
Emotion Elicitation in a Socially Intelligent Service: The Typing Tutor


Abstract
:1. Introduction
2. Related Work
2.1. Social Intelligence, Social Signals, and Nonverbal Communication Cues
Behavioral Measurements
2.2. Intelligent Tutoring Systems
2.3. Computational Models of Emotion
2.3.1. Emotion Recognition From Facial Expressions
2.3.2. Emotion Elicitation Using Graphical Elements
3. Emotion Elicitation in a Socially Intelligent Service: The Intelligent Typing Tutor
3.1. General Requirements for Emotion Elicitation in a Socially Intelligent Service
- Conduct behavioral measurements and gather data for relevant user behavior. Human emotions are conveyed via behavior and non-verbal communication cues, such as face expression, gestures, body posture, voice color, among others. Selected behavioral measurements (pupil size, acceleration of the wrist, etc.) are believed to be correlated with user’s affective state and other non-verbal communication cues.
- Analyze, estimate, and model user emotions and non-verbal (social) communication cues via computational models. Selected behavioral measurements are used as an input to the computational model of user emotions and for modeling machine emotion feedback.
- Use emotion elicitation to reward performance and improve user engagement. For example, the notion of positive reinforcement could be integrated into a service to reward and improve performance and user engagement, taking into account user’s temporary affective state and other non-verbal communication cues.
- Naturalistic affective interaction. A continuous feedback loop between a user and a service, based on non-verbal communication cues.
- Context and task-dependent adaptation: adapt a service according to the design goals. For example, in the intelligent typing tutor case study, the intended goal is to reward learner’s performance and progress. The touch-typing lessons are carefully designed and adapt in regard to the typing speed and difficulty to meet user’s capabilities, temporary affective state, and other non-verbal communication cues.
3.2. The Architecture of the Intelligent Typing Tutor
- Web GUI: to support typing lessons and machine-generated graphical emoticons (see Figure 1). Data is stored on the server for later analysis and human annotation procedures. Such architecture allows for crowd-sourced testing and efficient remote maintenance.
