
Continuity-Aware Scheduling Algorithm for Scalable Video Streaming



Abstract
:1. Introduction
2. Related Work
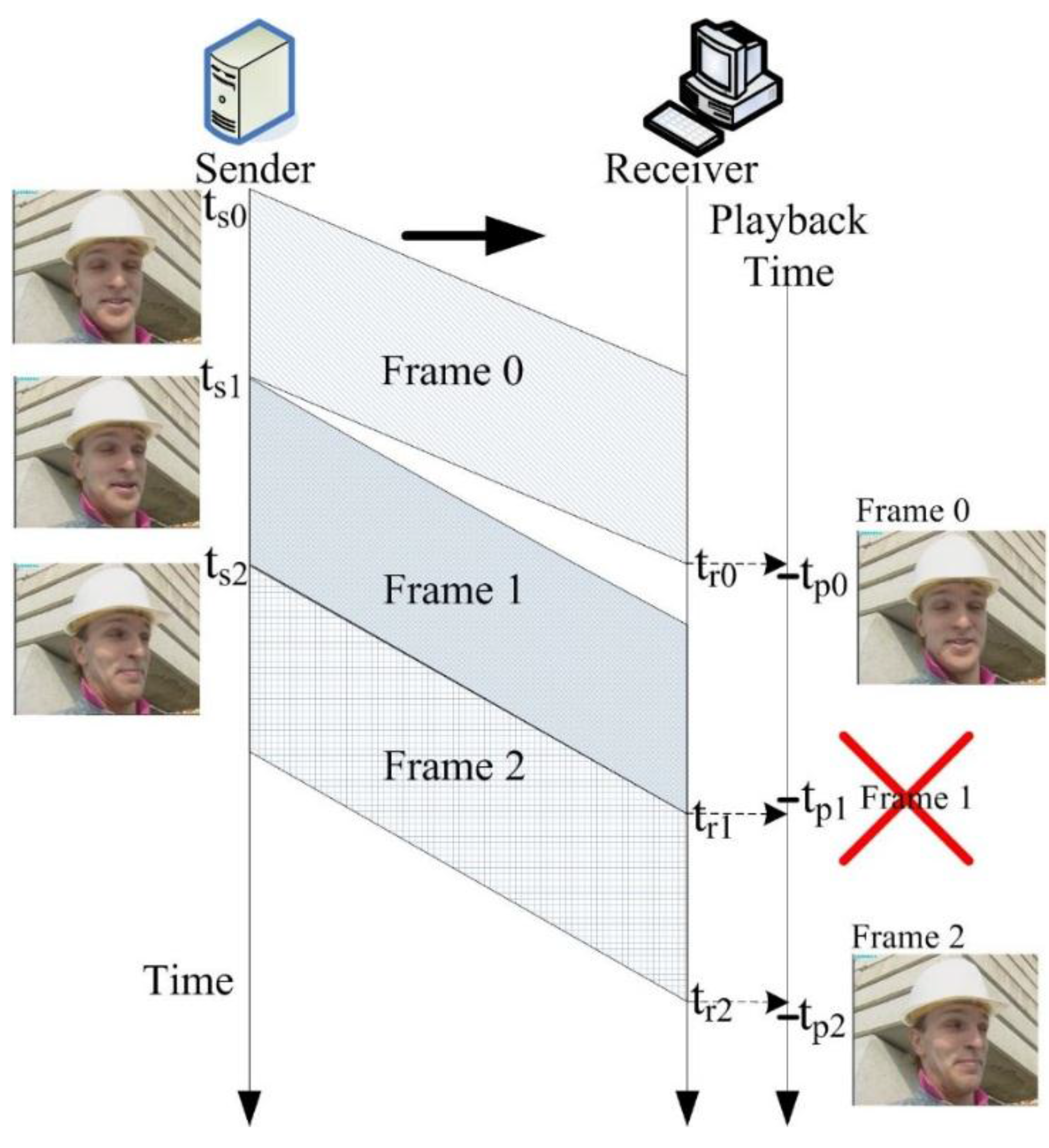
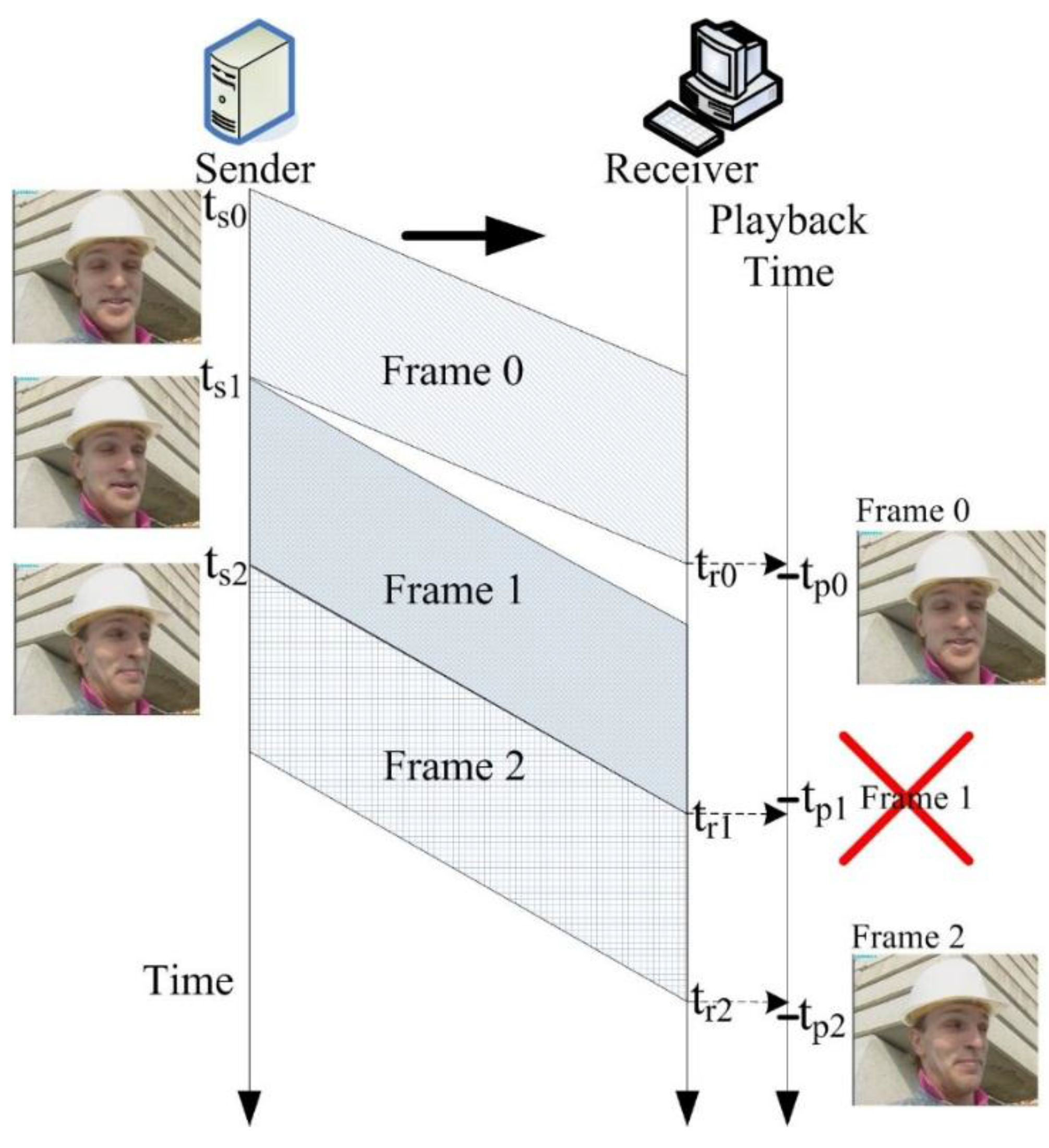
2.1. Effect of Jitter to Perceptual Video Quality
2.2. Jitter Buffer
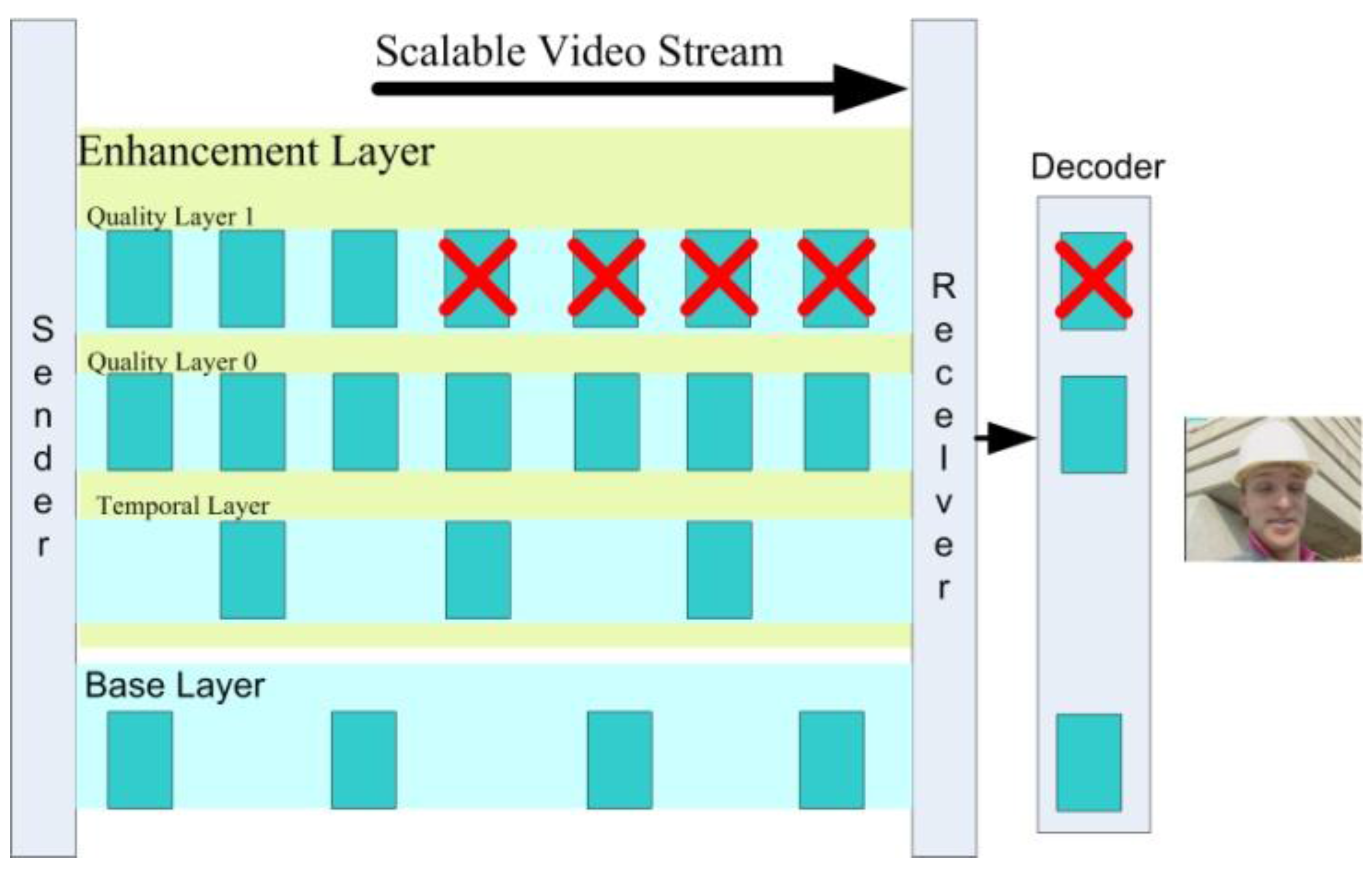
2.3. Scalable Video and Its Flexibility
2.4. Scalable Video Scheduling, Reordering and Packet Selection
2.5. Unequal Protection
3. Proposed Algorithm and Its Analysis
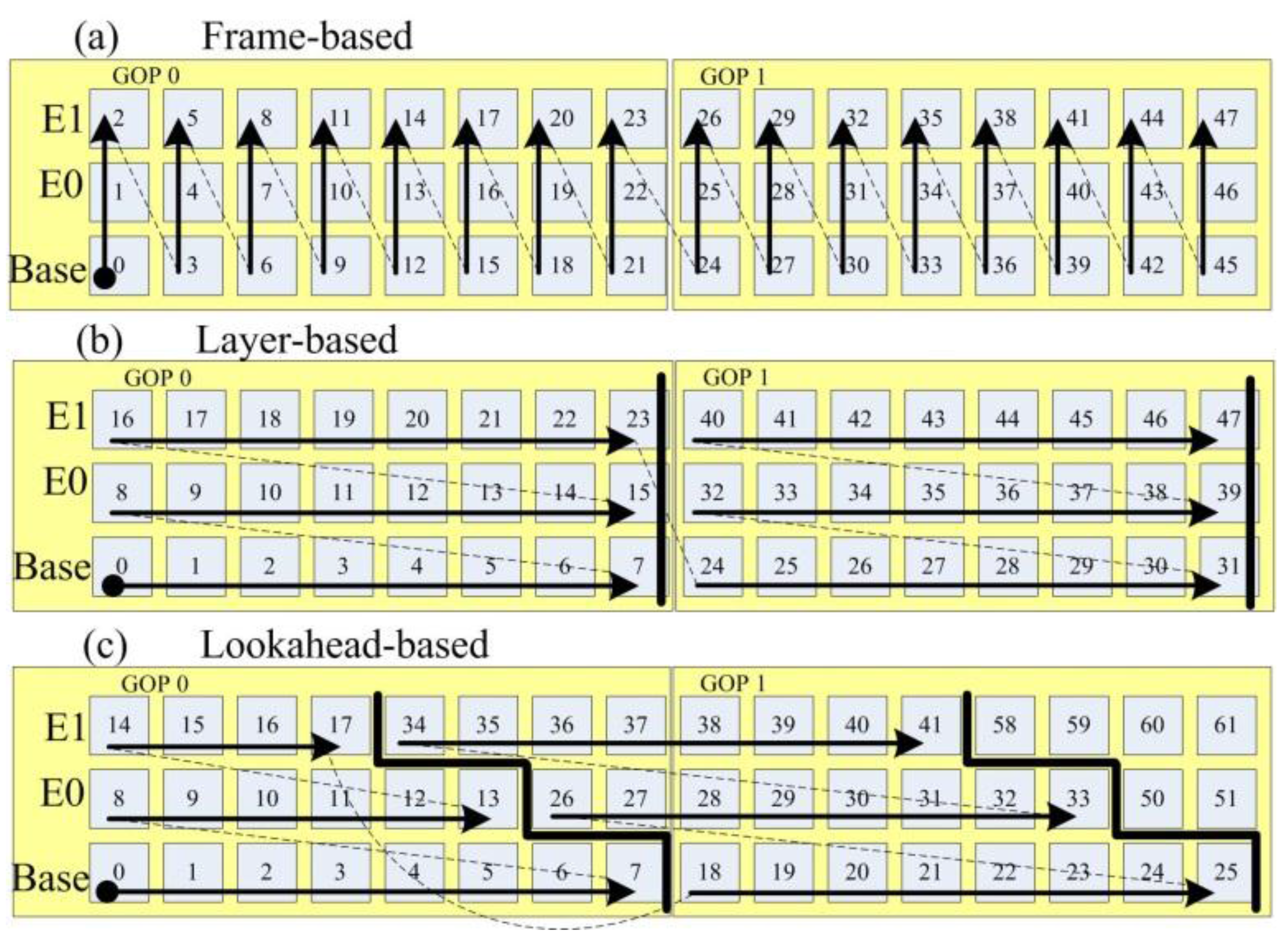
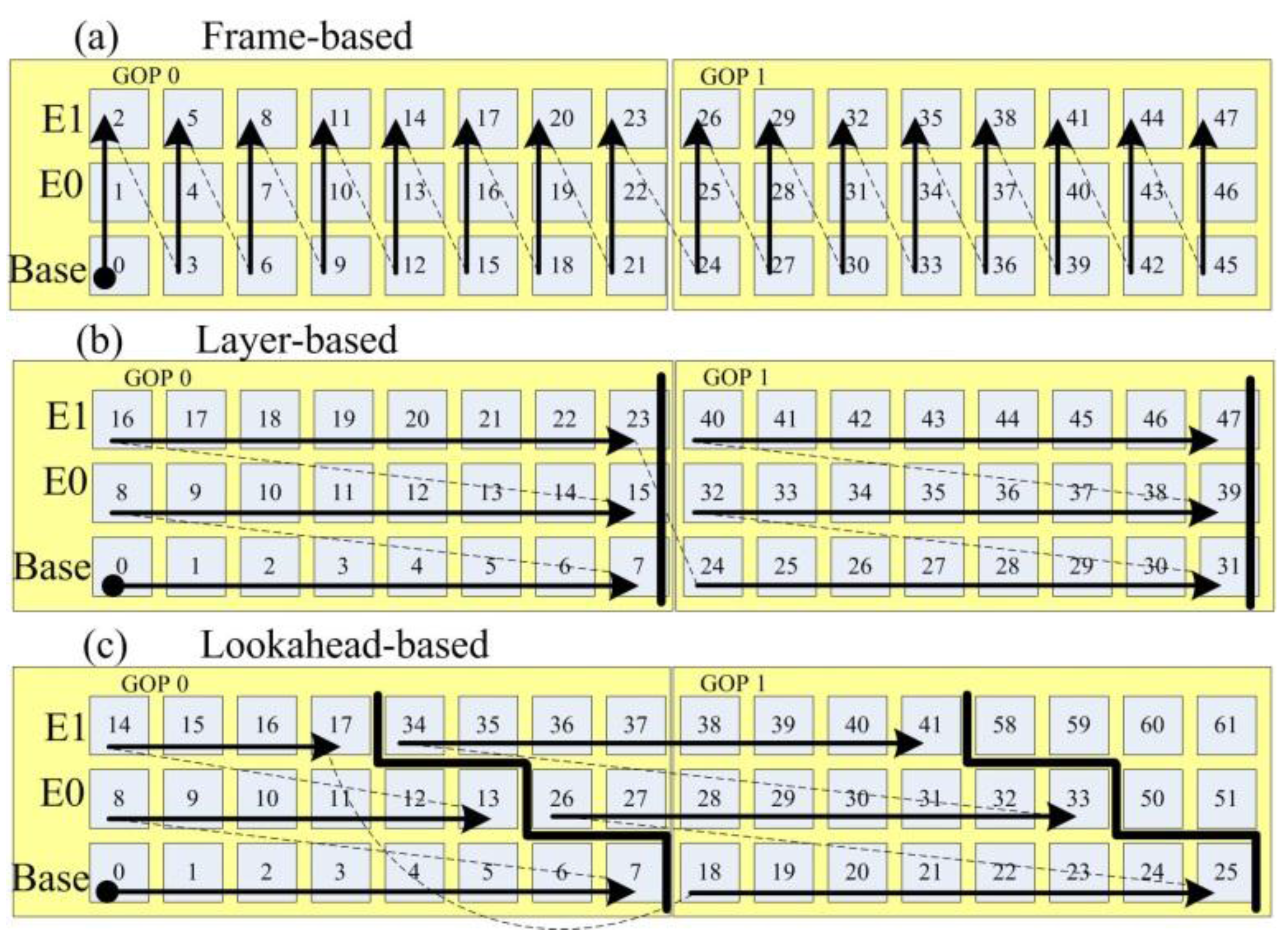
3.1. An Overview of the LASA Scheduling Algorithm
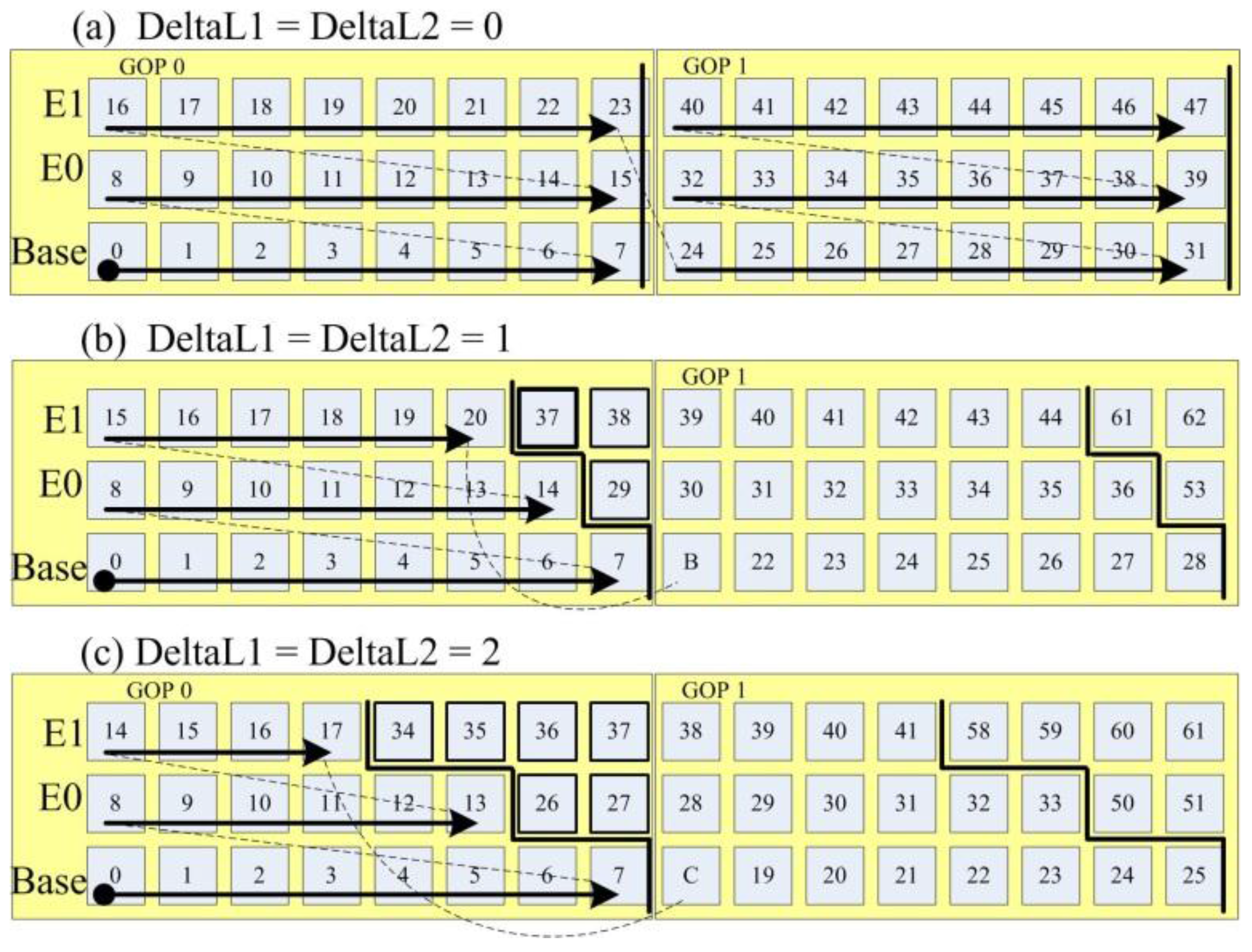
3.2. LASA Scheduling Algorithm and Its Look-Ahead Limit
