Abstract
Education values such as knowledge sharing, and the linked data (LD) abilities such as interoperability are in perfect harmony. Much research has exploited that and provided important contributions and improvements in education through LD. International universities, large open education repositories, OpenCourseWare (OCW) and Massive Open Online Courses (MOOCs) initiatives, educational search engines, blending and adaptive learning, learning analysis and other various areas were the targets of many works on leveraging LD. However, this research exists in a scattered way without any type of categorization or organization. In this paper, we present a survey on the current works in educational linked data (ELD) to provide a starting point and a comprehensive roadmap to help researchers in recognizing the main tracks in ELD area. In addition, the paper extracted the common life cycle, outcome datasets and vocabularies from the overall presented works. The paper also provides samples of applications that exhibit the practical benefit of adopting LD in the various tracks and highlights the challenges that each track faced during the utilization of LD. Pioneer ELD’s projects, other existing overviews and landscapes and the most used tools based on the stages and prevalent are presented. Lastly, discussion and recommendations were provided based on the overall study.
1. Introduction
Knowledge sharing is a virtuous value in education. At the same time, interoperability among other features is a great benefit of applying linked data (LD). Achieving interoperability in education leads to enabling sharing, reusing and raises the opportunity for accessibility and portability. Therefore, there is a favorable matching between education aspirations and LD abilities. The observer of the growth of linked open data (LOD) cloud (https://lod-cloud.net/) in recent years can easily notice how much education and science seek the highest connectivity. LD with its principles raises the value of educational resources by making them understandable by machines and more discoverable [1]. It provides promised solutions for heterogeneity problems in various contexts [2], even with data being distributed, and coming from different sources, with different formats. The integration solutions that LD provide are based on common analogies that provide a common understanding among machines, developers, domain experts and users. It can also express every aspect of education and science life [3]. Achieving integration in education will simplify answering complex and interdisciplinary queries and will eliminate the risk of having isolated educational resources. LD offers an important opportunity to enrich educational linked data (ELD) and make reasoning on them to extract new knowledge [4]. This work, in fact, contributes to boosting the studies of what LD could offer for education by discussing available works in this area.
However, large numbers of works in ELD exist in a scattered way without clear tracks or classification that can help a researcher who explores this area to decide to go ahead in one of them. In this research, we provide a start point and a comprehensive roadmap to help researchers recognize the main tracks in ELD. As Figure 1 shows, we categorized available works based on their purpose to the following main tracks:
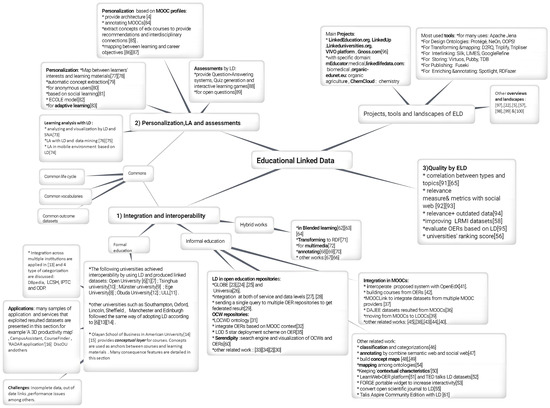
Figure 1.
Tracks and road map of ELD.
- ‘Integration and interoperability in ELD’ track, which includes: formal education, informal education and hybrid works.
- ‘Learning analysis, personalization and assessments with ELD’ track which depends on the previous track.
- ‘Quality by ELD’ track.
We have reviewed the existing works in light of the above-mentioned tracks, categorized them based on their purposes accordingly, and provided critical analyses that serve the researchers in the area. This does not mean that each work belongs to only one track without the possibility of relating to other tracks. Some tracks are dependent on each other, so when some works have cross interests and concerns between two tracks we put them under the closest context based on the focus of the work.
Based on that, this paper provides the following contributions that are summarized in Figure 1 to support ELD domain:
- Providing a categorized view and a roadmap of the various works in ELD.
- Extracting the common life cycle, outcome datasets and vocabularies and build analysis based on them. Thus, the researcher could constitute an analogous roadmap for his work based on the closest track that shows the procedures followed in it.
- Providing summarized samples of applications that embody the practical benefit of adopting LD in each track.
- Finding the challenges that various tracks faced during applying LD.
- Presenting the pioneer projects for education, in general, and also specialized projects based on specific domains in ELD field.
- Extracting the most used tools in ELD based on the stages and showing their prevalent.
- Stating discussions and recommendations based on the overall study that we initiated.
The rest of the paper is organized as follows: Section 2 presents integration and interoperability track including formal, informal and hybrid subsections. In Section 3, we address learning analysis, personalization and assessments track; and, in Section 4, quality by an ELD track is presented. Section 5 provides a summarized description of the common vocabularies used in ELD. Projects, tools and landscapes of ELD are introduced in Section 6. Section 7 presents discussion and recommendations while Section 8 concludes the work.
2. Integration and Interoperability in ELD
This track is the first to be presented, as integration and interoperability are the main features in LD and due to the large number of works that have been done in it. Works in this track are either efforts intended to achieve integration and interoperability in universities and institutions (formal education) or to achieve integration in open large repositories or among OCWs and MOOCs and so on (informal education). Some works are not specific for any of them, so we classify them under integration in hybrid education.
2.1. Integration in a Formal Education
With the emerging of LD paradigm and its potentials, many universities and institutions found promising opportunities in following it. Mainly, they look at LD as an alternative to achieve integration among institutions’ systems and provide interoperability in a cost-effective way. In this section, we review the published research in this direction and provide a roadmap of the common life cycle they followed to produce institutions’ LD datasets, the used vocabularies with analytical comments, the main outcome datasets, sample of applications that present the benefits of adopting LD, and how it is exploited, and finally the main challenges that require researchers to contribute to solving it.
The Open University (UK) is one of the first institutions that adopted an LD platform and produced a large amount of its data as LOD. They produced “around 5 million triples about 3000 audio-video resources, 700 courses, 300 qualifications, 100 Buildings, 13,000 people” [5]. Besides achieving integration and connectivity among their datasets, they make these data reusable and accessible to others by providing a SPARQL endpoint. Work presented in [1,6,7] give a blueprint and a roadmap of the procedures that they applied. Ege, a Turkish university, introduced their experience of developing Ege LOD datasets in [8]. Moreover, this research discussed using LD technologies as a means to discover as much as possible of interlinks among datasets, and therefore reaching the best integration situation, plus keeping these links updated and consistent. Along the same lines, Münster University (Germany), Tsinghua University (China) are universities that introduced their efforts in [9,10] to produce their open data as LOD. Similarly, the University of La Laguna (ULL) did, but they indicated the following of an iterative and incremental methodology to make frequent refinements on results [11]. Lastly, Óbuda University published a research in [12], which illustrated their needs to build a ‘glue’ ontology from existing educational ontologies to build the model that satisfies their requirements. Since all of the above-mentioned universities followed the principle of reusing existing educational ontologies as much as possible, all of them confirmed their needs to extend these vocabularies and even making bridges between them to fulfill their requirements. Examples of universities that followed the same way of adopting LD are Southampton, Oxford, Lincoln, Sheffield, Manchester and Edinburgh [6,13,14].
Authors in [14,15] proposed some ideas that were applied at the Olayan School of Business of American University in Beirut. They went further and more deeply at detailed (granular) level by providing a conceptual layer for the courses that the university introduces. This conceptual layer is able to interlink courses and learning materials based on the concepts that courses contain. Thus, these concepts are used as anchors between courses and learning materials. This approach will increase connectivity significantly as it implies that one concept could belong to multiple courses. Therefore, one material could be beneficial to more than one course. In this way, the course creator could determine more particularly where each piece of the learning resource is more useful. Thus, the learning material could float across the whole program. This approach provides a comprehensive view for building more integral and productive learning programs; thus, it facilitates reviewing the university’s programs and syllabuses such as what courses should be prerequisite requirements and so on, and, accordingly, a tool that can visualize the overlapping between courses based on concepts that are introduced. Another favorable point in this research is enabling students to participate in reshaping connectivity among courses and learning resources by taking direct inputs from them. In order to support that, forms that work as guidance for users to help them to enter data based on the vocabulary are introduced. These ideas push courses’ curriculums to be more extensible, up to date, portable and reusable.
The work in [13] applied integration across multiple institutions, not just within one institution’s systems with video lectures obtained from 27 different institutions. In this context, it is definitely needed to make some kind of categorization for those integrated videos. Four types are discussed in this article: DBpedia categories, Library of Congress Subject Headings (LCSH), The International Press Telecommunications Council (IPTC) and finally they followed Open Directory Project (ODP). According to their results of using ODP, they were able to reach a high level of coverage and correctness.
It is useful for other educational organizations to have an overview of how these institutions generated educational linked datasets, its applications and the challenges and research questions in order to achieve that. The following subsections discuss these issues.
2.1.1. Common Life Cycle
Here, we summarize the lifecycle that is most common among the various institutions that used LD. The detailed processes are found in papers [1,6,7,8,10,11,13,15].
The lifecycle consists of the following stages:
- Raw data collection,
- Defining the vocabulary model based on reusing existing ontologies and extend them when it is needed,
- Extracting and generating RDF datasets according to the defined vocabulary, and this stage could include data cleaning,
- Achieving interlinking among datasets internally and externally,
- Storing outcome datasets and exposing them by providing SPARQL endpoint,
- Exploiting datasets by developing applications and services,
- Providing optimization and quality producers.
2.1.2. Common Outcome Datasets
It is noticeable that the main outcome datasets in all universities are the different details about course information. However, the following datasets generated by many universities: geographical and campus buildings information, research and scientific publications, libraries catalogue, staff members’ information, events and podcasts datasets. Details about such datasets could be found in [6,10,12,16].
