
A Hybrid Content-Aware Network for Single Image Deraining


Abstract
1. Introduction
- (1)
- A hybrid content-aware deraining (CAD) network is proposed to generate high-quality deraining results, which incorporates a content-aware convolution and attention mixer module (CAMM) to apply simple convolution for plain areas and attention mechanism for complex areas and a deraining multi-scale double-gated feed-forward module (MDFM) to preserve local detail features and enhance image restoration capabilities.
- (2)
- An attention model named four-token contextual attention (FTCA) is designed to explore the rich context information among neighbor keys. The proposed FTCA applies four tokens, rather than the usual three tokens in transformers, to process the input features and exploit the introduced token to alleviate computational costs and enhance the expressiveness by aggregating global information.
- (3)
- Qualitative and quantitative evaluations both on synthetic and real-world datasets have verified that the proposed method not only exhibits excellent superiority and effectiveness in image deraining compared to other methods, but also maintains higher operational efficiency.
2. Related Works
2.1. Single Image Deraining
2.2. Accelerating and Lightweight Framework
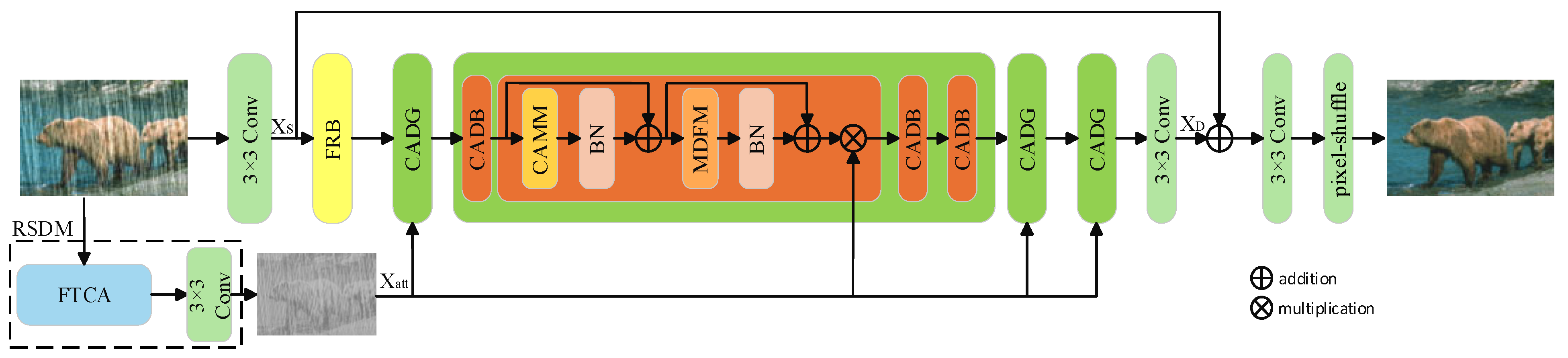
3. Method
3.1. Backbone Pipeline
3.2. Four-Token Contextual Attention Module
3.3. Feature Refinement Block
3.4. Content-Aware Deraining Block
3.5. Loss Function
4. Experiments and Discussions
4.1. Datasets and Implementation Details
4.2. Comparison with State-of-the-Art
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Math Notations | Meaning |
|---|---|
| Element-wise multiplication | |
| Sigmoid activation function | |
| ReLU activation function | |
| GELU non-linearity function |
References
- Jiang, X.; Liu, T.; Song, T.; Cen, Q. Optimized Marine Target Detection in Remote Sensing Images with Attention Mechanism and Multi-Scale Feature Fusion. Information 2025, 16, 332. [Google Scholar] [CrossRef]
- Liu, J.; Qi, J.; Zhong, P.; Jiang, J. A Hyperspectral Nonlinear Unmixing Network for Nearshore Underwater Target Detection. In Proceedings of the 2024 5th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT), Nanjing, China, 22–24 March 2024; pp. 2174–2178. [Google Scholar]
- Alvarado-Robles, G.; Espinosa-Vizcaino, I.; Manriquez-Padilla, G.; Saucedo-Dorantes, J. SDKU-Net: A Novel Architecture with Dynamic Kernels and Optimizer Switching for Enhanced Shadow Detection in Remote Sensing. Computers 2025, 14, 80. [Google Scholar] [CrossRef]
- Li, Y. Rain Streak Removal Using Layer Priors. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2276–3033. [Google Scholar]
- Chen, Y.L.; Hsu, C.T. A Generalized Low-Rank Appearance Model for Spatio-temporally Correlated Rain Streaks. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1968–1975. [Google Scholar]
- Luo, Y.; Xu, Y.; Ji, H. Removing Rain from a Single Image via Discriminative Sparse Coding. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3397–3405. [Google Scholar]