| Algorithm 1. The pseudocode of the LASA scheduling algorithm. |
LASA Algorithm: ----------------------------------------------Inintial Section------------------------------------------ - initialize LookAhead of Base layer (0th) to MaxLookAhead - initialize LookAhead of Enhancement layer i (ith) to MaxLookAhead- , where i is top layer. - initialize current upper bound of layer ith to LookAhead of layer ith - initialize current NAL Unit index of layer ith to 0 --------------------------------------------Main Section---------------------------------------------- While (NOT All Layers Reach End Of Frame Sequence) For each layer i = 0th to Top Layer While (current NAL Unit index of layer ith <= current upper bound of layer ith AND current NAL Unit index of layer ith <= LastFrame ) - send current NAL Unit of layer ith - Increment current NAL unit index of layer ith EndWhile - set current upper bound of layer ith to current upper bound of ith + LookAhead of layer ith - set LookAhead of layer ith to MaxLookAhead EndFor EndWhile |
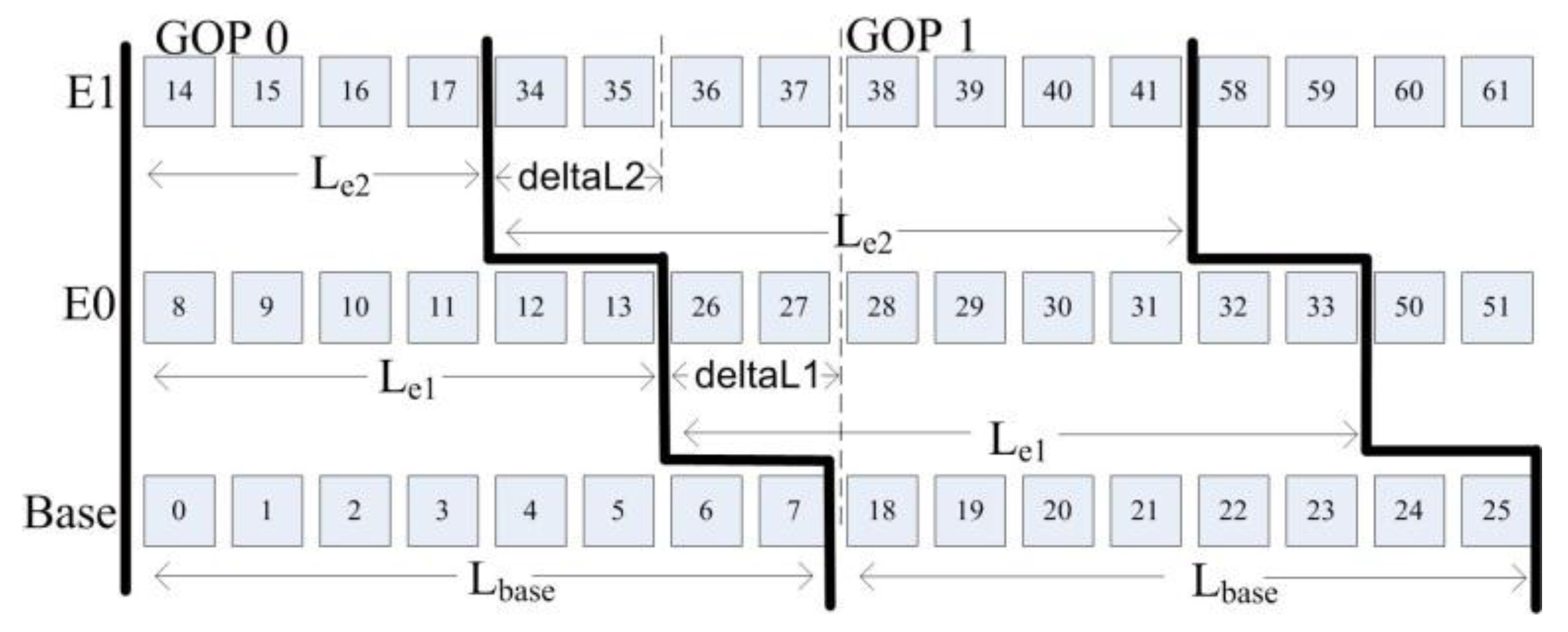
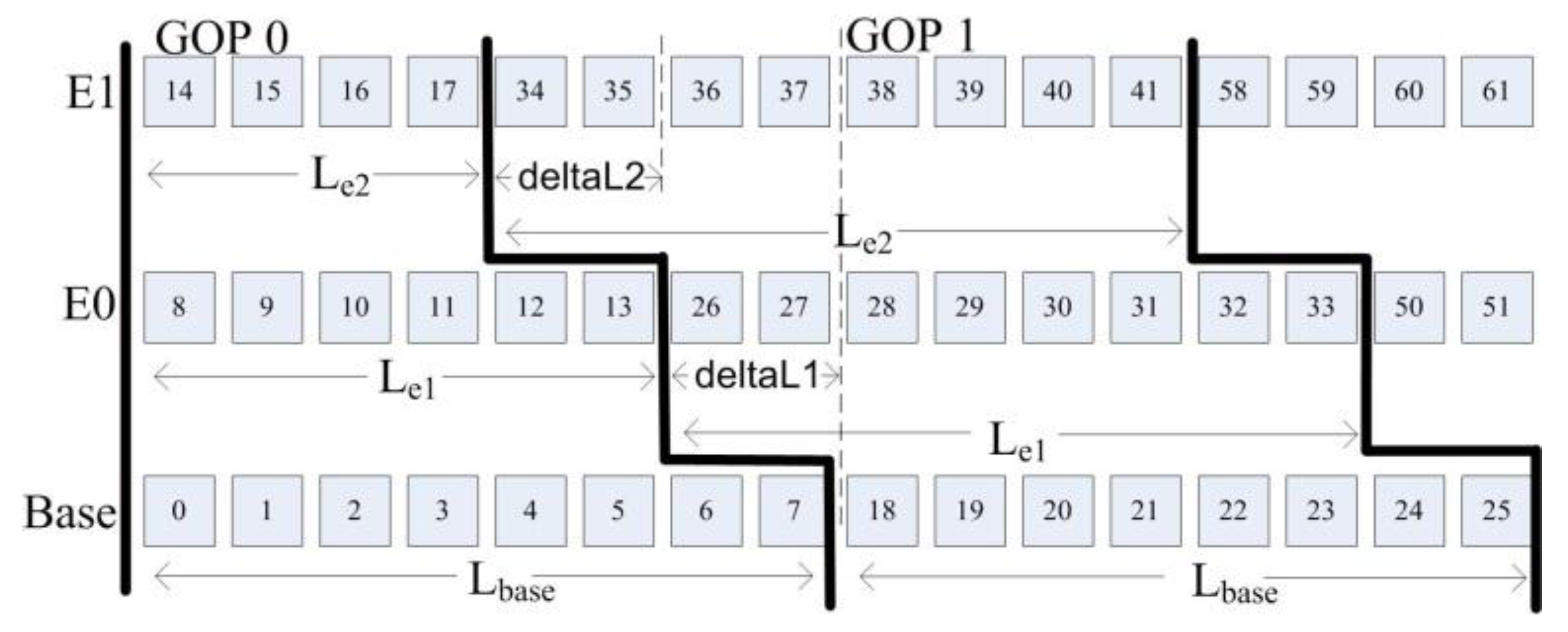
3.3. An Analysis of the LASA Scheduling Algorithm
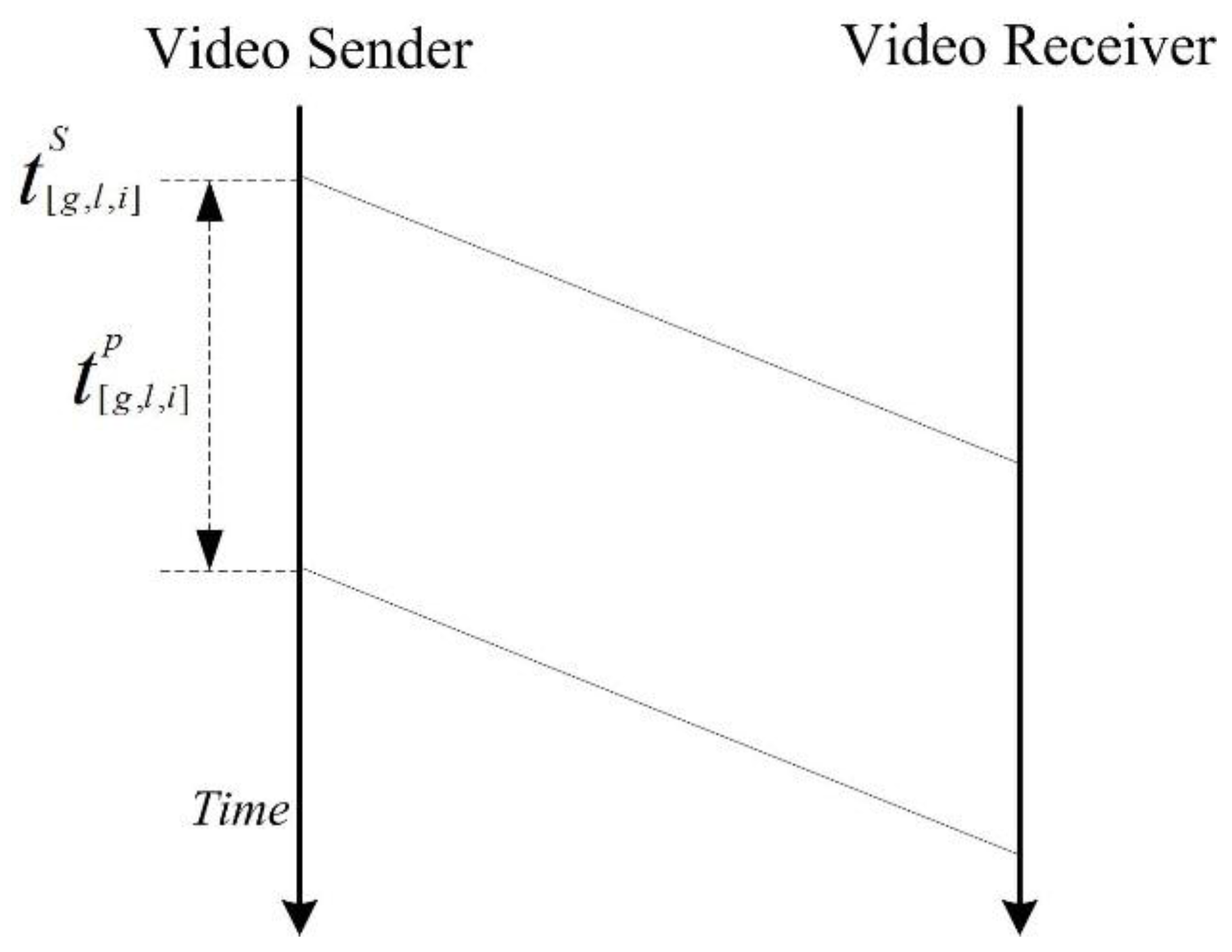
Mathematical Analysis
- is the time when layer-based scheduling starts sending a NAL unit where
- is a group of pictures number,
- is the layer number,
- is the sending order of frames, .