2.1.3. Common Vocabularies
By reviewing the various works within integration in formal education field that presented in [1,6,7,8,9,10,11,12,13,14,15] and CURONTO ontology [17], we extracted the most used vocabularies. AIISO (http://vocab.org/aiiso/schema) [18], Courseware (http://courseware.rkbexplorer.com/ontologies/courseware), TEACH (http://linkedscience.org/teach/ns/teach.rdf) [19], MLO (http://svn.cetis.ac.uk/xcri/trunk/bindings/rdf/mlo_rdfs.xml) [20] and XCRI (http://svn.cetis.ac.uk/xcri/trunk/bindings/rdf/xcri_rdfs.xml) [21] are major educational ontologies that are used in this track. In addition, DC (http://dublincore.org/documents/dces/), FOAF (http://xmlns.com/foaf/spec/), BIBO (http://purl.org/ontology/bibo/) and SKOS (http://www.w3.org/2004/02/skos/) are ontologies that have common use in different fields with high frequency in above mentioned works; therefore, they are candidates to be hubs among different datasets. AIISO ontology is applied in the most works, which give an indication that it is considered as a backbone ontology in this field. Section 5 provides a description for each one of these vocabularies.
2.1.4. Applications
Here, we present samples of applications the above-mentioned universities implemented upon their generated LD datasets. This will help to form an idea about the actual and practical benefits of including LD in educational institutions.
‘A 3D productivity map’ is an application implemented in [9] to visualize the buildings of Münster University in 3D, the highest building means the upper number of publications created by this department’s researchers. In this way, making a preliminary evaluation between the university’s faculties becomes easier. ‘WWU App’ [9] by Münster university and CampusAssistant [10] created by Tsinghua University are examples of using LD datasets in offering maps to simplify navigations inside the campus of universities.
In addition, CourseFinder (Tsinghua University) [10] is developed to provide different ways to make searching on courses and its related lecturers and departments based on various criteria. ‘Study at the OU’ (Open University) [6,16] mainly aims to exploit a course’s links to simplify reaching related learning materials such as podcasts, YouTube materials and other relevant educational resources. ‘OU Expert Search system’ [1] is developed by the same university to reach the OU’s experts according to the determined interests and topics. ‘RADAR application’ [16] works as a monitor for the researchers’ activities in the university such as researchers’: publications, supervision history, positions, projects and funding and so on.
‘Social Study application’ in [1] and ‘Open University’s Course Profile Facebook app’ [5] show the potential of combining social apps such as Facebook with LD to improve learning communication and interaction. DiscOU in [6,22] take advantage of knowing the learner’s TV interests to present learning resources from the OU based on it. ‘Leanback TV Webapp’ [6] is used to suggest to the students the exploration of new topics by providing a series of videos that run automatically one after the other.
2.1.5. Challenges
Here, we list the main challenges that institutions face during their works in producing and exploiting LD:
- A common challenge among all universities is the lack of a unified vocabulary that satisfies all universities’ requirements. Therefore, there is a need to investigate how to mitigate this diversity by creating a bridged vocabulary that is general and at the same time as descriptive as possible.
- Keeping and maintaining the current systems while generating new LD systems is a key decision in many universities for many reasons.
- Emerging performance shortcomings when federated queries are applied among diverse linked datasets in some situations.
- Incomplete data is a problem that could complicate data querying and retrieving if it is not considered.
- Out-of-date links is an issue that educational organizations need effective strategies to handle in an automatic and a dynamic manner.
- While applying links’ discovering approaches can be manageable internally, it becomes more challenging when it is applied with external large datasets. That is, results of scalable difficulties that come up during this process, however discovering as many valid links as possible, are desirable.
- Some data are not fully public, especially data related to personal information, so such data needs more filtering strategies to respect privacy and following appropriate licenses.
- Most developers are familiar with APIs with XML description more than SPARQL endpoints and RDF formats which could hinder the utmost exploitation of LD datasets. Using mediation techniques between them to pave the issue needs to be considered.
2.2. Integration in Informal Education
2.2.1. LD in Open Education Repositories
GLOBE and Universia are examples of huge repositories with thousands of learning objects. We here present a review on the role that LD has played to make them more accessible, discoverable, interoperable and reusable. There are several research works that have been conducted on GLOBE [23,24,25] with the main aim of achieving interlinking with help of some tools such as LIMES (http://aksw.org/Projects/LIMES.html), SILK (http://silkframework.org) and LODRefine (http://openrefine.org/). Prior that, the datasets need to be converted from IEEE LOM XML files to RDF format and finding best candidate elements to make interlinking. The authors noticed during the interlinking process that the same learning resource could have a different address when it is published by different providers. Thus, in [23], a workflow is suggested to detect duplicated resources in the semi-automatic process. In [24], a GoogleRefine tool is introduced to highlight the ‘reconciliation’ feature to clean and refine datasets. Besides the GoogleRefine’s ability to match learning resources automatically, it can find the similar concepts for users. Even though, the work in [25] provided a comparison between the three interlinking tools: Silk, LIMES and LODRefine and stipulated that Silk and then LIMES outperformed, while LODRefine gave noticeably lower results. This is thought to be so because LODRefine considers different mechanisms of selecting a matching algorithm. These experiments were applied by connecting GLOBE with DBpedia. The main emphasized result that experiments proved is the fitness of these tools and approaches to make a connection with an LOD cloud. These interlinking processes help to reach best enrichment and thus better learning outcomes.
Along the same lines [26], research worked on transforming Universia repository into semantic LO repository based on LD principles. It introduced an approach to make automatic classification of LOs based on DBpedia categorization that is comprehensive to a cross-domain not to a specific domain. This classification simplifies discovering LOs significantly. Even though this approach is ‘loose coupling’, which means it can go along with other LD repositories other than DBpedia, that is, since a filtering algorithm in this approach explores the RDF graph “independently of concrete relations of the DBpedia ontology” [26].
Achieving integration and interoperability among educational resources in such heterogeneous educational repositories at both service and data levels is the issue that was examined in [27,28]. The idea of sending a single query to multiple OER (Open Education Resources) repositories to get the federated result is experimented on by a system proposed in [29]. It maps the natural language query to one or more SPARQL queries and then broadcasting it to multiple different SPARQL endpoints. Doing this process on behalf of users offers saving time and effort. Research in [30] showed a comprehensive approach to build a large-scale educational data graph from various datasets. Their approach includes integrating at a schema-level (they made an upper-level schema that aligns various schemas used by different datasets), and an instance-level based and making clustering and correlation. A resulted graph is comprised of about 97 million of triples and 21.6 GB of educational resources and related data.
OCW repositories: Research presented in [31,32,33,34,35] discussed the interoperability and integration among OERs and especially in OCW repositories by using LD. In fact, when authors and institutions contribute to providing OER content; this definitely improves their reputation and it strongly motivates the OER initiative. In [35], the opportunities and challenges of applying LOD a 5-star deployment scheme (https://www.w3.org/DesignIssues/LinkedData.html) on OER to enhance using, reusing and remixing educational resources was discussed. The work in [31] contributed by LOCWD ontology that many other works are built upon it. The main concern of this work is (1) solving the problem of heterogeneity among OCW repositories; (2) unlocking the OCW data that used to be isolated in silos of learning materials to increase accessibility and visibility of them. In addition, it works on providing automatic links to LOD cloud to enrich those materials. By that, machines will be able to help in integrating and consolidating data by providing explicit meanings of links. One of the works that took advantage of the previous work is [32]. It intended to integrate OERs based on MOOC profiles to provide customized materials. Thus, it provided an architecture to suggest OER recommendations for MOOC designers across heterogeneous OER repositories. In other words, helping MOOC designers to design an MOOC course from existing OCW and OER materials. Their target was open materials with granted rights of use and also further reuse and alteration—that is, to have more freedom and facilitation of access and integrate, share and discover these materials among openly distributed repositories. It is noteworthy that the main providers of this work are OCW institutions.
2.2.2. LD in MOOCs
Coming to MOOC, fortunately, there is a group of works that addressed involving LD abilities to serve a MOOC learning paradigm. In addition to [32], effort that intersects with the last section, the [36,37,38,39,40,41] research works are published in this direction. The work in [41] is an effort of building ‘learning resource repository manager’ called COMETE based on LD principles. Thus, it is like an OER manager and it is established based on ISO-MLR, which is an OER referencing standard based on RDF. It is compatible with the traditional open educational models such as DC and LOM. COMETE enable data mining across those schemas. The interoperating proposed system with OpenEdX (a MOOC platform) is an example of achieving interoperability feature provided in this work. Thus, it helps course designers to easily find the appropriate OERs in the MOOC context. At the same time, it gives the MOOC itself a reference to be much more reusable for future usage and therefore constitutes the kind of MOOC portal. In this context, EUCLID, in [42], comes here like a case study for the idea of building courses from OERs. This work discussed how OER can be used to develop an educational curriculum about LD in addition of taking the benefit of involving the community to gain continuous feedback to support and validate it. In the end, they supported the learning analytics that they need by using LD that is comprised of transforming the feedback’s monitoring results coming from the community into RDF.
Integrating datasets from multiple MOOC providers is the core of another project called MOOCLink provided in [37]. Firstly, in this work, authors defined the ontology (including reusing others), generated linked datasets and built applications upon it. The directly needed application of this work is discovering courses across different MOOC providers. Thus, they provided search algorithms and frontend interface to support this thought. Along the same line, DAJEE (Dataset of Joint Educational Entities) is a dataset that resulted from educational resources that come from MOOC. In [36], authors worked on applying LD principles to this datasets and provided DAJEE ontology to help in making enrichment with LOD cloud. Additionally, the idea of providing the confidence value to measure the quality of association is presented in it. In addition, in [39], authors discussed moving from MOOCs to LOOCs (Linked Open Online Courses) to have integrated data with interoperability features by following LD technologies. Ref. [43] is a complement of [39], Ref. [43] utilizes semantic technologies to provide interlinked method across three e-learning applications (lecture recordings, application for annotating of PDF documents, and a discussion forum) for enabling users to comment on and discuss educational materials in an integrated manner. For example, “reference can be made from a forum post to the discussed lecture slide” [43]. They were able to do that by using shared ontologies. Not only PDF, but also generating the semantic format of the PowerPoint lecture slides is proposed in [40]. This semantic layer helps educators to reach the needed content at the level of the slide rather than the whole lecture that supports semantic MOOC tendency.
