1. Introduction
The ever increasing digitization of industries and the rise of data-centric technologies have led to an unprecedented demand for secure and privacy-preserving machine learning methodologies. Among these, deep federated learning (DFL) has gained significant traction as an approach that enables distributed clients to collaboratively train machine learning models while keeping sensitive data localized [
1]. By eliminating the need to transfer raw data to a centralized server, DFL inherently addresses some privacy concerns associated with traditional machine learning. However, the decentralized nature of DFL introduces unique security vulnerabilities and operational challenges, especially in environments characterized by untrusted participants [
2]. These challenges are further exacerbated by stringent data privacy regulations, such as the General Data Protection Regulation (GDPR).
The GDPR, which governs the processing of personal data throughout the European Union, has established a global benchmark for data privacy and protection. It requires organizations to implement robust technical and organizational measures to ensure the confidentiality, integrity, and availability of personal data [
3]. FL, although promising in its ability to distribute computations while safeguarding data, does not inherently meet the comprehensive requirements of GDPR. Issues such as exposure to adversarial attacks, model inversion, poisoning, and unauthorized access can compromise the privacy and security guarantees of FL, potentially leading to regulatory non-compliance [
4].
Moreover, traditional trust-based security models in DFL rely heavily on pre-established trust between participants, which is impractical in environments involving diverse and potentially malicious entities. This creates a critical need for a more robust and dynamic security paradigm capable of addressing the inherent vulnerabilities of DFL systems. ZTA has emerged as a revolutionary concept in cybersecurity, designed to address security challenges in highly distributed and heterogeneous environments. Unlike traditional security approaches, ZTA operates on the principle ’never trust, always verify’, emphasizing continuous monitoring, strict access control, and the principle of least privilege to ensure that no entity is inherently trusted, inside or outside the network.
Despite the growing adoption of ZTA in enterprise environments, its integration with FL remains largely unexplored. Existing research has focused mainly on applying differential privacy, encryption, and secure multiparty computation to enhance FL’s privacy guarantees [
5]. Although these techniques are critical, they often operate in isolation and do not address the broader security landscape required to protect against modern threats. Furthermore, these mechanisms do not align fully with GDPR’s emphasis on accountability, security by design, and granular data protection measures. Therefore, a significant gap in designing a holistic FL framework that integrates ZT principles to enhance security while ensuring GDPR compliance.
1.1. Deep Federated Learning
FL is a distributed machine learning approach in which data remain on local devices and only model updates, such as gradients or model weights, are sent to a central server [
6]. This decentralized paradigm addresses privacy concerns by ensuring that sensitive data never leave the local device, making it particularly well suited for applications involving personal or confidential information, such as healthcare, finance and IoT [
7]. However, a key limitation of traditional FL is its reliance on shallow models, which may struggle to capture complex patterns within high-dimensional large-scale data [
5]. In FL, the decentralized nature of the data introduces additional complexities [
8].
To overcome this limitation, DFL integrates the capabilities of Deep Learning (DL) with the FL framework. In DFL, deep neural networks are trained collaboratively across multiple edge devices or clients, leveraging the power of advanced deep learning techniques, such as hierarchical feature representations, automatic feature extraction, and high precision while maintaining the privacy of user data [
9]. In a typical DFL setup, local devices train deep models on their own data, and only the model parameters or updates are shared with the central server, ensuring that raw data never leaves the local device and effectively mitigating privacy risks [
10].
Although DFL improves FL flexibility and performance by using more sophisticated models, it also introduces several challenges, particularly in terms of data heterogeneity, model robustness, and security. The diversity in data distributions between different clients can lead to inefficiencies in the model-training process, since models between perform well on some clients but poorly on others. Moreover, deeper models are more susceptible to adversarial attacks and model inversion techniques, where attackers may exploit model updates to extract sensitive information about the training data. Furthermore, incorporating deep neural networks into FL increases the communication overhead, as updates from larger models require more bandwidth, thereby prolonging the time needed for model convergence.
These challenges underscore the need for a more robust security framework to protect both the data and the learning process. Existing FL protocols focus mainly on mitigating risks such as data leakage and model poisoning through techniques such as differential privacy and secure multiparty computation. However, these methods often fail to address the full spectrum of security concerns that arise in distributed systems, particularly in environments that are dynamic and untrusted.
In the context of DFL, a shared global model is collaboratively learned by multiple devices, such as smartphones or IoT devices, that hold local models without disclosing sensitive data. The central server coordinates communication and aggregates the updates of the model from the devices, allowing the training of complex models on vast, distributed datasets without compromising data privacy [
11]. The architecture of DFL, illustrated in
Figure 1, demonstrates this collaborative approach to model training on diverse, decentralized devices.
1.2. Zero Trust Architecture
The concept of ZTA has emerged as a paradigm-shifting approach to cybersecurity. Unlike traditional security models that rely on perimeter-based defenses (trusting internal network traffic and users), ZT operates under the assumption that every entity inside or outside the network could be compromised [
12]. This approach requires continuous verification of all users, devices, and applications, enforcing strict access controls, authentication, and authorization mechanisms.
ZTA is built on the principle of ’never trust, always verify’, ensuring that all access requests, regardless of their origin, are validated and authenticated. The core tenets of ZTA include continuous monitoring, least privilege access, and strict policy enforcement [
13]. Fine-grained access controls are implemented where users and devices are only granted the minimum level of access necessary to perform their tasks. This significantly reduces the surface of the attack and mitigates the risks associated with insider threats and external breaches.
In a ZT environment, trust is not implicitly granted to users or devices within the perimeter. Instead, access is granted based on dynamic trust assessments that consider factors such as the user’s role, device health, location, and the sensitivity of the requested resource [
14]. Security decisions are made in real time, ensuring that unauthorized access is quickly identified and mitigated. ZTA also employs identity and access management (IAM) systems, multifactor authentication (MFA), and continuous validation through threat detection systems to maintain robust security across all levels of the infrastructure.
Unlike traditional security models that assume that everything inside an organization’s network is trustworthy, ZT assumes that there is no implicit trust given to assets or user accounts based solely on their physical network or location (i.e., local area networks versus the Internet) or based on asset ownership (enterprise or personal) [
13]. ZTA is a collection of services that are operated on-site or off-site through a cloud. These services are composed of a variety of logical components. NIST identifies three of these components as the core: the policy enforcement point (PEP), policy administrator (PA), and policy engine (PE), as illustrated in
Figure 2.
Applying ZT principles in the context of FL offers several advantages. Since FL operates in a distributed manner with various untrusted clients, integrating ZTA into the FL framework can help prevent unauthorized access to sensitive model parameters and data. ZT ensures that even if an attacker compromises one client or node, the attacker cannot easily access or manipulate the entire FL process. Furthermore, ZTA provides real-time monitoring and anomaly detection, which is essential in detecting and mitigating attacks such as model poisoning, backdoor attacks, and malicious data insertion.
By continuously verifying the integrity and trustworthiness of participants, the ZTA offers a robust security model that aligns well with the decentralized and untrusted nature of FL. Its integration can significantly enhance the privacy and security of DFL systems, providing a framework that safeguards sensitive information and ensures regulatory compliance, such as adherence to GDPR.
1.3. Contributions
We developed a DFL architecture that ensures robust data privacy and adheres to the stringent requirements established by the GDPR.