- Sensors: to gather behavioral data and monitor learner’s status in real-time. The recorded data is later used to evaluate the effectiveness of the machine generated emotion elicitation. The list of sensors integrated into the typing tutor environment includes:
- Keyboard input recorder: to monitor cognitive and locomotor errors that occur while typing;
- Wrist accelerometer and gyroscope: to trace hand movement;
- Emotion recognition software: to extract learner’s facial emotion expressions in real-time;
- Eye tracking software: to measure eye gaze and pupil size, and estimate learner’s attention and possible correlates to typing performance.
- Machine emotion model: for modeling machine-generated emotion expressions (through graphical emoticons; see Section 3.3.1).
- User emotion model: for measuring learner’s emotion expressions (and performance) during a tutoring session (see Section 3.3.2).
- Typing content generator: which uses learner’s performance to recommend the appropriate level of typing lectures.
3.3. Modeling Emotions in the Intelligent Typing Tutor
3.3.1. Machine Emotion Elicitation Model
3.3.2. User Emotion Model
4. Experimental Study
- Before the experiment: the instructions are given to the test users, who are informed by the personnel about the goal and the procedure of the experiment. Setting up sensory equipment;
- At 00 s: the start of the experiment: the wrist accelerometer and the video camera are set on, and the experimental session starts;
- At 30 s: the self-report with three questions, inquiring about the participant’s attention, task difficulty, and performance. (The results of the self-reports are not presented in this paper.);
- At 60 s: the machine-generated sound disruption of the primary task: “Name the first and the last letter of the word: mouse, letter, backpack, clock”;
- At 240 s: the machine-generated sound disruption of the primary task: “Name the color of the smallest circle” on the image provided in the tutor’s graphical user interface. This cognitive task is expected to significantly disrupt the learner’s attention away from the typing exercise;
- The test segment ends at 380 s.
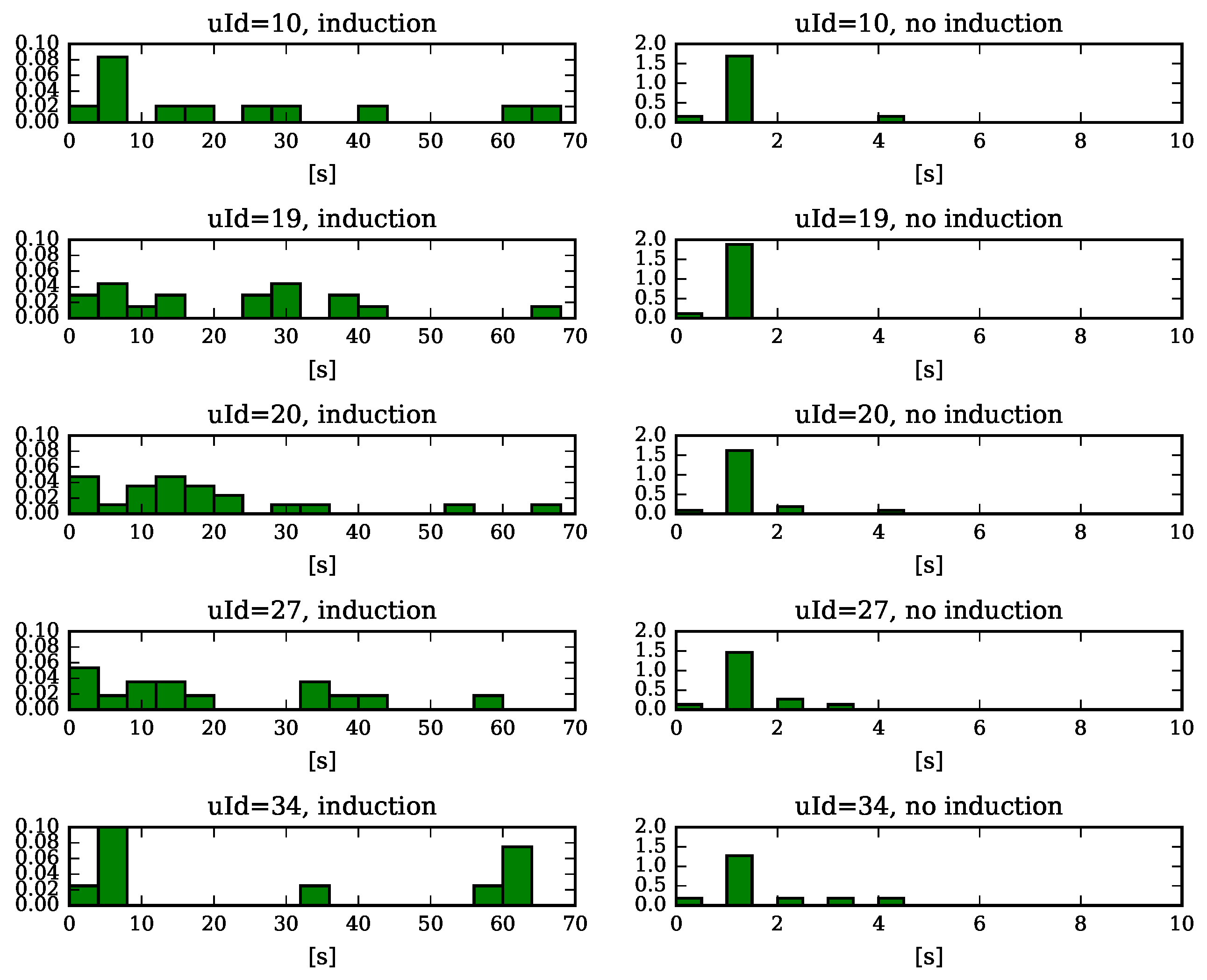
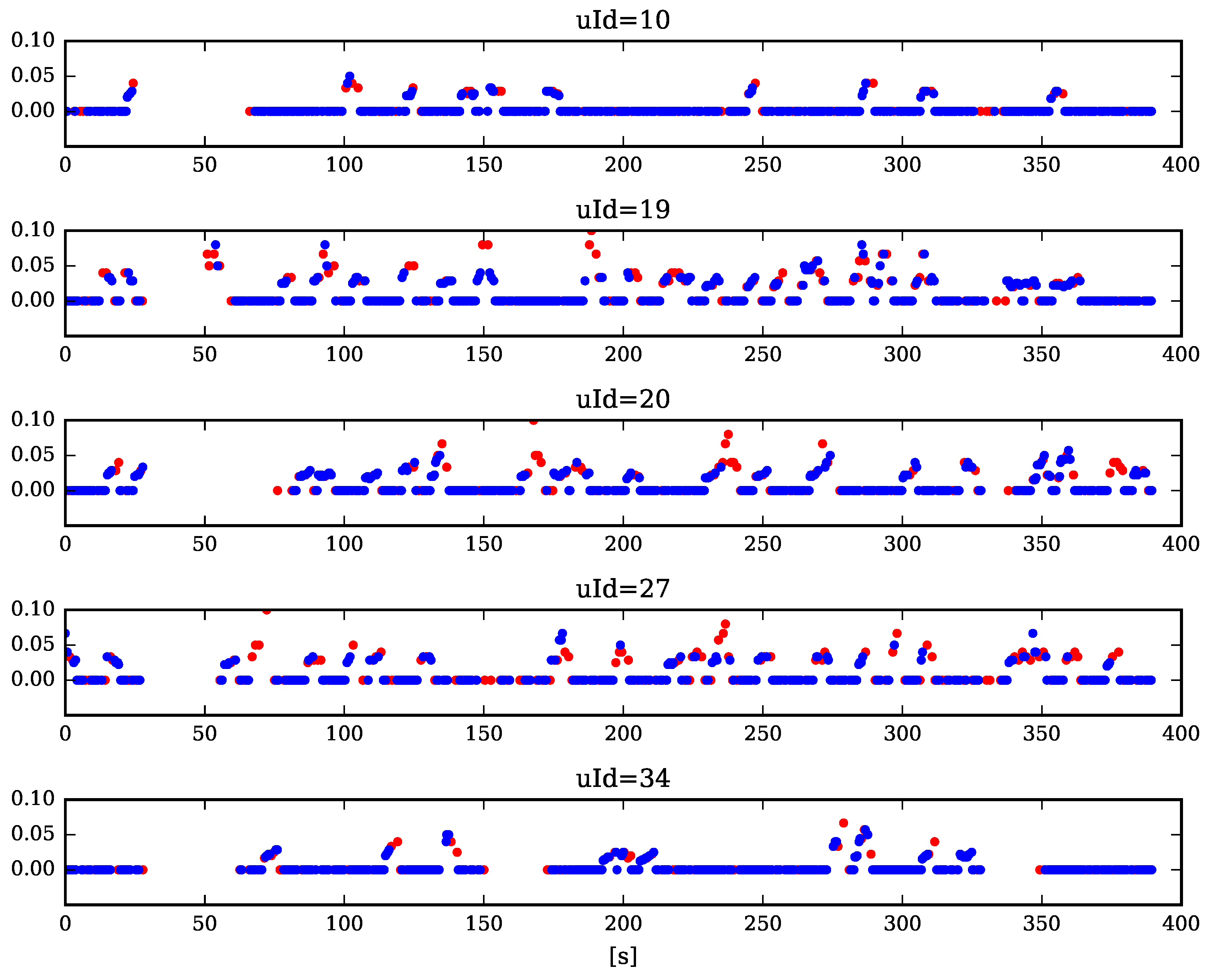
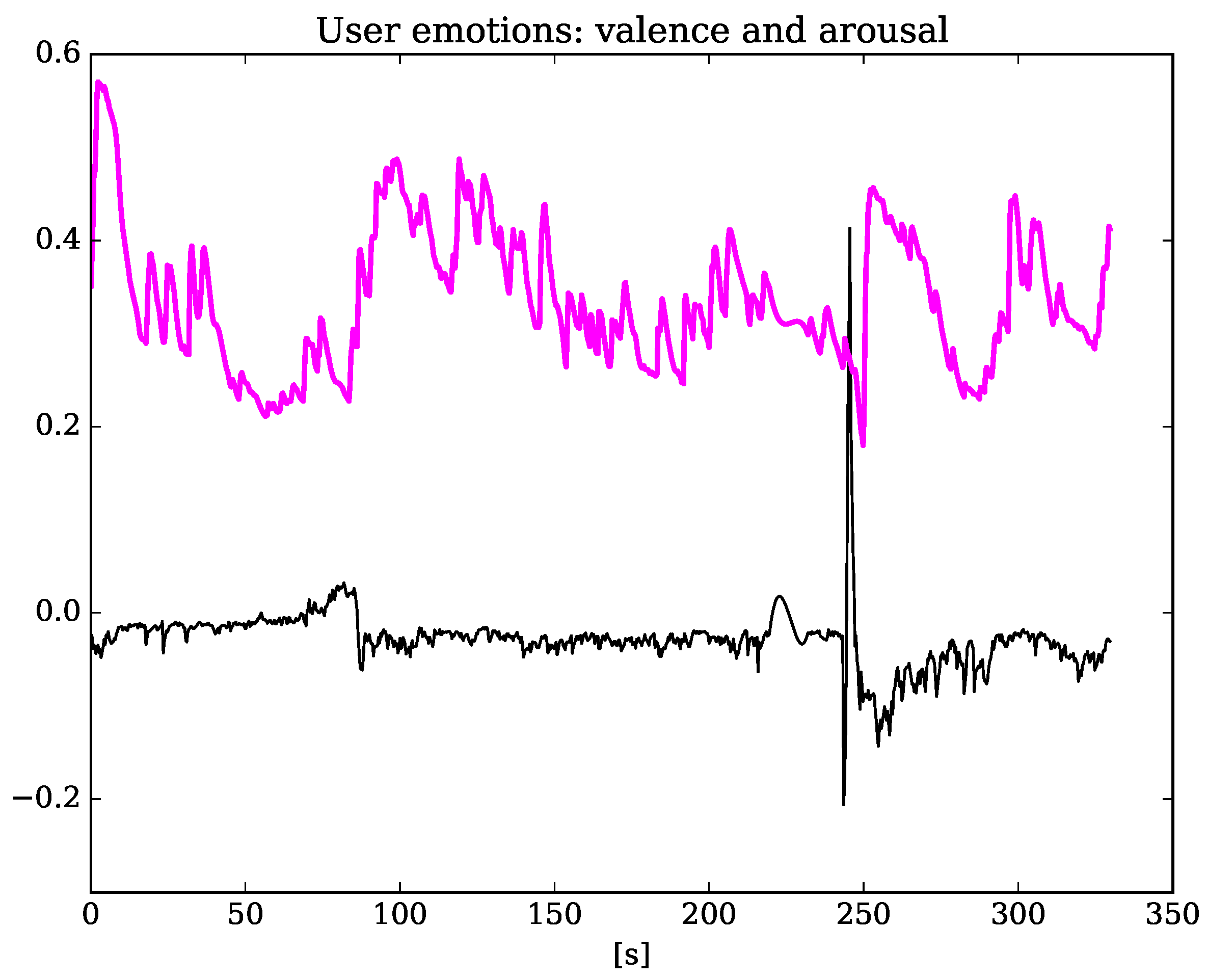
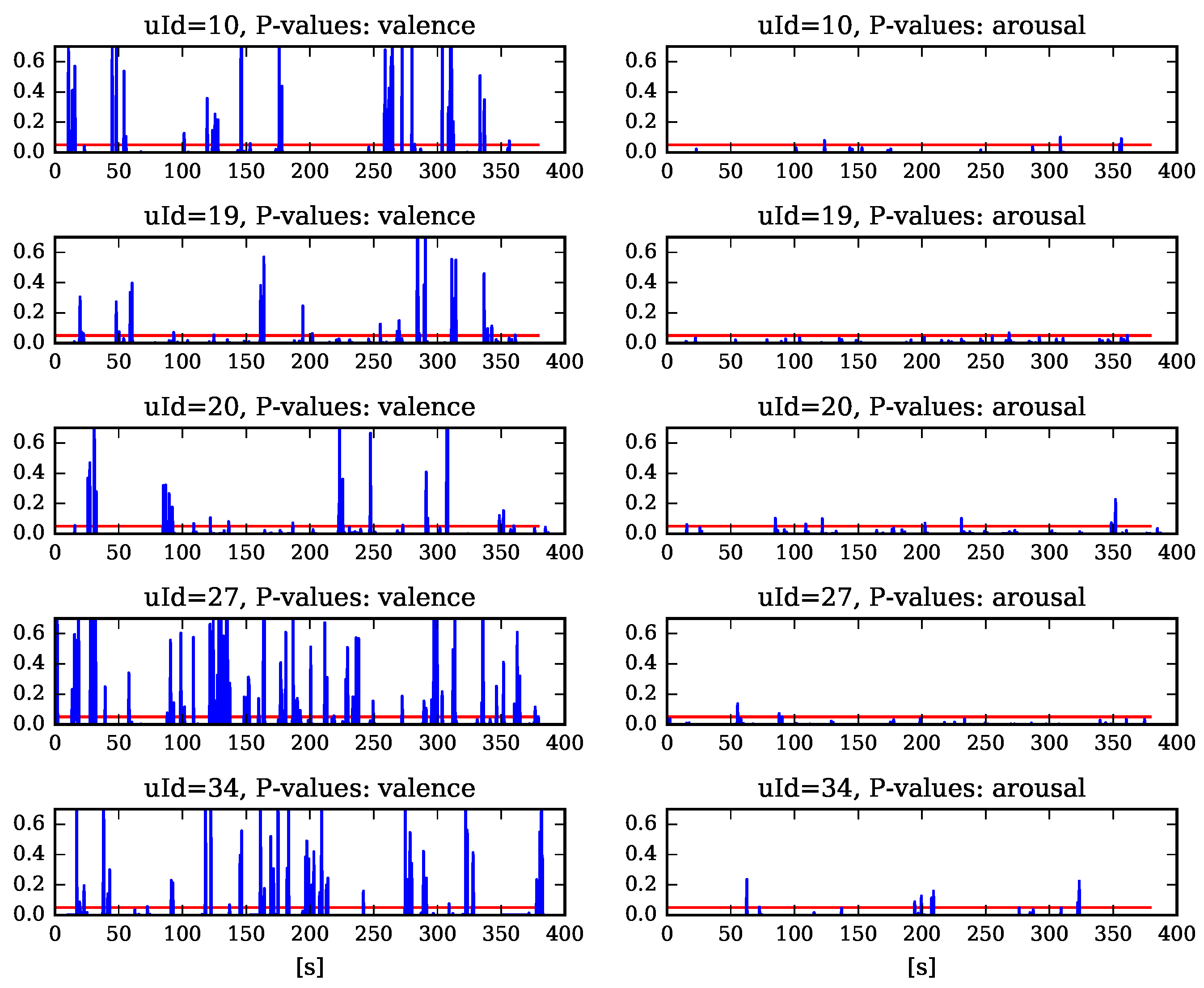
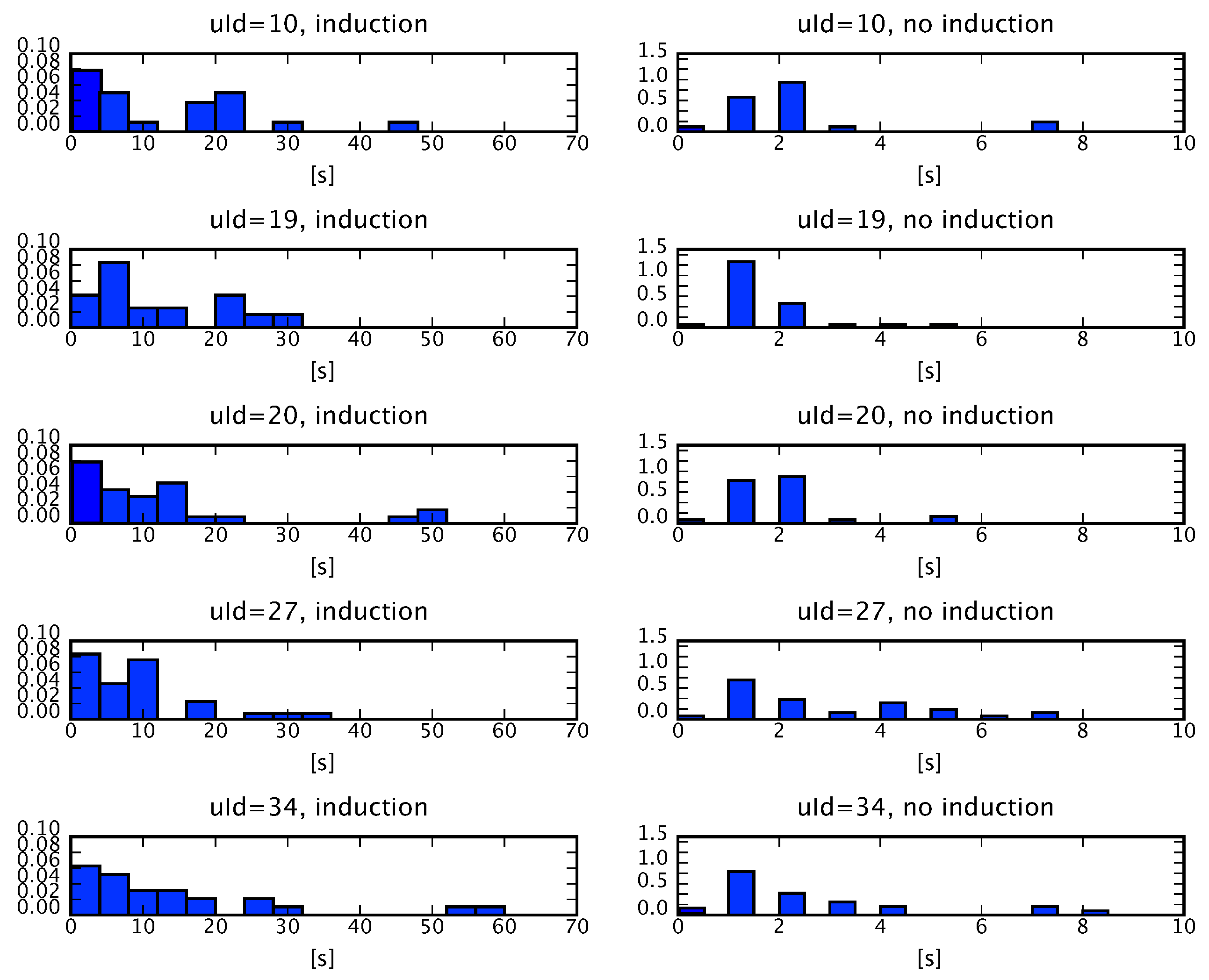
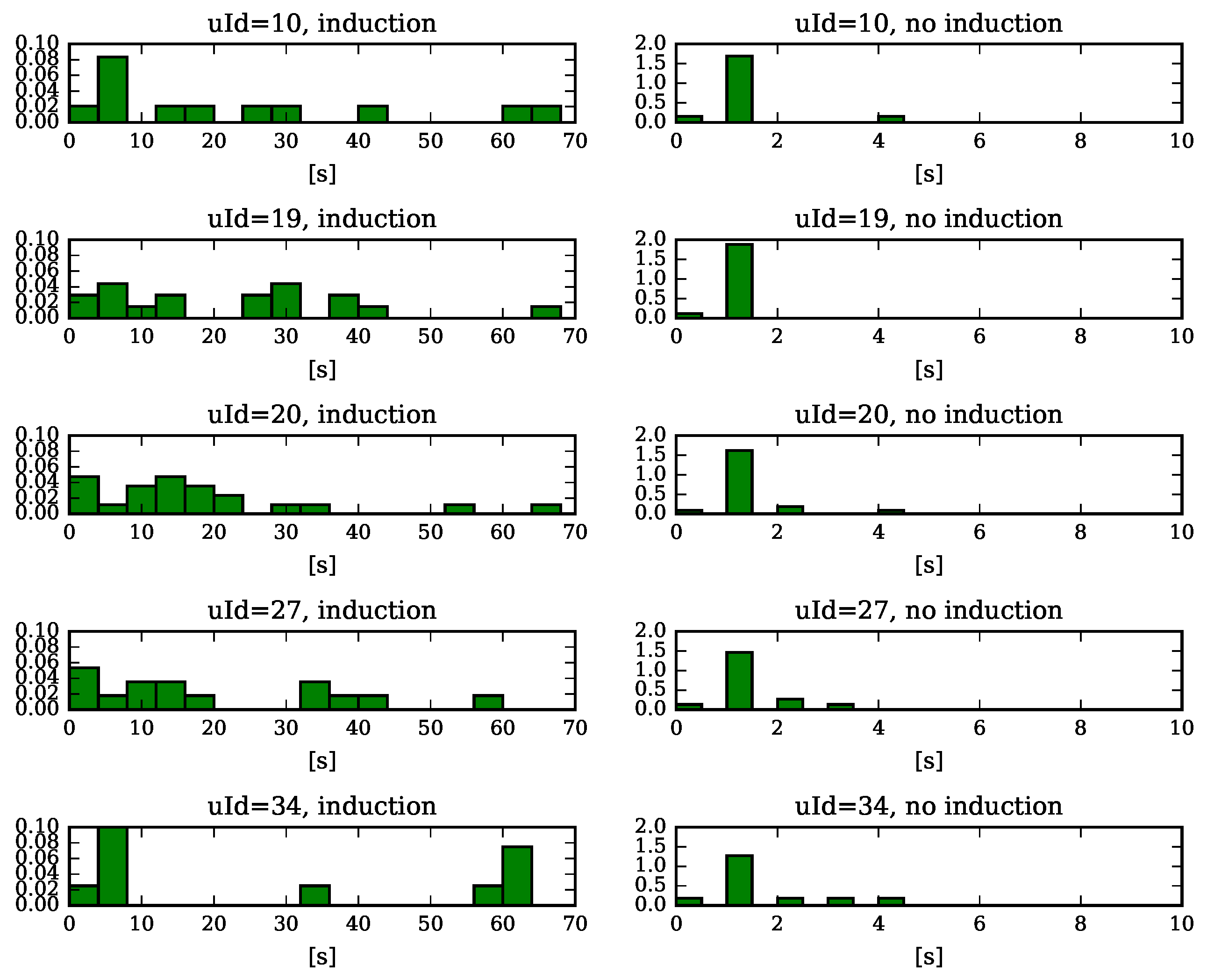
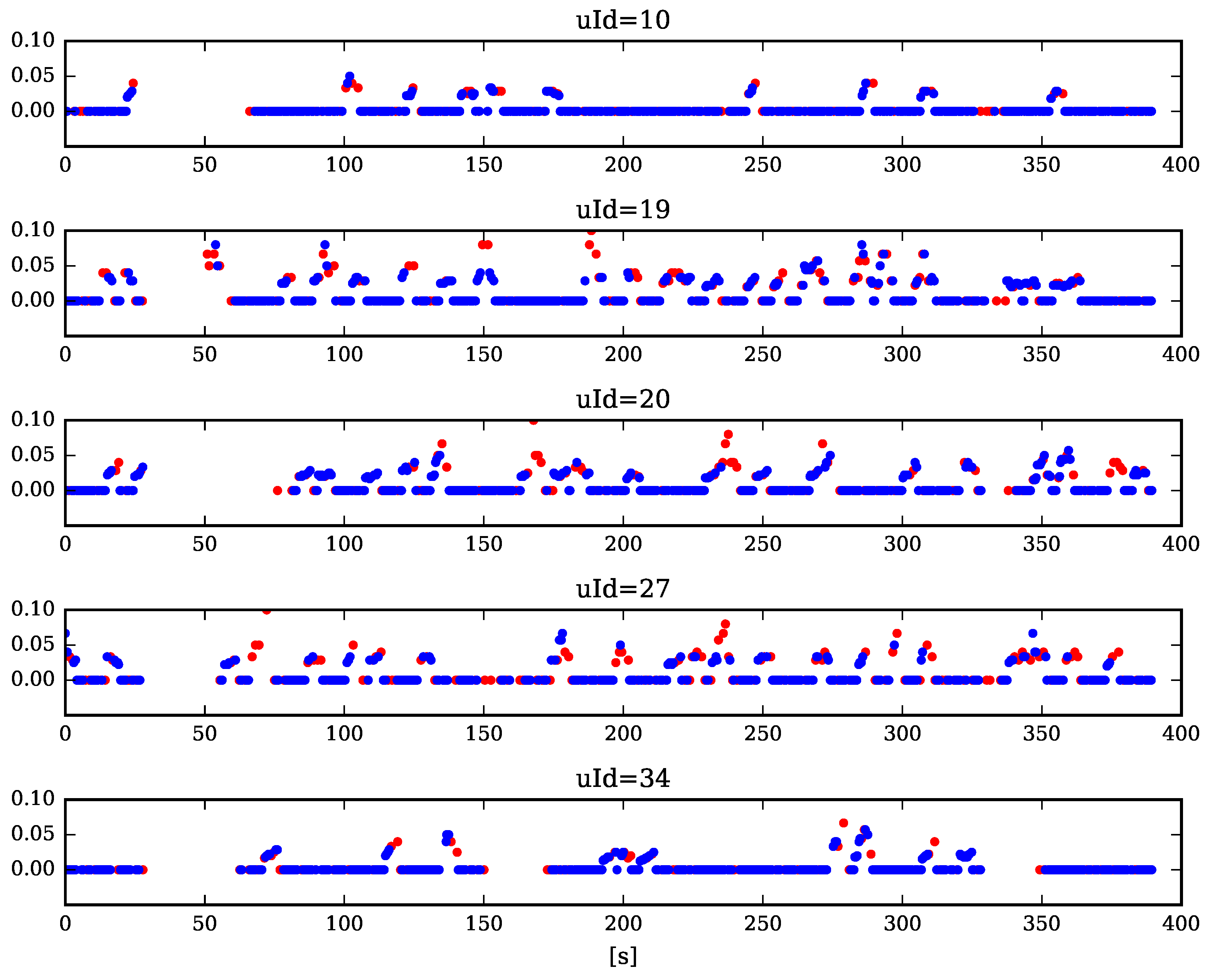
