This section describes how the proposed array multipliers are implemented and pipelined.
5.1. Partial-Product Selection and Generation
MacSorley’s algorithm adds zero when
by generating
and setting
. In the proposed multiplier,
is generated, and
is set to “1”. This complements each bit in
and adds “1” to subtract zero [
32]. With this modification, the operation bit
, as opposed to MacSorley’s algorithm where
is a function of three variables. This eliminates the logic resources and additional delay required to generate
and simplifies the layout on the FPGA fabric.
Table 4 shows the proposed partial-product selection (cf.
Table 2), and
Table 5 shows the proposed partial-product generation (cf.
Table 3).
5.2. Combined Partial-Product Generation and Addition
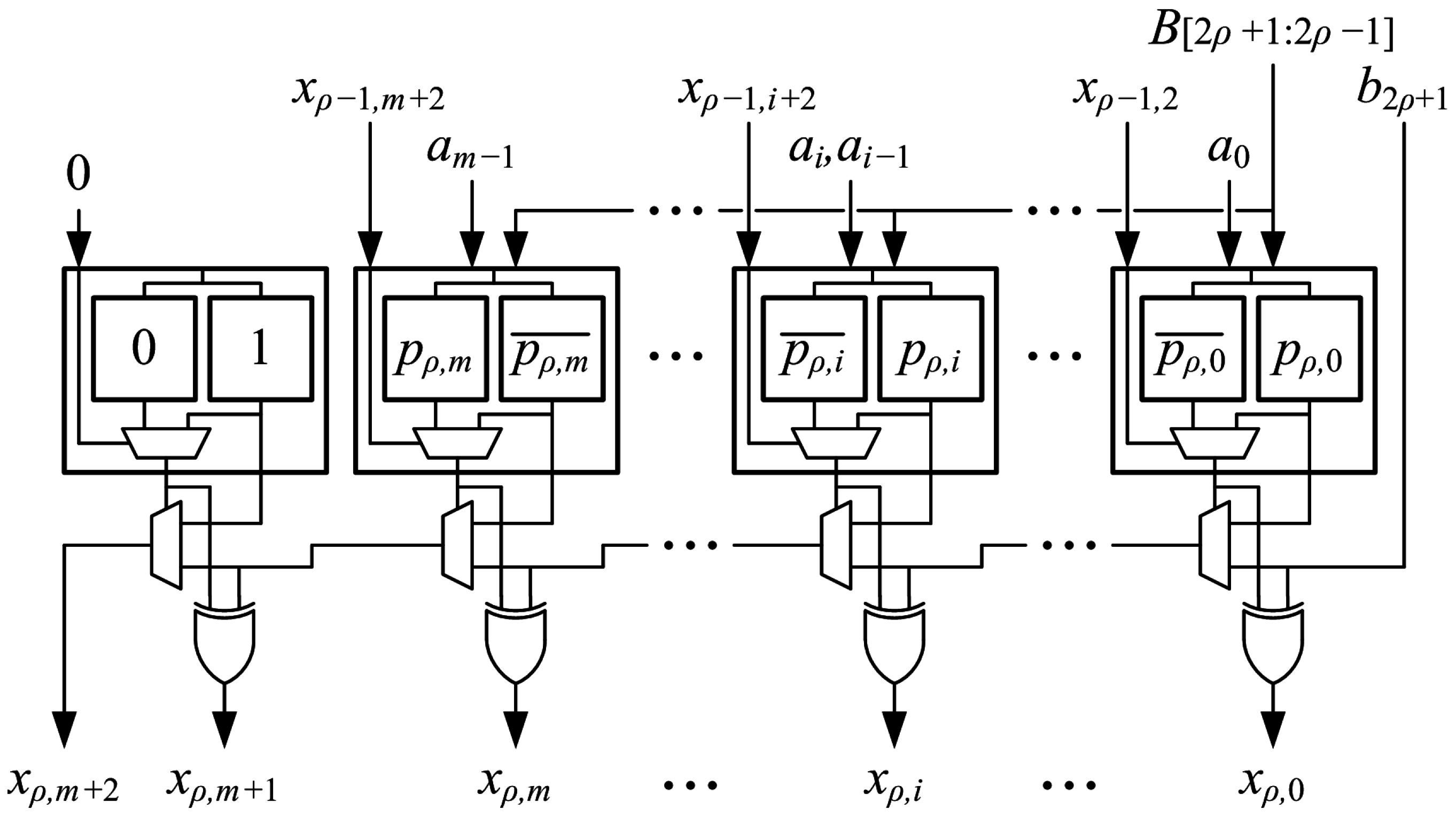
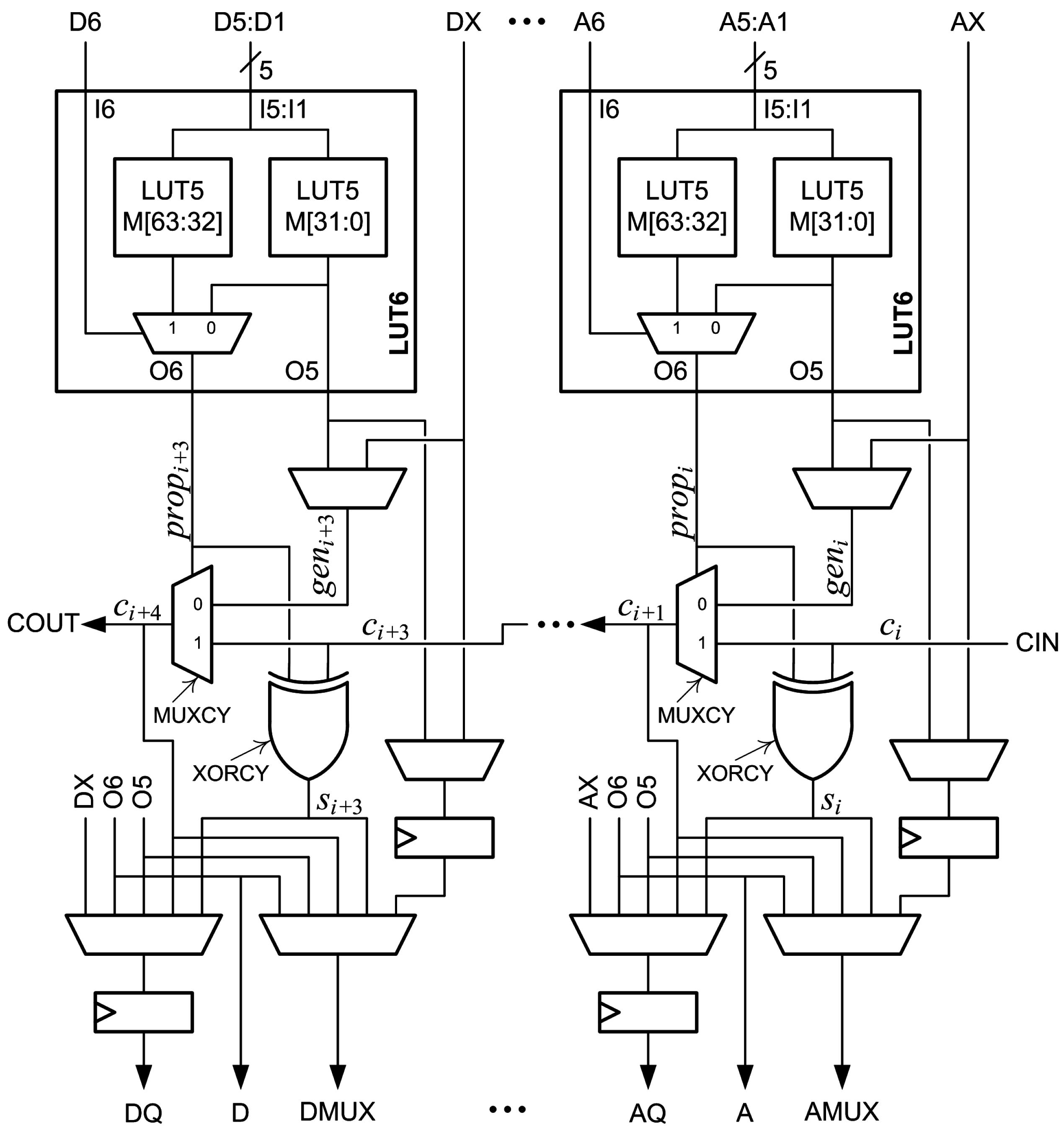
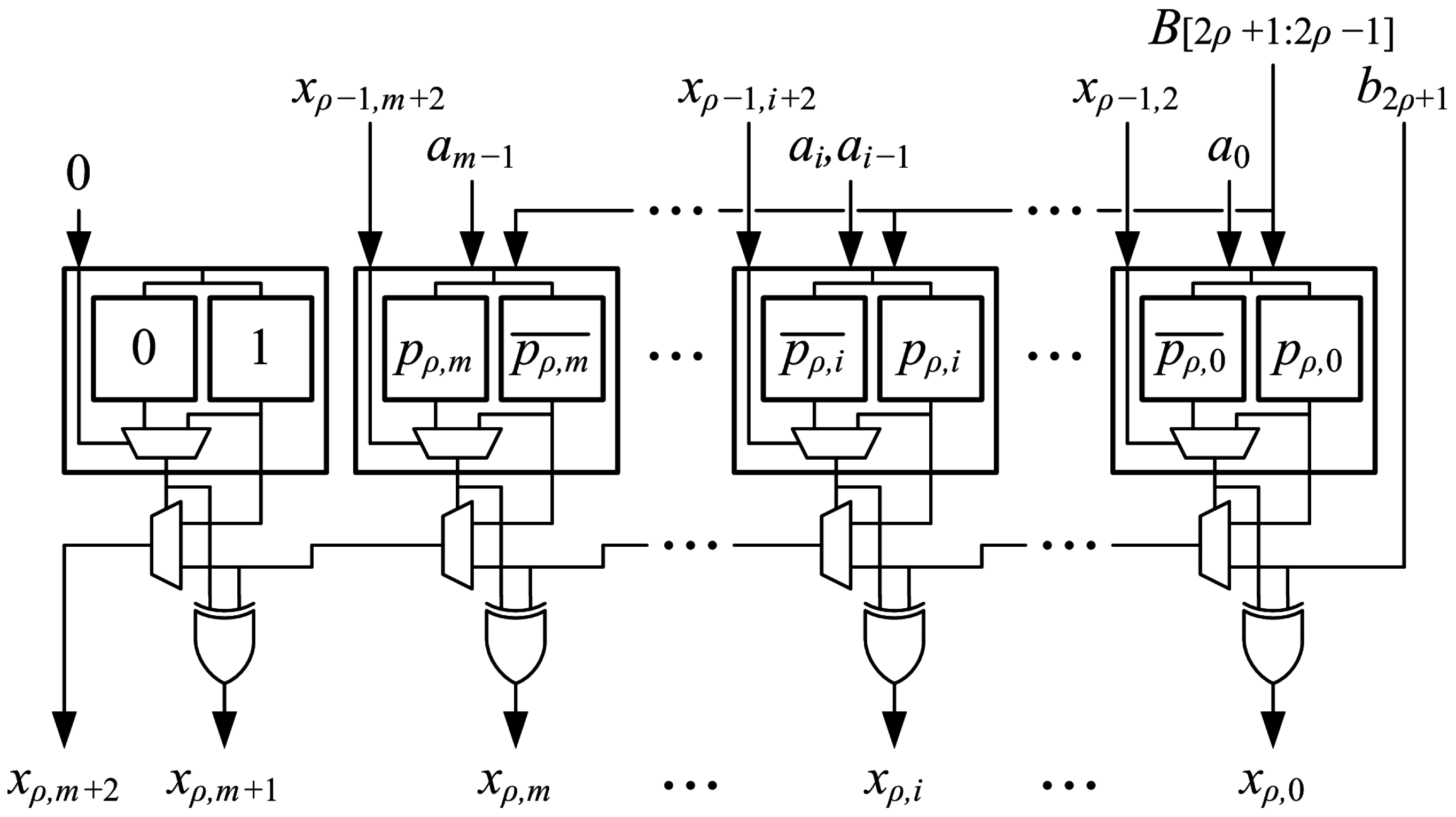
Partial-product generation and addition of a second value are combined into a generate-add unit, which is the main building block of the proposed array multipliers. The arithmetic operation is shown in
Figure 7. Each unit generates one radix-4 partial product,
, with a leading “1” and the most-significant bit (MSB) complemented to implement sign extension. The operation bit,
, and the
MSBs of the output from the previous generate-add unit,
, are added to produce an accumulated sum,