We used High-Level Petri Nets (HLPNs) as a formal modeling tool to verify the proposed architecture.
We evaluated the proposed system through a case study using the MNIST and CIFAR-10 datasets.
This paper is organized as follows.
Section 2 discusses the related work, focusing on the current state of the DFL and ZT security frameworks.
Section 3 provides a detailed explanation of the proposed architecture, its components, and their role in ensuring privacy and security.
Section 4 focuses on the formal verification of the proposed architecture using HLPNs.
Section 5 presents a real-world case study using the MNIST and CIFAR-10 dataset to evaluate the system’s performance and applicability.
Section 6 discusses the experimental results. Finally,
Section 7 concludes the paper and suggests future research directions.
| Algorithm 1: ZTA-based DFL. |
- 1:
Input: Clients N, epochs E, privacy parameter , dataset - 2:
Output: Global model , Blockchain Phase I: Initialization - 3:
Initialize blockchain , global model - 4:
Load and split dataset Phase II: Training - 5:
for to E do - 6:
Initialize weight set - 7:
for to N do - 8:
Train local model on subset - 9:
Compute loss, gradients, add noise - 10:
Update weights and record metrics - 11:
Append to , log transaction on - 12:
end for - 13:
Aggregate weights: - 14:
end for Phase III: Model Aggregation - 15:
Compute proof of work , add block to Phase IV: Model Testing - 16:
for to N do - 17:
Evaluate on test data, compute - 18:
end for - 19:
Print execution times and memory usage
|
2. Related Work
The field of DFL has gained significant traction in recent years as a promising approach to training models on decentralized data sources while preserving privacy. Several researchers have explored different aspects of FL and proposed various architectures to enhance its capabilities [
15]. Among these advancements, DFL has emerged as a pivotal development, leveraging deep neural networks to enable more complex and accurate models while maintaining the principles of data privacy and security.
DFL extends the core principles of traditional FL by incorporating the capabilities of deep neural networks (DNNs). This integration allows for the training of highly complex models across distributed data sources without centralizing the data itself, thereby enhancing both the learning performance and privacy-preserving aspects of the system. DFL addresses the limitations of classical FL in handling large-scale and high-dimensional data, typical in applications such as image recognition [
16], natural language processing [
17], autonomous driving [
18], etc. Using the power of DNNs, DFL allows for the development of more sophisticated and accurate models that can learn from a diverse array of data while maintaining principles of data privacy and security.
However, to fully realize the benefits of DFL, it is imperative to implement comprehensive and robust security measures to effectively mitigate the risks associated with data breaches and privacy vulnerabilities. The decentralized nature of DFL, while advantageous in preserving data privacy by keeping data localized, also introduces several security challenges. These include the potential for adversarial attacks during the training process, where malicious actors might attempt to infer private data or disrupt model integrity.
The industry has increasingly focused on ZT, as the security boundary of the network has progressively weakened [
19]. ZTA has emerged as a critical framework for improving the security of DFL systems. Unlike traditional security models that rely on perimeter defenses, ZTA operates on the principle of “never trust, always verify” [
20]. This paradigm shift requires continuous authentication and authorization of all devices, users, and applications regardless of their location within or outside the network. By integrating ZTA into DFL, each component and communication within the system is rigorously verified, ensuring that only authenticated and authorized entities can access sensitive data. This not only fortifies the privacy of the data during training, but also significantly reduces the attack surface, thereby safeguarding the integrity and confidentiality of the FL process.
In paper [
21], Hale et al. propose a methodology based on zero-trust principles and defense-in-depth principles to address the security challenges posed by incorporating machine learning components into complex systems. The methodology aims to prevent and mitigate security threats, particularly those arising from the unpredictable behavior of ML components due to malicious manipulation. Using established security principles, the study seeks to improve the security and assurance levels of systems that integrate machine learning, even in the face of evolving attack vectors and complex models that are not easily verifiable by humans.
A recent study [
22] demonstrates the effectiveness of integrating ZTA into DFL to enhance security and defend against adversarial attacks. For example, the FedBayes approach leverages Bayesian statistics to mitigate the impact of malicious clients by continuously evaluating the trustworthiness of their model updates. This integration ensures that the FL process remains robust against data poisoning attacks, thus preserving the integrity and accuracy of the global model.
Another study [
23], integrates blockchain technology and a ZT security model, Skunk eliminates the need for a central coordinator in FL, ensuring enhanced transparency, model provenance, and individual data privacy with an accuracy of 95 percent. Using a sharding-based architecture, Skunk enables the deployment of FL models in complex network environments, offering enhanced transparency and security mechanisms.
In the realm of intrusion detection systems for the Internet of Things (IoT), the FL-based ZT approach proposed by Javeed et al. [
24] presents a novel framework that combines a convolutional neural network (CNN) and bidirectional long-term short memory (BiLSTM) to improve intrusion detection accuracy and recall with an accuracy of 99.94 percent to 99.99 percent across different numbers of edge devices. By leveraging a horizontal FL model and emphasizing data security through a zero-trust model, this research contributes significantly to the advancement of scalable and effective security measures for interconnected IoT systems.
In paper [
25], the authors present a sophisticated ZTA that employs dynamic attribute-based access control (ABAC). Their approach integrated attributes from subject databases to formulate resource access policies, while a policy enforcement (PE) recommender system reduces uncertainty and enforces the principle of least privilege for each request. By continuously evaluating ABAC rules and trust levels using current data from multiple sources, including threat intelligence and activity logs, their ZTA model improved security and adaptability in real-time access control. A summary of previous work related to this research is shown in
Table 1.
3. Methodology
The growing need for secure and privacy-preserving collaborative learning systems has led to the development of innovative architectures that integrate stringent security measures. This section presents the framework toward a ZT-based GDPR-Compliant DFL architecture. The adoption of ZT in conjunction with ongoing data privacy and security compliance standards is especially powerful for maintaining distributed learning systems. This chapter will introduce the conceptual design and strategies that enable GDPR compliance while keeping data, privacy and integrity over federated networks.
3.1. ZT-Based GDPR-Compliant DFL Architecture
An architecture that integrates ZT with the objective of giving shape and structure to complete functional requirements, In ZT-based DFL; PA governs access policies and security policies; while TA evaluates trust scores for clients. These scores inform the critical decisions that are made by a PDP which in turn updates model weights. The PEP enforces these decisions to secure the FL process. The policies in the system define rules for model training and dictate how data is handled so that there is a consistent and secure way to do your ML/DL training.
The GDPR-Compliant DFL Architecture based on ZT is created to protect data privacy and security under the most restrictive worldwide regulations. This is based on ZT principles designed to address a scenario where threats could be from inside or outside the network and thus maintains compliance by continuously verifying and enforcing strict access controls.
