Parallel Computation of Rough Set Approximations in Information Systems with Missing Decision Data


Abstract
1. Introduction
2. Literature Review
3. Basic Concepts
3.1. Rough Set
3.2. MapReduce Model
3.3. The Usage of MapReduce to Rough Set Processing
4. Twofold Rough Approximations for IDS
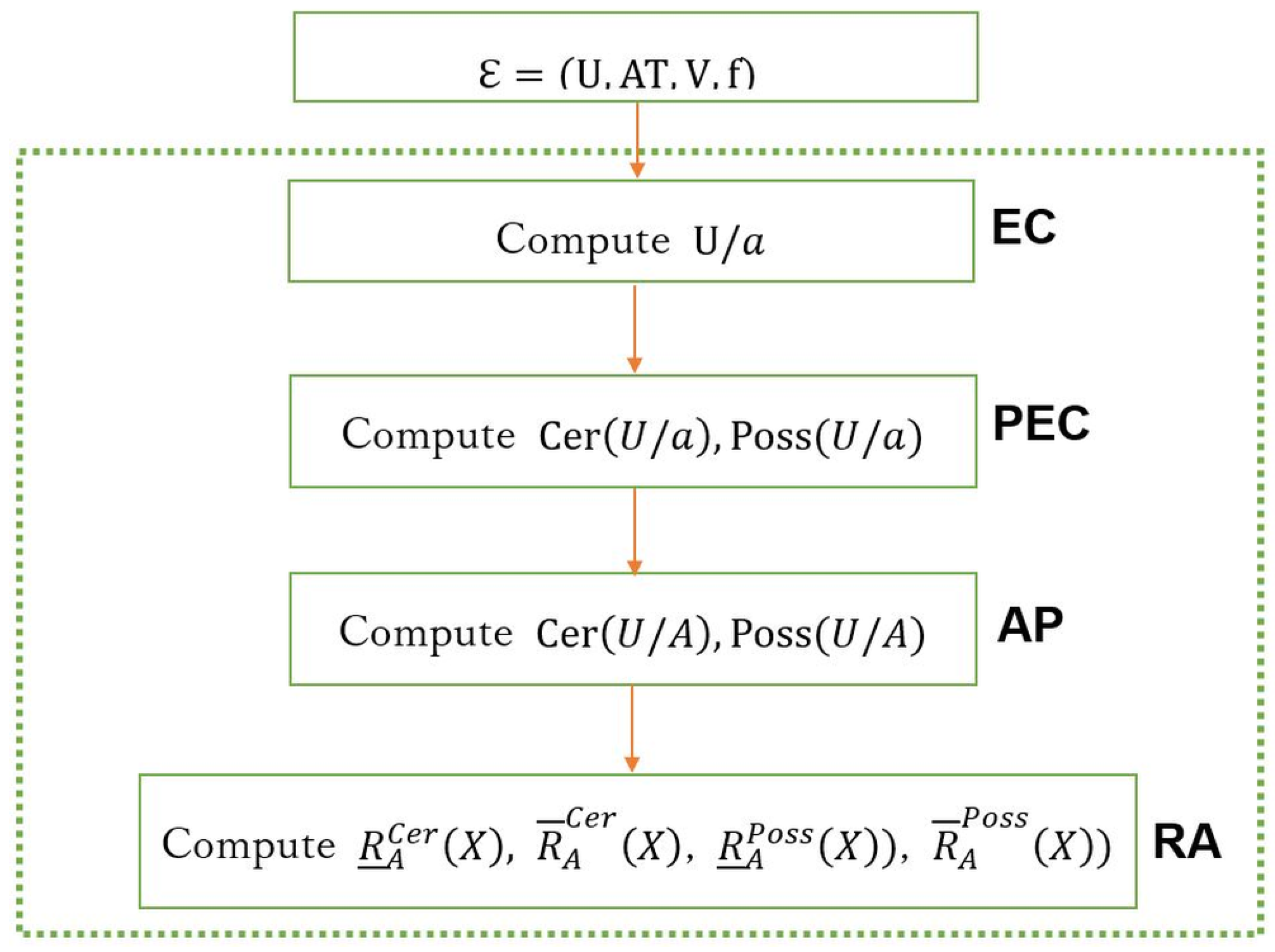
5. Computing Rough Approximations in IDS
5.1. Sequential Algorithm
| Algorithm 1 Sequential algorithm to calculate twofold rough approximations |
 |
5.2. MapReduce Based Algorithms
5.2.1. Computing Equivalence Classes in Parallel (EC)
| Algorithm 2 function EC Map |
 |