5. Results of the Experimental Study
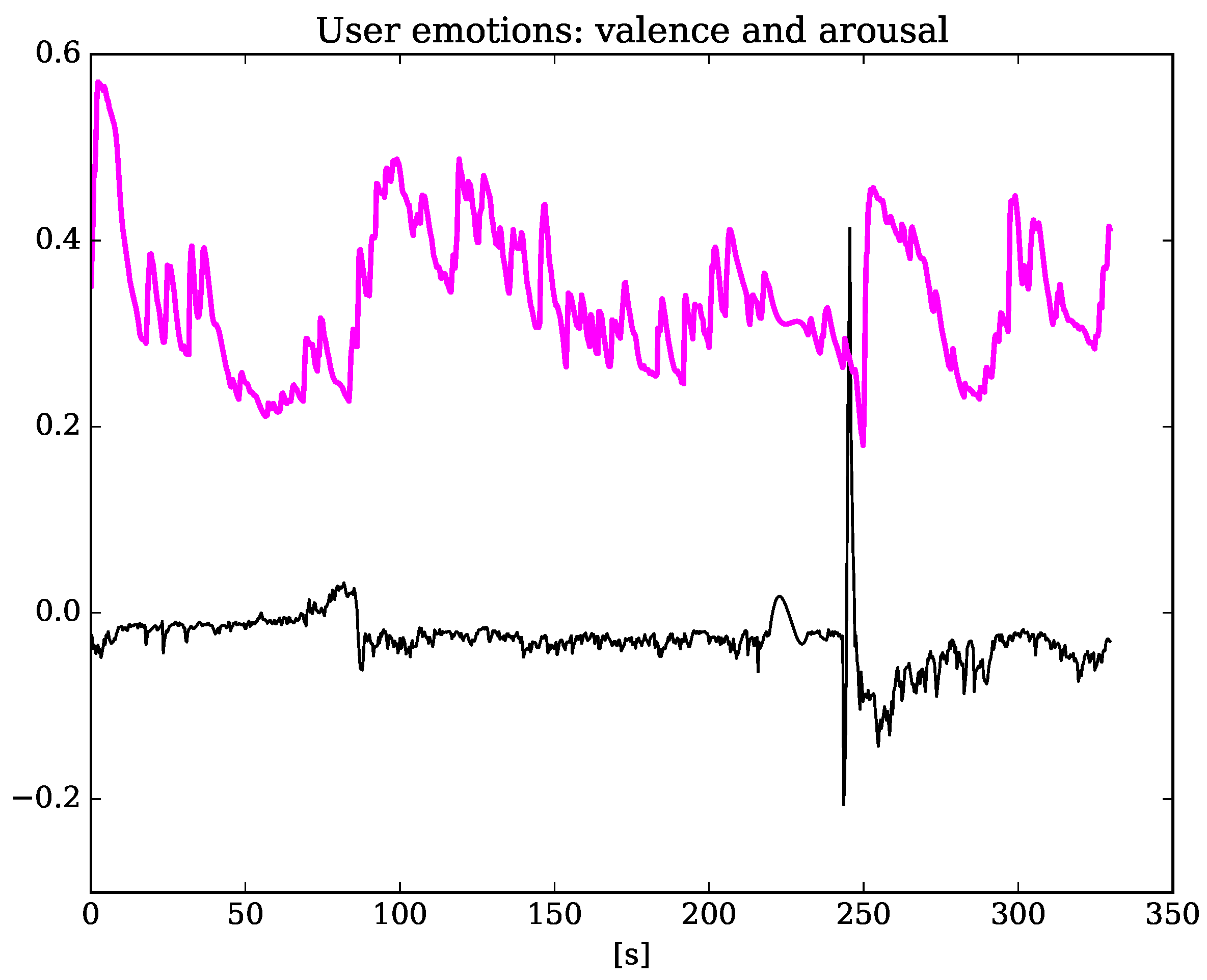
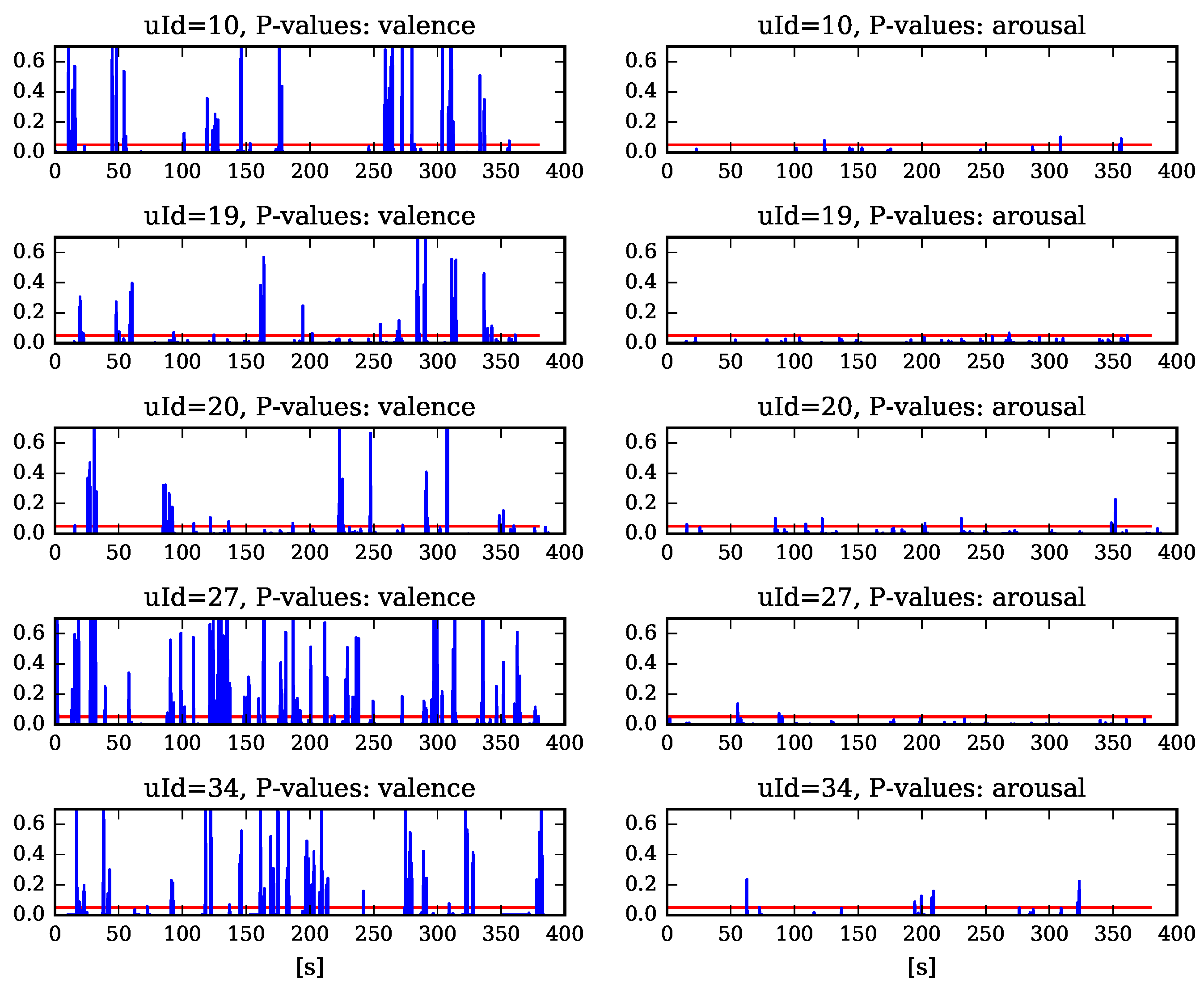
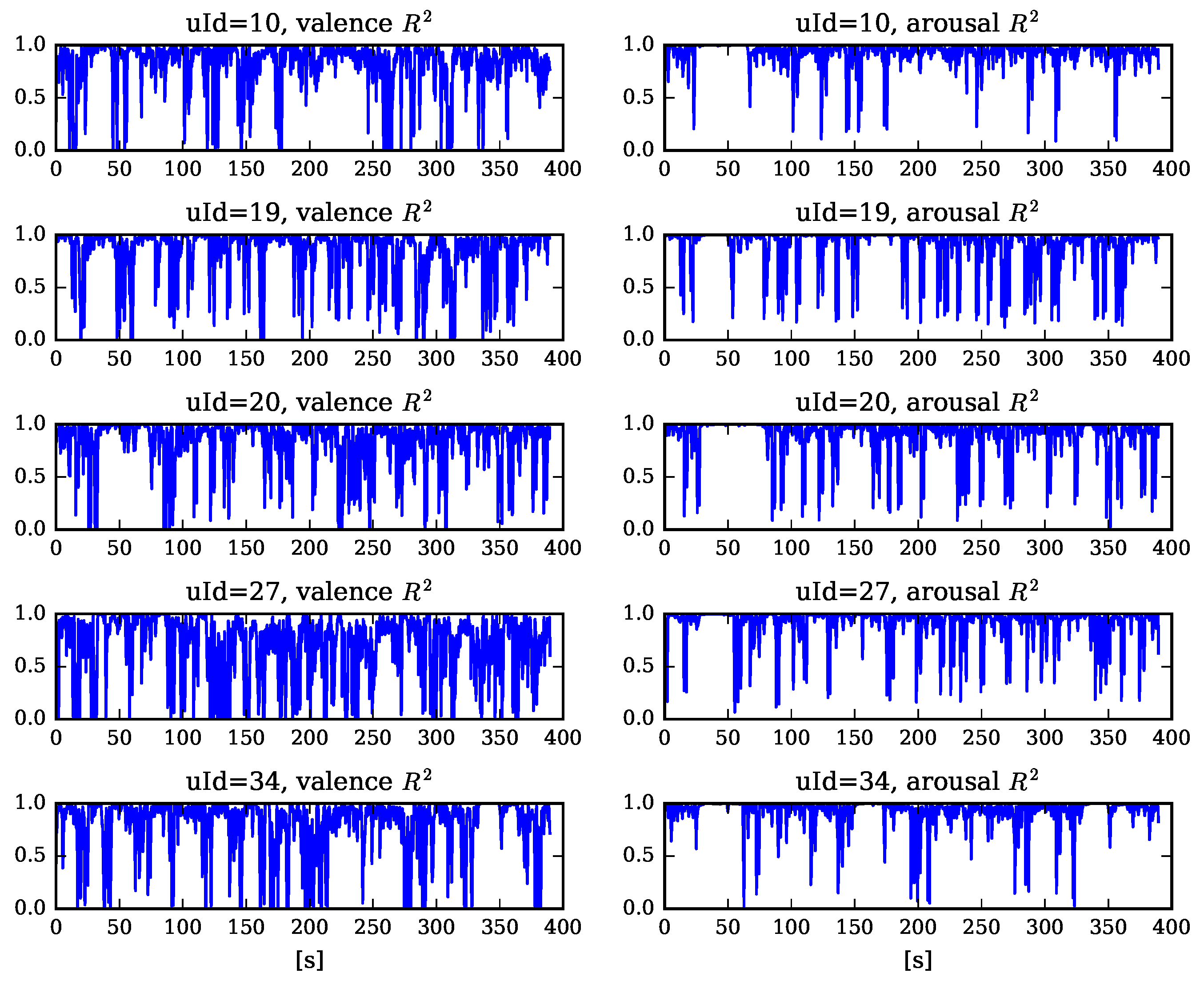
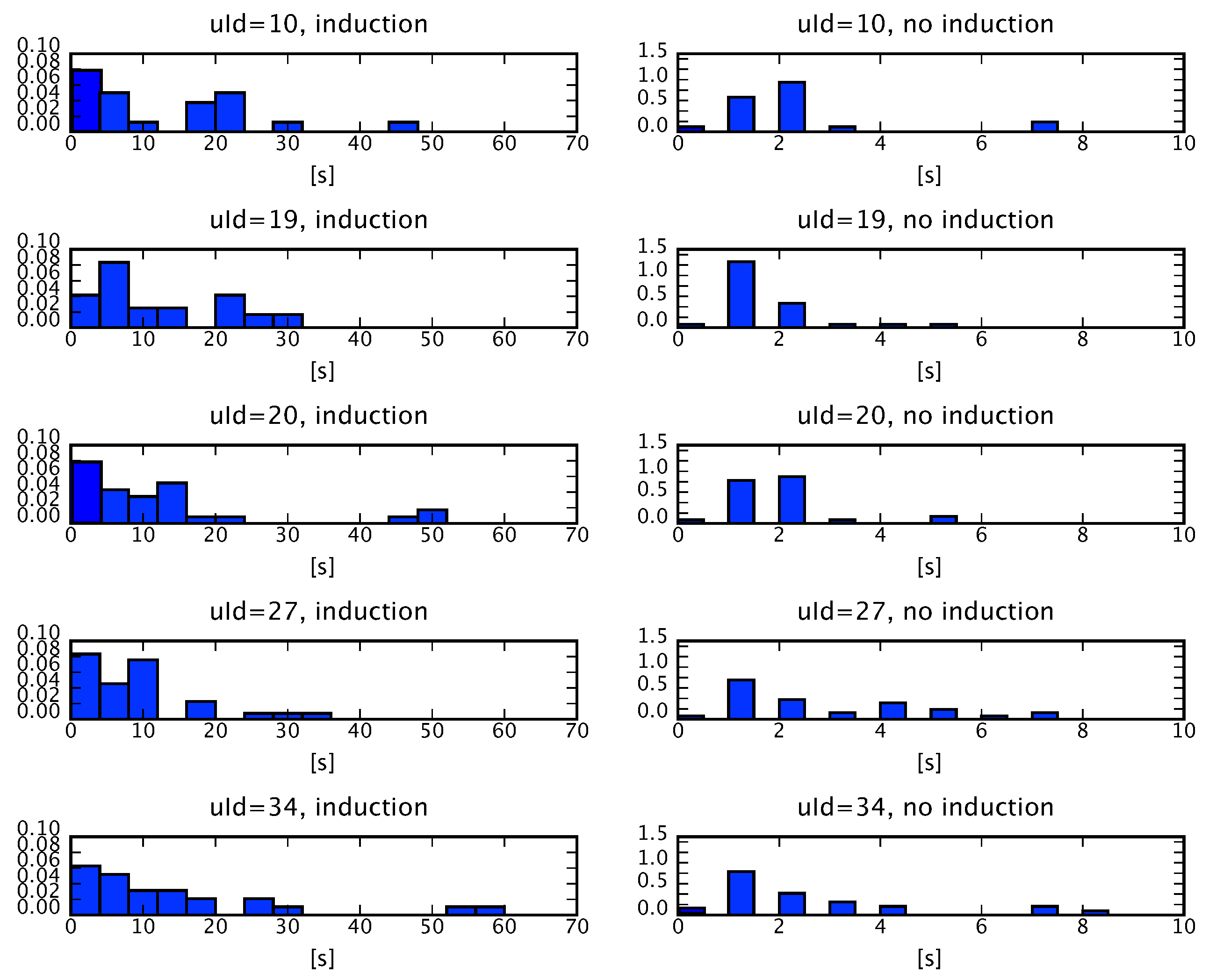
5.1. Measuring Learner’s Affective State
5.2. The Influence of the Machine Emotion Elicitation on the Learner’s Affective State
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ekman, P. Facial expression and emotion. Am. Psychol. 1993, 48, 384–392. [Google Scholar] [CrossRef] [PubMed]
- Horstmann, G. What do facial expressions convey: Feeling States, Behavioral Intentions, or Action Requests? Emotion 2003, 3, 150–166. [Google Scholar] [CrossRef] [PubMed]
- Tomasello, M. Origins of Human Communication; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Yiend, J. The effects of emotion on attention: A review of attentional processing of emotional information. Cognit. Emot. 2010, 24, 3–47. [Google Scholar] [CrossRef]
- Gunes, H.; Schuller, B.; Pantic, M.; Cowie, R. Emotion representation, analysis and synthesis in continuous space: A survey. In Proceedings of the 2011 IEEE International Conference on Automatic Face and Gesture Recognition and Workshops, FG 2011, Barbara, CA, USA, 21–25 March 2011; pp. 827–834. [Google Scholar]
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotion recognition in human-computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Picard, R.W. Affective computing: Challenges. Int. J. Hum. Comput. Stud. 2003, 59, 55–64. [Google Scholar] [CrossRef]
- Wehrle, T.; Scherer, G.R.; York, N. Towards Computational Modeling of Appraisal Theories; Oxford University Press: New York, NY, USA, 2001; pp. 350–365. [Google Scholar]
- Broekens, J.; Bosse, T.; Marsella, S.C. Challenges in computational modeling of affective processes. IEEE Trans. Affect. Comput. 2013, 4, 242–245. [Google Scholar] [CrossRef]
- Marsella, S.; Gratch, J. Computationally modeling human emotion. Commun. ACM 2014, 57, 56–67. [Google Scholar] [CrossRef]
- Roda, C.; Thomas, J. Attention aware systems: Theories, applications, and research agenda. Comput. Hum. Behav. 2006, 22, 557–587. [Google Scholar] [CrossRef]
- Chua, R.; Weeks, D.J.; Goodman, D. Perceptual-Motor Interaction: Some Implications for Human-Computer Interaction. In The Human-Computer Interaction Handbook; Jacko, J.A., Sears, A., Eds.; CRC Press: Boca Raton, FL, USA, 2008; pp. 23–34. [Google Scholar]
