Feature-Rich, GPU-Assisted Scatterplots for Millions of Call Events

 , ,
, ,
Abstract
:1. Introduction and Motivation
- A novel feature-rich interactive scatterplot application that visualizes 5,000,000 calls
- The ability to track customers over multiple calls
- Advanced interactive and hardware accelerated filtering of call and customer parameters with evaluation of performance
- Multiple methods of exploring call variables including animation features
- The reaction and feedback from partner domain experts in the call center industry
2. Related Work
2.1. Information Visualization and Hardware Acceleration
2.2. Call Center Analysis Literature
3. Call Center Data Characteristics
4. Hardware Accelerated Scatterplots
- Fully interactive zooming on two independent axes
- User-chosen axis variables (see Table 1)
- GPU enhanced filtering of multiple call attributes
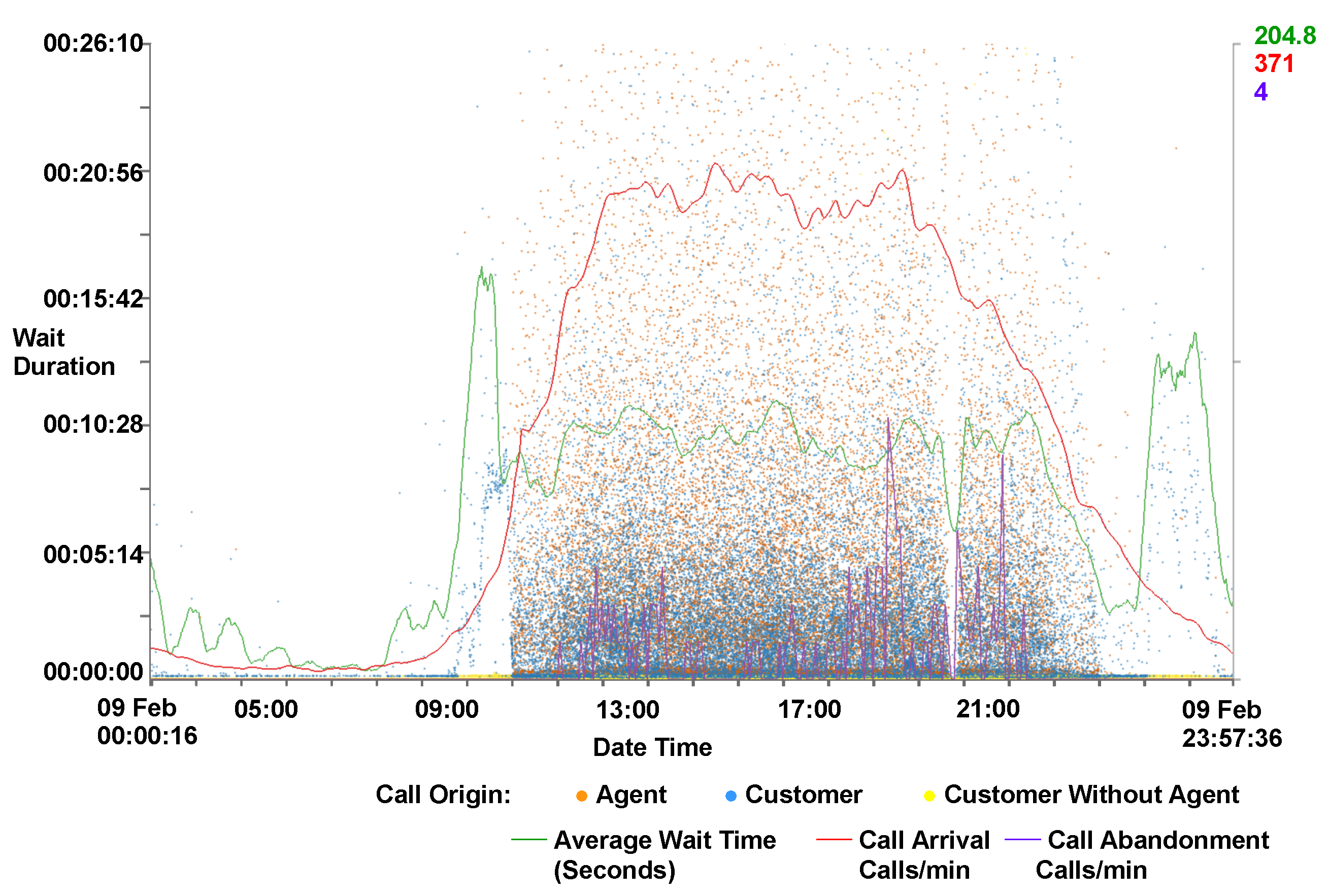
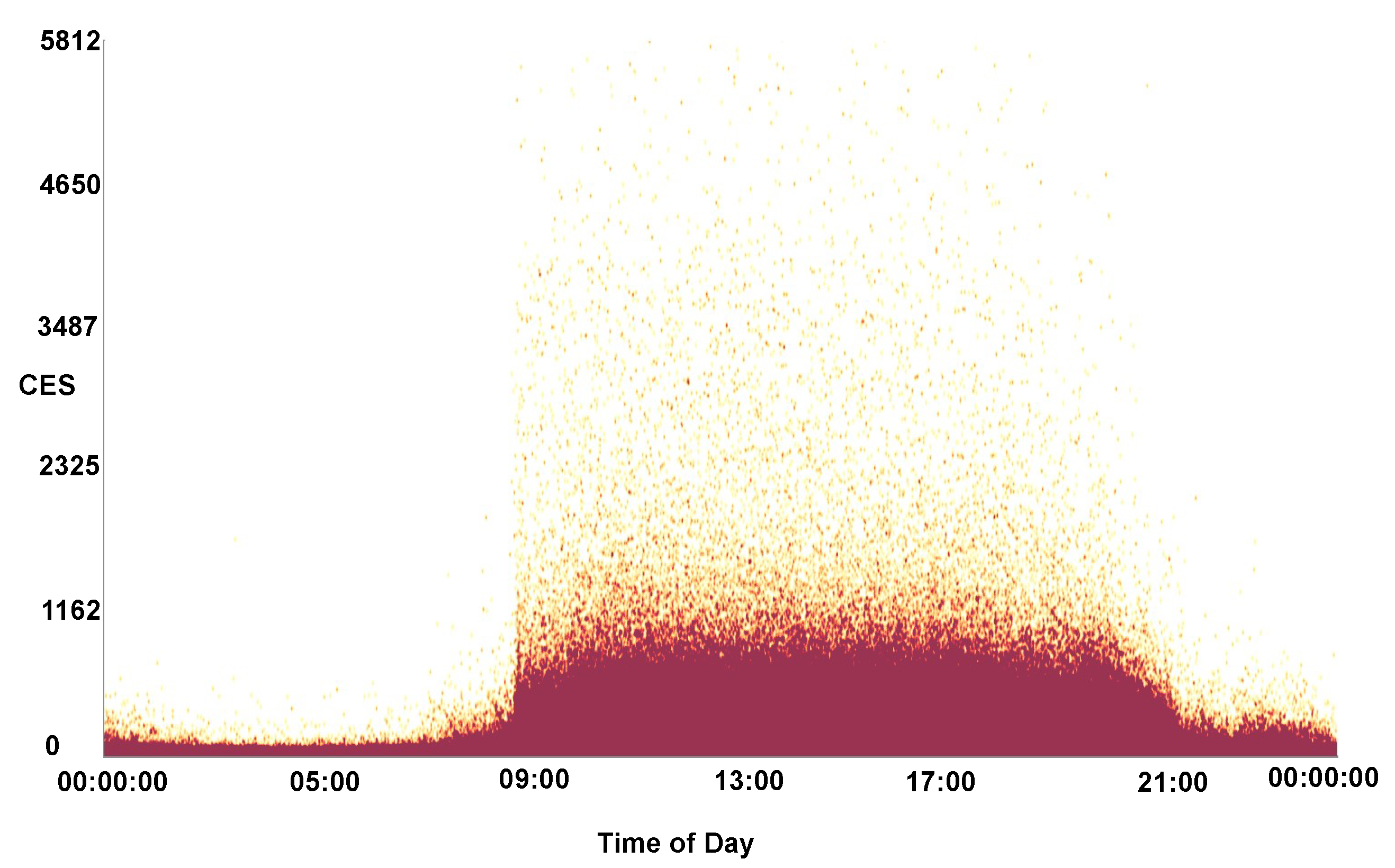
- Animation of call arrival
- Brushing data points for details on demand
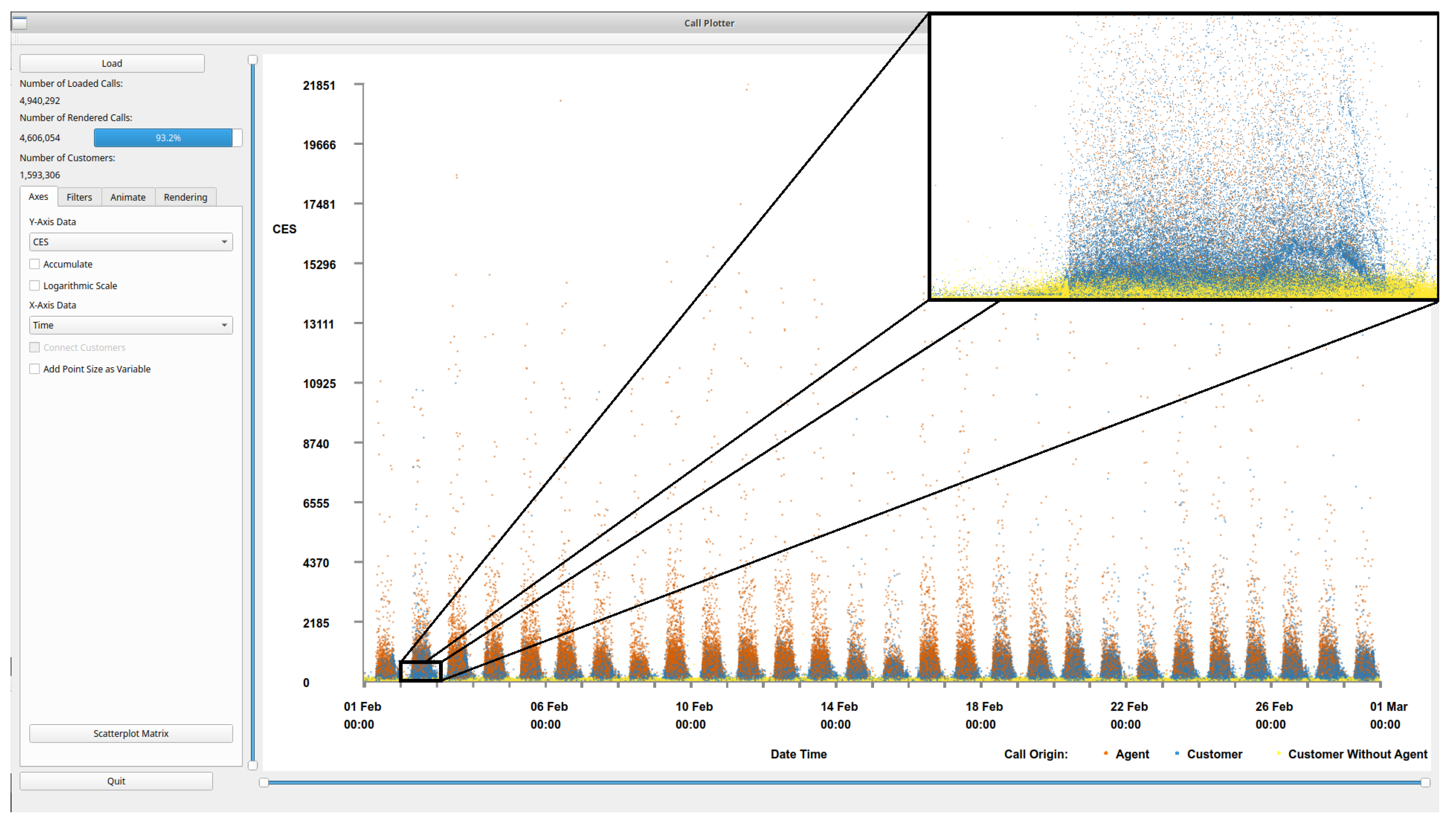
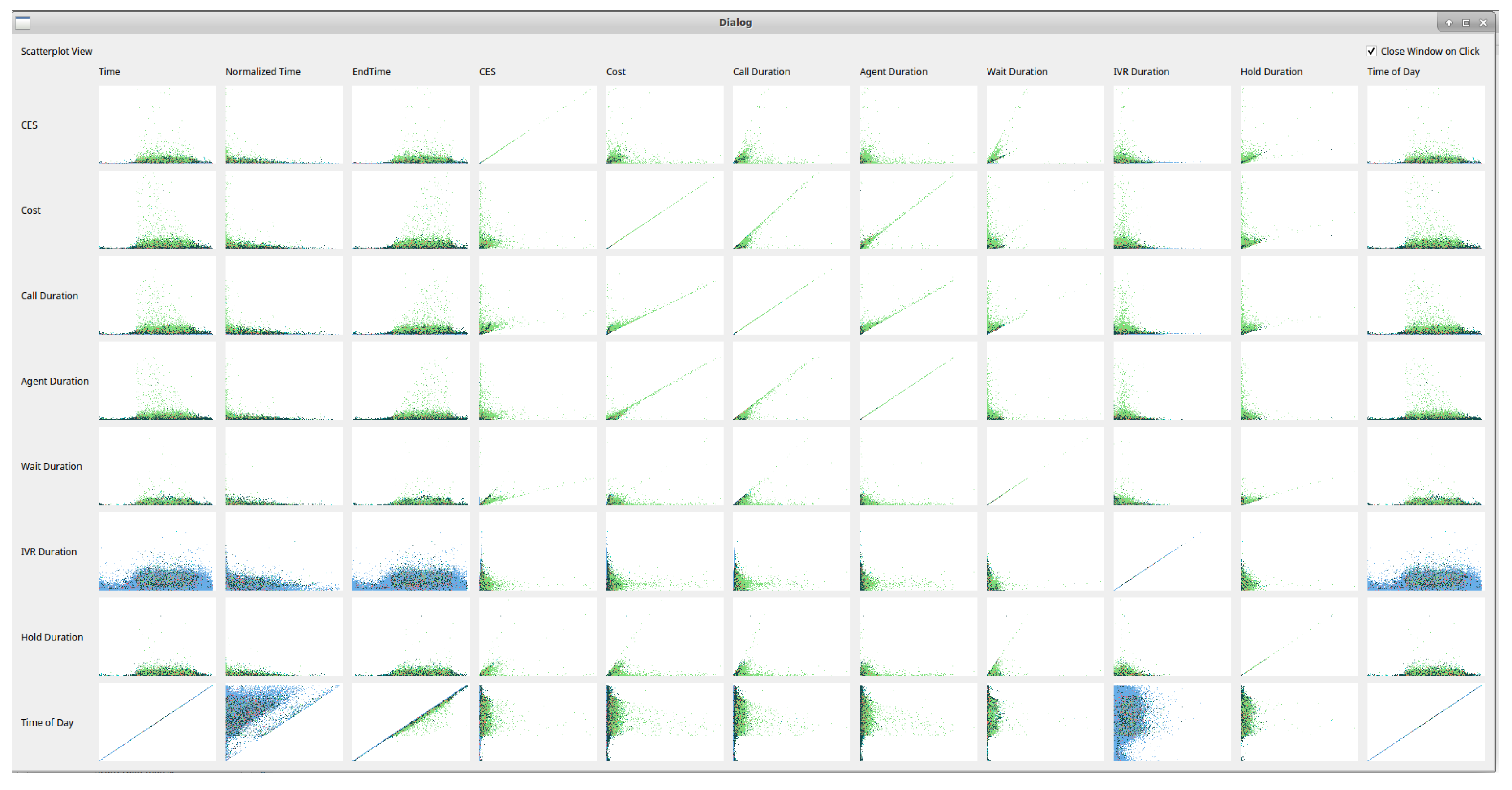
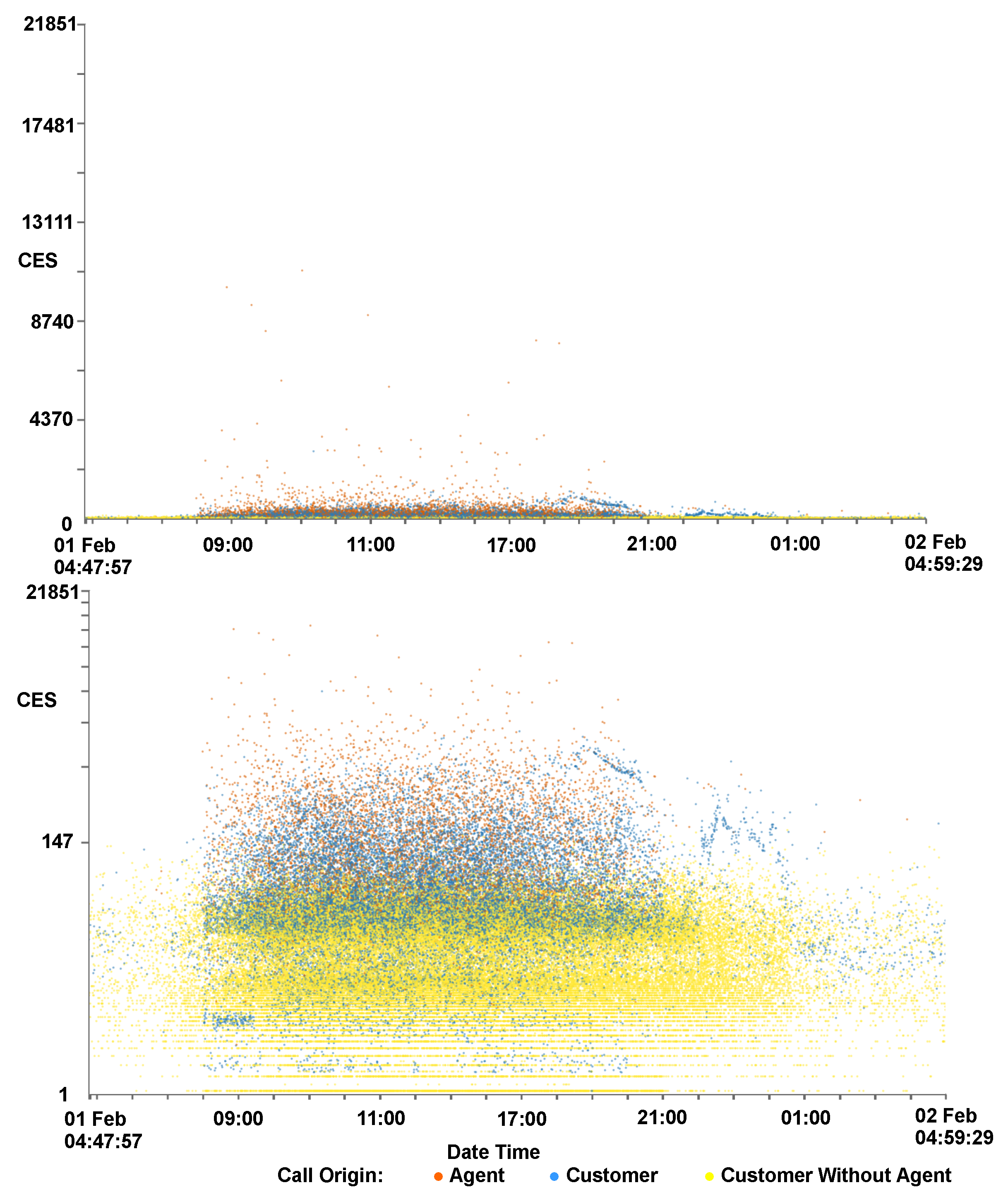
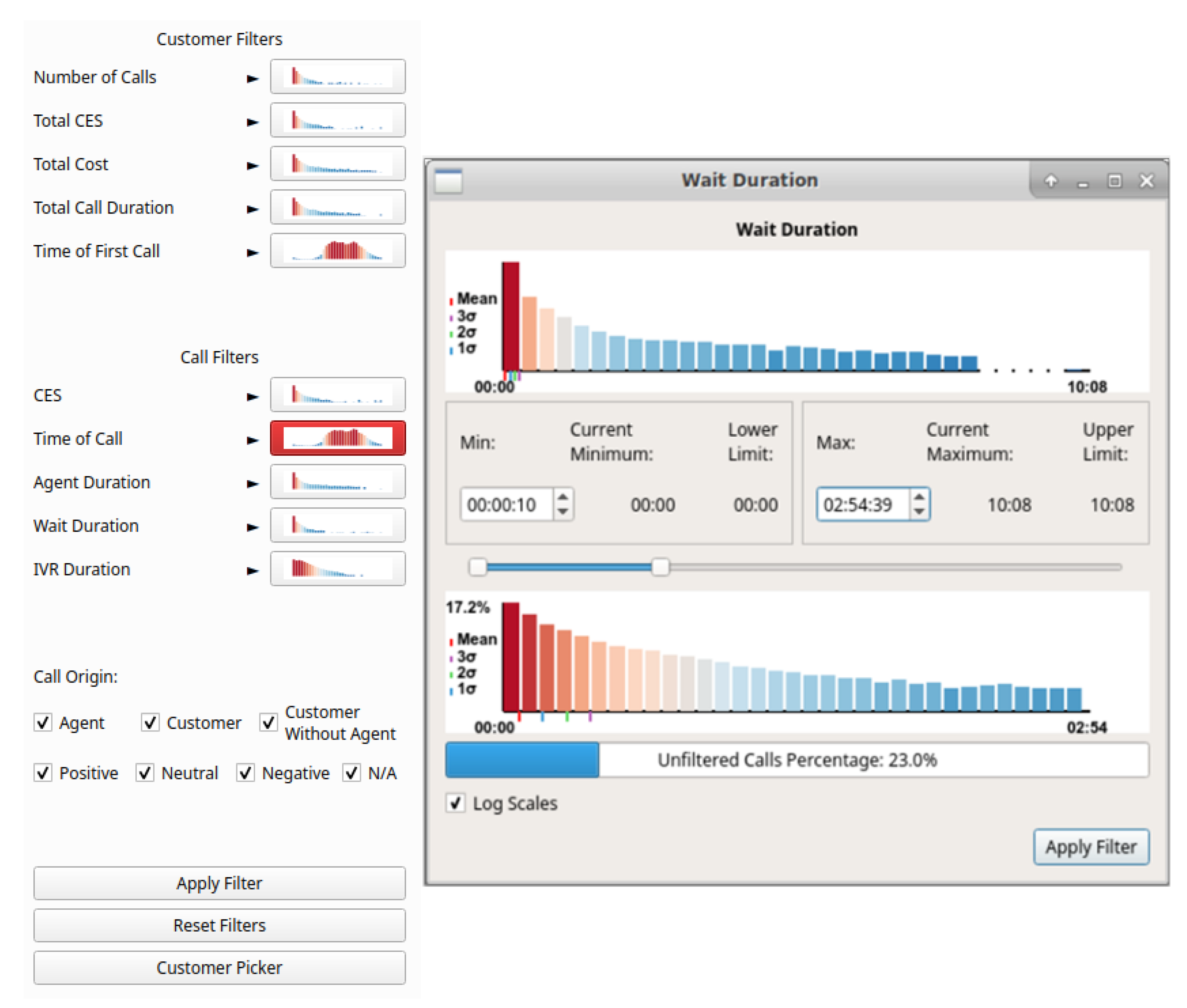