| Algorithm 3 function EC Reduce |
 |
5.2.2. Computing Possible and Certain Equivalence Classes in Parallel (PEC)
| Algorithm 4 function PEC Map |
 |
| Algorithm 5 function PEC Reduce |
 |
5.2.3. Aggregating Possible and Certain Equivalence Classes in Parallel (AP)
| Algorithm 6 function AP Map |
 |
| Algorithm 7 function AP Reduce |
 |
5.2.4. Computing Rough Approximations in Parallel (RA)
| Algorithm 8 function RA Map |
 |
| Algorithm 9 function RA Reduce |
 |
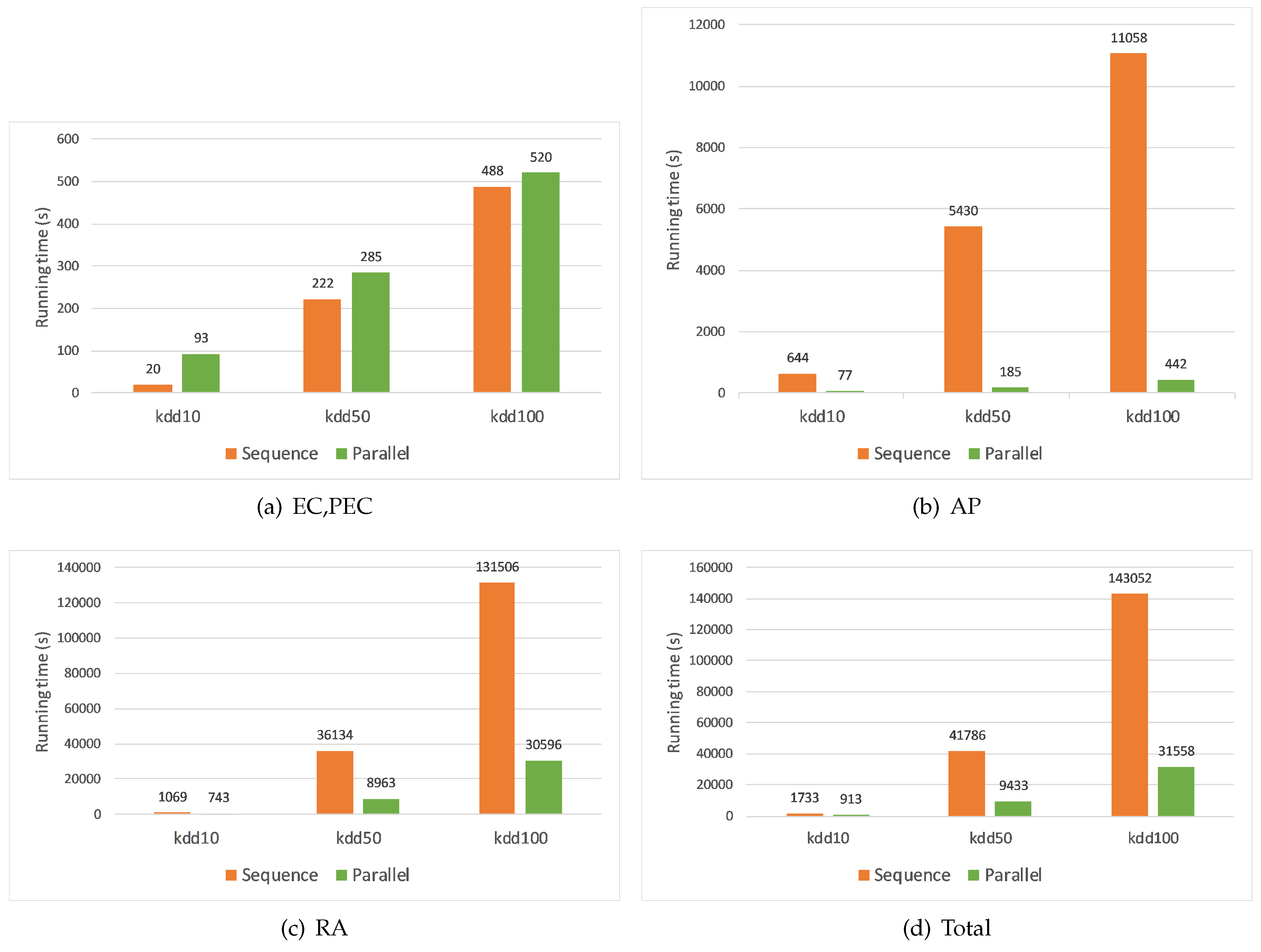
5.3. Evaluation Test
- Execution time increases when the volume of data increases in both sequential and parallel algorithms.