- Peters, C.; Castellano, G.; de Freitas, S. An exploration of user engagement in HCI. In Proceedings of the International Workshop on Affective-Aware Virtual Agents and Social Robots, Boston, MA, USA, 6 November 2009; pp. 9:1–9:3. [Google Scholar]
- Marko, T.; Berardina, C.D.; Marco, G.; Ante, O.; Andrej, K. (Eds.) Emotions and Personality in Personalized Services: Models, Evaluation and Applications; Human-Computer Interaction Series; Springer: New York, NY, USA, 2016. [Google Scholar]
- Biswas, P.; Robinson, P. A brief survey on user modelling in HCI. In Intelligent Techniques for Speech Image and Language Processing; Springer: New York, NY, USA, 2010. [Google Scholar]
- Ahmed, E.B.; Nabli, A.; Gargouri, F. A Survey of User-Centric Data Warehouses: From Personalization to Recommendation. Int. J. Database Manag. Syst. 2011, 3, 59–71. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl.-Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Vinciarelli, A.; Pantic, M.; Bourlard, H. Social signals, their function, and automatic analysis: A survey. In Proceedings of the 10th International Conference on Multimodal Interfaces (ICMI ’08), Crete, Greece, 20–22 October 2008; pp. 61–68. [Google Scholar]
- Harris, R.B.; Paradice, D. An Investigation of the Computer-mediated Communication of Emotions. J. Appl. Sci. Res. 2007, 3, 2081–2090. [Google Scholar]
- Thorndike, E.L. Intelligence and its use. Harper’s Mag. 1920, 140, 227–235. [Google Scholar]
- Gardner, H. Frames of Mind: The Theory of Multiple Intelligences; Basic books Press: New York, NY, USA, 1984. [Google Scholar]
- Cantor, N.; Kihlstrom, J. Personality and Social Intelligence; Century Psychology Series; Prentice Hall: Upper Saddle River, NJ, USA, 1987. [Google Scholar]
- Kihlstrom, J.F.; Cantor, N. Social intelligence. In The Cambridge Handbook of Intelligence; Cambridge University Press: Cambridge, UK, 2011; pp. 564–581. [Google Scholar]
- Vernon, P.E. Some Characteristics of the Good Judge of Personality. J. Soc. Psychol. 1933, 4, 42–57. [Google Scholar] [CrossRef]
- Albrecht, K. Social Intelligence: The New Science of Success, 1st ed.; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Ambady, N.; Rosenthal, R. Thin slices of expressive behavior as predictors of interpersonal consequences: A meta-analysis. Psychol. Bull. 1992, 111, 256–274. [Google Scholar] [CrossRef]