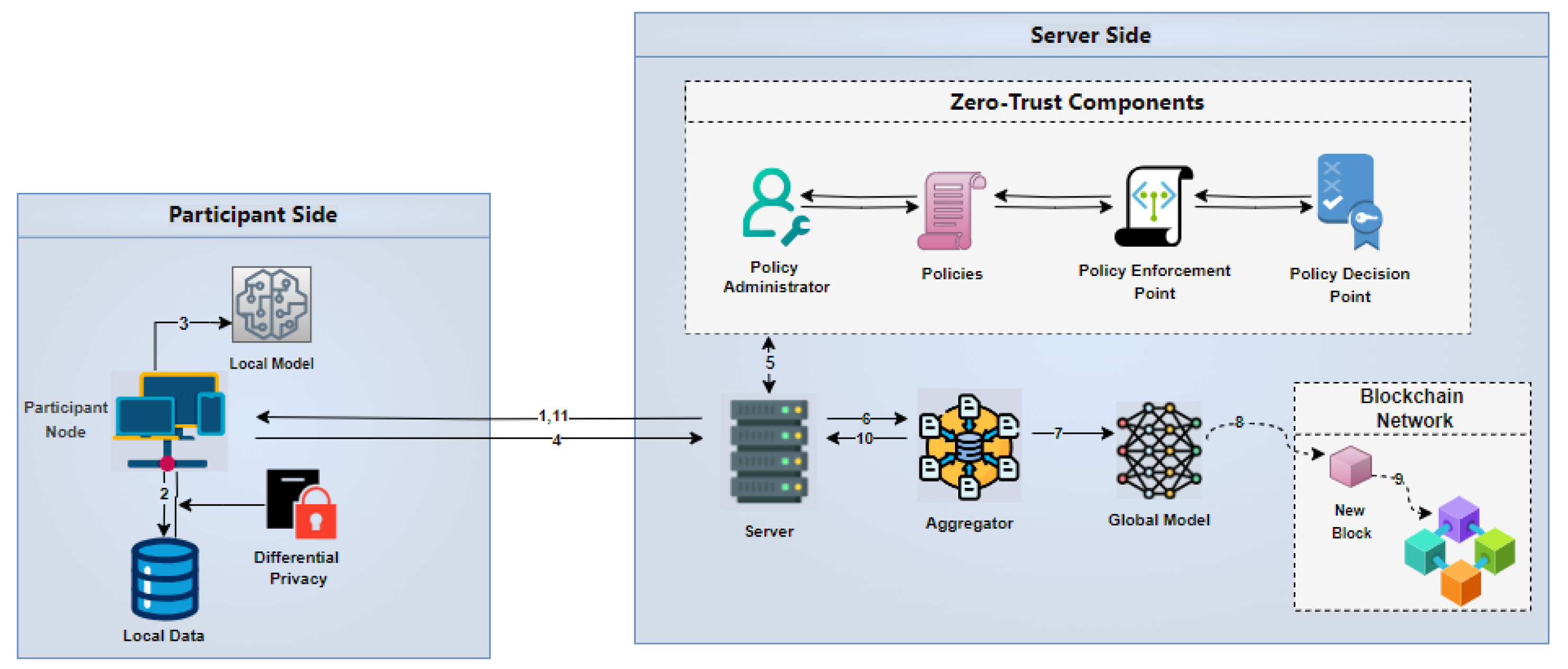
In
Figure 3, in the Participant Side, local data is modified with differential privacy to make it confidential, and then this private-mobilized local data trains a model that sends the server results. This includes ZT components on the Server Side that ensure security and policy compliance around these models before passing them into a Global Model (Steps 4–6). The global model is then verified and recorded on the blockchain for authenticity (Steps 7, 8) in a process similar to mining before it is re-distributed to participants (Step 10). The system which enables their vision for secure, privacy-preserving FL exploits ZTA, LDP with blockchain to still maintain the integrity and confidentiality of users’ data.
3.2. Mapping of ZTA Components to DFL
In the architecture of ZT-based DFL, we have mapped components of basic ZTA with the components of DFL as shown in
Table 2 the PA manages access and security policies, while the TA calculates trust scores for clients. The PDP uses these scores to make critical decisions, updating model weights. The PEP enforces these decisions, maintaining the security of the FL process. The policies in the system define rules for model training and data handling, ensuring a consistent and secure training process.
3.2.1. Policy Administrator (PA)
The PA entity is responsible for administering all access control and security policies of the system. It is responsible for client data and updates, it supervises that everything happens with respect to security policies. Mathematically, the management of data by PA is expressed as follows:
Where
denotes the total data managed by the Policy Administrator (PA),
represents individual data samples, and
N is the number of unsupervised sources, ensuring uniform security policies across all samples.
3.2.2. Trust Algorithm (TA)
The TA calculates trust scores for each e-NODE, and these are calculated using data analysis. It gives accuracies and losses to derive a measure for cross-client trust in FL. The trust score
is computed as:
where,
measures the performance of each client in terms of its prediction accuracy, providing a trust score that reflects the reliability and effectiveness of their local model.
3.2.3. Policy Decision Point (PDP)
The PDP is responsible for decisions based on implemented policies and trust scores. In this system, following local training, it rewrites the model weights so that global evolution of the task takes place. The equation for the average model weights by PDP can be written as follows:
where,
represents the average model weight decided by the PDP,
C is the total number of clients,
are the weights obtained after local training. This ensures that the global model weights are simply averages of all clients’ learned models, making it truly federated.
3.2.4. Policy Enforcement Point (PEP)
The PEP enforces the policies decided by the PDP. This includes applying the updated model weights, thereby maintaining the integrity and security of the FL process. The update mechanism is represented as:
where,
represents the enforcement of policy by updating model weights,
are the global model weights,
are the local model weights,
represents the function that updates local weights to global weights. The function
ensures that the updates in each local model are properly integrated into the global model, allowing synchronization between them.
3.2.5. Policies
Policies define the rules and parameters of what can be done around training a model and data processing. They include configurations such as learning rate, batch size, and other essential training parameters to ensure that the training process is consistent and secure. These policies are defined as follows.
where,
represents the learning rate (
),
represents the batch size (
),
represents the number of epochs (
).
3.3. Phases of the Architecture
3.3.1. Server Initialization Phase
The central part of setting a secure and efficient environment for model management based on data handling is the initialization phase of the server. This process is as shown in
Figure 4 and starts with Policy Setup, where the PA configures initial data access policies. The next step of the process is Model Preparation after defining policies. During this process, the server receives a starting model that includes all of the required data, algorithms, and parameters. The model, when ready, is passed to the PEP and PDP.
The model goes to the trust assessment after validation. The trust algorithm verifies the reliability of a participant node. This is done based on a number of factors, such as previous performance, security credentials, and how well-established policies are adhered to. The authentication phase is followed by a trust check and then comes Certificate Validation. In this step, the participant nodes request a Certificate Authority to verify their digital certificates. This is to validate the genuineness of the participants and the model.
3.3.2. Local Training Phase
During the local training phase as in
Figure 5, the server sends the initial model to the participant node, which is combined with local data to train the local model. In the local training phase, the server sends the initial model to the participant node. The node then combines this model with its local data to train a local version. This entire process is closely monitored by the GDPR Authority to make sure that data protection regulations are being followed.
After training the local model, some noise is added to the data to ensure privacy. After this, the participant node requests to send the updated model back to the server. The server reviews the request and then grants access. The server also checks if the model complies with the set of policies. After this, the certificate validation process is carried out to authenticate the process.
3.3.3. Model Transmission Phase
During the transmission of the model, as shown in
Figure 6, when the participant node sends the encrypted model to the server, it sends the encrypted model.
3.3.4. Global Model Updation Phase
The server sends the local model updates to an aggregator in
Figure 7. An aggregator that puts together updates from all the nodes which have participated. After accumulating all updates, a new block is added to the blockchain network, which contains the updated weights, and is mined. This step guarantees secure storage of the model update that cannot be tampered with. Finally, the server returns this global model to the other participant nodes. It enables them to retrain, using the updated model for the training of the AI core parts. DFL system is improved without ignoring data privacy and integrity.