- is the time when LASA starts sending the first bit of the NAL unit
- is the time spent between the beginning of the first bit and the end of a NAL unit
- is the number of layers, so
- is GOP size, so
- is the time when LASA starts sending NAL unit B.
- is the time when the layer-based scheduling algorithm starts sending NAL unit B.
- are the times spent for sending NAL units 29, 37 and 38, respectively.
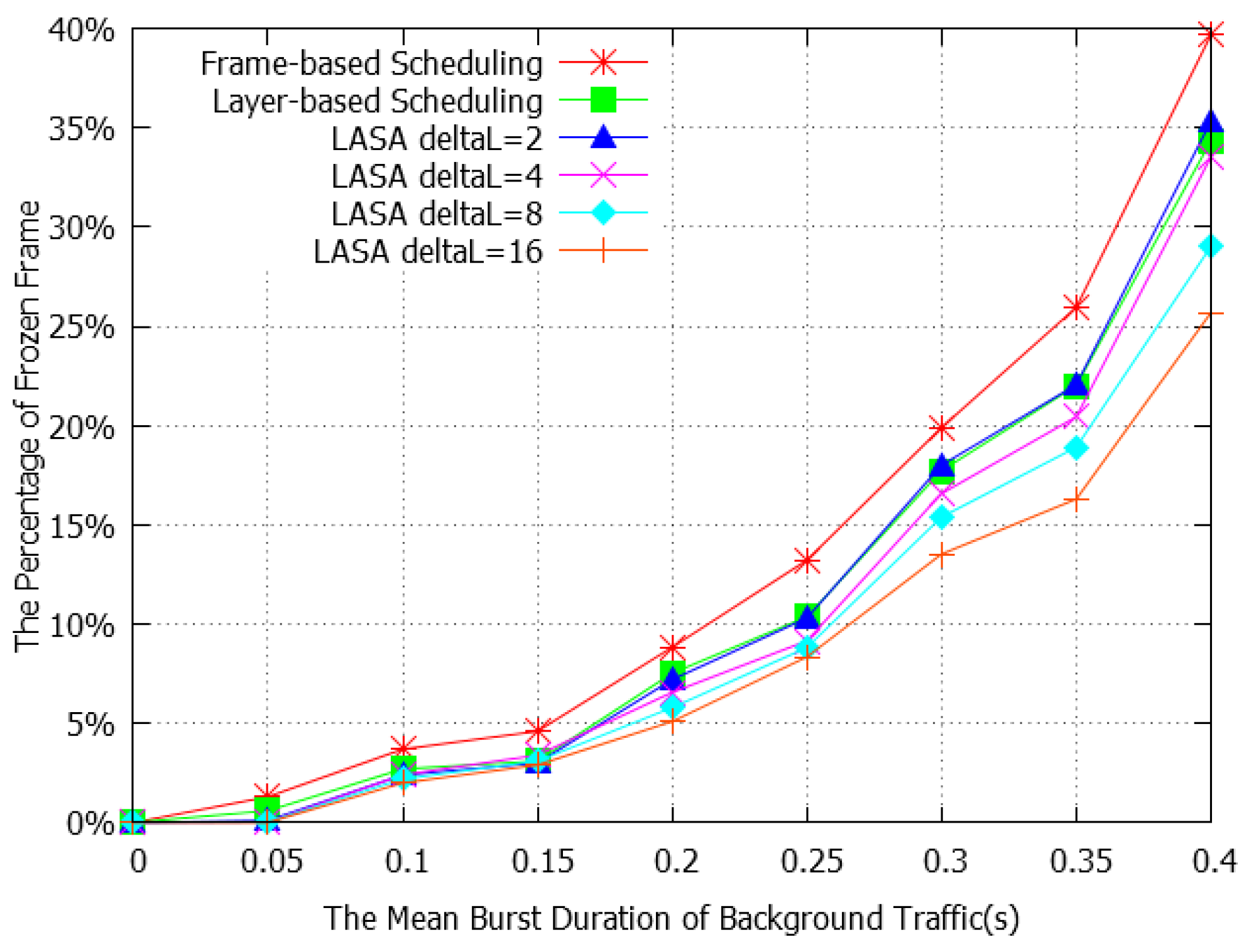
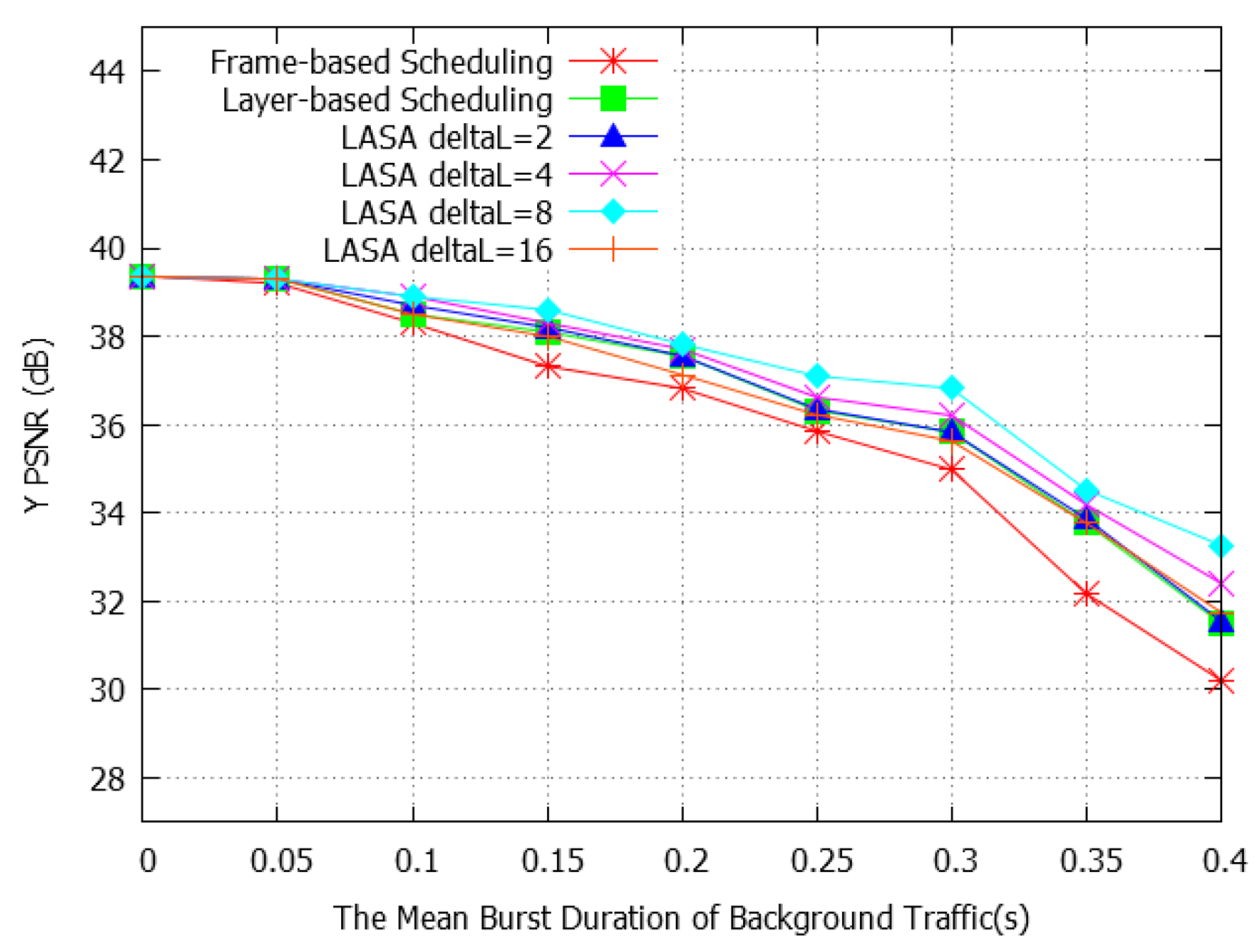
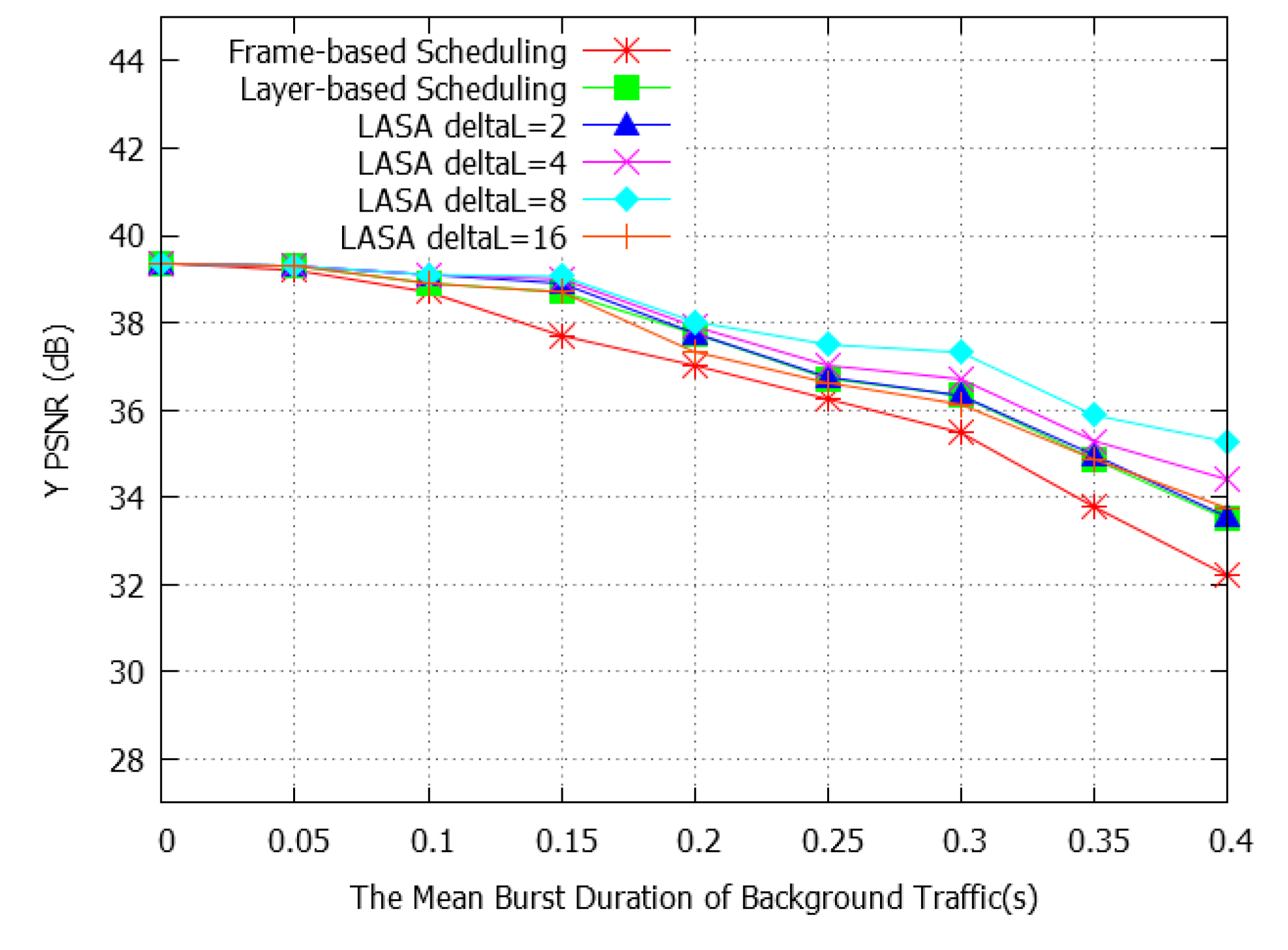
4. Simulation Results
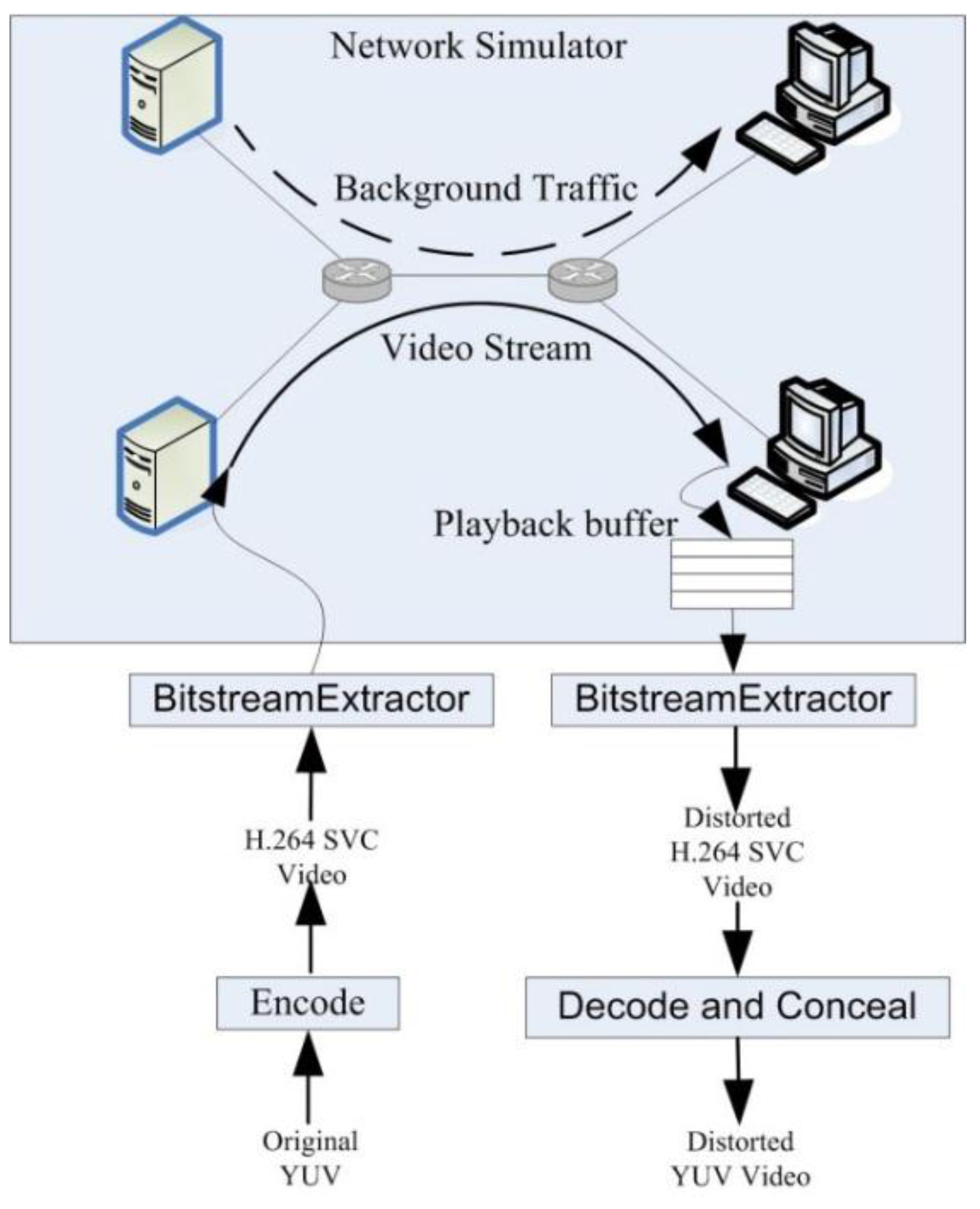
4.1. Simulation Setup