- The most intensive step is RA step, and the least intensive step is EC, PEC step. The AP step takes less time than the RA step in our experiments because we aggregate very few condition attributes. The more attributes we aggregate, the more time the AP step will take.
- In AP and RA steps, the parallel algorithms outperform the sequential algorithm. To the dataset Kdd100, the former performs 25 times faster than the latter at the AP step, and four times faster at the RA step, respectively. This is important since these are the most intensive computational steps. For the EC, PEC step, the parallel algorithm costs more time. This is because we divide this step into two separate MapReduce jobs: EC and PEC. Since each job requires a certain time to start up its mappers and reducers, the time consumed by both jobs becomes larger than the one of the sequential algorithm, especially when the input data is small. Notice that the time difference becomes smaller when the input data is larger (63 s in case of Kdd50, and 32 s in case of Kdd100). It is intuitive that the parallel algorithm is more efficient if we input larger datasets. In addition, since this step costs the least amount of time, it will not impact the total execution time of both algorithms.
- As the size of the input data increases, the parallel algorithm outperforms the sequential algorithm. We can verify this through the total execution time. The parallel algorithm is around four times less than the sequential algorithm in datasets Kdd50 and Kdd100. This proves the efficiency of our proposed parallel algorithm.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pawlak, Z. Rough sets. In International Journal of Computer and Information Sciences; Kluwer Acad.: South Holland, The Netherlands, 1982; Volume 11, pp. 341–356. [Google Scholar]
- Pawlak, Z. Rough Sets. In Theoretical Aspects of Reasoning Data; Kluwer Acad.: South Holland, The Netherlands, 1991. [Google Scholar]
- Zhao, H.; Wang, P.; Hu, Q. Cost-sensitive feature selection based on adaptive neighborhood granularity with multi-level confidence. Inf. Sci. 2016, 366, 134–149. [Google Scholar] [CrossRef]
- Ju, H.; Li, H.; Yang, X.; Zhou, X.; Huang, B. Cost-sensitive rough set: A multi-granulation approach. Knowl. Based Syst. 2017, 123, 137–153. [Google Scholar] [CrossRef]
- Liang, J.; Wang, F.; Dang, C.; Qian, Y. A Group Incremental Approach to Feature Selection Applying Rough Set Technique. IEEE Trans. Knowl. Data Eng. 2014, 26, 294–308. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, X. Class-specific attribute reducts in rough set theory. Inf. Sci. 2017, 418–419, 601–618. [Google Scholar] [CrossRef]
- Roy, J.; Adhikary, K.; Kar, S.; Pamucar, D. A rough strength relational DEMATEL model for analysing the key success factors of hospital service quality. In Decision Making: Applications in Management and Engineering; Electrocore: Bernards Township, NJ, USA, 2018. [Google Scholar]
- Tay, F.E.; Shen, L. Economic and financial prediction using rough sets model. Eur. J. Oper. Res. 2002, 141, 641–659. [Google Scholar] [CrossRef]
- Goh, C.; Law, R. Incorporating the rough sets theory into travel demand analysis. Tour. Manag. 2003, 24, 511–517. [Google Scholar] [CrossRef]
- Ma, T.; Zhou, J.; Tang, M.; Tian, Y.; Al-Dhelaan, A.; Al-Rodhaan, M.; Lee, S. Social network and tag sources based augmenting collaborative recommender system. IEICE Trans. Inf. Syst. 2015, E98D, 902–910. [Google Scholar] [CrossRef]