- Vinciarelli, A.; Valente, F. Social Signal Processing: Understanding Nonverbal Communication in Social Interactions. In Proceedings of the Measuring Behavior, Eindhoven, The Netherlands, 24–27 August 2010. [Google Scholar]
- Pantic, M.; Sebe, N.; Cohn, J.F.; Huang, T. Affective multimodal human-computer interaction. In Proceedings of the 13th Annual ACM International Conference on Multimedia—MULTIMEDIA ’05, Singapore, 6–11 November 2005; pp. 669–676. [Google Scholar]
- Vinciarelli, A.; Pantic, M.; Heylen, D.; Pelachaud, C.; Poggi, I.; D’Errico, F.; Schroeder, M. Bridging the gap between social animal and unsocial machine: A survey of social signal processing. IEEE Trans. Affect. Comput. 2012, 3, 69–87. [Google Scholar] [CrossRef]
- Richmond, V.P.; McCroskey, J.C.; Hickson, M.L., III. Nonverbal Behavior in Interpersonal Relations, 7th ed.; Allyn & Bacon: Boston, MA, USA, 2011. [Google Scholar]
- Pentland, A. Honest Signals: How They Shape Our World; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Fairclough, S.H. Fundamentals of physiological computing. Interact. Comput. 2009, 21, 133–145. [Google Scholar] [CrossRef]
- Derrick, D.C.; Jenkins, J.L.; Jay, F.; Nunamaker, J. Design Principles for Special Purpose, Embodied, Conversational Intelligence with Environmental Sensors (SPECIES) Agents. AIS Trans. Hum.-Comput. Interact. 2011, 3, 62–81. [Google Scholar]
- Allanson, J.; Wilson, G. Physiological Computing. In Proceedings of the CHI ’02 Extended Abstracts on Human Factors in Computing Systems, Minneapolis, MN, USA, 20–25 April 2002; pp. 21–42. [Google Scholar]
- Allanson, J.; Fairclough, S.H. A research agenda for physiological computing. Interact. Comput. 2004, 16, 857–878. [Google Scholar] [CrossRef]
- Sandulescu, V.; Andrews, S.; David, E.; Bellotto, N.; Mozos, O.M. Stress Detection Using Wearable Physiological Sensors. In International Work-Conference on the Interplay Between Natural and Artificial Computation; Springer: Heidelberg/Berlin, Germany, 2015; pp. 526–532. [Google Scholar]
- Novak, D.; Beyeler, B.; Omlin, X.; Riener, R. Workload estimation in physical human—Robot interaction using physiological measurements. Interact. Comput. 2014, 27, 616–629. [Google Scholar] [CrossRef]
- McDuff, D.; Gontarek, S.; Picard, R. Remote Measurement of Cognitive Stress via Heart Rate Variability. In Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Chicago, IL, USA, 26–30 August 2014; pp. 2957–2960. [Google Scholar]