. The two LSBs of
are bits
and
of the final product, so they are not added in the next unit. The generate-add unit is shown in
Figure 8. It is implemented using an
-bit proposed two-operand adder as described in
Section 4, with
and
as the
X and
Y addends, respectively.
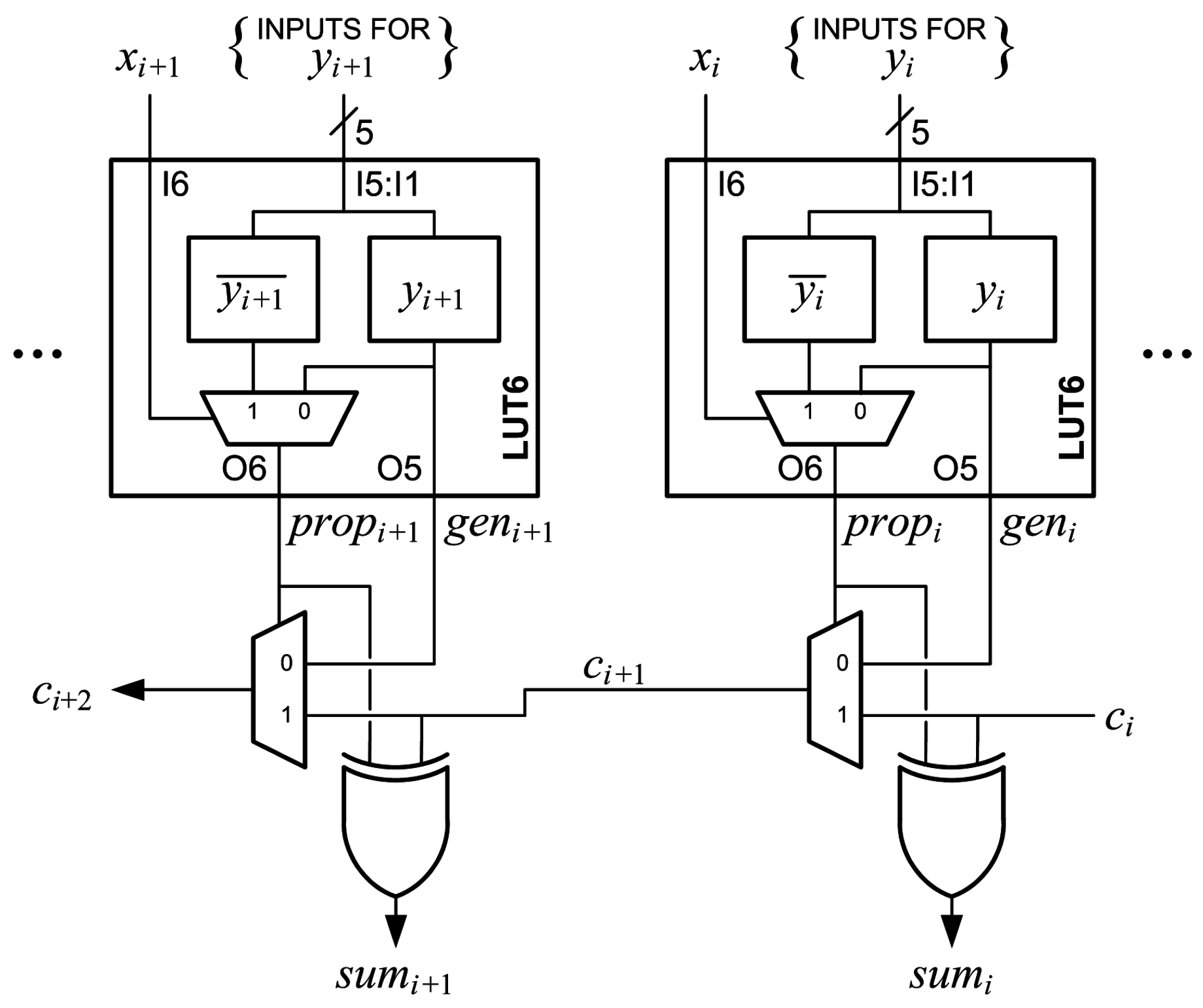
Bit
i of partial product
,
, is a function of five inputs:
The inputs for each bit, , are connected to the I5:I1 inputs of a LUT6. is connected to I6 of the same LUT6. The M[31:0] LUT5 is configured to generate , and the M[63:32] LUT5 is configured to generate . O6 then generates and drives . O5 generates and is selected to drive . This is done for all of the partial-product bits except the MSB, . The MSB is complemented for sign extension by generating in the M[31:0] LUT5 and in the the M[63:32] LUT5. O6 then generates and drives . O5 generates and is selected to drive . The leading “1”, , is added by configuring the M[31:0] LUT5 to generate “1”, configuring the M[63:32] LUT5 to generate “0” and wiring “0” to I6, so that and . To summarize, the M[31:0] LUT5s generate the bits of ; the M[63:32] LUT5s generate the complement of those bits; and the bits of to be added are wired to the I6 inputs. The operation bit, , is added by wiring to . The sum produced at the XORCY output is , which is added to in the next generate-add unit.