- Yang, W.; Tan, R.T.; Wang, S.; Fang, Y.; Liu, J. Single Image Deraining: From Model-Based to Data-Driven and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4059–4077. [Google Scholar] [CrossRef]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Paisley, J. Removing Rain from Single Images via a Deep Detail Network. In Proceedings of the 2017 IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1715–1723. [Google Scholar]
- Zhang, H.; Patel, V.M. Density-Aware Single Image De-raining Using a Multi-stream Dense Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 695–704. [Google Scholar]
- Zheng, Y.; Yu, X.; Liu, M.; Zhang, S. Single-Image Deraining via Recurrent Residual Multiscale Networks. IEEE Trans. Neural Networks Learn. Syst. 2022, 3, 1310–1323. [Google Scholar] [CrossRef]
- Chang, Y.; Chen, M.; Yu, C.; Li, Y.; Chen, L.; Yan, L. Direction and Residual Awareness Curriculum Learning Network for Rain Streaks Removal. IEEE Trans. Neural Networks Learn. Syst. 2024, 35, 8414–8428. [Google Scholar] [CrossRef]
- Yao, Y.J.; Shi, Z.M.; Hu, H.W.; Li, J.; Wang, G.C.; Liu, L.T. GSDerainNet: A Deep Network Architecture Based on a Gaussian Shannon Filter for Single Image Deraining. Remote Sens. 2023, 15, 4825. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, H.; Lin, S.; He, K. You Only Need Less Attention at Each Stage in Vision Transformers. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 23–28 June 2024; pp. 6057–6066. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhu, L.; Fu, C.W.; Lischinski, D.; Heng, P.A. Joint Bi-layer Optimization for Single-Image Rain Streak Removal. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2545–2553. [Google Scholar]
- Kang, L.W.; Lin, C.W.; Fu, Y.H. Automatic Single-Image-Based Rain Streaks Removal via Image Decomposition. IEEE Trans. Image Process. 2011, 21, 1742–1755. [Google Scholar] [CrossRef]
- Zheng, C.; Jiang, J.; Ying, W.; Wu, S.B. Single Image Deraining via Feature-based Deep Convolutional Neural Network. arXiv 2023, arXiv:2305.02100. [Google Scholar]
- Chen, X.; Pan, J.; Jiang, K.; Li, Y.; Huang, Y.; Kong, C.; Dai, L.; Fan, Z. Unpaired Deep Image Deraining Using Dual Contrastive Learning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2007–2016. [Google Scholar]
- Sivaanpu, A.; Thanikasalam, K. A Dual CNN Architecture for Single Image Raindrop and Rain Streak Removal. In Proceedings of the 2022 7th International Conference on Information Technology Research (ICITR), Moratuwa, Sri Lanka, 7–9 December 2022; pp. 1–6. [Google Scholar]
- Chen, H.; Chen, X.; Lu, J.; Li, Y. Rethinking Multi-Scale Representations in Deep Deraining Transformer. Proc. AAAI Conf. Artif. Intell. 2024, 38, 1046–1053. [Google Scholar] [CrossRef]
- Ragini, T.; Prakash, K. Progressive Multi-scale Deraining Network. In Proceedings of the 2022 IEEE International Symposium on Smart Electronic Systems (iSES), Warangal, India, 18–22 December 2022; pp. 231–235. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 5718–5729. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Liu, J. Uformer: A General U-Shaped Transformer for Image Restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 17662–17672. [Google Scholar]