Thinking of LD as a means of “orchestrating innovative learning activities” [38], and handling the major integration and federation issues in OER and MOOCs, as [44] showed, are considerable thoughts reviewed in this research. It is also worth noticing that the open term in MOOC needs to be clarified, and not all MOOC providers offer full open materials. Open in MOOC often comes in the meaning of ‘open enrollment’. However, this is not always the case; for example, edX provides wide open educational resources that can be used and reused by others. Ref. [45] highlights the main reasons that push towards adopting the MOOC paradigm in education.
2.2.3. Other Issues in Informal Education
Exploring classification and categorizations methods of OERs is another important part that was interested by [46]. This is to facilitate finding the associations among topics and pave the way to provide learners with best recommendations. Authors presented several knowledge organization systems and then proposed their own approach. The base of their categorization is blending formal classification systems with the dynamic repositories that are sourced by society such as DBpedia, thus ‘expanding the network of concepts’ and boosting the semi-automatic classification of OCW courses by using LD. In addition, the research in [47] studied annotating medical educational resources by combing both social Web and semantic Web. This will improve the enriching of a medical dataset and providing more relevant resources during the searching processes.
Going beyond just extracting and classifying educational resources, building a concept map of resources to detect its relationships is addressed in [48]. Some benefits of this direction are: using suggested candidate concepts to be part of the course subject, supporting and encouraging making reviews and refinements on current courses through facilitating looking at other colleagues’ courses by using semantic links. In addition, this helps in giving a context and comprehensive knowledge about the educational resources. Reliable datasets are built by trusting MOOCs and OERs that contain real courses made by professors. Thus, these datasets are considered as a base of the classifier to recognize other data coming from the web as valid educational resources or not. Reaching the concept maps, the model OER-CC is also introduced by [49] to enable representing OERs and Creative Commons open content licensing. It can describe metadata of OER repositories, do ranking and achieve deployment based on concept mapping. The idea of keeping and taking advantage of the ‘contextual characteristics’ that learning objects (LOs) are taken within, such as a certain place or event is part of [50], thus using such contextual characteristics to enrich the LOs and provide meaning and semantic that make them understandable by machines.
LearnWeb-OER platform in [51] acts as a combination of being a search engine, social network and repository. It is considered as a search engine and repository, since it offers access to various resources such as YouTube, Vimeo, Slideshare, Flickr, TED Talks datasets and so on. Besides allowing users to add comments and discussion as part of social activity, they enable users to contribute to making annotation and enrichment to normal resources. Since TED is mentioned, research in [52] presented an effort to exploit TED talks as a means to support education by exposing its linked datasets and facilitates the computation of links with related data and resources. They mentioned that the TED dataset is used by many educational applications and it is registered in the LinkedUP Data Catalog. For example, the University of Lecce (Italy) uses TED datasets in teaching their course “Interpretazione lingua inglese I”. One of the main concerns of learning is the matter of interactivity. In [53], the FORGE proposal stimulates the interactivity particularly in open education by using resources like eBooks. They came up with the idea of creating FORGE based ontology to be a portable widget that can be embedded in different online platforms, therefore increasing its reusability.
The dilemma of the diversity and competed schemas is a topic that [54] addressed. Starting with making comparisons between schemas and reaching to achieve mapping among them, the authors used three bases to make the comparison: (1) using owl: EquivalentClasses, (2) owl: equivalentProperty, and (3) using SPARQL query. Ref. [55] shows a detailed roadmap, guideline, procedures and tools in the purpose of illustrating what open scientific journals should do to adopt LD technologies and make their open data part of the LOD cloud. It is worth mentioning that ACM, IEEE, and DBLP research publication repositories are part of LOD cloud according to [56].
A question arises: Why does the above-mentioned research, particularly in large repositories, seek to use LD as an alternative or extension of IEEE Learning Object Metadata (LOM), ADL SCORM and query interface mechanisms such as OAI-PMH or SQI?
Actually, many factors lead to this tendency:
- The diversity of schemas: When repositories originally have heterogeneous metadata standards such as IEEE LOM or ADL SCORM and many query interfaces like OAI-PMH or SQI and others, this complicates the process of description and publication of metadata—while LD schemas mitigate this issue by following the principle of reusing vocabularies and particularly controlled vocabularies as much as possible. Diverse schemas mean that reusing is not ensured, thus having the lowest level of interoperability in repositories. Research in [2,27,28] illustrated this point of view.
- Discontinuity: [27,28,57] Research indicates the discontinuity of the efforts that concern such technologies, and also indicates that it is focusing only on the binding feature rather than all the abilities of LD such as referencing and others.
- Referencing and dereferencing mechanisms: The complexity of referencing process in LOM technology compared to LD referencing and dereferencing mechanism through using URI and its features are the point that [32,33,41,57] touched on.
- Costs and efforts: From a cost perspective, in [5], authors illustrated that such traditional technologies are costlier. On the other hand, LOs with traditional schemas IEEE LOM, and ADL SCORM need to be annotated manually [48], which needs more effort and time and slows down the sharing and reusing of Los—while LD, as we elaborated above with some works, uses automatic or semi-automatic approaches to achieve annotation.
In addition, unlike the SPARQL query mechanism with its endpoints, in SQI, the query format needs to be agreed upon with different repository providers before using the query functionalities [57]. At the same time, it is worth mentioning that, in some works, the LD approach is built upon these traditional techniques rather than being totally alternative to them.
2.2.4. Common Life Cycle
In general, the lifecycle in this track is close to what has been mentioned in the previous section except for some details: in an open repositories environment, it is needed at the beginning to find the data providers and choose intended repositories, followed by defining appropriate ontologies and vocabularies for OER domains, including reusing other controlled and well-known ones to ensure highest levels of interoperability. The natural following step is extracting data from OER repositories or MOOC providers combined with any necessary cleaning process to generate RDF datasets according to the defined vocabulary—then making interlinking among datasets and enrichment with LOD cloud or other open LD repositories, publishing datasets and providing a SPARQL Endpoint to make data accessible, establishing applications and services to consume and exploit datasets, and providing any needed maintenance, optimization and quality procedures. More details could be found in [2,55] and other works mentioned in this track.
2.2.5. Common Vocabularies
By reviewing the publications that we discussed in this section, we extract the most frequent vocabularies. We found that there are mainly LOCWD (http://carbono.utpl.edu.ec:8080/locwd/) [31,32], LOERD [32], LRMI (http://www.lrmi.net/) [58] and VIVO (http://vivoweb.org/ontology/core) [59] as educational ontologies that have the highest frequency, which implies their importance in this track. The high frequency for LOCWD as learning ontology indicates its impact and its success since some other works are built upon it. On the other hand, DC, FOAF, BIBO as ontologies that have common use in different fields have high frequencies, so they could be exploited as hubs among different datasets, while SKOS has the highest frequency as a model used in linking knowledge organization systems. Many works in this section depend on SKOS to help with making a classification, filtering, inferring, annotating, enrichment and alignment, which indicate its important role in LOD repositories and in LD in general. As a result, SKOS could be considered as a very strong candidate to act as a bridge and hubs among datasets. Section 5 provides a description for each one of these vocabularies.
2.2.6. Applications
In this section, three of the major applications that are built upon some of the previously discussed works are mentioned here:
Serendipity: (http://serendipity.utpl.edu.ec/) It is not fair to skip this part without mentioning serendipity, due to its contribution and services that it provides in this area. One of the descriptions for serendipity is “a platform to discover and visualize Open OER Data from OpenCourseWare repositories” [60]. Thus, Serendipity basically provides two main services: it is a search engine that is able to provide visualization of OER data. However, it is not a traditional search engine; it is based on semantic web and LD potentials. It gets data from OpenCourseWare Consortium and OCW-Universia that are comprised of large OER collections and several other institutions’ repositories that publish OERs and OCWs. One of its features is enabling the user to find needed facets and moreover discovering new ones by suggesting facets that users did not consider in advance. It provides accurate and integral results and has the ability to make a refinement on queries. In addition, Serendipity provides search criteria to be used in improving discovery.
By using LOCWD vocabulary, unified RDF data model and LD potentials, Serendipity is able to introduce advanced abilities and tools of visualization in dynamic and automatic ways. Such tools and potentials of visualization raise the interaction between users and datasets. In addition, it provides geographic information of universities and institutions that are a source of OCW and OER resources as Figure 2 shows. It also utilizes social network analysis (SNA) to provide related tags. Briefly, Serendipity helps users to support their educational interests and tracks. Thus, it provides query interface with complex abilities of expression. In addition, in this platform, OCW metadata is provided to facilitate achieving enrichment with LOD cloud. For example, when a user selects a specific course, besides general information about the course, a user is also provided with information about the publisher of the course and OER resources related to the course. Research in [60] mainly focused on this platform.
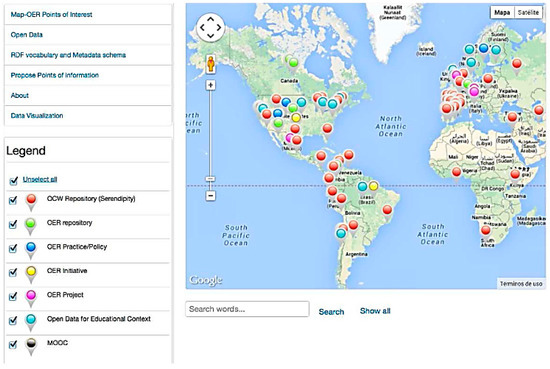
Figure 2.
Serendipity visualization.
Metamorphosis+3: it takes advantage of both semantic and social web to constitute a platform to publish, share and ruse medical educational resources [47].