- Karavidic, Z.; Projovic, D. A multi-criteria decision-making (MCDM) model in the security forces operations based on rough sets. In Decision Making: Applications in Management and Engineering; Electrocore: Bernards Township, NJ, USA, 2018; Volume 1, pp. 97–120. [Google Scholar]
- Swiniarski, R.; Skowron, A. Rough set methods in feature selection and recognition. Pattern Recognit. Lett. 2003, 24, 833–849. [Google Scholar] [CrossRef]
- Wei, J.M.; Wang, S.Q.; Yuan, X.J. Ensemble rough hypercuboid approach for classifying cancers. IEEE Trans. Knowl. Data Eng. 2010, 22, 381–391. [Google Scholar] [CrossRef]
- Yao, Y.; Zhou, B. Two Bayesian approaches to rough sets. Eur. J. Oper. Res. 2016, 251, 904–917. [Google Scholar] [CrossRef]
- Yao, Y. Three-Way Decisions and Cognitive Computing. Cognit. Comput. 2016, 8, 543–554. [Google Scholar] [CrossRef]
- Yao, Y. The two sides of the theory of rough sets. Knowl. Based Syst. 2015, 80, 67–77. [Google Scholar] [CrossRef]
- Liu, D.; Li, T.; Liang, D. Incorporating logistic regression to decision-theoretic rough sets for classifications. Int. J. Approx. Reason. 2014, 55, 197–210. [Google Scholar] [CrossRef]
- Xu, J.; Miao, D.; Zhang, Y.; Zhang, Z. A three-way decisions model with probabilistic rough sets for stream computing. Int. J. Approx. Reason. 2017, 88, 1–22. [Google Scholar] [CrossRef]
- Li, H.; Li, D.; Zhai, Y.; Wang, S.; Zhang, J. A novel attribute reduction approach for multi-label data based on rough set theory. Inf. Sci. 2016, 367, 827–847. [Google Scholar] [CrossRef]
- Zheng, Y.; Jeon, B.; Xu, D.; Wu, Q.J.; Zhang, H. Image Segmentation by Generalized Hierarchical Fuzzy C-means Algorithm. J. Intell. Fuzzy Syst. 2015, 28, 961–973. [Google Scholar]
- Lin, T. Data mining and machine oriented modeling: A granular computing approach. Appl. Intell. 2000, 13, 113–124. [Google Scholar] [CrossRef]
- Cao, T.; Yamada, K.; Unehara, M.; Suzuki, I.; Nguyen, D.V. Semi-supervised based rough set to handle missing decision data. In Proceedings of the 2016 IEEE International Conference on Fuzzy Systems, FUZZ-IEEE, Vancouver, BC, Canada, 24–29 July 2016; pp. 1948–1954. [Google Scholar]
- Cao, T.; Yamada, K.; Unehara, M.; Suzuki, I.; Nguyen, D.V. Rough Set Model in Incomplete Decision Systems. J. Adv. Comput. Intell. Intell. Inform. 2017, 21, 1221–1231. [Google Scholar] [CrossRef]
- Li, Y.; Jin, Y.; Sun, X. Incremental method of updating approximations in DRSA under variations of multiple objects. Int. J. Mach. Learn. Cybern. 2018, 9, 295–308. [Google Scholar] [CrossRef]
- Zhang, J.; Li, T.; Ruan, D.; Gao, Z.; Zhao, C. A parallel method for computing rough set approximations. Inf. Sci. 2012, 194, 209–223. [Google Scholar] [CrossRef]
- Zhang, J.; Wong, J.S.; Li, T.; Pan, Y. A comparison of parallel large-scale knowledge acquisition using rough set theory on different MapReduce runtime systems. Int. J. Approx. Reason. 2014, 55, 896–907. [Google Scholar] [CrossRef]
- Chen, H.; Li, T.; Cai, Y.; Luo, C.; Fujita, H. Parallel attribute reduction in dominance-based neighborhood rough set. Inf. Sci. 2016, 373, 351–368. [Google Scholar] [CrossRef]
- Li, S.; Li, T.; Zhang, Z.; Chen, H.; Zhang, J. Parallel computing of approximations in dominance-based rough sets approach. Knowl. Based Syst. 2015, 87, 102–111. [Google Scholar] [CrossRef]
- Qian, J.; Miao, D.; Zhang, Z.; Yue, X. Parallel attribute reduction algorithms using MapReduce. Inf. Sci. 2014, 279, 671–690. [Google Scholar] [CrossRef]