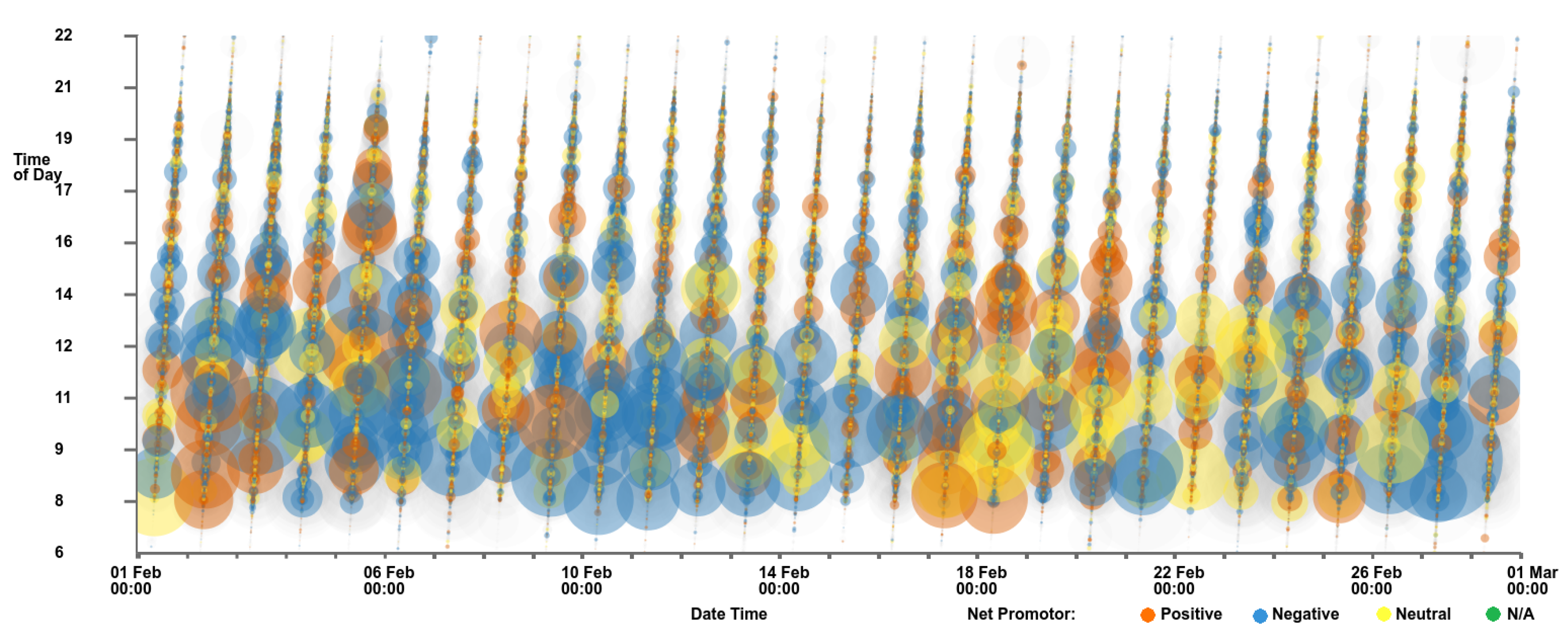
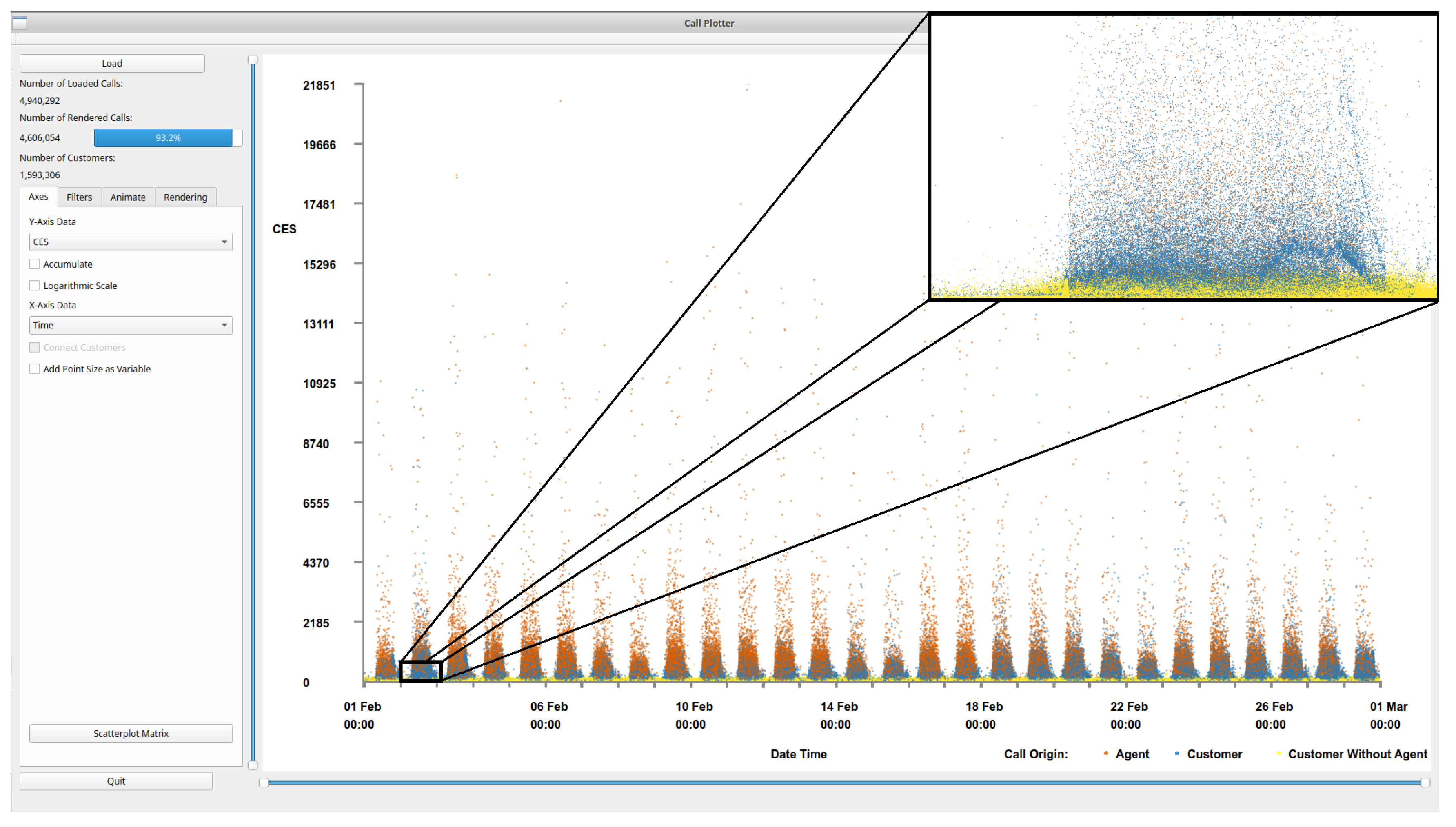
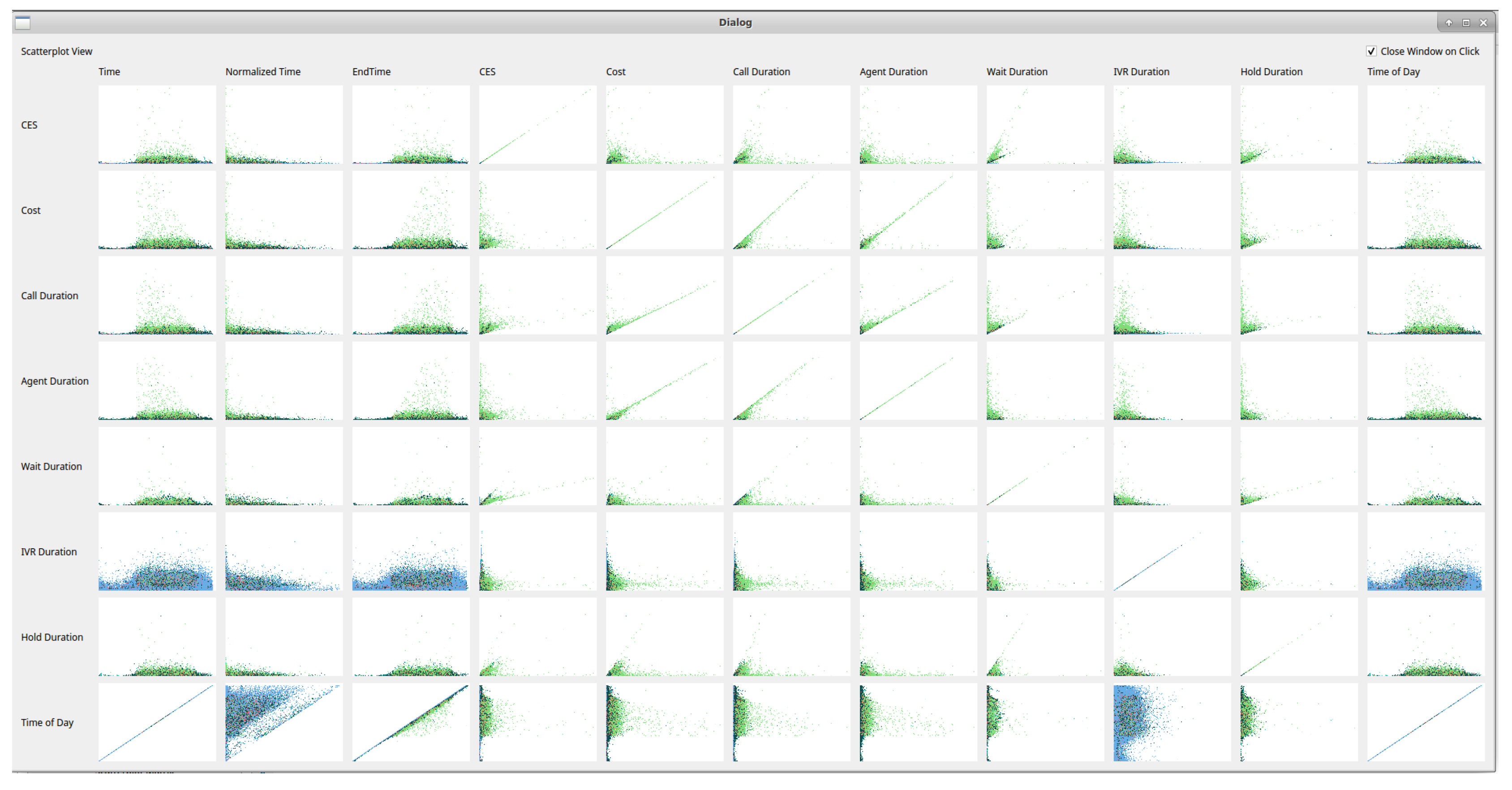
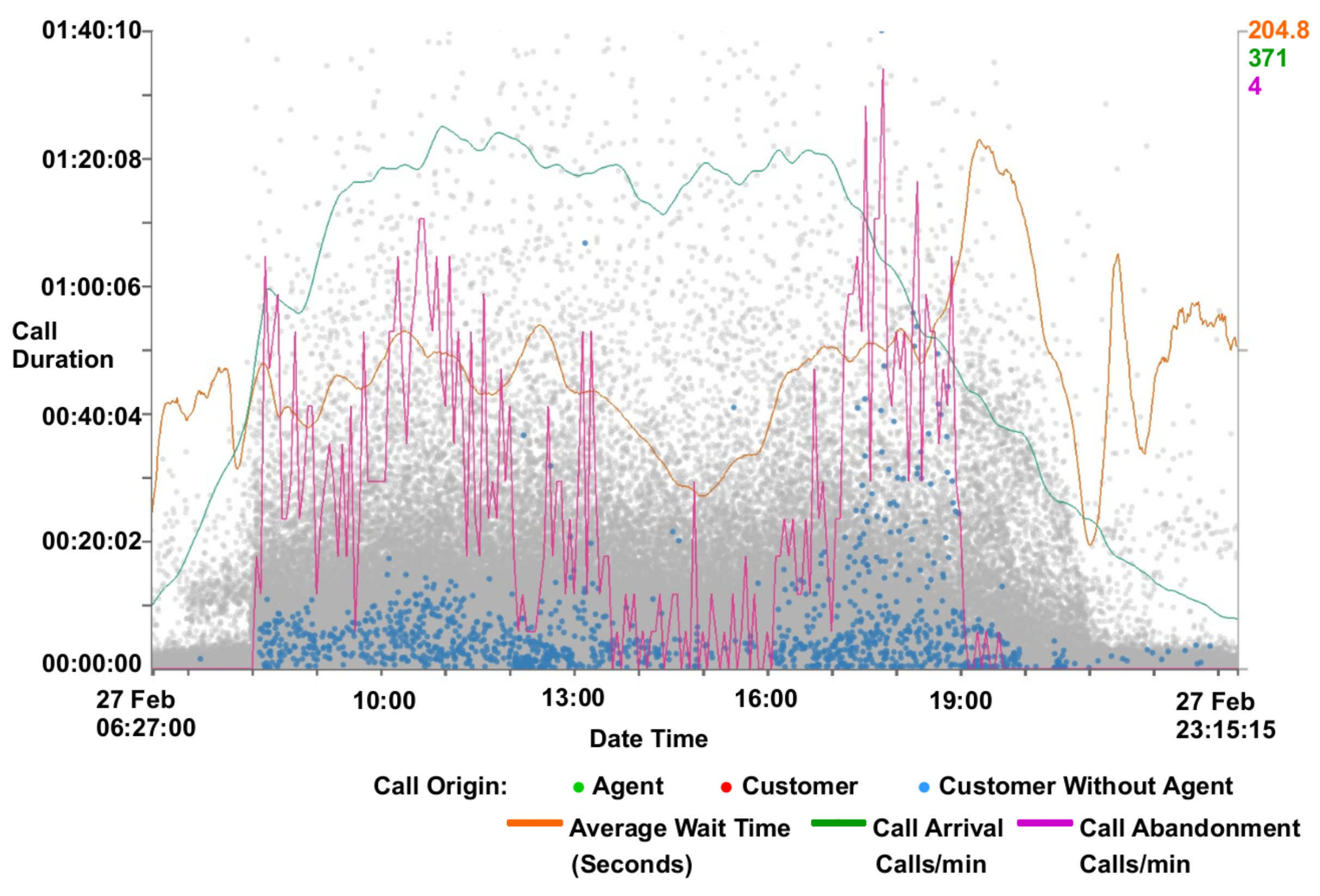
4.1. Scatterplots View

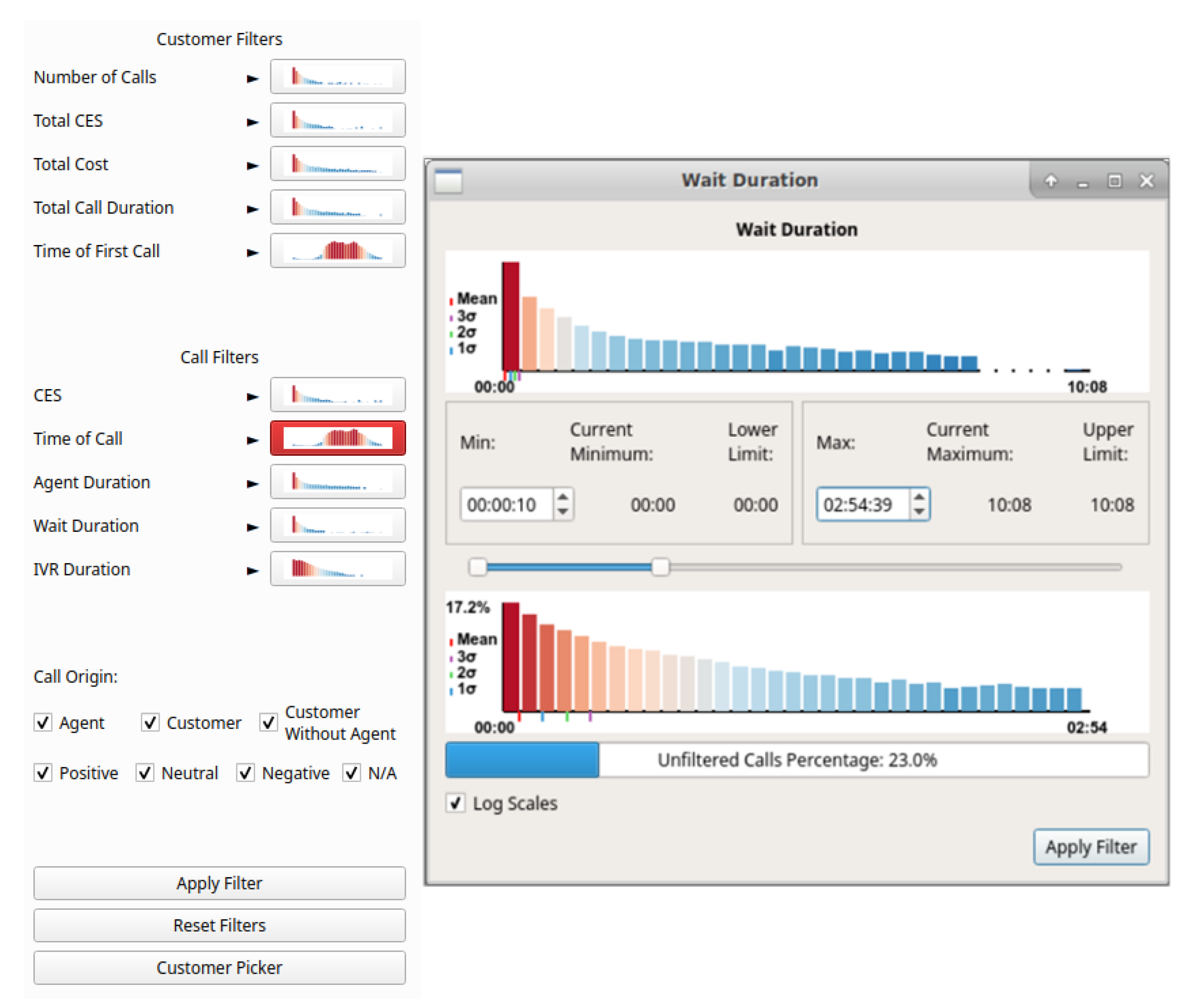
4.2. GPU Enhanced Filtering

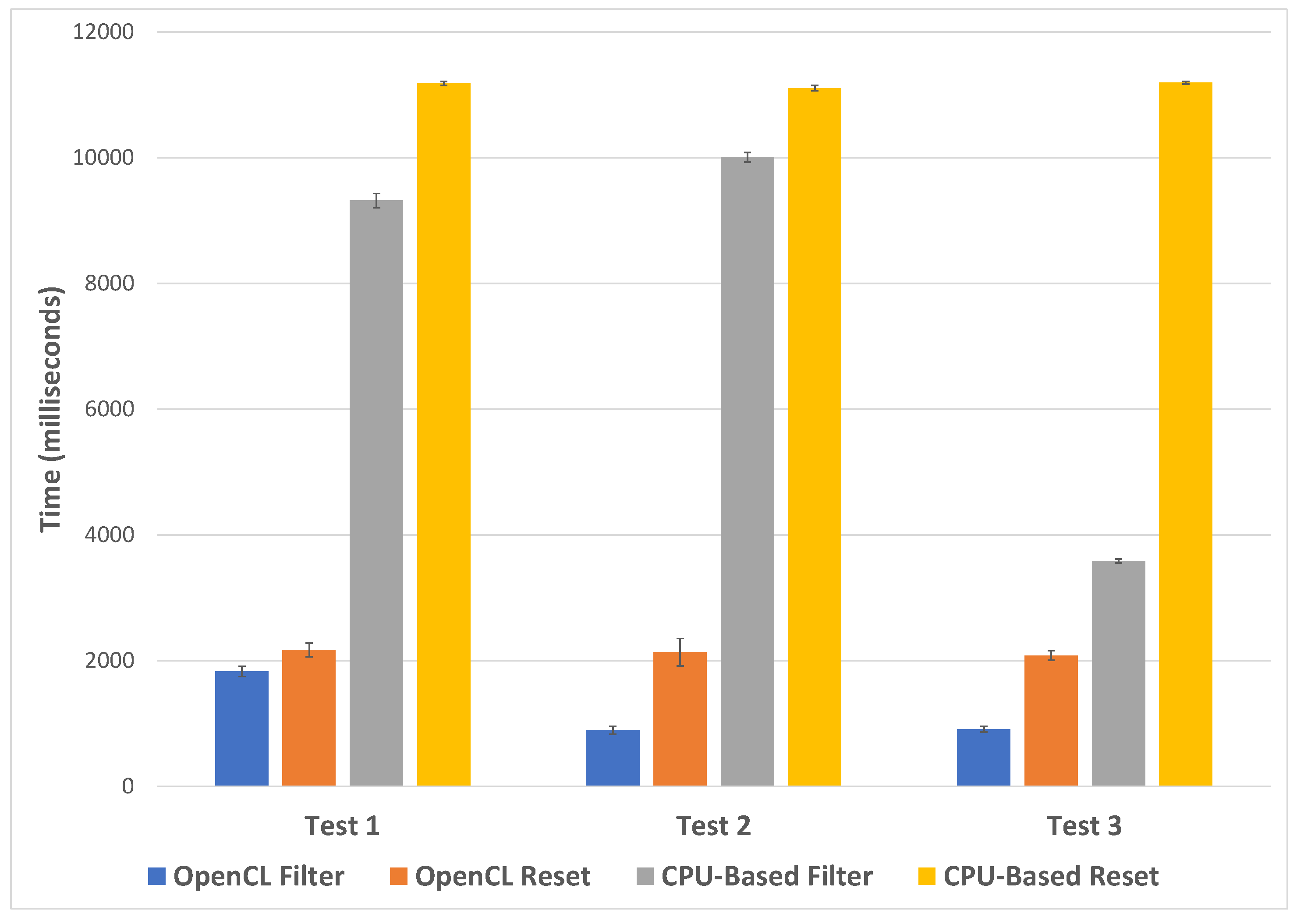
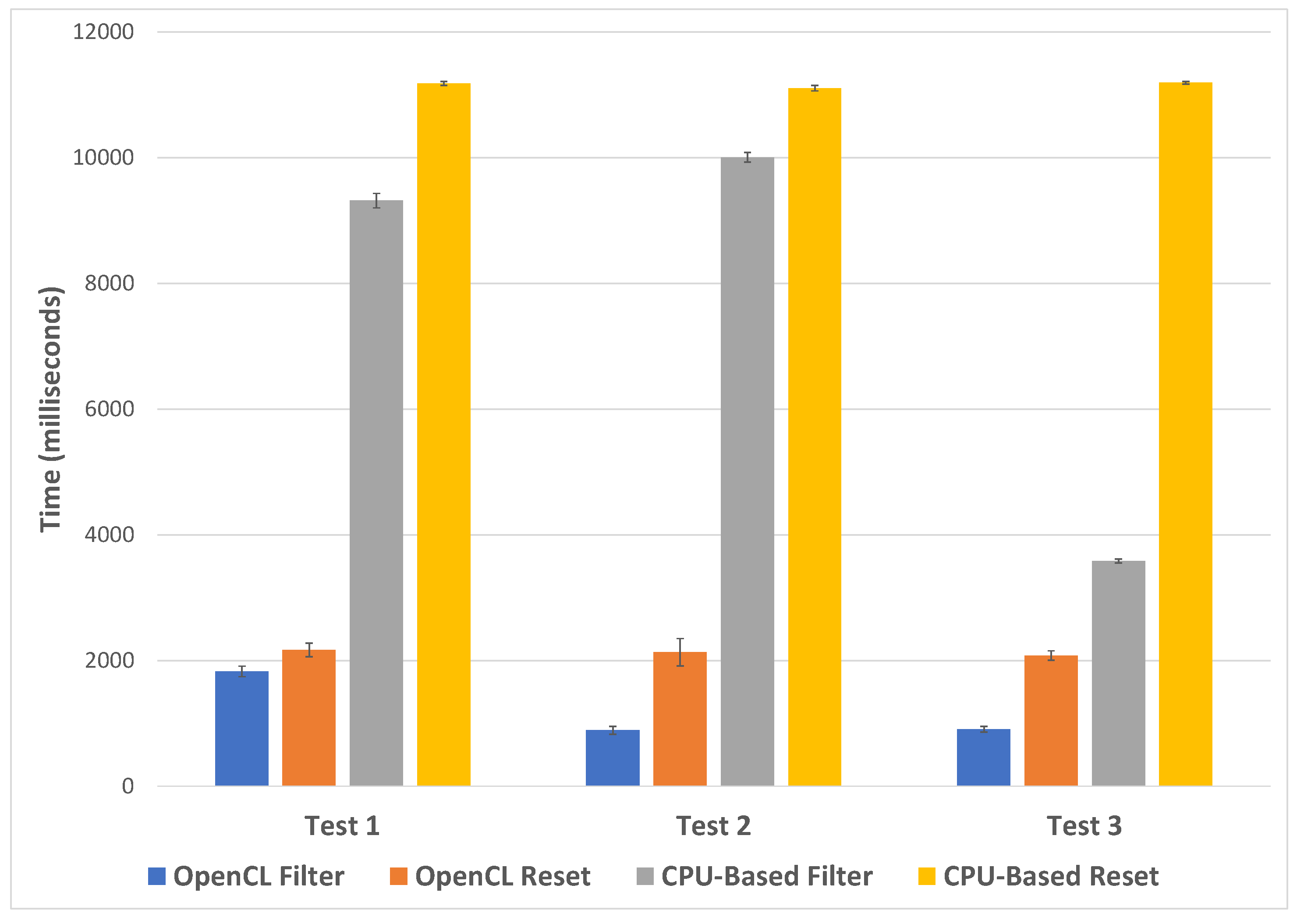
4.3. CPU vs. GPU Filtering Performance Comparison
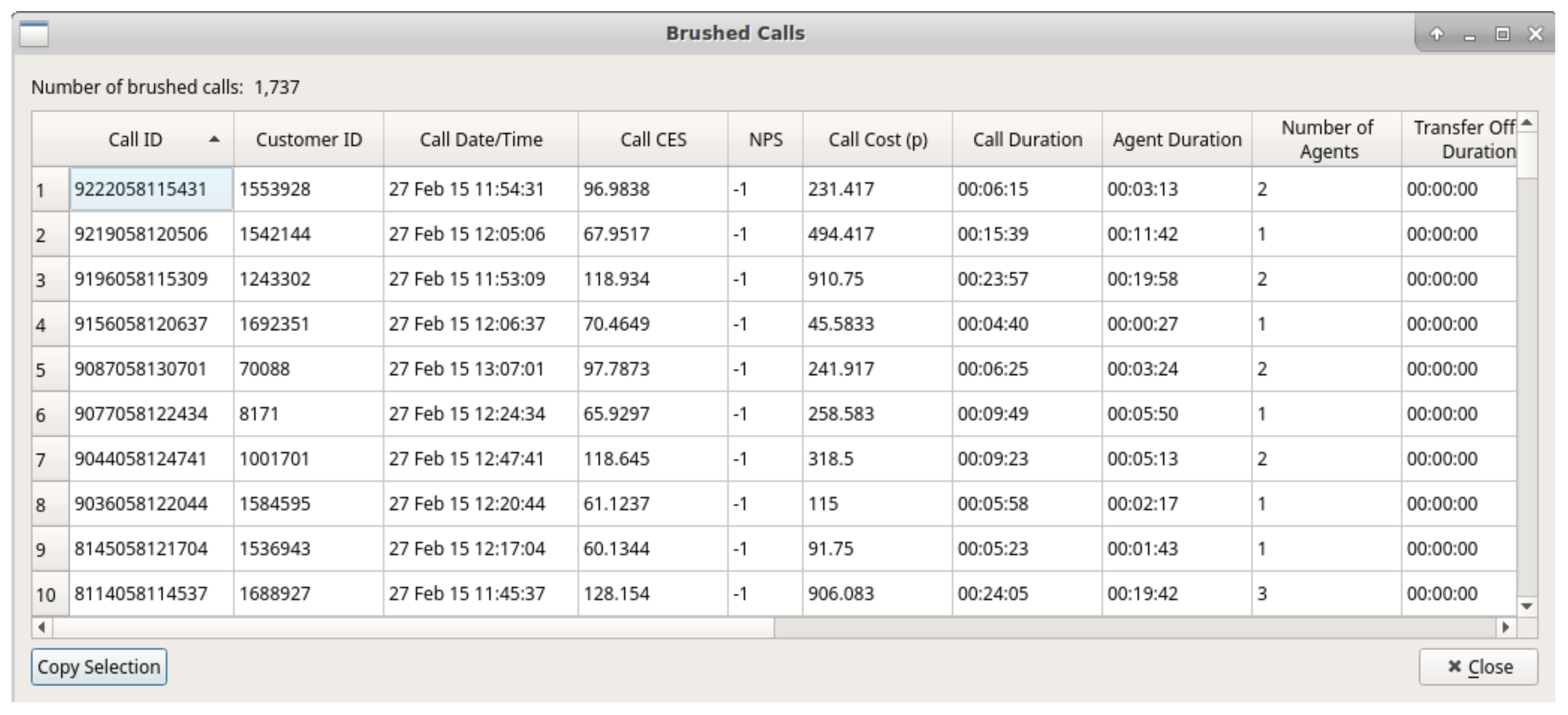
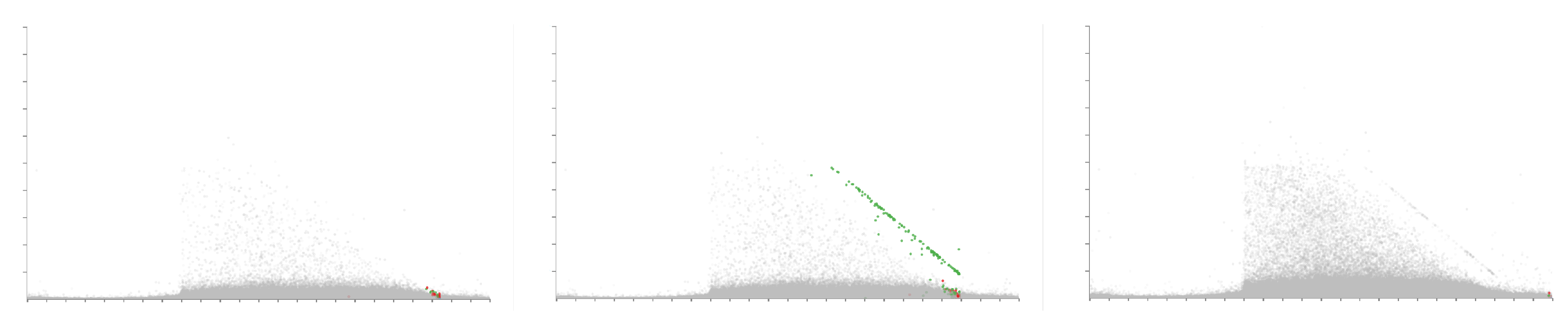
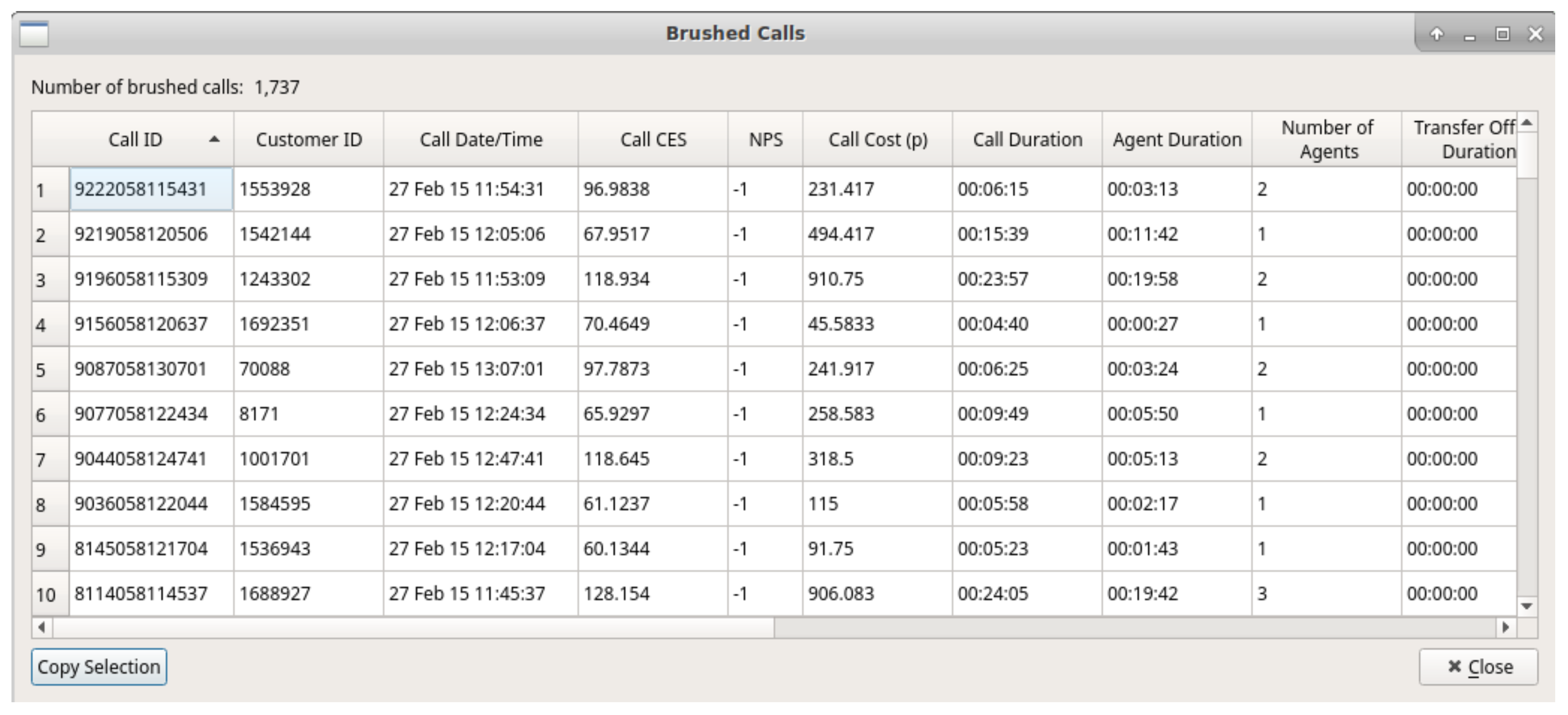
4.4. Brushing for Details
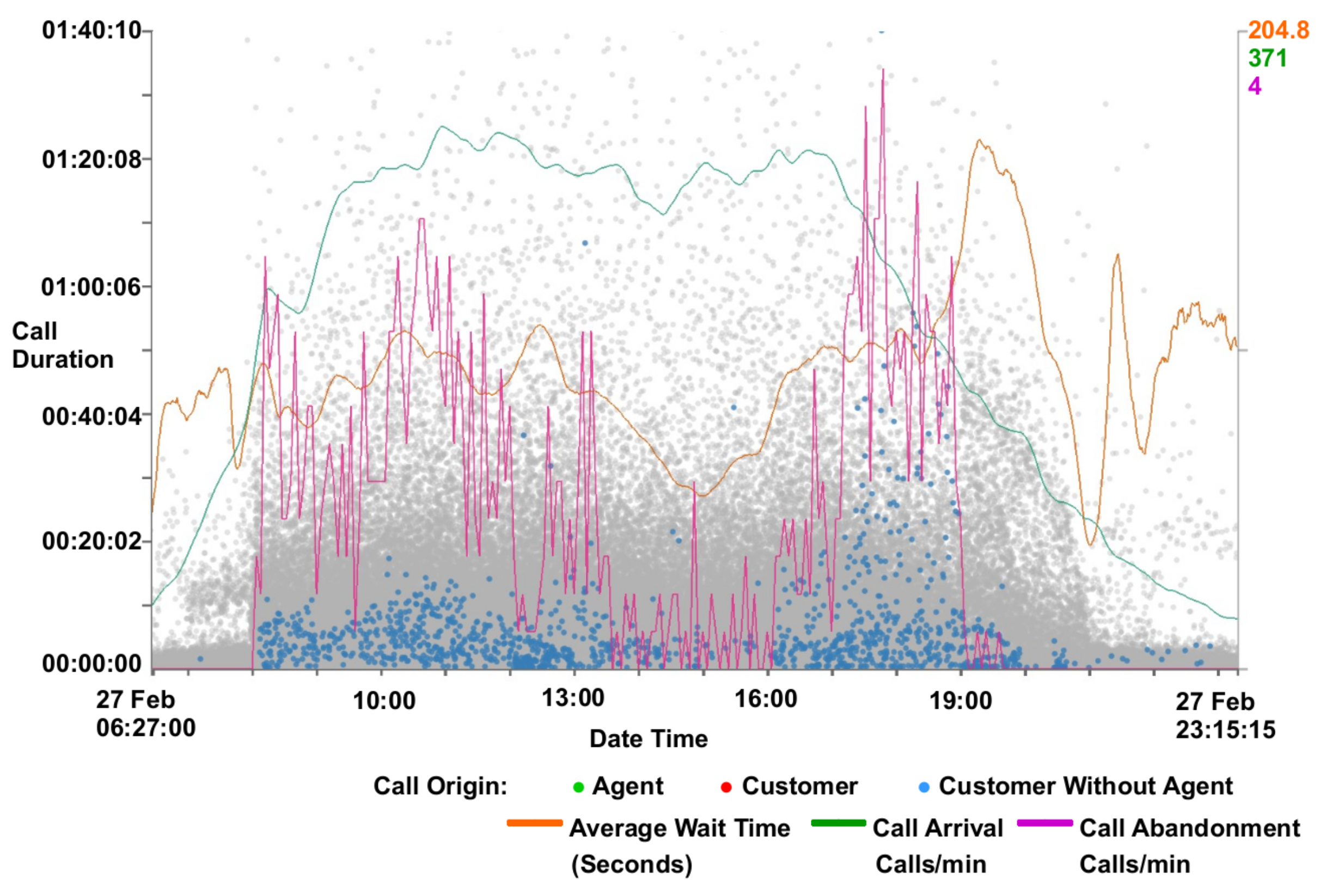
