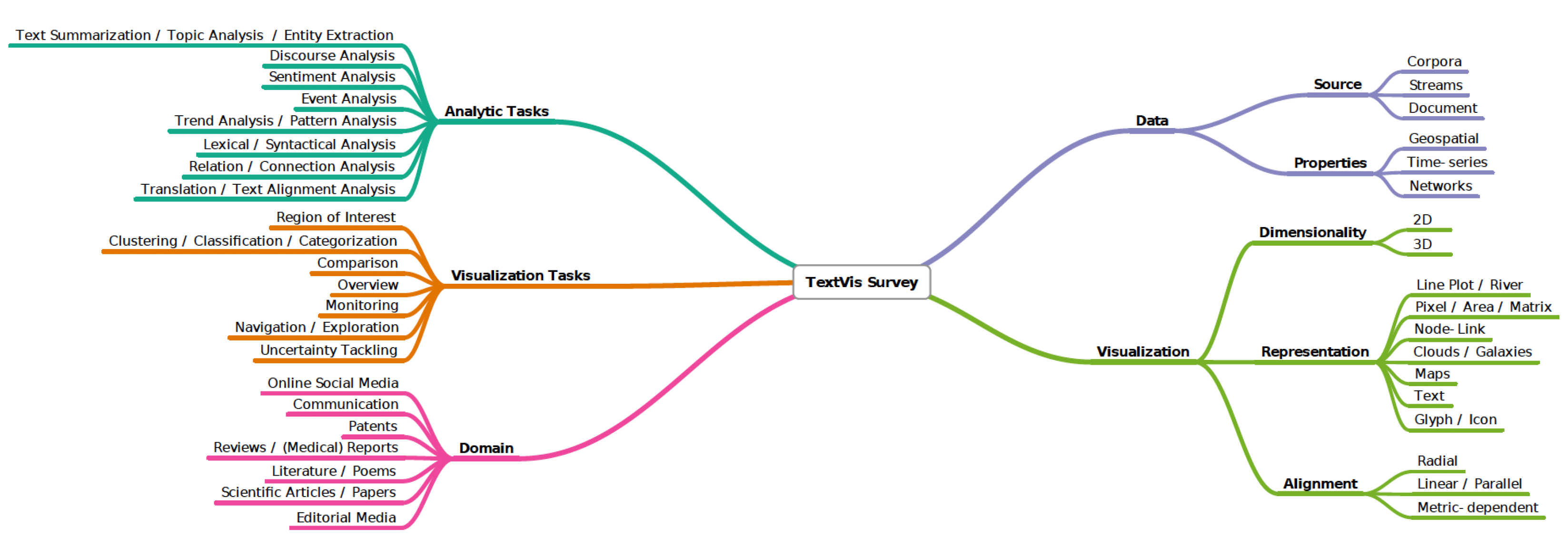
2.3. Multi-Faceted Text Visualization Surveys
- Bag-of-words methods extract text features by counting the term occurrences in the text.
- Entity recognition aims to extract proper name of entities, such as the names of persons, organizations, places, or countries.
- Summarization methods shorten the text and present only the most relevant information.
- Document structure parsing extracts structural information from text, such as titles, authors names, and publication dates.
- Sentiment and affect analysis is used to identify and quantify the emotional aspects of the text.
- Term trend approaches are based on the term frequency in the text. In such methods, feature selection is used to reduce the number of dimensions.
- Semantic space approaches facilitate semantic methods to extract features of text(s). In most cases, feature vectors representing text are high-dimensional, so more advanced dimensionality reduction algorithms are used to map these features to 2D or 3D space.
- Analytic tasks include the techniques that support high-level analytic tasks.
- Visualization tasks include techniques that support lower-level representation and interaction tasks.
- Domain describes the techniques that are developed for a specific application.
- Data consists of two subcategories, source and properties, that describe the data source and the special properties of data used by the techniques.
- Visualization contains three subcategories to describe the properties of visual representations, dimensionality, representation, and alignment.