- Qian, J.; Lv, P.; Yue, X.; Liu, C.; Jing, Z. Hierarchical attribute reduction algorithms for big data using MapReduce. Knowl. Based Syst. 2015, 73, 18–31. [Google Scholar] [CrossRef]
- Li, S.; Li, T. Incremental update of approximations in dominance-based rough sets approach under the variation of attribute values. Inf. Sci. 2015, 294, 348–361. [Google Scholar] [CrossRef]
- Liu, D.; Li, T.; Zhang, J. A rough set-based incremental approach for learning knowledge in dynamic incomplete information systems. Int. J. Approx. Reason. 2014, 55, 1764–1786. [Google Scholar] [CrossRef]
- Shu, W.; Shen, H. Incremental feature selection based on rough set in dynamic incomplete data. Pattern Recognit. 2014, 47, 3890–3906. [Google Scholar] [CrossRef]
- Hu, J.; Li, T.; Luo, C.; Li, S. Incremental fuzzy probabilistic rough sets over dual universes. In Proceedings of the 2015 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Istanbul, Turkey, 2–5 August 2015; pp. 1–8. [Google Scholar]
- Jin, Y.; Li, Y.; He, Q. A fast positive-region reduction method based on dominance-equivalence relations. In Proceedings of the 2016 International Conference on Machine Learning and Cybernetics (ICMLC), Jeju Island, South Korea, 10–13 July 2016; Volume 1, pp. 152–157. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. In Proceedings of the 6th conference on Symposium on Operating Systems Design and Implementation, San Francisco, CA, USA, 6–8 December 2004. [Google Scholar]
- Nakata, M.; Sakai, H. Twofold rough approximations under incomplete information. Int. J. Gen. Syst. 2013, 42, 546–571. [Google Scholar] [CrossRef]
- Slezak, D.; Ziarko, W. Bayesian rough set model. In Proceedings of the International Workshop on Foundation of Data Mining (FDM2002), Maebashi, Japan, 9 December 2002; pp. 131–135. [Google Scholar]
- Van Nguyen, D.; Yamada, K.; Unehara, M. Extended tolerance relation to define a new rough set model in incomplete information systems. Adv. Fuzzy Syst. 2013, 2013, 372091. [Google Scholar] [CrossRef]
- Van Nguyen, D.; Yamada, K.; Unehara, M. Rough set approach with imperfect data based on Dempster-Shafer theory. J. Adv. Comput. Intell. Intell. Inform. 2014, 18, 280–288. [Google Scholar] [CrossRef]
- Grzymala-Busse, J.W. On the unknown attribute values in learning from examples. In Methodologies for Intelligent Systems; Ras, Z., Zemankova, M., Eds.; Springer: Berlin, Germany, 1991; Volume 542, pp. 368–377. [Google Scholar]
- Grzymala-Busse, J.; Hu, M. A comparison of several approaches to missing attribute values in data mining. In Rough Sets and Current Trends in Computing; Ziarko, W., Yao, Y., Eds.; Springer: Berlin, Germany, 2001; Volume 2005, pp. 378–385. [Google Scholar]
- Grzymala-Busse, J. Characteristic relations for incomplete data: A generalization of the indiscernibility relation. In Proceedings of the Third International Conference on Rough Sets and Current Trends in Computing, Uppsala, Sweden, 1–5 June 2004; pp. 244–253. [Google Scholar]
- Grzymala-Busse, J. Three approaches to missing attribute values: A rough set perspective. In Data Mining: Foundations and Practice; Lin, T., Xie, Y., Wasilewska, A., Liau, C.J., Eds.; Springer: Berlin, Germany, 2008; Volume 118, pp. 139–152. [Google Scholar]
- Grzymala-Busse, J.W.; Rzasa, W. Definability and other properties of approximations for generalized indiscernibility relations. In Transactions on Rough Sets XI; Peters, J., Skowron, A., Eds.; Springer: Berlin, Germany, 2010; Volume 5946, pp. 14–39. [Google Scholar]