Table 6 is the truth table for a LUT6 that generates the partial product
and adds it to the bit input to I6, e.g.,
. Note that the values for O6 are stored in M[63:32], and the values for O5 are stored in M[31:0].
5.3. Optimizations for the Generate-Add Unit
The most-significant LUT, shown in
Figure 8, can be simplified and eliminated. Inspection of the circuit shows that the
input to the MUXCY is always “1”. This means that the
input to the MUXCY is never used, so it is a don’t-care. This could be implemented by storing all “1”s in the M[63:32] LUT5 and wiring “1” to the I6 input, which frees the M[31:0] LUT5 to be used for another purpose. When this is done, the Xilinx tools optimize the entire LUT6 away. The Verilog models used in this work simply assign “1” to the
input of the CARRY4 primitive.
Pipelined array multipliers reported in previous work [
22] had an interesting result for delay.
multipliers were slower than
multipliers (2.402 ns vs. 2.144 ns), and
multipliers were slower than
multipliers (2.471 ns vs. 2.160 ns). These multipliers were implemented using the generate-add structure shown in
Figure 8, which requires
LUT6s. When
is a multiple of four,
slices are fully utilized. Inspection of
Figure 1 shows that the XORCY output and the MUXCY output are registered using the same flip-flop. When
is a multiple of four, such as for
and
multipliers, the
output from the MUXCY cannot be registered within the same slice because the
output and the other XORCY outputs use all of the available flip-flops. This forces
to be routed outside of the slice to an available flip-flop, causing the additional delay due to longer and slower interconnect.
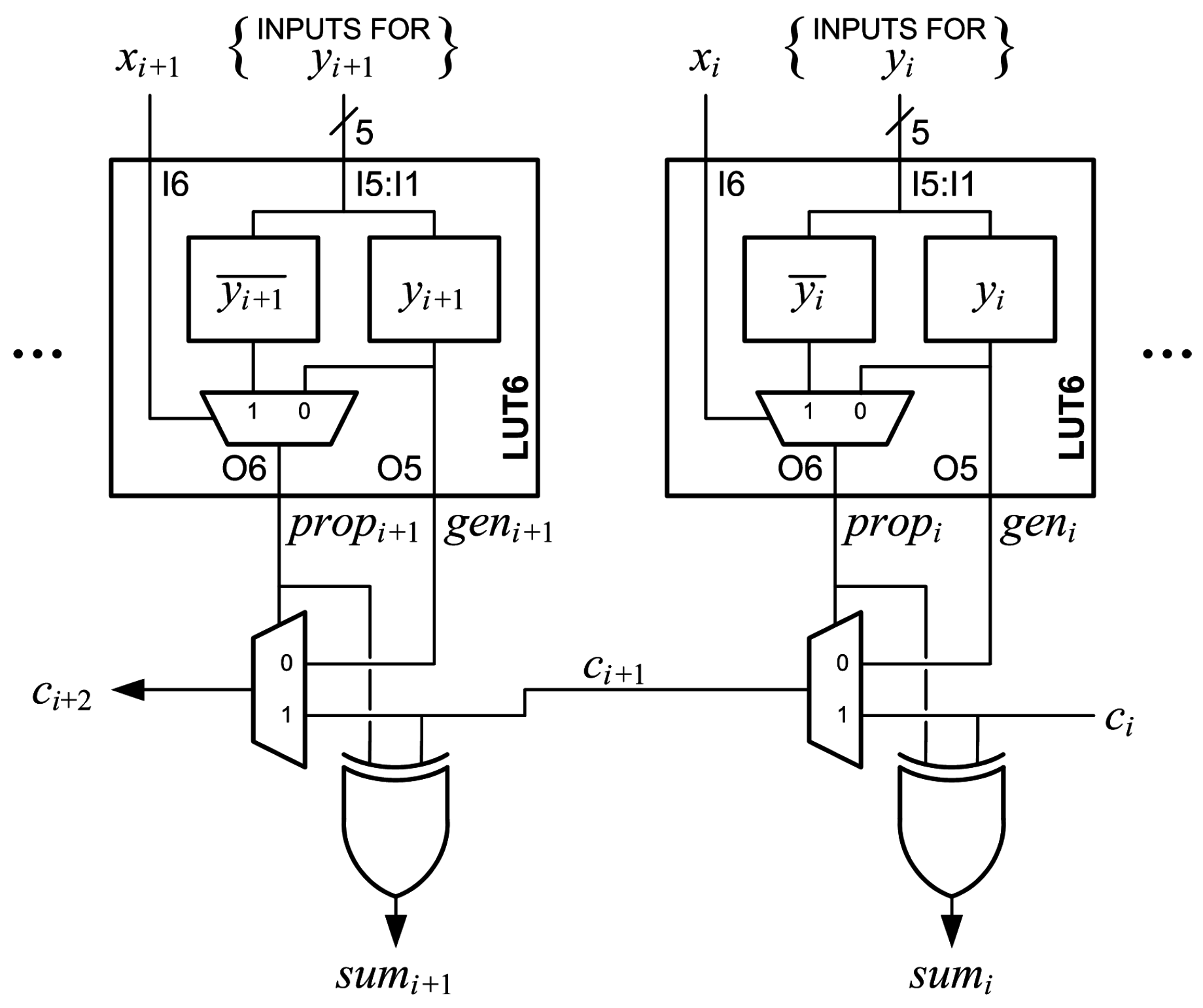
This problem is avoided by noting that
. The
output is used in the next row instead of
so that the MUXCY output does not need to be registered.
