
HFC-YOLO11: A Lightweight Model for the Accurate Recognition of Tiny Remote Sensing Targets


Abstract
1. Introduction
- Compared with traditional P3\P4\P5 layers, we add a P2 layer to extract finer features at high-resolution stages while removing the P5 layer, effectively reducing the model’s parameters and computational load. This modification improves small object detection’s accuracy through enhanced feature granularity;
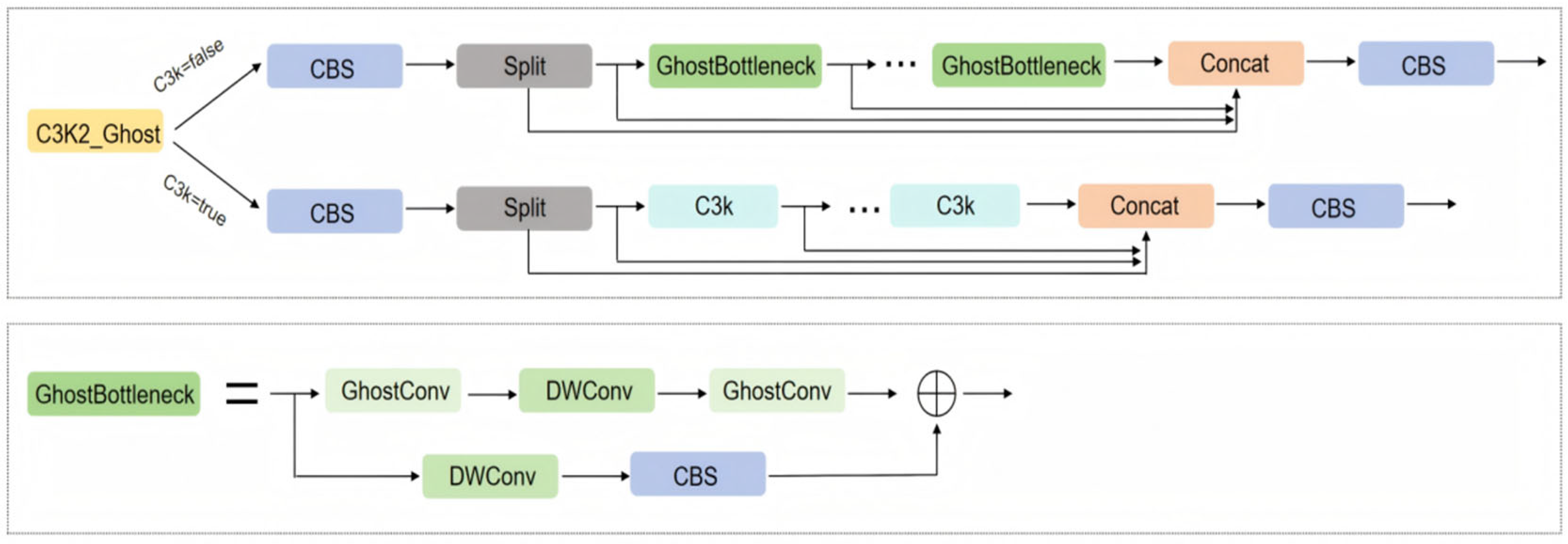
- A depth-aware heterogeneous architecture is developed by implementing GhostBottleneck in shallow layers and Bottleneck in deep layers. This design achieves the dynamic balancing of computational resources: GhostBottleneck efficiently processes abundant basic features in shallow networks, reducing unnecessary computations, while Bottleneck thoroughly explores complex semantic features in deep networks to ensure accuracy of recognition;
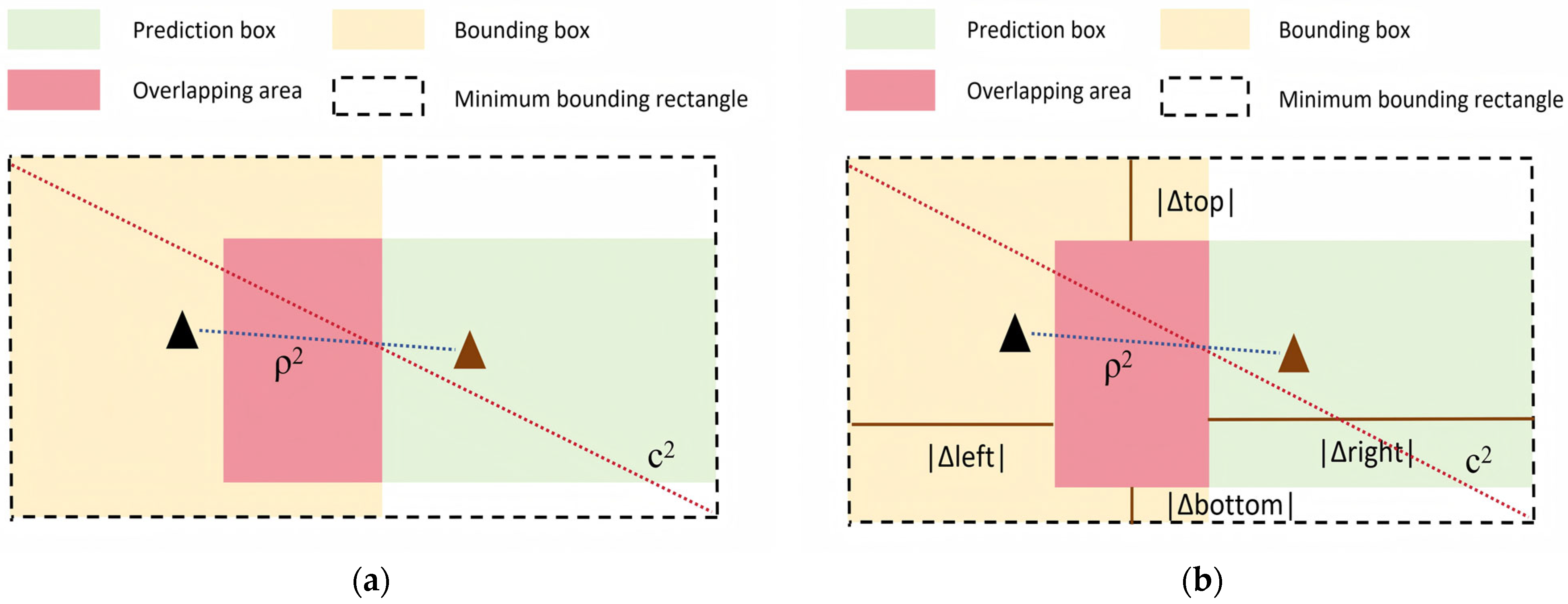
- An EIoU loss function is proposed, which innovatively integrates direct boundary alignment penalty terms and scale-adaptive weighting mechanisms into the CIoU geometric constraint framework. This advancement explicitly optimizes the coordinate errors of all four bounding box edges, while dynamically amplifying the loss contributions of small targets based on their areas.
2. Related Work
2.1. Single-Stage Detection Models
2.2. Loss Functions for Object Detection
2.3. GhostNet and Cheap Operations
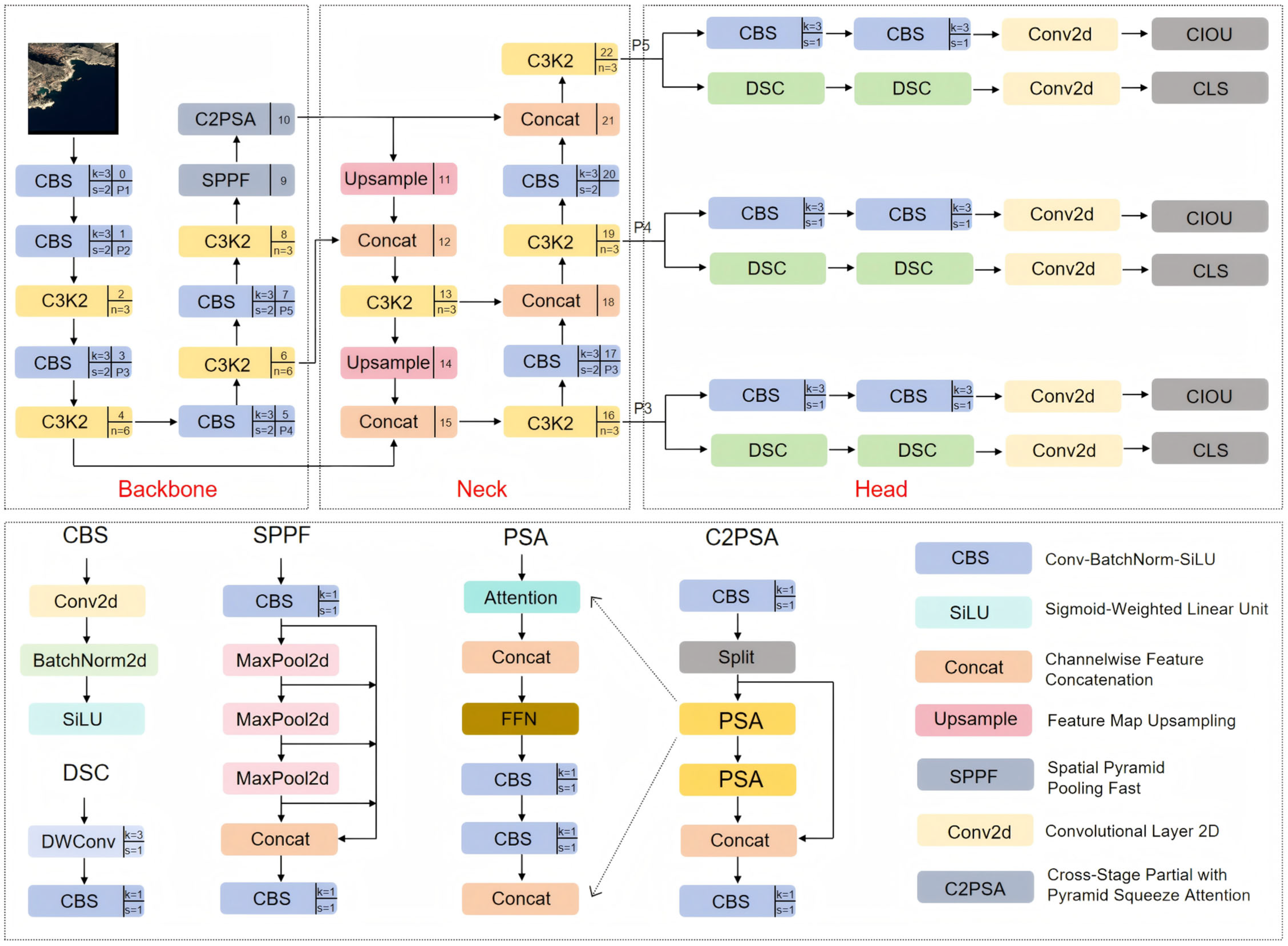
3. Proposed Model
3.1. YOLO11 Baseline Model
3.2. HFC-YOLO11 Architecture
3.3. GhostBottleneck Module
3.4. EIoU Loss Function
4. Experiments
4.1. Experimental Environment and Parameters