- Guan, L.; Wang, G. Generalized approximations defined by non-equivalence relations. Inf. Sci. 2012, 193, 163–179. [Google Scholar] [CrossRef]
- Stefanowski, J.; Tsoukias, A. On the extension of rough sets under incomplete information. In Proceedings of the New directions in rough sets, data mining and granular-soft computing, Yamaguchi, Japan, 11–19 November 1999; pp. 73–82. [Google Scholar]
- Stefanowski, J.; Tsoukias, A. Incomplete information tables and rough classication. Comput. Intell. 2001, 17, 545–566. [Google Scholar] [CrossRef]
- Katzberg, J.D.; Ziarko, W. Variable precision rough sets with asymmetric bounds. In Proceedings of the International Workshop on Rough Sets and Knowledge Discovery: Rough Sets, Fuzzy Sets and Knowledge Discovery, Banff, AB, Canada, 12–15 October 1993; Springer: London, UK, 1994; pp. 167–177. [Google Scholar]
- Kryszkiewicz, M. Rough set approach to incomplete information systems. Inf. Sci. 1998, 112, 39–49. [Google Scholar] [CrossRef]
- Kryszkiewicz, M. Rules in incomplete information systems. Inf. Sci. 1999, 113, 271–292. [Google Scholar] [CrossRef]
- Leung, Y.; Li, D. Maximal consistent block technique for rule acquisition in incomplete information systems. Inf. Sci. 2003, 153, 85–106. [Google Scholar] [CrossRef]
- Leung, Y.; Wu, W.Z..; Zhang, W.X. Knowledge acquisition in incomplete information systems: A rough set approach. Eur. J. Oper. Res. 2006, 168, 164–180. [Google Scholar] [CrossRef]
- Nakata, M.; Sakai, H. Handling missing values in terms of rough sets. In Proceedings of the 23rd Fuzzy System Symposium, Nayoga, Japan, 29–31 August 2007. [Google Scholar]
- Miao, D.; Zhao, Y.; Yao, Y.; Li, H.; Xu, F. Relative reducts in consistent and inconsistent decision tables of the Pawlak rough set model. Inf. Sci. 2009, 179, 4140–4150. [Google Scholar] [CrossRef]
- Slezak, D.; Ziarko, W. Variable precision bayesian rough set model. Lect. Notes Comput. Sci. 2003, 2639, 312–315. [Google Scholar]
- Slezak, D.; Ziarko, W. Attribute reduction in the Bayesian version of variable precision rough set model. Electron. Notes Theor. Comput. Sci. 2003, 82, 263–273. [Google Scholar]
- Slezak, D.; Ziarko, W. The investigation of the Bayesian rough set model. Int. J. Approx. Reason. 2005, 40, 81–91. [Google Scholar] [CrossRef]
- Wang, G. Extension of rough set under incomplete information systems. In Proceedings of the 2002 IEEE International Conference on Fuzzy Systems, FUZZ-IEEE’02, Honolulu, Hawaii, 12–17 May 2002; Volume 2, pp. 1098–1103. [Google Scholar]
- Yang, X.; Yu, D.; Yang, J.; Song, X. Difference relation-based rough set and negative rules in incomplete information system. Int. J. Uncertain. Fuzz. Knowl. Based Syst. 2009, 17, 649–665. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J. Incomplete Information System and Rough Set Theory, 1st ed.; Springer: Berlin, Germany, 2012. [Google Scholar]
- Medhat, T. Prediction of missing values for decision attribute. J. Inform. Technol. Comput. Sci. 2012, 4, 58–66. [Google Scholar] [CrossRef]
- El-Alfy, E.S.M.; Alshammari, M.A. Towards scalable rough set based attribute subset selection for intrusion detection using parallel genetic algorithm in MapReduce. Simul. Model. Pract. Theory 2016, 64, 18–29. [Google Scholar] [CrossRef]
- Verma, A.; Llora, X.; Goldberg, D.E.; Campbell, R.H. Scaling Genetic Algorithms Using MapReduce. In Proceedings of the 2009 Ninth International Conference on Intelligent Systems Design and Applications, Pisa, Italy, 30 November–2 December 2009; pp. 13–18. [Google Scholar]