Talis Aspire Community Edition: the source of this work is the learning resources that come from UK universities. Based on these learning resources, an educational graph is assembled and applied by using LD and technologies [61].
2.2.7. Challenges
The works above faced some challenges to achieve its purpose and some of these challenges are still open questions, with the major ones mentioned below:
Trust issue: other than data coming from a formal institution, as the situation was in the previous section, here in open repositories, more procedures are needed to ensure trusting. This is because integrating data from a remote learning repository needs to confirm credibility of educational resources before allowing them to be part of curriculums and before sharing them with other teachers and students.
Mapping between traditional open repositories schemas such as IEEE LOM and LD vocabularies: this issue concerned most of the works in this field. It is a necessity not a marginal concern, since traditional existing schemas are not sufficient to describe and annotate OER resources perfectly, as we elaborated above and as discussed in other works like [27,33,35].
Full or semi-automatic mapping: one of the issues that have not been resolved regarding mapping approaches especially regarding OERs and open repositories are: which is the more suitable, semi or full automatic approaches. It is a controversial point, since there is kind of trade-off between scalability and precision.
Out of date and duplication resources: is the issue that open repositories suffer from, especially during interlinking when learning resources may be identical but have different addresses.
Heterogeneity in open educational repositories and URIs referencing mechanism: open educational repositories look like a sea full of wealth resources, but the problem is how we can reach the needed resources easily, and how to determine the more appropriate sources. Actually, with the URI mechanism that LD provides, the problem is more addressable but many emerging problems with making referencing and dereferencing come up, which needs more examination.
2.3. Integration in Hybrid Works
In this section, we review works that serve both formal and informal ELD.
Both Refs. [62] and [63] addressed LD in blended learning models to integrate OER material with the traditional class by using LD. Ref. [62] highlighted the dilemma of the tendencies of teachers to overload students by just adding new online activities, plus the old traditional ones in their courses, rather than rethinking all the course content. At the same time, it indicates the issue of maintaining students’ engagement; doing the in and out class’s duties to be at the intended productive level and the issue of maintaining the students’ interactivity. An approach that aims to use LD to manage educational resources from both higher educational institutions and MOOCs to achieve better integration is presented in [64]. In addition, they used text mining in their approach to make interlinking and association among concepts.
Refs. [65,66,67] confirm some helpful findings that deserve to be considered in both formal and informal education integration, such as: popular vocabularies like Dublin Core and FOAF and others could play an essential role to be used as connectors and hubs among the isolated datasets [65]; making alignment between specific vocabularies leading to a great effect in increasing the cohesion among datasets and making them more connected [65]; size of datasets could give some indications: for example, the number of classes indicates the variety of the dataset while the number of properties indicates the richness [67]. Authors in [66] show how educations on both sides formal and informal constitute the perfect use case for LOD, being one of its main feeds.
In addition, Refs. [68,69] were interested in annotating documents and learning resources, which is helpful for integration in all kinds of education, annotating LFs (learning fruits: special kind of learning resources) discussed in [69] to provide links to other content that complements and extends the knowledge of both students and teachers, achieving this by determining the main topic of the LFs, and selecting, based on it, the best DBpedia nodes that are relevant to this topic; and making successful annotations and enrichment for the content and terms of LFs. Authors in [68] worked on enriching documents with semantic annotation. The main point in this approach is expanding the annotation of the relevant term to be with a (sub)graph of the ontology rather than with just one instance, while connecting the relevant term of the document with the ontology. The greatest effect is improving the description of the document, but, they indicate “Filtering linked data is computationally expensive, and thus this process cannot be performed in real time”. Along the same line of annotation: Linked science initiative [70] intended to have links between all scientific components (such as models, methods and evaluation metrics, etc.) based on ontologies and vocabularies. Achieving this goal leads to having collections of scientific data and enabling applying discovery patterns upon them. Transforming from RDB to RDF is one of the essential concerns in making integration in all areas of ELD. Thus, Ref. [71] provided a procedure that is devoted to automatically extracting and mapping data from RDB to RDF based on LO ontology with considering accuracy and performance. They support their work by introducing the DB2RDF (https://sourceforge.net/projects/db2rdf/) tool. This work contributes to releasing the LOs from being invisible in scattered databases to be discoverable, reusable and accessible, with more relevant content to the needs of educators and considering avoiding redundancy and duplications.
Lastly, regarding multimedia, Ref. [72] focused on the role of LD that can be played in this field. They provided their experiments in an education context. The main feature of this system was enabling lay and inexpert users to build the multimedia LD resources without needing to learn any semantic web techniques and in an easy way.
3. Personalization, Learning Analysis and Assessments with ELD
The previous section about integration and interoperability is a significant pavement step to reach the best recommendation and achieve accurate personalization.
Reaching good educational personalization, recommendation and correct decisions needs to be preceded by good learning analysis. This is what Refs. [73,74,75,76]’s research efforts have addressed. Providing a new opportunity to perform analyzing and visualization on OER, by using both LD and SNA, is introduced in [73]. Learning analysis by incorporating LD with data mining is explored in [75]. The base of this approach is exploiting LOD to help in achieving a better interpretation of data mining results, and reaching a better understanding by having linked patterns rather than just data mining patterns. These ideas are applied in courses’ enrollment process. In addition, Ref. [76] studied involving data mining and LD in learning analysis by modelling learners’ logs and learning traces to make enrichment with LOD datasets. Thus, it studied using this modelling to support personal learning frameworks. Ref. [74] managed research regarding the learning analytics in a mobile environment and based on LOD. Since it is in mobile learning, it considered location and place aspects such as tracking students’ interaction and communication during a visit; and analyzing these data to help tacking decisions based on this analysis. They used the MeLOD (a Mobile Environment for learning with Linked Open Data) to illustrate a case study of their research. The MeLOD environment connects the DBpedia and GeoNames and other datasets with contextual information about the students’ learning history. Based on that, the position is going further than just latitude and longitude to be as a concept that could be enriched by using DBpedia.
Enabling self-learners to build their learning objectives, learning paths, skills and therefore their future jobs as accurate as possible is one of the core directions in personalization. In [77,78], the authors researched using LD to map current learners’ experience, interests and objectives from one side and the open learning materials from the other side. The idea of making ‘User Interests’ as concepts of a knowledge domain is adopted. Users’ preferences are considered as the base of the model, as well as considering the possibility of users’ information being distributed and gained from different sources. The matter in such direction is feeding recommender systems with enough information about users to enable making more appropriate recommendations of OERs, based on the needs and types of users and their level of knowledge and skills. This is based on semantic models that enable making more enrichment, inferences and better classification. In addition, in seeking to enhance discoverability, a service that makes suggestion, categorization, visualization and exploration of OER topics is introduced. Along the same line, Ref. [79] provided an initial study to present a system that aims to do automatic concept extraction. The goal is to enhance searching and retrieval to provide more personal and relevant items based on LD technologies. Based on the comparison that they did between their automatic approach and the manual ones, it showed that the extracted concepts can generate good summarization of document contents. On the other hand, the challenging of providing recommendations to anonymous users with a minimum amount of users’ information in a heterogeneous OER environment that engages heterogeneous types of users is discussed in [80]. The need of going in this direction is because classical approaches based on enough historical information about users does not fit into such OER repositories. The authors followed a ‘knowledge filtering’ approach that is flexible enough to support the needs of heterogeneous or anonymous users.
The social part of learning is an engaging part to learn more quickly and with more passion and encouragement of communication. Taking advantages of social learning to reduce the time that a student needs to absorb information to shape his knowledge by involving LD technology in e-book navigation tools is addressed in [81]. More clearly, modifying the e-book display based on users’ annotations is intended. While Ref. [82] focused on the Enhanced Course Ontology for Linked Education (ECOLE) and its potentials and features, the ultimate aim of this work was providing personalized electronic materials by providing a model that combines three issues: ‘knowledge domain, user activity and knowledge assessment’. By this combination, they were able to provide more customizable, interactive contents to users. Teachers, for example, with this system can reuse external resources in their courses. In addition, providing assessment tools such as ‘the rating of the terms’ helps teachers to tune their teaching and materials based on their students’ needs with consideration of reusing other ontologies and resources such as making the TEACH oncology as the target of their mapping. Incorporating the idea of using SCORM as a mediation between ECOLE and LMS systems, such as the Moodle system, since the direct integration can’t be achieved. For adaptive learning, Ref. [83] explains how LinkedUP projects contribute to this direction based on LD.
In order to take advantage of users’ MOOC profiles and support users by recommending related OERs based on their MOOC profiles, the authors in [4] worked to provide the architecture to help suggesting what is useful for users, even if they don’t realize their needs for such materials during their original search. Such architecture aims to make OERs reusable and discoverable in the context of MOOC, based on users’ needs and requirements. Thus, it matches between user’s learning needs and learning resources. Going further in this discussion leads to a challenging question: how could MOOC serve large numbers of learners with content appropriate and personalized to everyone? The work in [84] tried to discuss this idea and presented an approach to make MOOCs more responsive to the different learning requirements by using semantic technologies and achieving that by annotating different parts of MOOCs and making them involved in the semantic learning platform. They mentioned an INTUITEL project as an effort in this direction by integrating it with an MOOC platform. One important idea that they outlined is “how complex large courses may be constructed from Small OER, thereby resolving the problems’ maintainability and adaptability of current MOOCs”. Another work on the same line is [85] that worked on gaining metadata of Open edX online courses to apply LD and semantic technologies on it, thus combining the benefits of MOOC with LD and therefore providing RDF datasets and SPARQL endpoint for edX courses. They also worked on extracting the concepts of the course lectures. This enables many benefits such as: making analysis based on the extracted concepts and then constructing the semantic of the subject areas, so that it will improve the navigation and binding and providing recommendation and more personalized contents. This has a significant impact when we have interdisciplinary concepts, therefore making interdisciplinary connections. In [86], authors considered mapping between learning and career objectives especially in MOOCs. In addition, in the same direction, Ref. [87] suggested a recommender system that helps the student to build his/her program planning.