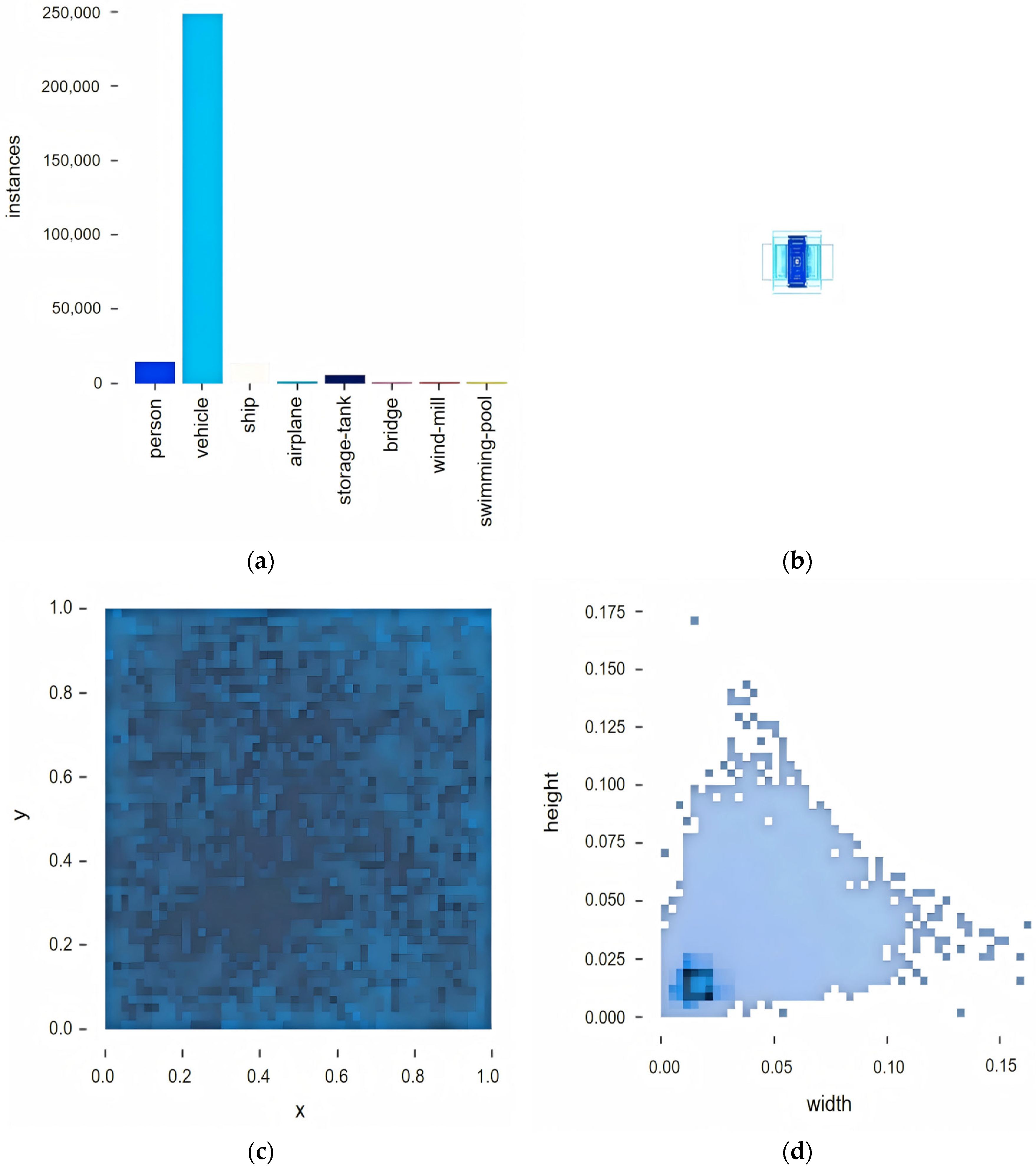
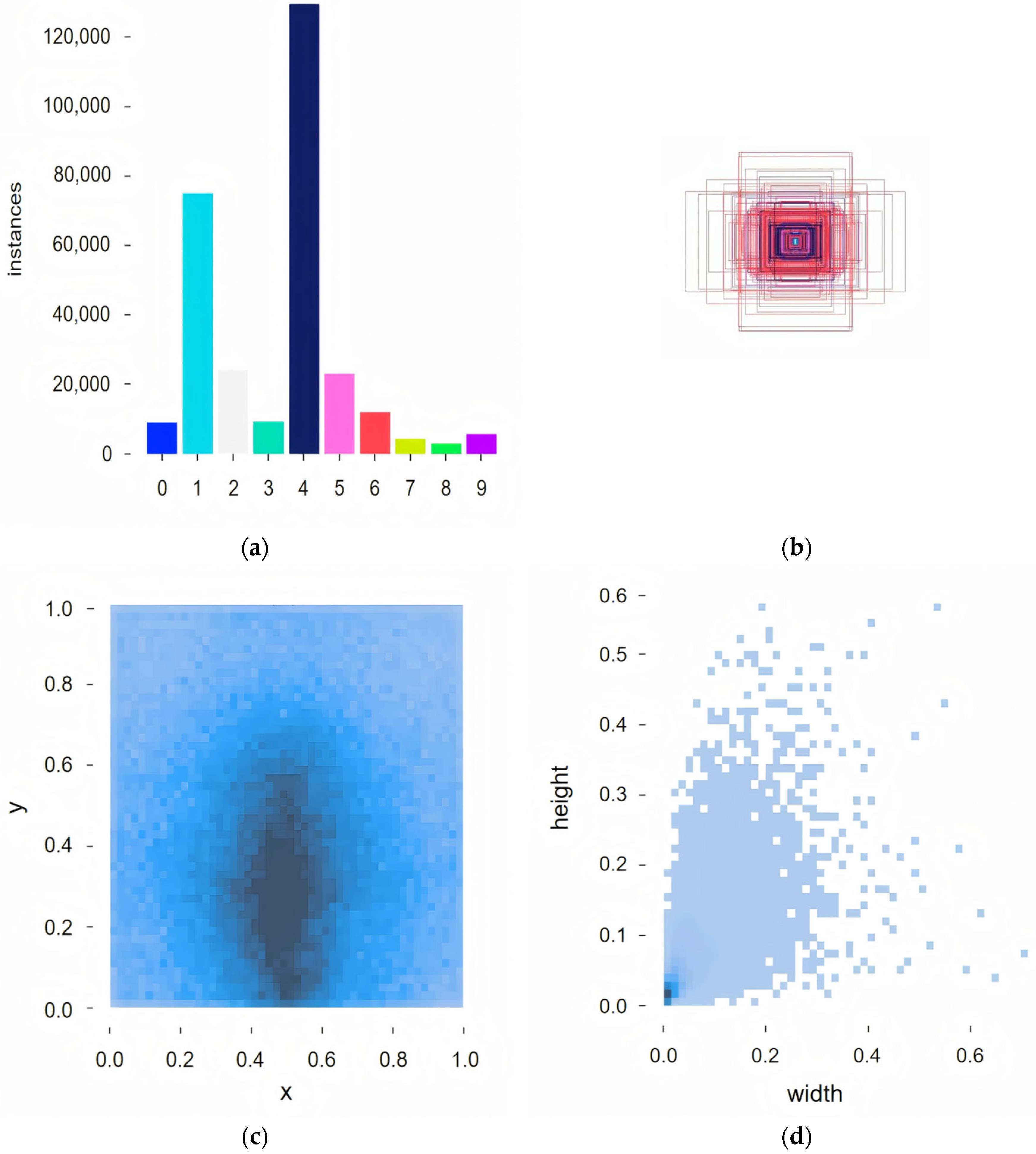
4.2. Experimental Datasets
4.2.1. AI-TOD Dataset
4.2.2. VisDrone2019 Dataset
4.3. Evaluation Metrics
4.4. Experimental Results
4.5. Visualization Analysis
4.6. Ablation Study
4.7. Experiments on VisDrone Dataset
4.8. Analysis of Model Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yao, F.; Liu, S.; Wang, D.; Geng, X.; Wang, C.; Jiang, N.; Wang, Y. Review on the development of multi- and hyperspectral remote sensing technology for exploration of copper-gold deposits. Ore Geol. Rev. 2023, 162, 105732. [Google Scholar] [CrossRef]
- Liu, S.; Du, K.; Zheng, Y.; Chen, J.; Du, P.; Tong, X. Remote sensing change detection technology in the era of artificial intelligence: Inheritance, development and challenges. Natl. Remote Sens. Bull. 2023, 27, 1975–1987. [Google Scholar] [CrossRef]
- Acharya, T.D.; Lee, D.H. Remote sensing and geospatial technologies for sustainable development: A review of applications. Sens. Mater. 2019, 31, 3931–3945. [Google Scholar] [CrossRef]
- Bi, S.; Lin, X.; Wu, Z.; Yang, S. Development technology of principle prototype of high-resolution quantum remote sensing imaging. Proc. SPIE 2018, 10540, 105400Q. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Z.; Qi, G.; Hu, G.; Zhu, Z.; Huang, X. Remote sensing micro-object detection under global and local attention mechanism. Remote Sens. 2024, 16, 644. [Google Scholar] [CrossRef]
- Wu, J.; Zhao, F.; Jin, Z. LEN-YOLO: A lightweight remote sensing small aircraft object detection model for satellite on-orbit detection. J. Real-Time Image Process 2024, 22, 25. [Google Scholar] [CrossRef]