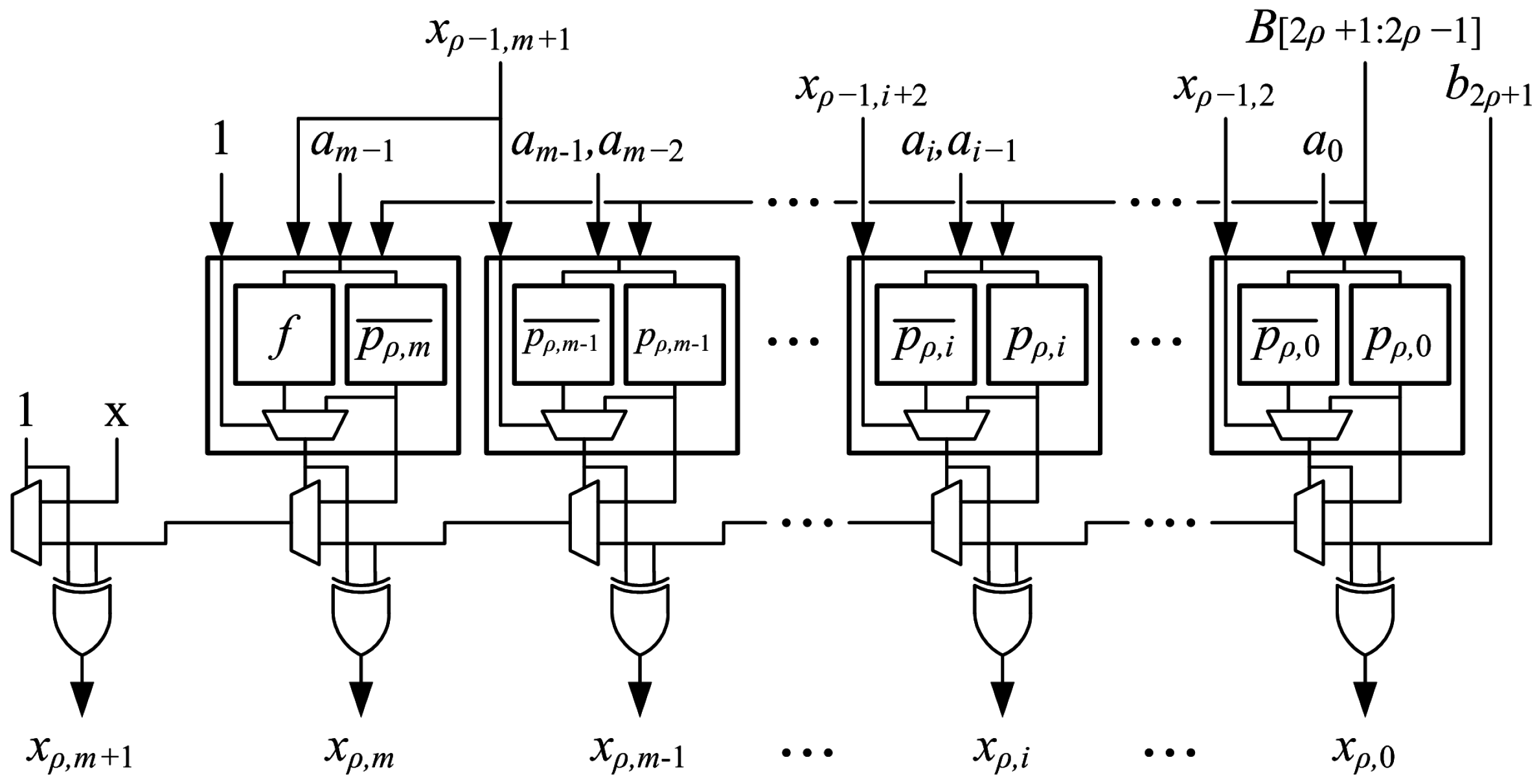
Figure 9 shows the arithmetic that is performed (cf.
Figure 7). The optimized generate-add unit generates
with a leading “1” and the MSB complemented to implement sign extension as in the original generate-add unit. The operation bit,
, and the (
) MSBs of
, using
instead of
, are added to produce an accumulated sum,
. The MSB of the output,
, is not needed in the next row, so it is not produced.
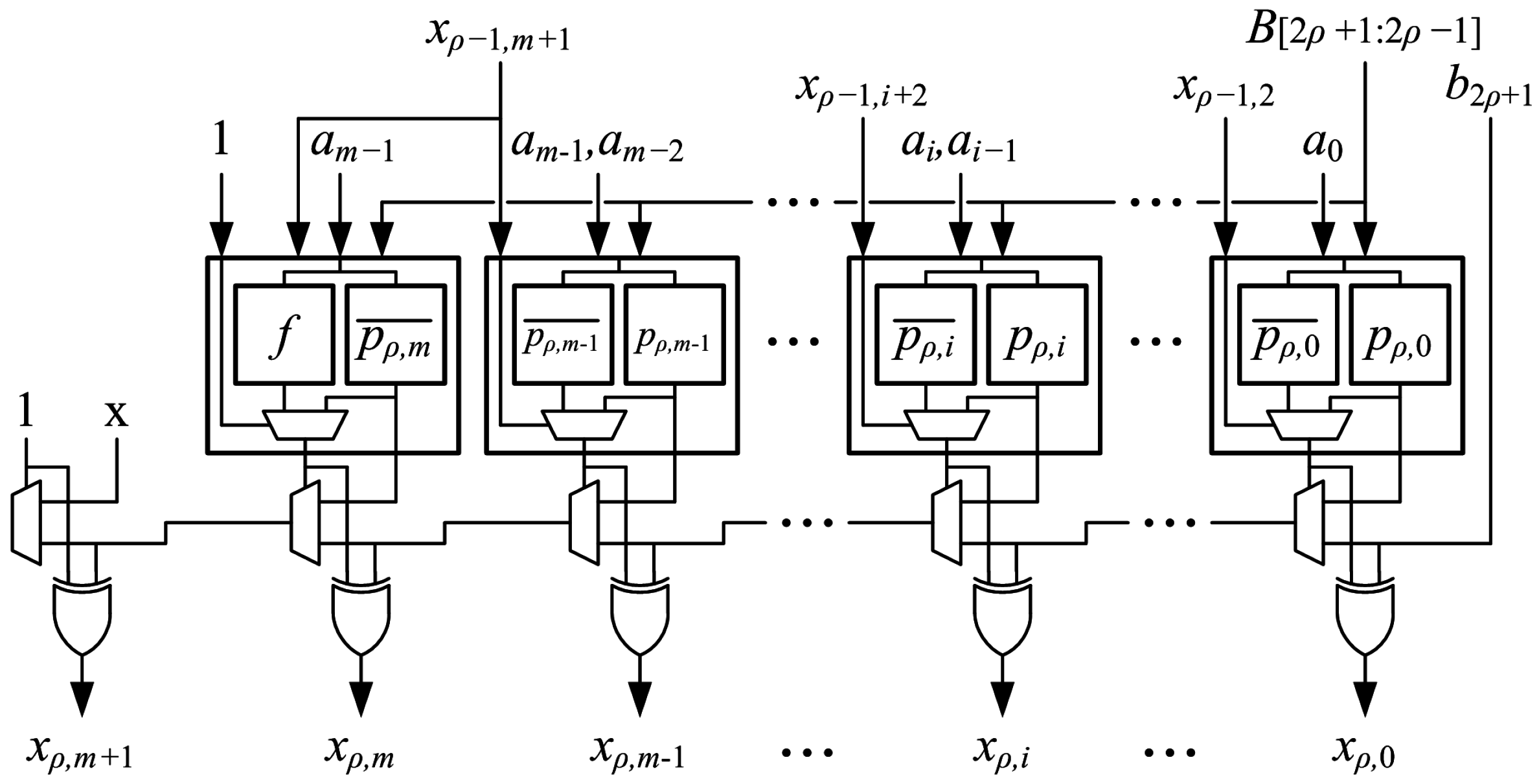
The most-significant LUT6 of the optimized generate-add unit is configured differently than the other LUT6s. The MSB from the previous unit,
, is connected to one of the shared I5:I1 inputs, and “1” is input to I6. The M[31:0] LUT5 is configured to produce
at O5 to drive the
signal. The M[63:32] LUT5 is configured to produce the function
at O6 to drive the
signal. Since
,
Table 7 gives the truth table the for the most-significant LUT6 of an optimized generate-add unit.