The assessment is a natural complement step of users’ personalization to provide a personal evaluation of their levels and learning outcomes. Thus, authors in [88] suggested an approach to consume LD differently by generating semi-automatic various styles of assessments such as question-answering systems, quiz generation and interactive learning games. The issue in their approach is involving humans to participate in improving the automated tasks by making checks and controls. In addition, since people are involved, this contributes to making a refinement on the original educational dataset and improves the quality of data by cleaning, checking and detecting the problematic data. This work facilitates producing an assessment part of course production. Making assessment by using ELD is another innovative way to increase consumption and achieve reusing of educational datasets by generation of automatic assessment approaches. Thus, Ref. [89] also addressed the same challenge of doing an assessment but more particularly in open questions assessments by exploiting semantic web technologies. Primarily, the ‘domain ontologies, semantic annotations and semantic similarity measurements’ methods are used. Since the focus is on open questions, which required the use of algorithms to extract knowledge from answers, the importance of making semantic annotations is the means by which it can gain the accurate semantic specification of the questions and the answers. Course ontologies with semantic annotations lead to gaining an automatic constructive feedback. This approach featured with enabling the teacher to set some parameters and thus tune the assessment process. They stated that their approach was able to make assessments for students that are close to the one done by humans. In the end, this approach enables reusing and sharing questions and answers. Actually, we think the original structure of the RDF statement helps and encourages going ahead in the automatic or semi-automatic assessment successfully.
3.1. Common Vocabularies
By reviewing ontologies that were used in this part, we found that FOAF is the most used one followed by the BIBO, AIISO [18] and TEACH [19]. This is logical as a result of making personalization in the educational environment. AIISO and TEACH are educational ontologies, while FOAF is dedicated for people. Other used ontologies are: VIVO [59], DC, SKOS, LOCWD [31] and IMS QTI (http://www.imsglobal.org/question) [90]. Most of these ontologies are mentioned earlier and used originally in the integration and interoperable parts, which indicate that personalization and recommendation basically depend on achieving a kind of integration firstly. Section 5 provides a description for each one of these common vocabularies.
3.2. Challenges
The main challenges regarding personalization and recommendation on open educational resources and environment are summarized in the following issues: users in open platforms are heterogeneous and don’t have formal and detailed registration information as traditional universities, which could cause some lack of users’ historical data. Therefore, more efforts on exploring the idea of using LD to allow the interoperability in obtaining distributed personal data from various platforms and services deserves to be considered. In addition, one of the characteristics in such open platforms is serving a large numbers of users, which makes providing content that suits all kinds of users more challenging. Another issue in open platforms is related to the low interaction of users, which makes offering responsive personalized content harder. Another issue, which involves tracing learning outcomes, is a very important aspect of providing good recommendations. Unfortunately, learning outcomes are often implicit in curriculums under no clear sections. Thus, making annotations on learning outcomes in an obvious way will enhance personalization and recommendations tremendously.
4. Quality by ELD
At the beginning of this section, it is worth indicating that the main quality issue that the research discussed regarding EDL is the relevance. For example, Refs. [65,91] studied the correlation between resource types (categories) and topics of datasets. They explained that considering the association between types and topics of datasets has a significant impact on improving the annotation and therefore retrieving the best results of the datasets. In addition, a profile explorer is provided that “allows users to navigate topic profiles associated with datasets with respect to the type of the resource in the dataset”. In addition, Ref. [92] introduced a relevance measure to evaluate learning resources by utilizing social web aspects such as votes, comments, and number of visualizations to weigh the relationships between resources. In Ref. [93], the authors proposed metrics particularly regarding educational resources to evaluate the relevance among OERs. This metric considered adding a new dimension to consider the dynamic educational resources coming from a social semantic web as well as taking advantage of the “conceptual learning context” from LOD such as DBpedia. In addition, to handle the relevance by “coupling and de-coupling of wrong relationships amongst data entities”, the work in [94] considered other quality issues such as updating the outdated data by developing algorithms to maintain links. Furthermore, Ref. [95] expands the view by providing a rating system based on LD principles to examine OERs based on evaluation criteria as the following: open license, availability on the web, scope of the resource identifier, metadata availability, availability of documentation and vocabulary for metadata/data and query mechanism. In Ref. [58], besides studying the adoption and distribution of the Learning Resource Metadata Initiative (LRMI) vocabulary (a vocabulary that is made to annotate learning resources by using schema.org’s terms on the web), they considered various quality issues and provided several cleansing techniques for improving LRMI datasets.
Lastly, in [56], the work introduced an interesting idea by providing ranking scores of universities, which succeed in providing ranking close to the international ranking systems such as Times Higher Education and Shanghai Jiao Tong University and others, but at a low-cost. This ranking system is built based on computing the quality facts available publicly in LOD about the universities. Information such as universities’ achievements regarding prizes, publications, number of citations, doctoral students, university alumni and faculty members, the proportion of international staff and students and other contributions that build the reputation is used as indicators to this system. Thus, they provided “a novel metric to compute the informativeness of semantics (resources and relations) that signify the universities in Linked Data“. In other words, the available LOD is exploited to measure the university reputation and standing. This research gives a decisive indication of the importance of revealing the contributions and achievements of the universities and makes them visible on the web especially as LD to put the university in its deserve scores.
5. Summarized Description of the Common ELD’s Vocabularies
In this section, we provide a summarized description for the common vocabularies used in ELD. Table 1 shows the name, abbreviation and description for each vocabulary.

Table 1.
Summarized description for the common vocabularies used in ELD.
6. Projects, Tools and Landscapes of ELD
In this section, we mention major projects, tools, and other overviews and landscapes that concerned ELD.
6.1. Projects in ELD
To complete the picture about ELD, this work cannot conclude without mentioning essential projects that are developed particularly to evolve this paradigm. LinkedEducation.org is an initiative aims to reach well-interlinked educational Web of Data by following LD principles [27]. Sharing and reusing educational data among institutions and repositories is a purposeful result of this initiative. Thus, it provides an open platform to share educational relevance datasets, ontologies, tools and the opportunities to consume such data in applications with multiple goals and valuable services and here where LinkedUp project comes. LinkedUP sets up competitions to encourage consuming ELD in innovative and novel ways [67,83]. In addition, it provides a ‘LinkedUp Dataset Catalog’ or the ‘Linked Education Cloud’ that concerns collecting all types of data related to education. Linkeduniversities.org went in the same direction and enabled sharing and linking different universities’ videos of lectures using well-known vocabularies [30,65]. In addition, the VIVO platform that “collect information within universities, that can then be opened through LD to others, forming a network of resources from many different universities” [22]. Gnoss.com allows users to discover knowledge from both of Learning Analytics Knowledge (LAK) and Educational Data Mining (EDM) [96]. Thus, it enables building applications based on Learning Analytics such as faceted searches, visualization graphs and so on [96].
On the other hand, some projects that have specific domains were developed such as an mEducator project for medical education that provides educational metadata in a medical domain [30]. In addition, linkedlifedata.com for biomedical domain, organic-edunet.eu for organic agriculture and agroecology [5]. Lastly, ChemCloud is dedicated to a chemistry domain [97].
6.2. Common Tools Used in ELD
Regarding tools, in Table 2, we detailed the most used tools in each stage of the LD cycle based on the overall works that we reviewed.
Table 2.
Summary of the most used tools and its stages in ELD.
6.3. Overviews and Landscapes in ELD
In addition, in Figure 3, we refer to the overviews and landscape works of ELD with their publication years as well as number of citations until this writing in researches [5,22,57,97,98,99,100].

Figure 3.
Other overviews and landscapes.
7. Discussion and Recommendations
Throughout the paper, we have indicated some of the most important recommendations and notes that we deduced through this research. However, in this part, we emphasize general important issues that need to be considered when ELD research is intended.
For ontologies, which is a fundamental issue in LD, reusing existing ontologies, especially controlled ontologies as much as possible, is an admitted thing. However, some discussions regarding lightweight and minimum commitments have come up in some works. Actually, adopting the reuse of existing ontologies means increasing interoperability opportunities and decreasing the risk of having isolated silos of educational datasets. The more reusing of well-known ontologies makes outcome datasets more easily consumable and exploitable by the different applications. In addition, sticking to reusing existing ontologies enhances the ability to make automatic visualization. However, when the existing ontologies can’t cover the requirements, developing specific ones become mandatory. In this case, mapping those specifically developed ontologies to the related popular ones is an important issue, in order to avoid the possibility of having isolated datasets, even though the other point of view argued that the idea of mapping and aligning to well-known ontologies rather than a high commitment to existing ones and the complications of modifying could simplify things. In all cases, mapping and bridging among ontologies, especially among the various ontologies that represent the same thing, will mean more interlinked and connected datasets, which is desired. When some works are facing the choice of using competitive ontologies, it should choose the more popular ones and, at the same time, the ones that cover the needs of the work with simplicity as much as possible. In addition, making refinements on those educational ontologies is needed to be up-to-date with the education needs.
The nature of LD encourages users to be producers rather than just consumers, even without them being aware. Exploiting this feature will benefit ELD significantly. To allow this role of users, especially students, it is necessary to provide tools and systems that enable lay users without previous experience of LD technologies to contribute in making the content, by, for example, annotating and enriching. Users could contribute to making relations between any related entities such as people, places and so on and also producing small OERs by making some videos, audio or comments, etc. Regarding recommendation and personalization, putting efforts into having perfect integration of educational resources leads to the best comprehensive results and at the same time accurate recommendations. In addition, exploiting ELD by developing assessments for students could be considered another innovative way of exploiting ELD. The natural structure of the LD model encourages going along this direction. In a related area, examining LD abilities in learning analyses could lead to new approaches and more accurate results, as we have shown with some works in this matter. Combining LD with learning analyses needs more research. In addition, works that were carried out regarding quality issues and providing measurements and metrics with regard to ELD are very limited. Thus, making an evaluation regarding ELD needs more effort.