- Hua, X.; Wang, X.; Rui, T. A fast self-attention cascaded network for object detection in large scene remote sensing images. Appl. Soft Comput. 2020, 94, 106495. [Google Scholar] [CrossRef]
- Molla, Y.K.; Mitiku, E.A. CNN-HOG-Based Hybrid Feature Mining for Classification of Coffee Bean Varieties Using Image Processing. Multimed. Tools Appl. 2025, 84, 749–764. [Google Scholar] [CrossRef]
- Qadir, I.; Iqbal, M.A.; Ashraf, S.; Akram, S. A Fusion of CNN and SIFT for Multicultural Facial Expression Recognition. Multimed. Tools Appl. 2025, 84. [Google Scholar] [CrossRef]
- Wang, Z.N.; He, D.; Zhao, M.J. Lane line detection and lane departure warning algorithm based on sliding window searching. Automot. Eng. 2023, 9, 15–20+28. [Google Scholar] [CrossRef]
- Guan, Q.; Liu, Y.; Chen, L.; Zhao, S.; Li, G. Aircraft detection and fine-grained recognition based on high-resolution remote sensing images. Electronics 2023, 12, 3146. [Google Scholar] [CrossRef]
- Guo, D.; Zhao, C.; Shuai, H.; Zhang, J.; Zhang, X. Enhancing sustainable traffic monitoring: Leveraging NanoSight–YOLO for precision detection of micro-vehicle targets in satellite imagery. Sustainability 2024, 16, 7539. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1483–1498. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A review of YOLO algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, Y. A steel surface defect detection method based on improved RetinaNet. Sci. Rep. 2025, 15, 6045. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Yan, J.; Cai, J.; Deng, J.; Qin, Q.; Cheng, Y. Super-resolution reconstruction of single image for latent features. Comput. Vis. Media 2024, 6, 1219–1239. [Google Scholar] [CrossRef]