3.4. Blockchain-Based Update Verification
The blockchain component integrated into the proposed ZT-compliant DFL framework is designed as a lightweight, permissioned ledger that ensures secure logging, update verification, and auditability of all federated transactions. This design choice aligns with the principles of GDPR-compliant, where transparency, accountability, and controlled data propagation are required without sacrificing performance or trust enforcement.
3.4.1. Blockchain Type
The blockchain network is implemented as a private, permissioned system that allows only authenticated nodes, such as client devices, the global aggregator, and policy enforcement modules, to participate. This setup supports the ZT model, where all participating entities must be continuously authenticated and authorized. Unlike public blockchains, this configuration reduces the attack surface and supports operational compliance with GDPR by controlling who can write to and read from the chain.
3.4.2. Consensus Algorithm
To ensure consistency and verifiability of model updates, the system employs a Proof-of-Authority (PoA) consensus mechanism. Although initial consideration was given to Proof-of-Work (PoW), it was deemed inefficient for the latency sensitive and resource-constrained environment of federated learning. In PoA, only trusted validator nodes, such as designated aggregator instances or approved edge devices, are authorized to propose and validate blocks. This consensus approach offers deterministic finality, low energy consumption, and rapid propagation of verified model contributions.
3.4.3. Scalability Considerations
As the number of participating clients or validators increases, conventional blockchains often suffer from scalability bottlenecks due to increased communication latency and block propagation overhead. To address this, the proposed framework adopts a local block verification mechanism, where each client pre-validates its update by computing and attaching a block hash before submission. This decentralized pre-verification reduces the burden on the central ledger, allowing only authenticated and verified updates to be recorded. Additionally, only selected updates, such as those exceeding a trust threshold or flagged for audit, are permanently committed to the blockchain, further minimizing congestion and ensuring the scalability of the architecture under large-scale deployment.
4. Formal Verification of the Proposed Model
4.1. HLPN-Based Modeling and Simulation
To formally verify the correctness, security, enforcement, and trust-based decision mechanisms within the proposed Zero Trust–compliant Deep Federated Learning (DFL) architecture, we adopt High-Level Petri Nets (HLPNs) as the modeling and simulation formalism. HLPNs provide a powerful framework for modeling distributed and concurrent systems due to their ability to represent control flows, data conditions, and token-based dynamics. In our DFL system, where local differential privacy (LDP), blockchain-integrated model verification, and Zero Trust enforcement are tightly integrated, HLPNs offer a modular and data-aware abstraction of system interactions. The simulation captures the behaviors of the components from end-to-end component, including local training, trust evaluation through the Policy Decision Point (PDP), and tamper-resistant model update log-on via blockchain.
The HLPN architecture is divided into distinct subnets, each mapped to a specific DFL phase. These mappings formally translate real-world operations into Petri net elements:
Places represent passive data states, such as model weights or access tokens.
Transitions represent active processes such as training, policy enforcement, or block validation.
The mappings between DFL operations and HLPN elements allow for detailed analysis and formal verification, supporting both simulation and mathematical encoding using Satisfiability Modulo Theories (SMT).
4.2. Formal Analysis and Verification
By modeling the architecture using HLPNs and validating it through formal techniques, we ensure reliability, compliance, and trust [
26]. HLPNs, especially in the form of colored Petri nets, support the representation of complex systems with data and concurrency in a manageable and analyzable way [
27]. Their applicability in industrial contexts has proven effective in modeling, simulating, and analyzing real-world processes [
28]. Formal analysis ensures that system specifications, such as access control enforcement, privacy preservation, and data integrity, are adhered to throughout the DFL pipeline [
29].
We use SMT-based reasoning, specifically through the Z3 solver, to validate the HLPN model. SMT solvers extend traditional Boolean SAT solvers by supporting additional mathematical theories [
30], enabling precise constraint checking over models. Z3 is a widely adopted SMT-LIB-compliant solver capable of handling the rich symbolic structures produced by HLPNs. For a detailed understanding of the functionality and commands of Z3, refer to [
31].
Table 3 introduces the notation used throughout the formal verification process, while
Table 4 shows the mappings of the HLPN places to their corresponding semantic data types in the system. This notation set enables the consistent expression of mathematical relations used in HLPN modeling, transition conditions, and SMT encoding for verification of Z3.
4.2.1. Mapping of DFL Phases to HLPN Subnets
Each DFL phase is explicitly represented as a subnet within the HLPN model. These mappings allow modular verification of security, privacy, and trust mechanisms as in the
Table 5.
Local Model Training:Encodes training and differential privacy application.
Trust Evaluation:Models Zero Trust access control using policy enforcement.
Blockchain Logging:Ensures tamper-evident logging of model updates.
Secure Aggregation:Captures federated averaging and global model synthesis.
Testing and Evaluation:Validates final model performance metrics.
4.2.2. HLPN Verification Artifacts and Solver Configuration
The formal verification process was conducted using the Z3 SMT solver (version 4.12.2), which is fully compatible with the SMT-LIB standard. The solver was configured with a timeout threshold of 3000 milliseconds to ensure timely responses during property checking. The search strategy used a combination of DPLL(T) and E-matching to efficiently handle quantifiers and reasoning. The primary theories utilized in the verification process included integer arithmetic, bit vectors, and quantified logic, which were sufficient to capture the behaviors modeled in the HLPN representations. Additionally, model generation was enabled to facilitate the extraction of counterexamples or witnesses, where applicable.
For failed properties (unsatisfiable conditions), the generation of the Z3 model was used to inspect possible violations. For example, if model poisoning was attempted (via gradient manipulation), the solver returned modified update vectors that violated policy constraints. These counterexamples were reviewed and matched with the attacker behavior modeled in our adversarial simulation module.
4.3. Training and Blockchain HLPN Model
The
Figure 8, represents the training phase within a ZT FL architecture, focusing on data privacy and security during local model updates. The process begins with the distribution of a global model (GM) to client devices, which utilize this model as a baseline for localized training without sharing their data.
Each client has a private dataset that remains secure on the client side, thus maintaining privacy. Before training, client data undergoes a Sample Transformation (ST) to anonymize sensitive information. Clients then initialize an Initial Local Model (ILM)based on the global model, which is subsequently refined through local training to produce an updated local model ().
To maintain security, the Zero-knowledge FL (ZgFL) mechanism verifies the update using zero-knowledge proofs, allowing validation without revealing the underlying data. This verified update is then recorded in a Zero Trust Blockchain (Zb), securely logging each client’s model update as part of an immutable Blockchain (BC). This approach ensures data privacy while enabling effective model updates and aggregation through blockchain traceability and integrity.