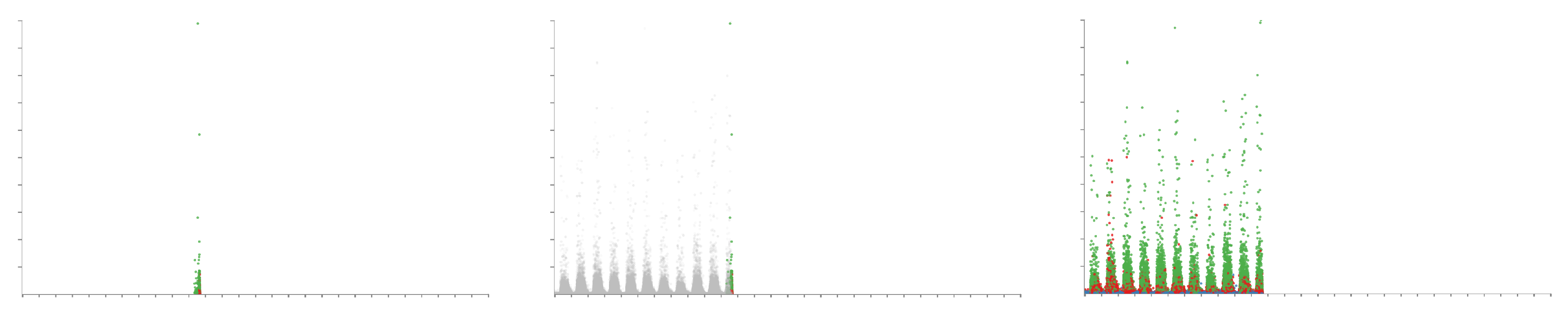
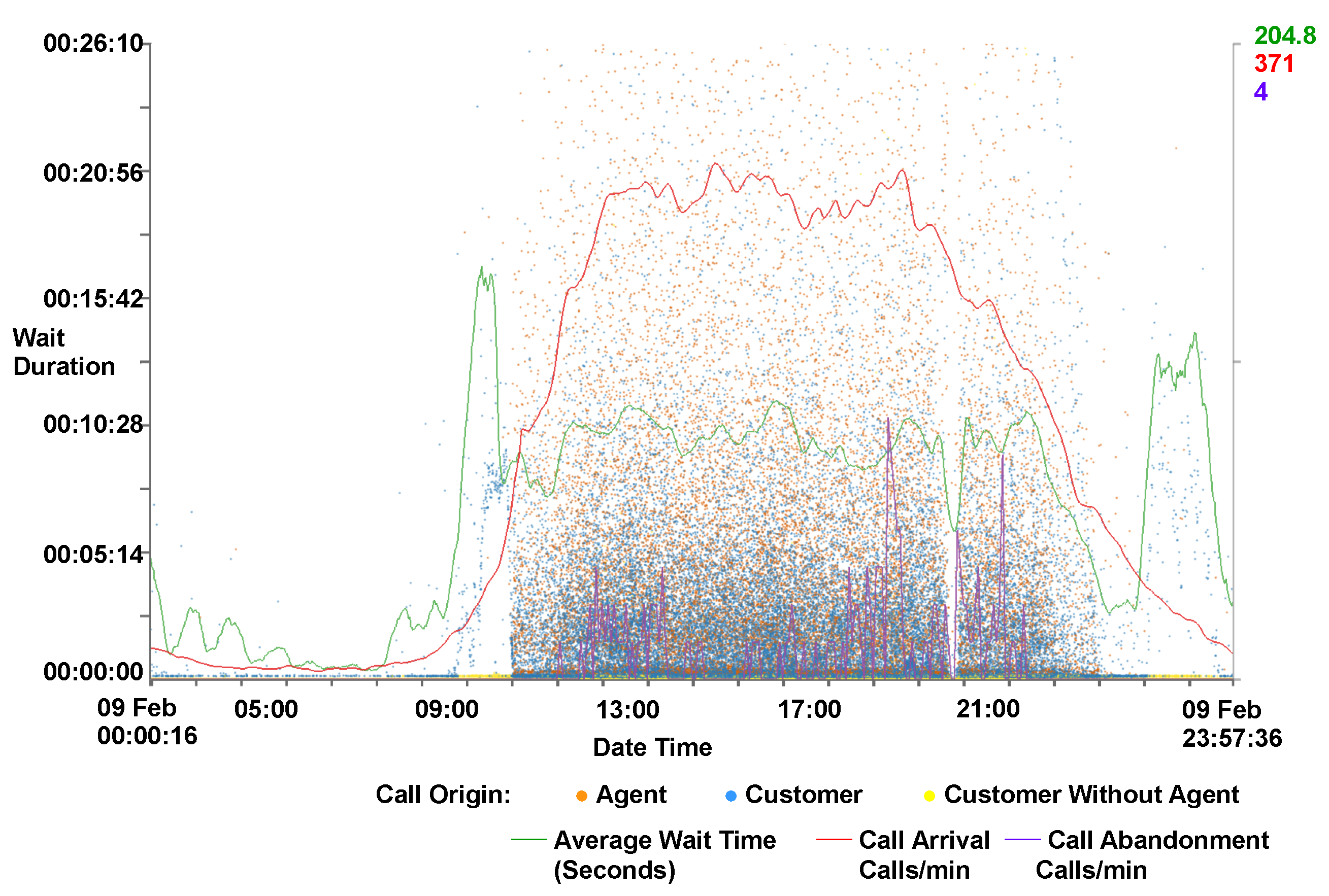
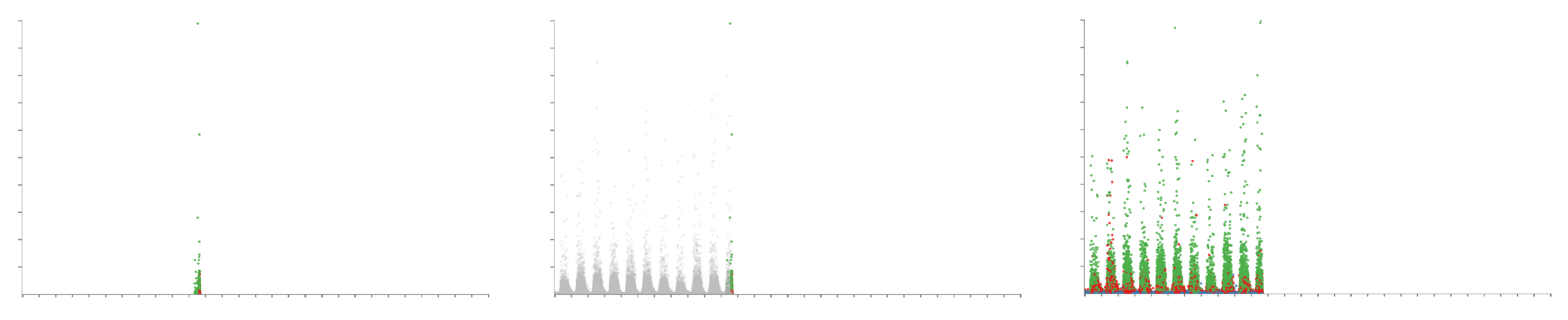
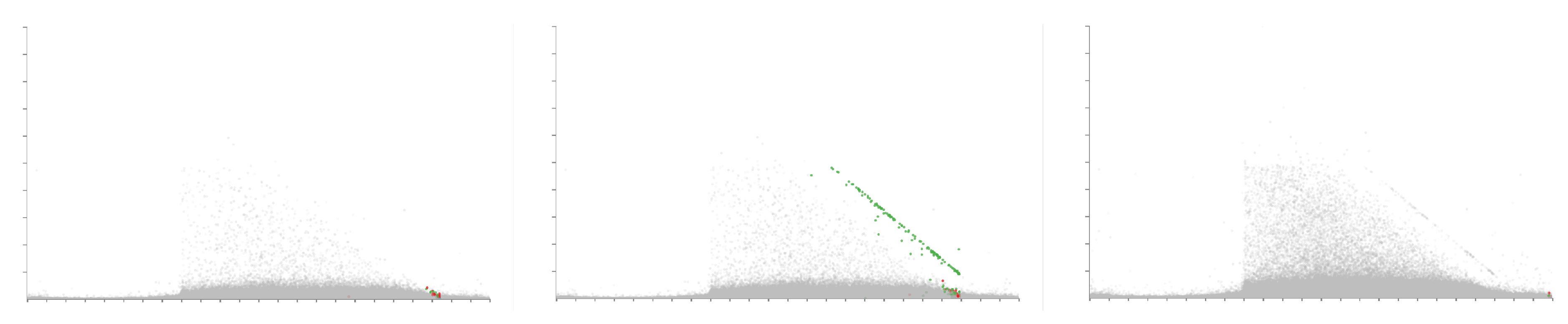
4.5. Animation
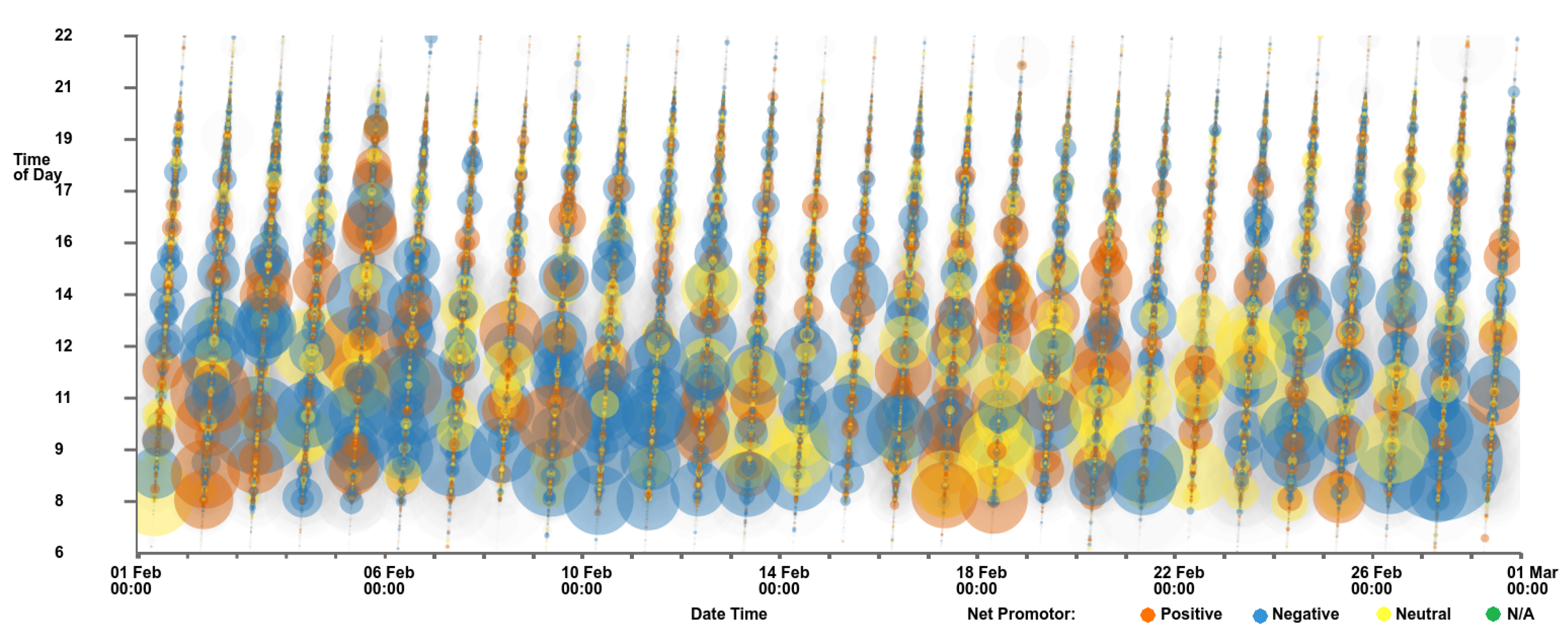
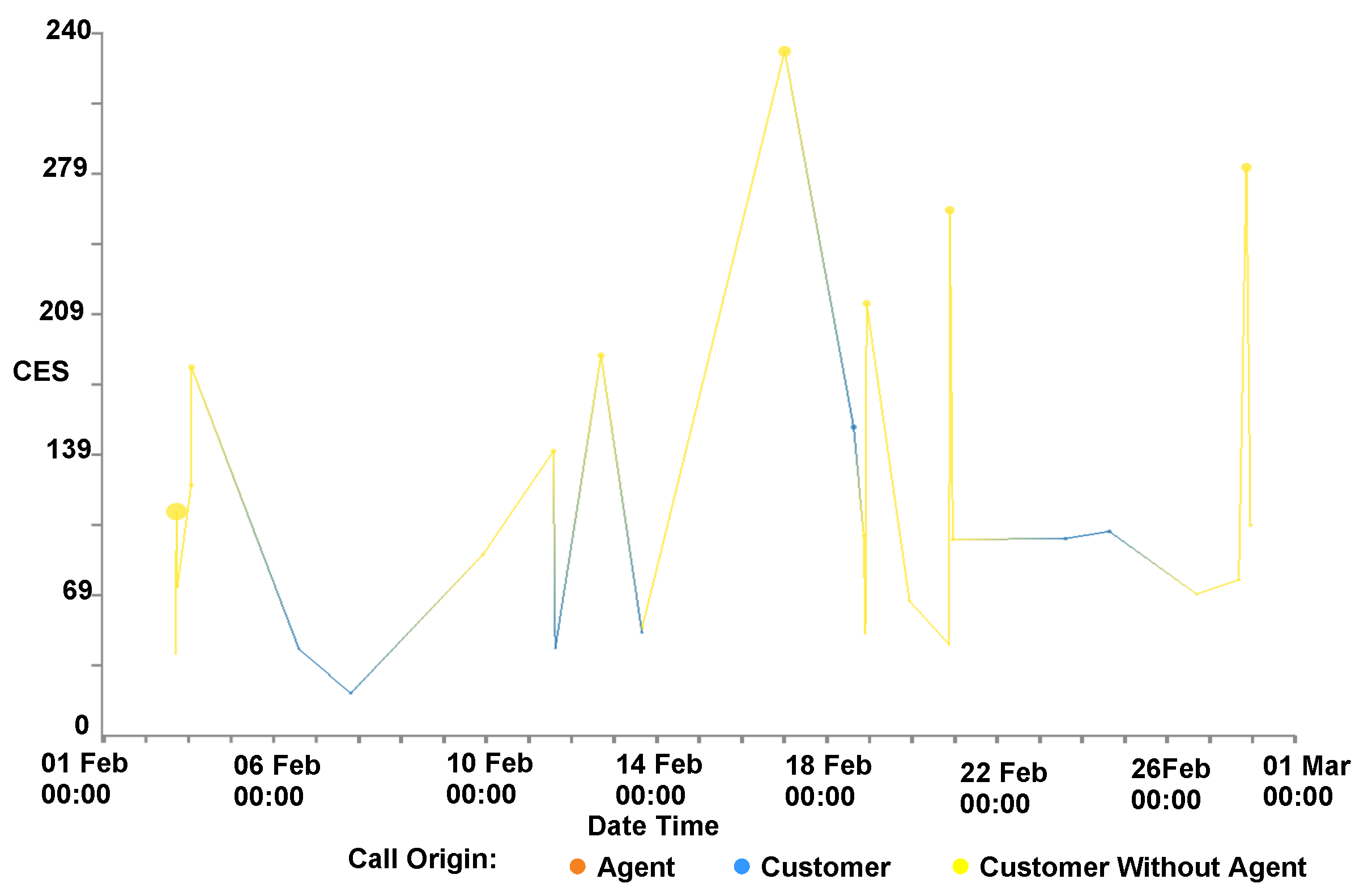
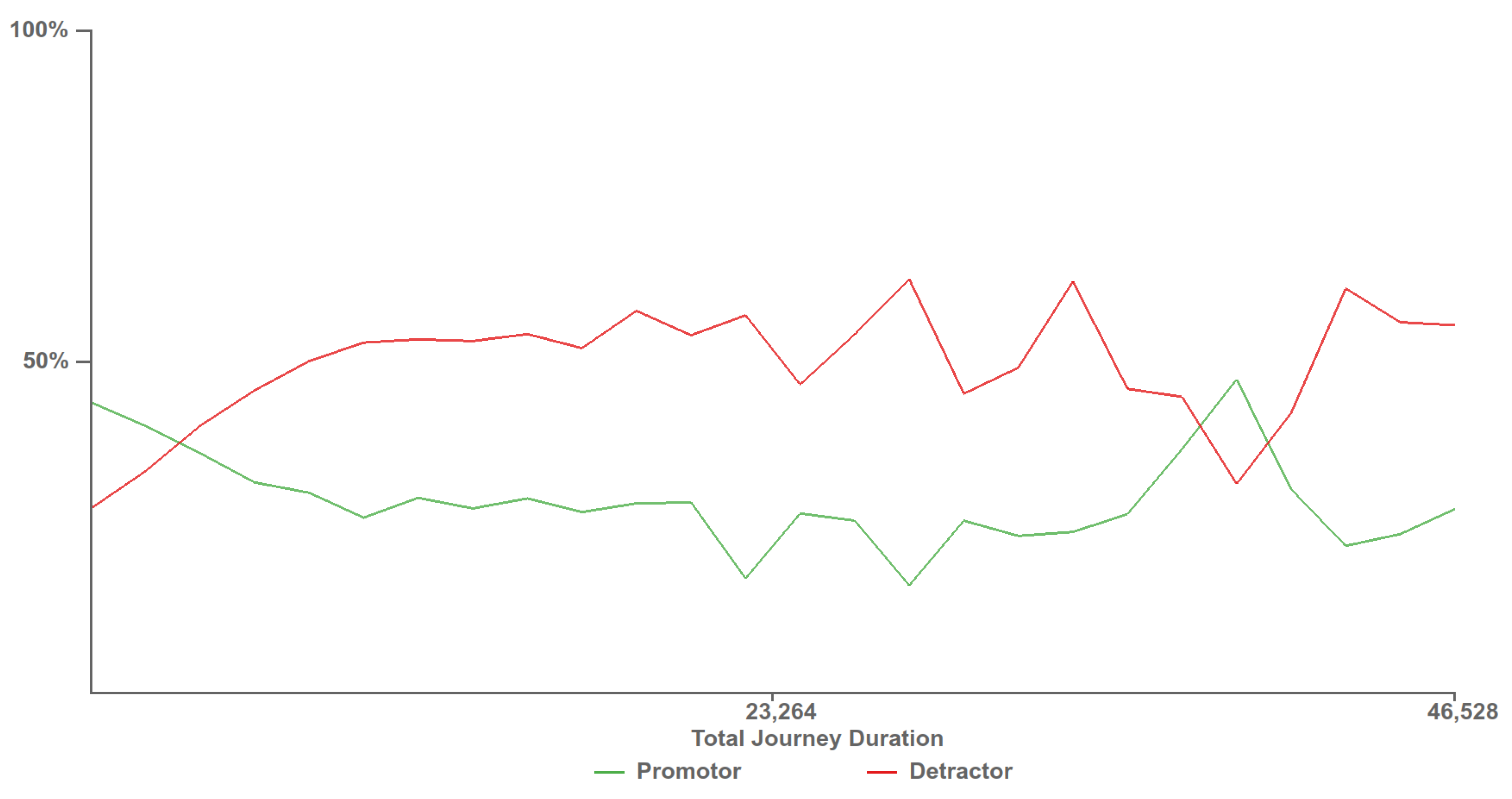
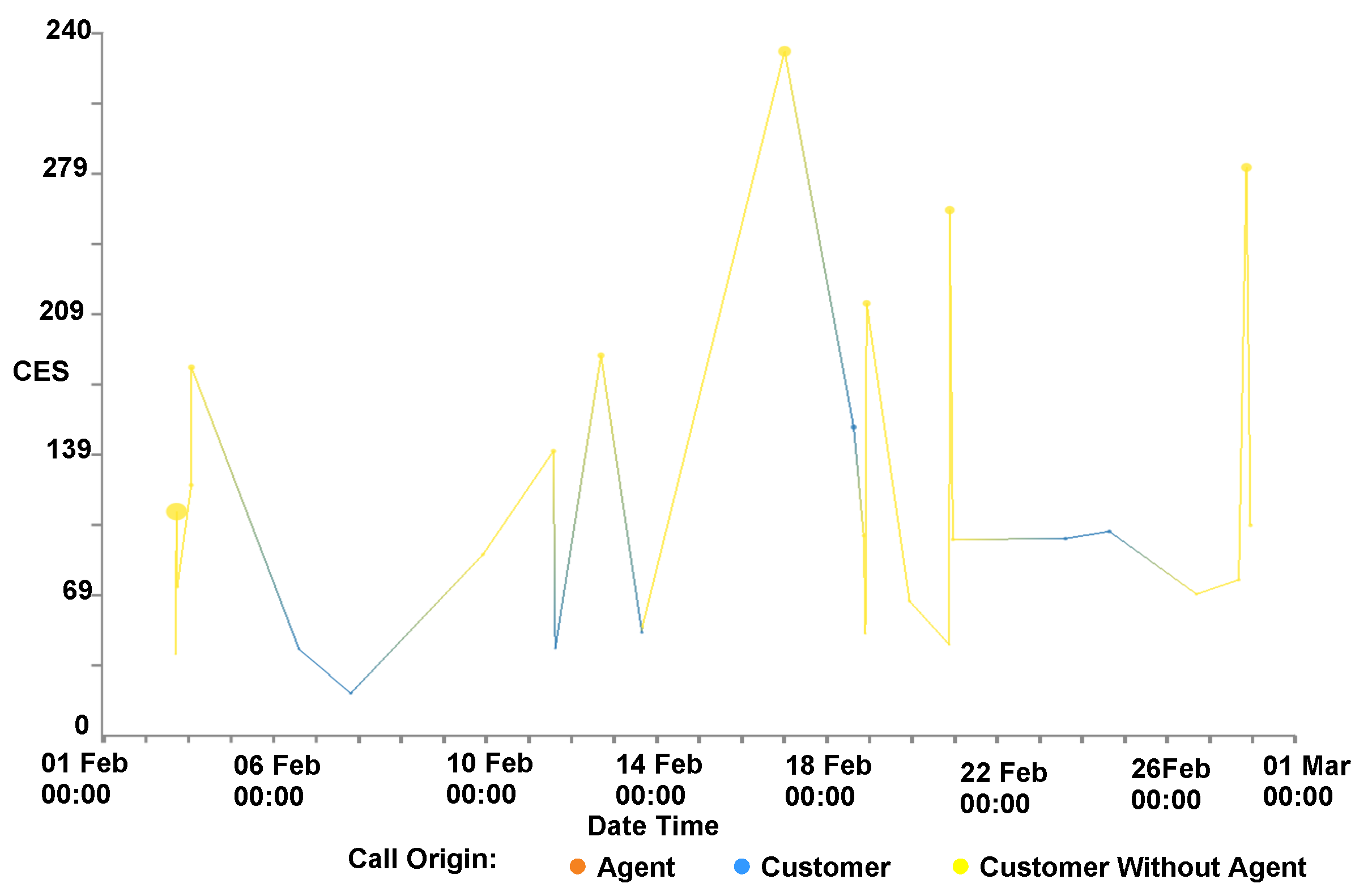
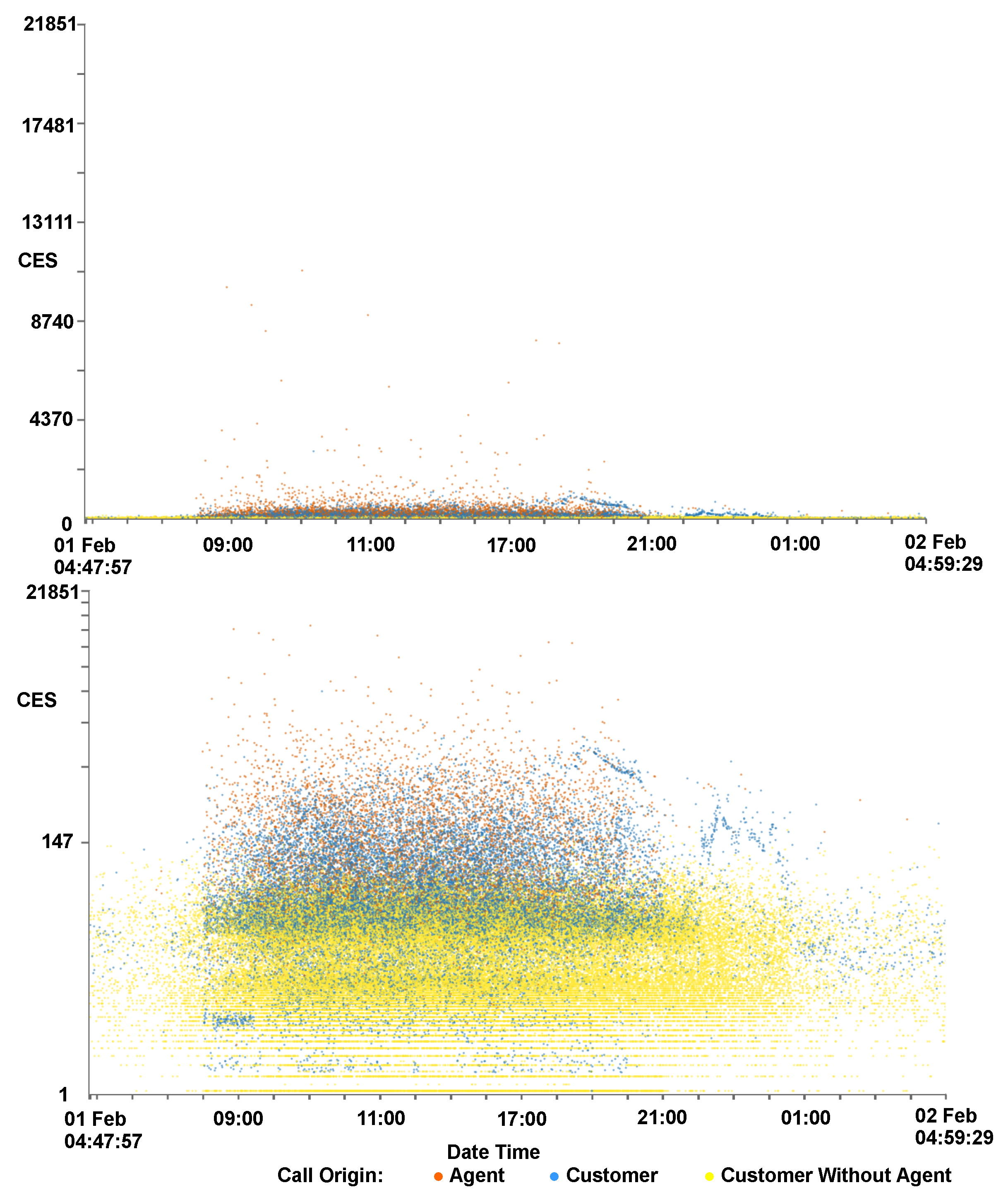
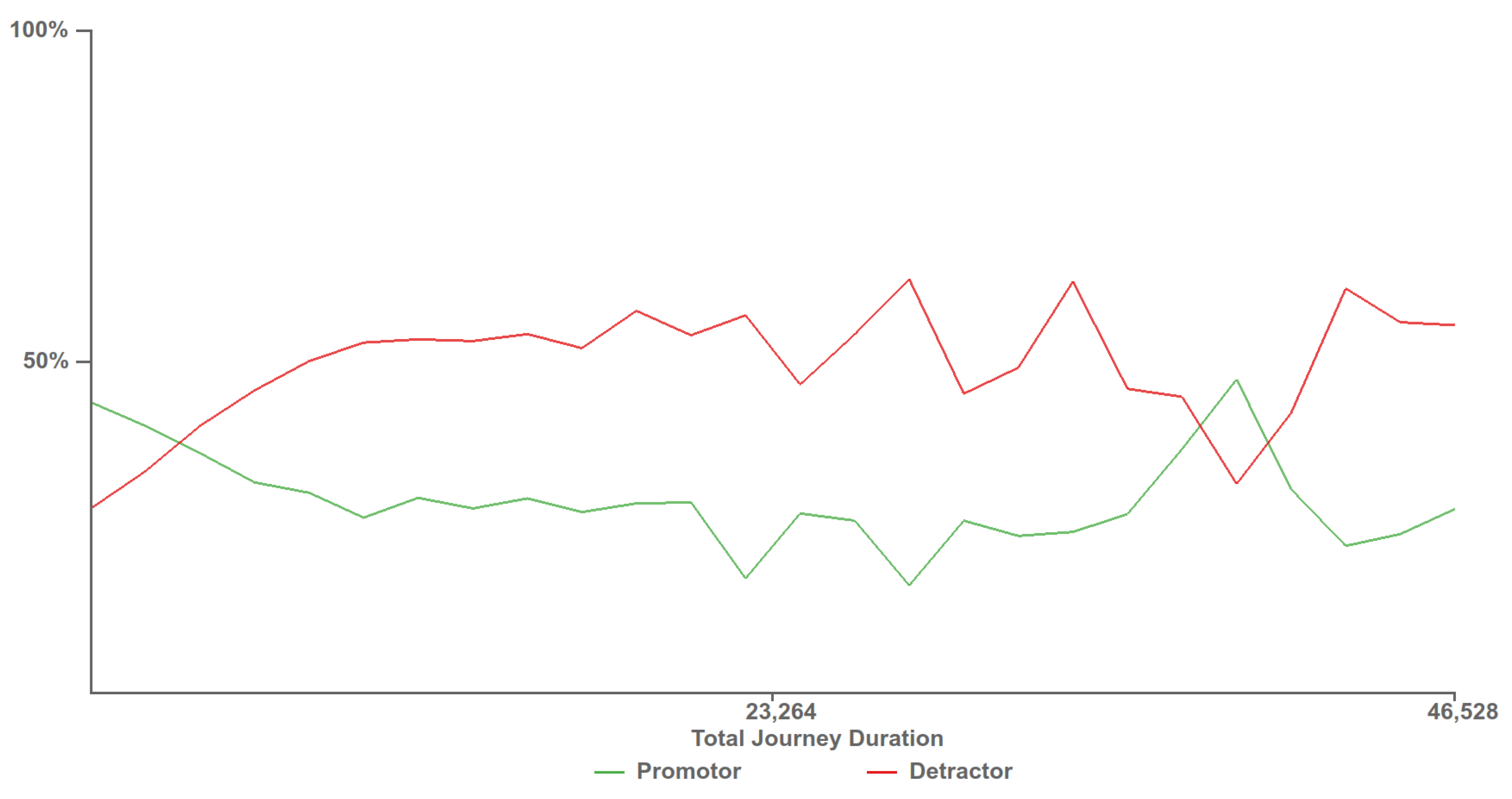
4.6. Customer Experience Tipping Point Chart
5. Domain Expert Feedback
“Not at this speed, no. We’ve had to go down the route of pre-aggregating the data to get the speed.”