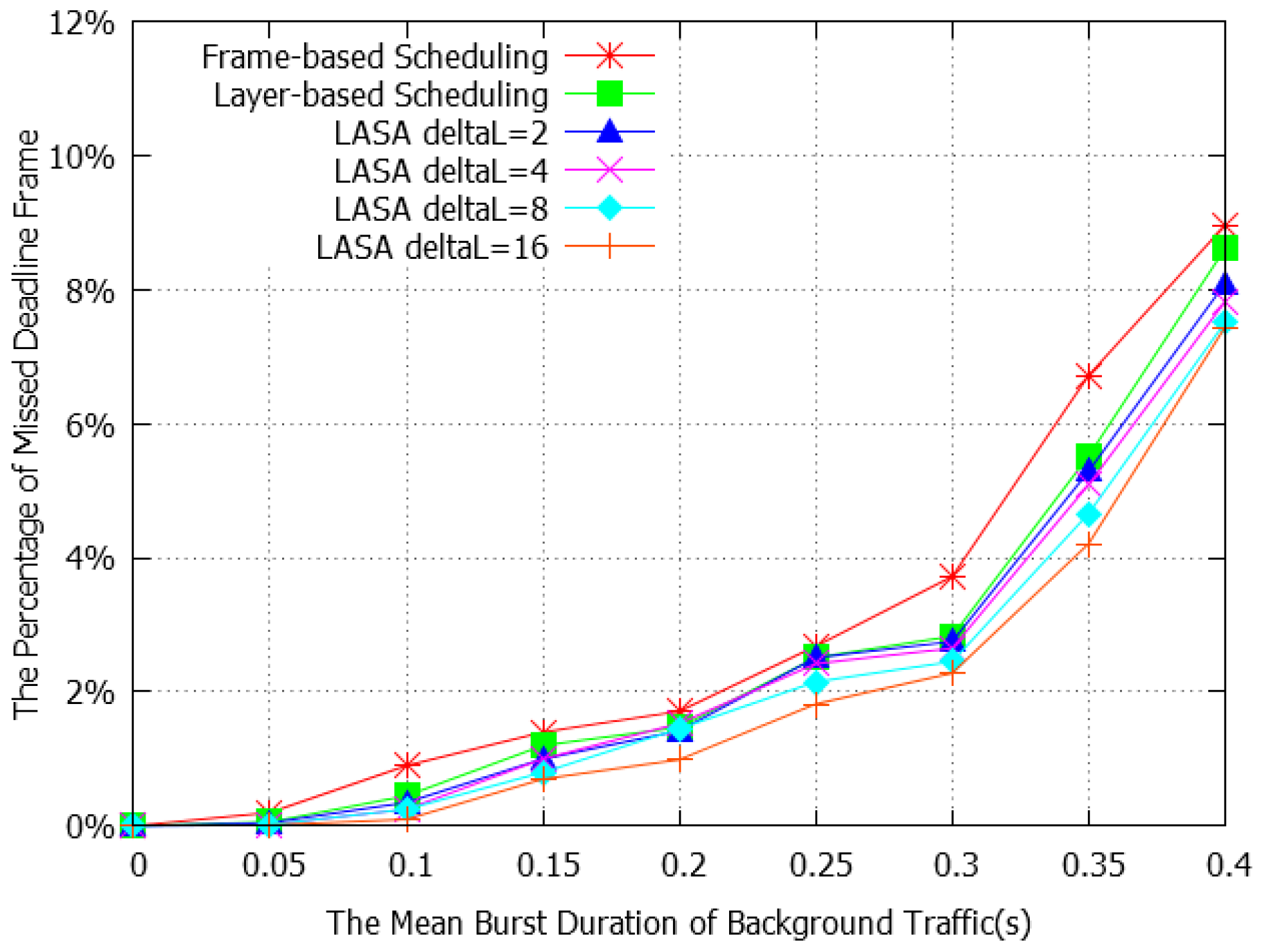
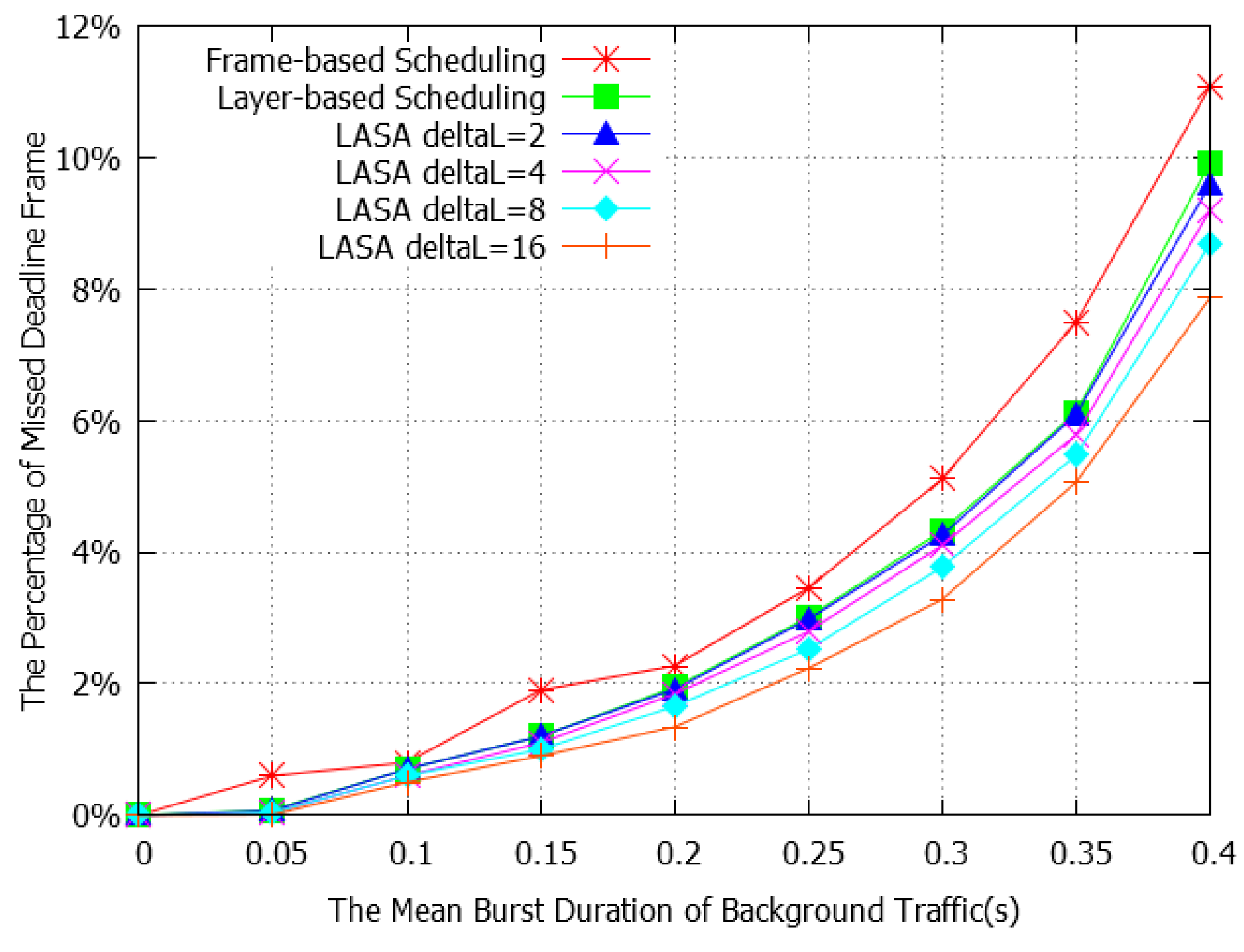
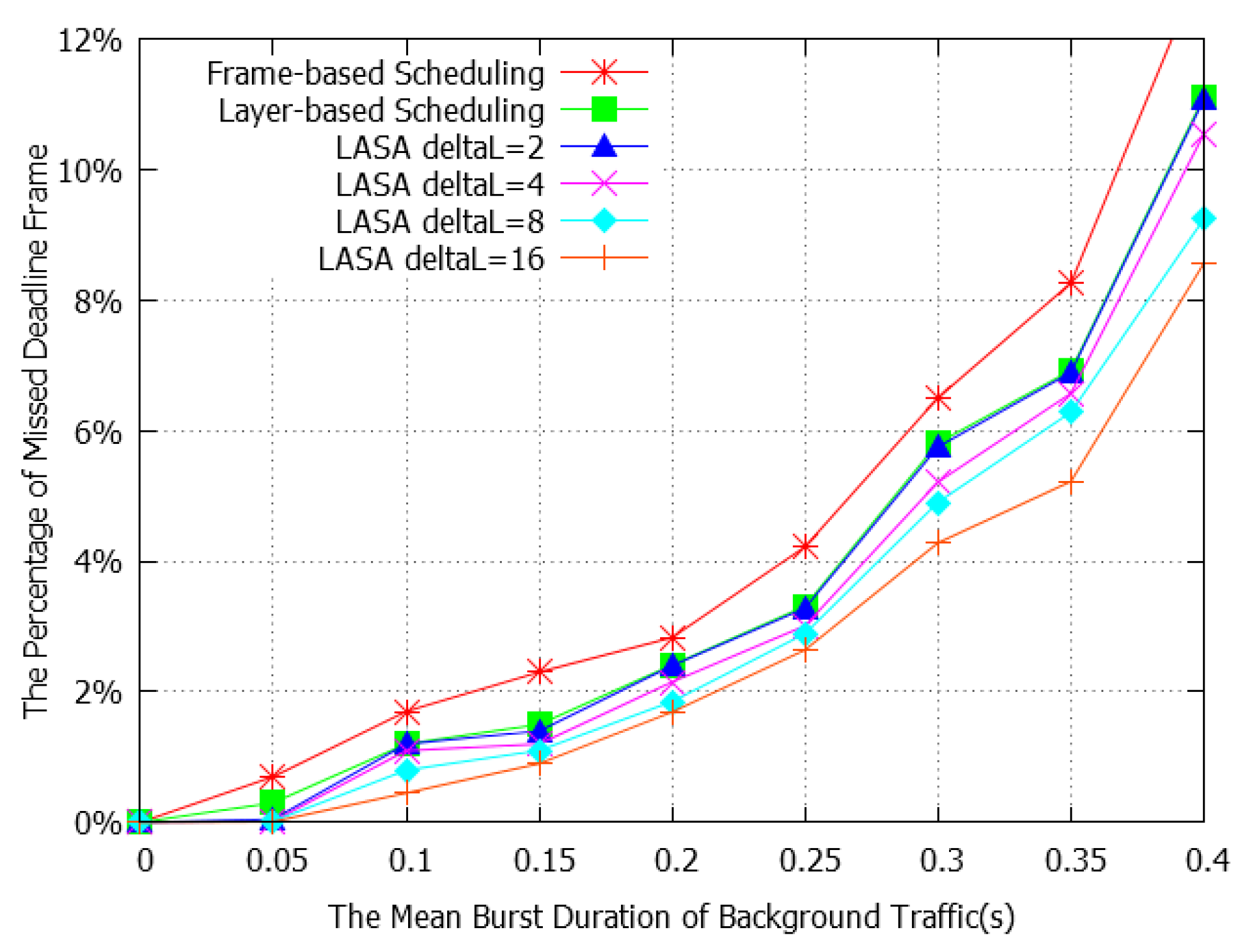
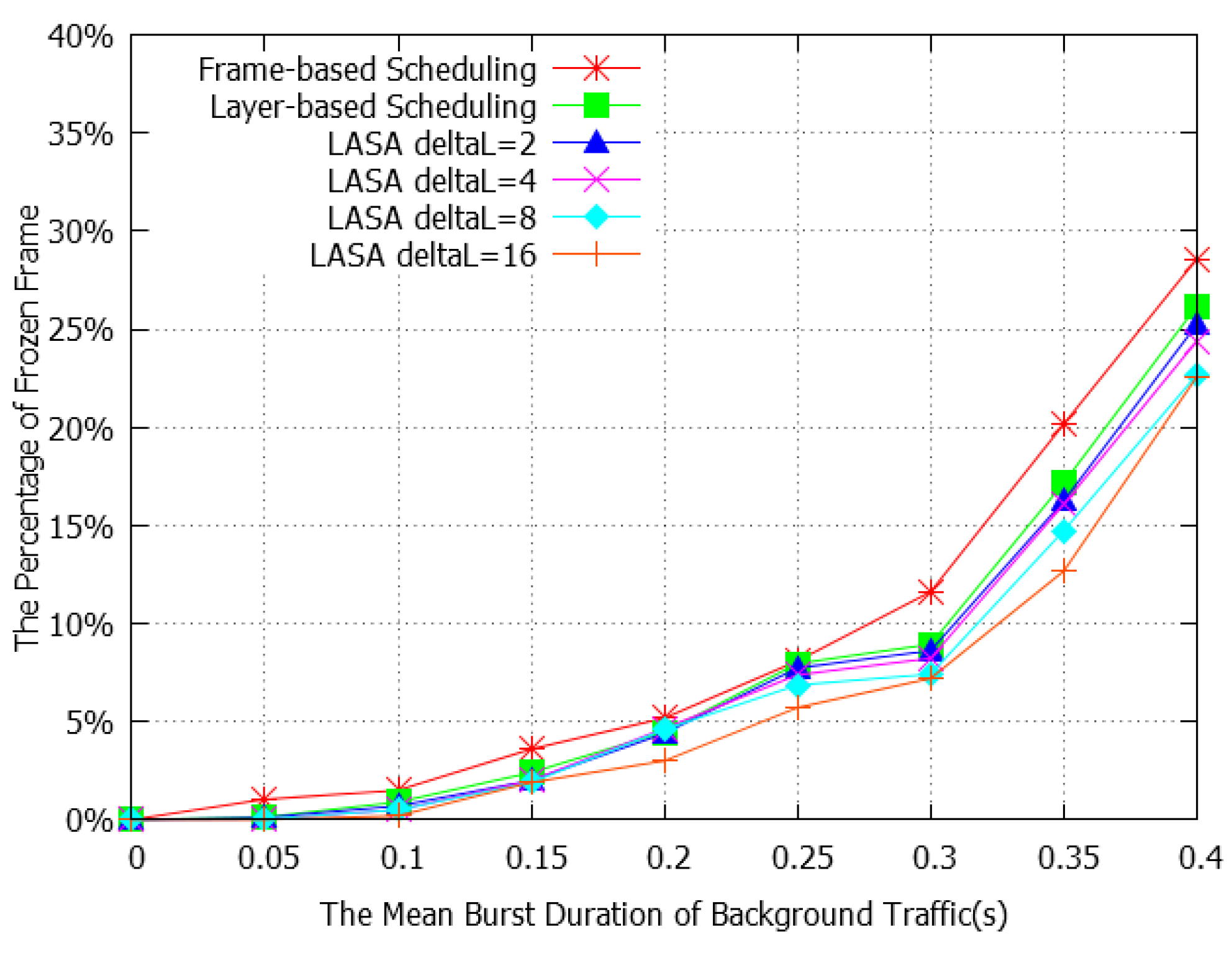
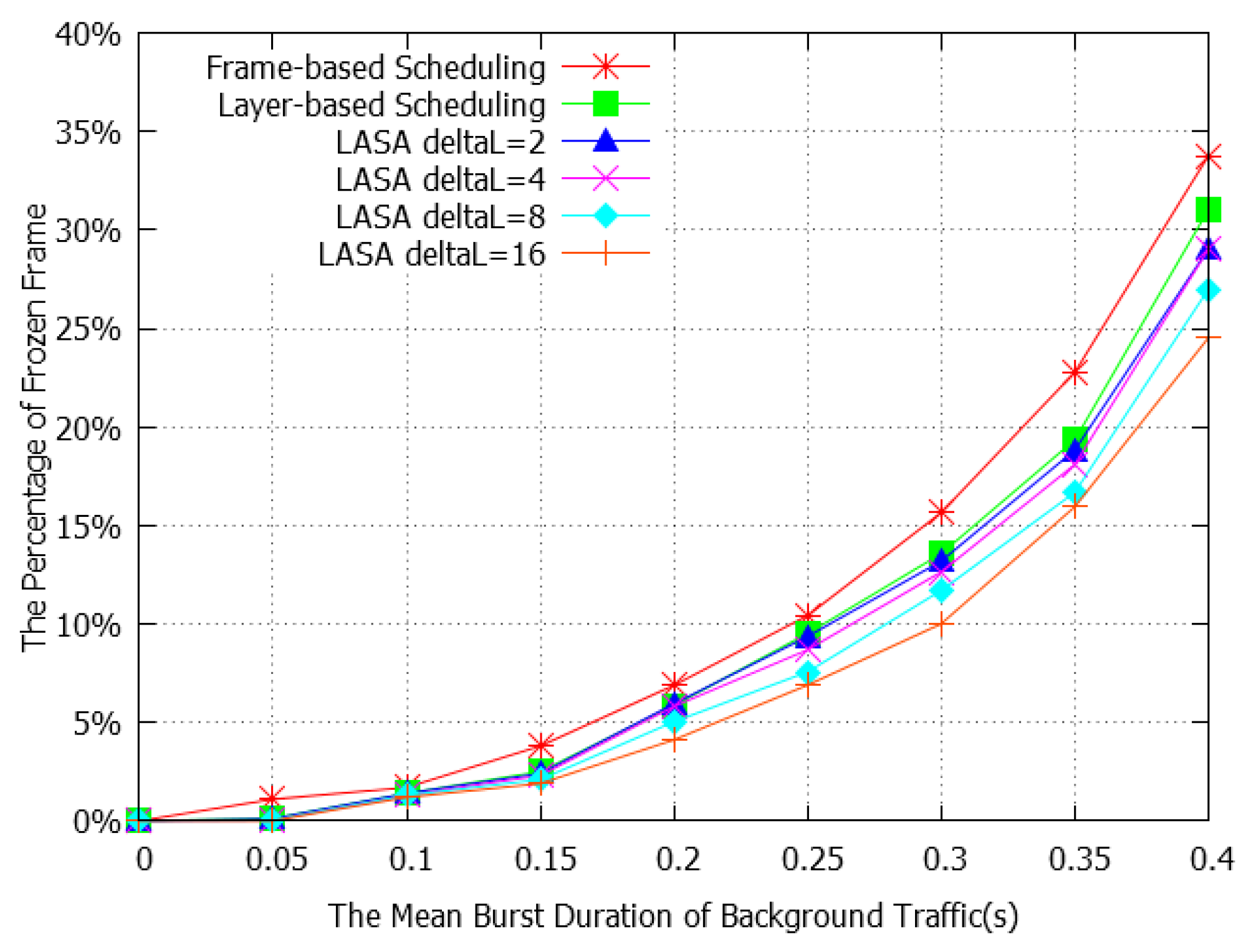
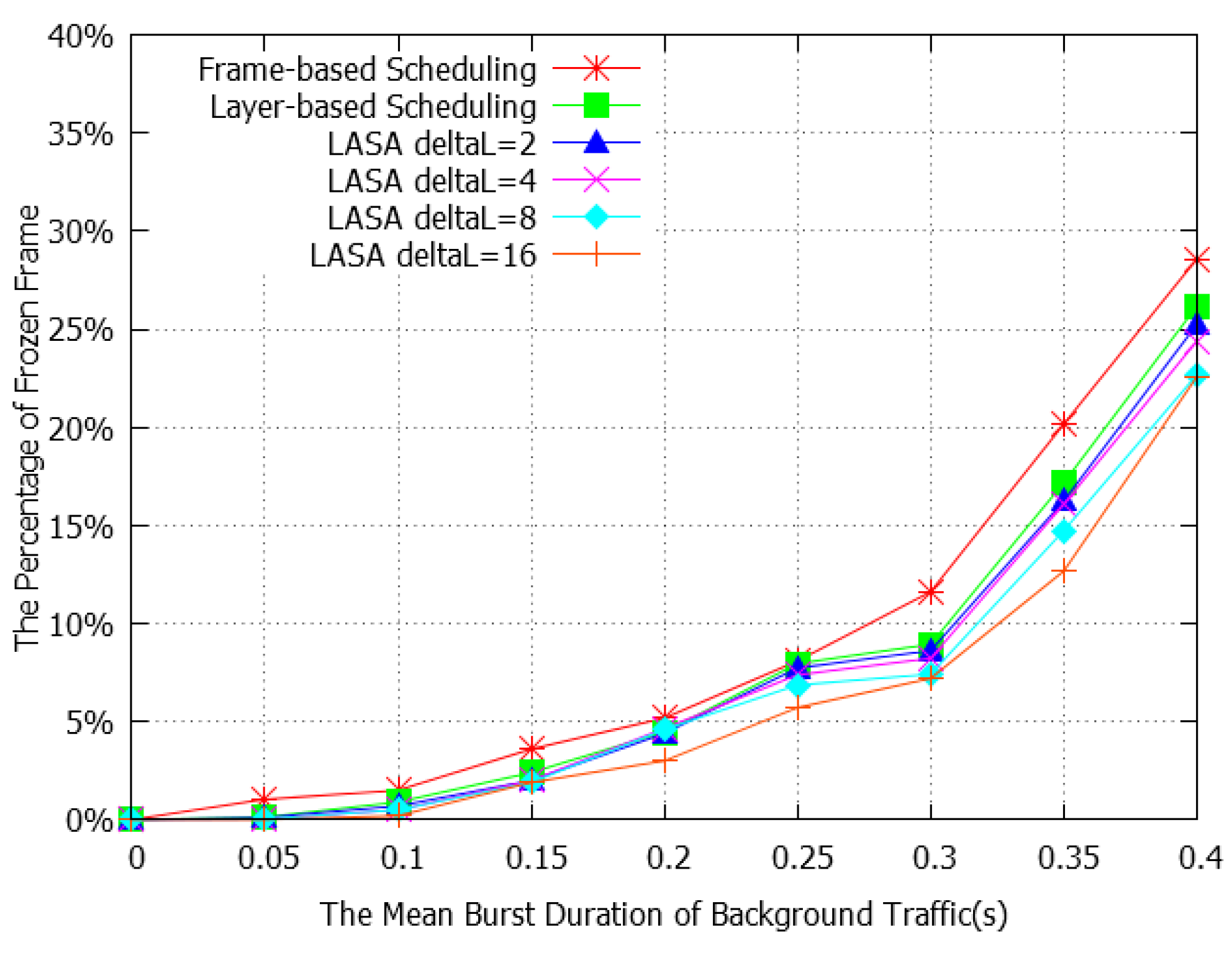
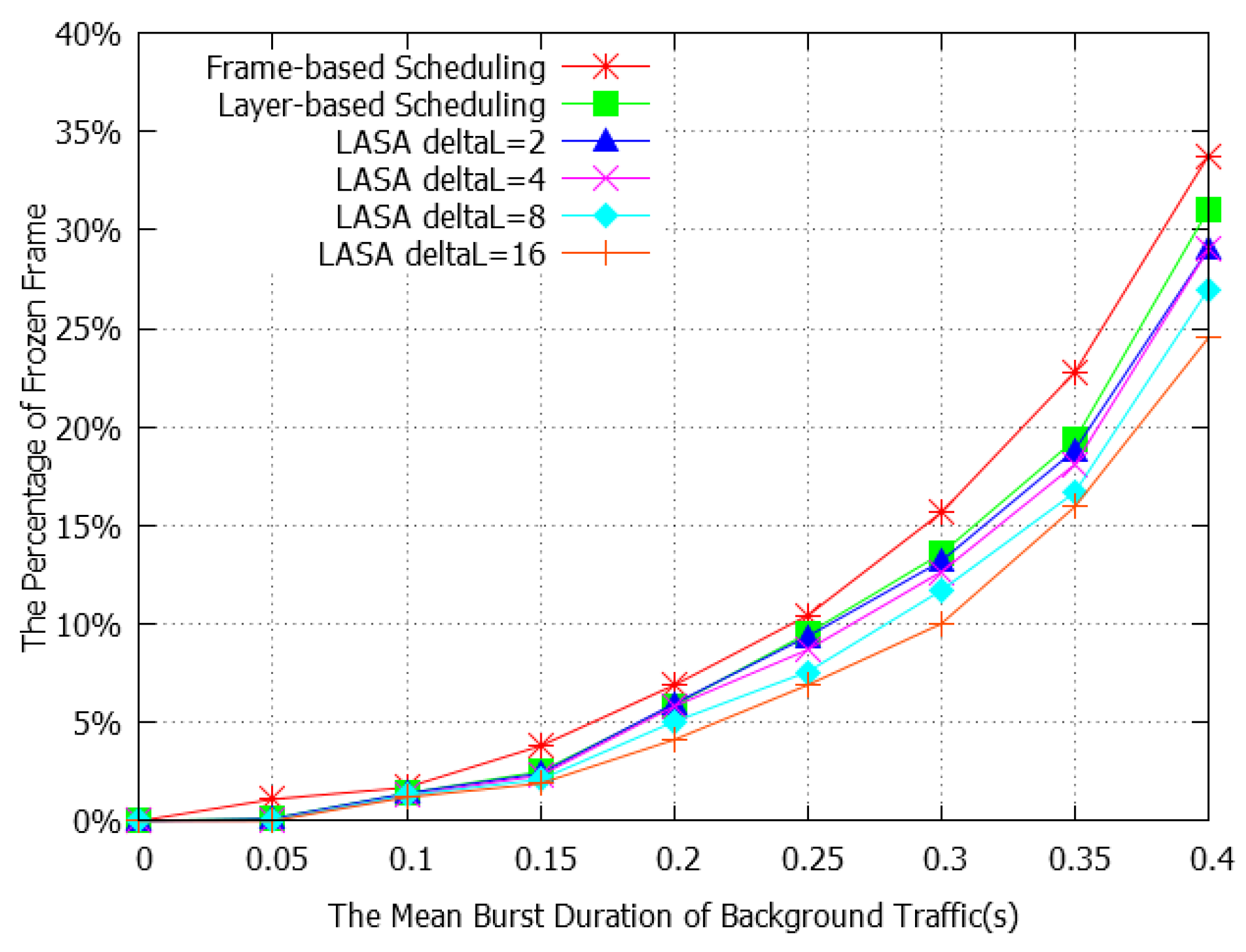
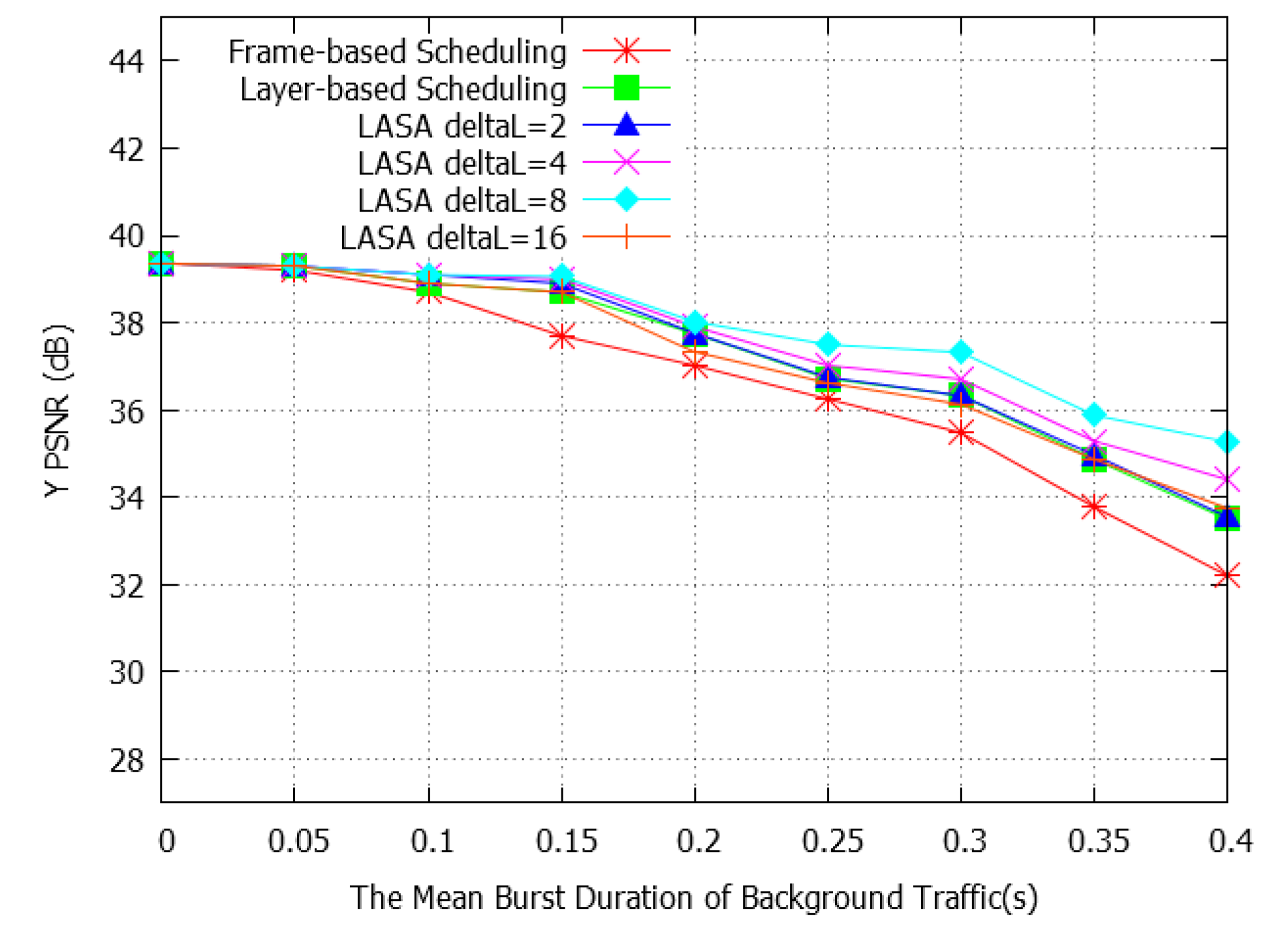
4.2. Performance Evaluation
5. Conclusions and Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| LASA | Look Ahead Scheduling Algorithm |
| NAL | Network Abstraction Layer |
| SVC | Scalable Video Coding |
| PSNR | Peek Signal-to-Noise Ratio |
| FEC | Forward Error Correction |
References