- Zhang, K.; Teng, G.; Fan, T.; Li, C. FPN multi-scale object detection algorithm based on dense connectivity. Comput. Appl. Softw. 2020, 37, 165–171. [Google Scholar]
- Wang, A.; Liang, G.; Wang, X.; Song, Y. Application of the YOLOv6 combining CBAM and CIoU in forest fire and smoke detection. Forests 2023, 14, 2261. [Google Scholar] [CrossRef]
- Tang, Y.; Liu, M.; Li, B.; Wang, Y.; Ouyang, W. NAS-PED: Neural architecture search for pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 1800–1817. [Google Scholar] [CrossRef] [PubMed]
- Su, W.; Jing, D. DDL R-CNN: Dynamic direction learning R-CNN for rotated object detection. Algorithms 2025, 18, 21. [Google Scholar] [CrossRef]
- Li, F.; Sun, T.; Dong, P.; Wang, Q.; Li, Y.; Sun, C. MSF-CSPNet: A specially designed backbone network for Faster R-CNN. IEEE Access 2024, 12, 52390–52399. [Google Scholar] [CrossRef]
- Yuan, M.; Meng, H.; Wu, J.; Cai, S. Global recurrent Mask R-CNN: Marine ship instance segmentation. Comput. Graph. 2025, 126, 104112. [Google Scholar] [CrossRef]
- Shao, Y.; Zhang, D.; Chu, H.; Zhang, X.; Rao, Y. A review of YOLO object detection based on deep learning. J. Electron. Inf. Technol. 2022, 44, 3697–3708. [Google Scholar] [CrossRef]
- Wang, Z.; Li, F.; Zheng, X.; Nong, H.; Zeng, B.; Yang, W. Detection of cassava stem based on deep convolutional neural network. J. Agric. Mech. Res. 2023, 45, 144–148. [Google Scholar] [CrossRef]
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An improved YOLOv2 for vehicle detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef]