- Ayzenberg, Y.; Hernandez, J.; Picard, R. FEEL: frequent EDA and event logging—A mobile social interaction stress monitoring system. In Proceedings of the 2012 ACM Annual Conference Extended Abstracts on Human Factors in Computing Systems Extended Abstracts CHI EA 12, Austin, TX, USA, 5–10 May 2012; p. 2357. [Google Scholar]
- Jiang, X.; Zheng, B.; Bednarik, R.; Atkins, M.S. Pupil responses to continuous aiming movements. Int. J. Hum.-Comput. Stud. 2015, 83, 1–11. [Google Scholar] [CrossRef]
- Xia, V.; Jaques, N.; Taylor, S.; Fedor, S.; Picard, R. Active learning for electrodermal activity classification. In Proceedings of the 2015 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), Philadelphia, PA, USA, 12 December 2015; pp. 1–6. [Google Scholar]
- Mello, S.K.D.; Craig, S.D.; Gholson, B.; Franklin, S.; Picard, R.; Graesser, A.C. Integrating Affect Sensors in an Intelligent Tutoring System. Available online: https://goo.gl/3EXu8R (accessed on 29 March 2017).
- Vanlehn, K. The relative effectiveness of human tutoring, intelligent tutoring systems, and other tutoring systems. Educ. Psychol. 2011, 46, 197–221. [Google Scholar] [CrossRef]
- Partala, T.; Surakka, V. The effects of affective interventions in human-computer interaction. Interact. Comput. 2004, 16, 295–309. [Google Scholar] [CrossRef]
- Hascher, T. Learning and emotion: Perspectives for theory and research. Eur. Educ. Res. J. 2010, 9, 13–28. [Google Scholar] [CrossRef]
- Moridis, C.N.; Economides, A.A. Affective learning: Empathetic agents with emotional facial and tone of voice expressions. IEEE Trans. Affect. Comput. 2012, 3, 260–272. [Google Scholar] [CrossRef]
- D’mello, S.; Graesser, A. AutoTutor and Affective Autotutor: Learning by Talking with Cognitively and Emotionally Intelligent Computers That Talk Back. ACM Trans. Interact. Intell. Syst. 2013, 2, 23:1–23:39. [Google Scholar] [CrossRef]
- Anderson, J.R.; Corbett, A.T.; Koedinger, K.R.; Pelletier, R. Cognitive Tutors: Lessons Learned. J. Learn. Sci. 1995, 4, 167–207. [Google Scholar] [CrossRef]
- Aleven, V.; Mclaren, B.; Roll, I.; Koedinger, K. Toward meta-cognitive tutoring: A model of help seeking with a cognitive tutor. Int. J. Artif. Intell. Educ. 2006, 16, 101–128. [Google Scholar]
- Azevedo, R.; Witherspoon, A.; Chauncey, A.; Burkett, C.; Fike, A. MetaTutor: A MetaCognitive Tool for Enhancing Self-Regulated Learning. Available online: https://goo.gl/dUMZo9 (accessed on 29 March 2017).