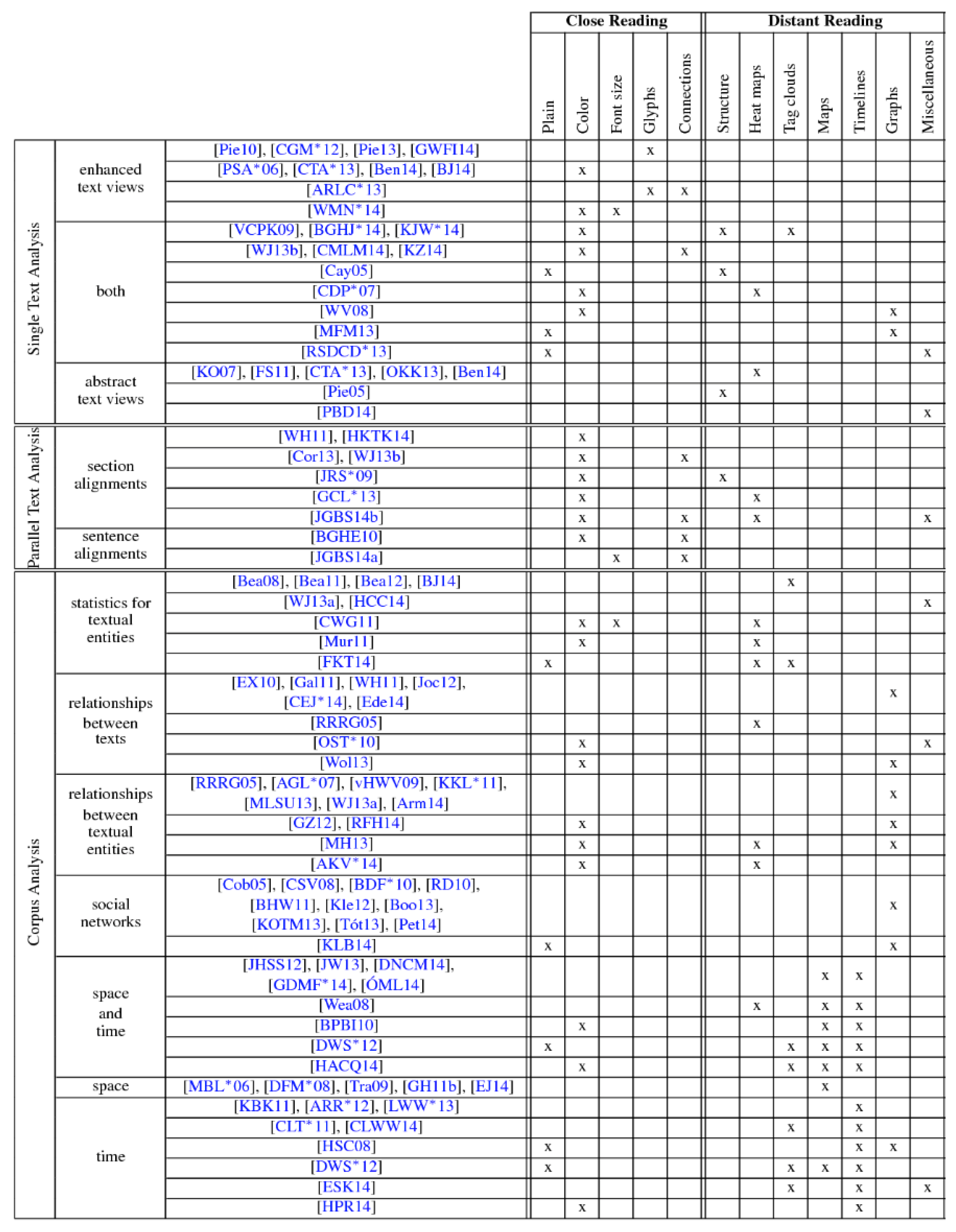
2.4. Cross-Disciplinary Text Visualization Surveys
- Color is used to show a great variety of features, e.g., classification, similarity or importance.
- Font size is also used to convey text features, e.g., word frequency or significance.
- Glyphs are used to present some aspects of the text that are difficult to express using other techniques and are mostly used in poems to draw phonetic units.
- Connections help illustrate the relationship between text entities, e.g., to show subsequent words to track variation among various text editions or to convey sentence structure.
- Structural overviews illustrate the hierarchy of document or collection of documents.
- Heat maps are usually used to show textual patterns such as similarities.
- Tag clouds encode word occurrence frequency within a text using variable font size.