- Xu, F.; Huang, L.; Gao, X.; Yu, T.; Zhang, L. Research on YOLOv3 model compression strategy for UAV deployment. Cogn. Robot. 2024, 4, 8–18. [Google Scholar] [CrossRef]
- Nguyen, D.; Nguyen, D.; Le, M.; Nguyen, Q. FPGA-SoC implementation of YOLOv4 for flying-object detection. J. Real-Time Image Process 2024, 21, 63. [Google Scholar] [CrossRef]
- Li, Y.; Shi, X.; Xu, X.; Zhang, H.; Yang, F. Yolov5s-PSG: Improved Yolov5s-based helmet recognition in complex scenes. IEEE Access 2025, 13, 34915–34924. [Google Scholar] [CrossRef]
- Li, N.; Wang, M.; Yang, G.; Li, B.; Yuan, B.; Xu, S. DENS-YOLOv6: A small object detection model for garbage detection on water surface. Multimed. Tools Appl. 2024, 83, 55751–55771. [Google Scholar] [CrossRef]
- Qin, Z.; Chen, D.; Wang, H. MCA-YOLOv7: An improved UAV target detection algorithm based on YOLOv7. IEEE Access 2024, 12, 42642–42650. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, Z.; Wang, K.; Huang, W.; Li, P. OBC-YOLOv8: An improved road damage detection model based on YOLOv8. PeerJ Comput. Sci. 2025, 11, e2593. [Google Scholar] [CrossRef] [PubMed]
- Geng, X.; Han, X.; Cao, X.; Su, Y.; Shu, D. YOLOV9-CBM: An improved fire detection algorithm based on YOLOV9. IEEE Access 2025, 13, 19612–19623. [Google Scholar] [CrossRef]
- Sun, H.; Yao, G.; Zhu, S.; Zhang, L.; Xu, H.; Kong, J. SOD-YOLOv10: Small object detection in remote sensing images based on YOLOv10. IEEE Geosci. Remote Sens. Lett. 2025, 22. [Google Scholar] [CrossRef]
- Xuan, Y.; Zhang, X.; Li, C.; Wang, H.; Mu, C. LAM-YOLOv11 for UAV transmission line inspection: Overcoming environmental challenges with enhanced detection efficiency. Multimed. Syst. 2025, 31. [Google Scholar] [CrossRef]