- Mitrovic, A.; Martin, B.; Suraweera, P. Intelligent Tutors for All: The Constraint-Based Approach. IEEE Intell. Syst. 2007, 22, 38–45. [Google Scholar] [CrossRef]
- Shen, L.; Wang, M.; Shen, R. Affective e-Learning: Using emotional data to improve learning in pervasive learning environment related work and the pervasive e-learning platform. Educ. Technol. Soc. 2009, 12, 176–189. [Google Scholar]
- Koedinger, K.R.; Corbett, A. Cognitive tutors: Technology bringing learning sciences to the classroom. In The Cambridge Handbook of the Learning Sciences; Sawyer, R.K., Ed.; Cambridge University Press: New York, NY, USA, 2006; pp. 61–78. [Google Scholar]
- VanLehn, K.; Graesser, A.C.; Jackson, G.T.; Jordan, P.; Olney, A.; Rosé, C.P. When are tutorial dialogues more effective than reading? Cogn. Sci. 2006, 30, 1–60. [Google Scholar] [CrossRef] [PubMed]
- Hone, K. Empathic agents to reduce user frustration: The effects of varying agent characteristics. Interact. Comput. 2006, 18, 227–245. [Google Scholar] [CrossRef]
- Beale, R.; Creed, C. Affective interaction: How emotional agents affect users. Int. J. Hum. Comput. Stud. 2009, 67, 755–776. [Google Scholar] [CrossRef]
- Marsella, S.; Gratch, J.; Petta, P. Computational models of Emotion. Blueprint Affect. Comput. 2010, 11, 21–46. [Google Scholar]
- Rodriguez, L.F.; Ramos, F. Development of Computational Models of Emotions for Autonomous Agents: A Review. Cogn. Comput. 2014, 6, 351–375. [Google Scholar]
- Russell, J.A. A circumplex model of affect. J. Pers. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Yeh, Y.C.; Lai, S.C.; Lin, C.W. The dynamic influence of emotions on game-based creativity: An integrated analysis of emotional valence, activation strength, and regulation focus. Comput. Hum. Behav. 2016, 55, 817–825. [Google Scholar] [CrossRef]
- Tijs, T.; Brokken, D.; Ijsselsteijn, W. Creating an emotionally adaptive game. In International Conference on Entertainment Computing; Springer: Heidelberg/Berlin, Germany, 2008; pp. 122–133. [Google Scholar]
- Plass, J.L.; Heidig, S.; Hayward, E.O.; Homer, B.D.; Um, E. Emotional design in multimedia learning: Effects of shape and color on affect and learning. Learn. Instr. 2014, 29, 128–140. [Google Scholar] [CrossRef]
- Dryer, D.C. Dominance and Valence: A Two-Factor Model for Emotion in HCI. Available online: https://goo.gl/uJvLhD (accessed on 29 March 2017).