- ITU-T. Analysis, Measurement and Modelling of Jitter. In ITU-T Delayed Contribution COM 12—D98; ITU-T: Geneva, Switzerland, 2003. [Google Scholar]
- Bertsekas, D.; Gallager, R. Data Networks, 2nd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1992; p. 556. [Google Scholar]
- Venkataraman, M.; Chatterjee, M. Quantifying video-qoe degradations of internet links. IEEE/ACM Trans. Netw. 2012, 20, 396–407. [Google Scholar] [CrossRef]
- ITU-T. Perceptual Video Quality Measurement Techniques for Digital Cable Television in the Presence of a Reduced Reference. In Recommendation ITU-T J.249; ITU-T: Geneva, Switzerland, 2010. [Google Scholar]
- Kyungtae, K.; Jeon, W.J. Differentiated protection of video layers to improve perceived quality. IEEE Trans. Mob. Computing 2012, 11, 292–304. [Google Scholar] [CrossRef]
- Schwarz, H.; Marpe, D.; Wiegand, T. Overview of the scalable video coding extension of the h.264/avc standard. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1103–1120. [Google Scholar] [CrossRef]
- Palawan, A.; Woods, J.; Ghanbari, M. A jitter-tolerant scheduling algorithm to improve continuity in scalable video streaming. In Proceedings of the 2015 7th Computer Science and Electronic Engineering Conference (CEEC), Colchester, UK, 24–25 September 2015.