According to many works that we presented, it is shown that having educational linked datasets increasing the opportunities to facilitate building more effective, integrated and innovative applications based on outcome datasets. Almost all universities provide examples of such applications. In general, web app applications for mobile rather than native ones were preferred to provide the best experience with LD. One of the benefits of having ELD is making interlinking and enriching with the LOD cloud. The ability to create more and more correction links around the educational resource means more and more useful educational resources. Tools such as SILK and LIMES proved their effectiveness to make interlinking, thus increasing the enrichment of LD, which leads to improving the learning process.
The MOOCs trend faces many challenges such as “analytics, adaptability, orchestration, course development, and mobile assistants high dropout rates, student anonymity, insufficient support” [38]. Based on the review that we did, we found that LD could serve as a potential solution for many of these issues. MOOC in ELD could be considered as a trust educational source, so it is worth making more efforts to combine it with LOD cloud.
Lastly, having universities publish papers about LD contributions will increase its ranks and enhance its reputation among international universities and institutions. In addition, considering the providing of multilingual abilities by LD will be provide even more support.
8. Conclusions
By conducting this study, it is apparent that LD in education has attracted many researchers to provide useful contributions in this area. However, it still has open issues that require more investigations, discussions and proposals to be resolved and improved. This research has provided a systematic and categorized view of the various works in ELD by suggesting organizing them into three main tracks: an ‘Integration and interoperability’ track that includes: formal education, informal education and hybrid works; a ‘Learning analysis, personalization and assessments ‘ track and lastly a ‘Quality by ELD’ track. It was noted that the larger proportion of works were in the integration and interoperability track. In addition, the number of universities that publish their open data as LD is increasing and some presented works confirmed that this orientation in universities contributes to improving the reputation and thereby the ranking score of the university. In addition, many innovative applications and services resulted from adopting LD in universities and have the opportunity to be enriched with an LOD cloud. On the other hand, large educational repositories such as GLOBE and Universia became more integrated, accessible and discoverable by LD. In addition, OCWs took advantage of LD and the Serendipity visualized search engine is established based on it. As well as, MOOCs gained by using LD a shared platform from various MOOC providers. Some important approaches were also addressed regarding using LD in: building courses from OERs, the various types of classification and categorization for educational resources, annotating by the social web, the role of concept maps and the contextual characteristics in mobile environments. Blended learning, adaptive learning and multimedia are also discussed by LD as shown. We extracted some commonalities between different works such as common lifecycle, vocabularies and outcome datasets to simplify constitute a roadmap in this area.
Combining LA, data mining with LD introduced new approaches in these fields. In addition, regarding personalization, making users’ interests as concepts has brought many advantages to match with learning materials and make interdisciplinary connections. Some works exploited the interoperability of LD to gather open users’ information from several services to offer more personalized resources. Other works took benefits from MOOC profiles to make recommendations for users. Anonymous users in heterogonous environments were one of the challenges that were also discussed. Other research exploited LD in another way by providing different kinds of assessments including open questions for students. Regarding the quality issues, two things are remarkable: relevance is the main quality attribute that was addressed in this area, and there are limitations of works that have been provided in this track. Some pioneer projects such as LinkedEducation.org in general education and mEducator for medical and other projects have a noteworthy role in motivating ELD.
Funding
This research received no external funding
Conflicts of Interest
The authors declare no conflict of interest
References
- Zablith, F.; Fernandez, M.; Rowe, M. Production and consumption of university linked data. Interact. Learn. Environ. 2015, 23, 55–78. [Google Scholar] [CrossRef]
- Piedra, N.; Chicaiza, J.; Lopez-Vargas, J.; Caro, E.T. Guidelines to producing structured interoperable data from Open Access Repositories. In Proceedings of the 2016 IEEE Frontiers in Education Conference (FIE), Erie, PA, USA, 12–15 October 2016. [Google Scholar]
- Nahhas, S.; Bamasag, O.; Khemakhem, M.; Bajnaid, N. Linked data approach to mutually enrich traditional education resources with global open education. In Proceedings of the IEEE International Conference on Computer Applications and Information Security (ICCAIS), Riyadh, Saudi Arabia, 4–5 April 2018. [Google Scholar]
- Piedra, N.; Chicaiza, J.A.; López, J.; Tovar, E. An Architecture based on Linked Data technologies for the Integration and reuse of OER in MOOCs Context. Open Prax. 2014, 6, 171–187. [Google Scholar] [CrossRef]
- Keßler, C.; d’Aquin, M.; Dietze, S. Linked Data for science and education. Semant. Web 2013, 4, 1–2. [Google Scholar]
- Zablith, F.; d’Aquin, M.; Brown, S.; Green-Hughes, L. Consuming linked data within a large educational organization. In Proceedings of the 10th International Semantic Web Conference (ISWC 2011), Bonn, Germany, 23–27 October 2011. [Google Scholar]
- Zablith, F.; Fernandez, M.; Rowe, M. The OU linked open data: Production and consumption. In Proceedings of the Semantic Web: ESWC 2011 Workshops, Heraklion, Greece, 29–30 May 2011. [Google Scholar]
- Halaç, T.G.; Erden, B.; Inan, E.; Oguz, D.; Gocebe, P.; Dikenelli, O. Publishing and linking university data considering the dynamism of datasources. In Proceedings of the 9th International Conference on Semantic Systems, Graz, Austria, 4–6 September 2013. [Google Scholar]
- Keßler, C.; Kauppinen, T. Linked open data university of münster–infrastructure and applications. In Proceedings of the Semantic Web: ESWC 2012 Satellite Events, Crete, Greece, 27–31 May 2012. [Google Scholar]
- Ma, Y.; Xu, B.; Bai, Y.; Li, Z. Building linked open university data: Tsinghua university open data as a showcase. In Proceedings of the Joint International Semantic Technology Conference (JIST 2011), Hangzhou, China, 4–7 December 2011. [Google Scholar]
- Juanes, G.G.; Barrios, A.R.; García, J.L.R.; Medina, L.G.; Adán, R.D.; Yanes, P.G. Linked Data Strategy to Achieve Interoperability in Higher Education. In Proceedings of the 10th International Conference on Web Information Systems and Technologies, Barcelona, Spain, 3–5 April 2014. [Google Scholar]
- Szász, B.; Fleiner, R.; Micsik, A. A case study on Linked Data for University Courses. In Proceedings of the OTM Confederated International Conferences, Rhodes, Greece, 24–28 October 2016. [Google Scholar]
- Fernandez, M.; d’Aquin, M.; Motta, E. Linking data across universities: An integrated video lectures dataset. In Proceedings of the 10th International Semantic Web Conference, Bonn, Germany, 23–27 October 2011. [Google Scholar]
- Zablith, F. Interconnecting and enriching higher education programs using linked data. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015. [Google Scholar]
- Zablith, F. Towards a Linked and Reusable Conceptual Layer Around Higher Education Programs. In Open Data for Education; Springer: Cham, Switzerland, 2016; pp. 86–102. [Google Scholar]
- d’Aquin, M. Putting linked data to use in a large higher-education organization. In Proceedings of the Interacting with Linked Data (ILD) Workshop at Extended Semantic Web Conference (ESWC), Heraklion, Greece, 28 May 2012. [Google Scholar]
- Al-Yahya, M.; Al-Faries, A.; George, R. Curonto: An ontological model for curriculum representation. In Proceedings of the 18th ACM Conference on Innovation and Technology in Computer Science Education, Canterbury, UK, 1–3 July 2013. [Google Scholar]
- Styles, R.; Shabir, N. Academic Institution Internal Structure Ontology (AIISO). Available online: http://vocab.org/aiiso/schema (accessed on 10 August 2018).
- Kauppinen, T.; Trame, J.; Westermann, A. Teaching Core Vocabulary Specification. Available online: http://linkedscience.org/teach/ns-20130425/ (accessed on 10 August 2018).
- Metadata for Learning Opportunities (MLO)—Advertising. Workshop Agreement. 2008. Available online: https://www.immagic.com/eLibrary/ARCHIVES/TECH/CEN_EU/C081208O.pdf (accessed on 10 August 2018).
- Stubbs, M.; Wilson, S. eXchanging course-related information: A UK service-oriented approach. In Proceedings of the International Workshop in Learning Networks for Lifelong Competence Development, TENCompetence Conference, Sofia, Bulgaria, 30–31 March 2006. [Google Scholar]
- D’Aquin, M. Linked Data for Open and Distance Learning. Available online: http://hdl.handle.net/11599/219 (accessed on 10 August 2018).