- Maps display geospatial information contained in a text.
- Timelines are used to visualize text that conveys temporal information. Such a technique could use the text’s meta-data and support the temporal analysis of the use of a word over time.
- Graphs usually use nodes and edges to visualize certain structural features of a text corpus.
- Miscellaneous methods are used to explore specific aspects within text interactively.
- Top-down approaches implement the information seeking mantra, ‘overview first, zoom and filter, details-on-demand’ [37]. Initially, an overview of the textual data is shown, and then the user interacts with the graphics by filtering or zooming, and finally, clicking on the interesting sub-set to obtain details-on-demand.
- Bottom-up methods start with the desired text or part of it and then generate an overview layout which relates to the given section or text.
- Top-down and bottom-up methods provide a mechanism of switching between close (text view) and distant reading (structural overview).
2.5. Satellite-Themed Text Visualization Surveys
2.6. Survey Recommendations
3. Discussion of Future Challenges
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Reddy, R.; StClair, G. The million book digital library project. Comput. Sci. Present. 2001. Available online: www.rr.cs.cmu.edu/mbdl.doc (accessed on 18 February 2019).
- Andre, P.Q.; Eaton, N.L. National agricultural text digitizing project. Libr. Hi Tech. 1988, 6, 61–66. [Google Scholar] [CrossRef]
- Mendelsson, D.; Falk, E.; Oliver, A.L. The Albert Einstein archives digitization project: Opening hidden treasures. Libr. Hi Tech. 2014, 32, 318–335. [Google Scholar] [CrossRef]
- Kucher, K.; Kerren, A. Text visualization techniques: Taxonomy, visual survey, and community insights. In Proceedings of the 8th IEEE Pacific Visualization Symposium (PacificVis 2015), Hangzhou, China, 14–17 April 2015. [Google Scholar]
- Šilić, A.; Bašić, B. Visualization of text streams: A survey. In Proceedings of the International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, Cardiff, UK, 12–14 September 2010. [Google Scholar]
- Alharbi, M.; Laramee, R.S. SoS TextVis: A Survey of Surveys on Text Visualization. In Proceedings of the Computer Graphics & Visual Computing (CGVC), Wales, UK, 13–14 September 2018. [Google Scholar]
- McNabb, L.; Laramee, R.S. Survey of Surveys (SoS)—Mapping The Landscape of Survey Papers in Information Visualization. Comput. Graph. Forum 2017, 36, 589–617. [Google Scholar] [CrossRef]
- Rees, D.; Laramee, R.S. A Survey of Information Visualization Books. Comput. Graph. Forum 2019. [Google Scholar] [CrossRef]
- Kucher, K.; Paradis, C.; Kerren, A. The State of the Art in Sentiment Visualization. Comput. Graph. Forum 2018, 37, 71–96. [Google Scholar] [CrossRef]