- Xiao, J.; Fu, X.; Liu, A.; Wu, F.; Zha, Z.J. Image De-Raining Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12978–12995. [Google Scholar] [CrossRef]
- Sun, S.; Ren, W.; Gao, X.; Wang, R.; Cao, X. Restoring Images in Adverse Weather Conditions via Histogram Transformer. arXiv 2024, arXiv:2407.10172. [Google Scholar]
- Kong, X.; Zhao, H.; Qiao, Y.; Dong, C. ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12011–12020. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans Pattern Anal Mach Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef]
- Hui, Z.; Wang, X.; Gao, X. Fast and Accurate Single Image Super-Resolution via Information Distillation Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 723–731. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight Image Super-Resolution with Information Multi-distillation Network. arXiv 2019, arXiv:1909.11856. [Google Scholar]
- Wang, Y. Edge-enhanced Feature Distillation Network for Efficient Super-Resolution. arXiv 2022, arXiv:2204.08759. [Google Scholar]
- Kong, F.; Li, M.; Liu, S.; Liu, D.; He, J.; Bai, Y.; Chen, F.; Fu, L. Residual Local Feature Network for Efficient Super-Resolution. arXiv 2022, arXiv:2205.07514. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Gool, L.V.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. arXiv 2021, arXiv:2108.10257. [Google Scholar]
- Wang, Y.; Li, Y.; Wang, G.; Liu, X. Multi-scale Attention Network for Single Image Super-Resolution. arXiv 2024, arXiv:2209.14145. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Wang, Y.; Liu, Y.; Zhao, S.; Li, J.; Zhang, L. CAMixerSR: Only Details Need More “Attention”. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 25837–25846. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep Joint Rain Detection and Removal from a Single Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1685–1694. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image De-Raining Using a Conditional Generative Adversarial Network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3943–3956. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive Image Deraining Networks: A Better and Simpler Baseline. arXiv 2019, arXiv:1901.09221. [Google Scholar]
- Wang, H.; Yue, Z.; Xie, Q.; Zhao, Q.; Zheng, Y.; Meng, D. From Rain Generation to Rain Removal. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14786–14796. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Multi-Stage Progressive Image Restoration. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14816–14826. [Google Scholar]
- Zheng, S.; Lu, C.; Wu, Y.; Gupta, G. SAPNet: Segmentation-Aware Progressive Network for Perceptual Contrastive Deraining. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 3–8 January 2022; pp. 52–62. [Google Scholar]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. HINet: Half Instance Normalization Network for Image Restoration. arXiv 2021, arXiv:2105.06086. [Google Scholar]
- Li, Y.; Lu, J.; Chen, H.; Wu, X.; Chen, X. Dilated Convolutional Transformer for High-Quality Image Deraining. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 18–22 June 2023; pp. 4199–4207. [Google Scholar]