- Wang, H.; Qian, H.; Feng, S.; Wang, W. L-SSD: Lightweight SSD target detection based on depth-separable convolution. J. Real-Time Image Process 2024, 21, 33. [Google Scholar] [CrossRef]
- Wu, J.; Fan, X.; Sun, Y.; Gui, W. Ghost-RetinaNet: Fast shadow detection method for photovoltaic panels based on improved RetinaNet. CMES-Comput. Model. Eng. Sci. 2023, 134, 1305–1321. [Google Scholar] [CrossRef]
- Li, X.; Liu, F.; Han, B.; Wu, Z. MEDMCN: A novel multi-modal EfficientDet with multi-scale CapsNet for object detection. J. Supercomput. 2024, 80, 1–28. [Google Scholar] [CrossRef]
- Liu, F.; Li, Y. SAR remote sensing image ship detection method NanoDet based on visual saliency. J. Radars. 2021, 10, 885. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection. arXiv 2022, arXiv:2110.13389. [Google Scholar]
- Gao, Y.; Xin, Y.; Yang, H.; Wang, Y. A lightweight anti-unmanned aerial vehicle detection method based on improved YOLOv11. Drones 2024, 9, 11. [Google Scholar] [CrossRef]
- Wang, Z.; Su, Y.; Kang, F.; Wang, L.; Lin, Y.; Wu, Q.; Li, H.; Cai, Z. PC-YOLO11s: A lightweight and effective feature extraction method for small target image detection. Sensors 2025, 25, 348. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Haroon, M.; Shahzad, M.; Fraz, M.M. Multisized object detection using spaceborne optical imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3032–3046. [Google Scholar] [CrossRef]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Specification | Parameter | Value |
|---|---|---|---|
| Operating System | Windows11 | Image size | 640 × 640 |
| CPU | Intel Core i9-13900HX (2.20 GHz) | Batch size | 4 |