- Jänicke, S.; Franzini, G.; Cheema, M.; Scheuermann, G. Visual text analysis in digital humanities. Comput. Graph. Forum 2017, 36, 226–250. [Google Scholar] [CrossRef]
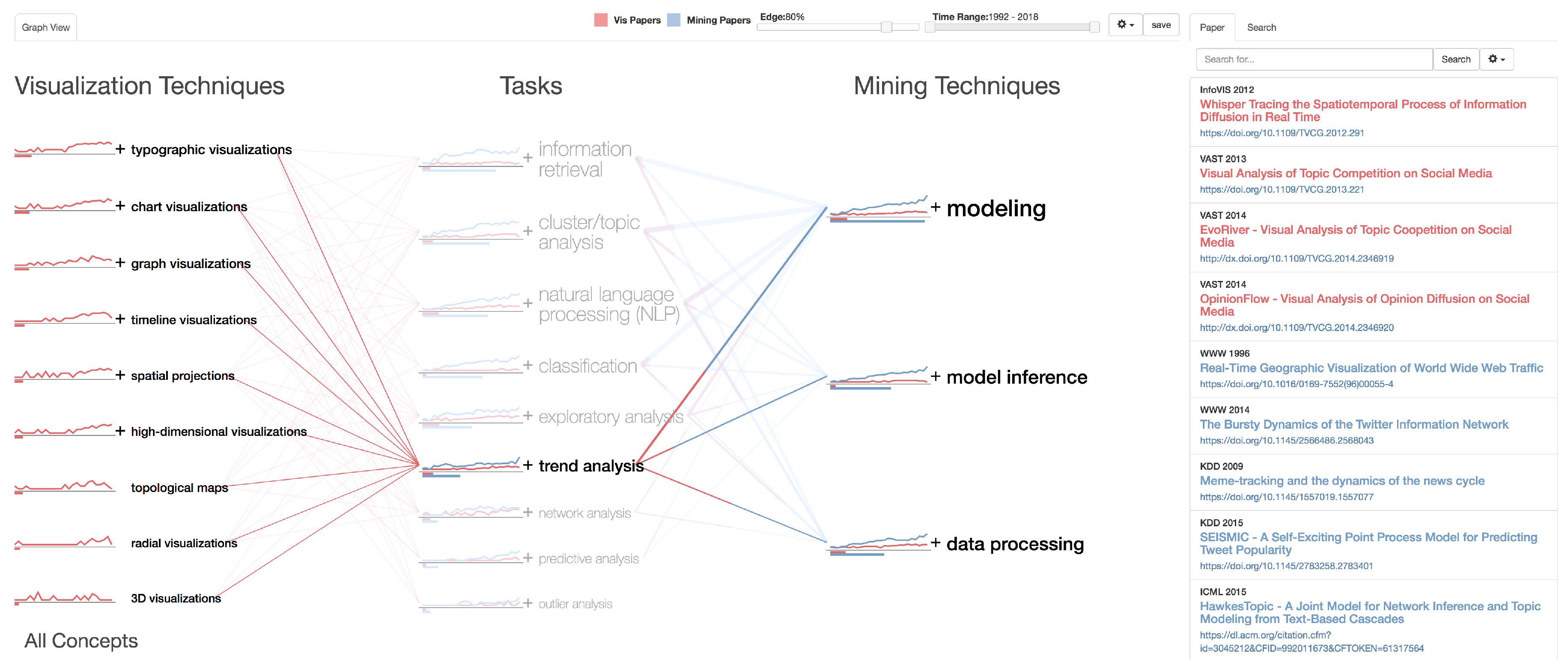
- Liu, S.; Wang, X.; Collins, C.; Dou, W.; Ouyang, F.; El-Assady, M.; Jiang, L.; Keim, D. Bridging text visualization and mining: A task-driven survey. IEEE Trans.Vis. Comput. Graph. 2018. [Google Scholar] [CrossRef]
- IEEE Xplore. Available online: http://ieeexplore.ieee.org/Xplore/home.jsp (accessed on 26 February 2017).
- ACM Digital Library. Available online: http://dl.acm.org/ (accessed on 26 May 2017).
- Google Scholar. Available online: https://scholar.google.co.uk/ (accessed on 20 January 2017).
- Sun, G.D.; Wu, Y.C.; Liang, R.H.; Liu, S.X. A survey of visual analytics techniques and applications: State-of-the-art research and future challenges. J. Comput. Sci. Technol. 2013, 28, 852–867. [Google Scholar] [CrossRef]
- Liu, S.; Cui, W.; Wu, Y.; Liu, M. A survey on information visualization: Recent advances and challenges. Vis. Comput. 2014, 30, 1373–1393. [Google Scholar] [CrossRef]
- Gupta, V.; Lehal, G.S. A survey of text summarization extractive techniques. J. Emerg. Technol. Web Intell. 2010, 2, 258–268. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Zhai, C. A survey of text clustering algorithms. In Mining Text Data; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Jung, K.; Kim, K.I.; Jain, A.K. Text information extraction in images and video: A survey. Pattern Recognit. 2004, 37, 977–997. [Google Scholar] [CrossRef]
- Card, S.K.; Mackinlay, J.D.; Shneiderman, B. Readings in Information Visualization: Using Vision to Think; Morgan Kaufmann Publishers: Burlington, MA, USA, 1999. [Google Scholar]
- Alencar, A.B.; de Oliveira, M.C.F.; Paulovich, F.V. Seeing beyond reading: A survey on visual text analytics. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 476–492. [Google Scholar] [CrossRef]
- Gan, Q.; Zhu, M.; Li, M.; Liang, T.; Cao, Y.; Zhou, B. Document Visualization: An Overview of Current Research. Wiley Interdiscip. Rev. Comput. Stat. 2014, 6, 19–36. [Google Scholar] [CrossRef]
- Nualart-Vilaplana, J.; Pérez-Montoro, M.; Whitelaw, M. How we draw texts: A review of approaches to text visualization and exploration. El Prof. Inf. 2014, 23, 221–235. [Google Scholar] [CrossRef]
- Cao, N.; Cui, W. Overview of Text Visualization Techniques. In Introduction to Text Visualization; Springer: Berlin/Heidelberg, Germany, 2016; pp. 11–40. [Google Scholar]
- Federico, P.; Heimerl, F.; Koch, S.; Miksch, S. A Survey on Visual Approaches for Analyzing Scientific Literature and Patents. IEEE Trans. Vis. Comput. Graph. 2016, 23, 2179–2198. [Google Scholar] [CrossRef] [PubMed]