- Huynh-Thu, Q.; Ghanbari, M. Impact of jitter and jerkiness on perceived video quality. In Proceedings of the Workshop on Video Processing and Quality Metrics, Scottsdale, AZ, USA, 1–4 January 2006.
- Huynh-Thu, Q.; Ghanbari, M. Temporal aspect of perceived quality in mobile video broadcasting. IEEE Trans. Broadcast. 2008, 54, 641–651. [Google Scholar] [CrossRef]
- Claypool, M.; Tanner, J. The effects of jitter on the peceptual quality of video. In Proceedings of the seventh ACM international conference on Multimedia (Part 2), Orlando, FL, USA, 30 October 1999; pp. 115–118.
- Su, Y.-F.; Yang, Y.-H.; Lu, M.-T.; Chen, H.H. Smooth control of adaptive media playout for video streaming. Trans. Multi. 2009, 11, 1331–1339. [Google Scholar]
- Kalman, M.; Steinbach, E.; Girod, B. Adaptive media playout for low-delay video streaming over error-prone channels. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 841–851. [Google Scholar] [CrossRef]
- Liang, G.; Liang, B. Balancing interruption frequency and buffering penalties in vbr video streaming. In Proceedigns of the 2007 26th IEEE International Conference on Computer Communications, IEEE INFOCOM, Anchorage, AK, USA, 6–12 May 2007; pp. 1406–1414.
- Choi, H.; Kang, J.; Kim, J.-G. Dynamic and interoperable adaptation of SVC for QoS-enabled streaming. IEEE Trans. Consum. Electron. 2007, 53, 384–389. [Google Scholar] [CrossRef]
- Wien, M.; Cazoulat, R.; Graffunder, A.; Hutter, A.; Amon, P. Real-time system for adaptive video streaming based on SVC. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1227–1237. [Google Scholar] [CrossRef]
- Lee, H.; Lee, Y.; Lee, J.; Lee, D.; Shin, H. Design of a mobile video streaming system using adaptive spatial resolution control. IEEE Trans. Consum. Electron. 2009, 55, 1682–1689. [Google Scholar] [CrossRef]
- Kim, D.; Chung, K. A network-aware quality adaptation scheme for device collaboration service in home networks. IEEE Trans. Consum. Electron. 2012, 58, 374–381. [Google Scholar] [CrossRef]
- Chaurasia, A.K.; Jagannatham, A.K. Dynamic parallel tcp for scalable video streaming over mimo wireless networks. In Procedings of the 2013 6th Joint IFIP, Wireless and Mobile Networking Conference (WMNC), Dubai, United Arab Emirates, 23–25 April 2013; pp. 1–6.
- Radhakrishnan, R.; Nayak, A. An efficient video adaptation scheme for svc transport over lte networks. In Proceedings of the 2011 IEEE 17th International Conference on Parallel and Distributed Systems (ICPADS), Tainan, Taiwan, 7–9 December 2011; pp. 127–133.
- Maani, E.; Yijing, L.; Pahalawatta, P.; Katsaggelos, A. Packet scheduling for scalable video streaming over lossy packet access networks. In Proceedings of 16th International Conference on Computer Communications and Networks, 2007, ICCCN 2007, Honolulu, HI, USA, 13–16 August 2007; pp. 591–596.
- Miao, Z.; Ortega, A. Optimal scheduling for streaming of scalable media. In Proceedigns of the 2000 Conference Record of the Thirty-Fourth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 29 October–1 November 2000; Volume 1352, pp. 1357–1362.
- Chou, P.A.; Zhourong, M. Rate-distortion optimized streaming of packetized media. IEEE Trans. Multimedia 2006, 8, 390–404. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, J.; Song, J.; Argyriou, A. Scalable 3d video streaming over p2p networks with playback length changeable chunk segmentation. J. Visual Commun. Image Represent. 2015, 31, 41–53. [Google Scholar] [CrossRef]
- Seo, H.; Lee, K. Effective scalable video streaming transmission with TBS algorithm in an MC-CDMA system. Inf. Syst. 2015, 48, 313–319. [Google Scholar] [CrossRef]
- Liu, Z.; Qiao, Y.; Karunakar, A.K.; Lee, B.; Fallon, E.; Zhang, C.; Zhang, S. H. 264/mvc interleaving for real-time multiview video streaming. J. Real-Time Image Process. 2015, 10, 501–511. [Google Scholar] [CrossRef]
- Jurca, D.; Frossard, P. Video packet selection and scheduling for multipath streaming. IEEE Trans. Multimedia 2007, 9, 629–641. [Google Scholar] [CrossRef]
- De Vleeschouwer, C.; Frossard, P. Dependent packet transmission policies in rate-distortion optimized media scheduling. IEEE Trans. Multimedia 2007, 9, 1241–1258. [Google Scholar] [CrossRef]
- Hellge, C.; Gomez-Barquero, D.; Schierl, T.; Wiegand, T. Layer-aware forward error correction for mobile broadcast of layered media. IEEE Trans. Multimedia 2011, 13, 551–562. [Google Scholar] [CrossRef]
- Kuo, W.H.; Kaliski, R.; Wei, H.Y. A qoe-based link adaptation scheme for H.264/SVC video multicast over IEEE 802.11. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 812–826. [Google Scholar] [CrossRef]
- JVT. Iso/iec 14496–10 amd.3 Scalable Video Coding. In Doc. JVT-X201; ITU-T: Geneva, Switzerland, 2007. [Google Scholar]
- Blestel, M.; Raulet, M. Open SVC decoder: A flexible SVC library. In Proceedings of the international conference on Multimedia, Firenze, Italy, 8–10 October 2010; pp. 1463–1466.
- Pescador, F.; Samper, D.; Raulet, M.; Juarez, E.; Sanz, C. A DSP based H.264/SVC decoder for a multimedia terminal. In Proceedigns of the 2011 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 9–12 January 2011; pp. 401–402.
- Cho, Y.; Kwon, D.K.; Liu, J.; Kuo, C.J. Dependent r/d modeling techniques and joint t-q layer bit allocation for H.264/SVC. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1003–1015. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Threshold | deltaL = 2 | deltaL = 4 | deltaL = 8 | deltaL = 16 |
|---|---|---|---|---|
| 400 ms | −0.03 | −0.42 | −0.88 | −1.43 |
| 500 ms | −0.01 | −0.32 | −0.64 | −1.11 |
| 600 ms | −0.18 | −0.29 | −0.54 | −0.84 |
| Average | −0.07 | −0.34 | −0.69 | −1.13 |
| Threshold | deltaL = 2 | deltaL = 4 | deltaL = 8 | deltaL = 16 |
|---|---|---|---|---|
| 400 ms | 0.18 | −1.14 | −2.81 | −4.60 |
| 500 ms | −0.59 | −1.01 | −2.27 | −3.56 |
| 600 ms | −0.50 | −0.80 | −1.69 | −2.71 |
| Average | −0.30 | −0.98 | −2.25 | −3.63 |
| Threshold | deltaL = 2 | deltaL = 4 | deltaL = 8 | deltaL = 16 |
|---|---|---|---|---|
| 400 ms | 0.04 | 0.44 | 0.92 | −0.09 |
| 500 ms | 0.04 | 0.43 | 0.96 | −0.09 |
| 600 ms | 0.06 | 0.37 | 0.69 | −0.09 |
| Average | 0.05 | 0.41 | 0.86 | −0.09 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palawan, A.; Woods, J.C.; Ghanbari, M. Continuity-Aware Scheduling Algorithm for Scalable Video Streaming. Computers 2016, 5, 11. https://doi.org/10.3390/computers5020011
Palawan A, Woods JC, Ghanbari M. Continuity-Aware Scheduling Algorithm for Scalable Video Streaming. Computers. 2016; 5(2):11. https://doi.org/10.3390/computers5020011
Chicago/Turabian StylePalawan, Atinat, John C. Woods, and Mohammed Ghanbari. 2016. "Continuity-Aware Scheduling Algorithm for Scalable Video Streaming" Computers 5, no. 2: 11. https://doi.org/10.3390/computers5020011
APA StylePalawan, A., Woods, J. C., & Ghanbari, M. (2016). Continuity-Aware Scheduling Algorithm for Scalable Video Streaming. Computers, 5(2), 11. https://doi.org/10.3390/computers5020011