- Jiang, K.; Wang, Z.; Chen, C.; Wang, Z.; Cui, L.; Lin, C.-W. Magic ELF: Image Deraining Meets Association Learning and Transformer. arXiv 2022, arXiv:2207.10455. [Google Scholar]







| Datasets | Rain100L | Rain100H | Overhead | |||
|---|---|---|---|---|---|---|
| Metrics | PSNR/SSIM | PSNR/SSIM | Params [M] | FloPs [G] | Time/s | |
| Prior-based methods | GMM [4] | 26.945/0.844 | 16.317/0.431 | - | - | - |
| DSC [6] | 27.271/0.837 | 15.579/0.396 | - | - | - | |
| CNN-based methods | PReNet [41] | 32.420/0.950 | 26.770/0.858 | 0.169 | 16.576 | 0.163 |
| VRGNet [42] | 36.662/0.973 | 30.077/0.887 | 0.169 | 16.576 | 0.120 | |
| MPRNet [43] | 36.687/0.967 | 30.427/0.891 | 3.637 | 137.163 | 0.207 | |
| SAPNet [44] | 32.291/0.951 | 28.046/0.867 | 0.182 | 165.938 | 0.198 | |
| HINet [45] | 37.591/0.971 | 30.649/0.894 | 88.671 | 42.629 | 0.698 | |
| DRAN [11] | 37.830/0.980 | 30.650/0.900 | - | - | - | |
| Transformer-based methods | IDT [22] | 37.010/0.970 | 29.950/0.898 | 16.390 | 58.440 | 0.164 |
| DCT [46] | 38.190/0.970 | 30.740/0.890 | - | - | - | |
| Hybrid-based methods | ELF [47] | 36.672/0.968 | 30.480/0.896 | 1.532 | 66.390 | 0.125 |
| CAD (our) | 39.301/0.984 | 30.807/0.915 | 1.196 | 32.956 | 0.109 | |
| Methods | GMM | DSC | SAPNet | VRGNet | MPRNet | HINet | CAD |
|---|---|---|---|---|---|---|---|
| Scores | 4.11 | 3.52 | 6.27 | 7.14 | 8.17 | 8.56 | 9.25 |
| Model | MDFM | FTCA | DFTCA | FFTCA | FRB | CNN | Attention | PSNR | SSIM |
|---|---|---|---|---|---|---|---|---|---|
| model (a) | × | √ | √ | √ | √ | × | × | 30.203 | 0.907 |
| model (b) | √ | × | √ | √ | √ | × | × | 30.615 | 0.912 |
| model (c) | √ | √ | × | √ | √ | × | × | 30.703 | 0.913 |
| model (d) | √ | √ | √ | × | √ | × | × | 30.697 | 0.913 |
| model (e) | √ | √ | √ | √ | × | × | × | 30.562 | 0.910 |
| model (f) | √ | √ | × | √ | √ | √ | × | 30.361 | 0.907 |
| model (g) | √ | √ | × | √ | √ | × | √ | 30.062 | 0.906 |
| CAD (ours) | √ | √ | √ | √ | √ | × | × | 30.807 | 0.915 |
| Window Size | Params [M] | FLOPs [G] | PSNR | SSIM |
|---|---|---|---|---|
| 8 × 8 | 1.124 | 32.950 | 30.542 | 0.908 |
| 16 × 16 | 1.196 | 32.956 | 30.807 | 0.915 |
| 32 × 32 | 1.771 | 33.007 | 30.681 | 0.911 |
| Pool Size | Params [M] | FloPs [G] | PSNR | SSIM |
|---|---|---|---|---|
| 5 | 1.195 | 32.878 | 30.623 | 0.912 |
| 6 | 1.196 | 32.956 | 30.807 | 0.915 |
| 7 | 1.198 | 33.056 | 30.696 | 0.912 |
| 8 | 1.201 | 33.215 | 30.702 | 0.912 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chai, G.; Yang, R.; Ge, J.; Chen, Y. A Hybrid Content-Aware Network for Single Image Deraining. Computers 2025, 14, 262. https://doi.org/10.3390/computers14070262
Chai G, Yang R, Ge J, Chen Y. A Hybrid Content-Aware Network for Single Image Deraining. Computers. 2025; 14(7):262. https://doi.org/10.3390/computers14070262
Chicago/Turabian StyleChai, Guoqiang, Rui Yang, Jin Ge, and Yulei Chen. 2025. "A Hybrid Content-Aware Network for Single Image Deraining" Computers 14, no. 7: 262. https://doi.org/10.3390/computers14070262
APA StyleChai, G., Yang, R., Ge, J., & Chen, Y. (2025). A Hybrid Content-Aware Network for Single Image Deraining. Computers, 14(7), 262. https://doi.org/10.3390/computers14070262