4.4. Model Aggregation and Trust Evaluation
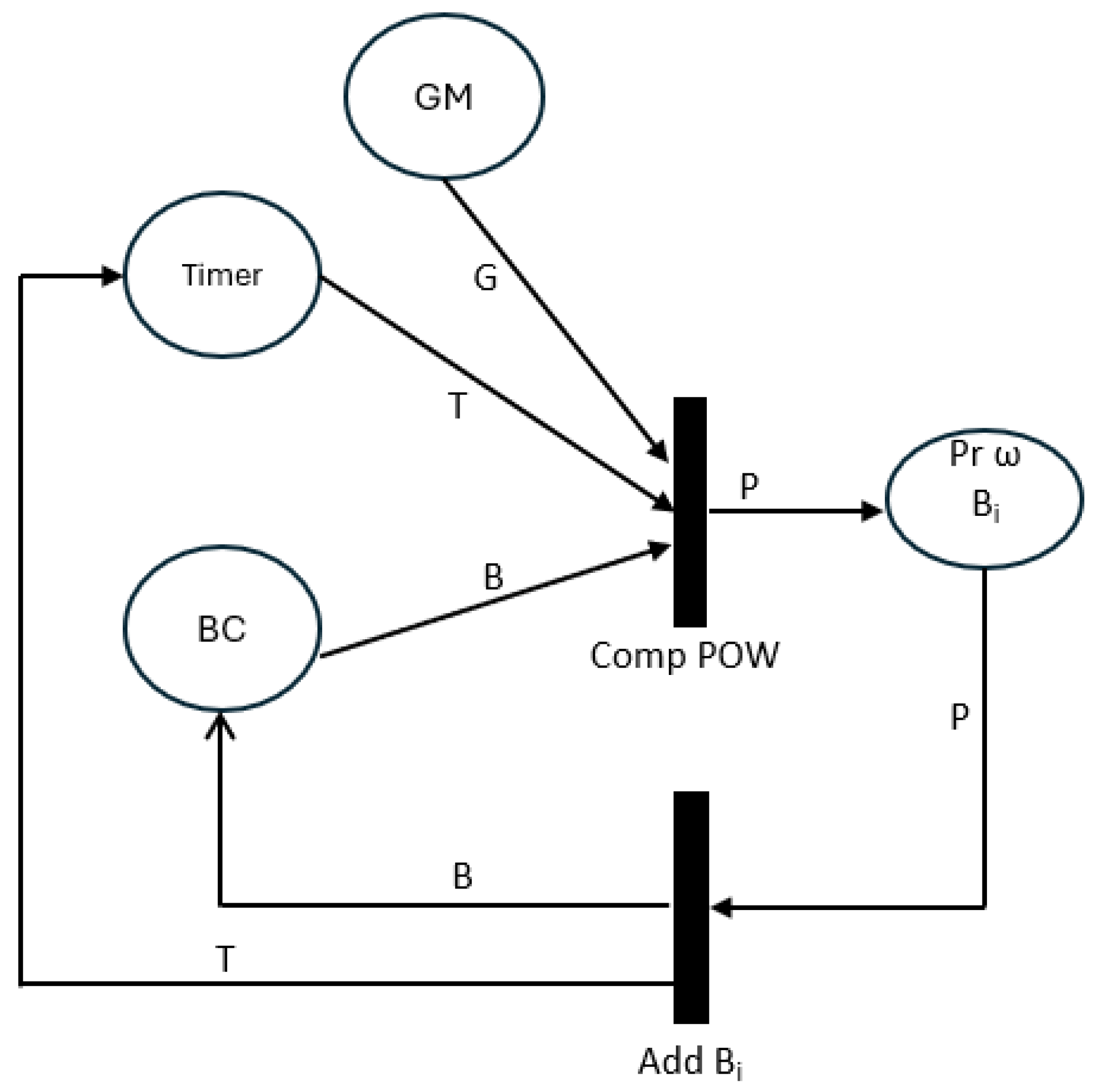
In
Figure 9, the model describes the process of aggregation of the model and the trust evaluation. It validates each client’s model update before contributing to the global model, ensuring that only secure and trustworthy data is included.
The Global Model (GM) acts as an aggregator, collecting validated updates from clients. A Timer synchronizes model aggregation, managing the intervals at which the updates are processed. Each client update is logged in the Blockchain (BC), and its authenticity is verified through a Proof of Work (Comp POW) mechanism, which prevents unauthorized updates. Upon validation, a new block () is added to the blockchain, recording the update and verification data of the model to maintain a tamper-proof record. In addition, a Trust Probability () is calculated for each new block, assessing the reliability of each client update. By employing proof-of-work and calculating trust probabilities, this model strengthens the security and reliability of the FL system, ensuring that only authenticated, trustworthy updates influence the global model.
4.5. Model Testing and Performance Evaluation
As in
Figure 10, the model focuses on model testing and performance evaluation to verify the accuracy and generalizability of the global model after aggregation.
The global model (GM) undergoes testing in a separate dataset (Data) reserved specifically for performance evaluation. This dataset, different from the training data, is used to assess the effectiveness of the global model in generating accurate predictions. During the Federated Prediction (F-P) phase, the model generates predictions on this test dataset, comparing these predictions with actual labels to calculate an Intermediate Accuracy (). Following this, a True Label Accuracy Calculation (Calc_TL_Acc) is conducted to determine the true label accuracy, a key metric indicating the model’s performance. The final accuracy, stored as Test Accuracy (TL Acc), serves as a benchmark to confirm that the global model meets the performance standards required for deployment.
4.6. Mathematical Representation of Rules
This section focuses on formalizing system rules through the use of mathematical notation, specifically employing Z-notation. The Z-notation is a formal specification language used to model complex systems and processes, providing a clear and precise framework for defining system behavior and constraints.
4.6.1. Training Rule ()
The following rule below defines the local data
Z in the first layer (
), which is then updated by including certain components (
and
) from the previous state. It models the local update rule for a given data value
v, where the updated data
is a combination (union) of the current state and specific elements from the previous layers.
4.6.2. Noise Addition Rule ()
The rule for noise addition introduces noise to the local data
Z by adding a noise term generated based on the privacy parameter
. The value
is updated with the noisy data and the variable
is updated with modified values. The rule also aggregates new data into the set
N by adding
,
, and
.
4.6.3. Loss Calculation Rule ()
The following rule calculates the loss
between the predicted and actual values (from
and
), then updates the model parameters accordingly. It also aggregates the accuracy metric (
) from the loss value and other terms, ensuring that the loss calculation contributes to the overall performance evaluation of the model.
4.6.4. Proof of Work Rule ()
The proof of work rule ensures the proper computation of Proof of Work (POW). It checks that the first layer (
) is null and the third layer (
) is not, indicating that POW can be computed. The rule then updates the POW calculation based on some block
b and appends it to the set
p.
4.6.5. Blockchain Addition Rule ()
In the blockchain addition rule, it involves adding a new block
to the blockchain set
B. The block is processed through a function
, and the resulting block is appended to the set of blockchain entries
p.
4.6.6. Real Loss Calculation Rule ()
The following rule calculates the “real” loss by comparing the values
and
, updating the loss function accordingly. Condition
ensures that the loss is meaningful (i.e., it does not compare identical values). The set
L is updated by adding new loss values
,
, and
to the loss history.
4.6.7. False Positive Detection Rule ()
In the following rule, the logic for detecting false positives (FP) in the model predictions is defined. It applies a function FPass to process the data and updates the set
Z based on the output of the function, ensuring that false positives are tracked in the system.
4.7. Privacy Properties and Their Evaluation Parameters
4.7.1. Data Confidentiality
Data confidentiality ensures that only model weights, and not raw data, are shared between clients and the server. This is verified by confirming that only aggregated model weights are accessible to other clients, while local datasets remain private. Furthermore, it is essential to verify that the partitioning of the data is properly maintained, ensuring that the client data are never exchanged directly.