“It’ll be interesting to put a new data set in that we haven’t looked at before, that we haven’t got any knowledge of and to instantly then be able to see something.”
“I like the look of that, it looks nice first of all, it’s giving you a good summary of the different fields and distributions.”
“You’ve given the ability to filter the contacts in quite a few different ways and to enable you to focus in on particular areas and for the individual contacts you come down to you can look closer, maybe in a different application.”
“Yeah, I think it’s nice, it lets you look at some standard call center metrics.”
“I think there are two immediate purposes it serves, one is validation, it’ll throw up those outliers we’ve got... and two, from an insight perspective... we’d probably show this to the customer to demonstrate the insight, to show how flexible the data is.”
“It makes the application that you’ve created a stepping stone... because you can look at a large set of data and filter down to a smaller number of calls, this application looks useful for that then potentially you can go and look at some more specific detail with another application or even you just literally go to the database and take those call I.D.’s you’ve listed out there even just go directly to the database.”
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rees, D.; Roberts, R.C.; Laramee, R.S.; Brookes, P.; D’Cruze, T.; Smith, G.A. GPU-Assisted Scatterplots for Millions of Call Events. In Computer Graphics and Visual Computing (CGVC); Tam, G.K.L., Vidal, F., Eds.; The Eurographics Association: Munich, Germany, 2018. [Google Scholar]
- Res, D. Feature-Rich, GPU-Accelerated Scatterplots for Millions of Call Events—Demonstration Video, 2018. Available online: https://vimeo.com/305933032 (accessed on 4 February 2019).