- Rajabi, E.; Sicilia, Mi.; Sanchez-Alonso, S. Discovering duplicate and related resources using an interlinking approach: The case of educational datasets. J. Inf. Sci. 2015, 41, 329–341. [Google Scholar] [CrossRef]
- Rajabi, E.; Sicilia, M.A.; Sanchez-Alonso, S. Interlinking educational data: An experiment with GLOBE resources. In Proceedings of the First International Conference on Technological Ecosystem for Enhancing Multiculturality, Salamanca, Spain, 14–15 November 2013. [Google Scholar]
- Rajabi, E.; Sicilia, M.A.; Sanchez-Alonso, S. An empirical study on the evaluation of interlinking tools on the Web of Data. J. Inf. Sci. 2014, 40, 637–648. [Google Scholar] [CrossRef]
- Lama, M.; Vidal, J.C.; Otero-García, E.; Bugarín, A.; Barro, S. Semantic linking of learning object repositories to DBpedia. J. Educ. Technol. Soc. 2012, 15, 47. [Google Scholar]
- Dietze, S.; Yu, H.Q.; Giordano, D.; Kaldoudi, E.; Dovrolis, N.; Taibi, D. Linked Education: Interlinking educational Resources and the Web of Data. In Proceedings of the 27th Annual ACM Symposium on Applied Computing, Trento, Italy, 26–30 March 2012. [Google Scholar]
- Yu, H.Q.; Dietze, S.; Li, N.; Pedrinaci, C.; Taibi, D.; Dovrolls, N.; Stefanut, T.; Kaldoudi, E.; Domingue, J. A Linked Data-driven & Service-oriented Architecture for Sharing Educational Resources; Linked Learning 2011. In Proceedings of the 1st International Workshop on eLearning Approaches for the Linked Data Age, Heraklion, Greece, 2–31 May 2011. [Google Scholar]
- Mosharraf, M.; Taghiyareh, F. Federated Search Engine for Open Educational Linked Data. Bull. IEEE Tech. Comm. Learn. Technol. 2016, 18, 6. [Google Scholar]
- Taibi, D.; Fetahu, B.; Dietze, S. Towards integration of web data into a coherent educational data graph. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Piedra, N.; Tovar, E.; Colomo-Palacios, R.; Lopez-Vargas, J.; Alexandra Chicaiza, J. Consuming and producing linked open data: The case of Opencourseware. Program Electron. Libr. Inf. Syst. 2014, 48, 16–40. [Google Scholar] [CrossRef]
- Piedra, N.; Chicaiza, J.; López-Vargas, J.; Caro, E.T. Seeking Open Educational Resources to Compose Massive Open Online Courses in Engineering Education an Approach based on Linked Open Data. J. UCS 2015, 21, 679–711. [Google Scholar]
- Piedra, N.; Chicaiza, J.; Atenas, J.; Lopez-Vargas, J.; Tovar, E. Using Linked Data to Blended Educational Materials With OER—A General Context of Synergy: Linked Data for Describe, Discovery and Retrieve OER and Human Beings Knowledge to Provide Context. In Open Education: From OERs to MOOCs; Springer: Berlin/Heidelberg, Germany, 2017; pp. 283–313. [Google Scholar]
- Piedra, N.; Chicaiza, J.; López, J.; Tovar, E.; Martinez-Bonastre, O. Combining Linked Data and Mobiles to improve access to OCW. In Proceedings of the IEEE EDUCON Education Engineering 2012—Collaborative Learning & New Pedagogic Approaches in Engineering Education, Morocco, Marrakesh, 17–21 April 2012. [Google Scholar]
- Navarrete, R.; Luján-Mora, S. Use of linked data to enhance open educational resources. In Proceedings of the 2015 International Conference on Information Technology Based Higher Education and Training (ITHET), Lisbon, Portugal, 11–13 June 2015. [Google Scholar]
- Imongelli, C.; Lombardi, M.; Marani, A.; Taibi, D. Enrichment of the dataset of joint educational entities with the web of data. In Proceedings of the 2017 IEEE 17th International Conference on Advanced Learning Technologies (ICALT), Timisoara, Romania, 3–7 July 2017. [Google Scholar]
- Kagemann, S.; Bansal, S. MOOCLink: Building and Utilizing Linked Data from Massive Open Online Courses. In Proceedings of the 2015 IEEE International Conference on Semantic Computing (ICSC), Anaheim, CA, USA, 7–9 February 2015. [Google Scholar]
- Hernández-Rizzardini, R.; Delgado Kloss, C.; García Peñalvo, F.J. Massive open online courses: Combining methodologies and architecture for a success learning. J. Univser. Comput. Sci. 2015, 21, 636–6367. [Google Scholar]
- Höver, K.M.; Mühlhäuser, M. LOOCs—Linked Open Online Courses: A Vision. In Proceedings of the 2014 IEEE 14th International Conference on Advanced Learning Technologies (ICALT), Athens, Greece, 7–10 July 2014. [Google Scholar]
- Ihsan, I. Making MOOC Slides Semantically Accessible: A Semantic Content Generation Tool for PowerPoint Slides. J. Distance Educ. Res. 2017, 40–52. [Google Scholar]
- Paquette, G.; Miara, A. Managing open educational resources on the web of data. IJACSA Int. J. Adv. Comput. Sci. Appl. 2014, 5, 40–47. [Google Scholar] [CrossRef]
- Mikroyannidis, A.; Domingue, J.; Maleshkova, M.; Norton, B.; Simperl, E. Developing a curriculum of open educational resources for Linked Data. In Proceedings of the 10th Annual OpenCourseWare Consortium Global Conference (OCWC), Ljubljana, Slovenia, 23–25 April 2014. [Google Scholar]
- Höver, K.M.; Max, M. Evaluating a Linked Open Online Course. In Proceedings of the 2014 IEEE International Symposium on Multimedia (ISM), Taichung, Taiwan, 10–12 December 2014. [Google Scholar]
- Núñez, J.L.M.; Caro, E.T.; González, J.R.H. From Higher Education to Open Education: Challenges in the Transformation of an Online Traditional Course. IEEE Trans. Educ. 2017, 60, 134–142. [Google Scholar] [CrossRef]
- Sandeen, C. Integrating MOOCs into traditional higher education: The emerging “MOOC 3.0” era. Chang. Mag. High. Learn. 2013, 45, 34–39. [Google Scholar] [CrossRef]
- Chicaiza, J.; Piedra, N.; Lopez-Vargas, J.; Tovar-Caro, E. Domain categorization of open educational resources based on linked data. In Proceedings of the 5th International Conference on Knowledge Engineering and the Semantic Web, Kazan, Russia, 29 September–1 October 2014. [Google Scholar]
- Dovrolis, N.; Stefanut, T.; Dietze, S.; Yu, H.Q.; Valentine, C.; Kaldoudi, E. Semantic annotation and linking of medical educational resources. In Proceedings of the 5th European Conference of the International Federation for Medical and Biological Engineering, Budapest, Hungary, 14–18 September 2011. [Google Scholar]
- Lombardi, M. Discovering Educational Resources on the Web for Technology Enhanced Learning. In Proceedings of the Applications, ICWL Doctoral Consortium, Rome, Italy, 26–29 October 2016. [Google Scholar]
- Tovar, E.; Piedra, N.; Chicaiza, J.; Lopez, J.; Martinez-Bonastre, O. OER development and promotion. Outcomes of an international research project on the OpenCourseWare model. J. Univer. Comput. Sci. 2012, 18, 123–141. [Google Scholar]
- Svensson, M.; Kurti, A.; Milrad, M. Enhancing emerging learning objects with contextual metadata using the linked data approach. In Proceedings of the 2010 6th IEEE International Conference on Wireless, Mobile and Ubiquitous Technologies in Education (WMUTE), Kaohsiung, Taiwan, 12–16 April 2010. [Google Scholar]
- Singh, J.; Fernando, Z.T.; Chawla, S. LearnWeb-OER: Improving Accessibility of Open Educational Resources. arXiv 2015, arXiv:1509.02739. [Google Scholar]
- Taibi, D.; Chawla, S.; Dietze, S.; Marenzi, I.; Fetahu, B. Exploring TED talks as linked data for education. Br. J. Educ. Technol. 2015, 46, 1092–1096. [Google Scholar] [CrossRef]
- Mikroyannidis, A.; Domingue, J. Interactive learning resources and linked data for online scientific experimentation. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Hajri, H.; Bourda, Y.; Popineau, F. Querying Repositories of OER Descriptions: The Challenge of Educational Metadata Schemas Diversity. In Design for Teaching and Learning in a Networked World; Springer: Cham, Switzerland, 2015; pp. 582–586. [Google Scholar]
- Hallo, M.; Mora, S.L.; Chávez, C. An Approach to Publish Scientific Data of Open-access Journals using Linked Data Technologies. In Proceedings of the EDULEARN14, Barcelona, Spain, 7–9 July 2014. [Google Scholar]
- Meymandpour, R.; Davis, J.G. Ranking Universities Using Linked Open Data. In Proceedings of the LDOW, Rio de Janeiro, Brazil, 14 May 2013. [Google Scholar]
- Dietze, S.; Sanchez-Alonso, S.; Ebner, H.; Qing Yu, H.; Giordano, D.; Marenzi, I.; Pereira Nunes, B. Interlinking educational resources and the web of data: A survey of challenges and approaches. Program 2013, 47, 60–91. [Google Scholar] [CrossRef]
- Dietze, S.; Taibi, D.; Yu, R.; Barker, P.; d’Aquin, M. Analysing and improving embedded markup of learning resources on the web. In Proceedings of the 26th International Conference on World Wide Web Companion. International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Krafft, D.B.; Cappadona, N.A.; Caruso, B.; Corson-Rikert, J.; Devare, M.; Lowe, B.J. VIVO Collaboration. Vivo: Enabling national networking of scientists. In Proceedings of the Web Science Conference 2010, Raleigh, NC, USA, 26–27 April 2010. [Google Scholar]
- Piedra, N.; López, J.; Chicaiza, J.; Caro, E.T. Serendipity a platform to discover and visualize Open OER Data from OpenCourseWare repositories. In Proceedings of the Open Education Multicultural World (OCWC), Ljubljana, Slovenia, 23–25 April 2014. [Google Scholar]
- Heath, T.; Singer, R.; Shabir, N.; Clarke, C.; Leavesley, J. Assembling and applying an education graph based on learning resources in universities. In Proceedings of the Linked Learning (LILE) Workshop, Lyon, France, 17 April 2012; Volume 80. [Google Scholar]
- Piedra, N.; Chicaiza, J.; López, J.; Caro, E.T. Integrating OER in the design of educational material: Blended learning and linked-open-educational-resources-data approach. In Proceedings of the 2016 IEEE Global Engineering Education Conference (EDUCON), Abu Dhabi, UAE, 10–13 April 2016. [Google Scholar]
- Sherimon, P.C.; Vinu, P.V.; Krishnan, R. Enhancing the learning experience in blended learning systems: A semantic approach. In Proceedings of the 2011 International Conference on Communication, Computing & Security, Rourkela, Odisha, India, 12–14 December 2011. [Google Scholar]
- Duran, C.K.G.; Medina-Ramírez, R.C.; Juganaru-Mathieu, M. Using Linked Open Data to Enrich a Corporate Memory of Universities. In Proceedings of the International Conference on e-Learning, e-Business, Enterprise Information Systems, and e-Government (EEE), Las Vegas, NV, USA, 21–24 July 2014. [Google Scholar]
- d’Aquin, M.; Adamou, A.; Dietze, S. Assessing the educational linked data landscape. In Proceedings of the 5th Annual ACM Web Science Conference, Paris, France, 2–4 May 2013. [Google Scholar]
- d’Aquin, M.; Dietze, S. Open Education: A Growing, High Impact Area for Linked Open Data. ERCIM News. Available online: https://ercim-news.ercim.eu/en96/special/open-education-a-growing-high-impact-area-for-linked-open-data (accessed on 10 August 2018).