| GPU | NVIDIA RTX 4080 | Optimizer | AdamW |
| RAM | 32 GB DDR5 (4800 MHz) | Learning rate | 1 × 10−4 |
| IDE | PyCharm 2024.1 | Momentum | 0.937 |
| Programming Language | Python 3.9.12 | Weight decay | 5 × 10−4 |
| CUDA | 11.7.1 | Epochs | 100 |
| Model | P (%) | R (%) | F1 | mAP50 (%) | mAP50-95 (%) | Parameter (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| YOLO11n | 34.5 | 29.7 | 31.9 | 23.6 | 10.2 | 2.59 | 6.4 |
| HFC-YOLO11n | 36.2 | 31.6 | 33.7 | 26.5 | 11.7 | 1.89 | 9.2 |
| YOLO11s | 41.4 | 34.2 | 37.6 | 32.8 | 13.6 | 9.46 | 21.7 |
| HFC-YOLO11s | 45.9 | 35.3 | 40.4 | 36.2 | 15.6 | 6.87 | 24.5 |
| YOLO11m | 48.1 | 36.0 | 41.2 | 38.3 | 16.8 | 20.11 | 68.5 |
| HFC-YOLO11m | 49.6 | 36.7 | 42.2 | 40.9 | 18.3 | 16.12 | 84.8 |
| Model | P (%) | R (%) | F1 | mAP50 (%) | mAP50-95 (%) | Parameter (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| YOLOv5su | 41.7 | 31.8 | 36.1 | 30.5 | 12.4 | 9.13 | 24.1 |
| YOLOv6s | 41.3 | 27.8 | 33.2 | 27.7 | 11.1 | 16.3 | 44.2 |
| YOLOv8s | 42.5 | 33.0 | 37.2 | 32.2 | 13.2 | 11.14 | 28.7 |
| YOLOv10s | 40.2 | 31.3 | 35.2 | 30.3 | 12.3 | 8.07 | 24.8 |
| YOLO11s | 41.4 | 34.2 | 37.6 | 32.8 | 13.6 | 9.46 | 21.7 |
| HFC-YOLO11s | 45.9 | 35.3 | 40.4 | 36.2 | 15.6 | 6.87 | 24.5 |
| HRS | GhostBottleneck | EIoU | P (%) | R (%) | F1 | mAP50 (%) | mAP50-95 (%) | Parameter (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|---|
| × | × | × | 41.4 | 34.2 | 37.6 | 32.8 | 13.6 | 9.46 | 21.7 |
| √ | × | × | 45.5 | 35.3 | 40.1 | 35.6 | 15.3 | 7.13 | 27.1 |
| × | √ | × | 40.9 | 33.8 | 36.7 | 32.4 | 13.4 | 9.08 | 19.4 |
| × | × | √ | 43.4 | 34.9 | 38.7 | 33.9 | 14.1 | 9.46 | 21.7 |
| √ | √ | × | 44.6 | 34.8 | 39.4 | 35.1 | 15.0 | 6.87 | 24.5 |