- Hudlicka, E. Guidelines for Designing Computational Models of Emotions. Int. J. Synth. Emot. 2011, 2, 26–79. [Google Scholar] [CrossRef]
- Shuman, V.; Clark-Polner, E.; Meuleman, B.; Sander, D.; Scherer, K.R. Emotion perception from a componential perspective. Cogn. Emot. 2015, 9931, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Shuman, V.; Sander, D.; Scherer, K.R. Levels of valence. Front. Psychol. 2013, 4, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P.; Friesen, W.V. Unmasking the Face: A Guide to Recognizing Emotions from Facial Cues; Prentice Hall: Englewood Cliffs, NJ, USA, 1975. [Google Scholar]
- Ekman, P.; Friesen, W.V. Facial Action Coding System: Investigatoris Guide; Consulting Psychologists Press: Sunnyvale, CA, USA, 1978. [Google Scholar]
- Ostermann, J. Face animation in MPEG-4. MPEG-4 Facial Animation. The Standard, Implementation and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Essa, I.A.; Pentland, A.P. Coding, analysis, interpretation, and recognition of facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 757–763. [Google Scholar] [CrossRef]
- Rivera, K.; Cooke, N.J.; Bauhs, J.A. The Effects of Emotional Icons on Remote Communication. In Proceedings of the Conference Companion on Human Factors in Computing Systems, Vancouver, BC, Canada, 13–18 April 1996; pp. 99–100. [Google Scholar]
- Coan, J.A.; Allen, J.J. (Eds.) Handbook of Emotion Elicitation and Assessment (Series in Affective Science), 1st ed.; Oxford University Press: Oxford, UK, 2007; p. 504. [Google Scholar]
- Derks, D.; Bos, A.E.R.; von Grumbkow, J. Emoticons in computer-mediated communication: Social motives and social context. CyberPsychol. Behav. 2008, 11, 99–101. [Google Scholar] [CrossRef] [PubMed]
- Ganster, T.; Eimler, S.C.; Krämer, N.C. Same Same But Different!? The Differential Influence of Smilies and Emoticons on Person Perception. Cyberpsychol. Behav. Soc. Netw. 2012, 15, 226–230. [Google Scholar] [CrossRef] [PubMed]
- Lazzeri, N.; Mazzei, D.; Greco, A.; Rotesi, A.; Lanatà, A.; De Rossi, D. Can a Humanoid Face be Expressive? A Psychophysiological Investigation. Front. Bioeng. Biotechnol. 2015, 3, 64. [Google Scholar] [CrossRef] [PubMed]
- Dunlap, J.; Bose, D.; Lowenthal, P.R.; York, C.S.; Atkinson, M.; Murtagh, J. What sunshine is to flowers: A literature review on the use of emoticons to support online learning. Emot. Des. Learn. Technol. 2015, 163, 1–17. [Google Scholar]
- Gross, J.J.; Levenson, R.W. Emotion elicitation using films. Cogn. Emot. 1995, 9, 87–108. [Google Scholar] [CrossRef]
- Uhrig, M.K.; Trautmann, N.; Baumgärtner, U.; Treede, R.D.; Henrich, F.; Hiller, W.; Marschall, S. Emotion Elicitation: A Comparison of Pictures and Films. Front. Psychol. 2016, 7, 180. [Google Scholar] [CrossRef] [PubMed]
- Churches, O.; Nicholls, M.; Thiessen, M.; Kohler, M.; Keage, H. Emoticons in mind: An event-related potential study. Soc. Neurosci. 2014, 9, 196–202. [Google Scholar] [CrossRef] [PubMed]
- Brave, S.; Nass, C. Emotion in Human-Computer Interaction. In Human-Computer Interaction Fundamentals, 2nd ed.; Jacko, J., Sears, A., Eds.; CRC Press: Boca Raton, FL, USA, 2003; Volume 29, pp. 81–96. [Google Scholar]
- Jacko, J.A. (Ed.) Human Computer Interaction Handbook: Fundamentals, Evolving Technologies, and Emerging Applications, Third Edition (Human Factors and Ergonomics), 3rd ed.; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Košir, A. The intelligent typing tutor. 2017. Available online: http://nacomnet.lucami.org/expApp/TypingTutorEng/ (accessed on 10 January 2017).
- Skinner, B.F. Reinforcement today. Am. Psychol. 1958, 13, 94. [Google Scholar] [CrossRef]
- Amsel, A. Frustrative nonreward in partial reinforcement and discrimination learning: Some recent history and a theoretical extension. Psychol. Rev. 1962, 69, 306. [Google Scholar] [CrossRef] [PubMed]
- Bandura, A.; Walters, R.H. Social Learning Theory; Prentice-Hall: Englewood Cliffs, NJ, USA, 1977. [Google Scholar]
- Stipek, D.J. Motivation to Learn: From Theory to Practice, 2nd ed.; Allyn & Bacon: Boston, MA, USA, 1993; p. 292. [Google Scholar]
- Official Unicode Consortium. Official Unicode Consortium code chart. 2017. Available online: http://www.unicode.org/ (accessed 3 January 2017).
- Mahmood, T.; Mujtaba, G.; Venturini, A. Dynamic personalization in conversational recommender systems. Inf. Syst. e-Bus. Manag. 2013, 12, 213–238. [Google Scholar] [CrossRef]
- Noldus Information Technology. Noldus FaceReader. 2017. Available online: http://www.noldus.com/ (accessed on 10 January 2017).
- Kahneman, D. Attention and Effort; Prentice-Hall: Englewood Cliffs, NJ, USA, 1973; p. 246. [Google Scholar]
- Hodgson, T.L.; Müller, H.J.; O’Leary, M.J. Attentional localization prior to simple and directed manual responses. Percept. Psychophys. 1999, 61, 308–321. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Valence | Arousal | |||
|---|---|---|---|---|
| uID | All int | Pos. reinf. | All int | Pos. reinf. |
| 3 | 20.8 | 34.6 | 28.1 | 39.9 |
| 8 | 24.1 | 38.2 | 30.9 | 43.4 |
| 10 | 18.3 | 32.5 | 19.7 | 36.3 |
| 15 | 15.7 | 29.7 | 17.9 | 33.1 |
| 16 | 20.4 | 33.2 | 26.9 | 38.7 |
| 18 | 21.8 | 35.8 | 34.6 | 47.8 |
| 19 | 19.4 | 33.8 | 27.4 | 39.2 |
| 20 | 24.5 | 39.3 | 31.4 | 44.9 |
| 22 | 17.4 | 32.6 | 18.9 | 35.0 |
| 26 | 23.6 | 38.5 | 29.2 | 42.2 |
| 27 | 19.8 | 33.3 | 23.9 | 39.9 |
| 30 | 25.1 | 40.1 | 31.9 | 45.1 |
| 34 | 21.7 | 35.4 | 26.8 | 40.2 |
| uID | Val. p-val | Arou. p-val. |
|---|---|---|
| 3 | 0.03 | <0.01 |
| 8 | <0.01 | <0.01 |
| 10 | <0.01 | <0.01 |
| 15 | 0.069 | <0.01 |
| 16 | <0.01 | <0.01 |
| 18 | 0.073 | <0.01 |
| 19 | <0.01 | <0.01 |
| 20 | <0.01 | <0.01 |
| 22 | 0.054 | <0.01 |
| 26 | 0.077 | <0.01 |
| 27 | 0.033 | <0.01 |
| 30 | <0.01 | <0.01 |
| 34 | 0.015 | <0.01 |
| uID | m(V) neu | m(V) poz | p val | m(A) neu | m(A) poz | p val |
|---|---|---|---|---|---|---|
| 3 | 0.094 | 0.012 | <0.01 | 0.306 | 0.33 | 0.032 |
| 8 | −0.097 | −0.145 | 0.499 | 0.26 | 0.27 | 0.291 |
| 10 | −0.031 | −0.119 | <0.01 | 0.308 | 0.289 | <0.01 |
| 15 | −0.01 | 0.01 | 0.085 | 0.37 | 0.31 | <0.01 |
| 16 | 0.079 | 0.027 | 0.026 | 0.271 | 0.253 | 0.049 |
| 18 | 0.067 | 0.025 | <0.01 | 0.274 | 0.269 | 0.199 |
| 19 | −0.188 | −0.241 | 0.045 | 0.319 | 0.342 | <0.01 |
| 20 | 0.07 | 0.074 | 0.252 | 0.282 | 0.295 | 0.459 |
| 22 | 0.056 | 0.036 | <0.01 | 0.277 | 0.285 | 0.353 |
| 26 | 0.114 | 0.015 | <0.01 | 0.277 | 0.25 | <0.01 |
| 27 | −0.004 | −0.026 | <0.01 | 0.299 | 0.305 | 0.367 |
| 30 | 0.004 | −0.012 | 0.01 | 0.262 | 0.259 | 0.199 |
| 34 | −0.108 | −0.1 | 0.28 | 0.297 | 0.365 | 0.04 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Košir, A.; Strle, G. Emotion Elicitation in a Socially Intelligent Service: The Typing Tutor. Computers 2017, 6, 14. https://doi.org/10.3390/computers6020014
Košir A, Strle G. Emotion Elicitation in a Socially Intelligent Service: The Typing Tutor. Computers. 2017; 6(2):14. https://doi.org/10.3390/computers6020014
Chicago/Turabian StyleKošir, Andrej, and Gregor Strle. 2017. "Emotion Elicitation in a Socially Intelligent Service: The Typing Tutor" Computers 6, no. 2: 14. https://doi.org/10.3390/computers6020014
APA StyleKošir, A., & Strle, G. (2017). Emotion Elicitation in a Socially Intelligent Service: The Typing Tutor. Computers, 6(2), 14. https://doi.org/10.3390/computers6020014