- d’Aquin, M. On the use of Linked Open Data in education: Current and future practices. In Open Data for Education; Springer: Cham, Switzerland, 2016; pp. 3–15. [Google Scholar]
- Vidal, J.C.; Lama, M.; Otero-García, E.; Bugarín, A. Graph-based semantic annotation for enriching educational content with linked data. Knowl.-Based Syst. 2014, 55, 29–42. [Google Scholar] [CrossRef]
- Otero-Garcıa, E.; Vidal, J.C.; Lama, M.; Bugarın, A.; Domenech, J.E. A context-based algorithm for annotating educational content with Linked Data. In Proceedings of the 3rd Future Internet Symposium (FIS 2010), FIS-Workshop on Mining Future Internet (MIFI 2010), Berlin, Germany, 20–22 September 2010. [Google Scholar]
- Kauppinen, T.; Baglatzi, A.; Keßler, C. Linked science: Interconnecting scientific assets. In Data Intensive Science; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Thangsupachai, N.; Niwattanakul, S.; Chamnongsri, N. Learning object metadata mapping for linked open data. In Proceedings of the 16th International Conference on Asia-Pacific Digital Libraries, ICADL 2014, Chiang Mai, Thailand, 5–7 November 2014. [Google Scholar]
- Chae, J.; Cho, Y.; Lee, M.; Lee, S.; Choi, M.; Park, S. Design and implementation of a system for creating multimedia linked data and its applications in education. Multimed. Tools Appl. 2016, 75, 13121–13134. [Google Scholar] [CrossRef]
- Piedra, N.; Chicaiza, J.; López, J.; Caro, E.T. Towards a learning analytics approach for supporting discovery and reuse of OER an approach based on Social Networks Analysis and Linked Open Data. In Proceedings of the 2015 IEEE Global Engineering Education Conference (EDUCON), Tallinn, Estonia, 18–20 March 2015. [Google Scholar]
- Fulantelli, G.; Taibi, D.; Arrigo, M. A framework to support educational decision making in mobile learning. Comput. Hum. Behav. 2015, 47, 50–59. [Google Scholar] [CrossRef]
- d’Aquin, M.; Jay, N. Interpreting data mining results with linked data for learning analytics: Motivation, case study and directions. In Proceedings of the Third International Conference on Learning Analytics and Knowledge, Leuven, Belgium, 8–13 April 2013. [Google Scholar]
- Zouaq, A.; Jovanovic, J.; Joksimovic, S.; Gasevic, D. Linked Data for Learning Analytics: Potentials and Challenges. Handb. Learn. Anal. 2017, 347–355. [Google Scholar] [CrossRef]
- Chicaiza, J.; Piedra, N.; López, J.; Caro, E.T. Promotion of self-learning by means of open educational resources and semantic technologies. In Proceedings of the 2015 International Conference on Information Technology Based Higher Education and Training (ITHET), Lisbon, Portugal, 11–13 June 2015. [Google Scholar]
- Chicaiza, J.; Piedra, N.; Lopez-Vargas, J.; Tovar-Caro, E. A user profile definition in context of recommendation of open educational resources. An approach based on linked open vocabularies. In Proceedings of the 2015 IEEE Frontiers in Education Conference (FIE), El Paso, TX, USA, 21–24 October 2015. [Google Scholar]
- Carbonaro, A. Interlinking e-Learning Resources and the Web of Data for Improving Student Experience. J. e-Learn. Knowl. Soc. 2012, 8, 33–44. [Google Scholar]
- Chicaiza, J.; Piedra, N.; Lopez-Vargas, J.; Tovar-Caro, E. Recommendation of open educational resources. An approach based on linked open data. In Proceedings of the 2017 IEEE Global Engineering Education Conference (EDUCON), Athens, Greece, 25–28 April 2017. [Google Scholar]
- Robinson, J.; Stan, J.; Ribiere, M. Using linked data to reduce learning latency for e-book readers. In Proceedings of the Semantic Web: ESWC 2011 Workshops, Heraklion, Greece, 29–30 May 2011. [Google Scholar]
- Vasiliev, V.; Kozlov, F.; Mouromtsev, D.; Stafeev, S.; Parkhimovich, O. ECOLE: An ontology-based open online course platform. In Open Data for Education; Springer: Cham, Switzerland, 2016; pp. 41–66. [Google Scholar]
- Herder, E.; Dietze, S.; d’Aquin, M. LinkedUp-Linking Web Data for Adaptive Education. In Proceedings of the UMAP Workshops, Rome, Italy, 10–14 June 2013. [Google Scholar]
- Henning, P.A.; Heberle, F.; Streicher, A.; Zielinski, A.; Swertz, C.; Bock, J.; Zander, S. Personalized Web Learning: Merging Open Educational Resources into Adaptive Courses for Higher Education. In Proceedings of the UMAP Workshops, Dublin, Ireland, 29 June–3 July 2014. [Google Scholar]
- Volchek, D.; Romanov, A.; Mouromtsev, D. Towards the Semantic MOOC: Extracting, Enriching and Interlinking E-Learning Data in Open edX Platform. In Proceedings of the 8th International Conference on Knowledge Engineering and the Semantic Web, Szczecin, Poland, 8–10 November 2017. [Google Scholar]
- Zotou, M.; Papantoniou, A.; Kremer, K.; Peristeras, V.; Tambouris, E. Implementing Rethinking Education”: Matching skills profiles with open courses through linked open data technologies. Bull. IEEE Tech. Comm. Learn. Technol. 2014, 16, 18–21. [Google Scholar]
- Li, N.; Suri, N.; Gao, Z.; Xia, T.; Börner, K.; Liu, X. Enter a job, get course recommendations. In Proceedings of the iConference 2017, Wuhan, China, 25 March 2017. [Google Scholar]
- Rey, G.Á.; Celino, I.; Alexopoulos, P.; Damljanovic, D.; Damova, M.; Li, N.; Devedzic, V. Semi-automatic generation of quizzes and learning artifacts from linked data. In Proceedings of the Linked Learning 2012: 2nd International Workshop on Learning and Education with the Web of Data, Lyon, France, 16–26 April 2012. [Google Scholar]
- Castellanos-Nieves, D.; Fernández-Breis, J.T.; Valencia-García, R.; Martínez-Béjar, R.; Iniesta-Moreno, M. Semantic web technologies for supporting learning assessment. Inf. Sci. 2011, 181, 1517–1537. [Google Scholar] [CrossRef]
- IMS Global Learning Consortium. IMS Question & Test Interoperability Specification; IMS Global Learning Consortium: Lake Mary, FL, USA, 2005. [Google Scholar]
- Taibi, D.; Fulantelli, G.; Dietze, S.; Fetahu, B. Educational Linked Data on the Web-Exploring and Analysing the Scope and Coverage. In Open Data for Education; Springer: Cham, Switzerland, 2016; pp. 16–37. [Google Scholar]
- Taibi, D.; Fulantelli, G.; Dietze, S.; Fetahu, B. Evaluating relevance of educational resources of social and semantic web. In Proceedings of the 8th European Conference on Technology Enhanced Learning, EC-TEL 2013, Paphos, Cyprus, 17–21 September 2013. [Google Scholar]
- Taibi, D.; Fulantelli, G.; Dietze, S.; Fetahu, B. A Linked Data approach to evaluate Open Education Resources. In Proceedings of the 2013 International Conference on Education and Modern Educational Technologies, Cambridge, MA, USA, 30 January–1 February 2013. [Google Scholar]
- Dhekne, C.; Bansal, S.K. Linking and maintaining quality of data about MOOCs using Semantic Computing. In Proceedings of the 2017 IEEE 11th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, 30 January–1 February 2017. [Google Scholar]
- Piedra, N.; Chicaiza, J.; López, J.; Caro, E.T. A rating system that open-data repositories must satisfy to be considered OER: Reusing open data resources in teaching. In Proceedings of the 2017 IEEE Global Engineering Education Conference (EDUCON), Athens, Greece, 25–28 April 2017. [Google Scholar]
- Maturana, R.A.; Alvarado, M.E.; López-Sola, S.; Ibáñez, M.J.; Elósegui, L.R. Linked Data based applications for Learning Analytics Research: Faceted searches, enriched contexts, graph browsing and dynamic graphic visualisation of data. Riam 2013, 34, 941248905. [Google Scholar]
- Krieger, K.; Rösner, D. Linked data in e-learning: A survey. J. Semant. Web 2011, 1, 1–9. [Google Scholar]
- Vega-Gorgojo, G.; Asensio-Pérez, J.I.; Gómez-Sánchez, E.; Bote-Lorenzo, M.L.; Muñoz-Cristóbal, J.A.; Ruiz-Calleja, A. A Review of Linked Data Proposals in the Learning Domain. J. UCS 2015, 21, 326–364. [Google Scholar]
- Al-Yahya, M.; George, R.; Alfaries, A. Ontologies in E-learning: Review of the literature. Int. J. Softw. Eng. Its Appl. 2015, 9, 67–84. [Google Scholar]
- Pereira, C.K.; Siqueira, S.; Nunes, B.P.; Dietze, S. Linked data in Education: A survey and a synthesis of actual research and future challenges. IEEE Trans. Learn. Technol. 2017. [Google Scholar] [CrossRef]
















© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).