Figure 10 shows the optimized generate-add unit. The optimized generate-add unit uses only
LUT6s and avoids the delay of routing a MUXCY output out of a slice to be registered.
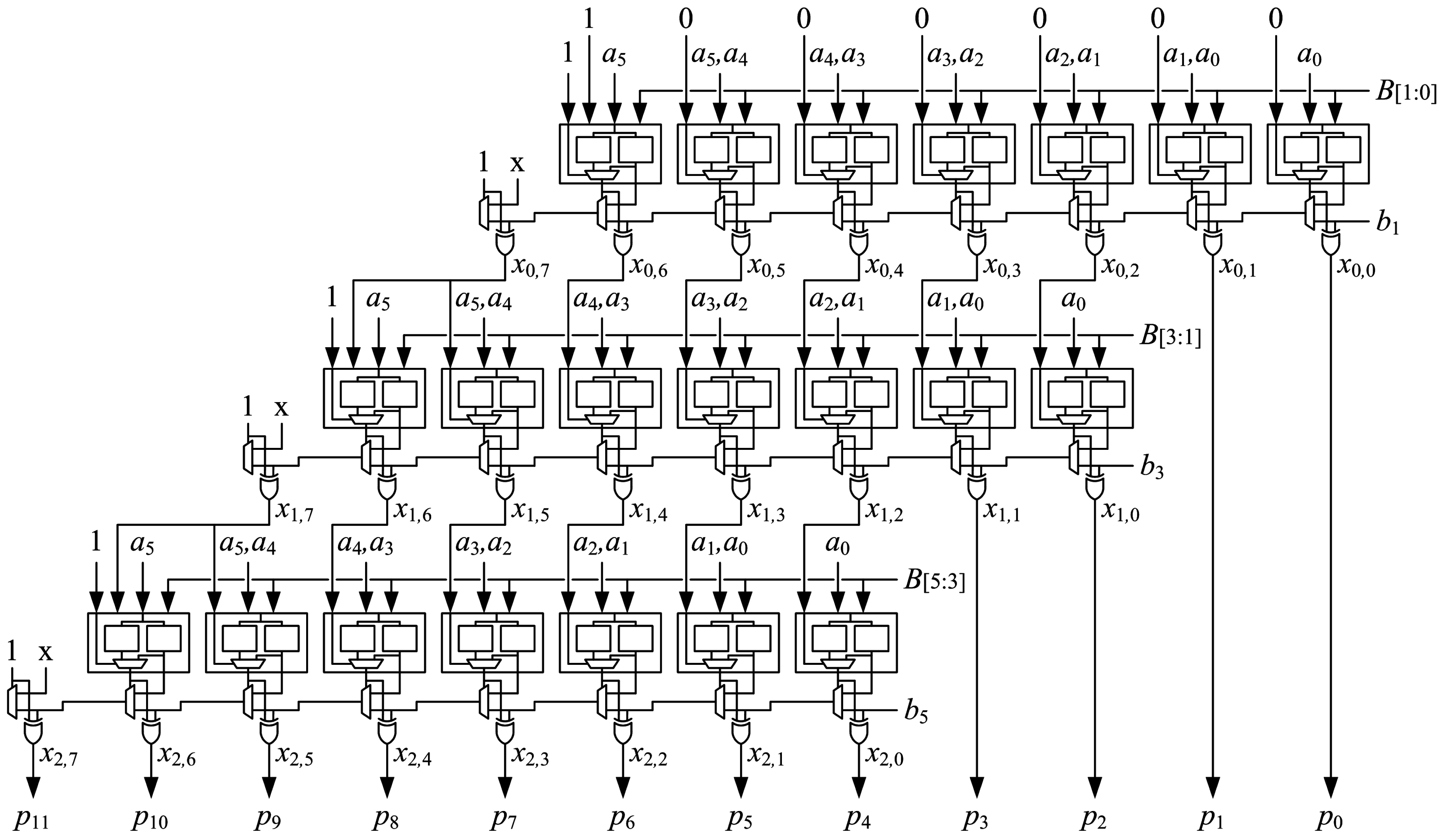
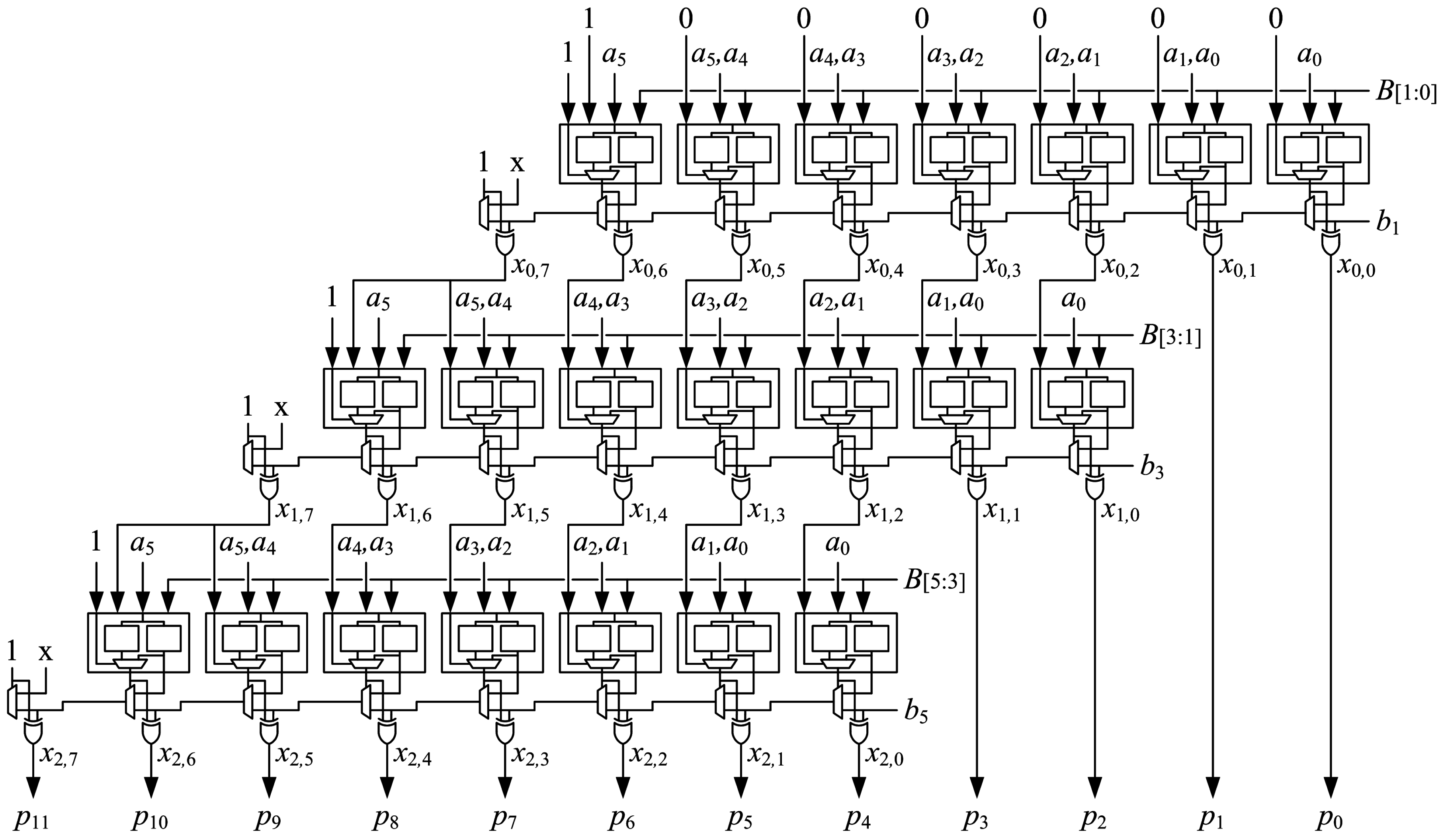
5.4. Array Structure and Pipelining
An array of
optimized generate-add units is used to implement an
multiplier. Optimized generate-add units are connected in an array structure as shown in
Figure 11. Each generate-add unit requires
LUT6s, so the number of LUT6s required to implement an
array multiplier is:
The multiplier can be pipelined to reduce cycle time and increase throughput for applications that can tolerate increased latency.