- Wanner, F.; Stoffel, A.; Jäckle, D.; Kwon, B.C.; Weiler, A.; Keim, D.A. State-of-the-art report of visual analysis for event detection in text data streams. Comput. Graph. Forum 2014, 33, 1–15. [Google Scholar]
- Jänicke, S.; Franzini, G.; Cheema, M.F.; Scheuermann, G. On close and distant reading in digital humanities: A survey and future challenges. In Proceedings of the Eurographics Conference on Visualization (EuroVis) 2015, Cagliari, Italy, 25–29 May 2015. [Google Scholar]
- Steinbock, D. TagCrowd. Available online: http://www.tagcrowd.com/blog/about/ (accessed on 13 Feburary 2018).
- Viegas, F.B.; Wattenberg, M.; Feinberg, J. Participatory visualization with wordle. IEEE Trans. Vis. Comput. Graph. 2009, 15, 1137–1144. [Google Scholar] [CrossRef]
- Skupin, A. A cartographic approach to visualizing conference abstracts. IEEE Comput. Graph. Appl. 2002, 22, 50–58. [Google Scholar] [CrossRef]
- Wise, J.A. The ecological approach to text visualization. J. Assoc. Inf. Sci. Technol. 1999, 50, 1224. [Google Scholar] [CrossRef]
- Andrews, K.; Kienreich, W.; Sabol, V.; Becker, J.; Droschl, G.; Kappe, F.; Granitzer, M.; Auer, P.; Tochtermann, K. The infosky visual explorer: Exploiting hierarchical structure and document similarities. Inf. Vis. 2002, 1, 166–181. [Google Scholar] [CrossRef]
- Strobelt, H.; Oelke, D.; Rohrdantz, C.; Stoffel, A.; Keim, D.A.; Deussen, O. Document cards: A top trumps visualization for documents. IEEE Trans. Vis. Comput. Graph. 2009, 15, 1145–1152. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.W.; Huang, L.C. Detecting and Visualizing Emerging Trends and Transient Patterns in Fuel Cell Scientific Literature. In Proceedings of the International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 19–21 September 2008. [Google Scholar]
- Lee, B.; Riche, N.H.; Karlson, A.K.; Carpendale, S. Sparkclouds: Visualizing trends in tag clouds. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1182–1189. [Google Scholar] [PubMed]
- Hearst, M.A. TileBars: Visualization of term distribution information in full text information access. In Proceedings of the Human Factors in Computing Systems, CHI ’95 Conference Proceedings, Denver, CO, USA, 7–11 May 1995. [Google Scholar]
- Shneiderman, B. The eyes have it: A task by data type taxonomy for information visualizations. In The Craft of Information Visualization; Elsevier: Amsterdam, The Netherlands, 1996. [Google Scholar]
- Andrienko, N.; Andrienko, G. Exploratory Analysis of Spatial and Temporal Data: A Systematic Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Moretti, F. Graphs, Maps, Trees: Abstract Models for a Literary History; Verso: New York, NY, USA, 2005. [Google Scholar]
- Google Books. Available online: https://books.google.com/ (accessed on 17 April 2017).