4.7.2. Differential Privacy
Differential privacy is enforced by adding controlled noise to gradients during training, limiting the risk of information leakage about individual data points. Evaluation of this property involves adjusting the noise level through the privacy parameter and ensuring that the noise-added gradient updates preserve privacy while maintaining the model learning capability.
4.7.3. Resilience to Model Poisoning
Resilience to model poisoning is verified by monitoring gradients and accuracy distributions to detect anomalies or malicious updates. Significant deviations in the accuracy of the local model between clients can indicate an attack, while unusually high or low loss values could suggest suspicious updates that affect model integrity.
4.8. Security Properties and Their Evaluation Parameters
4.8.1. Model Integrity
Model integrity is ensured using blockchain technology, which validates and stores legitimate model updates, preventing tampering and ensuring traceability. The integrity of each update is verified using a block hash , which guarantees that modifications to the model remain detectable. Furthermore, every update of the model is recorded as a transaction on the blockchain, ensuring accountability and transparency.
4.8.2. Client Authentication and Trust
Client authentication and trust are crucial for preventing unauthorized participation in model training. Clients are authenticated on the basis of predefined policies and their trustworthiness is continuously evaluated. The effectiveness of this process is measured using the policy administrator timer , which tracks the decision time for authentication policies, and the trust algorithm timer , which ensures a timely assessment of client trustworthiness.
4.8.3. Access Control
Access control mechanisms ensure that only authorized clients can update the model, with enforcement managed by the Policy Decision and Policy Enforcement Points. The policy decision point timer measures the time taken to evaluate access requests, to ensure that decisions are made efficiently. The policy enforcement point timer tracks policy enforcement, guaranteeing that unauthorized clients are restricted from training and updating the model.
4.9. Results
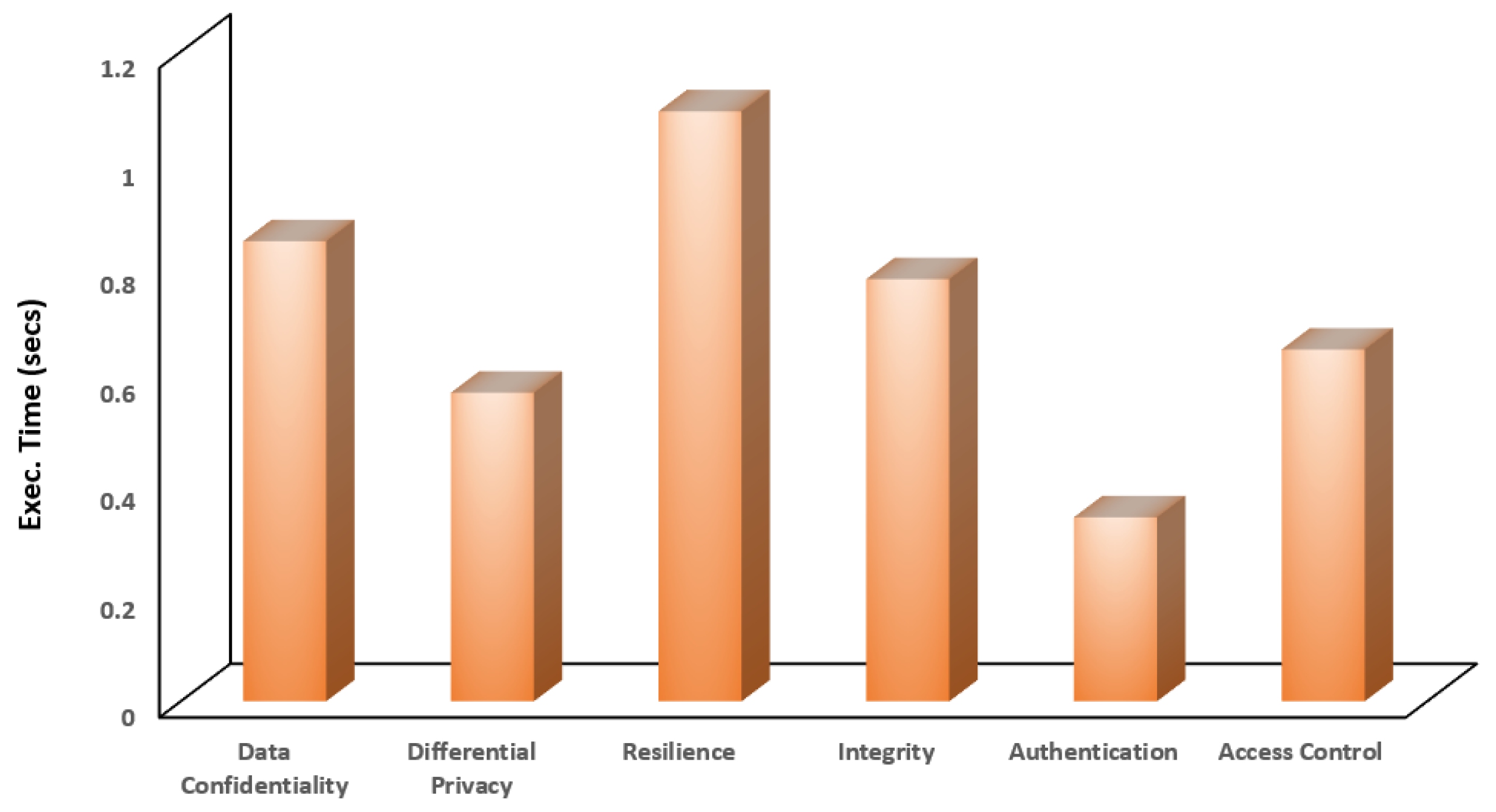
The execution times to verify the various properties are presented in
Figure 11. The execution time indicates the duration taken by the solver to verify each property.
The Z3 solver required 0.85 s to verify the Data Confidentiality property, which ensures that sensitive information remains protected throughout the process. Differential Privacy took slightly less time, at 0.57 s, as it focuses on adding noise to data to maintain privacy while preserving utility. The Resilience property, which checks the system’s ability to recover from disruptions, required the most time at 1.09 s. Integrity, which ensures that the data were not altered, was verified in 0.78 s. Authentication, which verifies the identity of entities within the system, took only 0.34 s. Lastly, Access Control, which manages permissions and access rights, took 0.65 s to verify. These execution times demonstrate the efficiency of the Z3 solver in verifying a range of important properties within the system.
The summary of the results is presented in
Table 6, which shows the execution time required to verify each property to represent “SAT” (satisfied) if true. In the results section, the results of the experiments that were conducted to assess the performance and efficacy of the ZT-based DFL architecture are presented. This section offers a comprehensive examination of the primary metrics and observations that were derived from the experiments, thereby illustrating the system’s ability to securely and efficiently facilitate collaborative machine learning.
5. Experimental Setup
5.1. Dataset
Researchers in the computer vision and ML communities often refer to MNIST [
32,
33] as a benchmark for class separation [
13,
34,
35]. Due to its popularity, MNIST often serves as the ‘hello world’ of deep learning frameworks (e.g., TensorFlow). In fact, MNIST is so widely used that it is even used in ‘hello world’ tutorials of some deep learning frameworks, such as TensorFlow. It is a collection of 28 pixels by 28 pixels gray scale photographs that depict the numerals 0 through 9 as written by hand, along with the accompanying labels as in
Figure 12. In addition to MNIST, the CIFAR-10 dataset [
36] has also become a standard reference for more complex image classification tasks. CIFAR-10 consists of 60,000 color images (32 × 32 pixels) across 10 distinct classes as in
Figure 13, including animals and vehicles, and is widely used to evaluate model performance in more challenging visual conditions.