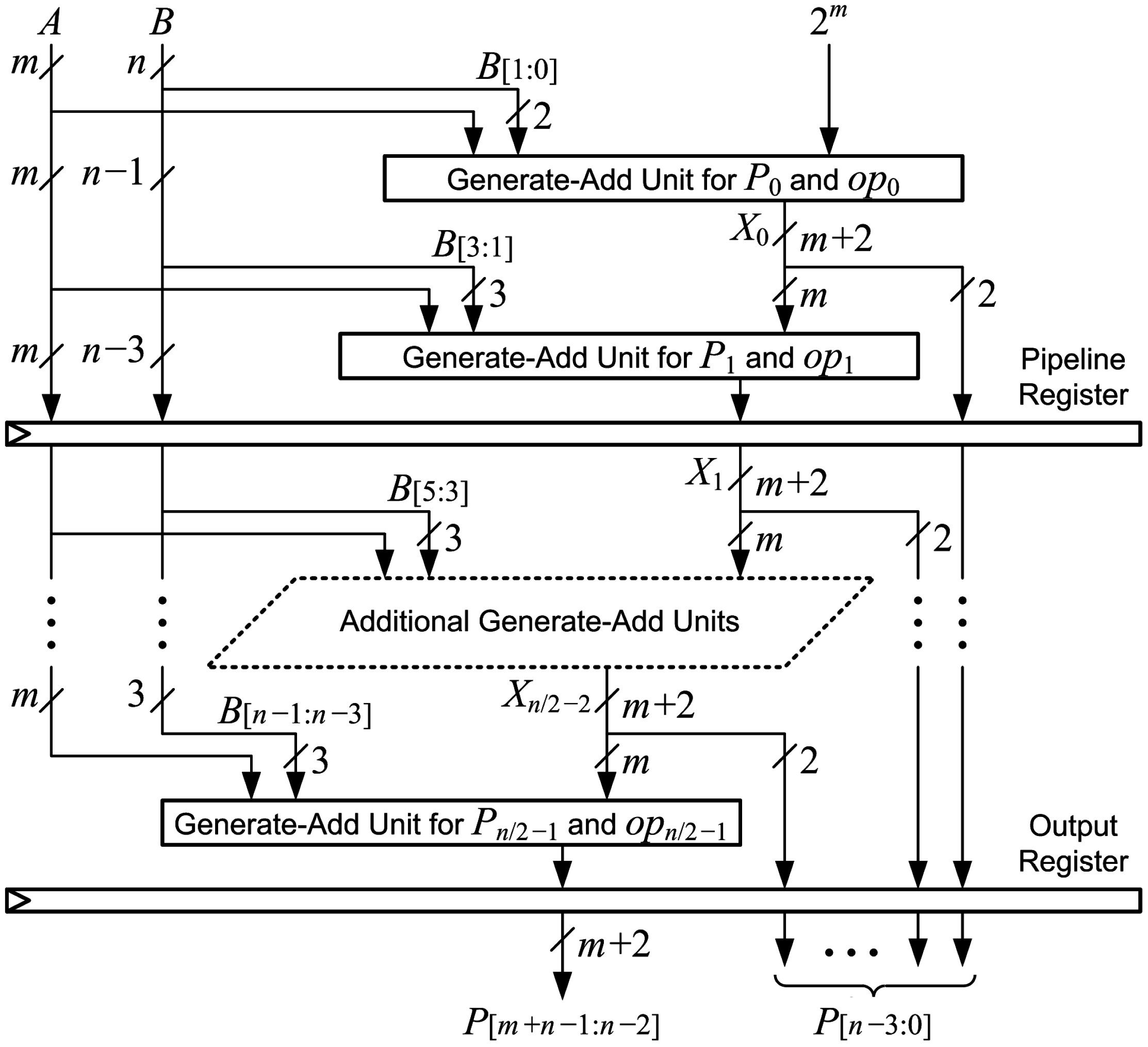
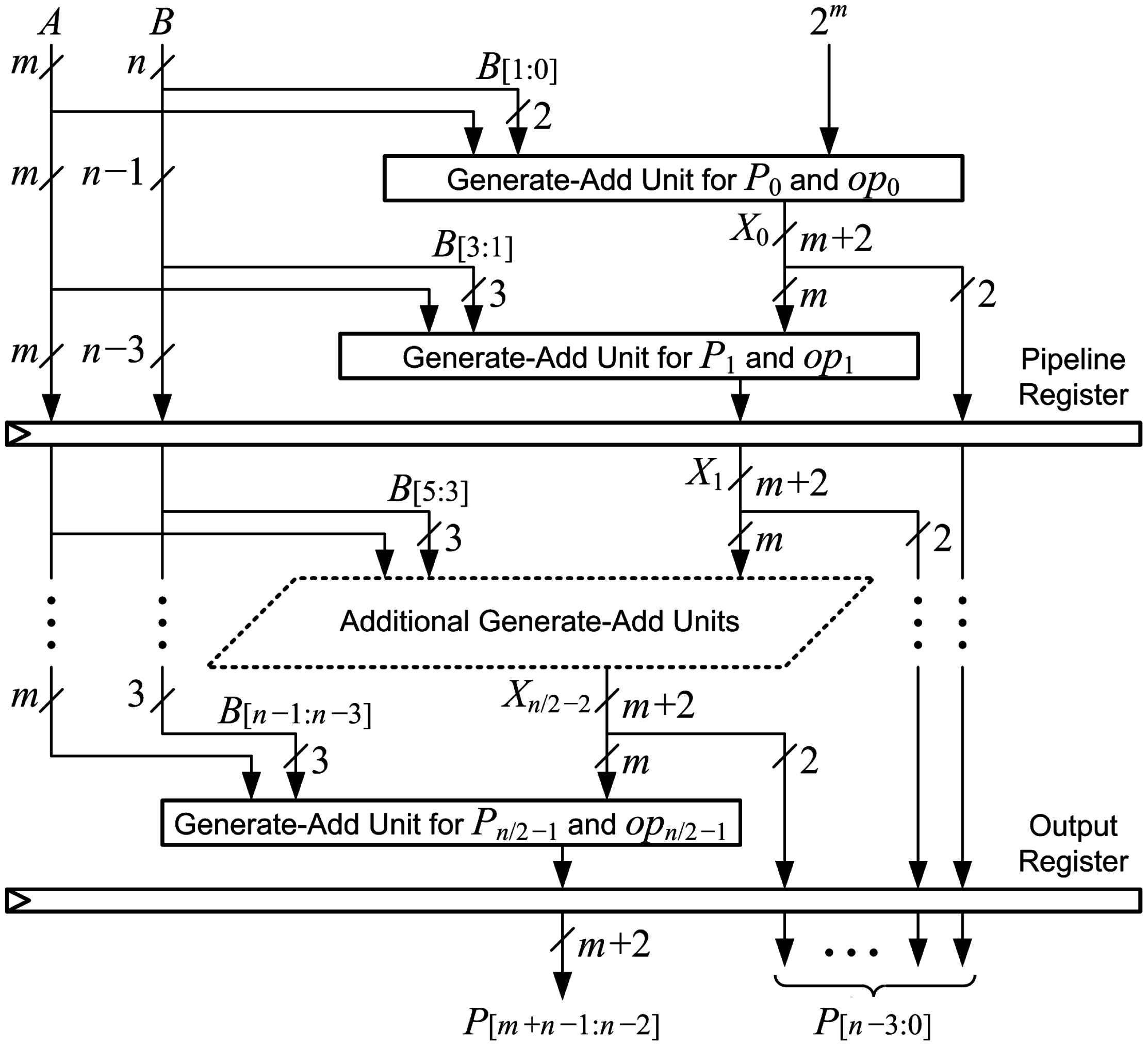
Figure 12 shows the connections for optimized generate-add units in a pipelined
array multiplier with
stages. The multiplier can be pipelined by placing a register after every two generate-add units to increase the maximum clock frequency with a modest increase in latency. All
m bits of operand
A and
bits output from the second generate-add unit are registered at the end of the first stage. The three LSBs of operand
B are not needed after the first stage, so only
bits are registered. The two LSBs from the output of the first generate-add unit are also registered for a total of
bits registered at the end of the first stage. In each subsequent stage, four fewer bits of
B are registered while four additional LSBs from generate-add units are registered, so
flip-flops are used to implement pipeline registers in each stage. There are
pipeline registers, and
flip-flops are needed to register the output, so the number of flip-flops required for an
-stage pipelined array multiplier is:
Each of the LUT6s used to implement the array multiplier has two flip-flops, so there are flip-flops available within the footprint of the multiplier. If , there are enough flip-flops to implement an -stage pipeline with a significant number left over for other uses. This does not imply that all flip-flops used to implement the pipeline must be placed within the footprint of the multiplier. It does imply that a large number of multipliers can be densely placed on the FPGA fabric, and there will be enough flip-flops available within the logic of the multipliers for pipelining. Other designs that use the bypass input only have one flip-flop available per LUT6 and would not have enough flip-flops available for deep pipelining. If the product is truncated or rounded, the LSBs of the generate-add units do not need to be registered, and additional flip-flops are available for other uses.
The proposed array multipliers can also be pipelined with