- Keim, D.; Ellis, G.; Mansmann, F. Mastering the information age solving problems with visual analytics. Eurographics 2010, 2, 5. [Google Scholar]
- Cui, W.; Liu, S.; Tan, L.; Shi, C.; Song, Y.; Gao, Z.; Qu, H.; Tong, X. Textflow: Towards better understanding of evolving topics in text. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2412–2421. [Google Scholar] [CrossRef] [PubMed]
- Luo, D.; Yang, J.; Krstajic, M.; Ribarsky, W.; Keim, D. Eventriver: Visually exploring text collections with temporal references. IEEE Trans. Vis. Comput. Graph. 2012, 18, 93–105. [Google Scholar] [PubMed]
- Cao, N.; Sun, J.; Lin, Y.R.; Gotz, D.; Liu, S.; Qu, H. Facetatlas: Multifaceted visualization for rich text corpora. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1172–1181. [Google Scholar] [PubMed]
- Mueller, A. Word_cloud: A Little Word Cloud Generator in Python. Available online: https://github.com/amueller/word_cloud (accessed on 15 December 2018).
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Alharbi, M.; Laramee, R.S. Parallel Coordinates of SoS. Available online: http://cs.swan.ac.uk/~msalharbi/pc_public/ (accessed on 15 November 2018).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Conferences & Journals | Papers |
|---|---|
| Springer | 4 |
| The Annual EuroVis Conference/Computer Graphics Forum | 3 |
| Wiley Online Library | 3 |
| IEEE Transactions on Visualization and Computer Graphics | 2 |
| El profesional de la información | 1 |
| Journal of Visual Languages & Computing | 0 |
| Information Visualization Journal | 0 |
| ACM Computing Surveys | 0 |
| Proceedings of the Annual Conference of the Alliance of Digital Humanities Organizations | 0 |
| Literary and Linguistic Computing | 0 |
| Digital Humanities Quarterly | 0 |
| Total | 14 |
| Document-Centered | User Task Analysis | Multi-Faceted | Cross-Disciplinary | Satellite-Themed |
|---|---|---|---|---|
| Alencar et al. [21] Gan et al. [22] Nualart-Vilaplana et al. [23] | Cau and Cui [24] Federico et al. [25] | Šilić and Bašić [5] Wanner et al. [26] Kucher and Kerren [4] Kucher et al. [9] Liu et al. [11] | Jänicke et al. [27] Jänicke et al. [10] | Sun et al. [15] Liu et al. [16] |
| Future Challenges | SoS [7] | [5] | [21] | [15] | [22] | [23] | [26] | [16] | [4] | [27] | [25] | [24] | [9] | [10] | [11] | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Scalability | √ | √ | √ | √ | √ | √ | √ | √ | √ | 9 | ||||||
| Lacking in-depth/effective quantitative or qualitative evaluation | √ | √ | √ | √ | √ | √ | √ | √ | √ | 9 | ||||||
| Adopting advanced linguistics techniques | √ | √ | √ | √ | √ | √ | √ | √ | 8 | |||||||
| Natural language ambiguity and uncertainty | √ | √ | √ | √ | √ | √ | 6 | |||||||||
| Lacking user interactivity that support the analysis tasks | √ | √ | √ | √ | √ | 5 | ||||||||||
| Designing general models for different tasks (versatility) | √ | √ | √ | √ | 4 | |||||||||||
| Multidisciplinary framework | √ | √ | √ | 3 | ||||||||||||
| Lacking of cognitive and/or psychological analysis | √ | √ | 2 | |||||||||||||
| Lacking well-defined general concepts | √ | √ | 2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alharbi, M.; Laramee, R.S. SoS TextVis: An Extended Survey of Surveys on Text Visualization. Computers 2019, 8, 17. https://doi.org/10.3390/computers8010017
Alharbi M, Laramee RS. SoS TextVis: An Extended Survey of Surveys on Text Visualization. Computers. 2019; 8(1):17. https://doi.org/10.3390/computers8010017
Chicago/Turabian StyleAlharbi, Mohammad, and Robert S. Laramee. 2019. "SoS TextVis: An Extended Survey of Surveys on Text Visualization" Computers 8, no. 1: 17. https://doi.org/10.3390/computers8010017
APA StyleAlharbi, M., & Laramee, R. S. (2019). SoS TextVis: An Extended Survey of Surveys on Text Visualization. Computers, 8(1), 17. https://doi.org/10.3390/computers8010017