- Han, L.; Liew, C.; Van Hemert, J.; Atkinson, M. A generic parallel processing model for facilitating data mining and integration. Parallel Comput. 2011, 37, 157–171. [Google Scholar] [CrossRef]
- McNabb, A.W.; Monson, C.K.; Seppi, K.D. Parallel PSO using MapReduce. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 7–14. [Google Scholar]
- Chu, C.T.; Kim, S.K.; Lin, Y.A.; Yu, Y.; Bradski, G.; Ng, A.Y.; Olukotun, K. Map-reduce for Machine Learning on Multicore. In Proceedings of the 19th International Conference on Neural Information Processing Systems, Doha, Qatar, 12–15 November 2012; MIT Press: Cambridge, MA, USA, 2006; pp. 281–288. [Google Scholar]
- Srinivasan, A.; Faruquie, T.A.; Joshi, S. Data and task parallelism in ILP using MapReduce. Mach. Learn. 2012, 86, 141–168. [Google Scholar] [CrossRef]
- Zhao, W.; Ma, H.; He, Q. Parallel K-Means Clustering Based on MapReduce. In Cloud Computing; Jaatun, M.G., Zhao, G., Rong, C., Eds.; Springer: Berlin, Germany, 2009; pp. 674–679. [Google Scholar]
- Zinn, D.; Bowers, S.; Kohler, S.; Ludascher, B. Parallelizing XML data-streaming workflows via MapReduce. J. Comput. Syst. Sci. 2010, 76, 447–463. [Google Scholar] [CrossRef]
- Li, P.; Wu, J.; Shang, L. Fast approximate attribute reduction with MapReduce. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2013; pp. 271–278. [Google Scholar]
- Zhang, J.; Wong, J.S.; Pan, Y.; Li, T. A Parallel Matrix-Based Method for Computing Approximations in Incomplete Information Systems. IEEE Trans. Knowl. Data Eng. 2015, 27, 326–339. [Google Scholar] [CrossRef]
- Yuan, J.; Chen, M.; Jiang, T.; Li, T. Complete tolerance relation based parallel filling for incomplete energy big data. Knowl. Based Syst. 2017, 132, 215–225. [Google Scholar] [CrossRef]
- Data, K.C. KDD Cup 1999 Data. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 18 August 2018).
- Sourcecode. Available online: https://github.com/KennyThinh/ParallelComputationTwoFoldRS (accessed on 18 August 2018).



{kind=link}
{kind=link}
| d | |||
|---|---|---|---|
| 1 | 2 | 0 | |
| * | 1 | 1 | |
| 2 | * | 2 | |
| 1 | 2 | * | |
| 1 | 1 | 0 | |
| 2 | * | 2 | |
| * | 2 | 0 | |
| 3 | 1 | 3 |
| a | ||
|---|---|---|
| ∅ | ||
| ∅ | ∅ | |
| ∅ | ∅ | |
| ∅ |
| d | d | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 0 | 1 | 1 | 0 | ||
| * | 1 | 1 | 2 | * | 2 | ||
| 2 | * | 2 | * | 2 | 1 | ||
| 1 | 2 | * | 3 | 1 | 3 |
| Records | Size (MB) | |
|---|---|---|
| Kdd10 | 489,844 | 44 |
| Kdd50 | 2,449,217 | 219 |
| Kdd10 | 4,898,431 | 402 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, T.; Yamada, K.; Unehara, M.; Suzuki, I.; Nguyen, D.V. Parallel Computation of Rough Set Approximations in Information Systems with Missing Decision Data. Computers 2018, 7, 44. https://doi.org/10.3390/computers7030044
Cao T, Yamada K, Unehara M, Suzuki I, Nguyen DV. Parallel Computation of Rough Set Approximations in Information Systems with Missing Decision Data. Computers. 2018; 7(3):44. https://doi.org/10.3390/computers7030044
Chicago/Turabian StyleCao, Thinh, Koichi Yamada, Muneyuki Unehara, Izumi Suzuki, and Do Van Nguyen. 2018. "Parallel Computation of Rough Set Approximations in Information Systems with Missing Decision Data" Computers 7, no. 3: 44. https://doi.org/10.3390/computers7030044
APA StyleCao, T., Yamada, K., Unehara, M., Suzuki, I., & Nguyen, D. V. (2018). Parallel Computation of Rough Set Approximations in Information Systems with Missing Decision Data. Computers, 7(3), 44. https://doi.org/10.3390/computers7030044