5.2. Experiment Settings
In this paper, Python 3 was employed to implement the ZTA integrated with DFL. The experiments were carried out on the Google Colaboratory, using a T4 GPU hardware accelerator for efficient simulation and analysis.
5.3. Performance Metrics
This section outlines the key performance metrics used to evaluate the effectiveness and efficiency of our deep learning model. Specifically, we measure accuracy, loss, and execution time.
5.3.1. Accuracy
Accuracy quantifies the proportion of correct predictions made by the model. We conducted experiments to analyze how the accuracy degrades as the noise parameter increases. Mathematically, accuracy is defined as follows:
where
N denotes the total number of samples,
represents the true label,
is the predicted label for the
i-th sample, and
is an indicator function that equals 1 if the argument is true and 0 otherwise.
5.3.2. Loss
Loss quantifies the discrepancy between the predictions of the model and the actual labels. The training loss for a batch
b is expressed as:
where
represents the predicted outputs and
denotes the ground truth labels for batch
b. The choice of loss function (e.g., cross entropy for classification, mean squared error for regression) depends on the nature of the learning task.
5.3.3. Test Accuracy
The test accuracy evaluates the generalization performance of the model by computing the proportion of correct predictions on unseen test data. It is given by:
where
is the number of test samples,
is the true label, and
is the predicted label for the
i-th test sample.
5.3.4. Test Loss
The test loss assesses the performance of the model on unseen data by computing the average loss over the test set.
where
represents the applied loss function.
5.3.5. Execution Time
Execution time quantifies the computational efficiency of various components of the system. It is expressed as follows:
where
measures the cumulative duration required to complete a given task.
5.4. Training Hyper-Parameters and Implementation Settings
The proposed architecture was implemented in Python using PyTorch, and experiments were conducted on the MNIST dataset. The experiments simulate federated learning with blockchain integration and local differential privacy (LDP) support, where each client trains a local model on its data and contributes to a global model via federated averaging.
Table 7 summarizes the hyper-parameters and training configurations used in the experiments.
5.5. Adversarial Attacks and Their Defenses
In DFL environments, adversarial participants can exploit the lack of central control to launch various attacks that compromise privacy, accuracy, and system trust. Evaluating such threats is essential in a Zero Trust-based architecture where no entity is assumed trustworthy by default. This section presents simulations of key adversarial threats and demonstrates how our system components, including ZTA, Local Differential Privacy (LDP), and Blockchain, effectively mitigate them, aligning with GDPR requirements for security, accountability, and data protection.
5.5.1. Types of Attacks Considered
We simulate five prevalent adversarial attack types, chosen for their relevance to federated learning and real-world exploitability.
Model Poisoning Attack: A client manipulates its model updates (e.g., scaling gradients) to degrade or bias the global model.
Data Poisoning Attack: Malicious clients inject incorrect or misleading samples into local training data to distort the global model.
Inference Attack: An attacker attempts to infer whether a specific data record was part of a client’s training set (e.g., Membership Inference).
Sybil Attack: A single adversary emulates multiple clients to gain disproportionate influence on the model aggregation process.
Backdoor Attack: An attacker embeds hidden triggers into the local model such that specific inputs will yield incorrect outputs post-aggregation.
5.5.2. Defense Mechanism
Figure 14 illustrates the integrated defense architecture employed in our trusted Deep Federated Learning (DFL) system. This architecture leverages three core defense components: Zero-Trust Architecture (ZTA), Local Differential Privacy (LDP), and Blockchain Technology. These mechanisms work collectively to protect the system from a variety of adversarial threats.
ZTA ensures that only authenticated and behaviorally trusted participants can contribute to the training process by enforcing strict policy-driven access control through its Policy Administrator, Enforcement Point, and Decision Point. This mechanism is particularly effective against Sybil attacks, which involve fake or duplicate clients attempting to join the network, and Backdoor attacks, where malicious clients try to introduce hidden behaviors into the model.
LDP is employed at the participant side to inject calibrated noise into local data before training, which thwarts both Data Poisoning and Inference Attacks. By randomizing sensitive information at the source, LDP ensures that malicious actors cannot exploit local training data or infer the membership of individual records from the global model. Blockchain technology provides a decentralized and immutable ledger for logging updates of the model and enforcing verifiability. It supports ZTA in defending against Model Poisoning and Sybil attacks by offering an auditable history of participant actions and model contributions. Moreover, every model update recorded on-chain enhances transparency and prevents tampering.
Table 8 summarizes the mapping between common adversarial attacks and their corresponding defense mechanisms within our architecture.
Together, these components create a multi-layered security perimeter that enables only trusted, privacy-preserving, and verified models to be integrated into the federated learning process.
These components form a robust trust boundary around each client, ensuring that only verified, privacy-preserving, and compliant model updates contribute to the federated learning process.
5.6. Demonstrating GDPR Compliance Through System Component Mapping
To strengthen the demonstrability of GDPR compliance in our architecture, we provide a detailed mapping of the system components to specific GDPR articles in
Table 9. This alignment illustrates how each architectural feature operationally satisfies the corresponding legal obligations under the regulation.
6. Results and Discussion
The performance of the ZTA-based DFL model in varying epsilon values () provides valuable information on the interaction between privacy parameters and model efficacy. Our results underscore several key observations pertinent to the problem statement, particularly in the context of privacy challenges, GDPR compliance, and trust issues within federated systems.
6.1. Comparative Analysis with Prior Works
Table 10 presents a comparative summary of different DFL-based approaches from previous works, including our proposed model. The comparison includes the number of clients, training epochs, and reported accuracy and loss. In particular, our model achieves competitive accuracy in both MNIST and CIFAR-10 datasets using significantly fewer clients and training epochs, indicating its efficiency and practical feasibility. Although some prior works achieve high accuracy, they often do so with large-scale setups or omit key metrics like loss.
To provide a detailed performance breakdown,
Table 11 compares various DFL-based methods evaluated under the same experimental conditions on both the MNIST and CIFAR-10 datasets. The results highlight that our model outperforms existing DFL variants by achieving the highest accuracy and the lowest loss on both datasets. This demonstrates the effectiveness of integrating Zero Trust principles, Local Differential Privacy, and Blockchain mechanisms within a unified federated learning framework.