stages to further increase the maximum clock frequency. This is accomplished by placing pipeline registers after every generate-add unit. As with the
-stage pipeline, this requires
bits to be registered in each stage plus
bits for the output register, so the number of flip-flops required for an
-stage pipelined array multiplier is:
There are not enough flip-flops available within the footprint of the multiplier to implement an -stage pipeline. Unused flip-flops in nearby logic can be used to make up the difference if available. The number of required flip-flops can be reduced by using shift-register LUTs (SRLs). A single SRL can be used to replace a number of flip-flops connected as a shift register, such as the least-significant bits of the product that are shifted through each stage. The two flip-flops associated with the SRL are available for use, so using SRLs increases the number of flip-flops available in the multiplier footprint while reducing the number that is required. When SRLs are used to replace chains of three or more flip-flops, the Vivado synthesis default, there are more than enough flip-flops within the multiplier footprint to implement the -stage pipeline. As noted earlier, this does not imply that pipeline flip-flops must be placed with the footprint. Routing into or out of an SRL may be longer than the longest route between two flip-flops in a chain that it replaces, so it may be on the critical path and increase the delay of the multiplier.
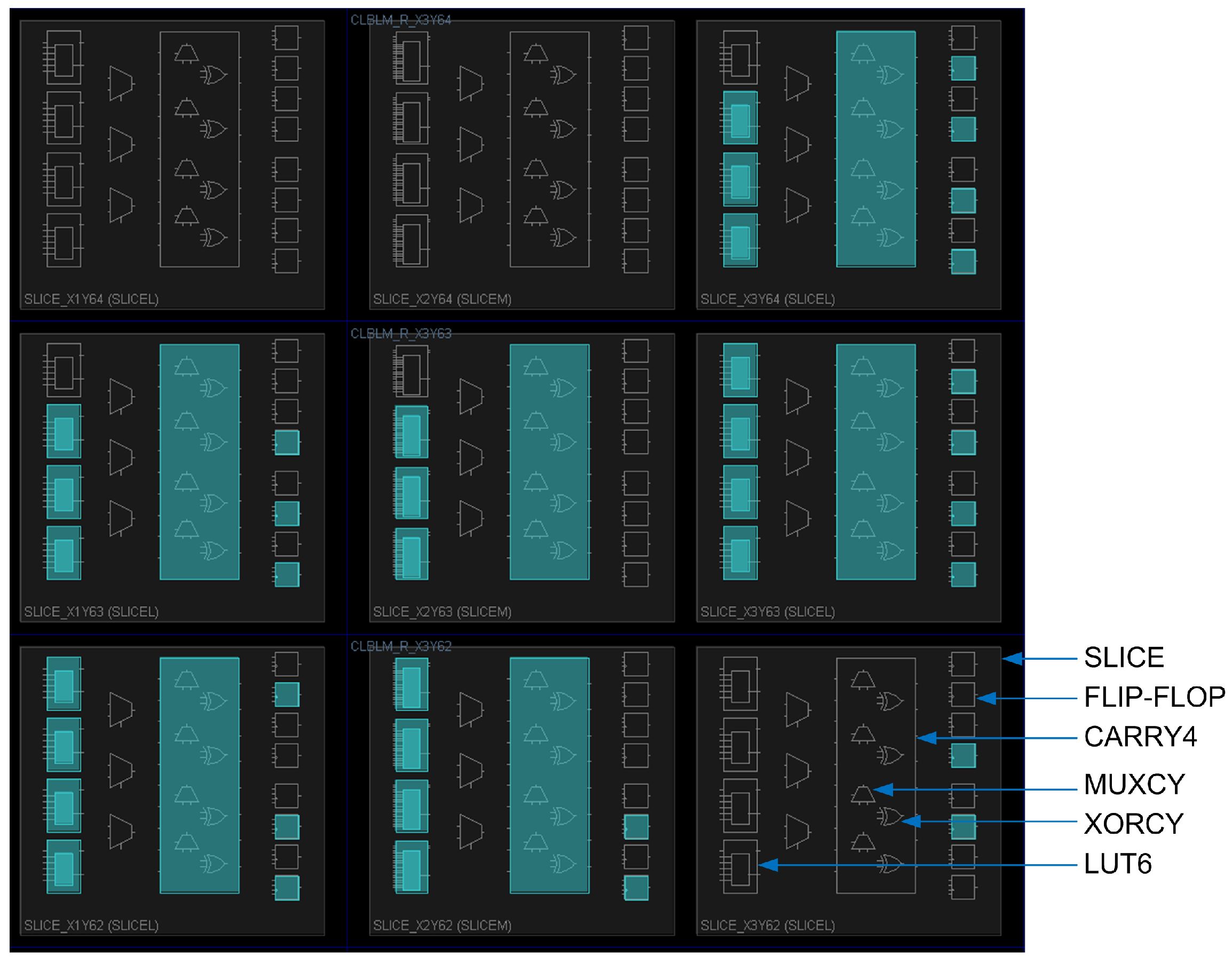
The proposed array structure is easy to layout. LUT6s are placed in the fabric much like a mirror image of how they are shown in the schematic of
Figure 11, which simplifies routing, as well. Deeper pipelining, i.e., using
instead of
stages, reduces delay significantly.
5.5. Row 0 Generate-Add Estimation Unit
The generate-add unit in the first row,
, does not have an input value
to add. The unit only needs to generate
and add
and
to produce
, the input to the next generate-add unit.