| × | √ | √ | 42.6 | 34.6 | 38.1 | 33.1 | 13.7 | 9.08 | 19.4 |
| √ | × | √ | 46.4 | 35.5 | 40.9 | 36.5 | 15.8 | 7.13 | 27.1 |
| √ | √ | √ | 45.9 | 35.3 | 40.4 | 36.2 | 15.6 | 6.87 | 24.5 |
| Model | P (%) | R (%) | F1 | mAP50 (%) | mAP50-95 (%) | Parameter (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| YOLOv5su | 47.5 | 22.6 | 30.6 | 35.1 | 21.9 | 9.13 | 24.1 |
| YOLOv6s | 47.9 | 19.5 | 27.7 | 33.8 | 20.8 | 16.3 | 44.2 |
| YOLOv8s | 48.4 | 23.2 | 31.4 | 35.9 | 22.7 | 11.14 | 28.7 |
| YOLOv10s | 48.9 | 20.0 | 28.4 | 34.6 | 21.8 | 8.07 | 24.8 |
| YOLO11s | 49.7 | 25.8 | 34.0 | 39.6 | 25.8 | 9.46 | 21.7 |
| HFC-YOLO11s | 51.3 | 26.4 | 34.9 | 42.3 | 27.1 | 6.87 | 24.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, J.; Zhu, W.; Nie, Z.; Yang, X.; Xu, Q.; Li, D. HFC-YOLO11: A Lightweight Model for the Accurate Recognition of Tiny Remote Sensing Targets. Computers 2025, 14, 195. https://doi.org/10.3390/computers14050195
Bai J, Zhu W, Nie Z, Yang X, Xu Q, Li D. HFC-YOLO11: A Lightweight Model for the Accurate Recognition of Tiny Remote Sensing Targets. Computers. 2025; 14(5):195. https://doi.org/10.3390/computers14050195
Chicago/Turabian StyleBai, Jinyin, Wei Zhu, Zongzhe Nie, Xin Yang, Qinglin Xu, and Dong Li. 2025. "HFC-YOLO11: A Lightweight Model for the Accurate Recognition of Tiny Remote Sensing Targets" Computers 14, no. 5: 195. https://doi.org/10.3390/computers14050195
APA StyleBai, J., Zhu, W., Nie, Z., Yang, X., Xu, Q., & Li, D. (2025). HFC-YOLO11: A Lightweight Model for the Accurate Recognition of Tiny Remote Sensing Targets. Computers, 14(5), 195. https://doi.org/10.3390/computers14050195