- ContactBabel. US Contact Centres: 2018–2022 The State of the Industry & Technology Penetration; Technical Report; ContactBabel: Newcastle-upon-Tyne, UK, 2018. [Google Scholar]
- ContactBabel. UK Contact Centres: 2018–2022 The State of the Industry & Technology Penetration; Technical Report; ContactBabel: Newcastle-upon-Tyne, UK, 2018. [Google Scholar]
- Dimension Data. Global Contact Centre Benchmarking Report; Technical Report; Dimension Data: Johannesburg, South Africa, 2016. [Google Scholar]
- Aksin, Z.; Armony, M.; Mehrotra, V. The modern call center: A multi-disciplinary perspective on operations management research. Prod. Oper. Manag. 2007, 16, 665–688. [Google Scholar] [CrossRef]
- Mehrotra, V.; Grossman, T. New Processes Enhance Crossfunctional Collaboration and Reduce Call Center Costs; Technical Report, Working Paper; Department of Decision Sciences, San Francisco State University: San Francisco, CA, USA, 2006. [Google Scholar]
- Shneiderman, B. The eyes have it: A task by data type taxonomy for information visualizations. In Proceedings of the 1996 IEEE Symposium on Visual Languages, Boulder, CO, USA, 3–6 September 1996; pp. 336–343. [Google Scholar]
- McNabb, L.; Laramee, R.S. Survey of Surveys (SoS)-Mapping The Landscape of Survey Papers in Information Visualization. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2017; Volume 36, pp. 589–617. [Google Scholar]
- Rees, D.; Laramee, R.S. A Survey of Information Visualization Books. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2019; forthcoming. [Google Scholar]
- Friendly, M.; Denis, D. The early origins and development of the scatterplot. J. Hist. Behav. Sci. 2005, 41, 103–130. [Google Scholar] [CrossRef] [PubMed]
- Ellis, G.; Dix, A. A taxonomy of clutter reduction for information visualisation. IEEE Trans. Vis. Comput. Gr. 2007, 13, 1216–1223. [Google Scholar] [CrossRef] [PubMed]
- Sarikaya, A.; Gleicher, M. Scatterplots: Tasks, Data, and Designs. IEEE Trans. Vis. Comput. Gr. 2018, 24, 402–412. [Google Scholar] [CrossRef] [PubMed]
- Carr, D.B.; Littlefield, R.J.; Nicholson, W.; Littlefield, J. Scatterplot matrix techniques for large N. J. Am. Stat. Assoc. 1987, 82, 424–436. [Google Scholar] [CrossRef]
- Keim, D.A.; Hao, M.C.; Dayal, U.; Janetzko, H.; Bak, P. Generalized scatter plots. Inf. Vis. 2010, 9, 301–311. [Google Scholar] [CrossRef]
- Dang, T.N.; Wilkinson, L.; Anand, A. Stacking graphic elements to avoid over-plotting. IEEE Trans. Vis. Comput. Gr. 2010, 16, 1044–1052. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Chen, W.; Mei, H.; Liu, Z.; Zhou, K.; Chen, W.; Gu, W.; Ma, K.L. Visual abstraction and exploration of multi-class scatterplots. IEEE Trans. Vis. Comput. Gr. 2014, 20, 1683–1692. [Google Scholar] [CrossRef] [PubMed]
- Mayorga, A.; Gleicher, M. Splatterplots: Overcoming overdraw in scatter plots. IEEE Trans. Vis. Comput. Gr. 2013, 19, 1526–1538. [Google Scholar] [CrossRef] [PubMed]
- Elmqvist, N.; Do, T.N.; Goodell, H.; Henry, N.; Fekete, J.D. ZAME: Interactive large-scale graph visualization. In Proceedings of the IEEE Pacific Visualization Symposium, PacificVIS’08, Kyoto, Japan, 5–7 March 2008; pp. 215–222. [Google Scholar]
- McDonnel, B.; Elmqvist, N. Towards utilizing GPUs in information visualization: A model and implementation of image-space operations. IEEE Trans. Vis. Comput. Gr. 2009, 15, 1105–1112. [Google Scholar] [CrossRef] [PubMed]
- Mwalongo, F.; Krone, M.; Reina, G.; Ertl, T. State-of-the-Art Report in Web-based Visualization. Comput. Gr. Forum 2016, 35, 553–575. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, B.; Heer, J. imMens: Real-time Visual Querying of Big Data. Comput. Gr. Forum 2013, 32, 421–430. [Google Scholar] [CrossRef]
- Andrews, K.; Wright, B. FluidDiagrams: Web-Based Information Visualisation using JavaScript and WebGL; EuroVis—Short Papers; Elmqvist, N., Hlawitschka, M., Kennedy, J., Eds.; The Eurographics Association: Geneva, Switzerland, 2014. [Google Scholar]
- Sarikaya, A.; Gleicher, M.; Chang, R.; Scheidegger, C.; Fisher, D.; Heer, J. Using webgl as an interactive visualization medium: Our experience developing splatterjs. In Proceedings of the Data Systems for Interactive Analysis Workshop, Chicago, IL, USA; 2015; Volume 15. [Google Scholar]
- Sharp, D. Call Center Operation: Design, Operation, and Maintenance; Elsevier: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Jongbloed, G.; Koole, G. Managing uncertainty in call centres using Poisson mixtures. Appl. Stoch. Models Bus. Ind. 2001, 17, 307–318. [Google Scholar] [CrossRef]
- Weinberg, J.; Brown, L.D.; Stroud, J.R. Bayesian forecasting of an inhomogeneous Poisson process with applications to call center data. J. Am. Stat. Assoc. 2007, 102, 1185–1198. [Google Scholar] [CrossRef]
- Brown, L.; Gans, N.; Mandelbaum, A.; Sakov, A.; Shen, H.; Zeltyn, S.; Zhao, L. Statistical analysis of a telephone call center: A queueing-science perspective. J. Am. Stat. Assoc. 2005, 100, 36–50. [Google Scholar] [CrossRef]
- Shi, J.; Erdem, E.; Peng, Y.; Woodbridge, P.; Masek, C. Performance analysis and improvement of a typical telephone response system of VA hospitals: A discrete event simulation study. Int. J. Oper. Prod. Manag. 2015, 35, 1098–1124. [Google Scholar] [CrossRef]
- Roberts, R.; Tong, C.; Laramee, R.; Smith, G.A.; Brookes, P.; D’Cruze, T. Interactive analytical treemaps for visualisation of call centre data. In Proceedings of the Smart Tools and Applications in Computer Graphics, Genova, Italy, 3–4 October 2016; pp. 109–117. [Google Scholar]
- Roberts, R.; Laramee, R.S.; Smith, G.A.; Brookes, P.; D’Cruze, T. Smart Brushing for Parallel Coordinates. IEEE Trans. Vis. Comput. Gr. 2019, 25, 1575–1590. [Google Scholar] [CrossRef] [PubMed]
- The Qt Company. Qt Application Framework; The Qt Company: Helsinki, Finland, 1995. [Google Scholar]
- The Khronos Group Inc. OpenGL; The Khronos Group Inc.: Beaverton, OR, USA, 1992. [Google Scholar]
- Card, S.K.; Mackinlay, J.D.; Shneiderman, B. Readings in Information Visualization: Using Vision to Think; Morgan Kaufmann: San Francisco, CA, USA, 1999. [Google Scholar]
- Brown, L.D. Empirical Analysis of Call Center Traffic; Presentation for Call Center Forum; Wharton School of the University of Pennsylvania: Philadelphia, PA, USA, 2003. [Google Scholar]
- Kessenich, J.; Sellers, G.; Shreiner, D. OpenGL Programming Guide: The Official Guide to Learning OpenGL, Version 4.5 with SPIR-V; Addison-Wesley Professional: Boston, MA, USA, 2016. [Google Scholar]
- Munshi, A. The opencl specification. In Proceedings of the Hot Chips 21 Symposium (HCS), Stanford, CA, USA, 23–25 August 2009; pp. 1–314. [Google Scholar]
- Munshi, A.; Gaster, B.; Mattson, T.G.; Ginsburg, D. OpenCL Programming Guide; Pearson Education: Boston, MA, USA, 2011. [Google Scholar]
- Scarpino, M. OpenCL in Action: How to Accelerate Graphics and Computations; Manning Publications: New York, NY, USA, 2011. [Google Scholar]
- Hogan, T.; Hinrichs, U.; Hornecker, E. The Elicitation Interview Technique: Capturing People’s Experiences of Data Representations. IEEE Trans. Vis. Comput. Gr. 2016, 22, 2579–2593. [Google Scholar] [CrossRef] [PubMed]
- Alharbi, N.; Chavent, M.; Laramee, R.S. Real-Time Rendering of Molecular Dynamics Simulation Data: A Tutorial. In Computer Graphics and Visual Computing (CGVC); Wan, T.R., Vidal, F., Eds.; The Eurographics Association: Geneva, Switzerland, 2017. [Google Scholar]
- The Khronos Group Inc. Vulkan Overview; The Khronos Group Inc.: Beaverton, OR, USA, 2016. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| Time | The time and date at the start of the call |
| Normalized Time | The time (duration) since the first contact of that customer |
| End Time | The time and date at the end of the call |
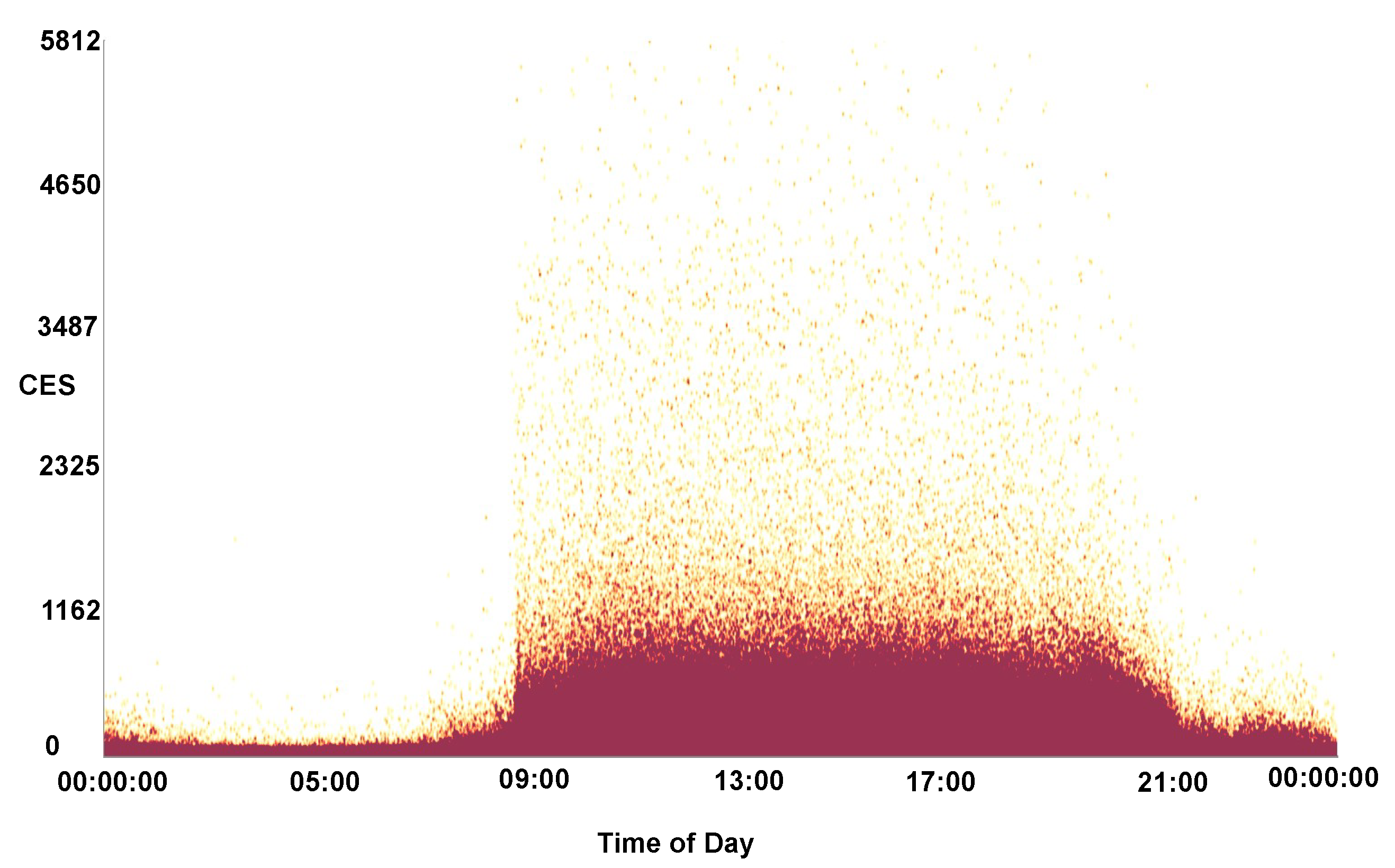
| CES | Customer Effort Score—A derived metric for customer investment |
| Cost | The cost of the call to the operator in pence |
| Call Duration | The length of the complete call (in seconds) |
| Agent Duration | The number of seconds of agent interaction in the call |
| Wait Duration | The length of waiting in a call (in seconds) |
| IVR Duration | The length of IVR interaction (in seconds) |
| Hold Duration | The length of hold in a call (in seconds) |
| Time of Day | The time of day at the start of a call |
| Customer Filters | Call Filters |
|---|---|
| Number of Calls | Time of Call |
| Total CES | CES |
| Total Cost | Agent Duration |
| Total Call Duration | Wait Duration |
| Time of First Call | IVR Duration |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rees, D.; Roberts, R.C.; Laramee, R.S.; Brookes, P.; D’Cruze, T.; Smith, G.A. Feature-Rich, GPU-Assisted Scatterplots for Millions of Call Events. Computers 2019, 8, 12. https://doi.org/10.3390/computers8010012
Rees D, Roberts RC, Laramee RS, Brookes P, D’Cruze T, Smith GA. Feature-Rich, GPU-Assisted Scatterplots for Millions of Call Events. Computers. 2019; 8(1):12. https://doi.org/10.3390/computers8010012
Chicago/Turabian StyleRees, Dylan, Richard C. Roberts, Roberts S. Laramee, Paul Brookes, Tony D’Cruze, and Gary A. Smith. 2019. "Feature-Rich, GPU-Assisted Scatterplots for Millions of Call Events" Computers 8, no. 1: 12. https://doi.org/10.3390/computers8010012
APA StyleRees, D., Roberts, R. C., Laramee, R. S., Brookes, P., D’Cruze, T., & Smith, G. A. (2019). Feature-Rich, GPU-Assisted Scatterplots for Millions of Call Events. Computers, 8(1), 12. https://doi.org/10.3390/computers8010012