Figure 13 shows the arithmetic for the Row 0 generate-add unit. If a maximum absolute error of one unit in the last place (ulp) can be tolerated, the generate-add unit in the first row can be replaced with an estimation unit that uses only
LUT6s instead of
.
Figure 14 shows the Row 0 generate-add estimation unit, which produces an estimate,
, instead of
.
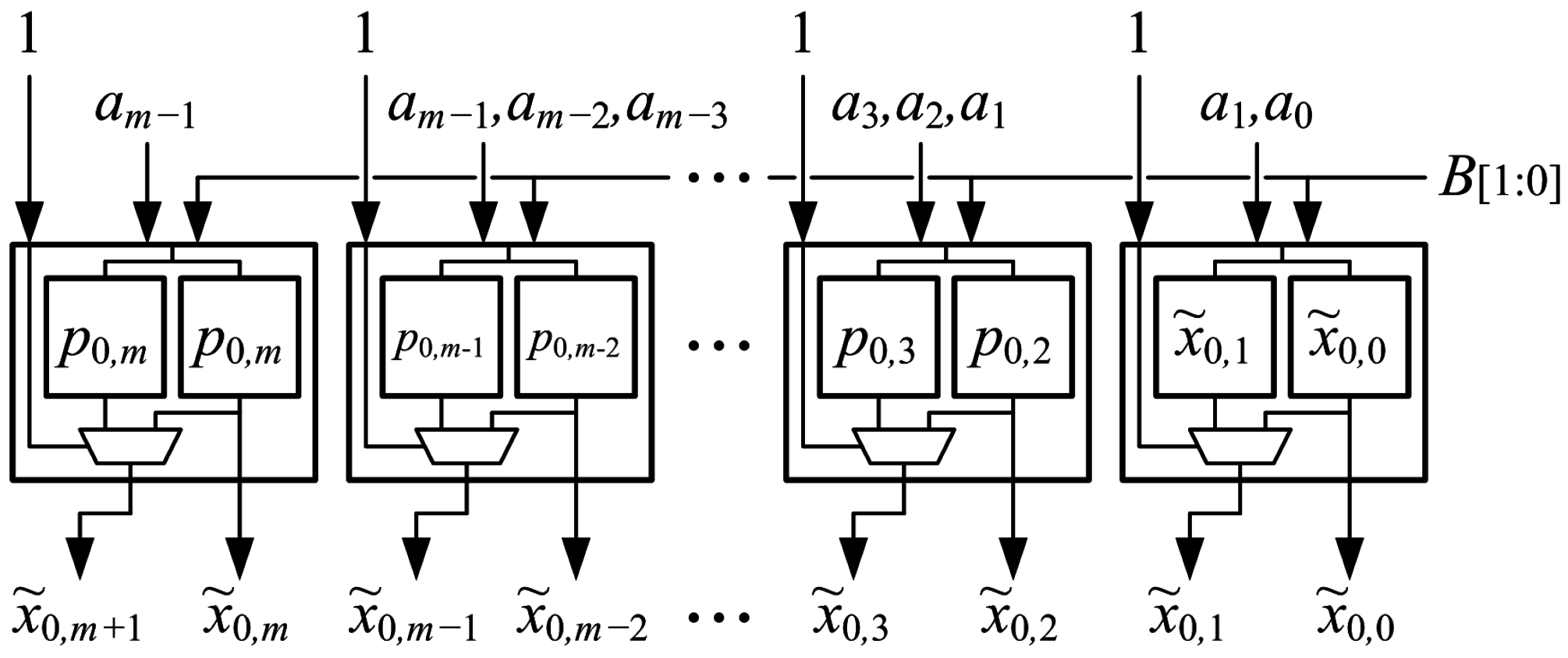
For any adjacent pair of bits in
, each bit is a function of four variables:
Together,
and
are a function of five variables,
The two bits can be computed using two LUT5s in the same LUT6, generating
at O6 and
at O5. This allows
to be generated using only
LUT6s instead of the
LUT6s required for a generate-add unit, but does not allow the fast carry chain to be used.
Table 8 gives the truth table for a LUT6 that generates adjacent partial products
and
in the top row, Row 0.
The least-significant LUT6 can generate and , but cannot properly add because there cannot be a carry-out to the next LUT6. One option is to discard and simply output and . Another option is to generate and , add and output and if there is no carry out or and if there is a carry out. Another option is to output a function of , and that has a desired statistical result, such as an average error of zero.
The LUT5s that output
for
generate
. The sum of
and the two constant “1”s is
. The LUT5s that output
and
generate
and
. As described in
Section 5.3, the generate-add unit in the second row uses
for
and complements it internally, so
does not need to be generated. The only error introduced into
is the error from the least-significant LUT6, so the maximum absolute error is easily constrained to 1 ulp. Although not shown in
Figure 14,
could be generated using a single LUT5 and used for
,
and
.






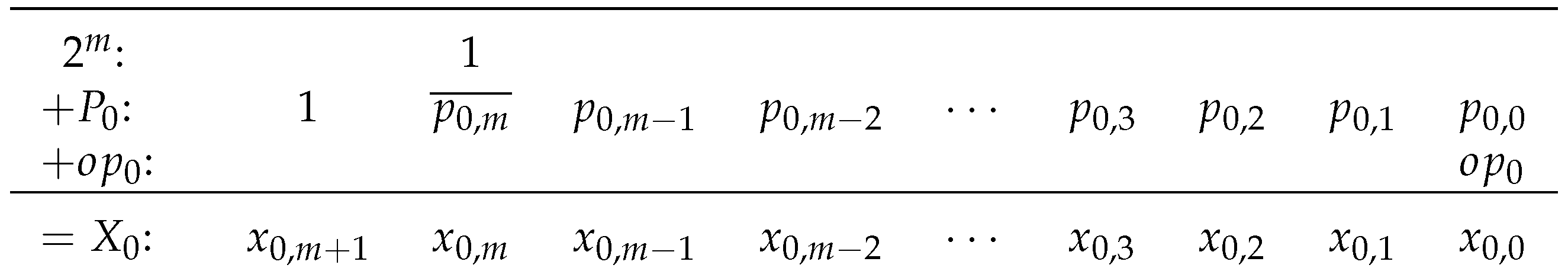



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
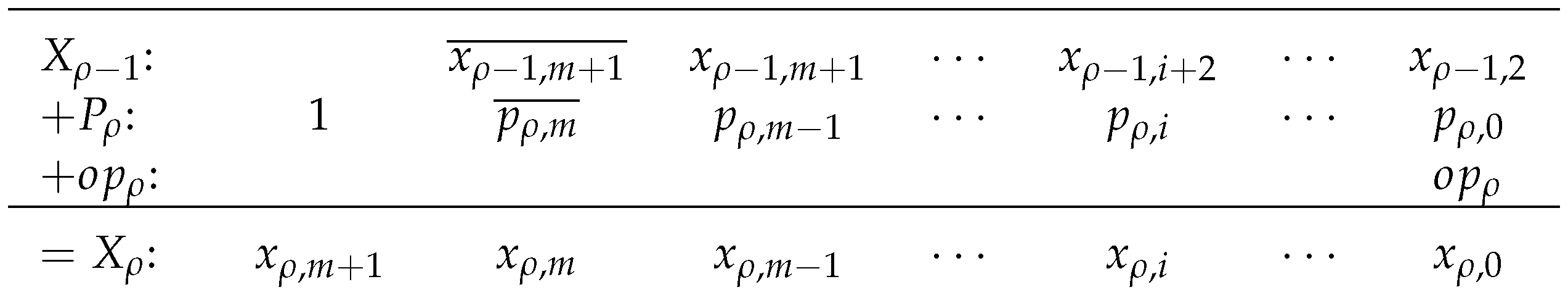{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}