6.2. Impact of Epsilon on Privacy and Model Performance
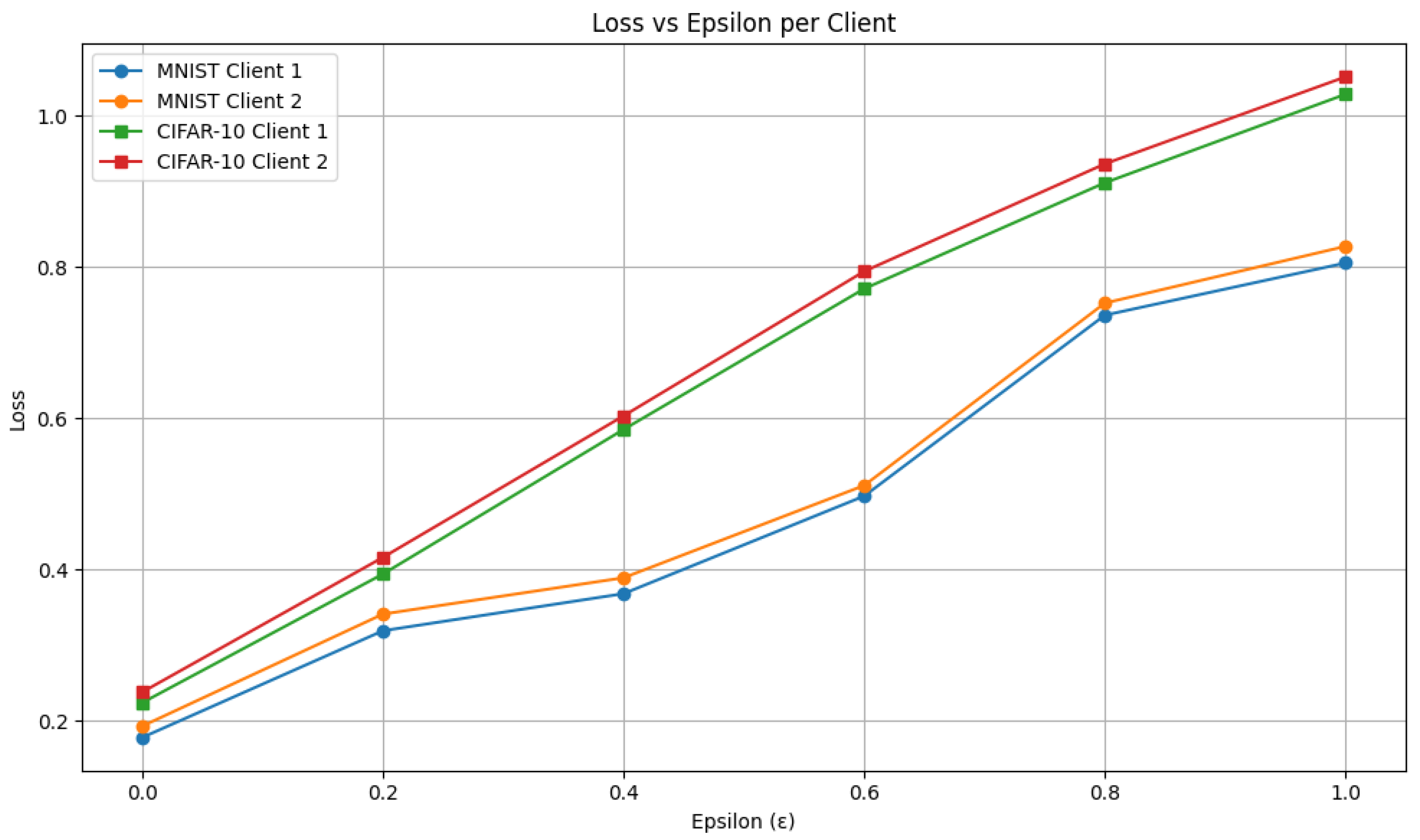
To assess the impact of Local Differential Privacy (LDP) on model utility, we varied the privacy budget
from 0.0 to 1.0 and evaluated the resulting changes in accuracy and loss across both MNIST and CIFAR-10 datasets. The results reveal a clear trade-off between privacy and utility, as
increases, the performance of the model declines due to the added noise. At
, representing the baseline without privacy, the models achieve their highest accuracy (MNIST: 92.02%, CIFAR-10: 93.10%) and lowest loss (MNIST: 0.1855, CIFAR-10: 0.231). Introducing light noise at
leads to a moderate reduction in accuracy (MNIST: 84.28%, CIFAR-10: 85.33%) and a noticeable increase in loss (MNIST: 0.33, CIFAR-10: 0.405). At
, performance degradation becomes more evident, with accuracy dropping to 82.22% (MNIST) and 74.41% (CIFAR-10), and corresponding losses increasing to 0.3785 and 0.594. Higher noise at
causes a further decrease in accuracy (MNIST: 75.44%, CIFAR-10: 61.90%) and increased loss (MNIST: 0.504, CIFAR-10: 0.7825). With
, utility is severely compromised as accuracy falls to 59.70% (MNIST) and 54.10% (CIFAR-10), and loss rises to 0.744 and 0.923. At the highest noise level (
), performance deteriorates further, with MNIST accuracy at 54.78%, CIFAR-10 at 48.56%, and peak loss values of 0.816 and 1.0395 respectively. These results highlight the critical balance required between privacy preservation and model performance in DFL systems that employ LDP as in
Figure 15 and
Figure 16.
6.3. Execution Times and Computational Efficiency
We evaluated the execution times of various security and trust components in our architecture specifically the Policy Administrator (PA), Policy Decision Point (PDP), Policy Enforcement Point (PEP), and Trust Algorithm (TA) to assess the computational efficiency of our proposed system. Execution time measurements were recorded per client in 10 training epochs for both the CIFAR-10 dataset as in
Table 12 and MNIST datasets as in
Table 13.
For the CIFAR-10 dataset, the PA exhibited a constant execution time of approximately 4.88 s across all epochs and clients. Similarly, the PEP remained lightweight with a stable runtime of 0.0002 s. The PDP showed a gradual reduction in computation time, decreasing from 27.99 s in epoch 1 to 25.68 s by epoch 10, indicating improved processing efficiency as the model converged. The execution time of TA was dynamic, reaching 0.0834 s in epoch 5 before declining to 0.0214 s in epoch 10, reflecting the reduced complexity of trust evaluation in later stages of training.
In contrast, the MNIST dataset showed lower execution times overall. PA consistently took 2.14 s, while PEP remained negligible at 0.0001 to 0.0003 s. The PDP’s runtime was mostly stable around 25.5 s, with minor fluctuations due to dataset-specific variance. TA run times varied more significantly, ranging from 0.0015 s in early epochs to a peak of 0.1442 s in epoch 7 suggesting sensitivity to early trust assessments but eventual stabilization as training matured.
Overall, the security components particularly PA, PEP, and TA, incurs minimal computational overhead. Although PDP requires relatively more time due to its decision-making responsibilities, it shows a consistent trend toward efficiency over time. These results confirm that the integration of security and trust mechanisms in our framework does not compromise scalability or real-time performance.
7. Conclusions
DFL represents a groundbreaking approach to machine learning (ML),by enabling collaborative model training across decentralized data sources without direct data sharing. However, its adoption in sensitive sectors faces challenges related to GDPR compliance. Traditional setups struggle to meet these rigorous standards while maintaining trust. Our research introduces an innovative ZT-based DFL architecture designed specifically for GDPR-compliant systems. Initially proposed in our base paper, the GDPR-Compliant DFL Architecture is now formally verified using High-Level Petri Nets (HLPNs). The ZT-based framework facilitates secure, decentralized model training without direct data sharing. Furthermore, we conducted a case study using the MNIST and CIFAR-10 datasets to evaluate the existing approach alongside the proposed ZT-based DFL methodology.
Future work will focus on further enhancing the scalability and efficiency of the proposed GDPR-Compliant DFL Architecture. In addition, investigating the applicability of the architecture to other sensitive sectors beyond healthcare will be a key area of exploration.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}